Refactoring – Eine kurze Geschichte des Scheiterns
Für mein kleines Open Source-Projekt TP-CORE, das Sie auf GitHub finden können, hatte ich die großartige Idee, die iText-Bibliothek für OpenPDF zu ersetzen. Nachdem ich einen Plan gemacht hatte, wie ich mein Ziel erreichen könnte, startete ich alle notwendigen Aktivitäten. Aber im wirklichen Leben sind die Dinge nie so einfach, wie wir es uns ursprünglich vorgestellt haben. In diesem Vortrag erfahren Sie was genau passiert ist. Ich spreche über meine Motivation, warum ich die Änderung wollte und wie mein Plan war, alle Aktivitäten zum Erfolg zu führen. Sie werden erfahren wie es war, als ich den Punkt erreichte bei dem mir klar wurde, dass ich so nicht zum Ziel gelange. Ich erkläre kurz, was ich getan habe, dass dieses kurze Abenteuer den Rest des Projekts nicht beeinflusst hat.
Als mir im Studium die Vorzüge der OOP mit Java schmackhaft gemacht wurden, war ein sehr beliebtes Argument die Wiederverwendung. Das der Grundsatz write once use everywhere – in der Praxis dann doch nicht so leicht umzusetzen ist, wie es die Theorie suggeriert, haben die meisten Entwickler am eigene Leib erfahren. Woran liegt es also, das die Idee der Wiederverwendung in realen Projekten so schwer umzusetzen ist? Machen wir also einen gemeinsamen Streifzug durch die Welt der Informatik und betracten verschiedene Vorhaben aus einer sicheren Distanz.
Als mir im Studium die Vorzüge der objektorientierten Programmierung mit Java schmackhaft gemacht wurden, war ein sehr beliebtes Argument die Wiederverwendung. Dass der Grundsatz „write once use everywhere“ in der Praxis dann doch nicht so leicht umzusetzen ist, wie es die Theorie suggeriert, haben die meisten Entwickler bereits am eigenen Leib erfahren. Woran liegt es also, dass die Idee der Wiederverwendung in realen Projekten so schwer umzusetzen ist? Machen wir also einen gemeinsamen Streifzug durch die Welt der Informatik und betrachten verschiedene Vorhaben aus sicherer Distanz.
Wenn ich daran denke, wie viel Zeit ich während meines Studiums investiert habe, um eine Präsentationsvorlage für Referate zu erstellen. Voller Motivation habe ich alle erdenklichen Ansichten in weiser Voraussicht erstellt. Selbst rückblickend war das damalige Layout für einen Nichtgrafiker ganz gut gelungen. Trotzdem kam die tolle Vorlage nur wenige Male zum Einsatz und wenn ich im Nachhinein einmal Resümee ziehe, komme ich zu dem Schluss, dass die investierte Arbeitszeit in Bezug auf die tatsächliche Verwendung in keinem Verhältnis gestanden hat. Von den vielen verschiedenen Ansichten habe ich zum Schluss exakt zwei verwendet, das Deckblatt und eine allgemeine Inhaltsseite, mit der alle restlichen Darstellungen umgesetzt wurden. Die restlichen 15 waren halt da, falls man das künftig noch brauchen würde. Nach dieser Erfahrung plane ich keine eventuell zukünftig eintreffenden Anforderungen mehr im Voraus. Denn den wichtigsten Grundsatz in Sachen Wiederverwendung habe ich mit dieser Lektion für mich gelernt: Nichts ist so beständig wie die Änderung.
Diese kleine Anekdote trifft das Thema bereits im Kern. Denn viele Zeilen Code werden genau aus der gleichen Motivation heraus geschrieben. Der Kunde hat es noch nicht beauftragt, doch die Funktion wird er ganz sicher noch brauchen. Wenn wir in diesem Zusammenhang einmal den wirtschaftlichen Kontext ausblenden, gibt es immer noch ausreichend handfeste Gründe, durch die Fachabteilung noch nicht spezifizierte Funktionalität nicht eigenmächtig im Voraus zu implementieren. Für mich ist nicht verwendeter, auf Halde produzierter Code – sogenannter toter Code – in erster Linie ein Sicherheitsrisiko. Zusätzlich verursachen diese Fragmente auch Wartungskosten, da bei Änderungen auch diese Bereiche möglicherweise mit angepasst werden müssen. Schließlich muss die gesamte Codebasis kompilierfähig bleiben. Zu guter Letzt kommt noch hinzu, dass die Kollegen oft nicht wissen, dass bereits eine ähnliche Funktion entwickelt wurde, und diese somit ebenfalls nicht verwenden. Die Arbeit wird also auch noch doppelt ausgeführt. Nicht zu vergessen ist auch das von mir in großen und langjährig entwickelten Applikationen oft beobachtete Phänomen, dass ungenutzte Fragmente aus Angst, etwas Wichtiges zu löschen, über Jahre hinweg mitgeschleppt werden. Damit kommen wir auch schon zum zweiten Axiom der Wiederverwendung: Erstens kommt es anders und zweitens als man denkt.
Über die vielen Jahre, genauer gesagt Jahrzehnte, in denen ich nun verschiedenste IT- beziehungsweise Softwareprojekte begleitet habe, habe ich ein Füllhorn an Geschichten aus der Kategorie „Das hätte ich mir sparen können!“ angesammelt. Virtualisierung ist nicht erst seit Docker [1] auf der Bildfläche erschienen – es ist schon weitaus länger ein beliebtes Thema. Die Menge der von mir erstellten virtuellen Maschinen (VMs) kann ich kaum noch benennen – zumindest waren es sehr viele. Für alle erdenklichen Einsatzszenarien hatte ich etwas zusammengebaut. Auch bei diesen tollen Lösungen erging es mir letztlich nicht viel anders als bei meiner Office-Vorlage. Grundsätzlich gab es zwei Faktoren, die sich negativ ausgewirkt haben. Je mehr VMs erstellt wurden, desto mehr mussten dann auch gewertet werden. Ein Worst-Case-Szenario heutzutage wäre eine VM, die auf Windows 10 basiert, die dann jeweils als eine .NET- und eine Java-Entwicklungsumgebung oder Ähnliches spezialisiert wurde. Allein die Stunden, die man für Updates zubringt, wenn man die Systeme immer mal wieder hochfährt, summieren sich auf beachtliche Größen. Ein Grund für mich zudem, soweit es geht, einen großen Bogen um Windows 10 zu machen. Aus dieser Perspektive können selbsterstellte DockerContainer schnell vom Segen zum Fluch werden.
Dennoch darf man diese Dinge nicht gleich überbewerten, denn diese Aktivitäten können auch als Übung verbucht werden. Wichtig ist, dass solche „Spielereien“ nicht ausarten und man neben den technischen Erfahrungen auch den Blick für tatsächliche Bedürfnisse auf lange Sicht schärft.
Gerade bei Docker bin ich aus persönlicher Erfahrung dazu übergegangen, mir die für mich notwendigen Anpassungen zu notieren und zu archivieren. Komplizierte Skripte mit Docker-Compose spare ich mir in der Regel. Der Grund ist recht einfach: Die einzelnen Komponenten müssen zu oft aktualisiert werden und der Einsatz für jedes Skript findet in meinem Fall genau einmal statt. Bis man nun ein lauffähiges Skript zusammengestellt hat, benötigt man, je nach Erfahrung, mehrere oder weniger Anläufe. Also modifiziere ich das RUN-Kommando für einen Container, bis dieser das tut, was ich von ihm erwarte. Das vollständige Kommando hinterlege ich in einer Textdatei, um es bei Bedarf wiederverwenden zu können. Dieses Vorgehen nutze ich für jeden Dienst, den ich mit Docker virtualisiere. Dadurch habe ich die Möglichkeit, verschiedenste Konstellationen mit minimalen Änderungen nach dem „Klemmbaustein“-Prinzip zu rchestrieren. Wenn sich abzeichnet, dass ein Container sehr oft unter gleichen Bedienungen instanziiert wird, ist es sehr hilfreich, diese Konfiguration zu automatisieren. Nicht ohne Grund gilt für Docker-Container die Regel, möglichst nur einen Dienst pro Container zu virtualisieren.
Aus diesen beiden kleinen Geschichten lässt sich bereits einiges für Implementierungsarbeiten am Code ableiten. Ein klassischer Stolperstein, der mir bei der täglichen Projektarbeit regelmäßig unterkommt, ist, dass man mit der entwickelten Applikation eine eierlegende Wollmilchsau – oder, wie es in Österreich heißt: ein Wunderwutzi – kreieren möchte. Die Teams nehmen sich oft zu viel vor und das Projektmanagement versucht, den Product Owner auch nicht zu bekehren, lieber auf Qualität statt auf Quantität zu setzen. Was ich mit dieser Aussage deutlich machen möchte, lässt sich an einem kleinen Beispiel verständlich machen.
Gehen wir einmal davon aus, dass für eigene Projekte eine kleine Basisbibliothek benötigt wird, in der immer wiederkehrende Problemstellungen zusammengefasst werden – konkret: das Verarbeiten von JSON-Objekten [2]. Nun könnte man versuchen, alle erdenklichen Variationen im Umgang mit JSON abzudecken. Abgesehen davon, dass viel Code produziert wird, erzielt ein solches Vorgehen wenig Nutzen. Denn für so etwas gibt es bereits fertige Lösungen – etwa die freie Bibliothek Jackson [3]. Anstelle sämtlicher denkbarer JSON-Manipulationen ist in Projekten vornehmlich das Serialisieren und das Deserialisieren gefragt. Also eine Möglichkeit, wie man aus einem Java-Objekt einen JSON-String erzeugt, und umgekehrt. Diese beiden Methoden lassen sich leicht über eine Wrapper-Klasse zentralisieren. Erfüllt nun künftig die verwendete JSON-Bibliothek die benötigten Anforderungen nicht mehr, kann sie leichter durch eine besser geeignete Bibliothek ersetzt werden. Ganz nebenbei erhöhen wir mit diesem Vorgehen auch die Kompatibilität [4] unserer Bibliothek für künftige Erweiterungen. Wenn JSON im Projekt eine neu eingeführte Technologie ist, kann durch die Minimal-Implementierung stückweise Wissen aufgebaut werden. Je stärker der JSONWrapper nun in eigenen Projekten zum Einsatz kommt, desto wahrscheinlicher ist es, dass neue Anforderungen hinzukommen, die dann erst umgesetzt werden, wenn sie durch ein Projekt angefragt werden. Denn wer kann schon abschätzen, wie der tatsächliche Bedarf einer Funktionalität ist, wenn so gut wie keine Erfahrungen zu der eingesetzten Technologie vorhanden sind?
Das soeben beschriebene Szenario läuft auf einen einfachen Merksatz hinaus: Eine neue Implementierung möglichst so allgemein wie möglich halten, um sie nach Bedarf immer weiter zu spezialisieren.
Bei komplexen Fachanwendungen hilft uns das Domain-driven Design (DDD) Paradigma, Abgrenzungen zu Domänen ausfindig zu machen. Auch hierfür lässt sich ein leicht verständliches, allgemein gefasstes Beispiel finden. Betrachten wir dazu einmal die Domäne einer Access Control List (ACL). In der ACL wird ein Nutzerkonto benötigt, mit dem Berechtigungen zu verschiedenen Ressourcen verknüpft werden. Nun könnte man auf die Idee kommen, im Account in der ACL sämtliche Benutzerinformationen wie Homepage, Postadresse und Ähnliches abzulegen. Genau dieser Fall würde die Domäne der ACL verletzen, denn das Benutzerkonto benötigt lediglich Informationen, die zur Authentifizierung benötigt werden, um eine entsprechende Autorisierung zu ermöglichen.
Jede Anwendung hat für das Erfassen der benötigten Nutzerinformationen andere Anforderungen, weshalb diese Dinge nicht in eine ACL gehören sollten. Das würde die ACL zu sehr spezialisieren und stetige Änderungen verursachen. Daraus resultiert dann auch, dass die ACL nicht mehr universell einsatzfähig ist.
Man könnte nun auf die Idee kommen, eine sehr generische Lösung für den Speicher zusätzlicher Nutzerinformationen zu entwerfen und ihn in der ACL zu verwenden. Von diesem Ansatz möchte ich abraten. Ein wichtiger Grund ist, dass diese Lösung die Komplexität der ACL unnötig erhöht. Ich gehe obendrein so weit und möchte behaupten, dass unter ungünstigen Umständen sogar Code-Dubletten entstehen. Die Begründung dafür ist wie folgt: Ich sehe eine generische Lösung zum Speichern von Zusatzinformationen im klassischen Content Management (CMS) verortet. Die Verknüpfung zwischen ACL und CMS erfolgt über die Benutzer-ID aus der ACL. Somit haben wir gleichzeitig auch zwischen den einzelnen Domänen eine lose Kopplung etabliert, die uns bei der Umsetzung einer modularisierten Architektur sehr behilflich sein wird.
Zum Thema Modularisierung möchte ich auch kurz einwerfen, dass Monolithen [5] durchaus auch aus mehreren Modulen bestehen können und sogar sollten. Es ist nicht zwangsläufig eine Microservice-Architektur notwendig. Module können aus unterschiedlichen Blickwinkeln betrachtet werden. Einerseits erlauben sie es einem Team, in einem fest abgegrenzten Bereich ungestört zu arbeiten, zum anderen kann ein Modul mit einer klar abgegrenzten Domäne ohne viele Adaptionen tatsächlich in späteren Projekten wiederverwendet werden.
Nun ergibt sich klarerweise die Fragestellung, was mit dem Übergang von der Generalisierung zur Spezialisierung gemeint ist. Auch hier hilft uns das Beispiel der ACL weiter. Ein erster Entwurf könnte die Anforderung haben, dass, um unerwünschte Berechtigungen falsch konfigurierter Rollen zu vermeiden, die Vererbung von Rechten bestehender Rollen nicht erwünscht ist. Daraus ergibt sich dann der Umstand, dass jedem Nutzer genau eine Rolle zugewiesen werden kann. Nun könnte es sein, dass durch neue Anforderungen der Fachabteilung eine Mandantenfähigkeit eingeführt werden soll. Entsprechend muss nun in der ACL eine Möglichkeit geschaffen werden, um bestehende Rollen und auch Nutzeraccounts einem Mandanten zuzuordnen. Eine Domänen-Erweiterung dieser hinzugekommenen Anforderung ist nun basierend auf der bereits bestehenden Domäne durch das Hinzufügen neuer Tabellenspalten leicht umzusetzen.
Die bisher aufgeführten Beispiele beziehen sich ausschließlich auf die Implementierung der Fachlogik. Viel komplizierter verhält sich das Thema Wiederverwendung beim Punkt der grafischen Benutzerschnittelle (GUI). Das Problem, das sich hier ergibt, ist die Kurzlebigkeit vieler chnologien. Java Swing existiert zwar noch, aber vermutlich würde sich niemand, der heute eine neue Anwendung entwickelt, noch für Java Swing entscheiden. Der Grund liegt in veraltetem Look-and-Feel der Grafikkomponenten. Um eine Applikation auch verkaufen zu können, darf man den Aspekt der Optik nicht außen vor lassen. Denn auch das Auge isst bekanntlich mit. Gerade bei sogenannten Green-Field-Projekten ist der Wunsch, eine moderne, ansprechende Oberfläche anbieten zu können, implizit. Deswegen vertrete ich die Ansicht, dass das Thema Wiederverwendung für GUI – mit wenigen Ausnahmen – keine wirkliche Rolle spielt.
Lessons Learned
Sehr oft habe ich in der Vergangenheit erlebt, wie enthusiastisch bei Kick-off-Meetings die Möglichkeit der Wiederverwendung von Komponenten in Aussicht gestellt wurde. Dass dies bei den verantwortlichen Managern zu einem Glitzern in den Augen geführt hat, ist auch nicht verwunderlich. Als es dann allerdings zu ersten konkreten Anfragen gekommen ist, eine Komponente in einem anderen Projekt einzusetzen, mussten sich alle Beteiligten eingestehen, dass dieses Vorhaben gescheitert war. In den nachfolgenden Retrospektiven sind die Punkte, die ich in diesem Artikel vorgestellt habe, regelmäßig als Ursachen identifiziert worden. Im Übrigen genügt oft schon ein Blick in das Datenbankmodell oder auf die Architektur einer Anwendung, um eine Aussage treffen zu können, wie realistisch eine Wiederverwendung tatsächlich ist. Bei steigendem Komplexitätsgrad sinkt die Wahrscheinlichkeit, auch nur kleinste Segmente erfolgreich für eine Wiederverwendung herauslösen zu können.
Nach einigen Jahren hat das Virtualisierungstool Docker seine Bedeutung für die Softwarebranche unter Beweis gestellt. Wenn man von Virtualisierung hört, könnte man meinen, dass dies nur etwas für Administratoren ist und mich als Entwickler nicht so stark betrifft. Aber Moment mal. Da könntest du falsch liegen. Denn Grundkenntnisse über Docker können Entwicklern im Alltag helfen.
Schritt 1: Erstellen Sie den Container und initialisieren Sie die Datenbank
Wenn Sie möchten, dass PostgreSQL nach einem Neustart immer aktiv ist, ändern Sie die Neustartrichtlinie von „nein“ auf „immer“. Nachdem Sie die Instanz „pg-dbms“ Ihres PostgreSQL 11 Docker-Images erstellt haben, überprüfen Sie, ob der Neustart erfolgreich war. Dies gelingt über den Befehl:
dockerps-a
Schritt 2: Kopieren Sie das initialisierte Datenbankverzeichnis in ein lokales Verzeichnis auf Ihrem Hostsystem
Das größte Problem mit dem aktuellen Container ist, dass beim Löschen alle Daten verloren gehen. Wir müssen also eine Möglichkeit finden, diese Daten dauerhaft zu speichern. Am einfachsten kopieren Sie das Datenverzeichnis Ihres Containers in ein Verzeichnis auf Ihrem Hostsystem. Der Kopierbefehl benötigt die Parameter „Quelle“ und „Ziel“. Geben Sie als Quelle den Container an, aus dem die Dateien stammen sollen. In unserem Fall heißt der Container „pg-dbms“. Das Ziel ist ein PostgreSQL-Ordner im Home-Verzeichnis des Benutzers „ed“. Unter Windows funktioniert es genauso. Passen Sie einfach den Verzeichnispfad an und vermeiden Sie Leerzeichen. Sobald die Dateien im angegebenen Verzeichnis liegen, ist dieser Schritt abgeschlossen.
Schritt 3: Stoppen Sie den aktuellen Container
dockerstoppg-dbms
Wenn Sie einen Container starten möchten, ersetzen Sie einfach „Stop“ durch „Start“. Der Container, den wir zum Abrufen der ursprünglichen Dateien für das PostgreSQL-DBMS erstellt haben, wird nicht mehr benötigt. Wir können ihn löschen. Dazu muss jedoch zunächst der laufende Container gestoppt werden.
Schritt 4: Starten Sie den aktuellen Container
dockerstartpg-dbms
Nachdem der Container gestoppt wurde, können wir ihn löschen.
Schritt 5: Container mit einem externen Volume neu erstellen
Jetzt können wir das Verzeichnis mit der exportierten ursprünglichen Datenbank mit einem neu erstellten PostgreSQL-Container verknüpfen. Das ist alles. Der große Vorteil dieser Vorgehensweise ist, dass sich nun jede in PostgreSQL erstellte Datenbank und deren Daten außerhalb des Docker-Containers auf unserem lokalen Rechner befinden. Dies ermöglicht eine wesentlich einfachere Sicherung und verhindert Informationsverluste bei Containeraktualisierungen.
Wenn Sie anstelle von PostgreSQL andere Images haben, aus denen Sie Dateien zur Wiederverwendung extrahieren müssen, können Sie dieses Tutorial ebenfalls verwenden. Passen Sie es einfach an das Image und die benötigten Pfade an. Die Vorgehensweise ist nahezu identisch. Wenn Sie mehr über Docker erfahren möchten, können Sie sich auch mein Video „Docker-Grundlagen in weniger als 10 Minuten“ ansehen. Wenn Ihnen dieses kurze Tutorial gefällt, teilen Sie es mit Ihren Freunden und Kollegen. Abonnieren Sie meinen Newsletter, um auf dem Laufenden zu bleiben.
Jeder macht es, manche sogar mehrmals täglich. Aber nur wenige kennen die komplexen ineinander greifenden Mechanismen, die ein vollständiges Software Release ausmachen. Deshalb kommt es hin und wieder vor, das sich ein Paket in der automatisierten Verarbeitungskette querstellt.
Mit ein wenig Theorie und einem typischen Beispiele aus dem Java Universum zeige ich, wie man ein wenig Druck aus dem Softwareentwicklungsprozess nehmen kann, um zu schlanken leicht automatisierten Prozessen gelangt.
Maven secrets unlocked – verbessern Sie Ihren Build
Apache Maven ist seit mehr als einem Jahrzehnt als Build- und Reporting-Tool für Java-Projekte etabliert. Der Erfolg dieses Tools wurde, weil es als eines der ersten Build-Tools eine einfache Lösung für das Abhängigkeitsmanagement ansprach. Entwickler lassen mehrmals am Tag einen Maven-Build laufen, wissen aber oft nicht, wie sie Probleme beheben können, wenn ein Build kaputt ist.
In diesem praxisorientierten Vortrag beginnen wir mit den Grundlagen und gehen schnell zu fortgeschrittenen Themen über und lernen, wie man den Lebenszyklus eines Builds modifiziert:
Nachdem die Gang Of Four (GOF) Erich Gamma, Richard Helm, Ralph Johnson und John Vlissides das Buch Design Patterns: Elements of Reusable Object-Oriented Software (Elemente wiederverwendbarer objektorientierter Software), wurde das Erlernen der Beschreibung von Problemmustern und deren Lösungen in fast allen Bereichen der Softwareentwicklung populär. Ebenso populär wurde das Erlernen der Beschreibung von Don’ts und Anti-Patterns.
In Publikationen, die sich mit den Konzepten der Entwurfsmuster und Anti-Pattern befassen, finden wir hilfreiche Empfehlungen für Softwaredesign, Projektmanagement, Konfigurationsmanagement und vieles mehr. In diesem Artikel möchte ich meine Erfahrungen im Umgang mit Versionsnummern für Software-Artefakte weitergeben.
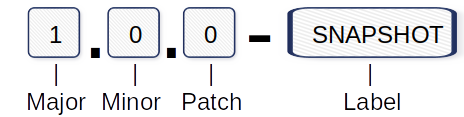
Die meisten von uns sind bereits mit einer Methode namens semantische Versionierung vertraut, einem leistungsstarken und leicht zu erlernenden Regelwerk dafür, wie Versionsnummern strukturiert sein sollten und wie die einzelnen Segmente zu inkrementieren sind.
Beispiel für eine Versionsnummerierung:
Major: Inkompatible API-Änderungen.
Minor: Hinzufügen neuer Funktionen.
Patch: Fehlerbehebungen und Korrekturen.
Label: SNAPSHOT zur Kennzeichnung des Status “in Entwicklung”.
Eine inkompatible API-Änderung liegt dann vor, wenn eine von außen zugängliche Funktion oder Klasse gelöscht oder umbenannt wurde. Eine andere Möglichkeit ist eine Änderung der Signatur einer Methode. Das bedeutet, dass der Rückgabewert oder die Parameter gegenüber der ursprünglichen Implementierung geändert wurden. In diesen Fällen ist es notwendig, das Major-Segment der Versionsnummer zu erhöhen. Diese Änderungen stellen für API-Kunden ein hohes Risiko dar, da sie ihren eigenen Code anpassen müssen.
Beim Umgang mit Versionsnummern ist es auch wichtig zu wissen, dass 1.0.0 und 1.0 gleichwertig sind. Dies hat mit der Anforderung zu tun, dass die Versionen einer Softwareversion eindeutig sein müssen. Wenn dies nicht der Fall ist, ist es unmöglich, zwischen Artefakten zu unterscheiden. In meiner beruflichen Praxis war ich mehrfach an Projekten beteiligt, bei denen es keine klar definierten Prozesse für die Erstellung von Versionsnummern gab. Dies hatte zur Folge, dass das Team die Qualität des Artefakts sicherstellen musste und sich nicht mehr sicher war, mit welcher Version des Artefakts es sich gerade befasste.
Der größte Fehler, den ich je gesehen habe, war die Speicherung der Version eines Artefakts in einer Datenbank zusammen mit anderen Konfigurationseinträgen. Die korrekte Vorgehensweise sollte sein: die Version innerhalb des Artefakts so zu platzieren, dass niemand nach einem Release diese von außen ändern kann. Die Falle, in die man sonst tappt, ist der Prozess, wie man die Version nach einem Release oder Neuinstallation aktualisiert.
Vielleicht haben Sie eine Checkliste für alle manuellen Tätigkeiten während eines Release. Aber was passiert, nachdem eine Version in einer Testphase installiert wurde und aus irgendeinem Grund eine andere Version der Anwendung eneut installiert werden muss? Ist Ihnen noch bewusst, dass Sie die Versionsnummer manuell in der Datenbank ändern müssen? Wie finden Sie heraus, welche Version installiert ist, wenn die Informationen in der Datenbank nicht stimmen?
Die richtige Version in dieser Situation zu finden, ist eine sehr schwierige Aufgabe. Aus diesem Grund haben gibt es die Anforderung, die Version innerhalb der Anwendung zu halten. Im nächsten Schritt werden wir einen sicheren und einfachen Weg aufzeigen, wie man dieses Problem voll automatisiert lösen kann.
Die Voraussetzung ist eine einfache Java-Bibliothek die mit Maven gebaut wird. Standardmäßig wird die Versionsnummer des Artefakts in der POM notiert. Nach dem Build-Prozess wird unser Artefakt erstellt und wie folgt benannt: artifact-1.0.jar oder ähnlich. Solange wir das Artefakt nicht umbenennen, haben wir eine gute Möglichkeit, die Versionen zu unterscheiden. Selbst nach einer Umbenennung kann mit einem einfachen Trick nach einem Unzip des Archives im META-INF-Ordner der richtige Wert gefunden werden.
Wenn Sie die Version in einer Poroperty oder Klasse fest einkodiert haben, würde das auch funktionieren, solange Sie nicht vergessen diese immer aktuell zu halten. Vielleicht müssen Sie dem Branching und Merging in SCM Systemen wie Git besondere Aufmerksamkeit schenken, um immer die korrekte Version in Ihrer Codebasis zu haben.
Eine andere Lösung ist die Verwendung von Maven und dem Tokenreplacement. Bevor Sie dies in Ihrer IDE ausprobieren, sollten Sie bedenken, dass Maven zwei verschiedene Ordner verwendet: Sources und Ressourcen. Die Token-Ersetzung in den Quellen wird nicht richtig funktionieren. Nach einem ersten Durchlauf ist Ihre Variable durch eine feste Zahl ersetzt und verschwunden. Ein zweiter Durchlauf wird daher fehlschlagen. Um Ihren Code für die Token-Ersetzung vorzubereiten, müssen Sie Maven als erstes im Build-Lifecycle konfigurieren:
Nach diesem Schritt müssen Sie die Property ${project.version} aus dem POM kennen. Damit können Sie eine Datei mit dem Namen version.property im Verzeichnis resources erstellen. Der Inhalt dieser Datei besteht nur aus einer Zeile: version=${project.version}. Nach einem Build finden Sie in Ihrem Artefakt die version.property mit der gleichen Versionsnummer, die Sie in Ihrem POM verwendet haben. Nun können Sie eine Funktion schreiben, die die Datei liest und diese Property verwendet. Sie können das Ergebnis zum Beispiel in einer Konstante speichern, um es in Ihrem Programm zu verwenden. Das ist alles, was Sie tun müssen!
Testfalle – Richtiges und effizientes Softwaretesten
Das Software getestet werden muss ist allen Beteiligten klar. Oft stellt sich nicht die Frage welche Test Frameworks eingesetzt werden sollten, sondern viel mehr das Wie bereitet die meisten Unklarheiten. Am Beispiel eines realen Open Source Projektes werden zentrale Aspekte des Softwaretesting anschaulich besprochen. Dazu gehören die Punkte:
Wie erzeuge ich testbaren Code
Wie kann mit einem Testfall die Qualität verbessert werden
Was ist Testabdeckung und wo liegen die Grenzen
Wer ist für welche Tests zuständig
Wie entwickelt man testgetrieben ohne Mehraufwand
Wie kann das Management die Testqualität beurteilen
m Umgang mit Source-Control-Management-Systemen (SCM) wie Git oder Subversion haben sich im Lauf der Zeit vielerlei Praktiken bewährt. Neben unzähligen Beiträgen über Workflows zum Branchen und Mergen ist auch das Formulieren verständlicher Beschreibungen in den Commit-Messages ein wichtiges Thema.
(c) 2018 Marco Schulz, Java PRO Ausgabe 3, S.50-51
Ab und zu kommt es vor, dass in kollaborativen Teams vereinzelte Code-Änderungen zurückgenommen werden müssen. So vielfältig die Gründe für ein Rollback auch sein mögen, das Identifizieren betroffener Code-Fragmente kann eine beachtliche Herausforderung sein. Die Möglichkeit jeder Änderung des Code-Repository eine Beschreibung anzufügen, erleichtert die Navigation zwischen den Änderungen. Sind die hinterlegten Kommentare der Entwickler dann so aussagekräftig wie „Layout-Anpassungen“ oder „Tests hinzugefügt“, hilft dies wenig weiter. Diese Ansicht vertreten auch diverse Blog-Beiträge [siehe Weitere Links] und sehen das Formulieren klarer Commit-Messages als wichtiges Instrument, um die interne Kommunikation zwischen einzelnen Team-Mitgliedern deutlich zu verbessern.
Das man als Entwickler nach vollbrachter Arbeit nicht immer den optimalen Ausdruck findet, seine Aktivitäten deutlich zu formulieren, kann einem hohen Termindruck geschuldet sein. Ein hilfreiches Instrument, ein aussagekräftiges Resümee der eigenen Arbeit zu ziehen, ist die nachfolgend vorgeschlagene Struktur und ein darauf operierendes aussagekräftiges Vokabular inklusive einer festgelegten Notation. Die vorgestellte Lösung lässt sich sehr leicht in die eigenen Prozesse einfügen und kann ohne großen Aufwand erweitert bzw. angepasst werden.
Mit den standardisierten Expressions besteht auch die Möglichkeit die vorhandenen Commit-Messages automatisiert zu Parsen, um die Projektevolution gegebenenfalls grafisch darzustellen. Sämtliche Einzelheiten der hier vorgestellten Methode sind in einem Cheat-Sheet auf einer Seite übersichtlich zusammengefasst und können so leicht im Team verbreitet werden. Das diesem Text zugrundeliegende Paper ist auf Research-Gate [1] in englischer Sprache frei verfügbar.
Eine Commit-Message besteht aus einer verpflichtenden (mandatory) ersten Zeile, die sich aus der Funktions-ID, einem Label und der Spezifikation zusammensetzt. Die zweite und dritte Zeile ist optional. Die Task-ID, die Issue-Management-Systeme wie Jira vergeben, wird in der zweiten Zeile notiert. Grund dafür ist, dass nicht jedes Projekt an ein Issue-Management-System gekoppelt ist. Viel wichtiger ist auch die Tatsache, dass Funktionen meist auf mehrere Tasks verteilt werden. Eine Suche nach der Funktions-ID fördert alle Teile einer Funktionalität zu tage, auch wenn dies unterschiedlichen Task-IDs zugeordnet ist. Die ausführliche Beschreibung in Zeile drei ist ebenfalls optional und rückt auf Zeile zwei vor, falls keine Task-ID notiert wird. Das gesamte Vokabular zu dem nachfolgenden Beispiel ist im Cheat-Sheet notiert und soll an dieser Stelle nicht wiederholt werden.
[CM-05] #CHANGE ’function:pom’
<QS-0815>
{Change version number of the dependency JUnit from 4 to 5.0.2}
Projektübergreifende Aufgaben wie das Anpassen der Build-Logik, Erzeugen eines Releases oder das Initiieren eines Repositories können in allgemeingültigen Funktions-IDs zusammengefasst werden. Entsprechende Beispiele sind im Cheat-Sheet angeführt.
Möchte man nun den Projektfortschritt ermitteln, ist es sinnvoll aussagekräftige Meilensteine miteinander zu vergleichen. Solche Punkte (POI) stellen üblicherweise Releases dar. So können bei Berücksichtigung des Standard-Release-Prozesses und des Semantic-Versionings Metriken über die Anzahl der Bug-Fixes pro Release erstellt werden. Aber auch klassische Erhebungen wie Lines-of-Code zwischen zwei Minor-Releases können interessante Erkenntnisse fördern.
Auch wenn zur Qualitätssteigerung der Software- Projekte in den letzten Jahren ein erheblicher Mehraufwand für das Testen betrieben wurde [1], ist der Weg zu kontinuierlich wiederholbaren Erfolgen keine Selbstverständlichkeit. Stringentes und zielgerichtetes Management aller verfügbaren Ressourcen war und ist bis heute unverzichtbar für reproduzierbare Erfolge.
(c) 2016 Marco Schulz, Java aktuell Ausgabe 4, S.14-19
Es ist kein Geheimnis, dass viele IT-Projekte nach wie vor ihre liebe Not haben, zu einem erfolgreichen Abschluss zu gelangen. Dabei könnte man durchaus meinen, die vielen neuen Werkzeuge und Methoden, die in den letzten Jahren aufgekommen sind, führten wirksame Lösungen ins Feld, um der Situation Herr zu werden. Verschafft man sich allerdings einen Überblick zu aktuellen Projekten, ändert sich dieser Eindruck.
Der Autor hat öfter beobachten können, wie diese Problematik durch das Einführen neuer Werkzeuge beherrscht werden sollte. Nicht selten endeten die Bemühungen in Resignation. Schnell entpuppte sich die vermeintliche Wunderlösung als schwergewichtiger Zeiträuber mit einem enormen Aufwand an Selbstverwaltung. Aus der anfänglichen Euphorie aller Beteiligten wurde schnell Ablehnung und gipfelte nicht selten im Boykott einer Verwendung. So ist es nicht verwunderlich, dass erfahrene Mitarbeiter allen Veränderungsbestrebungen lange skeptisch gegenüberstehen und sich erst dann damit beschäftigen, wenn diese absehbar erfolgreich sind. Aufgrund dieser Tatsache hat der Autor als Titel für diesen Artikel das provokante Zitat von Grady Booch gewählt, einem Mitbegründer der UML.
Oft wenden Unternehmen zu wenig Zeit zum Etablieren einer ausgewogenen internen Infrastruktur auf. Auch die Wartung bestehender Fragmente wird gern aus verschiedensten Gründen verschoben. Auf Management-Ebene setzt man lieber auf aktuelle Trends, um Kunden zu gewinnen, die als Antwort auf ihre Ausschreibung eine Liste von Buzzwords erwarten. Dabei hat es Tom De Marco bereits in den 1970er-Jahren ausführlich beschrieben [2]: Menschen machen Projekte (siehe Abbildung 1).
Wir tun, was wir können, aber können wir etwas tun?
Das Vorhaben, trotz bester Absichten und intensiver Bemühungen ein glückliches Ende finden, ist leider nicht die Regel. Aber wann kann man in der Software-Entwicklung von einem gescheiterten Projekt sprechen? Ein Abbruch aller Tätigkeiten wegen mangelnder Erfolgsaussichten ist natürlich ein offensichtlicher Grund, in diesem Zusammenhang allerdings eher selten. Vielmehr gewinnt man diese Erkenntnis während der Nachbetrachtung abgeschlossener Aufträge. So kommen beispielsweise im Controlling bei der Ermittlung der Wirtschaftlichkeit Schwachstellen zutage.
Gründe für negative Ergebnisse sind meist das Überschreiten des veranschlagten Budgets oder des vereinbarten Fertigstellungstermins. Üblicherweise treffen beide Bedingungen gleichzeitig zu, da man der gefährdeten Auslieferungsfrist mit Personal-Aufstockungen entgegenwirkt. Diese Praktik erreicht schnell ihre Grenzen, da neue Teammitglieder eine Einarbeitungsphase benötigen und so die Produktivität des vorhandenen Teams sichtbar reduzieren. Einfach zu benutzende Architekturen und ein hohes Maß an Automatisierung mildern diesen Effekt etwas ab. Hin und wieder geht man auch dazu über, den Auftragnehmer auszutauschen, in der Hoffnung, dass neue Besen besser kehren.
Wie eine fehlende Kommunikation, unzureichende Planung und schlechtes Management sich negativ auf die äußere Wahrnehmung von Projekten auswirkt, zeigt ein kurzer Blick auf die Top-3-Liste der in Deutschland fehlgeschlagenen Großprojekte: Berliner Flughafen, Hamburger Elbphilharmonie und Stuttgart 21. Dank ausführlicher Berichterstattung in den Medien sind diese Unternehmungen hinreichend bekannt und müssen nicht näher erläutert werden. Auch wenn die angeführten Beispiele nicht aus der Informatik stammen, finden sich auch hier die stets wiederkehrenden Gründe für ein Scheitern durch Kostenexplosion und Zeitverzug.
Abbildung 1: Problemlösung – „A bisserl was geht immer“, Monaco Franze
Der Wille, etwas Großes und Wichtiges zu erschaffen, allein genügt nicht. Die Verantwortlichen benötigen auch die notwendigen fachlichen, planerischen, sozialen und kommunikativen Kompetenzen, gepaart mit den Befugnissen zum Handeln. Luftschlösser zu errichten und darauf zu warten, dass Träume wahr werden, beschert keine vorzeigbaren Resultate.
Große Erfolge werden meist dann erzielt, wenn möglichst wenige Personen bei Entscheidungen ein Vetorecht haben. Das heißt nicht, dass man Ratschläge ignorieren sollte, aber auf jede mögliche Befindlichkeit kann keine Rücksicht genommen werden. Umso wichtiger ist es, wenn der Projektverantwortliche die Befugnis hat, seine Entscheidung durchzusetzen, dies jedoch nicht mit aller Härte demonstriert.
Es ist völlig normal, wenn man als Entscheidungsträger nicht sämtliche Details beherrscht. Schließlich delegiert man die Umsetzung an die entsprechenden Spezialisten. Dazu ein kurzes Beispiel: Als sich in den frühen 2000er-Jahren immer bessere Möglichkeiten ergaben, größere und komplexere Web-Anwendungen zu erstellen, kam in Meetings oft die Frage auf, mit welchem Paradigma die Anzeigelogik umzusetzen sei. Die Begriffe „Multi Tier“, „Thin Client“ und „Fat Client“ dominierten zu dieser Zeit die Diskussionen der Entscheidungsgremien. Dem Auftraggeber die Vorteile verschiedener Schichten einer verteilten Web-Applikation zu erläutern, war die eine Sache. Einem technisch versierten Laien aber die Entscheidung zu überlassen, wie er auf seine neue Applikation zugreifen möchte – per Browser („Thin Client“) oder über eine eigene GUI („Fat Client“) –, ist schlicht töricht. So galt es in vielen Fällen, während der Entwicklung auftretende Missverständnisse auszuräumen. Die schmalgewichtige Browser-Lösung entpuppte sich nicht selten als schwer zu beherrschende Technologie, da Hersteller sich selten um Standards kümmerten. Dafür bestand üblicherweise eine der Hauptanforderungen darin, die Applikation in den gängigsten Browsern nahezu identisch aussehen zu lassen. Das ließ sich allerdings nur mit erheblichem Mehraufwand umsetzen. Ähnliches konnte beim ersten Hype der Service-orientierten Architekturen beobachtet werden.
Die Konsequenz aus diesen Beobachtungen zeigt, dass es unverzichtbar ist, vor dem Projektstart eine Vision zu erarbeiten, deren Ziele auch mit dem veranschlagten Budget übereinstimmen. Eine wiederverwendbare Deluxe-Variante mit möglichst vielen Freiheitsgraden erfordert eine andere Herangehensweise als eine „We get what we need“-Lösung. Es gilt, sich weniger in Details zu verlieren, als das große Ganze im Blick zu halten.
Besonders im deutschsprachigen Raum fällt es Unternehmen schwer, die notwendigen Akteure für eine erfolgreiche Projektumsetzung zu finden. Die Ursachen dafür mögen recht vielfältig sein und könnten unter anderem darin begründet sein, dass Unternehmen noch nicht verstanden haben, dass Experten sich selten mit schlecht informierten und unzureichend vorbereiteten Recruitment-Dienstleistern unterhalten möchten.
Getting things done!
Erfolgreiches Projektmanagement ist kein willkürlicher Zufall. Schon lange wurde ein unzureichender Informationsfluss durch mangelnde Kommunikation als eine der negativen Ursachen identifiziert. Vielen Projekten wohnt ein eigener Charakter inne, der auch durch das Team geprägt ist, das die Herausforderung annimmt, um gemeinsam die gestellte Aufgabe zu bewältigen. Agile Methoden wie Scrum [3], Prince2 [4] oder Kanban [5] greifen diese Erkenntnis auf und bieten potenzielle Lösungen, um IT-Projekte erfolgreich durchführen zu können.
Gelegentlich ist jedoch zu beobachten, wie Projektleiter unter dem Vorwand der neu eingeführten agilen Methoden die Planungsaufgaben an die zuständigen Entwickler zur Selbstverwaltung übertragen. Der Autor hat des Öfteren erlebt, wie Architekten sich eher bei Implementierungsarbeiten im Tagesgeschäft gesehen haben, anstatt die abgelieferten Fragmente auf die Einhaltung von Standards zu überprüfen. So lässt sich langfristig keine Qualität etablieren, da die Ergebnisse lediglich Lösungen darstellen, die eine Funktionalität sicherstellen und wegen des Zeit- und Kostendrucks nicht die notwendigen Strukturen etablieren, um die zukünftige Wartbarkeit zu gewährleisten. Agil ist kein Synonym für Anarchie. Dieses Setup wird gern mit einem überfrachteten Werkzeugkasten voller Tools aus dem DevOps-Ressort dekoriert und schon ist das Projekt scheinbar unsinkbar. Wie die Titanic!
Nicht ohne Grund empfiehlt man seit Jahren, beim Projektstart allerhöchstens drei neue Technologien einzuführen. In diesem Zusammenhang ist es auch nicht ratsam, immer gleich auf die neuesten Trends zu setzen. Bei der Entscheidung für eine Technologie müssen im Unternehmen zuerst die entsprechenden Ressourcen aufgebaut sein, wofür hinreichend Zeit einzuplanen ist. Die Investitionen sind nur dann nutzbringend, wenn die getroffene Wahl mehr als nur ein kurzer Hype ist. Ein guter Indikator für Beständigkeit sind eine umfangreiche Dokumentation und eine aktive Community. Diese offenen Geheimnisse werden bereits seit Jahren in der einschlägigen Literatur diskutiert.
Wie geht man allerdings vor, wenn ein Projekt bereits seit vielen Jahren etabliert ist, aber im Sinne des Produkt-Lebenszyklus ein Schwenk auf neue Techniken unvermeidbar wird? Die Gründe für eine solche Anstrengung mögen vielseitig sein und variieren von Unternehmen zu Unternehmen. Die Notwendigkeit, wichtige Neuerungen nicht zu verpassen, um im Wettbewerb weiter bestehen zu können, sollte man nicht zu lange hinauszögern. Aus dieser Überlegung ergibt sich eine recht einfach umzusetzende Strategie. Aktuelle Versionen werden in bewährter Tradition fortgesetzt und erst für das nächste beziehungsweise übernächste Major-Release wird eine Roadmap erarbeitet, die alle notwendigen Punkte enthält, um einen erfolgreichen Wechsel durchzuführen. Dazu erarbeitet man die kritischen Punkte und prüft in kleinen Machbarkeitsstudien, die etwas anspruchsvoller als ein „Hallo Welt“- Tutorial sind, wie eine Umsetzung gelingen könnte. Aus Erfahrung sind es die kleinen Details, die das Krümelchen auf der Waagschale sein können, um über Erfolg oder Misserfolg zu entscheiden.
Bei allen Bemühungen wird ein hoher Grad an Automatisierung angestrebt. Gegenüber stetig wiederkehrenden, manuell auszuführenden Aufgaben bietet Automatisierung die Möglichkeit, kontinuierlich wiederholbare Ergebnisse zu produzieren. Dabei liegt es allerdings in der Natur der Sache, dass einfache Tätigkeiten leichter zu automatisieren sind als komplexe Vorgänge. Hier gilt es, zuvor die Wirtschaftlichkeit der Vorhaben zu prüfen, sodass Entwickler nicht gänzlich ihrem natürlichen Spieltrieb frönen und auch unliebsame Tätigkeiten des Tagesgeschäfts abarbeiten.
Wer schreibt, der bleibt
Dokumentation, das leidige Thema, erstreckt sich über alle Phasen des Software-Entwicklungsprozesses. Ob für API-Beschreibungen, das Benutzer-Handbuch, Planungsdokumente zur Architektur oder erlerntes Wissen über optimales Vorgehen – das Beschreiben zählt nicht zu den favorisierten Aufgaben aller beteiligten Protagonisten. Dabei lässt sich oft beobachten, dass anscheinend die landläufige Meinung vorherrscht, dicke Handbücher ständen für eine umfangreiche Funktionalität des Produkts. Lange Texte in einer Dokumentation sind jedoch eher ein Qualitätsmangel, der die Geduld des Lesers strapaziert, weil dieser eine präzise auf den Punkt kommende Anleitung erwartet. Stattdessen erhält er schwammige Floskeln mit trivialen Beispielen, die selten problemlösend sind.
Abbildung 2: Test Coverage mit Cobertura
Diese Erkenntnis lässt sich auch auf die Projekt-Dokumentation übertragen und wurde unter anderem von Johannes Sidersleben [6] unter der Metapher über viktorianische Novellen ausführlich dargelegt. Hochschulen haben diese Erkenntnisse bereits aufgegriffen. So hat beispielsweise die Hochschule Merseburg den Studiengang „Technische Redaktion“ [7] etabliert. Es bleibt zu hoffen, zukünftig mehr Absolventen dieses Studiengangs in der Projekt-Landschaft anzutreffen.
Bei der Auswahl kollaborativer Werkzeuge als Wissensspeicher ist immer das große Ganze im Blick zu halten. Erfolgreiches Wissensmanagement lässt sich daran messen, wie effizient ein Mitarbeiter die gesuchte Information findet. Die unternehmensweite Verwendung ist aus diesem Grund eine Managemententscheidung und für alle Abteilungen verpflichtend.
Informationen haben ein unterschiedliches Naturell und variieren sowohl in ihrem Umfang als auch bei der Dauer ihrer Aktualität. Daraus ergeben sich verschiedene Darstellungsformen wie Wiki, Blog, Ticketsystem, Tweets, Foren oder Podcasts, um nur einige aufzuzählen. Foren bilden sehr optimal die Frage- und Antwort-Problematik ab. Ein Wiki eignet sich hervorragend für Fließtext, wie er in Dokumentationen und Beschreibungen vorkommt. Viele Webcasts werden als Video angeboten, ohne dass die visuelle Darstellung einen Mehrwert bringt. Meist genügt eine gut verständliche und ordentlich produzierte Audiospur, um Wissen zu verteilen. Mit einer gemeinsamen und normierten Datenbasis lassen sich abgewickelte Projekte effizient miteinander vergleichen. Die daraus resultierenden Erkenntnisse bieten einen hohen Mehrwert bei der Erstellung von Prognosen für zukünftige Vorhaben.
Test & Metriken − das Maß aller Dinge
Bereits beim Überfliegen des Quality Reports 2014 erfährt man schnell, dass der neue Trend „Software testen“ ist. Unternehmen stellen vermehrt Kontingente dafür bereit, die ein ähnliches Volumen einnehmen wie die Aufwendungen für die Umsetzung des Projekts. Genau genommen löscht man an dieser Stelle Feuer mit Benzin. Bei tieferer Betrachtung wird bereits bei der Planung der Etat verdoppelt. Es liegt nicht selten im Geschick des Projektleiters, eine geeignete Deklarierung für zweckgebundene Projektmittel zu finden.
Nur deine konsequente Überprüfung der Testfall-Abdeckung durch geeignete Analyse-Werkzeuge stellt sicher, dass am Ende hinreichend getestet wurde. Auch wenn man es kaum glauben mag: In einer Zeit, in der Software-Tests so einfach wie noch nie erstellt werden können und verschiedene Paradigmen kombinierbar sind, ist eine umfangreiche und sinnvolle Testabdeckung eher die Ausnahme (siehe Abbildung 2).
Es ist hinreichend bekannt, dass sich die Fehlerfreiheit einer Software nicht beweisen lässt. Anhand der Tests weist man einzig ein definiertes Verhalten für die erstellten Szenarien nach. Automatisierte Testfälle ersetzen in keinem Fall ein manuelles Code-Review durch erfahrene Architekten. Ein einfaches Beispiel dafür sind in Java hin und wieder vorkommende verschachtelte „try catch“-Blöcke, die eine direkte Auswirkung auf den Programmfluss haben. Mitunter kann eine Verschachtelung durchaus gewollt und sinnvoll sein. In diesem Fall beschränkt sich die Fehlerbehandlung allerdings nicht einzig auf die Ausgabe des Stack-Trace in ein Logfile. Die Ursache dieses Programmierfehlers liegt in der Unerfahrenheit des Entwicklers und dem an dieser Stelle schlechten Ratschlag der IDE, für eine erwartete Fehlerbehandlung die Anweisung mit einem eigenen „try catch“-Block zu umschliessen, anstatt die vorhandene Routine durch ein zusätzliches „catch“-Statement zu ergänzen. Diesen offensichtlichen Fehler durch Testfälle erkennen zu wollen, ist aus wirtschaftlicher Betrachtung ein infantiler Ansatz.
Typische Fehlermuster lassen sich durch statische Prüfverfahren kostengünstig und effizient aufdecken. Publikationen, die sich besonders mit Codequalität und Effizienz der Programmiersprache Java beschäftigen [8, 9, 10], sind immer ein guter Ansatzpunkt, um eigene Standards zu erarbeiten.
Sehr aufschlussreich ist auch die Betrachtung von Fehlertypen. Beim Issue-Tracking und bei den Commit-Messages in SCM-Systemen der Open-Source-Projekte wie Liferay [11] oder GeoServer [12] stellt man fest, dass ein größerer Teil der Fehler das Grafische User Interface (GUI) betreffen. Dabei handelt es sich häufig um Korrekturen von Anzeigetexten in Schaltflächen und Ähnlichem. Die Meldung vornehmlicher Darstellungsfehler kann auch in der Wahrnehmung der Nutzer liegen. Für diese ist das Verhalten einer Anwendung meist eine Black Box, sodass sie entsprechend mit der Software umgehen. Es ist durchaus nicht verkehrt, bei hohen Nutzerzahlen davon auszugehen, dass die Anwendung wenig Fehler aufweist.
Das übliche Zahlenwerk der Informatik sind Software-Metriken, die dem Management ein Gefühl über die physische Größe eines Projekts geben können. Richtig angewendet, liefert eine solche Übersicht hilfreiche Argumente für Management-Entscheidungen. So lässt sich beispielsweise über die zyklische Komplexität nach McCabe [13] die Anzahl der benötigten Testfälle ableiten. Auch eine Statistik über die Lines of Code und die üblichen Zählungen der Packages, Klassen und Methoden zeigt das Wachstum eines Projekts und kann wertvolle Informationen liefern.
Eine sehr aufschlussreiche Verarbeitung dieser Informationen ist das Projekt Code-City [14], das eine solche Verteilung als Stadtplan visualisiert. Es ist eindrucksvoll Abbildung 3: Maven JDepend Plugin – Zahlen mit wenig Aussagekraft zu erkennen, an welchen Stellen gefährliche Monolithe entstehen können und wo verwaiste Klassen beziehungsweise Packages auftreten.
Abbildung 3: Maven JDepend Plugin – Zahlen mit wenig Aussagekraft
Fazit
Im Tagesgeschäft begnügt man sich damit, hektische Betriebsamkeit zu verbreiten und eine gestresste Miene aufzusetzen. Durch das Produzieren unzähliger Meter Papier wird anschließend die persönliche Produktivität belegt. Die auf diese Art und Weise verbrauchte Energie ließe sich durch konsequent überlegtes Vorgehen erheblich sinnvoller einsetzen.
Frei nach Kants „Sapere Aude“ sollten einfache Lösungen gefördert und gefordert werden. Mitarbeiter, die komplizierte Strukturen benötigen, um die eigene Genialität im Team zu unterstreichen, sind möglicherweise keine tragenden Pfeiler, auf denen sich gemeinsame Erfolge aufbauen lassen. Eine Zusammenarbeit mit unbelehrbaren Zeitgenossen ist schnell überdacht und gegebenenfalls korrigiert.
Viele Wege führen nach Rom – und Rom ist auch nicht an einem Tag erbaut worden. Es lässt sich aber nicht von der Hand weisen, dass irgendwann der Zeitpunkt gekommen ist, den ersten Spatenstich zu setzen. Auch die Auswahl der Wege ist kein unentscheidbares Problem. Es gibt sichere Wege und gefährliche Pfade, auf denen auch erfahrene Wanderer ihre liebe Not haben, sicher das Ziel zu erreichen.
Für ein erfolgreiches Projektmanagement ist es unumgänglich, den Tross auf festem und stabilem Grund zu führen. Das schließt unkonventionelle Lösungen nicht grundsätzlich aus, sofern diese angebracht sind. Die Aussage in Entscheidungsgremien: „Was Sie da vortragen, hat alles seine Richtigkeit, aber es gibt in unserem Unternehmen Prozesse, auf die sich Ihre Darstellung nicht anwenden lässt“, entkräftet man am besten mit dem Argument: „Das ist durchaus korrekt, deswegen ist es nun unsere Aufgabe, Möglichkeiten zu erarbeiten, wie wir die Unternehmensprozesse entsprechend bekannten Erfolgsstories adaptieren, anstatt unsere Zeit darauf zu verwenden, Gründe aufzuführen, damit alles beim Alten bleibt. Sie stimmen mir sicherlich zu, dass der Zweck unseres Treffens darin besteht, Probleme zu lösen, und nicht, sie zu ignorieren.“ … more voice
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.