Die Software-Entwicklung bietet einige äußerst effiziente Möglichkeiten, wiederkehrende Handgriffe durch Automatisierung zu vereinfachen. Das Wegfallen lästiger, sich wiederholender, monotoner Aufgaben und eine dadurch reduzierte Fehlerhäufigkeit im Entwicklungsprozess sind längst nicht alle Facetten dieser Thematik.
(c) 2011 Marco Schulz, Materna Monitor, Ausgabe 1, S.32-34
Die Motivation, Automatismen in der IT-Landschaft zu etablieren, ist weitgehend die Gleiche. Wiederkehrende Aufgaben sollen vereinfacht und ohne menschliches Zutun maschinell gelöst werden. Die Vorteile sind weniger Fehler bei der Benutzung von IT-Systemen, was wiederum die Kosten senkt. So einfach und vorteilhaft sich der Gedanke der selbstständig ablaufenden Prozesse auch anhört, die Umsetzung ist weniger trivial. Schnell wird klar, dass für jede identifizierte Möglichkeit einer Automation nicht immer eine Umsetzung machbar ist. Auch hier gilt der Grundsatz: Je komplexer ein Problem ist, umso aufwendiger ist dessen Lösung.
Um abzuwägen, ob sich der wirtschaftliche Aufwand zur Einführung bestimmter Automatismen lohnt, müssen die Kosten einer manuellen Lösung mit dem Faktor der zu wiederholenden Häufigkeit dieser Arbeit multipliziert werden. Diesen Kosten sind die Aufwendungen für die Entwicklung und den Betrieb der automatisierten Lösung entgegenzusetzen. Anhand dieser Gegenüberstellung wird schnell klar, ob ein Unternehmen die angedachte Verbesserung durchführen sollte.
Tools unterstützen den Entwicklungsprozess
Besonders bei der Entwicklung von Software-Projekten gibt es einen erhebliches Optimierungspotenzial durch automatische Prozesse. Dabei unterstützen die Entwickler eine Vielzahl an Tools, die es gekonnt zu orchestrieren gilt. Besonders das Konfigurations- und Release-Management beschäftigt sich sehr ausführlich mit dem praktischen Einsatz verschiedenster Werkzeuge zur Automatisierung des Software-Entwicklungsprozesses.
Das Vorhandensein einer separaten Build-Logik, beispielsweise in Form eines simplen Shell-Skriptes, ist zwar bereits ein guter Ansatz, aber nicht immer zielführend. Für solche Fälle sind plattformunabhängige Lösungen notwendig, da die Entwicklung mit sehr hoher Wahrscheinlichkeit in einem heterogenen Umfeld stattfindet. Eine Insellösung bedeutet stets erhöhten Anpassungs- und Pflegeaufwand. Schließlich sollen die Automatisierungsbestrebungen vorhandene Abläufe vereinfachen. Aktuelle Build-Werkzeuge wie Maven und Ant nutzen diesen Vorteil der Plattformunabhängigkeit. Die Kapselung der gesamten Build-Logik erfolgt bei beiden Werkzeugen in separaten XML-Dateien. Da sich XML bereits als Standard in der Software-Entwicklung etabliert hat, ist die Lernkurve steiler als bei rudimentären Lösungen.
Die Nutzung zentraler Build-Logiken bildet die Grundlage für weitere Automatismen während der Entwicklungsarbeit. Einen Aspekt bilden dabei automatisierte Tests in Form von UnitTests in einer Continuous-Integration-(CI)-Umgebung. Eine CI-Lösung fügt alle Teile einer Software zu einem Ganzen zusammen und arbeitet alle definierten Testfälle ab. Konnte die Software nicht gebaut werden oder ist ein Test fehlgeschlagen, wird der Entwickler per E-Mail benachrichtigt, um den Fehler schnell zu beheben. Moderne CI-Server werden gegen ein Versionsverwaltungssystem, wie beispielsweise Subversion oder Git, konfiguriert. Das bewirkt, dass der Server ein Build erst dann beginnt, wenn auch tatsächlich Änderungen im Sourcecode gemacht wurden.
Komplexe Software-Systeme verwenden in aller Regel Abhängigkeiten zu fremden Komponenten (Bibliotheken), die nicht durch das eigene Projekt beeinflusst werden können. Die effiziente Verwaltung der im Projekt verwendeten Artefakte ist die Hauptstärke des Build-Tools Maven, was zu dessen starker Verbreitung beigetragen hat. Bei richtiger Verwendung ist es so nicht mehr nötig, binäre Programmteile innerhalb der Versionsverwaltung zu archivieren, was zu kleineren Repositories und kürzeren Commit-Zeiten (erfolgreicher Abschluss einer Transaktion) führt. Neue Versionen der verwendeten Bibliotheken können schneller eingebunden und ausprobiert werden, ohne dass sie fehleranfällige manuelle Kopieraktionen verursachen. Inhouse entwickelte Bibliotheken lassen sich im Sinne der Wiederverwendung mit der Verwendung eines eigenen Repository-Servers (Apache Nexus) im Firmennetzwerk auf einfache Weise geschützt verteilen.
Bei der Evaluierung eines Build-Werkzeuges sollte die Möglichkeit des Reportings nicht vernachlässigt werden. Die automatisierte Überwachung der Code-Qualität anhand von Metriken, beispielsweise durch das Tool Checkstyle, ist ein hervorragendes Instrument für die Projektleitung, um den aktuellen Stand des Projekts realistisch zu beurteilen.
Nicht zu viele neue Technologien
Bei allen Möglichkeiten, Prozesse zu automatisieren, können mehrere Wege beschritten werden. Nicht selten führen Entwicklerteams lange Diskussionen darüber, welches Werkzeug besonders für das aktuelle Projekt geeignet ist. Diese Frage lässt sich schwer allgemein beantworten, da jedes Projekt einzigartig ist und die Vor- und Nachteile verschiedener Werkzeuge mit den Projektanforderungen abgeglichen werden müssen.
Im praktischen Einsatz hat sich die Beschränkung auf maximal zwei neuartige Technologien im Projekt bewährt. Ob ein Werkzeug geeignet ist, entschiedet auch die Tatsache, ob im Unternehmen Personen mit dem geeigneten Know-how verfügbar sind. Eine gute Lösung ist eine vom Management freigegebene Liste mit Empfehlungen der eingesetzten Tools, die bereits verwendet werden oder sich in die bestehende Systemlandschaft integrieren lassen. Damit wird sichergestellt, dass die eingesetzten Werkzeuge übersichtlich und beherrschbar bleiben.
Projekte, die über viele Jahre laufen, müssen sich in größeren Abständen einer Modernisierung der verwendeten Technologien unterziehen. In diesem Zusammenhang müssen geeignete Zeitpunkte gefunden werden, um mit möglichst wenig Aufwand zur neuen Technologie zu migrieren. Sinnvolle Termine, um auf eine neuere Technologie zu schwenken, sind beispielsweise ein Wechsel auf ein neues Major Release des eigenen Projektes. Dieses Vorgehen erlaubt eine saubere Trennung, ohne alte Projektstände auf die neue Technik migrieren zu müssen. In vielen Fällen ist das auch nicht so einfach möglich.
Fazit
Die Verwendung von Automatismen zur Software-Entwicklung kann bei bedachtem Einsatz das Erreichen des Projektziels tatkräftig unterstützen. Wie bei allen Dingen ist der übermäßige Einsatz mit einigen Risiken verbunden. Die verwendete Infrastruktur muss bei aller Technisierung verständlich und beherrschbar bleiben, so dass bei Systemausfällen die Projektarbeit nicht ins Stocken gerät.
Schon in einem recht frühen Stadium müssen die fertigen Sourcen auf verschiedenste Zielsysteme eingespielt werden. Üblicherweise existieren mehrere zentrale Entwicklungsserver, zu denen noch für jeden Entwickler eine eigene lokale Installation hinzukommt. Bei dieser Vielzahl an Systemen, auf der das Projekt lauffähig sein muss, rechnet sich schnell der Aufwand, den eine zentrale und wiederverwendbare Build-Logik erfordert.
Wer schon das eine oder andere Deployment hinter sich gebracht hat, weiß, dass die Softwareverteilung einiges an Tücken zu bieten hat und in aller Regel nichts mal schnell eingespielt wird. Um die üblichen und immer wiederkehrenden Fallstricke vermeiden zu können, werden in der Software-Entwicklung seit Jahren verschiedenste Automatisierungswerkzeuge eingesetzt. In diesem Artikel lernen Sie das Werkzeug Ant kennen und erfahren, wie Sie es in Ihren PHP-Projekten verwenden können.
Das Akronym Ant steht für Another Neat Tool und bedeutet frei übersetzt: Ein weiteres hübsches Werkzeug. Zusätzlich bedeutet nt im Englischen Ameise. Genau diese Bezeichnung beschreibt Ant mit nur einem Wort sehr treffend, denn es ist wie eine Ameise: klein, fleißig, äußerst robust, zuverlässig und leistet im Vergleich zu seiner Größe Unglaubliches.
Ant ist ein Top-Level-Projekt der Apache Group und wird seit Jahren in unzähligen Projekten erfolgreich eingesetzt. Auf der Projekt-Homepage können die bereits kompilierten Binarys sowie die Sourcen kostenlos heruntergeladen werden. Die Grundintention von Ant ist die Verwendung als Build-Werkzeug im Java-Umfeld. Die enorme Vielfalt der Funktionen und die einfache Erweiterbarkeit machen das Tool auch außerhalb der Java-Welt interessant. Mit Ant können Sie unter anderem komplette Verzeichnisse kopieren, komprimieren und dabei einzelne Dateien ausschließen. In Textdateien können Variablen definiert werden, die dann durch konkrete Werte ersetzt werden, und es gibt FTP- und SVN-Anbindungen.
Besonders durch den Leistungsumfang, die Stabilität, die einfache Installation und die reichhaltige Dokumentation unterscheidet sich Ant von anderen Deployment-Tools für PHP, wie beispielsweise dem in Ruby implementierten PHP-Build-Tool Capistrano.
Deployment-Strategien
Unter Deployment versteht man in der IT sämtliche Maßnahmen, die zur Verteilung von Software auf die Zielumgebungen notwendig sind. Für PHP-Applikationen zählt dazu beispielsweise das Anpassen der Konfiguration des Webservers und der Datenbank sowie das Einspielen der Datenbankschemata und der PHP-Skripts.
Das folgende Szenario stellt den Rahmen für die Komposition unserer Build-Logik dar. Die Vorgehensweise lässt sich auch ohne Weiteres auf andere Projekte übertragen und den eigenen Anforderungen anpassen.
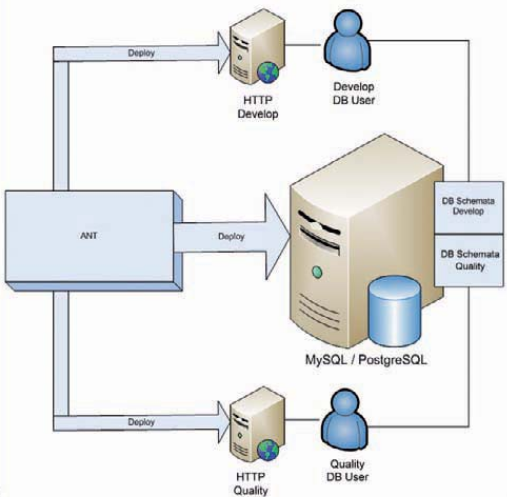
Auf dem Entwicklungsrechner befinden sich zwei unabhängige Webserver-Installationen sowie ein Datenbank-Server, den sich die beiden Webserver teilen. Ein Webserver wird Develop benannt und hat eine lockere Konfiguration der Sicherheitseinstellungen. Die Ausgabe von PHP- und SQL-Fehlern wird hier nicht unterdrückt. Beim zweiten Webserver verhält sich die Konfiguration schon bedeutend anders. Auf diesem als Quality benannten System herrschen starke Sicherheitsrestriktiven, zum Beispiel, dass keine Dateien per Remote im Skript verarbeitet werden dürfen. Der Quality-Server (QS) hat im Idealfall die gleiche Konfiguration wie später das Live-System des Kunden. Beide Systeme teilen sich einen Datenbank-Server, auf dem für jedes System ein eigener Benutzer mit eigenem Schema angelegt ist. Die Grafik in Bild 1 verdeutlicht den Zusammenhang.
Für unser Szenario ist der populäre Webshop Magento als Build-Projekt auserkoren, es kann aber auch jedes beliebige andere CMS- beziehungsweise PHP-Projekt zur Entwicklung Ihrer Deployment-Strategie genutzt werden.
Nach dem Download und dem Entpacken des aktuellen Magentos in ein frisches Projektverzeichnis auf dem Development-Server wird das Programm über den mitgelieferten Webinstaller auf dem Server Develop installiert. Dazu kommen noch alle notwendigen Translation-Files und zusätzliche Plug-ins. Nachdem der Shop so weit funktionsfähig ist, werden alle Dateien unter das Konfigurationsmanagement gestellt und dieser Stand mit inital installation markiert.
In dem hier beschriebenem Szenario soll das Konfigurationsmanagement der Wahl die Versionsverwaltung Subversion sein. Würden wir nun diesen Stand unverändert in das Live-System einspielen wollen, würden wir feststellen das der Shop nicht läuft, weil unter anderem die Datenbankparameter nicht korrekt sind. Außerdem ist es auch nicht wünschenswert, die .svn-Verzeichnisse samt Inhalt in das Live-System zu übertragen, da diese schnell zu einer nicht unerheblichen Datenmenge anwachsen.
Mit dem QS-System haben wir nun eine Zwischenstufe eingebaut, mit der das Deployment für das Zielsystem risikofrei getestet werden kann. In größeren Projekten werden zu diesem Zweck sogar mehrere QS-Instanzen parallel betrieben.
Die Installation
Bevor es losgeht, muss Ant auf dem Entwicklungsrechner verfügbar sein. Wer bereits Eclipse, Netbeans oder Intellij Idea als Entwicklungsumgebung verwendet, hat bereits alles an Bord, was notwendig ist. Sollte Ihre IDE keine native Ant-Integration besitzen, können Sie das Tool schnell nachinstallieren.
Ant selbst ist ein Programm, das klassisch über die Textkonsole im Root des aktuellen Projektverzeichnisses mit dem Kommando ant aufgerufen wird. Die einzelnen abzuarbeitenden Anweisungen innerhalb eines Targets werden Task genannt. Die build.xml beinhaltet die gesamte Build-Logik. Alle Anweisungen werden in XML notiert, und es ist keine zusätzliche Skriptsprache notwendig.
Damit die build.xml fehlerfrei von Ant verar-eitet werden kann, muss sie wohlgeformt und valide sein. Die Verwendung der bereits genannten Entwicklungsumgebungen unterstützt Sie tatkräftig beim Schreiben dieser Konfigurationsdatei und ermöglicht das komfortable Starten der einzelnen Tasks über eine grafische Oberfläche.
Die Konfigurationsdatei
Der Name der Konfigurationsdatei ist stets build.xml und sie befindet sich im Root-Verzeichnis des aktuellen Projekts. Listing 1 zeigt den grundlegenden Aufbau.
<projectname="Magento Project"default="start"basedir="."><description>Deploymentfile for PHP Projects</description><propertyfile="build.properties"/><propertyname=" deploy.directory” value=”_build”/> <target name="start" description="Full Deployment"> <echo>Ant PHP Deploy Script for PHP Projects</echo> <antcall target="clean_deploy_dir" /> </target> <target name="clean_deploy_dir"> <echo message="Delete the current Deploy Directory for clean up"/> <delete dir="${deploy.directory}" /> </target></project>
XML
Listing 1: Die build.xml
In wird angegeben, um welches Projekt es sich handelt und wo die Projektdateien relativ zur build.xml liegen. Es ist also durchaus möglich, die build.xml auch an eine andere Stelle als ins Root-Verzeichnis zu platzieren – was allerdings nicht zu empfehlen ist, da dies schnell zu ungewünschtem Verhalten führen kann. Mit erfolgt eine kurze Projektbeschreibung, die optional ist und zum besseren Verständnis beiträgt.
Über steigen wir schon voll in die Ant-Syntax ein. definiert Platzhalter, die dann über ${Platzhalter.Name} in der gesamten build.xml verwendet werden können. Diese Eigenschaft ist eine wichtige Grundlage, um saubere Build-Files zu schreiben, weshalb an dieser Stelle der Mechanismus etwas ausführlicher erläutert werden soll.
Platzhalter sind deswegen so wichtig, weil damit Werte befüllt werden, die sich oft ändern können. Beispielsweise wird der Pfad des Verzeichnisses, in das die fertigen Dateien kopiert werden sollen (deploy.directory) an vielen verschiedenen Stellen benötigt. Ändert sich nun dieser Wert, ist es lästig, die gesamte build.xml danach zu durchsuchen und das neue Verzeichnis per Hand an den jeweiligen Stellen zu ändern. Viel angenehmer ist es, diesen Wert zentral an einer festen Position pflegen zu können.
Mit dem Attribut file können die Propertys auch in eine Datei ausgelagert werden. Vor allem Werte, die sich in jedem Fall auf den einzelnen Systemen unterscheiden, sind hervorragende Kandidaten für ausgelagerte Propertys.
Auf diese Weise vermeidet man, dass der Entwickler aus Versehen in der build.xml Änderungen vornimmt und die Build-Logik damit zerstört. Die Syntax in solchen Property-Dateien folgt dem Schema key=value. Die anschließende Benutzung der Platzhalter in der build.xml erfolgt genauso wie für Propertys, die direkt in der Build-Datei definiert werden.
Im Listing sind außerdem zwei definiert. Das Target start wird automatisch beim Aufruf der build.xml ausgeführt. Das Attribut default in bestimmt für den Konsolenaufruf den Task, welcher initial ausgeführt werden soll. Im ersten Target wird ein auf ein weiteres Target mit der Bezeichnung clean_deploy_dir aufgerufen.
Das Auslagern kleiner Operationen in eigene Tasks erhöht die Lesbarkeit der gesamten Datei. Über den antcall können dann die Subtasks in einem zusammenführenden Task wieder orchestriert werden, wobei die Reihenfolge der einzelnen Calls von Bedeutung ist, da die Aufgaben nacheinander ausgeführt werden. Im zweiten Target wird ein delete aufgerufen, das die Verwendung des Platzhalters ${deploy.directory} für das zu löschende Verzeichnis demonstriert.
Eine der wichtigsten Operationen ist das Kopieren von Dateien. Im Kopiervorgang sollen die Inhalte der .svn-Ordner nicht mit berücksichtigt werden. Um wieder das Beispiel Magento aufzugreifen, sollen während des Copys auch noch die Datenbankparameter in der local.xml ersetzt werden. Um diese Aufgabe zu lösen, erweitern wir das vorige Listing um ein neues , das copy_all heißen soll (Listing 2).
Mit wird das Verzeichnis erzeugt, in dem anschließend die Dateien zu finden sind. Der -Befehl erwartet als Attribut todir für das Verzeichnis, in das die Dateien kopiert werden sollen. Hier macht sich die Verwendung der Propertys bezahlt. Mit overwrite=“true“ werden vorhandene Dateien überschrieben. Das eingebettet Element gilt für das Verzeichnis, in dem die build.xml liegt, was durch dir=“.“ bestimmt wird. Es können natürlich auch andere Verzeichnisse angegeben werden. Include und Exclude sind zwar selbsterklärend und es lässt sich schnell ahnen, welche Bewandtnis es damit hat. Die Verwendung ist aber nicht ganz so simpel. Als Werte sind für diese beiden Attribute unter anderem Wildcards möglich, /* bedeutet: »Nimm alles inklusive der Unterverzeichnisse.« Die Excludes sind der Übersicht halber wieder in eine eigene Property ausgelagert. Wie gut zu erkennen ist, dürfen die Verzeichnisse und Dateien kommasepariert als Wert übergeben werden. Auch hier sind verschiedene Kombinationen von Wildcards gestattet.
Als Nächstes lernen wir die Textersetzung kennen. Für die Datei local.xml sollen die Datenbank-Verbindungsparameter vom Zielsystem verwendet werden.
Die Ersetzung selbst ist recht einfach zu handhaben. Es wird der bereits bekannte -Task verwendet, der wiederum aufruft. Der Matcher sollte in der Form @ERSET-ZUNGSTEXT@ in den Template-Dateien verwendet werden.
Datenbanken
Eine weitere Grundfunktion von Ant ist der Zugriff auf Datenbanken. Um diese Funktion nutzen zu können, muss man wissen, dass Java-Programme die Java-Database-Connectivity-Treiber für den Zugriff auf Datenbanken benötigen. Diese Treiber sind einfache JAR-Dateien die von der Webseite des Datenbankherstellers heruntergeladen werden können. Das Listing 3 zeigt, wie mittels Ant auf eine MySQL-Datenbank zugegriffen wird.
In sind die spezifischen Datenbankparameter hinterlegt. In wird für Ant die Position zur JDBC-Treiberdatei hinterlegt. Neben der Angabe einer SQL-Datei in können innerhalb dieses Tags auch reine SQL-Statements eingetragen werden.
Es ist nun nicht weiter nötig, aufwendig ein Datenbank-Dump-File manuell zu erzeugen, um dieses dann auf die gleiche Art in das Zielsystem einzuspielen. Mit dem Task sql können Sie diese Aufgabe zukünftig an Ant delegieren.
Kompression und FTP
Nachdem alle notwendigen Dateien in das Deploy-Verzeichnis kopiert wurden, könnten die nächsten Aufgaben darin bestehen, die benötigten Skripts in einer ZIP-Datei zu komprimieren und per FTP auf den Webserver zu übertragen. Das Listing 4 bewirkt genau dieses.
Dank des bereits erworbenen Wissens ist das Listing selbsterklärend. Es stellt sich jedoch die Frage, was passiert, wenn die Datei auf dem Webserver übertragen wurde. Hier bietet sich die Verwendung eines einfachen PHP-Skripts zum Entpacken des Archivs an (Listing 5).
So einfach, wie das Skript gestaltet ist, hat auch diese Lösung ihre Eigenheiten. Wer eine komplette Magento-Installation komprimiert und auf diese Art auf dem Live-Server entpacken möchte, wird schnell die PHP-Grundeinstellung max_execution_time seines Servers kennenlernen. Komplexe Applikationen wie Magento sind sehr umfangreich und benötigen zum Entpacken eine längere Ausführungszeit des Skripts, als von der PHP-Konfiguration vorgesehen.
Eine Lösung wäre, die verschiedenen Verzeichnisse einzeln zu komprimieren und diese Dateien dann zu übertragen und nacheinander zu entpacken. Das bietet sich eher bei einer Gesamtinstallation an. Bei einem einfachem Update ist die Verwendung der Diff-Funktion der Versionsverwaltung wesentlich eleganter.
Ant Erweitern
Der modulare Aufbau von Ant erlaubt es auch, das Werkzeug um eigene Funktionen, die nicht im Core enthalten sind, zu erweitern. Neben der bereits erwähnten Erweiterung für Subversion existieren im Web noch zahlreiche weitere Plugins, zum Beispiel ein Javascript-Minimizer oder der PHP-Documentator.
Der Javascript-Minimizer optimiert die JavaScript-Dateien, in dem er unter anderem Kommentare und unnötige Leerzeichen entfernt (Listing 6). Nach der Komprimierung hat die Javascript-Datei einiges abgespeckt. Dadurch wird sie schneller vom Browser geladen. definiert einen neuen Task mit dem Namen jsmin und verweist mit classpath auf die Datei des Plug-ins. Der classname ist die ausführende Klasse und muss aus der Dokumentation des entsprechenden Plug-ins entnommen werden. Anschließend wird in das bereits bekannte Element verwendet, um die zu komprimierenden Javascript-Dateien anzugeben. Mit der Einstellung force=“true“ werden bereits vorhandene Dateien überschrieben.
<taskdefname="jsmin"classname="net.matthaynes.jsmin.JSMin_Task"classpath="jsmin-0.2.4.jar"/><targetname="jsCompressor"><echomessage="minimize all JS."/><jsminforce="true"><filesetdir="${deploy.dir}/js"includes="**/*.js"/></jsmin></target>
XML
Listing 6: JavaScript minimieren
Dokumentation erzeugen
Das an Java Doc angelehnte PHP Doc lässt sich auch mit Ant erzeugen. Mit ist Ant in der Lage, sogenannte Executables auszuführen. Da PHP Doc in PHP implementiert ist, muss die php.exe die Dokumentation generieren. Das Listing 7 demonstriert das Vorgehen.
Die Werte, welche durch übergeben werden, sind Kommandozeilen-Parameter, mit denen PHP gestartet wird. In der Property ${php.exe} wird der absolute Pfad zur php.exe hinterlegt. Der Dokumentator startet im aktuellen Projektverzeichnis, wozu er mit dir=“.“ bewegt wird. Die fertige Doku wird in das Verzeichnis geschrieben, das über die Property ${deploy.dir.phpdoc} angegeben wurde. Schließlich ist es noch notwendig, den Pfad zu PHP Doc anzugeben, was mit der Property ${phpdoc.extension .inc} getan wurde.
Windows Nutzer kennen die typischen INI-Files, in denen Werte zur Laufzeit in eine Applikation geladen werden können. Dieses Konzept hat mit der starken Verbreitung von XML eine neue Renaissance erfahren. In diesem Zusammenhang sind die Paradigmen Don’t Repeat Yourself (DRY) und Convention Over Configuration (COC) zum Maß der Dinge avanciert. Die freien Frameworks Ruby On Rails und Maven 2, gehören zu den bekanntesten Tools, die mit dieser Technologie arbeiten.
In Hochsprachen wie C oder Java müssen die Quelldateien in ein binäres Format gebracht werden, dieser Vorgang kann je nach Umfang eines Programms, einiges an Rechenzeit verbrauchen. Um verschiedene Parameter einer Anwendung zur Laufzeit verändern zu können, wurde eine Möglichkeit geschaffen, die Werte aus einfachen Textdateien lesen kann.
Damit erübrigt sich das Kompilieren, da die Initialisierung der Variablen nun nicht mehr im Quelltext hinterlegt ist. Hinter dem Begriff DRY verbirgt daher nichts anderes, als die Vermeidung unnötiger und sich wiederholender Arbeitsschritte. COC erweitert diese Idee um die Forderung, dass jede Variable die konfiguriert werden kann, mit einem Defaultwert vorbelegt ist. In der Konfigurationsdatei werden nur noch Parameter angegeben, die vom vorgegebenen Standart abweichen. Die Übersichtlichkeit und Lesbarkeit der Konfiguration steigt somit rapide an, da es im praktischen Einsatz sehr unwahrscheinlich ist, dass alle Konfigurationsmöglichkeiten überschreiben werden müssen. Um effektiv mit den Paradigmen DRY und COC arbeiten zu können ist es, wichtig die möglichen Konfigurationsparameter und deren Bedeutung zu kennen. Daher sollte an einer ausführlichen Dokumentation nicht gespart werden.
Für PHP ist die Verwendung von XML als Konfigurationsdatei aus zwei Gründen sinnvoll. Die wichtigste Eigenschaft ist vor allem eine Trennung von internen Applikationszuständen, die dem Anwender verborgen bleiben sollen. Ausschließlich die notwendigen Anpassungen an das Zielsystem, wie Datenbankanbindungen und Layouteinstellungen werden zentral in der Konfigurationsdatei vorgehalten. Der zweite Aspekt, der für XML spricht, ist die Möglichkeit Daten einfach und lesbar zu strukturieren. So praktisch die Nutzung von XML auch ist, so soll die davon ausgehende Gefahr nicht unterschlagen werden. Ohne geeignete Maßnahmen können die Daten der Konfigurationsdatei von Dritten ausgespäht werden. Der Aspekt über die Sicherheit wird im Anschluss an eine kurze Einführung zu XML besprochen.
XML
Die Extensible Markup Language (XML) wird für die unterschiedlichsten Aufgaben verwendet. Der Grund liegt in der einfachen Möglichkeit, Strukturen und Daten zu modellieren. Im Gegensatz zu HTML sind die Tags nicht mehr fest vorgeschrieben, sondern können frei gewählt werden. Genauso verhält es sich auch mit den Attributen für die Elemente. Damit dies auch gelingt, muss eine XML-Datei verschiedenen Regeln entsprechen. Werden die Regeln eingehalten, spricht man von einem wohlgeformten Dokument. Einige XML Editoren verweigern das Abspeichern nicht wohlgeformter Dokumente.
Um festzustellen, ob das Dokument auch der vorgegebenen Datenstruktur entspricht, kann entweder gegen eine Dokument Type Definition (DTD) oder ein XML Schema (XSD) validiert werden. Entwicklungsumgebungen greifen oft auf die angegebene DTD bzw. XSD Datei zu, um eine intelligente Codevervollständigung anbieten zu können. Wer mehr über das breite Spektrum der Extensible Markup Language erfahren möchte, dem sei andieser Stelle die einschlägige iteratur zur Thematik Herz gelegt, da dieser Artikel lediglich die Grundlagen von XML streift und seinen Fokus auf die Verwendung mit PHP legt.
Regeln für wohlgeformte XML Dokumente:
Das Wurzel-Element (Root) darf nur einmalig im Dokument vorkommen
Tags werden stets kleingeschrieben und sind durch die Zeichen < > begrenzt
Namen für Tags dürfen nur mit _ und Buchstaben beginnen, anschließend können Zahlen,
Buchstaben, Punkte, Bindestriche und Unterstriche verwendet werden.
Jedes geöffnete Tag muss geschlossen werden, Beispiel:
Verschachtelte Tags müssen immer in der Reihenfolge geschlossen werden wie sie geöffnet werden
Die Sondernotation für Elemente, die kein schließendes Tag benötigen, nennt sich leeres Tag und
hat folgende Syntax:
Werte für Attribute müssen durch Anführungszeichen eingeschlossen werden
Es existiert mittlerweile eine erhebliche Menge an XML Editoren, die um die Gunst der Nutzer buhlen. Im kommerziellen Umfeld ist der XMLSpy von Altova der absolute Platzhirsch. XMLSpy beherrscht sämtliche Disziplinen, die im Umgang mit XML notwendig sind, dafür müssen für die Anschaffung der Enterprise Version allerdings ca. 800€ eingeplant werden. Wer lieber auf Freeware zurückgreifen möchte, findet in Notepad++ einen sehr vielseitigen Editor. Verfechter von Microsoft können auf eine sehr gelungene Anwendung mit dem Namen XML Notepad zurückgreifen. Unter den IDE’s ist vor allem Eclipse zu nennen, das neben XML auch ein sehr leistungsstarkes PHP-Plugin bietet. Gerade die Tatsache, das PHP und XML mit ein und demselben Werkzeug bearbeitet werden ist maßgebend für einen flüssigen Arbeitsablauf.
Datenbank vs. XML
Sicherlich wird sich der ein oder andere Leser die Frage stellen, wieso die in der XML gespeicherten Daten nicht einfach in eine Datenbanktabelle ausgelagert werden. Die meisten Applikationen benötigen generell von Haus aus eine Datenbank zur Datenhaltung, also kann diese, die Aufgabe der Konfiguration mit übernehmen. Die Verwaltung komplexer Datenbanksysteme ist dank geeigneter Werkzeuge wie beispielsweise phpMyAdmin auch relativ gut beherrschbar. Da die typischen Verbindungsparameter wie Host und Datenbankname nicht in der Datenbank gespeichert werden können, müssen diese in der Anwendung vorgehalten werden. Um alle notwendigen Einstellungen nicht in der gesamten Applikation zu verstreuen, hat sich das DRY und COC Prinzip etabliert. Die mitgelieferten Installationsroutinen zum Deployen der Programme besitzen einen entscheidenden Nachteil.
Meist wird eine solches System auf einem lokalen Testsystem installiert und soll dann später per FTP auf den Webserver übertragen werden. Zu 99% aller Fälle beginnt nun das große Suchen nach den Einstellungen, die angepasst werden müssen, um die Applikation auf dem Webserver lauffähig zu bekommen. Selbst ein kompletter Database -Dump vom Testsystem auf Produktionsumgebung beherbergt stets die Gefahr falsche Konfigurationseinstellungen mit zu übertragen. Das Szenario lässt sich noch weiter steigern, mit der Annahme eines Datenbank Clusters und verschiedener Replikationsstrategien. Der Abschnitt XML und PHP zeigt in der Beispielanwendung wie zwischen Testumgebung und Produktionssystem unterschieden werden kann. Für kleinere Projekte, kann es durchaus sinnvoll sein komplett auf Datenbanken zu verzichten und die gesamte Datenhaltung über XML zu organisieren. Das erspart zum einen den Aufwand der Datenbankkonfiguration und vereinfacht das Backup der Datenhaltung. Eine simpler Link oder Terminverwaltung kann ohne Content Management System (CMS) auch problemlos vom Kunden gepflegt werden. Vorraussetzung ist, dass die Datenmenge gering ist und der Anwender ein geeignetes Maß an Erfahrung mitbringt. Unter Verwendung dieser Technologie lassen sich äußerst kostengünstig Projekte realisieren.
Sicherheitsaspekte
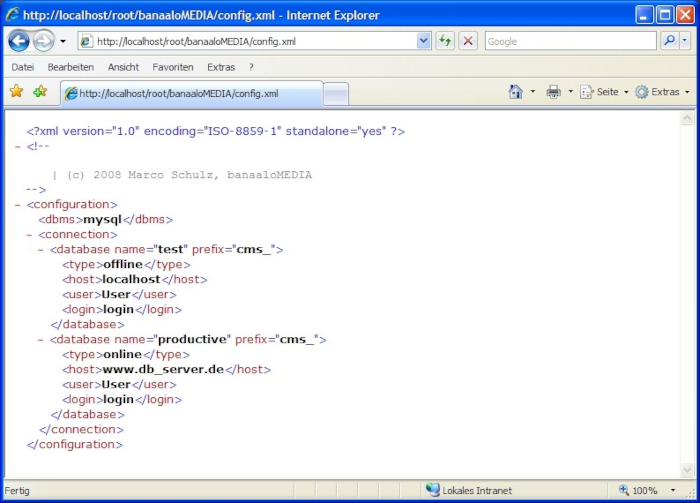
Da es sich bei XML um eine einfache Textdatei handelt, kann sie problemlos von Menschen gelesen und interpretiert werden. Wenn der Name und der Pfad zur Datei auf dem Server bekannt ist, wird beim Aufruf in aller Regel der Inhalt der Datei im Webbrowser angezeigt. Dieses Verhalten ist natürlich für unseren Fall äußerst problematisch, da in der Datei wichtige Daten hinterlegt sind, die nicht für Dritte bestimmt sind. Das Finden solcher Informationen kann durch unglückliche Dateinamen begünstigt werden, da mit sehr hoher Wahrscheinlichkeit bei einem Angriff zuerst config.xml im Root Verzeichnis des Webservers ausprobiert wird. Das Ergebnis einer solchen Abfrage ist im Screenshot_01 zu sehen.
Ein wirksamer Schutz besteht aus mehreren Schritten. Die Grundidee ist zuerst die config.xml gut zu verstecken. Damit das Versteck auch sicher ist, wird es mit einem simplen aber effektiven Zugriffsschutz verschlossen. Als Erstes wird ein Verzeichnis unterhalb des Root im Projekt mit dem Namen var angelegt. Dieses Verzeichnis darf nicht in der robots.txt mit auftauchen, damit würde man einem potenziellen Angreifer eine Wegbeschreibung in die Hand geben. Es besteht auch keine Gefahr für eine unbeabsichtigte Indizierung des Verzeichnisses durch eine Suchmaschine, da die nur den Links auf URL-Ebene folgen kann. Wer dennoch auf Nummer sicher gehen möchte, kann in var eine eigenständige robots.txt erstellen, die sämtliche Suchmaschinen aussperrt. Dazu genügen die folgenden Einträge:
User-agent: * Disallow: *
Die beiden Zeilen gelten für alle Dateien und Verzeichnisse, die sich im selben Directory wie die robots.txt befindet. Die Indexierung wird allen Suchmaschinen untersagt. Wichtig ist das es außerhalb des geschützten Verzeichnisses, keinen Hinweis auf dessen Existenz vorhanden ist. Im zweiten Schritt wird eine index.php in var erzeugt. Der gewünschte Effekt ist, dass nun nicht mehr sämtliche Files des Verzeichnisses aufgelistet werden, sondern automatisch die index.php aufgerufen wird. Die Index -File kann leer bleiben oder einen redirect auf die Domain des eigenen Webauftritts haben.
$url="Location: http://".$_SERVER['SERVER_NAME'];header("HTTP/1.1 301 Moved Permanently");header('$url');header("Connection: close");
PHP
Zu Beginn des Listings wird die Zieladresse festgelegt, die in unserem Fall automatisch die Server URL zugewiesen bekommt. Einige Provider haben ihre Webserver mit einem ähnlichen Verhalten konfiguriert. Der Provider 1 und 1 zeigt beispielsweise bei fehlendem Index eine leere Seite an. Die übrigen Funktionen steuern das HTTP Protokoll. Die Header – Funktion ist ein sehr mächtiges Werkzeug, das bei seiner Verwendung einige Sorgfalt erfordert. Nur wenige Operationen sind vor den Funktionen gestattet. Die Verwendung von echo gehört zu den beliebten Fehlern im Umgang mit header. Wer diese Maßnahmen beachtet, kann getrost seine Konfiguration in eine XML-Datei auslagern, ohne böse Überraschungen zu erleben.
XML und PHP
Ab der Version 5 ist die SimpleXML Extension Bestandteil von PHP und ermöglicht, damit eine sehr einfache Art und Weise XML Dateien zu verarbeiten. Zur Demonstration greife ich auf ein kleines Beispiel zurück, das die Datenbankkonfiguration aus einer XML-Datei ausliest und anschließend Werte von einer Datenbank ausgibt. Der Aufbau der Datenbank ist über das Listing database.sql ersichtlich, das auch gleich zum Anlegen der Datenbank verwendet werden kann.
CREATETABLEIFNOTEXISTS links (urlchar(255) NOT NULL, category char(255) NOT NULLDEFAULT'sonstige',descriptionTEXT);
SQL
Die Ausgabe des Listings config.xml ist im Screenshot_01 bereits zu sehen. Der Wurzelknoten ist als dessen Kind angefügt wurde. In dem Tag wird das verwendete Datenbankmanagmentsystem angegeben. Wegen der vielen möglichen Umgebungen in die eine PHP Applikation installiert werden kann besteht der Wunsch nach Flexibilität. Auf das Element wird üblicherweise ein Factory Pattern [8] angewendet, um die verwendete Datenbank problemlos ohne Quelltextänderungen austauschen zu können. Diese Option ist hier nur der Vollständigkeit erwähnt, da eine genauere Erläuterung den Rahmen des Artikels übersteigt.
Spannend ist das folgende Tag . Hier werden zwei Verbindungen gespeichert. Die Überlegung ist, eine lokale (Testumgebung) und eine Server-Konfiguration (Produktionsumgebung) zu definieren. Das erspart bei der Übertragung der der Projektdateien zum Server eine vorherige Anpassung an die dort vorhandene Datenbank. Das Tag besitzt als Attribute name und prefix. Mit name ist der Datenbankname gemeint, während prefix eine „Vorsilbe“ der Tabellen definiert. Ein Präfix ist stets optional und gestattet eine mehrfache Installation der Anwendung in der gleichen Datenbank. Das ergibt sich aus der Forderung, das Tabellennamen stets eindeutig sein müssen und nicht mehrfach vergeben werden dürfen. Die Elemente Host, User und Login sind selbstsprechend. Type ist der Indikator, welcher uns verrät ob es sich um die Test- oder die Produktionsumgebung handelt. Eine spätere Abfrage der Variable $_SERVER['SERVER_NAME'] == “localhost”; stellt die Prüfbedingung für das Zielsystem. Soweit nur zur Vorbereitung.
Der erste Schritt besteht darin, die zu verarbeitende Datei zu öffnen. Dies geschieht mit der Anweisung: $config = simplexml_load_file(“config.xml”); in der die Variable $config steht nun der gesamte Inhalt aus config.xml zur Verfügung. Um dbms auslesen zu können, wird folgende Zeile benötigt: $dbms = $config->dbms; für den Fall das es mehrere Tag’s mit derselben Bezeichnung gibt kann der gestammte Inhalt sequentiell ausgelesen werden.
Das Beispiel iteriert mit einer foreach Schleife über dem Kindelement , das sich unterhalb von befindet. In dem assoziativen Array $xmlvars, kann nun auf die einzelnen Element zugegriffen werden. Wie in Zeile 01 bereits zu erkennen ist, muss nicht zwangsläufig die gesamte XML Datei ab dem Root- Element verarbeitet werden, um ein Ergebnis zu erzielen. Die Bezeichnungen aus dem Beispiel leiten sich aus den Namen der XML-Elemente ab. In Zeile 02 wird demonstriert, wie Attribute eines Tags ausgelesen werden. In den Zeilen 03 bis 05 werden die Werte der Kindelemente , und den Entsprechenden Variablen zugewiesen. Würde man beabsichtigen in dieser Konstellation auf ein Attribut von zu zugreifen ist die korrekte Syntax: $hostAttribut = $xmlvars->host['attribut']. Wie man sieht, enthalten die wenigen Zeilen des Listings den Großteil des notwenigen Know-hows für den praktischen Einsatz. Die Logik für die Unterscheidung zwischen Webserver und lokaler Installation erweitert das vorangegangene Listing und ist zwischen die Zeile 01 und 02 einzufügen.
Die IF-Anweisung wird erst dann ausgeführt, wenn die Server-Variable den Wert localhost annimmt. Alternativ kann auch anstatt des Domainnamenes die IP-Adresse zur Identifizierung des Rechners herangezogen werden. Um den korrekten Datensatz an den ermittelten Server zu binden, wird eine zweite Prüfbedingung benötigt. In iesem Beispiel werden die korrekten Einstellungen über das Element erkannt. Sobald beide Kriterien erfüllt sind, können die Variablen ihre Werte aufnehmen. Die break Anweisung sorgt dafür, dass die foreach Schleife nach der Initialisierung verlassen wird. Das verhindert ein versehentliches überschreiben der Werte durch den nächsten Datensatz in einem weiteren Schleifendurchlauf. Das würde zwangsläufig passieren, da der nachfolgende Datensatz keiner Prüfbedingung standhalten muss. Wenn mehrere Server zu berücksichtigen sind, kann die IF–Anweisung um den ifelse Ausdruck erweitert werden. Selbstverständlich lässt sich das Konstrukt auch durch eine switch Kontrollstruktur abbilden. Eine Datenbankabfrage sowie die Ausgabe werden durch die üblichen Bordmittel von PHP realisiert. Die auf der Heft CD beigefügten Listings sind vollständig und zeigen, wie die gesamte Applikation arbeitet.
Der aufmerksame Leser erwartet, sicherlich an dieser Stelle geeignete Möglichkeiten in eine XML-Datei zu schreiben. Diese Erwartung muss leider enttäuscht werden, da die SimpleXML Extension keine Funktionen zum Schreiben von Dateien bereitstellt. Dies ist auch nicht notwendig, da die bereits in PHP vorhandenen Möglichkeiten völlig ausreichend sind. Dafür können in der Verarbeitungslogik Reguläre Ausdrücke, Stringoperationen und Sortieralgorithmen benutzt werden. Das Ergebnis wird dann über die fwrite Funktion in eine Datei geschrieben.
Resümee
Wie man sehen konnte, ist die Verarbeitung von XML Dateien mit PHP Mitteln recht unkompliziert und Erfolge werden schnell sichtbar. Der Artikel hat zudem einige Anreize für die Verwendungsmöglichkeiten aufgezeigt und Hinweise für Sicherheitsaspekte beschrieben. Dem regen praktischen Einsatz in Ihren eigenen Projekten steht nun nichts mehr im Wege.
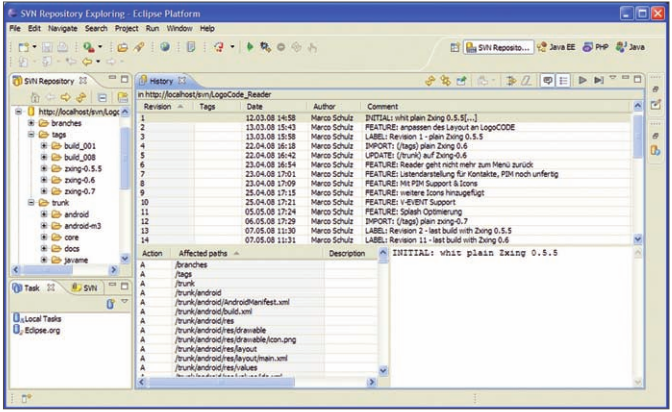
Seit einiger Zeit steht die neue Version 1.5 des Versionsverwaltungs-Tools Subversion (SVN) zum kostenlosen Download bereit. Das Programm ist für verschiedene Plattformen erhältlich, dazu zählen Windows und Linux als die wichtigsten Vertreter. Der Artikel bezieht sich zwar auf das Windows-Betriebssystem, aber mit geringem Aufwand lassen sich die wenigen spezifischen Unterschiede leicht adaptieren. Man kann Subversion auf unterschiedliche Art und Weise betreiben. Für eine lokale Verwendung, bei sehr kleinen Projekten mit lediglich einem einzigen Entwickler, genügt oft die Installation eines Clients. Für Windows Systeme sollte die Wahl des Clients auf TortoiseSVN fallen. Die Anwendung arbeitet als Explorer-Erweiterung und beherrscht alle notwendigen Funktionen zur Arbeit mit SVN. Dazu zählt unter anderem das Anlegen der Projektverzeichnisse, die Repository genannt werden. Der Zugriff auf ein lokales Repository erfolgt über das file:///-Protokoll. Sobald das Repository für mehrere Entwickler bereitstehen soll, wird ein Server benötigt. Man hat die Wahl zwischen einem Standalone-Server oder einer Integration in den Apache Web Server. Die aktuelle Version des SVN-Servers bringt für Windows-Nutzer eine Verbesserung der Konfiguration als Windows-Dienst. Für den Standalone-Server stehen die Protokolle svn:// und svn+ssh:// zur Verfügung. Für diesen Artikel wird vor allem auf die Installation des Apache-Moduls eingegangen. Der Vorteil des Apache liegt darin, mit den Protokollen http:// und https:// auf die Projektverzeichnisse zugreifen zu können. Mit Subclipse liefert Tigris.org SVN als Plug-in für Eclipse, das dem Tortoise-Client kaum in etwas nachsteht. Dank der PHP-Tools ist die Eclipse-IDE nicht mehr nur von Java-Programmierern geschätzt. Abbildung 1 zeigt die Subversion View mit einem geöffneten Projekt in Eclipse.
Abb. 1: Eclipse in der Subversion-Ansicht mit einem geöffneten Projekt
Subversion im Apache
Eine sehr bequeme Möglichkeit Subversion zu nutzen, ist die Integration in den Apache Web Server; damit kann das Repository über das HTTP-Protokoll angesprochen werden. Die Installation ist nicht weiter schwierig, erfordert allerdings eine funktionsfähige Apache-Installation. Wer die aufwändige Installation einer vollständigen Serverumgebung scheut, kann getrost auf XAMPP [4] zurückgreifen. Als Erstes müssen dann die Binaries des SVN für den Apache 2.2.X von der Webseite [5] geladen werden. Die Dateien mod_dav_svn.so, mod_authz_svn.so und der Ordner iconv sind in das Verzeichnis %APACHE_HOME%\modules zu kopieren. Um die Module dem Webserver bekannt zu machen, muss schließlich die Datei httpd.conf im Verzeichnis conf des Apache gemäß Listing 1 editiert werden.
# Anpassungen der httpd.confLoadModule dav_svn_module modules/mod_dav_svn.soLoadModule authz_svn_module modules/mod_authz_svn.soInclude conf/svn.conf
Plaintext
Die ersten beiden Zeilen aktivieren die SVN-Module für den Apache. Um die Konfigurationsdatei übersichtlich zu halten, wird die eigentliche Konfiguration von Subversion über die Anweisung aus Zeile drei in die Datei svn.conf ausgelagert (Listing 2). Die Datei muss im gleichen Verzeichnis wie die httpd.conf angelegt werden.
<IfModule dav_svn_module><Location /svn> DAV svn SVNListParentPath on SVNParentPath D:\Subversion</Location></IfModule>
XML
Über den Eintrag wird die darin eingeschlossene Konfiguration nur dann ausgeführt, wenn das Modul dav_svn_module wie in Listing 1 aktiviert wurde. bestimmt den Pfad, wie das Repository angesprochen werden soll. In diesem Fall ist http://127.0.0.1/svn der korrekte URL, um auf die Repositories zuzugreifen. Der absolute Pfad, in dem die Projektverzeichnisse abgelegt werden, wird mit dem Eintrag SVNParentPath gesetzt. Die Option SVN-ListPArentPath on listet alle Repositories in D:/Subversion über den URL http://localhost/svn auf. Kommentare werden mit # in Apache-Konfigurationsdateien eingeleitet und gelten nur bis zum Zeilenende. Sobald die Konfiguration abgeschlossen ist, muss der Server neu gestartet werden, um die Änderungen wirksam zu machen.
Das Repository
Wie schon erwähnt, heißt das Projektverzeichnis, das von SVN verwaltet wird, Repository. Für jedes Projekt wird üblicherweise ein eigenes Repository verwendet, es ist aber auch möglich, mehrere Projekte in einem gemeinsamen Verzeichnis abzulegen. Neue Projekte werden im Hauptverzeichnis Subversion angelegt, das für den Apache konfiguriert wurde. Für unser Beispiel aus Listing 2 ist dieses Hauptverzeichnis D:/Subversion. Darin wird ein neuer Ordner erzeugt, der den Namen des Projekts erhält. Im nächsten Schritt wird in dem neuen Ordner das eigentliche Repository generiert. Dazu wird mit einem Rechtsklick auf den Ordner, der das Projektverzeichnis beherbergen soll, der Eintrag TortoiseSVN/Projektverzeichnis hier erstellen ausgewählt. Die notwendigen Schritte werden von Tortoise anschließend automatisch ausgeführt und das Projektverzeichnis kann nun benutzt werden. Die von SVN angelegte Ordnerstruktur sollte nun nicht weiter verändert werden, alle Zugriffe auf das Verzeichnis erfolgen über den SVN-Client Tortoise.
In den einzelnen Repositories hat es sich bewährt, die Unterverzeichnisse trunk, branches und tags anzulegen. Der trunk (Stamm) beinhaltet das aktuelle Arbeitsverzeichnis, dort werden alle Projektdateien nach den persönlichen Vorlieben organisiert. Damit stellt der trunk den aktuellen Projektstand dar. In tags (Markierungen) werden spezielle Markierungen während des Projektfortschritts erzeugt. Eine solche Markierung ist beispielsweise eine neue Version der Anwendung. Branches (Verzweigungen) stellen parallele Entwicklungsstränge dar. Das ist meist dann der Fall, wenn eine Version abgeschlossen ist und nach einer Auslieferung weitergepflegt wird. Eine Weiterentwicklung von abgeschlossenen Versionen ist in der Regel dann notwendig, wenn nachträglich Fehler bekannt werden, die direkt behoben werden müssen, noch bevor eine neue Version ausgeliefert werden kann. Damit die Änderungen anschließend auch in der neuen Version verfügbar sind, können beide branches mit einem Merge zusammengeführt werden. Der besondere Vorteil von SVN gegenüber CVS ist die effiziente Art, wie die Verzweigungen und Markierungen gespeichert sind. Subversion erzeugt dafür keine physische Kopie, sondern nutzt Verlinkungen zum Hauptentwicklungsstrang.
Nachträgliche Manipulationen am Repository
Nach einem erfolgreichen Commit lassen sich mit der Standardeinstellung keine Änderungen mehr vornehmen. Wenn Logmeldungen nach dem Commit bearbeitet werden sollen, ist es notwendig, einige Veränderungen vorzunehmen. Dazu wechselt man in den Ordner hooks des betreffenden Repositories. Dort wird die Datei pre-revprop-change.bat mit dem folgenden Inhalt angelegt:
if “%4“ == “svn:log“ exit 0 echo Eigenschaft ‘%4‘ kann nicht geändert werden >&2 exit 1
Das Listing ermöglicht es, die Logmeldungen im Nachhinein noch zu ändern. In hooks können verschiedene Skripte abhängig zu den Aktionen gesteuert werden.
Erste Schritte mit SVN
Um die Projektstruktur in das Repository übertragen zu können, müssen die Ordner und Dateien zuerst im Dateisystem angelegt werden. Sobald das geschehen ist, kann der erste Commit ins Subversion erfolgen. Das Senden der Daten ist als Transaktion angelegt, das bedeutet, im Fehlerfall wird die gesamte Übertragung verworfen. Nur wenn alle Dateien erfolgreich übermittelt worden sind, ist die Änderung erfolgreich. Um einen Import auszuführen, muss auf das Root-Verzeichnis mit den zu übertragenden Dateien navigiert werden. Nun kann mit einem Rechtsklick auf den Hauptordner die Option TortoiseSVN/Import ausgewählt werden. Im Importdialog muss nun der URL zum Projektarchiv angegeben werden. Wenn der Apache Web Server nach Listing 2 konfiguriert wurde, lautet die richtige Adresse http://127.0.0.1/svn/[meinProjekt]. Dazu kann noch eine Logmeldung eingetragen werden.
Der Erfolg des Importierens kann wie üblich über eine Rechtsklick mit dem Eintrag TortoiseSVN/Projektarchiv kontrolliert werden. War der Import erfolgreich, kann die erzeugte Projektstruktur getrost gelöscht werden und es steht der erste Checkout aus dem Projektarchiv an. Dazu wird an die gewünschte Position im Dateisystem gewechselt und dort mit Rechtsklick der Eintrag SVN Auschecken genutzt. Damit nun nicht das gesamte Repository heruntergeladen wird, sondern nur der aktuelle Projektfortschritt, muss der Download-URL um das Verzeichnis trunk erweitert werden. Die übertragenen Dateien werden als lokale Arbeitskopie bezeichnet und sind durch kleine Icons gekennzeichnet. So kann auf einen Blick erkannt werden, wo Änderungen gemacht wurden.
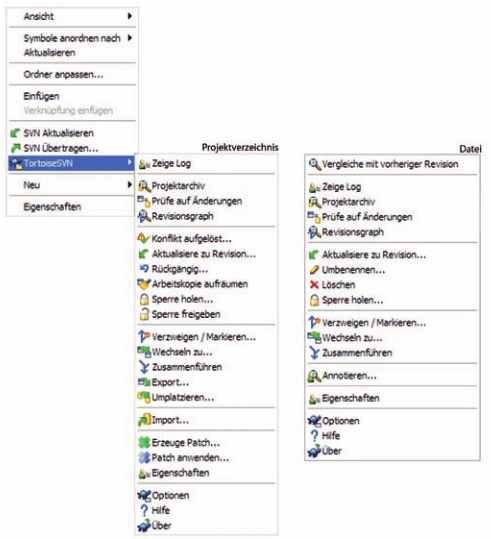
Abb. 2: Funktionsumfang des TortoiseSVN-Clients
Der Screenshot in Abbildung 2 zeigt die typischen Funktionen von TortoiseSVN, die stets mit einem Rechtsklick erreicht werden. Das Kontextmenü unterscheidet bei einer Selektion zwischen Dateien und Verzeichnissen. Bei nichtversionierten Verzeichnissen stehen die Optionen Hinzufügen, Importieren und Ignorieren zur Auswahl. Wenn die Optionen gleich nach der Aufnahme neuer Dateien in die lokale Arbeitskopie gesetzt werden, sind spätere Falschübertragungen bei einem Commit wesentlich geringer. Durch die Verwendung solcher Markierungen werden stets die richtigen Dateien für die Übertragung vorselektiert, und einem falsch gesetzten Haken unter Zeitstress ist so einfach vorzubeugen.
Jeder Commit in das SVN lässt eine interne Revisionsnummer um eins erhöhen. Die letzte übermittelte Revision wird als HEAD bezeichnet und stellt immer den aktuellen Stand dar. Um auf frühere Versionen des Projekts zugreifen zu können, wird diese Revisionsnummer benötigt. Über die Logmeldungen lässt sich nachvollziehen, welche Änderung in einer Revision gemacht wurde. Es ist somit möglich, jederzeit eine bestimmte Revision aus dem Projektarchiv auszuchecken. Bei sehr vielen Revisionen kann die interne Suchfunktion des Clients verwendet werden, um bestimmte Schlüsselwörter in den Logs zu finden. Dies ist auch ein Grund, von vornherein mit Weitblick sinnvolle Beschreibungen zu finden. Eine Logmeldung sollte die Art der Änderung, die betroffenen Funktionen und eine kurze Beschreibung beinhalten. Ein Beispiel für eine solche Meldung ist: >>FEATURE: Kalender – Berechnung Ostersonntag hinzugefügt.<<
Revision oder Version?
Wichtig im Umgang mit einer Versionsverwaltung ist die Unterscheidung der Begriffe Build und Version. Ein Build ist ein einzelner Iterationsschritt, welcher der erstellten Anwendung nur eine einzige neue Funktion, beziehungsweise ein Feature hinzufügt. Ein Build ist mit der Revisionsnummer im SVN gleichzusetzen. Die Version einer Software ist eine Zusammenstellung verschiedener Funktionen und Features. Erst wenn die geforderte Funktionalität einer Version implementiert ist, erfolgt das Erhöhen der Versionsnummer. Die Version besteht also aus mehreren Builds.
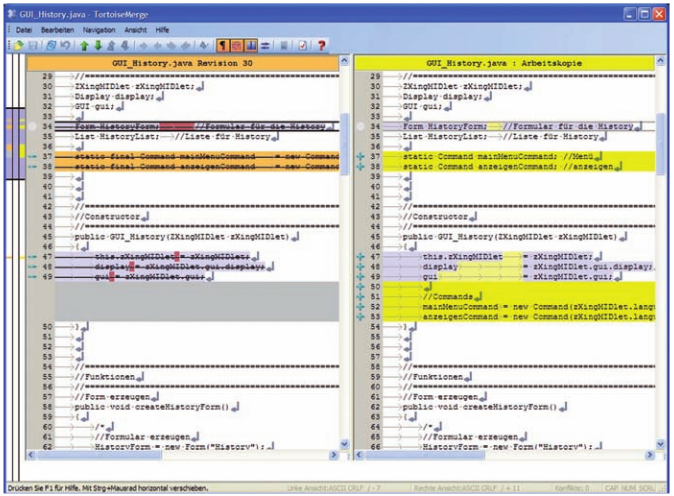
In manchen Fällen ist es wichtig, im Repository Dateien gegen Veränderungen zu sichern. Dafür kann der Mechanismus Sperre holen und Sperre freigeben benutzt werden. Solange Dateien gesperrt sind, können sie nicht durch einen Commit verändert werden. Das beugt Konflikten vor, die entstehen, wenn eine Datei gleichzeitig editiert wird. Um Unterschiede in den Revisionen einer Datei zu erkennen, steht ein so genannter Diff zur Verfügung. Die Abbildung 3 zeigt einen solchen Diff. Es wird immer der Unterschied der aktuellen Arbeitskopie zur vorhergehenden Revision angezeigt. Tortoise lässt sich auch mit dem freien Tool WinMerge kombinieren, um weitere Funktionen zum Dateivergleich zur Verfügung zu haben. Das ist besonders dann interessant, wenn mehrere Revisionen einer Datei verglichen werden müssen. Dazu muss nicht immer das ganze Projekt ausgecheckt werden, es genügt durchaus, nur die betreffenden Files herunterzuladen.
Abb. 3: Diff-Ansicht des Tortoise-Clients
Markieren und Verzweigen
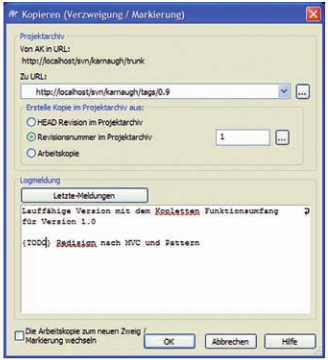
Abb. 4: Verzweigen/Markieren-Dialog
Eine Markierung stellt einen semantischen Zusammenhang des Projektfortschritts zu einer Revisionsnummer im Repository dar. Um das Repository übersichtlich zu halten, werden nur vorher festgelegte Revisionen getaggt. Eine solche Revision kann beispielsweise der Sprung auf eine neue Version der eigenen Applikation sein oder ein Upgrade eines verwendeten Frameworks auf eine aktuelle Version. Wenn einmal eine Markierung nicht sofort angelegt wurde, ist dies auch nicht problematisch. Tags können jederzeit auch aus jeder beliebigen Revisionsnummer erzeugt werden. Daher ist es unproblematisch, nach mehreren Commits die gewünschte Revision im Nachhinein zu taggen. Um eine Markierung zu erzeugen, wird der Eintrag Verzweigen/Markieren im Kontexmenü benutzt. Dazu ist es wichtig, auch im Root-Ordner des gesamten Projekts zu sein, da sonst nur Teile getaggt werden. In Abbildung 4 ist der betreffende Dialog dargestellt. An der ersten Position ist das Quellverzeichnis angegeben. Im Eingabefeld Zu URL wird der Pfad von trunk nach tags korrigiert. In tags ist es notwendig, den Pfad mit einem neuen Ordner zu erweitern, der z. B. die Versionsnummer als Namen besitzt. Wenn der Pfad des trunks nicht erweitert wird, kommt es zu einer Fehlermeldung und der tag wird nicht angelegt. Als Nächstes wird die Auswahl getroffen, welche Revision verwendet werden soll. Zu guter Letzt darf natürlich auch eine Logmeldung nicht fehlen. Wenn nun das Projektarchiv geöffnet wird, ist im Verzeichnis tags ein neuer Ordner angelegt, der sämtliche Projektdateien zu einem bestimmten Revisionsstand enthält. In tags werden keine Änderungen übertragen.
Für Verzweigungen wird analog vorgegangen, nur dass das Verzeichnis tags durch branches ersetzt werden muss. Bei der späteren Arbeit mit Entwicklungszweigen, die vom trunk abweichen, muss der Commit auch stets in das entsprechende Unterverzeichnis von branches übertragen werden. Das Zusammenführen eines branchs mit der HEAD-Revision des trunks erfolgt über das Kontexmenü. Die vorhandenen Konflikte müssen von Hand über den Diff-Betrachter aufgelöst werden.
Fazit
Wie zu erkennen ist, handelt es sich bei Subversion um ein sehr leistungsfähiges Werkzeug, dessen Leistungsspektrum von diesem Artikel nur angerissen werden konnte. Eine ausführliche Abhandlung zur Theorie und weiterführende Konzepte mit Subversion sind im SVN Book zu finden.