Für Hobbyprogrammierer als auch professionelle Softwareentwickler sind gut Informationsquellen essenziell. Eine kleine, überschaubare Privatbibliothek mit zeitlosen Büchern über Programmierung ist daher immer eine gute Sache. Leider ist das Angebot zu IT-Literatur sehr umfangreich und oft veralten die Bücher auch schnell wieder. Hinzu kommt außerdem noch, dass einige Titel aus unterschiedlichen Gründen nicht unbedingt das Prädikat lesenswert besitzen. Manche Texte sind nur sehr verständlich. Andere wiederum enthalten kaum relevante Informationen, die bereits leicht über öffentliche Quellen bezogen werden können. Deswegen habe ich mir einmal die Mühe gemacht und meine Top 10 Bücher zum Thema Softwareentwicklung zusammengestellt.
Alle Titel sind im Original in englischer Sprache veröffentlicht worden. Die meisten davon wurden aber auch ins Deutsche übersetzt. Wem das Lesen englischer Bücher keine Schwierigkeiten bereitet, sollte sich das Original besorgen, da manchmal die Übersetzungen etwas holprig sind.
Ein wichtiges Kriterium für eine Auswahl ist, dass die Bücher sehr generell sind und sich nicht auf eine spezifische Version beschränken. Hinzu kommt noch, dass ich die hier vorgeschlagenen Werke auch tatsächlich in meinem Bücherregal stehen habe, und daher auch gelesen habe.
Effective Java 3rd Edition, J. Bloch, 2017, ISBN: 0-134-68599-7 | Für alle Java-Entwickler, das Standardwerk mit vielen Hintergrundinformationen über die Funktionsweise der Sprache und Optimierungen des eigenen Source Codes.
The Linux Command Line2nd Edition, W. Shotts, 2019, ISBN: 1-59327-952-3 | Linux hat in der Softwareentwicklung einen hohen Stellenwert, da nicht nur Cloud-Anwendungen in Linux Umgebungen deployed werden. Um so wichtiger ist es sich auf der Kommandozeile sicher bewegen zu können. Dieses Buch widmet sich ausschließlich dem Umgang mit der Bash und ist für alle Linux Distributionen geeignet.
Angry Tests, Y. Bugayenko, 2025, ISBN: 978-1982063740 | Testgetriebene Softwareentwicklung ist eine wichtige Fähigkeit, um eine hohe Qualität sicherzustellen. Dieses Buch ist nicht auf eine konkrete Programmiersprache ausgerichtet, sondern befasst sich ausschließlich damit, wie man aussagekräftige Testfälle schreibt.
Clean Architecture, R. C. Martin, 2018, ISBN: 0-13-449416-4 | Neben einem Abriss der Historie, wie die verschiedenen Programmier-Paradigmen in Beziehung zueinander stehen, beschreibt das Buch grundlegende Architekturentwurfsstile. Nicht nur für Softwarearchitekten, sondern auch für Entwickler sehr lesenswert.
Mastering Regular Expressions3rd Edition, J. E. F. Friedl, 2006, ISBN: 0-596-52812-4 | Das absolute Standardwerk zum Thema reguläre Ausdrücke. Ein Muss für jeden, der das Thema wirklich verstehen muss.
Head First Design Pattern, Eric & Elisabeth Freeman, 2004, ISBN: 0-596-00712-4 | Entwurfsmuster gehören zu den Grundfähigkeiten eines jeden Programmierers. In diesem Buch werden die einzelnen Konzepte der GOF Muster umfassend besprochen. Es eignet sich sowohl zum Einstieg als auch als Referenz.
Advanced API Security2nd Edition, P. Siriwardena, 2020, ISBN: 978-1-4842-2049-8 | API Entwurf für RESTful Services gehört mittlerweile zum Standardrepertoire eines Entwicklers. Aber auch das Thema Sicherheit darf dabei nicht zu kurz kommen. Dieses Buch bespricht neue Konzepte, die zum Industriestandard erhoben wurden. Ein guter Einstieg für Programmierer, die bisher nicht mit SAML, OAuth und Open ConnectID in Berührung gekommen sind.
SQL Antipatterns, B. Karwin, 2010, ISBN: 987-1-934356-55-5 | Selbst für gestandene Programmierer sind Datenbanken oft ein Buch mit sieben Siegeln. Auch wenn SQL Statements schnell hingeschrieben sind und diese auch das gewünschte Resultat hervorbringen, können im Produktivbetrieb zu erheblichen Problemen führen. Dieses Buch beschreibt, warum Statements sehr langsam ausgeführt werden und wie diese richtig formuliert werden können.
Domain Driven Design, E. Evans, 2003, ISBN: 0-32-112521-5 | Die Verbindung zwischen objektorientierter Programmierung (OOP) und Datenbankentwurf wird mit dem Paradigma Domain Driven Design geschlagen.
The Art of Computer Programming I-IV, D.E. Knuth, 2021, ISBN: 0-137-93510-2 | Vier einzelne Bücher im Schuber beschreiben auf sehr mathematische Weise wie Algorithmen funktionieren.
Das Thema künstliche Intelligenz wird für unsere Gesellschaft erhebliche Veränderungen bewirken. Das Jahr 2022 läutete diese Veränderungen mit dem Launch von ChatGPT für private Nutzer ein. Mächtige K. I. basierte Werkzeuge erblicken mittlerweile fast täglich das Licht der Welt. Sie versprechen höhere Produktivität und eröffnen neue und auch ungeahnte Möglichkeiten. Selbst wenn es im ersten Moment etwas gruselig erscheint was diese Tools leisten ist es zudem auch faszinierend, denn die meisten dieser Anwendungen haben wir uns schon seit vielen Jahren herbeigesehnt.
Bevor ich also auf die Details eingehe, möchte ich noch kurz ein paar mahnende Worte loswerden. Denn so spannend das ganze Thema auch ist, es hat auch seine Schattenseiten, die wir bei aller Euphorie nicht übersehen sollten. Besonders Unternehmen müssen sich bewusst sein, das sämtliche Anfragen an die K. I. protokolliert und zu Trainingszwecken weiter genutzt werden. Das kann bei sensiblen Geschäftsgeheimnissen durchaus zu einem Sicherheitsrisiko werden.
Technisch gesehen sind die hier besprochenen K. I. Werkzeuge sogenannte künstliche Neuronale Netze und imitieren das menschliche Gehirn. In der Beschreibung wie ChatGPT funktioniert findet sich unter anderem der Begriff Large Vision-Language Model (LVLM). Das bedeutet das diese den Kontext menschlicher Sprache verstehen und entsprechend agieren beziehungsweise reagieren. Alle die in diesem Artikel besprochenen K. I. Systeme sind im Gegensatz zu Lebewesen nicht selbst motiviert. Sie brauchen sozusagen eine Initialzündung um aktiv zu werden. Egal welches Lebewesen hingegen hat permanent die Notwendigkeit für den eigen Energiebedarf Nahrung zu finden. Gelingt es dem Lebewesen nicht über eine längeren Zeitraum keine Nahrung zu finden stirbt es und sein Wesen ist für immer verloren. Ein künstliches Neuronales Netz wiederum kann solange der Computer auf dem es installiert ist Anfragen bearbeiten. Geht der Computer einmal kaputt kann das neuronale Netz auf einem neuen Computer installiert werden und es kann wie bisher weiterarbeiten. Aber nun genug von den technischen Details. Wer an dieser Stelle noch mehr erfahren möchte kann sich auch mein Podcast anhören oder schaut mal in diesem Blog in die anderen K. I. Artikel hinein.
Bevor ich nun K. I. Systeme für den Hausgebrauch vorstelle möchte ich noch ein paar hochspezialisierte Industrieanwendungen besprechen. Denn ich muss durchaus zugeben das mich die Leistungsfähigkeit dieser Systeme sehr beeindruckt. Zudem demonstriert dies auch die enorme Vielfältigkeit.
PTC CREO
PTC CREO ist ein computergestütztes Designsystem (CAD) mit dem technische Konstruktionszeichnungen erstellt werden können. CREO kann auch basierend auf Grundlage von Material- und Fertigungsanforderungen bestehende Designs optimieren.
YOU.COM
YOU.COM ist eine K. I. gestützt Suchmaschine mit integriertem Chatbot. Im gegensatz zu Google und Co präsentiert YOU.COM keine langen Ergebnislisten aus denen man das für sich treffen heraus suchen muss. Vielmehr bekommt man auf seine Anfrage eine Zusammenfassung der gefundenen informationen.
absci
absci nutzt künstliche neuronale Netze um von Grund auf Medikamente zu entwerfen. Der so extrem beschleunigte Prozess ermöglicht in der Zukunft auf dem Patienten abgestimmte personalisierte Medikamente zu entwickeln.
PassGAN
Auf der freien SourceCode Hosting Plattform GitHub findet sich das Tool PassGAN, ein Python geschriebener K. I. gestützter Passwortknacker. Auch wenn die Verwendung kompliziert ist und PassGAN vornehmlich von Sicherheits Forschern genutzt wird, ist es eine Frage der Zeit bis fähige Spezialisten dieses Tool für illegale Aktivitäten nutzen.
Wer nun auf den Geschmack gekommen ist sollte unbedingt einmal einen Blick auf hugging face werfen. Auf dieser Webseite tummelt sich die K. I. Community und es können alle möglichen LVLM mit unterschiedlichen Datensätzen ausprobiert werden. Natürlich gibt es auch eine umfangreiche Sektion mit aktuellen wissenschaftlichen Publikationen zum Thema.
Nachdem ich mit einigen Beispielen das Potenzial den neuronalen Netze im kommerziellen Umfeld demonstriert habe, ist es nun an der zeit sich den Tools für den Hausgebrauch zuzuwenden. So kann man die im folgenden vorstellten auch für Alltagsaufgaben nutzen.
Eine der ältesten Domänen für künstliche Intelligenz ist das Feld der Übersetzungen. Alle die bereits im Urlaub fleißig den Google Translator genutzt haben wissen vielleicht gar nicht das dieser auch K. I. Technologien verwendet. Dafür braucht der Translator auch eine Verbindung ins Internet, denn auch moderne Smartphones sind nicht leistungsstark genug für komplexe Übersetzungen durch neuronale Netze. Allerdings hatte der Google Translator in der Vergangenheit für mich erhebliche Schwächen. Besonders bei komplexen Sätzen kam das Tool schnell an seine Grenzen. Viel bessere Resultate erreiche ich mit DeepL, das ich vornehmlich für die Sprachen Deutsch / Spanisch und Englisch nutze. Mit dem gleichnamigen Browserplugin lassen sich so auch ganze Webseiten übersetzen. In der kostenlosen Variante von DeepL können auf der Webseite Texte mit bis zu 1500 pro Anfrage übersetzt werden. Wer allerdings oft umfangreiche Dokumente in kurzer Zeit übersetzen möchte kann auch auf die kommerzielle Version wechseln. Dann lassen sich verschiedene Formate wie PDF, DOCX etx auf die Webseite hochladen und in wenigen Augenblicken erhält man die entsprechende Übersetzung. Es gibt auch eine Option um den Ausgangstext stilistisch etwas aufzupeppen. Das ist besonders für diejenigen geeignet, denen es schwerfällt eigene Texte (Briefe etc.) zu formulieren.
Wer wiederum für seine Homepage individuelle Grafiken benötigt musste bisher entweder ein professionellen Grafikdesigner beauftragen oder langwierig auf freien Plattformen wie Pixabay nach frei verwendbaren Grafiken suchen. Gerade im Bereich der K. I. gestützten Bildgenerierung gibt es eine erhebliche Auswahl an Lösungen. Denn aktuell im Jahre 2023 gibt es noch keine Regulatoren zum Copyright der durch die K. I. erzeugten Bilder. Das könnte sich allerdings in den nächste Jahren ändern. Hier müssen wir abwarten und ein Auge auf die aktuelle Gesetzeslage haben. Im privaten Umfeld ist dies natürlich kein Thema. Wer soll schon die ganzen Schmuckgrafiken in Fotobüchern oder auf Einladungskarten zur Hochzeit oder zum Geburtstag kontrollieren. Im folgenden findet sich eine Liste verschidener Anbietr. Diese sind in ihren Grundfunktionen recht identisch, so das man hier nach persönlichem Geschmack und Befindlichkeiten seine Wahl treffen kann.
Stable Diffusion hat den Fokus fotorealistische Bilder zu generieren.
Ein weiterer für K. I. prädestinierter Anwendungsbereich ist das Erzeugen von Text. Wer sich hier schwer tut kann für seine Homepage z. B. Blogbeiträge mit K: I. Unterstützung generieren lassen. Aber auch auf juristische Formulierungen spezialisierte Anwendung zum Erstellen ganzer Vertragsentwürfe, Impressumstexte u. s. w. sind für einfache Aufgaben auch für Privatanwender sehr interessant. Einfche Untermietverträge, Verkaufsverträge etc. sind klassische Bereiche in denen man nicht gleich einen Anwalt beauftragt. Im folgenden habe ich eine kleine Liste verschiedener K. I. Basierter Textgeneratoren zusammen gestellt:
Chat-GPT ist ein Chatbot der bei der Recherche zu neuen Thematiken unterstützen kann.
Wordtune erlaubt es eigene Formulierungen stilistisch zu verbessern und nach Vorgaben wie Formaler Ausdruck abzuändern.
Spellbook unterstützt Anwälte bei der Erstellung von Vertragsentwürfen unterstützt.
Rytr hat seinen Fokus bei Content Creatoren und erlaub das Angeben von SEO Schlüsselwörtern. Zudem gibt es auch ein WordPress Plugin.
BARD von Google ünterstützt bei der Formulierung von komplexen Suchanfragen um die Trefferliste zu optimieren.
Wer nun glaubt mit den bereits vorgestellten Systemen wären wir schon am Ende möglicher Einsatzgebiete, der irrt. Ein weiterer großer Einsatzbereich ist die Audio / Video Bearbeitung. Hier muss man nicht gleich von hochwertigen Filmproduktionen wie sie aus den Hollywood Studios kommen denken. Es gibt viele kleine Aufgaben, die auch für den Hausgebrauch relevant sind. Aus Audio- oder Videodateien den Text als Exzerpt zu extrahieren, diese Vorlage dann beispielsweise übersetzen um eine neue Audiodatei in einer anderen Sprache zu erzeugen. Die Umwandlung von Text nach Audio und wieder zurück sind keine Neuigkeit denn sie sind besonders für Blinde und Taube Menschen eine Verbesserung der Lebensqualität.
Elevenlabs bitete eine K. I. basierte Text-to-Speech Engine an, deren Ausgabe bereits sehr realistich klingt.
Dadabots erzeugt einen Musik-Livestream und kann dabei Genres und bekannte Bands imitieren. Was bei Veranstaltungen den Einsatz von GEMA freier Musik ermöglicht.
Elai.io erlaubt es personalisierte Videos mit digitalen Avataren zu erstellen. Anwendungsbereiche sind beispielsweise Bildung und Marketing.
MuseNet unterstützt Musiker auf Basis vorgegebener MIDI Sampels bei der Komosition neuer Stücke.
Als letzten großen Anwendungsbereich für K. I. gestützte Software in dieser Liste ist das Erstellen von Source Code. Auch wenn Codegeneratoren für Programmierer keine Neuheit sind und diese schon seit längerer Zeit den Arbeitsfluss beschleunigen, bietet der K. I. basierte Ansatz weitaus mehr Flexibilität. Aber auch hier gilt wie für alle zuvor beschriebene Applikationen ein wachsamer Blick des Nutzers ist unumgänglich. Es lassen sich durchaus bestehende Programmfragmente nach Vorgaben optimieren oder sogenannte Templates als Vorlagen erzeugen, die dann manuell weiter ausgearbeitet werden können. Die meisten der im Folgenden vorgestellten Werkzeuge sind für die komerzielle Softwareentwicklung kostenpflichtig. Es gibt aber auf Anfrage für Studenten, Lehrer und Open Source Entwickler jeals eine kostenlose Variante.
CodeStarter Integration für Ubuntu Linux ist spezialisiert auf Webanwendungen
CodeWP für WordPress und erlaubt das Erstellen eigener Plugins oder Templates
Tabnineist eine IDE Erweiterung für Visual Studio Code, Android Studio, Eclipse und IDEA
Wir sehen es gibt unzählige Anwendungen die bereits nutzbar sind und diese Liste ist bei weitem noch nicht vollständig. Aus diesem Grunde möchte ich zum Schluß noch die Webseite Futurepedia vorstellen. Dort werden regelmäßig neue K. I. Tools aufgelistet und kurz vorgestellt. Falls Sie also in diesem Artikel noch nicht das passende Werkzeug für sich gefunden haben schauen sie ruhig einmal auf Futurepedia vorbei.
Für viele ist Bitcoin (BTC) ein reines Spekulationsobjekt, mit dem sie ausschließlich Geld verdienen wollen. Die Kryptowährung Bitcoin eignet sich aber auch hervorragend zum Bezahlen. Um mit Bitcoin zu bezahlen benötigt man kein tiefgreifendes technisches Wissen. Es können auch bereits mit vergleichsweise geringen Beträgen zum Beispiel 10 Euro Bitcoin gekauft werden. Alles was man für den Anfang benötigt wird in diesem Artikel leicht verständlich erklärt.
Um den ersten Bitcoin zu kaufen benötigt man reguläres Bankkonto, 20 € und circa 10 Minuten Zeit. Je nach Bank dauert die Überweisung von Euro bis diese als Bitcoin gutgeschrieben wird, bis zu einem Tag. Übrigens können auch alle Dienstleistungen von elmar-dott.com über Bitcoin bezahlt werden.
Wer möchte, kann sich die Reportage des digitalen Aktivisten als Einstieg zu Bitcoin hier anschauen. Um Bitcoin zu verwenden muss man Bitcoin aber nicht verstehen.
Bevor wir die erste Transaktion starten müssen wir ein Wallet erstellen. Wallet ist die englische Bezeichnung für Geldbörse. Das heißt, das ein Bitcoin Walltet nichts anderes als eine digitale Geldbörse ist. Das Programm mit dem man ein Wallet anlegen und verwalten kann ist der typischen BankingApp sehr ähnlich. Wallets lassen sich auf Computern, Smartphones und Tablets (Android & iPhone/ iPad) problemlos einrichten. Es gibt aber auch Hardware Wallets, die ähnlich wie ein USB Stick funktionieren und die Bitcoins dort speichern.
Der wichtigste Unterschied zwischen einem Bankkonto und einem Wallet ist, das die Bitcoins die auf dem eigene Wallet abgelegt sind, tatsächlich mir gehören. Denn es gibt keine Bank oder andere Institution die Zugriff auf dieses Wallet hat. Man kann Bitcoin die im eigene Wallet gespeichert sind mit dem Bargeld vergleichen, das man in seiner Brieftasche hat. Schauen wir uns daher im ersten Schritt an, wie man sein eigenes Wallet anlegt. Hierfür nutzen wir die freie Open Source Software Electrum. Das Electrum Bitcoin Wallet wurde in Phyton 3 entwickelt und ist für: Linux, Windows, MacOS und Android verfügbar.
Schritt 1: Ein Wallet erstellen
Nachdem die App heruntergeladen wurde und gestartet ist, können wir loslegen und unser erstes Bitcoin Wallet anlegen. Zuerst vergeben wir eine Namen für unser Wallet und drücken auf Next. Anschließend werden wir gefragt welchen Wallet Typen wir anlegen möchten. Hier belassen wir es bei dem Standard. Anschließend müssen wir einen Seed erzeugen. Der Seed (dt. Samen) sind 12 zufällig erstellte Wörter, die wir über die Schaltfläche Option um eigene Begriffe / Zeichenketten erweitern können. Die festgelegten Begriffe (Seed) sind äußerst wichtig und müssen sicher aufbewahrt werden. Am Besten auf ein Stück Papier schreiben.
Nachdem die App heruntergeladen wurde und gestartet ist, können wir loslegen und unser Bitcoin Wallet anlegen. Zuerst vergeben wir einen Namen für unser Wallet und drücken auf Next. Anschließend werden wir gefragt welchen Wallet Typen wir anlegen möchten. Hier belassen wir es bei dem Standard. Anschließend müssen wir eine Seed erzeugen. Der Seed (dt. Samen) sind 12 zufällig erstellte Wörter, die wir über die Schaltfläche Option um eigene Begriffe / Zeichenketten erweitern können. Die festgelegten Begriffe (Seed) sind äußerst wichtig und müssen sicher aufbewahrt werden. Am Besten auf ein Stück Papier schreiben. Der Seed ermöglicht den vollen Zugriff auf das persönliche Wallet. Mit dem Seed kann man sein Wallet auf jedes beliebige Gerät problemlos übertragen. Anschließend wird noch ein sicheres Passwort vergeben und die Wallet Datei verschlüsselt. Damit haben wir bereits unser eigenes Bitcoin Wallet angelegt, mit dem wir in der Lage sind Bitcoin zu versenden und zu empfangen.
Auf diese Art und Weise lassen sich beliebig viele Wallets erstellen. Viele Leute nutzen 2 oder mehr Wallets gleichzeitig. Dieses Verfahren nennt sich Proxy Pay oder auf deutsch Stellvertreter Weiterleitung. Diese Maßnahme verschleiert den tatsächlichen Empfänger und soll verhindern das Transferdienste Transaktionen an unliebsame Empfänger verweigern können.
Um die eigene Euros in Bitcoin zu verwandeln wird ein sogenannter Broker benötigt. An diesen Broker überweist man Euros oder andere Währungen und erhält dafür Bitcoin. Die Bitcoin werden zuerst auf ein Wallet das der Broker verwaltet übertragen. Von diesem Wallet kann man bereits Bitcoin an ein beliebiges anderes Wallet senden. Solange die Bitcoin aber noch im Wallet des Brokers liegen kann der Broker das Wallet sperren oder die darauf befindlichen Bitcoin stehlen. Erst wenn wir die gekauften Bitcoin auf ein selbstverwaltetes Wallet transferieren, wie wir es in Schritt 1 erstellt haben sind die Coins auch in unserem Besitz und keine außenstehende Person hat noch darauf Zugriff.
Das Problem welches entstehen kann, ist das diese Brokerdienste auch Krypto-Börsen genannt, eine Liste von Bitcoin Wallets führen können zu denen sie keine Transaktionen senden. Um dies zu umgehen transferiert man seine Bitcoins von dem Wallet der Bitcoin Börse, wo man seine Coins gekauft hat auf ein eigenes Wallet. Mann kann auch mehrere Wallets nutzen um Zahlungen zu empfangen. Diese Strategie erschwert die Nachverfolgung von Zahlungströmen. Das Geld was auf verschiedenen Wallets eingegangen ist lässt sich nun problemlos auf ein zentrales Wallet transferieren, auf dem man seine Coins ansparen kann. Es ist wichtig zu wissen, das auch bei dem Versand von Bitcoin Gebühren fällig werden. Genau so wie bei einem Girokonto.
Transaktionsgebühren für Bitcoin verstehen
Jedes Mal, wenn eine Transaktion durchgeführt wird, wird sie in einem Block gespeichert. Diese Blöcke haben eine begrenzte Größe von 1 MB, was die Anzahl der Transaktionen pro Block limitiert. Da die Anzahl der Transaktionen, die in einen Block passen, begrenzt ist, konkurrieren die Nutzer darum, dass ihre Transaktionen in den nächsten Block aufgenommen werden. Hier kommen die Bitcoin Transaktionsgebühren ins Spiel. Nutzer bieten Gebühren an, um ihre Transaktionen für Miner attraktiver zu machen. Je höher die Gebühr, desto wahrscheinlicher wird die Transaktion schneller bestätigt. Die Höhe der Gebühren hängt von mehreren Faktoren ab:
Netzwerkauslastung: Bei hoher Auslastung steigen die Gebühren, da mehr Nutzer ihre Transaktionen priorisieren möchten.
Transaktionsgröße: Größere Transaktionen benötigen mehr Platz im Block und verursachen daher höhere Gebühren.
Marktbedingungen: Die allgemeine Nachfrage nach Bitcoin und die Marktvolatilität können die Gebühren beeinflussen.
Die meisten Wallets berechnen die Gebühren automatisch basierend auf diesen Faktoren. Einige Wallets bieten jedoch die Möglichkeit, die Gebühren manuell anzupassen, um entweder Kosten zu sparen oder eine schnellere Bestätigung zu erzielen.
Die Bitcoin Transaktionsgebühren sind nicht festgelegt und können stark variieren. Bitcoin-Transaktionen können je nach Höhe der Gebühren innerhalb von Minuten bis Stunden bestätigt werden. Die Gebühren bei Bitcoin werden nicht anhand des Wertes der Transaktion (also wie viel Bitcoin du sendest) berechnet, sondern basieren auf der Größe der Transaktion in Bytes. Die Gebühr, die du zahlst, wird in Satoshis pro Byte (sat/byte) angegeben. Ein Satoshi ist die kleinste Einheit von Bitcoin (1 BTC = 100 Millionen Satoshis).
Wieviele Satoshi man für 1 € bekommt erfahrt ihr auf coincodex.com und die aktuelle Transaktionsgebühr findet ihr auf bitinfocharts.com
Anmerkungen zur Anonymität von Bitcoin
Wenn man mit Bitcoin bezahlt sendet man Coins von seinem Wallet zu einem Empfängerwallet. Diese Transaktion ist öffentlich einsehbar. Grundsätzlich wird beim Anlegen eines Wallets über Sotware wie Electrum nicht gespeichert wer der Besitzer des Wallet ist. Dennoch lassen sich Rückschlüsse zum Besitzer eines Wallets über die Transaktionen herleiten. Man kann durch die Verwendung mehrere Wallets die Zuordnung zu einer realen Person erschweren und Geldflüsse verschleiern. Aber eine 100% Anonymität kann nicht gewährleistet werden. Nur Bargeld bietet absolute Anonymität.
Dennoch hat Bitcoin gegenüber Bargeld einige Vorteile. Wer viel auf Reisen ist und sein Geld nicht auf dem Bankkonto liegen haben möchte kann problemlos sehr hohe Beträge mit sich führen, ohne das diese bei Grenzübertritten aufgefunden und eingezogen werden können. Auch vor Diebstal ist man recht gut geschützt. Wer sein Wallet in einer verschlüsselten Datei auf verschiedenen Datenträgen sichert kann es mittels der Seed leicht wieder herstellen.
Schritt 2: Bitcoin kaufen
Bevor wir uns daran machen können Bitcoin zu verwenden müssen wir zu ersteinmal Bitcoin in unseren Besitz bringen. Das gelingt uns recht einfach in dem wir Bitcoin kaufen. Da Bitcoin je nach Kurs mehrere tausend Euro wert sein kann, ist es sinnvol Teiel eines Bitcoin zu kaufen. Wie bereits erwähnt die kleinste Einheit eines Bitcoin ist Satoshi und entspricht einem μBTC (1 BTC = 100 Millionen Satoshis). Btcoin kauft man am einfachsten über eine offizielle Bitcoin Börse. Eine sehr leicht zu verwendende Börse ist Wallet of Satoshi für Android & iPhone.
Mit dieser App kann man Bitcoin kaufen, empfangen und versenden. Nach dem man das Wallet of Satoshi auf seinem Smartphone installiert hat und das Wallet eingerichtet ist kann man über das Menü auch sofort per Banküberweisung mit nur 20 Euro Satoshis kaufen. Ein sehr praktisches Detail ist das man mit dem Wallet of Satoshi auch Bitcoin über andere Währungen wie beispielsweise US Dollar kaufen kann. Das ist hervorragend für internationale Geschäftsbeziehungen, wo man sich nun nicht mehr mit allen möglichen Wechselkursen umher schlagen muss. Da aus meiner Überlegung Bitcoin ein alternatives Zahlungsmittel ist ist es für mich sinnvoll stets ein Betrag von 200 bis 500 Euro im Wallet of Satoshi zu belassen. Alles was darüber hinausgeht wird auf das Electrum Wallet übertragen. Dies ist eine reine Vorsichtsmaßnahme, denn Wallet of Satoshi basiert auf dem Lightning Netzwerk und ist ein privater Anbieter. Treu nach dem Motto Vorsicht ist besser als Nachsicht. Diese Strategie spart außerdem auch Transaktionsgebühren, was sich besonders bei micro payments von wenigen Euros zu einem stattlichen Betrag aufsummieren kann.
Schritt 3: Mit Bitcoin bezahlen
Um mit Bitcoin bezahlen zu können benötigt man eine gültige Wallet Adresse. Diese Adresse ist in der Regel eine lange kryptische Zeichenkette. Da bei der manuellen Eingabe schnell etwas schiefgehen kann wird diese Adresse oft als QR Code angegeben.
Um eine Zahlung zum Beispiel über das Wallet of Satoshi an ein beliebiges Bitcoin Wallet durchzuführen wird entweder die Zeichenkette oder besser der QR Code benötigt. Dazu öffnet man die Applikation drückt auf den Button senden und scannt dann mit der Kamera den QR Code des Wallets wohin die Bitcoin gehen sollen.
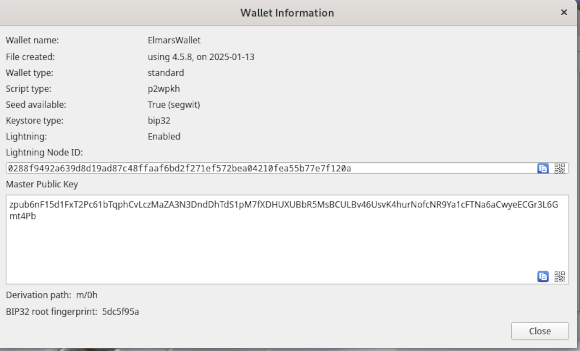
Wenn ihr beispielsweise an das Wallet of Satoshi Bitcoin sendet sind alle Transaktion vollständig transparent. Deswegen könnt Ihr auch an ein anonymes Wallet Bitcoin senden. In Schritt 1 habe ich breites gezeigt wie das Electrum Wallet erstellt wird. Nun schauen wir uns an wie wir An die Adresse des Wallets gelangen. Dazu gehen wir im Menü von Electrum auf den Eintrag Wallet und wählen den Punkt Information aus. Dann erhalten wir eine Anzeige wie im folgenden Screenshot.
Der Master Public Key ist die Zeichenkette für unser Wallet an das Bitcoins gesendet werden können. Drückt man rechts unten in dem Feld auf das QR Symbol erhält man den zugehörigen QR Code der als Bilddatei gespeichert werden kann. Wenn ihr nun Überweisungen von einer Bitcoin Börse wie dem Wallet of Satoshi durchführt weis die Börse nicht wer der Inhaber ist. Um das herauszubekommen sind wiederum aufwendige Analysen notwendig.
Hinterlasst auch gern einen Kommentar wie Ihr Bitcoin nutzt und mit welcher Software Ihr arbeitet.
Wenn Ihr denkt das die Informationen in diesem Artikel sehr hilfreich sind dann könnt ihr meine Arbeit unterstützen in dem Ihr diesen Artikel weiter empfehlt oder mit Bitcoin bzw. Satoshi auf mein Electrtum Walles spendet. Die Adresse lautet:
Den Satz: lieber man hat als man hätte hat sicher jeder einzelne von uns bereits am eigene Leibe erfahren, ganz egal ob im berufliche oder privaten Umfeld. Hätte man doch bloß nicht auf den schädlichen Link in der E-Mail geklickt oder so ähnlich geht es einem dann durch den Kopf. Wenn das Kind aber erst einmal in den Brunnen gefallen ist dann ist es auch schon zu spät für eine Vorsorge.
Was im Privaten meist nur ärgerlich ist, kann im Geschäftsumfeld aber sehr schnell existenzbedrohend werden. Aus diesem Grunde ist es wichtig sich rechtzeitig ein Sicherheitsnetz für den möglichen Schadensendfall aufzubauen. Leider wird in vielen Unternehmen das Thema Notfallwiederherstellung und Geschäftskontinuität nicht angemessen beachtet, was dann im Ernstfall zu hohen finanziellen Verlusten führt.
Die Menge an möglichen Bedrohungsszenarien ist lang. Das Eintreten mancher Szenarien ist wahrscheinlicher als als anderer. Deswegen gilt es eine realistische Risikobewertung durchzuführen die einzelne Optionen gewichtet. Das hilft die entstehenden Kosten nicht ausufern zu lassen.
Die Corona Pandemie war für viele Menschen ein einschneidendes Erlebnis. Besonders die staatlich auferlegten Hygieneregeln stellten viele Betriebe vor enorme Herausforderungen. Hier sei das Stichwort Home Office genannt. Um der Lage Herr zu werden wurden Arbeitnehmer kurzerhand heimgeschickt um von dort aus zu arbeiten. Da speziell im deutschsprachigen Raum es keine etablierte Kultur und noch viel weniger eine vorhandenen Infrastruktur für Heimarbeit gibt musste diese unter sehr hohem Druck kurzerhand erschaffen werden. Das geschah natürlich nicht ohne Reibungspunkte.
Es muss aber nicht immer gleich ein drastisches Ereignis sein. Auch ein profaner Stromausfall oder eine Netzüberspannung kann erheblichen Schaden verursachen. Es muss auch kein Gebäudebrand oder eine Überschwemmung sein die zu sofortigem Stillstand führt. Auch ein Hackerangriff zählt in die Kategorie ernstzunehmender Bedrohungslagen. Damit soll es auch gut sein. Ich denke die Problematik ist mit diesen Beispielen ausführlich dargelegt. Kümmern wir uns daher zu Beginn um die Frage was man als gute Vorsorge bereits leisten kann.
Die am leichtesten umzusetzende und auch wirkungsvollste Maßnahme ist eine umfangreiche Datensicherung. Damit auch wirklich keine Daten verloren gehen hilft es die verschiedenen Daten aufzulisten und zu kategorisieren. In eine solche Tabelle gehören Informationen über die Speicherpfade die zu sichern sind, ungefährer Speicherverbrauch, Priorisierung nach Vertraulichkeit und Kategorie der Daten. Kategorien sind beispielsweise Projektdaten, Austreibungen, E-Mail Korrespondenz, Finanzbuchhaltung, Zulieferlisten, Lohnabrechnungen und so weiter. Es ist natürlich klar das im Rahmen des Datenschutzes nicht jeder im Unternehmen berechtigt ist die Information zu lesen. Deswegen gilt es verdauliche Daten durch Verschlüsselung zu schützen. Je nach Schutzklasse kann es sich um ein einfaches Passwort für komprimierte Daten handeln oder ein kryptographisch verschlüsseltes Verzeichnis oder eine verschlüsselte Festplatte. Die Frage wie oft eine Datensicherung ausgeführt werden sollte ergibt sich aus der Häufigkeit der Änderung der originalen Daten. Je häufiger die Daten verändert werden um so kürzer sollten die Intervalle der Datensicherung sein. Ein anderer Punkt ist der Zielspeicher der Datensicherung. Ein komplett verschlüsseltes Archiv das lokal im Unternehmen liegt kann nach erfolgreichem BackUp durchaus auf einen Cloud-Speicher hochgeladen werden. Diese Lösung kann allerdings bei großen Datenmengen sehr teuer werden und ist daher nicht unbedingt für Kleine und Mittelständische Unternehmen (KMU) geeignet. Ideal ist es natürlich wenn es von einer Datensicherung mehrere Replikationen gibt die an verschieden Orten aufbewahrt werden.
Es nützt natürlich wenig umfangreiche Sicherungen zu erstellen um dann im Ernstfall festzustellen, dass diese fehlerhaft sind. Deswegen ist eine Verifikation der Sicherung enorm wichtig. Professionelle Werkzeuge für Datensicherung enthalten einen Mechanismus der die geschriebene Daten mit dem Original vergleicht. Das Linux-Kommando rsync nutzt ebenfalls diesen Mechanismus. Ein einfaches copy & paste erfüllt die Anforderung nicht. Aber auch ein Blick auf die Dateigröße der Sicherung ist wichtig. Hier lässt sich schnell erkennen ob Informationen fehlen. Natürlich lässt sich noch viel mehr zum Thema Backup sagen, das würde aber an dieser Stelle zu weit führen. Wichtig ist das richtige Verständnis für die Thematik zu entwickeln.
Wenn wir einen Blick auf die IT Infrastruktur von Unternehmen werfen stellen wir sehr schnell fest das die Bereitstellung von Softwareinstallationen überwiegend ein manueller Prozess ist. Wenn wir uns überlegen das beispielsweise ein Rechensystem auf Grund eines Hardwarefehlers seien Dienst nicht mehr verrichten kann gilt es auch hier eine geeignete Strategie zur Nothilfe in der Hand zu haben. Die Zeitintensive Arbeit beim Auftreten von Hardwarefehlern ist das Aufspielen der Programme nach einem Gerätetausch. Nun macht es für viele Unternehmen aus Kostengründen wenig Sinn eine redundante Infrastruktur bereitzuhalten. Eine bewährte Lösung kommt aus dem Bereich DevOps und nennt sich Infrastructure as a Code (IaaC). Hier geht es vor allem darum Dienste wie E-Mail oder Datenbanken etc. via Script bereitzustellen. Für den Business Continuity & Desaster Recovery Ansatz genügt es wenn die automatisierte Installation beziehungsweise Aktualisierung manuell angestoßen wird. Dabei sollte man nicht auf proprietäre Lösungen von möglichen Cloud Anbietern setzen sondern frei verfügbare Werkzeuge nutzen. Denn ein mögliches Szenario ist auch eine Preiserhöhung des Cloud Anbieters oder für Unternehmen nicht akzeptable Änderungen der Geschäftsbedingungen die eien schnellen Wechsel nötig machen können. Basiert die Automatisierungslösung auf einer speziellen Technologie die Andere Anbieter nicht bereitstellen können, gestaltet sich ein schneller Wechsel äußerst schwierig.
Auch auf die Flexibilität der Angestellten sollte geachtet werden. Die Anschaffung von Notebooks anstatt Desktoprechner erlaubt eine hohe Mobilität. Das inkludiert natürlich auch die Erlaubnis den Laptop mit heim zunehmen und sich von dort in das Firmennetzwerk einzuwählen. Teams die Anfang 2020 bereits mit Home Office vertraut waren konnten nahezu nahtlos ihre Arbeit von zu Hause fortsetzen. Das hat den entsprechenden Unternehmen ein gewaltigen Wettbewerbsvorteil verschafft. Es ist auch davon auszugehen das im Rahmen der digitalen Transformation große repräsentative Firmenzentralen immer weniger Bedeutung haben. Die Teams organisieren sich dann flexibel mit modernen Kommunikationswerkzeugen remote. Aktuelle Untersuchungen zeigen das ein solches Setup in den meisten Fällen die Produktivität steigert. Ein verschnupfter Kollege der sich dennoch in der Lage fühlt sein Pensum zu leisten kann so unbesorgt zur Arbeit erscheinen ohne das die Kollegen Gefahr laufen auch angesteckt zu werden.
Wir sehen schon wie weit sich dieses Thema denken lässt. Die Herausforderung besteht allerdings darin eine schrittweise Transformation durchzuführen. Denn in aller Konsequenz entsteht als Ergebnis eine dezentrale Struktur, die mit Redundanzen arbeitet. Genau diese Redundanzen verschaffen bei einer Störung genügend Handlungsspielräume gegenüber einer zentralisierten Struktur. Redundanzen verursachen natürlich einen zusätzlichen Kostenfaktor. Die Ausstattung von Arbeitnehmern mit einem Laptop anstatt eines stationären Desktop PCs ist in der Anschaffung etwas teurer. Mittlerweile ist die Preisdifferenz der beiden Lösungen nicht mehr so dramatisch wie noch zur Jahrtausendwende und die Vorteile überwiegen allerdings. Die Transformation hin die Geschäftsfähigkeit bei Störungen aufrecht zu erhalten bedeutet nicht dass man nun sofort loszieht und allen Arbeitnehmern neues Equipment kauft. Nach dem festgestellt wurde was für das Unternehmen notwendig und sinnvoll ist können Neuanschaffungen priorisiert werden. Kollegen deren Gräte abgeschrieben sind und für einen Austausch vorgesehen sind erhalten nun Equipment der neuen Unternehmensrichtlinie nach. Nach diesem Vorbild folgt man nun auch in allen anderen Bereichen. Diese schrittweise Optimierung erlaubt einen guten Lernprozess und stellt sicher das jeder bereits abgeschlossene Schritt auch tatsächlich korrekt umgesetzt wurde.
Wer als Freiberufler Akquise für neue Aufträge betreibt erlebt seit einiger Zeit markante Veränderungen. Immer weniger Unternehmen haben kaum noch direkten Kontakt zu ihren Auftragnehmern bei der Beauftragung. Personalvermittlungsfirmen drängen sich immer mehr zwischen Unternehmen und selbstständige Auftragnehmer.
Wenn im Projekt Spezialwissen benötigt wird greifen Unternehmen gern auf externe Fachkräfte zurück. Dieses Vorgehen gibt den Firmen grösstmögliche Flexibilität bei der Kostenkontrolle. Aber auch die Freelancer haben ihre Vorteil mit dieser Praktik. Sie können sich ausschließlich um Themen kümmern für die sie eine starkes Interesse haben. So vermeidet man für langweilige routinierte Standartaufgaben eingesetzt zu werden. Auf Grund der Erfahrung in unterschiedlichen Organisationsstrukturen und der Vielfalt der Projekte haben selbständige Auftragnehmer ein breites Portfolio an unkonventionellen Lösungsstrategien. Diese Wissensbasis ist für Auftraggeber sehr attraktiv auch wenn ein freiberuflicher externer Mitarbeiter im ersten Moment teurer ist als sein festangestellter Kollege. Freiberufler können auf Grund ihrer vielfältigen Erfahrung positive Impulse in das Projekt tragen die einen Stillstand überwinden.
Leider bemühen sich Unternehmen seit einiger Zeit nicht mehr eigenständig darum die benötigten Fachkräfte zu gewinnen. Der Aufgabenbereich der Personalbeschaffung ist mittlerweile nahezu überall an externe Vermittlungsfirmen ausgelagert. Diese sogenannten Recruitment-Firmen werben nun damit für offene Positionen die optimal geeigneten Kandidaten zu finden und für eine Besetzung vorzuschlagen. Schließlich können diese Personalvermittler auf einen großen Pool an Bewerberprofilen zugreifen. Unternehmen die eine freie Stelle besetzen wollen wissen oft nicht wie Spezialisten zu finden sind und wie diese direkt kontaktiert werden können. Aus diesem Grund ist das Angebot der Vermittlungsfirmen auch für mittelständische Unternehmen attraktiv. Nach ausreichend persönlicher Erfahrung habe ich über die Jahre ein völlig anderes Bild gewonnen. Von dem was ich erlebt habe ist das was Recruitment-Firmen versprechen weit von dem entfernt was sie tatsächlich leisten.
Eigentlich finde ich die Idee einen eigenen Vermittler für mich zu haben, der meine Auftragsakquise übernimmt sehr reizvoll. Es ist wie in der Film und Musik Branche. Man hat einen Agenten der einem den Rücken frei hält und regelmäßig Feedback gibt. So bekommt man ein Bild über gefragte Technologien in denen man sich beispielsweise Weiterbilden kann. Dadurch lasst sich die eigene Marktrelevanz verbessern und sichert eine regelmäßige Beauftragung. Das wäre eigentlich eine ideale Win-Win Situation für alle Beteiligten. Leider ist das was tatsächlich in der Realität passiert etwas völlig anderes.
Anstatt das Personalvermittler eine gute Beziehung zu ihren Fachkräften aufbauen und deren Entwicklung fördern agieren diese Recruiter wie schädliche Parasiten. Sie schädigen sowohl die Freiberufler als auch die Unternehmen die offene Stellen besetzen wollen. Denn im Business geht es nicht darum für eine Firma wirklich den am besten geeigneten Kandidaten zu finden. Es geht ausschließlich darum Kandidaten anzubieten die mit einem möglichst niedrigen Stundenlohn halbwegs auf das gesuchte Profil passen. Ob diese Kandidaten dann dwirklich die Dinge können die sie vorgeben zu können ist oft fragwürdig.
Das Vorgehen der Personalvermittler ist sehr identisch. Sie versuchen eine großen Pool an aktuellen Bewerberprofilen zu generieren. Diese Profile werden dann mittels automatischer K. I. Texterkennungssysteme auf Schlüsselwörter durchsucht. Dann werden aus den vorgeschlagenen Kandidaten die mit dem geringsten Stundensatz für ein Vorgespräch kontaktiert. Wer in diesem Vorgespräch keine groben Auffälligkeiten zeigt wird dann den unternehmen für einen Interviewtermin vorgeschlagen. Der Gewinn der Vermittlungsfirma ist enorm. Denn sie streichen die Differenz des Stundensatz den der Auftraggeber bezahlt zum Stundensatz den der Selbstständige bekommt ein. Das können in manchen Fällen bis zu 40% ausmachen.
Das ist aber noch nicht alles was diese parasitären Vermittler zu bieten haben. Oft verzögern sie noch den Auszahlungstermin für die gestellte Rechnung. Zudem versucht man das gesamte Unternehmerische Risiko auf den Freiberufler abzuwälzen. Das geschieht in dem man sinnlose Haftpflichtversicherungen verlangt, die für die ausgeschriebene Position nicht relevant sind. Als Resultat erhalten Firmen auf freie Stellen dann vermeidliche Fachkräfte die eher als Hilfsarbeiter zu deklarieren sind.
Nun könnte man sich fragen wieso die Firmen dennoch weiterhin mit den Vermittlern zusammen arbeiten. Ein grund ist auch die aktuelle politische Situation. So gibt es seit ca. 2010 beispielsweise in Deutschland Gesetze die eine Scheinselbständigkeit verhindern sollen. Unternehmen die direkt mit Freelancern zusammen arbeiten werden oft durch Rentenversicherungen bedrängt. Das sorgt für sehr viel Unsicherheiten und dient nicht dem Schutz der Freiberufler. Es sichert ausschließlich das Geschäftsmodell der Vermittlerfirmen.
Ich habe mir mittlerweile angewöhnt kommentarlos und unverzüglich aufzulegen wenn ich verschiedene Grundmuster bemerke. Solche Telefonate sind Zeitverschwendung und führen zu nichts außer das man sich über die Dreistigkeit der Personalvermittler ärgert. Wichtigstes Indiz für unseriöse Recruiter ist das am Telefon auf einmal eine völlig andere Person ist als die die eine zu erst kontaktiert hat. Hat diese Person dann noch einen sehr starken indischen Akzent kann man sich zu 100% sicher sein mit einem Callcenter verbunden zu sein. Auch wenn die Nummer als Vorwahl England anzeigt sitzen die Leuten tatsächlich irgendwo in Indien oder Pakistan. Nichts das die Seriosität unterstreichen würde.
Ich habe mich im Laufe der vielen Jahre meiner Karriere auf diversen Jobportalen registriert. Mein Fazit is das man sich die Zeit dafür sparen kann. 95% aller Kontakte die darüber zustande kamen sind Recruiter wie zuvor beschrieben. Diese Leute haben dann die Masche das du sie als Kontakt speicherst. Es ist aber naiv zu glauben das es bei diesen sogenannten Netzwerkanfragen wirklich um den direkten Kontakt geht. Sinn und Zweck dieser Aktion ist es an die Kontaktliste zu kommen. Denn viele Portale wie XING und LinkedIn haben die Einstellung das Kontakte die Kontakte aus der eigenen Liste sehen oder auch über die Netzwerkfunktion angeboten bekommen. Diese Kontaktlisten können bares Geld wert sein. So finden sich dort Abteilungsleiter oder andere Professionals die es sicher lohnt einmal anzuschreiben. Daher habe ich in allen sozialen Netzwerken auch den Zugriff der Freundesliste auch für Freunde deaktiviert. Zudem lehne ich pauschal alle Verbindungsanfragen von Personen mit dem Titel Recruitment ausnahmslos ab. Meine Präsenz in sozialen Netzwerken dient mittlerweile nur noch dazu den Profilnahmen gegen Indentitatsdiebstahl zu sichern. Die meisten Anfragen auf das Zusenden eines Lebenslaufs beantworte ich nicht mehr. Aber auch meine persönlichen Informationen zu Aufträgen, Studium und Arbeitgebern trage ich nicht in diese Netzwerkprofile ein. Wer mich erreichen möchte dem gelingt dies über meine Homepage.
Eine andere Angewohnheit die ich mir über die Jahre zugelegt habe ist niemals als erstes über meine Gehaltsvorstellung zu sprechen. Wenn mein Gegenüber keine konkrete Zahl nennen kann die sie bereit sind für meine Dienste zu zahlen wollen sie nur Daten abgreifen. Also ein weiterer Grund das Gespräch abrupt zu beenden. Es geht auch keine dieser Leute an was ich bereits in früheren Projekten an Stundensatz hatte. Sie nutzen diese Information ausschließlich um den Preis zu drücken. Wer etwas sensibel ist und keine unhöfliche Antwort geben möchte nennt einfach einen sehr hohen Stundensatz beziehungsweise Tagessatz.
Wir sehen es ist gar nicht so schwer die wirklichen schwarzen Schafe sehr schnell an ihrem Verhalten zu erkennen. Mein Rat ist, sobald eines der zuvor beschriebenen Muster vorkommt Zeit und vor allem Nerven zu sparen und einfach das Gespräch beenden. Aus Erfahrung kann ich sagen das wenn sich die Vermittler wie beschrieben verhalten wird definitiv keine Vermittlung zustande kommen. Es ist dann besser seine Energie auf realistische Kontakte zu konzentrieren. Denn es gibt auch wirklich gute Vermittlungsfirmen. Diese sind an einer langen Zusammenarbeit interessiert und verhalten sich völlig anders. Sie Unterstützen und geben Hinweise zu Verbesserung des Lebenslaufes und beraten Unternehmen bei der Formulierung Realistischer Stellenangebote.
Leider befürchte ich das sich die Situation weiterhin von Jahr zu Jahr verschlechtern wird. Auch der Einfluss der wirtschaftlichen Entwicklung und die breite Verfügbarkeit neue Technologien werden den Druck auf den Arbeitsmarkt weiter erhöhen. Weder Unternehmen noch Auftragnehmer werden in der Zukunft weiter Chancen haben, wenn sie sich nicht an die neue Zeit anpassen und andere Wege gehen.
Wer sein Git Repository zur gemeinsamen Bearbeitung für Quelltexte benutzen möchte benötigt einen Git Server. Der Git Server ermöglicht die Kollaboration mehrere Entwickler auf der gleichen Codebasis. Die Installation des Git Clients auf einem Linux Server ist zwar ein erster Schritt zur eigenen Serverlösung aber bei weitem nicht ausreichend. Um den Zugriff mehrere Personen auf ein Code Repository zu ermöglichen benötigen wir eine Zugriffsberechtigung. Schließlich soll das Repository öffentlich über das Internet erreichbar sein. Wir möchten über die Benutzerverwaltung verhindern, dass unberechtigte Personen den Inhalt der Repositories lesen und verändern können.
Für den Betrieb eines Git Servers gibt es viele hervorragende und komfortable Lösungen, die man einer nativen Serverlösung vorziehen sollte. Die Administration eines nativen Git Servers erfordert Linux Kenntnisse und wird ausschließlich über die Kommandozeile bewerkstelligt. Lösungen wir beispielsweise der SCM-Manager haben eine grafische Benutzeroberfläche und bringen viele nützliche Werkzeuge zur Administration des Servers mit. Diese Werkzeuge stehen bei einer nativen Installation nicht zur Verfügung.
Wieso sollte man nun Git als nativen Server Installieren? Diese Frage lässt sich recht leicht beantworten. Der Grund ist wenn der Server auf dem das Code Repository bereitgestellt werden soll nur wenige Hardware Ressourcen besitzt. Besonders Arbeitsspeicher ist in diesem Zusammenhang immer ein wenig problematisch. Gerade bei angemieteten Virtuellen Private Servern (VPS) oder einem kleinen RaspberryPI ist das oft der Fall. Wir sehen also es kann durchaus Sinn ergeben einen nativen Git Server betreiben zu wollen.
Als Voraussetzung benötigen wir einen Linux Server auf dem wir den Git Server installieren können. Das kann ein Debian oder Ubuntu Server sein. Wer CentOs oder andere Linux Distributionen verwendet muss anstatt APT zur Softwareinstallation den Paketmanager seiner Distribution nutzen.
Wir beginnen im ersten Schritt mit der Aktualisierung der Pakete und der Installation des Git Clients.
Als zweiten Schritt erstellen wir einen neuen Benutzer mit dem Namen git und legen für diesen ein eigenes home Verzeichnis an und aktivieren dort den SSH Zugriff.
Nun können wir im dritten Schritt in dem neu angelegten home Verzeichnis des git Users unsere Git Repositories erstellen. Diese unterscheiden sich gegenüber dem lokalen Arbeitsbereich darin das diese den Source Code nicht ausgecheckt haben.
Leider sind wir noch nicht ganz fertig mit unserem Vorhaben. Im vierten Schritt müssen wir die Benutzerberechtigung für das erstellte Repository setzen. Dies geschieht durch das Ablegen des öffentlichen Schlüssels auf dem Git Server für den SSH Zugriff. Dazu kopieren wir den Inhalt aus der Datei unseres privaten Schlüssels in die Datei /home/git/.ssh/authorized_keys in eine eigene Zeile. Möchte man nun vorhandene Nutzern den Zugriff verwehren kommentiert man lediglich mit einem # die zeie des privaten Schlüssels wieder aus.
Wenn alles korrekt durchgeführt wurde erhält man den Zugriff auf das Repository über folgenden Kommandozeilenbefehl: git clone ssh://git@<IP>/~/<repo>
Dabei ist <IP> durch die tatsächliche Server IP zu ersetzen. Für unser Beispiel lautet der korrekte Pfad für <repo> project.git es ist also das von uns erstellte Verzeichnis für das Git repository.
Auf dem nativen Git Server können mehrere Repositories angelegt werden. Dabei gilt zu beachten, dass alle berechtigenden Nutzer auf alle so angelegenen Reposiories lesenden und schreibenden Zugriff haben. Das lässt sich nur dadurch einschränken, dass auf dem Linux Server der unsere Git Repositories bereitstellt mehrere Benutzer auf dem Betriebssystem angelegt werden denen dann die Repositories zugewiesen werden.
Wir sehen das eine native Git Server Installation zwar schnell umgesetzt werden kann, diese aber für die kommerzielle Softwareentwicklung nicht ausreichend ist. Wer gerne Experimentiert kann sich eine virtuelle Maschine erstellen und diesen Workshop darin ausprobieren.
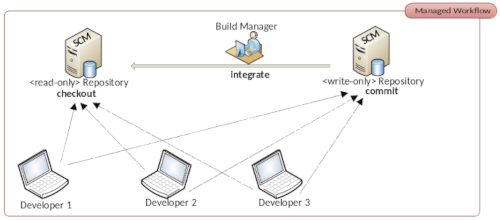
Der sichere Umgang mit Source Control Management (SCM) Systemen wie Git ist für Programmierer (Development) und auch Systemadministratoren (Operations) essenziell. Diese Gruppe von Werkzeugen hat eine lange Tradition in der Softwareentwicklung und versetzt Entwicklungsteams in die Lage gemeinsam an einer Codebasis zu arbeiten. Dabei werden vier Fragen beantwortet: Wann wurde die Änderung gemacht? Wer hat die Änderung vorgenommen? Was wurde geändert? Warum wurde etwas geändert? Es ist also ein reines Kollaborationswerkzeug.
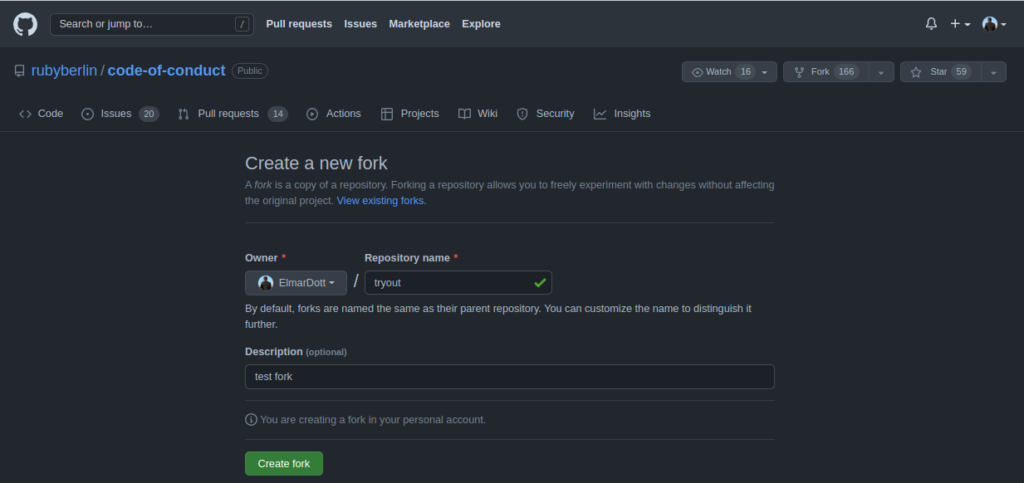
Mit dem Aufkommen der Open Source Code Hosting Platform GitHub wurden sogenannte Pull Requests eingeführt. Pull Requests ist in GitHub ein Workflow der es Entwicklern erlaubt Codeänderungen für Repositories bereitzustellen auf die sie nur lesenden Zugriff haben. Erst nachdem der Besitzer des originalen Repositories die vorgeschlagene Änderungen überprüft und für gut befunden hat werden diese Änderungen von ihm übernommen. So setzt sich auch die Bezeichnung zusammen. Ein Entwickler kopiert sozusagen das originale Repository in seine GitHub Arbeitsbereich, nimmt Änderungen vor und stellt an den Inhaber des originalen Repositories eine Anfrage die Änderung zu übernehmen. Dieser kann dann die Änderungen übernehmen und gegebenenfalls noch selbst anpassen oder mit einer Begründung zurückweisen.
Wer nun glaubt das GitHub besonders innovativ war, der irrt. Denn dieser Prozess ist in der Open Source Community ein ‚sehr‘ alter Hut. Ursprünglich nennt man dieses Vorgehen Dictatorship Workflow. Das 1990 zum ersten Mal veröffentlichte kommerzielle SCM Rational Synergy von IBM basiert genau auf dem Dictarorship Workflow. Mit der Klasse der verteilten Versionsverwaltungswerkzeugen, zu denen auch Git gehört, lässt sich der Dictatorship Worflow recht einfach umsetzen. Also lag es auf der Hand das GitHub diesen Prozess seinen Nutzern auch zur Verfügung stellt. Lediglich die Namensgebung ist von GitHub weitaus ansprechender gewählt. Wer beispielsweise mit der freien DevOps Lösung GitLab arbeitet kennt Pull Requests unter der Bezeichnung Merge Requests. Mittlerweile enthalten die gängigsten Git Server den Prozess der Pull Requests. Ohne zu sehr auf die technischen Details zur Umsetzung der Pull Request einzugehen richten wir unserer Aufmerksamkeit auf die üblichen Probleme mit denen Open Source Projekte konfrontiert sind.
Entwickler die sich an einem Open Source Projekt beteiligen möchten werden Maintainer genannt. Nahezu jedes Projekt hat eine kleine Anleitung wie man das entsprechende Projekt unterstützen kann und welche Regeln gelten. Für Personen die das Programmieren erlernen eigene sich Open Source Projekte hervorragend um die eigene Fähigkeiten schnell signifikant zu verbessern. Das bedeutet für das Open Source Projekt, dass man Maintainer mit den unterschiedlichsten Fähigkeiten und Erfahrungsschatz hat. Wenn man also keinen Kontrollmechanismus etabliert erodiert die Codebasis in sehr kurzer Zeit.
Wenn das Projekt nun recht groß ist und sehr viele Mainatainer auf der Codebasis agieren, ist es für den Inhaber des Repositories kaum noch möglich alle Pull Requests zeitnahe zu bearbeiten. Um diesem Bottelneck entgegenzuwirken wurde der Dictatorship Workflow zum Dictatorship – Lieutenant Workflow erweitert. Es wurde also eine Zwischeninstanz eingeführt, mit der die Überprüfung der Pull Requests auf mehrere Schultern verteilt wird. Diese Zwischenschicht die sogenannten Lieutenants sind besonders aktive Maintainer mit einer bereits etablierten Reputation. Somit braucht der Dictator nur noch die Pull Requests der Lieutenants zu reviewen. Eine ungemein Arbeitsentlastung die sicher stellt, das es zu keinem Feature Stau durch nicht abgearbeitet Pull Requests kommt. Schließlich sollen die Verbesserungen beziehungsweise die Erweiterungen so schnell als möglich in die Codebasis aufgenommen werden um dann im nächsten Release den Nutzern zur Verfügung zu stehen.
Dieses Vorgehen ist bis heute der Standard in Open Source Projekten um Qualität gewährleisten zu können. Man kann ja nie sagen wer sich alles am Projekt beteiligt. Möglicherweise mag es ja auch den ein oder anderen Saboteur geben. Diese Überlegung ist nicht so abwegig. Unternehmen die für ihre kommerzielles Produkt eine starke Konkurrenz aus dem feien Open Source Bereich haben könnten hier auf unfaire Gedanken kommen, wenn es keine Reglementierungen geben würde. Außerdem lassen sich Maintainer nicht disziplinieren, wie es beispielsweise für Teammitglieder in Unternehmen gilt. Einem beratungsresistenter Maintainer, der sich trotz mehrfachen bitten nicht an die Vorgaben des Projektes hält kann man schwer mit Gehaltskürzungen drohen. Einzige Handhabe ist diese Person vom Projekt auszuschließen.
Auch wenn das gerade beschriebene Problem der Disziplinierung von Mitarbeitern in kommerziellen Teams kein Problem darstellt, gibt es in diesen Umgebungen ebenfalls Schwierigkeiten die es zu meistern gilt. Diese Probleme rühren noch aus den Anfängen von Visualisierungswerkzeugen. Denn die ersten Vertreter dieser Spezies waren keine verteilten Lösungen sondern zentralisiert. CVS und Subversion (SVN) halten auf dem lokalen Entwicklungsrechner immer nur die letzte Revision der Codebasis. Ohne Verbindung zum Server kann man faktisch nicht arbeiten. Bei Git ist dies anders. Hier hat man eine Kopie des Repositories auf dem eigen Rechner, so das man seine Arbeiten lokal in einem separaten Branch durchführt und wenn man fertig ist bringt man diese Änderungen in den Hauptentwicklungszweig und überträgt diese dann auf den Server. Die Möglichkeit offline Branches zu erstellen und diese lokal zu mergen hat einen entscheidenden Einfluss auf die Stabilität der eigen Arbeit wenn das Reopsitory in einen inkonsistenten Zustand gerät. Denn im Gegensatz zu zentralisierten SCM Systemen kann man nun weiter arbeiten ohne darauf warten zu müssen das der Hauptentwicklungszweig repariert wurde.
Diese Inkonsistenten entstehen sehr leicht. Es genügt nur eine Datei beim Commit zu vergessen und schon können die Teamkollegen das Projekt nicht mehr lokal kompilieren und sind in der Arbeit behindert. Um diesem Problem Herr zu werden wurde das Konzept Continuous Integration (CI) etabliert. Es handelt sich dabei nicht wie oft fälschlicherweise angenommen um die Integration verschiedene Komponenten zu einer Anwendung. Die Zielstellung bei CI ist die Commit Satge – das Code Repository – in einem konsistenten Zustand zu halten. Dazu wurden Build Server etabliert die in regelmäßigen Abständen das Repository auf Änderungen überprüfen um dann den aus dem Quelltext das Artefakt bauen. Ein sehr beliebter und seit vielen Jahren etablierter Build Server ist Jenkins. Jenkins ging ursprünglich aus dem Projekt Hudson als Abspaltung hervor und übernimmt mittlerweile viele weitere Aufgaben. Deswegen ist es sehr sinnvoll diese Klasse von Tools als Automatisierungsserver zu bezeichnen.
Mit diesem kleine Abriss in die Geschichte der Softwareentwicklung verstehen wir nun die Probleme von Open Source Projekten und kommerzieller Softwareentwicklung. Dazu haben wir die Entstehungsgeschichte der Pull Request besprochen. Nun kommt es in kommerziellen Projekten sehr oft vor, das Teams durch das Projektmanagement gezwungen werden mit Pull Requests zu arbeiten. Für einen Projektleiter ohne technisches Hintergrundwissen klingt es nun sehr sinnvoll in seinem Projekt ebenfalls Pull Requests zu etablieren. Schließlich hat er die Idee das er somit die Codequalität verbessert. Leider ist das aber nicht der Fall. Das Einzige was passiert ist ein Feature Stau zu provozieren und eine erhöhte Auslastung des Teams zu erzwingen ohne die Produktivität zu verbessern. Denn der Pull Request muss ja von einer kompetenten Person inhaltlich bewertet werden. Das verursacht bei großen Projekten unangenehme Verzögerungen.
Nun erlebe ich es oft das argumentiert wird, man könne die Pull Requests ja automatisieren. Das heißt der Build Server nimmt den Branch mit dem Pull Request versucht diesen zu bauen und im Fall dass das Kompilieren und die automatisierten Tests erfolgreich sind versucht der Server die Änderungen in den Hauptentwicklungszweig zu übernehmen. Möglicherweise sehe ich da etwas falsch aber wo ist die Qualitätskontrolle? Es handelt sich um einen einfachen Continuous Integration Prozess, der die Konsistenz des Repositories aufrecht erhält. Da Pull Requests vornehmlich im Git Umfeld zu finden sind bedeutet ein kurzzeitig inkonsistentes Repository kein kompletten Entwicklungstop für das gesamte Team wie es bei Subversion der Fall ist.
Interessant ist auch die Frage wie man bei einem automatischen Merge mit semantischen Mergekonflikten umgeht. Die per se kein gravierendes Problem sind. Sicher führt das zur Ablehnung des Pull Requests mit entsprechender Nachricht an den Entwickler um das Problem mit einem neuen Pull Request zu lösen. Ungünstige Branchstrategien können hier allerdings zu unverhältnismäßigen Mehraufwand führen.
Für die Verwendung von Pull Requests in kommerziellen Softwareprojekten sehe ich keinen Mehrwert, weswegen ich davon abrate in diesem Kontext Pull Request zu verwenden. Außer eine Verkomplizierung der CI / CD Pipeline und einem erhöhten Ressourcenverbrauch des Automatisierungsservers der nun die Arbeit doppelt macht ist nichts passiert. Die Qualität eines Softwareprojektes verbessert man durch das Einführen von automatisierten Unit Tests und einem Testgetrieben Vorgehen bei der Umsetzung von Features. Hier ist es notwendig die Testabdeckung des Projektes kontinuierlich im Auge zu behalten und zu verbessern. Statische Codeanalyse und das aktivieren von Compilerwarnings bringt mit erheblich weniger Aufwand bessere Ergebnisse.
Ich persönlich vertrete die Auffassung das Unternehmen, die auf Pull Requests setzen diese entweder für ein verkompliziertes CI nutzen oder ihren Entwicklern komplett misstrauen und ihnen in Abrede stellen gute Arbeit abzuliefern. Natürlich bin ich offen für eine Diskussion zum Thema, möglicherweise lässt sich dann eine noch bessere Lösung finden. Von daher freue ich mich über reichliche Kommentare mit euren Ansichten und Erfahrungen im Umgang mit Pull Requests.










 Unlock with Patreon
Unlock with Patreon