
The secure use of source control management (SCM) systems such as Git is essential for programmers (development) and system administrators (operations). This group of tools has a long tradition in software development and enables development teams to work together on a code base. Four questions are answered: When was the change made? Who made the change? What was changed? Why was something changed? It is therefore a pure collaboration tool.
With the advent of the open source code hosting platform GitHub, so-called Pull Requests were introduced. Pull requests are a workflow in GitHub that allows developers to provide code changes for repositories to which they only have read access. Only after the owner of the original repository has reviewed the proposed changes and approved them are these changes integrated by him. This is also how the name comes about. A developer copies the original repository into his GitHub workspace, makes changes and requests the owner of the original repository to adopt the change. The latter can then accept the changes and if necessary adapt them himself or reject them with a reason.
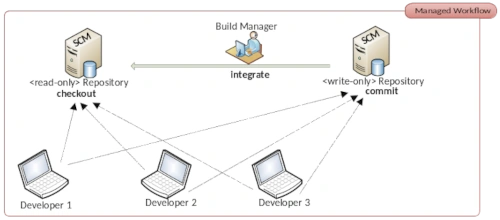
Anyone who thinks that GitHub was particularly innovative is mistaken. This process is very old hat in the open source community. Originally, this procedure was called the Dictatorship Workflow. IBM’s commercial SCM Rational Synergy first published in 1990 is based precisely on the Dictatorship Workflow. With the class of distributed version management tools which Git also belongs to the Dictatorship Workflow is quite easy to implement. So it was obvious that GitHub would make this process available to its users. GitHub has chosen a much more appealing name. Anyone who works with the free DevOps solution GitLab, for example will know pull requests as merge requests. The most common Git servers now contain the pull request process. Without going into too much detail about the technical details of implementing pull requests we will focus our attention on the usual problems that open source projects face.
Developers who want to participate in an open source project are called maintainers. Almost every project has a short guide on how to support the project and which rules apply. For people who are learning to program, open source projects are ideal for quickly and significantly improving their own skills. For the open source project this means that you have maintainers with a wide range of skills and experience. If you don’t establish a control mechanism the code base will erode in a very short time.
If the project is quite large and there are a lot of maintainers working on the code base it is hardly possible for the owner of the repository to process all pull requests in a timely manner. To counteract this bottleneck the Dictatorship Workflow was expanded to the Dictatorship – Lieutenant Workflow. An intermediate instance was introduced that distributes the review of pull requests across several shoulders. This intermediate layer the so-called Lieutenants are particularly active maintainers with an already established reputation. The Dictator therefore only needs to review the Lieutenants’ pull requests. An immense reduction in workload that ensures that there is no backlog of features due to unprocessed pull requests. After all the improvements or extensions should be included in the code base as quickly as possible so that they can be made available to users in the next release.
This approach is still the standard in open source projects to ensure quality. You can never say who is involved in the project. There may even be one or two saboteurs. This idea is not so far-fetched. Companies that have strong competition for their commercial product from the free open source sector could come up with unfair ideas here if there were no regulations. In addition maintainers cannot be disciplined as is the case with team members in companies, for example. It is difficult to threaten a maintainer who is resistant to advice and does not adhere to the project’s conventions despite repeated requests with a pay cut. The only option is to exclude this person from the project.
Even if the problem of disciplining employees in commercial teams described above is not a problem. There are also difficulties in these environments that need to be overcome. These problems date back to the early days of version control tools. The first representatives of this species were not distributed solutions just centralized. CVS and Subversion (SVN) only ever keep the latest revision of the code base on the local development computer. Without a connection to the server you can actually not work. This is different with Git. Here you have a copy of the repository on your own computer, so you can do your work locally in a separate branch and when you are finished you bring these changes into the main development branch and then transfer them to the server. The ability to create offline branches and merge them locally has a decisive influence on the stability of your own work if the repository gets into an inconsistent state. Because in contrast to centralized SCM systems you can now continue working without having to wait for the main development branch to be repaired.
These inconsistencies arise very easily. All it takes is forgetting a file when committing and team members can no longer compile the project locally and are hampered in their work. The concept of Continuous Integration (CI) was established to overcome this problem. It is not as is often wrongly assumed about integrating different components into an application. The aim of CI is to keep the commit stage – the code repository – in a consistent state. For this purpose build servers were established which regularly check the repository for changes and then build the artifact from the source code. A very popular build server that has been established for many years is Jenkins. Jenkins originally emerged as a fork of the Hudson project. Build Servers now takes on many other tasks. That is why it makes a lot of sense to call this class of tools automation servers.
With this brief overview of the history of software development, we now understand the problems of open source projects and commercial software development. We have also discussed the history of the pull request. In commercial projects, it often happens that teams are forced by project management to work with pull requests. For a project manager without technical background knowledge, it makes a lot of sense to establish pull requests in his project as well. After all, he has the idea that this will improve code quality. Unfortunately, this is not the case. The only thing that happens is that a feature backlog is provoked and the team is forced to work harder without improving productivity. The pull request must be evaluated by a competent person. This causes unpleasant delays in large projects.

Now I often see the argument that pull requests can be automated. This means that the build server takes the branch with the pull request and tries to build it, and if the compilation and automated tests are successful, the server tries to incorporate the changes into the main development branch. Maybe I’m seeing something wrong, but where is the quality control? It’s a simple continuous integration process that maintains the consistency of the repository. Since pull requests are primarily found in the Git environment, a temporarily inconsistent repository does not mean a complete stop to development for the entire team, as is the case with Subversion.
Another interesting question is how to deal with semantic merge conflicts in an automatic merge. These are not a serious problem per se. This will certainly lead to the rejection of the pull request with a corresponding message to the developer so that the problem can be solved with a new pull request. However, unfavorable branch strategies can lead to disproportionate additional work.
I see no added value for the use of pull requests in commercial software projects, which is why I advise against using pull requests in this context. Apart from a complication of the CI / CD pipeline and increased resource consumption of the automation server which now does the work twice, nothing else has happened. The quality of a software project can be improved by introducing automated unit tests and a test-driven approach to implementing features. Here it is necessary to continuously monitor and improve the test coverage of the project. Static code analysis and activating compiler warnings bring better results with significantly less effort.
Personally, I believe that companies that rely on pull requests either use them for complicated CI or completely distrust their developers and deny that they do a good job. Of course, I am open to a discussion on the topic, perhaps an even better solution can be found. I would therefore be happy to receive lots of comments with your views and experiences about dealing with pull requests.



Leave a Reply
You must be logged in to post a comment.