im Original auf Englisch auch auf DZone 04.2020 veröffentlicht
Nachdem die Gang Of Four (GOF) Erich Gamma, Richard Helm, Ralph Johnson und John Vlissides das Buch Design Patterns: Elements of Reusable Object-Oriented Software (Elemente wiederverwendbarer objektorientierter Software), wurde das Erlernen der Beschreibung von Problemmustern und deren Lösungen in fast allen Bereichen der Softwareentwicklung populär. Ebenso populär wurde das Erlernen der Beschreibung von Don’ts und Anti-Patterns.
In Publikationen, die sich mit den Konzepten der Entwurfsmuster und Anti-Pattern befassen, finden wir hilfreiche Empfehlungen für Softwaredesign, Projektmanagement, Konfigurationsmanagement und vieles mehr. In diesem Artikel möchte ich meine Erfahrungen im Umgang mit Versionsnummern für Software-Artefakte weitergeben.
Die meisten von uns sind bereits mit einer Methode namens semantische Versionierung vertraut, einem leistungsstarken und leicht zu erlernenden Regelwerk dafür, wie Versionsnummern strukturiert sein sollten und wie die einzelnen Segmente zu inkrementieren sind.
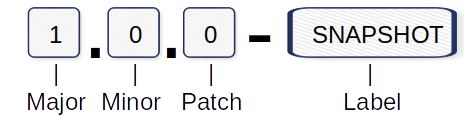
Beispiel für eine Versionsnummerierung:
Major: Inkompatible API-Änderungen.
Minor: Hinzufügen neuer Funktionen.
Patch: Fehlerbehebungen und Korrekturen.
Label: SNAPSHOT zur Kennzeichnung des Status “in Entwicklung”.
Eine inkompatible API-Änderung liegt dann vor, wenn eine von außen zugängliche Funktion oder Klasse gelöscht oder umbenannt wurde. Eine andere Möglichkeit ist eine Änderung der Signatur einer Methode. Das bedeutet, dass der Rückgabewert oder die Parameter gegenüber der ursprünglichen Implementierung geändert wurden. In diesen Fällen ist es notwendig, das Major-Segment der Versionsnummer zu erhöhen. Diese Änderungen stellen für API-Kunden ein hohes Risiko dar, da sie ihren eigenen Code anpassen müssen.
Beim Umgang mit Versionsnummern ist es auch wichtig zu wissen, dass 1.0.0 und 1.0 gleichwertig sind. Dies hat mit der Anforderung zu tun, dass die Versionen einer Softwareversion eindeutig sein müssen. Wenn dies nicht der Fall ist, ist es unmöglich, zwischen Artefakten zu unterscheiden. In meiner beruflichen Praxis war ich mehrfach an Projekten beteiligt, bei denen es keine klar definierten Prozesse für die Erstellung von Versionsnummern gab. Dies hatte zur Folge, dass das Team die Qualität des Artefakts sicherstellen musste und sich nicht mehr sicher war, mit welcher Version des Artefakts es sich gerade befasste.
Der größte Fehler, den ich je gesehen habe, war die Speicherung der Version eines Artefakts in einer Datenbank zusammen mit anderen Konfigurationseinträgen. Die korrekte Vorgehensweise sollte sein: die Version innerhalb des Artefakts so zu platzieren, dass niemand nach einem Release diese von außen ändern kann. Die Falle, in die man sonst tappt, ist der Prozess, wie man die Version nach einem Release oder Neuinstallation aktualisiert.
Vielleicht haben Sie eine Checkliste für alle manuellen Tätigkeiten während eines Release. Aber was passiert, nachdem eine Version in einer Testphase installiert wurde und aus irgendeinem Grund eine andere Version der Anwendung eneut installiert werden muss? Ist Ihnen noch bewusst, dass Sie die Versionsnummer manuell in der Datenbank ändern müssen? Wie finden Sie heraus, welche Version installiert ist, wenn die Informationen in der Datenbank nicht stimmen?
Die richtige Version in dieser Situation zu finden, ist eine sehr schwierige Aufgabe. Aus diesem Grund haben gibt es die Anforderung, die Version innerhalb der Anwendung zu halten. Im nächsten Schritt werden wir einen sicheren und einfachen Weg aufzeigen, wie man dieses Problem voll automatisiert lösen kann.
Die Voraussetzung ist eine einfache Java-Bibliothek die mit Maven gebaut wird. Standardmäßig wird die Versionsnummer des Artefakts in der POM notiert. Nach dem Build-Prozess wird unser Artefakt erstellt und wie folgt benannt: artifact-1.0.jar oder ähnlich. Solange wir das Artefakt nicht umbenennen, haben wir eine gute Möglichkeit, die Versionen zu unterscheiden. Selbst nach einer Umbenennung kann mit einem einfachen Trick nach einem Unzip des Archives im META-INF-Ordner der richtige Wert gefunden werden.
Wenn Sie die Version in einer Poroperty oder Klasse fest einkodiert haben, würde das auch funktionieren, solange Sie nicht vergessen diese immer aktuell zu halten. Vielleicht müssen Sie dem Branching und Merging in SCM Systemen wie Git besondere Aufmerksamkeit schenken, um immer die korrekte Version in Ihrer Codebasis zu haben.
Eine andere Lösung ist die Verwendung von Maven und dem Tokenreplacement. Bevor Sie dies in Ihrer IDE ausprobieren, sollten Sie bedenken, dass Maven zwei verschiedene Ordner verwendet: Sources und Ressourcen. Die Token-Ersetzung in den Quellen wird nicht richtig funktionieren. Nach einem ersten Durchlauf ist Ihre Variable durch eine feste Zahl ersetzt und verschwunden. Ein zweiter Durchlauf wird daher fehlschlagen. Um Ihren Code für die Token-Ersetzung vorzubereiten, müssen Sie Maven als erstes im Build-Lifecycle konfigurieren:
Nach diesem Schritt müssen Sie die Property ${project.version} aus dem POM kennen. Damit können Sie eine Datei mit dem Namen version.property im Verzeichnis resources erstellen. Der Inhalt dieser Datei besteht nur aus einer Zeile: version=${project.version}. Nach einem Build finden Sie in Ihrem Artefakt die version.property mit der gleichen Versionsnummer, die Sie in Ihrem POM verwendet haben. Nun können Sie eine Funktion schreiben, die die Datei liest und diese Property verwendet. Sie können das Ergebnis zum Beispiel in einer Konstante speichern, um es in Ihrem Programm zu verwenden. Das ist alles, was Sie tun müssen!
IT-Professionals bekommen schon zu Beginn ihrer Karriere kuriose Anfragen. So auch ich. Bereits während meines Studiums klingelte hin und wieder das Telefon und besonders kluge Menschen erklärten mir, wie ich für sie so etwas wie Facebook nachprogrammieren könne. Natürlich ohne Bezahlung.
(c) 2019 Marco Schulz, Java aktuell Ausgabe 2, S.64-65
Die pfiffige Idee dieser Zeitgenossen war es, das ich für sie kostenlos eine Plattform erstelle, natürlich exklusiv nach ihren Wünschen. Dank deren hervorragender Vernetzung würde das Ganze sehr schnell erfolgreich und wir könnten den Gewinn untereinander aufteilen. Ich wollte dann immer wissen, wozu ich für die Entwicklung eines Systems, dessen Kosten und Risiken ich allein zu tragen habe, einen Partner benötige, um dann mit ihm den Gewinn zu teilen. Diese Frage beendete solche Gespräche recht schnell.
Vor nicht allzu langer Zeit erreichte mich wieder einmal eine Projektanfrage mit einem umfangreichen Skill-Set zu einem offerierten Stundenlohn, der bereits für Studenten unverschämt gering ausfiele. Dies erinnerte mich an einen sehr sarkastischen Artikel von Yegor Bugayenko aus dem Jahre 2016, den ich hier ins Deutsche übertragen habe:
Um Software erstellen zu können, benötigt man Programmierer. Unglücklicherweise. Sie sind in aller Regel teuer, faul und meistens unkontrollierbar. Die Software, die sie erstellen, funktioniert vielleicht oder vielleicht auch nicht. Trotzdem erhalten sie jeden Monat ihren Lohn. Aus diesem Grund ist es immer eine gute Idee, möglichst wenig zu zahlen. Wie dem auch sei. Manchmal erklären sie einem, wie unterbezahlt sie sind, und kündigen einfach. Aber wie will man dies unterbinden? Leider ist es uns nicht mehr gestattet, gewalttätig zu sein, aber es gibt einige andere Möglichkeiten. Last mich dies genauer erläutern.
Gehälter geheim halten
Es ist offensichtlich: Sie dürfen sich nicht über ihre Gehälter austauschen. Diese Information ist geheim zu halten. Ermahnt sie oder noch besser schreibt einen Geheimhaltungs-Paragraph in ihren Vertrag, der verhindert, dass über Löhne, Boni, Vergütungspläne gesprochen wird. Sie müssen fühlen, dass diese Information giftig ist. So dass sie sich nie über dieses Thema unterhalten. Wenn das Einkommen ihrer Kollegen unbekannt ist, kommen weniger Fragen nach Gehaltserhöhungen auf.
Zufällige Lohnerhöhungen
Es sollte kein erkennbares System geben, wie Lohnerhöhungen oder Kündigungen entschieden werden. Lohnerhöhungen werden ausschließlich nach Bauchgefühl verteilt, nicht etwa, weil jemand produktiver oder effektiver wurde. Entscheidungen sollten unvorhersehbar sein. Unvorhersagbarkeit erzeugt Angst und dies ist genau das, was wir wollen. Sie sind eingeschüchtert ihrem Auftraggeber gegenüber und werden sich lange Zeit nicht beschweren, wie unterbezahlt sie sind.
Keine Konferenzen
Es sollte ihnen nicht gestattet sein, an Meetups oder Konferenzen teilzunehmen. Dort könnten sie möglicherweise auf Vermittler treffen und herausfinden, dass ihre Bezahlung nicht fair genug ist. Es sollte die Idee verbreitet werden, dass Konferenzen lediglich Zeitverschwendungen sind. Es ist besser, Veranstaltungen im Büro durchzuführen. Sie haben immer zusammenzubleiben und niemals auf Programmierer aus anderen Unternehmen zu treffen. Je weniger sie wissen, desto sicherer ist man.
Keine Heimarbeit
Das Büro muss zu einem zweiten Zuhause werden. Besser noch, zum wichtigsten Platz in ihrem Leben. Sie müssen jeden Tag anwesend sein, am Schreibtisch, mit einem Computer, einem Stuhl und einer Ablage. Sie sind emotional verbunden mit ihrem Arbeitsplatz. So wird es viel schwieriger, ihn eines Tages zu kündigen, ganz gleich wie unterbezahlt sie auch sind. Sie sollten niemals eine Erlaubnis bekommen, per Remote zu arbeiten. Sie könnten dann beginnen, von einem neuen Zuhause und einem stattlicheren Gehalt zu träumen.
Überwacht sie
Es ist dafür zu sorgen, dass sie firmeneigene Systeme wie E-Mail, Computer, Server und auch Telefone nutzen. Darauf ist dann gängige Überwachungssoftware installiert, die sämtliche Nachrichten und Aktivitäten protokolliert. Idealerweise existiert eine Sicherheitsabteilung, um die Programme zu überwachen und bei abnormalem oder unerwartetem Verhalten das Management zu informieren. Videokameras sind auch sehr hilfreich. Jeglicher Kontakt zu anderen Unternehmen ist verdächtig. Angestellte sollten wissen, dass sie überwacht werden. Zusätzliche Angst ist immer hilfreich.
Vereinbarungen mit Mitbewerbern
Kontaktiert die größten Mitbewerber der Region und stellt sicher, dass keine Entwickler abgeworben werden, solange sie dies ebenfalls nicht tun. Falls sie diese Absprache zurückweisen, ist es gut, einige ihrer Schlüsselpersonen abzuwerben. Einfach durch das In–Aussicht-Stellen des doppelten bisherigen Gehalts. Natürlich will man sie nicht wirklich engagieren. Aber diese Aktion rüttelt den lokalen Markt ordentlich durch und Mitbewerber fürchten einen. Sie sind schnell einverstanden, keine deiner Entwickler jemals zu berühren.
Etabliert gemeinsame Werte
Unterzieht sie einer regelmäßigen Gehirnwäsche in gemeinsamen Jubelveranstaltungen, in denen begeistert verkündet wird, wie toll die Firma ist, was für großartige Ziele alle haben und wie wichtig die Zusammenarbeit als Team ist. Die Zahlen auf der Gehaltsabrechnung erscheinen weniger wichtig, im Vergleich zu einem Multi-Millionen-Euro-Vorhaben, das den Markt dominieren soll. Sie werden sich dafür aufopfern und eine recht lange Zeit wird dieser Trick motivieren.
Gründe eine Familie
Gemeinsame Firmenveranstaltungen, freitags Freibier, Team-Buil-ding-Veranstaltungen, Bowling, Geburtstagsfeiern, gemeinsame Mittagessen und Abendveranstaltungen – das sind Möglichkeiten, um das Gefühl zu erzeugen, dass die gesamte Firma die einzige Familie ist. In einer Familie spricht man als gutes Mitglied auch nicht über Geld. Korrekt? Die Frage nach einer Gehaltsvorstellung gilt als Verrat an der Familie. Aus diesem Grund werden sie davon Abstand nehmen.
Stresst sie
Sie dürfen sich nicht entspannt fühlen, das ist nicht zu unserem Vorteil. Sorgt für kurze Abgabetermine, komplexe Problemlösungen und ausreichend Schuldgefühle. Niemand wird nach einer Gehaltserhöhung fragen, wenn er sich schuldig fühlt, die Projektziele wieder einmal nicht erreicht zu haben. Daher sind sie so oft wie möglich für ihre Fehler zur Verantwortung zu ziehen.
Versprechungen machen
Es ist nicht notwendig, die Versprechen einzuhalten, aber sie müssen gemacht werden. Versprecht ihnen, das Gehalt demnächst zu erhöhen oder künftige Investitionen oder die Ausfertigung eines unbefristeten Abseitsvertrags. Natürlich unter der Bedingung, dass die Zeit dafür auch reif ist. Es ist sehr wichtig, dass die Versprechungen an ein Ereignis geknüpft sind, das man selbst nicht beeinflussen kann, um die eigenen Hände stets in Unschuld zu waschen.
Kauft ihnen weiche Sessel und Tischtennisplatten
Ein paar winzige Ausgaben für diese lustigen Bürosachen werden schnell kompensiert durch den Hungerlohn, den die Entwickler ausbezahlt bekommen. Eine hübsche, professionelle Kaffeemaschine kostet 1.000 Euro und spart pro Programmierer jeden Monat zwischen 200 bis 300 Euro ein. Rechnet es aus. Erstellt eine eigene Regel, die besagt, bevor irgendjemand eine Gehaltserhöhung bekommt, ist es sinnvoller, eine neue PlayStation für das Büro zu kaufen. Erlaubt ihnen, ihre Haustiere mit ins Büro zu bringen, und sie bleiben länger für weniger Geld.
Gut klingende Titel
Bezeichnet sie als Vizepräsident, beispielsweise „VP für Entwicklung“, „technischer VP“, VP von was auch immer. Keine große Sache. Aber sehr wichtig für Angestellte. Die Bezahlung hat so weitaus weniger Stellenwert als der Titel, den sie in ihre Profile auf sozialen Netzwerken schreiben können. Wenn alle Vizepräsidenten besetzt sind, versuche einmal Senior Architekt oder Lead Technical etc.
Überlebenshilfe
Die meisten Programmierer sind etwas unbeholfen wenn es darum geht, ihr Geld zu verwalten. Sie wissen einfach nicht, wie man eine Versicherung abschließt, die Rente organisiert, oder einfach nur, wie man Steuern zahlt. Natürlich erhalten sie Hilfe, nicht unbedingt zu ihren Gunsten. Aber sie werden glücklich sein, sich in euren Händen sicher fühlen und niemals daran denken, das Unternehmen zu verlassen. Niemand wird nach einer Lohnerhöhung fragen, weil sie sich schlecht fühlen, solche Geschäfte in die eigene Hand zu nehmen. Seid ihnen Vater oder Mutter – sie werden ihre Rolle als Kind annehmen. Es ist ein bewährtes Modell. Es funktioniert.
Sei ein Freund
Das ist die letzte und wirkungsvollste Methode. Sei ein Freund der Programmierer. Es ist verflixt schwierig, mit Freunden über Geld zu verhandeln. Sie sind nicht in der Lage, das einfach in Angriff zu nehmen. Sie bleiben und arbeiten gern für weniger Geld, einfach weil wir Freunde sind. Wie man zum Freund wird? Gut. Trefft ihre Familien, lade sie zum Essen in dein Haus ein, kleine Aufmerksamkeiten zu Geburtstagen – all diese Sachen. Sie sparen eine Menge Geld. Habe ich noch etwas vergessen?
Quelle • https://www.yegor256.com/2016/12/06/how-to-pay-programmers-less.html
Im Umgang mit Source-Control-Management-Systemen (SCM) wie Git oder Subversion haben sich im Lauf der Zeit vielerlei Praktiken bewährt. Neben unzähligen Beiträgen über Workflows zum Branchen und Mergen ist auch das Formulieren verständlicher Beschreibungen in den Commit-Messages ein wichtiges Thema.
(c) 2018 Marco Schulz, Java PRO Ausgabe 3, S.50-51
Ab und zu kommt es vor, dass in kollaborativen Teams vereinzelte Code-Änderungen zurückgenommen werden müssen. So vielfältig die Gründe für ein Rollback auch sein mögen, das Identifizieren betroffener Code-Fragmente kann eine beachtliche Herausforderung sein. Die Möglichkeit jeder Änderung des Code-Repository eine Beschreibung anzufügen, erleichtert die Navigation zwischen den Änderungen. Sind die hinterlegten Kommentare der Entwickler dann so aussagekräftig wie „Layout-Anpassungen“ oder „Tests hinzugefügt“, hilft dies wenig weiter. Diese Ansicht vertreten auch diverse Blog-Beiträge [siehe Weitere Links] und sehen das Formulieren klarer Commit-Messages als wichtiges Instrument, um die interne Kommunikation zwischen einzelnen Team-Mitgliedern deutlich zu verbessern.
Das man als Entwickler nach vollbrachter Arbeit nicht immer den optimalen Ausdruck findet, seine Aktivitäten deutlich zu formulieren, kann einem hohen Termindruck geschuldet sein. Ein hilfreiches Instrument, ein aussagekräftiges Resümee der eigenen Arbeit zu ziehen, ist die nachfolgend vorgeschlagene Struktur und ein darauf operierendes aussagekräftiges Vokabular inklusive einer festgelegten Notation. Die vorgestellte Lösung lässt sich sehr leicht in die eigenen Prozesse einfügen und kann ohne großen Aufwand erweitert bzw. angepasst werden.
Mit den standardisierten Expressions besteht auch die Möglichkeit die vorhandenen Commit-Messages automatisiert zu Parsen, um die Projektevolution gegebenenfalls grafisch darzustellen. Sämtliche Einzelheiten der hier vorgestellten Methode sind in einem Cheat-Sheet auf einer Seite übersichtlich zusammengefasst und können so leicht im Team verbreitet werden. Das diesem Text zugrundeliegende Paper ist auf Research-Gate [1] in englischer Sprache frei verfügbar.
Eine Commit-Message besteht aus einer verpflichtenden (mandatory) ersten Zeile, die sich aus der Funktions-ID, einem Label und der Spezifikation zusammensetzt. Die zweite und dritte Zeile ist optional. Die Task-ID, die Issue-Management-Systeme wie Jira vergeben, wird in der zweiten Zeile notiert. Grund dafür ist, dass nicht jedes Projekt an ein Issue-Management-System gekoppelt ist. Viel wichtiger ist auch die Tatsache, dass Funktionen meist auf mehrere Tasks verteilt werden. Eine Suche nach der Funktions-ID fördert alle Teile einer Funktionalität zu tage, auch wenn dies unterschiedlichen Task-IDs zugeordnet ist. Die ausführliche Beschreibung in Zeile drei ist ebenfalls optional und rückt auf Zeile zwei vor, falls keine Task-ID notiert wird. Das gesamte Vokabular zu dem nachfolgenden Beispiel ist im Cheat-Sheet notiert und soll an dieser Stelle nicht wiederholt werden.
[CM-05] #CHANGE ’function:pom’
<QS-0815>
{Change version number of the dependency JUnit from 4 to 5.0.2}
Projektübergreifende Aufgaben wie das Anpassen der Build-Logik, Erzeugen eines Releases oder das Initiieren eines Repositories können in allgemeingültigen Funktions-IDs zusammengefasst werden. Entsprechende Beispiele sind im Cheat-Sheet angeführt.
Möchte man nun den Projektfortschritt ermitteln, ist es sinnvoll aussagekräftige Meilensteine miteinander zu vergleichen. Solche Punkte (POI) stellen üblicherweise Releases dar. So können bei Berücksichtigung des Standard-Release-Prozesses und des Semantic-Versionings Metriken über die Anzahl der Bug-Fixes pro Release erstellt werden. Aber auch klassische Erhebungen wie Lines-of-Code zwischen zwei Minor-Releases können interessante Erkenntnisse fördern.
Zu der Erkenntnis, dass Menschen Projekte machen, gelangt man nicht erst durch die Lektüre von Tom De Marcos Büchern. Aber was hat sich in den letzten Jahrzehnten tatsächlich in der professionellen Software Entwicklung getan? Trotz der vielen neuen Innovationen und Methodiken hat sich augenscheinlich nur wenig bewegt. Die Klagelieder aus den Unternehmen summen nach wie vor die gleiche Melodie.
(c) 2017 Marco Schulz, Java PRO Ausgabe 2, S.51-53
Stellen wir uns bei all dem Wandel einmal eine essentielle Frage: Kann ein Softwareprojekt heute noch erfolgreich sein, wenn es nicht auf Methoden wie Scrum setzt oder die neuesten Innovationen verwendet? Anwendungen werden Dank leistungsfähigerer Maschinen zunehmend komplexer, so dass diese nicht mehr von einzelnen Personen in ihrer Gänze überblickt werden können. Das gute Teamarbeit ein wichtiger Bestandteil erfolgreicher Projekte ist, ist seit langem auch bei den Unternehmen angekommen. Daher zählen bei Bewerbungsgesprächen mittlerweile nicht allein harte technische Fähigkeiten. Auch ausgewogene Softskills und Kommunikationsfähigkeit sind wichtige Anforderungen bei der Auswahl von neuem Personal. Daher die provokante Behauptung, dass andere Faktoren für Projekterfolge wesentlich essentieller sind als technologische Details.
Alter Wein in neuen Schläuchen?
Ganz so einfach ist es dann doch nicht. Und nicht alles Neue macht der Mai. Aus persönlicher Erfahrung wiederholt sich die Geschichte kontinuierlich, lediglich die Protagonisten können ausgetauscht werden. Stellen wir die klassischen Modelle in einen Vergleich mit agilen Techniken, können wir nur wenige essentielle Unterschiede ausmachen. Die einzelnen Stufen wie Planung, Implementierung, Testen und Ausliefern sind wenig variabel. Ob man nun den Projektleiter als Scrum-Master bezeichnet oder Releases lieber als Sprints definiert, ist Geschmackssache. Allein ein neues Vokabular genügt allerdings nicht, um von tatsächlicher Innovation zu sprechen. Ein neues Vokabular hilft aber durchaus, sich leichter von alten und möglicherweise schlechten Gewohnheiten zu lösen. Der Ansatz von Scrum ist es, das Kommunikationsproblem in Teams zu adressieren und durch Techniken aus der Rhetorik, die gemeinsamen Ziele zu visualisieren. Kurze Entwicklungszyklen ermöglichen ein schnelles Feedback um mögliche Probleme bereits zu Beginn zu erkennen und berichtigen zu können. Auf tatsächliche Bedürfnisse zügig zu reagieren sind Kernkompetenzen eines Managers. Analysiert man in einer Retrospektive was zu Fehleinschätzungen beim Management geführt hat, ist es nicht selten die mangelnde Bereitschaft sich mit technischen Zusammenhängen auseinandersetzen zu wollen. Dies ist aber essentiell, für ein Gelingen der anvisierten Ziele. Klare Anweisungen lassen sich nur dann formulieren, wenn man deren Inhalt auch versteht. Ein sehr empfehlenswerter Titel für IT Management ist von Johanna Rothman und Esther Derby „Behind closed Doors“ welches hervorragend Motivierung, Teamentwicklung und Kommunikation bespricht.
Werfen wir einmal ein Blick in ein typisches Auftaktmeeting, wenn ein neues Projekt initiiert wird. Oft ist an dieser Stelle noch keine klare Vision vorhanden. Das wiederum hat zur Folge das schwammige Anforderungen formuliert werden. Sehr klassisch ist bei nicht funktionalen Anforderungen, dass sich alle Beteiligten einig sind, dass beispielsweise eine hohe Qualität eingehalten werden muss. Es wir schnell vergessen zu definieren, was man unter Qualität versteht und wie man dies erreichen will. Lenkt man in diesen Meetings alle Beteiligten auf die Details, fehlt oft die Bereitschaft sich diesen mit der notwendigen Sorgfalt zuzuwenden. Euphorisch benennt man fix einen Qualitätsverantwortlichen, ohne ihm die notwendige Entscheidungsgewalt zuzusprechen. Zum Thema Qualität hat sich sehr ausführlich bereits im Jahre 1976 B. W. Boehm auf knapp 14 Seiten geäußert. Eine Lösung für dieses Problem wäre es, sich zu entschließen einen hohen Wert auf Coding-Standarts zu legen. Diese Konvention ermöglicht es den einzelnen Entwicklern sich schnell in die Lösungen der Kollegen einzufinden. Es gewährleistet nicht, das die Applikation robust gegen Änderungen ist und diese über einen langen Zeitraum auch wartungsfähig bleibt. Eine Entscheidung alle diese Aspekte zu bedienen hat die Konsequenz, dass damit auch die bereitzustellenden Aufwände erhöht werden müssen. Von daher gilt es, bewusst abzuwägen was tatsächlich notwendig ist. Aber verweilen wir nicht allzu lange beim Management. Es gibt viele weitere Dinge die es lohnt ein wenig stärker auszuleuchten.
Im Gleichschritt Marsch!
Nicht alle Arbeiten zählen zu den begehrtesten Beschäftigungen, dennoch müssen sie erledigt werden. Eine gute Unterstützung findet man für solche Tätigkeiten in Automatisierungsmechanismen. Dazu muss man sich auch bewusst sein, dass eine automatisierte Lösung bei komplexen Problemen sehr aufwendig gestaltet werden kann. Die damit verbundenen Kosten können sich erst dadurch amortisieren, dass die gefundene Lösung sehr häufig eingesetzt wird oder die Anfälligkeiten für Fehler während der Ausführung massiv reduziert werden. Ein hervorragendes Beispiel für diese Thematik sind Build- und Testprozesse. Nicht das Werkzeug bestimmt das Ergebnis, sondern der Prozess definiert das zu verwendende Werkzeug. Auch an dieser Stelle überschätzt sich der Mensch hin und wieder, in dem er hochkomplexe Prozesse nicht in ihre Bestandteile zerlegt, um diese dann nacheinander abzuarbeiten. Schlägt dann ein Schritt fehl ist nur dieser Teilprozess zu wiederholen. Hierzu gab es, in unterschiedlichen persönlich erlebten Situationen des Autors, ähnliche Begebenheiten. Es war notwendig die Aussage zu entkräften, weswegen es sich bei der Wahl explizit gegen Maven und bewusst für Gradle entschieden werden sollte. Das Argument für Gradle war die Möglichkeit eines frei choreographierbaren Buil-Prozesses und die damit verbundene Flexibilität. Die Notwendigkeit einer Build-Choreographie kann ein wichtiger Indikator für eine mangelhafte Architektur sein. Fehlende Kapselung und dadurch implizierte Abhängigkeiten sind die üblichen Verdächtigen. Die strikten Konventionen von Maven reduzieren hingegen das Aufkommen von unlesbaren Build-Skripten, die kaum oder nur mit erheblichem Aufwand gewartet werden können. Es ist nicht immer förderlich, volles Vertrauen an die Verantwortlichen zu delegieren, in der Absicht, dass diese optimale Ergebnisse produzieren. Zuviel Freiheit führt auch schnell zu Anarchie. In diesem Zusammenhang wäre das Argument für die Verwendung von Gradle, bereits einen Experten für diese Technologie im Hause zu haben, so schwergewichtig, dass wenig Spielräume für eine andere Wahl offen stünden.
Auch die Erstellung von Testfällen ist ein Kapitel für sich. Es grenzt schon an ein Wunder, wenn überhaupt Testfälle existieren. Wenn diese dann auch noch eine hohe Testabdeckung erzielen, könnte man meinen einen Großteil möglicher Risiken minimiert zu haben. Dass Testen nicht gleich Testen ist, skizziert die folgende Überlegung: Sehr wichtig ist zu wissen, dass das Bestehen der Testfälle keine Fehlerfreiheit garantiert. Es wird lediglich garantiert, dass die Anwendung sich entsprechend den Vorgaben der Testfälle verhält. Hierzu ist es interessant zu wissen, dass für IT-Projekte der NASA sämtliche Compiler-Meldungen für selbst entwickelte Software, die sich in Produktion befindet, behoben sein müssen. Aber auch die Aussagekraft von Testfällen lässt sich etwas ausführlicher betrachten. Die zyklomatische Komplexität nach McCabe gibt einen guten Hinweis, wie viele Testfälle für eine Methode benötigt werden. Veranschaulichen wir die Zusammenhänge an einem kleinen Beispiel. Ein Validator prüft anhand eines regulären Ausdrucks (Regex) mit der Methode validate(), ob es sich bei der Benutzereingabe um ein korrektes 24-Stunden-Format der Uhrzeit handelt. Dabei werden ausschließlich die Stunden und Minuten in zweistelliger Notation (hh:mm) angenommen. Es besteht nun die Möglichkeit einen einzigen Testfall für den regulären Ausdruck der Uhrzeit zu schreiben. Schlägt dieser Test fehl, muss der Entwickler den vorhandenen Testfall analysieren um das Problem zu identifizieren. Genauso wenig sagt die Methode testUhrzeit24hFormat() über die tatsächlichen durchgeführten Tests etwas aus. So hat man möglicherweise nicht immer im Fokus, dass Werte wie 24:00 oder 00:60 unzulässig sind, hingegen 00:00 und 23:59 gültige Einträge darstellen. Splittet man den Testfall beispielsweise in die Teile testMinuten und testStunden, so erkennt man schnell die tatsächlichen Schranken. Dieser Formalismus gestattet es zudem fehlgeschlagene Testfälle schneller bewerten zu können. Die Kombination mit dem Framework jGiven ermöglicht es deskriptive Testszenarien zu formulieren, sodass nachgelagerte manuelle Akzeptanztest weniger aufwendig gestaltet werden müssen.
Wir messen, weil wir können
Die Vermessung der Welt ist nicht allein den rein physikalischen Größen vorbehalten. Auch für Softwareprojekte bilden Metriken eine nützliche Informationsquelle. Wie bereits erläutert ist die zyklomatische Komplexität ein guter Anhaltspunkt für die Bewertung von Testfällen. Auch die klassischen Lines-of-Code (LoC) sagen einiges über die Größe eines Projektes aus. Was bei all dem Zahlenwerk oft wenig beachtet wird, sind die tatsächlichen Points-of-Intrests (PoI). Sicher kann man Äpfel mit Birnen vergleichen. Aber der Nutzen bleibt etwas fragwürdig wenn man keinen geeigneten Kontext definiert. Auch an dieser Stelle ist es wichtig sich nicht mit einer Informationsflut an Daten zu überfordern. So ist es hilfreich, die Projektentwicklung der einzelnen Release Milestones zu dokumentieren und dann zu vergleichen. Auch die Vergleichbarkeit unterschiedlicher Projekte führt zu neuen Erkenntnissen. Dabei ist es aber nicht förderlich ein Projekt, welches bereits 10 Jahre Entwicklung beschritten hat, mit einer kleinen Hilfsbibliothek zu vergleichen. Auch die Repräsentation der ermittelten Informationen ist ein nicht zu vernachlässigendes Detail. Eine grafische Darstellung lässt die Zusammenhänge leichter fassen. So ist die reine Darstellung der LoC als nackte Zahl nett zu wissen, aber eine Bewertung gestaltet sich auf diese Weise eher schwer. Ein kumulierter Chart über die Entwicklung der LoC zu den einzelnen Releases vermittelt dagegen ein recht deutliches Bild. Dies lässt sich weiter befüllen mit der Anzahl der Klassen, Interfaces, Packages und JavaDocs und all dies in Relation zur Speichergröße des fertigen Artefaktes zu setzen. Der Einsatz hochkomplexer Werkzeuge kann durch ein geeignetes Tabellenkalkulationsprogramm und Methoden des Projekt-Controllings ohne weiteres ersetzt werden. Ein Skript, das die notwendigen Rohdaten einsammelt, kann von der Entwicklungsabteilung schnell bereitgestellt werden ohne, dass ein überfrachteter Werkzeugkasten den man mit sich herum tragen muss, zu „schweren Rückenproblemen“ führt.
Informationsdschungel
Ein weiterer Blick in den Werkzeugkasten bringt nicht selten verstaubte Infrastruktur zutage, die den Anschein erweckt als reiner Selbstzweck zu fungieren. Das Unternehmens-Wiki, bei dem die meisten Einträge aus weniger als 100 Zeichen bestehen sowie eine Navigation nur vermutet werden kann, ist leider die traurige die Regel. Aussagen zum Daily-Meeting wie „Ich bin Heiko und kümmere mich auch heute wieder um die Suchfunktion“ erinnern eher an eine Selbsthilfegruppe. Das Ganze wird dann noch durch SCM-Logeinträge (SCM ist ein Tool zur Kommentierung von Issues) wie „JIRA-KM-100 update Build-Skripte“ dekoriert. Gute Kommunikation ist mehr als sich seinen Mitmenschen mitzuteilen. Reflektierte Aussagen unterstützen uns bei der Bewältigung unserer täglichen Aufgaben. Sie strukturieren zugleich unser Denken. Wenn wir beim morgendlichen Treffen mit den Kollegen hingegen sagen „Für das Erzeugen des Suchindexes implementiere ich heute die Abfragen über die Keywords in den Content-Tabellen, sodass ich morgen bereits einige Testfälle formulieren kann“, kurz und auf den Punkt gebracht, dann sind die Kollegen informiert. Ein präziser Kommentar im SCM „JIRAKM-100 Hinzufügen der Lucene-Abhängigkeiten für die Suche“ gibt schnell Aufschluss über die vorgenommenen Arbeiten ohne, dass man erst den entsprechenden Task im Issue-Managment öffnen muss, um zu sehen welche Änderungen vorgenommen wurden. Bereits diese kleinen Aufmerksamkeiten in unserer Kommunikation bewirken einen enormen Anschub in die Motivation des gesamten Teams. Jeder einzelne empfindet sich so wesentlich mehr wertgeschätzt. Funktionierende und aktuelle Anleitungen über das Einrichten des Arbeitsplatzes, Hinweise mit Beispielen zum Schreiben von Kommentaren für SCM-Commits regen die Kollegen zum Mitmachen an. Der Mehrwert einer solchen Unternehmenskultur beschränkt sich nicht einzig auf einen funktionierenden Informationsaustausch. Das höhere Ziel dieser Bestrebungen ist auf eine angenehme Weise, die Produktivität zu steigern, ohne stetig Druck ausüben zu müssen.
Lessons Learned
Wie wir sehen konnten, genügt es nicht sich allein auf eine gute Methodik wie Scrum zu verlassen, um sich von den notwendigen Vorbereitungen befreien zu können. Der Wille allein, etwas Hervorragendes zu erschaffen, ist nicht ausschlaggebend für beste Resultate. Vor den Erfolg ist stets Fleiß zu setzen. Bevor man sich in Details verliert ist es unerlässlich, das große Ganze sehen zu können. Erst wenn alle Beteiligten die gleiche Vision teilen, können sie gemeinsam in die Mission starten. Anhand der beschriebenen Beispiele kann man gut nachvollziehen, dass die vielen neuen Techniken erhebliche Möglichkeiten bieten. Diese Chancen lassen sich allerdings nur dann nutzen, wenn man zuerst die notwendigen Grundlagen tief verinnerlicht hat.
Auch wenn zur Qualitätssteigerung der Software- Projekte in den letzten Jahren ein erheblicher Mehraufwand für das Testen betrieben wurde [1], ist der Weg zu kontinuierlich wiederholbaren Erfolgen keine Selbstverständlichkeit. Stringentes und zielgerichtetes Management aller verfügbaren Ressourcen war und ist bis heute unverzichtbar für reproduzierbare Erfolge.
(c) 2016 Marco Schulz, Java aktuell Ausgabe 4, S.14-19
Es ist kein Geheimnis, dass viele IT-Projekte nach wie vor ihre liebe Not haben, zu einem erfolgreichen Abschluss zu gelangen. Dabei könnte man durchaus meinen, die vielen neuen Werkzeuge und Methoden, die in den letzten Jahren aufgekommen sind, führten wirksame Lösungen ins Feld, um der Situation Herr zu werden. Verschafft man sich allerdings einen Überblick zu aktuellen Projekten, ändert sich dieser Eindruck.
Der Autor hat öfter beobachten können, wie diese Problematik durch das Einführen neuer Werkzeuge beherrscht werden sollte. Nicht selten endeten die Bemühungen in Resignation. Schnell entpuppte sich die vermeintliche Wunderlösung als schwergewichtiger Zeiträuber mit einem enormen Aufwand an Selbstverwaltung. Aus der anfänglichen Euphorie aller Beteiligten wurde schnell Ablehnung und gipfelte nicht selten im Boykott einer Verwendung. So ist es nicht verwunderlich, dass erfahrene Mitarbeiter allen Veränderungsbestrebungen lange skeptisch gegenüberstehen und sich erst dann damit beschäftigen, wenn diese absehbar erfolgreich sind. Aufgrund dieser Tatsache hat der Autor als Titel für diesen Artikel das provokante Zitat von Grady Booch gewählt, einem Mitbegründer der UML.
Oft wenden Unternehmen zu wenig Zeit zum Etablieren einer ausgewogenen internen Infrastruktur auf. Auch die Wartung bestehender Fragmente wird gern aus verschiedensten Gründen verschoben. Auf Management-Ebene setzt man lieber auf aktuelle Trends, um Kunden zu gewinnen, die als Antwort auf ihre Ausschreibung eine Liste von Buzzwords erwarten. Dabei hat es Tom De Marco bereits in den 1970er-Jahren ausführlich beschrieben [2]: Menschen machen Projekte (siehe Abbildung 1).
Wir tun, was wir können, aber können wir etwas tun?
Das Vorhaben, trotz bester Absichten und intensiver Bemühungen ein glückliches Ende finden, ist leider nicht die Regel. Aber wann kann man in der Software-Entwicklung von einem gescheiterten Projekt sprechen? Ein Abbruch aller Tätigkeiten wegen mangelnder Erfolgsaussichten ist natürlich ein offensichtlicher Grund, in diesem Zusammenhang allerdings eher selten. Vielmehr gewinnt man diese Erkenntnis während der Nachbetrachtung abgeschlossener Aufträge. So kommen beispielsweise im Controlling bei der Ermittlung der Wirtschaftlichkeit Schwachstellen zutage.
Gründe für negative Ergebnisse sind meist das Überschreiten des veranschlagten Budgets oder des vereinbarten Fertigstellungstermins. Üblicherweise treffen beide Bedingungen gleichzeitig zu, da man der gefährdeten Auslieferungsfrist mit Personal-Aufstockungen entgegenwirkt. Diese Praktik erreicht schnell ihre Grenzen, da neue Teammitglieder eine Einarbeitungsphase benötigen und so die Produktivität des vorhandenen Teams sichtbar reduzieren. Einfach zu benutzende Architekturen und ein hohes Maß an Automatisierung mildern diesen Effekt etwas ab. Hin und wieder geht man auch dazu über, den Auftragnehmer auszutauschen, in der Hoffnung, dass neue Besen besser kehren.
Wie eine fehlende Kommunikation, unzureichende Planung und schlechtes Management sich negativ auf die äußere Wahrnehmung von Projekten auswirkt, zeigt ein kurzer Blick auf die Top-3-Liste der in Deutschland fehlgeschlagenen Großprojekte: Berliner Flughafen, Hamburger Elbphilharmonie und Stuttgart 21. Dank ausführlicher Berichterstattung in den Medien sind diese Unternehmungen hinreichend bekannt und müssen nicht näher erläutert werden. Auch wenn die angeführten Beispiele nicht aus der Informatik stammen, finden sich auch hier die stets wiederkehrenden Gründe für ein Scheitern durch Kostenexplosion und Zeitverzug.
Abbildung 1: Problemlösung – „A bisserl was geht immer“, Monaco Franze
Der Wille, etwas Großes und Wichtiges zu erschaffen, allein genügt nicht. Die Verantwortlichen benötigen auch die notwendigen fachlichen, planerischen, sozialen und kommunikativen Kompetenzen, gepaart mit den Befugnissen zum Handeln. Luftschlösser zu errichten und darauf zu warten, dass Träume wahr werden, beschert keine vorzeigbaren Resultate.
Große Erfolge werden meist dann erzielt, wenn möglichst wenige Personen bei Entscheidungen ein Vetorecht haben. Das heißt nicht, dass man Ratschläge ignorieren sollte, aber auf jede mögliche Befindlichkeit kann keine Rücksicht genommen werden. Umso wichtiger ist es, wenn der Projektverantwortliche die Befugnis hat, seine Entscheidung durchzusetzen, dies jedoch nicht mit aller Härte demonstriert.
Es ist völlig normal, wenn man als Entscheidungsträger nicht sämtliche Details beherrscht. Schließlich delegiert man die Umsetzung an die entsprechenden Spezialisten. Dazu ein kurzes Beispiel: Als sich in den frühen 2000er-Jahren immer bessere Möglichkeiten ergaben, größere und komplexere Web-Anwendungen zu erstellen, kam in Meetings oft die Frage auf, mit welchem Paradigma die Anzeigelogik umzusetzen sei. Die Begriffe „Multi Tier“, „Thin Client“ und „Fat Client“ dominierten zu dieser Zeit die Diskussionen der Entscheidungsgremien. Dem Auftraggeber die Vorteile verschiedener Schichten einer verteilten Web-Applikation zu erläutern, war die eine Sache. Einem technisch versierten Laien aber die Entscheidung zu überlassen, wie er auf seine neue Applikation zugreifen möchte – per Browser („Thin Client“) oder über eine eigene GUI („Fat Client“) –, ist schlicht töricht. So galt es in vielen Fällen, während der Entwicklung auftretende Missverständnisse auszuräumen. Die schmalgewichtige Browser-Lösung entpuppte sich nicht selten als schwer zu beherrschende Technologie, da Hersteller sich selten um Standards kümmerten. Dafür bestand üblicherweise eine der Hauptanforderungen darin, die Applikation in den gängigsten Browsern nahezu identisch aussehen zu lassen. Das ließ sich allerdings nur mit erheblichem Mehraufwand umsetzen. Ähnliches konnte beim ersten Hype der Service-orientierten Architekturen beobachtet werden.
Die Konsequenz aus diesen Beobachtungen zeigt, dass es unverzichtbar ist, vor dem Projektstart eine Vision zu erarbeiten, deren Ziele auch mit dem veranschlagten Budget übereinstimmen. Eine wiederverwendbare Deluxe-Variante mit möglichst vielen Freiheitsgraden erfordert eine andere Herangehensweise als eine „We get what we need“-Lösung. Es gilt, sich weniger in Details zu verlieren, als das große Ganze im Blick zu halten.
Besonders im deutschsprachigen Raum fällt es Unternehmen schwer, die notwendigen Akteure für eine erfolgreiche Projektumsetzung zu finden. Die Ursachen dafür mögen recht vielfältig sein und könnten unter anderem darin begründet sein, dass Unternehmen noch nicht verstanden haben, dass Experten sich selten mit schlecht informierten und unzureichend vorbereiteten Recruitment-Dienstleistern unterhalten möchten.
Getting things done!
Erfolgreiches Projektmanagement ist kein willkürlicher Zufall. Schon lange wurde ein unzureichender Informationsfluss durch mangelnde Kommunikation als eine der negativen Ursachen identifiziert. Vielen Projekten wohnt ein eigener Charakter inne, der auch durch das Team geprägt ist, das die Herausforderung annimmt, um gemeinsam die gestellte Aufgabe zu bewältigen. Agile Methoden wie Scrum [3], Prince2 [4] oder Kanban [5] greifen diese Erkenntnis auf und bieten potenzielle Lösungen, um IT-Projekte erfolgreich durchführen zu können.
Gelegentlich ist jedoch zu beobachten, wie Projektleiter unter dem Vorwand der neu eingeführten agilen Methoden die Planungsaufgaben an die zuständigen Entwickler zur Selbstverwaltung übertragen. Der Autor hat des Öfteren erlebt, wie Architekten sich eher bei Implementierungsarbeiten im Tagesgeschäft gesehen haben, anstatt die abgelieferten Fragmente auf die Einhaltung von Standards zu überprüfen. So lässt sich langfristig keine Qualität etablieren, da die Ergebnisse lediglich Lösungen darstellen, die eine Funktionalität sicherstellen und wegen des Zeit- und Kostendrucks nicht die notwendigen Strukturen etablieren, um die zukünftige Wartbarkeit zu gewährleisten. Agil ist kein Synonym für Anarchie. Dieses Setup wird gern mit einem überfrachteten Werkzeugkasten voller Tools aus dem DevOps-Ressort dekoriert und schon ist das Projekt scheinbar unsinkbar. Wie die Titanic!
Nicht ohne Grund empfiehlt man seit Jahren, beim Projektstart allerhöchstens drei neue Technologien einzuführen. In diesem Zusammenhang ist es auch nicht ratsam, immer gleich auf die neuesten Trends zu setzen. Bei der Entscheidung für eine Technologie müssen im Unternehmen zuerst die entsprechenden Ressourcen aufgebaut sein, wofür hinreichend Zeit einzuplanen ist. Die Investitionen sind nur dann nutzbringend, wenn die getroffene Wahl mehr als nur ein kurzer Hype ist. Ein guter Indikator für Beständigkeit sind eine umfangreiche Dokumentation und eine aktive Community. Diese offenen Geheimnisse werden bereits seit Jahren in der einschlägigen Literatur diskutiert.
Wie geht man allerdings vor, wenn ein Projekt bereits seit vielen Jahren etabliert ist, aber im Sinne des Produkt-Lebenszyklus ein Schwenk auf neue Techniken unvermeidbar wird? Die Gründe für eine solche Anstrengung mögen vielseitig sein und variieren von Unternehmen zu Unternehmen. Die Notwendigkeit, wichtige Neuerungen nicht zu verpassen, um im Wettbewerb weiter bestehen zu können, sollte man nicht zu lange hinauszögern. Aus dieser Überlegung ergibt sich eine recht einfach umzusetzende Strategie. Aktuelle Versionen werden in bewährter Tradition fortgesetzt und erst für das nächste beziehungsweise übernächste Major-Release wird eine Roadmap erarbeitet, die alle notwendigen Punkte enthält, um einen erfolgreichen Wechsel durchzuführen. Dazu erarbeitet man die kritischen Punkte und prüft in kleinen Machbarkeitsstudien, die etwas anspruchsvoller als ein „Hallo Welt“- Tutorial sind, wie eine Umsetzung gelingen könnte. Aus Erfahrung sind es die kleinen Details, die das Krümelchen auf der Waagschale sein können, um über Erfolg oder Misserfolg zu entscheiden.
Bei allen Bemühungen wird ein hoher Grad an Automatisierung angestrebt. Gegenüber stetig wiederkehrenden, manuell auszuführenden Aufgaben bietet Automatisierung die Möglichkeit, kontinuierlich wiederholbare Ergebnisse zu produzieren. Dabei liegt es allerdings in der Natur der Sache, dass einfache Tätigkeiten leichter zu automatisieren sind als komplexe Vorgänge. Hier gilt es, zuvor die Wirtschaftlichkeit der Vorhaben zu prüfen, sodass Entwickler nicht gänzlich ihrem natürlichen Spieltrieb frönen und auch unliebsame Tätigkeiten des Tagesgeschäfts abarbeiten.
Wer schreibt, der bleibt
Dokumentation, das leidige Thema, erstreckt sich über alle Phasen des Software-Entwicklungsprozesses. Ob für API-Beschreibungen, das Benutzer-Handbuch, Planungsdokumente zur Architektur oder erlerntes Wissen über optimales Vorgehen – das Beschreiben zählt nicht zu den favorisierten Aufgaben aller beteiligten Protagonisten. Dabei lässt sich oft beobachten, dass anscheinend die landläufige Meinung vorherrscht, dicke Handbücher ständen für eine umfangreiche Funktionalität des Produkts. Lange Texte in einer Dokumentation sind jedoch eher ein Qualitätsmangel, der die Geduld des Lesers strapaziert, weil dieser eine präzise auf den Punkt kommende Anleitung erwartet. Stattdessen erhält er schwammige Floskeln mit trivialen Beispielen, die selten problemlösend sind.
Abbildung 2: Test Coverage mit Cobertura
Diese Erkenntnis lässt sich auch auf die Projekt-Dokumentation übertragen und wurde unter anderem von Johannes Sidersleben [6] unter der Metapher über viktorianische Novellen ausführlich dargelegt. Hochschulen haben diese Erkenntnisse bereits aufgegriffen. So hat beispielsweise die Hochschule Merseburg den Studiengang „Technische Redaktion“ [7] etabliert. Es bleibt zu hoffen, zukünftig mehr Absolventen dieses Studiengangs in der Projekt-Landschaft anzutreffen.
Bei der Auswahl kollaborativer Werkzeuge als Wissensspeicher ist immer das große Ganze im Blick zu halten. Erfolgreiches Wissensmanagement lässt sich daran messen, wie effizient ein Mitarbeiter die gesuchte Information findet. Die unternehmensweite Verwendung ist aus diesem Grund eine Managemententscheidung und für alle Abteilungen verpflichtend.
Informationen haben ein unterschiedliches Naturell und variieren sowohl in ihrem Umfang als auch bei der Dauer ihrer Aktualität. Daraus ergeben sich verschiedene Darstellungsformen wie Wiki, Blog, Ticketsystem, Tweets, Foren oder Podcasts, um nur einige aufzuzählen. Foren bilden sehr optimal die Frage- und Antwort-Problematik ab. Ein Wiki eignet sich hervorragend für Fließtext, wie er in Dokumentationen und Beschreibungen vorkommt. Viele Webcasts werden als Video angeboten, ohne dass die visuelle Darstellung einen Mehrwert bringt. Meist genügt eine gut verständliche und ordentlich produzierte Audiospur, um Wissen zu verteilen. Mit einer gemeinsamen und normierten Datenbasis lassen sich abgewickelte Projekte effizient miteinander vergleichen. Die daraus resultierenden Erkenntnisse bieten einen hohen Mehrwert bei der Erstellung von Prognosen für zukünftige Vorhaben.
Test & Metriken − das Maß aller Dinge
Bereits beim Überfliegen des Quality Reports 2014 erfährt man schnell, dass der neue Trend „Software testen“ ist. Unternehmen stellen vermehrt Kontingente dafür bereit, die ein ähnliches Volumen einnehmen wie die Aufwendungen für die Umsetzung des Projekts. Genau genommen löscht man an dieser Stelle Feuer mit Benzin. Bei tieferer Betrachtung wird bereits bei der Planung der Etat verdoppelt. Es liegt nicht selten im Geschick des Projektleiters, eine geeignete Deklarierung für zweckgebundene Projektmittel zu finden.
Nur deine konsequente Überprüfung der Testfall-Abdeckung durch geeignete Analyse-Werkzeuge stellt sicher, dass am Ende hinreichend getestet wurde. Auch wenn man es kaum glauben mag: In einer Zeit, in der Software-Tests so einfach wie noch nie erstellt werden können und verschiedene Paradigmen kombinierbar sind, ist eine umfangreiche und sinnvolle Testabdeckung eher die Ausnahme (siehe Abbildung 2).
Es ist hinreichend bekannt, dass sich die Fehlerfreiheit einer Software nicht beweisen lässt. Anhand der Tests weist man einzig ein definiertes Verhalten für die erstellten Szenarien nach. Automatisierte Testfälle ersetzen in keinem Fall ein manuelles Code-Review durch erfahrene Architekten. Ein einfaches Beispiel dafür sind in Java hin und wieder vorkommende verschachtelte „try catch“-Blöcke, die eine direkte Auswirkung auf den Programmfluss haben. Mitunter kann eine Verschachtelung durchaus gewollt und sinnvoll sein. In diesem Fall beschränkt sich die Fehlerbehandlung allerdings nicht einzig auf die Ausgabe des Stack-Trace in ein Logfile. Die Ursache dieses Programmierfehlers liegt in der Unerfahrenheit des Entwicklers und dem an dieser Stelle schlechten Ratschlag der IDE, für eine erwartete Fehlerbehandlung die Anweisung mit einem eigenen „try catch“-Block zu umschliessen, anstatt die vorhandene Routine durch ein zusätzliches „catch“-Statement zu ergänzen. Diesen offensichtlichen Fehler durch Testfälle erkennen zu wollen, ist aus wirtschaftlicher Betrachtung ein infantiler Ansatz.
Typische Fehlermuster lassen sich durch statische Prüfverfahren kostengünstig und effizient aufdecken. Publikationen, die sich besonders mit Codequalität und Effizienz der Programmiersprache Java beschäftigen [8, 9, 10], sind immer ein guter Ansatzpunkt, um eigene Standards zu erarbeiten.
Sehr aufschlussreich ist auch die Betrachtung von Fehlertypen. Beim Issue-Tracking und bei den Commit-Messages in SCM-Systemen der Open-Source-Projekte wie Liferay [11] oder GeoServer [12] stellt man fest, dass ein größerer Teil der Fehler das Grafische User Interface (GUI) betreffen. Dabei handelt es sich häufig um Korrekturen von Anzeigetexten in Schaltflächen und Ähnlichem. Die Meldung vornehmlicher Darstellungsfehler kann auch in der Wahrnehmung der Nutzer liegen. Für diese ist das Verhalten einer Anwendung meist eine Black Box, sodass sie entsprechend mit der Software umgehen. Es ist durchaus nicht verkehrt, bei hohen Nutzerzahlen davon auszugehen, dass die Anwendung wenig Fehler aufweist.
Das übliche Zahlenwerk der Informatik sind Software-Metriken, die dem Management ein Gefühl über die physische Größe eines Projekts geben können. Richtig angewendet, liefert eine solche Übersicht hilfreiche Argumente für Management-Entscheidungen. So lässt sich beispielsweise über die zyklische Komplexität nach McCabe [13] die Anzahl der benötigten Testfälle ableiten. Auch eine Statistik über die Lines of Code und die üblichen Zählungen der Packages, Klassen und Methoden zeigt das Wachstum eines Projekts und kann wertvolle Informationen liefern.
Eine sehr aufschlussreiche Verarbeitung dieser Informationen ist das Projekt Code-City [14], das eine solche Verteilung als Stadtplan visualisiert. Es ist eindrucksvoll Abbildung 3: Maven JDepend Plugin – Zahlen mit wenig Aussagekraft zu erkennen, an welchen Stellen gefährliche Monolithe entstehen können und wo verwaiste Klassen beziehungsweise Packages auftreten.
Abbildung 3: Maven JDepend Plugin – Zahlen mit wenig Aussagekraft
Fazit
Im Tagesgeschäft begnügt man sich damit, hektische Betriebsamkeit zu verbreiten und eine gestresste Miene aufzusetzen. Durch das Produzieren unzähliger Meter Papier wird anschließend die persönliche Produktivität belegt. Die auf diese Art und Weise verbrauchte Energie ließe sich durch konsequent überlegtes Vorgehen erheblich sinnvoller einsetzen.
Frei nach Kants „Sapere Aude“ sollten einfache Lösungen gefördert und gefordert werden. Mitarbeiter, die komplizierte Strukturen benötigen, um die eigene Genialität im Team zu unterstreichen, sind möglicherweise keine tragenden Pfeiler, auf denen sich gemeinsame Erfolge aufbauen lassen. Eine Zusammenarbeit mit unbelehrbaren Zeitgenossen ist schnell überdacht und gegebenenfalls korrigiert.
Viele Wege führen nach Rom – und Rom ist auch nicht an einem Tag erbaut worden. Es lässt sich aber nicht von der Hand weisen, dass irgendwann der Zeitpunkt gekommen ist, den ersten Spatenstich zu setzen. Auch die Auswahl der Wege ist kein unentscheidbares Problem. Es gibt sichere Wege und gefährliche Pfade, auf denen auch erfahrene Wanderer ihre liebe Not haben, sicher das Ziel zu erreichen.
Für ein erfolgreiches Projektmanagement ist es unumgänglich, den Tross auf festem und stabilem Grund zu führen. Das schließt unkonventionelle Lösungen nicht grundsätzlich aus, sofern diese angebracht sind. Die Aussage in Entscheidungsgremien: „Was Sie da vortragen, hat alles seine Richtigkeit, aber es gibt in unserem Unternehmen Prozesse, auf die sich Ihre Darstellung nicht anwenden lässt“, entkräftet man am besten mit dem Argument: „Das ist durchaus korrekt, deswegen ist es nun unsere Aufgabe, Möglichkeiten zu erarbeiten, wie wir die Unternehmensprozesse entsprechend bekannten Erfolgsstories adaptieren, anstatt unsere Zeit darauf zu verwenden, Gründe aufzuführen, damit alles beim Alten bleibt. Sie stimmen mir sicherlich zu, dass der Zweck unseres Treffens darin besteht, Probleme zu lösen, und nicht, sie zu ignorieren.“ … more voice
Für die Integration in IDEs ist es unerheblich, bei welcher IDE Ihre persönlichen Präferenzen angesiedelt sind, der Funktionsumfang der Integration ist in beiden IDEs weitgehend identisch und unterscheidet sich nur in Details. Während NetBeans von Haus aus Maven-Projekte unterstützt, ist für die meisten Eclipse-Distributionen die zusätzliche Installation des Eclipse-Maven-Plug-ins m2e notwendig.
Der Vorteil, die Funktionalitäten von Maven innerhalb einer IDE nutzen zu können, ist enorm. Ein Aspekt ist beispielsweise der Import bestehender Maven-Projekte in die Entwicklungsumgebung. Anhand der POM werden die notwendigen Konfigurationen des gesamten Projekts wie zum Beispiel Verzeichnisse für Sourcen, Test und Dependencies aus der POM gelesen. Ein mühseliges Adaptieren der Projekteigenschaften nach einem Import entfällt ebenso wie das Verteilen der IDE-Konfiguration über das Konfigurationsmanagement. Dadurch hat der Entwickler mehr Freiheit bei der Wahl seiner Entwicklungsumgebung. Eine Grundvoraussetzung für den erfolgreichen Import eines Projekts in eine IDE ist, dass die verwendeten Dependencies lokal oder remote verfügbar sind. Hin und wieder kommt es vor, dass einzelne Artefakte manuell in das lokale Repository installiert werden müssen. Diese Aufgabe lässt sich in beiden IDEs sehr komfortabel mit wenigen Mausklicks bewerkstelligen und ein optisches Feedback des Erfolgs kann über die Views der Repository-Browser eingeholt werden.
Ältere Projekte, die nicht im Maven-Format vorliegen und damit nicht die notwendige Verzeichnisstruktur und POM aufweisen, lassen sich in den meisten Fällen über die Konsole automatisiert migrieren. Der schnellere Weg ist allerdings eine manuelle Migration, da die automatisch generierte POM in aller Regel im Nachhinein weiter von Hand angepasst werden muss. Über Archetypes werden die Verzeichnisstruktur und die POM erzeugt. Im zweiten Schritt sind die Sourcen et cetera in die entsprechenden Verzeichnisse zu kopieren, um abschließend die Dependencies zu konfigurieren. In späteren Arbeitsschritten kann die POM den Projektanforderungen weiter angepasst werden.
Eine wichtige Eigenschaft ist unter anderem auch die Möglichkeit, das vorhandene Maven Build-in der IDEs durch eine eigene Maven-Installation auszutauschen. Der Vorteil einer externen Installation ergibt sich aus dem größtmöglichen Einfluss auf den Entwicklungsprozess, da beispielsweise festgelegt wird, welche Version von Maven verwendet wird. Vor allem, wenn stets auf die neueste Version zurückgegriffen werden soll, ist diese Option von unschätzbarem Wert, das es meist einige Zeit dauert, bis das entsprechende Plug-in aktualisiert wird.
Die größten Unterschiede zwischen NetBeans und Eclipse finden sich bei der Bearbeitung der POM. Während NetBeans auf eine Code-Vervollständigung setzt, bietet Eclipse einen grafischen POM-Editor. Für den korrekten Betrieb von Maven ist die Auszeichnung der Schemadefinition der POM nicht notwendig. Das Weglassen der XML-Schemadefinition quittiert Eclipse mit einer Fehlerausgabe, die folgende Auszeichnung des <project> Tags beendet die Belästigung umgehend:
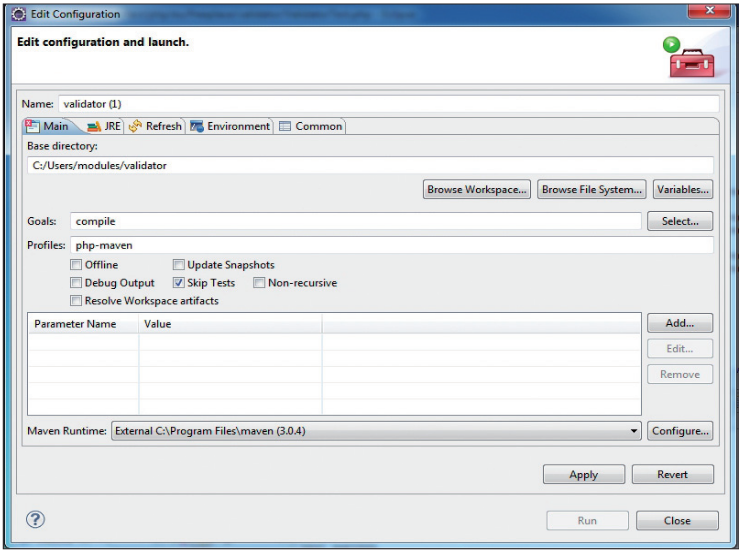
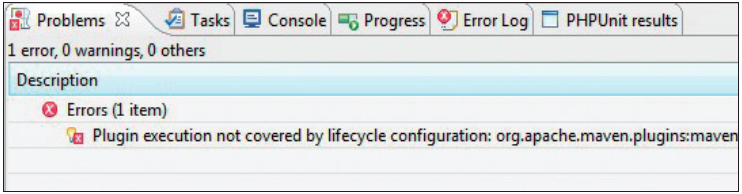
Das Anstoßen der einzelnen Build-Lifecycles aus Eclipse oder NetBeans heraus ist mittlerweile recht intuitiv. Der Übersichtlichkeit wegen werden nur die wichtigsten Phasen der Lifecycles zum direkten Ausführen über die Toolbar beziehungsweise das Kontextmenü angeboten. Dazu zählen vor allem Build, Clean, Clean Build und Test. Wenn dennoch einmal ein spezielles Goal gestartet werden muss, bieten beide IDEs die Möglichkeit, über einen Wizard die entsprechende Phase mit dem gewünschten Goal zu konfigurieren und auszuführen. Im Screenshot ist beispielhaft die Run-Konfiguration von Eclipse abgebildet. Für php-maven Projekte existiert ein Eclipse-Plug-in, das von Martin Eisengart entwickelt wurde. Aktuell ist dazu eine neue Version für Eclipse Indigo erschienen. Eine wichtige Eigenschaft dieses Plug-ins ist die Konvertierungsfunktion für Maven-Projekte nach php-maven. Nach erfolgreicher Konvertierung zeigt Eclipse in der View Problems den Fehler, dass das maven-plugin-Plug-in nicht ausgeführt werden kann. Diese Meldung ist kein wirklicher Fehler, sondern ergibt sich aus den Restriktionen des m2e-Plug-ins, das für alle unbekannten Plug-ins Fehler ausgibt.
Sehr komfortabel ist das Generieren der Site über das Plug-in. Dazu hält der Menüeintrag die Punkte generate, view und deploy bereit. Besonders angenehm ist die Option, die generierte Seite im Browser auszugeben, ohne umständlich über das Target-Verzeichnis navigieren zu müssen.
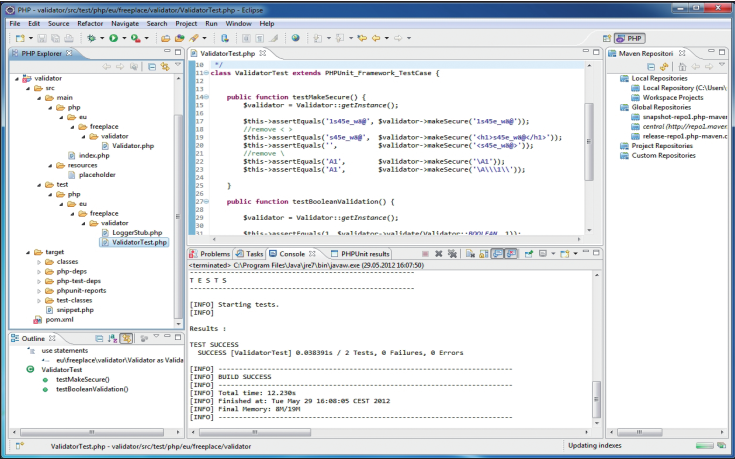
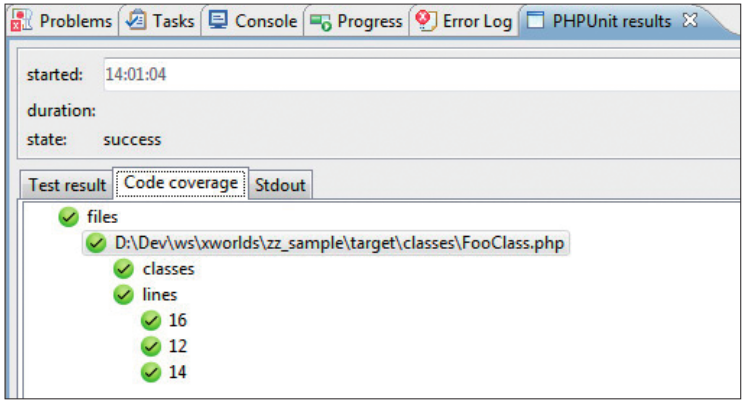
Wenn die Testfälle über das Kontextmenü in das Projekt eingebunden wurden, kann die View PHPUnit die wichtigsten Informationen der durchlaufenen Testfälle visualisieren. Neben den Testergebnissen wird auch eine Coverage ausgegeben (Bild 6).
Berichtswesen
Neben dem Build- und Clean-Lifecycle existiert als Dritter im Bunde der Site-Lifecycle, mit dem Reports und sogar komplette Webseiten automatisch generiert werden können. Ein gutes Beispiel der Site-Generierung ist die Homepage des php-maven Projekts, die mit Maven erzeugt wurde.
Innerhalb der POM können verschiedene Angaben zu wichtigen Projektinformationen gemacht werden, die über eine Projektseite publiziert werden können. Typische Informationen sind unter anderem der Projektname mit einer Kurzbeschreibung, dem Gründungsjahr und der Lizenz des Artefakts. Neben diesen allgemeinen Informationen können auch die URLs zu CI-Servern, Sourcecode-Repositories, Mailing-Listen und beteiligten Personen angegeben werden. Die notwendigen Einträge der POM zeigt Listing 1.
<licenses><license><name>BSD 3-Clause</name><url>http://www.opensource.org/licenses/BSD-3-Clause/</url></license></licenses><name>CMS</name><description> A Collection of diffrent Modules for a CMS.</description><url>https://elmar-dott.com</url><inceptionYear>2012</inceptionYear><scm><url>https://git.elmar-dott.com</url><connection>https://git.elmar-dott.com</connection><developerConnection>https://git.elmar-dott.com</developerConnection></scm><issueManagement><system>Redmine</system><url>https://issues.elmar-dott.com/</url></issueManagement><ciManagement><system>Jenkins</system><url>http://localhost/jenkins</url></ciManagement><developers><developer><name>Elmar Dott</name><id>ed</id><email>ed@elmar-dott.com</email><roles><role>Release-Management</role></roles><organization>Elmar Dott Consulting</organization><organizationUrl>https://elmar-dott.com</organizationUrl><timezone>+1</timezone></developer></developers>
XML
Um der Seite statische Inhalte zuzufügen, stehen unterschiedliche Mechanismen zur Auswahl. Grundlegend ist das Verzeichnis site unterhalb von src im Projektverzeichnis anzulegen, in dem unter anderem auch der Site-Deskriptor hinterlegt wird. Über den Site-Deskriptor site.xml werden unter anderem die Navigation zusammengebaut und zusätzliche Inhalte hinzugefügt. Es können drei unterschiedliche Content-Typen erzeugt werden: APT (Almost Plain Text) ist ein an Wiki Style angelehntes Format, während fml eine FAQ-Struktur erzeugt und überwiegend in Maven-1-Projekten zum Einsatz kam. Am verbreitetesten ist xDoc, ein XML-basiertes Format, um Inhalte zu erstellen.
Um der Seite verschiedenste Reports hinzuzufügen, ist das Site-Plug-in entsprechend zu konfigurieren. Der übliche Weg über den Abschnitt <reports> ist mittlerweile als deprecated gekennzeichnet und sollte nicht weiter verwendet werden. Um nicht benötigte Reports auszusparen, werden diese in der Konfiguration des <reportSets> weggelassen. Auf der Maven-Plugin-Seite finden sich noch weitere Plug-ins zu Reports, beispielsweise das Checkstyle-Plug-in, um den Code auf die Einhaltung festgelegter Style-Guides zu prüfen.
Wer bereits einmal in die Verlegenheit gekommen ist eine im Produktivzustand arbeitende PHP-Webapplikation zu aktualisieren, wird mir sicherlich beipflichten, das diese Arbeit äußerst ungern gemacht wird. Eine andere Unschönheit ergibt sich daraus, wenn ein solches System für die Entwicklung eines neuen Webauftritts beispielsweise lokal installiert wird. Nach getaner Arbeit sind dann verschiedene Hürden zu meistern, um die Anwendung über ein QS-System auf dem Live-Server lauffähig zu bekommen. Viele Probleme lassen sich bereits während der Entwicklungsphase durch etwas Planung und eine saubere Architektur vermeiden. Gerade bei Webanwendungen kann durch eine effiziente Modularisierung in Kombination mit Maven ein erheblicher Mehrwert erzielt werden.
Ziel dieses Teils der Artikelserie ist es nicht, Migrationswege für bereits bewährte Webapplikationen wie beispielsweise Magento, Media-Wiki und Jomoola nach Maven aufzuzeigen. Ein solches Vorhaben sollte aus verschiedenen Gründen reiflich überlegt werden und ist eher etwas für erfahrene Entwicklungsteams. Für eine erfolgreiche Migration ist tiefgreifendes Systemwissen unbedingt notwendig.
Gezeigt wird, wie mit PHP und Maven moderne und zukunftssichere Webanwendungen erstellt werden können. Die Basis dazu bilden die bereits vorgestellten Library-Artefakte, die nun zu einer gesamten Anwendung orchestriert werden. Etablierte Applikationen wie Magento, um nur einen willkürlich gewählten Vertreter zu nennen, sind weitaus älter als die vorgestellten OOP-Eigenschaften, die durch PHP 5.3 eingeführt wurden. Deswegen ist auch kein direkter Architekturvergleich möglich.
Die Segel in Richtung Zukunft
Die Vision in der Software-Entwicklung besteht vor allem darin, einmal entwickelte Module wiederverwenden zu können. Im PHP-Maven-Projekt ist das erklärte Ziel, ein umfangreiches Repository an freien und kommerziellen Artefakten im Lauf der Zeit anzusammeln und zur Verfügung zu stellen. Um Namenskonflikten aus dem Weg zu gehen, ist die Verwendung von Namespaces in Library-Projekten unumgänglich. Wichtige Designregeln sollten zwingend eingehalten werden, wofür die folgende Checkliste herangezogen werden kann:
echo und print sind innerhalb des Produktivcodes absolut tabu.
Die Entwicklung erfolgt rein objektorientiert (OOP).
Namespaces sind zu verwenden.
Eine Klasse pro Datei, wobei Klasse und Dateinamen identisch sind (korrespondieren).
Kein Modul darf direkt auf eine Datenbanktabelle eines anderen Artefakts zugreifen; es sind nur API-Aufrufe gestattet.
Content wird über Datenbanktabellen persistiert.
Die Konfiguration erfolgt über XML- oder INI-Dateien.
Diese Liste der aufgezählten Punkte stellt eine Mindestanforderung für Artefakte dar, die darauf abzielen, ihre Funktionalität möglichst vielen Projekten über einen langen Release-Zeitraum zur Verfügung zu stellen. Die Reihenfolge ist keine Priorisierung. Ein klarer Stil der Codierung sollet stringent eingehalten werden. Beachtet man diese Punkte nicht, kann sich das negativ auf den Entwicklungsprozess auswirken.
Die Problematik der Namespaces wurde bereits erläutert. Die Forderung, dem OOP-Paradigma zu folgen, begründet ihren Ursprung vor allem in der Kapselung der Funktionalitäten und der guten Strukturierung des Codes. Dass der Dateiname mit der Klasse zu korrespondieren hat, dient ebenfalls der besseren Übersicht und ermöglicht das Verwenden von Auto-Class-Loadern. In aller Regel werden fertige Artefakte durch eine übergeordnete Anwendung aufgerufen. Erzeugt ein Artefakt eigenständig sichtbare Systemausgaben in der Anwendung, ist dies ein ernstes Problem. Fehler oder Debug-Ausgaben sind aus diesem Grund ausschließlich über ein Logging-Verfahren zu behandeln. Ein sehr wichtiger Punkt im Hinblick auf die Wartbarkeit einer Applikation ist die Forderung nach Zugriffen auf Datenbanktabellen. Sicherlich mag im ersten Moment ein SQL-Statement attraktiver wirken als ein API-Aufruf. Immerhin attestiert es dem Entwickler einen tiefen Einblick in das vorhandene System. Dummerweise offenbart ein solches Vorgehen nicht die Brillanz des Akteurs, sondern dessen mangelnde Teamfähigkeit.
Ein weiterer Aspekt ist das Persistieren von Daten. Die Faustregel zur Entscheidung, wie Daten langfristig zu speichern sind, ist, dass alle Einstellungen, die das Verhalten eines Systems beeinflussen, in Textdateien abgelegt werden sollten. Durch Nutzer erzeugte Inhalte wie Texte gehören in eine Datenbank. Typische Konfigurationseinstellungen sind Datenbankparameter, da sie sich je nach System unterscheiden. Solche Dinge in einer Datenbank abzulegen erschwert den Aufwand des Deployments erheblich. Content hingegen hat keinen direkten Einfluss auf die Applikation und muss daher nicht in die Entwicklungssysteme synchronisiert werden. Im Gegenteil, dieser Zustand wäre ein erhebliches Sicherheitsrisiko. Ein Beispiel wären Accountdaten mit Adresse und Bankverbindung der Nutzer eines Webshops. Diese Information ist nur dem Betreiber zugedacht und nicht der Entwicklungsabteilung der Applikation.
Strukturarbeiten
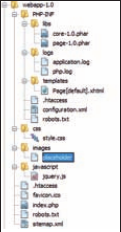
Nachdem nun die Voraussetzungen für optimales Artefakt-Design bekannt sind, ist es an der Zeit, diese durch eine Webanwendung zu einem Gesamtwerk zu vereinen. Auch wenn es auf den ersten Blick trivial erscheint: Ein geschickt gewähltes Verzeichnislayout ist bereits die halbe Miete. Bild 1 enthält eine empfohlene Verzeichnisstruktur für Webprojekte mit den wohlbekannten Elementen. Einzige Ausnahme bildet hier der Ordner PHP-INF mit sämtlichen geschützten Inhalten, die für Außenstehende nicht einsehbar sein dürfen. Das Vorbild dieses Verzeichnisses ist Java-Webprojekten entnommen. Um das PHP-INF Verzeichnis vor unerwünschten Blicken verborgen zu halten, bietet sich eine .htaccess Datei in Kombination mit einer robots.txt an, die sämtliche Suchmaschinen aussperrt, um nur einige Schutzmechanismen aufzuzeigen.
Von besonderem Interesse sind die Dateien des Unterverzeichnisses libs. Wie diese PHP-Archive erzeugt werden, wurde im vorangegangenen Teil dieser Serie beschrieben. Im Kontext der Webanwendung sind diese Artefakte einfache Dependencies, die durch Maven verwaltet werden und über die Bootstrap-Datei index.php eingebunden sind. Auf diese Weise entsteht im Lauf der Zeit ein Baukastenprinzip, ähnlich einem Komponenten-Framework.
Im Gegensatz zum vorgestellten Library-Projekt befinden sich die Sourcen nun im Ordner resources. Der Grund dafür ist sehr schnell aufgezeigt. Maven kopiert aus diesem Verzeichnis die Dateien in der gleichen Hierarchie in das target Verzeichnis. Ein besonders hilfreiches Feature ist, dass Maven im resources Verzeichnis Filter anwenden kann, die es ermöglichen, Texte zu ersetzen. Dazu ist lediglich über den Build-Lifecycle das Filtering in der POM zu aktivieren:
Diese Eigenschaft ist besonders wertvoll für das Deployment. In den Konfigurationsdateien der Anwendung können so Systemeigenschaften in Platzhalter ausgelagert werden. So erklärt sich auch die strikte Forderung, Systeminformationen in Textdateien vorzuhalten. Es besteht natürlich auch die Option, in SQL-Dateien eine Textersetzung vorzunehmen, um Konfigurationen vorzuhalten. Man sollte sich aber bewusst sein, dass Datenbanktabellen, die im schlimmsten Fall in einer Spalte Konfigurationen vorhalten, kaum zum Verständnis des Systems beitragen. Besonders aus Sicht der Wartbarkeit bietet eine Konfigurationsdatei mehr Flexibilität als SQL-Statements. Die Eigenheit, alles möglichst über Datenbanktabellen abzuspeichern, hat eine eher einfache Ursache. Eine Konfigurationsdatei im Filesystem muss durch verschiedene Mechanismen vor unbefugtem Zugriff geschützt werden. Datenbanktabellen bieten von Hause aus mehr Sicherheit. Ähnlich verhält es sich bei den bekannten config.php Files.
Um Texte ersetzen zu können, werden sogenannte Profile benötigt, die in dem vorgestellten Beispiel über die POM vorgehalten werden. Die verschiedenen Profile werden über eine ID unterschieden.
Ein möglicher Weg, um ein Profil zu aktivieren, ist das <activeByDefault> -Tag. Es gibt natürlich auch noch viele andere Wege, die auf der Manual-Page beschrieben werden.
PHP-CLI
Damit Maven seine volle Kraft ausschöpfen kann, ist es notwendig, das Command Line Interface (CLI) für PHP in der Konsole zu aktivieren.
Mit dem CLI ist es möglich, PHP-Skripts ohne Webbrowser direkt auf der Kommandozeile auszuführen. Diese Funktion wird beispielsweise benötigt, um aus Maven heraus die Sourcecode-Dokumentation über den php-Documentor anzustoßen. Sobald der Pfad zum Verzeichnis der php.exe in die PATH-Variable aufgenommen wurde, können PHP-Skripts über die Konsole ausgeführt werden. Der Erfolg einer Installation lässt sich durch die Anweisung php –v rasch überprüfen. Im Erfolgsfall wird sie mit der Ausgabe der installierten PHP-Version quittiert.
Packungsinhalte
Nachdem die Projektstruktur von Webapplikationen mit ihren Besonderheiten vorgestellt worden ist, ist es nun an der Zeit, einige Details über die POM zu erwähnen. Um die Vielseitigkeit von Maven zu demonstrieren, wird der Packagetyp rar gewählt. Durch etwas Zauberei wird allerdings keine RAR-Datei, sondern eine ZIP-Datei ausgeliefert. Der Grund für diese Entscheidung: Diese Webanwendung ist ein individuelles Projekt und soll nicht innerhalb anderer Projekte verwendet werden. Daher ist es nicht notwendig, das Artefakt in einem Repository vorzuhalten. Aus dieser Tatsache ergibt sich auch das verify.
Der Auszug der POM zeigt unter anderem auch, wie das Library-Projekt als Dependency eingebunden wird. Der Scope weist das Artefakt für die Verwendung zur Laufzeit aus. Damit die entsprechenden Dateien im target-Verzeichnis vollständig zu einer ZIP gepackt werden können, sind innerhalb des <build> Tags noch einige Plug-ins zu konfigurieren.
Eine zentrale Rolle spielt das antrun Plug-in. Um in Maven in Archiven zusätzlichen Inhalt einzufügen, sind Assemblies vorgesehen. Wesentlich einfacher ist der Weg über ANT. Das antrun Plug-in ermöglicht das Ausführen von ANT-Tasks.
Die Konfiguration des Plug-ins ist weitgehend selbsterklärend. Innerhalb von <configuration> können verschiedene Task definiert werden. Eine ausführliche Übersicht bietet das User-Manual von ANT.
Elternteile
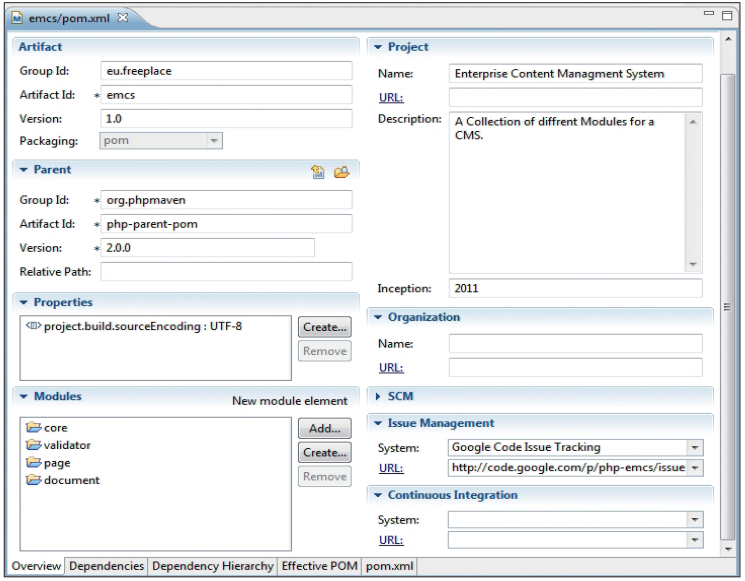
In den POMs der Library-Artefakte ist der Eintrag zu finden, der auf eine parent-pom für PHP-Maven-Projekte verweist. Dieses Konstrukt bedeutet, dass dem aktuellen Projekt noch ein Projekt übergeordnet ist. Grundsätzlich können Projekte verschiedenster Art beliebig tief verschachtelt werden. Damit das gesamte Konstrukt aber auch überschaubar bleibt, sollte vorher reiflich überlegt werden, wie feingranular ein Projekt aufgebaut werden muss. Um ein Multiprojekt zu erzeugen, muss lediglich die -POM angegeben werden, und über den Eintrag kann auf die untergeord- neten Module verwiesen werden:
Der Vorteil des Multiprojekts modules ist, dass die gesamte Konfiguration für die Unterprojekte in der übergeordneten POM erfolgt. Es werden nur noch die individuellen Konfigurationen in den Unterprojekten ergänzt:
Wie an der POM des Validators zu sehen ist, ist die Konfiguration erfreulich kurz. Die Effizienz ergibt sich, sobald mehr als ein Modul im gleichen Kontext erzeugt wird. Die Parent-POM stellt sicher, dass für alle Teilprojekte dieselben Dependencies verfügbar sind. So kann verhindert werden, dass beispielsweise Modul A für die XML-Verarbeitung ein anderes Artefakt verwendet als Modul B. Dies ist ein wichtiger Aspekt für die Qualität von Software.
Ausblick
Nachdem Sie nun viele Details zu den Möglichkeiten von Maven kennengelernt haben, stellt der nächste und abschließende Teil dieser Serie das Eclipse-Plug-in für Maven for PHP vor und zeigt unter anderem, wie Webseiten und Reports über Maven generiert werden.
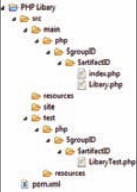
Der erste Teil der Serie hat gezeigt, dass Maven den Paradigmen DRY und COC folgt. Aus diesem Grund sollte beim Anlegen eines Projekts die vorgegebene Verzeichnisstruktur eingehalten werden. Es ist durchaus möglich, von dieser Empfehlung abzuweichen, was aber zur Folge hat, dass der Konfigurationsaufwand in der pom.xml erheblich anwächst und sich schnell Fehler einschleichen können. Bild 1 stellt eine einfache Ordnerstruktur für ein typisches Maven-Projekt dar.
Die beschriebene Struktur ist bis auf wenige Abweichungen für sämtliche Maven-Projekte identisch. Der wichtigste Teil ist die pom.xml im Wurzelverzeichnis des Projekts. Das optionale Verzeichnis site enthält alle notwendigen Dateien, um eine Projekt-Homepage durch Maven generieren zu lassen. In src vermuten Sie zu Recht die verschiedensten Quelltextdateien. Im Ordner test befinden sich sämtliche Testdateien. Die resources-Verzeichnisse sind optional und besitzen eine besondere Funktion: Dort werden vor allem Konfigurationsdateien abgelegt, in denen Platzhalter zur Textersetzung eingebunden werden können. Um die Zusammenhänge schneller zu erkennen, sollten Sie einen Blick in die Konfigurationsdatei pom.xml werfen.
Project Object Model
Das Project Object Model (POM) bildet die zentrale Steuereinheit für Maven und enthält alle nötigen Informationen. Eine vollständige Übersicht der Konfigurationsmöglichkeiten kann auf der Maven-Projektwebseite nachgeschlagen werden. Beginnen wir zuerst mit den wichtigsten Einträgen:
Diese vier Zeilen sind der essenzielle Bestandteil einer jeden POM. Nun wird auch ersichtlich, was es mit den Platzhaltern $groupID und $artifactID in der Projektstruktur auf sich hat. Die artifactId ist der Projektname, dem eine Version zugeordnet wird. Bei der groupId handelt es sich um die Domain des Projekts.
Diese Informationen benötigt Maven, um die Artefakte im Dependency-Management organisieren zu können. Daraus ergibt sich beim Anlegen eigener Projekte die Forderung, dass die Kombination aus Domäne, Projektnamen und Version nicht mehrfach vergeben werden darf, da sonst vorhandene Artefakte im lokalen Repository ohne Rückfrage sofort überschrieben werden. Da Maven für Java-Projekte konzipiert wurde, nutzte es auch den in Java vorhandenen Mechanismus der Packages. Das bedeutet für den Wert org.phpmaven in groupId, dass Maven den Punkt als Trennzeichen interpretiert und erst org und darunter phpmaven als Verzeichnis erzeugt. Auf diese Weise können Sie Ihre Artefakte im lokalen Repository jederzeit aufspüren.
Für Java-Projekte ist es notwendig, anhand des Package-Namens, der sich aus groupId und artifactId zusammensetzt, eine Ordnerhierarchie zu erzeugen. In PHP-Projekten ist das Anlegen einer solchen Struktur nicht zwingend notwendig. Mit Blick auf künftige Mehrfachverwendung von Artefakten in den verschiedenen eigenen Projekten ist die Verwendung von Namespaces unumgänglich. Das Risiko von Namenskonflikten zwischen den Artefakten steigt mit der Anzahl der verfügbareren Artefakte.
Der Eintrag php weist Maven an, aus den Source-Files ein Phar-Archiv zu erzeugen. Es gibt neben php noch weitere Package-Typen, etwa zip und pom. Der Package-Typ pom erlaubt die Verwendung von Multi-Projekten, auf die später noch eingegangen wird. Listing 1 zeigt eine vollständige POM für ein einfaches PHP-Library-Projekt, das Sie als Abhängigkeit in anderen Projekten nutzen können. Dependencies werden in der POM im Bereich eingetragen. Im Beispiel ist das Test-Framework PHPUnit eingebunden. Die Angabe teilt Maven mit, dass es sich bei diesem Artefakt um ein PHP-Archiv handelt. Ohne diese Konfiguration würde Maven ein Java-Archiv (JAR) erwarten. Der Scope einer Dependency konfiguriert die Sichtbarkeit des Artefakts im Build Lifecycle. Es gibt vier unterschiedliche Scopes:
compile: Das Artefakt ist in allen Phasen verfügbar (Default).
provide: Das Artefakt ist nur bis zur compile-Phase sichtbar und wird nicht mit deployed. Dieser Scope ist vor allem für Java-Projekte wichtig, um die Ressourcen korrekt zu verlinken.
runtime: Diesen Scope verwenden Dependencies, die nur zur Laufzeit benötigt werden, was für PHP-Projekte die Regel darstellt. Artefakte, die mit runtime gekennzeichnet sind, werden mit der Anwendung zusammen deployed.
test: Abhängigkeiten, die mit diesem Scope konfiguriert sind, werden nicht mit deployed und sind nur für die test-Phasen des Build-Lifecycles sichtbar.
Nachdem Sie nun eine Projektstruktur und die dazugehörige POM haben, wird es Zeit, Maven in Aktion zu erleben. Die Idee ist, eine Bibliothek zu erzeugen, die Benutzereingaben validiert. Dieses Artefakt kann dann später von Ihnen dahingehend erweitert werden, in Ihren Projekten an verschiedensten Stellen Benutzereingaben auf Gültigkeit zu überprüfen.
Mögliche Erweiterungen könnten etwa Validierungen von ISBN- und IBAN-Nummern sein. Um ohne Verzögerung zu beginnen, können Sie das fertige Projekt von der Website herunterladen und in einer aktuellen IDE Ihrer Wahl öffnen.
Das Artefakt besteht aus der Klasse Validator mit den beiden Methoden makeSecure() und validate(). Die Methode makeSecure() soll HTML-Tags escapen und Slashes sowie Backslashes aus dem übergebenen String entfernen. validate() prüft eine Eingabe gegen einen regulären Ausdruck auf Gültigkeit. In der Klasse sind bereits einige RegEx als Konstanten definiert. Damit haben wir schon alles, um erste Resultate zu sehen.
Validierungen
Öffnen Sie eine beliebige Konsole und navigieren Sie in das Projektverzeichnis zur POM. Nun müssen sie lediglich mvn package eingeben. Diese Anweisung bewirkt, dass Maven den Build Lifecycle bis zur Phase package abarbeitet. Die nachfolgenden Phasen install und deploy werden nicht aufgerufen. Die Phase install kopiert das erzeugte Artefakt direkt in das lokale Repository und deploy würde zusätzlich das Artefakt in einem Remote-Repository ablegen. Für den Moment genügt es uns, das Phar-Archiv erzeugt zu haben.
Wegen des POM-Eintrags install unterhalb von <build> genügt es, lediglich mvn install in der Konsole zu schreiben, um das erzeugte Artefakt ins lokale Repository zu kopieren. Nachdem mvn package ausgeführt wurde, hat Maven im Projektverzeichnis einen temporären Ordner namens target erzeugt und quittiert die Ausgabe mit BUILD SUCCESS. In dem neu angelegten Verzeichnis sind sämtliche generierten Dateien abgelegt, unter anderem auch das erwünschte Phar-Archiv.
Um negative Synergien zu vermeiden, sollte das target-Verzeichnis vor einem jedem Build gelöscht werden. Das erledigt die Anweisung mvn clean.
Das erzeugte Phar-Archiv lässt sich mit den folgenden Zeilen in eine Applikation einbinden:
Der Trick besteht darin, sämtliche Klassen des Archivs in der Datei src/main/php/index.php mittels include bekannt zu machen. Bei dieser Herangehensweise muss lediglich die index.php wie in der ersten Zeile des Listings geladen werden. Anschließend ist noch der Namespace aufzulösen und dann können die Klassen des Artefakts wie gewohnt verwendet werden.
Testgetriebene Entwicklung
Dank des Extreme Programming (XP) hat das Testen von Sourcecode mittlerweile einen sehr zentralen Stellenwert im Software-Entwicklungsprozess erhalten. Implementierte Funktionalität wird nicht erst nach Beendigung der Entwicklung auf Korrektheit hin überprüft, sondern schon während der Entwicklungsphase. Eine etablierte Form des Testens sind Unit-Tests, wofür das Framework PHPUnit von Sebastian Bergmann als Dependency in den Maven-Build-Lifecycle eingebunden ist. Die aktuell verwendete Version von PHPUnit ist 3.6.10. Ein ausführliche Übersicht zu PHPUnit bietet das Manual des Frameworks.
Sämtliche Testfälle sind im Verzeichnis test/php abzulegen. Wenn eine Verzeichnisstruktur für die Sourcen erzeugt wurde, sollte diese ebenfalls für die Testfälle übernommen werden. Eine weitere Konvention ist, die Testklassen analog der zu testenden Klassen zu benennen und das Postfix test anzufügen.
Zur Klasse Validator existiert die korrespon-ierende Klasse ValidatorTest, die von PHPUnit_Framework_TestCase abgeleitet ist. Um später in der Test-Auswertung bei Fehlern das betroffene Fragment schneller identifizieren zu können, sollten die Methoden sprechende Namen haben. Im vorgestellten Beispielprojekt wird die Validierung von Zahlen durch den Validator getestet. Dazu existiert die Methode testNumberValidation(). Um Klassen testen zu können, sollte schon während der Implementierung darauf geachtet werden, dass nur ein Einstiegspunkt und ein definierter Ausstiegspunkt vorhanden ist. Mehr als das Erstellen der Testfälle und das Einbinden von PHPUnit als Abhängigkeit ist nicht notwendig. Beim Ausführen von Maven werden nun jedes Mal alle Testfälle abgearbeitet. Falls ein Test fehlschlägt, wird der Build mit einer Fehlermeldung abgebrochen.
API-Dokumentation auf Knopfdruck
Ein weiterer wichtiger Aspekt in der SoftwareEntwicklung ist das Erzeugen einer aussagekräftigen API-Dokumentation. Für diese Aufgabe ist in Maven der Site-Lifecycle vorgesehen. Um den phpDocumentor dem Site-Lifecycle bekannt zu machen, muss die Konfiguration des site-Plug-ins überschrieben werden. In der Beispiel-POM ist dies bereits geschehen und deswegen muss die POM nicht weiter angepasst werden. Wie auch bei PHPUnit ist es nicht notwendig, das Tool phpDocumentor auf dem System zu installieren. Auf der Homepage des php Documentors ist das Werkzeug gut dokumentiert. Auf der Webseite ist unter anderem eine Übersicht der möglichen Annotationen zu finden. Um die Dokumentation zu erzeugen, muss der Site-Lifecycle mit der Anweisung mvn site ausgeführt werden.
Wie alle anderen durch Maven erzeugten Dateien wird auch die fertige API-Dokumentation im target-Verzeichnis abgelegt.
Jedes Mal aufs Neue von Hand eine Projektstruktur anzulegen ist mühsam. Damit das Erzeugen neuer Projekte automatisiert geschehen kann, bietet Maven den Mechanismus der Archetypen. Ein Archetyp erzeugt eine vorgegebene Verzeichnisstruktur und die dazugehörige POM. Für PHP existieren derzeit drei verschiedene Archetypen: library, web und zend, die im Lauf der Zeit noch erweitert werden. Der nachfolgende Code-Ausschnitt zeigt die benötigte Anweisung, um einen Archetyp auszuführen:
Falls Sie aus einem bereits bestehendem Projekt einen Archetyp erzeugen wollen, können Sie mvn archetype:create-from-project ausführen. Es kann auch vorkommen, dass anschließend der generierte Archtyp von Maven nicht gefunden wird. Der Grund ist in der Datei archetypecatalog.xml zu suchen. Um den neuen Archetyp in den Katalog aufzunehmen, ist die Anweisung mvn archetype:crawl auszuführen. Ein manuelles Editieren dieser Datei ist nicht notwendig.
Fazit
Library-Projekte sind Artefakte, die Funktionalitäten kapseln und diese Funktionalitäten in anderen Projektformen als Abhängigkeit zur Verfügung stellen. Im nächsten Teil der Serie wird gezeigt, wie Homepage-Projekte mit Maven verwaltet werden können, die wiederum Artefakte einbinden. In diesem Zusammenhang wird auch auf Multi-Projekte und deren Verwendung eingegangen. Sie erfahren auch, wie Sie erzeugte Artefakte für andere Entwickler in einem Remote-Repository verfügbar machen.
Wikipedia liefert für den Begriff Maven folgende Erklärung: »Ein Maven ist ein Experte, der andere berät und deren Entscheidungen beeinflusst«. Wegen seiner Bedeutung wurde der Begriff Maven für die Namensgebung der Software auserkoren. Jason van Zyl, Gründer und CTO von Sonatype, beschreibt das Programm mit folgenden Worten: »Apache Maven is a software project management and comprehension tool. Based on the concept of a project object model (POM), Maven can manage a project’s build, reporting and documentation from a central piece of information.«
Maven ist ein in Java geschriebenes plattform unabhängiges Projektmanagement-Tool. Es ist ein Open-Source-Projekt der Apache Software Foundation und frei erhältlich. In der Version 2 wurde das Programm völlig neu entwickelt. Das ist auch ein Grund dafür, dass Erweiterungen der Version 2 nicht abwärtskompatibel sind. Derzeit ist die Version 3 aktuell, welche auch mit Maven-2-Projekten kompatibel ist.
Wie bereits angedeutet, handelt es sich bei Maven um ein schlankes Werkzeug, das durch seinen modularen Aufbau problemlos durch eigene Plug-ins erweitert werden kann. Diese Möglichkeit nutzt das Projekt Maven for PHP und stellt eigene Erweiterungen für PHP bereit.
Bild 1: Homepage des Projekts Maven for PHP
Bevor wir nun mit der Installation der Software beginnen, ist es notwendig, etwas über das Konzept von Maven zu erfahren, da dieses Werkzeug mächtiger ist als sein Pendant Ant.
Maven erzeugt aus Java-Quellcode Binärdateien. Die hohe Akzeptanz erreichte das Tool aber durch das transitive Auflösen von Abhängigkeiten zu anderen Softwarebibliotheken. Im Maven-Jargon werden Bibliotheken oder Module als Artefakt bezeichnet. Das Verwalten von Artefakten ist allerdings nur ein kleiner, wenn auch sehr maßgeblicher Aspekt für den Einsatz in PHP-Projekten.
Nicht ohne Grund stellt Maven an sich selbst den Anspruch, ein Projekt-Management-Werkzeug zu sein. Im Projektalltag wird zwischen drei verschiedenen Einsatzbereichen unterschieden. Der umfangreichste Teil ist der Build-Life-cycle mit seinen 21 Unterschritten, die als Phase bezeichnet werden. Die Teilbereiche einer Phase werden wiederum als Goal bezeichnet. So erreicht man eine feingranulare Struktur, in die sich leicht eigene Funktionen einbringen lassen. Ein anderer Aspekt ist die Reporting-Engine, die ihre Arbeit unter dem Site-Lifecycle verrichtet. Für das Aufräumen nach dem vollendeten Werk ist der Clean-Lifecycle zuständig. Was es mit den einzelnen Lifecycles auf sich hat wird an späterer Stelle noch detaillierter geklärt.
Zentrale Steuereinheit
Im Wurzelverzeichnis eines Projekts liegt die zentrale Steuereinheit. Es handelt sich dabei um eine einfache XML-Datei mit dem Namen pom.xml, in der die gesamte Konfiguration des Projekts vorgehalten wird. Die Bezeichnung POM steht im Übrigen für Project Object Model. Bei umfangreichen Projekten kann diese Datei schnell eine beachtliche Größe erlangen. Aus diesem Grund verfolgt Maven das Prinzip »Don’t repeat yourself« (DRY) und »Convention over Configura tion« (COC). Das besagt, es müssen lediglich die Dinge in der POM-Datei eingetragen werden, die vom vorgegeben Standard abweichen. Um den Überblick auch zu einem späteren Zeitpunkt nicht zu verlieren, ist es sehr ratsam, nur in absoluten Ausnahmefällen vom Standard abzuweichen.
Nachdem Sie nun die wichtigsten Begriffe kennen, können wir zur ersten Tat schreiten und die Software installieren.
Schnell installierte Basis
Bild 2: Einstellungen der Umgebungsvariablen unter Windows
Für Maven existiert keine Installationsroutine, wie sie beispielsweise in Windows-Systemen üblich ist. Da das Programm in Java geschrieben ist, muss ein aktuelles Java-SDK auf dem System bereits vorhanden sein. Nach dem erfolgreichem Download und dem anschließenden Entpacken des Archivs sind folgende Schritte auszuführen:
Setzen der Umgebungsvariablen JAVA_HOME = {install.java},
Setzen der Umgebungsvariablen M2_HOME = {install.maven},
Erweitern der PATH-Variable %M2_HOME%\ bin und %JAVA_HOME%\bin.
Mit {install.maven} ist der Ort des ausgepackten Maven-Archivs gemeint. Unter Windows 7 ist die Einstellung der Umgebungsvariablen über die Systemsteuerung hinter der Option System versteckt, die sich dort über den Punkt Erweiterte Systemeinstellungen öffnen lässt. Bei geglückter Installation quittiert Maven die Konsolenausgabe für mvn -version mit der installierten Versionsnummer. Für PHP-Projekte sind allerdings noch einige andere Anpassungen notwendig, auf die später eingegangen wird. Zuvor wird erläutert, wie Maven Abhängigkeiten zu anderen Artefakten auflöst.
Bild 3: Ausgabe der Konsole bei erfolgreicher Maven-Installation
Dependency Management
Bild 4: Auszug aus einem lokalen Repository
Wie Sie bei der Installation bemerkt haben, ist der Kern von Maven recht kompakt. Die umfangreichen Funktionen werden durch Erweiterungen über die Plug-in-Schnittstelle realisiert. Soll beispielsweise eine Dokumentation mit der Anweisung mvn site erzeugt werden, holt sich Maven die notwendigen Artefakte über das Internet und speichert diese auf dem Rechner in einem lokalen Repository. Die Dateien sind im Home-Verzeichnis des aktuellen Benutzers unter .m2/repository/ zu finden. Wenn man sich die Ordnerstruktur aus Bild 4 ein wenig genauer ansieht, kann man erkennen, dass Maven die Artefakte nach Namen und Versionsnummer organisiert. In dem Screenshot sind im lokalen Repository für das Test-Framework JUnit vier unterschiedliche Versionen mit der dazugehörigen POM-Datei hinterlegt. Anhand des POM ist Maven nun in der Lage, die notwendigen Abhängigkeiten von JUnit ebenfalls aufzulösen. Die Archivierung der Versionen eines Artefakts ermöglicht es später, in einem Projekt innerhalb kürzester Zeit für eine Bibliothek die neueste Version auszuprobieren und im Fall einer Inkompatibilität die Änderung in wenigen Augenblicken wieder rückgängig zu machen. Es muss lediglich in der POM-Datei die Versionsnummer des Artefakts geändert werden.
Ein weiterer Vorteil ist, dass im Konfigurationsmanagement die verwendeten Artefakte nicht mehr archiviert werden müssen. Diese Arbeit übernimmt nun künftig in zuverlässiger Weise Maven. Dank dieses Umstands werden im Konfigurationsmanagement einige MByte an Speicher eingespart, was bei größeren Projekten mit vielen Artefakten einiges an Zeit beim Checkout einsparen kann. Eine Entlastung des Netzwerks ist eine weitere angenehme Randerscheinung.
Nun stellt sich berechtigterweise die Frage, von welchem Server Maven die benötigten Artefakte beziehen kann? Neben dem standardmäßig eingestelltem Remote-Repository repo1.maven.org können auch andere Repositories hinzugefügt werden. Dazu ist die Maven-Installation über die Datei settings.xml den eigenen Bedürfnissen anpassen. Hierbei können zwei Stufen genutzt werden:
User Level: Im Home-Directory des aktuellen Nutzers legt Maven den Ordner .m2 an, in dem die settings.xml zu finden ist. Dies ist vor allem im Mehrbenutzerbetrieb nützlich, da hier Passwörter für Logins et cetera hinterlegt werden können.
Global Level: Die Datei settings.xml ist in diesem Fall im Ordner conf der Maven-Installation abgelegt. Diese Konfiguration gilt für alle Nutzer auf einem System.
Die Konfiguration über die settings.xml ist projektübergreifend und enthält beispielsweise Einträge für das Login zum Versionskontrollsystem (SCM), den Pfad zum lokalen Repository beziehungsweise zu weiteren Remote-Repositories. Um PHP Maven nutzen zu können, muss das öffentliche Repository in einer der beiden Settings-Dateien eingetragen werden. Listing 1 enthält die hierfür notwendige Konfiguration.
Der Codeblock aus dem Listing ist in einer der settings.xml-Dateien unterhalb der Ebene des Root-Elements einzutragen. Die eigentliche Konfiguration befindet sich im Profil mit der ID profile-php-maven, welches auch als aktiv registriert ist. Es ist ohne Weiteres möglich, mehrere Profile in der Konfiguration aktiv zu setzen, wenn dies notwendig sein sollte. Im Profil werden die verschiedenen Remote-Repositories für PHP Maven registriert. Mit diesen Einträgen ist Maven nun in der Lage, die notwendigen Artefakte aus dem öffentlichen Repository zu laden.
Mittlerweile betreiben immer mehr Unternehmen eigene Repository-Server für ihre Produkte. Dazu gehören unter anderem Google, Java .NET und Activity, um einige öffentliche Server zu nennen. Da das Projekt Maven for PHP vergleichsweise sehr jung ist, sind derzeit nur die bekanntesten PHP-Projekte, wie beispielsweise Zend und Symfony, in das Repository migriert. In absehbarer Zukunft darf jedoch durchaus erwartet werden, dass weitere PHP-Projekte das Repository bereichern werden. Bei besonders dringlichen Fällen kann es hier hilfreich sein, eine Anfrage über die Google Mailing List zu stellen. Natürlich ist auch jeder, der sich an PHP for Maven beteiligen möchte, eingeladen, sich im Rahmen seiner Möglichkeiten einzubringen.
PHP-CLI
Damit Maven sich voll entfalten kann, ist es notwendig, das Command Line Interface (CLI) für PHP in der Konsole zu aktivieren. Mit dem CLI ist es möglich, PHP-Skripts ohne Webbrowser direkt auf der Kommandozeile auszuführen.
Bild 5: Output des Prompts für erfolgreiches Einbinden des PHP-CLI
Diese Funktion wird beispielsweise benötigt, um die Source-Code-Dokumentation über den phpDocumentor aus Maven heraus anzustoßen. Sobald der Pfad zum Verzeichnis der php.exe in die PATH-Variable aufgenommen wurde, können PHP-Skripts über die Konsole ausgeführt werden. Wie diese Aufgabe für Windows-Systeme gelöst wird, wurde bereits in dem vorangegangenen Abschnitt über die Installation ausführlich beschrieben. Der Erfolg dieser Bemühung lässt sich durch die Anweisung php –v rasch überprüfen und wird im Erfolgsfall mit der Ausgabe der installierten PHP-Version quittiert. Auch wenn im ersten Blick die Installation umfangreich erscheint, sind nur wenige Schritte durchzuführen, um ein einsatzfähiges System zu erhalten. Der geringe Aufwand wird durch umfangreiche Funktionen zur Projektautomatisierung schnell entlohnt.
Ein Füllhorn an Möglichkeiten
Es steht dem Benutzer frei, für welches Szenario er Maven in einem Projekt einsetzen möchte. Hier ein Liste möglicher Einsatzszenarien:
Die erste Position dieser Liste führt erwartungsgemäß das Dependency Management an. Über den Mechanismus können Artefakte fremder Hersteller ebenso dem eigenen Projekt hinzugefügt werden wie selbst entwickelte Bibliotheken.
Neben diesem Aspekt ist ein weiteres wichtiges Thema der Softwaretest. Maven erlaubt es, verschiedenste Test-Frameworks im Build-Lifecycle zu integrieren. Der bekannteste Vertreter unter den Unit-Tests, phpUnit, ist bereits im Public-Repository von Maven for PHP enthalten.
Wie bereits angedeutet, kommt die Generierung der API-Dokumentation mit dem phpDocumentator ebenfalls nicht zu kurz.
Aber auch ein Blick zu den klassischen Maven-Plug-ins ist in einigen Fällen lohnenswert. So besteht die Möglichkeit, aus Maven heraus Ant-Aufrufe zu starten und abzuarbeiten, was die Funktionsvielfalt um einiges erweitert.
Ein beliebtes Thema für Webseiten sind script- und CSS-Minimierer. Code-Beautifier oder Obsfukatoren stellen weitere Punkte auf der Liste dar. Auch Code-Analyzer-Werkzeuge wie Checkstyle können eingebunden werden und bieten damit der Projektleitung einen guten Einblick in die Softwarequalität.
Eine weitere Möglichkeit besteht darin, ganze Internetseiten zu generieren. So ist beispielsweise die Homepage des Projekts aus Maven heraus erzeugt worden.
Das Charmante an all diesen Möglichkeiten ist die Tatsache, dass für die Funktionalität keine weitere Software installiert werden muss. Alle Funktionen sind durch Maven-Plug-ins umgesetzt und werden bei Bedarf über das Dependency Management nachgeladen. Sollte dennoch Wünsche offen bleiben, ist es jederzeit möglich, über das Plug-in-API eigene Erweiterungen zu schreiben.
Für Unternehmen bietet Maven einen weiteren Vorteil. Der Einsatz dieses Werkzeugs unterstützt bei gutem Moduldesign die Wiederverwendung von Softwarekomponenten. Diese Tatsache kann den entscheidenden Vorsprung gegenüber der Konkurrenz bedeuten, da Projekte schneller abgewickelt werden können.
Das Fachwissen der eigenen Mitarbeiter ist für jede Organisation ein bedeutender Wirtschaftsfaktor. Umso wichtiger ist es, die Erfahrungen und Fachkenntnisse dauerhaft zu speichern und anderen Mitarbeitern zur Verfügung zu stellen. Ein zentraler Knowledge-Management-Server übernimmt diese Aufgabe und hilft, langfristig die Produktivität im Unternehmen zu sichern.
(c) 2011 Marco Schulz, Materna Monitor, Ausgabe 2, S.32-33
Die Komplexität der heutigen stark vernetzten Arbeitswelt erfordert ein reibungsloses Zusammenspiel unterschiedlichster Spezialisten. Eine wichtige Rolle spielt hierbei der Wissenstransfer. Erschwert wird dieser Austausch, wenn die Teammitglieder an unterschiedlichen Standorten mit verschiedenen Zeitzonen arbeiten oder aus anderen Kulturkreisen kommen. Unternehmen mit weltweiten Standorten kennen diese Problematik und haben entsprechende Strategien für ein unternehmensweites Wissens-Management entwickelt. Um dieses erfolgreich einzuführen, sollte die einzusetzende IT-Lösung als Methodik aufgefasst werden anstatt das eigentliche Werkzeug in den Vordergrund zu stellen. Haben die Verantwortlichen die Entscheidung für eine bestimmte Software-Lösung getroffen, sollte diese auch konsequent beibehalten werden. Ein häufiger Systemwechsel mindert die Qualität der Verknüpfungen zwischen den gespeicherten Inhalten. Da es keinen normierten Standard für die Repräsentation von Wissen gibt, können bei einem Wechsel auf neue Software-Lösungen erhebliche Konvertierungsverluste eintreten.
Verschiedene Mechanismen für unterschiedliche Inhalte
Informationen lassen sich in IT-Systemen auf verschiedene Weise speichern. Die einzelnen Repräsentationsformen unterscheiden sich durch die Darstellung, Strukturierung und Verwendung. Um Dokumente gemeinsam konfliktfrei bearbeiten und gleichzeitig versionieren zu können, wie es bei Spezifikationen oder Dokumentationen notwendig ist, eignen sich Wikis [1] optimal, da sie genau für diesen Einsatz ursprünglich entwickelt wurden. Die dort gespeicherten Dokumente sind üblicherweise projektspezifisch und sollten auch so organisiert werden.
Projektübergreifende Dokumente im Wiki sind zum Beispiel Fachworterklärungen, ein zentrales Abkürzungsverzeichnis oder ein Who is Who der Unternehmensmitarbeiter inklusive Kontaktdaten und Themengebieten. Letztere lassen sich wiederum mit der Fachworterklärung verknüpfen. Übergreifende Inhalte können dann zentral aktuell gehalten werden und lassen sich komfortabel in die entsprechenden Projektdokumente verlinken. Dieses Vorgehen vermeidet unnötige Wiederholungen und die zu lesenden Dokumente werden kürzer, enthalten aber dennoch alle notwendigen Informationen. Johannes Siedersleben hat bereits 2003 in seinem Buch Softwaretechnik [2] die Risiken zu langer Dokumentationen beschrieben.
Wissen, das eher den Charakter einer FAQ aufweist, sollte besser über ein Forum organisiert werden. Die Gruppierung nach Themen, in denen Fragen nach dem Muster „Wie kann ich …?“ hinterlegt sind, erleichtern das Auffinden möglicher Lösungen. Besonders attraktiv ist die Tatsache, dass ein solches Forum sich mit der Zeit dem Bedarf nach weiterentwickelt. Denn Nutzer haben die Möglichkeit, eigene Fragen zu formulieren und in das Forum einzustellen. In aller Regel lassen qualifizierte Antworten auf neu gestellte Fragen nicht lange auf sich warten.
Geeignete Kandidaten für Blogs sind zum Beispiel allgemeine Informationen zum Unternehmen, Statusberichte oder Tutorials. Dies sind Dokumente, die eher einen informativen Charakter haben, nicht formgebunden sind oder sich schwer einem speziellen Thema zuordnen lassen. Kurzinformationen (Tweets [3]) über Twitter, die in Kanälen thematisch zusammengefasst sind, können die Projektarbeit ebenfalls bereichern. Sie minimieren zusätzlich die E-Mails im eigenen Postkasten. Beispiele dafür sind Reminder zu einem bestimmten Event, ein Newsflash zu neuen Produktversionen oder eine Information über einen erfolgreich abgeschlossenen Arbeitsprozess. Tweets in die Projektarbeit zu integrieren, ist relativ neu und entsprechend rar sind hierfür geeignete Software-Lösungen.
Natürlich ist die Aufzählung von Möglichkeiten an dieser Stelle bei weitem noch nicht erschöpft. Die Beispiele vermitteln aber bereits einen guten Überblick, wie Unternehmen ihr Wissen organisieren können. Mit der Verknüpfung der einzelnen Systeme zu einem Portal [4], das eine übergreifende Suche und Benutzerverwaltung hat, entsteht so schnell ein Netzwerk, das sich auch als Cloud-Lösung eignet.
Für die Akzeptanz einer Wissensplattform ist die Anwenderfreundlichkeit ein entscheidender Faktor. Lange Einarbeitungszeiten, unübersichtliche Strukturierungen und eine umständliche Bedienung können schnell zur Ablehnung führen. Mit einer Zugangsberechtigung zu den einzelnen Inhalten auf Gruppenebene wird auch der Sicherheit genüge getan. Ein gutes Beispiel dafür ist das Enterprise Wiki Confluence [5]. Es ermöglicht, den einzelnen Dokument-Ebenen verschiedene Lese- und Schreib-Berechtigungen zuzuordnen.
Naturgemäß kann man von einem Entwickler nicht erwarten, dass er nach erfolgreicher Implementierung sein Werk mit den richtigen Worten für die Nachwelt verständlich beschreibt. Dass die Qualität der Texte in vielen Dokumentationen nicht immer ausreichend ist, hat auch die Hochschule Merseburg erkannt und bietet den Studiengang Technische Redaktion [6] an. Als geeignetes Mittel zur Qualitätssicherung der Inhalte hat sich daher das Querlesen durch andere Projektmitglieder erwiesen. Um das Verfassen von Texten zu erleichtern, ist es hilfreich, einen kleinen Leitfaden – ähnlich der Coding Convention – bereitzustellen.
Fazit
Eine Wissensdatenbank lässt sich nicht von heute auf morgen umsetzen. Es braucht Zeit, bis darin genügend Informationen zusammengetragen sind. Erst durch Interaktion und Korrekturen von Unverständlichkeiten erreicht das Wissen eine Qualität, die zum Transfer einlädt. Jeder Mitarbeiter sollte dazu ermutigt werden, vorhandene Texte mit neuen Erkenntnissen anzureichern, unverständliche Passagen aufzulösen oder Suchbegriffe zu ergänzen. Wenn der Prozess der Wissensschöpfung und Verteilung in dieser Form gelebt wird, werden weniger Dokumente verwaisen und die Informationen sind stets aktuell.