
Eines der wichtigsten Erkenntnisse zum Softwaretesting stammt von dem viel zitierten Artikel „The Humble Programmer“, den Dijkstra 1972 veröffentlichte. Sinngemäß besagt dies, dass durch Testen lediglich Fehler nachgewiesen werden können, aber es ist unmöglich, die Fehlerfreiheit des Programms nachzuweisen. Das bedeutet im Umkehrschluss, dass eine hohe Testqualität bereits möglichst viele Fehler aufdeckt und damit die Wahrscheinlichkeit sinkt, dass im Programm weitere Fehler vorhanden sind.
Nun stellt sich zuerst die Frage, was eine ‚gute‘ Testqualität ausmacht. Ein sehr wichtiger Faktor ist die Performance. Dauert die Testausführung länger als 5 Minuten, stört dies den Entwickler im Arbeitsfluss. Dauert die Testausführung länger als 10 Minuten, ist die Akzeptanz der Entwickler verloren, die Tests automatisiert im Buildprozess durchlaufen zu lassen. Das führt dazu, dass die Testausführung lokal deaktiviert wird, damit das Prinzip, möglichst schnell im Fehlerfall zu scheitern, verletzt wird. Das Prinzip des schnellen Scheiterns ist einer der wichtigen Grundpfeiler automatisierter Softwaretests, denn so kann man sich zeitnah dem Problem widmen und es beheben. Diese schnelle Reaktion, ist es welche den Arbeitsfluss des Entwicklers unterstützt und dadurch den sogenannten Kontextwechsel vermeidet. Je weniger man sich auf eine neue Situation einstellen muss, umso produktiver kann man arbeiten, was als Konsequenz eine erhebliche Senkung der Entwicklungskosten ausmachen kann. Wir können sagen, dass nicht die Anzahl der Tests relevant ist, sondern es darauf ankommt, die richtigen, also relevanten Tests zu schreiben.
Eine Idee davon, wie viele Testfälle man benötigt, gibt die Arbeit von McCabe, welcher 1976 ein Maß für die Komplexität formulierte. Die Komplexitätszahl einer Funktion oder Methode stellt einen Orientierungspunkt für die Menge der benötigten Testfälle dar. Allerdings bedeutet eine hohe Anzahl von Testfällen nicht automatisch, dass diese eine Relevanz für die Korrektheit der Methode beziehungsweise Funktion haben. Der Nutzen oder, auch anders ausgedrückt, die Ausdruckskraft der vorhandenen Testfälle ergibt sich aus der Tatsache, wie gut diese den vorhandenen Code überdecken. Nur eine vollständige Coverage stellt sicher, dass auch alle Bereiche einer Funktion ausgeführt wurden und somit durch einen Festfall abgedeckt sind. Bei der Testcoverage unterscheiden wir zwei Metriken, die Abdeckung aller Codezeilen und die Abdeckung aller Verzweigungen. Sicher kann man vor allem in sogenannten Legacy-Projekten nur sehr schwer eine hohe Testabdeckung erreichen. Um den Aufwand aussagekräftiger Tests auf ein überschaubares Maß zu begrenzen, ist es notwendig, ausschließlich bei neu hinzugefügten Funktionen eine Line- und Branch Coverage von 100 % zu erreichen. Kann die 100 % nicht erreicht werden, ist dies ein Indikator für ein Refactoring, um die Testbarkeit der hinzugefügten Funktionalität zu gewährleisten.

Gehen wir nun vom optimalen Fall aus und betrachten ein sogenanntes Greenfield-Projekt, dessen Anzahl der Testfälle auch dem Komplexitätsmaß nach McCabe entspricht und für das wir bereits eine 100 % Testabdeckung für Zeilen und Verzweigungen nachweisen können, stehen wir immer noch vor dem Problem, das Dijkstra formuliert hat. Denn es muss uns bewusst sein, dass wir zwar nachweisen, alle Codbereiche durch einen Testfall betreten zu haben, aber ob die von uns getroffenen Annahmen über das Verhalten des Quellcodes korrekt sind, können wir nicht belegen. Im Kontext der xUnit Tests geht es um die verschiedenen Assert-Funktionen, welche eine Funktion gegen einen Erwartungswert testen. Dazu ein klassisches Beispiel für Java Collections, das sich auch auf andere Programmiersprachen projezieren lässt.
Listen, genauer gesagt: Die in Java implementierte ArrayList speichert die Elemente der Liste nicht als Wert in der Liste, sondern nutzt das sogenannte Call-by-Reference, welches lediglich die Speicheradresse des Listenelements referenziert. Führt man nun Operationen auf bestehenden Listen aus, manipuliert man stets die originale Liste. Vergleicht man dann in einem Testfall die originale Liste mit der manipulierten Liste, sind diese immer identisch, da es sich um dieselbe Liste handelt. Erst wenn man beispielsweise mit einem Copy-Konstruktor eine wirkliche Kopie des Originals erstellt, welche man manipuliert, um Vergleichstests durchzuführen, sind die getroffenen Annahmen korrekt. Überspitzt ausgedrückt, kann man eine 100 %-Testabdeckung erreichen, ohne ein wirkliches Sicherheitsnetz zur Fehlererkennung aufzuspannen.
Um solche logischen Fehler, wie gerade beschrieben, in den Tests zu entdecken, können wir uns des sogenannten Mutationstestings bedienen. Auch das Konzept des Mutationtesting hat seine Ursprünge bereits in den 1970er Jahren. Mit dem Artikel „Fault Diagnostics of Computer Programms“ beschrieb Richard Lipton 1971 die Idee zu Mutation-Testing, welches zahlreiche weitere Forschungsarbeiten nach sich zog.
Die Idee für Mutationstests ist sehr einfach, wie so viele bahnbrechende Errungenschaften. Gehen wir davon aus, das im Quellcode ein Ausdruck if(var > 0) enthalten ist und zu diesem Ausdruck auch ein entsprechender Test formuliert wurde. Wenn wir nun hergehen und die Bedingung in der IF Anweisung verändern, sollte der zugehörige Test fehlschlagen. Nun gibt es verschiedene Möglichkeiten, wie die IF-Anweisung verändert werden kann. Eine Variante ist die Umkehrung des Operators von > nach <. Aber auch die Verwendung anderer Operatoren wie = oder ! ist möglich. Eine andere Variante wäre, den Vergleichswert 0 abzuändern. Die erreicht man durch das Erhöhen oder Reduzieren um 1. Alle diese Variationen stellen sogenannte Mutationen des Originalausdrucks dar, weswegen man diese auch als Mutanten bezeichnen kann. Das Ziel ist, dass möglichst viele Mutanten den vorhandenen Testfall fehlschlagen lassen. Jeder Mutant, der den Testfall fehlschlagen lässt, wird als Kill bezeichnet.
Wenn keiner der erzeugten Mutanten den Testfall fehlschlagen lässt, ist die Korrektheit des Testfalls anzuzweifeln und muss überprüft werden. Idealerweise lassen alle Mutanten den Testfall fehlschlagen, was eher als Ausnahme zu werten ist. Aussagekräftige Testfälle sollten einen Mutationsscore von mindestens 70 % erreichen. Die Berechnung des Mutation Scors, oder auch der Kill Rate lautet wie folgt: Um den Mutationswert zu berechnen, teilt man die Anzahl der abgetöteten Mutanten (Mutanten, die zu einem Fehlschlag der Tests geführt haben) durch die Gesamtzahl der erzeugten Mutanten und multipliziert das Ergebnis mit 100, um einen Prozentsatz zu erhalten. Wenn beispielsweise 7 von 10 Mutanten abgetötet werden, beträgt der Mutationswert 70 %.
Mutation Score = (Killed Mutants / (Total Mutants - Equivalent Mutants)) × 100
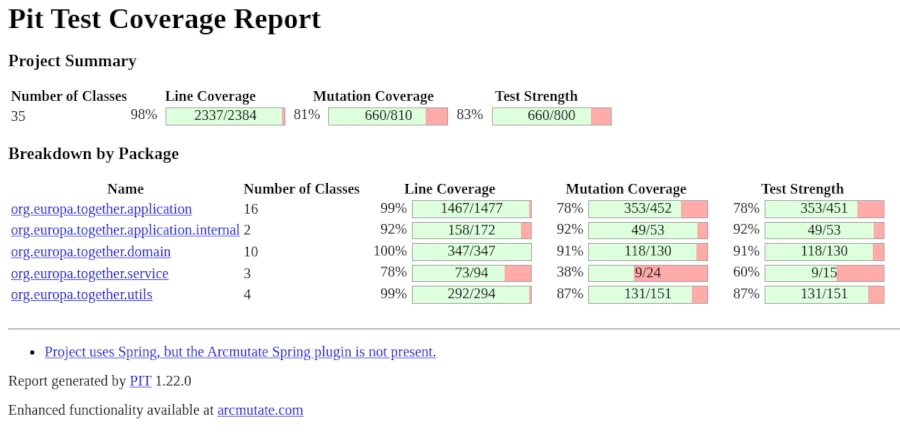
Manche Mutanten verhalten sich funktional identisch zum Originalcode. Diese äquivalenten Mutanten können durch keinen Test eliminiert werden, da sie keine eigentlichen Fehler darstellen. Damit haben wir ein Entscheidungskriterium, das bei niedrigem Mutations-Score und bei einer Bewertung der Situation weiterhelfen kann.
Auch wenn das hier beschriebene Konzept sehr leicht verständlich ist, liegt wie so oft der Teufel im Detail. Zum einen müssen sinnvolle Mutationsoperatoren ausgewählt und zum anderen sollte die Anzahl der generierten Mutanten aus Gründen der Testausführungsdauer begrenzt werden. Da je nach Größe der Codebasis die Ermittlung des Mutation Scores sehr langwierig sein kann, sollten Mutation-Tests nicht über den Standard Buildprozess ausgeführt werden und als eigenständige Testprozedur laufen. Grundsätzlich kann man allerdings sagen, dass Entwickler mit einem guten Verständnis für testgetriebene Softwareentwicklung sich auch zügig in das Thema Mutation Testing einfinden. Aber auch für die Bewertung seitens des Projektmanagements ist Mutant Testing in Kombination mit einer hohen Testcoverage ein sehr mächtiges Mittel, ohne den Quelltext zu lesen. Abschließend ist als sehr wichtiger Punkt anzumerken, dass die hier beschriebene Prozedur keine Aussage zu Fragestellungen der Sicherheit beantworten kann. Um sicherzustellen, dass die Anwendung gegen Hackerangriffe wie SQL Injections geschützt ist, sind auf Sicherheit spezialisierte Audits unvermeidlich.




Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.