
Schlagwort-Archiv: Programmierung
13. Globalkonfiguration: settings.xml
Featureitis
Antworten
Man muss nicht gleich Softwareentwickler sein, um ein gutes Anwendungsprogramm erkennen zu können. Doch aus eigener Erfahrung ist es mir oft passiert, dass Programme, die zu Beginn vielversprechend und innovativ waren, ab einer ‚gewissen‘ Nutzerzahl zu unhandlichen Boliden mutiert sind. Da ich diese Beobachtung nun schon einige Jahrzehnte regelmäßig aufs Neue mache, habe ich mich gefragt, woran das wohl liegen kann.
Das Phänomen, dass Softwareprogramme oder Lösungen im Allgemeinen mit Details überladen werden, hat Brooks in seinem Klassiker ‚The Mythical Man-Month‘ als Featuritis bezeichnet. Wenn man überlegt, dass die Erstausgabe des Buches im Jahr 1975 erschienen ist, kann man wohl von einem lange bekannten Problem sprechen. Das wohl bekannteste Beispiel für Featuritis ist das Betriebssystem Windows von Microsoft. Natürlich gibt es noch unzählige andere Beispiele für Verschlimmbesserungen.
Windowsnutzer, die bereits Windows XP kannten und dann mit dem tollen Nachfolger Vista konfrontiert wurden, um dann mit Windows 7 wieder besänftigt zu werden, um mit 8 und 8.1 beinahe einen Herzinfarkt erlitten zu haben, sich zu Beginn von Windows 10 wieder beruhigen. Jedenfalls für kurze Zeit, bis der Updatezwang für schnelle Ernüchterung sorgte. Von Windows 11 ganz zu schweigen. Zu Windows hieß es einmal, jede zweite Version ist Schrott, die sollte man überspringen. Nun ja, das stimmt seit Windows 7 schon lange nicht mehr. Für mich war Windows 10 dann der ausschlaggebende Punkt, vollständig auf Microsoft zu verzichten, und ich habe mir wie viele andere auch ein neues Betriebssystem zugelegt. Einige sind zu Apple gewechselt, und wer sich die teure Hardware nicht leisten kann oder will, hat wie ich auf ein Linuxsystem gesetzt. Hier zeigt sich, wie Uneinsichtigkeit schnell zum Verlust signifikante Marktanteile führt. Da Microsoft aus diesen Entwicklungen keine Konsequenzen zieht, scheint dem Unternehmen dieser Umstand weniger wichtig zu sein. Andere Unternehmen wiederum kann so etwas schnell an den Rand der Existenz bringen, und darüber hinaus.
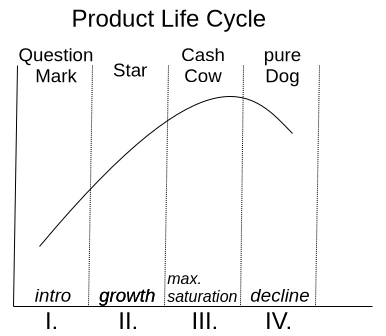
Eine Motivation, immer mehr Funktionen in eine bestehende Anwendung zu bringen, ist der sogenannte Produktlebenszyklus, der durch die BCG Matrix in Abbildung 1 dargestellt wird.
Mit der Einführung ist noch nicht sicher, ob das Produkt vom Markt akzeptiert wird. Wenn es die Nutzer annehmen, steigt es schnell zum Star auf und erreicht seine maximale Marktposition als Cash Cow. Sobald die Sättigung überschritten wurde, degradiert es zum Ladenhüter. Soweit, so gut. Leider herrscht im Management überwiegend die Idee, dass, wenn kein Wachstum zum vorherigen Quartal mehr erzeugt wird, die Sättigung bereits überschritten wurde. So kommt es zu der sinnbefreiten Annahme, den Nutzern müsste jedes Jahr eine aktualisierte Version des Produktes aufgedrängt werden. Die Motivation zu kaufen gelingt natürlich nur, wenn eine dickgefüllte Featureliste an Neuerungen auf die Verpackung gedruckt werden kann.
Da sinnvoll konzipierte Funktionen sich aber nicht wie am Fließband aus dem Ärmel schütteln lassen, kommt auch jedes Mal gleich ein Redesign der grafischen Benutzeroberfläche als Gratis-Schmankerl mit dazu. Schließlich hat man dann das Gefühl, man habe etwas völlig Neues, weil man erst wieder eine Eingewöhnung braucht, um die neue Platzierung alt bekannter Funktionen zu entdecken. Es ist ja nicht so, dass das Redesign in der Benutzung Wege verkürzen würde und die Produktivität erhöht. Die Zusammenstellung der Eingabemasken und Schaltflächen erscheint jedes Mal willkürlich zusammengewürfelt.
Aber keine Sorge, ich will nicht zum Updateboykott aufrufen, sondern einmal darüber sprechen, wie man es besser machen kann. Denn eines sei gewiss: Dank künstlicher Intelligenz wird sich der Markt für Softwareprodukte in wenigen Jahren massiv verändern. Ich erwarte nicht, dass komplexe und spezialisierte Anwendungsprogramme in absehbarer Zeit durch KI-Algorithmen produziert werden. Allerdings erwarte ich, dass in diesen Anwendungsprogrammen genügend KI generierte schlechte Codesequenzen, die der Entwickler nicht versteht, in die Codebasis eingebracht werden, was zu unstabilen Anwendungen führen wird. Diese Überlegung ist für mich ein Grund, wieder über saubere, handgemachte, leitungsfähige und verlässliche Software nachzudenken, denn ich bin mir sicher, dass dafür immer ein Markt bestehen bleiben wird.
Ich möchte einfach keinen Internetbrowser, der zu einer Kommunikationszentrale mutiert ist und neben dem eigentlichen Anzeigen von Internetseiten noch Chat, E-Mail, Kryptobezahlmethoden und was weiß ich noch alles enthält. Ich möchte, dass mein Browser schnell startet, wenn ich irgendetwas klicke, dann schnell reagiert und die Inhalte der Internetseiten korrekt und schnell darstellt. Sollte ich einmal den Wunsch haben, etwas anderes mit meinem Browser zu tun, wäre es nett, wenn ich dies aktiv durch ein Plug-in aktivieren kann.
Nun gibt es zu dieser gerade beschriebenen Problemstellung oft die Argumentation, dass man ja mit den vielen Funktionen einen breiten Nutzerkreis erreichen möchte. Gerade wenn eine Anwendung zu Beginn alle möglichen Optionen auch aktiv eingeschaltet hat, holt das schnell den unkundigen Benutzer ab, der dann nicht erst begreifen muss, wie sein Programm überhaupt funktioniert. Ich kann diese Überlegung durchaus nachvollziehen. Es ist auch völlig in Ordnung, wenn ein Hersteller sich ausschließlich auf unkundige Anwender konzentriert. Es gibt aber einen Mittelweg, der alle Nutzergruppen gleichmäßig berücksichtigt. Diese Lösung ist auch nicht neu und sehr gut bekannt, die sogenannten Produktlinien.
In der Vergangenheit haben Hersteller immer Zielgruppen wie Privatpersonen, Unternehmen und Experten definiert. Diesen Nutzergruppen wurden dann oft Produktbezeichnungen wie Home, Enterprise und Ultimate zugeordnet. Das führte dazu, dass jeder die Ultimate Version wollte. Das Phänomen nennt sich Fear Of Missing Out (FOMO), also etwas zu verpassen. Deswegen sind die Bezeichnungen der Produktgruppen und deren zugeordneten Funktionen psychologisch ungeschickt gewählt. Wie kann man das also besser machen?
Ein Experte konzentriert sich bei seiner Arbeit auf spezielle Basisfunktionen, mit denen er seine Aufgaben schnell und ohne Ablenkung erledigen möchte. Das impliziert für mich Begriffe wie Essentials, Pure oder Core als Produktline.
Wenn das Produkt dann noch im Unternehmen von mehreren Personen verwendet werden soll, benötigt dies oft zusätzliche Funktionen wie zum Beispiel ein externes Benutzermanagement, wie LDAP oder IAM. Diese spezialisierte Produktlinie assoziiert Begriffe wie Enterprise (verbrannt), Company, Business und so weiter.
Das zugemüllte Endergebnis, das eigentlich für NOOPS gedacht ist und alle möglichen Sachen bereits über die Installation aktiviert hat. Wenn den Leuten die Zeit, bis die Anwendung gestartet ist und sie reagiert, egal ist, dann nur zu. Immer in die Vollen. Rein, was rein geht! Hier eignen sich Bezeichnungen wie Ultimate, Full und Maximized Extended als Bezeichnung der Produktlinie. Wichtig ist nur, dass die Profis erkennen, dass es sich um die zugemüllte Variante handelt.
Wer nun geschickt mit diesen Produktlinien spielt und möglichst alle Funktionen über sogenannte Module bereitstellt, die nachinstallierbar sind, ermöglicht eine hohe Flexibilität auch im Expertenmodus, denen durchaus die eine oder andere Zusatzfunktion genehm ist.
Installiert man auf das Modulsystem zuvor noch ein Tracking, um festzustellen, wie professionelle Anwender ihre Version upgraden, dann hat man schon eine gute Idee, was in die neue Version von Essentials hinzugefügt werden könnte. Bei dem Tracking sollte man sich aber nicht auf die Downloads als Entscheidungskriterium stützen. Ich selbst probiere oft Dinge aus und lösche Erweiterungen auch schneller, als der Installationsprozess gedauert hat, wenn ich der Meinung bin, dass diese nutzlos sind.
Ich möchte zu der gerade beschriebenen Problematik ein kleines Beispiel geben, das aus dem DevOps Bereich stammt. Zum einen gibt es das bekannte GitLab, das ursprünglich einmal ein reines Code Repository-Hosting-Projekt gewesen ist. Darauf deutet auch der Name, bis heute. Eine Anwendung, die auf einem Server bereits 8 GB RAM in der Basis-Installation benötigt, um ein Git Repository für andere Entwickler erreichbar zu machen, ist für mich unbrauchbar, denn diese Software wurde über die Zeit zur EierlegendenWollmilchSau. Langsam, unflexibel und mit allem Kram zugemüllt, der über Speziallösungen besser umgesetzt wurde.
GitLab gegenüber steht eine andere Lösung namens SCM-Manager, die weniger bekannt ist und sich ausschließlich auf das Bereitstellen der Code Repositories konzentriert. Ich selbst nutze und empfehle den SCM-Manager, weil er mit der Basis-Installation extrem kompakt ist. Aber dennoch gibt es eine gigantische Funktionsvielfalt, die man über Plug-ins nachrüsten kann.
Für mich sind Lösungen, die eine All In One Solution bereitstellen wollen, eher suspekt. Das ist für mich immer gleich dem Motto: alles und nichts. Es gibt keine EierlegendeWollMilchSau oder wie man in Österreich zu sagen pflegt, keinen Wunderwuzzi!
Wenn ich Programme für meinen Arbeitsprozess auswähle, orientiere ich mich ausschließlich an deren Kernfunktionalität. Sind die Grundeigenschaften, die das Marketing verspricht, wirklich vorhanden und möglichst intuitiv nutzbar? Gibt es eine aussagekräftige Dokumentation, die über ein bloßes ‚Hallo Welt‘ hinausgeht? Konzentriert man sich darauf, die Kernfunktionen stets zu optimieren, und berücksichtigt neue innovative Konzepte? Das sind Fragen, die für mich relevant sind.
Gerade im kommerziellen Umfeld werden oft Programme eingesetzt, die nicht halten, was das Marketing verspricht. Man wählt nicht aus, was man tatsächlich für die Erledigung der Aufgaben benötigt, sondern Anwendungen, deren Beschreibung mit sogenannten Buzzwords vollgestopft ist. Deswegen glaube ich, dass Unternehmen, die sich wieder auf die Kernkompetenzen fokussieren und dazu hoch spezialisierte Anwendungen nutzen, die Gewinner von morgen sind.



Von Missmanagement und Alpha-Geeks
Als ich neulich das Buch „The Manager’s Path“ von Camille Fournier in die Hand bekam, war ich recht schnell an Tom DeMarco erinnert. Dieser hat den Klassiker „Peopleware“ geschrieben und Anfang 2000 das Buch „Adrenalin Junkies und Formular Junkies“ veröffentlicht. Eine Liste an Stereotypen, die man in Softwareprojekten antreffen kann, mit Hinweisen, wie man mit ihnen umgeht. Nach einigen Jahrzehnten im Geschäft kann ich jedes einzelne Wort aus eigener Erfahrung bestätigen. Und es ist auch heute noch immer ein Thema, denn Menschen machen nun einmal Projekte und wir alle haben so unsere Eigenheiten.
Damit Projekte erfolgreich verlaufen, müssen nicht nur technische Herausforderungen gemeistert werden. Auch zwischenmenschliche Beziehungen spielen eine wesentliche Rolle für deren Erfolg. Ein wichtiger Faktor in diesem Zusammenhang, der oft wenig Beachtung findet, ist die Projektleitung. Es gibt Regale voller hervorragender Literatur, wie man ein guter Manager werden kann. Das Problem ist leider, dass nur wenige, die diese Position besetzen, diese nicht ausfüllen und noch weniger Interesse besteht, die eigenen Fertigkeiten weiterzuentwickeln. Das Ergebnis von schlechtem Management sind aufgeriebene und gestresste Teams, extremer Druck im Tagesgeschäft und oft auch Verzug von Lieferterminen. Da braucht man sich auch nicht wundern, wenn dies Auswirkungen auf die Qualität des Produktes hat.
Einer der ersten Sprüche, den ich in meinem Berufsleben gelernt habe, war: Wer glaubt, dass ein Projektleiter Projekte leitet, der glaubt auch, dass ein Zitronefalter Zitronen faltet. Es scheint also eine sehr alte Weisheit zu sein. Was ist aber das wirkliche Problem bei schlechtem Management? Jeder, der eine Stelle für einen Manager zu besetzen hat, ist in der Pflicht, dessen Fertigkeiten und charakterliche Eignung auf Herz und Nieren zu prüfen. Hier lässt man sich schnell von inhaltslosen Floskeln und einer Liste großer Namen in der Branche in der Vita beeindrucken, ohne die tatsächliche Leistung zu hinterfragen. In meiner Erfahrung bin ich vornehmlich auf Projektleiter gestoßen, die oft nicht die notwendigen fachlichen Kenntnisse hatten, um wichtige Entscheidungen zu treffen. Nicht selten wurde ich in IT-Projekten von Managern mit den Worten „Ich bin kein Techniker, macht das unter euch aus.“, abgefertigt. Das ist natürlich fatal, wenn die Person, welche die Entscheidungen treffen soll, diese nicht treffen kann, weil das notwendige Wissen fehlt. Ein Manager im IT-Projekt muss natürlich nicht wissen, welcher Algorithmus schneller terminiert. Hierfür gibt es die Möglichkeit von Evaluierungen, als Grundlage von Entscheidungen. Aber ein Grundverständnis der Programmierung sollte vorhanden sein. Wer nicht weiß, was eine API ist und wieso Module, die später zu einer Software zusammengesetzt werden sollen, durch Versionskompatibilitäten nicht zusammenarbeiten, hat keine Berechtigung, sich als Entscheidungsträger aufzuspielen. Ein Grundverständnis über die Prozesse in der Softwareentwicklung und die verwendeten Programmierparadigmen ist auch für Projektleiter, die nicht am Code arbeiten, unumgänglich.
Ich plädiere daher dafür, dass man nicht nur die Entwickler, die man einstellt, auf ihre Fertigkeiten hin prüft, sondern auch die Manager, die in ein Unternehmen aufgenommen werden sollen. Für mich ist ein absolutes No Go bei der Auswahl meiner Projekte, ein externes Projektmanagement. Das führt in aller Regel nur zu Chaos und Frustration bei allen beteiligten Personen, weswegen ich solche Projekte ablehne. Manager, die nicht ins Unternehmen eingebunden sind und deren Leistung nach dem Erfolg von Projekten bewertet wird, liefern erfahrungsgemäß keine saubere Arbeit ab. Zudem können interne Manager, ebenso wie die Entwickler, durch Mentoring, Trainings und Workshops ihre Fertigkeiten entwickeln und weiter ausbauen. Das Ergebnis sind ein gesundes, entspanntes Arbeitsklima und erfolgreiche Projekte.
Der Titel dieses Artikels weist auf toxische Stereotypen im Projekteschäft hin. Ich bin mir sicher, jeder ist auf den ein oder anderen Stereotypen bereits im beruflichen Umfeld getroffen. Es wird viel diskutiert, wie man mit diesen Zeitgenossen umgehen soll. Ich möchte aber anmerken, dass kaum jemand als „Monster“ geboren wurde. Dass Menschen so sind, wie sie sind, ist das Resultat ihrer Erfahrungen. Lernt ein Kollege, dass er, wenn er gestresst ausschaut und immer hektisch wirkt, als guter Arbeiter wahrgenommen wird, perfektioniert er dieses Verhalten über die Zeit.
Camille Fournier hat es mit dem Begriff „The Alpha Geek“ sehr auf den Punkt gebracht. Jemand, der seine Rolle im Projekt unersetzlich gemacht hat und auf alles eine Antwort hat. Meist verächtlich auf die Kollegen herabschaut, aber nie eine Aufgabe wirklich ohne Nacharbeiten anderer sauber zu Ende bringen kann. Unrealistische Abschätzungen für umfangreiche Aufgaben sind ebenso typisch wie die Relativierung komplexer Sachverhalte. Natürlich ist das der Liebling aller Projektleiter, die sich wünschen, das ganze Team würde aus diesen „Alpha Geeks“ bestehen. Ich bin mir sehr sicher, wenn dieser Traum wahr werden könnte, es die optimale Strafe für die Projektleiter wäre, die solche Menschen erst möglich machen.
Damit man sich im eigenen Unternehmen keine „Alpha Geeks“ züchtet, ist es notwendig, keinen Personenkult zu etablieren und die persönlichen Favoriten gegenüber dem restlichen Team zu überhöhen und auf ein Podest zu stellen. Natürlich ist es auch unabdingbar, stets die Arbeitsergebnisse zu hinterfragen. Wer eine Aufgabe als erledigt markiert und diese Nacharbeiten erfordert, sollte diese Nacharbeiten stets erneut zugewiesen bekommen, bis das Ergebnis zufriedenstellend ist.
Ich persönlich habe die selbe Auffassung wie Tom DeMarco, was die Dynamiken eines Projektes betrifft. Die Produktivität kann man zwar über die Menge der erledigten Aufgaben bewerten, dennoch gibt es auch noch weitere Einflüsse, die eine wichtige Rolle spielen. So habe ich durch meine Erfahrung die Auffassung, dass man, wie bereits erwähnt, sehr viel Wert darauf legen sollte, dass Mitarbeiter die begonnenen Aufgaben sauber und vollständig lösen, bevor sie eine neue Aufgabe annehmen. Kollegen, die eine bestimmte Aufgabe „kleinreden“ und zu geringe, unrealistische Einschätzungen abgeben, genau diese Aufgabe übernehmen. Zudem gibt es auch Kollegen, die zwar einen recht geringen Output haben, dafür aber sehr viel für die Harmonie im Team beitragen.
Wenn ich über Menschen spreche, die ein gesundes Team formen, meine ich damit nicht jeden Tag Süßigkeiten hinzustellen. Es geht um die, die durchaus gute Fähigkeiten haben und diese als Mentor anderen Kollegen beibringen. Meist haben diese Personen einen guten Stand im Team und ihnen wird viel Vertrauen entgegengebracht, weswegen sie auch oft als Mediatoren bei Konflikten gute Ergebnisse erzielen. Es sind nicht die Menschen, die durch falsche Versprechen versuchen, everybodys Darling zu sein, sondern die, die zuhören und sich Zeit nehmen, eine Lösung zu finden. Sie sind oft das Mädchen für alles und haben nicht selten ein ruhiges, unscheinbares Auftreten. Da sie Lösungen haben und oft eine helfende Hand reichen, haben sie selbst eine mittelmäßige Bewertung ihrer Leistung in den typischen Prozessmetriken. Ein guter Manager erkennt diese Personen rasch, weil auf sie in aller Regel Verlass ist. Sie sind ausgeglichen und wirken wenig gestresst, weil sie mit Ruhe und Kontinuität vorgehen.
Natürlich kann man über die Stereotypen in einem Softwareprojekt noch viel mehr sagen, aber ich denke, die bereits getroffenen Ausführungen geben ein gutes Grundverständnis über das, was ich zum Ausdruck bringen möchte. Denn ein erfahrener Projektleiter kann viele der beschriebenen Probleme bereits während ihrer Entstehung wieder abstellen. Dazu gehören natürlich auch solides technisches Wissen und etwas Menschenkenntnis.
Es muss uns natürlich auch bewusst sein, dass erfahrene Projektleiter nicht einfach so da sind. Man muss sie genau wie die Mitglieder eines Teams entwickeln und fördern. Dazu gehört durchaus auch die Rotation durch alle technischen Abteilungen wie Entwicklung, Test und Betrieb. Dazu eignen sich Paradigmen wie Pairprogramming hervorragend. Denn es geht nicht darum, aus einem Manager einen Programmierer oder Tester zu machen, sondern ihm oder ihr ein Verständnis der täglichen Abläufe zu verschaffen. Das stärkt auch das Vertrauen in die Fertigkeiten des gesamten Teams, und Mentalitäten wie: Man müsse die faulen und unfähigen Programmierer kontrollieren und antreiben, damit sie einen Finger rühren, kommen gar nicht erst auf. In Projekten, die regelmäßig gute Qualität abliefern und ihre Termine einhalten, kommt selten der Wunsch auf, alle möglichen Prozessmetriken einzuführen.




Blockchain – eine Einführung
Das Konzept Blockchain ist grundlegender Bestandteil der verschiedenen Kryptobezahlmethoden wie Bitcoin und Ethereum. Was hat es aber mit der Technologie Blockchain auf sich und wozu kann man dieses Konzept noch anwenden? Grundlegend kann man sagen, dass Blockchain wie die Datenstruktur der rückwärtsverketteten Liste aufgebaut ist. Jedes Element der Liste zeigt auf den Vorgänger. Was macht die Blockchain aber nun so besonders?
Blockchain erweitert das Konzept der Liste um verschiedene Rahmenbedingungen. Eine dieser Rahmenbedingungen ist, sicherzustellen, dass kein Element der Liste verändert oder entfernt werden kann. Das lässt sich recht einfach bewerkstelligen. Hierzu verwendet man eine Hashfunktion. Wir codieren über einen Hashalgorithmus den Inhalt eines jeden Elements in der Liste zu einem Hash. Es gibt mittlerweile ein breites Angebot an Hashfunktionen, von denen ein aktueller Standard SHA-512 ist. In nahezu jeder Programmiersprache ist dieser Hashalgorithmus in der Standardbibliothek bereits implementiert und man kann ihn einfach verwenden. Im Konkreten bedeutet es, dass über die gesamten Daten eines Blockes der Hash SHA‑512 gebildet wird. Dieser Hash ist stets eineindeutig und kommt nicht noch einmal vor. Somit dient der Hash als Identifier (ID), um einen Block zu finden. Ein Eintrag in dem Block ist der Verweis auf seine Vorgänger. Dieser Verweis ist der Hashwert des Vorgängers, also seine ID. Bei der Implementierung einer Blockchain ist es essenziell, dass der Hashwert des Vorgängers Bestandteil der Berechnung des Hashwertes des aktuellen Blockes ist. Dieses Detail sorgt dafür, dass die in der Blockchain geänderten Elemente nur sehr aufwendig geändert werden können. Man muss sozusagen für das Element, das man manipulieren möchte, alle nachfolgenden Elemente ebenfalls ändern. Bei der umfangreichen Blockchain mit sehr vielen Blöcken bedeutet so ein Vorhaben einen enormen Rechenaufwand, der nur sehr schwer bis überhaupt nicht zu leisten ist.
Durch diese Verkettung erhalten wir eine lückenlose Transaktionshistorie. Dieser Umstand erklärt auch, weswegen Kryptobezahlmethoden nicht anonym sind. Auch wenn der Aufwand, einen Transaktionsteilnehmer eindeutig zu identifizieren, enorm werden kann. Nutzt dieser Transaktionsteilnehmer zudem noch verschiedene Verschleierungsmöglichkeiten mit unterschiedlichen und nicht durch weitere Transaktionen verknüpften Wallets, steigt der Aufwand exponentiell an.
Natürlich hat der gerade beschriebene Mechanismus noch erhebliche Schwachstellen. Denn Transaktionen, also das Hinzufügen neuer Blöcke, können erst als verifiziert und sicher eingestuft werden, wenn genügend Nachfolger in der Blockchain hinzugekommen sind, die sicherstellen, dass Änderungen wieder schwerer zu bewerkstelligen sind. Für Bitcoin und Co. gilt eine Transaktion als sicher, wenn fünf Nachfolgetransaktionen sind.
Damit es nun nicht nur eine Instanz gibt, die die Transaktionshistorie, also alle Blöcke der Blockchain, aufbewahrt, kommt ein dezentraler Ansatz ins Spiel. Es gibt also keinen zentralen Server, der als Vermittler agiert. Ein solcher zentraler Server könnte durch den Betreiber manipuliert werden. Man hätte so die Möglichkeit, mit genügend Rechenleistung auch sehr umfangreiche Blockchains neu aufzubauen. Im Kontext von Kryptowährungen spricht man hier von einer Reorganisation der Chain. Dies ist auch die Kritik an vielen Kryptowährungen. Außer Bitcoin existiert keine andere dezentrale und unabhängige Kryptowährung. Wenn die Blockchain mit allen ihren enthaltenen Elementen öffentlich gemacht wird und jeder Nutzer eine eigene Instanz dieser Blockchain lokal auf seinem Rechner besitzt und dort Elemente hinzufügen kann, die dann mit allen anderen Instanzen der Blockchain synchronisiert werden, haben wir einen dezentralen Ansatz.
Die Technologie zur dezentralen Kommunikation ohne einen Vermittler nennt sich Peer to Peer (P2P). P2P Netzwerke sind besonders in ihren Entstehungsphasen, also wenn nur wenige Teilnehmer im Netzwerk sind, schwach und angreifbar. Man könnte einfach mit sehr viel Rechenleistung eine große Anzahl von sogenannten Zomi Peers erstellen, die das Verhalten des Netzes beeinflussen. Gerade in Zeiten, in denen das Cloud-Computing mit AWS und der Google Cloud Platform als Anbieter, für vergleichsweise wenig Geld schier endlose Ressourcen bereitstellen kann, ist dies ein nicht zu unterschätzendes Problem. Besonders wenn es einen sehr hohen finanziellen Anreiz für Betrüger gibt, darf man diesen Punkt auf keinen Fall vernachlässigen.
Auch bei P2P gibt es verschiedene Konzepte, die miteinander konkurrieren. Um eine stabile und sichere Blockchain zu implementieren, ist es notwendig, nur auf Lösungen zurückzugreifen, die ohne unterstützende Backbone Server auskommen. Es soll vermieden werden, dass sich eine Master Chain etablieren kann. Daher müssen Fragen geklärt werden, wie sich die einzelnen Peers finden können und mit welchem Protokoll sie ihre Daten synchronisieren. Als Protokoll verstehen wir ein Regelwerk, also ein festes Schema, wie die Interaktion zwischen den Peers geregelt wird. Da bereits dieser Punkt sehr umfangreich ist, verweise ich zum Einstieg in das Thema auf meinen Vortrag 2022.
Eine weitere Eigenschaft von Blockchain‑Blöcken ist, dass sich diese problemlos und mit wenig Mühe auf Gültigkeit hin verifizieren lassen. Hierzu muss lediglich über die gesamten Inhalte eines Blocks der SHA-512 Hash erzeugt werden. Stimmt dieser mit der ID überein, ist der Block gültig. Aber auch zeitrelevante beziehungsweise zeitkritische Transaktionen, wie sie bei Bezahlsystemen relevant sind, lassen sich mit wenig Aufwand erstellen. Dazu werden auch keine komplexen Zeitserver als Vermittler benötigt. Jeder Block wird um einen Zeitstempel erweitert. Dieser Zeitstempel muss allerdings den Ort, an dem er erstellt wird, berücksichtigen, also die Zeitzone mit angeben. Um den Standort der Transaktionsteilnehmer zu verschleiern, können auch alle Uhrzeiten der verschiedenen Zeitzonen auf die aktuelle UTC 0 umgerechnet werden.
Um sicherzustellen, dass die Uhrzeit auch korrekt auf dem System eingestellt ist, kann man einen Zeitserver für die aktuelle Uhrzeit beim Start der Software abfragen und bei Abweichungen einen Hinweis zur Korrektur ausgeben.
Natürlich sind zeitkritische Transaktionen mit einer Reihe von Problemen behaftet. Es muss sichergestellt werden, dass eine Transaktion in einem festgelegten Zeitfenster durchgeführt wurde. Ein Problem, mit dem sich sogenannte Echtzeitsysteme auseinandersetzen müssen. Aber auch das Double Spending Problem muss verhindert werden. Also, dass derselbe Betrag zweimal an unterschiedliche Empfänger gesendet werden kann. Was in einem dezentralisierten Netzwerk die Bestätigung der Transaktion von mehreren Teilnehmern erfordert. Aber auch klassische Race Conditions können ein Problem darstellen. Race Conditions lassen sich durch die Anwendung des Immutable-Entwurfsmusters auf die Block-Elemente beherrschen.
Damit die Blockchain nun nicht durch Spam-Attacken gestört wird, benötigen wir eine Lösung, die das Erstellen eines einzelnen Blocks in der Masse teuer macht. Das erreichen wir, indem wir die Rechenleistung einbeziehen. Hierzu muss der Teilnehmer, der einen Block erstellt, ein Puzzle lösen, das eine ‚gewisse‘ Rechenzeit beansprucht. Wenn ein Spammer das Netzwerk mit vielen Blöcken fluten möchte, steigt seine Rechenleistung exorbitant an und es ist ihm unmöglich, in kurzer Zeit beliebig viele Blöcke zu erzeugen. Dieses kryptografische Puzzle nennt man Nonce, was für „number used only once“ steht. Der Mechanismus Nonce in der Blockchain wird auch oft als Proof of Work (POW) bezeichnet und dient bei Bitcoin zur Verifizierung der Blöcke durch die Miner.
Die Nonce ist eine (pseudo) zufällige Zahl, zu der ein Hash generiert werden muss. Dieser Hash muss dann ‚bestimmte‘ Kriterien erfüllen. Das können zum Beispiel zwei oder drei führende Nullen im Hash sein. Damit man nun keinen beliebigen Hash in den Block einfügt, wird die Zufallszahl, die das Rätsel löst, direkt abgespeichert. Eine bereits genutzte Nounce darf kein weiteres Mal verwendet werden, da sonst das Rätsel umgangen werden kann. Erzeugt man nun aus der Nonce den Hash, muss dieser die Vorgaben z. B. führende Nullen erfüllen, um akzeptiert zu werden.
Da je mehr Blöcke in einer Blockchain enthalten sind, es immer schwieriger wird, eine gültige Nonce zu finden, ist es notwendig, die Regeln für so eine Nonce zyklisch, beispielsweise alle 2048 Blöcke, zu verändern. Das bedeute aber auch, dass die Regeln für eine gültige Nonce ebenfalls den entsprechenden Blöcken zugeordnet werden müssen. Ein solches Regelwerk für die Nonce lässt sich problemlos über eine RegEx formulieren.
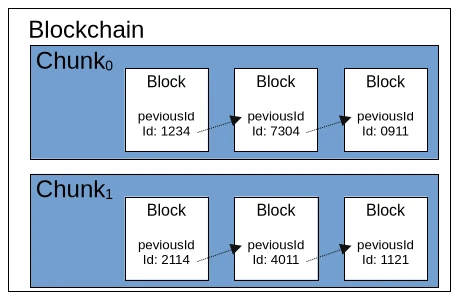
Mittlerweile haben wir auch eine beachtliche Menge an Regelwerk für eine Blockchain kennengelernt. Sodass es nun an der Zeit ist, sich ein wenig Gedanken über die Performance zu machen. Würden wir alle einzelnen Blöcke der Blockchain einfach in einer Liste abspeichern, würde uns recht bald der Arbeitsspeicher ausgehen. Jetzt könnte man die Blöcke auch in einer lokalen Datenbank speichern, was auch bei einer Embedded-Lösung wie SQLlite durchaus negative Auswirkungen auf die Geschwindigkeit der Blockchain haben würde. Eine einfache Lösung wäre hier, die Blockchain in gleichlange Teile zu zerlegen, sogenannte Chunks. Ein Chunk hätte sozusagen eine feste Länge von 2048 validen Blöcken und der erste Block eines neuen Chunk zeigt auf den letzten Block des vorhergehenden Chunk. In jedem Chunk kann man auch eine zentrale Regel für die Nonce hinterlegen und mögliche Metadaten wie beispielsweise Min- und Max-Zeitstempel abspeichern.
Wenn wir unseren aktuellen Stand des Blockchain-Regelwerks kurz rekapitulieren, kommen wir aktuell auf drei verschiedene Ebenen. Die größte Ebene ist die Blockchain selbst, welche grundlegende Metainformationen und Konfigurationen enthält. Solche Konfigurationen sind etwa der verwendete Hash Algorithmus. Die zweite Ebene stellen die sogenannten Chunks dar, die eine festgelegte Menge an Block-Elementen enthalten. Wie bereits erwähnt enthalten die Chunks auch Metadaten und Konfigurationen. Das kleinste Element der Blockchain ist der Block selbst, der aus einer ID, den beschriebenen Zusatzinformationen wie Zeitstempel und Nonce und dem Payload besteht. Der Payload ist eine allgemeine Bezeichnung für jedes beliebige Datenobjekt, das durch die Blockchain überprüfbar gemacht werden soll. Für Bitcoin und andere Kryptowährungen ist der Payload die Information, welcher Betrag von Wallet A (Quelle) an Wallet B (Ziel) transferiert wird.
Die Blockchain-Technologie eignet sich aber auch für viele andere Anwendungszenarien. So könnten beispielsweise die Hashwerte von Open-Source-Software Artefakten in einer Blockchain gespeichert werden. Damit könnte man auch Binärdateien aus unsicheren Quellen herunterladen und gegen die entsprechende Blockchain verifizieren. Das gleiche Prinzip wäre auf für die Signaturen von Antivirenprogrammen denkbar. Aber auch im behördlichen Umfeld könnten Anträge und andere Dokumente rechtssicher übermittelt werden. Die Blockchain würde hier als ‚Posteingangsstempel‘ funktionieren. Aber auch Buchhaltung inklusive aller Belege der Warenwirtschaft aus dem Einkauf und der verkauften Artikel und Dienstleistungen sind denkbare Szenarien.
Eine Erweiterung der Blockchain wäre je nach Anwendungsfall die eindeutige Signierung eines Blocks durch den Ersteller. Hierzu käme das klassische PKI Verfahren mit dem öffentlichen und privaten Schlüssel zum Einsatz. Der Unterzeichner speichert in Block seinen öffentlichen Schlüssel, erstellt mittels seines geheimen Schlüssels über den Payload eine Signatur, die als Signatur ebenfalls im Block mitgespeichert wird.
Bisher gibt es zwei frei verfügbare Implementierungen der Blockchain, BitcoinJ und für Ethereum Web3j. Natürlich ist es möglich, mit den gerade beschriebenen Prinzipien auch eine eigene allgemeingültige Blockchain-Implementierung zu erstellen. Hier liegen die Stolperfallen natürlich in den Details, von denen ich in diesem Artikel bereits einige angesprochen habe. Grundsätzlich ist Blockchain aber auch keine Raketentechnologie und für erfahrene Entwickler gut beherrschbar. Wer mit dem Gedanken spielt, sich an einer eigenen Implementierung zu versuchen, hat nun genügend Grundwissen, um sich mit dem notwendigen Detailwissen in den verschiedenen zum Einsatz kommenden Technologien tiefer vertraut zu machen.



Zähl auf mich – Java Enums
Eigentlich denkt man als erfahrener Entwickler oft, dass reine CORE Java Themen eher was für Anfänger sind. Das muss aber nicht unbedingt so sein. Ein Grund ist natürlich die Betriebsblindheit, die sich bei ‚Profis‘ mit der Zeit einstellt. Dieser Betriebsblindheit kann man nur entgegenwirken, wenn man sich gelegentlich auch mit vermeintlich vertrauten Themen erneut beschäftigt. Aufzählungen in Java sind leider zu Unrecht etwas unbeachtet und finden viel zu wenig Anwendung. Ein möglicher Grund für diese stiefmütterliche Behandlung können auch die vielen im Netz verfügbaren Tutorials zu Enums sein, die lediglich eine triviale Verwendung demonstrieren. Fangen wir zuallererst also damit an, wo Enums in Java ihre Verwendung finden.
Gehen wir einmal von ein paar einfachen Szenarien aus, die uns im Entwickleralltag begegnen. Stellen wir uns vor, wir müssen eine Hashfunktion implementieren, die mehrere Hash-Algorithmen wie MD5 und SHA-1 unterstützen kann. Als Einstiegspunkt haben wir auf Benutzerebene dann oft eine Funktion, die so oder ähnlich ausschauen kann: String hash(String text, String algorithm); – eine technisch korrekte Lösung.
Ein anderes Beispiel kann das Logging sein. Um einen Logeintrag zu schreiben, könnte die Methode wie folgt aussehen: void log(String message, String logLevel); und so lassen sich die Beispiele in diesem Stil beliebig fortführen.
Das Problem dieser Variante sind freie Parameter wie logLevel und algorithm, die für den korrekten Gebrauch nur eine sehr begrenzte Anzahl von Möglichkeiten gestatten. Das Risiko, dass Entwickler im Projektstress diesen Parameter falsch befüllen, ist recht hoch. Tippfehler, Variationen in Groß- und Kleinschreibung und so weiter sind mögliche Fehlerquellen. In der Java API gibt es durchaus einige solcher verbesserungswürdigen Designentscheidungen.
Um die Verwendung der API, also der nach außen genutzten Funktionen, zu verbessern, führen wie so oft viele Wege nach Rom. Ein Weg, der durchaus öfter zu sehen ist, ist die Verwendung von Konstanten. Um die Lösung ein wenig besser zu verdeutlichen, greife ich das Beispiel der Hash-Funktionalität auf. Es sollen die beiden Hash-Algorithmen MD5 und SHA-1 in der Klasse Hash unterstützt werden.
void Hash {
public final static MD5 = "1";
public final static SHA-1 = "2";
/**
* Creates a hash from text by using the chosen algorithm.
*/
public String calculateHash(String text, String algorithm) {
String hash = "";
if(algorithm.equals(MD5)) {
hash = MD5.hash(text);
}
if(algorithm.equals(SHA-1)) {
hash = SHA-1.hash(text);
}
return hash;
}
}
// Call
calculateHash("myHashValue", Hash.MD5);In der Klasse Hash werden die beiden Konstanten MD5 und SHA-1 definiert, um anzuzeigen, welche Werte für den Parameter algorithem gültige Werte darstellen. Entwickler mit etwas Erfahrung erkennen diese Konstellation recht schnell und verwenden sie auch korrekt. Auch hier ist die Lösung technisch gesehen absolut korrekt. Aber auch wenn Dinge syntaktisch richtig sind, heißt es nicht, dass sie im semantischen Kontext bereits eine optimale Lösung darstellen. Die hier vorgestellte Strategie missachtet nämlich die Entwurfskriterien für objektorientierte Programmierung. Obwohl wir bereits durch die Konstanten gültige Eingabewerte für den Parameter algorithm bereitstellen, gibt es keinen Mechanismus, der die Verwendung der Konstanten erzwingt.
Nun könnte man argumentieren, das ist doch nicht wichtig, solange die Methode mit einem gültigen Parameter aufgerufen wird. Dem ist aber nicht so. Denn jeder Aufruf der Methode calculateHash ohne die Verwendung der Konstanten führt bei Refactorings zu möglichen Problemen. Will man aus Vereinheitlichung beispielweise den Wert “2“ in sha1 ändern, wird das überall da zu Fehlern führen, wo die Konstanten nicht zum Einsatz kommen. Wie können wir es also besser machen? Die bevorzugte Lösung sollte die Verwendung von Enums sein.
Alle in Java definierten Enums sind von der Klasse java.lang.Enum [2] abgeleitet. Eine Auswahl der Methoden ist:
- name() gibt den Namen dieser Enum-Konstante genau so zurück, wie er in ihrer Enum-Deklaration angegeben ist.
- ordinal() gibt die Ordnungszahl dieser Enum-Konstante zurück (ihre Position in der Enum-Deklaration, wobei der ersten Konstante die Ordnungszahl Null zugewiesen wird).
- toString() gibt den Namen dieser Enum-Konstante so zurück, wie er in der Deklaration enthalten ist.
Enums gehören in Java von Anfang an zum Sprachkern und sind recht intuitiv zu benutzen. Für den Parameter algorithm erzeugen wir mit den beiden Werten MD5 und SHA1 die Enumklasse HashAlgorithm.
public enum HashAlgorithm {
MD5, SHA1
}
Dies ist die einfachste Variante, wie man ein Enum definieren kann. Eine einfache Aufzählung der gültigen Werte als Konstanten. In dieser Notation sind Konstantenname und Konstantenwert identisch. Wichtig beim Umgang mit Enums ist sich bewusst zu sein das die Namenkonventionen für Konstanten gelten.
Die Namen von als Klassenkonstanten deklarierten Variablen und von ANSI-Konstanten sollten ausschließlich in Großbuchstaben geschrieben und die Wörter durch Unterstriche („_“) getrennt werden. (ANSI-Konstanten sollten zur Vereinfachung der Fehlersuche vermieden werden.) Bsp.: static final int GET_THE_CPU = 1;
[1] Oracle Dokumentation
Diese Eigenschaft führt uns zum ersten Problem bei der vereinfachten Definition von Enums. Wenn wir aus irgendeinem Grund anstatt SHA-1 anstatt SHA1 definieren wollen, wird das zu einem Fehler führen, da “-“ nicht der Konvention für Konstanten entspricht. Daher findet sich für die Definition von Enums meist folgendes Konstrukt:
public enum HashAlgorithm {
MD5("MD5"),
SHA1("SHA-1");
private String value;
HashAlgorithm(final String value) {
this.value = value;
}
public String getValue() {
return this.value;
}
}
In diesem Beispiel wird die Konstante SHA1 um einen String Wert “SHA-1“ erweitert. Um an diesen Wert zu gelangen, ist es notwendig, einen Zugriff dafür zu implementieren. Dieser Zugriff erfolgt über die Variable value, welche den zugehörigen Getter getValue() besitzt. Damit die Variable value auch befüllt wird, benötigen wir noch einen zugehörigen Konstruktor. Wie die verschiedenen Zugriffe auf den Eintrag SHA1 mit den entsprechenden Ausgaben zeigt der nachfolgende Testfall.
public class HashAlgorithmTest {
@Test
void enumNames() {
assertEquals("SHA1",
HashAlgorithm.SHA1.name());
}
@Test
void enumToString() {
assertEquals("SHA1",
HashAlgorithm.SHA1.toString());
}
@Test
void enumValues() {
assertEquals("SHA-1",
HashAlgorithm.SHA1.getValue());
}
@Test
void enumOrdinals() {
assertEquals(1,
HashAlgorithm.SHA1.ordinal());
}
}
Zuerst greifen wir auf den Namen der Konstante zu, der für unser Beispiel SHA1 lautet. Das gleiche Ergebnis erhalten wir mit der toString() Methode. Den Inhalt von SHA1, also den Wert SHA-1 erhalten wir über den Aufruf unserer definierten Methode getValue(). Zusätzlich kann noch die Position von SHA1 in der Enum abgefragt werden. Dies ist für unser Beispiel die zweite Stelle, an der SHA1 vorkommt, und hat dadurch den Wert 1. Schauen wir uns für die Implementierung der Hash-Klasse aus Listing 1 die Änderung für Enums an.
public String calculateHash(String text, HashAlgorithm algorithm) {
String hash = "";
switch (algorithm) {
case MD5:
hash = MD5.hash(text);
break;
case SHA1:
hash = SHA1.hash(text);
break;
}
return hash;
}
//CaLL
calculateHash(“text2hash“, HashAlgorithm.MD5);Wir sehen in diesem Beispiel eine deutliche Vereinfachung der Implementierung und erreichen zudem eine sichere Verwendung für den Parameter algorithm, der nun durch die Enum bestimmt wird. Sicher gibt es einige Kritiker, die möglicherweise die Menge des zu schreibenden Codes bemängeln und darauf verweisen, dass dies viel kompakter möglich wäre. Solche Argumente kommen eher von Personen, die keine Erfahrung mit großen Projekten von mehreren Millionen Zeilen Quelltext konfrontiert wurden oder nicht in einem Team mit mehreren Programmierern zusammenarbeiten. Im objektorientierten Entwurf geht es nicht darum, möglichst jedes überflüssige Zeichen zu vermeiden, sondern lesbaren, fehlertoleranten, ausdruckstarken und leicht änderbaren Code zu schreiben. Alle diese Attribute haben wir in diesem Beispiel mit Enums abgedeckt.
Laut dem Tutorial von Oracle für Java Enums [3] sind noch viel komplexere Konstrukte möglich. Enums verhalten sich wie Java Klassen und können auch mit Logik angereichert werden. Die Spezifikation sieht hier vor allem die Methoden compare() und equals() vor, was Vergleichen und Sortieren ermöglicht. Für das Beispiel der Hashalgorithmen würde diese Funktionalität keinen Mehrwert bringen. Auch sollte man grundsätzlich davon Abstand nehmen, weitere Funktionalität beziehungsweise Logik in Enums unterzubringen, da diese ähnlich wie reine Datenklassen behandelt werden sollten.
Dass Enums durchaus ein wichtiges Thema in der Java Entwicklung darstellen, zeigt auch der Umstand, dass J. Bloch in seinem Buch “Effective Java“ dazu ein ganzes Kapitel mit knapp 30 Seiten gewidmet hat.
Damit haben wir ein ausführliches Beispiel über die korrekte Verwendung von Enums durchgearbeitet und vor allem auch erfahren, wo dieses Sprachkonstrukt in Java eine sinnvolle Anwendung findet.
Ressourcen
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.


Python-Programme über PIP unter Linux installieren
Vor sehr vielen Jahren hat die nach der britischen Komikertruppe benannte Skriptsprache Python unter Linux das altehrwürdige Perl abgelöst. Das heißt, jede Linux Distribution enthält einen Python-Interpreter von Hause aus. Eigentlich eine recht praktische Sache. Eigentlich! Wenn da nicht das leidige Thema mit der Sicherheit wäre. Aber fangen wir einmal der Reihe nach an, denn dieser kleine Artikel ist für Leute gedacht, die unter Linux in Python geschriebene Software zum Laufen bringen möchten, aber selbst weder Python kennen noch irgendetwas mit Programmieren am Hut haben. Daher ein paar kleine Hintergrundinformationen, um zu verstehen, worum es überhaupt geht.
Alle aktuellen Linux Varianten, die von der Distribution Debian abgeleitet sind, also Ubuntu, Mint und so weiter, werfen einen kryptischen Fehler, wenn man versucht, ein Pythonprogramm zu installieren. Da man vermeiden möchte, dass wichtige Systembibliotheken, die in Python geschrieben wurden, durch die Installation zusätzlicher Programme überschrieben werden und dadurch ein Fehlverhalten im Betriebssystem hervorrufen, wurde ein Schutz eingebaut, der das verhindert. Leider steckt auch hier wie so oft der Teufel im Detail.
ed@P14s:~$ python3 -m pip install ansible
error: externally-managed-environment
× This environment is externally managed
╰─> To install Python packages system-wide, try apt install
python3-xyz, where xyz is the package you are trying to
install.
If you wish to install a non-Debian-packaged Python package,
create a virtual environment using python3 -m venv path/to/venv.
Then use path/to/venv/bin/python and path/to/venv/bin/pip. Make
sure you have python3-full installed.
If you wish to install a non-Debian packaged Python application,
it may be easiest to use pipx install xyz, which will manage a
virtual environment for you. Make sure you have pipx installed.
See /usr/share/doc/python3.13/README.venv for more information.Als Lösung soll nun eine virtuelle Umgebung eingerichtet werden. Debian 12 und auch das gerade im August 2025 frisch erschienene Debian 13 nutzen Python in der Version 3. Python2 und Python 3 sind zueinander nicht kompatibel. Das heißt, in Python2 geschriebene Programme laufen nicht ohne Weiteres in Python 3.
Wenn man nun unter Python irgendein Programm installieren möchte, erledigt dies der sogenannte Paketmanager. Die meisten Programmiersprachen haben einen solchen Mechanismus. Der Paketmanager für Python heißt PIP. Hier kommen schon die ersten Komplikationen ins Spiel. Es gibt pip, pip3 und pipx. Solche Namensinkonsistenzen findet man auch beim Python Interpreter selbst. Version 2 startet man auf der Konsole mit python und Version 3 mit python3. Da sich dieser Artikel auf Debian 12 / Debian 13 und seine Derivate bezieht, wissen wir, dass zumindest mal Python 3 am Start ist. Um die tatsächliche Python Version zu erfahren, kann man auf der Shell auch python3 -V eingeben, was bei mir die Version 3.13.5 zutage fördert. Versucht man indies python oder python2 kommt eine Fehlermeldung, dass der Befehl nicht gefunden werden konnte.
Schauen wir uns zuerst einmal an, was überhaupt pip, pip3 und pipx bedeuten soll. PIP selbst heißt nichts anderes als Package Installer for Python [1]. Bis Python 2 galt PIP und ab Version 3 haben wir entsprechend auch PIP3. Ganz speziell ist PIPX [2] welches für isolierte Umgebungen gedacht ist, also genau das, was wir benötigen. Daher geht es im nächsten Schritt darum, PIPX zu installieren. Das erreichen wir recht leicht über den Linux-Paketmanager: sudo apt install pipx. Um festzustellen, welche PIP Variante bereits auf dem System installiert ist, benötigen wir folgenden Befehl: python3 -m pipx --version, der in meinem Fall 1.7.1 ausgibt. Das heißt, ich habe auf meinem System als Ausgangsbasis das originale Python3 und dazu PIPX installiert.
Mit der gerade beschriebenen Voraussetzung kann ich nun unter PIPX alle möglichen Python Module installieren. Der Grundbefehl lautet pipx install <module>. Um ein nachvollziehbares Beispiel zu schaffen, wollen wir jetzt im nächsten Schritt Ansible installieren. Auf die Verwendung von pip und pip3 sollte verzichtet werden, da diese zum einen erst installiert werden müssen und zum anderen zu dem eingangs krypischen Fehler führen.
Ansible [3] ist ein Programm, das in Python geschrieben wurde und ab der Version 2.5 auf Python 3 migriert wurde. Nur sehr knapp ein paar Worte zu dem, was Ansible selbst für ein Programm ist. Ansible gehört in die Klasse der Konfigurationsmanagementprogramme und erlaubt es völlig automatisiert mit einem Skript Systeme zu provisionieren. Eine Provisionierung kann zum Beispiel als virtuelle Maschine erfolgen und umfasst das Festlegen der Hardware-Ressourcen (RAM, HDD CPU Kerne, etc.), Installieren des Betriebssystems, das Einrichten des Benutzers und das Installieren und Konfigurieren weiterer Programme.
Als Erstes müssen wir Ansible mit pipx install ansible installieren. Wenn die Installation beendet ist, können wir den Erfolg mit pipx list überprüfen, was bei mir zu folgender Ausgabe führt:
ed@local:~$ pipx list
venvs are in /home/ed/.local/share/pipx/venvs
apps are exposed on your $PATH at /home/ed/.local/bin
manual pages are exposed at /home/ed/.local/share/man
package ansible 12.1.0, installed using Python 3.13.5
- ansible-communityDie Installation ist aber hier noch nicht beendet, denn der Aufruf ansible –version wird mit einer Fehlermeldung quittiert. Das Problem, welches sich hier ergibt, hat etwas mit der Ansible Edition zu tun. Wie wir bereits in der Ausgabe von pipx list sehen können, haben wir die Community Edition installiert. Weswegen der Befehl ansible-community --version lautet, der bei mir aktuell die Version 12.2.0 zutage fördert.
Wer lieber in der Konsole ansible anstatt ansible-community eingeben möchte, kann das über eien alias erreichen. Das Setzen des Alias ist hier nicht ganz so trivial, da dem Alias Parameter übergeben werden müssen. Wie das gelingt, ist aber Thema eines anderen Artikels.
Gelegentlich kommt es aber auch vor, dass Pythonprogramme über PIPX nicht installiert werden können. Ein Beispiel hierfür ist streamdeck-ui [4]. Die Hardware StreamDeck von Elgato konnte lange Zeit unter Linux mit dem in Python implementierten stremdeck-ui genutzt werden. Mittlerweile gibt es noch eine Alternative namens Boatswain, die nicht in Python geschrieben wurde, auf die man besser ausweichen sollte. Denn leider führt die Installation von streamdeck-ui zu einem Fehler, der aus der Abhängigkeit zur Bibliothek ‘pillow’ herrührt. Versucht man nun, das Installationsscript aus dem Git Repository von streamdeck-ui zu nutzen, findet man einen Verweis auf die Installation von pip3, über das streamdeck-ui bezogen werden kann. Kommt man dann an den Punkt, um den Befehl pip3 install --user streamdeck_ui auszuführen, erhält man die Fehlermeldung, externally-managed-environment die ich zu Anfang des Artikels bereits beschrieben habe. Da wir bereits PIPX nutzen, ist es nicht zielführend, eine weitere virtuelle Umgebung für Python Programme zu erstellen, da diese auch nur wieder zu dem Fehler mit der Bibliothek pillow führen wird.
Da ich selbst kein Python-Programmierer bin, aber durchaus einige Erfahrungen mit komplexen Abhängigkeiten in großen Java Projekten habe und das Programm streamdeck-ui eigentlich besser als Boatwain empfunden hatte, habe ich mich ein wenig im GitHub Repository umgeschaut. Zuerst fällt auf, dass die letzte Aktivität im Frühjahr 2023 stattgefunden hat und eine Reaktivierung eher unwahrscheinlich ist. Schauen wir uns dennoch einmal die Fehlermeldung genauer an, um eine Idee zu bekommen, wie man bei Installationen anderer Programme das Problem eingrenzen kann.
Fatal error from pip prevented installation. Full pip output in file:
/home/ed/.local/state/pipx/log/cmd_pip_errors.log
pip seemed to fail to build package:
'pillow'Wenn man nun einen Blick in die zugehörige Logfile wirft, erfährt man, dass die Abhängigkeit von pillow kleiner als Version 7 und größer als Version 6.1 definiert ist, was zur Verwendung von der Version 6.2.2 führt. Schaut man nun einmal nach, was pillow eigentlich macht, erfährt man, dass dies eine Bibliothek für Python 2 war, mit der Grafiken gerendert werden konnten. Die in streamdeck-ui verwendete Version ist ein Fork von pillow für Python 3 und Ende 2025 bereits in der Version 12 verfügbar. Möglicherweise könnte das Problem dadurch behoben werden, indem eine aktuelle Version von pillow zum Einsatz kommt. Damit das gelingt, sind mit hoher Wahrscheinlichkeit auch Anpassungen am Code von streamdeck-ui vorzunehmen, da vermutlich seit der Version 6.2.2 einige Inkompatibilitäten der genutzten Funktionen vorhanden sind.
Mit dieser Analyse sehen wir, dass die Wahrscheinlichkeit, streamdeck-ui unter pip3 zum Laufen zu bekommen, in dasselbe Ergebnis führt wie mit PIPX. Wer nun auf die Idee kommt, unbedingt auf Python 2 zu downzugraden, um alte Programme zum Laufen zu bekommen, der sollte dies besser in einer gesonderten, isolierten Umgebung, zum Beispiel mit Docker versuchen. Python 2 hat seit vielen Jahren keinen Support durch Updates und Security Patches, weswegen eine parallele Installation zu Python 3 auf dem eigenen Betriebssystem keine gute Idee ist.
Wir sehen also, dass die anfangs beschriebene Fehlermeldung gar nicht so kryptisch ist, wenn man indes gleich auf PIPX setzt. Bekommt man sein Programm dann immer noch nicht installiert, hilft ein Blick auf die Fehlermeldung, der uns meist darüber aufklärt, dass wir ein veraltetes und nicht mehr gepflegtes Programm verwenden wollen.
Resources
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.



PDF-Generierung mit TP-CORE
PDF ist vermutlich das wichtigste interoperable Dokumentenformat zwischen Betriebssystemen und Geräten wie Computer, Smartphone und Tablet. Die wichtigste Eigenschaft für PDF ist die Unveränderlichkeit der Dokumente. Natürlich sind auch hier Grenzen gesetzt und man kann heutzutage problemlos mit entsprechenden Programmen Seiten aus einem PDF Dokument entfernen oder hinzufügen. Dennoch lassen sich die Inhalte der einzelnen Seiten nicht ohne Weiteres verändern. Wo vor Jahren noch kostspielige Spezialsoftware wie beispielsweise Acrobat von Adobe nötig war, um mit PDF umzugehen, sind mittlerweile viele kostenfreie Lösungen auch für den kommerziellen Einsatz verfügbar. So beherrschen die gängigen Office Suiten den Export des Dokumentes als PDF.
Gerade im Geschäftsbereich ist PDF eine hervorragende Wahl, um Rechnungen oder Berichte zu generieren. Hier setzt auch dieser Artikel an. Ich beschreibe, wie einfache PDF Dokumente für die Rechnungslegung etc. genutzt werden können. Komplizierte Layouts, wie sie beispielsweise für Magazine und Zeitschriften in Verwendung kommen, sind nicht Teil dieses Artikels.
Technisch kommt die frei verfügbare Bibliothek openPDF zum Einsatz. Das Konzept ist, aus einem gültigen HTML Code, welcher in einem Template enthalten ist, eine PDF zu generieren. Da wir uns im JAVA Umfeld bewegen, ist die Template Engine der Wahl Velocity. Alle diese Abhängigkeiten nutzt TP-CORE in der Funktionalität PdfRenderer, welche als Fassade implementiert ist. Dies soll die Komplexität der PDF-Generierung in der Funktionalität kapseln und einen Austausch der Bibliothek ermöglichen.
Auch wenn ich nun kein Spezialist der PDF-Generierung bin, habe ich im Laufe der Jahre einige Erfahrungen speziell mit dieser Funktionalität in Bezug auf die Wartbarkeit von Softwareprojekten sammeln können. Dazu gibt es sogar einen Konferenzvortrag. Als ich vor sehr vielen Jahren den Entschluss gefasst hatte, PDF in TP-CORE zu unterstützen, gab es nur die iText-Bibliothek, die zu dieser Zeit mit der Version 5 frei verfügbar war. Ähnlich wie Linus Torvalds mit seinem ursprünglich genutzten Source Control-Management-System, erging es mir. Itext wurde kommerziell und ich brauchte eine neue Lösung. Nun, ich bin nicht Linus, der mal fix GIT aus dem Boden stampft, also habe ich nach einiger Wartezeit openPDF entdeckt. OpenPDF ist ein Fork von iText5. Jetzt musste ich meinen bestehenden Code entsprechend anpassen. Das erforderte einiges an Zeit, war aber dank meiner Kapselung eine überschaubare Aufgabe. In diesem Anpassungsprozess habe ich allerdings Probleme entdeckt, die mir in meiner kleinen Welt bereits das Leben schwer gemacht haben, also habe ich TP-CORE Version 3.0 veröffentlicht, um in der Funktionalität Stabilität zu erreichen. Wer also TP-CORE in einer 2.X Version verwendet, findet dort als PDF Lösung noch iText5. Das soll aber jetzt genug über die Entstehungsgeschichte sein. Kümmern wir uns darum, wie wir aktuell mit TP-CORE 3.1 PDF generieren können. Auch hier gilt: Mein größtes Ziel ist es, eine möglichst hohe Kompatibilität zu erreichen.
Bevor wir beginnen können, müssen wir TP-CORE als Abhängigkeit in unser Java Projekt einbinden. Das Beispiel demonstriert die Verwendung von Maven als Build Werkzeug, kann aber leicht auf Gradle umgestellt werden.
<dependency>
<groupId>io.github.together.modules</groupId>
<artifactId>core</artifactId>
<version>3.1.0</version>
</dependency>
Um etwa eine Rechnung zu generieren, brauchen wir verschiedene Schritte. Zu erst benötigen wir ein HTML Template, das wir mit Velocity erzeugen. Das Template kann natürlich Platzhalter für Namen und Adresse enthalten, wodurch Serienbriefe und Batchverarbeitung möglich sind. Der folgende Code zeigt, wie wir damit umgehen können.
<h1>HTML to PDF Velocity Template</h1>
<p>Lorem ipsum dolor sit amet, consetetur sadipscing elitr, sed diam nonumy eirmod tempor invidunt ut labore et dolore magna aliquyam erat, sed diam voluptua. At vero eos et accusam et justo duo dolores et ea rebum. Stet clita kasd gubergren, no sea takimata sanctus est Lorem ipsum dolor sit amet. Lorem ipsum dolor sit amet.</p>
<p>Duis autem vel eum iriure dolor in hendrerit in vulputate velit esse molestie consequat, vel illum dolore eu feugiat nulla facilisis at vero eros et accumsan et iusto odio dignissim qui blandit praesent luptatum zzril delenit augue duis dolore te feugait nulla facilisi. Lorem ipsum dolor sit amet, consectetuer adipiscing elit, sed diam nonummy nibh euismod tincidunt ut laoreet dolore magna aliquam erat volutpat.</p>
<h2>Lists</h2>
<ul>
<li><b>bold</b></li>
<li><i>italic</i></li>
<li><u>underline</u></li>
</ul>
<ol>
<li>Item</li>
<li>Item</li>
</ol>
<h2>Table 100%</h2>
<table border="1" style="width: 100%; border: 1px solid black;">
<tr>
<td>Property 1</td>
<td>$prop_01</td>
<td>Lorem ipsum dolor sit amet,</td>
</tr>
<tr>
<td>Property 2</td>
<td>$prop_02</td>
<td>Lorem ipsum dolor sit amet,</td>
</tr>
<tr>
<td>Property 3</td>
<td>$prop_03</td>
<td>Lorem ipsum dolor sit amet,</td>
</tr>
</table>
<img src="path/to/myImage.png" />
<h2>Links</h2>
<p>here we try a simple <a href="https://together-platform.org/tp-core/">link</a></p>template.vm
In dem Template sind drei Properties enthalten: $prop_01, $prop_02 und $prop_03, die wir mit Werten füllen müssen. Das gelingt uns mit einer einfachen HashMap, die wir mit dem TemplateRenderer einfügen, wie das folgende Beispiel zeigt.
Map<String, String> properties = new HashMap<>();
properties.put("prop_01", "value 01");
properties.put("prop_02", "value 02");
properties.put("prop_03", "value 03");
TemplateRenderer templateEngine = new VelocityRenderer();
String directory = Constraints.SYSTEM_USER_HOME_DIR + “/“;
String htmlTemplate = templateEngine
.loadContentByFileResource(directory, "template.vm", properties);Der TemplateRenderer benötigt drei Argumente:
- directory – Der vollständige Pfad vo das Template zu finden ist.
- template – den Namen des Velocity-Templates
- properties – Die HashMap mit den zu ersetzenden Variablen
Das Ergebnis ist ein gültiger HTML Code, aus dem wir nun über den PdfRenderer das PDF generieren können. Eine Besonderheit ist die Konstante SYSTEM_USER_HOME_DIR, welche auf das Nutzerverzeichnis des aktuell angemeldeten Benutzers zeigt und die Unterschiede einzelner Betriebssysteme wie Linux und Windows abfängt.
PdfRenderer pdf = new OpenPdfRenderer();
pdf.setTitle("Title of my own PDF");
pdf.setAuthor("Elmar Dott");
pdf.setSubject("A little description about the PDF document.");
pdf.setKeywords("pdf, html, openPDF");
pdf.renderDocumentFromHtml(directory + "myOwn.pdf", htmlTemplate);Das Listing zum Erstellen der PDF ist überschaubar und recht selbsterklärend. Es ist natürlich möglich, das HTML hardcodiert zu übergeben. Die Nutzung des Templates erlaubt hier eine Trennung von Code und Design, was auch spätere Anpassungen flexibel erlaubt.
Das Standardformat ist A4 mit den Dimensionen size: 21cm 29.7cm; margin: 20mm 20mm; und ist als inline CSS definiert. Über die Methode setFormat(String format); lässt sich dieser Wert individuell festlegen. Der erste Wert steht hierbei für die Breite und der zweite Wert für die Höhe.
Der PDF Renderer hat auch die Möglichkeit, einzelne Seiten aus einem Dokument zu löschen.
PdfRenderer pdf = new OpenPdfRenderer();
PdfDocument original = pdf.loadDocument( new File("document.pdf") );
PdfDocument reduced = pdf.removePage(original, 1, 5);
pdf.writeDocument(reduced, "reduced.pdf");
Wir sehen also, dass bei der Implementierung der PDF Funktionalität sehr viel Wert auf eine einfache Handhabung gelegt wurde. Dennoch gibt es viele Möglichkeiten, individuelle PDF Dokumente zu erstellen. Daher hat die Lösung, über HTML das Layout zu definieren, einen besonderen Reiz. Trotz, dass der PdfRenderer mit einer sehr überschaubaren Funktionalität aufwartet, ist es sehr einfach möglich, durch den Vererbungsmechanismus von Java das Interface und die zugehörige Implementierung durch eigene Lösungen zu erweitern. Diese Möglichkeit besteht auch für alle anderen Implementierungen aus TP-CORE.
TP-CORE ist auch für den kommerziellen Gebrauch frei und hat dank der Apache 2 Lizenz keine Einschränkungen. Der Source Code ist unter https://git.elmar-dott.com zu finden und die Dokumentation inklusive Security und Testcoverage findet sich unter https://together-platform.org/tp-core/.
RTFM – benutzbare Dokumentationen
Ein alter Handwerksmeister pflegte immer zu sagen: Wer schreibt, der bleibt. Seine Intention war vor allem, ein vernünftiges Aufmaß und Wochenberichte seiner Gesellen zu bekommen. Diese Informationen benötigte er, um eine korrekte Rechnung stellen zu können, was für den Erfolg des Unternehmens maßgeblich war. Dieses Bild lässt sich auch gut auf die Softwareentwicklung übertragen. Erst als die in Japan von Yukihiro Matsumoto entwickelte Programmiersprache Ruby eine englischsprachige Dokumentation besaß, begann der weltweite Siegeszug von Ruby.
Wir sehen also, dass Dokumentation einen durchaus hohen Stellenwert für den Erfolg eines Softwareprojektes haben kann. Es beschränkt sich nicht nur auf einen Informationsspeicher im Projekt, wo neue Kollegen notwendige Details erfahren. Natürlich ist für Entwickler Dokumentation ein recht leidiges Thema. Stetig muss diese aktuell gehalten werden und oft fehlen auch Fertigkeiten, um die eigenen Gedanken sortiert und nachvollziehbar für andere auf Papier zu bringen.
Ich selbst kam vor sehr vielen Jahren erstmalig mit dem Thema Dokumentation durch das Lesen des Buches „Softwaretechnik“ von Johannes Siedersleben in Berührung. Dort wurde Ed Yourdon mit der Aussage zitiert, dass vor Methoden wie UML die Dokumentation oft in der Form einer viktorianischen Novelle vorlag. Während meines Berufslebens habe ich auch einige solcher viktorianischen Novellen angetroffen. Das Ärgerliche daran war: Nachdem man sich durch die Textwüste gekämpft hatte – anders als mit Überwindung und Kampf kann man das Gefühl nicht beschreiben –, hatte man die gesuchten Informationen immer noch nicht. Frei nach Goethes Faust: „So steh ich da ich armer Tor und bin so klug als wie zuvor.“
Hier sehen wir bereits einen ersten Kritikpunkt für schlechte Dokumentationen: eine unangemessene Länge der Ausführungen, die wenig Informationen enthalten. Hier müssen wir uns der Tatsache bewusst werden, dass das Schreiben nicht jedem in die Wiege gelegt wurde. Schließlich ist man ja Softwareentwickler und nicht Buchautor geworden. Das bedeutet für das Konzept „erfolgreiche Dokumentation“, dass man möglichst niemanden zu seinem Glück zwingen sollte und sich besser im Team nach Personen umschaut, die für Dokumentation ein Händchen haben. Das soll nun aber nicht bedeuten, dass alle anderen von der Aufgabe Dokumentation freigestellt sind. Ihr Input ist für die Qualität essenziell. Korrekturlesen, auf Fehler hinweisen und Ergänzungen vorschlagen sind durchaus notwendige Punkte, die sich gut auf vielen Schultern verteilen lassen.
Es ist durchaus ratsam, das Team, oder einzelne Teammitglieder gelegentlich rhetorisch zu schulen. Dabei sollte der Fokus auf einer präzisen, kompakten und verständlichen Ausdrucksweise liegen. Dabei geht es auch darum, die eigenen Gedanken so zu sortieren, dass diese auf Papier gebracht werden können und dabei einem roten Faden folgen. Die dadurch verbesserte Kommunikation wirkt sich sehr positiv auf die Entwicklungsprojekte aus.
Eine aktuell gehaltene Dokumentation, die gut zu lesen ist und wichtige Informationen enthält, wird schnell zu einem lebenden Dokument, ganz gleich, welche Formen gewählt wurden. Dies ist auch ein grundlegendes Konzept für erfolgreiches DevOps und agile Vorgehensmodelle. Denn diese Paradigmen setzen auf einen guten Informationsaustausch und adressieren auch das Vermeiden von sogenannten Informationssilos.
Ein Punkt, der mich wirklich triggert, ist die Aussage: Unsere Tests sind die Dokumentation. Nicht alle Stakeholder können programmieren und sind daher auch nicht in der Lage, die Testfälle zu verstehen. Zudem demonstrieren Tests zwar das Verhalten von Funktionen, sie demonstrieren aber nicht per se die richtige Verwendung. Meist fehlen auch Variationen von verwendbaren Lösungen. Damit Testfälle einen dokumentativen Charakter haben, ist es notwendig, spezielle Tests exakt für diesen Zweck zu entwickeln. Dieses Vorgehen hat meiner Ansicht nach zwei gravierende Vorteile. Zum Ersten bleibt die Dokumentation zur Implementierung aktuell, denn bei Änderungen schlägt der Testfall fehl. Ein weiterer positiver Effekt ist, dass der Entwickler über die Verwendung seiner Implementierung bewusst wird und einen ungünstigen Entwurf zeitnah korrigieren kann.
Natürlich gibt es mittlerweile unzählige technische Lösungen, die je nach Sichtweise auf das System für unterschiedliche Personengruppen geeignet sind. Issue- und Bug-Tracking Systeme wie beispielsweise das kommerzielle JIRA oder das freie Redmine bilden ganze Prozesse ab. Sie erlauben es den Testern, erkannte Probleme und Fehler der Software einer Releaseversion zuzuordnen. Projektleiter können mit dem Release Management eine Priorisierung der Korrekturen vornehmen und die Entwickler dokumentieren die verwendete Korrektur. Soweit die Theorie. In der Praxis habe ich in nahezu jedem Projekt erlebt, wie in diesen Systemen die Kommentarfunktion als Chat missbraucht wurde, um den Änderungsstatus zu beschreiben. Als Ergebnis hat man eine Fehlerbeschreibung mit unzähligen nutzlosen Kommentaren und wirkliche weiterführende Informationen fehlen komplett.
Eine weitverbreitete technische Lösung in Entwicklungsprojekten sind auch sogenannte Enterprise Wikis. Sie ergänzen einfache Wikis durch eine Navigation und ermöglichen das Erstellen geschlossener Spaces, auf die nur explizit zugelassene Nutzergruppen feingranulare Berechtigungen wie Lesen oder Schreiben erhalten. Neben der weitverbreiteten kommerziellen Lösung Confluence gibt es auch eine freie Variante namens Blue Spice, die auf dem MediaWiki basiert. Wikis erlauben die kollaborative Arbeit an einem Dokument und die einzelnen Seiten können auch über verschiedene Zusammenstellungen als PDF exportiert werden. Damit die Wikiseiten auch benutzbar bleiben, sollte man Wert auf eine saubere und möglichst einheitliche Formatierung legen. Tabellen sollten mit ihrem Inhalt auf eine A4 Seite passen, ohne dass es zu unerwünschten Umbrüchen kommt. Das verbessert den Lesefluss. Es gibt auch viele Fälle, in denen Aufzählungen der Übersichtshalber Tabellen vorzuziehen sind.
Dies bringt uns auch zu einem weiteren sehr heiklen Thema, den Grafiken. Es ist durchaus korrekt, dass ein Bild oft mehr als tausend Worte sagt. Aber eben nicht immer! Im Umgang mit Grafiken ist es wichtig, sich bewusst zu sein, dass Bilder oft einiges an Zeit für die Erstellung benötigen und oft auch nur mit viel Aufwand angepasst werden können. Daraus ergeben sich einige Konsequenzen, um sich das Leben zu erleichtern. Zum Erstellen von Grafiken wird sich auf ein Standardprogramm (Format) festgelegt. Auf teure Grafikprogramme wie Photoshop und Corel ist zu verzichten. Grafiken, die für Wikiseiten erstellt wurden, sind in ihrem Original, also der änderbaren Datei, an die Wikiseite anzufügen. Es kann auch ein eigenes Repository dafür aufgebaut werden, um so eine Wiederverwendung in anderen Projekten zu ermöglichen.
Wenn ein Bild keinen Mehrwert bedeutet, sollte man darauf besser verzichten. Dazu ein kleines Beispiel. Es ist nicht notwendig, eine Grafik anzufertigen, auf der 10 Strichmännchen abgebildet sind, unter denen dann der Rollenname oder eine Person steht. Hier ist es zielführend, eine einfache Aufzählung anzufertigen, die sich im Übrigen auch leichter ergänzen beziehungsweise anpassen lässt.
Aber auch auf überfrachtete Grafiken sollte man verzichten. Treu nach dem Motto „Viel hilft viel“: Sorgen zu detaillierte Informationen eher für Verwirrung und können zu Missinterpretationen führen. Eine Buchempfehlung ist „Softwarearchitekturen dokumentieren und kommunizieren“ von Stefan Zörner. Er arbeite in diesem Titel optimal heraus, wie wichtig die verschiedenen Sichtweisen auf ein System sind und welche Personengruppen mit einer expliziten Sicht angesprochen werden. Dazu möchte ich auch die Gelegenheit nutzen, um seine 7. Regeln für eine gute Dokumentation wiederzugeben.
- Schreibe aus Sicht des Lesers.
- Vermeide unnötige Wiederholungen.
- Vermeide Mehrdeutigkeiten, wenn nötig Notation erläutern.
- Verwende Standards wie z. B. UML.
- Halte Begründungen (Warum) fest.
- Die Dokumentation ist aktuell zu halten, aber nie zu aktuell.
- Überprüfe die Gebrauchstauglichkeit (Review).
Wer im Projekt damit beauftragt ist, die Dokumentation zu schreiben beziehungsweise deren Fortschritt und Aktualität sicherzustellen hat, sollte sich immer bewusst sein, dass wichtige Informationen enthalten sind, diese auch korrekt und verständlich dargestellt werden. Eine kompakte und übersichtliche Dokumentation lässt sich auch bei fortschreitendem Projekt problemlos anpassen und erweitern. Anpassungen gelingen immer dann am besten, wenn der betroffene Bereich möglichst zusammenhängend ist und möglichst nur einmal vorkommt. Diese Zentralisierung erreicht man durch Referenzen und Verlinkungen, so dass die Änderung im Original sich auf die Referenzen auswirkt.
Natürlich gibt es zum Thema Dokumentation noch viel mehr zu sagen, schließlich ist es Gegenstand verschiedener Bücher, aber das würde den Rahmen dieses Artikels übersteigen. Mir ging es vor allem darum, für das Thema eine Sensibilisierung zu schaffen, denn Paradigmen wie Agilität und DevOps basieren auf einem guten Informationsfluss.



BugChaser – Die Grenze der Testabdeckung
Die mittlerweile im Software Engineering etablierten Paradigmen wie Test Driven Development (TDD) und Behavior Driven Development (BDD) mit entsprechend einfach zu bedienenden Werkzeugen haben eine neue pragmatische Sichtweise auf das Thema Software Tests eröffnet. Ein wichtiger Faktor in kommerziellen Softwareprojekten sind automatisierte Tests. Deshalb spricht man in diesem Kontext von einer erfolgreichen Teststrategie, wenn die Testausführung ohne menschliches Zutun vonstattengeht.
Testautomatisierung bildet die Grundlage, um Stabilität und Risikoreduzierung bei kritischen Arbeiten zu erreichen. Zu solchen kritischen Tätigkeiten zählen insbesondere das Refactoring, Maintenance und Fehlerkorrekturen. Allen diesen Aktivitäten obliegt eine Gemeinsamkeit: dass sich keine neuen Fehler in den Code einschleichen dürfen.
In dem Artikel „The Humble Programmer“ von 1972 stellte Edsger W. Dijkstra folgendes fest:
„Programmtests können ein sehr effektiver Weg sein, um das Vorhandensein von Fehlern aufzuzeigen, sind aber völlig unzureichend, um deren Abwesenheit nachzuweisen.“
Eine alleinige Automatisierung der Testausführung ist deshalb nicht ausreichend, um sicherzustellen, dass Änderungen der Codebasis keine unerwünschten Effekte auf bestehende Funktionen haben. Aus diesem Grund muss die Qualität der Testfälle bewertet werden. Hierzu gibt es bereits bewährte Werkzeuge.
Bevor wir tiefer in die Thematik einsteigen, wollen wir uns zuerst überlegen, was eigentlich automatisiertes Testen bedeutet. Diese Frage ist recht einfach zu beantworten. Nahezu jede Programmiersprache hat ein entsprechendes Unit Test Framework. Unit Tests rufen eine Methode mit verschiedenen Parametern auf und vergleichen den Rückgabewert mit einem Erwartungswert. Stimmen beide Werte überein, gilt der Test als bestanden. Zusätzlich kann noch überprüft werden, ob eine Ausnahme geworfen wurde.
Für den Fall, dass eine Methode keinen Rückgabewert hat oder keinen Fehler wirft, kann diese Methode nicht getestet werden. Auch als private gekennzeichnete Methoden oder innere Klassen, sind nicht ohne Weiteres zu testen, da sie nicht direkt aufgerufen werden können. Diese sind über öffentliche Methoden, welche die ‚versteckten‘ Methoden aufrufen, zu testen.
Im Umgang mit als private gekennzeichneten Methoden ist es keine Option, die dadurch abgebildete Funktionalität über Techniken wie die Verwendung der Reflection API zu erreichen und zu testen. Denn wir müssen uns bewusst machen, dass solche Methoden oft auch dazu verwendet werden, Fragmente zu kapseln, um Dopplungen zu vermeiden.
public boolean method() {
boolean success = false;
List collector = new ArryList();
collector.add(1);
collector.add(2);
collector.add(3);
sortAsc(collector);
if(collector.getFirst().equals(1)) {
success = true;
}
return success;
}
private void sortAsc(List collection) {
collection.sort(
(a, b) -> {
return -1 * a.compareTo(b);
});
}Um also effektiv automatisierte Tests schreiben zu können, ist es notwendig, einem gewissen Codingstil zu folgen. Das vorangegangene Listing 1 demonstriert auf einfache Weise, wie testbarer Code aussehen kann.
Da Entwickler für ihre eigene Implementierung auch die zugehörigen Komponententests schreiben, ist das Problem von schwer testbarem Code in Projekten, die einem testgetriebenen Ansatz folgen, weitgehend eliminiert. Die Motivation zu testen liegt nun beim Entwickler, da dieser mit diesem Paradigma feststellen kann, ob seine Implementierung sich wie gewünscht verhält. Dabei müssen wir uns aber fragen: Ist das bereits alles, was wir tun müssen, um gute und stabile Software zu entwickeln?
Wie wir uns bei solchen Fragen immer denken können, lautet die Antwort nein. Ein essenzielles Werkzeug, um die Qualität der Tests zu bewerten, ist das Erreichen einer möglichst hohen Testabdeckung. Dabei wird zwischen Branch und Line Coverage unterschieden. Um den Unterschied etwas besser zu verdeutlichen, schauen wir kurz auf den Pseudocode in Listing 2.
if( Expression-A OR Expression-B ) {
print(‘allow‘);
} else {
print(‘decline‘);
}
Unser Ziel ist es, nach Möglichkeit alle Zeilen zu durchlaufen. Dazu brauchen wir bereits zwei separate Testfälle. Einen für das Betreten des IF-Zweiges und einen für das Betreten des ELSE-Zweiges. Damit wir aber auch eine hundertprozentige Branch-Coverage erzielen, müssen wir alle Varianten des IF-Zweiges abdecken. Für das Beispiel heißt das: ein Test, der Expression-A true werden lässt, und ein weiterer Test, der Expression-B true werden lässt. Daraus ergeben sich insgesamt drei verschiedene Testfälle.
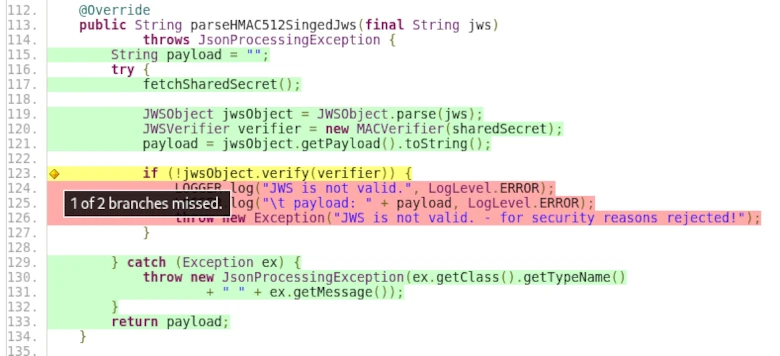
Der Screenshot aus dem Projekt TP-CORE zeigt, wie eine solche Testabdeckung in ‚echten‘ Projekten aussehen kann.
Natürlich ist dieses Beispiel sehr einfach und es gibt im wirklichen Leben oft Konstrukte, bei denen man trotz aller Bemühungen nicht alle Lines beziehungsweise Branches erreicht. Sehr typisch sind Exceptions aus Fremdbibliotheken, die zu fangen sind, aber unter normalen Umständen nicht provoziert werden können.
Aus diesem Grund versuchen wir zwar, eine möglichst hohe Testabdeckung zu erreichen, und streben natürlich die 100 % an, aber es gibt genügend Fälle, in denen dies nicht möglich ist. Eine Testabdeckung von 90% gelingt aber durchaus. Der Industriestandard für kommerzielle Projekte liegt bei 85 % Testabdeckung. Mit diesen Erkenntnissen können wir also sagen, dass die Testabdeckung mit der Testbarkeit einer Anwendung korreliert. Das bedeutet, die Testabdeckung ist ein geeignetes Maß für die Testbarkeit.
Hier muss man allerdings auch zugeben, dass die Metrik der Testabdeckung ihre Grenze hat. Reguläre Ausdrücke und Annotationen zur Datenvalidierung sind nur einige einfache Beispiele für eine nicht aussagefähige Testabdeckung.
Ohne allzu sehr in die Implementierungsdetails einzugehen, stellen wir uns vor, wir müssten einen regulären Ausdruck schreiben, um Eingaben auf ein korrektes 24 Stunden Format zu überprüfen. Haben wir das korrekte Intervall nicht im Auge, ist unser regulärer Ausdruck möglicherweise nicht korrekt. Das richtige Intervall für das 24-Stunden-Format lautet: 00:00 – 23:59. Beispiele für fehlerhafte Werte sind 24:00 oder 23:60. Ist uns dieser Fakt nicht bewusst, können trotz Testfällen Fehler in unserer Anwendung versteckt sein, bis sie verwendet werden un zu Fehlern führen.
Dies ist ein hervorragendes Beispiel für das Zitat von Dijkstra zu Beginn des Artikels. Zudem möchte ich noch ein weiteres Zitat aus einem Artikel anführen, an dem Christian Bird mitgewirkt hat. Der Artikel heißt „The Design of Bug Fixes“ und ist aus dem Jahr 2013.
„… In a few cases, participants were unable to think of alternative solutions …“
Hier ging es um die Fragestellung, ob eine Fehlerkorrektur immer die optimale Lösung darstellt. Abgesehen davon wäre zu klären, was in kommerziellen Softwareentwicklungsprojekten eine optimale Lösung darstellt. Sehr demonstrativ ist die Aussage, dass es Fälle gibt, in denen Entwickler nur einen Weg kennen beziehungsweise verstehen. Das spiegelt auch unser Beispiel der RegEx wider. Softwareentwicklung ist ein Denkprozess, der sich auch nicht beschleunigen lässt. Unser Denken wird durch unsere Vorstellungskraft bestimmt, die wiederum von unserer Erfahrung beeinflusst ist.
Dies zeigt uns bereits ein weiteres Beispiel für Fehlerquellen in Testfällen. Ein Klassiker sind z. B. inkorrekte Vergleiche in Collections. Es geht unter anderem um das Vergleichen von Arrays. Die Problematik, mit der wir hier zu kämpfen haben, ist das Thema, wie auf Variablen zugegriffen wird: Call by Value oder Call by Reference. Bei Arrays erfolgt der Zugriff über Call by Reference, also direkt auf die Speicherzelle. Weist man nun ein Array einer neuen Variable zu und vergleicht beide Variablen, sind diese immer gleich, da man das Array mit sich selbst vergleicht. Ein Beispiel für einen Testfall, der eigentlich keine Aussagekraft hat. Ist die Implementierung dennoch korrekt, wird dieser fehlerhafte Testfall nie ins Gewicht fallen.
Diese Erkenntnis zeigt uns, dass ein blindes Erreichen der Testabdeckung für die Qualität nicht zielführend ist. Natürlich ist es verständlich, dass im Management diese Metrik einen hohen Stellenwert hat. Wir haben aber auch nachweisen können, das man sich darauf alleine nicht verlassen darf. Wir sehen also, dass auch für Testfälle Codeinspektionen und Refactorings ein Bedarf besteht. Da man aus Zeitgründen nun nicht den ganzen Code von vorn bis hinten lesen und auch verstehen kann, ist es wichtig, auf problematische Bereiche zu konzentrieren. Wie kann man aber diese Problembereiche finden? Hier hilft uns eine vergleichsweise neue Technik. Die theoretischen Arbeiten dazu sind bereits etwas älter, es hat nur eine Weile gedauert, bis entsprechende Implementierungen verfügbar wurden.
Mutation Testing. Dies erlaubt, durch Veränderung des Originalcodes Testfälle zu finden, die trotz verschiedener Mutationen nicht fehlschlagen. Damit haben wir ein weiteres Werkzeug an der Hand, die Qualität der vorhandenen Tests zu bewerten. In diesem Artikel habe ich zeigen können, dass man sich nicht komplett auf die Testcoverage verlassen darf. Um dieses Problem zu lösen, können wir uns des Mutation Testing bedienen. Wie konkret Mutation Testing funktioniert, kann wiederum Thema eines eigenständigen Artikels sein und würde an dieser Stelle den Rahmen sprengen.