
Wir haben bereits mit GPT4all eine Anleitung, wie man ein eigenes lokales LLM betreiben kann. Leider gibt es bei der vorangegangenen Lösung eine kleine Einschränkung. Es können keine Dokumente wie PDF verarbeitet werden. In diesem neuen Workshop installieren wir AnythingLLM mit Ollama um Dokumente analysieren zu können.
Auch für diesen Workshop gilt als Mindestvoraussetzung ein Computer mit 16 GB RAM auf dem optimalerweise ein Linux (Mint, Ubuntu oder Debian) installiert ist. Mit einigen Anpassungen kann diese Anleitung auf Windows und Apple Computer ebenfalls durchgeführt werden. Je geringer die Hardwareressourcen sind, um so länger dauern die Antwortzeiten.
Beginnen wir auch gleich mit dem ersten Schritt und installieren Ollama. Dazu öffnen wir die Bash und benötigen folgendes Kommando: sudo curl -fsSL https://ollama.com/install.sh | sh. Der Befehl bewirkt, das Ollama heruntergeladen wird und das Installationsscript ausgeführt wird. Damit die Installation auch beginnt, muss noch das Administratorkennwort eingegeben werden. Ollama ist ein Kommandozeilenprogramm, das über die Konsole gesteuert wird. Nach erfolgreicher Installation muss noch ein Sprachmodell geladen werden. Auf der Internetseite https://ollama.com/search sind entsprechende Modelle zu finden.
Bewährte Sprachmodelle sind:
- lama 3.1 8B: Leistungsstark für anspruchsvollere Anwendungen.
- Phi-3-5 3B: Gut geeignet für logisches Denken und Mehrsprachigkeit.
- Llama 3.3 2B: Effizient für Anwendungen mit begrenzten Ressourcen.
- Phi 4 14B: State-of-the-art Modell mit erhöhter Hardware-Anforderung aber Leistung vergleichbar mit deutlich größeren Modellen.
Nachdem man sich für ein Sprachmodell entschieden hat, kann man den entsprechenden Befehl aus der Übersicht kopieren und in das Terminal eingeben. Für unser Beispiel soll das zu Demonstrationszwecken DeepSeek R1 sein.
Wie im Screenshot zu sehen ist lautet der entsprechende Befehl, den wir benötigen, um das Modell lokal in Ollama zu installieren: ollama run deepseek-r1. Die Installation des Sprachmodells kann ein wenig Zeit in Anspruch nehmen, Das hängt von der Internetverbindung und der Geschwindigkeit des Rechners ab. Nachdem das Modell lokal in Ollama installiert wurde, können wir das Terminal wieder schließen und zum nächsten Schritt übergehen, der Installation von AnythingLLM
Die Installation von AnythingLLm erfolgt ganz analog zu der Installation von Ollama. Dazu öffen wir das Terminal und geben folgenden Befehl ein: curl -fsSL https://cdn.anythingllm.com/latest/installer.sh | sh. Wenn die Installation abgeschlossen ist, können wir in das Installationsverzeichnis wechseln, welches in der Regel /home/<user>/AnythingLLMDesktop ist. Dort navigieren wir zum Link start und machen diese ausführbar (rechtsklick und Eigenschaften auswählen) und erstellen noch zusätzlich eine Verknüpfung auf dem Desktop. Nun können wir AnythingLLM bequem vom Desktop aus starten, was wir auch gleich tun.
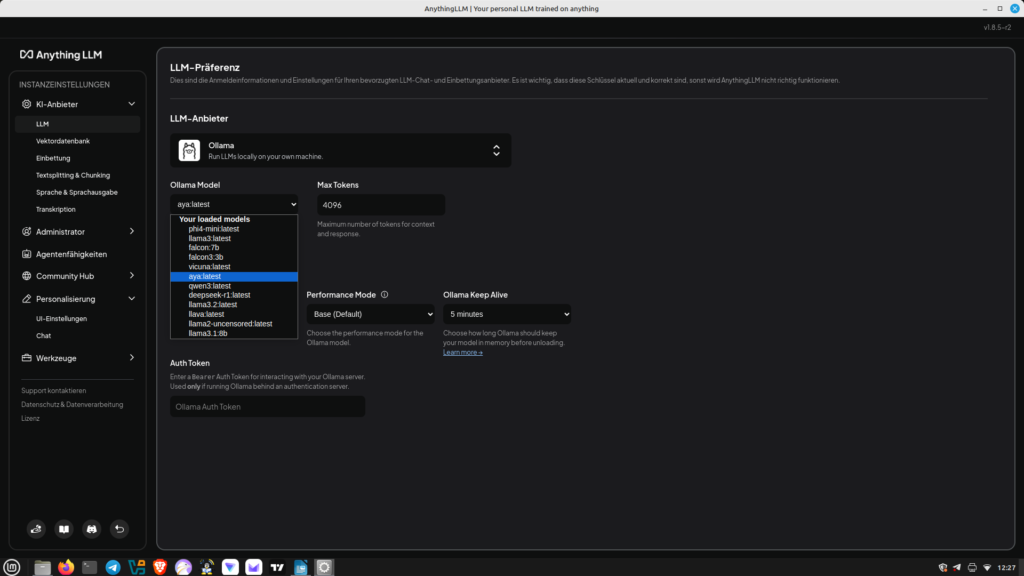
Nachdem wir den Workspace festgelegt haben, können wir Anything nun mit Ollama verknüpfen. Dazu gehen wir auf das kleine Schraubenschlüssel Icon (Einstellungen) im linken unteren Bereich. Dort wählen wir den Eintrag LLM und wählen Ollama aus. Nun können wir das für Ollama hinterlegte Sprachmodell auswählen. Jetzt speichern wir unsere Einstellung ab. Nun kann man in den Chatmodus wechseln. Es besteht natürlich jederzeit die Möglichkeit, das Sprachmodell zu wechseln. Im Gegensatz zu vorhergehenden Workshop können wir jetzt PDF Dokumente hochladen und zum Inhalt Fragen stellen. Viel Spaß damit.
Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.