
traducido por I. A.
El uso seguro de sistemas de gestión de control de código fuente (SCM) como Git es esencial para programadores (desarrollo) y administradores de sistemas (operaciones). Este grupo de herramientas tiene una larga tradición en el desarrollo de software y permite a los equipos de desarrollo trabajar juntos sobre una base de código. Se responden cuatro preguntas: ¿Cuándo se realizó el cambio? ¿Quién realizó el cambio? ¿Qué se cambió? ¿Por qué se cambió algo? Por lo tanto, es una herramienta de colaboración pura.
Con la llegada de la plataforma de alojamiento de código fuente abierto GitHub, se introdujeron las llamadas Pull Requests. Las Pull Requests son un flujo de trabajo en GitHub que permite a los desarrolladores proporcionar cambios de código para repositorios a los que solo tienen acceso de lectura. Solo después de que el propietario del repositorio original haya revisado los cambios propuestos y los haya aprobado, estos cambios son integrados por él. De ahí también el nombre. Un desarrollador copia el repositorio original en su espacio de trabajo de GitHub, realiza cambios y solicita al propietario del repositorio original que adopte el cambio. Este último puede entonces aceptar los cambios y, si es necesario, adaptarlos él mismo o rechazarlos con un motivo.
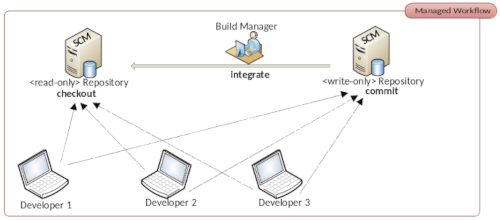
Quien piense que GitHub es especialmente innovador se equivoca. Este proceso es muy antiguo en la comunidad de código abierto. Originalmente, este procedimiento se llamaba Dictatorship Workflow. El SCM comercial Rational Synergy de IBM, publicado por primera vez en 1990, se basa precisamente en Dictatorship Workflow. Con la clase de herramientas de gestión de versiones distribuidas a la que también pertenece Git, Dictatorship Workflow es bastante fácil de implementar. Por lo tanto, era obvio que GitHub pondría este proceso a disposición de sus usuarios. GitHub ha elegido un nombre mucho más atractivo. Cualquiera que trabaje con la solución gratuita DevOps GitLab, por ejemplo, conocerá las solicitudes de extracción como solicitudes de fusión. Los servidores Git más comunes ahora contienen el proceso de solicitud de extracción. Sin entrar demasiado en detalles técnicos de la implementación de solicitudes de extracción, centraremos nuestra atención en los problemas habituales a los que se enfrentan los proyectos de código abierto.
Los desarrolladores que quieren participar en un proyecto de código abierto se denominan mantenedores. Casi todos los proyectos tienen una breve guía sobre cómo apoyar el proyecto y qué reglas se aplican. Para las personas que están aprendiendo a programar, los proyectos de código abierto son ideales para mejorar sus propias habilidades de manera rápida y significativa. Para el proyecto de código abierto, esto significa que tiene mantenedores con una amplia gama de habilidades y experiencia. Si no establece un mecanismo de control, la base de código se erosionará en muy poco tiempo.
Si el proyecto es bastante grande y hay muchos mantenedores trabajando en la base de código, es casi imposible para el propietario del repositorio procesar todas las solicitudes de extracción de manera oportuna. Para contrarrestar este cuello de botella, el flujo de trabajo Dictatorship se amplió al flujo de trabajo Dictatorship – Lieutenant. Se introdujo una instancia intermedia que distribuye la revisión de las solicitudes de extracción entre varios hombros. Esta capa intermedia, los llamados Lieutenants, son mantenedores particularmente activos con una reputación ya establecida. Por lo tanto, el Dictator solo necesita revisar las solicitudes de extracción de los Lieutenants. Una reducción enorme de la carga de trabajo que garantice que no haya retrasos en la ejecución de funciones debido a solicitudes de incorporación de cambios sin procesar. Después de todo, las mejoras o ampliaciones deben incluirse en la base de código lo antes posible para que puedan estar disponibles para los usuarios en la próxima versión.
Este enfoque sigue siendo el estándar en los proyectos de código abierto para garantizar la calidad. Nunca se puede decir quién está involucrado en el proyecto. Incluso puede haber uno o dos saboteadores. Esta idea no es tan descabellada. Las empresas que tienen una fuerte competencia por su producto comercial en el sector de código abierto libre podrían tener ideas injustas en este sentido si no hubiera regulaciones. Además, los mantenedores no pueden ser disciplinados como es el caso de los miembros del equipo en las empresas, por ejemplo. Es difícil amenazar con una reducción salarial a un mantenedor que se resiste a los consejos y no se adhiere a las convenciones del proyecto a pesar de las reiteradas solicitudes. La única opción es excluir a esta persona del proyecto.
Aunque el problema de disciplinar a los empleados en los equipos comerciales descrito anteriormente no es un problema, también existen dificultades en estos entornos que deben superarse. Estos problemas se remontan a los primeros tiempos de las herramientas de control de versiones. Los primeros representantes de esta especie no eran soluciones distribuidas, sino centralizadas. CVS y Subversion (SVN) solo guardan la última revisión de la base de código en el equipo de desarrollo local. Sin una conexión con el servidor, en realidad no se puede trabajar. Esto es diferente con Git. Aquí tienes una copia del repositorio en tu propio equipo, por lo que puedes hacer tu trabajo localmente en una rama separada y cuando hayas terminado, llevas estos cambios a la rama de desarrollo principal y luego los transfieres al servidor. La capacidad de crear ramas fuera de línea y fusionarlas localmente tiene una influencia decisiva en la estabilidad de tu propio trabajo si el repositorio entra en un estado inconsistente. Porque, a diferencia de los sistemas SCM centralizados, ahora puedes seguir trabajando sin tener que esperar a que se repare la rama de desarrollo principal.
Estas inconsistencias surgen muy fácilmente. Todo lo que se necesita es olvidar un archivo al realizar la confirmación y los miembros del equipo ya no pueden compilar el proyecto localmente y se ven obstaculizados en su trabajo. El concepto de Integración Continua (CI) se estableció para superar este problema. No es como se suele pensar erróneamente sobre la integración de diferentes componentes en una aplicación. El objetivo de la integración continua es mantener la etapa de confirmación (el repositorio de código) en un estado coherente. Para ello se establecieron servidores de compilación que comprueban periódicamente si hay cambios en el repositorio y luego construyen el artefacto a partir del código fuente. Un servidor de compilación muy popular que se ha establecido durante muchos años es Jenkins. Jenkins surgió originalmente como una bifurcación del proyecto Hudson. Los servidores de compilación ahora se encargan de muchas otras tareas. Por eso tiene mucho sentido llamar a esta clase de herramientas servidores de automatización.
Con este breve resumen de la historia del desarrollo de software, ahora entendemos los problemas de los proyectos de código abierto y el desarrollo de software comercial. También hemos hablado de la historia de las solicitudes de extracción. En los proyectos comerciales, a menudo sucede que los equipos se ven obligados por la gestión de proyectos a trabajar con solicitudes de extracción. Para un director de proyectos sin conocimientos técnicos, tiene mucho sentido establecer solicitudes de extracción también en su proyecto. Después de todo, tiene la idea de que esto mejorará la calidad del código. Lamentablemente, este no es el caso. Lo único que ocurre es que se genera un retraso en la carga de trabajo y el equipo se ve obligado a trabajar más duro sin mejorar la productividad. La solicitud de incorporación de cambios debe ser evaluada por una persona competente. Esto provoca retrasos desagradables en proyectos grandes.
Ahora veo a menudo el argumento de que las solicitudes de incorporación de cambios se pueden automatizar. Esto significa que el servidor de compilación toma la rama con la solicitud de incorporación de cambios e intenta compilarla y, si la compilación y las pruebas automatizadas son exitosas, el servidor intenta incorporar los cambios en la rama de desarrollo principal. Tal vez estoy viendo algo mal, pero ¿dónde está el control de calidad? Es un proceso de integración continua simple que mantiene la consistencia del repositorio. Dado que las solicitudes de incorporación de cambios se encuentran principalmente en el entorno Git, un repositorio temporalmente inconsistente no significa una detención completa del desarrollo para todo el equipo, como es el caso de Subversion.
Otra pregunta interesante es cómo lidiar con los conflictos de fusión semántica en una fusión automática. Estos no son un problema grave en sí mismos. Esto seguramente conducirá al rechazo de la solicitud de extracción con un mensaje correspondiente al desarrollador para que el problema pueda resolverse con una nueva solicitud de extracción. Sin embargo, las estrategias de ramificación desfavorables pueden conducir a un trabajo adicional desproporcionado.
No veo ningún valor agregado para el uso de solicitudes de extracción en proyectos de software comerciales, por lo que desaconsejo el uso de solicitudes de extracción en este contexto. Aparte de una complicación de la canalización de CI / CD y un mayor consumo de recursos del servidor de automatización que ahora hace el trabajo dos veces, no ha sucedido nada más. La calidad de un proyecto de software se puede mejorar mediante la introducción de pruebas unitarias automatizadas y un enfoque basado en pruebas para implementar funciones. Aquí es necesario monitorear y mejorar continuamente la cobertura de pruebas del proyecto. El análisis de código estático y la activación de advertencias del compilador brindan mejores resultados con significativamente menos esfuerzo.
Personalmente, creo que las empresas que dependen de las solicitudes de extracción o las usan para CI complicadas o desconfían completamente de sus desarrolladores y niegan que hagan un buen trabajo. Por supuesto, estoy abierto a debatir sobre el tema; tal vez se pueda encontrar una solución aún mejor. Por lo tanto, me encantaría recibir muchos comentarios con sus opiniones y experiencias sobre cómo gestionar las solicitudes de incorporación de cambios.






- 1
- 2