
Die mittlerweile im Software Engineering etablierten Paradigmen wie Test Driven Development (TDD) und Behavior Driven Development (BDD) mit entsprechend einfach zu bedienenden Werkzeugen haben eine neue pragmatische Sichtweise auf das Thema Software Tests eröffnet. Ein wichtiger Faktor in kommerziellen Softwareprojekten sind automatisierte Tests. Deshalb spricht man in diesem Kontext von einer erfolgreichen Teststrategie, wenn die Testausführung ohne menschliches Zutun vonstattengeht.
Testautomatisierung bildet die Grundlage, um Stabilität und Risikoreduzierung bei kritischen Arbeiten zu erreichen. Zu solchen kritischen Tätigkeiten zählen insbesondere das Refactoring, Maintenance und Fehlerkorrekturen. Allen diesen Aktivitäten obliegt eine Gemeinsamkeit: dass sich keine neuen Fehler in den Code einschleichen dürfen.
In dem Artikel „The Humble Programmer“ von 1972 stellte Edsger W. Dijkstra folgendes fest:
„Programmtests können ein sehr effektiver Weg sein, um das Vorhandensein von Fehlern aufzuzeigen, sind aber völlig unzureichend, um deren Abwesenheit nachzuweisen.“
Eine alleinige Automatisierung der Testausführung ist deshalb nicht ausreichend, um sicherzustellen, dass Änderungen der Codebasis keine unerwünschten Effekte auf bestehende Funktionen haben. Aus diesem Grund muss die Qualität der Testfälle bewertet werden. Hierzu gibt es bereits bewährte Werkzeuge.
Bevor wir tiefer in die Thematik einsteigen, wollen wir uns zuerst überlegen, was eigentlich automatisiertes Testen bedeutet. Diese Frage ist recht einfach zu beantworten. Nahezu jede Programmiersprache hat ein entsprechendes Unit Test Framework. Unit Tests rufen eine Methode mit verschiedenen Parametern auf und vergleichen den Rückgabewert mit einem Erwartungswert. Stimmen beide Werte überein, gilt der Test als bestanden. Zusätzlich kann noch überprüft werden, ob eine Ausnahme geworfen wurde.
Für den Fall, dass eine Methode keinen Rückgabewert hat oder keinen Fehler wirft, kann diese Methode nicht getestet werden. Auch als private gekennzeichnete Methoden oder innere Klassen, sind nicht ohne Weiteres zu testen, da sie nicht direkt aufgerufen werden können. Diese sind über öffentliche Methoden, welche die ‚versteckten‘ Methoden aufrufen, zu testen.
Im Umgang mit als private gekennzeichneten Methoden ist es keine Option, die dadurch abgebildete Funktionalität über Techniken wie die Verwendung der Reflection API zu erreichen und zu testen. Denn wir müssen uns bewusst machen, dass solche Methoden oft auch dazu verwendet werden, Fragmente zu kapseln, um Dopplungen zu vermeiden.
public boolean method() {
boolean success = false;
List collector = new ArryList();
collector.add(1);
collector.add(2);
collector.add(3);
sortAsc(collector);
if(collector.getFirst().equals(1)) {
success = true;
}
return success;
}
private void sortAsc(List collection) {
collection.sort(
(a, b) -> {
return -1 * a.compareTo(b);
});
}Um also effektiv automatisierte Tests schreiben zu können, ist es notwendig, einem gewissen Codingstil zu folgen. Das vorangegangene Listing 1 demonstriert auf einfache Weise, wie testbarer Code aussehen kann.
Da Entwickler für ihre eigene Implementierung auch die zugehörigen Komponententests schreiben, ist das Problem von schwer testbarem Code in Projekten, die einem testgetriebenen Ansatz folgen, weitgehend eliminiert. Die Motivation zu testen liegt nun beim Entwickler, da dieser mit diesem Paradigma feststellen kann, ob seine Implementierung sich wie gewünscht verhält. Dabei müssen wir uns aber fragen: Ist das bereits alles, was wir tun müssen, um gute und stabile Software zu entwickeln?
Wie wir uns bei solchen Fragen immer denken können, lautet die Antwort nein. Ein essenzielles Werkzeug, um die Qualität der Tests zu bewerten, ist das Erreichen einer möglichst hohen Testabdeckung. Dabei wird zwischen Branch und Line Coverage unterschieden. Um den Unterschied etwas besser zu verdeutlichen, schauen wir kurz auf den Pseudocode in Listing 2.
if( Expression-A OR Expression-B ) {
print(‘allow‘);
} else {
print(‘decline‘);
}
Unser Ziel ist es, nach Möglichkeit alle Zeilen zu durchlaufen. Dazu brauchen wir bereits zwei separate Testfälle. Einen für das Betreten des IF-Zweiges und einen für das Betreten des ELSE-Zweiges. Damit wir aber auch eine hundertprozentige Branch-Coverage erzielen, müssen wir alle Varianten des IF-Zweiges abdecken. Für das Beispiel heißt das: ein Test, der Expression-A true werden lässt, und ein weiterer Test, der Expression-B true werden lässt. Daraus ergeben sich insgesamt drei verschiedene Testfälle.
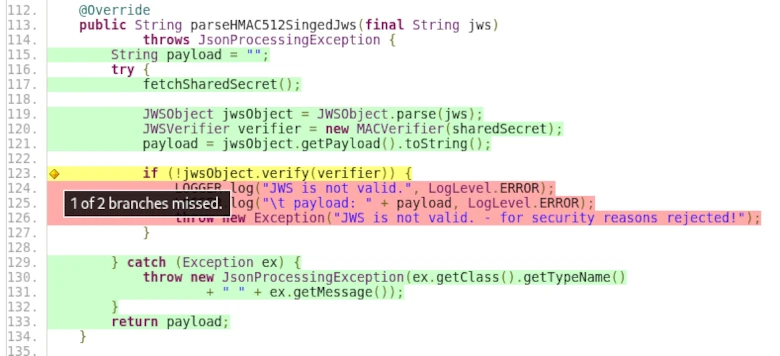
Der Screenshot aus dem Projekt TP-CORE zeigt, wie eine solche Testabdeckung in ‚echten‘ Projekten aussehen kann.
Natürlich ist dieses Beispiel sehr einfach und es gibt im wirklichen Leben oft Konstrukte, bei denen man trotz aller Bemühungen nicht alle Lines beziehungsweise Branches erreicht. Sehr typisch sind Exceptions aus Fremdbibliotheken, die zu fangen sind, aber unter normalen Umständen nicht provoziert werden können.
Aus diesem Grund versuchen wir zwar, eine möglichst hohe Testabdeckung zu erreichen, und streben natürlich die 100 % an, aber es gibt genügend Fälle, in denen dies nicht möglich ist. Eine Testabdeckung von 90% gelingt aber durchaus. Der Industriestandard für kommerzielle Projekte liegt bei 85 % Testabdeckung. Mit diesen Erkenntnissen können wir also sagen, dass die Testabdeckung mit der Testbarkeit einer Anwendung korreliert. Das bedeutet, die Testabdeckung ist ein geeignetes Maß für die Testbarkeit.
Hier muss man allerdings auch zugeben, dass die Metrik der Testabdeckung ihre Grenze hat. Reguläre Ausdrücke und Annotationen zur Datenvalidierung sind nur einige einfache Beispiele für eine nicht aussagefähige Testabdeckung.
Ohne allzu sehr in die Implementierungsdetails einzugehen, stellen wir uns vor, wir müssten einen regulären Ausdruck schreiben, um Eingaben auf ein korrektes 24 Stunden Format zu überprüfen. Haben wir das korrekte Intervall nicht im Auge, ist unser regulärer Ausdruck möglicherweise nicht korrekt. Das richtige Intervall für das 24-Stunden-Format lautet: 00:00 – 23:59. Beispiele für fehlerhafte Werte sind 24:00 oder 23:60. Ist uns dieser Fakt nicht bewusst, können trotz Testfällen Fehler in unserer Anwendung versteckt sein, bis sie verwendet werden un zu Fehlern führen.
Dies ist ein hervorragendes Beispiel für das Zitat von Dijkstra zu Beginn des Artikels. Zudem möchte ich noch ein weiteres Zitat aus einem Artikel anführen, an dem Christian Bird mitgewirkt hat. Der Artikel heißt „The Design of Bug Fixes“ und ist aus dem Jahr 2013.
„… In a few cases, participants were unable to think of alternative solutions …“
Hier ging es um die Fragestellung, ob eine Fehlerkorrektur immer die optimale Lösung darstellt. Abgesehen davon wäre zu klären, was in kommerziellen Softwareentwicklungsprojekten eine optimale Lösung darstellt. Sehr demonstrativ ist die Aussage, dass es Fälle gibt, in denen Entwickler nur einen Weg kennen beziehungsweise verstehen. Das spiegelt auch unser Beispiel der RegEx wider. Softwareentwicklung ist ein Denkprozess, der sich auch nicht beschleunigen lässt. Unser Denken wird durch unsere Vorstellungskraft bestimmt, die wiederum von unserer Erfahrung beeinflusst ist.
Dies zeigt uns bereits ein weiteres Beispiel für Fehlerquellen in Testfällen. Ein Klassiker sind z. B. inkorrekte Vergleiche in Collections. Es geht unter anderem um das Vergleichen von Arrays. Die Problematik, mit der wir hier zu kämpfen haben, ist das Thema, wie auf Variablen zugegriffen wird: Call by Value oder Call by Reference. Bei Arrays erfolgt der Zugriff über Call by Reference, also direkt auf die Speicherzelle. Weist man nun ein Array einer neuen Variable zu und vergleicht beide Variablen, sind diese immer gleich, da man das Array mit sich selbst vergleicht. Ein Beispiel für einen Testfall, der eigentlich keine Aussagekraft hat. Ist die Implementierung dennoch korrekt, wird dieser fehlerhafte Testfall nie ins Gewicht fallen.
Diese Erkenntnis zeigt uns, dass ein blindes Erreichen der Testabdeckung für die Qualität nicht zielführend ist. Natürlich ist es verständlich, dass im Management diese Metrik einen hohen Stellenwert hat. Wir haben aber auch nachweisen können, das man sich darauf alleine nicht verlassen darf. Wir sehen also, dass auch für Testfälle Codeinspektionen und Refactorings ein Bedarf besteht. Da man aus Zeitgründen nun nicht den ganzen Code von vorn bis hinten lesen und auch verstehen kann, ist es wichtig, auf problematische Bereiche zu konzentrieren. Wie kann man aber diese Problembereiche finden? Hier hilft uns eine vergleichsweise neue Technik. Die theoretischen Arbeiten dazu sind bereits etwas älter, es hat nur eine Weile gedauert, bis entsprechende Implementierungen verfügbar wurden.
Mutation Testing. Dies erlaubt, durch Veränderung des Originalcodes Testfälle zu finden, die trotz verschiedener Mutationen nicht fehlschlagen. Damit haben wir ein weiteres Werkzeug an der Hand, die Qualität der vorhandenen Tests zu bewerten. In diesem Artikel habe ich zeigen können, dass man sich nicht komplett auf die Testcoverage verlassen darf. Um dieses Problem zu lösen, können wir uns des Mutation Testing bedienen. Wie konkret Mutation Testing funktioniert, kann wiederum Thema eines eigenständigen Artikels sein und würde an dieser Stelle den Rahmen sprengen.



Schreibe einen Kommentar
Du musst angemeldet sein, um einen Kommentar abzugeben.