[Teil 1] [Teil 2] [Teil 3] [Teil 4]
Wikipedia liefert für den Begriff Maven folgende Erklärung: »Ein Maven ist ein Experte, der andere berät und deren Entscheidungen beeinflusst«. Wegen seiner Bedeutung wurde der Begriff Maven für die Namensgebung der Software auserkoren. Jason van Zyl, Gründer und CTO von Sonatype, beschreibt das Programm mit folgenden Worten: »Apache Maven is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a project’s build, reporting and documentation from a central piece of information.«
Maven ist ein in Java geschriebenes plattformunabhängiges Projektmanagement-Tool. Es ist ein Open-Source-Projekt der Apache Software Foundation und frei erhältlich. In der Version 2 wurde das Programm völlig neu entwickelt. Das ist auch ein Grund dafür, dass Erweiterungen der Version 2 nicht abwärtskompatibel sind. Derzeit ist die Version 3 aktuell, welche auch mit Maven-2-Projekten kompatibel ist.
Wie bereits angedeutet, handelt es sich bei Maven um ein schlankes Werkzeug, das durch seinen modularen Aufbau problemlos durch eigene Plug-ins erweitert werden kann. Diese Möglichkeit nutzt das Projekt Maven for PHP und stellt eigene Erweiterungen für PHP bereit.

Bevor wir nun mit der Installation der Software beginnen, ist es notwendig, etwas über das Konzept von Maven zu erfahren, da dieses Werkzeug mächtiger ist als sein Pendant Ant.
Maven erzeugt aus Java-Quellcode Binärdateien. Die hohe Akzeptanz erreichte das Tool aber durch das transitive Auflösen von Abhängigkeiten zu anderen Softwarebibliotheken. Im Maven-Jargon werden Bibliotheken oder Module als Artefakt bezeichnet. Das Verwalten von Artefakten ist allerdings nur ein kleiner, wenn auch sehr maßgeblicher Aspekt für den Einsatz in PHP-Projekten.
Nicht ohne Grund stellt Maven an sich selbst den Anspruch, ein Projekt-Management-Werkzeug zu sein. Im Projektalltag wird zwischen drei verschiedenen Einsatzbereichen unterschieden. Der umfangreichste Teil ist der Build-Life-cycle mit seinen 21 Unterschritten, die als Phase bezeichnet werden. Die Teilbereiche einer Phase werden wiederum als Goal bezeichnet. So erreicht man eine feingranulare Struktur, in die sich leicht eigene Funktionen einbringen lassen. Ein anderer Aspekt ist die Reporting-Engine, die ihre Arbeit unter dem Site-Lifecycle verrichtet. Für das Aufräumen nach dem vollendeten Werk ist der Clean-Lifecycle zuständig. Was es mit den einzelnen Lifecycles auf sich hat wird an späterer Stelle noch detaillierter geklärt.
Zentrale Steuereinheit
Im Wurzelverzeichnis eines Projekts liegt die zentrale Steuereinheit. Es handelt sich dabei um eine einfache XML-Datei mit dem Namen pom.xml, in der die gesamte Konfiguration des Projekts vorgehalten wird. Die Bezeichnung POM steht im Übrigen für Project Object Model. Bei umfangreichen Projekten kann diese Datei schnell eine beachtliche Größe erlangen. Aus diesem Grund verfolgt Maven das Prinzip »Don’t repeat yourself« (DRY) und »Convention over Configura tion« (COC). Das besagt, es müssen lediglich die Dinge in der POM-Datei eingetragen werden, die vom vorgegeben Standard abweichen. Um den Überblick auch zu einem späteren Zeitpunkt nicht zu verlieren, ist es sehr ratsam, nur in absoluten Ausnahmefällen vom Standard abzuweichen.
Nachdem Sie nun die wichtigsten Begriffe kennen, können wir zur ersten Tat schreiten und die Software installieren.
Schnell installierte Basis
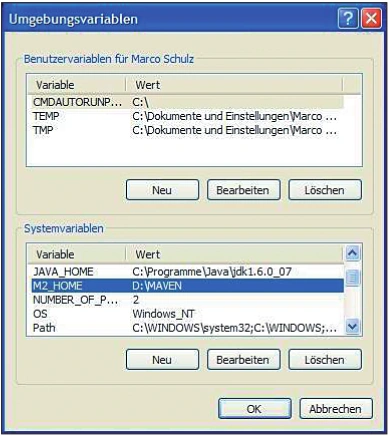
Für Maven existiert keine Installationsroutine, wie sie beispielsweise in Windows-Systemen üblich ist. Da das Programm in Java geschrieben ist, muss ein aktuelles Java-SDK auf dem System bereits vorhanden sein. Nach dem erfolgreichem Download und dem anschließenden Entpacken des Archivs sind folgende Schritte auszuführen:
- Setzen der Umgebungsvariablen
JAVA_HOME = {install.java}, - Setzen der Umgebungsvariablen
M2_HOME = {install.maven}, - Erweitern der PATH-Variable
%M2_HOME%\ binund%JAVA_HOME%\bin.
Mit {install.maven} ist der Ort des ausgepackten Maven-Archivs gemeint. Unter Windows 7 ist die Einstellung der Umgebungsvariablen über die Systemsteuerung hinter der Option System versteckt, die sich dort über den Punkt Erweiterte Systemeinstellungen öffnen lässt. Bei geglückter Installation quittiert Maven die Konsolenausgabe für mvn -vers

Dependency Management
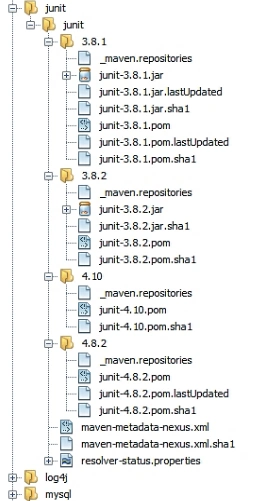
Wie Sie bei der Installation bemerkt haben, ist der Kern von Maven recht kompakt. Die umfangreichen Funktionen werden durch Erweiterungen über die Plug-in-Schnittstelle realisiert. Soll beispielsweise eine Dokumentation mit der Anweisung mvn site erzeugt werden, holt sich Maven die notwendigen Artefakte über das Internet und speichert diese auf dem Rechner in einem lokalen Repository. Die Dateien sind im Home-Verzeichnis des aktuellen Benutzers unter .m2/repository/ zu finden. Wenn man sich die Ordnerstruktur aus Bild 4 ein wenig genauer ansieht, kann man erkennen, dass Maven die Artefakte nach Namen und Versionsnummer organisiert. In dem Screenshot sind im lokalen Repository für das Test-Framework JUnit vier unterschiedliche Versionen mit der dazugehörigen POM-Datei hinterlegt. Anhand des POM ist Maven nun in der Lage, die notwendigen Abhängigkeiten von JUnit ebenfalls aufzulösen. Die Archivierung der Versionen eines Artefakts ermöglicht es später, in einem Projekt innerhalb kürzester Zeit für eine Bibliothek die neueste Version auszuprobieren und im Fall einer Inkompatibilität die Änderung in wenigen Augenblicken wieder rückgängig zu machen. Es muss lediglich in der POM-Datei die Versionsnummer des Artefakts geändert werden.
Ein weiterer Vorteil ist, dass im Konfigurationsmanagement die verwendeten Artefakte nicht mehr archiviert werden müssen. Diese Arbeit übernimmt nun künftig in zuverlässiger Weise Maven. Dank dieses Umstands werden im Konfigurationsmanagement einige MByte an Speicher eingespart, was bei größeren Projekten mit vielen Artefakten einiges an Zeit beim Checkout einsparen kann. Eine Entlastung des Netzwerks ist eine weitere angenehme Randerscheinung.
Nun stellt sich berechtigterweise die Frage, von welchem Server Maven die benötigten Artefakte beziehen kann? Neben dem standardmäßig eingestelltem Remote-Repository repo1.maven.org können auch andere Repositories hinzugefügt werden. Dazu ist die Maven-Installation über die Datei settings.xml den eigenen Bedürfnissen anpassen. Hierbei können zwei Stufen genutzt werden:
- User Level: Im Home-Directory des aktuellen Nutzers legt Maven den Ordner .m2 an, in dem die settings.xml zu finden ist. Dies ist vor allem im Mehrbenutzerbetrieb nützlich, da hier Passwörter für Logins et cetera hinterlegt werden können.
- Global Level: Die Datei settings.xml ist in diesem Fall im Ordner conf der Maven-Installation abgelegt. Diese Konfiguration gilt für alle Nutzer auf einem System.
Die Konfiguration über die settings.xml ist projektübergreifend und enthält beispielsweise Einträge für das Login zum Versionskontrollsystem (SCM), den Pfad zum lokalen Repository beziehungsweise zu weiteren Remote-Repositories. Um PHP Maven nutzen zu können, muss das öffentliche Repository in einer der beiden Settings-Dateien eingetragen werden. Listing 1 enthält die hierfür notwendige Konfiguration.
Der Codeblock aus dem Listing ist in einer der settings.xml-Dateien unterhalb der Ebene des Root-Elements einzutragen. Die eigentliche Konfiguration befindet sich im Profil mit der ID profile-php-maven, welches auch als aktiv registriert ist. Es ist ohne Weiteres möglich, mehrere Profile in der Konfiguration aktiv zu setzen, wenn dies notwendig sein sollte. Im Profil werden die verschiedenen Remote-Repositories für PHP Maven registriert. Mit diesen Einträgen ist Maven nun in der Lage, die notwendigen Artefakte aus dem öffentlichen Repository zu laden.
<activeProfiles>
<activeProfile>profile-php-maven</activeProfile>
</activeProfiles>
<profiles>
<profile>
<id>profile-php-maven</id>
<pluginRepositories>
<pluginRepository>
<id>release-repo1.php-maven.org</id>
<name>PHP-Maven 2 Release Repository</name>
<url>http://repos.php-maven.org/releases</url>
<releases>
<enabled>true</enabled>
</releases>
</pluginRepository>
<pluginRepository>
<id>snapshot-repo1.php-maven.org</id>
<name>PHP-Maven 2 Snapshot Repository</name>
<url>http://repos.php-maven.org/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
</pluginRepositories>
<repositories>
<repository>
<id>release-repo1.php-maven.org</id>
<name>PHP-Maven 2 Release Repository</name>
<url>http://repos.php-maven.org/releases</url>
<releases>
<enabled>true</enabled>
</releases>
</repository>
<repository>
<id>snapshot-repo1.php-maven.org</id>
<name>PHP-Maven 2 Snapshot Repository</name>
<url>http://repos.php-maven.org/snapshots</url>
<releases>
<enabled>false</enabled>
</releases>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
</repositories>
</profile>
</profiles>Mittlerweile betreiben immer mehr Unternehmen eigene Repository-Server für ihre Produkte. Dazu gehören unter anderem Google, Java .NET und Activity, um einige öffentliche Server zu nennen. Da das Projekt Maven for PHP vergleichsweise sehr jung ist, sind derzeit nur die bekanntesten PHP-Projekte, wie beispielsweise Zend und Symfony, in das Repository migriert. In absehbarer Zukunft darf jedoch durchaus erwartet werden, dass weitere PHP-Projekte das Repository bereichern werden. Bei besonders dringlichen Fällen kann es hier hilfreich sein, eine Anfrage über die Google Mailing List zu stellen. Natürlich ist auch jeder, der sich an PHP for Maven beteiligen möchte, eingeladen, sich im Rahmen seiner Möglichkeiten einzubringen.
PHP-CLI
Damit Maven sich voll entfalten kann, ist es notwendig, das Command Line Interface (CLI) für PHP in der Konsole zu aktivieren. Mit dem CLI ist es möglich, PHP-Skripts ohne Webbrowser direkt auf der Kommandozeile auszuführen.

Diese Funktion wird beispielsweise benötigt, um die Source-Code-Dokumentation über den phpDocumentor aus Maven heraus anzustoßen. Sobald der Pfad zum Verzeichnis der php.exe in die PATH-Variable aufgenommen wurde, können PHP-Skripts über die Konsole ausgeführt werden. Wie diese Aufgabe für Windows-Systeme gelöst wird, wurde bereits in dem vorangegangenen Abschnitt über die Installation ausführlich beschrieben. Der Erfolg dieser Bemühung lässt sich durch die Anweisung php –v rasch überprüfen und wird im Erfolgsfall mit der Ausgabe der installierten PHP-Version quittiert. Auch wenn im ersten Blick die Installation umfangreich erscheint, sind nur wenige Schritte durchzuführen, um ein einsatzfähiges System zu erhalten. Der geringe Aufwand wird durch umfangreiche Funktionen zur Projektautomatisierung schnell entlohnt.
Ein Füllhorn an Möglichkeiten
Es steht dem Benutzer frei, für welches Szenario er Maven in einem Projekt einsetzen möchte. Hier ein Liste möglicher Einsatzszenarien:
Die erste Position dieser Liste führt erwartungsgemäß das Dependency Management an. Über den Mechanismus können Artefakte fremder Hersteller ebenso dem eigenen Projekt hinzugefügt werden wie selbst entwickelte Bibliotheken.
Neben diesem Aspekt ist ein weiteres wichtiges Thema der Softwaretest. Maven erlaubt es, verschiedenste Test-Frameworks im Build-Lifecycle zu integrieren. Der bekannteste Vertreter unter den Unit-Tests, phpUnit, ist bereits im Public-Repository von Maven for PHP enthalten.
Wie bereits angedeutet, kommt die Generierung der API-Dokumentation mit dem phpDocumentator ebenfalls nicht zu kurz.
Aber auch ein Blick zu den klassischen Maven-Plug-ins ist in einigen Fällen lohnenswert. So besteht die Möglichkeit, aus Maven heraus Ant-Aufrufe zu starten und abzuarbeiten, was die Funktionsvielfalt um einiges erweitert.
Ein beliebtes Thema für Webseiten sind script- und CSS-Minimierer. Code-Beautifier oder Obsfukatoren stellen weitere Punkte auf der Liste dar. Auch Code-Analyzer-Werkzeuge wie Checkstyle können eingebunden werden und bieten damit der Projektleitung einen guten Einblick in die Softwarequalität.
Eine weitere Möglichkeit besteht darin, ganze Internetseiten zu generieren. So ist beispielsweise die Homepage des Projekts aus Maven heraus erzeugt worden.
Das Charmante an all diesen Möglichkeiten ist die Tatsache, dass für die Funktionalität keine weitere Software installiert werden muss. Alle Funktionen sind durch Maven-Plug-ins umgesetzt und werden bei Bedarf über das Dependency Management nachgeladen. Sollte dennoch Wünsche offen bleiben, ist es jederzeit möglich, über das Plug-in-API eigene Erweiterungen zu schreiben.
Für Unternehmen bietet Maven einen weiteren Vorteil. Der Einsatz dieses Werkzeugs unterstützt bei gutem Moduldesign die Wiederverwendung von Softwarekomponenten. Diese Tatsache kann den entscheidenden Vorsprung gegenüber der Konkurrenz bedeuten, da Projekte schneller abgewickelt werden können.
- Teil 1 – Einführung, CoC, DRY
- Teil 2 – POM, Testen & API Dokumentation
- Teil 3 – Web-Anwendungen mit Maven
- Teil 4 – IDE-Integration