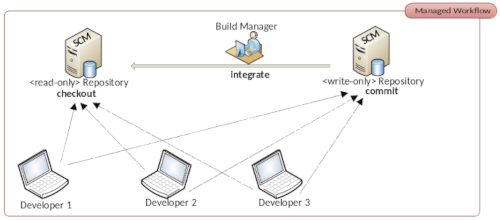
Si desea utilizar su repositorio Git para la edición colaborativa de código fuente, necesita un servidor Git. El servidor Git permite que varios desarrolladores colaboren en la misma base de código. Instalar el cliente Git en un servidor Linux es un primer paso hacia su propia solución de servidor, pero está lejos de ser suficiente. Para permitir que varias personas accedan a un repositorio de código, necesitamos autorización de acceso. Después de todo, el repositorio debe ser accesible públicamente a través de Internet. Queremos utilizar la gestión de usuarios para evitar que personas no autorizadas lean y modifiquen el contenido de los repositorios.
Existen muchas soluciones excelentes y convenientes para operar un servidor Git que deberían preferirse a una solución de servidor nativo. La administración de un servidor Git nativo requiere conocimientos de Linux y se realiza exclusivamente a través de la línea de comandos. Soluciones como SCM-Manager tienen una interfaz gráfica de usuario y vienen con muchas herramientas útiles para administrar el servidor. Estas herramientas no están disponibles con una instalación nativa.
¿Por qué debería instalar Git como servidor nativo? Esta pregunta es bastante fácil de responder. La razón es cuando el servidor en el que se pondrá a disposición el repositorio de código tiene solo unos pocos recursos de hardware. La memoria RAM en particular siempre es un problema en este contexto. Este suele ser el caso de servidores privados virtuales (VPS) alquilados o una pequeña RaspberryPI. Por lo tanto, podemos ver que puede tener sentido querer ejecutar un servidor Git nativo.
Como requisito previo, necesitamos un servidor Linux en el que podamos instalar el servidor Git. Este puede ser un servidor Debian o Ubuntu. Si usa CentOs u otras distribuciones de Linux, debe usar el administrador de paquetes de su distribución en lugar de APT para instalar el software.
En el primer paso, comenzamos actualizando los paquetes e instalando el cliente Git.
Ahora, en el tercer paso, podemos crear nuestros repositorios Git en el directorio de inicio recién creado del usuario git. Estos se diferencian del espacio de trabajo local en que no tienen el código fuente extraído.
Lamentablemente, aún no hemos terminado con nuestro proyecto. En el cuarto paso, tenemos que establecer la autorización del usuario para el repositorio creado. Esto se hace almacenando la clave pública en el servidor Git para el acceso SSH. Para ello, copiamos el contenido de nuestro archivo de clave privada en el archivo /home/git/.ssh/authorized_keys en una línea separada. Si ahora desea denegar el acceso a los usuarios existentes, simplemente comente el número de clave privada con un #.
Si todo se ha hecho correctamente, puede acceder al repositorio utilizando el siguiente comando de línea de comandos: git clone ssh://git@<IP>/~/<repo>
Reemplace con la IP del servidor real. Para nuestro ejemplo, la ruta correcta es project.git, por lo que es el directorio que creamos para el repositorio Git.
Se pueden crear varios repositorios en el servidor Git nativo. Es importante tener en cuenta que todos los usuarios autorizados tienen acceso de lectura y escritura a todos los repositorios creados de esta manera. Esto solo se puede restringir creando varios usuarios en el sistema operativo del servidor Linux que proporciona nuestros repositorios Git, a quienes luego se les asignan los repositorios.
Vemos que una instalación de servidor Git nativo se puede implementar rápidamente, pero no es suficiente para el desarrollo de software comercial. Si te gusta experimentar, puedes crear una máquina virtual y probar este taller en ella.
El uso seguro de sistemas de gestión de control de código fuente (SCM) como Git es esencial para programadores (desarrollo) y administradores de sistemas (operaciones). Este grupo de herramientas tiene una larga tradición en el desarrollo de software y permite a los equipos de desarrollo trabajar juntos sobre una base de código. Se responden cuatro preguntas: ¿Cuándo se realizó el cambio? ¿Quién realizó el cambio? ¿Qué se cambió? ¿Por qué se cambió algo? Por lo tanto, es una herramienta de colaboración pura.
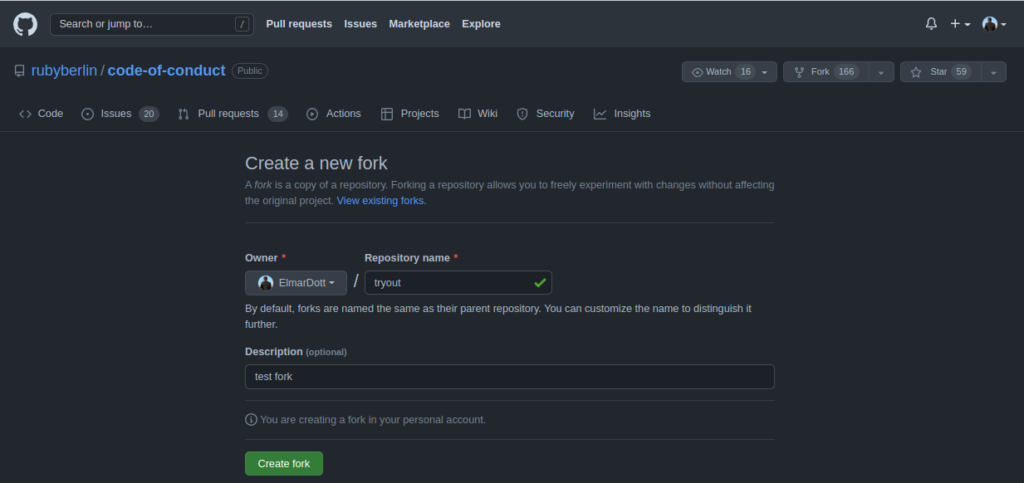
Con la llegada de la plataforma de alojamiento de código fuente abierto GitHub, se introdujeron las llamadas Pull Requests. Las Pull Requests son un flujo de trabajo en GitHub que permite a los desarrolladores proporcionar cambios de código para repositorios a los que solo tienen acceso de lectura. Solo después de que el propietario del repositorio original haya revisado los cambios propuestos y los haya aprobado, estos cambios son integrados por él. De ahí también el nombre. Un desarrollador copia el repositorio original en su espacio de trabajo de GitHub, realiza cambios y solicita al propietario del repositorio original que adopte el cambio. Este último puede entonces aceptar los cambios y, si es necesario, adaptarlos él mismo o rechazarlos con un motivo.
Quien piense que GitHub es especialmente innovador se equivoca. Este proceso es muy antiguo en la comunidad de código abierto. Originalmente, este procedimiento se llamaba Dictatorship Workflow. El SCM comercial Rational Synergy de IBM, publicado por primera vez en 1990, se basa precisamente en Dictatorship Workflow. Con la clase de herramientas de gestión de versiones distribuidas a la que también pertenece Git, Dictatorship Workflow es bastante fácil de implementar. Por lo tanto, era obvio que GitHub pondría este proceso a disposición de sus usuarios. GitHub ha elegido un nombre mucho más atractivo. Cualquiera que trabaje con la solución gratuita DevOps GitLab, por ejemplo, conocerá las solicitudes de extracción como solicitudes de fusión. Los servidores Git más comunes ahora contienen el proceso de solicitud de extracción. Sin entrar demasiado en detalles técnicos de la implementación de solicitudes de extracción, centraremos nuestra atención en los problemas habituales a los que se enfrentan los proyectos de código abierto.
Los desarrolladores que quieren participar en un proyecto de código abierto se denominan mantenedores. Casi todos los proyectos tienen una breve guía sobre cómo apoyar el proyecto y qué reglas se aplican. Para las personas que están aprendiendo a programar, los proyectos de código abierto son ideales para mejorar sus propias habilidades de manera rápida y significativa. Para el proyecto de código abierto, esto significa que tiene mantenedores con una amplia gama de habilidades y experiencia. Si no establece un mecanismo de control, la base de código se erosionará en muy poco tiempo.
Si el proyecto es bastante grande y hay muchos mantenedores trabajando en la base de código, es casi imposible para el propietario del repositorio procesar todas las solicitudes de extracción de manera oportuna. Para contrarrestar este cuello de botella, el flujo de trabajo Dictatorship se amplió al flujo de trabajo Dictatorship – Lieutenant. Se introdujo una instancia intermedia que distribuye la revisión de las solicitudes de extracción entre varios hombros. Esta capa intermedia, los llamados Lieutenants, son mantenedores particularmente activos con una reputación ya establecida. Por lo tanto, el Dictator solo necesita revisar las solicitudes de extracción de los Lieutenants. Una reducción enorme de la carga de trabajo que garantice que no haya retrasos en la ejecución de funciones debido a solicitudes de incorporación de cambios sin procesar. Después de todo, las mejoras o ampliaciones deben incluirse en la base de código lo antes posible para que puedan estar disponibles para los usuarios en la próxima versión.
Este enfoque sigue siendo el estándar en los proyectos de código abierto para garantizar la calidad. Nunca se puede decir quién está involucrado en el proyecto. Incluso puede haber uno o dos saboteadores. Esta idea no es tan descabellada. Las empresas que tienen una fuerte competencia por su producto comercial en el sector de código abierto libre podrían tener ideas injustas en este sentido si no hubiera regulaciones. Además, los mantenedores no pueden ser disciplinados como es el caso de los miembros del equipo en las empresas, por ejemplo. Es difícil amenazar con una reducción salarial a un mantenedor que se resiste a los consejos y no se adhiere a las convenciones del proyecto a pesar de las reiteradas solicitudes. La única opción es excluir a esta persona del proyecto.
Aunque el problema de disciplinar a los empleados en los equipos comerciales descrito anteriormente no es un problema, también existen dificultades en estos entornos que deben superarse. Estos problemas se remontan a los primeros tiempos de las herramientas de control de versiones. Los primeros representantes de esta especie no eran soluciones distribuidas, sino centralizadas. CVS y Subversion (SVN) solo guardan la última revisión de la base de código en el equipo de desarrollo local. Sin una conexión con el servidor, en realidad no se puede trabajar. Esto es diferente con Git. Aquí tienes una copia del repositorio en tu propio equipo, por lo que puedes hacer tu trabajo localmente en una rama separada y cuando hayas terminado, llevas estos cambios a la rama de desarrollo principal y luego los transfieres al servidor. La capacidad de crear ramas fuera de línea y fusionarlas localmente tiene una influencia decisiva en la estabilidad de tu propio trabajo si el repositorio entra en un estado inconsistente. Porque, a diferencia de los sistemas SCM centralizados, ahora puedes seguir trabajando sin tener que esperar a que se repare la rama de desarrollo principal.
Estas inconsistencias surgen muy fácilmente. Todo lo que se necesita es olvidar un archivo al realizar la confirmación y los miembros del equipo ya no pueden compilar el proyecto localmente y se ven obstaculizados en su trabajo. El concepto de Integración Continua (CI) se estableció para superar este problema. No es como se suele pensar erróneamente sobre la integración de diferentes componentes en una aplicación. El objetivo de la integración continua es mantener la etapa de confirmación (el repositorio de código) en un estado coherente. Para ello se establecieron servidores de compilación que comprueban periódicamente si hay cambios en el repositorio y luego construyen el artefacto a partir del código fuente. Un servidor de compilación muy popular que se ha establecido durante muchos años es Jenkins. Jenkins surgió originalmente como una bifurcación del proyecto Hudson. Los servidores de compilación ahora se encargan de muchas otras tareas. Por eso tiene mucho sentido llamar a esta clase de herramientas servidores de automatización.
Con este breve resumen de la historia del desarrollo de software, ahora entendemos los problemas de los proyectos de código abierto y el desarrollo de software comercial. También hemos hablado de la historia de las solicitudes de extracción. En los proyectos comerciales, a menudo sucede que los equipos se ven obligados por la gestión de proyectos a trabajar con solicitudes de extracción. Para un director de proyectos sin conocimientos técnicos, tiene mucho sentido establecer solicitudes de extracción también en su proyecto. Después de todo, tiene la idea de que esto mejorará la calidad del código. Lamentablemente, este no es el caso. Lo único que ocurre es que se genera un retraso en la carga de trabajo y el equipo se ve obligado a trabajar más duro sin mejorar la productividad. La solicitud de incorporación de cambios debe ser evaluada por una persona competente. Esto provoca retrasos desagradables en proyectos grandes.
Ahora veo a menudo el argumento de que las solicitudes de incorporación de cambios se pueden automatizar. Esto significa que el servidor de compilación toma la rama con la solicitud de incorporación de cambios e intenta compilarla y, si la compilación y las pruebas automatizadas son exitosas, el servidor intenta incorporar los cambios en la rama de desarrollo principal. Tal vez estoy viendo algo mal, pero ¿dónde está el control de calidad? Es un proceso de integración continua simple que mantiene la consistencia del repositorio. Dado que las solicitudes de incorporación de cambios se encuentran principalmente en el entorno Git, un repositorio temporalmente inconsistente no significa una detención completa del desarrollo para todo el equipo, como es el caso de Subversion.
Otra pregunta interesante es cómo lidiar con los conflictos de fusión semántica en una fusión automática. Estos no son un problema grave en sí mismos. Esto seguramente conducirá al rechazo de la solicitud de extracción con un mensaje correspondiente al desarrollador para que el problema pueda resolverse con una nueva solicitud de extracción. Sin embargo, las estrategias de ramificación desfavorables pueden conducir a un trabajo adicional desproporcionado.
No veo ningún valor agregado para el uso de solicitudes de extracción en proyectos de software comerciales, por lo que desaconsejo el uso de solicitudes de extracción en este contexto. Aparte de una complicación de la canalización de CI / CD y un mayor consumo de recursos del servidor de automatización que ahora hace el trabajo dos veces, no ha sucedido nada más. La calidad de un proyecto de software se puede mejorar mediante la introducción de pruebas unitarias automatizadas y un enfoque basado en pruebas para implementar funciones. Aquí es necesario monitorear y mejorar continuamente la cobertura de pruebas del proyecto. El análisis de código estático y la activación de advertencias del compilador brindan mejores resultados con significativamente menos esfuerzo.
Personalmente, creo que las empresas que dependen de las solicitudes de extracción o las usan para CI complicadas o desconfían completamente de sus desarrolladores y niegan que hagan un buen trabajo. Por supuesto, estoy abierto a debatir sobre el tema; tal vez se pueda encontrar una solución aún mejor. Por lo tanto, me encantaría recibir muchos comentarios con sus opiniones y experiencias sobre cómo gestionar las solicitudes de incorporación de cambios.
Ruby es un lenguaje de programación bien establecido desde hace muchos años y también puede recomendarse a los principiantes. Ruby sigue el paradigma orientado a objetos y contiene muchos conceptos que soportan bien la programación orientada a objetos. Además, el framework Ruby on Rails facilita mucho el desarrollo de aplicaciones web complejas.
El obstáculo más difícil de superar cuando se empieza con Ruby es la instalación de todo el entorno de desarrollo. Por esta razón, he escrito este breve tutorial sobre cómo empezar con Ruby. Así que vamos a empezar con la instalación de inmediato.
Mi sistema operativo es un Linux Debian 12 y Ruby se puede instalar muy fácilmente con el comando sudo apt-get install ruby-full. Este procedimiento se puede aplicar a todas las distribuciones de Linux basadas en Debian, como Ubuntu. A continuación, puede utilizar ruby -v para comprobar el éxito en el bash.
Si ahora seguimos el tutorial de la página principal de Ruby on Rails y queremos instalar el framework Rails mediante gem rails, ya nos encontramos con el primer problema. No se pueden instalar las librerías para Ruby porque faltan autorizaciones. Ahora se nos ocurre instalar las librerías como superusuario con sudo. Desafortunadamente, esta solución es sólo temporal e impide que las bibliotecas se encuentren correctamente más tarde en el entorno de desarrollo. Es mejor crear una carpeta para los GEMs en el directorio home del usuario y hacer que esté disponible a través de una variable de sistema.
export GEM_HOME=/home/<user>/.ruby-gems
export PATH=$PATH:/home/<user>/.ruby-gems
La línea anterior debe introducirse al final del archivo .bashrc para que los cambios permanezcan. Es importante que se sustituya <user> por el nombre de usuario correcto. El éxito de esta acción se puede comprobar a gem environment y debe dar lugar a una salida similar a la siguiente.
Con esta configuración, los GEM de Ruby ya se pueden instalar sin dificultad. Vamos a probarlo ahora mismo e instalar el framework Ruby on Rails, que nos ayuda en el desarrollo de aplicaciones web: gem install rails. Esto debería ejecutarse sin mensajes de error y con el comando rails -v podemos ver si hemos tenido éxito.
En el siguiente paso podemos crear un nuevo proyecto Rails. Aquí utilizo el ejemplo de la documentación de Ruby on Rails y escribo en bash: rails new blog. Esto crea un directorio llamado blog con los archivos del proyecto. Después de haber cambiado al directorio, todavía tenemos que instalar todas las dependencias. Esto se hace mediante: bundle install.
Aquí nos encontramos con otro problema. La instalación no puede completarse porque parece haber un problema con la biblioteca psych. El verdadero problema, sin embargo, es que no hay soporte para archivos YAML a nivel de sistema operativo. Esto se puede arreglar muy rápidamente instalando el paquete YAML.
sudo apt-get install libyaml-dev
El problema con psych en Ruby on Rails ha existido durante un tiempo y se ha solucionado con la instalación de YAML, de modo que el comando bundle install ahora también se ejecuta correctamente. Ahora también podemos iniciar el servidor para la aplicación Rails: bin/rails server.
ed@:~/blog$bin/railsserver=> BootingPuma=> Rails7.1.3.3applicationstartingindevelopment=> Run`bin/rails server --help`for more startup optionsPumastartinginsinglemode...* Puma version: 6.4.2 (ruby3.1.2-p20)("The Eagle of Durango")* Min threads: 5* Max threads: 5* Environment: development* PID: 12316* Listening on http://127.0.0.1:3000* Listening on http://[::1]:3000UseCtrl-Ctostop
Bash
Si ahora llamamos a la URL http://127.0.0.1:3000 en el navegador web, veremos nuestra aplicación web Rails.
Con estos pasos, ya hemos creado un entorno Ruby funcional en nuestro sistema. Ahora es el momento de decidir un entorno de desarrollo adecuado. Si sólo se adaptan ocasionalmente algunos scripts, VIM y Sublime Text son suficientes como editores. Para proyectos de software complejos, se debe utilizar un IDE completo, ya que simplifica el trabajo considerablemente. La mejor recomendación es el IDE de pago RubyMine de JetBrains. Si apoyas proyectos Ruby de código abierto como desarrollador, puedes solicitar una licencia gratuita.
Un IDE para Ruby disponible gratuitamente es VSCode de Microsoft. Sin embargo, primero hay que integrar algunos plugins y VSCode no es muy intuitivo para mi gusto. La integración de Ruby para los IDEs clásicos de Java, Eclipse y NetBeans, está bastante desfasada y sólo puede hacerse funcionar con mucho esfuerzo.
Con esto ya hemos tratado todos los puntos importantes que son necesarios para configurar un entorno Ruby que funcione en tu propio sistema. Espero que este pequeño taller haya reducido significativamente la barrera de entrada al aprendizaje de Ruby. Si te ha gustado este artículo, por favor, dale a me gusta y recomiéndalo a tus amigos.
Desde Windows 10 los usuarios pierden cada vez más control sobre sus sistemas. La palabra clave es la gobernanza donde las empresas tratan de educar a sus usuarios. No te preocupes no voy a dar un gran discurso sobre el libre albedrío y el mal las empresas de tecnología. En este artículo te doy la oportunidad de recuperar el control de tu dispositivo informático. Despídete de Microsoft y Windows y comienza tu viaje con Linux.
Allá por el año 2015 tomé la decisión de deshacerme de Microsoft windows y pasarme al 100% a Linux. Ya tenía en ese momento varias experiencias con Linux en el lado del servidor. Pero usar Linux a diario en el escritorio para todas las tareas era un nuevo reto, porque las cosas son diferentes. Así que pasé alrededor de 4 semanas y varios intentos para encontrar una distribución de Linux de escritorio que mejor se adapte a mis necesidades. Las cosas a las que tienes que prestar atención para obtener el mejor resultado para ti son la disponibilidad de un enorme repositorio de software donde puedas conseguir todas las aplicaciones que necesites. Otro punto importante es el aspecto de tu escritorio. Aquí también hay varias opciones entre las que puedes elegir. Antes de dar una breve visión general sobre las distribuciones y los escritorios, explicaré el problema de las versiones de software y los repositorios.
Un repositorio de software no es más que un gran almacén donde se encuentran los binarios y los instaladores de su aplicación. Si te decides por una distribución y una versión específica tienes un repositorio definido donde puedes comprar las actualizaciones de tu software y distribución. Supongamos que tenemos una distribución Linux con una versión de 2019. El soporte para esta versión es, digamos, hasta 2020. Eso significa que para el repositorio de software el software incluido sólo contiene un estado de este tiempo. Si desea tener para esta distribución la versión más reciente de GIMP como la 2.10.36 de noviembre de 2023 no podrá obtenerla del repositorio de su distribución original. La última versión de software para GIMP en el repositorio original es la versión de 2020. El mismo problema se da con versiones de software más antiguas. Este es un problema muy específico para los desarrolladores de software y lenguajes de programación disponibles. Si necesitas mantener aplicaciones PHP o JAVA antiguas necesitas compiladores e intérpretes muy específicos que pueden no estar incluidos en tu repositorio de software. Para resolver este problema existen varias soluciones. Los desarrolladores, por ejemplo, pueden utilizar Docker. Como usuario normal puedes intentar conseguir versiones más antiguas o más nuevas de un software directamente del desarrollador / fabricante. Con este conocimiento ahora podemos aprender lo que es una distribución y cuáles existen.
Si quieres elegir para ti una distribución Linux o, abreviado, Distro, tienes una enorme selección donde elegir. ¿Pero qué es una distribución? En general se puede decir que un fabricante junta un Kernel Linux, una colección de software y un repositorio y decora todo con su propio look and feel. También es posible que crees tu propio Linux, incluyendo la compilación de tu propio kernel. Pero Linux no es en todos los casos Linux. Debemos distinguir entre Linux y Unix. Linux es una derivación de Unix, como ya sugiere el nombre LinUx, una combinación de Linus y Unix. La gran diferencia entre Linux y Unix son las funcionalidades de red, que en Unix son más avanzadas. El sistema operativo (OS) de Apple, por ejemplo, está basado en Unix. Un SO Unix muy común es FreeBSD. BSD significa Barkley Software Distribution y es desarrollado continuamente por la Universidad de Barkley en California.
Al lado de esto distinguen existen ramas principales de Linux del árbol que también incluyen más derivación. La primera es la alemana Suse con el gestor de paquetes YAST para sus repositorios de software. Por cierto Suse 7.2 fue mi primera prueba de escritorio en 2002. Suse no es tan común y, a veces es muy difícil de encontrar para preguntas especiales o problemas de contenido suficiente. Otra distribución viene de Red Hat, un pionero del código abierto. RHEL o Red Hat Enterprise Linux es una distribución comercial de Linux para servidores. La razón de un Linux comercial se basa en la existencia de sistemas productivos para servidores. Con una licencia RHEL las empresas obtienen de Red Hat un soporte profesional en caso de emergencias. Red Hat Desktop ya no recibe soporte y se ha transformado en Fedora Linux. El gestor de paquetes por defecto para sus repositorios de software es YUM. La última pero no menos importante rama de las principales distribuciones de Linux es Debian, con un gran número de sub-distribuciones. Todas esas populares Distros para principiantes como Linux Mint, Ubuntu o Zorin OS se basan en Debian. Cuando cambié en 2015 a Linux Desktop empecé con Ubuntu Mate LTS y desde finales de 2023 cambié a Debian 12 con un Gnome 3 Desktop. El gestor de paquetes por defecto de los sistemas Debian es APT. Ubuntu introdujo en 2023 su propio gestor de paquetes SNAP.
Otro término importante en el universo Linux es el gestor de escritorio. Aquí puedes elegir entre: KDE, Gnome, Mate, XFCE y Cinnamon. Al igual que mi lista de Distros la lista de Dektops disponibles tampoco está completa. Sólo menciono los más comunes. La mayoría de las Distros Linux vienen con varios gestores de Escritorio por defecto. Usted puede elegir durante el procedimiento de inicio de sesión que Dektop desea utilizar. Así tienes una manera fácil de probar que Escritorio se adapta mejor a ti. Más tarde, cuando tengas más experiencia y ya hayas elegido tu escritorio para tu trabajo diario, puedes deseleccionar los escritorios no deseados durante el proceso de instalación para ahorrar un poco de espacio en disco.
Mucha gente recomienda a los nuevos usuarios de Linux una distribución Ubuntu con el argumento de que es más fácil para los principiantes. Ellos dan golpes como que se puede cambiar a Debian más tarde cuando se tiene más experiencia. Yo tengo una opinión completamente diferente. La complicacion en Linux no es el Distro es el Dektop. Ubuntu / Debian tienen una muy buena comunidad y documentación. Si necesitas solucionar un problema encontrarás ayuda. Por eso es importante saber en que familia se basa tu Distro, para buscar ayuda. Antes de empezar con cosas como multi o dual boot. Crea tu propia máquina virtual con el Linux que deseas probar. Así aprenderás algo sobre el proceso de instalación y el sistema de archivos.
Lo más difícil al principio de mis aventuras en Linux era entender dónde se almacenaban las cosas. Por ejemplo, el software de terceros normalmente se instala en el directorio opt. Complicado es también el sistema de permisos para archivos y directorios en ext3 / ext4. Este concepto no existe en el sistema de archivos FAT o NTFS de Windows. No te preocupes por eso. Durante tu trabajo diario te darás cuenta muy rápido de cómo va.
Microsoft Surface 3 PRO con Ubuntu
Cuando até la primera vez Ubuntu fue alrededor de 2010 donde canonical el distribuidor de Ubuntu introdujo por defecto el Escritorio UNITY. No me gusto porque contiene mucha publicidad y Apps no deseadas como Spotify y Facebook. Me enteré que Ubuntu tiene una Versión con un Clon de Gnome Dektop llamado Mate. Decidí probar y me gustó desde el primer momento. Después de la primera Instalación en mi Laptop en 2015 me fue necesario hasta 2023 solo 2 veces instalar Ubuntu nuevo en mi sistema. Las razones fueron que reemplacé mi SSD interno primero a 1 TB más tarde a 2TB. No hay problemas que los sistemas más lento o el disco en mal estado con archivos huérfanos. No hay limpieza regular y tareas de servicio como son comunes en las ventanas. El sistema simplemente funcionaba estable sin fallos graves. Tampoco tuve ningún problema con los controladores de hardware. AL mis nuevos componentes siempre fueron detectados correctamente desde linux y a menudo existen pequeñas herramientas de administración. Stremdeck UI o Noson para Sonos Speaker por ejemplo. Cuando conseguí mi nuevo portátil en diciembre de 2023 decidí pasar de Ubuntu al original. Porque Ubuntu está hecho por una empresa y a menudo deciden seguir su propio camino. Quién sabe si en el futuro se transforman a un comportamiento de Microsoft. Prefiero siempre hacer mi transición temprano sin presión para estar preparado antes de que no tengo otra opción.
Por supuesto que uso un Antivirus y un Firewall en mi sistema. Porque Linux no está libre contra los malos ataques, así que también hay necesidades de protección.
Mucha gente se equivoca al cambiar de Microsoft Office a Libre Office. El verdadero secreto para no perder el diseño es tener cuidado con las fuentes. Cuando tus documentos originales de MS Office usan las fuentes por defecto de Microsoft, necesitas instalarlas también en tu máquina Linux para no destruir el diseño de los documentos de Office.
Para mi no hay necesidad de volver a Windows. Bueno, yo no soy un jugador, pero también para este existen muchas soluciones. Steam también está disponible en Linux. La mayoría de las personas que conozco ya ni siquiera juegan en PC o portátiles, prefieren consolas como PlayStation. Para mi Linux es genial porque tengo control total sobre mi sistema, es gratis y puedo personalizarlo como quiera. Si tienes un viejo portátil que ya no funciona con Windows, prueba a instalar Linux y disfruta.
Linux se convierte cada vez más en un sistema operativo popular para los profesionales de TI. Una de las razones de este movimiento son las soluciones de servidor. La estabilidad y el bajo consumo de recursos son algunas de las características importantes para esta elección. Si ya ha jugado con un servidor Microsoft, echará de menos el escritorio gráfico de un servidor Linux. Después de un inicio de sesión en un servidor Linux sólo se ve el símbolo del sistema está a la espera de sus entradas.
En este breve artículo te presento algunos programas útiles de Linux para trabajar con archivos en la línea de comandos. Esto te permite recopilar información, por ejemplo, de archivos de registro. Antes de empezar me gustaría recomendarte un sencillo y potente editor llamado joe.
Ctrl + C – Abortar la edición actual de un fichero sin guardar los cambios Ctrl + KX – Salir de la edición actual y guardar el archivo Ctrl + KF – Buscar texto en el archivo actual Ctrl + V – Pegar el portapapeles en el documento (CMD + V para Mac) Ctrl + Y – Borrar la línea actual donde está el cursor
Para instalar joe en una distribución Linux basada en Debian basta con teclear:
1. Cuando necesite encontrar contenido en un archivo de texto enorme, GREP será su mejor amigo. GREP le permite buscar patrones de texto en archivos.
Cuando empecé con la programación dirigida por pruebas hace más de 10 años, conocía muchos conceptos diferentes en teoría. Pero este enfoque de escribir primero los casos de prueba y luego implementarlos no era, de alguna manera, la forma con la que me llevaba bien. Para ser honesto, este sigue siendo el caso hoy en día. Así que encontré una adaptación del paradigma TDD de Kent Beck que me funciona. Pero lo primero es lo primero. Quizás mi enfoque también sea bastante útil para unos u otros.
Originalmente provengo de entornos para aplicaciones web altamente escalables a las que todas las grandes teorías de la universidad no pueden aplicarse fácilmente en la práctica. La razón principal es la gran complejidad de dichas aplicaciones. Por un lado, varios sistemas adicionales como la caché en memoria, la base de datos y la gestión de identidades y accesos (IAM) forman parte del sistema global. Por otro lado, muchos marcos modernos como OR Mapper ocultan la complejidad tras diferentes capas de acceso. Como desarrolladores, necesitamos dominar todas estas cosas. Por eso existen soluciones robustas y probadas en la práctica que son bien conocidas pero que rara vez se utilizan. Kent Beck es una de las voces más importantes a favor del uso práctico de las pruebas automatizadas de software.
Si queremos involucrarnos en el concepto de TDD, es importante no dar demasiada importancia a cada personaje. No todo está escrito en piedra. Lo importante es el resultado al final del día. Por ello, es esencial tener presente el objetivo de todos los esfuerzos para lograr un valor añadido personal. Así que empecemos por ver qué queremos conseguir en primer lugar.
El éxito nos da la razón
Cuando empecé como desarrollador, necesitaba un feedback constante sobre si lo que estaba montando funcionaba realmente. La mayoría de las veces generaba esta retroalimentación esparciendo durante mi implementación innumerables salidas de consola, por un lado, y por el otro siempre intentaba integrar todo en una interfaz de usuario y luego ‘hacer clic’ manualmente. Básicamente una configuración de prueba muy engorrosa, que luego tiene que ser eliminada de nuevo al final. Si más tarde había que hacer correcciones de errores, todo el procedimiento comenzaba de nuevo. Todo resultaba en cierto modo insatisfactorio y muy alejado de una forma productiva de trabajar. Había que mejorar esto de alguna manera sin tener que reinventarse cada vez.
Por último, mi enfoque original tiene exactamente dos puntos débiles importantes. El más obvio es la entrada y salida de información de depuración a través de la consola.
Pero el segundo punto es mucho más grave. Porque todo el conocimiento adquirido sobre esta implementación en particular no se conserva. Por lo tanto, corre el riesgo de desvanecerse con el tiempo y, en última instancia, perderse. Sin embargo, estos conocimientos especializados son muy valiosos para muchas fases posteriores del proceso de desarrollo de software. Con esto me refiero explícitamente al tema de la calidad. La refactorización, las revisiones de código, las correcciones de errores y las solicitudes de cambio son sólo algunos de los posibles ejemplos en los que se requieren conocimientos detallados en profundidad.
Personalmente, el trabajo monótono y repetitivo me cansa rápidamente y me gustaría evitarlo. Pasar una y otra vez por una aplicación con el mismo procedimiento de prueba está muy lejos de lo que para mí constituye una jornada laboral satisfactoria. Quiero descubrir cosas nuevas. Pero sólo puedo hacerlo si no estoy atrapado en el pasado.
Pero antes de entrar en cómo he condimentado mi trabajo diario de desarrollo con TDD, tengo que decir unas palabras sobre la responsabilidad y la valentía. En conversaciones, otras personas me han dicho con frecuencia que tengo razón, pero que no pueden tomar medidas para seguir mis recomendaciones porque el jefe de proyecto o algún otro superior no da luz verde.
Esa actitud me parece muy poco profesional. No le pregunto a un director de marketing qué algoritmo termina siendo el mejor. Simplemente no tiene ni idea de lo que estoy hablando, porque no es su área de responsabilidad. Un jefe de proyecto que hable en contra del trabajo basado en pruebas en el equipo de desarrollo también ha perdido su trabajo. Hoy en día, los marcos de pruebas están tan bien integrados en el entorno de compilación que incluso las personas sin experiencia pueden preparar TDD en cuestión de momentos. Por lo tanto, no es necesario darle demasiada importancia. Puedo prometer que incluso los primeros intentos no llevarán más tiempo que con el enfoque original. Al contrario, habrá un notable aumento de la productividad muy rápidamente.
La primera etapa de la evolución
Como ya he mencionado, el registro es una parte central del desarrollo basado en pruebas para mí. Siempre que tiene sentido, intento mostrar el estado de los objetos o variables en la consola. Si utilizamos los medios que nos proporciona el lenguaje de programación empleado para ello, esto significa que al menos debemos comentar esta salida del sistema una vez realizado el trabajo y volver a comentarla más tarde cuando busquemos errores. Un procedimiento redundante y propenso a errores.
Si, por el contrario, utilizamos un marco de logging desde el principio, podemos dejar tranquilamente la información de depuración en el código y desactivarla más tarde en el funcionamiento productivo mediante la configuración del nivel de log.
También utilizo el logging como trazador. Esto significa que cada constructor de una clase escribe una entrada de registro correspondiente por la información de nivel de registro mientras está siendo llamado. Esto me permite ver el orden en que se instancian los objetos. De vez en cuando también me he dado cuenta de la instanciación excesivamente frecuente de un mismo objeto. Esto es útil para las medidas de rendimiento y optimización de memoria.
Registro los errores que se lanzan durante el manejo de excepciones como errores o advertencias, dependiendo del contexto. Esta es una herramienta muy útil para localizar errores más adelante en la operación.
Así que si tengo un acceso a la base de datos, escribo una salida de registro en la depuración de nivel de registro como el SQL asociado fue montado. Si este SQL conduce a una excepción porque contiene un error, esta excepción se escribe con el error de nivel de registro. Si, por el contrario, se realiza una simple consulta de búsqueda con una sintaxis SQL correcta y el conjunto de resultados está vacío, este evento se clasifica como Debug o Warning, en función de las necesidades. Por ejemplo, si se trata de una solicitud de inicio de sesión con un nombre de usuario o una contraseña incorrectos, suelo optar por el nivel de registro Advertencia, ya que puede contener aspectos relacionados con la seguridad durante el funcionamiento.
En el contexto general, tiendo a configurar el registro para la ejecución del caso de prueba de forma muy locuaz y me limito a una salida de consola pura. Durante el funcionamiento, la información de registro se escribe en un archivo de registro.
El huevo o la gallina
Una vez que hemos sentado las bases para un bucle de retroalimentación adicional con el registro, el siguiente paso es decidir qué hacer a continuación. Como ya he mencionado, me resulta muy difícil escribir primero un caso de prueba y luego encontrar una implementación adecuada para él. Muchos otros desarrolladores que empiezan con TDD también se enfrentan a este problema.
Una cosa que ya puedo anticipar es el problema de asegurarse de que una implementación es comprobable. Una vez que tengo el caso de prueba, inmediatamente me doy cuenta de si lo que estoy creando es realmente comprobable. Los desarrolladores TDD experimentados han aprendido rápidamente en carne y hueso cómo debe ser el código comprobable. El punto más importante aquí es que los métodos siempre deben tener un valor de retorno que preferiblemente no sea nulo. Esto se puede conseguir, por ejemplo, devolviendo una lista vacía en lugar de null.
El requisito de tener un valor de retorno se debe a la forma en que funcionan los marcos de pruebas unitarias. Un caso de prueba compara el valor de retorno de un método con un valor esperado. La aserción de prueba tiene diferentes características y por lo tanto puede ser: igual, desigual, verdadero o falso. Por supuesto, aquí también hay diferentes variaciones. Por ejemplo, es posible probar métodos que no tienen valor de retorno utilizando excepciones. Todos estos detalles se aclaran en muy poco tiempo durante el uso de TDD. De modo que todo el mundo puede empezar inmediatamente sin largas preparaciones.
Al leer el libro Test Driven Development by Example de Kent Beck, también encontramos rápidamente una explicación de por qué los casos de prueba deben escribirse primero. Se trata de un factor psicológico. Debería ayudarnos a sobrellevar mejor el estrés habitual que surge en el proyecto. Crea en nosotros un estado mental sobre el estado y el progreso del trabajo actual. Nos guía en un proceso iterativo para ampliar y mejorar paso a paso la solución existente a través de los distintos casos de prueba.
Para quienes, como yo, no tienen una idea concreta del resultado final al inicio de una aplicación, este enfoque es difícil de aplicar. El efecto previsto de relajación se convierte en negativo. Como todos los seres humanos somos diferentes, tenemos que averiguar qué es lo que nos hace funcionar para conseguir el mejor resultado posible. Lo mismo ocurre con las estrategias de aprendizaje. Algunas personas procesan mejor la información visualmente, otras de forma más háptica y otras extraen todo lo importante de las palabras habladas. Así que intentemos no doblegarnos contra nuestra naturaleza para producir resultados mediocres o pobres.
Trazar la primera línea
Un tema sólo se me aclara mientras trabajo en él. Así que pruebo a ponerlo en práctica hasta que necesito un primer feedback. Es entonces cuando escribo la primera prueba. Este enfoque da lugar automáticamente a preguntas, cada una de las cuales merece su propio caso de prueba. ¿Puedo encontrar todos los resultados disponibles? ¿Qué ocurre si el conjunto de resultados está vacío? ¿Cómo se puede reducir el conjunto de resultados? Todas estas cuestiones pueden anotarse en un papel y marcarse paso a paso. La idea de anotar en un papel una lista de tareas pendientes la tuve mucho antes de que apareciera en el libro de Kent Beck mencionado anteriormente. Me ayuda a conservar pensamientos rápidos sin distraerme de lo que estoy haciendo en ese momento. También me da una sensación de logro al final del día.
Dado que no espero hasta que he implementado todo para escribir la primera prueba, este enfoque también da lugar a un enfoque iterativo. También me doy cuenta muy rápidamente si mi diseño no es suficientemente comprobable, ya que recibo feedback inmediato. Esto da lugar a mi propia interpretación de TDD, que se caracteriza por el cambio permanente entre la implementación y la escritura de pruebas.
Como resultado de mis primeros intentos de TDD, ya noté una aceleración de mis métodos de trabajo en la primera semana. También adquirí más confianza. Pero mi forma de programar también empezó a cambiar muy pronto. He notado que mi código se ha vuelto más compacto y robusto. Cosas que sólo se habían hecho evidentes con el tiempo surgieron durante actividades como la refactorización y las ampliaciones. Los casos de prueba fallidos me han salvado de sorpresas desagradables.
Empezar sin exceso de celo
Si decidimos utilizar TDD en un proyecto existente, es una mala idea empezar a escribir casos de prueba para la funcionalidad existente. Aparte del tiempo que hay que planificar para ello, el resultado no cumplirá las altas expectativas.
Uno de los problemas es que ahora hay que familiarizarse con cada funcionalidad y esto lleva mucho tiempo. La calidad de los casos de prueba resultantes también es inadecuada. El problema también surge de la falta de experiencia. Cuando se empieza a acumular experiencia, la calidad de los casos de prueba tampoco es óptima y es posible que haya que reescribir el código para que se pueda probar. Esto crea muchos riesgos que son problemáticos para el día a día del proyecto.
Un procedimiento probado para introducir TDD es simplemente utilizarlo para la implementación actual en la que se está trabajando. El estado actual del problema actual se documenta mediante pruebas automatizadas. Como ya estás en territorio conocido, no tienes que familiarizarte con un tema nuevo, así que puedes concentrarte plenamente en formular pruebas significativas. Aparte del hecho de que asumes la responsabilidad del trabajo de otras personas sin que te lo pidan cuando implementas casos de prueba para ellos.
La funcionalidad existente sólo se complementa con casos de prueba cuando se corrigen errores. Para la corrección, hay que ocuparse de todos modos de los detalles de implementación, de modo que aquí se sabe lo suficiente sobre cómo debe comportarse una funcionalidad. Las pruebas resultantes también documentan la corrección y garantizan que el comportamiento no cambie en el futuro durante los trabajos de optimización.
Si sigue este procedimiento de forma disciplinada, no se perderá en la llamada actividad frenética, que a su vez es lo contrario de la productividad. Además, adquirirá rápidamente conocimientos sobre cómo implementar pruebas eficaces y significativas. Sólo cuando se haya adquirido suficiente experiencia y, posiblemente, se planifique una amplia refactorización, podrá plantearse cómo mejorar gradualmente la cobertura de las pruebas para todo el proyecto.
Nivel de calidad
Que haya casos de prueba disponibles no significa que sean significativos. Una cobertura de pruebas elevada tampoco demuestra que un programa no contenga errores. Una cobertura de pruebas alta sólo garantiza que un programa se comporta dentro del ámbito de las pruebas.
Entonces, ¿cómo asegurarse de que las pruebas existentes suponen realmente un enriquecimiento y tienen un buen valor informativo? El primer punto, y en mi opinión el más importante, es que los casos de prueba sean lo más breves posible. En concreto, esto significa que una prueba sólo responde a una pregunta explícita, por ejemplo: ¿Qué ocurre si el conjunto de resultados está vacío? El método de prueba se denomina en función de la pregunta. El valor añadido de este enfoque surge cuando el caso de prueba falla. Si la prueba es muy corta, a menudo es posible saber a partir del método de prueba cuál es el problema sin tener que dedicar mucho tiempo a familiarizarse con un caso de prueba.
Otro punto importante en el procedimiento TDD es comprobar la cobertura de la prueba para las líneas de código, así como para las ramas de mi funcionalidad implementada. Si, por ejemplo, no puedo simular la ocurrencia de una sola condición en una sentencia IF, esta condición se puede eliminar sin dudarlo.
Por supuesto, también tiene bastantes dependencias de bibliotecas externas en su propio proyecto. Ahora puede ocurrir que un método de esta librería lance una excepción que no pueda ser simulada por ningún caso de prueba. Esta es exactamente la razón por la que deberías esforzarte por conseguir una alta cobertura de pruebas, pero no desesperar si no se puede alcanzar el 100%. Especialmente cuando se introduce TDD, una buena medida de cobertura de pruebas superior al 85% es habitual. A medida que el equipo de desarrollo adquiere experiencia, este valor puede incrementarse hasta el 95%.
Por último, sin embargo, hay que tener en cuenta que no hay que dejarse llevar demasiado. Porque puede convertirse rápidamente en excesivo y entonces todas las ventajas obtenidas se pierden rápidamente. La cuestión es que no escribas pruebas que a su vez prueben pruebas. Aquí es donde el gato se muerde la cola. Esto también se aplica a las bibliotecas de terceros. Tampoco se escriben pruebas para ellas. Kent Beck es muy claro al respecto: “Aunque haya buenas razones para desconfiar del código ajeno, no lo pruebes. El código externo requiere más de tu propia lógica de implementación”.
Lecciones aprendidas
Las lecciones que se pueden aprender cuando se intenta conseguir la mayor cobertura de pruebas posible son las que repercutirán en la programación futura. El código se vuelve más compacto y robusto.
La productividad aumenta simplemente porque se evita el trabajo monótono y propenso a errores gracias a la automatización. No hay pasos de trabajo adicionales porque los viejos hábitos se sustituyen por otros nuevos y mejores.
Un efecto que he observado una y otra vez es que cuando miembros individuales del equipo han optado por TDD, sus éxitos se reconocen rápidamente. En pocas semanas, todo el equipo había desarrollado el TDD. Cada uno según sus capacidades. Algunos con Test First, otros como acabo de describir. Al final, lo que cuenta es el resultado y era uniformemente excelente. Cuando el trabajo es más fácil y al final del día cada individuo tiene la sensación de que también ha conseguido algo, esto da al equipo un enorme impulso de motivación, lo que da al proyecto y al ambiente de trabajo un enorme impulso. ¿A qué espera? Pruébelo usted mismo ahora mismo.
Los nuevos términos y condiciones de los servicios de Microsoft publicados en octubre de 2023 causaron indignación en el mundo de la informática. El motivo fue un párrafo en el que se afirmaba que todos los servicios de Microsoft se basan ahora en la inteligencia artificial. Se supone que esta inteligencia artificial se utilizará para reconocer las infracciones de los derechos de autor. Esto incluye música, películas, gráficos, libros electrónicos y, por supuesto, software. Si esta inteligencia artificial detecta infracciones de los derechos de autor en el sistema, estos archivos se eliminarán automáticamente del “sistema”. Por el momento no está claro si esta norma se aplica al propio disco duro local del usuario o sólo a los archivos en la nube de Microsoft. Microsoft también ha declarado que los usuarios que infrinjan las normas sobre derechos de autor serán excluidos de todos los servicios de Microsoft en el futuro.
Esta exclusión tiene varios “sabores”. Las primeras preguntas que vienen a la mente son: ¿Qué ocurre con los planes de pago como Skype? ¿Me bloquearán y luego me devolverán el crédito no utilizado? Un escenario aún peor sería que también podría perder todo mi crédito y mis compras digitales, como el acceso a juegos y otras cosas. ¿O no se verán afectadas las suscripciones de pago? Hasta ahora esta parte no está clara.
Si eres usuario de Apple y crees que esto no te afecta, asegúrate de no utilizar un servicio de Microsoft que no sepas que pertenece a Microsoft. No todos los productos llevan el nombre de la empresa. Piénselo, porque quién sabe si estos productos están espiando su sistema. Algunas aplicaciones como Skype, Teams, Edge Browser y Visual Studio Code también están disponibles para otras plataformas como Apple y Linux.
Microsoft también es propietaria de la plataforma de alojamiento de código fuente GitHub y de una red social para especialistas llamada LinkedIn. Con Office 360, puedes utilizar todo el paquete de Microsoft Office a través del navegador web como una solución en la nube y todos tus documentos se almacenan en la nube de Microsoft. La misma nube en la que instituciones gubernamentales estadounidenses como la CIA, la NSA y muchas otras almacenan sus archivos. Parece ser un lugar seguro para todos tus pensamientos escritos en un documento de Office.
Este pequeño detalle sobre los documentos de Office nos lleva a una pequeña nota al margen en los nuevos términos y condiciones de Microsoft. La lucha contra la incitación al odio. Signifique lo que signifique. El insulto público y la difamación siempre han sido tratados estrictamente como un delito penal por la ley. No se trata de un delito trivial castigado con una pequeña multa. Así que no me queda claro qué significa toda esta charla sobre el discurso del odio. Quizá sea un intento de introducir la censura pública de la libertad de expresión.
Pero volvamos a la nota al margen de las condiciones de uso de Microsoft sobre la incitación al odio. Microsoft ha escrito algo como Si se detecta incitación al odio, se advertirá al usuario y, si las infracciones se producen más de una vez, se desactivará la cuenta Microsoft del usuario.
Si crees que esto es sólo algo que está ocurriendo ahora de la mano de Microsoft, ten por seguro que muchas otras empresas están trabajando para introducir servicios equivalentes. La plataforma de comunicaciones Zoom, por ejemplo, también incluye técnicas de Inteligencia Artificial para supervisar las comunicaciones de los usuarios con “fines formativos”.
Con todas estas novedades, hay una gran pregunta que necesita respuesta: ¿Qué puedo hacer yo mismo? La respuesta es sencilla. Abandone el universo digital y vuelva al mundo real. Vuelva a encender su cerebro. Utiliza papel y bolígrafo, paga en efectivo, deja el smartphone en casa y nunca en la mesilla de noche. Si no lo usas, ¡apágalo! Queda con tus amigos físicamente siempre que sea posible y luego no lleves el smartphone. No habrá gobierno, ni presidente, ni mesías que traiga el cambio. Depende de nosotros hacerlo.












 Unlock with Patreon
Unlock with Patreon



