Während meiner Arbeit als Konfiguration Manager / DevOps für große Webprojekte habe ich beobachtet, wie Unternehmen Conways Gesetzt missachten und dabei kläglich scheiterten. Ein solches Scheitern äußerte sich dann oft in erheblichen Budgetüberziehungen und Terminverzug.
Die interne Infrastruktur in der Projekt Kollaboration wurde genau der internen Organisationsstrukturen nachempfunden und sämtliche Erfahrungen und etablierte Standards so ‚verbogen‘, dass diese auf die interne Organisation passten. Daraus resultierten Probleme das die aufgesetzten CI / CD Pipelines besonders schwerfällig wurden und lange Ausführungszeiten hatten. Aber auch Anpassungen waren nur unter viel Aufwand vorzunehmen. Anstatt bestehende Prozesse zu vereinfachen und an etablierte Standards anzugleichen wurden Ausreden vorgeschoben um möglichst alles wie bisher zu belassen. Schauen wir uns daher einmal an, was Conways Gesetz ist und wieso man es beachten sollte.
Der US amerikanische Forscher und Programmierer Melvin E. Conway erhielt 1961 von der Case Western Reserve University die Doktorwürde. Sein Fachgebiet sind Programmiersprachen und Compiler Design.
Im Jahr 1967 reichte er bei The Harvard Business Review seinen Aufsatz „How Do Committees Invent?“ (dt.: Wie machen Ausschüsse Erfindungen?) ein und wurde abgelehnt. Die Begründung lautete, das seine These nicht belegt wurde. Das zu der Zeit größte IT Magazin Datamation akzeptierte allerdings seinen Artikel und veröffentlichte ihn im April 1968. Und diese Arbeit ist mittlerweile vielfach zitiert. Die Kernaussage lautet:
Jede Organisation, die ein System (im weitesten Sinne) entwirft, wird ein Design erstellen, dessen Struktur eine Kopie der Kommunikationsstruktur der Organisation ist.
Conway, Melvin E. “How do Committees Invent?” 1968, Datamation, vol. 14, num. 4, pp. 28–31
Als Fred Brooks in seinem 1975 erschienen legendärem Buch „The Mythical Man-Month“ den Aufsatz zitierte nannte er diese Kernaussage das Gesetz von Conway. Brooks erkannt den Zusammenhang von Conways Gesetz und der Managementtheorie. Hierzu finden wir in dem Artikel folgendes Beispiel:
Da der zuerst gewählte Entwurf fast nie der bestmögliche ist, muss möglicherweise das vorherrschende System Systemkonzepte ändern. Daher ist die Flexibilität der Organisation für eine effektive Gestaltung wichtig.
The Mythical Man-Month: Essays on Software Engineering
Ein oft zitiertes Beispiel für eine “ideale” Teamgröße im Sinne des Conway’schen Gesetzes ist die Zwei-Pizza-Regel von Amazon, die besagt, dass einzelne Projektteams nicht mehr Mitglieder haben sollten, als zwei Pizzen in einem Meeting satt werden können. Der wichtigste Faktor, der bei der Teamausrichtung zu berücksichtigen ist, ist jedoch die Fähigkeit, teamübergreifend zu arbeiten und nicht in Silos zu leben.
Conways Gesetz war nicht als Scherz oder Zen-Koan gedacht, sondern ist eine gültige soziologische Beobachtung. Schauen Sie sich dazu Strukturen aus Behörden und deren digitale Umsetzung an. Aber auch Prozesse in großen Konzernen zu finden sind wurden durch Softwaresysteme nachempfunden. Solche Anwendungen gelten als sehr schwerfällig und Kompliziert, so das diese wenig Akzeptanz bei Nutzern finden und diese lieber auf Alternativen zurückgreifen. Leider ist es oft aus politisch motivierten Gründen in großen Organisationsstrukturen schier unmöglich Abläufe zu vereinfachen.
Unter anderem findet sich ein ausführlicher Artikel von Martin Fowler, der expliziert auf Softwarearchitekturen eingeht und die Bedeutung der Kopplung von Objekten und Modulen herausarbeitet. Dabei spielt die Kommunikation der Entwickler untereinander eine wesentliche Rolle, um bestmögliche Ergebnisse zu erzielen. Dieser Umstand über die Wichtigkeit der Kommunikation wurde auch von der agilen Softwareentwicklung aufgegriffen und als essentieller Punkt umgesetzt. Besonders wenn rümlich verteilte Teams an einem gemeinsamen Projekt arbeiten ist die Zeitverschiebung ein limitierender Faktor in der Teamkommunikation. Diese muss dann besonders effizient gestaltet werden.
Im Jahr 2010 haben Jonny Leroy und Matt Simons in dem Artikel „Dealing with creaky legacy platforms“ den Begriff Inverse Conway Maneuver geprägt:
Conway’s Law … lässt sich wie folgt zusammenfassen: “Dysfunktionale Organisationen neigen dazu, dysfunktionale Anwendungen zu schaffen.” Um Einstein zu paraphrasieren: Man kann ein Problem nicht aus derselben Denkweise heraus beheben, die es geschaffen hat. Daher lohnt es sich oft zu untersuchen, ob eine Umstrukturierung Ihrer Organisation oder Ihres Teams verhindern würde, dass die neue Anwendung dieselben strukturellen Dysfunktionen aufweist wie die ursprüngliche. In einer Art “umgekehrtem Conway-Manöver” können Sie damit beginnen, Silos aufzubrechen, die die Fähigkeit des Teams zur effektiven Zusammenarbeit einschränken.
Seit den 2010 Jahren hat ein neuer Architekturstil in der Softwareindustrie Einzug gehalten. Die sogenannten Microservices, welche von kleine agilen Teams erstellt werden. Wichtigstes Kriterium eines Microservices zu einem modular aufgebauten Monolithen ist, das ein Microsoervice als eigenständig lebensfähiges Modul bzw. Subsystem gesehen werden kann. Das erlaubt zum einen eine Wiederverwendung des Microservice in anderen Anwendungen. Zum Anderen gibt es eine starke Kapselung der Funktionsdomäne, was eine sehr hohe Flexibilität für Anpassungen eröffnet.
Conways Gesetz lässt sich aber auch auf viele andere Bereiche anwenden und ist nicht ausschließlich auf die Softwareindustrie beschränkt. Das macht die Arbeit so wertvoll.
Der Hyphe um das Thema künstliche Intelligenz hält bereits mehrere Jahre an. Aktuell sorgen Firmen wie OpenAI mit frei zugänglichen neuronalen Netzen wie ChatGPT für erhebliches Aufsehen. Die Anwender sind fasziniert von den Möglichkeiten und einige intellektuelle Persönlichkeiten unserer Zeit warnen die Menschheit vor der künstlichen Intelligenz. Was ist also daran am Schreckgespenst KI? In diesem Artikel gehe ich dieser Frage auf den Grund und Sie sind zu dieser Reise herzlich eingeladen. Auf geht’s und folgen Sie mir in die Zukunft.
Im Frühjahr 2023 überhäuften sich die Meldungen über die Leistungsfähigkeiten von künstlichen Neuronalen Netzen. Dieser Trend hält weiterhin an und wird meines Erachtens nicht so schnell abklingen. In mitten der gerade entstehenden Goldgräberstimmung machen aber auch vereinzelte Hiobsbotschaften die Runde. So verkündete das Unternehmen Microsoft im großen Stil in das Thema künstliche Intelligenz massiv zu investieren. Diese Meldung wurde im Frühjahr 2023 mit der Entlassung von knapp 1000 Angestellten unterstrichen und ließ altbekannte Ängste der Industrialisierung und Automatisierung aufkommen. Weniger spektakulär verlief es bei Digital Ocean, die das gesamte Team der Contenterstellung und Dokumentation freigesetzt hat. Schnell stellten einige Menschen zu recht die Frage ob KI nun Berufe wie Programmierer, Übersetzer, Journalisten, Redakteure und so weiter obsolet werden? Für den Moment möchte ich diese Frage mit einem Nein beantworten. Mittelfristig werden sich aber Veränderungen ergeben, wie es uns die Geschichte bereits gelehrt hat. Etwas altes vergeht, während neue Dinge entstehen. Folgen Sie mir daher zu einem kleinen historischen Exkurs.
Dazu schauen wir erst einmal auf die verscheiden Stufen der Industrialisierung, die in der zweiten Hälfte des 18 Jahrhunderts ihren Ursprung in England hatte. Bereits die Bedeutung des ursprünglich lateinischen Begriffs Industria, welche mit Fleiß übersetzt werden kann ist äußerst interessant. Was uns zu Norbert Wiener und seinem Buch aus den 1960 ern God and Golem Inc. [1] führt. Er dachte öffentlich darüber nach, ob Menschen die Maschinen kreieren die wiederum Maschinen erschaffen können Götter sind. Etwas das ich von meinem Empfinden nicht unterschreiben möchte. Aber kommen wir vorerst zurück zur Industrialisierung.
Die Einführung der Dampfmaschine und die Nutzung von standortunabhängigen Energiequellen wie Kohle ermöglichten eine präzise Massenfertigung. Mit einer günstigeren Automatisierung der Produktion durch Maschinen wurden manuelle Heimarbeitsplätze verdrängt. Dafür standen nun günstigere Produkte in den Geschäften. Aber auch im Transportwesen gab es erhebliche Veränderungen. Die Eisenbahn erlaubte ein schnelles, komfortableres und günstiges Reisen. Dies katapultierte die Menschheit in eine globalisierte Welt. Denn auch Waren konnten nun problemlos in kurzer Zeit lange Strecken zurücklegen. Wenn wir heute auf damalige Diskussionen zurückblicken, als die Eisenbahn ihren Siegeszug angetreten hatte, können wir nur noch Schmunzeln. Schließlich Argumentierten einige Intellektuelle der damaligen Zeit, dass Geschwindigkeiten in einem Zug von mehr als 30 Kilometer in einer Stunde die menschlichen Insassen förmlich zerquetschen würde. Eine Befürchtung, die sich glücklicherweise als unbegründet herausgestellt hat.
Während nun die Menschen in der ersten industriellen Revolution keine Einnahmen mehr durch Heimarbeit erzielen konnten fanden Sie mit der Anstellung in einer Fabrik eine Alternative um weiterhin den Lebensunterhalt bestreiten zu können.
Die zweite industrielle Revolution ist geprägt durch die Elektrifizierung, was den Grad der Automatisierung weiterhin erhöhte. Maschinen wurden weniger schwerfällig und präziser. Aber auch neue Erfindungen nahmen Einzug in das tägliche Leben. Telefax, Telefon und Radio verbreiteten Informationen im Eiltempo. Dies führte uns in das Informationszeitalter und beschleunigte nicht nur unsere Kommunikation, sondern auch unser Leben. Wir schufen eine Gesellschaft, die vornehmlich durch den Ausspruch „Zeit ist Geld“ geprägt ist.
Die dritte industriellen Revolution segnete die Menschheit mit einer universellen Maschine, welche ihre Funktionalität durch die darauf laufenden Programme (Software) bestimmte. Computer unterstützen uns in der heutigen Zeit bei einer Vielzahl an Tätigkeiten. Moderne Kassensystem leisten weitaus mehr als nur den Gesamtbetrag des getätigten Einkaufes auszuspucken. Sie protokollieren Geld und Warenströme und erlauben mit den erhobenen Daten Auswertungen zur Optimierung. Dies ist eine neue Qualität der Automatisierung die wir in den letzten 200 Jahren erreicht haben. Mit der breiten Verfügbarkeit künstlicher neuronaler Netze sind wir nun auf dem Weg diese Phase zu verlassen, weswegen wir uns gerade in der Transformation zur vierten industriellen Revolution befinden. Denn wie sonst gedenken wir als Menschen der stetig wachsenden Informationsflut Herr zu werden?
Auch wenn Industrie 4.0 den Fokus auf die Vernetzung von Maschinen legt, ist dies keine wirkliche Revolution. Das Internet ist nur eine Konsequenz aus der vorangegangen Entwicklung um zwischen Maschinen die Kommunikation zu ermöglichen. Wir können dies mit der Ersetzung der Dampfmaschine durch elektrische Motoren vergleichen. Die wirkliche Innovation lag in elektrischen Maschinen die unsere Kommunikation veränderte. Dies geschieht nun in unserer Zeit durch das breite Feld der künstlichen Intelligenz.
In naher Zukunft werden wir Computer nicht mehr so benutzen, wie wir es bisher getan haben. Denn die Computer von heute sind der bisher beschränkten Kommunikation zwischen Mensch und Maschine geschuldet. Tastatur und Maus sind eigentlich unhandliche Eingabegeräte. Sie sind langsam und fehleranfällig. Sprach- und Gestensteuerung über Mikrofon und Kamera werden Maus und Tastatur ersetzen. Wir werden uns mit unseren Computern unterhalten, wie wir mit andern Menschen reden. Das bedeutet aber auch, das Computerprogramme von heute obsolet werden. Wir werden nicht mehr langwierig in grafischen Benutzeroberflächen Eingabemasken ausfüllen um zu unserem Ziel zu kommen. Vorbei ist die Zeit wo ich meine Artikel umständlich tippe. Ich werde diese dann einsprechen und mein Computer stellt das dann visuell für mich zum gegenlesen dar. Vermutlich wird dann der Beruf des Logopäden einen erheblichen Aufwind erleben.
Sicher wird es auch genügend Aufschreie von Menschen geben, die den Zerfall der menschlichen Kommunikation befürchten. Diese Angst ist gar nicht so unbegründet. Schauen wir nur einmal auf die Entwicklung der deutschen Sprache in dem Zeitraum seit der Jahrtausendwende. Dies war geprägt durch das Aufkommen verschiedene Textnachrichtendienste und der Optimierung der Nachrichten durch möglichst viele Abkürzungen. Das wiederum schuf bei Eltern nur Fragezeichen auf die Stirn, wenn es darum ging den Inhalt der Nachrichten ihrer Kinder zu entziffern. Auch wenn der aktuelle Trend weg von Textnachrichten hin zu Audiomitteilungen geht, bedeutet es nicht das sich unsere Sprache nicht weiter verändern wird. Ich selbst habe seit Jahren beobachtet, das viele Menschen nicht mehr in der Lage sind sich einerseits schriftlich korrekt auszudrücken oder auch Inhalte aus geschriebene Texten zu extrahieren. Das könnte langfristig dazu führen, das wir die Fähigkeiten wie Lesen und Schreiben verlernen. Somit werden auch klassische Printartikel wie Bücher und Zeitschriften obsolet. Schließlich kann man die Inhalte auch als Video oder Podcast produzieren. Unsere intellektuellen Fähigkeiten werden sich langfristig degenerieren.
Seit der Jahrtausendwende wurde es für viele Menschen immer einfacher Computer zu benutzen. Daher zu erst die gute Nachricht. Es wird noch viel einfacher in Zukunft Computer zu benutzen, weil die Mensch Maschine Interaktion immer intuitiver wird. In der Zwischenzeit werden wir beobachten, wie zunehmend große Internetportale ihren Dienst einstellen, da sich deren Geschäftsmodell nicht mehr trägt. Dazu ein kleines Beispiel.
Als Programmierer nutze ich die Webseite StackOverflow sehr oft, um bei Problemen Hilfe zu finden. Die Informationen dieser Webseite zu Fragestellungen der Programmierung sind mittlerweile so umfangreich, das man über die Suche von Google und Co recht schnell passende Lösungen zum eigene Anliegen findet, ohne das man selbst Fragen formuliert. Soweit so gut. Bindet man aber nun in die eigene Programmierumgebung ein neuronales Netz wie ChatGPT um dort die Antwort auf alle Fragen zu finden, werden die Besucherzahlen für StackOverflow kontinuierlich sinken. Das hat wiederum Auswirkungen auf Werbeeinahnen um den Dienst kostenlos im Netz anbieten zu können. Anfänglich wird man das dadurch kompensieren, das Betreiber von KI Systemen, die auf die Daten von StackOverflow zugreifen eine Pauschalbetrag für die Nutzung der Datenbasis abführen. Dies wird aber den Schwund der Besucherzahlen nicht aufhalten. Was dazu führt, das entweder eine Bezahlschranke die freie Nutzung verhindert oder aber der Dienst komplett eingestellt wird. Es gibt sehr viele Angebote im Internet, die auf ähnliche Probleme stoßen werden was langfristig dafür sorgen wird, das dass Internet so wie wir es bislang kennen in der Zukunft verschwunden ist.
Stellen wir uns einmal vor, wie eine künftige Suchanfrage für den Suchbegriff ‚industrielle Revolution‘ aussehen könnte. Ich frage meinen digitalen Assistenten: Was weist du über industrielle Revolution? – Anstatt nun eine endlos scheinende Liste von tausenden Einträgen nach relevanten Ergebnissen zu durchsuchen, bekomme ich eine kurze Erklärung vorgelesen, mit einer personalisierten Ansprache passend zu meinem Alter und Bildungsstand. Wobei sich mir auch gleich die Frage aufdrängt wer beurteilt meinen Bildungsstand und wie?
Dies ist eine weitere Herabstufung unserer Fähigkeiten. Auch wenn es im ersten Moment als sehr komfortabel wahrgenommen wird. Wenn wir keine Notwendigkeit mehr haben unsere Aufmerksamkeit über einen langen Zeitraum auf eine konkrete Sache zu richten, wird es sicher schwer für uns künftig neue Dinge zu ersinnen. Unsere Kreativität wird auf ein absolutes Minimum zurück gefahren.
Es wird auch die Art und Weise wie Daten künftig gespeichert werden verändern. Komplizierte Strukturen die optimiert in Datenbanken abgelegt werden sind dann eher die Ausnahme anstatt die Regel. Vielmehr erwarte ich unabhängige Daten Brocken, die wie Listen verkettet werden. Schauen wir uns das gemeinsam an, um eine gute Vorstellung davon zu bekommen, von dem was ich meine.
Als Ausgangsbasis nehmen wir einmal das Buch von Aldous Huxley ‚Brave New World‘ aus dem Jahre 1932. Neben dem Titel, dem Autor und dem Erscheinungsjahr können wir als Sprache englisch den Metainformationen hinzufügen. Dies wird dann gefolgt vom gesamten Inhalt des Buches inklusive Vor- und Nachwort als einfacher ASCII Text. Generische oder veränderliche Dinge wie Inhaltsverzeichnis oder Copyright werden in diesem Stadium nicht berücksichtigt. Mit einem solchem chunk haben wir ein atomares Datum definiert, welches durch einen Hashwert eindeutig identifiziert werden kann. Da Huxleys Brave New World im Original in englisch verfasst hat, ist diese Datum auch eine unveränderliche Quelle für sämtliche davon abgeleiteten und generierten Daten.
Wird das Werk von Huxley nun ins Deutsche oder Spanische übersetzt, handelt es sich um die erste Ableitung mit der Referenz zum Orginal. Es kann nun vorkommen, das Bücher von verschiedenen Übersetzern in unterschiedlichen Epochen übersetzt worden sind. Daraus ergibt sich für die deutsche Übersetzung von Herbert E. Herlitschka, aus dem Jahre 1933 mit dem Titel ‚Schöne neue Welt‘ ein anderer Referenz Hash als für die von 1978 erschienene Übersetzung von Eva Walch mit dem gleichnamigen Titel ‚Schöne neue Welt‘.
Werden nun aus den verschiedenen Texten wiederum Hörbücher produziert, so sind diese Hörbücher die zweite Ableitung des originalen Textes, da sie eine gekürzte Fassung darstellen. Es entsteht vor dem Einsprechen ebenfalls ein Text als eigenständige Version. Die aus dem gekürzten Originaltext entstehende Tonspur hat als Urheber den Regisseur und verweist auf den beziehungsweise die Sprecher. Denn wie im Theater kann ein Text von unterschiedlichen Personen verschiedenen interpretiert und inszeniert werden. Identisch kann mit Verfilmungen umgegangen werden.
Bücher, Hörbücher und Filme besitzen wiederum Grafiken für das Cover. Diese Grafiken stellen wiederum eigenständige Werke dar, welche mit der entsprechenden Version des Originales referenziert werden.
Auch Zitate die aus Büchern stammen lassen sich so hervorragend verlinken. Ähnlich verhält es sich mit Kritiken, Interpretationen, Besprechungen und allen möglichen anderen Variationen von Inhalten, die sich auf ein Original beziehen.
Solche Datenblöcke sind aber nicht nur auf Bücher beschränkt, sondern können auch auf Musiknoten, Liedtexte etc. angewendet werden. Ausschlaggebend ist das man möglichst vom Original ausgehen kann. Die so entstehenden Dateien sind ausschließlich für Softwareprogramme optimiert, da sie keine für das menschliche Auge enthaltenen Formatierungen aufweisen. Schließlich genügt als Dateiname der entsprechende Hashwert über den Inhalt der Datei.
An dieser Stelle beginnt auch schon die Zukunftsvision. Denn wir können als Verfasser unseres Werkes nun künstliche Intelligenz nutzen um selbst von einem Buch automatisiert Übersetzungen, Illustrationen, Hörbücher und Animationen erstellen zu lassen. Ich möchte an dieser Stelle kurz auf das neuronale Netz DeepL [2] hinweisen, das bereits beeindruckende Übersetzungen liefert und sogar bei geschickter Handhabung den Originaltext verbessert. Macht DeepL nun Übersetzer und Lektoren arbeitslos? Ich meine nein! Denn auch wie wir Menschen sind künstliche Intelligenzen nicht unfehlbar. Auch Sie machen Fehler. Deswegen bin ich der Meinung das der Preis für diese Arbeiten künftig stark sinken wird, denn diese Personen können dank ihrer Kenntnisse und der hervorragenden Werkzeuge nun ein vielfaches der bisherigen Arbeit verrichten. Dadurch wird die Einzelleistung zwar erheblich günstiger, weil aber im gleichen Zeitraum mehr Einzelleistungen durch Automatisierung möglich sind, kompensiert dies die Preisreduktion für den Anbieter.
Wenn wir uns nun anschauen, welche neuen Möglichkeiten uns damit offen stehen schient es doch gar nicht so problematisch für uns zu werden. Wovor wollen uns also Leute wie Elon Musk warnen?
Wenn wir nun davon ausgehen, das durch die vierte industrielle Revolution das gesamte menschliche Wissen digitalisiert wird und alle neuen Erkenntnisse nur noch digitalisiert erschaffen werden, steht es Computeralgorithmen frei, mit geeigneter Rechenleistung diese Wissensbrocken so zu verändern, das wir Menschen dies nicht bemerken. Ein Szenario frei nach Orwells Wahrheitsministerium aus dem Roman 1984. Wenn wir aus Bequemlichkeit unsere Fähigkeiten verlernen haben wir auch wenig Möglichkeiten einer Überprüfung.
Wenn Sie denken, das wäre doch kein Problem, so möchte ich auf den Vortag „Traue keinem Scan“ von David Kriesel [3] hinweisen.Was war passiert? In Kurzform ging es darum das einem Bauunternehmen Unstimmigkeiten bei Kopien ihrer Baupläne aufgefallen sind. So entstanden vom gleichen Original verschieden Kopien, in denen die Zahlenwerte verändert wurden. Ein sehr fatales Problem bei einem Bauvorhaben für die ausführenden Gewerke. Wenn der Maurer andere Größenangaben bekommt als die Betonschaler. Der Fehler ließ sich letztendlich darauf zurückführen, das Xerox in ihren Scannern für die OCR und die anschließende Komprimierung eine KI als Software nutzte, die die eingelesene Zeichen nicht zuverlässig erkennen konnte.
Aber auch das Zitat von Ted Chiang „Think of ChatGPT as a blurry jpeg of all the text on the Web.“ sollte uns zu denken geben. Sicher ist der Sinn für Menschen die KI lediglich als Anwendung kennen, schwer nachzuvollziehen was mit dem Ausspruch: „ChatGPT ist nur ein verschwommenes Bild des gesamten Textes im Internet“. Es ist aber nicht so schwer zu verstehen wie es im ersten Moment scheint. Neuronale Netze sind auf Grund ihrer Struktur immer nur eine Momentaufnahme. Denn mit jeder Eingabe ändert sich der Interne Zustand eines Neuronalen Netze. Ganz gleich wie bei uns Menschen. Wir sind schließlich auch nur die Summe unserer Erfahrungen. Werden nun künftig immer mehr Texte die von einer KI erschaffen wurden unreflektiert ins Netz gestellt, bildet sich die KI ihr wissen aus ihren eigene Ableitungen. Die Original verblassen mit der zeit da si durch immer geringere Referenzen an Gewichtung verlieren. Käme nun jemand auf die Idee das Internet mit Themen wie flache Erde und Echsenmenschen zu überfluten, würden Programme wie ChatGPT unweigerlich darauf reagieren und dies in ihren Texten mit einfließen lassen. Diese Texte könnten dann entweder selbständig durch die KI im Netz automatisiert publiziert werden oder von unreflektierten Personen entsprechend ihre Verbreitung finden. Damit haben wir eine Spirale geschaffen, die nur dann durchbrochen werden kann, wenn die Menschen ihre Fähigkeit der Urteilskraft nicht aus Bequemlichkeit aufgegeben haben.
Wir sehen also die Warnungen zur Vorsicht im Umgang mit KI sind nicht unbegründet. Auch wenn ich Szenarien wie im Film WarGames von 1983 [4] für unwahrscheinlich halte, sollten wir uns sehr gut überlegen wieweit wir mit der Technologie der KI gehen wollen. Nicht das es uns wie dem Zauberlehrling ergeht und wir feststellen müssen, das wir es Sache nicht mehr Herr werden können.
Beim Entwurf von Datenmodellen und den dazugehörigen Tabellen nutzen wir manchmal Boolean als Datentyp. Im Allgemeinen sind diese Flags nicht wirklich problematisch. Aber vielleicht gibt es eine bessere Lösung für dieses Datendesign. Lassen Sie mich Ihnen ein kurzes Beispiel für meine Anliegen geben.
Nehmen wir an, wir müssen eine einfache Domäne zum Speichern von Artikeln entwerfen. Wie ein Blog-System oder ein Content-Management-System. Neben dem Inhalt des Artikels und dem Namen des Autors könnten wir ein Flag benötigen, das dem System mitteilt, ob der Artikel für die Öffentlichkeit sichtbar ist. So etwas wie veröffentlicht als boolescher Wert. Aber es gibt auch weitere Anforderung, ein Datum wann für den Atikel die Veröffentlichung geplant ist. In den meisten Datenbankentwürfen, die ich beobachtet habe, gibt es für diese Umstände einen Boolean: published und ein Datum: publishingDate. Meiner Meinung nach ist dieses Design ein wenig redundant und auch fehleranfällig. Als schnelle Schlussfolgerung möchte ich eher dazu raten, von Anfang an nur Date anstelle von Boolean zu verwenden.
Das Szenario, das ich oben beschrieben habe, kann auch auf viele andere Domänenlösungen übertragen werden. Nachdem wir eine Vorstellung davon bekommen haben, warum wir Boolean durch den Datentyp Date ersetzen sollten, werden wir uns nun den Details widmen, wie wir dieses Ziel erreichen können.
Der Umgang mit Standard-SQL lässt vermuten, dass der Austausch eines Datenbankmanagementsystems (DBMS) gegen ein anderes kein großes Problem darstellen sollte. Die Realität sieht leider ein wenig anders aus. Nicht alle verfügbaren Datentypen für Datum wie Timestamp sind wirklich empfehlenswert zu verwenden. Aus Erfahrung ziehe ich es vor, das einfache java.util.Date zu verwenden, um zukünftige Probleme und andere Überraschungen zu vermeiden. Das gespeicherte Format in der Datenbanktabelle sieht wie folgt aus: ‘JJJJ-MM-tt HH:mm:ss.0’. Zwischen dem Datum und der Uhrzeit steht ein einzelnes Leerzeichen und .0 bezeichnet einen Offset. Dieser Offset beschreibt die Zeitzone. Die mitteleuropäische Standardzeitzone CET hat einen Versatz von einer Stunde. Das bedeutet UTC+01:00 im internationalen Format. Um den Offset separat zu definieren, habe ich gute Ergebnisse mit java.util.TimeZone erzielt, das perfekt mit Date zusammenarbeitet.
Bevor wir fortfahren, zeige ich Ihnen einen kleinen Codeschnipsel in Java für den O/R Manager Hibernate und wie damit die zugehörigen Tabellenspalten erstellt werden können.
Schauen wir uns das obige Listing etwas genauer an. Als erstes sehen wir die @CreationTimestamp Annotation. Das bedeutet, dass beim Erstellen des ArticleDO-Objekts die Variable created mit der aktuellen Zeit initialisiert wird. Dieser Wert sollte sich nie ändern, da ein Artikel nur einmal erstellt, aber mehrmals geändert werden kann. Die Zeitzone wird in einem String gespeichert. Im Constructor kann man sehen, wie die System Timezone ausgelesen werden kann – aber Vorsicht, dieser Wert sollte nicht zu sehr vertraut werden. Wenn Sie einen Benutzer wie mich haben, der viel reist, werden Sie sehen, dass ich an allen Orten die gleiche Systemzeit habe, da ich diese normalerweise nie ändere. Als Standardzeitzone definiere ich den richtigen String für UTC-0. Das gleiche mache ich für die Variable published. Datum kann auch durch einen String erstellt werden, den wir verwenden, um unseren Standard-Nullwert zu setzen. Der Setter für published hat die Möglichkeit, ein zukünftiges Datum zu definieren oder die aktuelle Zeit zu verwenden, falls der Artikel sofort veröffentlicht werden soll. Am Ende des Listings demonstriere ich einen einfachen SQL-Import für einen einzelnen Datensatz.
Aber man sollte nicht zu schnell vorgehen. Wir müssen auch ein wenig darauf achten, wie wir mit dem UTC-Offset umgehen. Denn ich habe in großen Systemen mehrfach Probleme beobachtet, die auftraten, weil Entwickler nur Standardwerte verwendet haben.
Die Zeitzone im Allgemeinen ist Teil des Internationalisierungskonzepts. Um die Zeitverschiebungen korrekt zu verwalten, können wir zwischen verschiedenen Strategien wählen. Wie in so vielen anderen Fällen gibt es kein eindeutiges Richtig oder Falsch. Alles hängt von den Umständen und Notwendigkeiten Ihrer Anwendung ab. Wenn eine Website nur national genutzt wird, wie für ein kleines Unternehmen, und keine zeitkritischen Ereignisse involviert sind, wird alles sehr einfach. In diesem Fall ist es unproblematisch, die Zeitzoneneinstellungen automatisch durch das DBMS zu verwalten. Aber bedenken Sie, dass es auf der Welt Länder wie Mexiko gibt, die mehr als nur eine Zeitzone haben. Bei einem internationalen System, bei dem die Clients über den ganzen Globus verteilt sind, könnte es sinnvoll sein, jedes einzelne DBMS im Cluster auf UTC-0 einzustellen und den Offset durch die Anwendung und die angeschlossenen Clients zu verwalten.
Ein weiteres Problem, das wir lösen müssen, ist die Frage, wie der Datumswert eines einzelnen Datensatzes standardmäßig initialisiert werden soll. Denn Nullwerte sollten vermieden werden. Eine ausführliche Erklärung, warum die Rückgabe von Nullwerten kein guter Programmierstil ist, findet sich in Büchern wie ‘Effective Java’ und ‘Clean Code’. Der Umgang mit Null Pointer Exceptions ist etwas, das ich nicht wirklich brauche. Ein bewährtes Verfahren, das sich für mich bewährt hat, ist die Vorgabe eines Datums- und Zeitwerts durch ‘0000-00-00 00:00:00.0’. Auf diese Weise vermeide ich unerwünschte Veröffentlichungen und die Bedeutung ist sehr klar – für jeden.
Wie Sie sehen können, gibt es gute Gründe, warum boolesche Datentypen durch Datum ersetzt werden sollten. In diesem kleinen Artikel habe ich gezeigt, wie einfach man mit Datum und Zeitzone in Java und Hibernate umgehen kann. Es sollte auch keine große Sache sein, dieses Beispiel auf andere Programmiersprachen und Frameworks zu übertragen. Wenn Sie eine eigene Lösung haben, können Sie gerne einen Kommentar hinterlassen und diesen Artikel mit Ihren Kollegen und Freunden teilen.
Sämtlich in einem Unternehmen aufgestellten Regeln und durchgeführten Aktivitäten stellen Prozesse dar. Deswegen kann auch pauschal gesagt werden, das die Summe der Prozesse eine Organisation beschreibt. Leider sind manchmal die Prozesse so kompliziert gestaltet, das diese sich negativ auf das Unternehmen auswirken. Was kann also getan werden um die Situation zu verbessern?
(c) 2022 Marco Schulz, JAVA aktuell Ausgabe 6
Laut ISO 900 Definition ist ein Prozess, ein Satz von in Wechselbeziehung stehenden Tätigkeiten. der Eingaben in Ergebnisse umwandelt. Dabei spielt es keine Rolle, ob der Prozess atomar ist, also nicht weiter zerlegt werden kann oder aus mehreren Prozessen zusammengesetzt wurde. An dieser Stelle ist es wichtig auch kurz auf einige Begriffe einzugehen.
Choreographie: beschreibt einzelne Operationen, aber nicht die Nachrichtenreihenfolge (Ablauf). Es behandelt die etablierte Kommunikation zwischen zwei Teilnehmern.
Orchestration: beschreibt die Reihenfolge und Bedingungen der aufrufenden Teilprozesse.
Konversation: beschreibt die Abfolgen zwischen Prozessen. Es wird die gesamte zulässige Kommunikation (Vollständigkeit) zwischen zwei Teilnehmern beschrieben.
Die aufgeführten Begrifflichkeiten spielen für die Beschreibung von Prozessen eine wichtige Rolle. Wenn sie beispielsweise die Idee haben die für Ihr Unternehmen wichtigen Geschäftsprozesse in einem Prozessbrowser visualisiert darzustellen, müssen Sie sich bereits im Vorfeld über die Detailtiefe der bereitgestellten Informationen im Klaren sein. Sollten Sie die Absicht hegen möglichst alle Informationen in so einem Schaubild einzubringen, werden Sie schnell feststellen wie sehr die Übersichtlichkeit darunter leidet. Wählen Sie daher immer für die benötigte Anwendung die geeignete Darstellung aus.
Ansichtssachen
Hier kommen wir auch schon zur nächsten Fragestellung. Was sind geeignete Mittel um Prozesse verständlich darzustellen. Aus persönlicher Erfahrung hat sich in meinen Projekten ein Darstellung über den Informationsfluss gut bewährt. Dazu wiederum nutze ich die Business Process Model Notation, kurz BPMN die für solche Zwecke geschaffen wurde. Ein frei verfügbares Werkzeug um BPMN Prozesse aufzuzeichnen ist der BigAzi Modeler [1]. Die Möglichkeit aus BPMN Diagrammen wiederum softwaregestützte Programme mittels serviceorientierter Architekturen (SOA) zu erzeugen ist für ein Großteil der Unternehmen weniger nutzbringend und nicht so einfach umzusetzen wie es auf den ersten Blick scheint. Viel wichtiger bei einer Umsetzung zur grafischen Darstellung interner Unternehmensprozesse sind die so zu tage geförderten versteckten Erkenntnisse über mögliche Verbesserungen.
Besonders Unternehmen, die eine eigenständige Softwareentwicklung betreiben und die dort angewendeten Vorgehensweisen, möglichst in einem hohen Grade automatisieren wollen, können den Schritt zur Visualisierung interner Strukturen selten auslassen. Die hier viel zitierten Stichwörter Continuous Integration, Continuous Delivery und DevOps haben eine sehr hohe Automatisierungsstufe zum Ziel. Um in diesem Bereich erfolgreiche Ergebnisse erreichen zu können, ist es unumgänglich möglichst einfache und standardisierte Prozesse etabliert zu haben. Das beschreibt auch das Paradoxon der Automatisierung.
Prozessautomation reduziert das Risiko, dass Fehler gemacht werden. Aber hochkomplexe Prozesse sind naturgemäß nur sehr schwer zu automatisieren!
Wenn Sie den Entschluss gefasst haben die hauseigenen Geschäftsprozesse zu optimieren benötigen Sie selbstredend zuerst eine realistische Analyse des aktuellen IST – Zustands um daraus den gewünschten SOLL – Zustand zu beschreiben. Sobald diese beiden wichtigen Punkte feststehen können Sie geeignete Maßnahmen ergreifen, mit der sie die Transformation vollziehen können.
Abbildung 1: Die Transformation von der Ausgangssituation hin zu Zielstellung.
Es wäre an dieser Stelle nicht sehr hilfreich verschiedene Vorgehnsmodelle zu beschreiben, wie eine solche Transformation von statten gehen kann. Solche Vorhaben sind stets sehr individuell und den tatsächlichen Gegebenheiten im Unternehmen geschuldet. Hier sei Ihnen nur ein wichtiger Ratschlag mit auf den Weg gegeben. Gehen Sie kleine einfache Schritte und vermeiden Sie es möglichst alles auf einmal umsetzen zu wollen. Manchmal entdecken Sie während einer Umstellung wichtige Details die angepasst werden müssen. Das gelingt Ihnen gefahrlos wenn Sie genügend Reserven eingeplant haben. Sie sehen auch hier spiegeln sich agile Gedanken wieder, die Ihnen die Möglichkeit geben direkt auf Veränderungen einzugehen.
Richten Sie Ihr Augenmerk vor allem auf den zu erreichenden Sollzustand. Im Großen und Ganzen wird zwischen zwei Prozesstypen unterschieden. Autonome Prozesse laufen im Idealfall vollständig automatisiert ab und erfordern keinerlei manuelles Eingreifen. Dem gegenüber stehen die interaktiven Prozess, welche an ein oder mehreren Stellen auf eine manuelle Eingabe warten um weiter ausgeführt werden zu können. Ein sehr oft angestrebtes Ziel für den SOLL – Zustand der Prozesslandschaften sind möglichst kompakte und robuste autonome Prozesse um den Automatisierungsgrad zu verbessern. Folgende Punkte helfen Ihnen dabei das gesteckte Ziel zu erreichen:
Definieren Sie möglichst atomare Prozesse, die ausschließlich einen einzigen Vorgang oder einen Teilaspekt eines Vorgangs beschreiben.
Halten Sie die Prozessbeschreibung möglichst sehr einfach und orientieren Sie sich dabei an vorhanden Standards und suchen Sie nicht nach eigenen individuellen Lösungen.
Vermeiden Sie so gut es möglichst jegliche manuelle Interaktion.
Wägen Sie bei Ausnahmen sehr kritisch ab, wie oft diese tatsächlich auftreten und suchen Sie nach möglichen Lösungen diese Ausnahmen mit dem Standartvorgehen abarbeiten zu können.
Setzen Sie komplexe Prozessmodelle ausschließlich aus bereits vollständig beschriebenen atomaren Teilprozessen zusammen.
Sicher stellen Sie sich die Frage, was es mit meinem Hinweis auf die Verwendung von etablierten Standards auf sich hat. Viele der in einem Unternehmen auftretenden Probleme wurden meist bereist umfangreich und bewährt gelöst. Nicht nur aus Zeit und Kostengründen sollte bei der Verfügbarkeit bereits etablierter Vorgehensmodelle kein eigenes Süppchen gekocht werden. So erschweren Sie zum einem den Wissenstransfer zwischen Ihren Mitarbeitern und zum anderen erschweren Sie die Verwendung von standardisierter Branchensoftware. Hierzu möchte ich Ihnen ein kleines Beispiel aus meinem Alltag vorstellen, wo es darum geht in Unternehmen möglichst automatisierte DevOps Prozesse für die Softwareentwicklung und den Anwendungsbetrieb zu etablieren.
Die Kunst des Loslassen
Die größte Hürde die ein Unternehmen hier nehmen muss, ist eine Neuorientierung an dem Begriff Release und dem dahinterliegenden Prozess, der meist eigenwillig interpretiert wurde. Die Abweichung von bekannten Standards hat wiederum mehrere spürbare Folgen. Neben erhöhtem Personalaufwand für die administrativen Eingriffe im Releaseprozess besteht auch stets die Gefahr durch unglückliche äußere Umstände in zeitlichen Verzug zum aktuellen Plan zu geraten. Ohne auf die vielen ermüden technischen Details einzugehen liegt das gravierendste Missverständnis in dem Glauben es gäbe nach dem Erstellen eines Releases noch die Möglichkeit die in der Testphase erkannten Fehler im selben Release zu beheben. Das sieht dann folgendermaßen aus: nach einem Sprint wird beispielsweise das Release 2.3.0 erstellt, welches dann ausgiebig in der Testphase auf Herz und Nieren überprüft wird. Stellt man nun ein Fehler fest, ist es nicht möglich eine korrigiert Version 2.3.0 zu erzeugen. Die Korrektur hat ein neues Release zur Folge, welches dann die Versionsnummer 2.3.1 trägt. Ein wichtiger Standard der hier zum Tragen kommt ist die Verwendung des Semantic Versioning, welcher jedem einzelnen Segment der Versionsnummer eine Bedeutung zuordnet. In dem hier verwendeten Beispiel zeigt die letzte Stelle die für ein Release durchgeführten Korrekturen an. Falls Sie sich etwas intensiver mit dem Thema Semantic Versioning beschäftigen mögen, empfehle ich dazu die zugehörige Internetseite [2].
Was aber spricht nun dagegen ein bereits geplantes und auf den Weg gebrachtes Release bei der Detektion von Fehlern nicht zu stoppen, zu korrigieren und ‘repariert’ erneut unter der bereits vergebenen Versionsnummer auf den Weg zu schicken? Die Antwort ist recht einfach. Der erhebliche Arbeitsaufwand, welcher ausschließlich manuell durchgeführt werden muss, um den Fehler wieder auszubügeln. Abgesehen davon wird Ihre gesamte Entwicklungsarbeit für das Folgerelease erheblich ausgebremst. Ressourcen können nicht frei gegeben werden und der Fortschritt beginnt zu stagnieren.
Deswegen ist es wichtig sich so zu disziplinieren, das ein bereits auf den Weg gebrachtes Release sämtliche Prozeduren durchläuft und erst im letzten Schritt dann die manuell ausgeführte Entscheidung getroffen wird, ob das Release für den Produktive Einsatz auch geeignet ist. Deswegen rate ich grundsätzlich dazu den Begriff Release Kandidat aus dem Sprachgebrauch zu streichen und besser von einem Production Kandidat zu sprechen. Diese Bezeichnung spiegelt den Releaseprozess viel deutlicher wieder.
Sollten sich währen der Testphase Mängel aufzeigen, gilt zu erst zu entscheiden wie schwerwiegend diese sind und deren Behebung ist zu priorisieren. Das kann soweit gehen, das direkt ein Korrekturrelease auf den Weg gebracht werden muss, während parallel der nächste Sprint abgearbeitet wird. Weniger gravierende Fehler können dann auf die nächsten Folgesprits verteilt werden. Wie das alles in der täglichen Praxis umgesetzt werden kann – habe ich letztes Jahr in meinem Vortag “Rolling Stones: Vom Release überrollt” auf der JCON präsentiert. Den Videomitschnitt finden Sie frei zugänglich im Internet.
Unter dem Gesichtspunkt der Prozessoptimierung bedeute es für das aufgeführte Beispiel des Release Prozesses, das der Prozess beendet wurde, wenn aus dem Sourcecode erfolgreich eine binäres Artefakt mit einer noch nicht belegten Versionsnummer erstellt werden konnte. Das so entstandene Release wird umgehend an einer zentralen Stelle veröffentlicht (deliverd), wo es in den Testprozess übergeben werden kann. Erst wenn der Testprozess mit dem Ergebnis abgeschlossen wurde, dass das erzeugte Release auch in Produktion verwendet werden darf erfolgt die Übergabe in den Deployment Prozess. Sie sehen, das was vielerorts als ein gesamter Prozess angesehen wird ist genau betrachtet eine Orchestration aus mindestens 3 eiegnständigen Prozessen.
Abbildung 2 : Continuous Delivery und Continuous Deployment.
Ein wichtiger Punkt den Sie In Abbildung 2 zum Thema DevOps ebenfalls herauslesen können ist, das der Schritt zwischen Continuous Delivery und Continuous Deployment besser nicht vollautomatisiert werden sollte, denn Deplyoment meint in diesem Kontext nicht das automatisierte bereitstellen der Anwendung auf allen verfügbaren Testinstanzen. Continuous Deployment meint in erste Linie ein automatisiertes Einsetzen der Anwendung in Produktion. Ob das immer eine gute Idee ist sollt sehr sorgfältig abgewogen werden.
Ein wertvoller Aspekt der Prozessbeschreibung in Organisationen ist die Ausarbeitung wichtiger Kriterien die erfüllt sein müssen, damit ein Prozess autonom ablaufen kann. Mit diesem Wissen können Sie bei der Evaluierung benötigter Werkzeuge sehr leicht einen Anforderungskatalog mit priorisierten Punkten erstellen, der einfach abgearbeitet wird. Kann das ins Auge gefasste Tool die aufgelisteten Punkte zufriedenstellend lösen und der aufgerufene Preis passt auch ins Budget, ist Ihre Suche erfolgreich beendet.
Fazit
Sehr oft wird mir entgegengebracht, das durch moderne DevOps Strategien der klassische Release Prozess obsolet geworden ist. Dem kann ich nicht zustimmen. Es mag wenige Ausnahmen geben, in den Unternehmen tatsächlich jede Codeänderung sofort in Produktion bringen. Aus Gründen der Gewährleistung und Haftung, kommt für viel Firmen ein so vollständig automatisiertes Vorgehen aber nicht in Frage. Auch der Datenschutz sorgt dafür, das die Bereich Entwicklung und Betrieb voneinander getrennt werden. Zudem benötigen umfangreiche Softwareprojekte auch eine strategische Planungsinstanz über die umzusetzenden Funktionalitäten. Diese Entscheidbarkeit wird auch künftig nicht beim Entwickler liegen, ganz gleich wie hervorgehoben der Punkt DevOps in der Stellenbeschreibung auch sein mag.
Wie Sie sehen ist das Thema der Prozessbeschreibung und Prozessoptimierung nicht ausschließlich ein Thema für produzierende Branchen. Auch der vielrorts detailreich beschriebene Softwareentwicklungsprozess hält einiges an Verbesserungspotenzial bereit. Ich hoffe ich konnte Sie mit meinen Zeilen ein wenig für das Thema sensibilisieren, ohne zu sehr ins technische verfallen zu sein.
Als mir im Studium die Vorzüge der objektorientierten Programmierung mit Java schmackhaft gemacht wurden, war ein sehr beliebtes Argument die Wiederverwendung. Dass der Grundsatz „write once use everywhere“ in der Praxis dann doch nicht so leicht umzusetzen ist, wie es die Theorie suggeriert, haben die meisten Entwickler bereits am eigenen Leib erfahren. Woran liegt es also, dass die Idee der Wiederverwendung in realen Projekten so schwer umzusetzen ist? Machen wir also einen gemeinsamen Streifzug durch die Welt der Informatik und betrachten verschiedene Vorhaben aus sicherer Distanz.
Wenn ich daran denke, wie viel Zeit ich während meines Studiums investiert habe, um eine Präsentationsvorlage für Referate zu erstellen. Voller Motivation habe ich alle erdenklichen Ansichten in weiser Voraussicht erstellt. Selbst rückblickend war das damalige Layout für einen Nichtgrafiker ganz gut gelungen. Trotzdem kam die tolle Vorlage nur wenige Male zum Einsatz und wenn ich im Nachhinein einmal Resümee ziehe, komme ich zu dem Schluss, dass die investierte Arbeitszeit in Bezug auf die tatsächliche Verwendung in keinem Verhältnis gestanden hat. Von den vielen verschiedenen Ansichten habe ich zum Schluss exakt zwei verwendet, das Deckblatt und eine allgemeine Inhaltsseite, mit der alle restlichen Darstellungen umgesetzt wurden. Die restlichen 15 waren halt da, falls man das künftig noch brauchen würde. Nach dieser Erfahrung plane ich keine eventuell zukünftig eintreffenden Anforderungen mehr im Voraus. Denn den wichtigsten Grundsatz in Sachen Wiederverwendung habe ich mit dieser Lektion für mich gelernt: Nichts ist so beständig wie die Änderung.
Diese kleine Anekdote trifft das Thema bereits im Kern. Denn viele Zeilen Code werden genau aus der gleichen Motivation heraus geschrieben. Der Kunde hat es noch nicht beauftragt, doch die Funktion wird er ganz sicher noch brauchen. Wenn wir in diesem Zusammenhang einmal den wirtschaftlichen Kontext ausblenden, gibt es immer noch ausreichend handfeste Gründe, durch die Fachabteilung noch nicht spezifizierte Funktionalität nicht eigenmächtig im Voraus zu implementieren. Für mich ist nicht verwendeter, auf Halde produzierter Code – sogenannter toter Code – in erster Linie ein Sicherheitsrisiko. Zusätzlich verursachen diese Fragmente auch Wartungskosten, da bei Änderungen auch diese Bereiche möglicherweise mit angepasst werden müssen. Schließlich muss die gesamte Codebasis kompilierfähig bleiben. Zu guter Letzt kommt noch hinzu, dass die Kollegen oft nicht wissen, dass bereits eine ähnliche Funktion entwickelt wurde, und diese somit ebenfalls nicht verwenden. Die Arbeit wird also auch noch doppelt ausgeführt. Nicht zu vergessen ist auch das von mir in großen und langjährig entwickelten Applikationen oft beobachtete Phänomen, dass ungenutzte Fragmente aus Angst, etwas Wichtiges zu löschen, über Jahre hinweg mitgeschleppt werden. Damit kommen wir auch schon zum zweiten Axiom der Wiederverwendung: Erstens kommt es anders und zweitens als man denkt.
Über die vielen Jahre, genauer gesagt Jahrzehnte, in denen ich nun verschiedenste IT- beziehungsweise Softwareprojekte begleitet habe, habe ich ein Füllhorn an Geschichten aus der Kategorie „Das hätte ich mir sparen können!“ angesammelt. Virtualisierung ist nicht erst seit Docker [1] auf der Bildfläche erschienen – es ist schon weitaus länger ein beliebtes Thema. Die Menge der von mir erstellten virtuellen Maschinen (VMs) kann ich kaum noch benennen – zumindest waren es sehr viele. Für alle erdenklichen Einsatzszenarien hatte ich etwas zusammengebaut. Auch bei diesen tollen Lösungen erging es mir letztlich nicht viel anders als bei meiner Office-Vorlage. Grundsätzlich gab es zwei Faktoren, die sich negativ ausgewirkt haben. Je mehr VMs erstellt wurden, desto mehr mussten dann auch gewertet werden. Ein Worst-Case-Szenario heutzutage wäre eine VM, die auf Windows 10 basiert, die dann jeweils als eine .NET- und eine Java-Entwicklungsumgebung oder Ähnliches spezialisiert wurde. Allein die Stunden, die man für Updates zubringt, wenn man die Systeme immer mal wieder hochfährt, summieren sich auf beachtliche Größen. Ein Grund für mich zudem, soweit es geht, einen großen Bogen um Windows 10 zu machen. Aus dieser Perspektive können selbsterstellte DockerContainer schnell vom Segen zum Fluch werden.
Dennoch darf man diese Dinge nicht gleich überbewerten, denn diese Aktivitäten können auch als Übung verbucht werden. Wichtig ist, dass solche „Spielereien“ nicht ausarten und man neben den technischen Erfahrungen auch den Blick für tatsächliche Bedürfnisse auf lange Sicht schärft.
Gerade bei Docker bin ich aus persönlicher Erfahrung dazu übergegangen, mir die für mich notwendigen Anpassungen zu notieren und zu archivieren. Komplizierte Skripte mit Docker-Compose spare ich mir in der Regel. Der Grund ist recht einfach: Die einzelnen Komponenten müssen zu oft aktualisiert werden und der Einsatz für jedes Skript findet in meinem Fall genau einmal statt. Bis man nun ein lauffähiges Skript zusammengestellt hat, benötigt man, je nach Erfahrung, mehrere oder weniger Anläufe. Also modifiziere ich das RUN-Kommando für einen Container, bis dieser das tut, was ich von ihm erwarte. Das vollständige Kommando hinterlege ich in einer Textdatei, um es bei Bedarf wiederverwenden zu können. Dieses Vorgehen nutze ich für jeden Dienst, den ich mit Docker virtualisiere. Dadurch habe ich die Möglichkeit, verschiedenste Konstellationen mit minimalen Änderungen nach dem „Klemmbaustein“-Prinzip zu rchestrieren. Wenn sich abzeichnet, dass ein Container sehr oft unter gleichen Bedienungen instanziiert wird, ist es sehr hilfreich, diese Konfiguration zu automatisieren. Nicht ohne Grund gilt für Docker-Container die Regel, möglichst nur einen Dienst pro Container zu virtualisieren.
Aus diesen beiden kleinen Geschichten lässt sich bereits einiges für Implementierungsarbeiten am Code ableiten. Ein klassischer Stolperstein, der mir bei der täglichen Projektarbeit regelmäßig unterkommt, ist, dass man mit der entwickelten Applikation eine eierlegende Wollmilchsau – oder, wie es in Österreich heißt: ein Wunderwutzi – kreieren möchte. Die Teams nehmen sich oft zu viel vor und das Projektmanagement versucht, den Product Owner auch nicht zu bekehren, lieber auf Qualität statt auf Quantität zu setzen. Was ich mit dieser Aussage deutlich machen möchte, lässt sich an einem kleinen Beispiel verständlich machen.
Gehen wir einmal davon aus, dass für eigene Projekte eine kleine Basisbibliothek benötigt wird, in der immer wiederkehrende Problemstellungen zusammengefasst werden – konkret: das Verarbeiten von JSON-Objekten [2]. Nun könnte man versuchen, alle erdenklichen Variationen im Umgang mit JSON abzudecken. Abgesehen davon, dass viel Code produziert wird, erzielt ein solches Vorgehen wenig Nutzen. Denn für so etwas gibt es bereits fertige Lösungen – etwa die freie Bibliothek Jackson [3]. Anstelle sämtlicher denkbarer JSON-Manipulationen ist in Projekten vornehmlich das Serialisieren und das Deserialisieren gefragt. Also eine Möglichkeit, wie man aus einem Java-Objekt einen JSON-String erzeugt, und umgekehrt. Diese beiden Methoden lassen sich leicht über eine Wrapper-Klasse zentralisieren. Erfüllt nun künftig die verwendete JSON-Bibliothek die benötigten Anforderungen nicht mehr, kann sie leichter durch eine besser geeignete Bibliothek ersetzt werden. Ganz nebenbei erhöhen wir mit diesem Vorgehen auch die Kompatibilität [4] unserer Bibliothek für künftige Erweiterungen. Wenn JSON im Projekt eine neu eingeführte Technologie ist, kann durch die Minimal-Implementierung stückweise Wissen aufgebaut werden. Je stärker der JSONWrapper nun in eigenen Projekten zum Einsatz kommt, desto wahrscheinlicher ist es, dass neue Anforderungen hinzukommen, die dann erst umgesetzt werden, wenn sie durch ein Projekt angefragt werden. Denn wer kann schon abschätzen, wie der tatsächliche Bedarf einer Funktionalität ist, wenn so gut wie keine Erfahrungen zu der eingesetzten Technologie vorhanden sind?
Das soeben beschriebene Szenario läuft auf einen einfachen Merksatz hinaus: Eine neue Implementierung möglichst so allgemein wie möglich halten, um sie nach Bedarf immer weiter zu spezialisieren.
Bei komplexen Fachanwendungen hilft uns das Domain-driven Design (DDD) Paradigma, Abgrenzungen zu Domänen ausfindig zu machen. Auch hierfür lässt sich ein leicht verständliches, allgemein gefasstes Beispiel finden. Betrachten wir dazu einmal die Domäne einer Access Control List (ACL). In der ACL wird ein Nutzerkonto benötigt, mit dem Berechtigungen zu verschiedenen Ressourcen verknüpft werden. Nun könnte man auf die Idee kommen, im Account in der ACL sämtliche Benutzerinformationen wie Homepage, Postadresse und Ähnliches abzulegen. Genau dieser Fall würde die Domäne der ACL verletzen, denn das Benutzerkonto benötigt lediglich Informationen, die zur Authentifizierung benötigt werden, um eine entsprechende Autorisierung zu ermöglichen.
Jede Anwendung hat für das Erfassen der benötigten Nutzerinformationen andere Anforderungen, weshalb diese Dinge nicht in eine ACL gehören sollten. Das würde die ACL zu sehr spezialisieren und stetige Änderungen verursachen. Daraus resultiert dann auch, dass die ACL nicht mehr universell einsatzfähig ist.
Man könnte nun auf die Idee kommen, eine sehr generische Lösung für den Speicher zusätzlicher Nutzerinformationen zu entwerfen und ihn in der ACL zu verwenden. Von diesem Ansatz möchte ich abraten. Ein wichtiger Grund ist, dass diese Lösung die Komplexität der ACL unnötig erhöht. Ich gehe obendrein so weit und möchte behaupten, dass unter ungünstigen Umständen sogar Code-Dubletten entstehen. Die Begründung dafür ist wie folgt: Ich sehe eine generische Lösung zum Speichern von Zusatzinformationen im klassischen Content Management (CMS) verortet. Die Verknüpfung zwischen ACL und CMS erfolgt über die Benutzer-ID aus der ACL. Somit haben wir gleichzeitig auch zwischen den einzelnen Domänen eine lose Kopplung etabliert, die uns bei der Umsetzung einer modularisierten Architektur sehr behilflich sein wird.
Zum Thema Modularisierung möchte ich auch kurz einwerfen, dass Monolithen [5] durchaus auch aus mehreren Modulen bestehen können und sogar sollten. Es ist nicht zwangsläufig eine Microservice-Architektur notwendig. Module können aus unterschiedlichen Blickwinkeln betrachtet werden. Einerseits erlauben sie es einem Team, in einem fest abgegrenzten Bereich ungestört zu arbeiten, zum anderen kann ein Modul mit einer klar abgegrenzten Domäne ohne viele Adaptionen tatsächlich in späteren Projekten wiederverwendet werden.
Nun ergibt sich klarerweise die Fragestellung, was mit dem Übergang von der Generalisierung zur Spezialisierung gemeint ist. Auch hier hilft uns das Beispiel der ACL weiter. Ein erster Entwurf könnte die Anforderung haben, dass, um unerwünschte Berechtigungen falsch konfigurierter Rollen zu vermeiden, die Vererbung von Rechten bestehender Rollen nicht erwünscht ist. Daraus ergibt sich dann der Umstand, dass jedem Nutzer genau eine Rolle zugewiesen werden kann. Nun könnte es sein, dass durch neue Anforderungen der Fachabteilung eine Mandantenfähigkeit eingeführt werden soll. Entsprechend muss nun in der ACL eine Möglichkeit geschaffen werden, um bestehende Rollen und auch Nutzeraccounts einem Mandanten zuzuordnen. Eine Domänen-Erweiterung dieser hinzugekommenen Anforderung ist nun basierend auf der bereits bestehenden Domäne durch das Hinzufügen neuer Tabellenspalten leicht umzusetzen.
Die bisher aufgeführten Beispiele beziehen sich ausschließlich auf die Implementierung der Fachlogik. Viel komplizierter verhält sich das Thema Wiederverwendung beim Punkt der grafischen Benutzerschnittelle (GUI). Das Problem, das sich hier ergibt, ist die Kurzlebigkeit vieler chnologien. Java Swing existiert zwar noch, aber vermutlich würde sich niemand, der heute eine neue Anwendung entwickelt, noch für Java Swing entscheiden. Der Grund liegt in veraltetem Look-and-Feel der Grafikkomponenten. Um eine Applikation auch verkaufen zu können, darf man den Aspekt der Optik nicht außen vor lassen. Denn auch das Auge isst bekanntlich mit. Gerade bei sogenannten Green-Field-Projekten ist der Wunsch, eine moderne, ansprechende Oberfläche anbieten zu können, implizit. Deswegen vertrete ich die Ansicht, dass das Thema Wiederverwendung für GUI – mit wenigen Ausnahmen – keine wirkliche Rolle spielt.
Lessons Learned
Sehr oft habe ich in der Vergangenheit erlebt, wie enthusiastisch bei Kick-off-Meetings die Möglichkeit der Wiederverwendung von Komponenten in Aussicht gestellt wurde. Dass dies bei den verantwortlichen Managern zu einem Glitzern in den Augen geführt hat, ist auch nicht verwunderlich. Als es dann allerdings zu ersten konkreten Anfragen gekommen ist, eine Komponente in einem anderen Projekt einzusetzen, mussten sich alle Beteiligten eingestehen, dass dieses Vorhaben gescheitert war. In den nachfolgenden Retrospektiven sind die Punkte, die ich in diesem Artikel vorgestellt habe, regelmäßig als Ursachen identifiziert worden. Im Übrigen genügt oft schon ein Blick in das Datenbankmodell oder auf die Architektur einer Anwendung, um eine Aussage treffen zu können, wie realistisch eine Wiederverwendung tatsächlich ist. Bei steigendem Komplexitätsgrad sinkt die Wahrscheinlichkeit, auch nur kleinste Segmente erfolgreich für eine Wiederverwendung herauslösen zu können.
Als IT-Dienstleister müssen wir unsere Kunden oft dabei unterstützen, alte Windows-Systeme neu zu installieren. Die häufigste Herausforderung, der wir uns bei dieser Aktivität stellen müssen, besteht darin, alte Dateien zu sichern und sie auf dem neuen System wiederherzustellen. Nicht nur Privatpersonen, auch Unternehmen nutzen den E-Mail-Client Thunderbird. Deshalb haben wir uns entschlossen, diese kurze Anleitung zu veröffentlichen, wie Ihr Thunderbird-Profil gesichert und wiederhergestellt werden kann. Um einem Datenverlust vorzubeugen, sollten Sie regelmäßig Backups erstellen, falls Ihre Hardware oder Ihr Betriebssystem vollständig abgestürzt ist.
Sichern
Einen USB-Stick oder -Festplatte (USB-Medium) an den Rechner anschließen.
Erstellen Sie auf dem USB-Medium ein Verzeichnis Ihrer Wahl, zur Sicherung Ihres Profils. (z. B. 2022-01-19_Thunderbird-profil)
Halten Sie das „Explorer Fenster“ offen und achten Sie darauf, dass das Verzeichnis „aktiv“ ist.
Starten Sie nun Ihren Thunderbird E-Mail Client auf dem Rechner (Quelle) den Sie sichern möchten.
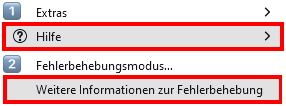
Zum Auffinden Ihres alten Profils klicken Sie auf die „drei Balken“ oben rechts.
In dem Fenster days such deann öffnent klicken Sie auf “Hilfe” (wie in dem Screenshot zu seen) 1️⃣ und dann 2️⃣ gehen Sie auf „weitere Hilfe zur Fehlerbehebung“.
Im nächsten, sich öffnenden Fenster, wählen Sie das Feld „Ordner öffnen“ aus.
Ein neues „Explorer Fenster“ öffnet sich und zeigt Ihnen alle Dateien Ihres Profils an.
Markieren Sie alle Dateien, indem Sie die 1. Datei anklicken, dann die <Shift> Taste auf Ihrer Tastatur gedrückt halten und gleichzeitig die Taste <Pfeil nach unten> solange gedrückt halten bis der graue „Scroll-Balken“ im Fenster ganz unten angekommen ist. Sind alle Dateien ausgewählt (blau markiert), klicken Sie mit der „rechten Maustaste„ auf eine beliebige Datei und wählen den Menüpunkt „Kopieren“ aus
Gehen Sie zurück zu dem „Explorer Fenster“ in dem Sie das USB Medium geöffnet haben und klicken die „rechte Maustaste“ und dann auf „Einfügen“.
Ist der Kopiervorgang abgeschlossen, können Sie den Thunderbird E-Mail Client schließen.
Wiederherstellen
Schließen Sie Ihr USB-Medium an den Ziel-Rechner an.
Öffnen Sie den „Explorer“ und legen Sie folgende Verzeichnisse an: „Daten“ ➡️ „ Thunderbird“ ➡️ „Postamt xxx“ (C:\Data\Thunderbird\Postamt-Office xxx\ xxx müssen Sie mit dem Namen Ihres Thunderbird Profiles ersetzen)
Kopieren Sie nun Ihre Profildaten von Ihrem USB-Medium in das neu erstellte Verzeichnis „C:\Data\Thunderbird\Postamt-Office xxx“.
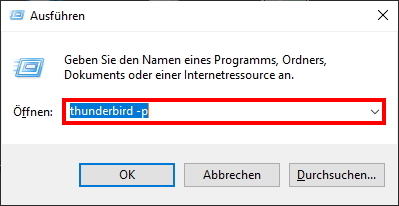
Nach Abschluss des Kopiervorgangs müssen Sie Ihr neues Profil Verzeichnis noch in der Thunderbird Installtion einrichten.
Drücken Sie auf der Tastatur die Tasten <Windows Key>+<R>. Der Dialog „Ausführen” öffnet sich. Dort geben Sie im Screenshot „rot“ eingerahmten Befehl “thunderbird -p” ein und drücken die auf „OK“.
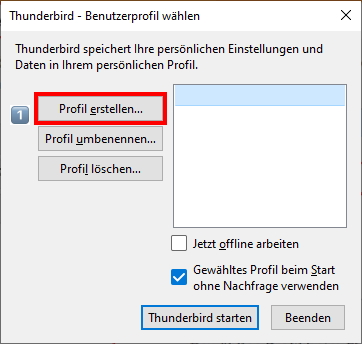
Im neu geöffneten Fenster „Thunderbird – Benutzerprofil wählen“ klicken Sie auf den Eintrag „Profil erstellen“.
Im 1. Fenster des „Profil-Assistent – Willkommen“ klicken Sie auf „Weiter“.
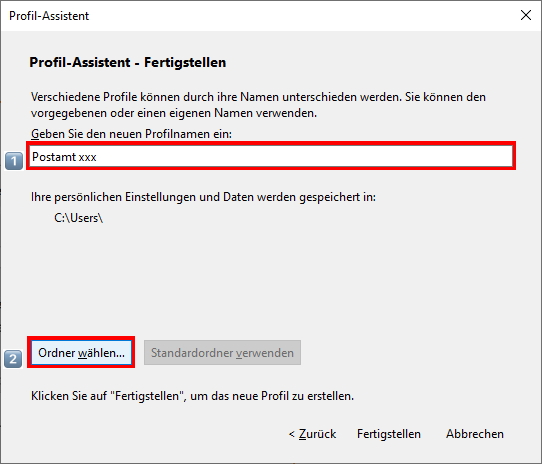
Im 2. Fenster des „Profil-Assistent – Fertigstellen” tragen Sie unter “1“ den „Profilnamen“ (Postamt xxx) ein. Unter „2“ wählen Sie den Profilpfad durch klicken auf „Ordner wählen“ aus. (C:\Daten\Thunderbird\Postamt xxx).
Zum Abschließen der Einrichtung Ihres Thunderbird Profils, müssen Sie nur noch auf „Fertigstellen“ drücken Sie können ab jetzt Thunderbird normal über die Startleiste starten – alle Ihre e-Mails & Einstellungen sind nun wiederhergestellt.
Wenn Sie Fragen oder Anregungen haben können Sie uns gerne eine E-Mail schreiben oder einen Kommentar hier hinterlassen. Wenn Sie diese kleine Anleitung hilfreich finden, freuen wir uns wenn Sie diesen Artikel mit Ihren Freunden und Bekannten teilen.
In den meisten Fällen wird der Aspekt Eingabegeräte für viele bei der Einrichtung von Computerarbeitsplätzen wenige beachtet. Das stundenlange Lesen von Texten auf einem Monitor ermüdet schnell die Augen, so das dies weitaus mehr Beachtung findet, als die Verwendung geeigneter Eingabegeräte. Dabei ist es kein Geheimnis, das die falsche Computertastatur ebenfalls zu gesundheitlichen Problemen führen kann. So gibt es beispielsweise Auflagekissen für den Handballen, damit das Handgelenk nicht stark angewinkelt werden muss. Auch das lange Überspreizen der einzelnen Finger um beim Tippen die Sonderzeichen zu erreichen, kann auf Dauer zu sehr schmerzhaften Sehnenschneidentzündungen führen. Ein Umstand der vor allem für Programmierer mit dem falschen Tastaturlayout zum Tragen kommt. Wird dann die Ursache nicht abgestellt, kann die Entzündung sogar chronisch werden.
Sie sehen schon, es ist durchaus nicht verkehrt sich ein wenig Gedanken über die Wahl der eigenen Tastatur zu machen. Dabei gibt es neben den gesundheitlichen Aspekten auch ein paar praktische Überlegungen, die ich in diesem kleinen Überblick zusammen getragen habe.
Angestöpselt
Einer der ersten Gründe mich etwas intensiver mit dem Thema Tastaturen zu beschäftigen war die Konnektivität. Kabelgebunden oder doch besser Funk? Nun ja wem bereits einmal die Batterien während einer wichtigen Arbeit ausgegangen sind, wird entweder sehr stark darauf achten immer ausreichend Ersatz griffbereit zu haben oder entscheidet sich grundsätzlich für ein Keyboard mit Kabel. Ich persönlich habe mich für die erstere Variante entschieden. Als zusätzliches Sicherheitsnetz habe ich auch ein kabelgebundenes Ersatzgerät im Schrank deponiert. Es wäre für mich nicht das erste Mal, das ich nachdem ich Kaffee zwischen den einzelnen Tasten verteilt habe auf mein Backup zurückgreifen muss, bis ein geeigneter Austausch möglich ist.
In Zeiten von Tablets und Hybridgeräten wie beispielsweise das Surface von Microsoft ist es nicht verkehrt von Beginn an gleich auf ein Bluetooth Gerät zu setzen. Der Grund ist das oft nicht genügend USB Anschlüsse frei sind und das Hantieren mit Verteilern etwas umständlich ist. Bei der Verbindung über Bluetooth bleibt der USB Anschluss für andere Geräte frei. Leider ist es nicht möglich die gleiche Tastatur bei mehreren Geräten gleichzeitig zu registrieren. Die vom Hersteller angebotenen Covertastaturen konnten mich bisher nicht überzeugen, auch wenn diese durchaus ihren praktischen Nutzen haben.
Ein sehr wichtiger Punkt ist für mich auch das die Tasten möglichst beleuchtet sind. Da ich viel auf Reisen bin und nicht immer optimale Lichtverhältnisse habe, sind illuminierte Keybords für mich vornehmlich die erste Wahl. Das trifft natürlich in erster Linie auf Laptoptastaturen zu. Bisher habe ich noch keine kabellose Tastatur mit Beleuchtung ausfindig machen können. Der Grund liegt vermutlich im höheren Stromverbrauch, was die Batterien sehr schnell entleeren würde. Viele argumentieren an dieser Stelle, das man doch blind schrieben kann. Das ist schon richtig, wenn man es kann. Ich zähle leider nicht dazu, auch wenn ich es hin und wieder versucht habe zu erlernen.
Wer wiederum mit einer Dockingstation für den stationären Einsatz arbeitet erspart sich das regelmäßige umständliche Aufbauen des Arbeitsplatzes. Gerade beim Umgang mit Laptops habe ich mir angewöhnt mit einer externen Maus zu arbeiten und das Touchpad rigoros zu deaktivieren. Zu oft passiert es mir während des Schreibens, das bei aktiviertem Touchpad der Courser irgendwo an eine andere Stelle im Text springt und ich dann mühselig alles ausbessern darf. Glücklicherweise haben die meisten Laptops hierfür Funktionstasten, die schnell erreichbar sind, falls doch zurück gewechselt werden muss.
Gefühlsecht
Für so machen ist auch das haptische Gefühl beim Tastenanschlag wichtig. Aus diesem Grund probiere ich meine Tastatur vorher gern aus und bevorzuge den Kauf direkt im Laden. Es sei den ich bestelle ein Ersatz. Während das Sounddesign, wie es bei mechanischen Tastaturen der Fall ist und das richtige “klack” Geräusch für mich eher unwichtig ist. Lieber leiser als laut. Eine zu laute Geräuschkulisse ist auch weniger geeignet, wenn das Büro mit Kollegen geteilt wird. Gerade bei Kundentelefonaten können Tippgeräusche sehr störend wirken.
Ergonomische Tastaturen mit angewinkeltem Layout in V-Form sind auch eher nichts für mich. Vor langer Zeit hatte ich ein solch ein Keyboard von Microsoft, der Tastenanschlag war ein Traum und auch die Handgelenke sind nicht so schnell ermüdet. Auch wenn die Position der Hände durch die Form optimal ist, war der Bruch zwischen den Tasten nicht so leicht zu bewerkstelligen. Die fehlende Beleuchtung war dann das zusätzliche Knockout Kriterium. Genauso ein no go ist eine zu kurz geratene Entertaste. Solche Kleinigkeiten stören meinen Arbeitsfluss ungemein, das ich sehr auf solche Details achte.
Eine sehr spaßige Variante die ich unbedingt einmal Ausprobieren wollte war eine flexible vollständig in Silikon gehüllte und aufrollbare Tastatur. Grundsätzlich keine Schlechte Idee, vor allem in industriellen Einsatz. Zudem würde das meine hin und wieder auftretenden Unfälle mit der Kaffeetasse deutlich entschärfen. Auch wenn das gesamte Design sehr flach gehalten ist, kann ich diese spezielle Variante für den regelmäßigen Gebrauch weniger empfehlen. Der Tastenanschlag ist einfach nicht sensitiv genug und man muss sehr hart drücken, damit die Eingabe auch angenommen wird.
Zeichensalat
Kommen wir nun zum nächsten Punkt, dem Tastaturlayout. Hier haben wir die Wahl der Qual. Welcher Zeichensatz soll es sein? Deutsch oder Englisch? Wer ausschließlich programmiert, wird wegen der leichter erreichbaren Sonderzeichen wie Klammern und Semikolon durchaus seine Präferenz auf das US Layout legen.
Wer aber viel Text zu schreiben hat legt hingegen viel Wert auf die leichte Erreichbarkeit von beispielsweise deutschen Umlauten. Kommen täglich einige Seiten zusammen wird man und auch Frau sich erst einmal bewusst wie viele Umlaute in so einem Text zusammen kommen. Dazu auch eine kleine Anekdote die mir vor vielen Jahren einmal passiert ist.
Auf einer Reise nach Barcelona, zu einer Zeit als es noch keine Smartphones gab, führte mich mein Weg in ein Internet Café um nachzuschauen ob eine wichtige E-Mail eingetroffen ist. Dank Web Access ist das in aller Regel auch kein Problem. Meistens jedenfalls. Als ich auf der spanischen Tastatur nun ein Umlaut für das Passwort eingeben wollte, stand ich vor einem Problem. Die Lösung war in diesem Moment Google mit Copy and Paste.
Es gibt übrigens eine elegantere Methode deutsche Sonderzeichen auf einer englischen Tastatur einzugeben. Als voraussetzungslos muss der Nummernblock eingeschaltet sein. Dann die <ALT> Taste gedrückt halten und den 4 stelligen Zahlencode eingeben. Nachdem Loslassen der <ALT> Taste erscheint dann das Sonderzeichen.
Auf Android haben die meisten Bildschirmtastaturen die Sonderzeichen hinter den entsprechenden Buchstaben verborgen. Dazu muss man lediglich länger auf den Buchstaben drücken bis eine Auswahl auf geht, die dann Umlaute zur Auswahl anbietet. Falls Sie ein Telefon haben, das diese Möglichkeit nicht unterstützt, gibt es die Möglichkeit beispielsweise das Microsoft SwiftKey Keybord zu installieren.
Eine sehr spannende Lösung, mit der sämtliche Probleme behandelt werden ist das Euro Key Layout von Steffen Brüntjen (https://eurkey.steffen.bruentjen.eu). Dieses Layout richtet sich an Übersetzer und Programmierer. Als Grundlage wurde das englische QUERZ System hergenommen und unter GNU Version 3 veröffentlicht. Laut FAQ gibt es wohl auch eine Unterstützung für Linux Betriebssysteme. Da ich bereits ein Keyboard in Verwendung hatte, das zwischen der <Backspace> und der <Enter> Taste auch eine Zwischentaste eingefügt hatte, kann ich sagen das ich kein geeigneter Kandidat für die Verwendung bin.
Resümee
Als das Thema von Sandra Parsik und Daniel Zenzes in Ihrem Podcast Ready For Review zur Sprache gekommen ist, war dies für mich Anlass auch einmal meine Erfahrungen zu rekapitulieren. Schnell wurde mir bewusst, das ich auch so einiges beitragen kann, was zu diesem Artikel hier geführt hat.
Eins bleibt zu guter Letzt noch aus. Die Gretchen-Frage, welche Tastatur ich selbst nutze. Aktuell ist dies das Wireless Ultra Slim Touche Keyboard von Rapoo. Der Grund für diese Wahl ist recht einfach. Zum einem ist der Stromverbrauch sehr gering und die beiden AA Batterien reichen bei starker Nutzung problemlos bis zu 4 Monate. Ein Andere Aspekt ist das haptische Gefühl beim Tippen und natürlich auch der unschlagbare Preis von knapp 30 €. Großes Manko ist die fehlende Beleuchtung, die ich mit einer sehr hochwertigen Schreibtisch LED wieder ausgeglichen habe. Dafür sind sämtliche Laptops mit beleuchten Tasten ausgestattet.
Als Maus Nutze ich noch die Logitech MX Anwhere 25. Die zeichnet sich insbesondere dadurch aus, das sie auch auf Glasoberflächen funktioniert. Auch die Konnektivität kann sich sehen lassen. Wireless und Bluetooth sind sowohl als auch vorhanden. Die Aufladung erfolgt per USB und ganz wichtig, während des Ladevorgangs kann die Maus auch benutzt werden und die Batterie hält je nach Nutzung zwischen 4-6 Wochen. Als Linux Nutzer kann ich auch bestätigen das die Maus unter Linux einen eigenen Treiber (https://pwr-solaar.github.io/Solaar/) hat und bestens funktioniert.
Viele Ideen sind auf dem Papier hervorragend. Oft fehlt aber das Wissen wie man brillante Konzepte in den eigenen Alltag einbauen kann. Dieser kleine Workshop soll die Lücke zwischen Theorie und Praxis schließen und zeigt mit welchen Maßnahmen man langfristig zu einer stabile API gelangt.
(c) 2021 Marco Schulz, Java PRO Ausgabe 1, S.31-34
Bei der Entwicklung kommerzieller Software ist vielen Beteiligten oft nicht klar, das die Anwendung für lange Zeit in Benutzung sein wird. Da sich unsere Welt stetig im Wandel befindet, ist es leicht abzusehen, dass im Laufe der Jahre große und kleine Änderungen der Anwendung ausstehen werden. Zu einer richtigen Herausforderung wird das Vorhaben, wenn die zu erweiternde Anwendung nicht für sich isoliert ist, sondern mit anderen Systemkomponenten kommuniziert. Denn das bedeutet für die Konsumenten der eigenen Anwendung in den meisten Fällen, das sie ebenfalls angepasst werden müssen. Ein einzelner Stein wird so schnell zu einer Lawine. Mit einem guten Lawinenschutz lässt sich die Situation dennoch beherrschen. Das gelingt aber nur, wenn man berücksichtigt, das die im nachfolgenden beschriebenen Maßnahmen ausschließlich für eine Prävention gedacht sind. Hat sich die Gewalt aber erst einmal entfesselt, kann ihr kaum noch etwas entgegengesetzt werden. Klären wir deshalb zu erst was eine API ausmacht.
Verhandlungssache
Ein Softwareprojekt besteht aus verschieden Komponenten, denen spezialisierte Aufgaben zuteil werden. Die wichtigsten sind Quelltext, Konfiguration und Persistenz. Wir befassen uns hauptsächlich mit dem Bereich Quelltext. Ich verrate keine Neuigkeiten, wenn ich sage dass stets gegen Interfaces implementiert werden soll. Diese Grundlage bekommt man bereits in der Einführung der Objektorientierten Programmierung vermittelt. Bei meiner täglichen Arbeit sehe ich aber sehr oft, das so manchem Entwickler die Bedeutung der Forderung gegen Interfaces zu Entwickeln, nicht immer ganz klar ist, obwohl bei der Verwendung der Java Standard API, dies die übliche Praxis ist. Das klassische Beispiel hierfür lautet:
List<String>collection=newArrayList<>();
Java
Diese kurze Zeile nutzt das Interface List, welches als eine ArrayList implementiert wurde. Hier sehen wir auch, das keine Anhängsel in Form eines I die Schnittstelle kennzeichnet. Auch die zugehörige Implementierung trägt kein Impl im Namen. Das ist auch gut so! Besonders bei der Implementierungsklasse könnten ja verschiedene Lösungen erwünscht sein. Dann ist es wichtig diese gut zu kennzeichnen und leicht durch den Namen unterscheidbar zu halten. ListImpl und ListImpl2 sind verständlicherweise nicht so toll wie ArrayList und LinkedList auseinander zu halten. Damit haben wir auch schon den ersten Punk einer stringenten und sprechenden Namenskonvention klären können.
Im nächsten Schritt beschäftigen uns die Programmteile, welche wir möglichst nicht für Konsumenten der Anwendung nach außen geben wollen, da es sich um Hilfsklassen handelt. Ein Teil der Lösung liegt in der Struktur, wie die Packages zu organisieren sind. Ein sehr praktikabler Weg ist:
Bereits über diese simple Architektur signalisiert man anderen Programmierern, das es keine gute Idee ist Klassen aus dem Package helper zu benutzen. Ab Java 9 gibt es noch weitreichendere Restriktion, das Verwenden interner Hilfsklassen zu unterbinden. Die Modularisierung, welche mit dem Projekt Jingsaw [1] in Java 9 Einzug genommen hat, erlaubt es im Moduldescriptor module-info.java Packages nach außen hin zu verstecken.
Separatisten und ihre Flucht vor der Masse
Schaut man sich die meisten Spezifikationen etwas genauer an, so stellt man fest, das viele Schnittstellen in eigene Bibliotheken ausgelagert wurden. Technologisch betrachtet würde das auf das vorherige Beispiel bezogen bedeuten, dass das Package business welches die Interfaces enthält in eine eigene Bibliothek ausgelagert wird. Die Trennung von API und der zugehörigen Implementierung erlaubt es grundsätzlich Implementierungen leichter gegeneinander auszutauschen. Es gestattet außerdem einem Auftraggeber eine stärkeren Einfluss auf die Umsetzung seines Projektes bei seinem Vertragspartner auszuüben, indem der Hersteller die API durch den Auftraggeber vorgefertigt bekommt. So toll wie die Idee auch ist, damit es dann auch tatsächlich so klappt, wie es ursprünglich gedacht wurde, sind aber ein paar Regeln zu beachten.
Beispiel 1: JDBC. Wir wissen, das die Java Database Connectivity ein Standard ist, um an eine Applikation verschiedenste Datenbanksysteme anbinden zu können. Sehen wir von den Probleme bei der Nutzung von nativem SQL einmal ab, können JDBC Treiber von MySQL nicht ohne weiteres durch postgreSQL oder Oracle ersetzt werden. Schließlich weicht jeder Hersteller bei seiner Implementierung vom Standard mehr oder weniger ab und stellt auch exklusive Funktionalität des eigene Produktes über den Treiber mit zu Verfügung. Entscheidet man sich im eigenen Projekt massiv diese Zusatzfeatures nutzen zu wollen, ist es mit der leichten Austauschbarkeit vorüber.
Beispiel 2: XML. Hier hat man gleich die Wahl zwischen mehreren Standards. Es ist natürlich klar das die APIs von SAX, DOM und StAX nicht zueinander kompatibel sind. Will man beispielsweise wegen einer besseren Performance von DOM zum ereignisbasierten SAX wechseln, kann das unter Umständen umfangreiche Codeänderungen nach sich ziehen.
Beispiel 3: PDF. Zu guter letzt habe ich noch ein Szenario von einem Standard parat, der keinen Standard hat. Das Portable Document Format selbst ist zwar ein Standard wie Dokumentdateien aufgebaut werden, aber bei der Implementierung nutzbarer Programmbibliotheken für die eigene Anwendung, köchelt jeder Hersteller sein eigenes Süppchen.
Die drei kleinen Beispiele zeigen die üblichen Probleme auf die im täglichen Projektgeschäft zu meistern sind. Eine kleine Regel bewirkt schon großes: Nur Fremdbibliotheken nutzen, wenn es wirklich notwendig ist. Schließlich birgt jede verwendete Abhängigkeit auch ein potenzielles Sicherheitsrisiko. Es ist auch nicht notwendig eine Bibliothek von wenigen MB einzubinden um die drei Zeile einzusparen, die benötigt werden um einen String auf leer und null zu prüfen.
Musterknaben
Wenn man sich für eine externe Bibliothek entschieden hat, so ist es immer vorteilhaft sich anfänglich die Arbeit zu machen und die Funktionalität über eine eigene Klasse zu kapseln, welche man dann exzessiv nutzen kann. In meinem persönlichen Projekt TP-CORE auf GitHub [2] habe ich dies an mehreren Stellen getan. Der Logger kapselt die Funktionalität von SLF4J und Logback. Im Vergleich zu den PdfRenderer ist die Signatur der Methoden von den verwendeten Logging Bibliotheken unabhängig und kann somit leichter über eine zentrale Stelle ausgetauscht werden. Um externe Bibliotheken in der eigenen Applikation möglichst zu kapseln, stehen die Entwurfsmuster: Wrapper, Fassade und Proxy zur Verfügung.
Wrapper: auch Adaptor Muster genannt, gehört in die Gruppe der Strukturmuster. Der Wrapper koppelt eine Schnittstelle zu einer anderen, die nicht kompatibel sind.
Fassade: ist ebenfalls ein Strukturmuster und bündelt mehrere Schnittstellen zu einer vereinfachten Schnittstelle.
Proxy: auch Stellvertreter genannt, gehört ebenfalls in die Kategorie der Strukturmuster. Proxies sind eine Verallgemeinerung einer komplexen Schnittstelle. Es kann als Komplementär der Fassade verstanden werden, die mehrere Schnittstellen zu einer einzigen zusammenführt.
Sicher ist es wichtig in der Theorie diese unterschiedlichen Szenarien zu trennen, um sie korrekt beschreiben zu können. In der Praxis ist es aber unkritisch, wenn zur Kapselung externer Funktionalität Mischformen der hier vorgestellten Entwurfsmuster entstehen. Für alle diejenigen die sich intensiver mit Design Pattern auseinander Setzen möchten, dem sei das Buch „Entwurfsmuster von Kopf bis Fuß“ [3] ans Herz gelegt.
Klassentreffen
Ein weiterer Schritt auf dem Weg zu einer stabilen API ist eine ausführliche Dokumentation. Basierend auf den bisher besprochenen Schnittstellen, gibt es eine kleine Bibliothek mit der Methoden basierend der API Version annotiert werden können. Neben Informationen zum Status und der Version, können für Klassen über das Attribute consumers die primäre Implementierungen aufgeführt werden. Um API Gaurdian dem eigenen Projekt zuzufügen sind nur wenige Zeilen der POM hinzuzufügen und die Property ${version} gegen die aktuelle Version zu ersetzen.
Die Auszeichnung der Methoden und Klassen ist ebenso leicht. Die Annotation @API hat die Attribute: status, since und consumers. Für Status sind die folgenden Werte möglich:
DEPRECATED: Veraltet, sollte nicht weiterverwendet werden.
EXPERIMENTAL: Kennzeichnet neue Funktionen, auf die der Hersteller gerne Feedback erhalten würde. Mit Vorsicht verwenden, da hier stets Änderungen erfolgen können.
INTERNAL: Nur zur internen Verwendung, kann ohne Vorwarnung entfallen.
STABLE: Rückwärts kompatibles Feature, das für die bestehende Major-Version unverändert bleibt.
MAINTAINED: Sichert die Rückwärtsstabilität auch für das künftige Major-Release zu.
Nachdem nun sämtliche Interfaces mit diesen nützlichen META Informationen angereichert wurden, stellt sich die Frage wo der Mehrwert zu finden ist. Dazu verweise ich schlicht auf Abbildung 1, welche den Arbeitsalltag demonstriert.
Abbildung 1: Suggestion in Netbeans mit @API Annotation in der JavaDoc
Für Service basierte RESTful APIs, gibt es ein anderes Werkzeug, welches auf den Namen Swagger [4] hört. Auch hier wird der Ansatz aus Annotationen eine API Dokumentation zu erstellen verfolgt. Swagger selbst scannt allerdings Java Webservice Annotationen, anstatt eigene einzuführen. Die Verwendung ist ebenfalls recht leicht umzusetzen. Es ist lediglich das swagger-maven-plugin einzubinden und in der Konfiguration die Packages anzugeben, in denen die Webservices residieren. Anschließend wird bei jedem Build eine Beschreibung in Form einer JSON Datei erstellt, aus der dann Swagger UI eine ausführbare Dokumentation generiert. Swagger UI selbst wiederum ist als Docker Image auf DockerHub [5] verfügbar.
Abbildung 2: Swagger UI Dokumentation der TP-ACL RESTful API.
Versionierung ist für APIs ein wichtiger Punkt. Unter Verwendung des Semantic Versioning lässt sich bereits einiges von der Versionsnummer ablesen. Im Bezug auf eine API ist das Major Segment von Bedeutung. Diese erste Ziffer kennzeichnet API Änderungen, die inkompatibel zueinander sind. Eine solche Inkompatibilität ist das Entfernen von Klassen oder Methoden. Aber auch das Ändern bestehender Singnaturen oder der Rückgabewert einer Methode erfordern bei Konsumenten im Rahmen einer Umstellung Anpassungen. Es ist immer eine gute Entscheidung Arbeiten, die Inkompatibilitäten verursachen zu bündeln und eher selten zu veröffentlichen. Dies zeugt von Stabilität im Projekt.
Auch für WebAPIs ist eine Versionierung angeraten. Die geschieht am besten über die URL, in dem eine Versionsnummer eingebaut wird. Bisher habe ich gute Erfahrungen gesammelt, wenn lediglich bei Inkompatibilitäten die Version hochgezählt wird.
Beziehungsstress
Der große Vorteil eines RESTful Service mit „jedem“ gut auszukommen, ist zugleich der größte Fluch. Denn das bedeutet das hier viel Sorgfalt walten muss, da viele Klienten versorgt werden. Da die Schnittstelle eine Ansammlung von URIs darstellt, liegt unser Augenmerk bei den Implementierungsdetails. Dazu nutze ich ein Beispiel aus meinen ebenfalls auf GitHub verfügbaren Projekt TP-ACL.
Der kurze Auszug aus dem try Block der fetchRole Methode die in der Klasse RoleService zu finden ist. Die GET Anfrage liefert für den Fall, das eine Rolle nicht gefunden wird den 404 Fehlercode zurück. Sie ahnen sicherlich schon worauf ich hinaus will.
Bei der Implementierung der einzelnen Aktionen GET, PUT, DELETE etc. einer Resource wie Rolle, genügt es nicht einfach nur den sogenannten HappyPath umzusetzen. Bereits während des Entwurfes sollte berücksichtigt werden, welche Stadien eine solche Aktion annehmen kann. Für die Implementierung eines Konsumenten (Client) ist es schon ein beachtlicher Unterschied ob eine Anfrage, die nicht mit 200 abgeschlossen werden kann gescheitert ist, weil die Ressource nicht existiert (404) oder weil der Zugriff verweigert wurde (403). Hier möchte ich an die vielsagende Windows Meldung mit dem unerwarteten Fehler anspielen.
Fazit
Wenn wir von eine API sprechen, dann bedeutet es, das es sich um eine Schnittstelle handelt, die von anderen Programmen genutzt werden kann. Der Wechsel eine Major Version indiziert Konsumenten der API, das Inkompatibilität zur vorherigen Version vorhanden ist. Weswegen möglicherweise Anpassungen erforderlich sind. Dabei ist es völlig irrelevant um welche Art API es sich handelt oder ob die Verwendung der Anwendung öffentlich beziehungsweise fetchRole Methode, die Unternehmensintern ist. Die daraus resultierenden Konsequenzen sind identisch. Aus diesem Grund sollte man sich mit den nach außen sichtbaren Bereichen seiner Anwendung gewissenhaft auseinandersetzen.
Arbeiten, welche zu einer API Inkompatibilität führen, sollten durch das Release Management gebündelt werden und möglichst nicht mehr als einmal pro Jahr veröffentlicht werden. Auch an dieser Stelle zeigt sich wie wichtig regelmäßige Codeinspektionen für eine stringente Qualität sind.
Das Scheitern von Projekten ist Gegenstand vieler Publikationen. Seit Jahrzehnten versucht man diesem Umstand durch verschiedenste Methodiken und Werkzeuge mehr oder minder erfolgreich beizukommen. Obwohl auf den ersten Blick die Gründe eines Misserfolges mannigfaltig scheinen, kann überwiegend schlechtes Management als Problemquelle identifiziert werden. So verweist auch der nachfolgend übersetzte Artikel von Yegor Bugayenko, welche Umstände dafür sorgen tragen können, das Projekte in schlechtes Fahrwasser geraten.
Wartbarkeit gehört zu den wertvollsten Tugenden moderner Software Entwicklung. Eine einfache Möglichkeit Wartbarkeit zu messen, besteht darin die Arbeitszeit zu messen, welche ein Entwickler benötigt um in einem neuen Projekt eigenständig ernsthafte Änderungen vorzunehmen. Je mehr Zeit benötigt wird um so schlechter ist die Wartbarkeit. In einigen Projekten ist diese Zeitanforderung beinahe unendlich. Was einfach ausgedrückt bedeutet, das diese Projekte schlichtweg nicht wartbar sind. Ich glaube das es sieben fundamentale und fatale Anzeichen gibt, das Projekte unwartbar werden. Hier sind sie:
1. Anti-Pattern
Unglücklicherweise sind die Programmiersprachen, welche wir benutzen zu flexibel. Sie ermöglichen zu viel und unterbinden zu wenig. Java zum Beispiel, besitzt keine Restriktionen ein ganze Anwendung mit ein paar tausend Methoden in nur eine Klasse zu packen. Technisch gesehen wird die Anwendung kompilieren und laufen, dennoch handelt es sich um das bekannte Anti-Pattern God Object.
Somit sind Anti-Pattern technisch akzeptierte Möglichkeiten eines Entwurfes, welcher allgemein als schlecht anerkannt ist. Es gibt für ede Sprache unzählige Anti-Pattern. Ihre Gegenwartin unserem Produkt is gleichzusetzen mit einem Tumor in einem lebendem Organismus. Wenn er einmal beginnt zu wachsen ist es sehr schwierig ihm Einhalt zu gebieten. Möglicherweise stirbt der gesamte Organismus. Möglicherweise muss die gesamte Anwendung neu geschrieben werden, weil sie unwartbar geworden ist.
Wenn nur einige Anti-Pattern zugelassen werden, werden denen möglicherweise schnell weitere folgen und der “Tumor” beginnt zu wachsen.
Dies trifft besonders auf objektorientierte Sprachen (Java, C++, Ruby und Phyton) zu, vor allem wegen ihrer Erblast aus prozeduralen Sprachen (C, Fortran und COBOL) und weil Entwickler zu einer imperativen und prozeduralen Denkweise neigen. Unglücklicherweise.
Übrigens empfehle ich zu der Liste von Anti-Pattern [2] einige Dinge ebenfalls als schlechte Programmierlösungen [3].
Meine einzige praktische Empfehlung an dieser Stelle ist lesen und lernen. Vielleicht helfen dieses Bücher [4] oder mein eigenes [5]. Eine generelle skeptische Einstellung zur eigenen Arbeit und keine Entspannungshaltung wenn es nur funktioniert. Genauso wie bei Krebs. Je früher es diagnostiziert wird um so größer ist die Chance zu überleben.
2. Unverfolgte Änderungen
Bei einem Blick auf die commit history sollte man in der Lage sein für jede einzelne Änderung sagen zu können was geändert wurde, wer die Änderung vorgenommen hat und warum die Änderung statt gefunden hat. Es sollte nicht mehr als einige Sekunden benötigen um diese drei Fragen zu beantworten. In den meisten Projekten ist das nicht der Fall. Hier sind einige praktische Vorschläge:
Benutze stets Tickets: Ganz gleich wie klein das Projekt oder das Team ist, selbst wenn es nur eine Person umfasst. Erzeugt stets Tickets (Z. B. GitHub Issues) für jedes Problem welches gelöst wird. Erläutert das Problem kurz im Ticket und dokumentiert die Lösungsansätze. Das Ticket sollte als temporäres Sammelbecken für alle Informationen die sich auf das Problem beziehen dienen. Alles was in Zukunft dazu beitragen kann die paar „komischen“ commits zu verstehen sollte in dem Ticket veröffentlicht werden.
Referenzieren von Tickets in den Commits: Unnötig zu erwähnen ist das jeder Commit eine Beschreibung (Message) haben muss. Commits ohne Beschreibung gehören zu einer sehr unsauberen Arbeitsweise, die ich hier nicht mehr ausführen muss. Allerdings eine saloppe Beschreibung wird den Ansprüchen ebenfalls nicht gerecht. So sollte die Beschreibung stets mit der Ticketnummer beginnen, an der gerade gearbeitet wurde. GitHub beispielsweise verknüpft automatisch Commits mit den zugehörigen Tickets um die Nachverfolgbarkeit von Änderungen zu gewährleisten.
Nicht alles löschen: Git ermöglicht sogenannte „forched“ push, welche den gesamten remote Branch überschreiben.Dies ist nur ein Beispiel wie die Entwicklungshistorie zerstört werden kann. Oft habe ich beobachten können wie Leute ihre Kommentare in GitHub gelöscht haben, um die Tickets zu bereinigen. Das ist schlichtweg falsch. Lösche niemals alles. Behaltet eure Historie ganz gleich wie schlecht oder unaufgeräumt sie erscheinen mag.
3. Ad Hoc Releases
Jedes Stück Software muss vor einer Auslieferung zum Endkunden paketiert werden. Handelt es sich um eine Java Bibliothek ist das Paketformat eine .jar Datei die in die üblichen Repositorien abgelegt wurde. Ist es eine Webapplikation muss sie auf eine Plattform installiert werden. Gleich wie groß oder klein das Produkt ist es existiert eine Standartprozedur für testen, paketieren und ausliefern.
Eine optimale Lösung könnte eine Automatisierung dieser Vorgänge sein. Dies ermöglicht eine Ausführung über die Kommandozeile mit einer einfachen Anweisung.
$ ./release.sh...DONE (took 98.7s)
Die meisten Projekte sind sehr weit entfernt von solch einem Ansatz. Ihr Releaseansatz beinhaltet einige Magie. Die Leute welche dafür verantwortlich sind, auch bekannt als DevOps, müssen lediglich einige Knöpfe drücken, irgendwo einloggen und Metriken prüfen et Cetera. Solch ein Ad Hoc Releaseprozess ist ein sehr typisches Zeichen für die gesamte Software Entwicklungsindustrie.
Ich habe einige praktische Ratschläge zu geben: automatisiert. Ich verwende rultor.com dafür, aber es steht natürlich frei jedes beliebe andere Werkzeug dafür einzusetzen. Das einzig wichtige ist das der gesamte Prozess vollständig automatisiert ist und von der Kommandozeile ausgeführt werden kann.
4. Freiwillige statische Analyse
Statische Analyse [6] ist das, was den Quelltext besser aussehen lässt. Implizit sind wir bei dem Vorgang dazu eingeladen den Code auch effektiver zu machen. Dies gelingt allerdings nur wenn das gesamte Team dazu angehalten ist den Vorgaben der statischen Analysewerkzeuge zu folgen. Ich schrieb bereits darüber in [7]. Für Java Projekte hab ich qulice.com und für Ruby Projekte rubocop verwendet. Es gibt sehr viele ähnliche Werkzeuge für nahezu jede Programmiersprache.
Jedes Tool kann verwendet werden, solange es für alle Verpflichtend ist. In vielen Projekten in denen statische Analyse in Verwendung kommt, erzeugen die Entwickler lediglich aufgehübschte Reports und behalten ihre alten Programmier-Gewohnheiten bei. Solche freiwilligen Ansätze bringen keine Verbesserungen für das Projekt. Sie erzeugen lediglich eine Illusion von Qualität.
Mein Rat ist, dass die statische Analyse ein verpflichtender Schritt der Deployment Pipline ist. Ein Build kann nur dann erfolgreich sein, wenn keine der statischen Regeln verletzt wurden.
5. Unbekannte Testabdeckung
Einfach ausgerückt bedeutet Testabdeckung in welchen Grad die Software durch Unit- oder Integrationstests getestet wurde. Je höher die Testabdeckung ist, us so mehr Code wurde durch die Testfälle ausgeführt. Offensichtlich ist eine hohe Abdeckung eine gute Sache.
Wie immer kennen viele Entwickler den Grad ihre Testabdeckung nicht. Sie messen diese Metrik einfach nicht. Vielleicht haben sie einige Testfälle aber niemand vermag zu sagen wie tief diese die Software überprüfen und welche Teile nicht getestet wurden. Diese Situation ist weitaus schlimmer als eine niedrige Testabdeckung welche jedem bekannt ist.
Eine hohe Testabdeckung ist keine Garantie für gute Qualität, das ist offensichtlich. Aber eine unbekannte Testabdeckung ist ein eindeutiger Indikator von Wartbarkeitsproblemen. Wenn eine neuer Entwickler in das Projekt integriert wird, sollte er in der Lage sein einige Änderungen vorzunehmen und sehen wie die Testabdeckung sich dadurch verändert. Idealerweise sollte wie Testabdeckung auf gleiche Weise wie statische Analyse überprüft werden. Der Buld sollte fehlschlagen wenn die Voreinstellung unterschritten wird. Idealerweise beträgt die Testabdeckung um die 80%.
6. Nonstop Entwicklung
Was ich mit nonstop meine ist Entwicklung ohne Meilensteine und Releases. Egal welche Art von Software implementiert wird, sie muss Released und die Ergebnisse regelmäßig visualisiert werden. Ein Projekt ohne eine eindeutige Releasehistorie ist ein unwartbares Chaos.
Der Grund dafür ist, das Wartbarkeit nur dann möglich ist, wenn der Quelltext gelesen und auch verstanden wurde.
Wenn ich einen Blick auf die Sourcen werfe, den zugehörigen Commits und der Release Historie sollte ich in der Lage sein zu sagen was die Intension des Autors war. Was passierte im Projekt vor einem Jahr? Wie steht es mit dem aktuellen Status? Wie sind die künftigen Schritte geplant? Alle diese Informationen müssen Bestandteil des Quelltextes sein und noch viel wichtiger, in der Git Historie.
Git Tags und GitHub Release Notes sind zwei wirkungsvolle Instrumente die mir diese Informationen zu Verfügung stellen. Nutze sie in vollem Umfang. Ebenso sollte nicht vergessen werden, das jede binäre Version des Produktes als ständiger Download verfügbar sein muss. Das bedeutet das ich in der Lage sein sollt die Version 0.1.3 herunter zu aden und zu testen, selbst wenn das Projekt bereits an der Version 3.4 arbeitet.
7. Undokumentierte Interfaces
Jede Software hat Schnittstellen, die verwendet werden sollten. Handelt es sich um eine Ruby gem, so existieren Klassen und Methoden die von Endanwendern Verwendung finden. Geht es um eine Webapplikation so gibt es Webseiten welche von einem Endbenutzer aufgerufen werden um mit der Anwendung zu interagieren. Jedes Software Projekt hat also ein Interface welches ausführlich beschreiben werden muss.
Wie mit den andern Punkten, welche bereits erwähnt wurden handelt es sich hierbei auch um Wartbarkeit. Als neuer Programmierer in einem Projekt beginnt die Einarbeitung bei den Interfaces. Jeder sollte daher verstehen was die Aufgabe des Interfaces ist und wie es benutzt werden kann.
Ich spreche von der Dokumentation für die Benutzer, nicht für Entwickler. Im allgemeinen bin ich gegen Dokumentation innerhalb der Software. An dieser Stelle stimme ich vollständig mit dem Agilen Manifest [7] überein. Funktionierende Anwendungen sind wichtiger als ausschweifende Dokumentation. Aber das meint nicht das Referenzieren auf eine externe Dokumentation welche für die Anwender gedacht ist.
Endanwender Interaktion mit der Anwendung muss sauber dokumentiert werden.
Handelt es sich um eine Bibliothek, so sind die Anwender Entwickler welche das Produkt verwenden und es nicht durch eigenen Code erweitern. Die Nutzung erfolgt ausschließlich als Black Box.
Diese Kriterien verwenden wir um Open Source Projekte für unseren Award [8] zu evaluieren.



 Unlock with Patreon
Unlock with Patreon