
One of the most important insights into software testing comes from the much-cited article “The Humble Programmer,” published by Dijkstra in 1972. In essence, it states that testing can only detect errors, but it is impossible to prove that the program is error-free. Conversely, this means that high-quality testing uncovers as many errors as possible, thus reducing the likelihood of further errors existing in the program.
The first question that arises is what constitutes “good” test quality. A crucial factor is performance. If test execution takes longer than 5 minutes, it disrupts the developer’s workflow. If test execution takes longer than 10 minutes, developers lose acceptance of running tests automatically during the build process. This leads to test execution being disabled locally, thus violating the principle of failing as quickly as possible in case of an error. The principle of rapid failure is one of the cornerstones of automated software testing, as it allows for timely addressing and fixing of the problem. This rapid response is what supports the developer’s workflow and thus avoids so-called context switching. The less time one has to adapt to a new situation, the more productive one can be, which can result in a significant reduction in development costs. We can say that it’s not the number of tests that matters, but rather writing the right, i.e., relevant, tests.
The work of McCabe, who formulated a measure of complexity in 1976, provides an idea of how many test cases are needed. The complexity score of a function or method serves as a benchmark for the number of required test cases. However, a high number of test cases does not automatically mean that they are relevant to the correctness of the method or function. The usefulness, or in other words, the expressiveness of the existing test cases, results from how well they cover the existing code. Only complete coverage ensures that all areas of a function have been executed and are thus covered by a test case. When considering test coverage, we distinguish between two metrics: the coverage of all lines of code and the coverage of all branches. Achieving high test coverage is particularly difficult in so-called legacy projects. To keep the effort required for meaningful tests manageable, it’s necessary to achieve 100% line and branch coverage only for newly added features. If 100% coverage cannot be reached, this indicates the need for refactoring to ensure the testability of the added functionality.

Let’s assume the optimal case and consider a so-called greenfield project, whose number of test cases corresponds to McCabe’s complexity measure and for which we can already demonstrate 100% test coverage for lines and branches. We still face the problem Dijkstra formulated. We must be aware that while we can prove we’ve entered all code sections with a test case, we cannot verify whether our assumptions about the source code’s behavior are correct. In the context of xUnit tests, this involves the various assert functions that test a function against an expected value. Here’s a classic example for Java Collections, which can also be applied to other programming languages:
Lists, or more precisely, the ArrayList implemented in Java, doesn’t store the list elements as values within the list itself, but uses call-by-reference, which only references the memory address of the list element. Therefore, when performing operations on existing lists, we are always manipulating the original list. When comparing the original list with the manipulated list in a test case, they are always identical because they are the same list. Only when a true copy of the original is created, for example, using a copy constructor, which is then manipulated to perform comparison tests, are the assumptions made correct. To put it bluntly, 100% test coverage can be achieved without a real safety net for error detection.
To discover such logical errors as just described in tests, we can use so-called mutation testing. The concept of mutation testing also has its origins in the 1970s. In his 1971 article “Fault Diagnostics of Computer Programs,” Richard Lipton described the idea of mutation testing, which led to numerous further research projects.
The idea behind mutation testing is very simple, like so many groundbreaking achievements. Let’s assume that the source code contains an expression if(var > 0) and a corresponding test has been formulated for this expression. If we now change the condition in the if statement, the associated test should fail. There are several ways to modify the if statement. One option is to reverse the operator from > to <. Using other operators like = or ! is also possible. Another option is to change the comparison value of 0. This can be achieved by incrementing or decrementing it by 1. All these variations represent so-called mutations of the original expression, which is why they can also be referred to as mutants. The goal is to ensure that as many mutants as possible cause the existing test case to fail. Each mutant that causes the test case to fail is called a “kill.”
If none of the generated mutants cause the test case to fail, the correctness of the test case is questionable and must be verified. Ideally, all mutants should cause the test case to fail, although this is rather the exception. Meaningful test cases should achieve a mutation score of at least 70%. The calculation of the mutation score, or kill rate, is as follows: To calculate the mutation score, divide the number of killed mutants (mutants that caused the test to fail) by the total number of mutants generated and multiply the result by 100 to obtain a percentage. For example, if 7 out of 10 mutants are killed, the mutation score is 70%.
Mutation Score = (Killed Mutants / (Total Mutants - Equivalent Mutants)) × 100
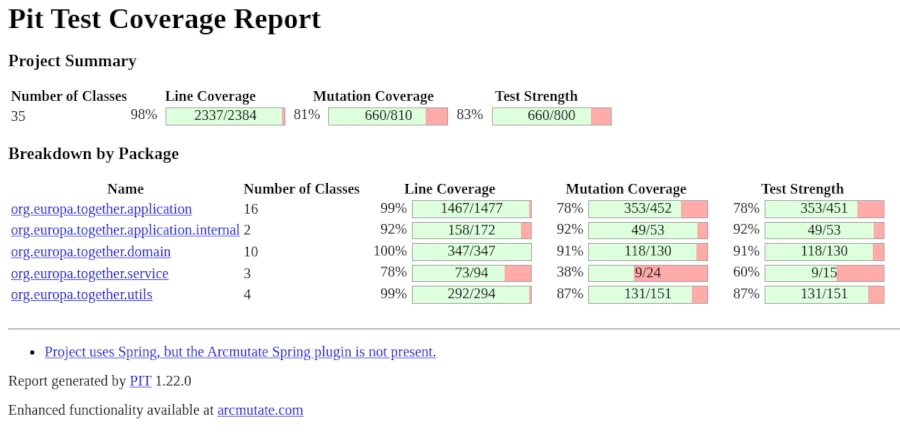
Some mutants behave functionally identically to the original code. These equivalent mutants cannot be eliminated by any test, as they do not represent actual errors. This provides us with a decision criterion that can be helpful when the mutation score is low and when assessing the situation.
Even though the concept described here is very easy to understand, as is so often the case, the devil is in the details. Firstly, appropriate mutation operators must be selected, and secondly, the number of generated mutants should be limited to minimize test execution time. Since determining the mutation score can be very time-consuming depending on the size of the codebase, mutation tests should not be run via the standard build process but rather as a separate test procedure. Generally speaking, however, developers with a good understanding of test-driven software development will quickly grasp the topic of mutation testing. Mutant testing, combined with high test coverage, is also a very powerful tool for project management evaluation, allowing them to assess the system without reading the source code. Finally, it is crucial to note that the procedure described here cannot address security concerns. To ensure that the application is protected against hacker attacks such as SQL injections, specialized security audits are essential.











![jConf Peru 2021 [2]](https://elmar-dott.com/wp-content/uploads/2021-JCONF-Peru-Deploy-MVN-Central.webp)






