
Schlagwort-Archiv: Datenbank
Date vs. Boolean
Antworten
Beim Entwurf von Datenmodellen und den dazugehörigen Tabellen nutzen wir manchmal Boolean als Datentyp. Im Allgemeinen sind diese Flags nicht wirklich problematisch. Aber vielleicht gibt es eine bessere Lösung für dieses Datendesign. Lassen Sie mich, Ihnen ein kurzes Beispiel für meine Anliegen geben.
Nehmen wir an, wir müssen eine einfache Domäne zum Speichern von Artikeln entwerfen. Wie ein Blog-System oder ein Content-Management-System. Neben dem Inhalt des Artikels und dem Namen des Autors könnten wir ein Flag benötigen, das dem System mitteilt, ob der Artikel für die Öffentlichkeit sichtbar ist. So etwas wie veröffentlicht als boolescher Wert. Aber es gibt auch weitere Anforderung, ein Datum, wann für den Artikel die Veröffentlichung geplant ist. In den meisten Datenbankentwürfen, die ich beobachtet habe, gibt es für diese Umstände einen Boolean: published und ein Datum: publishingDate. Meiner Meinung nach ist dieses Design ein wenig redundant und auch fehleranfällig. Als schnelle Schlussfolgerung möchte ich eher dazu raten, von Anfang an nur Date anstelle von Boolean zu verwenden.
Das Szenario, das ich oben beschrieben habe, kann auch auf viele andere Domänenlösungen übertragen werden. Nachdem wir eine Vorstellung davon bekommen haben, warum wir Boolean durch den Datentyp Date ersetzen sollten, werden wir uns nun den Details widmen, wie wir dieses Ziel erreichen können.
Der Umgang mit Standard-SQL lässt vermuten, dass der Austausch eines Datenbankmanagementsystems (DBMS) gegen ein anderes kein großes Problem darstellen sollte. Die Realität sieht leider ein wenig anders aus. Nicht alle verfügbaren Datentypen für Datum wie Timestamp sind wirklich empfehlenswert zu verwenden. Aus Erfahrung ziehe ich es vor, das einfache java.util.Date zu verwenden, um zukünftige Probleme und andere Überraschungen zu vermeiden. Das gespeicherte Format in der Datenbanktabelle sieht wie folgt aus: ‘JJJJ-MM-tt HH:mm:ss.0’. Zwischen dem Datum und der Uhrzeit steht ein einzelnes Leerzeichen und .0 bezeichnet einen Offset. Dieser Offset beschreibt die Zeitzone. Die mitteleuropäische Standardzeitzone CET hat einen Versatz von einer Stunde. Das bedeutet UTC+01:00 im internationalen Format. Um den Offset separat zu definieren, habe ich gute Ergebnisse mit java.util.TimeZone erzielt, das perfekt mit Date zusammenarbeitet.
Bevor wir fortfahren, zeige ich Ihnen einen kleinen Codeschnipsel in Java für den O/R Manager Hibernate und wie damit die zugehörigen Tabellenspalten erstellt werden können.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Schauen wir uns das obige Listing etwas genauer an. Als erstes sehen wir die @CreationTimestamp Annotation. Das bedeutet, dass beim Erstellen des ArticleDO-Objekts die Variable created mit der aktuellen Zeit initialisiert wird. Dieser Wert sollte sich nie ändern, da ein Artikel nur einmal erstellt, aber mehrmals geändert werden kann. Die Zeitzone wird in einem String gespeichert. Im Konstruktor kann man sehen, wie die System Timezone ausgelesen werden kann – aber Vorsicht, dieser Wert sollte nicht zu sehr vertraut werden. Wenn Sie einen Benutzer wie mich haben, der viel reist, werden Sie sehen, dass ich an allen Orten die gleiche Systemzeit habe, da ich diese normalerweise nie ändere. Als Standardzeitzone definiere ich den richtigen String für UTC-0. Das Gleiche mache ich für die Variable published. Datum kann auch durch einen String erstellt werden, den wir verwenden, um unseren Standard-Nullwert zu setzen. Der Setter für published hat die Möglichkeit, ein zukünftiges Datum zu definieren oder die aktuelle Zeit zu verwenden, falls der Artikel sofort veröffentlicht werden soll. Am Ende des Listings demonstriere ich einen einfachen SQL-Import für einen einzelnen Datensatz.
Aber man sollte nicht zu schnell vorgehen. Wir müssen auch ein wenig darauf achten, wie wir mit dem UTC-Offset umgehen. Denn ich habe in großen Systemen mehrfach Probleme beobachtet, die auftraten, weil Entwickler nur Standardwerte verwendet haben.
Die Zeitzone im Allgemeinen ist Teil des Internationalisierungskonzepts. Um die Zeitverschiebungen korrekt zu verwalten, können wir zwischen verschiedenen Strategien wählen. Wie in so vielen anderen Fällen gibt es kein eindeutiges Richtig oder Falsch. Alles hängt von den Umständen und Notwendigkeiten Ihrer Anwendung ab. Wenn eine Website nur national genutzt wird, wie für ein kleines Unternehmen, und keine zeitkritischen Ereignisse involviert sind, wird alles sehr einfach. In diesem Fall ist es unproblematisch, die Zeitzoneneinstellungen automatisch durch das DBMS zu verwalten. Aber bedenken Sie, dass es auf der Welt Länder wie Mexiko gibt, die mehr als nur eine Zeitzone haben. Bei einem internationalen System, bei dem die Clients über den ganzen Globus verteilt sind, könnte es sinnvoll sein, jedes einzelne DBMS im Cluster auf UTC-0 einzustellen und den Offset durch die Anwendung und die angeschlossenen Clients zu verwalten.
Ein weiteres Problem, das wir lösen müssen, ist die Frage, wie der Datumswert eines einzelnen Datensatzes standardmäßig initialisiert werden soll. Denn Nullwerte sollten vermieden werden. Eine ausführliche Erklärung, warum die Rückgabe von Nullwerten kein guter Programmierstil ist, findet sich in Büchern wie ‘Effective Java’ und ‘Clean Code’. Der Umgang mit Null Pointer Exceptions ist etwas, das ich nicht wirklich brauche. Ein bewährtes Verfahren, das sich für mich bewährt hat, ist die Vorgabe eines Datums- und Zeitwerts durch ‘0000-00-00 00:00:00.0’. Auf diese Weise vermeide ich unerwünschte Veröffentlichungen, und die Bedeutung ist sehr klar – für jeden.
Wie Sie sehen können, gibt es gute Gründe, warum boolesche Datentypen durch Datum ersetzt werden sollten. In diesem kleinen Artikel habe ich gezeigt, wie einfach man mit Datum und Zeitzone in Java und Hibernate umgehen kann. Es sollte auch keine große Sache sein, dieses Beispiel auf andere Programmiersprachen und Frameworks zu übertragen. Wenn Sie eine eigene Lösung haben, können Sie gerne einen Kommentar hinterlassen und diesen Artikel mit Ihren Kollegen und Freunden teilen.


Erste Schritte in Docker mit PostgreSQL
Nach einigen Jahren hat das Virtualisierungstool Docker seine Bedeutung für die Softwarebranche unter Beweis gestellt. Wenn man von Virtualisierung hört, könnte man meinen, dass dies nur etwas für Administratoren ist und mich als Entwickler nicht so stark betrifft. Aber Moment mal. Da könntest du falsch liegen. Denn Grundkenntnisse über Docker können Entwicklern im Alltag helfen.
Schritt 1: Erstellen Sie den Container und initialisieren Sie die Datenbank
docker run -d --name pg-dbms --restart=no \
--ip 172.18.0.20 \
-e POSTGRES_PASSWORD=s3cr3t \
-e PGPASSWORD=s3cr3t \
postgres:11Wenn Sie möchten, dass PostgreSQL nach einem Neustart immer aktiv ist, ändern Sie die Neustartrichtlinie von „nein“ auf „immer“. Nachdem Sie die Instanz „pg-dbms“ Ihres PostgreSQL 11 Docker-Images erstellt haben, überprüfen Sie, ob der Neustart erfolgreich war. Dies gelingt über den Befehl:
docker ps -aSchritt 2: Kopieren Sie das initialisierte Datenbankverzeichnis in ein lokales Verzeichnis auf Ihrem Hostsystem
docker cp pg-dbms:/var/lib/postgresql/data /home/user/pgDas größte Problem mit dem aktuellen Container ist, dass beim Löschen alle Daten verloren gehen. Wir müssen also eine Möglichkeit finden, diese Daten dauerhaft zu speichern. Am einfachsten kopieren Sie das Datenverzeichnis Ihres Containers in ein Verzeichnis auf Ihrem Hostsystem. Der Kopierbefehl benötigt die Parameter „Quelle“ und „Ziel“. Geben Sie als Quelle den Container an, aus dem die Dateien stammen sollen. In unserem Fall heißt der Container „pg-dbms“. Das Ziel ist ein PostgreSQL-Ordner im Home-Verzeichnis des Benutzers „ed“. Unter Windows funktioniert es genauso. Passen Sie einfach den Verzeichnispfad an und vermeiden Sie Leerzeichen. Sobald die Dateien im angegebenen Verzeichnis liegen, ist dieser Schritt abgeschlossen.
Schritt 3: Stoppen Sie den aktuellen Container
docker stop pg-dbmsWenn Sie einen Container starten möchten, ersetzen Sie einfach „Stop“ durch „Start“. Der Container, den wir zum Abrufen der ursprünglichen Dateien für das PostgreSQL-DBMS erstellt haben, wird nicht mehr benötigt. Wir können ihn löschen. Dazu muss jedoch zunächst der laufende Container gestoppt werden.
Schritt 4: Starten Sie den aktuellen Container
docker start pg-dbmsNachdem der Container gestoppt wurde, können wir ihn löschen.
Schritt 5: Container mit einem externen Volume neu erstellen
docker run -d --name pg-dbms \
--ip 172.18.0.20 \
-e POSTGRES_PASSWORD=s3cr3t \
-e PGPASSWORD=s3cr3t \
-v /home/user/pg:/var/lib/postgresql/data \
postgres:11Jetzt können wir das Verzeichnis mit der exportierten ursprünglichen Datenbank mit einem neu erstellten PostgreSQL-Container verknüpfen. Das ist alles. Der große Vorteil dieser Vorgehensweise ist, dass sich nun jede in PostgreSQL erstellte Datenbank und deren Daten außerhalb des Docker-Containers auf unserem lokalen Rechner befinden. Dies ermöglicht eine wesentlich einfachere Sicherung und verhindert Informationsverluste bei Containeraktualisierungen.
Wenn Sie anstelle von PostgreSQL andere Images haben, aus denen Sie Dateien zur Wiederverwendung extrahieren müssen, können Sie dieses Tutorial ebenfalls verwenden. Passen Sie es einfach an das Image und die benötigten Pfade an. Die Vorgehensweise ist nahezu identisch. Wenn Sie mehr über Docker erfahren möchten, können Sie sich auch mein Video „Docker-Grundlagen in weniger als 10 Minuten“ ansehen. Wenn Ihnen dieses kurze Tutorial gefällt, teilen Sie es mit Ihren Freunden und Kollegen. Abonnieren Sie meinen Newsletter, um auf dem Laufenden zu bleiben.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.



Applikationskonfiguation mit XML Dateien

Windows Nutzer kennen die typischen INI-Files, in denen Werte zur Laufzeit in eine Applikation geladen werden können. Dieses Konzept hat mit der starken Verbreitung von XML eine neue Renaissance erfahren. In diesem Zusammenhang sind die Paradigmen Don’t Repeat Yourself (DRY) und Convention Over Configuration (COC) zum Maß der Dinge avanciert. Die freien Frameworks Ruby On Rails und Maven 2, gehören zu den bekanntesten Tools, die mit dieser Technologie arbeiten.
In Hochsprachen wie C oder Java müssen die Quelldateien in ein binäres Format gebracht werden, dieser Vorgang kann je nach Umfang eines Programms, einiges an Rechenzeit verbrauchen. Um verschiedene Parameter einer Anwendung zur Laufzeit verändern zu können, wurde eine Möglichkeit geschaffen, die Werte aus einfachen Textdateien lesen kann.
Damit erübrigt sich das Kompilieren, da die Initialisierung der Variablen nun nicht mehr im Quelltext hinterlegt ist. Hinter dem Begriff DRY verbirgt daher nichts anderes, als die Vermeidung unnötiger und sich wiederholender Arbeitsschritte. COC erweitert diese Idee um die Forderung, dass jede Variable die konfiguriert werden kann, mit einem Defaultwert vorbelegt ist. In der Konfigurationsdatei werden nur noch Parameter angegeben, die vom vorgegebenen Standart abweichen. Die Übersichtlichkeit und Lesbarkeit der Konfiguration steigt somit rapide an, da es im praktischen Einsatz sehr unwahrscheinlich ist, dass alle Konfigurationsmöglichkeiten überschreiben werden müssen. Um effektiv mit den Paradigmen DRY und COC arbeiten zu können ist es, wichtig die möglichen Konfigurationsparameter und deren Bedeutung zu kennen. Daher sollte an einer ausführlichen Dokumentation nicht gespart werden.
Für PHP ist die Verwendung von XML als Konfigurationsdatei aus zwei Gründen sinnvoll. Die wichtigste Eigenschaft ist vor allem eine Trennung von internen Applikationszuständen, die dem Anwender verborgen bleiben sollen. Ausschließlich die notwendigen Anpassungen an das Zielsystem, wie Datenbankanbindungen und Layouteinstellungen werden zentral in der Konfigurationsdatei vorgehalten. Der zweite Aspekt, der für XML spricht, ist die Möglichkeit Daten einfach und lesbar zu strukturieren. So praktisch die Nutzung von XML auch ist, so soll die davon ausgehende Gefahr nicht unterschlagen werden. Ohne geeignete Maßnahmen können die Daten der Konfigurationsdatei von Dritten ausgespäht werden. Der Aspekt über die Sicherheit wird im Anschluss an eine kurze Einführung zu XML besprochen.
XML
Die Extensible Markup Language (XML) wird für die unterschiedlichsten Aufgaben verwendet. Der Grund liegt in der einfachen Möglichkeit, Strukturen und Daten zu modellieren. Im Gegensatz zu HTML sind die Tags nicht mehr fest vorgeschrieben, sondern können frei gewählt werden. Genauso verhält es sich auch mit den Attributen für die Elemente. Damit dies auch gelingt, muss eine XML-Datei verschiedenen Regeln entsprechen. Werden die Regeln eingehalten, spricht man von einem wohlgeformten Dokument. Einige XML Editoren verweigern das Abspeichern nicht wohlgeformter Dokumente.
Um festzustellen, ob das Dokument auch der vorgegebenen Datenstruktur entspricht, kann entweder gegen eine Dokument Type Definition (DTD) oder ein XML Schema (XSD) validiert werden. Entwicklungsumgebungen greifen oft auf die angegebene DTD bzw. XSD Datei zu, um eine intelligente Codevervollständigung anbieten zu können. Wer mehr über das breite Spektrum der Extensible Markup Language erfahren möchte, dem sei andieser Stelle die einschlägige iteratur zur Thematik Herz gelegt, da dieser Artikel lediglich die Grundlagen von XML streift und seinen Fokus auf die Verwendung mit PHP legt.
Regeln für wohlgeformte XML Dokumente:
- Das Wurzel-Element (Root) darf nur einmalig im Dokument vorkommen
- Tags werden stets kleingeschrieben und sind durch die Zeichen < > begrenzt
- Namen für Tags dürfen nur mit _ und Buchstaben beginnen, anschließend können Zahlen,
- Buchstaben, Punkte, Bindestriche und Unterstriche verwendet werden.
- Jedes geöffnete Tag muss geschlossen werden, Beispiel:
- Verschachtelte Tags müssen immer in der Reihenfolge geschlossen werden wie sie geöffnet werden
- Die Sondernotation für Elemente, die kein schließendes Tag benötigen, nennt sich leeres Tag und
- hat folgende Syntax:
- Werte für Attribute müssen durch Anführungszeichen eingeschlossen werden
Es existiert mittlerweile eine erhebliche Menge an XML Editoren, die um die Gunst der Nutzer buhlen. Im kommerziellen Umfeld ist der XMLSpy von Altova der absolute Platzhirsch. XMLSpy beherrscht sämtliche Disziplinen, die im Umgang mit XML notwendig sind, dafür müssen für die Anschaffung der Enterprise Version allerdings ca. 800€ eingeplant werden. Wer lieber auf Freeware zurückgreifen möchte, findet in Notepad++ einen sehr vielseitigen Editor. Verfechter von Microsoft können auf eine sehr gelungene Anwendung mit dem Namen XML Notepad zurückgreifen. Unter den IDE’s ist vor allem Eclipse zu nennen, das neben XML auch ein sehr leistungsstarkes PHP-Plugin bietet. Gerade die Tatsache, das PHP und XML mit ein und demselben Werkzeug bearbeitet werden ist maßgebend für einen flüssigen Arbeitsablauf.
Datenbank vs. XML
Sicherlich wird sich der ein oder andere Leser die Frage stellen, wieso die in der XML gespeicherten Daten nicht einfach in eine Datenbanktabelle ausgelagert werden. Die meisten Applikationen benötigen generell von Haus aus eine Datenbank zur Datenhaltung, also kann diese, die Aufgabe der Konfiguration mit übernehmen. Die Verwaltung komplexer Datenbanksysteme ist dank geeigneter Werkzeuge wie beispielsweise phpMyAdmin auch relativ gut beherrschbar. Da die typischen Verbindungsparameter wie Host und Datenbankname nicht in der Datenbank gespeichert werden können, müssen diese in der Anwendung vorgehalten werden. Um alle notwendigen Einstellungen nicht in der gesamten Applikation zu verstreuen, hat sich das DRY und COC Prinzip etabliert. Die mitgelieferten Installationsroutinen zum Deployen der Programme besitzen einen entscheidenden Nachteil.
Meist wird eine solches System auf einem lokalen Testsystem installiert und soll dann später per FTP auf den Webserver übertragen werden. Zu 99% aller Fälle beginnt nun das große Suchen nach den Einstellungen, die angepasst werden müssen, um die Applikation auf dem Webserver lauffähig zu bekommen. Selbst ein kompletter Database -Dump vom Testsystem auf Produktionsumgebung beherbergt stets die Gefahr falsche Konfigurationseinstellungen mit zu übertragen. Das Szenario lässt sich noch weiter steigern, mit der Annahme eines Datenbank Clusters und verschiedener Replikationsstrategien. Der Abschnitt XML und PHP zeigt in der Beispielanwendung wie zwischen Testumgebung und Produktionssystem unterschieden werden kann. Für kleinere Projekte, kann es durchaus sinnvoll sein komplett auf Datenbanken zu verzichten und die gesamte Datenhaltung über XML zu organisieren. Das erspart zum einen den Aufwand der Datenbankkonfiguration und vereinfacht das Backup der Datenhaltung. Eine simpler Link oder Terminverwaltung kann ohne Content Management System (CMS) auch problemlos vom Kunden gepflegt werden. Vorraussetzung ist, dass die Datenmenge gering ist und der Anwender ein geeignetes Maß an Erfahrung mitbringt. Unter Verwendung dieser Technologie lassen sich äußerst kostengünstig Projekte realisieren.
Sicherheitsaspekte
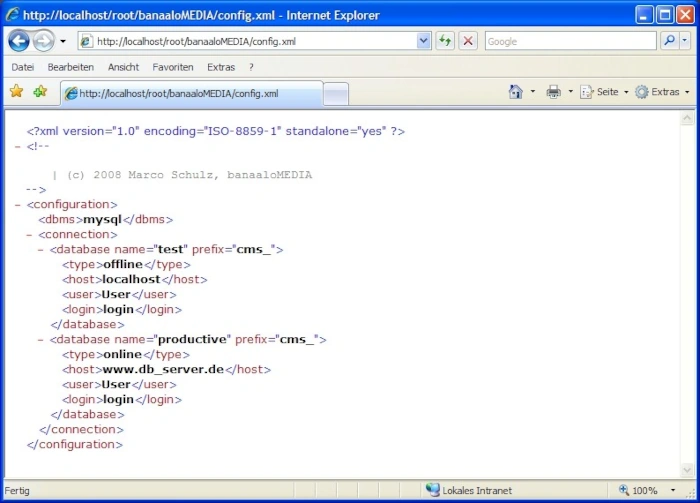
Da es sich bei XML um eine einfache Textdatei handelt, kann sie problemlos von Menschen gelesen und interpretiert werden. Wenn der Name und der Pfad zur Datei auf dem Server bekannt ist, wird beim Aufruf in aller Regel der Inhalt der Datei im Webbrowser angezeigt. Dieses Verhalten ist natürlich für unseren Fall äußerst problematisch, da in der Datei wichtige Daten hinterlegt sind, die nicht für Dritte bestimmt sind. Das Finden solcher Informationen kann durch unglückliche Dateinamen begünstigt werden, da mit sehr hoher Wahrscheinlichkeit bei einem Angriff zuerst config.xml im Root Verzeichnis des Webservers ausprobiert wird. Das Ergebnis einer solchen Abfrage ist im Screenshot_01 zu sehen.
Ein wirksamer Schutz besteht aus mehreren Schritten. Die Grundidee ist zuerst die config.xml gut zu verstecken. Damit das Versteck auch sicher ist, wird es mit einem simplen aber effektiven Zugriffsschutz verschlossen. Als Erstes wird ein Verzeichnis unterhalb des Root im Projekt mit dem Namen var angelegt. Dieses Verzeichnis darf nicht in der robots.txt mit auftauchen, damit würde man einem potenziellen Angreifer eine Wegbeschreibung in die Hand geben. Es besteht auch keine Gefahr für eine unbeabsichtigte Indizierung des Verzeichnisses durch eine Suchmaschine, da die nur den Links auf URL-Ebene folgen kann. Wer dennoch auf Nummer sicher gehen möchte, kann in var eine eigenständige robots.txt erstellen, die sämtliche Suchmaschinen aussperrt. Dazu genügen die folgenden Einträge:
User-agent: *
Disallow: *
Die beiden Zeilen gelten für alle Dateien und Verzeichnisse, die sich im selben Directory wie die robots.txt befindet. Die Indexierung wird allen Suchmaschinen untersagt. Wichtig ist das es außerhalb des geschützten Verzeichnisses, keinen Hinweis auf dessen Existenz vorhanden ist. Im zweiten Schritt wird eine index.php in var erzeugt. Der gewünschte Effekt ist, dass nun nicht mehr sämtliche Files des Verzeichnisses aufgelistet werden, sondern automatisch die index.php aufgerufen wird. Die Index -File kann leer bleiben oder einen redirect auf die Domain des eigenen Webauftritts haben.
$url = "Location: http://".$_SERVER['SERVER_NAME'];
header("HTTP/1.1 301 Moved Permanently");
header('$url');
header("Connection: close");Zu Beginn des Listings wird die Zieladresse festgelegt, die in unserem Fall automatisch die Server URL zugewiesen bekommt. Einige Provider haben ihre Webserver mit einem ähnlichen Verhalten konfiguriert. Der Provider 1 und 1 zeigt beispielsweise bei fehlendem Index eine leere Seite an. Die übrigen Funktionen steuern das HTTP Protokoll. Die Header – Funktion ist ein sehr mächtiges Werkzeug, das bei seiner Verwendung einige Sorgfalt erfordert. Nur wenige Operationen sind vor den Funktionen gestattet. Die Verwendung von echo gehört zu den beliebten Fehlern im Umgang mit header. Wer diese Maßnahmen beachtet, kann getrost seine Konfiguration in eine XML-Datei auslagern, ohne böse Überraschungen zu erleben.
XML und PHP
Ab der Version 5 ist die SimpleXML Extension Bestandteil von PHP und ermöglicht, damit eine sehr einfache Art und Weise XML Dateien zu verarbeiten. Zur Demonstration greife ich auf ein kleines Beispiel zurück, das die Datenbankkonfiguration aus einer XML-Datei ausliest und anschließend Werte von einer Datenbank ausgibt. Der Aufbau der Datenbank ist über das Listing database.sql ersichtlich, das auch gleich zum Anlegen der Datenbank verwendet werden kann.
CREATE TABLE IF NOT EXISTS links (
url char(255) NOT NULL,
category char(255) NOT NULL DEFAULT 'sonstige',
description TEXT
);Die Ausgabe des Listings config.xml ist im Screenshot_01 bereits zu sehen. Der Wurzelknoten ist als dessen Kind angefügt wurde. In dem Tag wird das verwendete Datenbankmanagmentsystem angegeben. Wegen der vielen möglichen Umgebungen in die eine PHP Applikation installiert werden kann besteht der Wunsch nach Flexibilität. Auf das Element wird üblicherweise ein Factory Pattern [8] angewendet, um die verwendete Datenbank problemlos ohne Quelltextänderungen austauschen zu können. Diese Option ist hier nur der Vollständigkeit erwähnt, da eine genauere Erläuterung den Rahmen des Artikels übersteigt.
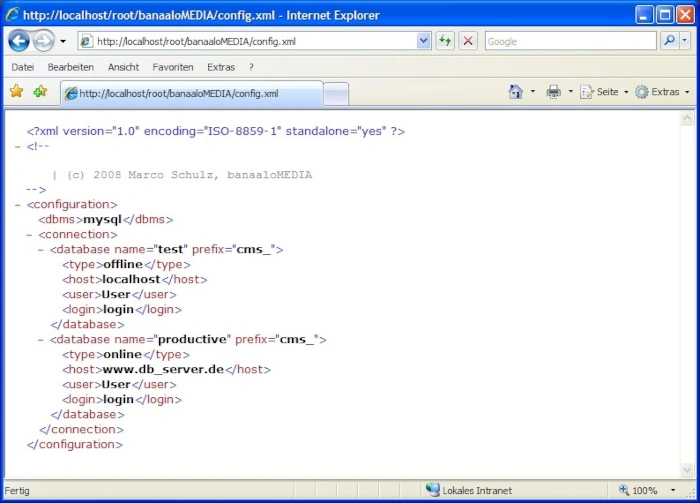
Spannend ist das folgende Tag . Hier werden zwei Verbindungen gespeichert. Die Überlegung ist, eine lokale (Testumgebung) und eine Server-Konfiguration (Produktionsumgebung) zu definieren. Das erspart bei der Übertragung der der Projektdateien zum Server eine vorherige Anpassung an die dort vorhandene Datenbank. Das Tag besitzt als Attribute name und prefix. Mit name ist der Datenbankname gemeint, während prefix eine „Vorsilbe“ der Tabellen definiert. Ein Präfix ist stets optional und gestattet eine mehrfache Installation der Anwendung in der gleichen Datenbank. Das ergibt sich aus der Forderung, das Tabellennamen stets eindeutig sein müssen und nicht mehrfach vergeben werden dürfen. Die Elemente Host, User und Login sind selbstsprechend. Type ist der Indikator, welcher uns verrät ob es sich um die Test- oder die Produktionsumgebung handelt. Eine spätere Abfrage der Variable $_SERVER['SERVER_NAME'] == “localhost”; stellt die Prüfbedingung für das Zielsystem. Soweit nur zur Vorbereitung.
Der erste Schritt besteht darin, die zu verarbeitende Datei zu öffnen. Dies geschieht mit der Anweisung: $config = simplexml_load_file(“config.xml”); in der die Variable $config steht nun der gesamte Inhalt aus config.xml zur Verfügung. Um dbms auslesen zu können, wird folgende Zeile benötigt: $dbms = $config->dbms; für den Fall das es mehrere Tag’s mit derselben Bezeichnung gibt kann der gestammte Inhalt sequentiell ausgelesen werden.
foreach ($config->connection->database as $xmlvars) {
$database = $xmlvars['prefix']." ".$xmlvars['name'];
$host = $xmlvars->host;
$user = $xmlvars->user;
$login = $xmlvars->login;
}Das Beispiel iteriert mit einer foreach Schleife über dem Kindelement , das sich unterhalb von befindet. In dem assoziativen Array $xmlvars, kann nun auf die einzelnen Element zugegriffen werden. Wie in Zeile 01 bereits zu erkennen ist, muss nicht zwangsläufig die gesamte XML Datei ab dem Root- Element verarbeitet werden, um ein Ergebnis zu erzielen. Die Bezeichnungen aus dem Beispiel leiten sich aus den Namen der XML-Elemente ab. In Zeile 02 wird demonstriert, wie Attribute eines Tags ausgelesen werden. In den Zeilen 03 bis 05 werden die Werte der Kindelemente , und den Entsprechenden Variablen zugewiesen. Würde man beabsichtigen in dieser Konstellation auf ein Attribut von zu zugreifen ist die korrekte Syntax: $hostAttribut = $xmlvars->host['attribut']. Wie man sieht, enthalten die wenigen Zeilen des Listings den Großteil des notwenigen Know-hows für den praktischen Einsatz. Die Logik für die Unterscheidung zwischen Webserver und lokaler Installation erweitert das vorangegangene Listing und ist zwischen die Zeile 01 und 02 einzufügen.
if($_SERVER['SERVER_NAME'] == "localhost" && $xmlvars->type == "offline") {
$database = $xmlvars ['name'];
$host = $xmlvars->host;
$user = $xmlvars->user;
$login = $xmlvars->login;
break;
}Die IF-Anweisung wird erst dann ausgeführt, wenn die Server-Variable den Wert localhost annimmt. Alternativ kann auch anstatt des Domainnamenes die IP-Adresse zur Identifizierung des Rechners herangezogen werden. Um den korrekten Datensatz an den ermittelten Server zu binden, wird eine zweite Prüfbedingung benötigt. In iesem Beispiel werden die korrekten Einstellungen über das Element erkannt. Sobald beide Kriterien erfüllt sind, können die Variablen ihre Werte aufnehmen. Die break Anweisung sorgt dafür, dass die foreach Schleife nach der Initialisierung verlassen wird. Das verhindert ein versehentliches überschreiben der Werte durch den nächsten Datensatz in einem weiteren Schleifendurchlauf. Das würde zwangsläufig passieren, da der nachfolgende Datensatz keiner Prüfbedingung standhalten muss. Wenn mehrere Server zu berücksichtigen sind, kann die IF–Anweisung um den ifelse Ausdruck erweitert werden. Selbstverständlich lässt sich das Konstrukt auch durch eine switch Kontrollstruktur abbilden. Eine Datenbankabfrage sowie die Ausgabe werden durch die üblichen Bordmittel von PHP realisiert. Die auf der Heft CD beigefügten Listings sind vollständig und zeigen, wie die gesamte Applikation arbeitet.
Der aufmerksame Leser erwartet, sicherlich an dieser Stelle geeignete Möglichkeiten in eine XML-Datei zu schreiben. Diese Erwartung muss leider enttäuscht werden, da die SimpleXML Extension keine Funktionen zum Schreiben von Dateien bereitstellt. Dies ist auch nicht notwendig, da die bereits in PHP vorhandenen Möglichkeiten völlig ausreichend sind. Dafür können in der Verarbeitungslogik Reguläre Ausdrücke, Stringoperationen und Sortieralgorithmen benutzt werden. Das Ergebnis wird dann über die fwrite Funktion in eine Datei geschrieben.
Resümee
Wie man sehen konnte, ist die Verarbeitung von XML Dateien mit PHP Mitteln recht unkompliziert und Erfolge werden schnell sichtbar. Der Artikel hat zudem einige Anreize für die Verwendungsmöglichkeiten aufgezeigt und Hinweise für Sicherheitsaspekte beschrieben. Dem regen praktischen Einsatz in Ihren eigenen Projekten steht nun nichts mehr im Wege.