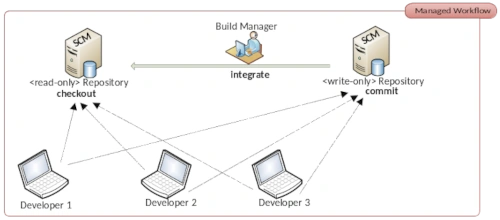
Wer sein Git-Repository zur gemeinsamen Bearbeitung für Quelltexte benutzen möchte, benötigt einen Git-Server. Der Git Server ermöglicht die Kollaboration mehrere Entwickler auf der gleichen Codebasis. Die Installation des Git-Clients auf einem Linux Server ist zwar ein erster Schritt zur eigenen Serverlösung, aber bei Weitem nicht ausreichend. Um den Zugriff mehrere Personen auf ein Code Repository zu ermöglichen, benötigen wir eine Zugriffsberechtigung. Schließlich soll das Repository öffentlich über das Internet erreichbar sein. Wir möchten über die Benutzerverwaltung verhindern, dass unberechtigte Personen den Inhalt der Repositories lesen und verändern können.
Für den Betrieb eines Git-Servers gibt es viele hervorragende und komfortable Lösungen, die man einer nativen Serverlösung vorziehen sollte. Die Administration eines nativen Git Servers erfordert Linux Kenntnisse und wird ausschließlich über die Kommandozeile bewerkstelligt. Lösungen wie beispielsweise der SCM-Manager haben eine grafische Benutzeroberfläche und bringen viele nützliche Werkzeuge zur Administration des Servers mit. Diese Werkzeuge stehen bei einer nativen Installation nicht zur Verfügung.
Wieso sollte man nun Git als nativen Server installieren? Diese Frage lässt sich recht leicht beantworten. Der Grund ist wenn der Server, auf dem das Code Repository bereitgestellt werden soll, nur wenige Hardware-Ressourcen besitzt. Besonders der Arbeitsspeicher ist in diesem Zusammenhang immer ein wenig problematisch. Gerade bei angemieteten Virtuellen Private Servern (VPS) oder einem kleinen RaspberryPI ist das oft der Fall. Wir sehen also, es kann durchaus Sinn ergeben, einen nativen Git Server betreiben zu wollen.
Als Voraussetzung benötigen wir einen Linux-Server, auf dem wir den Git-Server installieren können. Das kann ein Debian oder Ubuntu Server sein. Wer CentOS oder andere Linux Distributionen verwendet, muss anstatt APT zur Softwareinstallation den Paketmanager seiner Distribution nutzen.
Wir beginnen im ersten Schritt mit der Aktualisierung der Pakete und der Installation des Git-Clients.
Als zweiten Schritt erstellen wir einen neuen Benutzer mit dem Namen git und legen für diesen ein eigenes home Verzeichnis an und aktivieren dort den SSH-Zugriff.
Nun können wir im dritten Schritt in dem neu angelegten home Verzeichnis des git Users unsere Git-Repositories erstellen. Diese unterscheiden sich gegenüber dem lokalen Arbeitsbereich darin, dass diese den Source Code nicht ausgecheckt haben.
Leider sind wir noch nicht ganz fertig mit unserem Vorhaben. Im vierten Schritt müssen wir die Benutzerberechtigung für das erstellte Repository setzen. Dies geschieht durch das Ablegen des öffentlichen Schlüssels auf dem Git Server für den SSH-Zugriff. Dazu kopieren wir den Inhalt aus der Datei unseres privaten Schlüssels in die Datei /home/git/.ssh/authorized_keys in eine eigene Zeile. Möchte man nun vorhandenen Nutzern den Zugriff verwehren, kommentiert man lediglich mit einem # die zeie des privaten Schlüssels wieder aus.
Wenn alles korrekt durchgeführt wurde, erhält man den Zugriff auf das Repository über folgenden Kommandozeilenbefehl: git clone ssh://git@<IP>/~/<repo>
Dabei ist <IP> durch die tatsächliche Server-IP zu ersetzen. Für unser Beispiel lautet der korrekte Pfad für <repo> project.git es ist also das von uns erstellte Verzeichnis für das Git-Repository.
Auf dem nativen Git Server können mehrere Repositories angelegt werden. Dabei gilt zu beachten, dass alle berechtigenden Nutzer auf alle so angelegenen Reposiories lesenden und schreibenden Zugriff haben. Das lässt sich nur dadurch einschränken, dass auf dem Linux-Server der unsere Git-Repositories bereitstellt, mehrere Benutzer auf dem Betriebssystem angelegt werden, denen dann die Repositories zugewiesen werden.
Wir sehen, dass eine native Git Server Installation zwar schnell umgesetzt werden kann, diese aber für die kommerzielle Softwareentwicklung nicht ausreichend ist. Wer gerne experimentiert, kann sich eine virtuelle Maschine erstellen und diesen Workshop darin ausprobieren.
Der sichere Umgang mit Source Control Management (SCM) Systemen wie Git ist für Programmierer (Development) und auch Systemadministratoren (Operations) essenziell. Diese Gruppe von Werkzeugen hat eine lange Tradition in der Softwareentwicklung und versetzt Entwicklungsteams in die Lage, gemeinsam an einer Codebasis zu arbeiten. Dabei werden vier Fragen beantwortet: Wann wurde die Änderung gemacht? Wer hat die Änderung vorgenommen? Was wurde geändert? Warum wurde etwas geändert? Es ist also ein reines Kollaborationswerkzeug.
Mit dem Aufkommen der Open Source Code Hosting Plattform GitHub wurden sogenannte Pull Requests eingeführt. Pull Requests ist in GitHub ein Workflow, der es Entwicklern erlaubt, Codeänderungen für Repositories bereitzustellen, auf die sie nur lesenden Zugriff haben. Erst nachdem der Besitzer des originalen Repositories die vorgeschlagenen Änderungen überprüft und für gut befunden hat, werden diese Änderungen von ihm übernommen. So setzt sich auch die Bezeichnung zusammen. Ein Entwickler kopiert sozusagen das originale Repository in seinen GitHub Arbeitsbereich, nimmt Änderungen vor und stellt an den Inhaber des originalen Repositories eine Anfrage, die Änderung zu übernehmen. Dieser kann dann die Änderungen übernehmen und gegebenenfalls noch selbst anpassen oder mit einer Begründung zurückweisen.
Wer nun glaubt, dass GitHub besonders innovativ war, der irrt. Denn dieser Prozess ist in der Open Source Community ein ‚sehr‘ alter Hut. Ursprünglich nennt man dieses Vorgehen Dictatorship Workflow. Das 1990 zum ersten Mal veröffentlichte kommerzielle SCM Rational Synergy von IBM basiert genau auf dem Dictarorship Workflow. Mit der Klasse der verteilten Versionsverwaltungswerkzeuge, zu denen auch Git gehört, lässt sich der Dictatorship Worflow recht einfach umsetzen. Also lag es auf der Hand das GitHub diesen Prozess seinen Nutzern auch zur Verfügung stellt. Lediglich die Namensgebung ist von GitHub weitaus ansprechender gewählt. Wer beispielsweise mit der freien DevOps Lösung GitLab arbeitet, kennt Pull Requests unter der Bezeichnung Merge Requests. Mittlerweile enthalten die gängigsten Git-Server den Prozess der Pull Requests. Ohne zu sehr auf die technischen Details zur Umsetzung der Pull Request einzugehen, richten wir unsere Aufmerksamkeit auf die üblichen Probleme mit denen Open Source Projekte konfrontiert sind.
Entwickler, die sich an einem Open Source Projekt beteiligen möchten, werden Maintainer genannt. Nahezu jedes Projekt hat eine kleine Anleitung, wie man das entsprechende Projekt unterstützen kann und welche Regeln gelten. Für Personen, die das Programmieren erlernen, eignen sich Open Source Projekte hervorragend, um die eigenen Fähigkeiten schnell signifikant zu verbessern. Das bedeutet für das Open Source Projekt, dass man Maintainer mit den unterschiedlichsten Fähigkeiten und Erfahrungsschatz hat. Wenn man also keinen Kontrollmechanismus etabliert, erodiert die Codebasis in sehr kurzer Zeit. Wenn das Projekt nun recht groß ist und sehr viele Mainatainer auf der Codebasis agieren, ist es für den Inhaber des Repositories kaum noch möglich, alle Pull Requests zeitnahe zu bearbeiten. Um diesem Bottelneck entgegenzuwirken, wurde der Dictatorship Workflow zum Dictatorship – Lieutenant Workflow erweitert. Es wurde also eine Zwischeninstanz eingeführt, mit der die Überprüfung der Pull Requests auf mehrere Schultern verteilt wird. Diese Zwischenschicht, die sogenannten Lieutenants sind besonders aktive Maintainer mit einer bereits etablierten Reputation. Somit braucht der Dictator nur noch die Pull Requests der Lieutenants zu reviewen. Eine ungemeine Arbeitsentlastung, die sicherstellt, dass es zu keinem Feature Stau durch nicht abgearbeitete Pull Requests kommt. Schließlich sollen die Verbesserungen beziehungsweise die Erweiterungen so schnell wie möglich in die Codebasis aufgenommen werden, um dann im nächsten Release den Nutzern zur Verfügung zu stehen.
Dieses Vorgehen ist bis heute der Standard in Open Source Projekten, um Qualität gewährleisten zu können. Man kann ja nie sagen, wer sich alles am Projekt beteiligt. Möglicherweise mag es ja auch den ein oder anderen Saboteur geben. Diese Überlegung ist nicht so abwegig. Unternehmen, die für ihr kommerzielles Produkt eine starke Konkurrenz aus dem feien Open Source Bereich haben, könnten hier auf unfaire Gedanken kommen, wenn es keine Reglementierungen geben würde. Außerdem lassen sich Maintainer nicht disziplinieren, wie es beispielsweise für Teammitglieder in Unternehmen gilt. Einem beratungsresistenten Maintainer, der sich trotz mehrfachen Bitten nicht an die Vorgaben des Projektes hält, kann man schwer mit Gehaltskürzungen drohen. Einzige Handhabe ist diese Person vom Projekt auszuschließen.
Auch wenn das gerade beschriebene Problem der Disziplinierung von Mitarbeitern in kommerziellen Teams kein Problem darstellt, gibt es in diesen Umgebungen ebenfalls Schwierigkeiten, die es zu meistern gilt. Diese Probleme rühren noch aus den Anfängen von Visualisierungswerkzeugen. Denn die ersten Vertreter dieser Spezies waren keine verteilten Lösungen, sondern zentralisiert. CVS und Subversion (SVN) halten auf dem lokalen Entwicklungsrechner immer nur die letzte Revision der Codebasis. Ohne Verbindung zum Server kann man faktisch nicht arbeiten. Bei Git ist dies anders. Hier hat man eine Kopie des Repositories auf dem eigenen Rechner, sodass man seine Arbeiten lokal in einem separaten Branch durchführt und wenn man fertig ist, bringt man diese Änderungen in den Hauptentwicklungszweig und überträgt diese dann auf den Server. Die Möglichkeit, offline Branches zu erstellen und diese lokal zu mergen hat einen entscheidenden Einfluss auf die Stabilität der eigenen Arbeit, wenn das Reopsitory in einen inkonsistenten Zustand gerät. Denn im Gegensatz zu zentralisierten SCM Systemen kann man nun weiter arbeiten, ohne darauf warten zu müssen, dass der Hauptentwicklungszweig repariert wurde.
Diese Inkonsistenten entstehen sehr leicht. Es genügt nur eine Datei beim Commit zu vergessen und schon können die Teamkollegen das Projekt nicht mehr lokal kompilieren und sind in der Arbeit behindert. Um diesem Problem Herr zu werden, wurde das Konzept Continuous Integration (CI) etabliert. Es handelt sich dabei nicht, wie oft fälschlicherweise angenommen, um die Integration verschiedener Komponenten zu einer Anwendung. Die Zielstellung bei CI ist die Commit Satge – das Code Repository – in einem konsistenten Zustand zu halten. Dazu wurden Build Server etabliert, die in regelmäßigen Abständen das Repository auf Änderungen überprüfen, um dann den aus dem Quelltext das Artefakt bauen. Ein sehr beliebter und seit vielen Jahren etablierter Build-Server ist Jenkins. Jenkins ging ursprünglich aus dem Projekt Hudson als Abspaltung hervor und übernahm mittlerweile viele weitere Aufgaben. Deswegen ist es sehr sinnvoll, diese Klasse von Tools als Automatisierungsserver zu bezeichnen.
Mit diesem kleinen Abriss in die Geschichte der Softwareentwicklung verstehen wir nun die Probleme von Open Source Projekten und kommerzieller Softwareentwicklung. Dazu haben wir die Entstehungsgeschichte der Pull Request besprochen. Indessen kommt es in kommerziellen Projekten sehr oft vor, dass Teams durch das Projektmanagement gezwungen werden mit Pull Requests zu arbeiten. Für einen Projektleiter ohne technisches Hintergrundwissen klingt es nun sehr sinnvoll, in seinem Projekt ebenfalls Pull Requests zu etablieren. Schließlich hat er die Idee, dass er somit die Codequalität verbessert. Leider ist das aber nicht der Fall. Das Einzige was passiert ist ein Feature Stau zu provozieren und eine erhöhte Auslastung des Teams zu erzwingen, ohne die Produktivität zu verbessern. Denn der Pull Request muss ja von einer kompetenten Person inhaltlich bewertet werden. Das verursacht bei großen Projekten unangenehme Verzögerungen.
Nun erlebe ich es oft, dass argumentiert wird, man könne die Pull Requests ja automatisieren. Das heißt, der Build Server nimmt den Branch, mit dem Pull Request versucht diesen zu bauen und im Fall dass das Kompilieren und die automatisierten Tests erfolgreich sind, versucht der Server die Änderungen in den Hauptentwicklungszweig zu übernehmen. Möglicherweise sehe ich da etwas falsch, aber wo ist die Qualitätskontrolle? Es handelt sich um einen einfachen Continuous Integration Prozess, der die Konsistenz des Repositories aufrechterhält. Da Pull Requests vornehmlich im Git Umfeld zu finden sind, bedeutet ein kurzzeitig inkonsistentes Repository kein kompletten Entwicklungstop für das gesamte Team, wie es bei Subversion der Fall ist.
Interessant ist auch die Frage wie man bei einem automatischen Merge mit semantischen Mergekonflikten umgeht. Die per se kein gravierendes Problem sind. Sicher führt das zur Ablehnung des Pull Requests mit entsprechender Nachricht an den Entwickler, um das Problem mit einem neuen Pull Request zu lösen. Ungünstige Branchstrategien können hier allerdings zu unverhältnismäßigen Mehraufwand führen.
Für die Verwendung von Pull Requests in kommerziellen Softwareprojekten sehe ich keinen Mehrwert, weswegen ich davon abrate, in diesem Kontext Pull Request zu verwenden. Außer einer Verkomplizierung der CI / CD Pipeline und einem erhöhten Ressourcenverbrauch des Automatisierungsservers, der nun die Arbeit doppelt macht, ist nichts passiert. Die Qualität eines Softwareprojektes verbessert man durch das Einführen von automatisierten Unit-Tests und einem testgetriebenen Vorgehen bei der Umsetzung von Features. Hier ist es notwendig, die Testabdeckung des Projekts kontinuierlich im Auge zu behalten und zu verbessern. Statische Codeanalyse und das Aktivieren von Compilerwarnings bringen mit erheblich weniger Aufwand bessere Ergebnisse.
Ich persönlich vertrete die Auffassung, dass Unternehmen, die auf Pull Requests setzen, diese entweder für ein verkompliziertes CI nutzen oder ihren Entwicklern komplett misstrauen und ihnen in Abrede stellen, gute Arbeit abzuliefern. Natürlich bin ich offen für eine Diskussion zum Thema, möglicherweise lässt sich dann eine noch bessere Lösung finden. Von daher freue ich mich über reichliche Kommentare mit euren Ansichten und Erfahrungen im Umgang mit Pull Requests.
Wieso benötigen wir überhaupt die Möglichkeit, Konfigurationen einer Anwendung in Textdateien zu speichern? Genügt nicht einfach eine Datenbank für diesen Zweck? Die Antwort auf diese Frage ist recht trivial. Denn die Information, wie sich eine Anwendung mit einer Datenbank verbinden kann, lässt sich ja schlecht in der Datenbank selbst speichern.
Jetzt könnte man sicher argumentieren, dass man solche Dinge mit einer integrierten Datenbank (embedded) wie beispielsweise SQLite hinbekommt. Das mag auch grundsätzlich korrekt sein. Leider ist diese Lösung für hoch skalierbare Anwendungen nicht wirklich praktikabel. Zudem muss man nicht immer gleich mit Kanonen auf Spatzen schießen. Das Speichern wichtiger Konfigurationsparameter in Textdateien hat bereits eine lange Tradition in der Softwareentwicklung. Mittlerweile haben sich aber auch verschiedene Textformate wie INI, XML, JSON und YAML für diesen Anwendungsfall etabliert. Angesichts dessen stellt sich die Frage, auf welches Format man am besten für das eigene Projekt zurückgreifen sollte.
INI Dateien
Eines der ältesten Formate sind die bekannten INI Dateien. Sie speichern Informationen nach dem Schlüssel = Wert Prinzip. Wenn ein Schlüssel in solch einer INI-Datei mehrfach vorkommt, wird der finale Wert immer durch den zuletzt in der Datei vorkommenden Wert überschrieben.
; Example of an INI File[Section-name]key=value ; inline text="text configuration with spaces and \' quotas"string='can be also like this'char=passwort# numbers & digetsnumber=123hexa=0x123octa=0123binary=0b1111float=123.12# boolean valuesvalue-1=truevalue-0=false
Wie wir in dem kleinen Beispiel sehen können, ist die Syntax in INI-Dateien sehr einfach gehalten. Der Sektionsname [section] dient vor allem der Gruppierung einzelner Parameter und verbessert die Lesbarkeit. Kommentare können entweder durch ; oder # gekennzeichnet werden. Ansonsten gibt es die Möglichkeit, verschiedene Text- und Zahlen-Formate, sowie Boolean-Wert zu definieren.
Web-Entwickler kennen INI Files vor allem von der PHP-Konfiguration, der php.ini in der wichtige Eigenschaften wie die Größe des Datei-Uploads festgelegt werden können. Auch unter Windows sind INI-Dateien noch immer verbreitet, obwohl seit Windows 95 für diesen Zweck die Registry eingeführt wurde.
Properties
Eine andere sehr bewährte Lösung sind sogenannte property Files. Besonders verbreitet ist diese Lösung in Java-Programmen, da Java bereits eine einfache Klasse mitbringt, die mit Properties umgehen kann. Das Format key=value ist den INI-Dateien entlehnt. Kommentare werden ebenfalls mit # eingeleitet.
Um in Java-Programmen beim Einlesen der .propreties auch die Typsicherheit zu gewährleisten, hat die Bibliothek TP-CORE eine erweiterte Implementierung. Trotz dass die Properties als Strings eingelesen werden, kann auf die Werte mittels Typisierung zugegriffen werden. Eine ausführliche Beschreibung, wie die Klasse PropertyReader verwendet werden kann, findet sich in der Dokumentation.
Auch im Maven Build Prozess können .property Dateien als Filter für Substitutionen genutzt werden. Selbstredend sind Properties nicht nur auf Maven und Java beschränkt. Auch in Sprachen wie Dart, nodeJS, Python und Ruby ist dieses Konzept nutzbar. Um eine größtmögliche Kompatibilität der Dateien zwischen den verschiedenen Sprachen zu gewährleisten, sollten exotische Optionen zur Notation vermieden werden.
XML
XML ist seit vielen Jahren auch eine weitverbreitete Option, Konfigurationen in einer Anwendung veränderlich zu speichern. Gegenüber INI und Property Dateien bietet XML mehr Flexibilität in der Definition der Daten. Ein sehr wichtiger Aspekt ist die Möglichkeit, fixe Strukturen durch eine Grammatik zu definieren. Dies erlaubt eine Validierung auch für sehr komplexe Daten. Dank der beiden Prüfmechanismen Wohlgeformtheit und Datenvalidierung gegen eine Grammatik lassen sich mögliche Konfigurationsfehler erheblich reduzieren.
Bekannte Einsatzszenarien für XML finden sich beispielsweise in Java Enterprise Projekten (J EE) mit der web.xml oder der Spring Framework und Hibernate Konfiguration. Die Mächtigkeit von XML gestattet sogar die Nutzung als Domain Specific Language (DSL), wie es bei dem Build-Werkzeug Apache Maven zum Einsatz kommt.
Dank vieler frei verfügbarer Bibliotheken existiert für nahezu jede Programmiersprache eine Implementierung, um XML-Dateien einzulesen und gezielt auf Daten zuzugreifen. Die bei Web-Entwicklern beliebte Sprache PHP hat zum Beispiel mit der Simple XML Erweiterung eine sehr einfache und intuitive Lösung, um mit XML umzugehen.
JavaScript Object Notation oder kurz JSON ist eine vergleichsweise neue Technik, obwohl diese mittlerweile auch schon einige Jahre existiert. Auch JSON hat für nahezu jede Programmiersprache eine entsprechende Implementierung. Das häufigste Einsatzszenario für JSON ist der Datentausch in Microservices. Der Grund liegt in der Kompaktheit von JSON. Gegenüber XML ist der zu übertragene Datenstrom in Webservices wie XML RPC oder SOAP mit JSON aufgrund der Notation wesentlich geringer.
Ein signifikanter Unterschied zwischen JSON und XML besteht aber auch im Bereich der Validierung. Grundsätzlich findet sich auf der offiziellen Homepage [1] zu JSON keine Möglichkeit, eine Grammatik wie in XML mit DTD oder Schema zu definieren. Auf GitHub existiert zwar ein Proposal zu einer JSON-Grammatik [2] hierzu fehlen aber entsprechende Implementierungen, um diese Technologie auch in Projekten einsetzen zu können.
Eine Weiterentwicklung zu JSON ist JSON5 [3], das bereits 2012 begonnen wurde und als Spezifikation in der Version 1.0.0 [4] seit dem Jahr 2018 offiziell veröffentlicht ist. Zweck dieser Entwicklung war es, die Lesbarkeit von JSON für Menschen erheblich zu verbessern. Hier wurden wichtige Funktionen, wie beispielsweise die Möglichkeit, Kommentare zu schreiben, hinzugefügt. JSON5 ist als Erweiterung vollständig zu JSON kompatibel. Um einen kurzen Eindruck zu JSON5 zu gewinnen, hier ein kleines Beispiel:
Viele moderne Anwendungen, wie zum Beispiel YAML, zur Konfiguration. Die sehr kompakte Notation erinnert stark an die Programmiersprache Python. Aktuell ist YAML in der Version 1.2 veröffentlicht.
Der Vorteil von YAML gegenüber anderen Spezifikationen ist die extreme Kompaktheit. Gleichzeitig besitzt die Version 1.2 eine Grammatik zu Validierung. Trotz der Kompaktheit liegt der Fokus von YAML 1.2 in einer guten Lesbarkeit für Maschinen als auch Menschen. Ob YAML dieses Ziel erreicht hat, überlasse ich jedem selbst zu entscheiden. Auf der offiziellen Homepage findet man alle Ressourcen, die für eine Verwendung im eigenen Projekt benötigt werden. Dazu zählt auch eine Übersicht zu den vorhandenen Implementierungen. Das Design der YAML Homepage gibt auch schon einen guten Vorgeschmack auf die Übersichtlichkeit von YAML Dateien. Anbei noch ein sehr kompaktes Beispiel einer Prometheus Konfiguration in YAML:
global:scrape_interval:15sevaluation_interval:15srule_files:# - "first.rules" # - "second.rules"#IP: 127.0.0.1scrape_configs:-job_name:prometheusstatic_configs:-targets:['127.0.0.1:8080']# SPRING BOOT WEB APP-job_name:spring-boot-samplescrape_interval:60sscrape_timeout:50sscheme:"http"metrics_path:'/actuator/prometheus'static_configs:-targets:['127.0.0.1:8888']tls_config:insecure_skip_verify:true
Resümee
Alle hier vorgestellten Techniken sind im praktischen Einsatz in vielen Projekten erprobt. Sicher mag es für spezielle Anwendungen wie REST Services einige Präferenzen geben. Für meinen persönlichen Geschmack bevorzuge ich für Konfigurationsdateien das XML Format. Dies ist leicht im Programm zu verarbeiten, extrem flexibel und bei geschickter Modellierung auch kompakt und hervorragend für Menschen lesbar.
Ruby ist seit vielen Jahren eine sehr etablierte Programmiersprache, die durchaus auch Anfängern empfohlen werden kann. Ruby folgt dem objektorientierten Paradigma und enthält sehr viele Konzepte, um OOP gut zu unterstützen. Außerdem lassen sich dank des Frameworks Ruby on Rails unkompliziert komplexe Webanwendungen entwickeln.
Die schwierigste Hürde beim Einstieg in Ruby, die es zu meistern gilt, ist die Installation der gesamten Entwicklungsumgebung. Angesichts dessen habe ich dieses kurze Tutorial zum Einstieg mit Ruby verfasst. Beginnen wir daher auch gleich mit der Installation.
Mein Betriebssystem ist ein Debian 12 Linux und Ruby lässt sich sehr einfach mit der Anweisung sudo apt-get install ruby-full installieren. Dieses Vorgehen kann auf alle Debian basierte Linux Distributionen wie z. B. Ubuntu übertragen werden. Anschließend kann mit ruby -v der Erfolg in der Bash überprüft werden.
Wenn wir nun dem Tutorial auf der Ruby on Rails Homepage folgen und das Rails Framework über gem rails installieren wollen, stoßen wir bereits auf das erste Problem. Wegen fehlender Berechtigungen lassen sich keine Bibliotheken für Ruby installieren. Nun konnten wir auf die Idee kommen, die Bibliotheken, als Superuser mit sudo zu installieren. Dies Losung ist leider nur temporär und verhindert, dass später in der Entwicklungsumgebung die Bibliotheken korrekt gefunden werden. Besser ist es, einen Ordner für die GEMs im home Verzeichnis des Nutzers anzulegen und dies über eine Systemvariable bereitzustellen.
Die oben stehende Zeile ist an das Ende der Datei .bashrc einzutragen, damit die Änderungen auch persistent bleiben. Wichtig ist, dass <user> gegen den richtigen Nutzernamen ausgetauscht wird. Den Erfolg dieser Aktion lasst sich über gem environment überprüfen und sollte eine ähnliche Ausgabe wie nachstehend ergeben.
Mit dieser Einstellung lassen sich nun ohne Schwierigkeiten Ruby GEMs installieren. Das probieren wir auch gleich aus und installieren, das Ruby on Rails Framework, was uns bei der Entwickelung von Webapplikationen unterstützt: gem install rails. Dies sollte indessen ohne Fehlermeldungen durchlaufen und mit dem Kommando rails -v sehen wir, ob wir erfolgreich waren.
Im nächsten Schritt können wir nun ein neues Rails Projekt anlegen. Hier bediene ich mich dem Beispiel aus der Ruby on Rails Dokumentation und schreibe in die Bash: rails new blog. Dies erzeugt ein entsprechendes Verzeichnis namens blog mit den Projektdateien. Nachdem wir in das Verzeichnis gewechselt sind müssen wir noch alle Abhängigkeiten installieren. Das geschieht über: bundle install.
Hier stoßen wir nun auf ein weiteres Problem. Die Installation kann nicht beendet werden, weil es anscheinend ein Problem mit der Bibliothek psych gibt. Das tatsächliche Problem ist allerdings, dass auf der Betriebssystemebene die Unterstützung für YAML-Dateien fehlt. Das lässt sich rasch beheben, indem das YAML-Paket nachinstalliert wird.
sudo apt-get install libyaml-dev
Das Problem mit psych bei Ruby on Rails besteht schon eine Weile und ist mit der YAML Installation behoben, so, dass nun auch die Anweisung bundle install erfolgreich durchläuft. Jetzt sind wir auch in der Lage, den Server für die Rails Anwendung zu starten: bin/rails server.
ed@:~/blog$bin/railsserver=> BootingPuma=> Rails7.1.3.3applicationstartingindevelopment=> Run`bin/rails server --help`for more startup optionsPumastartinginsinglemode...* Puma version: 6.4.2 (ruby3.1.2-p20)("The Eagle of Durango")* Min threads: 5* Max threads: 5* Environment: development* PID: 12316* Listening on http://127.0.0.1:3000* Listening on http://[::1]:3000UseCtrl-Ctostop
Rufen wir nun im Webbrowser die URL http://127.0.0.1:3000 auf, sehen wir unsere Rails Webanwendung.
Mit diesen Schritten haben wir nun eine funktionierende Ruby Umgebung auf unserem System erstellt. Nun ist es an der Zeit, sich für eine geeignete Entwicklungsumgebung zu entscheiden. Wer nur gelegentlich ein paar Scripte anpasst, dem genügen VIM und Sublime Text als Editoren. Für komplexe Softwareprojekte sollte wiederum auf eine vollständige IDE zurückgegriffen werden, da dies die Arbeit erheblich vereinfacht. Die beste Empfehlung ist die kostenpflichtige IDE RubyMine von JetBrains. Wer Ruby Open Source Projekte als Entwickler unterstützt, kann eine kostenfreie Lizenz beantragen.
Eine frei verfügbare Ruby IDE ist VSCode von Microsoft. Hier müssen aber zunächst ein paar Plug-ins eingebunden werden, und für meinen Geschmack ist VSCode auch nicht sehr intuitiv. Ruby Integration für die klassischen Java IDEs Eclipse und NetBeans sind recht veraltet und nur mit sehr viel Mühe zum Laufen zu bekommen.
Damit haben wir auch schon alle wichtigen Punkte, die notwendig sind, eine funktionierende Ruby-Umgebung auf dem eigenen System einzurichten, besprochen. Ich hoffe, mit diesem kleinen Workshop die Einstiegshürde zum Erlernen von Ruby erheblich gesenkt zu haben. Wenn Ihr diesen Artikel mögt, freue ich mich über ein Like und die Weiterempfehlung an eure Freunde.
In der Softwarebranche ist es üblich, dass die Codebasis eine ausreichende Testautomatisierung aufweist. Denn dies ist für einen stabilen DevOps-Prozess und sicheres Refactoring notwendig. Aber die Realität sieht oft ganz anders aus. Fast jedes Projekt, an dem ich während meiner Karriere teilgenommen habe, hatte keine Zeile Testcode. Wenn wir darüber nachdenken, dass seit über 40 Jahren immer noch 80% aller kommerziellen Softwareprojekte scheitern, sollte uns das nicht überraschen. Aber das muss nicht so sein. In diesem Vortrag zeige ich, wie einfach es ist, auch in großen Projekten einen testgetriebenen Ansatz einzuführen. Das technische Setup ist ein Standard-Java-Projekt mit Apache Maven und JUnit 5.
Die meisten DevOps-Teams sind überzeugt, dass die Automatisierung selbst und die Automatisierung selbst eine große Herausforderung darstellt. Es scheint dringend notwendig zu sein, alles zu automatisieren – sogar die Automatisierung selbst. Dies ist für die meisten DevOps-Teams ein allgemeines Verständnis und somit Motivation. Werfen wir einen Blick auf typische, kontinuierliche Dummheiten bei der Transformation vom reinen Konfigurationsmanagement zum DevOps-Engineer.
Die meisten DevOps-Teams sind davon überzeugt, dass die Automatisierung selbst und die Automatisierung selbst eine große Herausforderung darstellt. Es scheint dringend notwendig zu sein, alles zu automatisieren – sogar die Automatisierung selbst. Dies ist für die meisten DevOps-Teams ein allgemeines Verständnis und somit Motivation. Werfen wir einen Blick auf typische, kontinuierliche Dummheiten bei der Transformation vom reinen Konfigurationsmanagement zum DevOps-Engineer.
Build-Logik kann eine fehlerhafte Architektur nicht reparieren. Zahlreiche SCM-Zusammenführungskonflikte entstehen durch die fehlende Kapselung der Geschäftslogik. Bei Funktionen, die über viele Module oder Dienste verteilt sind, ist die Wahrscheinlichkeit hoch, dass eine Datei von mehreren Entwicklern bearbeitet wird.
Die Notwendigkeit orchestrierter Builds deutet auf Architekturprobleme hin. Transitive Abhängigkeiten, fehlende Kapselung und eine umfangreiche Abhängigkeitskette sind typische Gründe für das Henne-Ei-Problem. Entwerfen Sie Ihre Artefakte so unabhängig wie möglich.
Build-Logik wird von Entwicklern und nicht von Administratoren entwickelt. Personen mit Fokus auf den Betrieb haben andere Konzepte zur Pflege von Artefakt-Builds als Softwareentwickler. Ein gutes Beispiel für eine Anti-Pattern-Build-Struktur sind webMethods der Software AG. webMethods bietet keinen Repository-Server wie Sonatype Nexus zum Teilen von Abhängigkeiten. Der Build verweist immer auf die Abhängigkeiten innerhalb einer webMethods-Installation. Diese Vorgehensweise verstößt gegen die Grundidee der Build-Automatisierung, die im Buch „Praktiken eines agilen Entwicklers“ von 2006 beschrieben wird.
Nicht alles auf einmal. Teilen Sie die Build-Jobs in konkrete Ziele auf, wie z. B. Artefakt erstellen, Abnahmetests durchführen, API-Dokumentation erstellen und Berichte generieren. Wenn einer der letzten Schritte fehlschlägt, müssen Sie nicht alles wiederholen. Die Ausführungszeit des Builds wird drastisch reduziert, und die Build-Infrastruktur lässt sich leichter warten.
Geben Sie Ihrer Build-Infrastruktur nicht zu viel Flexibilität. Dieser Punkt hängt eng mit dem ersten Thema zusammen, das ich erläutert habe. Ein undisziplinierter Build-Manager erstellt extrem komplexe Skripte, die niemand versteht. Der JavaScript-Task-Runner Grunt ist ein Beispiel dafür, wie eine Build-Logik unübersichtlich und unleserlich werden kann. Dies ist einer der Gründe, warum ich mich für Maven als Build-Tool für Java-Projekte entscheide, da es die Steuerung verständlicher Builds ermöglicht.
Es besteht keine Notwendigkeit, die Automatisierung zu automatisieren. Komplexe Automatisierungsstufen verursachen per Definition höhere Kosten als einfache Aufgaben. Überlegen Sie sich immer vorher, welchen Nutzen Ihre Automatisierungsaktivitäten bringen, um zu prüfen, ob es sich lohnt, Zeit und Geld dafür aufzuwenden.
Wir tun, was wir können, aber können wir auch, was wir tun? Oder mit den Worten von Gardy Bloch: „A fool with a tool is still a fool.“ Verstehen Sie die Anforderungen Ihres Projekts und entscheiden Sie auf dieser Grundlage, welches Tool Sie wählen. Wenn Ihnen die Ressourcen fehlen, kann Sie selbst die professionellste Lösung nicht unterstützen. Wenn Sie Ihr Problem verstanden haben, können Sie neue, professionelle und fortgeschrittene Prozesse erlernen.
Die Build-Logik wurde zunächst in der lokalen Entwicklungsumgebung ausgeführt. Wenn Ihr Build nicht auf Ihrem lokalen Entwicklungsrechner läuft, nennen Sie es nicht Build-Logik. Es ist nur ein Hack. Die Build-Logik muss plattform- und IDE-unabhängig sein.
Vermischen Sie Quellcode-Repositories nicht. mit anderen Dateien Die Organisation der Quellen in mehreren Ordnern innerhalb eines riesigen Verzeichnisses führt zu einem komplexen Build ohne jegliche Flexibilität. Quellen sollten nach Technologie oder separaten, unabhängigen Modulen strukturiert sein.
Viele der genannten Punkte lassen sich anhand der aktuellen Situation in fast jedem Projekt nachvollziehen. Die Lösung für eine erfolgreiche Problembehebung ist meist nicht allzu kompliziert. Sie erfordert lediglich ein wenig Aufmerksamkeit und gute Planung. Mein wichtigster Ratschlag ist das KISS-Prinzip (Keep it simple, stupid). Das bedeutet, den Standardprozess so weit wie möglich unverändert zu übernehmen. Man muss das Rad nicht neu erfinden. Es gibt Gründe, warum ein Standard zum Standard wird. Hier ist ein kurzer Plan, dem Sie folgen können:
Erstens: Verstehen Sie das Problem.
Zweitens: Suchen Sie nach einer Standardlösung für den Prozess.
Drittens: Entwickeln Sie einen Plan zur Integration der Lösung in die bestehende Prozesslandschaft. Dies bedeutet, Tools zu entfernen, die Standardprozesse nicht unterstützen.
Wenn Sie Ihren eigenen Weg Schritt für Schritt gehen, ohne zu weit zu springen, können Sie schnell positive Ergebnisse erzielen.
Übrigens: Wenn Sie Unterstützung für einen erfolgreichen DevOps-Prozess benötigen, kontaktieren Sie mich gerne. Ich biete praktische Beratung und Schulungen zum Aufbau eines leistungsstarken DevOps-Teams an.
Auch wenn es früher Konfigurationsmanagement hieß, bedeutet das nicht, dass die alten Probleme mit dem schönen neuen Namen DevOps beseitigt wurden. Durch die zunehmende Komplexität der Projekte und die Unkenntnis der Tools erreichen die heutigen Strategien und Arbeitsabläufe, die von den Entwicklungsteams erwartet werden, erst eine neue Qualität.
Viele DevOps-Teams verfolgen den Ansatz, alle möglichen Arbeitsschritte zu automatisieren. Das geht sogar so weit, dass sie versuchen, die Automatisierung selbst zu automatisieren. Daran wäre prinzipiell nichts auszusetzen, wenn die Lösung dann auch den Entwicklungsteams helfen würde, ihre täglichen Aufgaben effizient abzuarbeiten. Leider sind viele der Lösungen, die ich in den letzten Jahren in meinem Berufsleben kennen gelernt habe, weit davon entfernt. Vielmehr schaffen sie Entwicklungsumgebungen, die die tägliche Arbeit erschweren, anstatt sie zu vereinfachen. Schauen wir uns also gemeinsam an, welche gravierenden Auswirkungen unbedacht getroffene Entscheidungen auf den späteren Erfolg eines Projekts haben. Natürlich werden wir auch das eine oder andere Highlight aus der Entwicklung finden, das dem Unternehmen mehr als nur ein wenig Kopfzerbrechen bereitet.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.