
Das dauerhafte Speichern von Daten nennt man im Fachchinesisch Persistieren. Damit man auf diese Daten gezielt auch wieder zugreifen kann, benötigt man eine Software, die Daten strukturiert und durchsuchbar macht. Eine solche Software nennt sich Datenbank Management System (DBMS). Damit man von einer Programmiersprache wie Java, Ruby, Python oder PHP auf eine Datenbank zugreifen kann, benötigt man einen entsprechenden Treiber. Dieser Treiber wird auch oft als Client bezeichnet, denn das DBMS ist der Server, welcher mehreren Clients Zugriff gestattet. In diesem Artikel kümmern wir uns nicht darum, wie man sich mit welcher Programmiersprache auf die entsprechenden Datenbanken verbinden kann, sondern schauen uns an, was es für unterschiedliche Datenbanktechnologien gibt und wofür diese eingesetzt werden.
[Relationale DB (Zeilen, Spalten) | GIS DB | embedded DB]
[NoSQL | {Key Value Store | Document DB (JSON, XML) | Graph DB | Zeitreihen Server]
Mittlerweile gibt es für die klassischen Datenbanksysteme, die sogenannten relationalen Datenbanken, eine Vielzahl von Lösungen zur Auswahl. Sowohl kommerzielle, als auch professionelle freie Open Source Vertreter buhlen um die Gunst der Anwender. Im Web bieten die meisten Hoster zum Speichern der Daten die freien DBMS MySQL (Oracle) und MariaDB (Abspaltung von MySQL nach der Übernahme durch Oracle) ihren Anwendern zur Auswahl an. Wer seine Server allerdings selbst betreuen kann, kann natürlich auch auf das professionellere PostgreSQL setzen.
Postgres ist allerdings für die meisten PHP-Standardapplikationen eher ungeeignet, obwohl WordPress und Joomla dieses Datenbanksystem durchaus unterstützen. Probleme bereiten üblicherweise die Entwickler der Erweiterungen. Der Zugriff auf die Datenbanken erfolgt dann nicht über die Schnittstellen der Anwendung, sondern aus Unwissenheit wird oft über die nativen Befehle von MySQL auf die Daten zugegriffen.
In der kommerziellen Anwendungsentwicklung verwendet man üblicherweise Oracle oder den Microsoft SQL Server, je nachdem, wie affin man mit der Microsoft-Windows-Welt ist. Der Grund für den Einsatz kommerzieller Datenbankserver liegt im kostenpflichtigen Support, bei Bekanntwerden von Schwachstellen und Fehlern. Geschäftskritische Anwendungen, müssen das Fortbestehen des Herstellers und auch der Kunden dieser Anwendung sicherstellen. Gerade die Geschwindigkeit der Auslieferung von Korrekturen für Sicherheitsschwachstellen ist ein gewichtiger Grund für den Einsatz kommerzieller Software.
Die Funktionsweise von relationalen Datenbanken ist über Tabellen definiert. Die Spalten einer Tabelle definieren die Eigenschaft und eine Zeile der Tabelle bildet den Datensatz. Um einen expliziten Datensatz ansprechen zu können, muss eine Spalte (Primärschlüssel) eindeutige, nicht noch einmal in dieser Spalte vorkommende Einträge enthalten. Diese Eigenschaft der Primärschlüssel nennt sich unique. Über die Primärschlüssel lassen sich Verknüpfungen, sogenannte Relationen, zwischen den Tabellen aufbauen. Um den Artikel nicht ins Unermessliche ausufern zu lassen, belasse ich es an dieser Stelle mit der Tiefe zur Funktionsweise von relationalen Datenbanken und gehe zur nächsten Kategorie über.

Natürlich gibt es auch relationale Datenbanken, die nicht zeilenorientiert, sondern spaltenorientiert arbeiten. Dies ermöglicht effizientere Abfragen und Analysen, insbesondere bei großen Datenmengen. Hier sind einige der Hauptmerkmale und Vorteile spaltenorientierter Datenbanken:
- Datenorganisation: Speichert Daten in Spalten, was die Verarbeitung spezifischer Spalten in Abfragen beschleunigt.
- Komprimierung: Bietet oft bessere Komprimierungsraten für spaltenweise gespeicherte Daten, da ähnliche Datentypen hintereinander gespeichert werden.
- Analytische Abfragen: Optimiert für Analysen und aggregierte Abfragen, die große Datenmengen schnell abfragen müssen.
- Reduzierte I/O: Reduziert die Menge an Daten, die von der Festplatte gelesen werden müssen, da nur die benötigten Spalten abgerufen werden.
Spaltenorientierte Datenbanken sind Apache Cassandra, SAP Hanna, IBM DB2 und Amazon BigQuery mit klassichen Anwendungsfällen für:
- Business Intelligence: Ideal für Datenbanken, die große Mengen an Daten für analytische Zwecke verarbeiten müssen.
- Data Warehousing: Effizient bei der Speicherung und Analyse historischer Daten.
- Echtzeitanalysen: Geeignet für Anwendungen, die schnelle Entscheidungen basierend auf aktuellen Daten treffen müssen.
| ID | Lieferant | Artikel | Preis | Packung | Menge |
| 13 | MongoDB | JSON | 7.88 | Stück | 1 |
| 21 | Xindice | XML | 15.67 | Stück | 1 |
// Zeilen orientierte DBMS
[{13, MongoDB, JSON, 7.88, Stück, 1} {21, Xindice, XML, 15.67, Stück, 1}]
// Spalten orientierte DBMS
[{13,21} {MongoDB, Xindice} {JSON, XML} {7.88, 15.67} {Stück, Stück} {1, 1}]
Um Daten für geografische Informationssysteme (GIS) wie Google Maps bereitzustellen, werden sogenannte Geospatial Datenbanken eingesetzt. Bei Geospatial Datenbanken handelt es sich um Erweiterungen relationaler Datenbanken, die für geometrische Objekte optimierte und standardisierte Tabellen und Relationen bereitstellen. Die GIS Erweiterung für PostgreSQL heißt PostGIS. Die Datensätze für das frei verfügbare OpenStreetMap liegen in einem spezialsierten XML Format vor und können aber auch in Geospatial Datenstrukturen transformiert werden.
Key – Value Speicher, werden oft in Konfigurationsdateien verwendet. Will man allerdings ein schnelles Caching-System aufbauen, benötigt man ein wenig mehr Komplexität. Denn die Schlüssel / Wert Bezeihung kann von einfachen Zeichenketten hin zu komplexen Objekten ausarten. Grundsätzlich besteht ein Speicher aus einem uniquen Schlüssel, dem je nach Datentyp Werte zugeordnet werden können. Datentypen können Zeichenketten (Strings), Zahlen (Integer, Float), Wahrheitswerte (Boolean) und Listen sein. Key – Value Datenbanken gehören zu den NoSQL Datenbanken, da die Abfrage nicht wie bei relationalen Datenbanken über SQL erfolgt, sondern datenbank- und herstellerspezifisch ist.
Typische Key -Value Datenbanken sind Redis, MemCached, Amazon DynamoDB und die etwas in die Tage gekommene BarkleyDB, die von Oracle übernommen wurde. Eine Eigenschaft von Key – Value Datenbanken ist, dass die Daten im Speicher gehalten und in regelmäßigen Abständen auf die Festplatte gesichert werden. Das Vorhalten der Daten im Arbeitsspeicher erfordert natürlich auch eine entsprechende Ausstattung der Maschine mit ausreichend RAM. Besonders bei großen Anwendungen kann für das Chaching eine enorme Datenmenge zusammenkommen.
Eine weitere Kategorie für Datenbanken sind Embedded-Datenbanken. Embedded meint auf Deutsch „eingebunden“ und bezieht sich auf den Datenbankserver. Das bedeutet im Konkreten, dass das Datenbanksystem keine eigenständige Installation ist, sondern als Bibliothek einen Teil der Anwendung darstellt. Der Vorteil einer solchen Lösung ist, dass die Installationsroutine der Anwendung einfacher ist. Meist geht das allerdings zulasten der Sicherheit, da viele der embedded Datenbanken keine zusätzliche Schicht für eine Benutzerverwaltung haben. Dieser Umstand gilt besonders für SQLite und die in Java implementierte H2. Aber auch die bereits erwähnte NoSQL BarkelyDB die als Java- oder C-Bibliothek verfügbar ist, hat keine Benutzerverwaltung. Das heißt, wer Zugriff auf die Anwendung hat, kann mit einem Client die Daten aus der Datenbank lesen. Daher sind die gerade genannten Systeme nicht für Anwendungen geeignet, die eine hohe Sicherheitsstufe erfordern.
Zur Java Version der BarkelyDB kann man noch sagen, dass die letzte verfügbare Implementierung aus dem Jahr 2017 stammt und in Java / Apache Ant als Quelltext vorhanden ist, der aber selbst kompiliert werden muss. Ein offizielles Binary von Oracle ist nicht mehr verfügbar, es können aber sogenannte inoffizielle Versionen im Maven Central Repository gefunden werden.
Wer eine voll funktionsfähige relationale Datenbank in seine Anwendung integrieren möchte, kann auf die embedded Variante von PostgreSQL – pgx – zurückgreifen, die alle Funktionen des PostgreSQL Servers lokal bereitstellt.
Die nächste Klasse der Datenbanken gehört wieder zu den NoSQL Vertretern. Dokumentenbasierte Datenbanken. Die beiden DBSM MongoDB und CouchDB sind im Funktionsumfang durchaus identisch, dennoch gibt es markante Unterschiede.
- MongoDB wird aufgrund seiner umfangreichen Abfragesprache und hohen Performance häufig für Anwendungen gewählt, die komplexe Abfragen und Echtzeitanalysen erfordern.
- CouchDB eignet sich besonders für Anwendungen, die Zuverlässigkeit, eine verteilte Architektur und einfache Replikation benötigen, insbesondere in Szenarien, in denen Offline-Zugriff unerlässlich ist.
Die grundlegende Arbeitsweise von Dokumentendatenbanken ist, dass sich das Schema aus der hinterlegten Datenstruktur ergibt. Diese Datenstrukturen haben meist das JSON Format und werden entsprechend angesprochen. Dokumente der selben Datenstruktur werden einer Collection zugeordnet. Es handelt sich also nicht um klassische Office Dokumente die in diesen Datenbanken abgelegt werden, sondern um Formate wie JSON und XML. Dokumentendatenbanken, die sich auf XML spezialisiert haben, sind Oracle XML DB oder Apache Xindice.
Viele Webentwickler, die sich auf FrontEnd (UX / UI) spezialisiert haben, greifen gern auf Dokumentdatenbanken zurück. Das erlaubt ihnen, die Daten im JSON Format abzulegen, um damit REST Zugriffe zu simulieren und damit die dynamischen Inhalte der Benutzeroberfläche zu befüllen.
Eine sehr exotische Variante der NoSQL Datenbanken sind die Gaphdatenbanken, die Daten als Graphen repräsentieren. Diese Speicherform ermöglicht das effiziente Ablegen von Informationen nach Beziehungen. Solche Beziehungen können Verlinkungen von Webseiten sein oder die Repräsentation einer Person in sozialen Medien. Aber auch die komplexen Beziehungen für Empfehlungssysteme können als Graph dargestellt werden. Die nachfolgende Abbildung zeigt ein einfaches Beispiel für Neo4J einer in Java implementierten Graphdatenbank, um sich eine Vorstellung des Einsatzszenarios machen zu können.
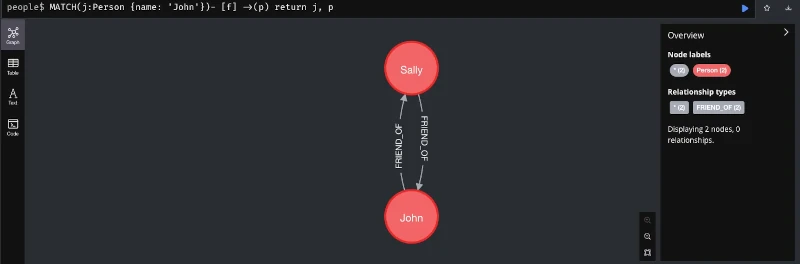
Andere Graphdatenbanken sind Amazon Neptune und ArangoDB.
Als letzte Datenbanklösung möchte ich die sogenannten Zeitreihen (Time Series) vorstellen. Da besonders im Kontext für den Betrieb von Anwendungen das Monitoring essenziell geworden ist, haben Daten, die als Zeitreihen vorliegen, an Bedeutung gewonnen. Typische Datenbanken, die sich auf die Verarbeitung von Zeitreihen spezialisiert haben, sind Prometheus und InfluxDB. Aber auch für klassische relationale Datenbanken gibt es entsprechende Erweiterungen. Die bereits mehrfach erwähnte PostgreSQL-Datenbank hat auch für diesen Anwendungsfall eine entsprechende Erweiterung namens TimescaleDB.
Natürlich kann man über das Thema noch viel mehr sagen. Schließlich füllen unzählige Bücher einige Regalmeter in Bibliotheken zum Thema Datenbanken. Für den Einstieg und die Übersicht zu den verschiedenen Datenbanksystemen beziehungsweise NoSQL Lösungen soll es aber an dieser Stelle genügen. Mit den Informationen aus diesem Artikel, haben sie nun eine Vorstellung, welche Datenbank sich für ihren speziellen Anwendungsfall eignet. Wir konnten auch sehen, dass relationale Datenbanken, insbesondere die freie Open Source Datenbank PostgreSQL mit den verfügbaren Erweiterungen, sehr universell einsetzbar sind. Weiterführende Themen zu Datenbanken sind die Datenmodellierung und Sicherheit gegen Hackerangriffe.



Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.