
Nicht nur sogenannte Hochsprachen, die den Quelltext in Maschinencode überführen müssen, damit dieser ausführbar ist, benötigen sogenannte Build Werkzeuge. Auch für moderne Scriptsprachen wie Python, Ruby oder PHP sind diese Werkzeuge mittlerweile verfügbar, da deren Verantwortungsbereich stetig wächst. Blickt man in die Anfänge dieser Werkzeugkategorie, stößt man unweigerlich auf make, der erste offizielle Vertreter von dem, was man heute als Build Werkzeug bezeichnet. Die Hauptaufgabe von make war das Erstellen von Maschinencode und das Paketieren der Dateien zu einer Bibliothek oder ausführbaren Datei. Man kann also sagen, das Buildwerkzeuge unter die Kategorie der Automatisierungswerkzeuge fallen. Da liegt es nahe, viele andere immer wiederkehrende Aufgaben, die im Entwickleralltag anfallen, ebenfalls zu übernehmen. So war eine der wichtigsten Innovationen, die für den Erfolg von Maven verantwortlich war, die Verwaltung von Abhängigkeiten zu anderen Programmbibliotheken.
Eine andere Klasse an Automatisierungswerkzeugen, die fast verschwunden ist, sind die sogenannten Installer. Produkte wie Inno SetUp oder Wise Installer wurden verwendet, um den Installationsprozess auf Desktopanwendungen zu automatisieren. Diese Installationsroutinen sind eine spezielle Form des Deployments. Der Deploymentprozess wiederum hängt von verschiedenen Faktoren ab. Zuallererst ist natürlich das verwendete Betriebssystem ein wichtiges Kriterium. Aber auch die Art der Anwendung hat einen erheblichen Einfluss. Handelt es sich etwa um eine Webanwendung, die eine definierte Laufzeitumgebung (Server) benötigt? Wir können hier bereits sehen, dass viele der gestellten Fragen mittlerweile im Themenbereich DevOps angesiedelt sind.
Als Entwickler genügt es nun nicht mehr, nur zu wissen, wie man Programmcode schreibt und Funktionen implementiert. Wer eine Webanwendung bauen möchte, muss zuerst den entsprechenden Server zum Laufen bekommen, auf dem die Applikation ausgeführt wird. Glücklicherweise gibt es mittlerweile viele Lösungen, die das Bereitstellen einer lauffähigen Runtime erheblich vereinfachen. Aber gerade für Anfänger ist es nicht immer so leicht, das ganze Thema zu überblicken. Ich erinnere mich noch an Fragen in einschlägigen Foren, dass man jetzt Java Enterprise heruntergeladen hat, aber nur der Applikationsserver enthalten ist.
Wo Anfang der 2000er noch Automatisierungslösungen fehlten, ist heute eher die Herausforderung, das richtige Werkzeug zu wählen. Auch hier gibt es eine Analogie aus dem Java Universum. Als das Build-Werkzeug Gradle auf dem Markt erschien, stiegen viele Projekte von Maven auf Gradle um. Das Argument war, eine höhere Flexibilität zu erhalten. Oft benötigte man die Möglichkeit, orchestrierte Builds zu definieren. Also die Reihenfolge, in der Teilprojekte erstellt werden. Anstatt sich einzugestehen, dass es sich bei dieser Anforderung um einen Architekturmangel handelt und anstatt diesen zu beheben, wurden komplizierte und kaum überschaubare Build Logiken in Gradle gebaut. Das führte wiederum dazu, dass Anpassungen nur schwer umzusetzen waren und viele Projekte zurück nach Maven migriert wurden.
Aus den DevOps Automatisierungen haben sich mittlerweile sogenannte Pipelines etabliert. Pipelines können auch als Prozess verstanden werden und diese Prozesse lassen sich wiederum standardisieren. Das beste Beispiel für einen standardisierten Prozess, ist der in Maven definierte Build Lifecycle, der auch als Default-Lifecycle bezeichnet wird. In diesem Prozess werden 23 sequenzielle Schritte definiert, die im Groben zusammengefasst folgende Aufgaben abarbeiten:
- Auflösen und Bereitstellen von Abhängigkeiten
- Kompilieren der Quelltexte
- Kompilieren und Ausführen von Komponententests
- Paketieren der Dateien zu einer Bibliothek oder Anwendung
- Lokales Bereitstellen des Artefaktes zur Verwendung in anderen lokalen Entwicklungsprojekten
- Ausführen von Integrationstests
- Deployen der Artefakte auf einem Remote Repository Server.
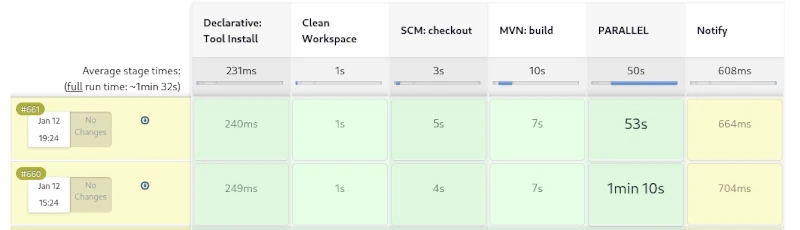
Dieser Prozess hat sich über Jahre in unzähligen Javaprojekten bestens bewährt. Führt man diesen Prozess allerdings auf einem CI Server wie Jenkins als Pipeline aus, bekommt man wenig zu sehen. Die einzelnen Schritte des Build Lifecycles bauen aufeinander auf und können nicht einzeln angesteuert werden. Es ist nur möglich, den Lifecycle vorzeitig zu verlassen. Man kann also nach dem Paketieren die nachfolgenden Schritte des lokalen Deployments und das Ausführen der Integrationstests auslassen.

Eine Schwäche des hier beschriebenen Build Prozesses kommt bei der Erstellung von Webapplikationen zutage. Web Frontends enthalten meist CSS und JavaScript Code, der ebenfalls automatisiert optimiert wird. Um in SCSS definierte Variablen in korrektes CSS zu überführen, muss ein SASS Präprozessor verwendet werden. Zudem ist es sehr nützlich, CSS Dateien und JavaScript Dateien möglichst stark zu komprimieren. Dieser Vorgang der Obfuskation optimiert die Ladezeiten von Webanwendungen. Aber auch für CSS und JavaScript gibt es bereits unzählige Bibliotheken, die mit dem Werkzeug NPM verwaltet werden können. NPM wiederum stellt sogenannte Entwicklungsbibliotheken wie Grunt bereit, mit denen wiederum CSS-Prozessierung und -Optimierung möglich sind.
Wir sehen, wie komplex der Buildprozess von modernen Anwendungen werden kann. Das Kompilieren ist nur ein kleiner Teil davon. Ein wichtiges Feature moderner Build Werkzeuge ist das Optimieren des Build Vorgangs. Eine mittlerweile etablierte Lösung dafür ist das Erstellen von inkrementellen Builds. Dies ist eine Variante des Cachings, bei der nur geänderte Dateien kompiliert beziehungsweise prozessiert werden.
Was ist aber bei einem Release zu tun? Ein Prozess, der wiederum nur dann benötigt wird, wenn eine Implementierungsphase beendet ist, um das Artefakt für die Verteilung bereitzustellen. Nun könnte man alle Schritte, die ein Release enthalten, ebenfalls in den Build einbauen, was wiederum zu längeren Buildzeiten führt. Längere lokale Buildzeiten stören wiederum den Arbeitsfluss des Entwicklers, weswegen es sinnvoller ist, hierfür einen eigenen Prozess zu definieren.
Bei einem Release sollte eine wichtige Bedingung sein, dass alle verwendeten Bibliotheken ebenfalls als finale Releaseversion vorliegen. Ist dies nicht der Fall, kann nicht sichergestellt werden, dass erneut erstellte Releases dieser Version identisch sind. Aber auch alle Testfälle müssen korrekt durchlaufen werden und ein Fehlschlagen bricht den Vorgang ab. Zudem sollte ein entsprechendes Tag im Source-Control-Repository auf die Revision gesetzt werden. Die fertigen Artefakte sind zu signieren und auch eine API Dokumentation ist zu erstellen. Natürlich sind die hier beschriebenen Regeln nur eine kleine Auswahl und einige der beschriebenen Aufgaben können sogar parallelisiert werden. Nutzt man zudem noch ein raffiniertes Caching, kann das Erstellen eines Releases auch für umfangreiche Monolithen in kurzer Zeit vonstattengehen.
Für Maven wurde beispielsweise kein kompletter Releaseprozess, ähnlich dem Buildprozess, definiert. Hier wurde durch die Community ein spezielles Plug-in entwickelt, mit dem einfache Aufgaben, die während eines Releases anstehen, semiautomatisiert werden können.
Wenn wir das Thema Dokumentation und Reporting ein wenig genauer betrachten, finden wir auch hier genügend Möglichkeiten, einen vollständigen Prozess zu beschreiben. So wäre das Erstellen der API Dokumentation nur ein untergeordneter Punkt. Wesentlich spannender an einem standardisierten Reporting sind die verschiedenen Codeinspektionen, die teilweise auch parallel durchlaufen werden können.
Natürlich darf auch das Deployment nicht fehlen. Aufgrund der Vielfalt, der möglichen Zielumgebungen ist an dieser Stelle eine andere Strategie angebracht. Ein denkbarer Weg wäre eine breite Unterstützung von Konfigurationswerkzeugen wie Ansible, Chef und Puppet. Aber auch Virtualisierungstechnologien wie Docker und LXC Container gehören in Zeiten der Cloud zum Standard. Hauptaufgabe des Deployments wäre dann vor allem die Provisionierung der Zielumgebung und das Einspielen der Artefakte aus einem Repository Server. Mit einer Fülle verschiedener Deployment Templates würde dies eine erhebliche Vereinfachung darstellen.
Wenn wir die hier getroffenen Annahmen konsequent weiterdenken, kommen wir zu dem Schluss, dass es unterschiedliche Projekttypen geben kann. Das wären klassische Entwicklungsprojekte, aus denen dann Artefakte für Bibliotheken und Anwendungen entstehen, Testprojekte, die wiederum die erstellten Artefakte als Abhängigkeit enthalten, und natürlich Deploymentprojekte zur Bereitstellung der Infrastruktur. Der Bereich des automatisierten Deployments findet sich auch in der Idee Infrastructure as a Code und GitOps wieder,die man an dieser Stelle aufgreifen und weiterentwickeln kann.
Wir sehen, dass bei weitem noch nicht alle Innovationen für sogenannte Build Werkzeuge ausgeschöpft sind. Viele der hier besprochenen Ideen sind bereits existierende Konzepte und erfordern lediglich eine Standardisierung. Durch die formalen Beschreibungen eines Prozesses und die flexible Konfiguration einzelner Komponenten in den Prozessschritten wird eine individuelle Anpassung ermöglicht.



Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.