

In the previous part of the article treasure chest, I described how the database connection for the TP-CORE library got established. Also I gave a insight to the internal structure of the ConfiguartionDO. Now in the second part I explain the ConfiguartionDAO and its corresponding service. With all this knowledge you able to include the application configuration feature of TP-CORE in your own project to build your own configuration registry.
Lets resume in short the architectural design of the TP-CORE library and where the fragments of the features located. TP-CORE is organized as layer architecture as shown in the graphic below.

As you can see there are three relevant packages (layer) we have to pay attention. As first the business layer resides like all other layers in an equal named package. The whole API of TP-CORE is defined by interfaces and stored in the business layer. The implementation of the defined interfaces are placed in the application layer. Domain Objects are simple data classes and placed in the domain layer. Another important pattern is heavily used in the TP-CORE library is the Data Access Object (DAO).
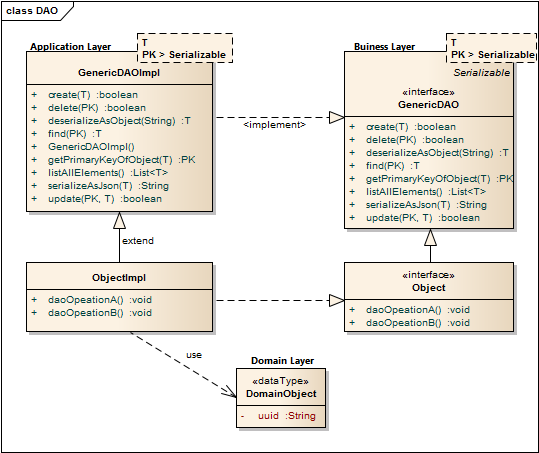
The GenericDAO provides the basic CRUD operations, we don’t need to repeat in every specialization again. A full description how the GenericDAO is implemented I documented in the GitHub Wiki of TP-CORE.
Now the days micro services and RESTful application are state of the art. Especially in TP-CORE the defined services aren’t REST. This design decision is based on the mind that TP-CORE is a dependency and not a standalone service. Maybe in future, after I got more feedback how and where this library is used, I could rethink the current concept. For now we treat TP-CORE as what it is, a library. That implies for the usage in your project, you can replace, overwrite, extend or wrap the basic implementation of the ConfigurationDAO to your special necessities.
To keep the portability of changing the DBMS Hibernate (HBM) is used as JPA implementation and O/R mapper. The Spring configuration for Hibernate uses the EntityManager instead of the Session, to send requests to the DBMS. Since version 5 Hibernate use the JPA 2 standard to formulate queries.
As I already mentioned, the application configuration feature of TP-CORE is implemented as DAO. The domain object and the database connection was topic of the first part of this article. Now I discuss how to give access to the domain object with the ConfigurationDAO and its implementation ConfigurationHbmDAO. The domain object ConfigurationDO or a list of domain objects will be in general the return value of the DAO. Actions like create are void and throw just an exception in the case of a failure. For a better style the return type is defined as Boolean. This simplifies also writing unit tests.
Sometimes it could be necessary to overwrite a basic implementation. A common scenario is a protected delete. For example: a requirement exist that a special entry is protected against a unwanted deletion. The most easy solution is to overwrite the delete whit a statement, refuses every time a request to delete a domain object whit a specific UUID. Only adding a new method like protectedDelete() is not a god idea, because a developer could use by accident the default delete method and the protected objects are not protected anymore. To avoid this problem you should prefer the possibility of overwriting GenericDAO methods.
As default query to fetch an object, the identifier defined as primary key (PK) is used. A simple expression fetching an object is written in the find method of the GenericHbmDAO. In the specialization as ConfigurationHbmDAO are more complex queries formulated. To keep a good design it is important to avoid any native SQL. Listing 1 shows fetch operations.
//GenericHbmDAO
public T find(final PK id) {
return mainEntityManagerFactory.find(genericType, id);
}
//ConfigurationHbmDAO
public List getAllConfigurationSetEntries(final String module,
final String version, final String configSet) {
CriteriaBuilder builder = mainEntityManagerFactory.getCriteriaBuilder();
CriteriaQuery query = builder.createQuery(ConfigurationDO.class);
// create Criteria
Root root = query.from(ConfigurationDO.class);
query.where(
builder.equal(root.get("modulName"), module),
builder.equal(root.get("version"), version),
builder.equal(root.get("configurationSet"), configSet)
);
return mainEntityManagerFactory.createQuery(query).getResultList();
}The readability of these few lines of source is pretty easy. The query we formulated for getAllConfigurationSetEntries() returns a list of ConfigurationDO objects from the same module whit equal version of a configSet. A module is for example the library TP-CORE it self or an ACL and so on. The configSet is a namespace that describes configuration entries they belong together like a bundle and will used in a service like e-mail. The version is related to the service. If in future some changes needed the version number have increase. Lets get a bit closer to see how the e-mail example will work in particular.
We assume that a e-mail service in the module TP-CORE contains the configuration entries: mailer.host, mailer.port, user and password. As first we define the module=core, configSet=email and version=1. If we call now getAllConfigurationSetEntries(core, 1, email); the result is a list of four domain objects with the entries for mailer.host, mailer.port, user and password. If in a newer version of the email service more configuration entries will needed, a new version will defined. It is very important that in the database the already exiting entries for the mail service will be duplicated with the new version number. Of course as effect the registry table will grow continual, but with a stable and well planned development process those changes occur not that often. The TP-CORE library contains an simple SMTP Mailer which is using the ConfigurationDAO. If you wish to investigate the usage by the MailClient real world example you can have a look on the official documentation in the TP-CORE GitHub Wiki.
The benefit of duplicate all existing entries of a service, when the service configuration got changed is that a history is created. In the case of update a whole application it is now possible to compare the entries of a service by version to decide exist changes they take effect to the application. In practical usage this feature is very helpful, but it will not avoid that updates could change our actual configuration by accident. To solve this problem the domain object has two different entries for the configuration value: default and configuration.
The application configuration follows the convention over configuration paradigm. Each service need by definition for all existing configuration entries a fix defined default value. Those default values can’t changed itself but when the value in the ConfigurationDO is set then the defaultValue entry will ignored. If an application have to be updated its also necessary to support a procedure to capture all custom changes of the updated configuration set and restore them in the new service version. The basic functionality (API) for application configuration in TP-CORE release 3.0 is:
- void updateConfigurationEntries(List<ConfigurationDO> configuration)
- ConfigurationDO getConfigurationByKey( String key, String module, String version)
- List<ConfigurationDO> getAllConfigurationSetEntries(String module, String version, String configSet)
- List<ConfigurationDO> getAllModuleEntries(String module)
- List<ConfigurationDO> getAllDeprecatedEntries()
- List<ConfigurationDO> getHistoryOfAEntry(String module, String key, String configSet)
- String getValueByKey(String key, String module, String version)
- void restoreKeyToDefault(ConfigurationDO entry)
The following listing gives you an idea how a implementation in your own service could look like. This snipped is taken from the JavaMailClient and shows how the internal processing of the fetched ConfigurationDO objects are managed.
private void processConfiguration() {
List configurationEntries =
configurationDAO.getAllConfigurationSetEntries("core", 1, "email");
for (ConfigurationDO entry : configurationEntries) {
String value;
if (StringUtils.isEmpty(entry.getValue())) {
value = <strong>entry.getDefaultValue</strong>();
} else {
value = <strong>entry.getValue</strong>();
}
if (entry.getKey()
.equals(cryptoTools.calculateHash("mailer.host",
HashAlgorithm.SHA256))) {
configuration.replace("mailer.host", value);
} else if (entry.getKey()
.equals(cryptoTools.calculateHash("mailer.port",
HashAlgorithm.SHA256))) {
configuration.replace("mailer.port", value);
} else if (entry.getKey()
.equals(cryptoTools.calculateHash("user",
HashAlgorithm.SHA256))) {
configuration.replace("mailer.user", value);
} else if (entry.getKey()
.equals(cryptoTools.calculateHash("password",
HashAlgorithm.SHA256))) {
configuration.replace("mailer.password", value);
}
}
}Another functionality of the application configuration is located in the service layer. The ConfigurationService operates on the module perspective. The current methods resetModuleToDefault() and filterMandatoryFieldsOfConfigSet() already give a good impression what that means.
If you take a look on the MailClientService you detect the method updateDatabaseConfiguration(). May you wonder why this method is not part of the ConfigurationService? Of course this intention in general is not wrong, but in this specific implementation is the update functionality specialized to the MailClient configuration. The basic idea of the configuration layer is to combine several DAO objects to a composed functionality. The orchestration layer is the correct place to combine services together as a complex process.
Resume
The implementation of the application configuration inside the small library TP-CORE allows to define an application wide configuration registry. This works also in the case the application has a distribute architecture like micro services. The usage is quite simple and can easily extended to own needs. The proof that the idea is well working shows the real world usage in the MailClient and FeatureToggle implementation of TP-CORE.
I hope this article was helpful and may you also like to use TP-CORE in your own project. Feel free to do that, because of the Apache 2 license is also no restriction for commercial usage. If you have some suggestions feel free to leave a comment or give a thumbs up.
