Für viele ist Bitcoin (BTC) ein reines Spekulationsobjekt, mit dem sie ausschließlich Geld verdienen wollen. Die Kryptowährung Bitcoin eignet sich aber auch hervorragend zum Bezahlen. Um mit Bitcoin zu bezahlen benötigt man kein tiefgreifendes technisches Wissen. Es können auch bereits mit vergleichsweise geringen Beträgen zum Beispiel 10 Euro Bitcoin gekauft werden. Alles was man für den Anfang benötigt wird in diesem Artikel leicht verständlich erklärt.
Um den ersten Bitcoin zu kaufen benötigt man reguläres Bankkonto, 20 € und circa 10 Minuten Zeit. Je nach Bank dauert die Überweisung von Euro bis diese als Bitcoin gutgeschrieben wird, bis zu einem Tag. Übrigens können auch alle Dienstleistungen von elmar-dott.com über Bitcoin bezahlt werden.
Wer möchte, kann sich die Reportage des digitalen Aktivisten als Einstieg zu Bitcoin hier anschauen. Um Bitcoin zu verwenden muss man Bitcoin aber nicht verstehen.
Bevor wir die erste Transaktion starten müssen wir ein Wallet erstellen. Wallet ist die englische Bezeichnung für Geldbörse. Das heißt, das ein Bitcoin Walltet nichts anderes als eine digitale Geldbörse ist. Das Programm mit dem man ein Wallet anlegen und verwalten kann ist der typischen BankingApp sehr ähnlich. Wallets lassen sich auf Computern, Smartphones und Tablets (Android & iPhone/ iPad) problemlos einrichten. Es gibt aber auch Hardware Wallets, die ähnlich wie ein USB Stick funktionieren und die Bitcoins dort speichern.

Der wichtigste Unterschied zwischen einem Bankkonto und einem Wallet ist, das die Bitcoins die auf dem eigene Wallet abgelegt sind, tatsächlich mir gehören. Denn es gibt keine Bank oder andere Institution die Zugriff auf dieses Wallet hat. Man kann Bitcoin die im eigene Wallet gespeichert sind mit dem Bargeld vergleichen, das man in seiner Brieftasche hat. Schauen wir uns daher im ersten Schritt an, wie man sein eigenes Wallet anlegt. Hierfür nutzen wir die freie Open Source Software Electrum. Das Electrum Bitcoin Wallet wurde in Phyton 3 entwickelt und ist für: Linux, Windows, MacOS und Android verfügbar.
Schritt 1: Ein Wallet erstellen
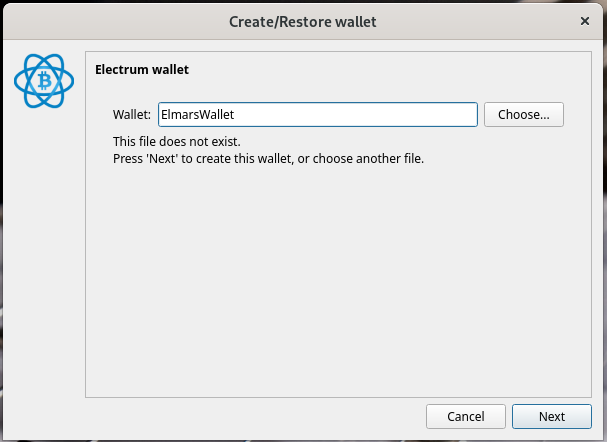
Nachdem die App heruntergeladen wurde und gestartet ist, können wir loslegen und unser erstes Bitcoin Wallet anlegen. Zuerst vergeben wir eine Namen für unser Wallet und drücken auf Next. Anschließend werden wir gefragt welchen Wallet Typen wir anlegen möchten. Hier belassen wir es bei dem Standard. Anschließend müssen wir einen Seed erzeugen. Der Seed (dt. Samen) sind 12 zufällig erstellte Wörter, die wir über die Schaltfläche Option um eigene Begriffe / Zeichenketten erweitern können. Die festgelegten Begriffe (Seed) sind äußerst wichtig und müssen sicher aufbewahrt werden. Am Besten auf ein Stück Papier schreiben.
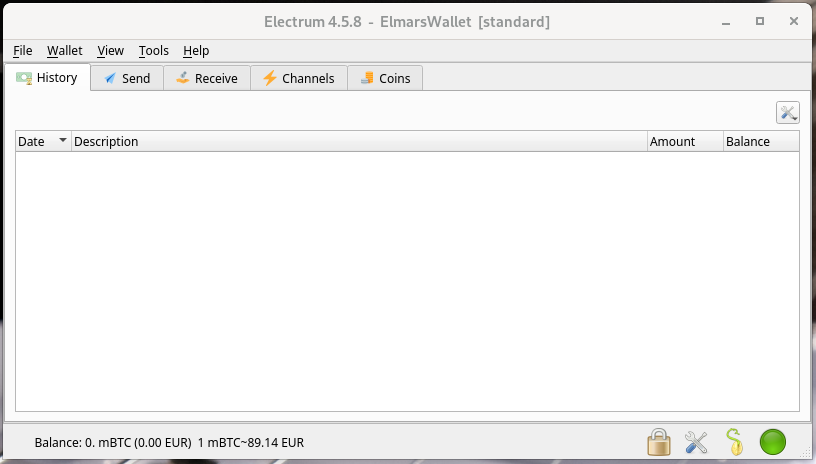
Nachdem die App heruntergeladen wurde und gestartet ist, können wir loslegen und unser Bitcoin Wallet anlegen. Zuerst vergeben wir einen Namen für unser Wallet und drücken auf Next. Anschließend werden wir gefragt welchen Wallet Typen wir anlegen möchten. Hier belassen wir es bei dem Standard. Anschließend müssen wir eine Seed erzeugen. Der Seed (dt. Samen) sind 12 zufällig erstellte Wörter, die wir über die Schaltfläche Option um eigene Begriffe / Zeichenketten erweitern können. Die festgelegten Begriffe (Seed) sind äußerst wichtig und müssen sicher aufbewahrt werden. Am Besten auf ein Stück Papier schreiben. Der Seed ermöglicht den vollen Zugriff auf das persönliche Wallet. Mit dem Seed kann man sein Wallet auf jedes beliebige Gerät problemlos übertragen. Anschließend wird noch ein sicheres Passwort vergeben und die Wallet Datei verschlüsselt. Damit haben wir bereits unser eigenes Bitcoin Wallet angelegt, mit dem wir in der Lage sind Bitcoin zu versenden und zu empfangen.
Screenshots




Auf diese Art und Weise lassen sich beliebig viele Wallets erstellen. Viele Leute nutzen 2 oder mehr Wallets gleichzeitig. Dieses Verfahren nennt sich Proxy Pay oder auf deutsch Stellvertreter Weiterleitung. Diese Maßnahme verschleiert den tatsächlichen Empfänger und soll verhindern das Transferdienste Transaktionen an unliebsame Empfänger verweigern können.
Um die eigene Euros in Bitcoin zu verwandeln wird ein sogenannter Broker benötigt. An diesen Broker überweist man Euros oder andere Währungen und erhält dafür Bitcoin. Die Bitcoin werden zuerst auf ein Wallet das der Broker verwaltet übertragen. Von diesem Wallet kann man bereits Bitcoin an ein beliebiges anderes Wallet senden. Solange die Bitcoin aber noch im Wallet des Brokers liegen kann der Broker das Wallet sperren oder die darauf befindlichen Bitcoin stehlen. Erst wenn wir die gekauften Bitcoin auf ein selbstverwaltetes Wallet transferieren, wie wir es in Schritt 1 erstellt haben sind die Coins auch in unserem Besitz und keine außenstehende Person hat noch darauf Zugriff.
Das Problem welches entstehen kann, ist das diese Brokerdienste auch Krypto-Börsen genannt, eine Liste von Bitcoin Wallets führen können zu denen sie keine Transaktionen senden. Um dies zu umgehen transferiert man seine Bitcoins von dem Wallet der Bitcoin Börse, wo man seine Coins gekauft hat auf ein eigenes Wallet. Mann kann auch mehrere Wallets nutzen um Zahlungen zu empfangen. Diese Strategie erschwert die Nachverfolgung von Zahlungströmen. Das Geld was auf verschiedenen Wallets eingegangen ist lässt sich nun problemlos auf ein zentrales Wallet transferieren, auf dem man seine Coins ansparen kann. Es ist wichtig zu wissen, das auch bei dem Versand von Bitcoin Gebühren fällig werden. Genau so wie bei einem Girokonto.
Transaktionsgebühren für Bitcoin verstehen
Jedes Mal, wenn eine Transaktion durchgeführt wird, wird sie in einem Block gespeichert. Diese Blöcke haben eine begrenzte Größe von 1 MB, was die Anzahl der Transaktionen pro Block limitiert. Da die Anzahl der Transaktionen, die in einen Block passen, begrenzt ist, konkurrieren die Nutzer darum, dass ihre Transaktionen in den nächsten Block aufgenommen werden. Hier kommen die Bitcoin Transaktionsgebühren ins Spiel. Nutzer bieten Gebühren an, um ihre Transaktionen für Miner attraktiver zu machen. Je höher die Gebühr, desto wahrscheinlicher wird die Transaktion schneller bestätigt. Die Höhe der Gebühren hängt von mehreren Faktoren ab:
- Netzwerkauslastung: Bei hoher Auslastung steigen die Gebühren, da mehr Nutzer ihre Transaktionen priorisieren möchten.
- Transaktionsgröße: Größere Transaktionen benötigen mehr Platz im Block und verursachen daher höhere Gebühren.
- Marktbedingungen: Die allgemeine Nachfrage nach Bitcoin und die Marktvolatilität können die Gebühren beeinflussen.
Die meisten Wallets berechnen die Gebühren automatisch basierend auf diesen Faktoren. Einige Wallets bieten jedoch die Möglichkeit, die Gebühren manuell anzupassen, um entweder Kosten zu sparen oder eine schnellere Bestätigung zu erzielen.
Die Bitcoin Transaktionsgebühren sind nicht festgelegt und können stark variieren. Bitcoin-Transaktionen können je nach Höhe der Gebühren innerhalb von Minuten bis Stunden bestätigt werden. Die Gebühren bei Bitcoin werden nicht anhand des Wertes der Transaktion (also wie viel Bitcoin du sendest) berechnet, sondern basieren auf der Größe der Transaktion in Bytes. Die Gebühr, die du zahlst, wird in Satoshis pro Byte (sat/byte) angegeben. Ein Satoshi ist die kleinste Einheit von Bitcoin (1 BTC = 100 Millionen Satoshis).
Wieviele Satoshi man für 1 € bekommt erfahrt ihr auf coincodex.com und die aktuelle Transaktionsgebühr findet ihr auf bitinfocharts.com
Anmerkungen zur Anonymität von Bitcoin
Wenn man mit Bitcoin bezahlt sendet man Coins von seinem Wallet zu einem Empfängerwallet. Diese Transaktion ist öffentlich einsehbar. Grundsätzlich wird beim Anlegen eines Wallets über Sotware wie Electrum nicht gespeichert wer der Besitzer des Wallet ist. Dennoch lassen sich Rückschlüsse zum Besitzer eines Wallets über die Transaktionen herleiten. Man kann durch die Verwendung mehrere Wallets die Zuordnung zu einer realen Person erschweren und Geldflüsse verschleiern. Aber eine 100% Anonymität kann nicht gewährleistet werden. Nur Bargeld bietet absolute Anonymität.
Dennoch hat Bitcoin gegenüber Bargeld einige Vorteile. Wer viel auf Reisen ist und sein Geld nicht auf dem Bankkonto liegen haben möchte kann problemlos sehr hohe Beträge mit sich führen, ohne das diese bei Grenzübertritten aufgefunden und eingezogen werden können. Auch vor Diebstal ist man recht gut geschützt. Wer sein Wallet in einer verschlüsselten Datei auf verschiedenen Datenträgen sichert kann es mittels der Seed leicht wieder herstellen.
Schritt 2: Bitcoin kaufen
Bevor wir uns daran machen können Bitcoin zu verwenden müssen wir zu ersteinmal Bitcoin in unseren Besitz bringen. Das gelingt uns recht einfach in dem wir Bitcoin kaufen. Da Bitcoin je nach Kurs mehrere tausend Euro wert sein kann, ist es sinnvol Teiel eines Bitcoin zu kaufen. Wie bereits erwähnt die kleinste Einheit eines Bitcoin ist Satoshi und entspricht einem μBTC (1 BTC = 100 Millionen Satoshis). Btcoin kauft man am einfachsten über eine offizielle Bitcoin Börse. Eine sehr leicht zu verwendende Börse ist Wallet of Satoshi für Android & iPhone.

Mit dieser App kann man Bitcoin kaufen, empfangen und versenden. Nach dem man das Wallet of Satoshi auf seinem Smartphone installiert hat und das Wallet eingerichtet ist kann man über das Menü auch sofort per Banküberweisung mit nur 20 Euro Satoshis kaufen.
Ein sehr praktisches Detail ist das man mit dem Wallet of Satoshi auch Bitcoin über andere Währungen wie beispielsweise US Dollar kaufen kann. Das ist hervorragend für internationale Geschäftsbeziehungen, wo man sich nun nicht mehr mit allen möglichen Wechselkursen umher schlagen muss. Da aus meiner Überlegung Bitcoin ein alternatives Zahlungsmittel ist ist es für mich sinnvoll stets ein Betrag von 200 bis 500 Euro im Wallet of Satoshi zu belassen. Alles was darüber hinausgeht wird auf das Electrum Wallet übertragen. Dies ist eine reine Vorsichtsmaßnahme, denn Wallet of Satoshi basiert auf dem Lightning Netzwerk und ist ein privater Anbieter. Treu nach dem Motto Vorsicht ist besser als Nachsicht. Diese Strategie spart außerdem auch Transaktionsgebühren, was sich besonders bei micro payments von wenigen Euros zu einem stattlichen Betrag aufsummieren kann.
Schritt 3: Mit Bitcoin bezahlen

Um mit Bitcoin bezahlen zu können benötigt man eine gültige Wallet Adresse. Diese Adresse ist in der Regel eine lange kryptische Zeichenkette. Da bei der manuellen Eingabe schnell etwas schiefgehen kann wird diese Adresse oft als QR Code angegeben.
Um eine Zahlung zum Beispiel über das Wallet of Satoshi an ein beliebiges Bitcoin Wallet durchzuführen wird entweder die Zeichenkette oder besser der QR Code benötigt. Dazu öffnet man die Applikation drückt auf den Button senden und scannt dann mit der Kamera den QR Code des Wallets wohin die Bitcoin gehen sollen.
Wenn ihr beispielsweise an das Wallet of Satoshi Bitcoin sendet sind alle Transaktion vollständig transparent. Deswegen könnt Ihr auch an ein anonymes Wallet Bitcoin senden. In Schritt 1 habe ich breites gezeigt wie das Electrum Wallet erstellt wird. Nun schauen wir uns an wie wir An die Adresse des Wallets gelangen. Dazu gehen wir im Menü von Electrum auf den Eintrag Wallet und wählen den Punkt Information aus. Dann erhalten wir eine Anzeige wie im folgenden Screenshot.
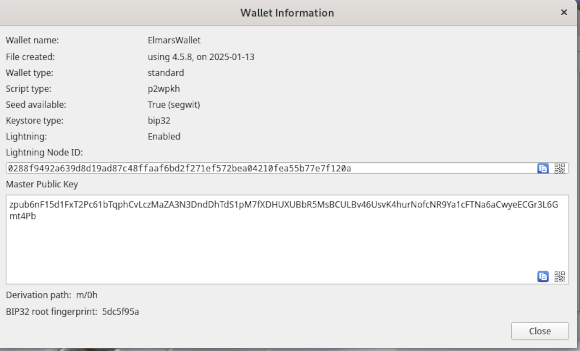
Der Master Public Key ist die Zeichenkette für unser Wallet an das Bitcoins gesendet werden können. Drückt man rechts unten in dem Feld auf das QR Symbol erhält man den zugehörigen QR Code der als Bilddatei gespeichert werden kann. Wenn ihr nun Überweisungen von einer Bitcoin Börse wie dem Wallet of Satoshi durchführt weis die Börse nicht wer der Inhaber ist. Um das herauszubekommen sind wiederum aufwendige Analysen notwendig.

Hinterlasst auch gern einen Kommentar wie Ihr Bitcoin nutzt und mit welcher Software Ihr arbeitet.
Wenn Ihr denkt das die Informationen in diesem Artikel sehr hilfreich sind dann könnt ihr meine Arbeit unterstützen in dem Ihr diesen Artikel weiter empfehlt oder mit Bitcoin bzw. Satoshi auf mein Electrtum Walles spendet. Die Adresse lautet:
zpub6nh5hzmJPGLHxV25hREtCUFLdS5RPjnxnxUhVq5MyDP9eUqYZe9JDoZRBj3eXBQ5nKK7133u7hpwHukxcPnJv4eP9xch4AiWHwThJuwrieA Unlock with Patreon
Unlock with Patreon