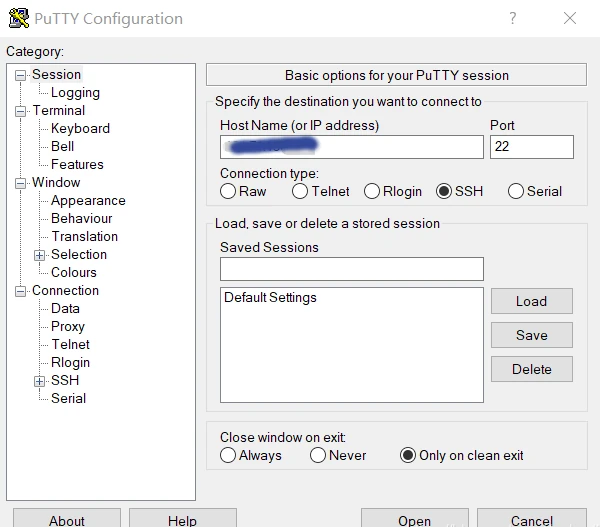
Die Verwaltung von Linux-Servern oder Docker-Containern erfordert grundlegende Kenntnisse des Terminals, auch bekannt als Kommandozeile. Windows-Benutzer können beispielsweise das Programm PuTTY verwenden, um über Secure Shell (SSH) Fernzugriff auf einen Linux Server zu erhalten. SSH ist eine sichere Fernverbindung, die eine verschlüsselte Terminalverbindung zu einem Linux-Rechner herstellt. SSH bietet zwei grundlegende Zugriffsarten auf ein entferntes System: die nicht empfohlene Methode mit Benutzername/Passwort und die sicherere Variante mit einem bereitgestellten RSA-Schlüsselpaar.
Per Definition sind „Terminal“ und „Shell“ nicht dasselbe, werden aber oft synonym verwendet. Im Allgemeinen ist das Terminal die Kommandozeilenschnittstelle (CLI), die Tastatureingaben von Benutzern empfängt. Die Shell ist ein Interpreter, der innerhalb des Terminals ausgeführt wird, um Programme zu starten. Bei den meisten Linux-Distributionen ist BASH (Bourne Again Shell) die Standard-System-Shell. Neben BASH gibt es weitere Shell-Varianten wie KornShell (ksh) oder C Shell (csh).
Beim Zugriff auf einen Rechner, sei es über eine Reverse Shell oder SSH, kann sich das Terminal ungewöhnlich verhalten. Häufige Probleme sind die Unfähigkeit, Text zu löschen, Strg+C oder Strg+L zu verwenden, und die fehlerhafte Textdarstellung. So verbessern Sie die Terminalnavigation.
Schritte für ein besseres Terminalerlebnis
1. Temporäres Skript starten
script /dev/null -c bash
Dies startet ein Skript, das sich automatisch löscht, da es auf /dev/null verweist.
2. Reverse Shell in den Hintergrund verschieben
Drücken Sie STRG+Z. Dadurch wird der Reverse-Shell-Prozess in den Hintergrund verschoben.
3. Prozess fortsetzen und stty konfigurieren
stty raw -echo; fg
Dies führt Sie zurück zum Prozess und passt das Terminal für Rohdateneingabe ohne Echo an.
4. Terminal zurücksetzen
reset xterm
Verwenden Sie diesen Befehl auch dann, wenn der Text nicht korrekt angezeigt wird oder ungewöhnliche Einrückungen vorhanden sind.
5. Umgebungsvariable TERM konfigurieren
export TERM=xterm
Überprüfen Sie die Variable $TERM vor und nach diesem Schritt mit echo $TERM.
Ersetzen Sie [tatsächliche Konsolenzeilennummer] und [tatsächliche Konsolenspaltennummer] durch die entsprechenden Werte, die Sie mit dem Befehl stty size in einer normalen Konsole ermitteln.
Sicherheitshinweis: Linux-Server, die über das Internet erreichbar sind, sollten weder die Anmeldung per Root-Benutzer noch per Benutzerpasswort ermöglichen. Das Problem besteht in verteilten Brute-Force-Angriffen von Botnetzen, die darauf abzielen, eine administrative Shell zu erlangen und das System zu kapern. Moderne, gehärtete Linux-Server deaktivieren daher das Root-Konto und stellen Administratoren lediglich den Befehl sudo zur Verfügung.
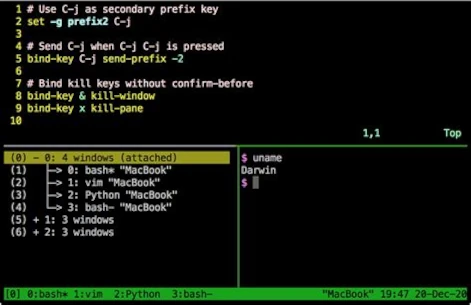
Administratoren, die mehrere geöffnete Shells verwalten müssen, um verschiedene Rechner zu warten, nutzen gerne das praktische Tool TMUX [1]. Es ist aktuell in Version 3 verfügbar und lässt sich einfach über die Shell installieren:
apt-get install tmux
TMUX ermöglicht die Nutzung mehrerer Terminal-Sitzungen in einem einzigen Terminal. Für die korrekte Verwendung konsultieren Sie bitte die offizielle Handbuchseite [2]. Die Bedienung des Programms ist etwas komplex und erfordert etwas Einarbeitungszeit. Eine kurze Einführung würde den Rahmen dieses Beitrags sprengen und einen eigenen Artikel füllen, der möglicherweise in Zukunft veröffentlicht wird. Um Ihnen einen Eindruck von den Möglichkeiten von TMUX zu vermitteln, sehen Sie sich den folgenden Screenshot an.
Wer sich als Entwickler ein wenig mit Netzwerktechnik auskennt, weiß, dass man anhand der IP Adresse des Users einige spannende Details herausfinden kann. Diese Details sind neben Informationen zum Ursprungsland und der Stadt, aus der der Request kommt, auch der Provider. Es lassen sich also auf diese Art und Weise wirkungsvoll die mittlerweile beliebten Proxy Server erkennen und blockieren. Natürlich ist die Geolocation nur ein Baustein in der langen Kette, Nutzer eindeutig zu erkennen.
Die aktuelle Version von GeoIP ist 2 und hat damit die veraltete Version 1 komplett abgelöst. GeoIP2 ist ein Dienst der Firma MaxMind [1] für die es auch eine kostenfreie Community Variante gibt. Wer beispielsweise ein selbstgehostetes Analytics wie Matomo betreibt, sollte um die vollständige Funktionalität des Werkzeugs auch auf eine korrekte GeoIP2 Konfiguration des Webservers achten.
Um GeoIP2 auf dem eigenen Server zu integrieren, gibt es zwei Möglichkeiten. Variante 1 ist die einfacher umzusetzende Option als PHP Modul. Variante 2 ist leistungsfähiger, erfordert aber auch mehr Kenntnisse aus dem Bereich Serveradministration. Bei dieser Lösung verwenden wir GeoIP2 als Apache2 Modul.
Wer auf dem eigenen Server bereits Fail2Ban [2] korrekt laufen hat, überlegt möglicherweise, ob es sinnvoll ist, Fail2Ban mit GeoIP2 zu verknüpfen. Diese Möglichkeit besteht durchaus, hat allerdings mehr Vorteile als Nachteile, denn Fail2Ban operiert direkt auf den Apache Logdateien. Dies ist der Grund, wieso Fail2Ban erst beim zweiten Request von einer IP Adresse aktiv werden kann. Um GeoIP2 in Fail2Ban zu aktivieren, muss ein entsprechender Filter gesetzt werden, was sich bei Servern mit hoher Nutzerlast schnell negativ auf die Performance auswirken kann. Daher ist es besser, die Requests zum Server zu monitoren und gezielte spezielle Länder bei vermuteten Angriffen direkt über den Request zu blockieren. Dazu muss allerdings GeoIP2 als Apache Modul installiert und konfiguriert sein.
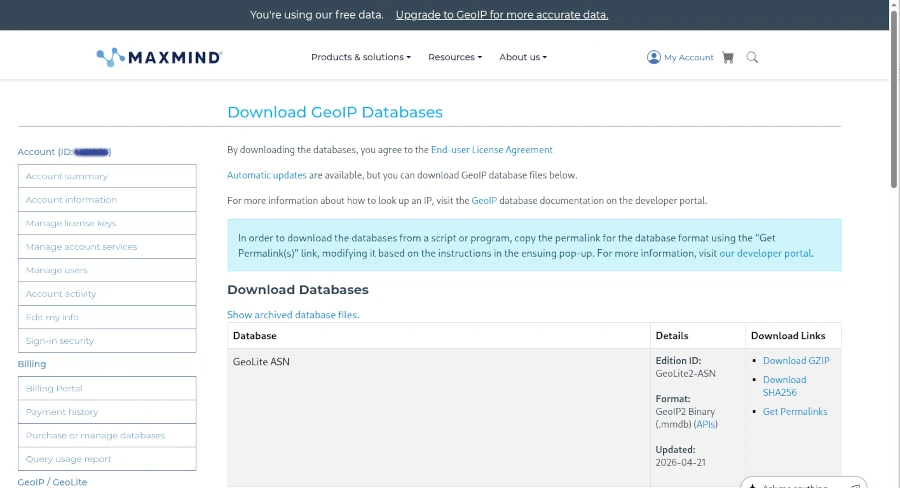
Bevor wir allerdings loslegen können, müssen wir uns bei MaxMind einen kostenfreien Account zulegen und für unser Beispiel die kostenfreien GeoIP2 (Lite Version) Datenbanken herunterladen.
Nachdem die erste Hürde genommen ist, können wir auch gleich loslegen. Um GeoIP2 in PHP Anwendungen nutzen zu können, benötigt man eine entsprechende Bibliothek. Mit Composer als Abhängigkeitsmanagement lässt sich die Bibliothek geoip2/geoip2 in einer aktuellen Version einbinden.
Wie man sieht, muss bei der Initialisierung auch das Verzeichnis zu MaxMind GeoLite Datenbank angegeben werden. Diese Variante eignet sich besonders für all diejenigen, die auf einem Managed Server oder Webspace unterwegs sind und keinen Einfluss auf die installierte Umgebung haben. Von der Nutzung von PECL (PHP Extension Community Library) sollte man wiederum Abstand nehmen, da diese als veraltet markiert wurde und künftig durch PIE (PHP Installer for Extensions) [4] ersetzt ist.
Um GeoIP2 global für alle PHP-Applikationen einzubinden, ist etwas mehr Aufwand notwendig. Hierzu haben wir als Grundvoraussetzung eine funktionierende Apache 2/ PHP-Installation auf einem Linux-Betriebssystem. Ist das gegeben, sind nur wenige Schritte durchzuführen:
Installieren der maxminddb Bibliothek
Herunterladen der PIE PHAR Bibliothek
Für PIE maxminddb installieren & Extension in der php.ini aktivieren
Die GeoLite Datenbanken auf dem Server bereitstellen
Bevor man aber diesem Weg folgt, sollte man sich überlegen, ob man nicht lieber gleich MaxMindDB als Apache Modul bereitstellt. Der gravierendste Vorteil dieser Variante ist die hohe Geschwindigkeit, die auch bei hoher Nutzerlast den Server nicht gleich in die Knie zwingt. Das Apache Modul stellt dafür Umgebungsvariablen bereit, die bereits in der Apache Konfiguration zur Filterung verwendet werden können. Die größte Herausforderung, welche es zu meistern gilt ist das Kompilieren des Apache 2 Moduls.
In Zeile 13 kopieren wir die zuvor von GitHub [5] heruntergeladene mod_maxminddb in der Version 1.3.0 in den Container, um diese im nachfolgenden Schritt zu kompilieren. Wichtig ist der Zusatz in Zeile 16, der die Fehlermeldung unterdrückt: dass automake in der Version 1.6 vorliegen muss. Anschließend kann das Modul aktiviert werden und die von MaxMind heruntergeladenen Datenbanken sind ebenfalls in den Docker Container zu kopieren. Zu guterletzt ist noch die Modulkonfiguration für den Apache in der Datei geoip.conf vorzunehmen und zu aktivieren. Der Inhalt der Konfigurationsdatei lautet wie folgt:
Die Feuerwand (engl. Firewall), war zu Zeiten des Zirkus und der Schausteller immer ein spektakuläres Ereignis. Menschen oder Tiere sprangen hindurch und wurden von der Menge bejubelt. So pathetisch eine solche Vorführung auch immer auf die Zuschauer wirkte, so kalkulierbar war das Spektakel für den Akrobaten. Denn wir wissen, dass Feuer eines der gewaltigsten Urelemente ist, das durch die Menschheit bezwungen wurde.
In der Cybersecurity ist die Firewall einer der elementarsten Schutzmechanismen für vernetzte Computersysteme. Das gilt sowohl für den Heimcomputer, als auch für den Großrechner im Rechenzentrum. Allerdings ist die Vorstellung, einen oder mehrere Feuerringe um den Computer zu entzünden, eher vergleichbar mit einem Zirkusspektakel, das gern melodramatisch in Kinofilmen aufgegriffen wird. Aussagen wie „Die erste Firewall ist gefallen und die zweite bereits zu 70 % überwunden“, sind perfekt für die Leinwand, haben mit der Realität aber nichts gemein.
Bevor wir in die Details gehen, betrachten wir kurz, wie Computersysteme miteinander zu einem Netzwerk verbunden werden. Das entscheidende Detail, welches wir benötigen, lautet IP Adresse. Allgemein ausgedrückt ist die IP Adresse die Telefonnummer des Computers beziehungsweise des Gerätes im Netzwerk. Damit man sich also mit einem anderen Computer verbinden kann, muss man dessen IP-Adresse kennen. Analog wie beim Telefon und der Telefonnummer. Wenn die Verbindung dann steht, kann man Informationen, also Daten, zwischen diesen beiden Geräten austauschen. Diese Informationen werden von den verschiedenen Internetprotokollen in kleine, handhabbare Pakete zerlegt. Ein Protokoll ist eine festgelegte Ablaufsteuerung, an die sich alle Teilnehmer halten müssen. Das lässt sich problemlos mit dem Versenden eines Briefes oder Päckchens mit der Post vergleichen.
Schreibe den Brief
Packe den Brief in einen Umschlag und klebe den Umschlag zu.
Schreibe die Empfängeradresse auf die Vorderseite des Umschlages.
Schreibe den Absender auf die Rückseite des Umschlages.
Klebe eine ausreichende Briefmarke auf den Umschlag und werfe ihn in den Briefkasten.
Ohne zu wissen, wie die internen Abläufe der Post sind, können wir davon ausgehen, dass der Brief beim Empfänger ankommt, wenn wir das Protokoll korrekt einhalten. Genauso verhält es sich mit dem Internet. Je nach der Art der Daten wählt der Computer ein geeignetes Programm aus, welches das zu verwendende Protokoll für uns umsetzt. Basierend auf dem Internet Protokoll (IP) welches die Verbindung zwischen Computern für uns regelt, gibt es weitere Protokolle, die sich um die Daten kümmern. Bekannte Protokolle sind HTTP(s) für Internetseiten oder FTP, um Dateien zu versenden.
Kommen wir nun zum eigentlichen Thema. Was also ist eine Firewall überhaupt und wozu wird sie verwendet? Stellen wir uns am besten einen sehr langen Flur vor mit unzählig vielen Türen, genauer gesagt 65.536 Türen. Diese Türen kann man nach innen oder außen öffnen. Wir können also aus dem Flur nach außen (outgoing Traffic) gelangen oder von außen in den Flur hinein (incoming Traffic).
Ein Browser Game, mit freundlicher Genehmigung von (c) mediasinres.tv
Diese Türen nennt man in Fachchinesisch Ports, die eine festdefinierte Nummer haben. Installiert man nun auf dem Rechner spezielle Programme, die mit anderen Computern kommunizieren können, wird dieses Programm üblicherweise fest an solch einen Port gebunden. Dazu ein kleines Beispiel. Lange vor WhatsApp und Co. gab es den Internet Relay Chat, kurz IRC. Hat man auf seinem Computer den IRC installiert, so hat sich dieser hinter der Tür 194 verborgen. Eine wichtige Eigenschaft zu Ports ist auch, dass, wenn bereits ein Programm an einen Port gebunden ist, kein anderes Programm diesen Port benutzen kann.
Mit einer Firewall kann man nun diese Türen in das Internet und aus dem Internet sehr gezielt blockieren. Grundsätzlich bestehen vier verschiedene Optionen für eine Tür zur Auswahl:
Vollständig blockiert,
Eingang blockiert,
Ausgang blockiert und
Vollständig offen.
Greifen wir dazu wieder unser Beispiel IRC auf. Ist die Tür vollständig blockiert, können wir keine Nachrichten senden oder empfangen, obwohl sich das Programm auf unserem Computer starten lässt. Es kann also keine Verbindung in das Netzwerk aufbauen. Ist der Eingang blockiert, können wir keine Nachrichten empfangen, aber senden. Ist der Ausgang blockiert, empfangen wir Nachrichten, können aber selbst keine senden. Die letzte Option hat keinerlei Einschränkungen.
Das größte Problem bei der Benutzung von Firewalls ist, dass diese oft nicht korrekt eingestellt (konfiguriert) sind. Hier unterscheiden wir zwei Möglichkeiten. Die verbreitetste Variante nennt sich Blacklist und reguliert nur die in der Liste angegebenen Ports. Wenn wir uns überlegen, dass es 65 536 Ports gibt, kann das eine sehr lange und unübersichtliche Liste werden. Das Risiko, etwas zu vergessen, ist hier sehr hoch. Der Vorteil dieser Option ist, dass sie sehr robust für unerfahrene Nutzer ist. Die andere Option ist die sogenannte Whitelist. Die funktioniert exakt entgegengesetzt der Blacklist. Per se sind nun erst einmal alle Ports geschlossen und der Nutzer muss explizit angeben, welche Ports geöffnet werden dürfen. Wie man sich jetzt leicht vorstellen kann, erfordert der Betriebsmodus Whitelist einiges an Erfahrung des Nutzers. Man muss wissen, welcher Port zu welchem Programm gehört und wie man diese Regeln in der Firewall einträgt.
Wie wir sehen, ist die Vorstellung, einen Feuerring um den Computer zu ziehen, keine geeignete Vorstellung davon, wie eine Firewall funktioniert. Wenn die Tür, also auf dem Computer, einmal blockiert ist, macht es auch wenig Sinn, noch eine andere Firewall auf dem Computer zu installieren. In diesem Fall gilt der Spruch „Doppelt hält besser“ nicht.
Angriffe auf Firewalls sind üblicherweise das Suchen nach offenen Türen, in die man dann eindringt. Dazu bedient man sich sogenannter Portscanner. Wer einmal einen solchen Protscanner ausprobieren möchte, darf das nicht so ohne Weiteres tun. Denn die Suche nach offenen Ports auf fremden Computern ist in Deutschland und vielen anderen Teilen der Welt bereits strafbar.
Ein anderes sehr fortgeschrittenes Angriffsszenario ist eine Attacke auf das Firewallprogramm selbst. Hier versucht man, mögliche vorhandene Programmierfehler der Firewall zu finden und auszunutzen.
Firewalls gibt es für jedes Betriebssystem in den verschiedensten Variationen. In professionellen Netzwerkgeräten wie Routern und Switches können bereits auch Firewalls integriert sein. Hier agiert der Router als Netzwerkcomputer und schützt alle an den Router angeschlossenen Geräte. Bevor man sich für ein konkretes Programm entscheidet, sollte man in Erfahrung bringen, dass es möglichst leicht zu bedienen ist und von einem seriösen Hersteller kommt.
Liste (unvollständig) der bekanntesten Standardports:
Das dauerhafte Speichern von Daten nennt man im Fachchinesisch Persistieren. Damit man auf diese Daten gezielt auch wieder zugreifen kann, benötigt man eine Software, die Daten strukturiert und durchsuchbar macht. Eine solche Software nennt sich Datenbank Management System (DBMS). Damit man von einer Programmiersprache wie Java, Ruby, Python oder PHP auf eine Datenbank zugreifen kann, benötigt man einen entsprechenden Treiber. Dieser Treiber wird auch oft als Client bezeichnet, denn das DBMS ist der Server, welcher mehreren Clients Zugriff gestattet. In diesem Artikel kümmern wir uns nicht darum, wie man sich mit welcher Programmiersprache auf die entsprechenden Datenbanken verbinden kann, sondern schauen uns an, was es für unterschiedliche Datenbanktechnologien gibt und wofür diese eingesetzt werden.
[Relationale DB (Zeilen, Spalten) | GIS DB | embedded DB] [NoSQL | {Key Value Store | Document DB (JSON, XML) | Graph DB | Zeitreihen Server]
Mittlerweile gibt es für die klassischen Datenbanksysteme, die sogenannten relationalen Datenbanken, eine Vielzahl von Lösungen zur Auswahl. Sowohl kommerzielle, als auch professionelle freie Open Source Vertreter buhlen um die Gunst der Anwender. Im Web bieten die meisten Hoster zum Speichern der Daten die freien DBMS MySQL (Oracle) und MariaDB (Abspaltung von MySQL nach der Übernahme durch Oracle) ihren Anwendern zur Auswahl an. Wer seine Server allerdings selbst betreuen kann, kann natürlich auch auf das professionellere PostgreSQL setzen.
Postgres ist allerdings für die meisten PHP-Standardapplikationen eher ungeeignet, obwohl WordPress und Joomla dieses Datenbanksystem durchaus unterstützen. Probleme bereiten üblicherweise die Entwickler der Erweiterungen. Der Zugriff auf die Datenbanken erfolgt dann nicht über die Schnittstellen der Anwendung, sondern aus Unwissenheit wird oft über die nativen Befehle von MySQL auf die Daten zugegriffen.
In der kommerziellen Anwendungsentwicklung verwendet man üblicherweise Oracle oder den Microsoft SQL Server, je nachdem, wie affin man mit der Microsoft-Windows-Welt ist. Der Grund für den Einsatz kommerzieller Datenbankserver liegt im kostenpflichtigen Support, bei Bekanntwerden von Schwachstellen und Fehlern. Geschäftskritische Anwendungen, müssen das Fortbestehen des Herstellers und auch der Kunden dieser Anwendung sicherstellen. Gerade die Geschwindigkeit der Auslieferung von Korrekturen für Sicherheitsschwachstellen ist ein gewichtiger Grund für den Einsatz kommerzieller Software.
Die Funktionsweise von relationalen Datenbanken ist über Tabellen definiert. Die Spalten einer Tabelle definieren die Eigenschaft und eine Zeile der Tabelle bildet den Datensatz. Um einen expliziten Datensatz ansprechen zu können, muss eine Spalte (Primärschlüssel) eindeutige, nicht noch einmal in dieser Spalte vorkommende Einträge enthalten. Diese Eigenschaft der Primärschlüssel nennt sich unique. Über die Primärschlüssel lassen sich Verknüpfungen, sogenannte Relationen, zwischen den Tabellen aufbauen. Um den Artikel nicht ins Unermessliche ausufern zu lassen, belasse ich es an dieser Stelle mit der Tiefe zur Funktionsweise von relationalen Datenbanken und gehe zur nächsten Kategorie über.
Natürlich gibt es auch relationale Datenbanken, die nicht zeilenorientiert, sondern spaltenorientiert arbeiten. Dies ermöglicht effizientere Abfragen und Analysen, insbesondere bei großen Datenmengen. Hier sind einige der Hauptmerkmale und Vorteile spaltenorientierter Datenbanken:
Datenorganisation: Speichert Daten in Spalten, was die Verarbeitung spezifischer Spalten in Abfragen beschleunigt.
Komprimierung: Bietet oft bessere Komprimierungsraten für spaltenweise gespeicherte Daten, da ähnliche Datentypen hintereinander gespeichert werden.
Analytische Abfragen: Optimiert für Analysen und aggregierte Abfragen, die große Datenmengen schnell abfragen müssen.
Reduzierte I/O: Reduziert die Menge an Daten, die von der Festplatte gelesen werden müssen, da nur die benötigten Spalten abgerufen werden.
Spaltenorientierte Datenbanken sind Apache Cassandra, SAP Hanna, IBM DB2 und Amazon BigQuery mit klassichen Anwendungsfällen für:
Business Intelligence: Ideal für Datenbanken, die große Mengen an Daten für analytische Zwecke verarbeiten müssen.
Data Warehousing: Effizient bei der Speicherung und Analyse historischer Daten.
Echtzeitanalysen: Geeignet für Anwendungen, die schnelle Entscheidungen basierend auf aktuellen Daten treffen müssen.
Um Daten für geografische Informationssysteme (GIS) wie Google Maps bereitzustellen, werden sogenannte Geospatial Datenbanken eingesetzt. Bei Geospatial Datenbanken handelt es sich um Erweiterungen relationaler Datenbanken, die für geometrische Objekte optimierte und standardisierte Tabellen und Relationen bereitstellen. Die GIS Erweiterung für PostgreSQL heißt PostGIS. Die Datensätze für das frei verfügbare OpenStreetMap liegen in einem spezialsierten XML Format vor und können aber auch in Geospatial Datenstrukturen transformiert werden.
Key – Value Speicher, werden oft in Konfigurationsdateien verwendet. Will man allerdings ein schnelles Caching-System aufbauen, benötigt man ein wenig mehr Komplexität. Denn die Schlüssel / Wert Bezeihung kann von einfachen Zeichenketten hin zu komplexen Objekten ausarten. Grundsätzlich besteht ein Speicher aus einem uniquen Schlüssel, dem je nach Datentyp Werte zugeordnet werden können. Datentypen können Zeichenketten (Strings), Zahlen (Integer, Float), Wahrheitswerte (Boolean) und Listen sein. Key – Value Datenbanken gehören zu den NoSQL Datenbanken, da die Abfrage nicht wie bei relationalen Datenbanken über SQL erfolgt, sondern datenbank- und herstellerspezifisch ist.
Typische Key -Value Datenbanken sind Redis, MemCached, Amazon DynamoDB und die etwas in die Tage gekommene BarkleyDB, die von Oracle übernommen wurde. Eine Eigenschaft von Key – Value Datenbanken ist, dass die Daten im Speicher gehalten und in regelmäßigen Abständen auf die Festplatte gesichert werden. Das Vorhalten der Daten im Arbeitsspeicher erfordert natürlich auch eine entsprechende Ausstattung der Maschine mit ausreichend RAM. Besonders bei großen Anwendungen kann für das Chaching eine enorme Datenmenge zusammenkommen.
Eine weitere Kategorie für Datenbanken sind Embedded-Datenbanken. Embedded meint auf Deutsch „eingebunden“ und bezieht sich auf den Datenbankserver. Das bedeutet im Konkreten, dass das Datenbanksystem keine eigenständige Installation ist, sondern als Bibliothek einen Teil der Anwendung darstellt. Der Vorteil einer solchen Lösung ist, dass die Installationsroutine der Anwendung einfacher ist. Meist geht das allerdings zulasten der Sicherheit, da viele der embedded Datenbanken keine zusätzliche Schicht für eine Benutzerverwaltung haben. Dieser Umstand gilt besonders für SQLite und die in Java implementierte H2. Aber auch die bereits erwähnte NoSQL BarkelyDB die als Java- oder C-Bibliothek verfügbar ist, hat keine Benutzerverwaltung. Das heißt, wer Zugriff auf die Anwendung hat, kann mit einem Client die Daten aus der Datenbank lesen. Daher sind die gerade genannten Systeme nicht für Anwendungen geeignet, die eine hohe Sicherheitsstufe erfordern.
Zur Java Version der BarkelyDB kann man noch sagen, dass die letzte verfügbare Implementierung aus dem Jahr 2017 stammt und in Java / Apache Ant als Quelltext vorhanden ist, der aber selbst kompiliert werden muss. Ein offizielles Binary von Oracle ist nicht mehr verfügbar, es können aber sogenannte inoffizielle Versionen im Maven Central Repository gefunden werden.
Wer eine voll funktionsfähige relationale Datenbank in seine Anwendung integrieren möchte, kann auf die embedded Variante von PostgreSQL – pgx – zurückgreifen, die alle Funktionen des PostgreSQL Servers lokal bereitstellt.
Die nächste Klasse der Datenbanken gehört wieder zu den NoSQL Vertretern. Dokumentenbasierte Datenbanken. Die beiden DBSM MongoDB und CouchDB sind im Funktionsumfang durchaus identisch, dennoch gibt es markante Unterschiede.
MongoDB wird aufgrund seiner umfangreichen Abfragesprache und hohen Performance häufig für Anwendungen gewählt, die komplexe Abfragen und Echtzeitanalysen erfordern.
CouchDB eignet sich besonders für Anwendungen, die Zuverlässigkeit, eine verteilte Architektur und einfache Replikation benötigen, insbesondere in Szenarien, in denen Offline-Zugriff unerlässlich ist.
Die grundlegende Arbeitsweise von Dokumentendatenbanken ist, dass sich das Schema aus der hinterlegten Datenstruktur ergibt. Diese Datenstrukturen haben meist das JSON Format und werden entsprechend angesprochen. Dokumente der selben Datenstruktur werden einer Collection zugeordnet. Es handelt sich also nicht um klassische Office Dokumente die in diesen Datenbanken abgelegt werden, sondern um Formate wie JSON und XML. Dokumentendatenbanken, die sich auf XML spezialisiert haben, sind Oracle XML DB oder Apache Xindice.
Viele Webentwickler, die sich auf FrontEnd (UX / UI) spezialisiert haben, greifen gern auf Dokumentdatenbanken zurück. Das erlaubt ihnen, die Daten im JSON Format abzulegen, um damit REST Zugriffe zu simulieren und damit die dynamischen Inhalte der Benutzeroberfläche zu befüllen.
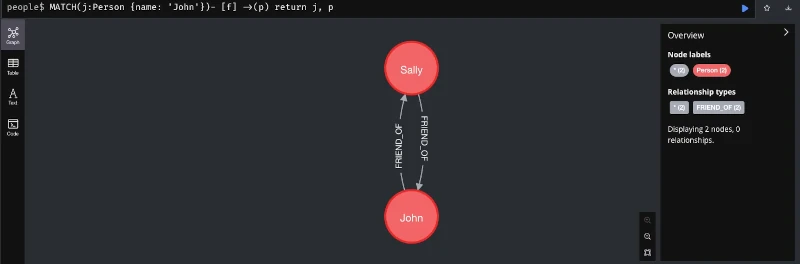
Eine sehr exotische Variante der NoSQL Datenbanken sind die Gaphdatenbanken, die Daten als Graphen repräsentieren. Diese Speicherform ermöglicht das effiziente Ablegen von Informationen nach Beziehungen. Solche Beziehungen können Verlinkungen von Webseiten sein oder die Repräsentation einer Person in sozialen Medien. Aber auch die komplexen Beziehungen für Empfehlungssysteme können als Graph dargestellt werden. Die nachfolgende Abbildung zeigt ein einfaches Beispiel für Neo4J einer in Java implementierten Graphdatenbank, um sich eine Vorstellung des Einsatzszenarios machen zu können.
Andere Graphdatenbanken sind Amazon Neptune und ArangoDB.
Als letzte Datenbanklösung möchte ich die sogenannten Zeitreihen (Time Series) vorstellen. Da besonders im Kontext für den Betrieb von Anwendungen das Monitoring essenziell geworden ist, haben Daten, die als Zeitreihen vorliegen, an Bedeutung gewonnen. Typische Datenbanken, die sich auf die Verarbeitung von Zeitreihen spezialisiert haben, sind Prometheus und InfluxDB. Aber auch für klassische relationale Datenbanken gibt es entsprechende Erweiterungen. Die bereits mehrfach erwähnte PostgreSQL-Datenbank hat auch für diesen Anwendungsfall eine entsprechende Erweiterung namens TimescaleDB.
Natürlich kann man über das Thema noch viel mehr sagen. Schließlich füllen unzählige Bücher einige Regalmeter in Bibliotheken zum Thema Datenbanken. Für den Einstieg und die Übersicht zu den verschiedenen Datenbanksystemen beziehungsweise NoSQL Lösungen soll es aber an dieser Stelle genügen. Mit den Informationen aus diesem Artikel, haben sie nun eine Vorstellung, welche Datenbank sich für ihren speziellen Anwendungsfall eignet. Wir konnten auch sehen, dass relationale Datenbanken, insbesondere die freie Open Source Datenbank PostgreSQL mit den verfügbaren Erweiterungen, sehr universell einsetzbar sind. Weiterführende Themen zu Datenbanken sind die Datenmodellierung und Sicherheit gegen Hackerangriffe.
Wer sich für diesen, eigentlich etwas spezialisierten Artikel interessiert, dem muss man nicht mehr erklären, was Docker ist und wofür das Virtualisierungswerkzeug eingesetzt wird. Daher richtet sich dieser Artikel vornehmlich an Systemadministratoren, DevOps und Cloud-Entwickler. Für alle, die bisher nicht ganz so fit mit der Technologie sind, empfehle ich unseren Docker Kurs: From Zero to Hero.
In einem Szenario, in dem wir regelmäßig neue Docker Images erstellen und verschiedene Container instanzieren, wird unsere Festplatte ordentlich gefordert. Images können je nach Komplexität durchaus problemlos einige hundert Megabyte bis Gigabyte erreichen. Damit das Erstellen neuer Images auch nicht gefühlt, wie ein Download einer drei Minuten langen MP3 mit einem 56k Modem dauert, nutzt Docker einen Build-Cache. Ist im Dockerfile wiederum ein Fehler, kann dieser Build-Cache recht lästig werden. Daher ist es eine gute Idee, den Build-Cache durchaus regelmäßig zu entleeren. Aber auch alte Containerinstanzen, die nicht mehr in Verwendung sind können zu komischen Fehlern führen. Wie hält man seine Dockerumgebung also stubenrein?
Sicher kommt man mit mit docker rm <container-nane>und docker rmi <image-id> schon recht weit. In Buildumgebungen wie Jenkins oder Serverclustern kann diese Strategie allerdings zu einer zeitintensiven und mühsamen Beschäftigung werden. Doch verschaffen wir uns zuerst einmal einen Überblick über die Gesamtsituation. Hier hilft uns der Befehl docker system df weiter.
Bevor ich gleich in die Details eintauche, noch ein wichtiger Hinweis. Die vorgestellten Befehle sind sehr effizient und löschen unwiderruflich die entsprechenden Bereiche. Daher wendet diese Befehle erst auf einer Übungsumgebung an, bevor ihr damit Produktivsysteme außer Gefecht setzt. Zudem hat es sich für mich bewährt, auch die Befehle zur Instanzierung von Containern in deiner Textdatei unter Versionsverwaltung zu stellen.
Der naheliegendste Schritt bei einem Docker System Cleanup ist das Löschen der nichtbenutzten Container. Im Konkreten bedeute das, dass durch den Löschbefehl alle Instanzen der Docker Container, die nicht laufen (also nicht aktiv sind), unwiederbringlich gelöscht werden. Will man auf einem Jenkins Buildnode vor einem Deployment Tabula Rasa durchführen, kann man zuvor alle auf der Maschine laufenden Container mit einem Befehl beenden.
Der Parameter -f unterdrückt die Nachfrage, ob man diese Aktion wirklich durchführen möchte. Also die ideale Option für automatisierte Skripte. Durch das Löschen der Container erhalten wir vergleichsweise wenig Festplattenplatz zurück. Die Hauptlast findet sich bei den heruntergeladenen Images. Diese lassen sich ebenfalls mit nur einem Befehl entfernen. Damit Images allerdings gelöscht werden können, muss vorher sichergestellt sein, dass diese nicht durch Container (auch inaktive) in Verwendung sind. Das Entfernen ungenutzter Container hat noch einen ganz anderen praktischen Vorteil. Denn beispielsweise durch Container blockierte Ports werden so wieder freigegeben. Schließlich lässt sich ein Port einer Hostumgebung nur exakt einmal an einen Container binden. Das kann stellenweise schnell zu Fehlermeldungen führen. Also erweitern wir unser Skript um den Eintrag, alle nicht durch Container benutzten Docker Images ebenfalls zu löschen.
Eine weitere Konsequenz unserer Bemühungen umfasst die Docker Layers. Hier sollte man aus Performancegründen, besonders in CI Umgebungen Abstand nehmen. Docker Volumes hingegen sind hier weniger problematisch. Beim Entfernen der Volumes, werden nur die Referenzen in Docker entfernt. Die in die Container verlinkten Ordner und Dateien bleiben von der Löschung unberührt. Der Parameter -a löscht alle Docker Volumes.
Ein weiterer Bereich, der von unseren Aufräumarbeiten betroffen ist, ist der Build-Cache. Besonders wenn man gerade ein wenig mit dem Erstellen neuer Dockerfiles experimentiert, kann es durchaus sehr nützlich sein, den Cache hin und wieder manuell zu löschen. Diese Maßnahme verhindert, dass sich falsch erstellte Layer in den Builds erhalten und es später im instanziierten Container zu ungewöhnlichen Fehlern kommt. Der entsprechende Befehl lautet:
Wir können die gerade vorgestellten Befehle natürlich auch für CI Buildumgebungen wie Jenkins oder GitLab CI nutzen. Allerdings kann es sein, dass dies nicht unbedingt zum gewünschten Ziel führt. Ein bewährter Ansatz für Continuous Integration / Continuous Deployment ist das Aufsetzen einer eigenen Docker-Registry, wohin man selbst erstellte Images deployen kann. Diese Vorgehensweise, ist ein gutes Backup & Chaching System für die genutzten Docker Images. Einmal korrekt erstellte Images lassen sich so bequem über das lokale Netzwerk auf die verschiedenen Serverinstanzen deployen, ohne dass diese ständig lokal neu erstellt werden müssen. Daraus ergibt sich als bewährter Ansatz ein eigens für Docker Images / Container optimierter Buildnode, um die erstellten Images vor der Verwendung optimal zu testen. Auch auf Cloudinstanzen wie Azure und der AWS sollte man auf eine gute Performanz und ressourcenschonendes Arbeiten Wert legen. Schnell können die anfallenden Kosten explodieren und ein stabiles Projekt in massive Schieflage bringen.
In diesem Artikel konnten wir sehen, dass tiefe Kenntnisse der eingesetzten Werkzeuge einige Möglichkeiten zur Kostenersparnis erlauben. Gerade das Motto „Wir machen, weil wir es können“, ist im kommerzeillen Umfeld weniger hilfreich und kann schnell zur teuren Resourcenverschwendung ausarten.
Der Umgang mit Massenspeichern wie Festplatten (HDD), Solid State Drive (SSD), USB, Speicherkarten oder Network Attached Storages (NAS) ist unter Linux gar nicht so schwer, wie viele glauben. Man muss es lediglich schaffen, alte Gewohnheiten, die man sich unter Windows angeeignet hat, wieder loszulassen. In diesem Kompaktkurs erfahren Sie alles Notwendige, um auf Linux Desktops und -Servern mögliche aufkommende Probleme zu meistern.
Bevor wir auch gleich in aller Tiefe in das Thema eintauchen, noch ein paar wichtige Fakten über die Hardware selbst. Hier gilt vor allem der Grundsatz: Wer billig kauft, kauft doppelt. Wobei das Problem nicht einmal das Gerät selbst ist, was man austauschen muss, sondern die möglicherweise verlorenen Daten und der Aufwand, alles wieder neu einzurichten. Diese Erfahrung habe ich vor allem bei SSDs und Speicherkarten gemacht, wo es durchaus einmal vorkommen kann, dass man einem Fake Produkt aufgesessen ist und der versprochene Speicherplatz nicht vorhanden ist, obwohl das Betriebssystem die volle Kapazität anzeigt. Wie man mit solchen Situationen umgeht, besprechen wir allerdings ein wenig später.
Ein weiterer wichtiger Punkt ist die Verwendung im Dauerbetrieb. Die meisten Speichermedien sind nicht dafür geeignet, 24 Stunden jeden Tag, 7 Tage die Woche eingeschaltet zu sein und verwendet zu werden. Festplatten und SSDs, die für Laptops gemacht worden sind, gehen bei einer Dauerbelastung zügig kaputt. Deswegen sollte man sich bei Dauerbetrieb, wie es bei NAS‑Systemen der Fall ist, explizit nach solchen speziellen Geräten umschauen. Die Firma Western Digital hat zum Beispiel verschiedene Produktlinien. Die Linie Red ist für Dauerbetrieb ausgelegt, wie es bei Servern und NAS der Fall ist. Wichtig ist, dass in der Regel die Datentransfergeschwindigkeit bei Speichermedien etwas geringer ist, wenn dafür die Lebensdauer erhöht wird. Aber keine Sorge, wir verlieren uns jetzt nicht in den ganzen Details, die man noch zum Thema Hardware sagen könnte, und wollen es dabei belassen, um zum nächsten Punkt zu gelangen.
Ein signifikanter Unterschied zwischen Linux und Windows ist das Dateisystem. Also der Mechanismus, wie das Betriebssystem den Zugriff auf die Informationen organisiert. Windows Nutzt als Dateisystem NTFS und USB Sticks oder Speicherkarten sind oft auch unter FAT formatiert. Der Unterschied ist, dass mit NTFS Dateien, die über 4 GB groß sind, gespeichert werden können. FAT wird der Stabilität eher von Geräteherstellern in Navigationssystemen oder Autoradios bevorzugt. Unter Linux sind vornehmlich die Dateisysteme ext3 oder ext4 anzutreffen. Natürlich gibt es noch viele Spezialformate, die wir aber an dieser Stelle nicht weiter besprechen wollen. Der große Unterschied zwischen Linux- und Windows Dateisystemen ist das Sicherheitskonzept. Während NTFS keinen Mechanismus hat, um das Erstellen, Öffnen oder Ausführen von Dateien und Verzeichnissen zu kontrollieren, ist dies für ext3 und ext4 ein grundlegendes Konzept.
Speicher, die in NTFS oder FAT formatiert sind, können problemlos an Linux Rechner angeschlossen werden und die Inhalte können gelesen werden. Um beim Schreiben von Daten auf Netzwerkspeicher, die wegen der Kompatibilität oft auf NTFS formatiert sind, keine Verluste zu riskieren, nutzt man das SAMBA Protokoll. Samba ist meist bereits Bestandteil vieler Linux Distributionen und kann in wenigen Augenblicken auch installiert werden. Es ist keine spezielle Konfiguration des Dienstes notwendig.
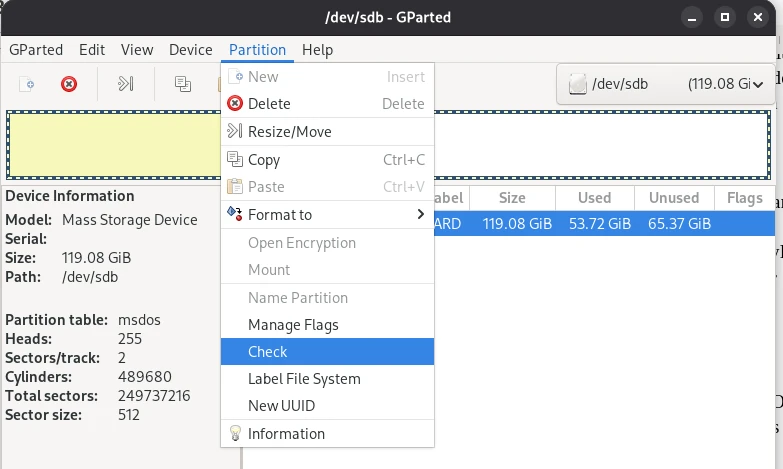
Nachdem wir nun gelernt haben, was ein Dateisystem ist und wozu diese notwendig sind, stellt sich nun die Frage, wie man einen externen Speicher unter Linux formatieren kann. Die beiden grafischen Programme Disks und Gparted sind hierzu ein gutes Gespann. Disks ist ein wenig universeller nutzbar und es lassen sich mit diesem Programm bootfähige USB Sticks erstellen, mit denen man anschließend Computer installieren kann. Gparted ist eher geeignet, bei Festplatten oder SSDs bestehende Partitionen zu erweitern oder kaputte Partitionen zu reparieren.
Bevor sie nun weiterlesen und sich gegebenenfalls daran machen, den ein oder anderen Tipp nachzustellen, ist es wichtig, dass ich an dieser Stelle einen Warnhinweis gebe. Bevor Sie irgendetwas mit Ihren Speichermedien ausprobieren, fertigen Sie zuallererst eine Datensicherung an, auf die Sie bei Unglücken zurückgreifen können. Zudem weise ich ausdrücklich darauf hin, sich nur an den Szenarien zu versuchen, die Sie verstehen und bei denen Sie wissen, was Sie tun. Für mögliche Datenverluste übernehme ich keine Haftung.
Ein Szenario, das wir gelegentlich benötigen, ist die Erstellung von bootfähigen Datenträgern. Ganz gleich, ob es ein USB‑Stick für die Installation eines Windows‑ oder Linux‑Betriebssystems oder das Installieren des Betriebssystems auf einer SD‑Karte für die Verwendung auf einem RaspberryPI ist: Das Vorgehen ist identisch. Bevor wir starten, benötigen wir ein Installationsmedium, das wir als ISO in der Regel von der Homepage des Betriebssystemherstellers herunterladen können, und einen zugehörigen USB‑Stick.
Als Nächstes öffnen wir das Programm Disks und wählen den USB Stick aus, auf den wir die ISO Datei installieren wollen. Danach klicken wir auf die drei Punkte im oberen Rahmen des Fensters und wählen aus dem erscheinenden Menü den Eintrag Restore Disk Image. In dem nun sich öffnenden Dialog wählen wir für das Eingabefeld Image to Restore unsere ISO Datei aus und klicken auf Start Restoring. Mehr ist nicht zu tun.
Partitionen und MTF mit Gparted reparieren
Ein anderes Szenario, mit dem man konfrontiert sein kann, ist das Daten auf einem Stick z. B. nicht lesbar sind. Wenn die Daten selbst nicht beschädigt sind, kann man Glück haben und mit GParted das Problem lösen. In einigen Fällen kann es sein, (A) dass die Partitionstabelle beschädigt ist und das Betriebssystem einfach nicht weiß, wo der Startpunkt ist. Eine andere Möglichkeit ist, (B) dass die sogenannte Master File Table (MFT) beschädigt ist. In der MTF ist der Vermerk, in welcher Speicherzelle eine Datei gefunden wird. Beide Probleme lassen sich mit GParted schnell wieder in Ordnung bringen.
Natürlich ist es nicht möglich, in einem allgemeinen Artikel auf die vielen komplexen Aspekte der Datenrettung einzugehen.
Nachdem wir nun wissen, dass eine Festplatte aus Partitionen besteht und diese Partitionen ein Dateisystem enthalten. Können wir jetzt sagen, dass alle Informationen zu einer Partition mit dem darauf formatierten Dateisystem in der Partitionstabelle gespeichert sind. Um alle Dateien und Verzeichnisse innerhalb einer Partition zu finden, bedient sich das Betriebssystem eines Index, in dem es nachschauen kann, die sogenannten Master File Table (MFT). Dieser Zusammenhang führt uns bereits zum nächsten Punkt, dem sicheren Löschen von Speichermedien.
Datenschredder – sicheres Löschen
Wenn wir Daten auf einem Speichermedium löschen, wird lediglich der Eintrag, wo die Datei zu finden ist aus der MFT entfernt. Die Datei ist also weiterhin vorhanden und kann von speziellen Programmen immer noch gefunden und ausgelesen werden. Das sichere Löschen von Dateien gelingt nur, wenn wir den freien Speicherplatz mehrfach überschreiben. Da wir nie wissen können, wo eine Datei physisch auf einem Speichermedium geschrieben wurde, müssen wir nach dem löschen den gesamten freien Speicherplatz mehrfach überschreiben. Spezialisten raten zu drei Schreibvorgängen, bei denen jeweils unterschiedliche Muster geschrieben werden, um selbst Speziallaboren eine Wiederherstellung unmöglich zu machen. Ein Programm unter Linux, mit dem man zusätzlich noch ‚Datenmüll‘ zusammenkehrt und löscht, ist BleachBit.
Das sichere Überschreiben von gelöschten Dateien ist je nach Größe des Speichermediums eine etwas länger andauernde Aktion, weswegen man dies nur sporadisch macht. Ganz sicher sollte man alte Speichermedien aber rückstandsfrei löschen, wenn diese ‚aussortiert‘ werden und dann entweder entsorgt oder an andere weitergegeben werden.
Ganze Festplatten 1:1 spiegeln – CloneZilla
Ein weiteres Szenario, mit dem wir konfrontiert werden können, ist die Notwendigkeit, eine Kopie der Festplatte anzufertigen. Das ist dann relevant, wenn für den aktuellen Computer die bestehende Festplatte bzw. SSD gegen eine neue mit höherer Speicherkapazität ausgetauscht werden soll. Windowsnutzer nutzen hier oft die Gelegenheit, ihr System neu zu installieren, um in Übung zu bleiben. Wer bereits länger mit Linux arbeitet, weiß es zu schätzen, dass Linux-Systeme sehr stabil laufen und die Notwendigkeit einer Neuinstallation nur sporadisch besteht. Daher bietet es sich an die Daten der aktuellen Festplatte bitweise auf die neue Platte zu kopieren. Das gilt natürlich auch für SSDs beziehungsweise von HDD zu SSD und umgekehrt. Dieses Vorhaben gelingt uns mit dem freien Werkzeug CloneZilla. Dazu erstellen wir einen bootfähigen USB mit CloneZilla und starten den Rechner im Livesystem von CloneZilla. Danach schließen wir die neue Platte mit einem SATA / USB Adapter an den Rechner an und starten die Datenübertragung. Bevor wir nach Fertigstellung unseren Computer aufschrauben und die Platten tauschen, ändern wir im BIOS die boot Reihenfolge und schauen, ob unser Vorhaben überhaupt geglückt ist. Nur wenn sich der Rechner über die neue Platte problemlos starten lässt, machen wir uns an den physischen Austausch. Diese kleine Anleitung beschreibt das prinzipielle Vorgehen und ich habe bewusst auf eine detaillierte Beschreibung verzichtet, da sich die Oberfläche und Bedienung von neueren Clonezilla-Versionen unterscheiden kann.
SWAP – die Auslagerungsdatei unter Linux
An dieser Stelle verlassen wir auch nun die grafische Benutzeroberfläche und wenden uns der Kommandozeile zu. Wir kümmern uns um eine sehr spezielle Partition, die manchmal erweitert werden muss. Es geht um die SWAP File. Die SWAP File ist das, was bei Windows Auslagerungsdatei heißt. Das heißt, hier schreibt das Betriebssystem Daten hin, die nicht mehr in den RAM passen, und kann bei Bedarf diese Daten schneller wieder in den RAM einlesen. Indessen kann es vorkommen, dass diese Auslagerungsdatei zu klein ist und erweitert werden muss. Aber auch das ist kein Hexenwerk, wie wir gleich sehen werden.
Wir haben an dieser Stelle bereits einiges über den Umgang mit Speichermedien unter Linux besprochen. Im zweiten Teil dieser Artikelserie vertiefen wir die Möglichkeiten von Kommandozeilenprogrammen und schauen zum Beispiel, wie NAS-Speicher permanent in das System gemountet werden können. Aber auch Strategien, um defekte Speicher zu identifizieren, werden Thema des nächsten Teils werden. Insofern hoffe ich, euer Interesse geweckt zu haben, und würde mich über ein reichliches Teilen der Artikel von diesem Block freuen.
Seit einiger Zeit steht die neue Version 1.5 des Versionsverwaltungs-Tools Subversion (SVN) zum kostenlosen Download bereit. Das Programm ist für verschiedene Plattformen erhältlich, dazu zählen Windows und Linux als die wichtigsten Vertreter. Der Artikel bezieht sich zwar auf das Windows-Betriebssystem, aber mit geringem Aufwand lassen sich die wenigen spezifischen Unterschiede leicht adaptieren. Man kann Subversion auf unterschiedliche Art und Weise betreiben. Für eine lokale Verwendung, bei sehr kleinen Projekten mit lediglich einem einzigen Entwickler, genügt oft die Installation eines Clients. Für Windows Systeme sollte die Wahl des Clients auf TortoiseSVN fallen. Die Anwendung arbeitet als Explorer-Erweiterung und beherrscht alle notwendigen Funktionen zur Arbeit mit SVN. Dazu zählt unter anderem das Anlegen der Projektverzeichnisse, die Repository genannt werden. Der Zugriff auf ein lokales Repository erfolgt über das file:///-Protokoll. Sobald das Repository für mehrere Entwickler bereitstehen soll, wird ein Server benötigt. Man hat die Wahl zwischen einem Standalone-Server oder einer Integration in den Apache Web Server. Die aktuelle Version des SVN-Servers bringt für Windows-Nutzer eine Verbesserung der Konfiguration als Windows-Dienst. Für den Standalone-Server stehen die Protokolle svn:// und svn+ssh:// zur Verfügung. Für diesen Artikel wird vor allem auf die Installation des Apache-Moduls eingegangen. Der Vorteil des Apache liegt darin, mit den Protokollen http:// und https:// auf die Projektverzeichnisse zugreifen zu können. Mit Subclipse liefert Tigris.org SVN als Plug-in für Eclipse, das dem Tortoise-Client kaum in etwas nachsteht. Dank der PHP-Tools ist die Eclipse-IDE nicht mehr nur von Java-Programmierern geschätzt. Abbildung 1 zeigt die Subversion View mit einem geöffneten Projekt in Eclipse.
Abb. 1: Eclipse in der Subversion-Ansicht mit einem geöffneten Projekt
Subversion im Apache
Eine sehr bequeme Möglichkeit Subversion zu nutzen, ist die Integration in den Apache Web Server; damit kann das Repository über das HTTP-Protokoll angesprochen werden. Die Installation ist nicht weiter schwierig, erfordert allerdings eine funktionsfähige Apache-Installation. Wer die aufwändige Installation einer vollständigen Serverumgebung scheut, kann getrost auf XAMPP [4] zurückgreifen. Als Erstes müssen dann die Binaries des SVN für den Apache 2.2.X von der Webseite [5] geladen werden. Die Dateien mod_dav_svn.so, mod_authz_svn.so und der Ordner iconv sind in das Verzeichnis %APACHE_HOME%\modules zu kopieren. Um die Module dem Webserver bekannt zu machen, muss schließlich die Datei httpd.conf im Verzeichnis conf des Apache gemäß Listing 1 editiert werden.
# Anpassungen der httpd.confLoadModule dav_svn_module modules/mod_dav_svn.soLoadModule authz_svn_module modules/mod_authz_svn.soInclude conf/svn.conf
Plaintext
Die ersten beiden Zeilen aktivieren die SVN-Module für den Apache. Um die Konfigurationsdatei übersichtlich zu halten, wird die eigentliche Konfiguration von Subversion über die Anweisung aus Zeile drei in die Datei svn.conf ausgelagert (Listing 2). Die Datei muss im gleichen Verzeichnis wie die httpd.conf angelegt werden.
<IfModule dav_svn_module><Location /svn> DAV svn SVNListParentPath on SVNParentPath D:\Subversion</Location></IfModule>
XML
Über den Eintrag wird die darin eingeschlossene Konfiguration nur dann ausgeführt, wenn das Modul dav_svn_module wie in Listing 1 aktiviert wurde. bestimmt den Pfad, wie das Repository angesprochen werden soll. In diesem Fall ist http://127.0.0.1/svn der korrekte URL, um auf die Repositories zuzugreifen. Der absolute Pfad, in dem die Projektverzeichnisse abgelegt werden, wird mit dem Eintrag SVNParentPath gesetzt. Die Option SVN-ListPArentPath on listet alle Repositories in D:/Subversion über den URL http://localhost/svn auf. Kommentare werden mit # in Apache-Konfigurationsdateien eingeleitet und gelten nur bis zum Zeilenende. Sobald die Konfiguration abgeschlossen ist, muss der Server neu gestartet werden, um die Änderungen wirksam zu machen.
Das Repository
Wie schon erwähnt, heißt das Projektverzeichnis, das von SVN verwaltet wird, Repository. Für jedes Projekt wird üblicherweise ein eigenes Repository verwendet, es ist aber auch möglich, mehrere Projekte in einem gemeinsamen Verzeichnis abzulegen. Neue Projekte werden im Hauptverzeichnis Subversion angelegt, das für den Apache konfiguriert wurde. Für unser Beispiel aus Listing 2 ist dieses Hauptverzeichnis D:/Subversion. Darin wird ein neuer Ordner erzeugt, der den Namen des Projekts erhält. Im nächsten Schritt wird in dem neuen Ordner das eigentliche Repository generiert. Dazu wird mit einem Rechtsklick auf den Ordner, der das Projektverzeichnis beherbergen soll, der Eintrag TortoiseSVN/Projektverzeichnis hier erstellen ausgewählt. Die notwendigen Schritte werden von Tortoise anschließend automatisch ausgeführt und das Projektverzeichnis kann nun benutzt werden. Die von SVN angelegte Ordnerstruktur sollte nun nicht weiter verändert werden, alle Zugriffe auf das Verzeichnis erfolgen über den SVN-Client Tortoise.
In den einzelnen Repositories hat es sich bewährt, die Unterverzeichnisse trunk, branches und tags anzulegen. Der trunk (Stamm) beinhaltet das aktuelle Arbeitsverzeichnis, dort werden alle Projektdateien nach den persönlichen Vorlieben organisiert. Damit stellt der trunk den aktuellen Projektstand dar. In tags (Markierungen) werden spezielle Markierungen während des Projektfortschritts erzeugt. Eine solche Markierung ist beispielsweise eine neue Version der Anwendung. Branches (Verzweigungen) stellen parallele Entwicklungsstränge dar. Das ist meist dann der Fall, wenn eine Version abgeschlossen ist und nach einer Auslieferung weitergepflegt wird. Eine Weiterentwicklung von abgeschlossenen Versionen ist in der Regel dann notwendig, wenn nachträglich Fehler bekannt werden, die direkt behoben werden müssen, noch bevor eine neue Version ausgeliefert werden kann. Damit die Änderungen anschließend auch in der neuen Version verfügbar sind, können beide branches mit einem Merge zusammengeführt werden. Der besondere Vorteil von SVN gegenüber CVS ist die effiziente Art, wie die Verzweigungen und Markierungen gespeichert sind. Subversion erzeugt dafür keine physische Kopie, sondern nutzt Verlinkungen zum Hauptentwicklungsstrang.
Nachträgliche Manipulationen am Repository
Nach einem erfolgreichen Commit lassen sich mit der Standardeinstellung keine Änderungen mehr vornehmen. Wenn Logmeldungen nach dem Commit bearbeitet werden sollen, ist es notwendig, einige Veränderungen vorzunehmen. Dazu wechselt man in den Ordner hooks des betreffenden Repositories. Dort wird die Datei pre-revprop-change.bat mit dem folgenden Inhalt angelegt:
if “%4“ == “svn:log“ exit 0 echo Eigenschaft ‘%4‘ kann nicht geändert werden >&2 exit 1
Das Listing ermöglicht es, die Logmeldungen im Nachhinein noch zu ändern. In hooks können verschiedene Skripte abhängig zu den Aktionen gesteuert werden.
Erste Schritte mit SVN
Um die Projektstruktur in das Repository übertragen zu können, müssen die Ordner und Dateien zuerst im Dateisystem angelegt werden. Sobald das geschehen ist, kann der erste Commit ins Subversion erfolgen. Das Senden der Daten ist als Transaktion angelegt, das bedeutet, im Fehlerfall wird die gesamte Übertragung verworfen. Nur wenn alle Dateien erfolgreich übermittelt worden sind, ist die Änderung erfolgreich. Um einen Import auszuführen, muss auf das Root-Verzeichnis mit den zu übertragenden Dateien navigiert werden. Nun kann mit einem Rechtsklick auf den Hauptordner die Option TortoiseSVN/Import ausgewählt werden. Im Importdialog muss nun der URL zum Projektarchiv angegeben werden. Wenn der Apache Web Server nach Listing 2 konfiguriert wurde, lautet die richtige Adresse http://127.0.0.1/svn/[meinProjekt]. Dazu kann noch eine Logmeldung eingetragen werden.
Der Erfolg des Importierens kann wie üblich über eine Rechtsklick mit dem Eintrag TortoiseSVN/Projektarchiv kontrolliert werden. War der Import erfolgreich, kann die erzeugte Projektstruktur getrost gelöscht werden und es steht der erste Checkout aus dem Projektarchiv an. Dazu wird an die gewünschte Position im Dateisystem gewechselt und dort mit Rechtsklick der Eintrag SVN Auschecken genutzt. Damit nun nicht das gesamte Repository heruntergeladen wird, sondern nur der aktuelle Projektfortschritt, muss der Download-URL um das Verzeichnis trunk erweitert werden. Die übertragenen Dateien werden als lokale Arbeitskopie bezeichnet und sind
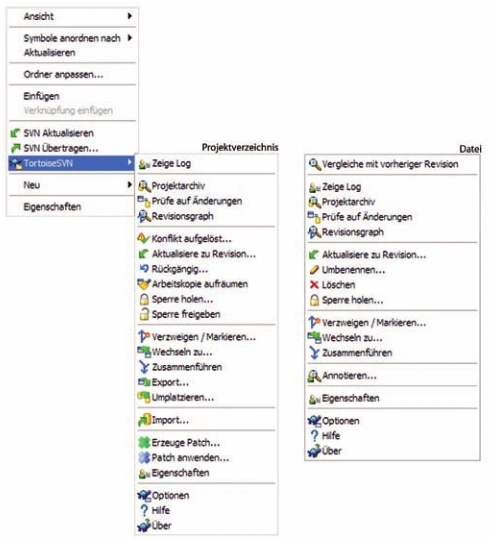
Abb. 2: Funktionsumfang des TortoiseSVN-Clients
Der Screenshot in Abbildung 2 zeigt die typischen Funktionen von TortoiseSVN, die stets mit einem Rechtsklick erreicht werden. Das Kontextmenü unterscheidet bei einer Selektion zwischen Dateien und Verzeichnissen. Bei nichtversionierten Verzeichnissen stehen die Optionen Hinzufügen, Importieren und Ignorieren zur Auswahl. Wenn die Optionen gleich nach der Aufnahme neuer Dateien in die lokale Arbeitskopie gesetzt werden, sind spätere Falschübertragungen bei einem Commit wesentlich geringer. Durch die Verwendung solcher Markierungen werden stets die richtigen Dateien für die Übertragung vorselektiert, und einem falsch gesetzten Haken unter Zeitstress ist so einfach vorzubeugen.
Jeder Commit in das SVN lässt eine interne Revisionsnummer um eins erhöhen. Die letzte übermittelte Revision wird als HEAD bezeichnet und stellt immer den aktuellen Stand dar. Um auf frühere Versionen des Projekts zugreifen zu können, wird diese Revisionsnummer benötigt. Über die Logmeldungen lässt sich nachvollziehen, welche Änderung in einer Revision gemacht wurde. Es ist somit möglich, jederzeit eine bestimmte Revision aus dem Projektarchiv auszuchecken. Bei sehr vielen Revisionen kann die interne Suchfunktion des Clients verwendet werden, um bestimmte Schlüsselwörter in den Logs zu finden. Dies ist auch ein Grund, von vornherein mit Weitblick sinnvolle Beschreibungen zu finden. Eine Logmeldung sollte die Art der Änderung, die betroffenen Funktionen und eine kurze Beschreibung beinhalten. Ein Beispiel für eine solche Meldung ist: >>FEATURE: Kalender – Berechnung Ostersonntag hinzugefügt.<<
Revision oder Version?
Wichtig im Umgang mit einer Versionsverwaltung ist die Unterscheidung der Begriffe Build und Version. Ein Build ist ein einzelner Iterationsschritt, welcher der erstellten Anwendung nur eine einzige neue Funktion, beziehungsweise ein Feature hinzufügt. Ein Build ist mit der Revisionsnummer im SVN gleichzusetzen. Die Version einer Software ist eine Zusammenstellung verschiedener Funktionen und Features. Erst wenn die geforderte Funktionalität einer Version implementiert ist, erfolgt das Erhöhen der Versionsnummer. Die Version besteht also aus mehreren Builds.
In manchen Fällen ist es wichtig, im Repository Dateien gegen Veränderungen zu sichern. Dafür kann der Mechanismus Sperre holen und Sperre freigeben benutzt werden. Solange Dateien gesperrt sind, können sie nicht durch einen Commit verändert werden. Das beugt Konflikten vor, die entstehen, wenn eine Datei gleichzeitig editiert wird. Um Unterschiede in den Revisionen einer Datei zu erkennen, steht ein so genannter Diff zur Verfügung. Die Abbildung 3 zeigt einen solchen Diff. Es wird immer der Unterschied der aktuellen Arbeitskopie zur vorhergehenden Revision angezeigt. Tortoise lässt sich auch mit dem freien Tool WinMerge kombinieren, um weitere Funktionen zum Dateivergleich zur Verfügung zu haben. Das ist besonders dann interessant, wenn mehrere Revisionen einer Datei verglichen werden müssen. Dazu muss nicht immer das ganze Projekt ausgecheckt werden, es genügt durchaus, nur die betreffenden Files herunterzuladen.
Abb. 3: Diff-Ansicht des Tortoise-Clients
Markieren und Verzweigen
Abb. 4: Verzweigen/Markieren-Dialog
Eine Markierung stellt einen semantischen Zusammenhang des Projektfortschritts zu einer Revisionsnummer im Repository dar. Um das Repository übersichtlich zu halten, werden nur vorher festgelegte Revisionen getaggt. Eine solche Revision kann beispielsweise der Sprung auf eine neue Version der eigenen Applikation sein oder ein Upgrade eines verwendeten Frameworks auf eine aktuelle Version. Wenn einmal eine Markierung nicht sofort angelegt wurde, ist dies auch nicht problematisch. Tags können jederzeit auch aus jeder beliebigen Revisionsnummer erzeugt werden. Daher ist es unproblematisch, nach mehreren Commits die gewünschte Revision im Nachhinein zu taggen. Um eine Markierung zu erzeugen, wird der Eintrag Verzweigen/Markieren im Kontexmenü benutzt. Dazu ist es wichtig, auch im Root-Ordner des gesamten Projekts zu sein, da sonst nur Teile getaggt werden. In Abbildung 4 ist der betreffende Dialog dargestellt. An der ersten Position ist das Quellverzeichnis angegeben. Im Eingabefeld Zu URL wird der Pfad von trunk nach tags korrigiert. In tags ist es notwendig, den Pfad mit einem neuen Ordner zu erweitern, der z. B. die Versionsnummer als Namen besitzt. Wenn der Pfad des trunks nicht erweitert wird, kommt es zu einer Fehlermeldung und der tag wird nicht angelegt. Als Nächstes wird die Auswahl getroffen, welche Revision verwendet werden soll. Zu guter Letzt darf natürlich auch eine Logmeldung nicht fehlen. Wenn nun das Projektarchiv geöffnet wird, ist im Verzeichnis tags ein neuer Ordner angelegt, der sämtliche Projektdateien zu einem bestimmten Revisionsstand enthält. In tags werden keine Änderungen übertragen.
Für Verzweigungen wird analog vorgegangen, nur dass das Verzeichnis tags durch branches ersetzt werden muss. Bei der späteren Arbeit mit Entwicklungszweigen, die vom trunk abweichen, muss der Commit auch stets in das entsprechende Unterverzeichnis von branches übertragen werden. Das Zusammenführen eines branchs mit der HEAD-Revision des trunks erfolgt über das Kontexmenü. Die vorhandenen Konflikte müssen von Hand über den Diff-Betrachter aufgelöst werden.
Fazit
Wie zu erkennen ist, handelt es sich bei Subversion um ein sehr leistungsfähiges Werkzeug, dessen Leistungsspektrum von diesem Artikel nur angerissen werden konnte. Eine ausführliche Abhandlung zur Theorie und weiterführende Konzepte mit Subversion sind im SVN Book zu finden.
Cookie Consent
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.