Die Prophezeiung, dass Programmierer obsolet werden, weil sich Computer quasi selbst programmieren, hat mittlerweile einige Jahrzehnte auf dem Buckel. Bisher ist das Berufsbild Programmierer aber noch nicht ausgestorben. Dennoch hat sich in den letzten Jahren einiges grundlegend verändert. Die Leistungsfähigkeit aktueller K. I. Systeme weckt unterschiedlichste Emotionen. Die einen hassen es, die anderen lieben es. Allerdings ist es wie so immer im Leben: Nicht alles ist schwarz oder weiß. Daher möchte ich meine Erfahrungen mit K. I. unterstützendem Programmieren zum Besten geben und eine Einschätzung der Gesamtsituation wagen.
Meine ersten Berührungspunkte mit künstlicher Intelligenz und Machine Learning liegen schon sehr weit zurück, sodass mich die Leistungsfähigkeit von ChatGPT und Co. bei der Markteinführung um das Jahr 2024 nicht wirklich beeindrucken konnte. Die ersten Versionen waren eher zur Gewöhnung gedacht und in ihrem Können sehr eingeschränkt. Dieser Umstand hat sich mittlerweile erheblich verändert und ist noch lange nicht am Scheitelpunkt angekommen.
Die Entwicklung erfolgt exponentiell. Grob kann gesagt werden, dass die Leistungsfähigkeit sich mit jedem Sprung in der Hälfte der Zeit zum vorhergehenden Sprung verdoppelt.
Aktuell befinden wir uns in der dritten Iteration. Die darauffolgende Iteration wird mit doppelter Leistungsfähigkeit keine 18 Monate mehr benötigen, sondern maximal 9 Monate. Meine Quintessenz für den Bereich Softwareentwicklung lautet: K. I. kann fähige Programmierer und Administratoren in ihrem Schaffen massiv unterstützen und deren Performance erheblich anheben. Allerdings hat wie so alles im Leben auch dieser Umstand seine Schattenseiten. In diesem Artikel nehme ich mir die Zeit und beleuchte zu dem Thema ein wenig den Hintergrund.
Vor einiger Zeit traf ich in meiner Timeline in den einschlägigen Social Media Plattformen immer wieder auf Nachrichten, wie Juniorentwickler über Vibe Coding schwärmten. Zuerst dachte ich, es ginge um die optimale Atmosphäre beim Arbeiten. Also Sachen wie die richtige Musik und ätherische Öle, um in den perfekten Arbeitsflow zu kommen. Aber nein. Das war nicht, worum es ging. Leute, die nichts vom Programmieren wussten, konnten auf einmal Code erzeugen, der augenscheinlich das gemacht hat, was die Ersteller beabsichtigt haben. Klingt im ersten Moment auch ganz toll. Die Realität ist aber eine andere.
Copy-Paste-eh kennen wir schon etwas länger. Dazu brauchten wir keine K. I. nicht so lang ist es her, dass man Codeschnipsel gegoogelt hat und dann auf Internetseiten wie Stack Overflow fündig wurde. Schnell wurden Fragmente von vermeintlichen Empfehlungen in die eigene Codebase kopiert, und wenn es funktioniert hat, blieb alles ungeprüft so stehen, wie man es übernommen hatte. Die vermeintlichen Schlauberger waren auch nicht in der Lage, die kopierten Codefragmente zu verstehen und geschweige denn, diese an das eigene Projekt korrekt anzupassen. Daher hat sich der Ausdruck >Copy-passt-eh< etabliert. Dass dieses Codefragment aber in Produktionsumgebungen für massive Probleme sorgen konnte, wurde von den vermeintlichen Experten gern ignoriert. Das Spektrum der Störungen reichte von schlechter Performance bis hin zu sicherheitskritischen Schwachstellen. Diese Situation hat sich mit der Verfügbarkeit von K. I. für die breite Masse nicht verändert. Daher habe ich die Prognose, dass in den nächsten Jahren eine Schwemme von qualitativ schlechter Software um die Gunst der Anwender buhlen wird.
Hier kann ich nur wieder Grady Booch zitieren: „A fool with a tool is still a fool.“ Denn meine Beobachtungen, in eigenen Projekten LLM zur Programmierung zu verwenden, sind eher verhalten. In meiner Wahrnehmung sind es eher Projektleiter und Leute, die nicht programmieren können, die in den sozialen Medien die Leistungsfähigkeit von K. I. Modellen massiv überbewerten.
Grundsätzlich bin ich ein skeptischer Mensch und habe natürlich die üblichen Verdächtigen, KI-Modelle, für meine tägliche Arbeit versucht einzusetzen. Ich war explizit bei den Community-Varianten, ohne Bezahlung. Denn mit diesen Versionen wird die Welt künftig mit schlechter Software überflutet. Auch hier kann ich massiv abkürzen. Sämtliche Ergebnisse von Grok im Bereich Programmierung/Scripting und Konfiguration waren unterdurchschnittlich. Es hat sich ein wenig wie in alten Foren angefühlt. Anstatt diese nervigen Fragen, wieso und warum zu stellen, gelang es Grok nicht, zum Punkt zu kommen. Geschweige denn, eine funktionsfähige Lösung zu präsentieren. Dafür brillierte das Modell mit sinnbefreiten Motivationssprüchen à la „Teamleiter auf Steroiden“. Es erinnert mich ein wenig an Aussagen von Joseph Weizenbaum über virtuelle Gespräche und seinen Eliza Chatbot.
Etwas besser ging es mit Deep Seek. Zumindest kamen da nutzbare Resultate heraus. Die waren auch sofort einsetzbar und haben augenscheinlich auch das gemacht, wofür sie angedacht waren. Hat man sich den Code aber richtig angeschaut, war dieser mit allem möglichen Zeug überfrachtet, das mindestens unnötig war. Ich hatte in diesen Fällen keine weitere Analyse gemacht, ob eventuell sicherheitskritische Probleme aufgetreten sind. Statistisch kann man davon ausgehen, dass je mehr Code vorhanden ist, umso höher die Wahrscheinlichkeit ist, dass Fehler enthalten sind. Opus wiederum nervte permanent damit, dass selbst bei minimalen Anfragen ein Abo notwendig ist. Die besten Ergebnisse habe ich tatsächlich mit ChatGPT erzielen können. Obwohl die Antworten auch teilweise widersprüchlich oder redundant waren.
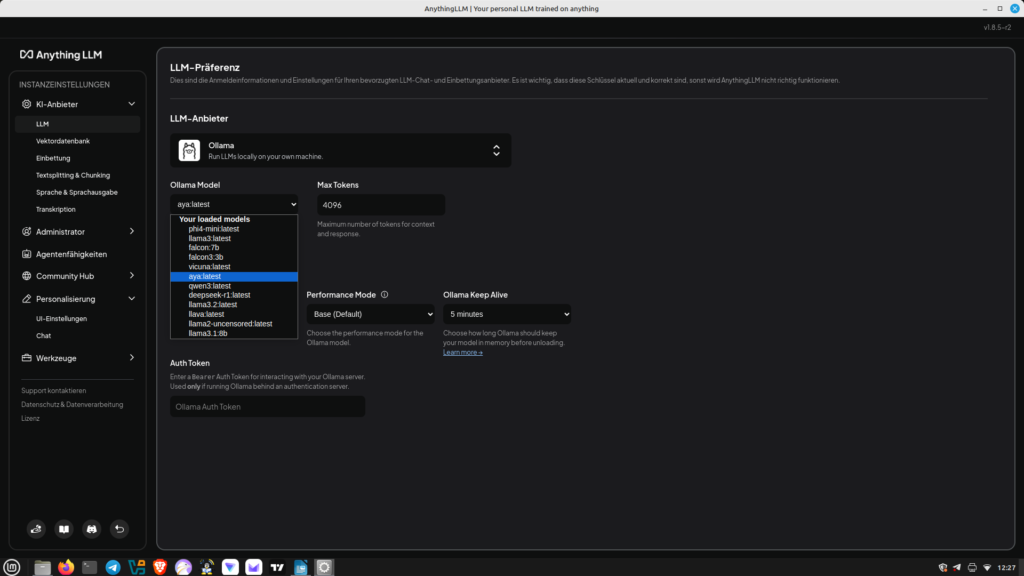
Wer die Idee hat, mit einem der freien KI Modelle eine lokale Instanz zum Beispiel mit LM Studio aufzusetzen und dafür eine sündhaft teure Grafikkarte kauft, dem sei gesagt: Das Geld kann man sich sparen. Die frei verfügbaren Modelle sind bei weitem nicht so leistungsfähig, wie ihre kommerziellen Versionen. Es wäre auch nicht gerade geschäftsfördernd, sich seine eigene Konkurrenz zu etablieren. Es stellt sich daher die Frage, wann es tatsächlich Sinn ergibt, mit KI Programmiermodellen zu arbeiten, um wirklich eine Beschleunigung des eigenen Outputs zu erfahren. Meiner Erfahrung nach geht es weniger um das Was oder Womit, sondern um das Wie. Dazu brauchen wir ein paar wichtige Abgrenzungen.
Ein K. I. Agent der direkt in die IDE eingebunden ist und alle Freiheiten hat, ist keine gute Idee. Oft hört man, dass diese K. I. Dinge tut, die sie nicht tun sollte, und Anweisungen, die Aktivitäten einzustellen, haben wenig Auswirkung. Wer es dennoch unbedingt versuchen möchte, ist sehr gut beraten, ein sauberes Branch Modell mit entsprechenden Zugriffseinschränkungen für den Agenten zu etablieren. Obwohl ich in kommerziellen Entwicklungsteams Pull Requests ablehne, ist diese Strategie beim Einsatz von K. I. Agenten unabdingbar. Auch der Zugriff auf die Build Logik wie zum Beispiel die Maven POM oder Gradle Projektdatei ist für die Agenten tabu. Es gilt auch hier der bewährte Sicherheitsansatz: So wenig wie möglich, so viel wie nötig. Die Sperrung der Build Logik verhindert, dass der K. I. Agent beliebig nach Gutdünken eine eigene Version von Abhängigkeiten definieren kann.
Auch ist darauf zu achten, dass die Codeänderungen überschaubar bleiben und iterativ vonstattengehen. Obwohl es etwas holprig erscheinen mag, nutze ich K. I. um Funktionen oder Klassen zu generieren. Die vorgeschlagenen Codefragmente kopiere ich dann in meine IDE und schaue zeilenweise durch, was mir da vorgeschlagen wird. Entsprechend meinen Qualitätskriterien modifiziere ich dann den Code und prüfe über selbsterstellte Testfälle, ob alles so funktioniert, wie ich es beabsichtige. Die Generierung umfangreicher Testdaten für Lattests ist ein ideales Beispiel dafür, welche Aufgaben man problemlos an K. I. übergeben kann und auch sollte. Natürlich ist es unverzichtbar, stetig die Testqualität zu monitoren, wozu die Testabdeckung ein wichtiger Indikator ist. Auch wenn der gerade beschriebene Ansatz etwas mehr Zeit kostet, hat er mehr Vorteile gegenüber den schnellen Lösungen. Ich bin in der Lage, die Codeänderungen zu verstehen, und kann sie den entsprechenden Anforderungen zuordnen. Ein weiterer nicht zu unterschätzender Faktor ist, dass diese Methode dafür sorgt, dass ich meine Programmierfähigkeiten weiterentwickle. Schnelles Überfliegen und unreflektiertes Akzeptieren der vorgeschlagenen Lösung sorgen eher dafür, dass meine Fähigkeiten über einen längeren Zeitraum verkümmern und dadurch auch meine Performance kontinuierlich sinkt. Dadurch wird sich der Arbeitsplatz langfristig nicht sichern lassen.
Das bringt mich auch gleich zu einem weiteren Punkt im Umgang mit LLM. Wie kann man effiziente Prompts, also Arbeitsanweisungen an das Modell, formulieren? Da die Kommunikation mit dem Modell über natürliche Sprache erfolgt, ist es notwendig, die eigenen Gedanken gut zu strukturieren, um sie dann auch verständlich formulieren zu können. Es ist also nicht förderlich, einen Kurs für Promptengineering zu besuchen. Wenn er oder sie die eigenen Ideen und Vorstellungen anderen Menschen nicht sauber vermitteln kann, wird mit K. I. ebenfalls wenig Erfolge erzielen. Worauf kommt es also wirklich an? Die Antwort ist fast so einfach, dass man sie übersehen kann. Klare Kommunikation mit prägnanten, kurzen und verständlichen Sätzen. Keine komplizierten Verschachtelungen, um das eigene Ego zu befriedigen. Natürlich benötigt man auch eine konkrete – zu Ende gedachte – Vorstellung von dem, was man erwartet. Vage Formulierungen können (zu viel) Raum für Interpretation lassen. Wer seine Absichten einem Vorschulkind in wenigen Minuten erklären kann, wird auch mit K. I. gute Ergebnisse erzielen. Damit möchte ich es auch belassen und einen weiteren Aspekt diskutieren.
Oft werde ich gefragt, wie ich die Qualität der durch LLM generierten Quelltexte beurteile. Hier ist die Antwort nicht so einfach. Denn es gibt verschiedene Kriterien, auf die es zu achten gilt. Alles, was UI betrifft, ist ein eigenes Kapitel. Denn UI / UX unterliegt Modeerscheinungen und hat gegenüber der Geschäftslogik eine höhere Änderungsfrequenz. In meinen Schulungen zu Java Testautomatisierung rate ich insbesondere komplett von der Erstellung von UI Tests ab. Der Grund ist, dass in diesem Bereich der Kosten Nutzen Faktor einfach nicht ausgewogen genug ist. Das bedeutet für generierten UI-Code, dass ich lediglich die Funktion und Optik anschaue und es dabei belasse. Bei der Geschäftslogik für Backendsysteme ist die Situation eine völlig andere. Hier habe ich festgestellt, dass der durch LLM produzierte Code in Aspekten der Sicherheit teilweise besser ist als der von so manchem Programmierer. Die üblichen Prüfpunkte wie SQL Parameter, Eingabevalidierung und Filterung werden berücksichtigt und umgesetzt. In den Bereichen Performance und Lesbarkeit beziehungsweise Verständlichkeit ist allerdings noch Luft nach oben. Hier erwarte ich in circa zwei weiteren Iterationen erhebliche Verbesserungen. Das ist auch ein markanter Grund, wieso LLM Optimierungen einer bestehenden Codebasis nie abgeschlossen sind und bei jeder neuen Generation von LLM erneut durchgeführt werden sollten.
Mein stärkster Kritikpunkt gegenüber Unternehmen, aber auch Entwicklern und Administratoren, die exzessiv LLM in ihren täglichen Projekten einsetzen, ist, dass diese schnell die Kontrolle über ihre Produkte/Dienstleistungen verlieren könnten. Das gesamte Thema lässt sich nicht in Schwarz oder Weiß einteilen, denn die Menge an Variationen der Zwischentöne ist zu umfangreich. Deswegen ist es an uns, dem Motto der literarischen Aufklärung nach Immanuel Kant – habe Mut, dich deines eigenen Verstandes zu bedienen – zu folgen.
Abschließend möchte ich noch den Kostenfaktor für leistungsfähige KI Modelle besprechen. Denn hier kann es schnell zu bösen Überraschungen kommen. Gehen wir einmal davon aus, wir haben eine Person mit einer tollen Startupidee, die auch die Fähigkeit hat, korrekte und sinnvolle Anforderungen verständlich zu formulieren. Im besten Fall sind sogar rudimentäre Programmierfähigkeiten vorhanden, um Quelltext lesen, verstehen und leicht modifizieren zu können. Diese Person entschließt sich, nur die Idee eigenständig ohne Programmierer umzusetzen. Selbst wenn man das Projekt in kleine Stücke zerlegt und diese Projekte an Freelancer vergibt, kommen schnell ein paar tausend Euro zusammen, je nach Umfang der Arbeitspakete. Verteilt man nun diese Aufgaben an KI Agenten, greifen die üblichen Tarife von 20 bis 50 Euro monatlich nicht mehr. Es wird eine tokenbasierte Abrechnung notwendig. Je nach Umfang des Prompts verbraucht dann eine Anfrage an die KI ein bis mehrere Token. Ein Token hat oft den Wert von einem Euro / US Dollar. Setzt man hier kein Limit, können in wenigen Stunden mehrere tausend Euro verbraucht sein. Zudem kann man vorher auch nicht sagen, wie gut der generierte Quelltext sein wird, den man erhält. Denn jede Nachbesserung kostet wiederum Token, die zu bezahlen sind. Ein Kostenfaktor, der bei Menschen so in der Form nicht entsteht. Auch wenn KI Agenten auf den ersten Blick keine Sozialversicherung und ähnliche Kosten verursachen, bedeutet es nicht, dass man günstigere Projekte umsetzen kann. Wichtiger ist, jemanden im Boot zu haben, der weiß, wie man Quelltext so strukturiert, dass dieser auch problemlos später erweitert werden kann.