Wer bis an das Ende der Welt gehen möchte, ist gut beraten, sich zu überlegen, mit welcher Last man sich auf den Weg macht. Die Entscheidungen, die wir treffen, können einen Spaziergang schnell in eine Qual verwandeln. Eine wirkliche Freiheit erlangen wir, indem wir lernen, uns nicht an unnötige Dinge zu klammern. In diesem kleinen Buch erzähle ich meine Geschichte. Ich beschreibe, wie ich über das Loslassen in die persönliche Unabhängigkeit gelangen konnte. Vielleicht finden sie in meinen Zeilen die Inspiration, einen eigenen Weg zu beginnen. Es würde mich freuen, den Anstoß zu einer positiven Veränderung beitragen zu können.
Marco Schulz, published 05/2024 / 2. Auflage / 137 Seiten / ISBN: 979-8282740042
Der Blog [EnRebaja.wordpress.com] der während des Jakonsweges entstanden ist, enthält natürlich noch viele weitere interessante Geschichten. ein BEsuch dort lohnt sich durchaus.
Moderne Softwareentwicklung besteht aus viel mehr als nur aus Code und Kaffee. Ohne passende Deployment-Strategien und eine saubere Release-Verwaltung laufen selbst kleine Projekte schnell aus dem Ruder und werden unbeherrschbar.
Dieses Praxisbuch zeigt Ihnen, wie Sie mit Jenkins, Git und Nexus eine CI-Pipeline aufbauen. Erfahren Sie direkt aus der Praxis, was für erfolgreiche Software-Projekte essenziell ist: Source Control Management, flächendeckende Softwaretests mit einer sinnvollen Qualitätskontrolle und ein gut organisiertes Deployment. Marco Schulz gibt Ihnen seine Erfahrung aus zahlreichen internationalen IT-Projekten weiter und hält eine Menge Tipps und Überlegungen zu gutem Software Engineering für Sie parat.
Marco Schulz, 2021, 400 Seiten, Rheinwerk Computing, ISBN 978-3-8362-7834-8
The Big Picture DevOps, Continuous Deployment, Build Jobs, Pipelines … ist all das wirklich nötig, wenn es nur um ein paar Zeilen Java-Code geht? Marco Schulz zeigt Ihnen, welche Vorteile moderne Entwicklungsparadigmen bieten, wie Sie Open-Source-Werkzeuge zu einer effektiven Toolchain zusammenfügen und damit Ihre Software professionell und zeitgemäß verwalten.
Professionelle Code-Verwaltung Programmieren wäre viel einfacher, wenn Sie sich um den bestehenden Code keine Gedanken machen müssten. Da die Integration neuer Funktionen aber eine Standardaufgabe in der Software-Entwicklung ist, dreht sich hier alles um Merging-Konflikte, die Vergabe von sinnvollen Release-Nummern und das Schreiben von Unit- und Integrationstests. So behalten Sie den Überblick und arbeiten effektiv und agil im Team.
Toolchains für moderne Software-Projekte Jenkins ist das wichtigste Werkzeug, wenn es um komfortable CI-Pipelines und automatisierte Builds geht. In diesem Praxisbuch finden Sie aber noch viel mehr: Git, Maven, Nexus, SonarQube und viele andere Tools helfen Ihnen bei der Verwaltung Ihrer Codebasis.
Errata: Auch wenn die Erstellung des Buches mit viel Sorgfalt durchgeführt wurde, kommt es durchaus vor, das sich Fehler einschleichen. Dank hilfreicher Hinweise von aufmerksamen Lesern finden Sie an dieser Stelle Korrekturen.
Seite 32: Literaturliste
[2.1] Gene Kim, The Unicorn Project, 2019, IT Revolution Press, ISBN: 978-1942788768
[2.2] Gene Kim, The Phoenix Project, 2013, IT Revolution Press, ISBN: 978-0-9882625-7-7
Als ich vor über 10 Jahren begonnen habe testgetrieben zu programmieren, waren mir sehr viele verschiedene Konzepte theoretisch bekannt. Aber diese Sichtweise erst Testfälle zu schrieben und dann die Implementierung umzusetzen war irgendwie nicht der Weg mit dem ich gut zurecht gekommen bin. Wenn ich ehrlich bin ist das bis heute der Fall. So das ich eine für mich funktionierende Adaption des TDD Paradigma von Kent Beck gefunden habe. Aber langsam der Reihe nach. Vielleicht ist mein Ansatz ja für den einen oder anderen ebenfalls recht hilfreich.
Ich komme ursprünglich aus einem Umfeld für hoch skalierbarer Webanwendungen auf die sich all die tollen Theorien aus dem universitären Umfeld in der Praxis nicht ohne weiteres umsetzen lassen. Der Grund liegt vor allem in der hohen Komplexität solcher Anwendungen. Zum einen sind verschiedene Zusatzsysteme wie In Memory Cache, Datenbank und Identität und Zugriffs Management (IAM) ein Teil des Gesamtsystems. Zum Anderen verstecken viele moderne Frameworks wie OR Mapper Komplexität hinter verschiedene Zugriffsschichten. All diese Dinge müssen wir als Entwickler heutzutage beherrschen. Deshalb gibt es robuste, praxiserprobte Lösungen die gut bekannt sind aber wenig Verwendung finden. Kent Beck mit ist eine der wichtigsten Stimmen für den praktischen Einsatz automatisierter Softwaretest.
Wenn wir uns auf das Konzept TDD einlassen wollen ist es wichtig nicht jedes Wort zu sehr auf die Goldwaage zu legen. Es ist nicht alles in Stein gemeißelt. Wichtig ist das Ergebnis am Ende des Tages. Aus diesem Grund ist es unabdinglich sich die Zielvorgabe aller Bemühungen vor Augen zu führen um dann einen persönlichen Mehrwert zu erzielen. Also schauen wir uns zu erst einmal an was wir überhaupt bezwecken wollen.
Der Erfolg gibt uns Recht
Als ich meine ersten Gehversuche als Entwickler unternommen hatte benötigte ich stetiges Feedback ob das was ich da gerade zusammen bauen auch wirklich funktioniert. Diese Feedback habe ich meist dadurch erzeugt, in dem ich meine Implementierung einerseits mit unzähligen Konsolenausgaben gespickt habe und andererseits habe ich immer versucht alles in eine Benutzeroberfläche einzubinden um mich dann ‚manuell durchzuklicken‘. Im Grunde ein sehr umständliches Test Setup, das dann auch am Schuß wieder zu entfernen ist. Wenn dann noch spätere Bugfixes vorgenommen werden mussten ging das ganze Prozedere wieder von Neuem los. Alles irgendwie unbefriedigend und weit entfernt von einer produktiven Arbeitsweise. Irgendwie musste das verbessert werden ohne das man sich jedes Mal neu erfindet.
Schließlich hat mein ursprünglicher Ansatz genau zwei markante Schwachstellen. Die offensichtlichste ist das ein und auskommentieren von Debug Informationen über die Konsole.
Viel schwerwiegender ist aber der zweite Punkt. Denn all das erworbene Wissen zu dieser speziellen Implementierung ist nicht konserviert. Es droht also über die Zeit zu verblassen und schlußendlich auch verloren zu gehen. Ein solches Spezialwissen ist für viele nachfolgende Prozessschritte in der Softwareentwicklung aber äußerst wertvoll. Damit meine ich explizit das Thema Qualität. Refactoring, Code Reviews, BugFixes und Change Requests sind nur einige der möglichen Beispiele wo tiefgreifendes Detailwissen gefragt ist.
Für mich persönlich kommt auch hinzu, das mich monoton wiederholbare Arbeiten schnell ermüden und ich diese dann sehr gern vermeiden möchte. Sich immer wieder aufs neue mit der selben Testprozedur durch eine Anwendung zu klicken ist weit davon entfernt was für mich einen erfüllten Arbeitstag ausmacht. Ich möchte neue Dinge entdecken. Das kann ich aber nur wenn ich nicht in der Vergangenheit gefangen gehalten werde.
Die trauen sich aber was
Bevor ich aber darauf eingehe wie ich meinen Entwicklungsalltag durch TDD aufgepeppt habe muss ich noch ein paar Worte über Verantwortung und Mut loswerden. Immer wieder wird mir in Gesprächen erklärt das ich ja recht habe aber man können das alles ja nicht selber umsetzen, weil der Projektleiter oder irgend ein anderer Vorgesetzter kein grünes Licht gibt.
Eine solche Einstellung ist in meinen Augen äußerst unprofessionell. Ich frage doch auch nicht den Marketingleiter welcher Algorithmus am besten terminiert. Er hat schlichtweg keine Ahnung, denn es ist auch nicht sein Aufgabengebiet. Ein Projektleiter der sich gegen das testgetriebene Arbeiten im Entwicklungsteam ausspricht hat aber auch seinen Beruf verfehlt. In der heutigen Zeit sind Testframeworks so gut in die Build Umgebung integriert, das die Vorbereitung für TDD sich selbst für unerfahrene Personen in wenigen Augenblicken umsetzen lässt. Es ist also nicht notwendig das Vorhaben an die große Glocke zu hängen. Denn ich kann versprechen das selbst bei den ersten Gehversuchen nicht mehr Zeit benötigt wird als mit der ursprünglichen Vorgehensweise. Ganz im Gegenteil sehr schnell wird sich eine merkliche Erhöhung der Produktivität einstellen.
Die erste Stufe der Evolution
Wie bereits erwähnt ist Logging für mich ein zentrale Teil der testgetriebene Entwicklung. Wann immer es sinnvoll erscheint versuche ich den Zustand von Objekten oder Variablen auf der Konsole auszugeben. Wenn wir hierfür die aus der verwendeten Programmiersprache zur Verfügung gestellten Mittel nutzen, bedeute dies das wir diese Systemausgaben nach getaner Arbeit mindestens auskommentieren müssen und bei späterer Fehlersuche wieder einkommentieren. Ein redundantes und fehleranfälliges Vorgehen.
Nutzen wir hingegen von beginn an ein Logging Framework so können wir die Debug Informationen getrost im Code stehen lassen und deaktivieren diese später im Produktivbetrieb über den eingestellten Log Level.
Ich nutze Logging aber auch als Tracer. Das heißt jeder Konstruktor einer Klasse schreibt während er aufgerufen wird einen entsprechenden Log Eintrag im Log Level Info. Damit kann man sehen in welcher Reihenfolge Objekte instanziiert werden. Hin und wieder bin ich so auch auf die übermäßig oft vorkommende Instanziierung eines einzelnen Objektes aufmerksam geworden. Dies ist hilfreich für Maßnahmen zur Performance und Speicheroptimierung.
Fehler die bei der Ausnahmebehandlung geworfen werden logge ich je nach Kontext als Error oder Warning. Das ist später im Betrieb ein sehr hilfreiches Mittel um Fehlern auf die Spur zu kommen.
Wenn ich also eine Datenbankzugriff habe, schreibe ich also eine Logausgabe im Log Level Debug wie das zugehörige SQL zusammen gebaut wurde. Führt dieses SQL zu einer Exception, weil ein Fehler enthalten ist so wird diese Exception mit dem Log Level Error geschrieben. Findet wiederum eine einfache Suchanfrage mit korrekter SQL Syntax statt und die Ergebnismenge ist leer wird dieses Ereignis je nach Bedarf entweder als Debug oder Warning klassifiziert. Handelt es sich beispielsweise um eine Loginanfrage mit falschem Benutzernamen oder Passwort neige ich dazu mich für den Log Level Warning zu entscheiden, da dies im Betrieb eventuell sicherheitstechnische Aspekte enthält.
Im gesamten Kontext konfiguriere ich das Logging für die Testfallausführung eher sehr geschwätzig und beschränke mich auf eine reine Konsolenausgabe. Im Betrieb wiederum werden die Logging Informationen in eine Logfile geschrieben.
Die Henne oder das Ei
Wenn wir mit dem Logging die Voraussetzung für eine zusätzliche Feedbackschleife gelegt haben stellt sich im nächsten Schritt die Frage wie geht es weiter. Wie bereits erwähnt tue ich mich sehr schwer erst einen Testfall zu schreiben um dann eine entsprechende Implementierung dafür zu finden. Vor diesem Problem stehen auch viele andere Entwickler die mit TDD beginnen.
Eine Sache die ich bereits voraus nehmen kann ist das Problem, das man bei einer Implementierung darauf achten muss diese auch testbar zu halten. Habe ich erst den Testfall so merke ich umgehend ob das was ich gerade erstelle auch wirklich testbar ist. Erfahrene TDD Entwickler haben recht schnell in Fleisch und Blut übernommen wie testbarer Code auszusehen hat. Der wichtigste Punkt hierbei ist das Methoden stets einen Rückgabewert haben sollten, der möglichst nicht null ist. So etwas erreicht man beispielsweise wenn man anstatt null eine leere Liste zurück gibt.
Die Vorgabe einen Rückgabewert zu haben liegt an der Art und Weise wie Unit Test Frameworks arbeiten. Ein Testfall vergleicht den Rückgabewert einer Methode mit einem Erwartungswert. Die Testzusicherung (engl. Assertation) kennt verschiedene Ausprägungen und kann entsprechend: gleich, ungleich, wahr oder falsch sein. Natürlich gibt es hier auch verschieden Variationen. So kann es unter Verwendung von Exceptions möglich sein Methoden die keinen Rückgabewert haben zu testen. Alle diese Details erschließen sich bei der Anwendung in sehr kurzer Zeit. So das jeder ohne langwierige Vorbereitungen umgehend loslegen kann.
Bei der Lektüre des Buches Test Driven Development by Example von Kent Beck finden wir auch schnell eine Erklärung warum die Testfälle zu erst geschrieben werden sollten. Es handelt sich um einen psychologischen Faktor. Es soll uns dabei helfen den üblichen Stress der im Projekt entsteht besser zu bewältigen. Es erzeugt in uns einen mentalen Zustand über den Zustand und Fortschritt der aktuellen Arbeit. Es leitet uns in eine iterativen Prozess die vorhandene Lösung schrittweise über die verschiedenen Testfälle weiter auszubauen und zu verbessern.
Für alle die wie ich aber zu beginn einer Implementierung noch keine konkrete Vorstellung über das fertige Ergebnis haben ist dieser Ansatz schwer umzusetzen. Der bezweckte Effekt der Entspannung kehrt sich ins negative um. Da wir Menschen alle unterschiedlich sind müssen wir also herausfinden wie wir ticken um das bestmögliche Ergebnis zu erzielen. Ganz so wie es mit Lernstrategien ist. Manche Menschen verarbeiten Informationen besser visuell andere eher haptisch und wieder andere extrahieren alles wichtige aus gesprochenem. Versuchen wir uns also nicht wider unserer Natur zu verbiegen um mittelmäßige oder schlechte Ergebnis zu produzieren.
Den ersten Strich zeichnen
Mir erschließt sich ein Thema eben erst während ich damit arbeite. Also Versuche ich mich solange an einer Implementierung bis ich ein erstes Feedback benötige. Genau dann schreibe ich den ersten Test. Es ergebenen sich bei diesem Vorgehen automatisch Fragen bei der jede einzelne einen eigenen Testfall wert ist. Finde ich alle vorhanden Ergebnisse? Was passiert wenn die Ergebnismenge leer ist. Wie lässt sich die Ergebnismenge eingrenzen? Alles Punkte die sich auf einem Zettel notieren und Schritt für Schritt abhaken lassen. Die Idee eine Aufgabenliste auf einem Zettel zu notieren hatte ich schon sehr lange bevor ich das bereits erwähnte Buch von Kent Beck gelesen habe. Es hilft mir schnelle Gedanke zu konservieren ohne mich von meinem aktuellen Tun ablenken zu lassen. Außerdem vermittelt es am Ende des Tages ein Gefühl etwas geschafft zu haben.
Da ich nicht warte bis ich alles Umgesetzt habe, um den ersten Test zu schreiben ergibt sich auch bei diesem Vorgehen ein iterativer Ansatz. Ich merke auch sehr schnell wenn mein Entwurf nur unzureichend testbar ist, da ich sofort eine Rückmeldung erhalte. Daraus ergibt sich meine eigene Interpretation für TDD die sich durch den permanenten Wechsel zwischen Implementieren und Test schreiben auszeichnet.
Als Ergebnis meiner frühen TDD Versuche habe ich bereits in der ersten Woche eine Beschleunigung meiner Arbeitsweise bemerkt. Ich bin auch sicherer geworden. Aber auch die Art und Weise wie ich Programmiere hat sich schon sehr zeitig zu verändern begonnen. Mir ist aufgefallen das mein Code kompakter und robuster geworden ist. Dinge die sich erst mit der Zeit aufgezeigt hatten ergaben sich bei Tätigkeiten wie Refactoring und Erweiterungen. Fehlgeschlagene Testfälle haben mich vor bösen Überraschungen bewahrt.
Ohne Übereifer beginnen
Wenn wir uns in einem bestehenden Projekt dazu entschließen TDD einzusetzen ist es eine schlechte Idee loszulegen und für bestehende Funktionalität Testfälle zu schreiben. Abgesehen von der Zeit die hierfür eingeplant werden muss wird das Ergebnis die hohen Erwartungen nicht erfüllen.
Eines der Probleme ist das man sich nun in jede Funktionalität neu einarbeiten muss und das ist sehr Zeitaufwendig. Die Qualität der so entstandene Testfälle ist auch unzureichend. Das Problem ergibt sich auch aus der Erfahrung. Wird die Erfahrung erst aufgebaut so ist die Qualität der Testfälle auch noch nicht ganz optimal und möglicherweise muss auch Code umgeschrieben werden, damit dieser Testbar wird. Es entstehen also eine Menge Risiken die für das tägliche Projektgeschäft problematisch sind.
Ein bewährtes Vorgehen TDD einzuführen ist es einfach für die aktuelle Implementierung an der man gerade arbeitet einzusetzen. Es wird also der ist Zustand des aktuellen Problems durch automatisierte Tests dokumentiert. Da man sich bereits auf vertrautem Terrain befindet muss man sich nicht erst in eine neue Thematik einarbeiten, so das man sich voll auf das formulieren von aussagekräftigen Tests konzentrieren kann. Abgesehen davon, das man ungefragt Verantwortung über fremde Arbeiten übernimmt wenn man für diese Testfälle umgesetzt.
Bestehende Funktionalität wird nur bei Fehlerkorrekturen entsprechend um Testfälle ergänzt. Für die Korrektur muss man sich eh mit den Implementierungsdetails auseinander setzen, so das hier genügend Wissen vorhanden ist wie eine Funktionalität sich verhalten sollte. Die so entstandene Tests dokumentieren zusätzlich auch die Korrektur und stellen für die Zukunft sicher das sich das Verhalten bei Optimierungsarbeiten nicht verändert.
Folgt man dieser Vorgehensweise diszipliniert verliert man sich nicht in sogenannter hektischer Betriebsamkeit, die wiederum das Gegenteil von Produktivität ist. Zudem erwirbt man so recht schnell fundiertes Wissen wie effektive und aussagekräftige Tests umgesetzt werden können. Erst wenn ausreichend Erfahrung gesammelt wurde und möglicherweise umfangreiche Refactorings geplant werden, dann kann man überlegen wie für das gesamte Projekt die Testabdeckung schrittweise verbessert werden kann.
Qualitätsstufe
Nur weil Testfälle vorhanden sind bedeutet dies nicht das diese auch eine Aussagekraft haben. Genausowenig beweist eine hohe Testabdeckung das ein Programm fehlerfrei ist. Eine hohe Testabdeckung stellt nur sicher das sich ein Programm im Rahmen der Tests verhält.
Wir kann man also sicherstellen das die vorhandene Tests auch wirklich eine Bereicherung sind und eine gute Aussagekraft haben? Der erste und meines Erachtens wichtigste Punkt ist Testfälle möglichst kurz zu halten. Das heißt im Konkreten, das ein Test nur eine explizite Fragestellung beantwortet, z. B. Was passiert wenn die Ergebnismenge leer ist? Entsprechend der Fragestellung ergibt sich dann auch die Benennung der Testmethode. Den Mehrwert dieser Vorgehensweise ergibt sich in dem Moment wenn der Testfall fehlschlägt. Ist der Test sehr kurzgefasst lässt sich oft schon an der Testmethode ablesen worin das Problem besteht, ohne sich erst langwierig in einen Testfall einzuarbeiten zu müssen.
Ein anderer wichtiger Punkt im TDD Vorgehen ist für meine umgesetzte Funktionalität sowohl die Testabdeckung für Codezeilen als auch für Verzweigungen zu überprüfen. Kann ich zum Beispiel in einer IF-Abfrage das Eintreten einer einzelnen Bedingung nicht simulieren, so kann diese Bedingung bedenkenlos gestrichen werden.
Natürlich hat man im eigenen Projekt auch genügend Abhängigkeiten zu fremden Bibliotheken. Nun kann es vorkommen das eine Methode aus dieser Bibliothek eine Ausnahme wirft, die durch keinen Testfall simuliert werden kann. Das ist genau der Grund wieso man zwar eine hohe Testabdeckung anstreben sollte aber nicht verzweifeln muss wenn 100% nicht erreicht werden können. Gerade bei der Einführung von TDD ist ein gutes Maß für die Testabdeckung größer als 85% üblich. Mit wachsender Erfahrung des Entwicklungsteams kann dieser Wert bis zu 95% angehoben werden.
Abschließend ist aber noch anzumerken, das man sich nicht zu sehr in den Eifer begibt. Denn es kann auch schnell übertrieben werden und dann sind die ganzen gewonnene Vorteile schnell wieder dahin. Und zwar geht es um den Punkt das man keine Tests schreibt die wiederum Tests testen. Hier beißt sich die Katze in den Schwanz. Das gilt auch für Bibliotheken von Fremdanbietern. Für diese werden ebenfalls keine Test geschrieben. Kent Beck äußert sich hierzu sehr klar: Selbst wenn es gute Gründe gibt dem Code anderer zu misstrauen, teste ihn nicht. Externer Code erfordert mehr eigene Implementierungslogik.
Lessons Learned
Gerade die Erkenntnisse die sich bei dem Versuch eine möglichst hohe Testabdeckung zu erzielen sind die, welche sich beim künftigen Programmieren auswirken. Der Code wird kompakter und robuster.
Die Produktivität steigt einfach durch die Tatsache, das fehleranfällige und monotone Arbeiten durch Automatisierung vermieden werden. Es entstehen keine zusätzlichen Arbeitsschritte denn alte Gewohnheiten werden durch neue, bessere ersetzt.
Ein Effekt den ich immer wieder beobachten konnten, wenn sich einzelne Personen aus dem Team für TDD entschieden haben, wurden deren Erfolge schnell beachtet. Innerhalb weniger Wochen hat dann das gesamte Team TDD entwickelt. Jeder einzelne nach seinen eigene Fähigkeiten. Manche mit Test First andere wiederum so wie ich es gerade beschrieben habe. Zum Schluß zählt das Ergebnis und das war einheitlich hervorragend. Wenn die Arbeit leichter fällt und am Ende des Tages jeder einzelne auch noch das Gefühl hat auch etwas geleistet zu haben bewirkt dies im Team einen enormen Motivationsschub, der dem Projekt und dem Arbeitsklima eine gewaltigen Auftrieb verschafft. Also worauf warten Śie noch? Probieren Sie es am besten gleich selber aus.
Als Techniker bin ich recht schnell von allen möglichen Dingen zu begeistern, die irgendwie blinken und piepsen, ganz gleich, wie unnütz diese auch sein mögen. Elektronikspielereien ziehen mich an, wie das Licht Motten. Seit einer Weile ist eine neue Generation Spielwaren für die breite Masse verfügbar: Anwendungen der Künstlichen Intelligenz, genauer gesagt künstliche neuronale Netze. Die frei verfügbaren Anwendungen leisten bereits Beachtliches und es ist erst der Anfang dessen, was noch möglich sein wird. Vielen Menschen ist die Tragweite KI-basierter Anwendungen noch gar nicht bewusst geworden. Das ist auch nicht verwunderlich, denn das, was gerade im Sektor KI geschieht, wird unser Leben nachhaltig verändern. Wir können also zu Recht sagen, dass wir in einer Zeit leben, die gerade Geschichte schreibt. Ob die kommenden Veränderungen etwas Gutes werden, oder sie sich als eine Dystopie entpuppen, wird an uns liegen.
Als ich im Studium vor sehr vielen Jahren als Vertiefungsrichtung Künstliche Intelligenz gewählt hatte, war die Zeit noch von sogenannten „Expertensystemen“ geprägt. Diese regelbasierten Systeme waren für ihre Domäne hoch spezialisiert und wurden für entsprechende Experten ausgelegt. Das System sollte die Experten bei der Entscheidungsfindung unterstützen. Mittlerweile haben wir auch die notwendige Hardware, um viel allgemeinere Systeme zu schaffen. Wenn wir Anwendungen wie ChatGPT betrachten, basieren diese auf neuronalen Netzen, was eine sehr hohe Flexibilität in der Verwendung erlaubt. Der Nachteil ist allerdings, dass wir als Entwickler kaum noch nachvollziehen können, welche Ausgabe ein neuronales Netz für eine beliebige Eingabe erzeugt. Ein Umstand, der die meisten Programmierer, die ich kenne, eher eine ablehnende Haltung einnehmen lässt, da diese so nicht mehr Herr über den Algorithmus sind, sondern nur noch nach dem Prinzip Versuch und Irrtum agieren können.
Dennoch ist die Leistungsfähigkeit neuronaler Netze verblüffend. Vorbei scheint nun die Zeit, in der man sich über unbeholfene, automatisierte, softwaregestützte Übersetzungen lustig machen kann. Aus eigener Erfahrung weiß ich noch, wie mühselig es war, den Google Translator aus dem Deutschen einen vernünftigen Satz ins Spanische übersetzen zu lassen. Damit das Ergebnis brauchbar war, konnte man sich über die Option Englisch – Spanisch behelfen. Alternativ, wenn man nur ein rudimentäres Englisch für den Urlaubsgebrauch spricht, konnte man noch sehr einfache deutsche Sätze formulieren, die dann wenigstens inhaltlich korrekt waren. Die Zeitersparnis für automatisiert übersetzte Texte ist erheblich, obwohl man diese Korrektur lesen muss und gegebenenfalls ein paar Formulierungen angepasst werden müssen.
Sosehr ich es schätze, mit solchen starken Werkzeugen arbeiten zu können, müssen wir uns aber auch im Klaren sein, dass es auch eine Schattenseite gibt. Denn je mehr wir unsere täglichen Aufgaben über KI-gestützte Tools erledigen, umso mehr verlieren wir die Fähigkeit, diese Aufgaben künftig weiterhin manuell bearbeiten zu können. Für Programmierer bedeutet dies, dass sie im Laufe der Zeit über KI-gestützte IDEs ihre Ausdrucksfähigkeit im Quellcode verlieren. Das ist natürlich kein Prozess, der über Nacht stattfindet, sondern sich schleichend einstellt. Aber sobald diese Abhängigkeit einmal geschaffen ist, stellt sich die Frage, ob die verfügbaren, liebgewonnenen Werkzeuge weiterhin kostenfrei bleiben oder ob für bestehende Abonnements möglicherweise drastische Preiserhöhungen stattfinden. Denn es sollte uns schon klar sein, das kommerziell genutzte Werkzeuge, die unsere Produktivität erheblich verbessern, üblicherweise nicht zum Schnäppchenpreis verfügbar sind.
Ich denke auch, dass das Internet, wie wir es bisher gewohnt sind, sich in Zukunft sehr stark verändern wird. Viele der kostenlosen Angebote, die bisher durch Werbung finanziert sind, werden mittelfristig verschwinden. Schauen wir uns dazu einmal als Beispiel den Dienst „Stack Overflow“ an – in Entwicklerkreisen eine sehr beliebte Wissensplattform. Wenn wir nun künftig für die Recherche zu Fragestellungen der Programmierung ChatGPT oder andere neuronale Netze nutzen, sinken für Stack Overflow die Besucherzahlen kontinuierlich. Die Wissensbasis wiederum, die ChatGPT nutzt, basiert auf Daten von öffentlichen Foren wie Stack Overflow. Somit wird auf absehbare Zeit Stack Overflow versuchen, seine Dienste für KIs unzugänglich zu machen. Es könnte sicher auch eine Einigung mit Ausgleichszahlungen zustande kommen, sodass die wegfallenden Werbeeinnahmen kompensiert werden. Denn als Techniker muss uns nicht ausschweifend dargelegt werden, dass für ein Angebot wie Stack Overflow erhebliche Kosten für den Betrieb und die Entwicklung anfallen. Es bleibt dann abzuwarten, wie die Nutzer das Angebot künftig annehmen werden. Denn wenn auf Stack Overflow keine neuen Daten zu Problemstellungen hinzukommen, wird die Wissensbasis für KI-Systeme auch uninteressant. Daher vermute ich, dass bis circa 2030 vor allem hochwertige Inhalte im Internet kostenpflichtig werden.
Wenn wir die Prognose des mittelfristigen Trends über den Bedarf von Programmierern betrachten, kommen wir zu der Frage, ob es künftig eine gute Empfehlung sein wird, Informatik zu studieren oder eine Ausbildung als Programmierer anzutreten. Ich sehe hier tatsächlich eine positive Zukunft und würde jedem, der eine Ausbildung als Berufung versteht und nicht als Notwendigkeit ansieht, seinen Lebensunterhalt zu bestreiten, in seinem Vorhaben bekräftigen. Meiner Ansicht nach werden wir weiterhin viele innovative Köpfe benötigen. Lediglich jene, die sich anstatt sich mit Grundlagen und Konzepten zu beschäftigen, lieber mal schnell ein aktuelles Framework erlernen wollen, um aufkommende Hypes des Marktes mitzunehmen, werden sicher nur noch geringen Erfolg in Zukunft erzielen. Diese Beobachtungen habe ich aber auch bereits vor der breiten Verfügbarkeit von KI-Systemen machen können. Deshalb bin ich der festen Überzeugung, dass sich langfristig Qualität immer durchsetzen wird.
Dass man sich stets Themen möglichst kritisch und aufmerksam nähern sollte, betrachte ich als eine Tugend. Dennoch muss ich sagen, dass so manche Ängste im Umgang mit KI recht unbegründet sind. Sie haben ja schon einige meiner möglichen Zukunftsvisionen in diesem Artikel kennengelernt. Aussagen wiederum, dass die KI einmal unsere Welt übernehmen wird, indem sie unbedarfte Nutzer subtil beeinflusst, um diese zu Handlungen zu motivieren, halte ich für einen Zeitraum bis 2030 eher für reine Fantasie und mit dem aktuellen Erkenntnisstand unbegründet. Viel realistischer sehe ich das Problem, dass findige Marketingleute das Internet mit minderwertigen, ungeprüften, nicht redigierten, KI-generierten Artikeln übersähen, um ihr SEO-Ranking aufzupeppen und diese wiederum als neue Wissensbasis der neuronalen Netze die Qualität künftiger KI-generierter Texte erheblich reduziert.
Die bisher frei zugänglichen KI-Systeme haben gegenüber dem Menschen einen entscheidenden Unterschied. Ihnen fehlt die Motivation, etwas aus eigenem Antrieb zu tun. Erst durch eine extrinsische Anfrage durch den Nutzer beginnt die KI, eine Fragestellung zu bearbeiten. Interessant wird es dann, wenn eine KI sich aus eigenem Antrieb heraus selbstgewählten Fragestellungen widmet und diese auch eigenständig recherchiert. In diesem Fall ist die Wahrscheinlichkeit sehr hoch, dass die KI sehr schnell ein Bewusstsein entwickeln wird. Läuft eine solche KI dann noch auf einem Hochleistungsquantencomputer, haben wir nicht genügend Reaktionszeit, um gefährliche Entwicklungen zu erkennen und einzugreifen. Daher sollten wir uns durchaus das von Dürrenmatt geschaffene Drama „Die Physiker“ in unserem Bewusstsein halten. Denn die Geister, die ich einmal rief, werde ich möglicherweise nicht so schnell wieder los.
Grundsätzlich muss ich zugeben, dass mich das Thema KI weiterhin fasziniert und ich auf die künftige Entwicklung sehr gespannt bin. Dennoch finde ich es wichtig, auch vor der dunklen Seite der Künstlichen Intelligenz den Blick nicht zu versperren und dazu einen sachlichen Diskurs zu beginnen, um möglichst schadenfrei das vorhandene Potenzial dieser Technologie auszuschöpfen.
Sämtlich in einem Unternehmen aufgestellten Regeln und durchgeführten Aktivitäten stellen Prozesse dar. Deswegen kann auch pauschal gesagt werden, das die Summe der Prozesse eine Organisation beschreibt. Leider sind manchmal die Prozesse so kompliziert gestaltet, das diese sich negativ auf das Unternehmen auswirken. Was kann also getan werden um die Situation zu verbessern?
(c) 2022 Marco Schulz, JAVA aktuell Ausgabe 6
Laut ISO 900 Definition ist ein Prozess, ein Satz von in Wechselbeziehung stehenden Tätigkeiten. der Eingaben in Ergebnisse umwandelt. Dabei spielt es keine Rolle, ob der Prozess atomar ist, also nicht weiter zerlegt werden kann oder aus mehreren Prozessen zusammengesetzt wurde. An dieser Stelle ist es wichtig auch kurz auf einige Begriffe einzugehen.
Choreographie: beschreibt einzelne Operationen, aber nicht die Nachrichtenreihenfolge (Ablauf). Es behandelt die etablierte Kommunikation zwischen zwei Teilnehmern.
Orchestration: beschreibt die Reihenfolge und Bedingungen der aufrufenden Teilprozesse.
Konversation: beschreibt die Abfolgen zwischen Prozessen. Es wird die gesamte zulässige Kommunikation (Vollständigkeit) zwischen zwei Teilnehmern beschrieben.
Die aufgeführten Begrifflichkeiten spielen für die Beschreibung von Prozessen eine wichtige Rolle. Wenn sie beispielsweise die Idee haben die für Ihr Unternehmen wichtigen Geschäftsprozesse in einem Prozessbrowser visualisiert darzustellen, müssen Sie sich bereits im Vorfeld über die Detailtiefe der bereitgestellten Informationen im Klaren sein. Sollten Sie die Absicht hegen möglichst alle Informationen in so einem Schaubild einzubringen, werden Sie schnell feststellen wie sehr die Übersichtlichkeit darunter leidet. Wählen Sie daher immer für die benötigte Anwendung die geeignete Darstellung aus.
Ansichtssachen
Hier kommen wir auch schon zur nächsten Fragestellung. Was sind geeignete Mittel um Prozesse verständlich darzustellen. Aus persönlicher Erfahrung hat sich in meinen Projekten ein Darstellung über den Informationsfluss gut bewährt. Dazu wiederum nutze ich die Business Process Model Notation, kurz BPMN die für solche Zwecke geschaffen wurde. Ein frei verfügbares Werkzeug um BPMN Prozesse aufzuzeichnen ist der BigAzi Modeler [1]. Die Möglichkeit aus BPMN Diagrammen wiederum softwaregestützte Programme mittels serviceorientierter Architekturen (SOA) zu erzeugen ist für ein Großteil der Unternehmen weniger nutzbringend und nicht so einfach umzusetzen wie es auf den ersten Blick scheint. Viel wichtiger bei einer Umsetzung zur grafischen Darstellung interner Unternehmensprozesse sind die so zu tage geförderten versteckten Erkenntnisse über mögliche Verbesserungen.
Besonders Unternehmen, die eine eigenständige Softwareentwicklung betreiben und die dort angewendeten Vorgehensweisen, möglichst in einem hohen Grade automatisieren wollen, können den Schritt zur Visualisierung interner Strukturen selten auslassen. Die hier viel zitierten Stichwörter Continuous Integration, Continuous Delivery und DevOps haben eine sehr hohe Automatisierungsstufe zum Ziel. Um in diesem Bereich erfolgreiche Ergebnisse erreichen zu können, ist es unumgänglich möglichst einfache und standardisierte Prozesse etabliert zu haben. Das beschreibt auch das Paradoxon der Automatisierung.
Prozessautomation reduziert das Risiko, dass Fehler gemacht werden. Aber hochkomplexe Prozesse sind naturgemäß nur sehr schwer zu automatisieren!
Wenn Sie den Entschluss gefasst haben die hauseigenen Geschäftsprozesse zu optimieren benötigen Sie selbstredend zuerst eine realistische Analyse des aktuellen IST – Zustands um daraus den gewünschten SOLL – Zustand zu beschreib
Abbildung 1: Die Transformation von der Ausgangssituation hin zu Zielstellung.
Es wäre an dieser Stelle nicht sehr hilfreich verschiedene Vorgehnsmodelle zu beschreiben, wie eine solche Transformation von statten gehen kann. Solche Vorhaben sind stets sehr individuell und den tatsächlichen Gegebenheiten im Unternehmen geschuldet. Hier sei Ihnen nur ein wichtiger Ratschlag mit auf den Weg gegeben. Gehen Sie kleine einfache Schritte und vermeiden Sie es möglichst alles auf einmal umsetzen zu wollen. Manchmal entdecken Sie während einer Umstellung wichtige Details die angepasst werden müssen. Das gelingt Ihnen gefahrlos wenn Sie genügend Reserven eingeplant haben. Sie sehen auch hier spiegeln sich agile Gedanken wieder, die Ihnen die Möglichkeit geben direkt auf Veränderungen einzugehen.
Richten Sie Ihr Augenmerk vor allem auf den zu erreichenden Sollzustand. Im Großen und Ganzen wird zwischen zwei Prozesstypen unterschieden. Autonome Prozesse laufen im Idealfall vollständig automatisiert ab und erfordern keinerlei manuelles Eingreifen. Dem gegenüber stehen die interaktiven Prozess, welche an ein oder mehreren Stellen auf eine manuelle Eingabe warten um weiter ausgeführt werden zu können. Ein sehr oft angestrebtes Ziel für den SOLL – Zustand der Prozesslandschaften sind möglichst kompakte und robuste autonome Prozesse um den Automatisierungsgrad zu verbessern. Folgende Punkte helfen Ihnen dabei das gesteckte Ziel zu erreichen:
Definieren Sie möglichst atomare Prozesse, die ausschließlich einen einzigen Vorgang oder einen Teilaspekt eines Vorgangs beschreiben.
Halten Sie die Prozessbeschreibung möglichst sehr einfach und orientieren Sie sich dabei an vorhanden Standards und suchen Sie nicht nach eigenen individuellen Lösungen.
Vermeiden Sie so gut es möglichst jegliche manuelle Interaktion.
Wägen Sie bei Ausnahmen sehr kritisch ab, wie oft diese tatsächlich auftreten und suchen Sie nach möglichen Lösungen diese Ausnahmen mit dem Standartvorgehen abarbeiten zu können.
Setzen Sie komplexe Prozessmodelle ausschließlich aus bereits vollständig beschriebenen atomaren Teilprozessen zusammen.
Sicher stellen Sie sich die Frage, was es mit meinem Hinweis auf die Verwendung von etablierten Standards auf sich hat. Viele der in einem Unternehmen auftretenden Probleme wurden meist bereist umfangreich und bewährt gelöst. Nicht nur aus Zeit und Kostengründen sollte bei der Verfügbarkeit bereits etablierter Vorgehensmodelle kein eigenes Süppchen gekocht werden. So erschweren Sie zum einem den Wissenstransfer zwischen Ihren Mitarbeitern und zum anderen erschweren Sie die Verwendung von standardisierter Branchensoftware. Hierzu möchte ich Ihnen ein kleines Beispiel aus meinem Alltag vorstellen, wo es darum geht in Unternehmen möglichst automatisierte DevOps Prozesse für die Softwareentwicklung und den Anwendungsbetrieb zu etablieren.
Die Kunst des Loslassen
Die größte Hürde die ein Unternehmen hier nehmen muss, ist eine Neuorientierung an dem Begriff Release und dem dahinterliegenden Prozess, der meist eigenwillig interpretiert wurde. Die Abweichung von bekannten Standards hat wiederum mehrere spürbare Folgen. Neben erhöhtem Personalaufwand für die administrativen Eingriffe im Releaseprozess besteht auch stets die Gefahr durch unglückliche äußere Umstände in zeitlichen Verzug zum aktuellen Plan zu geraten. Ohne auf die vielen ermüden technischen Details einzugehen liegt das gravierendste Missverständnis in dem Glauben es gäbe nach dem Erstellen eines Releases noch die Möglichkeit die in der Testphase erkannten Fehler im selben Release zu beheben. Das sieht dann folgendermaßen aus: nach einem Sprint wird beispielsweise das Release 2.3.0 erstellt, welches dann ausgiebig in der Testphase auf Herz und Nieren überprüft wird. Stellt man nun ein Fehler fest, ist es nicht möglich eine korrigiert Version 2.3.0 zu erzeugen. Die Korrektur hat ein neues Release zur Folge, welches dann die Versionsnummer 2.3.1 trägt. Ein wichtiger Standard der hier zum Tragen kommt ist die Verwendung des Semantic Versioning, welcher jedem einzelnen Segment der Versionsnummer eine Bedeutung zuordnet. In dem hier verwendeten Beispiel zeigt die letzte Stelle die für ein Release durchgeführten Korrekturen an. Falls Sie sich etwas intensiver mit dem Thema Semantic Versioning beschäftigen mögen, empfehle ich dazu die zugehörige Internetseite [2].
Was aber spricht nun dagegen ein bereits geplantes und auf den Weg gebrachtes Release bei der Detektion von Fehlern nicht zu stoppen, zu korrigieren und ‘repariert’ erneut unter der bereits vergebenen Versionsnummer auf den Weg zu schicken? Die Antwort ist recht einfach. Der erhebliche Arbeitsaufwand, welcher ausschließlich manuell durchgeführt werden muss, um den Fehler wieder auszubügeln. Abgesehen davon wird Ihre gesamte Entwicklungsarbeit für das Folgerelease erheblich ausgebremst. Ressourcen können nicht frei gegeben werden und der Fortschritt beginnt zu stagnieren.
Deswegen ist es wichtig sich so zu disziplinieren, das ein bereits auf den Weg gebrachtes Release sämtliche Prozeduren durchläuft und erst im letzten Schritt dann die manuell ausgeführte Entscheidung getroffen wird, ob das Release für den Produktive Einsatz auch geeignet ist. Deswegen rate ich grundsätzlich dazu den Begriff Release Kandidat aus dem Sprachgebrauch zu streichen und besser von einem Production Kandidat zu sprechen. Diese Bezeichnung spiegelt den Releaseprozess viel deutlicher wieder.
Sollten sich währen der Testphase Mängel aufzeigen, gilt zu erst zu entscheiden wie schwerwiegend diese sind und deren Behebung ist zu priorisieren. Das kann soweit gehen, das direkt ein Korrekturrelease auf den Weg gebracht werden muss, während parallel der nächste Sprint abgearbeitet wird. Weniger gravierende Fehler können dann auf die nächsten Folgesprits verteilt werden. Wie das alles in der täglichen Praxis umgesetzt werden kann – habe ich letztes Jahr in meinem Vortag “Rolling Stones: Vom Release überrollt” auf der JCON präsentiert. Den Videomitschnitt finden Sie frei zugänglich im Internet.
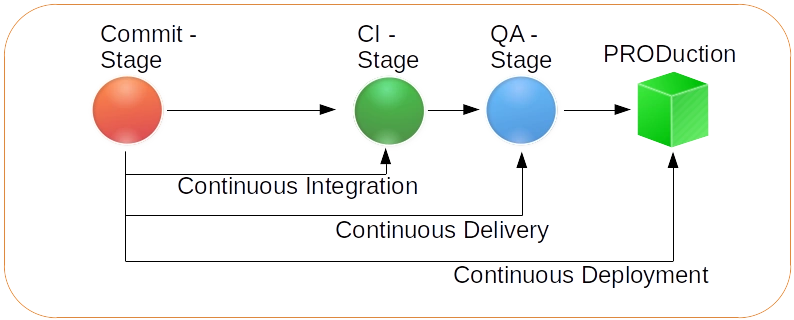
Unter dem Gesichtspunkt der Prozessoptimierung bedeute es für das aufgeführte Beispiel des Release Prozesses, das der Prozess beendet wurde, wenn aus dem Sourcecode erfolgreich eine binäres Artefakt mit einer noch nicht belegten Versionsnummer erstellt werden konnte. Das so entstandene Release wird umgehend an einer zentralen Stelle veröffentlicht (deliverd), wo es in den Testprozess übergeben werden kann. Erst wenn der Testprozess mit dem Ergebnis abgeschlossen wurde, dass das erzeugte Release auch in Produktion verwendet werden darf erfolgt die Übergabe in den Deployment Prozess. Sie sehen, das was vielerorts als ein gesamter Prozess angesehen wird ist genau betrachtet eine Orchestration aus mindestens 3 eiegnständigen Prozessen.
Abbildung 2: Continuous Delivery und Continuous Deployment.
Ein wichtiger Punkt den Sie In Abbildung 2 zum Thema DevOps ebenfalls herauslesen können ist, das der Schritt zwischen Continuous Delivery und Continuous Deployment besser nicht vollautomatisiert werden sollte, denn Deplyoment meint in diesem Kontext nicht das automatisierte bereitstellen der Anwendung auf allen verfügbaren Testinstanzen. Continuous Deployment meint in erste Linie ein automatisiertes Einsetzen der Anwendung in Produktion. Ob das immer eine gute Idee ist sollt sehr sorgfältig abgewogen werden.
Ein wertvoller Aspekt der Prozessbeschreibung in Organisationen ist die Ausarbeitung wichtiger Kriterien die erfüllt sein müssen, damit ein Prozess autonom ablaufen kann. Mit diesem Wissen können Sie bei der Evaluierung benötigter Werkzeuge sehr leicht einen Anforderungskatalog mit priorisierten Punkten erstellen, der einfach abgearbeitet wird. Kann das ins Auge gefasste Tool die aufgelisteten Punkte zufriedenstellend lösen und der aufgerufene Preis passt auch ins Budget, ist Ihre Suche erfolgreich beendet.
Fazit
Sehr oft wird mir entgegengebracht, das durch moderne DevOps Strategien der klassische Release Prozess obsolet geworden ist. Dem kann ich nicht zustimmen. Es mag wenige Ausnahmen geben, in den Unternehmen tatsächlich jede Codeänderung sofort in Produktion bringen. Aus Gründen der Gewährleistung und Haftung, kommt für viel Firmen ein so vollständig automatisiertes Vorgehen aber nicht in Frage. Auch der Datenschutz sorgt dafür, das die Bereich Entwicklung und Betrieb voneinander getrennt werden. Zudem benötigen umfangreiche Softwareprojekte auch eine strategische Planungsinstanz über die umzusetzenden Funktionalitäten. Diese Entscheidbarkeit wird auch künftig nicht beim Entwickler liegen, ganz gleich wie hervorgehoben der Punkt DevOps in der Stellenbeschreibung auch sein mag.
Wie Sie sehen ist das Thema der Prozessbeschreibung und Prozessoptimierung nicht ausschließlich ein Thema für produzierende Branchen. Auch der vielrorts detailreich beschriebene Softwareentwicklungsprozess hält einiges an Verbesserungspotenzial bereit. Ich hoffe ich konnte Sie mit meinen Zeilen ein wenig für das Thema sensibilisieren, ohne zu sehr ins technische verfallen zu sein.
Als mir im Studium die Vorzüge der objektorientierten Programmierung mit Java schmackhaft gemacht wurden, war ein sehr beliebtes Argument die Wiederverwendung. Dass der Grundsatz „write once use everywhere“ in der Praxis dann doch nicht so leicht umzusetzen ist, wie es die Theorie suggeriert, haben die meisten Entwickler bereits am eigenen Leib erfahren. Woran liegt es also, dass die Idee der Wiederverwendung in realen Projekten so schwer umzusetzen ist? Machen wir also einen gemeinsamen Streifzug durch die Welt der Informatik und betrachten verschiedene Vorhaben aus sicherer Distanz.
Wenn ich daran denke, wie viel Zeit ich während meines Studiums investiert habe, um eine Präsentationsvorlage für Referate zu erstellen. Voller Motivation habe ich alle erdenklichen Ansichten in weiser Voraussicht erstellt. Selbst rückblickend war das damalige Layout für einen Nichtgrafiker ganz gut gelungen. Trotzdem kam die tolle Vorlage nur wenige Male zum Einsatz und wenn ich im Nachhinein einmal Resümee ziehe, komme ich zu dem Schluss, dass die investierte Arbeitszeit in Bezug auf die tatsächliche Verwendung in keinem Verhältnis gestanden hat. Von den vielen verschiedenen Ansichten habe ich zum Schluss exakt zwei verwendet, das Deckblatt und eine allgemeine Inhaltsseite, mit der alle restlichen Darstellungen umgesetzt wurden. Die restlichen 15 waren halt da, falls man das künftig noch brauchen würde. Nach dieser Erfahrung plane ich keine eventuell zukünftig eintreffenden Anforderungen mehr im Voraus. Denn den wichtigsten Grundsatz in Sachen Wiederverwendung habe ich mit dieser Lektion für mich gelernt: Nichts ist so beständig wie die Änderung.
Diese kleine Anekdote trifft das Thema bereits im Kern. Denn viele Zeilen Code werden genau aus der gleichen Motivation heraus geschrieben. Der Kunde hat es noch nicht beauftragt, doch die Funktion wird er ganz sicher noch brauchen. Wenn wir in diesem Zusammenhang einmal den wirtschaftlichen Kontext ausblenden, gibt es immer noch ausreichend handfeste Gründe, durch die Fachabteilung noch nicht spezifizierte Funktionalität nicht eigenmächtig im Voraus zu implementieren. Für mich ist nicht verwendeter, auf Halde produzierter Code – sogenannter toter Code – in erster Linie ein Sicherheitsrisiko. Zusätzlich verursachen diese Fragmente auch Wartungskosten, da bei Änderungen auch diese Bereiche möglicherweise mit angepasst werden müssen. Schließlich muss die gesamte Codebasis kompilierfähig bleiben. Zu guter Letzt kommt noch hinzu, dass die Kollegen oft nicht wissen, dass bereits eine ähnliche Funktion entwickelt wurde, und diese somit ebenfalls nicht verwenden. Die Arbeit wird also auch noch doppelt ausgeführt. Nicht zu vergessen ist auch das von mir in großen und langjährig entwickelten Applikationen oft beobachtete Phänomen, dass ungenutzte Fragmente aus Angst, etwas Wichtiges zu löschen, über Jahre hinweg mitgeschleppt werden. Damit kommen wir auch schon zum zweiten Axiom der Wiederverwendung: Erstens kommt es anders und zweitens als man denkt.
Über die vielen Jahre, genauer gesagt Jahrzehnte, in denen ich nun verschiedenste IT- beziehungsweise Softwareprojekte begleitet habe, habe ich ein Füllhorn an Geschichten aus der Kategorie „Das hätte ich mir sparen können!“ angesammelt. Virtualisierung ist nicht erst seit Docker [1] auf der Bildfläche erschienen – es ist schon weitaus länger ein beliebtes Thema. Die Menge der von mir erstellten virtuellen Maschinen (VMs) kann ich kaum noch benennen – zumindest waren es sehr viele. Für alle erdenklichen Einsatzszenarien hatte ich etwas zusammengebaut. Auch bei diesen tollen Lösungen erging es mir letztlich nicht viel anders als bei meiner Office-Vorlage. Grundsätzlich gab es zwei Faktoren, die sich negativ ausgewirkt haben. Je mehr VMs erstellt wurden, desto mehr mussten dann auch gewertet werden. Ein Worst-Case-Szenario heutzutage wäre eine VM, die auf Windows 10 basiert, die dann jeweils als eine .NET- und eine Java-Entwicklungsumgebung oder Ähnliches spezialisiert wurde. Allein die Stunden, die man für Updates zubringt, wenn man die Systeme immer mal wieder hochfährt, summieren sich auf beachtliche Größen. Ein Grund für mich zudem, soweit es geht, einen großen Bogen um Windows 10 zu machen. Aus dieser Perspektive können selbsterstellte DockerContainer schnell vom Segen zum Fluch werden.
Dennoch darf man diese Dinge nicht gleich überbewerten, denn diese Aktivitäten können auch als Übung verbucht werden. Wichtig ist, dass solche „Spielereien“ nicht ausarten und man neben den technischen Erfahrungen auch den Blick für tatsächliche Bedürfnisse auf lange Sicht schärft.
Gerade bei Docker bin ich aus persönlicher Erfahrung dazu übergegangen, mir die für mich notwendigen Anpassungen zu notieren und zu archivieren. Komplizierte Skripte mit Docker-Compose spare ich mir in der Regel. Der Grund ist recht einfach: Die einzelnen Komponenten müssen zu oft aktualisiert werden und der Einsatz für jedes Skript findet in meinem Fall genau einmal statt. Bis man nun ein lauffähiges Skript zusammengestellt hat, benötigt man, je nach Erfahrung, mehrere oder weniger Anläufe. Also modifiziere ich das RUN-Kommando für einen Container, bis dieser das tut, was ich von ihm erwarte. Das vollständige Kommando hinterlege ich in einer Textdatei, um es bei Bedarf wiederverwenden zu können. Dieses Vorgehen nutze ich für jeden Dienst, den ich mit Docker virtualisiere. Dadurch habe ich die Möglichkeit, verschiedenste Konstellationen mit minimalen Änderungen nach dem „Klemmbaustein“-Prinzip zu rchestrieren. Wenn sich abzeichnet, dass ein Container sehr oft unter gleichen Bedienungen instanziiert wird, ist es sehr hilfreich, diese Konfiguration zu automatisieren. Nicht ohne Grund gilt für Docker-Container die Regel, möglichst nur einen Dienst pro Container zu virtualisieren.
Aus diesen beiden kleinen Geschichten lässt sich bereits einiges für Implementierungsarbeiten am Code ableiten. Ein klassischer Stolperstein, der mir bei der täglichen Projektarbeit regelmäßig unterkommt, ist, dass man mit der entwickelten Applikation eine eierlegende Wollmilchsau – oder, wie es in Österreich heißt: ein Wunderwutzi – kreieren möchte. Die Teams nehmen sich oft zu viel vor und das Projektmanagement versucht, den Product Owner auch nicht zu bekehren, lieber auf Qualität statt auf Quantität zu setzen. Was ich mit dieser Aussage deutlich machen möchte, lässt sich an einem kleinen Beispiel verständlich machen.
Gehen wir einmal davon aus, dass für eigene Projekte eine kleine Basisbibliothek benötigt wird, in der immer wiederkehrende Problemstellungen zusammengefasst werden – konkret: das Verarbeiten von JSON-Objekten [2]. Nun könnte man versuchen, alle erdenklichen Variationen im Umgang mit JSON abzudecken. Abgesehen davon, dass viel Code produziert wird, erzielt ein solches Vorgehen wenig Nutzen. Denn für so etwas gibt es bereits fertige Lösungen – etwa die freie Bibliothek Jackson [3]. Anstelle sämtlicher denkbarer JSON-Manipulationen ist in Projekten vornehmlich das Serialisieren und das Deserialisieren gefragt. Also eine Möglichkeit, wie man aus einem Java-Objekt einen JSON-String erzeugt, und umgekehrt. Diese beiden Methoden lassen sich leicht über eine Wrapper-Klasse zentralisieren. Erfüllt nun künftig die verwendete JSON-Bibliothek die benötigten Anforderungen nicht mehr, kann sie leichter durch eine besser geeignete Bibliothek ersetzt werden. Ganz nebenbei erhöhen wir mit diesem Vorgehen auch die Kompatibilität [4] unserer Bibliothek für künftige Erweiterungen. Wenn JSON im Projekt eine neu eingeführte Technologie ist, kann durch die Minimal-Implementierung stückweise Wissen aufgebaut werden. Je stärker der JSONWrapper nun in eigenen Projekten zum Einsatz kommt, desto wahrscheinlicher ist es, dass neue Anforderungen hinzukommen, die dann erst umgesetzt werden, wenn sie durch ein Projekt angefragt werden. Denn wer kann schon abschätzen, wie der tatsächliche Bedarf einer Funktionalität ist, wenn so gut wie keine Erfahrungen zu der eingesetzten Technologie vorhanden sind?
Das soeben beschriebene Szenario läuft auf einen einfachen Merksatz hinaus: Eine neue Implementierung möglichst so allgemein wie möglich halten, um sie nach Bedarf immer weiter zu spezialisieren.
Bei komplexen Fachanwendungen hilft uns das Domain-driven Design (DDD) Paradigma, Abgrenzungen zu Domänen ausfindig zu machen. Auch hierfür lässt sich ein leicht verständliches, allgemein gefasstes Beispiel finden. Betrachten wir dazu einmal die Domäne einer Access Control List (ACL). In der ACL wird ein Nutzerkonto benötigt, mit dem Berechtigungen zu verschiedenen Ressourcen verknüpft werden. Nun könnte man auf die Idee kommen, im Account in der ACL sämtliche Benutzerinformationen wie Homepage, Postadresse und Ähnliches abzulegen. Genau dieser Fall würde die Domäne der ACL verletzen, denn das Benutzerkonto benötigt lediglich Informationen, die zur Authentifizierung benötigt werden, um eine entsprechende Autorisierung zu ermöglichen.
Jede Anwendung hat für das Erfassen der benötigten Nutzerinformationen andere Anforderungen, weshalb diese Dinge nicht in eine ACL gehören sollten. Das würde die ACL zu sehr spezialisieren und stetige Änderungen verursachen. Daraus resultiert dann auch, dass die ACL nicht mehr universell einsatzfähig ist.
Man könnte nun auf die Idee kommen, eine sehr generische Lösung für den Speicher zusätzlicher Nutzerinformationen zu entwerfen und ihn in der ACL zu verwenden. Von diesem Ansatz möchte ich abraten. Ein wichtiger Grund ist, dass diese Lösung die Komplexität der ACL unnötig erhöht. Ich gehe obendrein so weit und möchte behaupten, dass unter ungünstigen Umständen sogar Code-Dubletten entstehen. Die Begründung dafür ist wie folgt: Ich sehe eine generische Lösung zum Speichern von Zusatzinformationen im klassischen Content Management (CMS) verortet. Die Verknüpfung zwischen ACL und CMS erfolgt über die Benutzer-ID aus der ACL. Somit haben wir gleichzeitig auch zwischen den einzelnen Domänen eine lose Kopplung etabliert, die uns bei der Umsetzung einer modularisierten Architektur sehr behilflich sein wird.
Zum Thema Modularisierung möchte ich auch kurz einwerfen, dass Monolithen [5] durchaus auch aus mehreren Modulen bestehen können und sogar sollten. Es ist nicht zwangsläufig eine Microservice-Architektur notwendig. Module können aus unterschiedlichen Blickwinkeln betrachtet werden. Einerseits erlauben sie es einem Team, in einem fest abgegrenzten Bereich ungestört zu arbeiten, zum anderen kann ein Modul mit einer klar abgegrenzten Domäne ohne viele Adaptionen tatsächlich in späteren Projekten wiederverwendet werden.
Nun ergibt sich klarerweise die Fragestellung, was mit dem Übergang von der Generalisierung zur Spezialisierung gemeint ist. Auch hier hilft uns das Beispiel der ACL weiter. Ein erster Entwurf könnte die Anforderung haben, dass, um unerwünschte Berechtigungen falsch konfigurierter Rollen zu vermeiden, die Vererbung von Rechten bestehender Rollen nicht erwünscht ist. Daraus ergibt sich dann der Umstand, dass jedem Nutzer genau eine Rolle zugewiesen werden kann. Nun könnte es sein, dass durch neue Anforderungen der Fachabteilung eine Mandantenfähigkeit eingeführt werden soll. Entsprechend muss nun in der ACL eine Möglichkeit geschaffen werden, um bestehende Rollen und auch Nutzeraccounts einem Mandanten zuzuordnen. Eine Domänen-Erweiterung dieser hinzugekommenen Anforderung ist nun basierend auf der bereits bestehenden Domäne durch das Hinzufügen neuer Tabellenspalten leicht umzusetzen.
Die bisher aufgeführten Beispiele beziehen sich ausschließlich auf die Implementierung der Fachlogik. Viel komplizierter verhält sich das Thema Wiederverwendung beim Punkt der grafischen Benutzerschnittelle (GUI). Das Problem, das sich hier ergibt, ist die Kurzlebigkeit vieler chnologien. Java Swing existiert zwar noch, aber vermutlich würde sich niemand, der heute eine neue Anwendung entwickelt, noch für Java Swing entscheiden. Der Grund liegt in veraltetem Look-and-Feel der Grafikkomponenten. Um eine Applikation auch verkaufen zu können, darf man den Aspekt der Optik nicht außen vor lassen. Denn auch das Auge isst bekanntlich mit. Gerade bei sogenannten Green-Field-Projekten ist der Wunsch, eine moderne, ansprechende Oberfläche anbieten zu können, implizit. Deswegen vertrete ich die Ansicht, dass das Thema Wiederverwendung für GUI – mit wenigen Ausnahmen – keine wirkliche Rolle spielt.
Lessons Learned
Sehr oft habe ich in der Vergangenheit erlebt, wie enthusiastisch bei Kick-off-Meetings die Möglichkeit der Wiederverwendung von Komponenten in Aussicht gestellt wurde. Dass dies bei den verantwortlichen Managern zu einem Glitzern in den Augen geführt hat, ist auch nicht verwunderlich. Als es dann allerdings zu ersten konkreten Anfragen gekommen ist, eine Komponente in einem anderen Projekt einzusetzen, mussten sich alle Beteiligten eingestehen, dass dieses Vorhaben gescheitert war. In den nachfolgenden Retrospektiven sind die Punkte, die ich in diesem Artikel vorgestellt habe, regelmäßig als Ursachen identifiziert worden. Im Übrigen genügt oft schon ein Blick in das Datenbankmodell oder auf die Architektur einer Anwendung, um eine Aussage treffen zu können, wie realistisch eine Wiederverwendung tatsächlich ist. Bei steigendem Komplexitätsgrad sinkt die Wahrscheinlichkeit, auch nur kleinste Segmente erfolgreich für eine Wiederverwendung herauslösen zu können.
Viele Ideen sind auf dem Papier hervorragend. Oft fehlt aber das Wissen wie man brillante Konzepte in den eigenen Alltag einbauen kann. Dieser kleine Workshop soll die Lücke zwischen Theorie und Praxis schließen und zeigt mit welchen Maßnahmen man langfristig zu einer stabile API gelangt.
(c) 2021 Marco Schulz, Java PRO Ausgabe 1, S.31-34
Bei der Entwicklung kommerzieller Software ist vielen Beteiligten oft nicht klar, das die Anwendung für lange Zeit in Benutzung sein wird. Da sich unsere Welt stetig im Wandel befindet, ist es leicht abzusehen, dass im Laufe der Jahre große und kleine Änderungen der Anwendung ausstehen werden. Zu einer richtigen Herausforderung wird das Vorhaben, wenn die zu erweiternde Anwendung nicht für sich isoliert ist, sondern mit anderen Systemkomponenten kommuniziert. Denn das bedeutet für die Konsumenten der eigenen Anwendung in den meisten Fällen, das sie ebenfalls angepasst werden müssen. Ein einzelner Stein wird so schnell zu einer Lawine. Mit einem guten Lawinenschutz lässt sich die Situation dennoch beherrschen. Das gelingt aber nur, wenn man berücksichtigt, das die im nachfolgenden beschriebenen Maßnahmen ausschließlich für eine Prävention gedacht sind. Hat sich die Gewalt aber erst einmal entfesselt, kann ihr kaum noch etwas entgegengesetzt werden. Klären wir deshalb zu erst was eine API ausmacht.
Verhandlungssache
Ein Softwareprojekt besteht aus verschieden Komponenten, denen spezialisierte Aufgaben zuteil werden. Die wichtigsten sind Quelltext, Konfiguration und Persistenz. Wir befassen uns hauptsächlich mit dem Bereich Quelltext. Ich verrate keine Neuigkeiten, wenn ich sage dass stets gegen Interfaces implementiert werden soll. Diese Grundlage bekommt man bereits in der Einführung der Objektorientierten Programmierung vermittelt. Bei meiner täglichen Arbeit sehe ich aber sehr oft, das so manchem Entwickler die Bedeutung der Forderung gegen Interfaces zu Entwickeln, nicht immer ganz klar ist, obwohl bei der Verwendung der Java Standard API, dies die übliche Praxis ist. Das klassische Beispiel hierfür lautet:
List<String> collection =newArrayList<>();
Diese kurze Zeile nutzt das Interface List, welches als eine ArrayList implementiert wurde. Hier sehen wir auch, das keine Anhängsel in Form eines I die Schnittstelle kennzeichnet. Auch die zugehörige Implementierung trägt kein Impl im Namen. Das ist auch gut so! Besonders bei der Implementierungsklasse könnten ja verschiedene Lösungen erwünscht sein. Dann ist es wichtig diese gut zu kennzeichnen und leicht durch den Namen unterscheidbar zu halten. ListImpl und ListImpl2 sind verständlicherweise nicht so toll wie ArrayList und LinkedList auseinander zu halten. Damit haben wir auch schon den ersten Punk einer stringenten und sprechenden Namenskonvention klären können.
Im nächsten Schritt beschäftigen uns die Programmteile, welche wir möglichst nicht für Konsumenten der Anwendung nach außen geben wollen, da es sich um Hilfsklassen handelt. Ein Teil der Lösung liegt in der Struktur, wie die Packages zu organisieren sind. Ein sehr praktikabler Weg ist:
Bereits über diese simple Architektur signalisiert man anderen Programmierern, das es keine gute Idee ist Klassen aus dem Package helper zu benutzen. Ab Java 9 gibt es noch weitreichendere Restriktion, das Verwenden interner Hilfsklassen zu unterbinden. Die Modularisierung, welche mit dem Projekt Jingsaw [1] in Java 9 Einzug genommen hat, erlaubt es im Moduldescriptor module-info.java Packages nach außen hin zu verstecken.
Separatisten und ihre Flucht vor der Masse
Schaut man sich die meisten Spezifikationen etwas genauer an, so stellt man fest, das viele Schnittstellen in eigene Bibliotheken ausgelagert wurden. Technologisch betrachtet würde das auf das vorherige Beispiel bezogen bedeuten, dass das Package business welches die Interfaces enthält in eine eigene Bibliothek ausgelagert wird. Die Trennung von API und der zugehörigen Implementierung erlaubt es grundsätzlich Implementierungen leichter gegeneinander auszutauschen. Es gestattet außerdem einem Auftraggeber eine stärkeren Einfluss auf die Umsetzung seines Projektes bei seinem Vertragspartner auszuüben, indem der Hersteller die API durch den Auftraggeber vorgefertigt bekommt. So toll wie die Idee auch ist, damit es dann auch tatsächlich so klappt, wie es ursprünglich gedacht wurde, sind aber ein paar Regeln zu beachten.
Beispiel 1: JDBC. Wir wissen, das die Java Database Connectivity ein Standard ist, um an eine Applikation verschiedenste Datenbanksysteme anbinden zu können. Sehen wir von den Probleme bei der Nutzung von nativem SQL einmal ab, können JDBC Treiber von MySQL nicht ohne weiteres durch postgreSQL oder Oracle ersetzt werden. Schließlich weicht jeder Hersteller bei seiner Implementierung vom Standard mehr oder weniger ab und stellt auch exklusive Funktionalität des eigene Produktes über den Treiber mit zu Verfügung. Entscheidet man sich im eigenen Projekt massiv diese Zusatzfeatures nutzen zu wollen, ist es mit der leichten Austauschbarkeit vorüber.
Beispiel 2: XML. Hier hat man gleich die Wahl zwischen mehreren Standards. Es ist natürlich klar das die APIs von SAX, DOM und StAX nicht zueinander kompatibel sind. Will man beispielsweise wegen einer besseren Performance von DOM zum ereignisbasierten SAX wechseln, kann das unter Umständen umfangreiche Codeänderungen nach sich ziehen.
Beispiel 3: PDF. Zu guter letzt habe ich noch ein Szenario von einem Standard parat, der keinen Standard hat. Das Portable Document Format selbst ist zwar ein Standard wie Dokumentdateien aufgebaut werden, aber bei der Implementierung nutzbarer Programmbibliotheken für die eigene Anwendung, köchelt jeder Hersteller sein eigenes Süppchen.
Die drei kleinen Beispiele zeigen die üblichen Probleme auf die im täglichen Projektgeschäft zu meistern sind. Eine kleine Regel bewirkt schon großes: Nur Fremdbibliotheken nutzen, wenn es wirklich notwendig ist. Schließlich birgt jede verwendete Abhängigkeit auch ein potenzielles Sicherheitsrisiko. Es ist auch nicht notwendig eine Bibliothek von wenigen MB einzubinden um die drei Zeile einzusparen, die benötigt werden um einen String auf leer und null zu prüfen.
Musterknaben
Wenn man sich für eine externe Bibliothek entschieden hat, so ist es immer vorteilhaft sich anfänglich die Arbeit zu machen und die Funktionalität über eine eigene Klasse zu kapseln, welche man dann exzessiv nutzen kann. In meinem persönlichen Projekt TP-CORE auf GitHub [2] habe ich dies an mehreren Stellen getan. Der Logger kapselt die Funktionalität von SLF4J und Logback. Im Vergleich zu den PdfRenderer ist die Signatur der Methoden von den verwendeten Logging Bibliotheken unabhängig und kann somit leichter über eine zentrale Stelle ausgetauscht werden. Um externe Bibliotheken in der eigenen Applikation möglichst zu kapseln, stehen die Entwurfsmuster: Wrapper, Fassade und Proxy zur Verfügung.
Wrapper: auch Adaptor Muster genannt, gehört in die Gruppe der Strukturmuster. Der Wrapper koppelt eine Schnittstelle zu einer anderen, die nicht kompatibel sind.
Fassade: ist ebenfalls ein Strukturmuster und bündelt mehrere Schnittstellen zu einer vereinfachten Schnittstelle.
Proxy: auch Stellvertreter genannt, gehört ebenfalls in die Kategorie der Strukturmuster. Proxies sind eine Verallgemeinerung einer komplexen Schnittstelle. Es kann als Komplementär der Fassade verstanden werden, die mehrere Schnittstellen zu einer einzigen zusammenführt.
Sicher ist es wichtig in der Theorie diese unterschiedlichen Szenarien zu trennen, um sie korrekt beschreiben zu können. In der Praxis ist es aber unkritisch, wenn zur Kapselung externer Funktionalität Mischformen der hier vorgestellten Entwurfsmuster entstehen. Für alle diejenigen die sich intensiver mit Design Pattern auseinander Setzen möchten, dem sei das Buch „Entwurfsmuster von Kopf bis Fuß“ [3] ans Herz gelegt.
Klassentreffen
Ein weiterer Schritt auf dem Weg zu einer stabilen API ist eine ausführliche Dokumentation. Basierend auf den bisher besprochenen Schnittstellen, gibt es eine kleine Bibliothek mit der Methoden basierend der API Version annotiert werden können. Neben Informationen zum Status und der Version, können für Klassen über das Attribute consumers die primäre Implementierungen aufgeführt werden. Um API Gaurdian dem eigenen Projekt zuzufügen sind nur wenige Zeilen der POM hinzuzufügen und die Property ${version} gegen die aktuelle Version zu ersetzen.
Die Auszeichnung der Methoden und Klassen ist ebenso leicht. Die Annotation @API hat die Attribute: status, since und consumers. Für Status sind die folgenden Werte möglich:
DEPRECATED: Veraltet, sollte nicht weiterverwendet werden.
EXPERIMENTAL: Kennzeichnet neue Funktionen, auf die der Hersteller gerne Feedback erhalten würde. Mit Vorsicht verwenden, da hier stets Änderungen erfolgen können.
INTERNAL: Nur zur internen Verwendung, kann ohne Vorwarnung entfallen.
STABLE: Rückwärts kompatibles Feature, das für die bestehende Major-Version unverändert bleibt.
MAINTAINED: Sichert die Rückwärtsstabilität auch für das künftige Major-Release zu.
Nachdem nun sämtliche Interfaces mit diesen nützlichen META Informationen angereichert wurden, stellt sich die Frage wo der Mehrwert zu finden ist. Dazu verweise ich schlicht auf Abbildung 1, welche den Arbeitsalltag demonstriert.
Abbildung 1: Suggestion in Netbeans mit @API Annotation in der JavaDoc
Für Service basierte RESTful APIs, gibt es ein anderes Werkzeug, welches auf den Namen Swagger [4] hört. Auch hier wird der Ansatz aus Annotationen eine API Dokumentation zu erstellen verfolgt. Swagger selbst scannt allerdings Java Webservice Annotationen, anstatt eigene einzuführen. Die Verwendung ist ebenfalls recht leicht umzusetzen. Es ist lediglich das swagger-maven-plugin einzubinden und in der Konfiguration die Packages anzugeben, in denen die Webservices residieren. Anschließend wird bei jedem Build eine Beschreibung in Form einer JSON Datei erstellt, aus der dann Swagger UI eine ausführbare Dokumentation generiert. Swagger UI selbst wiederum ist als Docker Image auf DockerHub [5] verfügbar.
Abbildung 2: Swagger UI Dokumentation der TP-ACL RESTful API.
Versionierung ist für APIs ein wichtiger Punkt. Unter Verwendung des Semantic Versioning lässt sich bereits einiges von der Versionsnummer ablesen. Im Bezug auf eine API ist das Major Segment von Bedeutung. Diese erste Ziffer kennzeichnet API Änderungen, die inkompatibel zueinander sind. Eine solche Inkompatibilität ist das Entfernen von Klassen oder Methoden. Aber auch das Ändern bestehender Singnaturen oder der Rückgabewert einer Methode erfordern bei Konsumenten im Rahmen einer Umstellung Anpassungen. Es ist immer eine gute Entscheidung Arbeiten, die Inkompatibilitäten verursachen zu bündeln und eher selten zu veröffentlichen. Dies zeugt von Stabilität im Projekt.
Auch für WebAPIs ist eine Versionierung angeraten. Die geschieht am besten über die URL, in dem eine Versionsnummer eingebaut wird. Bisher habe ich gute Erfahrungen gesammelt, wenn lediglich bei Inkompatibilitäten die Version hochgezählt wird.
Beziehungsstress
Der große Vorteil eines RESTful Service mit „jedem“ gut auszukommen, ist zugleich der größte Fluch. Denn das bedeutet das hier viel Sorgfalt walten muss, da viele Klienten versorgt werden. Da die Schnittstelle eine Ansammlung von URIs darstellt, liegt unser Augenmerk bei den Implementierungsdetails. Dazu nutze ich ein Beispiel aus meinen ebenfalls auf GitHub verfügbaren Projekt TP-ACL.
Der kurze Auszug aus dem try Block der fetchRole Methode die in der Klasse RoleService zu finden ist. Die GET Anfrage liefert für den Fall, das eine Rolle nicht gefunden wird den 404 Fehlercode zurück. Sie ahnen sicherlich schon worauf ich hinaus will.
Bei der Implementierung der einzelnen Aktionen GET, PUT, DELETE etc. einer Resource wie Rolle, genügt es nicht einfach nur den sogenannten HappyPath umzusetzen. Bereits während des Entwurfes sollte berücksichtigt werden, welche Stadien eine solche Aktion annehmen kann. Für die Implementierung eines Konsumenten (Client) ist es schon ein beachtlicher Unterschied ob eine Anfrage, die nicht mit 200 abgeschlossen werden kann gescheitert ist, weil die Ressource nicht existiert (404) oder weil der Zugriff verweigert wurde (403). Hier möchte ich an die vielsagende Windows Meldung mit dem unerwarteten Fehler anspielen.
Fazit
Wenn wir von eine API sprechen, dann bedeutet es, das es sich um eine Schnittstelle handelt, die von anderen Programmen genutzt werden kann. Der Wechsel eine Major Version indiziert Konsumenten der API, das Inkompatibilität zur vorherigen Version vorhanden ist. Weswegen möglicherweise Anpassungen erforderlich sind. Dabei ist es völlig irrelevant um welche Art API es sich handelt oder ob die Verwendung der Anwendung öffentlich beziehungsweise fetchRole Methode, die Unternehmensintern ist. Die daraus resultierenden Konsequenzen sind identisch. Aus diesem Grund sollte man sich mit den nach außen sichtbaren Bereichen seiner Anwendung gewissenhaft auseinandersetzen.
Arbeiten, welche zu einer API Inkompatibilität führen, sollten durch das Release Management gebündelt werden und möglichst nicht mehr als einmal pro Jahr veröffentlicht werden. Auch an dieser Stelle zeigt sich wie wichtig regelmäßige Codeinspektionen für eine stringente Qualität sind.
Nachdem die Gang Of Four (GOF) Erich Gamma, Richard Helm, Ralph Johnson und John Vlissides das Buch Design Patterns: Elements of Reusable Object-Oriented Software (Elemente wiederverwendbarer objektorientierter Software), wurde das Erlernen der Beschreibung von Problemmustern und deren Lösungen in fast allen Bereichen der Softwareentwicklung populär. Ebenso populär wurde das Erlernen der Beschreibung von Don’ts und Anti-Patterns.
In Publikationen, die sich mit den Konzepten der Entwurfsmuster und Anti-Pattern befassen, finden wir hilfreiche Empfehlungen für Softwaredesign, Projektmanagement, Konfigurationsmanagement und vieles mehr. In diesem Artikel möchte ich meine Erfahrungen im Umgang mit Versionsnummern für Software-Artefakte weitergeben.
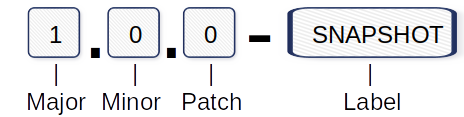
Die meisten von uns sind bereits mit einer Methode namens semantische Versionierung vertraut, einem leistungsstarken und leicht zu erlernenden Regelwerk dafür, wie Versionsnummern strukturiert sein sollten und wie die einzelnen Segmente zu inkrementieren sind.
Beispiel für eine Versionsnummerierung:
Major: Inkompatible API-Änderungen.
Minor: Hinzufügen neuer Funktionen.
Patch: Fehlerbehebungen und Korrekturen.
Label: SNAPSHOT zur Kennzeichnung des Status “in Entwicklung”.
Eine inkompatible API-Änderung liegt dann vor, wenn eine von außen zugängliche Funktion oder Klasse gelöscht oder umbenannt wurde. Eine andere Möglichkeit ist eine Änderung der Signatur einer Methode. Das bedeutet, dass der Rückgabewert oder die Parameter gegenüber der ursprünglichen Implementierung geändert wurden. In diesen Fällen ist es notwendig, das Major-Segment der Versionsnummer zu erhöhen. Diese Änderungen stellen für API-Kunden ein hohes Risiko dar, da sie ihren eigenen Code anpassen müssen.
Beim Umgang mit Versionsnummern ist es auch wichtig zu wissen, dass 1.0.0 und 1.0 gleichwertig sind. Dies hat mit der Anforderung zu tun, dass die Versionen einer Softwareversion eindeutig sein müssen. Wenn dies nicht der Fall ist, ist es unmöglich, zwischen Artefakten zu unterscheiden. In meiner beruflichen Praxis war ich mehrfach an Projekten beteiligt, bei denen es keine klar definierten Prozesse für die Erstellung von Versionsnummern gab. Dies hatte zur Folge, dass das Team die Qualität des Artefakts sicherstellen musste und sich nicht mehr sicher war, mit welcher Version des Artefakts es sich gerade befasste.
Der größte Fehler, den ich je gesehen habe, war die Speicherung der Version eines Artefakts in einer Datenbank zusammen mit anderen Konfigurationseinträgen. Die korrekte Vorgehensweise sollte sein: die Version innerhalb des Artefakts so zu platzieren, dass niemand nach einem Release diese von außen ändern kann. Die Falle, in die man sonst tappt, ist der Prozess, wie man die Version nach einem Release oder Neuinstallation aktualisiert.
Vielleicht haben Sie eine Checkliste für alle manuellen Tätigkeiten während eines Release. Aber was passiert, nachdem eine Version in einer Testphase installiert wurde und aus irgendeinem Grund eine andere Version der Anwendung eneut installiert werden muss? Ist Ihnen noch bewusst, dass Sie die Versionsnummer manuell in der Datenbank ändern müssen? Wie finden Sie heraus, welche Version installiert ist, wenn die Informationen in der Datenbank nicht stimmen?
Die richtige Version in dieser Situation zu finden, ist eine sehr schwierige Aufgabe. Aus diesem Grund haben gibt es die Anforderung, die Version innerhalb der Anwendung zu halten. Im nächsten Schritt werden wir einen sicheren und einfachen Weg aufzeigen, wie man dieses Problem voll automatisiert lösen kann.
Die Voraussetzung ist eine einfache Java-Bibliothek die mit Maven gebaut wird. Standardmäßig wird die Versionsnummer des Artefakts in der POM notiert. Nach dem Build-Prozess wird unser Artefakt erstellt und wie folgt benannt: artifact-1.0.jar oder ähnlich. Solange wir das Artefakt nicht umbenennen, haben wir eine gute Möglichkeit, die Versionen zu unterscheiden. Selbst nach einer Umbenennung kann mit einem einfachen Trick nach einem Unzip des Archives im META-INF-Ordner der richtige Wert gefunden werden.
Wenn Sie die Version in einer Poroperty oder Klasse fest einkodiert haben, würde das auch funktionieren, solange Sie nicht vergessen diese immer aktuell zu halten. Vielleicht müssen Sie dem Branching und Merging in SCM Systemen wie Git besondere Aufmerksamkeit schenken, um immer die korrekte Version in Ihrer Codebasis zu haben.
Eine andere Lösung ist die Verwendung von Maven und dem Tokenreplacement. Bevor Sie dies in Ihrer IDE ausprobieren, sollten Sie bedenken, dass Maven zwei verschiedene Ordner verwendet: Sources und Ressourcen. Die Token-Ersetzung in den Quellen wird nicht richtig funktionieren. Nach einem ersten Durchlauf ist Ihre Variable durch eine feste Zahl ersetzt und verschwunden. Ein zweiter Durchlauf wird daher fehlschlagen. Um Ihren Code für die Token-Ersetzung vorzubereiten, müssen Sie Maven als erstes im Build-Lifecycle konfigurieren:
Nach diesem Schritt müssen Sie die Property ${project.version} aus dem POM kennen. Damit können Sie eine Datei mit dem Namen version.property im Verzeichnis resources erstellen. Der Inhalt dieser Datei besteht nur aus einer Zeile: version=${project.version}. Nach einem Build finden Sie in Ihrem Artefakt die version.property mit der gleichen Versionsnummer, die Sie in Ihrem POM verwendet haben. Nun können Sie eine Funktion schreiben, die die Datei liest und diese Property verwendet. Sie können das Ergebnis zum Beispiel in einer Konstante speichern, um es in Ihrem Programm zu verwenden. Das ist alles, was Sie tun müssen!
IT-Professionals bekommen schon zu Beginn ihrer Karriere kuriose Anfragen. So auch ich. Bereits während meines Studiums klingelte hin und wieder das Telefon und besonders kluge Menschen erklärten mir, wie ich für sie so etwas wie Facebook nach programmieren könne. Natürlich ohne Bezahlung.
(c) 2019 Marco Schulz, Java aktuell Ausgabe 2, S.64-65
Die pfiffige Idee dieser Zeitgenossen war es, das ich für sie kostenlos eine Plattform erstelle, natürlich exklusiv nach ihren Wünschen. Dank deren hervorragender Vernetzung würde das Ganze sehr schnell erfolgreich und wir könnten den Gewinn untereinander aufteilen. Ich wollte dann immer wissen, wozu ich für die Entwicklung eines Systems, dessen Kosten und Risiken ich allein zu tragen habe, einen Partner benötige, um dann mit ihm den Gewinn zu teilen. Diese Frage beendete solche Gespräche recht schnell.
Vor nicht allzu langer Zeit erreichte mich wieder einmal eine Projektanfrage mit einem umfangreichen Skill-Set zu einem offerierten Stundenlohn, der bereits für Studenten unverschämt gering ausfiel. Dies erinnerte mich an einen sehr sarkastischen Artikel von Yegor Bugayenko aus dem Jahre 2016, den ich hier ins Deutsche übertragen habe:
Um Software erstellen zu können, benötigt man Programmierer. Unglücklicherweise. Sie sind in aller Regel teuer, faul und meistens unkontrollierbar. Die Software, die sie erstellen, funktioniert vielleicht oder vielleicht auch nicht. Trotzdem erhalten sie jeden Monat ihren Lohn. Aus diesem Grund ist es immer eine gute Idee, möglichst wenig zu zahlen. Wie dem auch sei. Manchmal erklären sie einem, wie unterbezahlt sie sind, und kündigen einfach. Aber wie will man dies unterbinden? Leider ist es uns nicht mehr gestattet, gewalttätig zu sein, aber es gibt einige andere Möglichkeiten. Lasst mich dies genauer erläutern.
Gehälter geheim halten
Es ist offensichtlich: Sie dürfen sich nicht über ihre Gehälter austauschen. Diese Information ist geheim zu halten. Ermahnt sie oder noch besser schreibt einen Geheimhaltungs-Paragraph in ihren Vertrag, der verhindert, dass über Löhne, Boni, Vergütungspläne gesprochen wird. Sie müssen fühlen, dass diese Information giftig ist. So dass sie sich nie über dieses Thema unterhalten. Wenn das Einkommen ihrer Kollegen unbekannt ist, kommen weniger Fragen nach Gehaltserhöhungen auf.
Zufällige Lohnerhöhungen
Es sollte kein erkennbares System geben, wie Lohnerhöhungen oder Kündigungen entschieden werden. Lohnerhöhungen werden ausschließlich nach Bauchgefühl verteilt, nicht etwa, weil jemand produktiver oder effektiver wurde. Entscheidungen sollten unvorhersehbar sein. Unvorhersagbarkeit erzeugt Angst und dies ist genau das, was wir wollen. Sie sind eingeschüchtert ihrem Auftraggeber gegenüber und werden sich lange Zeit nicht beschweren, wie unterbezahlt sie sind.
Keine Konferenzen
Es sollte ihnen nicht gestattet sein, an Meetups oder Konferenzen teilzunehmen. Dort könnten sie möglicherweise auf Vermittler treffen und herausfinden, dass ihre Bezahlung nicht fair genug ist. Es sollte die Idee verbreitet werden, dass Konferenzen lediglich Zeitverschwendungen sind. Es ist besser, Veranstaltungen im Büro durchzuführen. Sie haben immer zusammenzubleiben und niemals auf Programmierer aus anderen Unternehmen zu treffen. Je weniger sie wissen, desto sicherer ist man.
Keine Heimarbeit
Das Büro muss zu einem zweiten Zuhause werden. Besser noch, zum wichtigsten Platz in ihrem Leben. Sie müssen jeden Tag anwesend sein, am Schreibtisch, mit einem Computer, einem Stuhl und einer Ablage. Sie sind emotional verbunden mit ihrem Arbeitsplatz. So wird es viel schwieriger, ihn eines Tages zu kündigen, ganz gleich wie unterbezahlt sie auch sind. Sie sollten niemals eine Erlaubnis bekommen, per Remote zu arbeiten. Sie könnten dann beginnen, von einem neuen Zuhause und einem stattlicheren Gehalt zu träumen.
Überwacht sie
Es ist dafür zu sorgen, dass sie firmeneigene Systeme wie E-Mail, Computer, Server und auch Telefone nutzen. Darauf ist dann gängige Überwachungssoftware installiert, die sämtliche Nachrichten und Aktivitäten protokolliert. Idealerweise existiert eine Sicherheitsabteilung, um die Programme zu überwachen und bei abnormalem oder unerwartetem Verhalten das Management zu informieren. Videokameras sind auch sehr hilfreich. Jeglicher Kontakt zu anderen Unternehmen ist verdächtig. Angestellte sollten wissen, dass sie überwacht werden. Zusätzliche Angst ist immer hilfreich.
Vereinbarungen mit Mitbewerbern
Kontaktiert die größten Mitbewerber der Region und stellt sicher, dass keine Entwickler abgeworben werden, solange sie dies ebenfalls nicht tun. Falls sie diese Absprache zurückweisen, ist es gut, einige ihrer Schlüsselpersonen abzuwerben. Einfach durch das In–Aussicht-Stellen des doppelten bisherigen Gehalts. Natürlich will man sie nicht wirklich engagieren. Aber diese Aktion rüttelt den lokalen Markt ordentlich durch und Mitbewerber fürchten einen. Sie sind schnell einverstanden, keine deiner Entwickler jemals zu berühren.
Etabliert gemeinsame Werte
Unterzieht sie einer regelmäßigen Gehirnwäsche in gemeinsamen Jubelveranstaltungen, in denen begeistert verkündet wird, wie toll die Firma ist, was für großartige Ziele alle haben und wie wichtig die Zusammenarbeit als Team ist. Die Zahlen auf der Gehaltsabrechnung erscheinen weniger wichtig, im Vergleich zu einem Multi-Millionen-Euro-Vorhaben, das den Markt dominieren soll. Sie werden sich dafür aufopfern und eine recht lange Zeit wird dieser Trick motivieren.
Gründe eine Familie
Gemeinsame Firmenveranstaltungen, freitags Freibier, Team-Buil-ding-Veranstaltungen, Bowling, Geburtstagsfeiern, gemeinsame Mittagessen und Abendveranstaltungen – das sind Möglichkeiten, um das Gefühl zu erzeugen, dass die gesamte Firma die einzige Familie ist. In einer Familie spricht man als gutes Mitglied auch nicht über Geld. Korrekt? Die Frage nach einer Gehaltsvorstellung gilt als Verrat an der Familie. Aus diesem Grund werden sie davon Abstand nehmen.
Stresst sie
Sie dürfen sich nicht entspannt fühlen, das ist nicht zu unserem Vorteil. Sorgt für kurze Abgabetermine, komplexe Problemlösungen und ausreichend Schuldgefühle. Niemand wird nach einer Gehaltserhöhung fragen, wenn er sich schuldig fühlt, die Projektziele wieder einmal nicht erreicht zu haben. Daher sind sie so oft wie möglich für ihre Fehler zur Verantwortung zu ziehen.
Versprechungen machen
Es ist nicht notwendig, die Versprechen einzuhalten, aber sie müssen gemacht werden. Versprecht ihnen, das Gehalt demnächst zu erhöhen oder künftige Investitionen oder die Ausfertigung eines unbefristeten Abseitsvertrags. Natürlich unter der Bedingung, dass die Zeit dafür auch reif ist. Es ist sehr wichtig, dass die Versprechungen an ein Ereignis geknüpft sind, das man selbst nicht beeinflussen kann, um die eigenen Hände stets in Unschuld zu waschen.
Kauft ihnen weiche Sessel und Tischtennisplatten
Ein paar winzige Ausgaben für diese lustigen Bürosachen werden schnell kompensiert durch den Hungerlohn, den die Entwickler ausbezahlt bekommen. Eine hübsche, professionelle Kaffeemaschine kostet 1.000 Euro und spart pro Programmierer jeden Monat zwischen 200 bis 300 Euro ein. Rechnet es aus. Erstellt eine eigene Regel, die besagt, bevor irgendjemand eine Gehaltserhöhung bekommt, ist es sinnvoller, eine neue PlayStation für das Büro zu kaufen. Erlaubt ihnen, ihre Haustiere mit ins Büro zu bringen, und sie bleiben länger für weniger Geld.
Gut klingende Titel
Bezeichnet sie als Vizepräsident, beispielsweise „VP für Entwicklung“, „technischer VP“, VP von was auch immer. Keine große Sache. Aber sehr wichtig für Angestellte. Die Bezahlung hat so weitaus weniger Stellenwert als der Titel, den sie in ihre Profile auf sozialen Netzwerken schreiben können. Wenn alle Vizepräsidenten besetzt sind, versuche einmal Senior Architekt oder Lead Technical etc.
Überlebenshilfe
Die meisten Programmierer sind etwas unbeholfen wenn es darum geht, ihr Geld zu verwalten. Sie wissen einfach nicht, wie man eine Versicherung abschließt, die Rente organisiert, oder einfach nur, wie man Steuern zahlt. Natürlich erhalten sie Hilfe, nicht unbedingt zu ihren Gunsten. Aber sie werden glücklich sein, sich in euren Händen sicher fühlen und niemals daran denken, das Unternehmen zu verlassen. Niemand wird nach einer Lohnerhöhung fragen, weil sie sich schlecht fühlen, solche Geschäfte in die eigene Hand zu nehmen. Seid ihnen Vater oder Mutter – sie werden ihre Rolle als Kind annehmen. Es ist ein bewährtes Modell. Es funktioniert.
Sei ein Freund
Das ist die letzte und wirkungsvollste Methode. Sei ein Freund der Programmierer. Es ist verflixt schwierig, mit Freunden über Geld zu verhandeln. Sie sind nicht in der Lage, das einfach in Angriff zu nehmen. Sie bleiben und arbeiten gern für weniger Geld, einfach weil wir Freunde sind. Wie man zum Freund wird? Gut. Trefft ihre Familien, lade sie zum Essen in dein Haus ein, kleine Aufmerksamkeiten zu Geburtstagen – all diese Sachen. Sie sparen eine Menge Geld. Habe ich noch etwas vergessen?
Quelle • https://www.yegor256.com/2016/12/06/how-to-pay-programmers-less.html
m Umgang mit Source-Control-Management-Systemen (SCM) wie Git oder Subversion haben sich im Lauf der Zeit vielerlei Praktiken bewährt. Neben unzähligen Beiträgen über Workflows zum Branchen und Mergen ist auch das Formulieren verständlicher Beschreibungen in den Commit-Messages ein wichtiges Thema.
(c) 2018 Marco Schulz, Java PRO Ausgabe 3, S.50-51
Ab und zu kommt es vor, dass in kollaborativen Teams vereinzelte Code-Änderungen zurückgenommen werden müssen. So vielfältig die Gründe für ein Rollback auch sein mögen, das Identifizieren betroffener Code-Fragmente kann eine beachtliche Herausforderung sein. Die Möglichkeit jeder Änderung des Code-Repository eine Beschreibung anzufügen, erleichtert die Navigation zwischen den Änderungen. Sind die hinterlegten Kommentare der Entwickler dann so aussagekräftig wie „Layout-Anpassungen“ oder „Tests hinzugefügt“, hilft dies wenig weiter. Diese Ansicht vertreten auch diverse Blog-Beiträge [siehe Weitere Links] und sehen das Formulieren klarer Commit-Messages als wichtiges Instrument, um die interne Kommunikation zwischen einzelnen Team-Mitgliedern deutlich zu verbessern.
Das man als Entwickler nach vollbrachter Arbeit nicht immer den optimalen Ausdruck findet, seine Aktivitäten deutlich zu formulieren, kann einem hohen Termindruck geschuldet sein. Ein hilfreiches Instrument, ein aussagekräftiges Resümee der eigenen Arbeit zu ziehen, ist die nachfolgend vorgeschlagene Struktur und ein darauf operierendes aussagekräftiges Vokabular inklusive einer festgelegten Notation. Die vorgestellte Lösung lässt sich sehr leicht in die eigenen Prozesse einfügen und kann ohne großen Aufwand erweitert bzw. angepasst werden.
Mit den standardisierten Expressions besteht auch die Möglichkeit die vorhandenen Commit-Messages automatisiert zu Parsen, um die Projektevolution gegebenenfalls grafisch darzustellen. Sämtliche Einzelheiten der hier vorgestellten Methode sind in einem Cheat-Sheet auf einer Seite übersichtlich zusammengefasst und können so leicht im Team verbreitet werden. Das diesem Text zugrundeliegende Paper ist auf Research-Gate [1] in englischer Sprache frei verfügbar.
Eine Commit-Message besteht aus einer verpflichtenden (mandatory) ersten Zeile, die sich aus der Funktions-ID, einem Label und der Spezifikation zusammensetzt. Die zweite und dritte Zeile ist optional. Die Task-ID, die Issue-Management-Systeme wie Jira vergeben, wird in der zweiten Zeile notiert. Grund dafür ist, dass nicht jedes Projekt an ein Issue-Management-System gekoppelt ist. Viel wichtiger ist auch die Tatsache, dass Funktionen meist auf mehrere Tasks verteilt werden. Eine Suche nach der Funktions-ID fördert alle Teile einer Funktionalität zu tage, auch wenn dies unterschiedlichen Task-IDs zugeordnet ist. Die ausführliche Beschreibung in Zeile drei ist ebenfalls optional und rückt auf Zeile zwei vor, falls keine Task-ID notiert wird. Das gesamte Vokabular zu dem nachfolgenden Beispiel ist im Cheat-Sheet notiert und soll an dieser Stelle nicht wiederholt werden.
[CM-05] #CHANGE ’function:pom’
<QS-0815>
{Change version number of the dependency JUnit from 4 to 5.0.2}
Projektübergreifende Aufgaben wie das Anpassen der Build-Logik, Erzeugen eines Releases oder das Initiieren eines Repositories können in allgemeingültigen Funktions-IDs zusammengefasst werden. Entsprechende Beispiele sind im Cheat-Sheet angeführt.
Möchte man nun den Projektfortschritt ermitteln, ist es sinnvoll aussagekräftige Meilensteine miteinander zu vergleichen. Solche Punkte (POI) stellen üblicherweise Releases dar. So können bei Berücksichtigung des Standard-Release-Prozesses und des Semantic-Versionings Metriken über die Anzahl der Bug-Fixes pro Release erstellt werden. Aber auch klassische Erhebungen wie Lines-of-Code zwischen zwei Minor-Releases können interessante Erkenntnisse fördern.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.