
The paradigms now established in software engineering, such as Test-Driven Development (TDD) and Behavior-Driven Development (BDD), along with correspondingly easy-to-use tools, have opened up a new, pragmatic perspective on the topic of software testing. Automated tests are a crucial factor in commercial software projects. Therefore, in this context, a successful testing strategy is one in which test execution proceeds without human intervention.
Test automation forms the basis for achieving stability and reducing risk in critical tasks. Such critical tasks include, in particular, refactoring, maintenance, and bug fixes. All these activities share one common goal: preventing new errors from creeping into the code.
In his 1972 article “The Humble Programmer,” Edsger W. Dijkstra stated the following:
„Program testing can be a very effective way to show the presence of bugs, but is hopelessly inadequate for showing their absence.“
Therefore, simply automating test execution is not sufficient to ensure that changes to the codebase do not have unintended effects on existing functionality. For this reason, the quality of the test cases must be evaluated. Proven tools already exist for this purpose.
Before we delve deeper into the topic, let’s first consider what automated testing actually means. This question is quite easy to answer. Almost every programming language has a corresponding unit test framework. Unit tests call a method with various parameters and compare the return value with an expected value. If both values match, the test is considered passed. Additionally, it can also be checked whether an exception was thrown.
If a method has no return value or does not throw an error, it cannot be tested directly. Methods marked as private, or inner classes, are also not easily testable, as they cannot be called directly. These must be tested indirectly through public methods that call the ‘hidden’ methods.
When dealing with methods marked as private, it is not an option to access and test the functionality they represent using techniques such as the Reflection API. We must be aware that such methods are often also used to encapsulate code fragments to avoid duplication.
public boolean method() {
boolean success = false;
List collector = new ArryList();
collector.add(1);
collector.add(2);
collector.add(3);
sortAsc(collector);
if(collector.getFirst().equals(1)) {
success = true;
}
return success;
}
private void sortAsc(List collection) {
collection.sort(
(a, b) -> {
return -1 * a.compareTo(b);
});
}Therefore, to effectively write automated tests, it is necessary to follow a certain coding style. The preceding Listing 1 simply demonstrates what testable code can look like.
Since developers also write the corresponding component tests for their own implementations, the problem of difficult-to-test code is largely eliminated in projects that follow a test-driven approach. The motivation to test now lies with the developer, as this paradigm allows them to determine whether their implementation behaves as intended. However, we must ask ourselves: Is that all we need to do to develop good and stable software?
As we might expect with such questions, the answer is no. An essential tool for evaluating the quality of tests is achieving the highest possible test coverage. A distinction is made between branch and line coverage. To illustrate the difference more clearly, let’s briefly look at the pseudocode in Listing 2.
if( Expression-A OR Expression-B ) {
print(‘allow‘);
} else {
print(‘decline‘);
}
Our goal is to execute every line of code if possible. To achieve this, we already need two separate test cases: one for entering the IF branch and one for entering the ELSE branch. However, to achieve 100% branch coverage, we must cover all variations of the IF branch. In this example, that means one test that makes Expression A true, and another test that makes Expression B true. This results in a total of three different test cases.
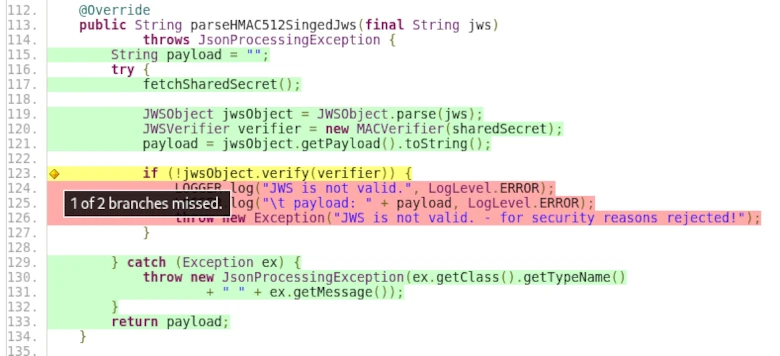
The screenshot from the TP-CORE project shows what such test coverage can look like in ‘real-world’ projects.
Of course, this example is very simple, and in real life, there are often constructs where, despite all efforts, it’s impossible to reach all lines or branches. Exceptions from third-party libraries that need to be caught but cannot be triggered under normal circumstances are a typical example.
For this reason, while we strive to achieve the highest possible test coverage and naturally aim for 100%, there are many cases where this is not feasible. However, a test coverage of 90% is quite achievable. The industry standard for commercial projects is 85% test coverage. Based on these observations, we can say that test coverage correlates with the testability of an application. This means that test coverage is a suitable measure of testability.
However, it must also be acknowledged that the test coverage metric has its limitations. Regular expressions and annotations for data validation are just a few simple examples of where test coverage alone is not a sufficient indicator of quality.
Without going too much into the implementation details, let’s imagine we had to write a regular expression to validate input against a correct 24-hour time format. If we don’t keep the correct interval in mind, our regular expression might be incorrect. The correct interval for the 24-hour format is 00:00 – 23:59. Examples of invalid values are 24:00 or 23:60. If we are unaware of this fact, errors can remain hidden in our application despite test cases, only to surface and cause problems when the application is actually used.
„… In a few cases, participants were unable to think of alternative solutions …“
The question here was whether error correction always represents the optimal solution. Beyond that, it would be necessary to clarify what constitutes an optimal solution in commercial software development projects. The statement that there are cases in which developers only know or understand one way of doing things is very illustrative. This is also reflected in our example of regular expressions (RegEx). Software development is a thought process that cannot be accelerated. Our thinking is determined by our imagination, which in turn is influenced by our experience.
This already shows us another example of sources of errors in test cases. A classic example is incorrect comparisons in collections, such as comparing arrays. The problem we are dealing with here is how variables are accessed: call by value or call by reference. With arrays, access is via call by reference, i.e., directly to the memory location. If you now assign an array to a new variable and compare both variables, they will always be the same because you are comparing the array with itself. This is an example of a test case that is essentially meaningless. However, if the implementation is correct, this faulty test case will never cause any problems.
This realization shows us that blindly striving for complete test coverage is not conducive to quality. Of course, it’s understandable that this metric is highly valued by management. However, we have also been able to demonstrate that one cannot rely on it alone. We therefore see that there is also a need for code inspections and refactorings for test cases. Since it’s impossible to read and understand all the code from beginning to end due to time constraints, it’s important to focus on problematic areas. But how can we find these problem areas? A relatively new technique helps us here. The theoretical work on this is already somewhat older; it just took a while for corresponding implementations to become available.



Leave a Reply
You must be logged in to post a comment.