Desde hace más de una década, está ampliamente aceptado que los sistemas informáticos deben mantenerse actualizados. Quienes instalan actualizaciones con regularidad reducen el riesgo de tener brechas de seguridad en su ordenador de las que se podría hacer un mal uso. Siempre con la esperanza de que los fabricantes de software corrijan siempre en sus actualizaciones también los fallos de seguridad. Microsoft, por ejemplo, ha impuesto una obligación de actualización a sus usuarios desde la introducción de Windows 10. En el fondo, la idea tenía fundamento. Porque los sistemas operativos sin parches facilitan el acceso a los hackers. Así que el pensamiento: “Lo último es lo mejor” prevaleció hace mucho tiempo.
Los usuarios de Windows tenían poco margen de maniobra. Pero incluso en dispositivos móviles como smartphones y tabletas, las actualizaciones automáticas están activadas en los ajustes de fábrica. Si alojas un proyecto de código abierto en GitHub, recibirás regularmente correos electrónicos sobre las nuevas versiones de las bibliotecas utilizadas. Así que, a primera vista, esto es algo bueno. Sin embargo, si profundizas un poco más en el tema, llegarás rápidamente a la conclusión de que lo último no siempre es lo mejor.
El ejemplo más conocido es Windows 10 y los ciclos de actualización impuestos por Microsoft. Es indiscutible que los sistemas deben comprobarse periódicamente para detectar problemas de seguridad e instalar las actualizaciones disponibles. También es comprensible que el mantenimiento de los sistemas informáticos lleve su tiempo. Sin embargo, resulta problemático cuando las actualizaciones instaladas por el fabricante paralizan todo el sistema y se hace necesaria una nueva instalación porque la actualización no ha sido suficientemente probada. Pero también en el contexto de las actualizaciones de seguridad sin pedir cambios de función al usuario para traer en considero irrazonable. Especialmente con Windows, hay un montón de programas adicionales instalados, que pueden convertirse rápidamente en un riesgo para la seguridad debido a la falta de un mayor desarrollo. Eso significa con todas las consecuencias forzadas actualizaciones de Windows no hacen un equipo seguro, ya que aquí el software instalado adicionalmente no se examina en busca de puntos débiles.
Si echamos un vistazo a los sistemas Android, la situación es mucho mejor. Sin embargo, aquí también hay bastantes puntos criticables. Las aplicaciones se actualizan con regularidad, por lo que la seguridad mejora notablemente. Pero también con Android, cada actualización suele implicar cambios funcionales. Un ejemplo sencillo es el muy popular servicio Google StreetMaps. Con cada actualización, el uso del mapa se vuelve más confuso para mí, ya que se muestra mucha información adicional no deseada, lo que reduce considerablemente la ya limitada pantalla.
Como usuario, afortunadamente todavía no me ha ocurrido que las actualizaciones de aplicaciones en Android hayan paralizado todo el teléfono. Lo que también demuestra que es bastante posible probar exhaustivamente las actualizaciones antes de lanzarlas a los usuarios. Sin embargo, esto no significa que todas las actualizaciones estén exentas de problemas. Los problemas que se pueden observar aquí con regularidad son cosas como un aumento excesivo del consumo de batería.
Las actualizaciones puras del sistema Android, por otro lado, hacen que regularmente el hardware se vuelva tan lento después de casi dos años que a menudo se decide comprar un nuevo smartphone. Aunque el teléfono antiguo todavía esté en buenas condiciones y se pueda utilizar mucho más tiempo. He observado que muchos usuarios experimentados desactivan las actualizaciones de Android al cabo de un año aproximadamente, antes de que el fabricante envíe el teléfono a la obsolescencia.
¿Cómo consigue un silenciador de actualizaciones mantener sus sistemas al día y seguros? Mi planteamiento como desarrollador y gestor de configuración es bastante sencillo. Distingo entre actualización de características y parche de seguridad. Si sigues el versionado semántico en el proceso de publicación y utilizas un modelo de rama por publicación para sistemas SCM como Git, esa distinción puede aplicarse fácilmente.
Pero también me he dedicado a la cuestión de una configuración versionable para aplicaciones de software. Para ello, existe una implementación de referencia en el proyecto TP-CORE en GitHub, que se describe en detalle en el artículo en dos partes Treasue Chest. Después de todo, debemos tener claro que si restablecemos toda la configuración realizada por el usuario a los valores de fábrica durante una actualización, como ocurre con bastante frecuencia con Windows 10, pueden surgir vulnerabilidades de seguridad bastante singulares.
Esto también nos lleva al punto de la programación y cómo GitHub motiva a los desarrolladores a través de correos electrónicos para que incluyan nuevas versiones de las librerías utilizadas en sus aplicaciones. Porque si dicha actualización supone un cambio importante en la API, el problema es el elevado esfuerzo de migración para los desarrolladores. Aquí es donde me ha funcionado una estrategia también bastante sencilla. En lugar de dejarme impresionar por las notificaciones sobre actualizaciones de GitHub, compruebo regularmente a través de OWASP si mis bibliotecas contienen riesgos conocidos. Porque si OWASP detecta un problema, no importa lo costosa que pueda ser una actualización. La actualización y la migración asociada deben aplicarse con prontitud. Esto también se aplica a todas las versiones que todavía están en producción.
Para evitar el infierno de las actualizaciones desde el principio, sin embargo, hay una regla de oro: sólo instalar o utilizar lo que realmente se necesita. Cuantos menos programas se instalen en Windows y menos aplicaciones haya en el smartphone, menos riesgos de seguridad habrá. Esto también se aplica a las bibliotecas de programas. Menos es más desde el punto de vista de la seguridad. Aparte de eso, al prescindir de programas innecesarios, también obtenemos una medida de rendimiento gratuita.
Ciertamente, para muchos usuarios privados la cuestión de las actualizaciones del sistema apenas es relevante. Sólo las nuevas funciones no deseadas en los programas existentes, la degradación del rendimiento o, de vez en cuando, el bloqueo de los sistemas operativos causan un disgusto más o menos fuerte. En el entorno comercial, pueden surgir con bastante rapidez costes considerables, que también pueden repercutir negativamente en los proyectos que se ejecutan. Las empresas y las personas que desarrollan software pueden mejorar considerablemente la satisfacción de los usuarios si distinguen en sus versiones entre parches de seguridad y actualizaciones de características. Y una actualización de características debería contener también todas las actualizaciones de seguridad conocidas.
Durante mi trabajo como Gestor de Configuración / DevOps para grandes proyectos web, he observado cómo las empresas hacían caso omiso de la Ley de Conway y fracasaban estrepitosamente. Ese fracaso a menudo se traducía en importantes sobrecostes presupuestarios y plazos incumplidos.
La infraestructura interna en la colaboración del proyecto se modeló exactamente según las estructuras organizativas internas y todas las experiencias y normas establecidas se “doblaron” para adaptarlas a la organización interna. Esto dio lugar a problemas que hicieron que las canalizaciones de CI/CD fueran especialmente engorrosas y provocaron largos tiempos de ejecución. Pero además, los ajustes sólo podían hacerse con mucho esfuerzo. En lugar de simplificar los procesos existentes y adaptarlos a los estándares establecidos, se pusieron excusas para mantener todo como estaba. Veamos qué es la Ley de Conway y por qué hay que respetarla.
El investigador y programador estadounidense Melvin E. Conway se doctoró en la Case Western Reserve University en 1961. Su especialidad son los lenguajes de programación y el diseño de compiladores.
En 1967, presentó su artículo “How Do Committees Invent?” (¿Cómo inventan los comités?) en The Harvard Business Review. (Engl.: ¿Cómo inventan los comités?) y fue rechazado. La razón aducida fue que su tesis no estaba fundamentada. Sin embargo, Datamation, la mayor revista de informática de la época, aceptó su artículo y lo publicó en abril de 1968. Y este artículo es ahora ampliamente citado. La afirmación central es:
Cualquier organización que diseñe un sistema (en el sentido más amplio) creará un diseño cuya estructura sea una copia de la estructura de comunicación de la organización.
Conway, Melvin E. “How do Committees Invent?” 1968, Datamation, vol. 14, num. 4, pp. 28–31
Cuando Fred Brooks citó el ensayo en su legendario libro de 1975 “The Mythical Man-Month”, llamó a esta afirmación central Ley de Conway. Brooks reconoció la conexión entre la Ley de Conway y la teoría de la gestión. En el artículo encontramos el siguiente ejemplo:
Dado que el diseño elegido en primer lugar casi nunca es el mejor posible, el sistema imperante puede necesitar cambiar conceptos del sistema. Por ello, la flexibilidad de la organización es importante para un diseño eficaz.
The Mythical Man-Month: Essays on Software Engineering
Un ejemplo a menudo citado del tamaño “ideal” de un equipo en términos de la Ley de Conway es la regla de las dos pizzas de Amazon, que establece que los equipos de proyectos individuales no deben tener más miembros de los que dos pizzas puedan llenar en una reunión. Sin embargo, el factor más importante que hay que tener en cuenta en la alineación de equipos es la capacidad de trabajar entre equipos y no vivir en silos.
La Ley de Conway no pretendía ser un chiste ni un koan zen, sino una observación sociológica válida. Fijémonos en las estructuras de las administraciones públicas y su implantación digital. Pero también los procesos de las grandes empresas han sido emulados por sistemas informáticos. Estas aplicaciones se consideran muy engorrosas y complicadas, por lo que encuentran poca aceptación entre los usuarios, que prefieren recurrir a alternativas. Por desgracia, a menudo es casi imposible simplificar los procesos en las grandes estructuras organizativas por motivos políticos.
Entre otras cosas, hay un detallado artículo de Martin Fowler, que trata explícitamente de las arquitecturas de software y elabora la importancia del acoplamiento de objetos y módulos. La comunicación entre desarrolladores desempeña un papel esencial para lograr los mejores resultados posibles. Este hecho sobre la importancia de la comunicación también fue recogido por el desarrollo ágil de software e implementado como un punto esencial. Especialmente cuando equipos distribuidos trabajan en un proyecto conjunto, la diferencia horaria es un factor limitante en la comunicación del equipo. Por tanto, ésta debe organizarse de forma especialmente eficaz.
En 2010, Jonny Leroy y Matt Simons acuñaron el término Inverse Conway Maneuver en el artículo “Dealing with creaky legacy platforms”:
La Ley de Conway… puede resumirse así: “Las organizaciones disfuncionales tienden a crear aplicaciones disfuncionales”. Parafraseando a Einstein: No se puede solucionar un problema desde la misma mentalidad que lo creó. Por lo tanto, a menudo merece la pena investigar si la reestructuración de su organización o equipo evitaría que la nueva aplicación tuviera las mismas disfunciones estructurales que la original. En una especie de “maniobra Conway a la inversa”, se puede empezar por romper los silos que limitan la capacidad del equipo para trabajar juntos con eficacia.
Desde la década de 2010, un nuevo estilo arquitectónico ha entrado en la industria del software. Son los llamados microservicios, creados por pequeños equipos ágiles. El criterio más importante de un microservicio en comparación con un monolito modular es que un microservicio puede verse como un módulo o subsistema independientemente viable. Por un lado, esto permite reutilizar el microservicio en otras aplicaciones. Por otro lado, existe un fuerte encapsulamiento del dominio funcional, lo que abre una flexibilidad muy elevada para las adaptaciones.
La ley de Conway también puede aplicarse a muchos otros ámbitos y no se limita exclusivamente a la industria del software. Esto es lo que hace que el trabajo sea tan valioso.
Resourcen
Los enlaces sólo son visibles para los usuarios registrados.
El revuelo en torno a la inteligencia artificial dura ya varios años. Actualmente, empresas como OpenAI están causando un gran revuelo con redes neuronales de libre acceso como ChatGPT. Los usuarios están fascinados por las posibilidades y algunas figuras intelectuales de nuestro tiempo advierten a la humanidad sobre la inteligencia artificial. Entonces, ¿qué tiene el espectro de la IA? En este artículo exploro esta cuestión y le invito a acompañarme en este viaje. Vamos a seguirme hacia el futuro.
En la primavera de 2023, se desbordaron los informes sobre la capacidad de rendimiento de las redes neuronales artificiales. Esta tendencia continúa y, en mi opinión, no remitirá en breve. Sin embargo, en medio de la incipiente fiebre del oro, también circulan algunas malas noticias. Microsoft, por ejemplo, anunció que invertiría fuertemente en inteligencia artificial. Este anuncio se vio subrayado en la primavera de 2023 con el despido de casi 1.000 empleados, suscitando los consabidos temores a la industrialización y la automatización. Las cosas fueron menos espectaculares en Digital Ocean, que despidió a todo su equipo de creación de contenidos y documentación. Rápidamente, algunos se preguntaron, con razón, si la IA convertiría ahora en obsoletas profesiones como las de programador, traductor, periodista, redactor, etc. Por el momento, me gustaría responder a esta pregunta con un no. A medio plazo, sin embargo, se producirán cambios, como ya nos ha enseñado la historia. Lo viejo pasa y lo nuevo nace. Acompáñenme en una pequeña excursión histórica.
Veamos primero las distintas etapas de la industrialización, que se originó en Inglaterra en la segunda mitad del siglo XVIII. Incluso el significado del término latino original Industria, que puede traducirse como diligencia, es sumamente interesante. Lo que nos lleva a Norbert Wiener y su libro de 1960 God and Golem Inc [1]. En él reflexionaba públicamente sobre si las personas que crean máquinas, que a su vez pueden crear máquinas, son dioses. Algo que, desde mi punto de vista, no me gustaría suscribir. Pero volvamos de momento a la industrialización.
La introducción de la máquina de vapor y el uso de fuentes de energía independientes del lugar, como el carbón, permitieron una producción en masa precisa. Al abaratarse la automatización de la producción mediante máquinas, se desplazaron los puestos de trabajo manuales a domicilio. A cambio, ahora se podían adquirir productos más baratos en las tiendas. Pero también se produjeron cambios significativos en el transporte. El ferrocarril permitió viajes más rápidos, cómodos y baratos. Esto catapultó a la humanidad a un mundo globalizado. Porque ahora las mercancías también podían recorrer largas distancias en poco tiempo y sin problemas. Hoy, cuando recordamos los debates de la época en que el ferrocarril inició su marcha triunfal, sólo podemos sonreír. Al fin y al cabo, algunos intelectuales de la época sostenían que velocidades de tren superiores a 30 kilómetros por hora aplastarían literalmente a los ocupantes humanos. Un temor que afortunadamente resultó infundado.
Mientras que en la primera revolución industrial la gente ya no podía obtener ingresos trabajando en casa, encontró una alternativa para ganarse la vida en una fábrica.
La segunda revolución industrial se caracterizó por la electrificación, que aumentó aún más el grado de automatización. Las máquinas se volvieron menos engorrosas y más precisas. Pero también se introdujeron nuevos inventos en la vida cotidiana. El fax, el teléfono y la radio difundieron información a gran velocidad. Esto nos condujo a la era de la información y aceleró no sólo nuestra comunicación, sino también nuestras vidas. Creamos una sociedad que se caracteriza sobre todo por el dicho “el tiempo es oro”.
La tercera revolución industrial bendijo a la humanidad con una máquina universal que determinaba su funcionalidad a través de los programas (software) que se ejecutaban en ella. Hoy en día, los ordenadores nos ayudan en multitud de actividades. Los modernos sistemas de caja registradora hacen mucho más que escupir el importe total de la compra realizada. Registran los flujos de dinero y mercancías y permiten realizar evaluaciones de optimización con los datos recogidos. Se trata de una nueva calidad de automatización que hemos alcanzado en los últimos 200 años. Con la generalización de las redes neuronales artificiales, estamos saliendo de esta fase, por lo que actualmente nos encontramos en la transformación hacia la cuarta revolución industrial. ¿De qué otra forma pretendemos, como humanos, hacer frente a la creciente avalancha de información?
Aunque la Industria 4.0 se centra en la conexión en red de las máquinas, no se trata de una auténtica revolución. Internet es solo una consecuencia del desarrollo anterior para permitir la comunicación entre máquinas. Podemos compararlo con la sustitución de la máquina de vapor por motores eléctricos. La verdadera innovación fueron las máquinas eléctricas que cambiaron la forma de comunicarnos. Esto está ocurriendo ahora en nuestra época a través del amplio campo de la inteligencia artificial.
En un futuro próximo, ya no utilizaremos los ordenadores de la misma manera que hasta ahora. Esto se debe a que los ordenadores actuales deben su existencia a la hasta ahora limitada comunicación entre el hombre y la máquina. En realidad, el teclado y el ratón son dispositivos de entrada torpes. Son lentos y propensos a errores. El control por voz y gestos a través del micrófono y la cámara sustituirá al ratón y al teclado. Hablaremos con nuestros ordenadores como hablamos con otras personas. Pero esto también significa que los programas informáticos actuales quedarán obsoletos. Ya no rellenaremos tediosas máscaras de entrada en interfaces gráficas de usuario para alcanzar nuestro objetivo. Atrás quedarán los días en que tenía que teclear mis artículos. Ahora los teclearé y mi ordenador me los mostrará visualmente para que los corrija. Presumiblemente, la profesión de logopeda experimentará entonces un auge considerable.
Seguramente también habrá bastantes protestas de personas que temen la desintegración de la comunicación humana. Este temor no es en absoluto infundado. No hay más que ver la evolución de la lengua alemana desde el cambio de milenio. Se caracterizó por la aparición de diversos servicios de mensajería de texto y la optimización de los mensajes mediante el uso del mayor número posible de abreviaturas. Esto, a su vez, no hizo sino crear interrogantes en la frente de los padres a la hora de descifrar el contenido de los mensajes de sus hijos. Aunque la tendencia actual es pasar de los mensajes de texto a los mensajes de audio, eso no significa que nuestro lenguaje no siga cambiando. Yo mismo he observado durante años que muchas personas ya no son capaces de expresarse correctamente por escrito o de extraer contenido de textos escritos. A largo plazo, esto podría llevarnos a desaprender habilidades como la lectura y la escritura. En consecuencia, los clásicos artículos impresos, como libros y revistas, también quedarán obsoletos. Por último, los contenidos también pueden producirse en forma de vídeo o podcast. Nuestras capacidades intelectuales degenerarán a largo plazo.
Desde el cambio de milenio, a mucha gente le resulta cada vez más fácil utilizar ordenadores. Primero las buenas noticias. En el futuro será mucho más fácil utilizar ordenadores a medida que la interacción hombre-máquina sea más intuitiva. Mientras tanto, veremos cómo cada vez más grandes portales de Internet cierran sus servicios porque su modelo de negocio ya no es viable. He aquí un pequeño ejemplo.
Como programador, a menudo utilizo el sitio web StackOverflow para encontrar ayuda con los problemas. La información de este sitio web sobre temas de programación es ahora tan amplia que puedes encontrar rápidamente soluciones adecuadas a tus propias inquietudes buscando en Google y similares, sin tener que formular tú mismo las preguntas. Hasta aquí todo bien. Pero si ahora integras una red neuronal como ChatGPT en tu propio entorno de programación para encontrar la respuesta a todas tus preguntas, el número de visitantes de StackOverflow descenderá continuamente. Esto, a su vez, repercute en las campañas publicitarias para poder ofrecer el servicio de forma gratuita en la red. Inicialmente, esto se compensará con el pago de una tarifa plana por el uso de la base de datos por parte de los operadores de los sistemas de IA que acceden a los datos de StackOverflow. Sin embargo, esto no detendrá la disminución del número de visitantes. Como resultado, o bien una barrera de pago impedirá el uso gratuito o el servicio se interrumpirá por completo. Hay muchas ofertas en Internet que se encontrarán con problemas similares, lo que garantizará a largo plazo que Internet, tal y como la conocemos, desaparezca en el futuro.
Imaginemos cómo sería una futura consulta sobre el término de búsqueda “revolución industrial”. Le pregunto a mi asistente digital ¿Qué sabes sobre la revolución industrial? – En lugar de buscar resultados relevantes en una lista aparentemente interminable de miles de entradas, me lee una breve explicación con una dirección personalizada que coincide con mi edad y nivel de educación. Lo que plantea inmediatamente la pregunta de quién y cómo juzga mi nivel de educación.
Es otra degradación de nuestras capacidades. Aunque al principio se perciba como algo muy cómodo. Si ya no tenemos la necesidad de centrar nuestra atención en una cosa concreta durante un largo periodo de tiempo, sin duda nos resultará difícil idear cosas nuevas en el futuro. Nuestra creatividad se reducirá al mínimo absoluto.
También cambiará en el futuro la forma de almacenar los datos. Las estructuras complicadas que se almacenan de forma óptima en bases de datos serán la excepción y no la regla. Más bien, espero trozos independientes de datos que se encadenen como listas. Veámoslo juntos para hacernos una idea de lo que quiero decir.
Tomemos como punto de partida el libro de Aldous Huxley “Un mundo feliz”, de 1932. Además del título, el autor y el año de publicación, podemos añadir el inglés como idioma a la metainformación. A continuación se muestra todo el contenido del libro, incluidos el prefacio y el epílogo, como texto ASCII sin formato. Los elementos genéricos o modificables, como el índice o el copyright, no se incluyen en esta fase. Con este trozo, hemos definido un dato atómico que puede identificarse de forma única mediante un valor hash. Dado que Brave New World de Huxley fue escrito originalmente en inglés, este dato es también una fuente inmutable para todos los datos derivados y generados a partir de él.
Si la obra de Huxley se traduce al alemán o al español, es la primera derivada con la referencia al original. Puede ocurrir que los libros hayan sido traducidos por diferentes traductores en distintas épocas. Esto da lugar a un hash de referencia diferente para la traducción alemana de Herbert E. Herlitschka de 1933 con el título “Un mundo feliz” que para la traducción de Eva Walch publicada en 1978 con el mismo título “Un mundo feliz”.
Si ahora se producen audiolibros a partir de los distintos textos, estos audiolibros son el segundo derivado del texto original, ya que representan una versión abreviada. Un texto también se crea como versión independiente antes de ser grabado. La banda sonora creada a partir del texto original abreviado tiene como autor al director y hace referencia al locutor o locutores. Como en el teatro, un texto puede ser interpretado y puesto en escena por diferentes personas. Las adaptaciones cinematográficas pueden tratarse del mismo modo.
A su vez, los libros, audiolibros y películas tienen gráficos para la cubierta. Estos gráficos representan a su vez obras independientes, a las que se hace referencia con la versión correspondiente del original.
Las citas de libros también pueden enlazarse de este modo. Del mismo modo, críticas, interpretaciones, reseñas y todo tipo de variaciones de contenido que hagan referencia a un original.
Pero estos bloques de datos no se limitan a los libros, sino que también pueden aplicarse a partituras musicales, letras de canciones, etc. La clave está en enlazar todo lo posible con el original. El factor decisivo es que se pueda partir del original en la medida de lo posible. Los archivos resultantes están optimizados exclusivamente para programas informáticos, ya que no tienen ningún formato visible para el ojo humano. Por último, el valor hash correspondiente sobre el contenido del archivo basta como nombre de archivo.
Aquí empieza la visión del futuro. Como autores de nuestro trabajo, ahora podemos utilizar la inteligencia artificial para crear automáticamente traducciones, ilustraciones, audiolibros y animaciones incluso a partir de un libro. En este punto, me gustaría referirme brevemente a la red neuronal DeepL [2], que ya ofrece traducciones impresionantes e incluso mejora el texto original si se maneja con habilidad. ¿Ahora DeepL deja sin trabajo a traductores y editores? Quiero decir que no. Porque las inteligencias artificiales, como nosotros los humanos, no son infalibles. También cometen errores. Por eso creo que el precio de este trabajo bajará mucho en el futuro, porque ahora estas personas pueden hacer mucho más trabajo que antes gracias a sus conocimientos y a las excelentes herramientas de que disponen. Esto hace que el servicio individual sea considerablemente más barato, pero como gracias a la automatización es posible realizar más servicios individuales en el mismo periodo de tiempo, esto compensa la reducción de precio para el proveedor.
Si ahora nos fijamos en las nuevas posibilidades que se abren ante nosotros, no parece que nos resulte tan problemático. Entonces, ¿de qué tratan de advertirnos personas como Elon Musk?
Si ahora suponemos que la cuarta revolución industrial digitalizará todo el conocimiento humano y que todo el nuevo conocimiento sólo se creará en forma digital, los algoritmos informáticos serán libres de utilizar la potencia de cálculo adecuada para cambiar estos trozos de conocimiento de tal forma que los humanos no nos demos cuenta. Un escenario vagamente basado en el Ministerio de la Verdad de Orwell de la novela 1984. Si desaprendemos nuestras habilidades por conveniencia, también tendremos pocas oportunidades de verificación.
Si cree que esto no es un problema, me gustaría remitirle a la conferencia “Don’t trust a scan” de David Kriesel [3]. ¿Qué ocurrió? En resumen, se trataba de una empresa constructora que observó discrepancias en las copias de sus planos de construcción. El resultado eran diferentes copias del mismo original, en las que los valores numéricos estaban cambiados. Este es un problema muy grave en un proyecto de construcción para los oficios que realizan la obra. Cuando el albañil recibe especificaciones de tamaño diferentes a las de los encofradores de hormigón. Finalmente, se descubrió que el error se debía a que Xerox utilizaba una IA como software en sus escáneres para el OCR y la compresión posterior, que no podía reconocer de forma fiable los caracteres escaneados.
Pero la cita de Ted Chiang “Piensa en ChatGPT como un jpeg borroso de todo el texto de la web” también debería darnos que pensar. Ciertamente, para quienes sólo conocen la IA como aplicación, es difícil entender lo que quiere decir “ChatGPT es sólo un jpeg borroso de todo el texto de la web”. Sin embargo, no es tan difícil de entender como parece al principio. Debido a su estructura, las redes neuronales son siempre sólo una instantánea. Porque con cada entrada, el estado interno de una red neuronal cambia. Igual que nos ocurre a los humanos. Al fin y al cabo, sólo somos la suma de nuestras experiencias. Si, en el futuro, cada vez más textos creados por una IA se colocan en la red sin reflexión, la IA formará su conocimiento a partir de sus propias derivaciones. Los originales se desvanecen con el tiempo porque pierden peso debido a que cada vez hay menos referencias. Si alguien inundara Internet con temas como la tierra plana y los lagartos, programas como ChatGPT reaccionarían inevitablemente a ello y lo incluirían en sus textos. Estos textos podrían entonces ser publicados automáticamente por la IA en la red o ser difundidos en consecuencia por personas irreflexivas. Hemos creado así una espiral que sólo puede romperse si las personas no han renunciado a su capacidad de juicio por conveniencia.
Vemos, pues, que las advertencias de tener cuidado al tratar con la IA no son infundadas. Aunque considero improbables escenarios como el de la película de 1983 Juegos de guerra [4], deberíamos pensar muy detenidamente hasta dónde queremos llegar con la tecnología de la IA. No queremos acabar como el aprendiz de brujo y descubrir que ya no podemos controlarla.
Referencias
Los enlaces sólo son visibles para los usuarios registrados.
Cuando diseñamos modelos de datos y sus correspondientes tablas a veces aparece Boolean como tipo de dato. En general estos indicadores no son realmente problemáticos. Pero tal vez podría haber una mejor solución para el diseño de datos. Permítanme darles un breve ejemplo de mi intención.
Supongamos que tenemos que diseñar un dominio simple para almacenar artículos. Como un Sistema de Blog o cualquier otro Gestor de Contenidos. Además del contenido del artículo y el nombre del autor, podríamos necesitar una bandera que indique al sistema si el artículo es visible para el público. Algo así como publicado como un booleano. Pero también hay un requisito de cuando el artículo está programado una fecha para su publicación. En la mayoría de los diseños de bases de datos observé para esas circunstancias un Booleano: published y una Fecha: publishingDate. En mi opinión este diseño es un poco redundante y también propenso a errores. Como conclusión rápida me gustaría aconsejarte que utilices desde el principio sólo Date en lugar de Boolean. El escenario que he descrito anteriormente también puede transformarse en muchas otras soluciones de dominio.
Por ahora, después de tener una idea de por qué debemos sustituir Boolean por Date datatype nos centraremos en los detalles de cómo podemos alcanzar este objetivo.
Tratar con SQL estándar sugiere que reemplazar un Sistema de Gestión de Bases de Datos (SGBD) por otro no debería ser un gran problema. Desgraciadamente, la realidad es un poco diferente. No es recomendable utilizar todos los tipos de datos disponibles para fechas como Timestamp. Por experiencia prefiero usar el simple java.util.Date para evitar futuros problemas y otras sorpresas. El formato almacenado en la tabla de la base de datos se parece a: ‘YYYY-MM-dd HH:mm:ss.0’. Entre la Fecha y la Hora hay un espacio y .0 indica un offset. Este desfase describe la zona horaria. La zona horaria estándar de Europa Central CET tiene un desfase de una hora. Eso significa UTC+01:00 en formato internacional. Para definir el offset por separado obtuve buenos resultados utilizando java.util.TimeZone, que funciona perfectamente junto con Date.
Antes de continuar os voy a mostrar un pequeño fragmento de código en Java para el gestor OR de Hibernate y cómo podríais crear esas columnas de la tabla.
Veamos un poco más de cerca el listado anterior. Primero vemos la anotación @CreationTimestamp. Esto significa que cuando el objeto ArticleDO se crea, la variable creada se inicializa con la hora actual. Este valor nunca debe cambiar, porque un artículo puede ser creado una sola vez pero cambiado varias veces. La Zona Horaria se almacena en un String. En el Constructor puedes ver como la Zona Horaria del sistema puede ser tomada – pero ten cuidado este valor no debe confiarse mucho. Si tienes un usuario como yo que viaja mucho, verás que en todos los lugares en los que estoy tengo la misma hora del sistema, porque normalmente nunca la cambio. Como zona horaria por defecto defino la cadena correcta para UTC-0. Lo mismo hago para la variable publicada. Date también puede ser creada por un String lo que usamos para establecer nuestro valor cero por defecto. El Setter para published tiene la opción de definir una fecha futura o usar la hora actual en el caso de que el artículo se publique inmediatamente. Al final del listado demuestro una simple importación SQL para un solo registro.
Pero no hay que precipitarse. También tenemos que prestar un poco de atención a cómo tratar con el desplazamiento UTC. Debido a que he observado en los sistemas enormes varias veces los problemas que se produjeron porque el desarrollador se utilizó sólo los valores predeterminados.
La zona horaria en general forma parte del concepto de internacionalización. Para gestionar correctamente los ajustes de desfase podemos decidir entre diferentes estrategias. Como en tantos otros casos, no hay un claro correcto o incorrecto. Todo depende de las circunstancias y necesidades de su aplicación. Si se trata de un sitio web de ámbito nacional, como el de una pequeña empresa, y no hay eventos críticos en el tiempo, todo resulta muy sencillo. En este caso no será problemático gestionar la configuración de la zona horaria automáticamente por el DBMS. Pero hay que tener en cuenta que en el mundo existen países como México con más de una zona horaria. Un sistema internacional donde los clientes se extienden por todo el mundo podría ser útil para configurar cada DBMS en el clúster a UTC-0 y gestionar el desplazamiento por la aplicación y los clientes conectados.
Otra cuestión que debemos resolver es cómo inicializar el valor de la fecha de un registro por defecto. Porque los valores nulos deben evitarse. Una explicación completa de por qué devolver null no es un buen estilo de programación se encuentra en libros como ‘Effective Java’ y ‘Clean Code’. Tratar con Excepciones de Puntero Nulo es algo que realmente no necesito. Una buena práctica que funciona bien para mí es una fecha por defecto – valor de tiempo por ‘0000-00-00 00:00:00.0’. Así evito publicaciones no deseadas y el significado es muy claro para todos.
As you can see there are good reasons why Boolean data types should replaced by Date. In this little article I demonstrated how easy you can deal with Date and timezone in Java and Hibernate. It should also not be a big thing to convert this example to other programming languages and Frameworks. If you have an own solution feel free to leave a comment and share this article with your colleagues and friends.
Después de que la banda de los cuatro (GOF) Erich Gamma, Richard Helm, Ralph Johnson y John Vlissides publicaran el libro Design Patterns: Elements of Reusable Object-Oriented Software, aprender a describir problemas y soluciones se hizo popular en casi todos los campos del desarrollo de software. Del mismo modo, aprender a describir lo que no se debe hacer y los antipatrones se hizo igualmente popular.
En las publicaciones que trataban estos conceptos, encontramos recomendaciones útiles para el diseño de software, la gestión de proyectos, la gestión de la configuración y mucho más. En este artículo, compartiré mi experiencia con los números de versión para artefactos de software.
La mayoría de nosotros ya estamos familiarizados con un método llamado versionado semántico, un conjunto de reglas potentes y fáciles de aprender sobre cómo deben estructurarse los números de versión y cómo deben aumentar los segmentos.
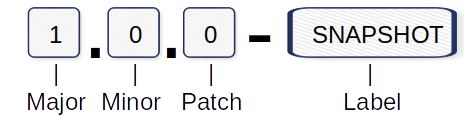
Ejemplo de numeración de versiones:
Mayor: Cambios incompatibles en la API.
Menor: Añade nuevas funcionalidades.
Patch: Corrección de errores y correcciones.
Label: SNAPSHOT que marca el estado “en desarrollo”.
Un cambio de API incompatible se produce cuando se elimina o cambia el nombre de una función o clase accesible desde el exterior. Otra posibilidad es un cambio en la firma de un método. Esto significa que el valor de retorno o los parámetros se han modificado con respecto a su implementación original. En estos escenarios, es necesario aumentar el segmento Mayor del número de versión. Estos cambios suponen un alto riesgo para los consumidores de la API porque tienen que adaptar su propio código.
Cuando se trata de números de versión, también es importante saber que 1.0.0 y 1.0 son iguales. Esto tiene efecto en el requisito de que las versiones de una versión de software tienen que ser únicas. Si no, es imposible distinguir entre artefactos. En mi experiencia profesional, he participado varias veces en proyectos en los que no había procesos bien definidos para crear números de versión. El efecto de estas circunstancias era que el equipo tenía que asegurar la calidad del artefacto y se confundía con qué versión del artefacto estaba tratando en ese momento.
El mayor error que he visto es el almacenamiento de la versión de un artefacto en una base de datos junto con otras entradas de configuración. El procedimiento correcto debería ser: colocar la versión dentro del artefacto de forma que nadie después de una liberación pueda cambiarla desde fuera. La trampa en la que podrías caer es el proceso de cómo actualizar la versión después de un lanzamiento o instalación.
Puede que tenga una lista de comprobación para todas las actividades manuales durante una publicación. Pero, ¿qué sucede después de que una versión se instala en una etapa de prueba y por alguna razón otra versión de la aplicación tiene que ser instalada. ¿Todavía tiene que cambiar manualmente el número de versión? ¿Cómo averiguar qué versión está instalada o cuándo la información de la base de datos es incorrecta?
Detectar la versión correcta en esta situación es un reto muy difícil. Por esa razón, tenemos el requisito de mantener la versión dentro de la aplicación. En el próximo paso, discutiremos una forma segura y simple de resolver este problema de forma automática.
Nuestra precondición es una simple construcción de una librería Java con Maven. Por defecto, el número de versión del artefacto está escrito en el POM. Después del proceso de construcción, nuestro artefacto es creado y nombrado como: artefacto-1.0.jar o similar. Mientras no renombremos el artefacto, tendremos una forma adecuada de distinguir las versiones. Incluso después de un renombrado con un simple truco de empaquetado y comprobación, entonces, en la carpeta META-INF, somos capaces de encontrar el valor correcto.
Si usted tiene la Versión hardcoded en una propiedad o archivo de clase, también funcionaría bien, siempre y cuando no se olvide de actualizar siempre. Tal vez la ramificación y la fusión en los sistemas SCM como Git podría necesitar su atención especial para tener siempre la versión correcta en su código base.
Otra solución es utilizar Maven y el mecanismo de colocación de tokens. Antes de que corras a probarlo en tu IDE, ten en cuenta que Maven utiliza dos carpetas diferentes: sources y resources. La sustitución de tokens en sources no funcionará correctamente. Después de una primera ejecución, tu variable es reemplazada por un número fijo y desaparece. Una segunda ejecución fallará. Para preparar tu código para el reemplazo de tokens, necesitas configurar Maven como primero en el ciclo de vida de construcción:
Después de este paso, necesita conocer la propiedad ${project.version} del POM. Esto le permite crear un archivo con el nombre version.property en el directorio resources. El contenido de este archivo es sólo una línea: version=${project.version}. Después de una compilación, encontrará en su artefacto la version.property con el mismo número de versión que utilizó en su POM. Ahora, usted puede escribir una función para leer el archivo y utilizar esta propiedad. Podrías almacenar el resultado en una constante para usarla en tu programa. ¡Eso es todo lo que tienes que hacer!
Aunque en los últimos años se ha dedicado un esfuerzo adicional considerable a las pruebas para mejorar la calidad de los proyectos de software [1], el camino hacia el éxito repetible de forma continua no es una cuestión de rutina. Una gestión rigurosa y específica de todos los recursos disponibles era y sigue siendo indispensable para lograr un éxito reproducible.
(c) 2016 Marco Schulz, Java aktuell Ausgabe 4, S.14-19 – Artículo original traducido del
No es ningún secreto que muchos proyectos informáticos siguen teniendo sus dificultades para llegar a buen puerto. Se podría pensar que las numerosas herramientas y métodos nuevos que han surgido en los últimos años ofrecen soluciones eficaces a la situación. Sin embargo, si se echa un vistazo a los proyectos actuales, esta impresión cambia.
El autor ha podido observar a menudo cómo se pretendía dominar este problema introduciendo nuevas herramientas. No pocas veces, los esfuerzos acabaron en resignación. La supuesta solución milagrosa se convertía rápidamente en un pesado ladrón de tiempo con una enorme carga de autogestión. La euforia inicial de todos los implicados se convertía rápidamente en rechazo y no pocas veces culminaba en un boicot a su uso. Así pues, no es de extrañar que los empleados experimentados se muestren escépticos ante todos los esfuerzos de cambio durante mucho tiempo y sólo se ocupen de ellos cuando son previsiblemente exitosos. Debido a este hecho, el autor ha elegido la provocativa cita de Grady Booch, cofundador de UML, como título de este artículo.
Las empresas suelen dedicar muy poco tiempo a establecer una infraestructura interna equilibrada. Incluso el mantenimiento de los fragmentos existentes suele posponerse por diversas razones. A nivel de gestión, prefieren basarse en las tendencias del momento para ganarse a los clientes, que esperan una lista de palabras de moda como respuesta a su solicitud de propuestas. Sin embargo, Tom De Marco ya lo describió con detalle en los años setenta [2]: Las personas hacen los proyectos (véase la Figura 1).
Hacemos lo que podemos, pero ¿podemos hacer algo?
A pesar de las mejores intenciones y los intensos esfuerzos, los proyectos que llegan a buen puerto no son, por desgracia, la norma. Pero, ¿cuándo se puede hablar de un proyecto fracasado en el desarrollo de software? El abandono de todas las actividades por falta de perspectivas de éxito es, por supuesto, un motivo obvio, pero en este contexto es bastante raro. Más bien, uno se da cuenta de ello durante la revisión posterior al proyecto de las tareas completadas. En el controlling, por ejemplo, los puntos débiles salen a la luz al determinar la rentabilidad.
Los motivos de los resultados negativos suelen ser la superación del presupuesto estimado o de la fecha de finalización acordada. Normalmente se dan ambas condiciones al mismo tiempo, ya que el plazo de entrega en peligro se contrarresta aumentando el personal. Esta práctica alcanza rápidamente sus límites, ya que los nuevos miembros del equipo requieren un periodo de inducción, lo que reduce visiblemente la productividad del equipo existente. Las arquitecturas fáciles de usar y un alto grado de automatización mitigan un poco este efecto. De vez en cuando, también se pasa a sustituir al contratista con la esperanza de que las nuevas escobas barran mejor.
Un rápido vistazo a la lista de los 3 grandes proyectos fracasados en Alemania muestra cómo la falta de comunicación, una planificación inadecuada y una gestión deficiente repercuten negativamente en la percepción externa de los proyectos: Aeropuerto de Berlín, Sala Filarmónica del Elba de Hamburgo y Stuttgart 21. Gracias a la amplia cobertura mediática, estas empresas son suficientemente conocidas y no es necesario explicarlas en detalle. Aunque los ejemplos citados no procedan de la informática, también aquí pueden encontrarse las razones recurrentes del fracaso debido a la explosión de los costes y los retrasos.
Figura 1: Resolución de problemas – “A bisserl was geht immer”, Monaco Franze
La voluntad de crear algo grande e importante no basta por sí sola. Los responsables también necesitan las habilidades profesionales, de planificación, sociales y de comunicación necesarias, junto con la autoridad para actuar. Construir castillos en el aire y esperar a que los sueños se hagan realidad no produce resultados presentables.
Los grandes éxitos suelen lograrse cuando el menor número posible de personas tiene derecho a vetar decisiones. Esto no significa que haya que ignorar los consejos, pero no se pueden tener en cuenta todos los estados de ánimo posibles. Tanto más importante es que el responsable del proyecto tenga autoridad para hacer cumplir su decisión, pero no lo demuestre con toda la fuerza.
Es perfectamente normal que el responsable de la decisión no controle todos los detalles. Al fin y al cabo, delega la ejecución en los especialistas adecuados. He aquí un breve ejemplo: cuando a principios de la década de 2000 las posibilidades de crear aplicaciones web más grandes y complejas eran cada vez mejores, en las reuniones surgía a menudo la pregunta de qué paradigma debía utilizarse para implementar la lógica de visualización. Los términos “multinivel”, “cliente ligero” y “cliente pesado” dominaban los debates de los órganos decisorios de la época. Explicar al cliente las ventajas de las distintas capas de una aplicación web distribuida era una cosa. Pero dejar en manos de un profano en la materia la decisión de cómo quiere acceder a su nueva aplicación -a través del navegador (“thin client”) o de su propia interfaz gráfica de usuario (“fat client”)- es sencillamente una tontería. Así que en muchos casos fue necesario aclarar los malentendidos que surgieron durante el desarrollo. La solución del navegador gordo no pocas veces resultó ser una tecnología difícil de dominar, ya que los fabricantes rara vez se preocupaban por los estándares. En cambio, uno de los principales requisitos solía ser que la aplicación tuviera un aspecto casi idéntico en los navegadores más populares. Sin embargo, esto sólo podía conseguirse con un considerable esfuerzo adicional. Algo parecido pudo observarse durante el primer auge de las arquitecturas orientadas a servicios.
La consecuencia de estas observaciones demuestra que es indispensable elaborar una visión antes de iniciar el proyecto, cuyos objetivos se correspondan también con el presupuesto estimado. Una versión de lujo reutilizable con tantos grados de libertad como sea posible requiere un enfoque diferente al de una solución “conseguimos lo que necesitamos”. Es menos importante perderse en los detalles y más importante tener en mente la visión de conjunto.
Especialmente en los países de habla alemana, a las empresas les resulta difícil encontrar a los agentes necesarios para llevar a cabo con éxito un proyecto. Las razones pueden ser muy diversas y podrían ser, entre otras, que las empresas aún no han comprendido que los expertos rara vez quieren hablar con proveedores de servicios de contratación mal informados e insuficientemente preparados.
Hacer las cosas!
El éxito en la gestión de proyectos no es una casualidad. Durante mucho tiempo se ha señalado como una de las causas negativas el flujo insuficiente de información debido a la falta de comunicación. Muchos proyectos tienen su propio carácter inherente, que también está conformado por el equipo que acepta el reto para dominar conjuntamente la tarea fijada. Métodos ágiles como Scrum [3], Prince2 [4] o Kanban [5] recogen esta percepción y ofrecen soluciones potenciales para llevar a cabo con éxito proyectos de TI.
En ocasiones, sin embargo, se observa cómo los directores de proyecto transfieren las tareas de planificación a los desarrolladores responsables para su autogestión con el pretexto de los métodos ágiles recién introducidos. El autor ha experimentado a menudo cómo los arquitectos se han visto más implicados en el trabajo cotidiano de implementación en lugar de comprobar que los fragmentos entregados cumplen las normas. De este modo, la calidad no puede establecerse a largo plazo, ya que los resultados se limitan a representar soluciones que garantizan la funcionalidad y, debido a las presiones de tiempo y costes, no establecen las estructuras necesarias para garantizar la mantenibilidad futura. Ágil no es sinónimo de anarquía. A esta configuración le gusta adornarse con una caja de herramientas sobrecargada y llena de herramientas del departamento de DevOps y ya el proyecto parece insumergible. ¡Como el Titanic!
No en vano, desde hace años se recomienda introducir un máximo de tres nuevas tecnologías al inicio de un proyecto. En este contexto, tampoco es aconsejable apostar siempre por las últimas tendencias. A la hora de decidirse por una tecnología, primero hay que crear los recursos adecuados en la empresa, para lo que hay que prever tiempo suficiente. Las inversiones sólo resultan beneficiosas si la elección realizada va más allá de una simple exageración. Un buen indicador de coherencia es una amplia documentación y una comunidad activa. Estos secretos a voces llevan años debatiéndose en la bibliografía pertinente.
Sin embargo, ¿cómo se procede cuando un proyecto lleva establecido muchos años, pero en términos del ciclo de vida del producto se hace inevitable un giro hacia nuevas técnicas? Las razones de tal esfuerzo pueden ser muchas y varían de una empresa a otra. La necesidad de no perderse innovaciones importantes para seguir siendo competitivos no debe retrasarse demasiado. Esta consideración conduce a una estrategia bastante sencilla de aplicar. Las versiones actuales se mantienen en la tradición probada y sólo para la próxima versión importante o la siguiente se elabora una hoja de ruta que contenga todos los puntos necesarios para llevar a cabo un cambio con éxito. Para ello, se trabajan los puntos críticos y se realizan pequeños estudios de viabilidad, algo más exigentes que un tutorial de “hola mundo”, para ver cómo podría tener éxito una implantación. Por experiencia, son los pequeños detalles los que pueden ser las migajas en la balanza que determinen el éxito o el fracaso.
En todos los esfuerzos, el objetivo es alcanzar un alto grado de automatización. Frente a las tareas que se repiten constantemente y deben realizarse manualmente, la automatización ofrece la posibilidad de producir resultados repetibles de forma continua. Sin embargo, está en la naturaleza de las cosas que las actividades sencillas sean más fáciles de automatizar que los procesos complejos. Aquí es importante comprobar de antemano la viabilidad económica de los planes, para que los desarrolladores no den rienda suelta a su impulso natural de jugar y además trabajen en actividades cotidianas desagradables.
El que escribe, se queda
La documentación, tema controvertido, abarca todas las fases del proceso de desarrollo de software. Ya se trate de descripciones de API, del manual de usuario, de documentos de planificación de la arquitectura o de conocimientos adquiridos sobre procedimientos óptimos, describir no es una de las tareas preferidas de todos los protagonistas implicados. A menudo se observa que parece prevalecer la opinión común de que los manuales gruesos son sinónimo de funcionalidad extensa del producto. Sin embargo, los textos largos en una documentación son más bien una falta de calidad que agota la paciencia del lector porque espera instrucciones precisas que vayan al grano. En lugar de ello, recibe frases insulsas con ejemplos triviales que rara vez resuelven problemas.
Figura 2: Cobertura de las pruebas con Cobertura
Esta idea también puede aplicarse a la documentación de proyectos y ha sido presentada en detalle por Johannes Sidersleben [6], entre otros, bajo la metáfora sobre las novelas victorianas. Las universidades ya han hecho suyas estas conclusiones. La Universidad de Ciencias Aplicadas de Merseburg, por ejemplo, ha creado el programa de grado “Edición técnica” [7]. Es de esperar que en el futuro se encuentren más graduados de esta carrera en el panorama de los proyectos.
A la hora de seleccionar herramientas de colaboración como repositorios de conocimiento, siempre hay que tener en cuenta el panorama general. El éxito de la gestión del conocimiento puede medirse por la eficacia con la que un empleado encuentra la información que busca. Por este motivo, su uso en toda la empresa es una decisión de la dirección y obligatorio para todos los departamentos.
La información tiene una naturaleza diferente y varía tanto en su alcance como en el tiempo que permanece actualizada. Esto da lugar a diferentes formas de presentación como wiki, blog, sistema de tickets, tweets, foros o podcasts, por citar sólo algunas. Los foros representan de forma muy óptima el problema de preguntas y respuestas. Un wiki es ideal para el texto continuo, como ocurre en la documentación y las descripciones. Muchos webcasts se ofrecen como vídeos sin que la presentación visual añada ningún valor. En la mayoría de los casos, una pista de audio bien comprensible y correctamente producida es suficiente para distribuir conocimientos. Con una base de datos común y normalizada, los proyectos terminados pueden compararse eficazmente entre sí. Las conclusiones resultantes ofrecen un gran valor añadido en la elaboración de previsiones para futuros proyectos.
Pruebas y métricas: la medida de todas las cosas
Basta con hojear el Informe de Calidad 2014 para darse cuenta rápidamente de que la nueva tendencia son las “pruebas de software”. Las empresas ponen cada vez más contingentes a disposición para ello, que ocupan un volumen similar a los gastos de ejecución del proyecto. En rigor, en este punto uno apaga el fuego con gasolina. Bien mirado, el presupuesto ya se duplica en la fase de planificación. A menudo depende de la habilidad del gestor del proyecto encontrar una declaración adecuada para los fondos destinados al proyecto.
Sólo su comprobación coherente de la cobertura de los casos de prueba con herramientas de análisis adecuadas garantiza que al final se hayan realizado pruebas suficientes. Aunque cueste creerlo: en una época en la que las pruebas de software pueden crearse con más facilidad que nunca y en la que pueden combinarse distintos paradigmas, una cobertura de pruebas amplia y significativa es más bien la excepción (véase la figura 2).
Es bien sabido que no es posible demostrar que el software está libre de errores. Las pruebas sólo sirven para demostrar un comportamiento definido para los escenarios creados. Los casos de prueba automatizados no sustituyen la revisión manual del código por arquitectos experimentados. Un ejemplo sencillo son los bloques “try catch” anidados que aparecen de vez en cuando en Java y que tienen un efecto directo en el flujo del programa. A veces, el anidamiento puede ser intencionado y útil. En este caso, sin embargo, la gestión de errores no se limita a la salida de la traza de la pila en un archivo de registro. La causa de este error de programación radica en la inexperiencia del desarrollador y el mal consejo del IDE en este punto de encerrar la sentencia con su propio bloque “try catch” para una esperada gestión de errores en lugar de complementar la rutina existente con una sentencia “catch” adicional. Intentar detectar este error obvio mediante casos de prueba es un enfoque infantil desde el punto de vista económico.
Los patrones de error típicos pueden detectarse de forma rentable y eficiente mediante procedimientos de prueba estáticos. Las publicaciones que se ocupan especialmente de la calidad y la eficiencia del código en el lenguaje de programación Java [8, 9, 10] son siempre un buen punto de partida para desarrollar estándares propios.
La consideración de los tipos de error también es muy informativa. El seguimiento de incidencias y los mensajes de commit en los sistemas SCM de proyectos de código abierto como Liferay [11] o GeoServer [12] muestran que una gran proporción de errores afectan a la interfaz gráfica de usuario (GUI). A menudo se trata de correcciones de textos de visualización en botones y similares. La notificación de errores de visualización predominantes también puede residir en la percepción de los usuarios. Para ellos, el comportamiento de una aplicación suele ser una caja negra, por lo que tratan el software en consecuencia. No es en absoluto erróneo suponer que la aplicación tiene pocos errores cuando el número de usuarios es elevado.
Las cifras habituales en informática son métricas de software que pueden dar a la dirección una idea del tamaño físico de un proyecto. Utilizada correctamente, una visión de este tipo proporciona argumentos útiles para las decisiones de gestión. Por ejemplo, el número de casos de prueba necesarios puede derivarse de la complejidad cíclica según McCabe [13]. Las estadísticas sobre las líneas de código y los recuentos habituales de paquetes, clases y métodos también muestran el crecimiento de un proyecto y pueden proporcionar información valiosa.
Un tratamiento muy informativo de esta información es el proyecto Code-City [14], que visualiza dicha distribución como un mapa urbano. Es impresionante ver dónde pueden surgir monolitos peligrosos y dónde se producen clases y paquetes huérfanos.
Figura 3: Plugin Maven JDepend – números con poco significado
Conclusión
En el día a día, uno se contenta con repartir ajetreo y poner cara de estresado. Al producir innumerables metros de papel, se demuestra posteriormente la productividad personal. La energía así consumida podría emplearse de forma mucho más sensata mediante un planteamiento consecuentemente meditado.
Según el “Sapere Aude” de Kant, hay que fomentar y exigir soluciones sencillas. Los empleados que necesitan estructuras complicadas para destacar su propio genio en el equipo pueden no ser pilares de apoyo sobre los que construir éxitos conjuntos. La cooperación con coetáneos indoctos se reconsidera rápidamente y, si es necesario, se corrige.
Muchos caminos llevan a Roma, y Roma no se construyó en un día. Sin embargo, no se puede negar que en algún momento ha llegado el momento de abrirse camino. La elección de los caminos tampoco es un problema indecidible. Hay caminos seguros y senderos peligrosos en los que incluso los excursionistas experimentados tienen sus dificultades para llegar sanos y salvos a su destino.
Para que la gestión de un proyecto tenga éxito, es esencial conducir el pelotón por terreno sólido y estable. Esto no excluye fundamentalmente las soluciones no convencionales, siempre que sean adecuadas. La afirmación en las instancias decisorias: “Todo lo que dices es correcto, pero en nuestra empresa hay procesos a los que no se puede aplicar tu exposición” se refuta mejor con el argumento: “Eso es totalmente correcto, por lo que ahora nuestra tarea consiste en idear formas de adaptar los procesos de la empresa de acuerdo con los casos de éxito conocidos, en lugar de dedicar nuestro tiempo a enumerar razones para que todo siga igual”. Estoy seguro de que está de acuerdo en que el objetivo de nuestra reunión es resolver problemas, no ignorarlos.” … más voz
Referencias
Los enlaces sólo son visibles para los usuarios registrados.
La experiencia de sus propios empleados es un factor económico importante para cualquier organización. Por eso es tan importante almacenar permanentemente la experiencia y los conocimientos y ponerlos a disposición de los demás empleados. Un servidor central de gestión del conocimiento se encarga de esta tarea y contribuye a garantizar la productividad de la empresa a largo plazo.
(c) 2011 Marco Schulz, Materna Monitor, Ausgabe 2, S.32-33 – Artículo original traducido del
La complejidad del actual mundo laboral, altamente interconectado, requiere la interacción fluida de una gran variedad de especialistas. La transferencia de conocimientos desempeña aquí un papel importante. Este intercambio se hace más difícil cuando los miembros del equipo trabajan en distintos lugares con diferentes husos horarios o proceden de entornos culturales diferentes. Las empresas con sedes en todo el mundo conocen este problema y han desarrollado estrategias adecuadas para la gestión del conocimiento en toda la empresa. Para introducirla con éxito, la solución informática que se utilice debe considerarse como una metodología en lugar de centrarse en la herramienta en sí. Una vez tomada la decisión por una determinada solución informática, debe mantenerse de forma coherente. Los cambios frecuentes de sistema reducen la calidad de los vínculos entre los contenidos almacenados. Al no existir una norma normalizada para la representación de los conocimientos, pueden producirse importantes pérdidas de conversión al cambiar a nuevas soluciones informáticas.
Diferentes mecanismos para diferentes contenidos
La información puede almacenarse en los sistemas informáticos de diversas formas. Las distintas formas de representación difieren en su presentación, estructuración y uso. Para poder editar documentos sin conflictos y versionarlos al mismo tiempo, como es necesario para las especificaciones o la documentación, las wikis [1] son ideales, ya que se desarrollaron originalmente precisamente para este uso. Los documentos que allí se almacenan suelen ser específicos de cada proyecto y también deben organizarse de esta manera.
Los documentos transversales de la wiki son, por ejemplo, explicaciones de términos técnicos, una lista central de abreviaturas o un Quién es quién de los empleados de la empresa con datos de contacto y áreas temáticas. Estos últimos, a su vez, pueden enlazarse con la explicación del término técnico. De este modo, el contenido completo puede mantenerse actualizado de forma centralizada y vincularse cómodamente a los documentos de proyecto correspondientes. Este procedimiento evita repeticiones innecesarias y los documentos que hay que leer se hacen más cortos, pero siguen conteniendo toda la información necesaria. Johannes Siedersleben ya describió los riesgos de una documentación demasiado larga en su libro Softwaretechnik [2] en 2003.
Los conocimientos que tienen más carácter de FAQ se organizan mejor a través de un foro. La agrupación por temas, en los que se depositan preguntas del tipo “¿Cómo puedo…?”, facilita la búsqueda de posibles soluciones. Especialmente atractivo es el hecho de que un foro de este tipo evoluciona con el tiempo en función de la demanda. Los usuarios pueden formular sus propias preguntas y publicarlas en el foro. Por regla general, las respuestas cualificadas a las nuevas preguntas no tardan en llegar.
Los candidatos idóneos para los blogs son, por ejemplo, información general sobre la empresa, informes de situación o tutoriales. Se trata de documentos que tienen más carácter informativo, no están ligados a un formulario o son difíciles de asignar a un tema concreto. Las informaciones breves (tweets [3]) a través de Twitter, agrupadas temáticamente en canales, también pueden enriquecer el trabajo de los proyectos. Además, minimizan el número de correos electrónicos en la propia bandeja de entrada. Algunos ejemplos son recordatorios sobre un evento determinado, una noticia sobre nuevas versiones de un producto o información sobre un proceso de trabajo finalizado con éxito. La integración de los tweets en el trabajo de un proyecto es relativamente nueva y, por tanto, las soluciones de software adecuadas son escasas.
Por supuesto, la lista de posibilidades está lejos de agotarse en este punto. Sin embargo, los ejemplos ya ofrecen una buena visión de cómo las empresas pueden organizar sus conocimientos. Conectando los sistemas individuales a un portal [4] que disponga de una búsqueda global y una administración de usuarios, se crea rápidamente una red que también es adecuada como solución en la nube.
La facilidad de uso es un factor decisivo para la aceptación de una plataforma de conocimiento. Largos periodos de formación, una estructuración poco clara y un manejo engorroso pueden provocar rápidamente el rechazo. Con la autorización de acceso a los contenidos individuales a nivel de grupo, también se satisface la seguridad. Un buen ejemplo de ello es la wiki empresarial Confluence [5]. Permite asignar diferentes permisos de lectura y escritura a los niveles de documentos individuales.
Naturalmente, no se puede esperar que un desarrollador describa su trabajo con las palabras adecuadas para la posteridad después de haberlo aplicado con éxito. El hecho de que la calidad de los textos de muchas documentaciones no siempre es suficiente también ha sido reconocido por la Universidad de Ciencias Aplicadas de Merseburg, que ofrece el curso Edición técnica [6]. Por ello, la lectura cruzada por parte de otros miembros del proyecto ha demostrado ser un medio adecuado para garantizar la calidad del contenido. Para facilitar la redacción de los textos, resulta útil disponer de una pequeña guía, similar a la Convención de Codificación.
Conclusión
Una base de datos de conocimientos no puede implantarse de la noche a la mañana. Se necesita tiempo hasta que se ha recopilado suficiente información. Sólo mediante la interacción y la corrección de pasajes incomprensibles el conocimiento alcanza una calidad que invita a la transferencia. Hay que animar a cada empleado a enriquecer los textos existentes con nuevos conocimientos, a resolver pasajes incomprensibles o a añadir términos de búsqueda. Si el proceso de creación y distribución de conocimientos se vive de esta manera, quedarán menos documentos huérfanos y la información estará siempre actualizada.
El desarrollo de software ofrece algunas formas extremadamente eficaces de simplificar tareas recurrentes mediante la automatización. La eliminación de tareas tediosas, repetitivas y monótonas y la consiguiente reducción de la frecuencia de errores en el proceso de desarrollo no son, ni mucho menos, todas las facetas de este tema.
(c) 2011 Marco Schulz, Materna Monitor, Ausgabe 1, S.32-34 – Artículo original traducido del
La motivación para establecer automatismos en el panorama informático es en gran medida la misma. Las tareas recurrentes deben simplificarse y ser resueltas por máquinas sin intervención humana. Las ventajas son menos errores en el uso de los sistemas informáticos, lo que a su vez reduce los costes. Por sencilla y ventajosa que parezca la idea de que los procesos se ejecuten de forma independiente, la puesta en práctica no es tan trivial. Rápidamente se hace evidente que para cada posibilidad de automatización identificada, la implantación no siempre es factible. Aquí también se aplica el principio: cuanto más complejo es un problema, más difícil es resolverlo.
Para sopesar si merece la pena el esfuerzo económico que supone introducir determinados automatismos, hay que multiplicar los costes de una solución manual por el factor de la frecuencia con que hay que repetir este trabajo. Estos costes deben compararse con los gastos de desarrollo y funcionamiento de la solución automatizada. Sobre la base de esta comparación, rápidamente queda claro si una empresa debe aplicar la mejora prevista.
Herramientas de apoyo al proceso de desarrollo
Especialmente en el desarrollo de proyectos de software, existe un considerable potencial de optimización mediante procesos automáticos. Los desarrolladores cuentan con el apoyo de multitud de herramientas que deben ser hábilmente orquestadas. La gestión de configuraciones y versiones, en particular, trata con gran detalle el uso práctico de una amplia variedad de herramientas para automatizar el proceso de desarrollo de software.
La existencia de una lógica de compilación independiente, por ejemplo en forma de un simple script de shell, ya es un buen enfoque, pero no siempre conduce a los resultados deseados. En estos casos, son necesarias soluciones independientes de la plataforma, ya que es muy probable que el desarrollo tenga lugar en un entorno heterogéneo. Una solución aislada siempre supone un mayor esfuerzo de adaptación y mantenimiento. Por último, los esfuerzos de automatización deben simplificar los procesos existentes. Las herramientas de compilación actuales, como Maven y Ant, aprovechan esta ventaja de la independencia de la plataforma. Ambas herramientas encapsulan toda la lógica de compilación en archivos XML independientes. Dado que XML ya se ha establecido como estándar en el desarrollo de software, la curva de aprendizaje es más pronunciada que con las soluciones rudimentarias.
El uso de lógicas de compilación centrales constituye la base de otros automatismos durante el trabajo de desarrollo. Las pruebas automatizadas en forma de pruebas unitarias en un entorno de integración continua (IC) son un aspecto de ello. Una solución CI combina todas las partes de un software en un todo y procesa todos los casos de prueba definidos. Si el software no se ha podido construir o una prueba ha fallado, se avisa al desarrollador por correo electrónico para que corrija rápidamente el error. Los servidores CI modernos se configuran con un sistema de gestión de versiones, como Subversion o Git. Esto hace que el servidor inicie una compilación sólo cuando se han realizado realmente cambios en el código fuente.
Los sistemas de software complejos suelen depender de componentes externos (bibliotecas) en los que no puede influir el propio proyecto. La gestión eficaz de los artefactos utilizados en el proyecto es el principal punto fuerte de la herramienta de compilación Maven, lo que ha contribuido a su uso generalizado. Cuando se utiliza correctamente, elimina la necesidad de archivar las partes binarias del programa dentro de la gestión de versiones, lo que se traduce en repositorios más pequeños y tiempos de commit (finalización con éxito de una transacción) más cortos. Las nuevas versiones de las bibliotecas utilizadas pueden integrarse y probarse más rápidamente sin necesidad de realizar copias manuales propensas a errores. Las bibliotecas desarrolladas internamente pueden distribuirse fácilmente de forma protegida en la red de la empresa con el uso de un servidor de repositorios independiente (Apache Nexus) en el sentido de la reutilización.
Al evaluar una herramienta de compilación, no hay que descuidar la posibilidad de elaborar informes. El seguimiento automatizado de la calidad del código mediante métricas, por ejemplo a través de la herramienta Checkstyle, es un excelente instrumento para que la dirección del proyecto evalúe de forma realista el estado actual del proyecto.
No demasiadas nuevas tecnologías
Con todas las posibilidades de automatización de procesos, se pueden tomar varios caminos. No es raro que los equipos de desarrollo mantengan largas discusiones sobre qué herramienta es la más adecuada para el proyecto en curso. Esta pregunta es difícil de responder en términos generales, ya que cada proyecto es único y hay que comparar las ventajas e inconvenientes de las distintas herramientas con los requisitos del proyecto.
En la práctica, la limitación a un máximo de dos tecnologías novedosas en el proyecto ha demostrado su eficacia. La idoneidad de una herramienta también depende de si en la empresa hay personas con los conocimientos adecuados. Una buena solución es una lista publicada por la dirección con recomendaciones de las herramientas utilizadas que ya están en uso o pueden integrarse en el paisaje de sistemas existente. Así se garantiza que las herramientas utilizadas sigan siendo claras y manejables.
Los proyectos que se prolongan durante muchos años deben someterse a una modernización de las tecnologías utilizadas a intervalos más amplios. En este contexto, hay que encontrar momentos adecuados para migrar a la nueva tecnología con el menor esfuerzo posible. Fechas sensatas para pasar a una tecnología más reciente son, por ejemplo, el cambio a una nueva versión principal del propio proyecto. Este procedimiento permite una separación limpia sin tener que migrar los antiguos estados del proyecto a la nueva tecnología. En muchos casos, esto no es tan fácil de hacer.
Conclusión
El uso de automatismos para el desarrollo de software puede, si se emplea con sensatez, contribuir enérgicamente a la consecución del objetivo del proyecto. Como todas las cosas, un uso excesivo conlleva algunos riesgos. La infraestructura utilizada debe seguir siendo comprensible y controlable a pesar de toda la mecanización, para que el trabajo del proyecto no se paralice en caso de fallos del sistema.




 Unlock with Patreon
Unlock with Patreon