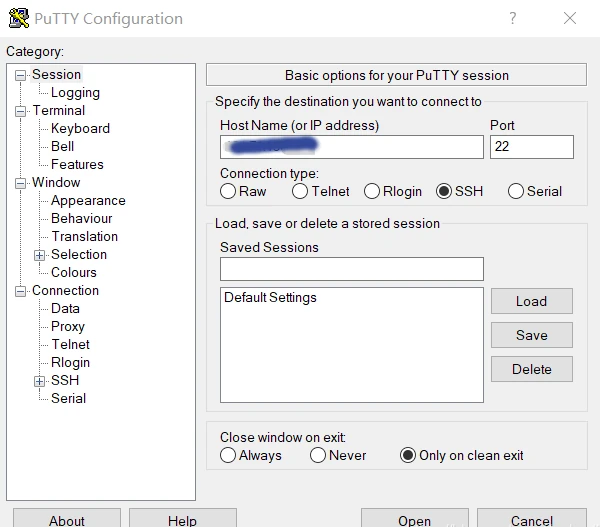
Die Verwaltung von Linux-Servern oder Docker-Containern erfordert grundlegende Kenntnisse des Terminals, auch bekannt als Kommandozeile. Windows-Benutzer können beispielsweise das Programm PuTTY verwenden, um über Secure Shell (SSH) Fernzugriff auf einen Linux Server zu erhalten. SSH ist eine sichere Fernverbindung, die eine verschlüsselte Terminalverbindung zu einem Linux-Rechner herstellt. SSH bietet zwei grundlegende Zugriffsarten auf ein entferntes System: die nicht empfohlene Methode mit Benutzername/Passwort und die sicherere Variante mit einem bereitgestellten RSA-Schlüsselpaar.
Per Definition sind „Terminal“ und „Shell“ nicht dasselbe, werden aber oft synonym verwendet. Im Allgemeinen ist das Terminal die Kommandozeilenschnittstelle (CLI), die Tastatureingaben von Benutzern empfängt. Die Shell ist ein Interpreter, der innerhalb des Terminals ausgeführt wird, um Programme zu starten. Bei den meisten Linux-Distributionen ist BASH (Bourne Again Shell) die Standard-System-Shell. Neben BASH gibt es weitere Shell-Varianten wie KornShell (ksh) oder C Shell (csh).
Beim Zugriff auf einen Rechner, sei es über eine Reverse Shell oder SSH, kann sich das Terminal ungewöhnlich verhalten. Häufige Probleme sind die Unfähigkeit, Text zu löschen, Strg+C oder Strg+L zu verwenden, und die fehlerhafte Textdarstellung. So verbessern Sie die Terminalnavigation.
Schritte für ein besseres Terminalerlebnis
1. Temporäres Skript starten
script /dev/null -c bash
Dies startet ein Skript, das sich automatisch löscht, da es auf /dev/null verweist.
2. Reverse Shell in den Hintergrund verschieben
Drücken Sie STRG+Z. Dadurch wird der Reverse-Shell-Prozess in den Hintergrund verschoben.
3. Prozess fortsetzen und stty konfigurieren
stty raw -echo; fg
Dies führt Sie zurück zum Prozess und passt das Terminal für Rohdateneingabe ohne Echo an.
4. Terminal zurücksetzen
reset xterm
Verwenden Sie diesen Befehl auch dann, wenn der Text nicht korrekt angezeigt wird oder ungewöhnliche Einrückungen vorhanden sind.
5. Umgebungsvariable TERM konfigurieren
export TERM=xterm
Überprüfen Sie die Variable $TERM vor und nach diesem Schritt mit echo $TERM.
Ersetzen Sie [tatsächliche Konsolenzeilennummer] und [tatsächliche Konsolenspaltennummer] durch die entsprechenden Werte, die Sie mit dem Befehl stty size in einer normalen Konsole ermitteln.
Sicherheitshinweis: Linux-Server, die über das Internet erreichbar sind, sollten weder die Anmeldung per Root-Benutzer noch per Benutzerpasswort ermöglichen. Das Problem besteht in verteilten Brute-Force-Angriffen von Botnetzen, die darauf abzielen, eine administrative Shell zu erlangen und das System zu kapern. Moderne, gehärtete Linux-Server deaktivieren daher das Root-Konto und stellen Administratoren lediglich den Befehl sudo zur Verfügung.
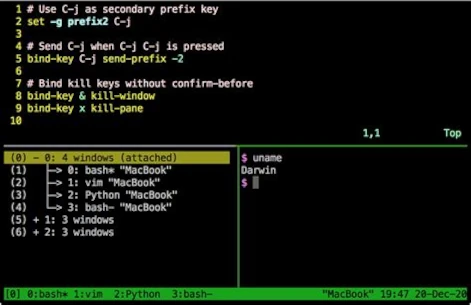
Administratoren, die mehrere geöffnete Shells verwalten müssen, um verschiedene Rechner zu warten, nutzen gerne das praktische Tool TMUX [1]. Es ist aktuell in Version 3 verfügbar und lässt sich einfach über die Shell installieren:
apt-get install tmux
TMUX ermöglicht die Nutzung mehrerer Terminal-Sitzungen in einem einzigen Terminal. Für die korrekte Verwendung konsultieren Sie bitte die offizielle Handbuchseite [2]. Die Bedienung des Programms ist etwas komplex und erfordert etwas Einarbeitungszeit. Eine kurze Einführung würde den Rahmen dieses Beitrags sprengen und einen eigenen Artikel füllen, der möglicherweise in Zukunft veröffentlicht wird. Um Ihnen einen Eindruck von den Möglichkeiten von TMUX zu vermitteln, sehen Sie sich den folgenden Screenshot an.
Eines der wichtigsten Erkenntnisse zum Softwaretesting stammt von dem viel zitierten Artikel „The Humble Programmer“, den Dijkstra 1972 veröffentlichte. Sinngemäß besagt dies, dass durch Testen lediglich Fehler nachgewiesen werden können, aber es ist unmöglich, die Fehlerfreiheit des Programms nachzuweisen. Das bedeutet im Umkehrschluss, dass eine hohe Testqualität bereits möglichst viele Fehler aufdeckt und damit die Wahrscheinlichkeit sinkt, dass im Programm weitere Fehler vorhanden sind.
Nun stellt sich zuerst die Frage, was eine ‚gute‘ Testqualität ausmacht. Ein sehr wichtiger Faktor ist die Performance. Dauert die Testausführung länger als 5 Minuten, stört dies den Entwickler im Arbeitsfluss. Dauert die Testausführung länger als 10 Minuten, ist die Akzeptanz der Entwickler verloren, die Tests automatisiert im Buildprozess durchlaufen zu lassen. Das führt dazu, dass die Testausführung lokal deaktiviert wird, damit das Prinzip, möglichst schnell im Fehlerfall zu scheitern, verletzt wird. Das Prinzip des schnellen Scheiterns ist einer der wichtigen Grundpfeiler automatisierter Softwaretests, denn so kann man sich zeitnah dem Problem widmen und es beheben. Diese schnelle Reaktion, ist es welche den Arbeitsfluss des Entwicklers unterstützt und dadurch den sogenannten Kontextwechsel vermeidet. Je weniger man sich auf eine neue Situation einstellen muss, umso produktiver kann man arbeiten, was als Konsequenz eine erhebliche Senkung der Entwicklungskosten ausmachen kann. Wir können sagen, dass nicht die Anzahl der Tests relevant ist, sondern es darauf ankommt, die richtigen, also relevanten Tests zu schreiben.
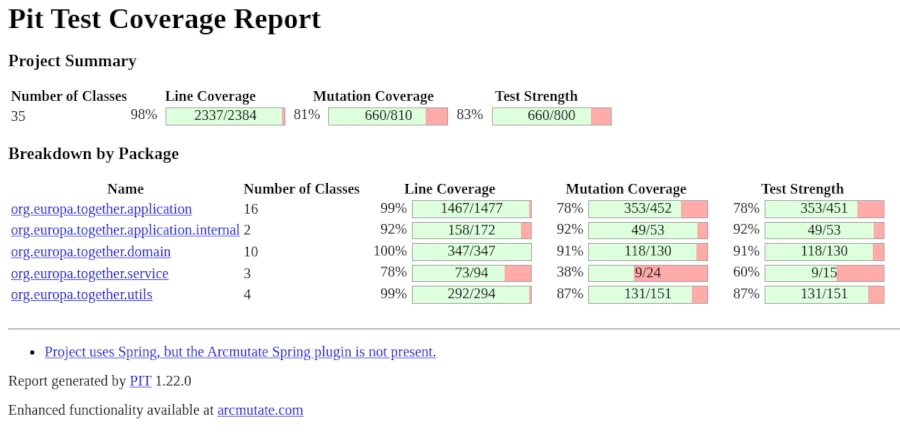
Eine Idee davon, wie viele Testfälle man benötigt, gibt die Arbeit von McCabe, welcher 1976 ein Maß für die Komplexität formulierte. Die Komplexitätszahl einer Funktion oder Methode stellt einen Orientierungspunkt für die Menge der benötigten Testfälle dar. Allerdings bedeutet eine hohe Anzahl von Testfällen nicht automatisch, dass diese eine Relevanz für die Korrektheit der Methode beziehungsweise Funktion haben. Der Nutzen oder, auch anders ausgedrückt, die Ausdruckskraft der vorhandenen Testfälle ergibt sich aus der Tatsache, wie gut diese den vorhandenen Code überdecken. Nur eine vollständige Coverage stellt sicher, dass auch alle Bereiche einer Funktion ausgeführt wurden und somit durch einen Festfall abgedeckt sind. Bei der Testcoverage unterscheiden wir zwei Metriken, die Abdeckung aller Codezeilen und die Abdeckung aller Verzweigungen. Sicher kann man vor allem in sogenannten Legacy-Projekten nur sehr schwer eine hohe Testabdeckung erreichen. Um den Aufwand aussagekräftiger Tests auf ein überschaubares Maß zu begrenzen, ist es notwendig, ausschließlich bei neu hinzugefügten Funktionen eine Line- und Branch Coverage von 100 % zu erreichen. Kann die 100 % nicht erreicht werden, ist dies ein Indikator für ein Refactoring, um die Testbarkeit der hinzugefügten Funktionalität zu gewährleisten.
Gehen wir nun vom optimalen Fall aus und betrachten ein sogenanntes Greenfield-Projekt, dessen Anzahl der Testfälle auch dem Komplexitätsmaß nach McCabe entspricht und für das wir bereits eine 100 % Testabdeckung für Zeilen und Verzweigungen nachweisen können, stehen wir immer noch vor dem Problem, das Dijkstra formuliert hat. Denn es muss uns bewusst sein, dass wir zwar nachweisen, alle Codbereiche durch einen Testfall betreten zu haben, aber ob die von uns getroffenen Annahmen über das Verhalten des Quellcodes korrekt sind, können wir nicht belegen. Im Kontext der xUnit Tests geht es um die verschiedenen Assert-Funktionen, welche eine Funktion gegen einen Erwartungswert testen. Dazu ein klassisches Beispiel für Java Collections, das sich auch auf andere Programmiersprachen projezieren lässt.
Listen, genauer gesagt: Die in Java implementierte ArrayList speichert die Elemente der Liste nicht als Wert in der Liste, sondern nutzt das sogenannte Call-by-Reference, welches lediglich die Speicheradresse des Listenelements referenziert. Führt man nun Operationen auf bestehenden Listen aus, manipuliert man stets die originale Liste. Vergleicht man dann in einem Testfall die originale Liste mit der manipulierten Liste, sind diese immer identisch, da es sich um dieselbe Liste handelt. Erst wenn man beispielsweise mit einem Copy-Konstruktor eine wirkliche Kopie des Originals erstellt, welche man manipuliert, um Vergleichstests durchzuführen, sind die getroffenen Annahmen korrekt. Überspitzt ausgedrückt, kann man eine 100 %-Testabdeckung erreichen, ohne ein wirkliches Sicherheitsnetz zur Fehlererkennung aufzuspannen.
Um solche logischen Fehler, wie gerade beschrieben, in den Tests zu entdecken, können wir uns des sogenannten Mutationstestings bedienen. Auch das Konzept des Mutationtesting hat seine Ursprünge bereits in den 1970er Jahren. Mit dem Artikel „Fault Diagnostics of Computer Programms“ beschrieb Richard Lipton 1971 die Idee zu Mutation-Testing, welches zahlreiche weitere Forschungsarbeiten nach sich zog.
Die Idee für Mutationstests ist sehr einfach, wie so viele bahnbrechende Errungenschaften. Gehen wir davon aus, das im Quellcode ein Ausdruck if(var > 0) enthalten ist und zu diesem Ausdruck auch ein entsprechender Test formuliert wurde. Wenn wir nun hergehen und die Bedingung in der IF Anweisung verändern, sollte der zugehörige Test fehlschlagen. Nun gibt es verschiedene Möglichkeiten, wie die IF-Anweisung verändert werden kann. Eine Variante ist die Umkehrung des Operators von > nach <. Aber auch die Verwendung anderer Operatoren wie = oder ! ist möglich. Eine andere Variante wäre, den Vergleichswert 0 abzuändern. Die erreicht man durch das Erhöhen oder Reduzieren um 1. Alle diese Variationen stellen sogenannte Mutationen des Originalausdrucks dar, weswegen man diese auch als Mutanten bezeichnen kann. Das Ziel ist, dass möglichst viele Mutanten den vorhandenen Testfall fehlschlagen lassen. Jeder Mutant, der den Testfall fehlschlagen lässt, wird als Kill bezeichnet.
Wenn keiner der erzeugten Mutanten den Testfall fehlschlagen lässt, ist die Korrektheit des Testfalls anzuzweifeln und muss überprüft werden. Idealerweise lassen alle Mutanten den Testfall fehlschlagen, was eher als Ausnahme zu werten ist. Aussagekräftige Testfälle sollten einen Mutationsscore von mindestens 70 % erreichen. Die Berechnung des Mutation Scors, oder auch der Kill Rate lautet wie folgt: Um den Mutationswert zu berechnen, teilt man die Anzahl der abgetöteten Mutanten (Mutanten, die zu einem Fehlschlag der Tests geführt haben) durch die Gesamtzahl der erzeugten Mutanten und multipliziert das Ergebnis mit 100, um einen Prozentsatz zu erhalten. Wenn beispielsweise 7 von 10 Mutanten abgetötet werden, beträgt der Mutationswert 70 %.
Manche Mutanten verhalten sich funktional identisch zum Originalcode. Diese äquivalenten Mutanten können durch keinen Test eliminiert werden, da sie keine eigentlichen Fehler darstellen. Damit haben wir ein Entscheidungskriterium, das bei niedrigem Mutations-Score und bei einer Bewertung der Situation weiterhelfen kann.
Auch wenn das hier beschriebene Konzept sehr leicht verständlich ist, liegt wie so oft der Teufel im Detail. Zum einen müssen sinnvolle Mutationsoperatoren ausgewählt und zum anderen sollte die Anzahl der generierten Mutanten aus Gründen der Testausführungsdauer begrenzt werden. Da je nach Größe der Codebasis die Ermittlung des Mutation Scores sehr langwierig sein kann, sollten Mutation-Tests nicht über den Standard Buildprozess ausgeführt werden und als eigenständige Testprozedur laufen. Grundsätzlich kann man allerdings sagen, dass Entwickler mit einem guten Verständnis für testgetriebene Softwareentwicklung sich auch zügig in das Thema Mutation Testing einfinden. Aber auch für die Bewertung seitens des Projektmanagements ist Mutant Testing in Kombination mit einer hohen Testcoverage ein sehr mächtiges Mittel, ohne den Quelltext zu lesen. Abschließend ist als sehr wichtiger Punkt anzumerken, dass die hier beschriebene Prozedur keine Aussage zu Fragestellungen der Sicherheit beantworten kann. Um sicherzustellen, dass die Anwendung gegen Hackerangriffe wie SQL Injections geschützt ist, sind auf Sicherheit spezialisierte Audits unvermeidlich.
Wer sich ernsthaft mit dem Thema Computersicherheit auseinandersetzt, kommt schnell zu dem Bereich Passwortsicherheit. Horrorgeschichten und Mythen lassen einen dann schnell glauben, man würde wie Don Quijote gegen Windmühlen kämpfen. Ganz unheikel ist der korrekte Umgang natürlich nicht, aber ganz so hilflos gegen potenzielle Angreifer, wie es auf den ersten Blick erscheinen mag, sind wir allerdings auch nicht.
Bevor wir in die Details eintauchen, ist es notwendig, dass uns eine wichtige Grundregel bewusst wird. Sicherheit und Komfort sind sich ausschließende Eigenschaften. Je besser das Sicherheitskonzept umgesetzt und auch erzwungen wird, umso unhandlicher wird es in der täglichen Benutzung. Deswegen ist es unausweichlich, einen sinnvollen und praktizierbaren Kompromiss aus Schutz und Anwendbarkeit umzusetzen. Also nähern wir uns dem Thema schrittweise, um mit falsch interpretiertem Halbwissen aufzuräumen.
Grundsätzlich unterscheiden wir zwei Anwendungsfälle. Authentifizierung soll sicherstellen, dass ich auch die Person bin, für die ich mich ausgebe. Autorisierung stellt sicher, dass ich nur die Aktionen durchführen darf, für die ich berechtigt bin. In diesem Artikel beschäftigen wir uns ausschließlich mit der Authentifizierung, also die Anmeldung auf einem Gerät oder zu einem Dienst.
Wenn wir einen Dienst oder auch ein Gerät, das wir benutzen, vor ungewolltem Zugriff schützen möchten, bringen wir sozusagen ein digitales Schloss an. Der Schlüssel für dieses Schloss ist unser Passwort. Wie im echten Leben gibt es auch in der digitalen Welt viele Analogien. Wenn wir Besuch von Freunden bekommen und diesen eine Kopie unseres Wohnungsschlüssels überlassen, hätten diese theoretisch die Möglichkeit, unbemerkt eine Kopie des Schlüssels anzufertigen, um unser Zuhause auch ohne unsere Zustimmung betreten zu können. Deswegen geben wir nur vertrauensvollen Menschen unseren Schlüssel. Mit dem Passwort, das wir für die Nutzung digitaler Dienste wie Streaming, Computerspiele oder sozialer Medien verwenden, ist es ähnlich. Stellen wir uns einmal vor, wir möchten eine Homepage und beauftragen jemanden, dies für uns umzusetzen. Damit die Homepage auch im Internet erreichbar wird, müssen einige Verträge für Server, Domain und möglicherweise auch zusätzliche Softwarelizenzen abgeschlossen werden. Wenn ich nun nicht das technische Wissen habe, diese Dinge selbst umzusetzen, benötige ich eine Person, der ich vertraue, die diese Aufgaben für mich übernimmt. Damit das auch gelingt, muss ich dieser Person meine Zugangsdaten für die technischen Systeme mitteilen. Solange ich mich mit dieser Person gut verstehe, ist das in aller Regel auch kein Problem. Kompliziert wird es erst dann, wenn aus irgendeinem Grund die Zusammenarbeit nicht mehr klappt. Dann sollte ich zumindest das technische Wissen besitzen, um meine Accounts zu kontrollieren und die Zugangsdaten zu ändern.
In diesem Beispiel sieht man auch ein anderes Problem. Hat man für alle Dinge, die man im Internet benutzt, dieselben Zugangsdaten, könnte nun diese Person auch mein E-Mail Postfach öffnen oder andere Dinge in meinem Namen in der digitalen Welt tun. Deswegen lautet die wichtigste Grundregel in der Computersicherheit: Benutze niemals dasselbe Passwort für mehrere Dienste. Es gibt natürlich noch viele andere Verhaltensregeln, die im Umgang mit Passwortsicherheit eingehalten werden sollten. Ich habe mir zu eigen gemacht, zwischen beruflichem und privatem Umfeld nicht zu unterscheiden. So wird mein Verhalten zu einer Gewohnheit und ich minimiere die Möglichkeit, Fehler zu machen.
Bevor wir uns aber überlegen, was überhaupt ein vernünftiges Passwort mit ausreichendem Schutz ist, müssen wir ein wichtiges Konzept kennenlernen. Und zwar geht es um die Möglichkeit, alle Kombinationen durchzuprobieren, bis man den richtigen Schlüssel gefunden hat. Dieses Konzept des schematischen Durchprobierens nennt man im IT-Jargon Brute Force. Wer also sein Fahrrad an einem unbeobachteten Ort mit einem Zahlenschloss, das ‚nur‘ vier Stellen hat, anschließt, schützt es nicht wirklich. Ein potenzieller Dieb muss nur beginnend mit 0000 alle Kombinationen der Reihe nach durchprobieren, bis das Schloss sich öffnet. Selbst wenn man sich Zeit damit lässt, dauert ein Durchtesten aller möglichen Kombinationen bis maximal 9999 nicht länger als 30 Minuten. Dieses Beispiel führt uns allerdings zu zwei Erkenntnissen. Steht das Fahrrad an einem gut frequentierten Ort, an dem es auffällt, wenn jemand am Schloss länger als 5 Minuten umherprobiert, ist dieser Schutz ausreichend. Die zweite Erkenntnis ist, dass die Zeitspanne, alle Nummern durchzuprobieren, mit jeder zusätzlichen Stelle erhöht wird. Die technische Umsetzung kann je nachdem, wie hoch der tatsächliche Schutz sein muss, extrem komplex werden.
Eine Maßnahme, die Webseitenbetreiber nutzen, nennt sich Informationssparsamenkeit. Macht man einen Fehler beim Login, erhält man nur die Rückmeldung, dass die Anmeldung nicht korrekt war. Das heißt, wir erfahren nicht, ob der Benutzer, unter dem wir uns anmelden, der richtige ist oder das Passwort falsch ist. Denn die Kombination aus Benutzeranmeldung und Passwort muss korrekt sein.
Auch die Menge der Versuche, sich bei einem bestehenden Nutzerkonto anzumelden, ist limitiert. In aller Regel ist es so, dass man 3 Versuche hat, das korrekte Passwort einzugeben. Tippfehler oder Feststelltaste können hier schnell zu Fehlversuchen führen. Gibt man nun ein viertes Mal das Passwort falsch ein, wird eine Zeitsperre aktiv und man muss zum Beispiel 5 Minuten warten, bis man das Passwort erneut eingeben kann. Jeder weitere Fehlversuch verdoppelt die Zeitspanne. Damit man als Webseitenbetreiber mehr Informationen zum Angreifer sammeln kann, werden bis zu 100 Fehlversuche zugelassen, die entsprechend protokolliert werden. Habe ich mich inzwischen aber erfolgreich eingeloggt, wird der Zähler mit den Fehlversuchen wieder zurückgesetzt. Hier ist es wichtig, dass der Betreiber diese Dinge beobachtet und beim Erkennen von Angriffen Maßnahmen zum Schutz des Nutzeraccounts einleitet. Das kann bisweilen zu einer zeitweiligen Deaktivierung des Accounts führen. Wir sehen, dass eine essenzielle Maßnahme die Beschränkung von Ressourcen ist, damit man nicht beliebig lang alle möglichen Passwortvarianten durchprobieren kann.
Natürlich ist es auch wichtig, ein ‚starkes‘ Passwort zu wählen. Wie wir bereits sehen konnten, ist die Anzahl der Stellen ein wichtiges Detail. Die Menge der möglichen Kombinationen erhöht sich aber auch, wenn man den Zeichensatz erweitert. Bei den Zahlen 0 bis 9 haben wir pro Stelle genau 10 Möglichkeiten. Hat unser Passwort nun 4 Stellen, sind das genau 9999 Kombinationen. In vielen Fällen, wie bei der Bankkarte, ist das ausreichend, denn nach 3 Fehlversuchen ist Schluss und die Karte ist gesperrt. Versucht man sein Glück am Bankautomaten, wird die Karte sogar eingezogen.
Erweitern wir unseren Zeichensatz der Zahlen mit großen und kleinen Buchstaben plus einiger Sonderzeichen, haben wir schnell pro Passwortstelle eine Kombinationsanzahl von über 60 Zeichen erreicht. Je nach Sprache variiert die Menge der Zeichen. Die deutsche Sprache hat noch die Buchstaben ä, ö, ü und ß zu bieten, die im englischen ABC nicht vorkommen. Wir sehen es gibt für Passwörter kulturelle Unterschiede. Die Zeichen a-z, A- Z und 0-9 bieten bereits 62 Kombinationen an. Ein Passwort, das 4 Stellen besitzt, hat also (62 * 62 * 62 * 62) = 624 = 14776336 Kombinationen. Hier ist ein Mensch, der das der Reihe nach durchprobieren soll, schon eine sehr lange Zeit beschäftigt. Ein Computer benötigt hierfür nur wenige Minuten. Deswegen ist es für ein sicheres Passwort notwendig, möglichst viele unterschiedliche Zeichen zu mischen, also Zahlen, Groß- und Kleinbuchstaben etc., und zusätzlich mindestens 15 Stellen zu verwenden. Solche Passwörter sind natürlich nicht gut zu merken. Schwieriger wird es, wenn man nun eine Vielzahl solcher unterschiedlicher Passwörter im Griff haben muss. Hier sorgen sogenannte Passwort Manager wie KeePass mit entsprechenden Browser Plugins für optimale Unterstützung. Lösungen, die vorschlagen, das Passwort in der Cloud, bei einem Unternehmen zu sichern, mögen durchaus gute Absichten haben, sind aber auch beliebte Angriffsziele von Hackern. Eingrund wieso für mich nur ein Offline-Passwortsafe auf meinem eigenen Rechner infrage kommt.
Mit all der Erkenntnis könnte man nun zu dem Schluss kommen, dass Passwörter keine gute Schutzfunktion besitzen und man besser auf andere Mechanismen ausweichen sollte. Tatsächlich gibt es genügend etablierte Lösungen, von denen die meisten auf dem Konzept der Biometrie beruhen. Wir kennen aus der Kriminalarbeit der Polizei das Konzept der Bestimmung von Fingerabdrücken. Wir gehen also davon aus, dass unser Körper biometrische Merkmale aufweist, die kein anderer Mensch besitzt, und so unsere Identität zweifelsfrei bestätigt werden kann. Seit vielen Jahren besitzen Geräte wie Laptops die Möglichkeit, den Fingerabdruck zu scannen und damit den Zugriff auf das Gerät freizugeben. Neben Fingerabdrücken zählen der Iriscan oder die Gesichtserkennung ebenfalls zu den eindeutigen Biometriemerkmalen.
Was auf den ersten Blick als sehr clever erscheint, könnte allerdings im Praxistest schnell als Sicherheitslücke bewertet werden. Das populärste Beispiel ist die FaceID, mit der man unter anderem über die Kamera das eigene Smartphone freischalten kann. Stellen wir uns die unschöne Situation vor, dass man uns das Telefon gewaltsam entwendet und bevor der Räuber erwischt wird, schaltet er das Telefon einfach frei, indem er es mir vors Gesicht hält, um sämtliche Sicherheitsüberprüfungen im Gerät zu deaktivieren. Wer nun argumentiert, dass in solch einer Raubsituation die Möglichkeiten durch Stress sehr eingeschränkt sind, mag durchaus recht haben, aber ausschließen kann man sie nicht. Es ist nur eine Beschreibung einer denkbaren Situation, wie sich Fremde unerlaubten Zugriff auf ein geschütztes Gerät durch Biometrie verschaffen können. Deswegen kann Biometrie ausschließlich eine Ergänzung des bestehenden Sicherheitskonzepts sein und nicht die zentrale Maßnahme. Zudem ist auch nicht geklärt, wie und wo die biometrischen Daten gespeichert werden, um sie vor Missbrauch zu schützen.
Moderne Sicherheitskonzepte basieren auf mehreren Komponenten, die ineinandergreifen. Bei der Anmeldung an Systemen kommen neben einem Passwort nun verschiedene weitere Faktoren zur Anwendung. Weit verbreitet ist die Zwei-Faktor Authentifizierung, bei der neben dem Passwort der zweite Faktor etwas darstellt, das man persönlich besitzt, auf das niemand anderes so einfach Zugriff hat. Momentan wird als zweiter Faktor das Telefon mit SMS oder E-Mail verwendet. Hier versendet die Anwendung an die hinterlegte Telefonnummer oder E-Mail Adresse einen einmaligen Code, der nur wenige Minuten gültig ist und dann verfällt. Nach erfolgreicher Verifizierung des Log-ins mit Passwort muss dann der Sicherheitscode eingegeben werden. Solange sichergestellt werden kann, dass niemand Zugriff auf den zweiten Faktor bekommt, also beispielsweise das Telefon entwendet wird, ist diese Methode sehr sicher. Jedem, dem das Telefon allerdings einmal abhanden gekommen ist und man nicht zeitnah eine Ersatz-SIM-Karte mit der Telefonnummer bekommen konnte, hat die Schwachstelle dieses Sicherheitskonzeptes bereits am eigenen Leibe erfahren. Das aber macht ein robustes und starkes Sicherheitskonzept aus, das es auch in schwierigen Situationen zuverlässig Schutz bietet und dennoch einen berechtigten Reset zulässt.
Ein Sicherheitskonzept lässt sich durch neue Schichten mit zusätzlichen Faktoren, die wie eine Kette aufgebaut sind, erweitern. Daher kommt die Bezeichnung N-Faktor. Das N ist ein Platzhalter der eingebauten Schichten. Allerdings muss man auch sagen, dass, je mehr Schichten zum Tragen kommen, die angestrebte Lösung immer unpraktikabler für die Nutzer wird. Schauen wir uns daher kurz einmal an, welche möglichen Faktoren zum Tragen kommen können.
Wissen (Knowledge): Passwort, Pin
Besitz (Ownership): E-Mail, Token, Telefon
Biometrie: Fingerabdruck
Standort (Location): GPS, IP
Zeit (Time): Authentifizierungscodes mit Ablaufzeit
Verhalten (Behavioral): Tippgeschwindigkeit
Gerät (Device): Laptop, Smartphone, Tablet
Wenn wir diese Liste genauer betrachten, erkennen wir viele Fragmente, die in unterschiedlichen Kombinationen in modernen Webdiensten genutzt werden. Das Ziel ist es den Passwortschutz so zu verstärken, dass auch unvorsichtige Nutzer nicht zum Einfallstor für Missbrauch werden können. Denn auch in der IT-Sicherheit gilt der Grundsatz, dass eine Kette nur so stark ist wie das schwächste Glied.
Natürlich haben wir das Thema in diesem Artikel nur streifen können und es gäbe noch viel mehr zu erwähnen. So haben wir den Bereich der Kryptografie vollständig ausgeblendet. Das sind aber Themen, die vor allem für IT-Profis bzw. Programmierer relevant sind. So kann man auf diesem Blog hier unteranderem einen Artikel lesen, der sich mit der sicheren Speicherung von Passwörtern in Datenbanken beschäftigt. Seit ich mich im Rahmen des aktuellen KI Trends intensiver mit dem Rekonstruieren gestohlener Passworthashes beschäftige, ist mir durchaus bewusst, wie wichtig die in diesem Artikel beschriebenen Konzepte und deren Beachtung sind. Denn mit geschickter Wahl von möglichen Kombinationen lassen sich die zu durchsuchenden Möglichkeiten massiv reduzieren, wodurch man erhebliche Rechenpower einsparen kann. Sicher darf man in absehbarer Zukunft einen sehr technischen Artikel aus der Kategorie Pentesting über die Möglichkeiten zum Knacken von Passwörtern geben.
Die Prophezeiung, dass Programmierer obsolet werden, weil sich Computer quasi selbst programmieren, hat mittlerweile einige Jahrzehnte auf dem Buckel. Bisher ist das Berufsbild Programmierer aber noch nicht ausgestorben. Dennoch hat sich in den letzten Jahren einiges grundlegend verändert. Die Leistungsfähigkeit aktueller K. I. Systeme weckt unterschiedlichste Emotionen. Die einen hassen es, die anderen lieben es. Allerdings ist es wie so immer im Leben: Nicht alles ist schwarz oder weiß. Daher möchte ich meine Erfahrungen mit K. I. unterstützendem Programmieren zum Besten geben und eine Einschätzung der Gesamtsituation wagen.
Meine ersten Berührungspunkte mit künstlicher Intelligenz und Machine Learning liegen schon sehr weit zurück, sodass mich die Leistungsfähigkeit von ChatGPT und Co. bei der Markteinführung um das Jahr 2024 nicht wirklich beeindrucken konnte. Die ersten Versionen waren eher zur Gewöhnung gedacht und in ihrem Können sehr eingeschränkt. Dieser Umstand hat sich mittlerweile erheblich verändert und ist noch lange nicht am Scheitelpunkt angekommen.
Die Entwicklung erfolgt exponentiell. Grob kann gesagt werden, dass die Leistungsfähigkeit sich mit jedem Sprung in der Hälfte der Zeit zum vorhergehenden Sprung verdoppelt.
Aktuell befinden wir uns in der dritten Iteration. Die darauffolgende Iteration wird mit doppelter Leistungsfähigkeit keine 18 Monate mehr benötigen, sondern maximal 9 Monate. Meine Quintessenz für den Bereich Softwareentwicklung lautet: K. I. kann fähige Programmierer und Administratoren in ihrem Schaffen massiv unterstützen und deren Performance erheblich anheben. Allerdings hat wie so alles im Leben auch dieser Umstand seine Schattenseiten. In diesem Artikel nehme ich mir die Zeit und beleuchte zu dem Thema ein wenig den Hintergrund.
Vor einiger Zeit traf ich in meiner Timeline in den einschlägigen Social Media Plattformen immer wieder auf Nachrichten, wie Juniorentwickler über Vibe Coding schwärmten. Zuerst dachte ich, es ginge um die optimale Atmosphäre beim Arbeiten. Also Sachen wie die richtige Musik und ätherische Öle, um in den perfekten Arbeitsflow zu kommen. Aber nein. Das war nicht, worum es ging. Leute, die nichts vom Programmieren wussten, konnten auf einmal Code erzeugen, der augenscheinlich das gemacht hat, was die Ersteller beabsichtigt haben. Klingt im ersten Moment auch ganz toll. Die Realität ist aber eine andere.
Copy-Paste-eh kennen wir schon etwas länger. Dazu brauchten wir keine K. I. nicht so lang ist es her, dass man Codeschnipsel gegoogelt hat und dann auf Internetseiten wie Stack Overflow fündig wurde. Schnell wurden Fragmente von vermeintlichen Empfehlungen in die eigene Codebase kopiert, und wenn es funktioniert hat, blieb alles ungeprüft so stehen, wie man es übernommen hatte. Die vermeintlichen Schlauberger waren auch nicht in der Lage, die kopierten Codefragmente zu verstehen und geschweige denn, diese an das eigene Projekt korrekt anzupassen. Daher hat sich der Ausdruck >Copy-passt-eh< etabliert. Dass dieses Codefragment aber in Produktionsumgebungen für massive Probleme sorgen konnte, wurde von den vermeintlichen Experten gern ignoriert. Das Spektrum der Störungen reichte von schlechter Performance bis hin zu sicherheitskritischen Schwachstellen. Diese Situation hat sich mit der Verfügbarkeit von K. I. für die breite Masse nicht verändert. Daher habe ich die Prognose, dass in den nächsten Jahren eine Schwemme von qualitativ schlechter Software um die Gunst der Anwender buhlen wird.
Hier kann ich nur wieder Grady Booch zitieren: „A fool with a tool is still a fool.“ Denn meine Beobachtungen, in eigenen Projekten LLM zur Programmierung zu verwenden, sind eher verhalten. In meiner Wahrnehmung sind es eher Projektleiter und Leute, die nicht programmieren können, die in den sozialen Medien die Leistungsfähigkeit von K. I. Modellen massiv überbewerten.
Grundsätzlich bin ich ein skeptischer Mensch und habe natürlich die üblichen Verdächtigen, KI-Modelle, für meine tägliche Arbeit versucht einzusetzen. Ich war explizit bei den Community-Varianten, ohne Bezahlung. Denn mit diesen Versionen wird die Welt künftig mit schlechter Software überflutet. Auch hier kann ich massiv abkürzen. Sämtliche Ergebnisse von Grok im Bereich Programmierung/Scripting und Konfiguration waren unterdurchschnittlich. Es hat sich ein wenig wie in alten Foren angefühlt. Anstatt diese nervigen Fragen, wieso und warum zu stellen, gelang es Grok nicht, zum Punkt zu kommen. Geschweige denn, eine funktionsfähige Lösung zu präsentieren. Dafür brillierte das Modell mit sinnbefreiten Motivationssprüchen à la „Teamleiter auf Steroiden“. Es erinnert mich ein wenig an Aussagen von Joseph Weizenbaum über virtuelle Gespräche und seinen Eliza Chatbot.
Etwas besser ging es mit Deep Seek. Zumindest kamen da nutzbare Resultate heraus. Die waren auch sofort einsetzbar und haben augenscheinlich auch das gemacht, wofür sie angedacht waren. Hat man sich den Code aber richtig angeschaut, war dieser mit allem möglichen Zeug überfrachtet, das mindestens unnötig war. Ich hatte in diesen Fällen keine weitere Analyse gemacht, ob eventuell sicherheitskritische Probleme aufgetreten sind. Statistisch kann man davon ausgehen, dass je mehr Code vorhanden ist, umso höher die Wahrscheinlichkeit ist, dass Fehler enthalten sind. Opus wiederum nervte permanent damit, dass selbst bei minimalen Anfragen ein Abo notwendig ist. Die besten Ergebnisse habe ich tatsächlich mit ChatGPT erzielen können. Obwohl die Antworten auch teilweise widersprüchlich oder redundant waren.
Wer die Idee hat, mit einem der freien KI Modelle eine lokale Instanz zum Beispiel mit LM Studio aufzusetzen und dafür eine sündhaft teure Grafikkarte kauft, dem sei gesagt: Das Geld kann man sich sparen. Die frei verfügbaren Modelle sind bei weitem nicht so leistungsfähig, wie ihre kommerziellen Versionen. Es wäre auch nicht gerade geschäftsfördernd, sich seine eigene Konkurrenz zu etablieren. Es stellt sich daher die Frage, wann es tatsächlich Sinn ergibt, mit KI Programmiermodellen zu arbeiten, um wirklich eine Beschleunigung des eigenen Outputs zu erfahren. Meiner Erfahrung nach geht es weniger um das Was oder Womit, sondern um das Wie. Dazu brauchen wir ein paar wichtige Abgrenzungen.
Ein K. I. Agent der direkt in die IDE eingebunden ist und alle Freiheiten hat, ist keine gute Idee. Oft hört man, dass diese K. I. Dinge tut, die sie nicht tun sollte, und Anweisungen, die Aktivitäten einzustellen, haben wenig Auswirkung. Wer es dennoch unbedingt versuchen möchte, ist sehr gut beraten, ein sauberes Branch Modell mit entsprechenden Zugriffseinschränkungen für den Agenten zu etablieren. Obwohl ich in kommerziellen Entwicklungsteams Pull Requests ablehne, ist diese Strategie beim Einsatz von K. I. Agenten unabdingbar. Auch der Zugriff auf die Build Logik wie zum Beispiel die Maven POM oder Gradle Projektdatei ist für die Agenten tabu. Es gilt auch hier der bewährte Sicherheitsansatz: So wenig wie möglich, so viel wie nötig. Die Sperrung der Build Logik verhindert, dass der K. I. Agent beliebig nach Gutdünken eine eigene Version von Abhängigkeiten definieren kann.
Auch ist darauf zu achten, dass die Codeänderungen überschaubar bleiben und iterativ vonstattengehen. Obwohl es etwas holprig erscheinen mag, nutze ich K. I. um Funktionen oder Klassen zu generieren. Die vorgeschlagenen Codefragmente kopiere ich dann in meine IDE und schaue zeilenweise durch, was mir da vorgeschlagen wird. Entsprechend meinen Qualitätskriterien modifiziere ich dann den Code und prüfe über selbsterstellte Testfälle, ob alles so funktioniert, wie ich es beabsichtige. Die Generierung umfangreicher Testdaten für Lattests ist ein ideales Beispiel dafür, welche Aufgaben man problemlos an K. I. übergeben kann und auch sollte. Natürlich ist es unverzichtbar, stetig die Testqualität zu monitoren, wozu die Testabdeckung ein wichtiger Indikator ist. Auch wenn der gerade beschriebene Ansatz etwas mehr Zeit kostet, hat er mehr Vorteile gegenüber den schnellen Lösungen. Ich bin in der Lage, die Codeänderungen zu verstehen, und kann sie den entsprechenden Anforderungen zuordnen. Ein weiterer nicht zu unterschätzender Faktor ist, dass diese Methode dafür sorgt, dass ich meine Programmierfähigkeiten weiterentwickle. Schnelles Überfliegen und unreflektiertes Akzeptieren der vorgeschlagenen Lösung sorgen eher dafür, dass meine Fähigkeiten über einen längeren Zeitraum verkümmern und dadurch auch meine Performance kontinuierlich sinkt. Dadurch wird sich der Arbeitsplatz langfristig nicht sichern lassen.
Das bringt mich auch gleich zu einem weiteren Punkt im Umgang mit LLM. Wie kann man effiziente Prompts, also Arbeitsanweisungen an das Modell, formulieren? Da die Kommunikation mit dem Modell über natürliche Sprache erfolgt, ist es notwendig, die eigenen Gedanken gut zu strukturieren, um sie dann auch verständlich formulieren zu können. Es ist also nicht förderlich, einen Kurs für Promptengineering zu besuchen. Wenn er oder sie die eigenen Ideen und Vorstellungen anderen Menschen nicht sauber vermitteln kann, wird mit K. I. ebenfalls wenig Erfolge erzielen. Worauf kommt es also wirklich an? Die Antwort ist fast so einfach, dass man sie übersehen kann. Klare Kommunikation mit prägnanten, kurzen und verständlichen Sätzen. Keine komplizierten Verschachtelungen, um das eigene Ego zu befriedigen. Natürlich benötigt man auch eine konkrete – zu Ende gedachte – Vorstellung von dem, was man erwartet. Vage Formulierungen können (zu viel) Raum für Interpretation lassen. Wer seine Absichten einem Vorschulkind in wenigen Minuten erklären kann, wird auch mit K. I. gute Ergebnisse erzielen. Damit möchte ich es auch belassen und einen weiteren Aspekt diskutieren.
Oft werde ich gefragt, wie ich die Qualität der durch LLM generierten Quelltexte beurteile. Hier ist die Antwort nicht so einfach. Denn es gibt verschiedene Kriterien, auf die es zu achten gilt. Alles, was UI betrifft, ist ein eigenes Kapitel. Denn UI / UX unterliegt Modeerscheinungen und hat gegenüber der Geschäftslogik eine höhere Änderungsfrequenz. In meinen Schulungen zu Java Testautomatisierung rate ich insbesondere komplett von der Erstellung von UI Tests ab. Der Grund ist, dass in diesem Bereich der Kosten Nutzen Faktor einfach nicht ausgewogen genug ist. Das bedeutet für generierten UI-Code, dass ich lediglich die Funktion und Optik anschaue und es dabei belasse. Bei der Geschäftslogik für Backendsysteme ist die Situation eine völlig andere. Hier habe ich festgestellt, dass der durch LLM produzierte Code in Aspekten der Sicherheit teilweise besser ist als der von so manchem Programmierer. Die üblichen Prüfpunkte wie SQL Parameter, Eingabevalidierung und Filterung werden berücksichtigt und umgesetzt. In den Bereichen Performance und Lesbarkeit beziehungsweise Verständlichkeit ist allerdings noch Luft nach oben. Hier erwarte ich in circa zwei weiteren Iterationen erhebliche Verbesserungen. Das ist auch ein markanter Grund, wieso LLM Optimierungen einer bestehenden Codebasis nie abgeschlossen sind und bei jeder neuen Generation von LLM erneut durchgeführt werden sollten.
Mein stärkster Kritikpunkt gegenüber Unternehmen, aber auch Entwicklern und Administratoren, die exzessiv LLM in ihren täglichen Projekten einsetzen, ist, dass diese schnell die Kontrolle über ihre Produkte/Dienstleistungen verlieren könnten. Das gesamte Thema lässt sich nicht in Schwarz oder Weiß einteilen, denn die Menge an Variationen der Zwischentöne ist zu umfangreich. Deswegen ist es an uns, dem Motto der literarischen Aufklärung nach Immanuel Kant – habe Mut, dich deines eigenen Verstandes zu bedienen – zu folgen.
Abschließend möchte ich noch den Kostenfaktor für leistungsfähige KI Modelle besprechen. Denn hier kann es schnell zu bösen Überraschungen kommen. Gehen wir einmal davon aus, wir haben eine Person mit einer tollen Startupidee, die auch die Fähigkeit hat, korrekte und sinnvolle Anforderungen verständlich zu formulieren. Im besten Fall sind sogar rudimentäre Programmierfähigkeiten vorhanden, um Quelltext lesen, verstehen und leicht modifizieren zu können. Diese Person entschließt sich, nur die Idee eigenständig ohne Programmierer umzusetzen. Selbst wenn man das Projekt in kleine Stücke zerlegt und diese Projekte an Freelancer vergibt, kommen schnell ein paar tausend Euro zusammen, je nach Umfang der Arbeitspakete. Verteilt man nun diese Aufgaben an KI Agenten, greifen die üblichen Tarife von 20 bis 50 Euro monatlich nicht mehr. Es wird eine tokenbasierte Abrechnung notwendig. Je nach Umfang des Prompts verbraucht dann eine Anfrage an die KI ein bis mehrere Token. Ein Token hat oft den Wert von einem Euro / US Dollar. Setzt man hier kein Limit, können in wenigen Stunden mehrere tausend Euro verbraucht sein. Zudem kann man vorher auch nicht sagen, wie gut der generierte Quelltext sein wird, den man erhält. Denn jede Nachbesserung kostet wiederum Token, die zu bezahlen sind. Ein Kostenfaktor, der bei Menschen so in der Form nicht entsteht. Auch wenn KI Agenten auf den ersten Blick keine Sozialversicherung und ähnliche Kosten verursachen, bedeutet es nicht, dass man günstigere Projekte umsetzen kann. Wichtiger ist, jemanden im Boot zu haben, der weiß, wie man Quelltext so strukturiert, dass dieser auch problemlos später erweitert werden kann.
Die Feuerwand (engl. Firewall), war zu Zeiten des Zirkus und der Schausteller immer ein spektakuläres Ereignis. Menschen oder Tiere sprangen hindurch und wurden von der Menge bejubelt. So pathetisch eine solche Vorführung auch immer auf die Zuschauer wirkte, so kalkulierbar war das Spektakel für den Akrobaten. Denn wir wissen, dass Feuer eines der gewaltigsten Urelemente ist, das durch die Menschheit bezwungen wurde.
In der Cybersecurity ist die Firewall einer der elementarsten Schutzmechanismen für vernetzte Computersysteme. Das gilt sowohl für den Heimcomputer, als auch für den Großrechner im Rechenzentrum. Allerdings ist die Vorstellung, einen oder mehrere Feuerringe um den Computer zu entzünden, eher vergleichbar mit einem Zirkusspektakel, das gern melodramatisch in Kinofilmen aufgegriffen wird. Aussagen wie „Die erste Firewall ist gefallen und die zweite bereits zu 70 % überwunden“, sind perfekt für die Leinwand, haben mit der Realität aber nichts gemein.
Bevor wir in die Details gehen, betrachten wir kurz, wie Computersysteme miteinander zu einem Netzwerk verbunden werden. Das entscheidende Detail, welches wir benötigen, lautet IP Adresse. Allgemein ausgedrückt ist die IP Adresse die Telefonnummer des Computers beziehungsweise des Gerätes im Netzwerk. Damit man sich also mit einem anderen Computer verbinden kann, muss man dessen IP-Adresse kennen. Analog wie beim Telefon und der Telefonnummer. Wenn die Verbindung dann steht, kann man Informationen, also Daten, zwischen diesen beiden Geräten austauschen. Diese Informationen werden von den verschiedenen Internetprotokollen in kleine, handhabbare Pakete zerlegt. Ein Protokoll ist eine festgelegte Ablaufsteuerung, an die sich alle Teilnehmer halten müssen. Das lässt sich problemlos mit dem Versenden eines Briefes oder Päckchens mit der Post vergleichen.
Schreibe den Brief
Packe den Brief in einen Umschlag und klebe den Umschlag zu.
Schreibe die Empfängeradresse auf die Vorderseite des Umschlages.
Schreibe den Absender auf die Rückseite des Umschlages.
Klebe eine ausreichende Briefmarke auf den Umschlag und werfe ihn in den Briefkasten.
Ohne zu wissen, wie die internen Abläufe der Post sind, können wir davon ausgehen, dass der Brief beim Empfänger ankommt, wenn wir das Protokoll korrekt einhalten. Genauso verhält es sich mit dem Internet. Je nach der Art der Daten wählt der Computer ein geeignetes Programm aus, welches das zu verwendende Protokoll für uns umsetzt. Basierend auf dem Internet Protokoll (IP) welches die Verbindung zwischen Computern für uns regelt, gibt es weitere Protokolle, die sich um die Daten kümmern. Bekannte Protokolle sind HTTP(s) für Internetseiten oder FTP, um Dateien zu versenden.
Kommen wir nun zum eigentlichen Thema. Was also ist eine Firewall überhaupt und wozu wird sie verwendet? Stellen wir uns am besten einen sehr langen Flur vor mit unzählig vielen Türen, genauer gesagt 65.536 Türen. Diese Türen kann man nach innen oder außen öffnen. Wir können also aus dem Flur nach außen (outgoing Traffic) gelangen oder von außen in den Flur hinein (incoming Traffic).
Ein Browser Game, mit freundlicher Genehmigung von (c) mediasinres.tv
Diese Türen nennt man in Fachchinesisch Ports, die eine festdefinierte Nummer haben. Installiert man nun auf dem Rechner spezielle Programme, die mit anderen Computern kommunizieren können, wird dieses Programm üblicherweise fest an solch einen Port gebunden. Dazu ein kleines Beispiel. Lange vor WhatsApp und Co. gab es den Internet Relay Chat, kurz IRC. Hat man auf seinem Computer den IRC installiert, so hat sich dieser hinter der Tür 194 verborgen. Eine wichtige Eigenschaft zu Ports ist auch, dass, wenn bereits ein Programm an einen Port gebunden ist, kein anderes Programm diesen Port benutzen kann.
Mit einer Firewall kann man nun diese Türen in das Internet und aus dem Internet sehr gezielt blockieren. Grundsätzlich bestehen vier verschiedene Optionen für eine Tür zur Auswahl:
Vollständig blockiert,
Eingang blockiert,
Ausgang blockiert und
Vollständig offen.
Greifen wir dazu wieder unser Beispiel IRC auf. Ist die Tür vollständig blockiert, können wir keine Nachrichten senden oder empfangen, obwohl sich das Programm auf unserem Computer starten lässt. Es kann also keine Verbindung in das Netzwerk aufbauen. Ist der Eingang blockiert, können wir keine Nachrichten empfangen, aber senden. Ist der Ausgang blockiert, empfangen wir Nachrichten, können aber selbst keine senden. Die letzte Option hat keinerlei Einschränkungen.
Das größte Problem bei der Benutzung von Firewalls ist, dass diese oft nicht korrekt eingestellt (konfiguriert) sind. Hier unterscheiden wir zwei Möglichkeiten. Die verbreitetste Variante nennt sich Blacklist und reguliert nur die in der Liste angegebenen Ports. Wenn wir uns überlegen, dass es 65 536 Ports gibt, kann das eine sehr lange und unübersichtliche Liste werden. Das Risiko, etwas zu vergessen, ist hier sehr hoch. Der Vorteil dieser Option ist, dass sie sehr robust für unerfahrene Nutzer ist. Die andere Option ist die sogenannte Whitelist. Die funktioniert exakt entgegengesetzt der Blacklist. Per se sind nun erst einmal alle Ports geschlossen und der Nutzer muss explizit angeben, welche Ports geöffnet werden dürfen. Wie man sich jetzt leicht vorstellen kann, erfordert der Betriebsmodus Whitelist einiges an Erfahrung des Nutzers. Man muss wissen, welcher Port zu welchem Programm gehört und wie man diese Regeln in der Firewall einträgt.
Wie wir sehen, ist die Vorstellung, einen Feuerring um den Computer zu ziehen, keine geeignete Vorstellung davon, wie eine Firewall funktioniert. Wenn die Tür, also auf dem Computer, einmal blockiert ist, macht es auch wenig Sinn, noch eine andere Firewall auf dem Computer zu installieren. In diesem Fall gilt der Spruch „Doppelt hält besser“ nicht.
Angriffe auf Firewalls sind üblicherweise das Suchen nach offenen Türen, in die man dann eindringt. Dazu bedient man sich sogenannter Portscanner. Wer einmal einen solchen Protscanner ausprobieren möchte, darf das nicht so ohne Weiteres tun. Denn die Suche nach offenen Ports auf fremden Computern ist in Deutschland und vielen anderen Teilen der Welt bereits strafbar.
Ein anderes sehr fortgeschrittenes Angriffsszenario ist eine Attacke auf das Firewallprogramm selbst. Hier versucht man, mögliche vorhandene Programmierfehler der Firewall zu finden und auszunutzen.
Firewalls gibt es für jedes Betriebssystem in den verschiedensten Variationen. In professionellen Netzwerkgeräten wie Routern und Switches können bereits auch Firewalls integriert sein. Hier agiert der Router als Netzwerkcomputer und schützt alle an den Router angeschlossenen Geräte. Bevor man sich für ein konkretes Programm entscheidet, sollte man in Erfahrung bringen, dass es möglichst leicht zu bedienen ist und von einem seriösen Hersteller kommt.
Liste (unvollständig) der bekanntesten Standardports:
Für Entwickler ist das Thema Datenbanken ein Bereich der Anwendungsentwicklung, den man nicht auf die leichte Schulter nehmen sollte. In diesem Artikel widme ich mich der Frage, was geeignete Primärschlüssel für relationale Datenbanken wie MySQL oder PostgreSQL sein können. Doch bevor ich mich auf die technischen Details stürze, möchte ich kurz ein Szenario beschreiben, mit dem ich vor einer Weile wieder einmal konfrontiert wurde.
Für einen Auftrag sollte ich ein Shopsystem migrieren. Da dieses System bereits über 10 Jahre im produktiven Einsatz war, ging es nun darum, auf eine neue Majorversion zu aktualisieren. Da wir bereits 3 Major-Releases im Rückstand zur aktuellen Version waren, haben wir uns entschieden, diese Gelegenheit zu nutzen, auch einige Altlasten loszuwerden. Es sollte sozusagen ein neuer Shop mit neuem Design und aktualisierter Funktionalität so weit neu aufgesetzt werden, dass dann die vorhandenen Artikel, Bestellungen und natürlich auch Kundendaten auf den neuen Shop importiert werden. Soweit erst einmal ein klassischer Routineauftrag.
Die Komplikation entstand durch den Umstand, das natürlich das alte System so lange im Betrieb bleiben musste, bis es nahtlos durch die neue Version ersetzt werden konnte. Wie es nun auch immer so ist, entwickelt sich Software weiter. So gab es in der neuen Version auch erhebliche Veränderungen, die ein direktes Datenmapping verkomplizierten. Im Konkreten ging es darum, wie intern die Artikelattribute gespeichert werden. Das heißt, wenn wir zum Beispiel T Shirts verkaufen, dann gibt es möglicherweise ein Modell aus Baumwolle, in weißer Farbe mit V-Ausschnitt in unterschiedlichen Größen. Jetzt wird man bei der Katalogauswahl in der Shopdarstellung nicht jedes einzelne Shirt in seiner Größe präsentieren. Vielmehr gibt es bei dem Artikel dann eine Auswahlbox mit den verschiedenen Größen. Diese Artikeleigenschaften können je nach Shop durchaus extrem komplex werden.
Mittlerweile gibt es sehr leistungsfähige Werkzeuge, die nicht gleich den Preis eines Mittelklassewagens haben, um zwischen den Versionen des Datenbankschemas ein Mapping zu definieren und die Daten dann automatisiert in die neue Version zu übernehmen. Das Ganze wird dann zu einem sogenannten ‚Höllenritt‘, wenn die Primärschlüssel als generische Auto-Increment erzeugt werden. Das alte System bleibt ja weiter aktiv und erzeugt permanent neue Primärschlüssel, die möglicherweise im neuen System bereits vergeben sind. Diesen Effekt versucht man durch sogenannte Freezes zu minimieren. Das bedeutet, der Shopbetreiber kann, solange die Migration nicht abgeschlossen ist, keine neuen Artikel im Shop aufnehmen und auch bestehende Artikeleigenschaften nur unter sehr eingeschränkten Bedingungen ändern.
Damit die Datenmigration einerseits leichter wird, aber andererseits auch weniger fehleranfällig ist, ist es in kommerziellen Umgebungen eher verpönt, auto increment für die Generierung des Primärschlüssels zu nutzen. Professionelle Datenbankmanagementsysteme (DBMS) wie Oracle und PostgreSQL können sogar nicht ohne Weiteres ein auto increment erstellen. Will man das dennoch nutzen, ist das meist über das Persistenzframework implementiert und nicht wie bei MySQL oder MariaDB eine Funktion im SQL.
Woher kommt überhaupt die Idee, einen solchen generischen Primärschlüssel zu nutzen? Sicher ist es ein sehr einfacher Mechanismus, der durchaus bewährt ist und gut in der Praxis funktioniert. Jedenfalls solange man nicht die Absicht hat eine Migration durchzuführen. Ein anderer Aspekt ist natürlich historisch bedingt, als Festplattenspeicher nocht teuer war und nicht so üppig verfügbar war wie heute. Damals zählte noch jedes einzelne Bit, das man sparen konnte. Diese Argument wird durch den verfügbaren günstigen Speicher entkräftet. Im Gegenteil, die Nachteile, die man sich im Bereich Wartung für ein paar eingesparte Megabyte erkauft, wichten sogar mehr.
Was sind demzufolge gut geeignete Primärschlüssel für Datensätze in relationalen Datenbanken? Hier unterscheiden wir in zwei Kategorien: natürliche und generierte Schlüssel. Da der Primärschlüssel eineindeutig sein muss und daher nicht zweimal vorkommen darf, gibt es wenig natürliche Kandidaten. Das klassische Beispiel für einen Nutzeraccount als Primärschlüssel ist die E-Mail. Auch die Telefonnummer hat die gewünschte Eigenschaft.
Automatisch generierte Primärschlüssel sind unter anderem der bereits beschriebene Auto Increment, den wir besser vermeiden sollten. Stadessen sollte man besser auf den Universal Unique Identifier, kurz UUID, zurückgreifen. Alle Programmiersprachen haben dazu eine Implementierung. Allerdings gibt es mittlerweile mehrere Versionen der UUID. Nicht allzulang wurde Version 7 der UUID veröffentlicht. Daher schauen wir uns die Eigenschaften der jeweiligen Versionen einmal genauer an. Die KI Grok stellt die Versionen wie folgt dar.
Version 1 (Time-based, RFC 4122/9562):
Kombiniert einen hochpräzisen Timestamp (60 Bit, 100-Nanosekunden-Intervalle seit 15.10.1582), eine 14-Bit-Clock-Sequence (gegen Rückwärtsdrehen der Uhr) und eine 48-Bit-Node-ID (meist MAC-Adresse des Rechners).
Nachteil: Die MAC-Adresse kann die Hardware verraten (Datenschutz). Die Sortierung ist nicht optimal, weil die Timestamp-Bits nicht in zeitlicher Reihenfolge liegen.
Beleg: RFC 9562, Section 5.1.
Version 2 (DCE Security):
Ähnlich wie v1, aber mit zusätzlichen Feldern für POSIX UID/GID (Local Domain). Der Timestamp ist weniger präzise.
Status: Kaum verwendet, in den meisten Bibliotheken nicht implementiert und nur für sehr spezielle Legacy-DCE-Anwendungen gedacht.
Beleg: RFC 9562 erwähnt es als reserviert mit Verweis auf alte DCE-Spezifikationen.
Version 3 & 5 (Name-based):
Deterministisch: Aus einem Namespace und einem Namen wird per Hash (v3: MD5, v5: SHA-1) ein UUID erzeugt. Gleicher Input → gleicher UUID.
Unterschied: Nur der Hash-Algorithmus. MD5 ist gebrochen, SHA-1 gilt als schwach → v5 ist etwas besser, aber beide nicht für kryptografische Sicherheit geeignet.
Beleg: RFC 9562, Sections 5.3 und 5.5.
Version 4 (Random):
Die klassische „zufällige“ UUID. 122 Bit sind echt zufällig (oder kryptografisch sicher pseudo-zufällig). Keine Zeitinformation, keine Node-ID.
Vorteil: Maximale Unvorhersagbarkeit und Privatsphäre.
Nachteil: Nicht sortierbar → schlechtere Performance als Primärschlüssel in Datenbanken (Fragmentierung der Indexe).
Beleg: RFC 9562, Section 5.4 – gilt als sicherer Standard für viele Anwendungen.
Version 6 (Reordered Time-based, RFC 9562):
Technisch fast identisch mit v1 (gleicher Timestamp, gleiche Clock-Sequence, gleiche Node), aber die Bits des Timestamps sind neu angeordnet (most-significant zuerst).
Dadurch sind v6-UUIDs byteweise sortierbar nach Erstellungszeit – ideal für Datenbanken.
Empfehlung im RFC: Nur als Drop-in-Ersatz für bestehende v1-Systeme verwenden; ansonsten v7 bevorzugen.
Beleg: RFC 9562, Section 5.6 – „field-compatible version of UUIDv1“.
Version 7 (Unix Time-based, RFC 9562):
Moderne Variante: 48 Bit Unix-Timestamp in Millisekunden (seit 1970), gefolgt von 12 Bit „rand_a“ (kann für Sub-Millisekunden oder Counter verwendet werden) und 62 Bit „rand_b“ (Zufall).
Vorteile:
Sehr gut sortierbar (Zeit steht vorne).
Hohe Entropie (74 Bit random).
Keine MAC-Adresse → besserer Datenschutz.
Gut für verteilte Systeme und Datenbank-Indexes.
Der RFC empfiehlt explizit: „Implementations SHOULD utilize UUIDv7 instead of UUIDv1 and UUIDv6 if possible.“
Beleg: RFC 9562, Section 5.7.
Die bisher verbreitetste Variante ist Version 4, die ich auch selbst nutze. Ein wichtiges Kriterium ist bereits aus den Hash Algorithmen bekannt. Bei Hash spricht man von Kollisionen, also wenn ein Hash auf zwei verschiedene Texte verweist. Ein ähnliches Problem haben wir bei der Generierung von UUIDs. Diese sollte im Produktivbetrieb auch bei großen Datenmengen nicht mehrfach erzeugt werden. Das würde einen Fehler im Datenbanksystem auslösen, da die Unique Bedingung verletzt wird. Problematischer ist die anschließende Fehlerbehandlung. Damit der Datensatz dennoch gespeichert werden kann, muss eine neue UIID erzeugt werden. Dieser Fall ist mir bei meiner bereits langjährigen Verwendung der UUID-Version 4 bisher nicht untergekommen.
Wieso sollte man nun auf UUID Version 7 zurückgreifen? Hier geht es um Sortierbarkeit. UUID 7 verspricht, dass neuere Einträge ein aufsteigendes Datum in den ersten Stellen berücksichtigen. Dadurch kann man ältere Einträge absteigend sortiert erkennen.
Um beispielsweise UUID 4 in Java zu benutzen, genügt der Aufruf UUID.randomUUID(). Der ORM Mapper Hibernate stellt über die Annotation @GeneratedValue auch andere Versionen der UUID bereit. Natürlich kann man auch zusätzliche Bibliotheken wie den uuid-creator unter der MIT Lizenz nutzen.
Damit soll es auch für heute genug sein. Ich hoffe, ich konnte mit diesem Artikel ein wenig Aufmerksamkeit in das Thema lenken und würde mcih sehr freuen, wenn es weitere Verbreitung findet.
Wer unter Linux ein Desktopprogramm nutzen möchte, ohne sein bestehendes System zu verändern, benötigt eine spezielle Umgebung, die in Fachkreisen Sandbox genannt wird. Natürlich kann man auch eine virtuelle Maschine mit VMWare oder dem freien VirtualBox von Oracle erstellen, die einen ganzen Computer samt Betriebssystem simuliert, und darin testweise Programme installieren, um zu sehen, wie diese sich verhalten. Diese Option verbraucht allerdings einiges an Ressourcen und ist auch ein wenig schwergewichtig.
Es gibt aber auch eine leichtgewichtigere Virtualisierungstechnologie unter Linux, die verschiedene Sicherheitsfunktionen anwendet, die unter Windows nicht verfügbar sind. Dazu gehört unter anderem das Berechtigungskonzept auf Datei- und Verzeichnisebene. Aber keine Sorge, wir steigen nicht zu tief in die vielen Details der einzelnen Lösungen ein, sondern kümmern uns vornehmlich um das Wie und Warum.
Auf der Serverseite gibt es bereits bewährte Virtualisierungsprogramme für abgegrenzte und sichere Umgebungen, wie beispielsweise LXC (Linux Container) und das vielbewährte Docker. Auf dem Desktop nutzt man eher Programme wie FireJail oder Bubblewarp um Programme mit grafischer Benutzeroberfläche in einem abgegrenzten Raum ausführen zu können. Bevor wir aber weiter in die Details des Wie vorstoßen, betrachten wir noch ein paar Szenarien, wieso der ganze Aufwand überhaupt sinnvoll sein kann.
Einer der ältesten Gründe für Sandboxing ist, eine Umgebung zu schaffen, dass man verschiedene Versionen einer Software zu Test- oder Entwicklungszwecken gleichzeitig installiert haben muss und die Installationsroutine das nicht zulässt. Typisches Verhalten ist dann, dass zuerst die alte Version einer Software deinstalliert wird, um die neue Version zu installieren, oder es wird einfach die vorhandene Version aktualisiert. Hier hilft das Einrichten einer Sandbox, also einer Spielwiese zum Ausprobieren.
Ein weiterer Grund, wieso man Sandboxen verwendet, ist, Programme aus Sicherheitsgründen zu isolieren. Hier ist das eigentliche Thema das Schützen der Privatsphäre. Man möchte verhindern, dass ein Programm auf andere Daten auf dem Computer Zugriff hat. Deshalb sprechen wir in diesem Kontext auch mehr von dem Errichten eines Gefängnisses (engl. jail). Der Klassiker, um den es hier geht, ist der Webbrowser. Meiner Meinung nach sehe ich für dieses Szenario eher das Smartphone als weitaus problematischer, wo dieser Datenabgriff durchaus für jeden User leicht zu beobachten ist. Ohne sarkastisch zu sein, beobachte ich aber regelmäßig Leute, die ihren Computer wie eine Festung ausbauen und alle Daten auf dem Smartphone sorglos in der Welt verteilen.
Das vor allem Webseiten der großen Techkonzerne alle möglichen Tricks einsetzen, um ihre Nutzer besser zu kennen, als diese sich selbst, ist in Fachkreisen ein offenes Geheimnis. Für Außenstehende wirken die Fachäußerungen oft unverständlich, was sich nicht selten in Resignation oder Gleichgültigkeit äußert. Um hier nicht zu tief in die Materie einzutauchen, möchte ich mit einem einfachen Beispiel aufzeigen, wie raffiniert die Möglichkeiten sind. Wer glaubt, dass eine VPN‑Verbindung der maximale Schutz der Privatsphäre darstellt, der unterliegt einem fatalen Irrtum. Nur weil man die eigene IP Adresse verschleiert, kann man dennoch Rückschlüsse auf auf den tatsächlichen Standort des Nutzers ziehen. Dazu muss man sich nicht einmal besonders anstrengen. Wer sich also angeblich aus Deutschland ins Internet einloggt, dessen Webbrowser aber als Spracheinstellung Russisch und als Zeitzone noch Moskau eingestellt hat, befindet sich vermutlich nicht in Deutschland. Natürlich greifen die Techkonzerne wie LinkedIn oder Facebook weitaus mehr Informationen zu ihren Nutzern ab. Jede einzelne Maßnahme mag isoliert eher trivial erscheinen, aber kombiniert man die verschiedenen Möglichkeiten, ändert sich die Situation grundlegend. Deswegen ist es absolut unerlässlich, Sicherheit als gesamtes Konzept zu denken.
Wir sehen, dass, um ein effizientes Gefängnis bauen zu können, durchaus viel mehr Spezialwissen und auch Erfahrung notwendig ist, als nur fix eine Software zu installieren. Ein Stichwort hierzu sei die Software AppAmor unter Linux. Zudem muss man sich auch im Klaren sein, dass, wenn man seinen Browser in eine Sandbox packt, dies auch Probleme mit sich bringt. Hier handelt es sich zum Beispiel um Zugriff auf Hardware wie Mikrofon und Kamera bei Videokonferenzen, oder das Herunterladen oder Hochladen von Dateien. Denn man hat ja den Browser vom Restsystem abgekoppelt und kann nun mal nicht eben schnell die Fotos auf Facebook posten. Wer also mit solchen Gedanken spielt, sollte sich die Zeit nehmen und diese Überlegungen auch zu Ende denken.
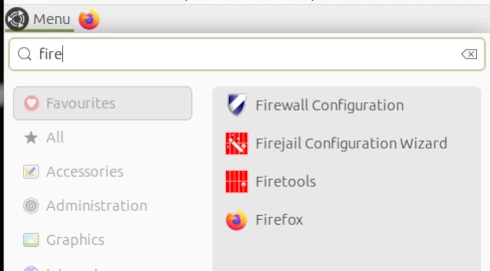
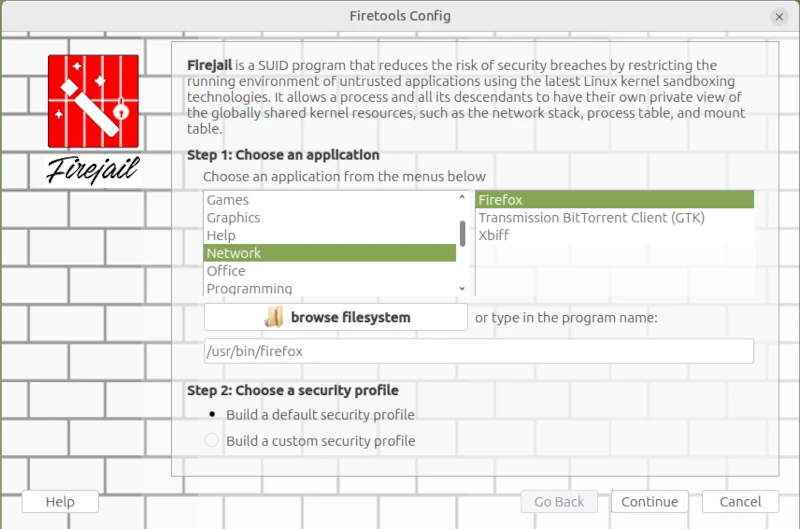
Nachdem ich sehr ausführlich das Warum erörtert habe, kommen wir nun zum Wie. Ich hatte bereits die beiden verbreitetsten Tools FireJail und BubbleWarp erwähnt. Da sich dieser Artikel an Power-User richtet, aber nicht an IT-Professionals mit Spezialwissen, steht für mich eine einfach benutzbare Lösung im Vordergrund. Deswegen fällt meine Wahl auf FireJail [1], das man zwar herunterladen und manuell installieren muss, dafür aber eine aktive Community besitzt und im Gegensatz zu BubbleWarp eine Dokumentation vorweisen kann.
Nach dem Download [2] von FireJail und FireTools für die entsprechende Distro können beide Programme auch leicht installiert werden. In meinem Fall handelt es sich um ein aktuelles Debian Linux, weswegen ich mir die deb Dateien von der Homepage geladen und diese mit einem einfachen Doppelklick problemlos über den Paketmanager installiert habe. Natürlich klappt das auch mit dem Standard-Paketmanager APT für Debian. Um allerdings aktuell zu bleiben, bevorzuge ich die erste Variante der Installation.
sudo apt-get install firejail firetool
ed:~$firejail--helpfirejailversion0.9.80FirejailisaSUIDsandboxprogramthatreducestheriskofsecuritybreachesbyrestrictingtherunningenvironmentofuntrustedapplicationsusingLinuxnamespaces.Usage:firejail [options] [program and arguments]
Über das Anwendungsmenü habe ich den Firejail-Configuration-Wizard gestartet.
Dadurch öffnet sich ein Wizard, mit dem Anwendungen als Sandbox konfiguriert werden. Dies unterscheidet sich von dem Konsolenbefehl insofern, das über die Kommandozeile alle durch FireJail unterstützten Programme in eine Sandbox gepackt werden. Das könnte allerdings die Funktionsweise so sehr einschränken, dass man damit die täglichen Aufgaben nicht mehr bearbeiten kann.
sudo firecfg
Damit kann man die Anwendungen in der Sandbox über die Icons des Windowmanagers-Menüs oder Dateiverlinkungen im Dateimanager starten. Diese automatisierte Variante unterstützt bisher die Desktop-Manager Mate, KDE, LXDE, Cinnamon und LXDE. Für Gnome3 und Unity gibt es nur rudimentäre Unterstützung. Es genügt ein Doppelklick auf das Desktopsymbol in Firetools oder auf der Bash der Befehl: firetools firefox. Alternativ kann auch FireTools gestartet werden. FirerTools ist ein grafischer Launcher für Anwendungen, die über FireJail in der Sandbox laufen.
In meinem Beispiel habe ich den Webbrowser Firefox über die von FireJail empfohlene deault Konfiguration eingerichtet. Es ist möglich, für jede installierte Anwendung entsprechende eigene Konfigurationen zu verwenden. Die zugehörigen Konfigurationsdateien befinden sich im Nutzerverzeichnis des angemedeten Users ~/.config/firejail/<app>.profile und /etc/firejail/<app>.profile.
# Firejail profile for firefox # Description: Safe and easy web browser from Mozilla # This file is overwritten after every install/update # Persistent local customizations include firefox.local # Persistent global definitions include globals.local
# Note: Sandboxing web browsers is as important as it is complex. Users might # be interested in creating custom profiles depending on the use case (e.g. one # for general browsing, another for banking, ...). Consult our FAQ/issue # tracker for more information. Here are a few links to get you going: # https://github.com/netblue30/firejail/wiki/Frequently-Asked-Questions#firefox-doesnt-open-in-a-new-sandbox-instead-it-opens-a-new-tab-in-an-existing-firefox-instance # https://github.com/netblue30/firejail/wiki/Frequently-Asked-Questions#how-do-i-run-two-instances-of-firefox # https://github.com/netblue30/firejail/issues/4206#issuecomment-824806968
# Note: Firefox requires a shell to launch on Arch and Fedora. # Add the next lines to firefox.local to enable private-bin. #private-bin bash,dbus-launch,dbus-send,env,firefox,sh,which #private-bin basename,bash,cat,dirname,expr,false,firefox,firefox-wayland,getenforce,ln,mkdir,pidof,restorecon,rm,rmdir,sed,sh,tclsh,true,uname private-etc firefox
Da die Konfiguration jeder einzelnen Anwendung schnell sehr komplex werden kann und man auch immer abwägen muss, was man mit einem Sandboxing erreichen möchte, verweise ich an dieser Stelle für weitere Informationen auf die Homepage [1].
Auf der Kommandozeile kann man sich sämtliche Anwendungen auflisten lassen, die aktuell über firejail gestartet wurden. Somit kann überprüft werden, ob die Sandbox für die entsprechende Anwendung funktioniert. Dazu stehen zwei Kommandos zur Verfügung: firejail –list und firejail –top. Der Parameter Top zeigt die Prozessauslastung in der Bash.
Eine Einschränkung habe ich bei meinem Test allerdings bemerkt: Besonders Browser in virtuellen Maschinen wollen unter Firejail nicht starten. Was natürlich auch etwas sinnfrei ist. Denn virtuelle Maschinen erzeugen bereits eine hervorragende Abschirmung der Anwendung zum Betriebssystem.
Fazit
Meiner Ansicht nach ist die Idee des Sandboxing durchaus reizvoll. Meine Kritik liegt eher an der Umsetzung. Ich würde das Thema Virtualisierung klassisch sehen, wie es beispielweise mit Docker oder PlayOnLinux umgesetzt wird. Eine Sandbox würde mir sozusagen im Desktop eine virtuelle Umgebung einrichten, in die ich isoliert Programme installieren kann, ohne dass dadurch das Betriebssystem verändert wird. Löscht man die Sandbox, so werden auch alle Dateien des installierten Programmes inklusive der Konfiguration rückstandslos entfernt. Die Funktionsweise von FireJail ist allerdings anders. FireJail erkennt unter den installierten Programmen, alle diejenigen, zu denen eine Jail-Konfiguration möglich ist, um diese in einem sogenannten Käfig auszuführen. Auch das Starten von AppImages in FireJail funktioniert in aller Regel nicht. Basierend auf meinen Erfahrungen im Thema Security und Penetration Testing bewerte ich den Kosten Nutzen Effekt speziell für FireJail als unzureichend und vertrete zudem die Meinung, dass die Art und Weise, wie FireJail arbeitet, den Anwendern ein falsches Gefühl von Sicherheit suggeriert. Denn ein Problem sind auch Updates, die oft vorgenommene sicherheitsrelevante Einstellungen wieder auf unerwünschte Standardeinstellungen unbemerkt zurücksetzen.
Das dauerhafte Speichern von Daten nennt man im Fachchinesisch Persistieren. Damit man auf diese Daten gezielt auch wieder zugreifen kann, benötigt man eine Software, die Daten strukturiert und durchsuchbar macht. Eine solche Software nennt sich Datenbank Management System (DBMS). Damit man von einer Programmiersprache wie Java, Ruby, Python oder PHP auf eine Datenbank zugreifen kann, benötigt man einen entsprechenden Treiber. Dieser Treiber wird auch oft als Client bezeichnet, denn das DBMS ist der Server, welcher mehreren Clients Zugriff gestattet. In diesem Artikel kümmern wir uns nicht darum, wie man sich mit welcher Programmiersprache auf die entsprechenden Datenbanken verbinden kann, sondern schauen uns an, was es für unterschiedliche Datenbanktechnologien gibt und wofür diese eingesetzt werden.
[Relationale DB (Zeilen, Spalten) | GIS DB | embedded DB] [NoSQL | {Key Value Store | Document DB (JSON, XML) | Graph DB | Zeitreihen Server]
Mittlerweile gibt es für die klassischen Datenbanksysteme, die sogenannten relationalen Datenbanken, eine Vielzahl von Lösungen zur Auswahl. Sowohl kommerzielle, als auch professionelle freie Open Source Vertreter buhlen um die Gunst der Anwender. Im Web bieten die meisten Hoster zum Speichern der Daten die freien DBMS MySQL (Oracle) und MariaDB (Abspaltung von MySQL nach der Übernahme durch Oracle) ihren Anwendern zur Auswahl an. Wer seine Server allerdings selbst betreuen kann, kann natürlich auch auf das professionellere PostgreSQL setzen.
Postgres ist allerdings für die meisten PHP-Standardapplikationen eher ungeeignet, obwohl WordPress und Joomla dieses Datenbanksystem durchaus unterstützen. Probleme bereiten üblicherweise die Entwickler der Erweiterungen. Der Zugriff auf die Datenbanken erfolgt dann nicht über die Schnittstellen der Anwendung, sondern aus Unwissenheit wird oft über die nativen Befehle von MySQL auf die Daten zugegriffen.
In der kommerziellen Anwendungsentwicklung verwendet man üblicherweise Oracle oder den Microsoft SQL Server, je nachdem, wie affin man mit der Microsoft-Windows-Welt ist. Der Grund für den Einsatz kommerzieller Datenbankserver liegt im kostenpflichtigen Support, bei Bekanntwerden von Schwachstellen und Fehlern. Geschäftskritische Anwendungen, müssen das Fortbestehen des Herstellers und auch der Kunden dieser Anwendung sicherstellen. Gerade die Geschwindigkeit der Auslieferung von Korrekturen für Sicherheitsschwachstellen ist ein gewichtiger Grund für den Einsatz kommerzieller Software.
Die Funktionsweise von relationalen Datenbanken ist über Tabellen definiert. Die Spalten einer Tabelle definieren die Eigenschaft und eine Zeile der Tabelle bildet den Datensatz. Um einen expliziten Datensatz ansprechen zu können, muss eine Spalte (Primärschlüssel) eindeutige, nicht noch einmal in dieser Spalte vorkommende Einträge enthalten. Diese Eigenschaft der Primärschlüssel nennt sich unique. Über die Primärschlüssel lassen sich Verknüpfungen, sogenannte Relationen, zwischen den Tabellen aufbauen. Um den Artikel nicht ins Unermessliche ausufern zu lassen, belasse ich es an dieser Stelle mit der Tiefe zur Funktionsweise von relationalen Datenbanken und gehe zur nächsten Kategorie über.
Natürlich gibt es auch relationale Datenbanken, die nicht zeilenorientiert, sondern spaltenorientiert arbeiten. Dies ermöglicht effizientere Abfragen und Analysen, insbesondere bei großen Datenmengen. Hier sind einige der Hauptmerkmale und Vorteile spaltenorientierter Datenbanken:
Datenorganisation: Speichert Daten in Spalten, was die Verarbeitung spezifischer Spalten in Abfragen beschleunigt.
Komprimierung: Bietet oft bessere Komprimierungsraten für spaltenweise gespeicherte Daten, da ähnliche Datentypen hintereinander gespeichert werden.
Analytische Abfragen: Optimiert für Analysen und aggregierte Abfragen, die große Datenmengen schnell abfragen müssen.
Reduzierte I/O: Reduziert die Menge an Daten, die von der Festplatte gelesen werden müssen, da nur die benötigten Spalten abgerufen werden.
Spaltenorientierte Datenbanken sind Apache Cassandra, SAP Hanna, IBM DB2 und Amazon BigQuery mit klassichen Anwendungsfällen für:
Business Intelligence: Ideal für Datenbanken, die große Mengen an Daten für analytische Zwecke verarbeiten müssen.
Data Warehousing: Effizient bei der Speicherung und Analyse historischer Daten.
Echtzeitanalysen: Geeignet für Anwendungen, die schnelle Entscheidungen basierend auf aktuellen Daten treffen müssen.
Um Daten für geografische Informationssysteme (GIS) wie Google Maps bereitzustellen, werden sogenannte Geospatial Datenbanken eingesetzt. Bei Geospatial Datenbanken handelt es sich um Erweiterungen relationaler Datenbanken, die für geometrische Objekte optimierte und standardisierte Tabellen und Relationen bereitstellen. Die GIS Erweiterung für PostgreSQL heißt PostGIS. Die Datensätze für das frei verfügbare OpenStreetMap liegen in einem spezialsierten XML Format vor und können aber auch in Geospatial Datenstrukturen transformiert werden.
Key – Value Speicher, werden oft in Konfigurationsdateien verwendet. Will man allerdings ein schnelles Caching-System aufbauen, benötigt man ein wenig mehr Komplexität. Denn die Schlüssel / Wert Bezeihung kann von einfachen Zeichenketten hin zu komplexen Objekten ausarten. Grundsätzlich besteht ein Speicher aus einem uniquen Schlüssel, dem je nach Datentyp Werte zugeordnet werden können. Datentypen können Zeichenketten (Strings), Zahlen (Integer, Float), Wahrheitswerte (Boolean) und Listen sein. Key – Value Datenbanken gehören zu den NoSQL Datenbanken, da die Abfrage nicht wie bei relationalen Datenbanken über SQL erfolgt, sondern datenbank- und herstellerspezifisch ist.
Typische Key -Value Datenbanken sind Redis, MemCached, Amazon DynamoDB und die etwas in die Tage gekommene BarkleyDB, die von Oracle übernommen wurde. Eine Eigenschaft von Key – Value Datenbanken ist, dass die Daten im Speicher gehalten und in regelmäßigen Abständen auf die Festplatte gesichert werden. Das Vorhalten der Daten im Arbeitsspeicher erfordert natürlich auch eine entsprechende Ausstattung der Maschine mit ausreichend RAM. Besonders bei großen Anwendungen kann für das Chaching eine enorme Datenmenge zusammenkommen.
Eine weitere Kategorie für Datenbanken sind Embedded-Datenbanken. Embedded meint auf Deutsch „eingebunden“ und bezieht sich auf den Datenbankserver. Das bedeutet im Konkreten, dass das Datenbanksystem keine eigenständige Installation ist, sondern als Bibliothek einen Teil der Anwendung darstellt. Der Vorteil einer solchen Lösung ist, dass die Installationsroutine der Anwendung einfacher ist. Meist geht das allerdings zulasten der Sicherheit, da viele der embedded Datenbanken keine zusätzliche Schicht für eine Benutzerverwaltung haben. Dieser Umstand gilt besonders für SQLite und die in Java implementierte H2. Aber auch die bereits erwähnte NoSQL BarkelyDB die als Java- oder C-Bibliothek verfügbar ist, hat keine Benutzerverwaltung. Das heißt, wer Zugriff auf die Anwendung hat, kann mit einem Client die Daten aus der Datenbank lesen. Daher sind die gerade genannten Systeme nicht für Anwendungen geeignet, die eine hohe Sicherheitsstufe erfordern.
Zur Java Version der BarkelyDB kann man noch sagen, dass die letzte verfügbare Implementierung aus dem Jahr 2017 stammt und in Java / Apache Ant als Quelltext vorhanden ist, der aber selbst kompiliert werden muss. Ein offizielles Binary von Oracle ist nicht mehr verfügbar, es können aber sogenannte inoffizielle Versionen im Maven Central Repository gefunden werden.
Wer eine voll funktionsfähige relationale Datenbank in seine Anwendung integrieren möchte, kann auf die embedded Variante von PostgreSQL – pgx – zurückgreifen, die alle Funktionen des PostgreSQL Servers lokal bereitstellt.
Die nächste Klasse der Datenbanken gehört wieder zu den NoSQL Vertretern. Dokumentenbasierte Datenbanken. Die beiden DBSM MongoDB und CouchDB sind im Funktionsumfang durchaus identisch, dennoch gibt es markante Unterschiede.
MongoDB wird aufgrund seiner umfangreichen Abfragesprache und hohen Performance häufig für Anwendungen gewählt, die komplexe Abfragen und Echtzeitanalysen erfordern.
CouchDB eignet sich besonders für Anwendungen, die Zuverlässigkeit, eine verteilte Architektur und einfache Replikation benötigen, insbesondere in Szenarien, in denen Offline-Zugriff unerlässlich ist.
Die grundlegende Arbeitsweise von Dokumentendatenbanken ist, dass sich das Schema aus der hinterlegten Datenstruktur ergibt. Diese Datenstrukturen haben meist das JSON Format und werden entsprechend angesprochen. Dokumente der selben Datenstruktur werden einer Collection zugeordnet. Es handelt sich also nicht um klassische Office Dokumente die in diesen Datenbanken abgelegt werden, sondern um Formate wie JSON und XML. Dokumentendatenbanken, die sich auf XML spezialisiert haben, sind Oracle XML DB oder Apache Xindice.
Viele Webentwickler, die sich auf FrontEnd (UX / UI) spezialisiert haben, greifen gern auf Dokumentdatenbanken zurück. Das erlaubt ihnen, die Daten im JSON Format abzulegen, um damit REST Zugriffe zu simulieren und damit die dynamischen Inhalte der Benutzeroberfläche zu befüllen.
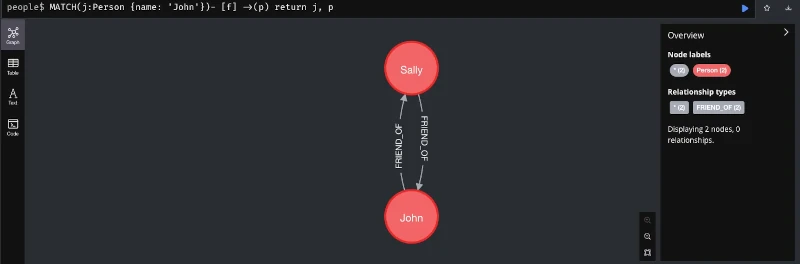
Eine sehr exotische Variante der NoSQL Datenbanken sind die Gaphdatenbanken, die Daten als Graphen repräsentieren. Diese Speicherform ermöglicht das effiziente Ablegen von Informationen nach Beziehungen. Solche Beziehungen können Verlinkungen von Webseiten sein oder die Repräsentation einer Person in sozialen Medien. Aber auch die komplexen Beziehungen für Empfehlungssysteme können als Graph dargestellt werden. Die nachfolgende Abbildung zeigt ein einfaches Beispiel für Neo4J einer in Java implementierten Graphdatenbank, um sich eine Vorstellung des Einsatzszenarios machen zu können.
Andere Graphdatenbanken sind Amazon Neptune und ArangoDB.
Als letzte Datenbanklösung möchte ich die sogenannten Zeitreihen (Time Series) vorstellen. Da besonders im Kontext für den Betrieb von Anwendungen das Monitoring essenziell geworden ist, haben Daten, die als Zeitreihen vorliegen, an Bedeutung gewonnen. Typische Datenbanken, die sich auf die Verarbeitung von Zeitreihen spezialisiert haben, sind Prometheus und InfluxDB. Aber auch für klassische relationale Datenbanken gibt es entsprechende Erweiterungen. Die bereits mehrfach erwähnte PostgreSQL-Datenbank hat auch für diesen Anwendungsfall eine entsprechende Erweiterung namens TimescaleDB.
Natürlich kann man über das Thema noch viel mehr sagen. Schließlich füllen unzählige Bücher einige Regalmeter in Bibliotheken zum Thema Datenbanken. Für den Einstieg und die Übersicht zu den verschiedenen Datenbanksystemen beziehungsweise NoSQL Lösungen soll es aber an dieser Stelle genügen. Mit den Informationen aus diesem Artikel, haben sie nun eine Vorstellung, welche Datenbank sich für ihren speziellen Anwendungsfall eignet. Wir konnten auch sehen, dass relationale Datenbanken, insbesondere die freie Open Source Datenbank PostgreSQL mit den verfügbaren Erweiterungen, sehr universell einsetzbar sind. Weiterführende Themen zu Datenbanken sind die Datenmodellierung und Sicherheit gegen Hackerangriffe.
Das Internet hat ein ganz eigenes Gedächtnis, das beinahe nichts vergisst. Ein Teil dieses Gedächtnisses ist das 1996 durch Brewster Kahle initiierte Projekt archive.org welches sich zur Aufgabe gemacht hat, das Internet zu archivieren. Zentraler Bestandteil von archive.org ist die Wayback Machine.
Laut eigenen Angaben hat die WaybackMachine Zugriff auf einen Bestand von ca. 1 Trillion Webseiten. Ähnlich wie Google wird die Wayback Machine über ein einfaches Suchfeld bedient. In diesem Suchfeld kann man entweder nach einer konkreten Internetdomain oder nach einem konkreten Schlüsselwort suchen. Wenn zu dem gesuchten Begriff etwas im Bestand von archive.org gespeichert ist, zeigt die Kalenderansicht an, welchem Tag ein sogenannter Snapshot erstellt wurde. Alle Inhalte einer Domain, die an diesem Tag frei zugänglich sind, wurden in den Snapshot aufgenommen. So kann man leicht bereits gelöschte Inhalte durchaus wieder erreichen.
Wenn man mit der Wayback Machine arbeitet, muss man sich allerdings einiger Rahmenbedingungen im Klaren sein. Bei archive.org handelt es sich zwar um eine sogenannte Non-Profit-Organisation, die sich durch Spenden finanziert. Zudem hat archive.org seinen Hauptsitz in den Vereinigten Staaten von Amerika. In Anbetracht der enormen Kosten, die allein für die Erhebung und Speicherung der Daten entstehen, ist es schon mehr als nur eine Vermutung, dass bei diesem Projekt durchaus eine Nähe zu Behörden vorhanden ist. Auch offizielle Stellen haben nicht wenig Gründe, so einen Dienst zur Verfügung zu haben, ohne dabei auf die engen Rahmenbedingungen von offiziellen Regierungsorganisationen achten zu müssen.
Ein Problem, das sich aus der Arbeit mit der Wayback Machine ergibt, ist die Änderungsfrequenz der archivierten Homepages. Besonders bei kleinen Webseiten sind zwischen den Snapshots mehrere Änderungen vorgenommen worden. Aber auch vermeintlich große Webseiten, wie spiegelonline.de haben keinen täglichen Snapshot, wie man eigentlich erwarten könnte. Die Gründe dafür sind durchaus vielfältig. Zudem gibt es verschiedene Mechanismen, die Crawler vom Indizieren der Webseite abhalten. Sinn solcher Bemühungen kann es unter anderem sein, den Traffic auf dem eigenen Server zu begrenzen, damit die Ressourcen den Lesern zur Verfügung stehen und nicht durch Bots blockiert werden.
Ein anderes Thema der gewaltigen Datenmenge ist natürlich auch der Zugriff von künstlicher Intelligenz zum Trainieren großer LLMs. Große Plattformen fürchten um den Verlust ihrer Nutzer, ein Aspekt, den ich bereits 2023 thematisiert habe. Im Februar 2026 gab es hier auch eine öffentliche Diskussion zwischen dem Vorstand der Wayback Machine Mark Graham und Nieman Lab, die auch als Blog unter archive.org zu finden ist. Diesem Problem stehen die meisten Webseitenbetreiber gegenüber. Denn das Erstellen und Veröffentlichen von Inhalten kostet Zeit und auch Geld. Am Beispiel von elmar-dott.com sind das explizit Beträge, die für den Server, die Domain, Bücher und diverse Abonnements zu Buche schlagen. Da wir uns explizit gegen automatische Erstellungen von Inhalten aussprechen, basieren alle Artikel auf elmar-dott.com auf konkreten Erfahrungen und einer tiefen Recherche zu den einzelnen Themenbereichen. Das bedeutet auch, dass viele der beschriebenen Lösungen von den entsprechenden Autoren auch tatsächlich so genutzt werden. Damit KI die Inhalte nicht abgreift und wir somit außer von Webcrawlern keine wirklichen Besucher haben, sind hochwertige Informationen nur über ein Abo einsehbar. Das betrifft vor allem Referenzen, Quelltexte und ausgewählte Artikel.
Ein anderer Aspekt ist natürlich die Vertrauenswürdigkeit der gespeicherten Inhalte. Auch wenn das Motto von archive.org gemeinnützig ist und durch die Bemühungen, ein frei zugängliches Internet zu gewährleisten, heißt das noch lange nicht, dass archive.org nicht möglicherweise andere nicht offizielle Interessen vertritt. Elektronisch gespeicherte Inhalte lassen sich bekanntlich auch leicht manipulieren. So sind die über Archivierungsdienste erhobenen Inhalte vielmehr als Indiz zu werten. Natürlich würde es Möglichkeiten geben, die erhobenen Inhalte gegen Veränderung zu schützen. Die Blockchain wäre eine solche Möglichkeit, Manipulationen zu erkennen.
Im Premiumartikel Erntezeit beschreibe ich, wie man über verschiedene freie und kostenpflichtige APIs Informationen erheben kann. Auch die Wayback Machine kann für brisante Rechercheaufgaben herangezogen werden. Denn wie so immer gilt auch in Unternehmen: Wo gehobelt wird, fallen Späne. Kleine Missgeschicke sind nun mal menschlich und bisweilen kann es vorkommen, dass Unternehmen ‚aus Versehen‘ brisante Interna veröffentlichen. Das können Fehlermeldungen auf der Webseite sein, die verraten, welches DBMS oder welcher Server im Einsatz ist. Sobald man davon Kenntnis erlangt, dass Informationen, die missbraucht werden können, in irgendeinem Datenbestand auftauchen, ist die erste Handlung, den Inhaber des Datenbestandes zu kontaktieren und um Löschung zu bitten. Oft hilft hier eine Erklärung und ein freundliches Wort.
Natürlich ist archive.org nicht einzig auf Webseiten spezialisiert. Das Ziel ist, eine umfassende Bibliothek zu erstellen, was natürlich auch das Digitalisieren von copyrightfreien Büchern umfasst. Ähnlich dem Projekt Gutenberg. Aber auch Filme, Audio und Software sind im Archiv zu finden. Interessanterweise findet man archive.org auch im Onion Tor Netzwerk unter einer eigenen Onion-Domain.
Natürlich ist archive.org nicht die einzige Organisation, die versucht, das Internet zu speichern. Auch die Webseite archive.today hat dieses Ziel. Allerdings ist der Datenbestand von archive.today nicht so umfassend. Dafür kann man die eigene URL über ein Eingabefeld rasch übermitteln und schon ist die Webseite auch im Bestand aufgenommen.
Wie wir sehen können, gibt es durchaus einige Perlen im Internet. Um sich intensiv mit Recherchetechniken auseinanderzusetzen, muss man kein Journalist sein. Auch der Bereich Reconnaissance (dt. Aufklärung) in der Cyber Security erfordert einiges an Gespür. Nicht ohne Grund heißt es: Wissen ist Macht.
Wenn Sie sich mit Java Enterprise beschäftigen möchten, mag es anfangs etwas überwältigend und verwirrend wirken. Aber keine Sorge, es ist nicht so schlimm, wie es scheint. Für den Anfang genügen grundlegende Kenntnisse über die Ideen und Konzepte.
Die Java Serie
zuletzt geändert::
Da Java EE weder ein Werkzeug noch ein Compiler ist, den man wie das Java Development Kit (JDK), auch bekannt als Software Development Kit (SDK), herunterlädt und verwendet, handelt es sich bei Java Enterprise um eine Reihe von Spezifikationen. Diese Spezifikationen werden durch eine API unterstützt, die wiederum eine Referenzimplementierung besitzt. Die Referenzimplementierung ist ein herunterladbares Paket namens Application Server.
Seit Java EE 8 wird Java Enterprise von der Eclipse Foundation gepflegt. Oracle und die Eclipse Foundation konnten sich nicht auf eine gemeinsame Vereinbarung zur Nutzung der Marke Java einigen, die Oracle gehört. Kurz gesagt: Die Eclipse Foundation benannte Java EE in Jakarta EE um. Dies hat auch Auswirkungen auf ältere Projekte, da sich in Jakarta EE 9 die Paketpfade von javax zu jakarta geändert haben. Jakarta EE 9.1 aktualisiert alle Komponenten von JDK 8 auf JDK 11.
Für die Entwicklung von Jakarta Enterprise [1]-Anwendungen sind einige Voraussetzungen erforderlich. Zunächst muss die richtige JDK-Version ausgewählt werden. Die Laufzeitumgebung Java Virtual Machine (JVM) ist bereits im JDK enthalten und muss nicht separat installiert werden. Eine gute Wahl ist stets die neueste LTS-Version. Java 17 JDK wurde 2021 veröffentlicht und wird bis 2024 unterstützt.
Um die Oracle-Lizenzbeschränkungen zu umgehen, können Sie auf eine freie Open-Source-Implementierung des JDK umsteigen. Eine der bekanntesten freien Varianten ist OpenJDK von adoptium [2]. Eine weitere interessante Implementierung ist GraalVM [3], das auf OpenJDK basiert. Die Enterprise Edition von GraalVM kann Ihre Anwendung um das 1,3-Fache beschleunigen. Für den Produktiveinsatz ist eine kommerzielle Lizenz der Enterprise Edition erforderlich. GraalVM enthält außerdem einen eigenen Compiler.
Version
Year
JSR
Servlet
Tomcat
JavaSE
J2EE – 1.2
1999
J2EE – 1.3
2001
JSR 58
J2EE – 1.4
2003
JSR 151
Java EE 5
2006
JSR 244
Java EE 6
2009
JSR 316
Java EE 7
2013
JSR 342
Java EE 8
2017
JSR 366
Jakarta 8
2019
4.0
9.0
8
Jakarta 9
2020
5.0
10.0
8 & 11
Jakarta 9.1
2021
5.0
10.0
11
Jakarta 10
2022
6.0
10.1
11
Jakarta 11
2023
6.1
11.0
17
Jakarta 12
under development
6.2
21
Die obige Tabelle ist nicht vollständig, enthält aber die wichtigsten aktuellen Versionen. Sollten Ihnen weitere Informationen fehlen, schreiben Sie mir gerne eine Nachricht.
Bitte beachten Sie, dass die Jakarta EE-Spezifikation ein bestimmtes Java SDK benötigt und der Anwendungsserver möglicherweise ein anderes Java JDK als Laufzeitumgebung benötigt. Die beiden Java-Versionen müssen nicht identisch sein.
Im nächsten Schritt wählen Sie die Implementierung der Jakarta EE-Umgebung. Das bedeutet, Sie entscheiden sich für einen Anwendungsserver. Es ist sehr wichtig, dass der gewählte Anwendungsserver mit der auf Ihrem System installierten JVM-Version kompatibel ist. Der Grund dafür ist einfach: Der Anwendungsserver ist in Java implementiert. Wenn Sie ein Servlet-Projekt entwickeln möchten, benötigen Sie keinen vollständigen Anwendungsserver. Ein einfacher Servlet-Container wie Apache Tomcat (Catalina) oder Jetty enthält alles Notwendige.
Referenzimplementierungen für Jakarta Enterprise sind beispielsweise: Payara (ein Fork von Glassfish), WildFly (ehemals JBoss), Apache Geronimo, Apache TomEE, Apache Tomcat und Jetty.
Vielleicht haben Sie schon von Microprofile [4] gehört. Keine Sorge, es ist gar nicht so kompliziert, wie es zunächst scheint. Microprofiles sind im Allgemeinen eine Teilmenge von JakartaEE zum Ausführen von Microservices. Sie wurden um verschiedene Technologien erweitert, um den Status der Dienste zu verfolgen, zu beobachten und zu überwachen. Version 5 wurde im Dezember 2021 veröffentlicht und ist vollständig kompatibel mit JakartaEE 9.
Core Technologies
Plain Old Java Beans
POJOs sind vereinfachte Java-Objekte ohne Geschäftslogik. Diese Art von Java-Beans enthält lediglich Attribute und die zugehörigen Getter und Setter. POJOs:
Erweitern keine vordefinierten Klassen: z. B. ist public class Test extends javax.servlet.http.HttpServlet keine POJO-Klasse.
Enthalten keine vordefinierten Annotationen: z. B. ist @javax.persistence.Entity public class Test keine POJO-Klasse.
Implementieren keine vordefinierten Schnittstellen: z. B. ist public class Test implements javax.ejb.EntityBean keine POJO-Klasse.
(Jakarta) Enterprise Java Beans
Eine EJB-Komponente, auch Enterprise Bean genannt, ist ein Codeblock mit Feldern und Methoden zur Implementierung von Modulen der Geschäftslogik. Man kann sich eine Enterprise Bean als Baustein vorstellen, der allein oder zusammen mit anderen Enterprise Beans verwendet werden kann, um Geschäftslogik auf dem Java-EE-Server auszuführen.
Enterprise Beans sind entweder zustandslose oder zustandsbehaftete Session Beans oder Message-Driven Beans. Zustandslos bedeutet, dass die Session Bean und ihre Daten gelöscht werden, sobald der Client die Ausführung beendet hat. Eine Message-Driven Bean kombiniert die Eigenschaften einer Session Bean mit denen eines Message Listeners und ermöglicht es einer Geschäftskomponente, asynchron (JMS-)Nachrichten zu empfangen.
(Jakarta) Servlet
Die Java-Servlet-Technologie ermöglicht die Definition HTTP-spezifischer Servlet-Klassen. Eine Servlet-Klasse erweitert die Funktionalität von Servern, die Anwendungen hosten, auf die über ein Anfrage-Antwort-Programmiermodell zugegriffen wird. Obwohl Servlets auf jede Art von Anfrage reagieren können, werden sie üblicherweise zur Erweiterung der von Webservern gehosteten Anwendungen eingesetzt.
(Jakarta) Server Pages
JSP ist eine UI-Technologie, mit der sich Servlet-Code-Schnipsel direkt in ein textbasiertes Dokument einfügen lassen. JSP-Dateien werden vom Compiler in ein Java-Servlet umgewandelt.
(Jakarta) Server Pages Standard Tag Library
Die JSTL kapselt Kernfunktionen, die vielen JSP-Anwendungen gemeinsam sind. Anstatt Tags verschiedener Anbieter in Ihren JSP-Anwendungen zu mischen, verwenden Sie einen einzigen, standardisierten Tag-Satz. Die JSTL enthält Iterator- und Bedingungs-Tags zur Ablaufsteuerung, Tags zur Bearbeitung von XML-Dokumenten, Internationalisierungs-Tags, Tags für den Datenbankzugriff mit SQL sowie Tags für häufig verwendete Funktionen.
(Jakarta) Server Faces
JSF ist ein Framework für Benutzeroberflächen zur Entwicklung von Webanwendungen. JSF wurde eingeführt, um das Problem von JSP zu lösen, bei dem Programmlogik und Layout stark voneinander getrennt waren.
(Jakarta) Managed Beans
Managed Beans sind leichtgewichtige, containerverwaltete Objekte (POJOs) mit minimalen Anforderungen. Sie unterstützen eine kleine Anzahl grundlegender Dienste wie Ressourceninjektion, Lebenszyklus-Callbacks und Interceptors. Managed Beans stellen eine Verallgemeinerung der von der Java Server Faces-Technologie spezifizierten Managed Beans dar und können überall in einer Java-EE-Anwendung eingesetzt werden, nicht nur in Webmodulen.
(Jakarta) Persistence API
Die Java Persistence API (JPA) ist eine auf Java-Standards basierende Lösung für die Datenpersistenz. Sie nutzt ein objektrelationales Mapping, um die Lücke zwischen einem objektorientierten Modell und einer relationalen Datenbank zu schließen. Die Java Persistence API kann auch in Java-SE-Anwendungen außerhalb der Java-EE-Umgebung verwendet werden. Hibernate und Eclipse Link sind Beispiele für JPA-Implementierungen.
(Jakarta) Transaction API
Die JTA bietet eine Standardschnittstelle zur Abgrenzung von Transaktionen. Die Java-EE-Architektur stellt standardmäßig einen automatischen Commit zur Verfügung, der Transaktions-Commits und -Rollbacks verarbeitet. Ein automatischer Commit bedeutet, dass alle anderen Anwendungen, die auf Daten zugreifen, nach jedem Lese- oder Schreibvorgang die aktualisierten Daten sehen. Führt Ihre Anwendung jedoch zwei voneinander abhängige Datenbankzugriffe durch, sollten Sie die JTA-API verwenden, um den Beginn, den Rollback und den Commit der gesamten Transaktion – einschließlich beider Operationen – festzulegen.
(Jakarta) API for RESTful Web Services
JAX-RS definiert APIs für die Entwicklung von Webdiensten gemäß dem REST-Architekturstil (Representational State Transfer). Eine JAX-RS-Anwendung ist eine Webanwendung, die aus Klassen besteht, die als Servlet in einer WAR-Datei zusammen mit den erforderlichen Bibliotheken verpackt sind.
(Jakarta) Dependency Injection for Java
Dependency Injection für Java definiert einen Standardsatz von Annotationen (und ein Interface) für die Verwendung injizierbarer Klassen wie Google Guice oder dem Sprig Framework. Auf der Java-EE-Plattform bietet CDI Unterstützung für Dependency Injection. Konkret können Injektionspunkte nur in einer CDI-fähigen Anwendung verwendet werden.
(Jakarta) Contexts & Dependency Injection for Java EE
CDI definiert eine Reihe von Kontextdiensten, die von Java-EE-Containern bereitgestellt werden und es Entwicklern erleichtern, Enterprise Beans zusammen mit Java Server Faces in Webanwendungen zu verwenden. CDI ist für die Verwendung mit zustandsbehafteten Objekten konzipiert, bietet aber auch viele weitere Einsatzmöglichkeiten und ermöglicht Entwicklern ein hohes Maß an Flexibilität bei der Integration verschiedener Komponententypen auf lose gekoppelte, aber typsichere Weise.
(Jakarta) Bean Validation
Die Bean-Validierungsspezifikation definiert ein Metadatenmodell und eine API zur Validierung von Daten in Java-Beans-Komponenten. Anstatt die Datenvalidierung auf mehrere Schichten, wie Browser und Server, zu verteilen, können die Validierungsbedingungen zentral definiert und schichtübergreifend genutzt werden.
(Jakarta) Message Service API
Die JMS-API ist ein Messaging-Standard, der es Java-EE-Anwendungskomponenten ermöglicht, Nachrichten zu erstellen, zu senden, zu empfangen und zu lesen. Sie ermöglicht eine lose gekoppelte, zuverlässige und asynchrone verteilte Kommunikation.
(Jakarta) EE Connector Architecture
Die Java-EE-Connector-Architektur wird von Softwareherstellern und Systemintegratoren verwendet, um Ressourcenadapter zu erstellen, die den Zugriff auf Enterprise-Informationssysteme (EIS) unterstützen und in jedes Java-EE-Produkt integriert werden können. Ein Ressourcenadapter ist eine Softwarekomponente, die es Java-EE-Anwendungskomponenten ermöglicht, auf den zugrunde liegenden Ressourcenmanager des EIS zuzugreifen und mit diesem zu interagieren. Da ein Ressourcenadapter spezifisch für seinen Ressourcenmanager ist, existiert typischerweise für jeden Datenbanktyp oder jedes Enterprise-Informationssystem ein eigener Ressourcenadapter.
Die Java EE Connector Architecture ermöglicht eine leistungsorientierte, sichere, skalierbare und nachrichtenbasierte Transaktionsintegration von Java EE-basierten Webdiensten mit bestehenden Enterprise-Integrated-Systemen (EIS), die sowohl synchron als auch asynchron arbeiten können. Bestehende Anwendungen und EIS, die über die Java EE Connector Architecture in die Java EE-Plattform integriert wurden, lassen sich mithilfe von JAX-WS und Java EE-Komponentenmodellen als XML-basierte Webdienste bereitstellen. JAX-WS und die Java EE Connector Architecture ergänzen sich somit ideal für die Enterprise Application Integration (EAI) und die durchgängige Geschäftsintegration.
(Jakarta) Mail API
Java-EE-Anwendungen nutzen die JavaMail-API zum Versenden von E-Mail-Benachrichtigungen. Die JavaMail-API besteht aus zwei Teilen:
einer Anwendungsschnittstelle, die von den Anwendungskomponenten zum Versenden von E-Mails verwendet wird,
und einer Dienstschnittstelle.
Die Java-EE-Plattform beinhaltet die JavaMail-API mit einem Dienstanbieter, der es Anwendungskomponenten ermöglicht, E-Mails über das Internet zu versenden.
(Jakarta) Authorization Contract for Containers
Die JACC-Spezifikation definiert einen Vertrag zwischen einem Java-EE-Anwendungsserver und einem Autorisierungsrichtlinienanbieter. Alle Java-EE-Container unterstützen diesen Vertrag. Die JACC-Spezifikation definiert java.security.Permission-Klassen, die dem Java-EE-Autorisierungsmodell entsprechen. Sie legt fest, wie Containerzugriffsentscheidungen an Operationen auf Instanzen dieser Berechtigungsklassen gebunden werden. Darüber hinaus definiert sie die Semantik von Richtlinienanbietern, die die neuen Berechtigungsklassen nutzen, um die Autorisierungsanforderungen der Java-EE-Plattform zu erfüllen, einschließlich der Definition und Verwendung von Rollen.
(Jakarta) Authentication Service Provider Interface for Containers
Die JASPIC-Spezifikation definiert eine Service-Provider-Schnittstelle (SPI), über die Authentifizierungsanbieter, die Mechanismen zur Nachrichtenauthentifizierung implementieren, in Client- oder Server-Container bzw. Laufzeitumgebungen zur Nachrichtenverarbeitung integriert werden können. Die über diese Schnittstelle integrierten Authentifizierungsanbieter verarbeiten Netzwerknachrichten, die ihnen von ihren aufrufenden Containern bereitgestellt werden. Sie transformieren ausgehende Nachrichten so, dass der Absender jeder Nachricht den Absender und der Empfänger den Absender authentifizieren kann. Eingehende Nachrichten werden von den Authentifizierungsanbietern authentifiziert, und die im Zuge der Nachrichtenauthentifizierung ermittelte Identität wird an die aufrufenden Container zurückgegeben.
(Jakarta) EE Security API
Ziel der Java EE Security API-Spezifikation ist die Modernisierung und Vereinfachung der Sicherheits-APIs. Dies geschieht durch die Etablierung einheitlicher Ansätze und Mechanismen sowie die Ausblendung komplexerer APIs aus der Entwicklersicht, wo immer möglich. Java EE Security führt die folgenden APIs ein:
SecurityContext-Schnittstelle: Bietet einen einheitlichen Zugriffspunkt, über den Anwendungen Aspekte der Aufruferdaten prüfen und den Zugriff auf Ressourcen gewähren oder verweigern können.
HttpAuthenticationMechanism-Schnittstelle: Authentifiziert Aufrufer einer Webanwendung und ist ausschließlich für die Verwendung im Servlet-Container vorgesehen.
IdentityStore-Schnittstelle: Bietet eine Abstraktion eines Identitätsspeichers, der zur Authentifizierung von Benutzern und zum Abrufen von Aufrufergruppen verwendet werden kann.
(Jakarta) Java API for WebSocket
WebSocket ist ein Anwendungsprotokoll, das Vollduplex-Kommunikation zwischen zwei Teilnehmern über TCP ermöglicht. Die Java-API für WebSocket erlaubt es Java-EE-Anwendungen, Endpunkte mithilfe von Annotationen zu erstellen, die die Konfigurationsparameter des Endpunkts festlegen und seine Lebenszyklus-Callback-Methoden definieren.
(Jakarta) Java API for JSON Processing
JSON-P ermöglicht Java-EE-Anwendungen das Parsen, Transformieren und Abfragen von JSON-Daten mithilfe des Objektmodells oder des Streaming-Modells.
JavaScript Object Notation (JSON) ist ein textbasiertes Datenaustauschformat, das von JavaScript abgeleitet ist und in Webdiensten und anderen verbundenen Anwendungen verwendet wird.
(Jakarta) Java API for JSON Binding
JSON-B stellt eine Bindungsschicht für die Konvertierung von Java-Objekten in und aus JSON-Nachrichten bereit. JSON-B ermöglicht zudem die Anpassung des standardmäßigen Mapping-Prozesses dieser Bindungsschicht durch Java-Annotationen für ein bestimmtes Feld, eine JavaBean-Eigenschaft, einen Typ oder ein Paket oder durch die Implementierung einer Strategie zur Benennung von Eigenschaften. JSON-B wurde mit der Java EE 8-Plattform eingeführt.
(Jakarta) Concurrency Utilities für Java EE
Concurrency Utilities for Java EE ist eine Standard-API zur Bereitstellung asynchroner Funktionen für Java EE-Anwendungskomponenten durch die folgenden Objekttypen: Managed Executor Service, Managed Scheduled Executor Service, Managed Thread Factory und Context Service.
(Jakarta) Batch Applications for the Java Platform
Batch-Jobs sind Aufgaben, die ohne Benutzerinteraktion ausgeführt werden können. Die Spezifikation „Batch Applications for the Java Platform“ (BAJP) ist ein Batch-Framework, das die Erstellung und Ausführung von Batch-Jobs in Java-Anwendungen unterstützt. Das Framework besteht aus einer Batch-Laufzeitumgebung, einer auf XML basierenden Job-Spezifikationssprache, einer Java-API zur Interaktion mit der Batch-Laufzeitumgebung und einer Java-API zur Implementierung von Batch-Artefakten.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.