
Der sichere Umgang mit Source Control Management (SCM) Systemen wie Git ist für Programmierer (Development) und auch Systemadministratoren (Operations) essenziell. Diese Gruppe von Werkzeugen hat eine lange Tradition in der Softwareentwicklung und versetzt Entwicklungsteams in die Lage, gemeinsam an einer Codebasis zu arbeiten. Dabei werden vier Fragen beantwortet: Wann wurde die Änderung gemacht? Wer hat die Änderung vorgenommen? Was wurde geändert? Warum wurde etwas geändert? Es ist also ein reines Kollaborationswerkzeug.
Mit dem Aufkommen der Open Source Code Hosting Plattform GitHub wurden sogenannte Pull Requests eingeführt. Pull Requests ist in GitHub ein Workflow, der es Entwicklern erlaubt, Codeänderungen für Repositories bereitzustellen, auf die sie nur lesenden Zugriff haben. Erst nachdem der Besitzer des originalen Repositories die vorgeschlagenen Änderungen überprüft und für gut befunden hat, werden diese Änderungen von ihm übernommen. So setzt sich auch die Bezeichnung zusammen. Ein Entwickler kopiert sozusagen das originale Repository in seinen GitHub Arbeitsbereich, nimmt Änderungen vor und stellt an den Inhaber des originalen Repositories eine Anfrage, die Änderung zu übernehmen. Dieser kann dann die Änderungen übernehmen und gegebenenfalls noch selbst anpassen oder mit einer Begründung zurückweisen.
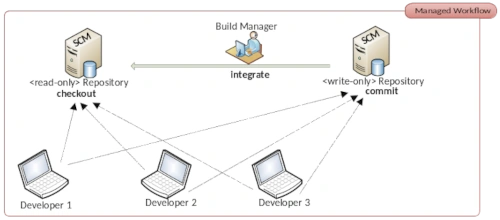
Wer nun glaubt, dass GitHub besonders innovativ war, der irrt. Denn dieser Prozess ist in der Open Source Community ein ‚sehr‘ alter Hut. Ursprünglich nennt man dieses Vorgehen Dictatorship Workflow. Das 1990 zum ersten Mal veröffentlichte kommerzielle SCM Rational Synergy von IBM basiert genau auf dem Dictarorship Workflow. Mit der Klasse der verteilten Versionsverwaltungswerkzeuge, zu denen auch Git gehört, lässt sich der Dictatorship Worflow recht einfach umsetzen. Also lag es auf der Hand das GitHub diesen Prozess seinen Nutzern auch zur Verfügung stellt. Lediglich die Namensgebung ist von GitHub weitaus ansprechender gewählt. Wer beispielsweise mit der freien DevOps Lösung GitLab arbeitet, kennt Pull Requests unter der Bezeichnung Merge Requests. Mittlerweile enthalten die gängigsten Git-Server den Prozess der Pull Requests. Ohne zu sehr auf die technischen Details zur Umsetzung der Pull Request einzugehen, richten wir unsere Aufmerksamkeit auf die üblichen Probleme mit denen Open Source Projekte konfrontiert sind.
Entwickler, die sich an einem Open Source Projekt beteiligen möchten, werden Maintainer genannt. Nahezu jedes Projekt hat eine kleine Anleitung, wie man das entsprechende Projekt unterstützen kann und welche Regeln gelten. Für Personen, die das Programmieren erlernen, eignen sich Open Source Projekte hervorragend, um die eigenen Fähigkeiten schnell signifikant zu verbessern. Das bedeutet für das Open Source Projekt, dass man Maintainer mit den unterschiedlichsten Fähigkeiten und Erfahrungsschatz hat. Wenn man also keinen Kontrollmechanismus etabliert, erodiert die Codebasis in sehr kurzer Zeit. Wenn das Projekt nun recht groß ist und sehr viele Mainatainer auf der Codebasis agieren, ist es für den Inhaber des Repositories kaum noch möglich, alle Pull Requests zeitnahe zu bearbeiten. Um diesem Bottelneck entgegenzuwirken, wurde der Dictatorship Workflow zum Dictatorship – Lieutenant Workflow erweitert. Es wurde also eine Zwischeninstanz eingeführt, mit der die Überprüfung der Pull Requests auf mehrere Schultern verteilt wird. Diese Zwischenschicht, die sogenannten Lieutenants sind besonders aktive Maintainer mit einer bereits etablierten Reputation. Somit braucht der Dictator nur noch die Pull Requests der Lieutenants zu reviewen. Eine ungemeine Arbeitsentlastung, die sicherstellt, dass es zu keinem Feature Stau durch nicht abgearbeitete Pull Requests kommt. Schließlich sollen die Verbesserungen beziehungsweise die Erweiterungen so schnell wie möglich in die Codebasis aufgenommen werden, um dann im nächsten Release den Nutzern zur Verfügung zu stehen.
Dieses Vorgehen ist bis heute der Standard in Open Source Projekten, um Qualität gewährleisten zu können. Man kann ja nie sagen, wer sich alles am Projekt beteiligt. Möglicherweise mag es ja auch den ein oder anderen Saboteur geben. Diese Überlegung ist nicht so abwegig. Unternehmen, die für ihr kommerzielles Produkt eine starke Konkurrenz aus dem feien Open Source Bereich haben, könnten hier auf unfaire Gedanken kommen, wenn es keine Reglementierungen geben würde. Außerdem lassen sich Maintainer nicht disziplinieren, wie es beispielsweise für Teammitglieder in Unternehmen gilt. Einem beratungsresistenten Maintainer, der sich trotz mehrfachen Bitten nicht an die Vorgaben des Projektes hält, kann man schwer mit Gehaltskürzungen drohen. Einzige Handhabe ist diese Person vom Projekt auszuschließen.
Auch wenn das gerade beschriebene Problem der Disziplinierung von Mitarbeitern in kommerziellen Teams kein Problem darstellt, gibt es in diesen Umgebungen ebenfalls Schwierigkeiten, die es zu meistern gilt. Diese Probleme rühren noch aus den Anfängen von Visualisierungswerkzeugen. Denn die ersten Vertreter dieser Spezies waren keine verteilten Lösungen, sondern zentralisiert. CVS und Subversion (SVN) halten auf dem lokalen Entwicklungsrechner immer nur die letzte Revision der Codebasis. Ohne Verbindung zum Server kann man faktisch nicht arbeiten. Bei Git ist dies anders. Hier hat man eine Kopie des Repositories auf dem eigenen Rechner, sodass man seine Arbeiten lokal in einem separaten Branch durchführt und wenn man fertig ist, bringt man diese Änderungen in den Hauptentwicklungszweig und überträgt diese dann auf den Server. Die Möglichkeit, offline Branches zu erstellen und diese lokal zu mergen hat einen entscheidenden Einfluss auf die Stabilität der eigenen Arbeit, wenn das Reopsitory in einen inkonsistenten Zustand gerät. Denn im Gegensatz zu zentralisierten SCM Systemen kann man nun weiter arbeiten, ohne darauf warten zu müssen, dass der Hauptentwicklungszweig repariert wurde.
Diese Inkonsistenten entstehen sehr leicht. Es genügt nur eine Datei beim Commit zu vergessen und schon können die Teamkollegen das Projekt nicht mehr lokal kompilieren und sind in der Arbeit behindert. Um diesem Problem Herr zu werden, wurde das Konzept Continuous Integration (CI) etabliert. Es handelt sich dabei nicht, wie oft fälschlicherweise angenommen, um die Integration verschiedener Komponenten zu einer Anwendung. Die Zielstellung bei CI ist die Commit Satge – das Code Repository – in einem konsistenten Zustand zu halten. Dazu wurden Build Server etabliert, die in regelmäßigen Abständen das Repository auf Änderungen überprüfen, um dann den aus dem Quelltext das Artefakt bauen. Ein sehr beliebter und seit vielen Jahren etablierter Build-Server ist Jenkins. Jenkins ging ursprünglich aus dem Projekt Hudson als Abspaltung hervor und übernahm mittlerweile viele weitere Aufgaben. Deswegen ist es sehr sinnvoll, diese Klasse von Tools als Automatisierungsserver zu bezeichnen.
Mit diesem kleinen Abriss in die Geschichte der Softwareentwicklung verstehen wir nun die Probleme von Open Source Projekten und kommerzieller Softwareentwicklung. Dazu haben wir die Entstehungsgeschichte der Pull Request besprochen. Indessen kommt es in kommerziellen Projekten sehr oft vor, dass Teams durch das Projektmanagement gezwungen werden mit Pull Requests zu arbeiten. Für einen Projektleiter ohne technisches Hintergrundwissen klingt es nun sehr sinnvoll, in seinem Projekt ebenfalls Pull Requests zu etablieren. Schließlich hat er die Idee, dass er somit die Codequalität verbessert. Leider ist das aber nicht der Fall. Das Einzige was passiert ist ein Feature Stau zu provozieren und eine erhöhte Auslastung des Teams zu erzwingen, ohne die Produktivität zu verbessern. Denn der Pull Request muss ja von einer kompetenten Person inhaltlich bewertet werden. Das verursacht bei großen Projekten unangenehme Verzögerungen.
Nun erlebe ich es oft, dass argumentiert wird, man könne die Pull Requests ja automatisieren. Das heißt, der Build Server nimmt den Branch, mit dem Pull Request versucht diesen zu bauen und im Fall dass das Kompilieren und die automatisierten Tests erfolgreich sind, versucht der Server die Änderungen in den Hauptentwicklungszweig zu übernehmen. Möglicherweise sehe ich da etwas falsch, aber wo ist die Qualitätskontrolle? Es handelt sich um einen einfachen Continuous Integration Prozess, der die Konsistenz des Repositories aufrechterhält. Da Pull Requests vornehmlich im Git Umfeld zu finden sind, bedeutet ein kurzzeitig inkonsistentes Repository kein kompletten Entwicklungstop für das gesamte Team, wie es bei Subversion der Fall ist.

Interessant ist auch die Frage wie man bei einem automatischen Merge mit semantischen Mergekonflikten umgeht. Die per se kein gravierendes Problem sind. Sicher führt das zur Ablehnung des Pull Requests mit entsprechender Nachricht an den Entwickler, um das Problem mit einem neuen Pull Request zu lösen. Ungünstige Branchstrategien können hier allerdings zu unverhältnismäßigen Mehraufwand führen.
Für die Verwendung von Pull Requests in kommerziellen Softwareprojekten sehe ich keinen Mehrwert, weswegen ich davon abrate, in diesem Kontext Pull Request zu verwenden. Außer einer Verkomplizierung der CI / CD Pipeline und einem erhöhten Ressourcenverbrauch des Automatisierungsservers, der nun die Arbeit doppelt macht, ist nichts passiert. Die Qualität eines Softwareprojektes verbessert man durch das Einführen von automatisierten Unit-Tests und einem testgetriebenen Vorgehen bei der Umsetzung von Features. Hier ist es notwendig, die Testabdeckung des Projekts kontinuierlich im Auge zu behalten und zu verbessern. Statische Codeanalyse und das Aktivieren von Compilerwarnings bringen mit erheblich weniger Aufwand bessere Ergebnisse.
Ich persönlich vertrete die Auffassung, dass Unternehmen, die auf Pull Requests setzen, diese entweder für ein verkompliziertes CI nutzen oder ihren Entwicklern komplett misstrauen und ihnen in Abrede stellen, gute Arbeit abzuliefern. Natürlich bin ich offen für eine Diskussion zum Thema, möglicherweise lässt sich dann eine noch bessere Lösung finden. Von daher freue ich mich über reichliche Kommentare mit euren Ansichten und Erfahrungen im Umgang mit Pull Requests.

