Die Verwaltung von Linux-Servern oder Docker-Containern erfordert grundlegende Kenntnisse des Terminals, auch bekannt als Kommandozeile. Windows-Benutzer können beispielsweise das Programm PuTTY verwenden, um über Secure Shell (SSH) Fernzugriff auf einen Linux Server zu erhalten. SSH ist eine sichere Fernverbindung, die eine verschlüsselte Terminalverbindung zu einem Linux-Rechner herstellt. SSH bietet zwei grundlegende Zugriffsarten auf ein entferntes System: die nicht empfohlene Methode mit Benutzername/Passwort und die sicherere Variante mit einem bereitgestellten RSA-Schlüsselpaar.
Per Definition sind „Terminal“ und „Shell“ nicht dasselbe, werden aber oft synonym verwendet. Im Allgemeinen ist das Terminal die Kommandozeilenschnittstelle (CLI), die Tastatureingaben von Benutzern empfängt. Die Shell ist ein Interpreter, der innerhalb des Terminals ausgeführt wird, um Programme zu starten. Bei den meisten Linux-Distributionen ist BASH (Bourne Again Shell) die Standard-System-Shell. Neben BASH gibt es weitere Shell-Varianten wie KornShell (ksh) oder C Shell (csh).
Beim Zugriff auf einen Rechner, sei es über eine Reverse Shell oder SSH, kann sich das Terminal ungewöhnlich verhalten. Häufige Probleme sind die Unfähigkeit, Text zu löschen, Strg+C oder Strg+L zu verwenden, und die fehlerhafte Textdarstellung. So verbessern Sie die Terminalnavigation.
Schritte für ein besseres Terminalerlebnis
1. Temporäres Skript starten
script /dev/null -c bash
Dies startet ein Skript, das sich automatisch löscht, da es auf /dev/null verweist.
2. Reverse Shell in den Hintergrund verschieben
Drücken Sie STRG+Z. Dadurch wird der Reverse-Shell-Prozess in den Hintergrund verschoben.
3. Prozess fortsetzen und stty konfigurieren
stty raw -echo; fg
Dies führt Sie zurück zum Prozess und passt das Terminal für Rohdateneingabe ohne Echo an.
4. Terminal zurücksetzen
reset xterm
Verwenden Sie diesen Befehl auch dann, wenn der Text nicht korrekt angezeigt wird oder ungewöhnliche Einrückungen vorhanden sind.
5. Umgebungsvariable TERM konfigurieren
export TERM=xterm
Überprüfen Sie die Variable $TERM vor und nach diesem Schritt mit echo $TERM.
Ersetzen Sie [tatsächliche Konsolenzeilennummer] und [tatsächliche Konsolenspaltennummer] durch die entsprechenden Werte, die Sie mit dem Befehl stty size in einer normalen Konsole ermitteln.
Sicherheitshinweis: Linux-Server, die über das Internet erreichbar sind, sollten weder die Anmeldung per Root-Benutzer noch per Benutzerpasswort ermöglichen. Das Problem besteht in verteilten Brute-Force-Angriffen von Botnetzen, die darauf abzielen, eine administrative Shell zu erlangen und das System zu kapern. Moderne, gehärtete Linux-Server deaktivieren daher das Root-Konto und stellen Administratoren lediglich den Befehl sudo zur Verfügung.
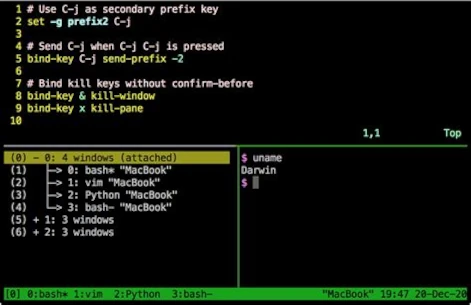
Administratoren, die mehrere geöffnete Shells verwalten müssen, um verschiedene Rechner zu warten, nutzen gerne das praktische Tool TMUX [1]. Es ist aktuell in Version 3 verfügbar und lässt sich einfach über die Shell installieren:
apt-get install tmux
TMUX ermöglicht die Nutzung mehrerer Terminal-Sitzungen in einem einzigen Terminal. Für die korrekte Verwendung konsultieren Sie bitte die offizielle Handbuchseite [2]. Die Bedienung des Programms ist etwas komplex und erfordert etwas Einarbeitungszeit. Eine kurze Einführung würde den Rahmen dieses Beitrags sprengen und einen eigenen Artikel füllen, der möglicherweise in Zukunft veröffentlicht wird. Um Ihnen einen Eindruck von den Möglichkeiten von TMUX zu vermitteln, sehen Sie sich den folgenden Screenshot an.
Eines der wichtigsten Erkenntnisse zum Softwaretesting stammt von dem viel zitierten Artikel „The Humble Programmer“, den Dijkstra 1972 veröffentlichte. Sinngemäß besagt dies, dass durch Testen lediglich Fehler nachgewiesen werden können, aber es ist unmöglich, die Fehlerfreiheit des Programms nachzuweisen. Das bedeutet im Umkehrschluss, dass eine hohe Testqualität bereits möglichst viele Fehler aufdeckt und damit die Wahrscheinlichkeit sinkt, dass im Programm weitere Fehler vorhanden sind.
Nun stellt sich zuerst die Frage, was eine ‚gute‘ Testqualität ausmacht. Ein sehr wichtiger Faktor ist die Performance. Dauert die Testausführung länger als 5 Minuten, stört dies den Entwickler im Arbeitsfluss. Dauert die Testausführung länger als 10 Minuten, ist die Akzeptanz der Entwickler verloren, die Tests automatisiert im Buildprozess durchlaufen zu lassen. Das führt dazu, dass die Testausführung lokal deaktiviert wird, damit das Prinzip, möglichst schnell im Fehlerfall zu scheitern, verletzt wird. Das Prinzip des schnellen Scheiterns ist einer der wichtigen Grundpfeiler automatisierter Softwaretests, denn so kann man sich zeitnah dem Problem widmen und es beheben. Diese schnelle Reaktion, ist es welche den Arbeitsfluss des Entwicklers unterstützt und dadurch den sogenannten Kontextwechsel vermeidet. Je weniger man sich auf eine neue Situation einstellen muss, umso produktiver kann man arbeiten, was als Konsequenz eine erhebliche Senkung der Entwicklungskosten ausmachen kann. Wir können sagen, dass nicht die Anzahl der Tests relevant ist, sondern es darauf ankommt, die richtigen, also relevanten Tests zu schreiben.
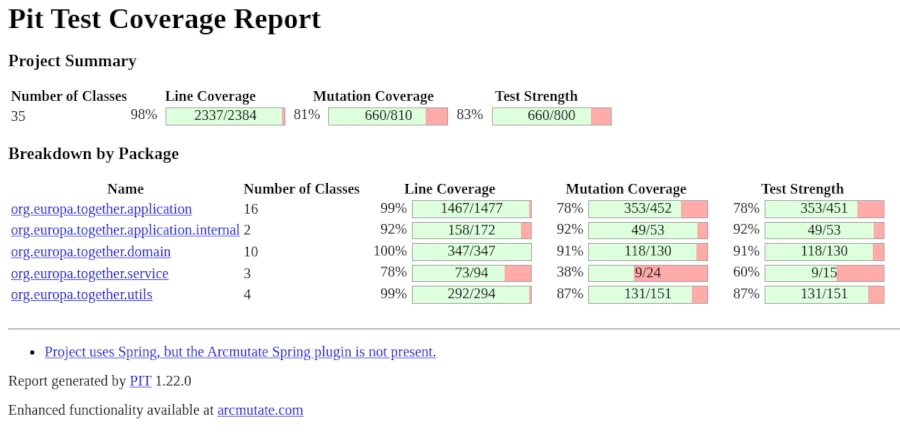
Eine Idee davon, wie viele Testfälle man benötigt, gibt die Arbeit von McCabe, welcher 1976 ein Maß für die Komplexität formulierte. Die Komplexitätszahl einer Funktion oder Methode stellt einen Orientierungspunkt für die Menge der benötigten Testfälle dar. Allerdings bedeutet eine hohe Anzahl von Testfällen nicht automatisch, dass diese eine Relevanz für die Korrektheit der Methode beziehungsweise Funktion haben. Der Nutzen oder, auch anders ausgedrückt, die Ausdruckskraft der vorhandenen Testfälle ergibt sich aus der Tatsache, wie gut diese den vorhandenen Code überdecken. Nur eine vollständige Coverage stellt sicher, dass auch alle Bereiche einer Funktion ausgeführt wurden und somit durch einen Festfall abgedeckt sind. Bei der Testcoverage unterscheiden wir zwei Metriken, die Abdeckung aller Codezeilen und die Abdeckung aller Verzweigungen. Sicher kann man vor allem in sogenannten Legacy-Projekten nur sehr schwer eine hohe Testabdeckung erreichen. Um den Aufwand aussagekräftiger Tests auf ein überschaubares Maß zu begrenzen, ist es notwendig, ausschließlich bei neu hinzugefügten Funktionen eine Line- und Branch Coverage von 100 % zu erreichen. Kann die 100 % nicht erreicht werden, ist dies ein Indikator für ein Refactoring, um die Testbarkeit der hinzugefügten Funktionalität zu gewährleisten.
Gehen wir nun vom optimalen Fall aus und betrachten ein sogenanntes Greenfield-Projekt, dessen Anzahl der Testfälle auch dem Komplexitätsmaß nach McCabe entspricht und für das wir bereits eine 100 % Testabdeckung für Zeilen und Verzweigungen nachweisen können, stehen wir immer noch vor dem Problem, das Dijkstra formuliert hat. Denn es muss uns bewusst sein, dass wir zwar nachweisen, alle Codbereiche durch einen Testfall betreten zu haben, aber ob die von uns getroffenen Annahmen über das Verhalten des Quellcodes korrekt sind, können wir nicht belegen. Im Kontext der xUnit Tests geht es um die verschiedenen Assert-Funktionen, welche eine Funktion gegen einen Erwartungswert testen. Dazu ein klassisches Beispiel für Java Collections, das sich auch auf andere Programmiersprachen projezieren lässt.
Listen, genauer gesagt: Die in Java implementierte ArrayList speichert die Elemente der Liste nicht als Wert in der Liste, sondern nutzt das sogenannte Call-by-Reference, welches lediglich die Speicheradresse des Listenelements referenziert. Führt man nun Operationen auf bestehenden Listen aus, manipuliert man stets die originale Liste. Vergleicht man dann in einem Testfall die originale Liste mit der manipulierten Liste, sind diese immer identisch, da es sich um dieselbe Liste handelt. Erst wenn man beispielsweise mit einem Copy-Konstruktor eine wirkliche Kopie des Originals erstellt, welche man manipuliert, um Vergleichstests durchzuführen, sind die getroffenen Annahmen korrekt. Überspitzt ausgedrückt, kann man eine 100 %-Testabdeckung erreichen, ohne ein wirkliches Sicherheitsnetz zur Fehlererkennung aufzuspannen.
Um solche logischen Fehler, wie gerade beschrieben, in den Tests zu entdecken, können wir uns des sogenannten Mutationstestings bedienen. Auch das Konzept des Mutationtesting hat seine Ursprünge bereits in den 1970er Jahren. Mit dem Artikel „Fault Diagnostics of Computer Programms“ beschrieb Richard Lipton 1971 die Idee zu Mutation-Testing, welches zahlreiche weitere Forschungsarbeiten nach sich zog.
Die Idee für Mutationstests ist sehr einfach, wie so viele bahnbrechende Errungenschaften. Gehen wir davon aus, das im Quellcode ein Ausdruck if(var > 0) enthalten ist und zu diesem Ausdruck auch ein entsprechender Test formuliert wurde. Wenn wir nun hergehen und die Bedingung in der IF Anweisung verändern, sollte der zugehörige Test fehlschlagen. Nun gibt es verschiedene Möglichkeiten, wie die IF-Anweisung verändert werden kann. Eine Variante ist die Umkehrung des Operators von > nach <. Aber auch die Verwendung anderer Operatoren wie = oder ! ist möglich. Eine andere Variante wäre, den Vergleichswert 0 abzuändern. Die erreicht man durch das Erhöhen oder Reduzieren um 1. Alle diese Variationen stellen sogenannte Mutationen des Originalausdrucks dar, weswegen man diese auch als Mutanten bezeichnen kann. Das Ziel ist, dass möglichst viele Mutanten den vorhandenen Testfall fehlschlagen lassen. Jeder Mutant, der den Testfall fehlschlagen lässt, wird als Kill bezeichnet.
Wenn keiner der erzeugten Mutanten den Testfall fehlschlagen lässt, ist die Korrektheit des Testfalls anzuzweifeln und muss überprüft werden. Idealerweise lassen alle Mutanten den Testfall fehlschlagen, was eher als Ausnahme zu werten ist. Aussagekräftige Testfälle sollten einen Mutationsscore von mindestens 70 % erreichen. Die Berechnung des Mutation Scors, oder auch der Kill Rate lautet wie folgt: Um den Mutationswert zu berechnen, teilt man die Anzahl der abgetöteten Mutanten (Mutanten, die zu einem Fehlschlag der Tests geführt haben) durch die Gesamtzahl der erzeugten Mutanten und multipliziert das Ergebnis mit 100, um einen Prozentsatz zu erhalten. Wenn beispielsweise 7 von 10 Mutanten abgetötet werden, beträgt der Mutationswert 70 %.
Manche Mutanten verhalten sich funktional identisch zum Originalcode. Diese äquivalenten Mutanten können durch keinen Test eliminiert werden, da sie keine eigentlichen Fehler darstellen. Damit haben wir ein Entscheidungskriterium, das bei niedrigem Mutations-Score und bei einer Bewertung der Situation weiterhelfen kann.
Auch wenn das hier beschriebene Konzept sehr leicht verständlich ist, liegt wie so oft der Teufel im Detail. Zum einen müssen sinnvolle Mutationsoperatoren ausgewählt und zum anderen sollte die Anzahl der generierten Mutanten aus Gründen der Testausführungsdauer begrenzt werden. Da je nach Größe der Codebasis die Ermittlung des Mutation Scores sehr langwierig sein kann, sollten Mutation-Tests nicht über den Standard Buildprozess ausgeführt werden und als eigenständige Testprozedur laufen. Grundsätzlich kann man allerdings sagen, dass Entwickler mit einem guten Verständnis für testgetriebene Softwareentwicklung sich auch zügig in das Thema Mutation Testing einfinden. Aber auch für die Bewertung seitens des Projektmanagements ist Mutant Testing in Kombination mit einer hohen Testcoverage ein sehr mächtiges Mittel, ohne den Quelltext zu lesen. Abschließend ist als sehr wichtiger Punkt anzumerken, dass die hier beschriebene Prozedur keine Aussage zu Fragestellungen der Sicherheit beantworten kann. Um sicherzustellen, dass die Anwendung gegen Hackerangriffe wie SQL Injections geschützt ist, sind auf Sicherheit spezialisierte Audits unvermeidlich.
Das dauerhafte Speichern von Daten nennt man im Fachchinesisch Persistieren. Damit man auf diese Daten gezielt auch wieder zugreifen kann, benötigt man eine Software, die Daten strukturiert und durchsuchbar macht. Eine solche Software nennt sich Datenbank Management System (DBMS). Damit man von einer Programmiersprache wie Java, Ruby, Python oder PHP auf eine Datenbank zugreifen kann, benötigt man einen entsprechenden Treiber. Dieser Treiber wird auch oft als Client bezeichnet, denn das DBMS ist der Server, welcher mehreren Clients Zugriff gestattet. In diesem Artikel kümmern wir uns nicht darum, wie man sich mit welcher Programmiersprache auf die entsprechenden Datenbanken verbinden kann, sondern schauen uns an, was es für unterschiedliche Datenbanktechnologien gibt und wofür diese eingesetzt werden.
[Relationale DB (Zeilen, Spalten) | GIS DB | embedded DB] [NoSQL | {Key Value Store | Document DB (JSON, XML) | Graph DB | Zeitreihen Server]
Mittlerweile gibt es für die klassischen Datenbanksysteme, die sogenannten relationalen Datenbanken, eine Vielzahl von Lösungen zur Auswahl. Sowohl kommerzielle, als auch professionelle freie Open Source Vertreter buhlen um die Gunst der Anwender. Im Web bieten die meisten Hoster zum Speichern der Daten die freien DBMS MySQL (Oracle) und MariaDB (Abspaltung von MySQL nach der Übernahme durch Oracle) ihren Anwendern zur Auswahl an. Wer seine Server allerdings selbst betreuen kann, kann natürlich auch auf das professionellere PostgreSQL setzen.
Postgres ist allerdings für die meisten PHP-Standardapplikationen eher ungeeignet, obwohl WordPress und Joomla dieses Datenbanksystem durchaus unterstützen. Probleme bereiten üblicherweise die Entwickler der Erweiterungen. Der Zugriff auf die Datenbanken erfolgt dann nicht über die Schnittstellen der Anwendung, sondern aus Unwissenheit wird oft über die nativen Befehle von MySQL auf die Daten zugegriffen.
In der kommerziellen Anwendungsentwicklung verwendet man üblicherweise Oracle oder den Microsoft SQL Server, je nachdem, wie affin man mit der Microsoft-Windows-Welt ist. Der Grund für den Einsatz kommerzieller Datenbankserver liegt im kostenpflichtigen Support, bei Bekanntwerden von Schwachstellen und Fehlern. Geschäftskritische Anwendungen, müssen das Fortbestehen des Herstellers und auch der Kunden dieser Anwendung sicherstellen. Gerade die Geschwindigkeit der Auslieferung von Korrekturen für Sicherheitsschwachstellen ist ein gewichtiger Grund für den Einsatz kommerzieller Software.
Die Funktionsweise von relationalen Datenbanken ist über Tabellen definiert. Die Spalten einer Tabelle definieren die Eigenschaft und eine Zeile der Tabelle bildet den Datensatz. Um einen expliziten Datensatz ansprechen zu können, muss eine Spalte (Primärschlüssel) eindeutige, nicht noch einmal in dieser Spalte vorkommende Einträge enthalten. Diese Eigenschaft der Primärschlüssel nennt sich unique. Über die Primärschlüssel lassen sich Verknüpfungen, sogenannte Relationen, zwischen den Tabellen aufbauen. Um den Artikel nicht ins Unermessliche ausufern zu lassen, belasse ich es an dieser Stelle mit der Tiefe zur Funktionsweise von relationalen Datenbanken und gehe zur nächsten Kategorie über.
Natürlich gibt es auch relationale Datenbanken, die nicht zeilenorientiert, sondern spaltenorientiert arbeiten. Dies ermöglicht effizientere Abfragen und Analysen, insbesondere bei großen Datenmengen. Hier sind einige der Hauptmerkmale und Vorteile spaltenorientierter Datenbanken:
Datenorganisation: Speichert Daten in Spalten, was die Verarbeitung spezifischer Spalten in Abfragen beschleunigt.
Komprimierung: Bietet oft bessere Komprimierungsraten für spaltenweise gespeicherte Daten, da ähnliche Datentypen hintereinander gespeichert werden.
Analytische Abfragen: Optimiert für Analysen und aggregierte Abfragen, die große Datenmengen schnell abfragen müssen.
Reduzierte I/O: Reduziert die Menge an Daten, die von der Festplatte gelesen werden müssen, da nur die benötigten Spalten abgerufen werden.
Spaltenorientierte Datenbanken sind Apache Cassandra, SAP Hanna, IBM DB2 und Amazon BigQuery mit klassichen Anwendungsfällen für:
Business Intelligence: Ideal für Datenbanken, die große Mengen an Daten für analytische Zwecke verarbeiten müssen.
Data Warehousing: Effizient bei der Speicherung und Analyse historischer Daten.
Echtzeitanalysen: Geeignet für Anwendungen, die schnelle Entscheidungen basierend auf aktuellen Daten treffen müssen.
Um Daten für geografische Informationssysteme (GIS) wie Google Maps bereitzustellen, werden sogenannte Geospatial Datenbanken eingesetzt. Bei Geospatial Datenbanken handelt es sich um Erweiterungen relationaler Datenbanken, die für geometrische Objekte optimierte und standardisierte Tabellen und Relationen bereitstellen. Die GIS Erweiterung für PostgreSQL heißt PostGIS. Die Datensätze für das frei verfügbare OpenStreetMap liegen in einem spezialsierten XML Format vor und können aber auch in Geospatial Datenstrukturen transformiert werden.
Key – Value Speicher, werden oft in Konfigurationsdateien verwendet. Will man allerdings ein schnelles Caching-System aufbauen, benötigt man ein wenig mehr Komplexität. Denn die Schlüssel / Wert Bezeihung kann von einfachen Zeichenketten hin zu komplexen Objekten ausarten. Grundsätzlich besteht ein Speicher aus einem uniquen Schlüssel, dem je nach Datentyp Werte zugeordnet werden können. Datentypen können Zeichenketten (Strings), Zahlen (Integer, Float), Wahrheitswerte (Boolean) und Listen sein. Key – Value Datenbanken gehören zu den NoSQL Datenbanken, da die Abfrage nicht wie bei relationalen Datenbanken über SQL erfolgt, sondern datenbank- und herstellerspezifisch ist.
Typische Key -Value Datenbanken sind Redis, MemCached, Amazon DynamoDB und die etwas in die Tage gekommene BarkleyDB, die von Oracle übernommen wurde. Eine Eigenschaft von Key – Value Datenbanken ist, dass die Daten im Speicher gehalten und in regelmäßigen Abständen auf die Festplatte gesichert werden. Das Vorhalten der Daten im Arbeitsspeicher erfordert natürlich auch eine entsprechende Ausstattung der Maschine mit ausreichend RAM. Besonders bei großen Anwendungen kann für das Chaching eine enorme Datenmenge zusammenkommen.
Eine weitere Kategorie für Datenbanken sind Embedded-Datenbanken. Embedded meint auf Deutsch „eingebunden“ und bezieht sich auf den Datenbankserver. Das bedeutet im Konkreten, dass das Datenbanksystem keine eigenständige Installation ist, sondern als Bibliothek einen Teil der Anwendung darstellt. Der Vorteil einer solchen Lösung ist, dass die Installationsroutine der Anwendung einfacher ist. Meist geht das allerdings zulasten der Sicherheit, da viele der embedded Datenbanken keine zusätzliche Schicht für eine Benutzerverwaltung haben. Dieser Umstand gilt besonders für SQLite und die in Java implementierte H2. Aber auch die bereits erwähnte NoSQL BarkelyDB die als Java- oder C-Bibliothek verfügbar ist, hat keine Benutzerverwaltung. Das heißt, wer Zugriff auf die Anwendung hat, kann mit einem Client die Daten aus der Datenbank lesen. Daher sind die gerade genannten Systeme nicht für Anwendungen geeignet, die eine hohe Sicherheitsstufe erfordern.
Zur Java Version der BarkelyDB kann man noch sagen, dass die letzte verfügbare Implementierung aus dem Jahr 2017 stammt und in Java / Apache Ant als Quelltext vorhanden ist, der aber selbst kompiliert werden muss. Ein offizielles Binary von Oracle ist nicht mehr verfügbar, es können aber sogenannte inoffizielle Versionen im Maven Central Repository gefunden werden.
Wer eine voll funktionsfähige relationale Datenbank in seine Anwendung integrieren möchte, kann auf die embedded Variante von PostgreSQL – pgx – zurückgreifen, die alle Funktionen des PostgreSQL Servers lokal bereitstellt.
Die nächste Klasse der Datenbanken gehört wieder zu den NoSQL Vertretern. Dokumentenbasierte Datenbanken. Die beiden DBSM MongoDB und CouchDB sind im Funktionsumfang durchaus identisch, dennoch gibt es markante Unterschiede.
MongoDB wird aufgrund seiner umfangreichen Abfragesprache und hohen Performance häufig für Anwendungen gewählt, die komplexe Abfragen und Echtzeitanalysen erfordern.
CouchDB eignet sich besonders für Anwendungen, die Zuverlässigkeit, eine verteilte Architektur und einfache Replikation benötigen, insbesondere in Szenarien, in denen Offline-Zugriff unerlässlich ist.
Die grundlegende Arbeitsweise von Dokumentendatenbanken ist, dass sich das Schema aus der hinterlegten Datenstruktur ergibt. Diese Datenstrukturen haben meist das JSON Format und werden entsprechend angesprochen. Dokumente der selben Datenstruktur werden einer Collection zugeordnet. Es handelt sich also nicht um klassische Office Dokumente die in diesen Datenbanken abgelegt werden, sondern um Formate wie JSON und XML. Dokumentendatenbanken, die sich auf XML spezialisiert haben, sind Oracle XML DB oder Apache Xindice.
Viele Webentwickler, die sich auf FrontEnd (UX / UI) spezialisiert haben, greifen gern auf Dokumentdatenbanken zurück. Das erlaubt ihnen, die Daten im JSON Format abzulegen, um damit REST Zugriffe zu simulieren und damit die dynamischen Inhalte der Benutzeroberfläche zu befüllen.
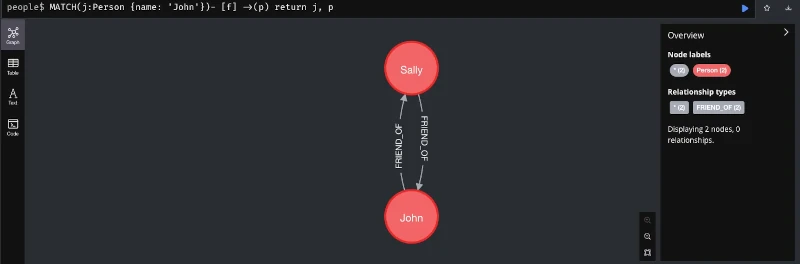
Eine sehr exotische Variante der NoSQL Datenbanken sind die Gaphdatenbanken, die Daten als Graphen repräsentieren. Diese Speicherform ermöglicht das effiziente Ablegen von Informationen nach Beziehungen. Solche Beziehungen können Verlinkungen von Webseiten sein oder die Repräsentation einer Person in sozialen Medien. Aber auch die komplexen Beziehungen für Empfehlungssysteme können als Graph dargestellt werden. Die nachfolgende Abbildung zeigt ein einfaches Beispiel für Neo4J einer in Java implementierten Graphdatenbank, um sich eine Vorstellung des Einsatzszenarios machen zu können.
Andere Graphdatenbanken sind Amazon Neptune und ArangoDB.
Als letzte Datenbanklösung möchte ich die sogenannten Zeitreihen (Time Series) vorstellen. Da besonders im Kontext für den Betrieb von Anwendungen das Monitoring essenziell geworden ist, haben Daten, die als Zeitreihen vorliegen, an Bedeutung gewonnen. Typische Datenbanken, die sich auf die Verarbeitung von Zeitreihen spezialisiert haben, sind Prometheus und InfluxDB. Aber auch für klassische relationale Datenbanken gibt es entsprechende Erweiterungen. Die bereits mehrfach erwähnte PostgreSQL-Datenbank hat auch für diesen Anwendungsfall eine entsprechende Erweiterung namens TimescaleDB.
Natürlich kann man über das Thema noch viel mehr sagen. Schließlich füllen unzählige Bücher einige Regalmeter in Bibliotheken zum Thema Datenbanken. Für den Einstieg und die Übersicht zu den verschiedenen Datenbanksystemen beziehungsweise NoSQL Lösungen soll es aber an dieser Stelle genügen. Mit den Informationen aus diesem Artikel, haben sie nun eine Vorstellung, welche Datenbank sich für ihren speziellen Anwendungsfall eignet. Wir konnten auch sehen, dass relationale Datenbanken, insbesondere die freie Open Source Datenbank PostgreSQL mit den verfügbaren Erweiterungen, sehr universell einsetzbar sind. Weiterführende Themen zu Datenbanken sind die Datenmodellierung und Sicherheit gegen Hackerangriffe.
Die Wolke ist eine der innovativsten Entwicklungen, seit der Jahrtausendwende und ermöglicht uns eine flächendeckende Nutzung neuronaler Netze, die wir im Volksmund als Large Language Models (LLM) bezeichnen. Dieser Technologiesprung ist nur noch durch Quantencomputing zu übertreffen. Aber genug der Buzzwords für die SEO-Optimierung, stattdessen schauen wir einmal hinter die Kulissen. Beginnen wir erst einmal damit, was Cloud überhaupt ist, und legen dafür die ganzen Marketingbegriffe einmal beiseite.
Am besten kann man sich die Wolke als gigantischen Supercomputer vorstellen, der aus vielen kleinen Computern bausteinartig zusammengesetzt wurde. Dadurch hat man theoretisch beliebig viel CPU‑Leistung, Arbeitsspeicher und Festplattenspeicher zusammenschalten. Auf diesem Supercomputer, der in einem Rechenzentrum läuft, können nun wiederum virtuelle Maschinen bereitgestellt werden, die einen echten Computer mit einer freidefinierbaren Hardware simulieren. Auf diese Weise können die physischen Hardwareresourcen optimal auf die bereitgestellten virtuellen Maschinen aufgeteilt werden.
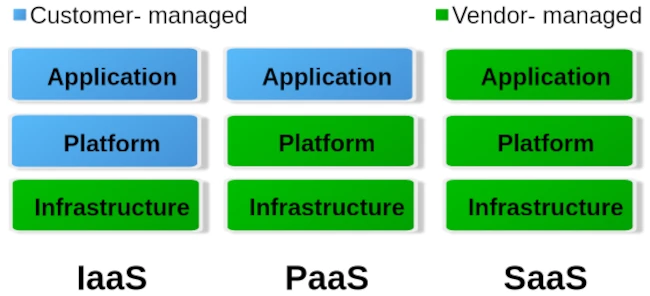
Bei Cloud unterscheiden wir grob drei unterschiedliche Betriebslevel: Infrastructure as a Service (IaaS), Platform as a Service (PaaS) und Software as a Service. Die nachfolgende Abbildung gibt eine Vorstellung davon, wie sich diese Ebenen aufteilen.
Vereinfacht kann man sagen, dass bei IaaS durch den Anbieter lediglich die Hardwarespezifikation bereitgestellt wird. Also CPU, RAM, Festplatte und Internetanschluss. Über die Administrationssoftware z. B. Kubernetes kann man nun eigene virtuelle Maschinen/Container erstellen und die entsprechenden Betriebssysteme und Services selbst installieren. Die gesamte Verantwortung der Sicherheit und des Netzwerkrouting liegt hier beim Kunden selbst. PaaS hingegen stellt bereits eine rudimentär eingerichtete virtuelle Maschine inklusive des ausgewählten Betriebssystems bereit. Was man schlussendlich auf diesem System oberhalb der Betriebssystemebene installiert, ist einem selbst überlassen. Aber auch hier ist das Thema Sicherheit zu großen Teilen in den Händen des Kunden. Bei den meisten Hostinganbietern sind typische PaaS-Produkte sogenannte virtuelle Server. Die geringste Freiheit haben Nutzer bei SaaS. Hier hat man meist nur die Berechtigung, durch ein Benutzerkonto eine Software zu nutzen. Sehr typische SaaS Produkte sind E-Mail Konten, aber auch sogenannte Managed Server. Managed Server findet man größtenteils zum Bereitstellen von eigenen Internetseiten. Hier wird die Version der Programmiersprache und der Datenbank durch den Betreiber des Servers vorgegeben.
Gerade die Managed Server haben eine lange Tradition. Sie kamen zur Jahrtausendwende auf um eine sofort benutzbare Umgebung für dynamische PHP Webseiten mit MySQL Datenbankanbindung bereitzustellen. Ähnlich verhält es sich mit den neu in Mode gekommenen Serverless Produkten. Je nach Erfahrungslevel kann man nun bei den Großen Anbietern AWS, Google und Microsoft Azure entsprechende Produkte kaufen.
Der Gedanke ist also, keine eigenen Server mehr für die Dienste zu betreiben und somit den kompletten Aufwand für Hardware, Betrieb und Sicherheit an die Cloudbetreiber auszulagern. Grundsätzlich ist das auch kein schlechter Gedanke, besonders wenn es sich um kleine Unternehmen oder Startups handelt, die einerseits nicht viele finanzielle Mittel zur Verfügung haben oder ihnen einfach das administrative Know-how für Netzwerk, Linux und Serversicherheit fehlt.
Natürlich kommt man mit vollständig extern verwalteten Serverless Angeboten auch schnell an Grenzen. Gerade wenn man die eigene entwickelte Individualsoftware Serverless mit möglichst wenig Aufwand in der Cloud bereitstellen möchte, kommt man an so manchem Stolperstein vorbei. Ein Problem ist oft die flexible Erweiterbarkeit bei wechselnden Anforderungen. Sicher kann man hier aus dem Portfolio der verschiedenen Anbieter Produkte zukaufen und diese wie ein Bausteinset beliebig kombinieren, aber die anfallenden Kosten können sich dabei schnell überschlagen.
Grundsätzlich ist an einem pay per use Modell (also bezahle, was du verwendest) nichts auszusetzen. Für Personen und Organisationen mit kleinem Geldbeutel ist das auf den ersten Blick keine schlechte Lösung. Aber auch hier sind es die kleinen Details, die schnell zu ernsthaften Problemen anwachsen können.
Wenn man sich für einen beliebigen Cloudanbieter entscheidet, ist man gut beraten, möglichst auf dessen proprietäre Management- und Automatisierungsprodukte zu verzichten und stattdessen nach Möglichkeit auf etablierte allgemeine Produkte auszuweichen. Bindet man sich mit allen Konsequenzen an einen Anbieter, so wird es nur unter sehr großem Aufwand möglich sein zu einem anderen Anbieter z wechseln. Änderungen der AGB oder kontinuierlich steigende Kosten sind mögliche Gründe für einen erzwungenen Wechsel. Daher prüfet, wer sich ewig bindet.
Aber auch unbedachte Ressourcennutzung in Cloudsystemen, z. B. durch falsche Konfigurationen oder ungünstige Deploy-Strategien, kann zu einer Kostenexplosion führen. Hier ist man gut beraten, wenn es die Möglichkeit gibt, Limits einzustellen, diese zu aktivieren. sodass man ab einem bestimmten Betrag darauf hingewiesen wird, dass nur noch ein ‚bestimmtes‘ Kontingent zur Verfügung steht. Gerade bei hochverfügbaren Diensten, die plötzlich sprunghaft enorm viele neue Anwender bekommen, können schnell durch solche Limits vom Netz abgestöpselt werden. Daher ist man immer gut beraten, möglichst zwei Lösungen im Bereich Cloud zu nutzen, eine für Entwicklung und eine separate für das Produktivsystem, um das Offlinerisiko zu minimieren.
Ähnlich wie beim Trading an der Börse, kann man auch bei Cloud Services wie AWS Schranken definieren. Die Stops an der Börse sollen verhindern, dass man eine Aktie nicht zu billig verkauft oder zu teuer einkauft. Durch das Pay per Use Modell ist es in der Cloud nicht viel anders. Hier muss man beim Anbieter geeignete Grenzen setzen, die verhindern, dass die Rechnung den Verfügungsrahmen des Kontos sprengt. Auch in der Cloud sind die Grenzen dynamisch. Das heißt, die Rahmenbedingungen verändern sich stetig, was bedeutet, dass die notwendigen Grenzen regelmäßig den Erfordernissen angepasst werden müssen. Um Engpässe rechtzeitig zu erkennen, sollte ein aussagekräftiges Monitoring etabliert sein. Die Mindestanforderung für ein AWS Node wird durch dessen Requests bestimmt. Die obere Schranke der verfügbaren Ressourcen wird durch das Limit bestimmt. Mit Werkzeugen wie Kubecost von IBM lässt sich die Kostenüberwachung in K8 Clustern weitgehend automatisieren.
Für Cloudentwicklungsumgebungen sollte man den eigenen Entwickler‑ und DevOps-Team auch ein wenig auf die Finger schauen. Wenn für eine einfache JavaScript Angular App ein NPM Docker Container von über 2 GB jedes Mal on the fly erstellt wird, sollte man diese Strategie durchaus hinterfragen. Auch wenn die Cloud scheinbar unendlich viele Ressourcen dynamisch allokieren kann, heißt das nicht, dass dies dann auch kostenfrei passiert.
Natürlich ist auch das Thema Sicherheit ein wichtiger Faktor. Natürlich kann man dem Cloudbetreiber so weit vertrauen, wenn er sagt, dass alles verschlüsselt ist und ein Zugriff auf Kundendaten und Geschäftsgeheimnisse nicht möglich ist. Sicher kann man davon ausgehen, dass die Informationen, die bei den meisten Unternehmungen abzugreifen sind, selten einen spannenden oder gar aufregenden Inhalt haben, der für große Cloudbetreiber von Interesse sein könnte. Wer dennoch auf Nummer sicher gehen möchte, sollte das Thema Serverless vollständig abschreiben und eher mit dem Gedanken spielen, seine eigene Cloud zu betreiben. Das geht dank moderner und freier Software mittlerweile leichter als gedacht.
Aus persönlicher Erfahrung habe ich gelernt, dass bei der Komplexität moderner Webanwendungen ein effizientes Monitoring mit Grafana und Prometheus oder anderen Lösungen wie dem ELK Stack oder Slunk unverzichtbar ist. Doch gerade mit der Datenerhebung und der richtigen Auswertung haben so manche DevOps Teams so ihre Schwierigkeiten. Hier sind vor allem die IT-Entscheider gefragt, sich einen technischen Überblick zu verschaffen, um nicht auf die wohlklingenden Marketingfallen bei Cloud und Serverless hereinzufallen.
Nicht nur sogenannte Hochsprachen, die den Quelltext in Maschinencode überführen müssen, damit dieser ausführbar ist, benötigen sogenannte Build Werkzeuge. Auch für moderne Scriptsprachen wie Python, Ruby oder PHP sind diese Werkzeuge mittlerweile verfügbar, da deren Verantwortungsbereich stetig wächst. Blickt man in die Anfänge dieser Werkzeugkategorie, stößt man unweigerlich auf make, der erste offizielle Vertreter von dem, was man heute als Build Werkzeug bezeichnet. Die Hauptaufgabe von make war das Erstellen von Maschinencode und das Paketieren der Dateien zu einer Bibliothek oder ausführbaren Datei. Man kann also sagen, das Buildwerkzeuge unter die Kategorie der Automatisierungswerkzeuge fallen. Da liegt es nahe, viele andere immer wiederkehrende Aufgaben, die im Entwickleralltag anfallen, ebenfalls zu übernehmen. So war eine der wichtigsten Innovationen, die für den Erfolg von Maven verantwortlich war, die Verwaltung von Abhängigkeiten zu anderen Programmbibliotheken.
Eine andere Klasse an Automatisierungswerkzeugen, die fast verschwunden ist, sind die sogenannten Installer. Produkte wie Inno SetUp oder Wise Installer wurden verwendet, um den Installationsprozess auf Desktopanwendungen zu automatisieren. Diese Installationsroutinen sind eine spezielle Form des Deployments. Der Deploymentprozess wiederum hängt von verschiedenen Faktoren ab. Zuallererst ist natürlich das verwendete Betriebssystem ein wichtiges Kriterium. Aber auch die Art der Anwendung hat einen erheblichen Einfluss. Handelt es sich etwa um eine Webanwendung, die eine definierte Laufzeitumgebung (Server) benötigt? Wir können hier bereits sehen, dass viele der gestellten Fragen mittlerweile im Themenbereich DevOps angesiedelt sind.
Als Entwickler genügt es nun nicht mehr, nur zu wissen, wie man Programmcode schreibt und Funktionen implementiert. Wer eine Webanwendung bauen möchte, muss zuerst den entsprechenden Server zum Laufen bekommen, auf dem die Applikation ausgeführt wird. Glücklicherweise gibt es mittlerweile viele Lösungen, die das Bereitstellen einer lauffähigen Runtime erheblich vereinfachen. Aber gerade für Anfänger ist es nicht immer so leicht, das ganze Thema zu überblicken. Ich erinnere mich noch an Fragen in einschlägigen Foren, dass man jetzt Java Enterprise heruntergeladen hat, aber nur der Applikationsserver enthalten ist.
Wo Anfang der 2000er noch Automatisierungslösungen fehlten, ist heute eher die Herausforderung, das richtige Werkzeug zu wählen. Auch hier gibt es eine Analogie aus dem Java Universum. Als das Build-Werkzeug Gradle auf dem Markt erschien, stiegen viele Projekte von Maven auf Gradle um. Das Argument war, eine höhere Flexibilität zu erhalten. Oft benötigte man die Möglichkeit, orchestrierte Builds zu definieren. Also die Reihenfolge, in der Teilprojekte erstellt werden. Anstatt sich einzugestehen, dass es sich bei dieser Anforderung um einen Architekturmangel handelt und anstatt diesen zu beheben, wurden komplizierte und kaum überschaubare Build Logiken in Gradle gebaut. Das führte wiederum dazu, dass Anpassungen nur schwer umzusetzen waren und viele Projekte zurück nach Maven migriert wurden.
Aus den DevOps Automatisierungen haben sich mittlerweile sogenannte Pipelines etabliert. Pipelines können auch als Prozess verstanden werden und diese Prozesse lassen sich wiederum standardisieren. Das beste Beispiel für einen standardisierten Prozess, ist der in Maven definierte Build Lifecycle, der auch als Default-Lifecycle bezeichnet wird. In diesem Prozess werden 23 sequenzielle Schritte definiert, die im Groben zusammengefasst folgende Aufgaben abarbeiten:
Auflösen und Bereitstellen von Abhängigkeiten
Kompilieren der Quelltexte
Kompilieren und Ausführen von Komponententests
Paketieren der Dateien zu einer Bibliothek oder Anwendung
Lokales Bereitstellen des Artefaktes zur Verwendung in anderen lokalen Entwicklungsprojekten
Ausführen von Integrationstests
Deployen der Artefakte auf einem Remote Repository Server.
Dieser Prozess hat sich über Jahre in unzähligen Javaprojekten bestens bewährt. Führt man diesen Prozess allerdings auf einem CI Server wie Jenkins als Pipeline aus, bekommt man wenig zu sehen. Die einzelnen Schritte des Build Lifecycles bauen aufeinander auf und können nicht einzeln angesteuert werden. Es ist nur möglich, den Lifecycle vorzeitig zu verlassen. Man kann also nach dem Paketieren die nachfolgenden Schritte des lokalen Deployments und das Ausführen der Integrationstests auslassen.
Eine Schwäche des hier beschriebenen Build Prozesses kommt bei der Erstellung von Webapplikationen zutage. Web Frontends enthalten meist CSS und JavaScript Code, der ebenfalls automatisiert optimiert wird. Um in SCSS definierte Variablen in korrektes CSS zu überführen, muss ein SASS Präprozessor verwendet werden. Zudem ist es sehr nützlich, CSS Dateien und JavaScript Dateien möglichst stark zu komprimieren. Dieser Vorgang der Obfuskation optimiert die Ladezeiten von Webanwendungen. Aber auch für CSS und JavaScript gibt es bereits unzählige Bibliotheken, die mit dem Werkzeug NPM verwaltet werden können. NPM wiederum stellt sogenannte Entwicklungsbibliotheken wie Grunt bereit, mit denen wiederum CSS-Prozessierung und -Optimierung möglich sind.
Wir sehen, wie komplex der Buildprozess von modernen Anwendungen werden kann. Das Kompilieren ist nur ein kleiner Teil davon. Ein wichtiges Feature moderner Build Werkzeuge ist das Optimieren des Build Vorgangs. Eine mittlerweile etablierte Lösung dafür ist das Erstellen von inkrementellen Builds. Dies ist eine Variante des Cachings, bei der nur geänderte Dateien kompiliert beziehungsweise prozessiert werden.
Jenkins Pipelines
Was ist aber bei einem Release zu tun? Ein Prozess, der wiederum nur dann benötigt wird, wenn eine Implementierungsphase beendet ist, um das Artefakt für die Verteilung bereitzustellen. Nun könnte man alle Schritte, die ein Release enthalten, ebenfalls in den Build einbauen, was wiederum zu längeren Buildzeiten führt. Längere lokale Buildzeiten stören wiederum den Arbeitsfluss des Entwicklers, weswegen es sinnvoller ist, hierfür einen eigenen Prozess zu definieren.
Bei einem Release sollte eine wichtige Bedingung sein, dass alle verwendeten Bibliotheken ebenfalls als finale Releaseversion vorliegen. Ist dies nicht der Fall, kann nicht sichergestellt werden, dass erneut erstellte Releases dieser Version identisch sind. Aber auch alle Testfälle müssen korrekt durchlaufen werden und ein Fehlschlagen bricht den Vorgang ab. Zudem sollte ein entsprechendes Tag im Source-Control-Repository auf die Revision gesetzt werden. Die fertigen Artefakte sind zu signieren und auch eine API Dokumentation ist zu erstellen. Natürlich sind die hier beschriebenen Regeln nur eine kleine Auswahl und einige der beschriebenen Aufgaben können sogar parallelisiert werden. Nutzt man zudem noch ein raffiniertes Caching, kann das Erstellen eines Releases auch für umfangreiche Monolithen in kurzer Zeit vonstattengehen.
Für Maven wurde beispielsweise kein kompletter Releaseprozess, ähnlich dem Buildprozess, definiert. Hier wurde durch die Community ein spezielles Plug-in entwickelt, mit dem einfache Aufgaben, die während eines Releases anstehen, semiautomatisiert werden können.
Wenn wir das Thema Dokumentation und Reporting ein wenig genauer betrachten, finden wir auch hier genügend Möglichkeiten, einen vollständigen Prozess zu beschreiben. So wäre das Erstellen der API Dokumentation nur ein untergeordneter Punkt. Wesentlich spannender an einem standardisierten Reporting sind die verschiedenen Codeinspektionen, die teilweise auch parallel durchlaufen werden können.
Natürlich darf auch das Deployment nicht fehlen. Aufgrund der Vielfalt, der möglichen Zielumgebungen ist an dieser Stelle eine andere Strategie angebracht. Ein denkbarer Weg wäre eine breite Unterstützung von Konfigurationswerkzeugen wie Ansible, Chef und Puppet. Aber auch Virtualisierungstechnologien wie Docker und LXC Container gehören in Zeiten der Cloud zum Standard. Hauptaufgabe des Deployments wäre dann vor allem die Provisionierung der Zielumgebung und das Einspielen der Artefakte aus einem Repository Server. Mit einer Fülle verschiedener Deployment Templates würde dies eine erhebliche Vereinfachung darstellen.
Wenn wir die hier getroffenen Annahmen konsequent weiterdenken, kommen wir zu dem Schluss, dass es unterschiedliche Projekttypen geben kann. Das wären klassische Entwicklungsprojekte, aus denen dann Artefakte für Bibliotheken und Anwendungen entstehen, Testprojekte, die wiederum die erstellten Artefakte als Abhängigkeit enthalten, und natürlich Deploymentprojekte zur Bereitstellung der Infrastruktur. Der Bereich des automatisierten Deployments findet sich auch in der Idee Infrastructure as a Code und GitOps wieder,die man an dieser Stelle aufgreifen und weiterentwickeln kann.
Wir sehen, dass bei weitem noch nicht alle Innovationen für sogenannte Build Werkzeuge ausgeschöpft sind. Viele der hier besprochenen Ideen sind bereits existierende Konzepte und erfordern lediglich eine Standardisierung. Durch die formalen Beschreibungen eines Prozesses und die flexible Konfiguration einzelner Komponenten in den Prozessschritten wird eine individuelle Anpassung ermöglicht.
Wer sich für diesen, eigentlich etwas spezialisierten Artikel interessiert, dem muss man nicht mehr erklären, was Docker ist und wofür das Virtualisierungswerkzeug eingesetzt wird. Daher richtet sich dieser Artikel vornehmlich an Systemadministratoren, DevOps und Cloud-Entwickler. Für alle, die bisher nicht ganz so fit mit der Technologie sind, empfehle ich unseren Docker Kurs: From Zero to Hero.
In einem Szenario, in dem wir regelmäßig neue Docker Images erstellen und verschiedene Container instanzieren, wird unsere Festplatte ordentlich gefordert. Images können je nach Komplexität durchaus problemlos einige hundert Megabyte bis Gigabyte erreichen. Damit das Erstellen neuer Images auch nicht gefühlt, wie ein Download einer drei Minuten langen MP3 mit einem 56k Modem dauert, nutzt Docker einen Build-Cache. Ist im Dockerfile wiederum ein Fehler, kann dieser Build-Cache recht lästig werden. Daher ist es eine gute Idee, den Build-Cache durchaus regelmäßig zu entleeren. Aber auch alte Containerinstanzen, die nicht mehr in Verwendung sind können zu komischen Fehlern führen. Wie hält man seine Dockerumgebung also stubenrein?
Sicher kommt man mit mit docker rm <container-nane>und docker rmi <image-id> schon recht weit. In Buildumgebungen wie Jenkins oder Serverclustern kann diese Strategie allerdings zu einer zeitintensiven und mühsamen Beschäftigung werden. Doch verschaffen wir uns zuerst einmal einen Überblick über die Gesamtsituation. Hier hilft uns der Befehl docker system df weiter.
Bevor ich gleich in die Details eintauche, noch ein wichtiger Hinweis. Die vorgestellten Befehle sind sehr effizient und löschen unwiderruflich die entsprechenden Bereiche. Daher wendet diese Befehle erst auf einer Übungsumgebung an, bevor ihr damit Produktivsysteme außer Gefecht setzt. Zudem hat es sich für mich bewährt, auch die Befehle zur Instanzierung von Containern in deiner Textdatei unter Versionsverwaltung zu stellen.
Der naheliegendste Schritt bei einem Docker System Cleanup ist das Löschen der nichtbenutzten Container. Im Konkreten bedeute das, dass durch den Löschbefehl alle Instanzen der Docker Container, die nicht laufen (also nicht aktiv sind), unwiederbringlich gelöscht werden. Will man auf einem Jenkins Buildnode vor einem Deployment Tabula Rasa durchführen, kann man zuvor alle auf der Maschine laufenden Container mit einem Befehl beenden.
Der Parameter -f unterdrückt die Nachfrage, ob man diese Aktion wirklich durchführen möchte. Also die ideale Option für automatisierte Skripte. Durch das Löschen der Container erhalten wir vergleichsweise wenig Festplattenplatz zurück. Die Hauptlast findet sich bei den heruntergeladenen Images. Diese lassen sich ebenfalls mit nur einem Befehl entfernen. Damit Images allerdings gelöscht werden können, muss vorher sichergestellt sein, dass diese nicht durch Container (auch inaktive) in Verwendung sind. Das Entfernen ungenutzter Container hat noch einen ganz anderen praktischen Vorteil. Denn beispielsweise durch Container blockierte Ports werden so wieder freigegeben. Schließlich lässt sich ein Port einer Hostumgebung nur exakt einmal an einen Container binden. Das kann stellenweise schnell zu Fehlermeldungen führen. Also erweitern wir unser Skript um den Eintrag, alle nicht durch Container benutzten Docker Images ebenfalls zu löschen.
Eine weitere Konsequenz unserer Bemühungen umfasst die Docker Layers. Hier sollte man aus Performancegründen, besonders in CI Umgebungen Abstand nehmen. Docker Volumes hingegen sind hier weniger problematisch. Beim Entfernen der Volumes, werden nur die Referenzen in Docker entfernt. Die in die Container verlinkten Ordner und Dateien bleiben von der Löschung unberührt. Der Parameter -a löscht alle Docker Volumes.
Ein weiterer Bereich, der von unseren Aufräumarbeiten betroffen ist, ist der Build-Cache. Besonders wenn man gerade ein wenig mit dem Erstellen neuer Dockerfiles experimentiert, kann es durchaus sehr nützlich sein, den Cache hin und wieder manuell zu löschen. Diese Maßnahme verhindert, dass sich falsch erstellte Layer in den Builds erhalten und es später im instanziierten Container zu ungewöhnlichen Fehlern kommt. Der entsprechende Befehl lautet:
Wir können die gerade vorgestellten Befehle natürlich auch für CI Buildumgebungen wie Jenkins oder GitLab CI nutzen. Allerdings kann es sein, dass dies nicht unbedingt zum gewünschten Ziel führt. Ein bewährter Ansatz für Continuous Integration / Continuous Deployment ist das Aufsetzen einer eigenen Docker-Registry, wohin man selbst erstellte Images deployen kann. Diese Vorgehensweise, ist ein gutes Backup & Chaching System für die genutzten Docker Images. Einmal korrekt erstellte Images lassen sich so bequem über das lokale Netzwerk auf die verschiedenen Serverinstanzen deployen, ohne dass diese ständig lokal neu erstellt werden müssen. Daraus ergibt sich als bewährter Ansatz ein eigens für Docker Images / Container optimierter Buildnode, um die erstellten Images vor der Verwendung optimal zu testen. Auch auf Cloudinstanzen wie Azure und der AWS sollte man auf eine gute Performanz und ressourcenschonendes Arbeiten Wert legen. Schnell können die anfallenden Kosten explodieren und ein stabiles Projekt in massive Schieflage bringen.
In diesem Artikel konnten wir sehen, dass tiefe Kenntnisse der eingesetzten Werkzeuge einige Möglichkeiten zur Kostenersparnis erlauben. Gerade das Motto „Wir machen, weil wir es können“, ist im kommerzeillen Umfeld weniger hilfreich und kann schnell zur teuren Resourcenverschwendung ausarten.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.