Wer sein Git-Repository zur gemeinsamen Bearbeitung für Quelltexte benutzen möchte, benötigt einen Git-Server. Der Git Server ermöglicht die Kollaboration mehrere Entwickler auf der gleichen Codebasis. Die Installation des Git-Clients auf einem Linux Server ist zwar ein erster Schritt zur eigenen Serverlösung, aber bei Weitem nicht ausreichend. Um den Zugriff mehrere Personen auf ein Code Repository zu ermöglichen, benötigen wir eine Zugriffsberechtigung. Schließlich soll das Repository öffentlich über das Internet erreichbar sein. Wir möchten über die Benutzerverwaltung verhindern, dass unberechtigte Personen den Inhalt der Repositories lesen und verändern können.
Für den Betrieb eines Git-Servers gibt es viele hervorragende und komfortable Lösungen, die man einer nativen Serverlösung vorziehen sollte. Die Administration eines nativen Git Servers erfordert Linux Kenntnisse und wird ausschließlich über die Kommandozeile bewerkstelligt. Lösungen wie beispielsweise der SCM-Manager haben eine grafische Benutzeroberfläche und bringen viele nützliche Werkzeuge zur Administration des Servers mit. Diese Werkzeuge stehen bei einer nativen Installation nicht zur Verfügung.
Wieso sollte man nun Git als nativen Server installieren? Diese Frage lässt sich recht leicht beantworten. Der Grund ist wenn der Server, auf dem das Code Repository bereitgestellt werden soll, nur wenige Hardware-Ressourcen besitzt. Besonders der Arbeitsspeicher ist in diesem Zusammenhang immer ein wenig problematisch. Gerade bei angemieteten Virtuellen Private Servern (VPS) oder einem kleinen RaspberryPI ist das oft der Fall. Wir sehen also, es kann durchaus Sinn ergeben, einen nativen Git Server betreiben zu wollen.
Als Voraussetzung benötigen wir einen Linux-Server, auf dem wir den Git-Server installieren können. Das kann ein Debian oder Ubuntu Server sein. Wer CentOS oder andere Linux Distributionen verwendet, muss anstatt APT zur Softwareinstallation den Paketmanager seiner Distribution nutzen.
Wir beginnen im ersten Schritt mit der Aktualisierung der Pakete und der Installation des Git-Clients.
Als zweiten Schritt erstellen wir einen neuen Benutzer mit dem Namen git und legen für diesen ein eigenes home Verzeichnis an und aktivieren dort den SSH-Zugriff.
Nun können wir im dritten Schritt in dem neu angelegten home Verzeichnis des git Users unsere Git-Repositories erstellen. Diese unterscheiden sich gegenüber dem lokalen Arbeitsbereich darin, dass diese den Source Code nicht ausgecheckt haben.
Leider sind wir noch nicht ganz fertig mit unserem Vorhaben. Im vierten Schritt müssen wir die Benutzerberechtigung für das erstellte Repository setzen. Dies geschieht durch das Ablegen des öffentlichen Schlüssels auf dem Git Server für den SSH-Zugriff. Dazu kopieren wir den Inhalt aus der Datei unseres privaten Schlüssels in die Datei /home/git/.ssh/authorized_keys in eine eigene Zeile. Möchte man nun vorhandenen Nutzern den Zugriff verwehren, kommentiert man lediglich mit einem # die zeie des privaten Schlüssels wieder aus.
Wenn alles korrekt durchgeführt wurde, erhält man den Zugriff auf das Repository über folgenden Kommandozeilenbefehl: git clone ssh://git@<IP>/~/<repo>
Dabei ist <IP> durch die tatsächliche Server-IP zu ersetzen. Für unser Beispiel lautet der korrekte Pfad für <repo> project.git es ist also das von uns erstellte Verzeichnis für das Git-Repository.
Auf dem nativen Git Server können mehrere Repositories angelegt werden. Dabei gilt zu beachten, dass alle berechtigenden Nutzer auf alle so angelegenen Reposiories lesenden und schreibenden Zugriff haben. Das lässt sich nur dadurch einschränken, dass auf dem Linux-Server der unsere Git-Repositories bereitstellt, mehrere Benutzer auf dem Betriebssystem angelegt werden, denen dann die Repositories zugewiesen werden.
Wir sehen, dass eine native Git Server Installation zwar schnell umgesetzt werden kann, diese aber für die kommerzielle Softwareentwicklung nicht ausreichend ist. Wer gerne experimentiert, kann sich eine virtuelle Maschine erstellen und diesen Workshop darin ausprobieren.
Wieso benötigen wir überhaupt die Möglichkeit, Konfigurationen einer Anwendung in Textdateien zu speichern? Genügt nicht einfach eine Datenbank für diesen Zweck? Die Antwort auf diese Frage ist recht trivial. Denn die Information, wie sich eine Anwendung mit einer Datenbank verbinden kann, lässt sich ja schlecht in der Datenbank selbst speichern.
Jetzt könnte man sicher argumentieren, dass man solche Dinge mit einer integrierten Datenbank (embedded) wie beispielsweise SQLite hinbekommt. Das mag auch grundsätzlich korrekt sein. Leider ist diese Lösung für hoch skalierbare Anwendungen nicht wirklich praktikabel. Zudem muss man nicht immer gleich mit Kanonen auf Spatzen schießen. Das Speichern wichtiger Konfigurationsparameter in Textdateien hat bereits eine lange Tradition in der Softwareentwicklung. Mittlerweile haben sich aber auch verschiedene Textformate wie INI, XML, JSON und YAML für diesen Anwendungsfall etabliert. Angesichts dessen stellt sich die Frage, auf welches Format man am besten für das eigene Projekt zurückgreifen sollte.
INI Dateien
Eines der ältesten Formate sind die bekannten INI Dateien. Sie speichern Informationen nach dem Schlüssel = Wert Prinzip. Wenn ein Schlüssel in solch einer INI-Datei mehrfach vorkommt, wird der finale Wert immer durch den zuletzt in der Datei vorkommenden Wert überschrieben.
; Example of an INI File[Section-name]key=value ; inline text="text configuration with spaces and \' quotas"string='can be also like this'char=passwort# numbers & digetsnumber=123hexa=0x123octa=0123binary=0b1111float=123.12# boolean valuesvalue-1=truevalue-0=false
Wie wir in dem kleinen Beispiel sehen können, ist die Syntax in INI-Dateien sehr einfach gehalten. Der Sektionsname [section] dient vor allem der Gruppierung einzelner Parameter und verbessert die Lesbarkeit. Kommentare können entweder durch ; oder # gekennzeichnet werden. Ansonsten gibt es die Möglichkeit, verschiedene Text- und Zahlen-Formate, sowie Boolean-Wert zu definieren.
Web-Entwickler kennen INI Files vor allem von der PHP-Konfiguration, der php.ini in der wichtige Eigenschaften wie die Größe des Datei-Uploads festgelegt werden können. Auch unter Windows sind INI-Dateien noch immer verbreitet, obwohl seit Windows 95 für diesen Zweck die Registry eingeführt wurde.
Properties
Eine andere sehr bewährte Lösung sind sogenannte property Files. Besonders verbreitet ist diese Lösung in Java-Programmen, da Java bereits eine einfache Klasse mitbringt, die mit Properties umgehen kann. Das Format key=value ist den INI-Dateien entlehnt. Kommentare werden ebenfalls mit # eingeleitet.
Um in Java-Programmen beim Einlesen der .propreties auch die Typsicherheit zu gewährleisten, hat die Bibliothek TP-CORE eine erweiterte Implementierung. Trotz dass die Properties als Strings eingelesen werden, kann auf die Werte mittels Typisierung zugegriffen werden. Eine ausführliche Beschreibung, wie die Klasse PropertyReader verwendet werden kann, findet sich in der Dokumentation.
Auch im Maven Build Prozess können .property Dateien als Filter für Substitutionen genutzt werden. Selbstredend sind Properties nicht nur auf Maven und Java beschränkt. Auch in Sprachen wie Dart, nodeJS, Python und Ruby ist dieses Konzept nutzbar. Um eine größtmögliche Kompatibilität der Dateien zwischen den verschiedenen Sprachen zu gewährleisten, sollten exotische Optionen zur Notation vermieden werden.
XML
XML ist seit vielen Jahren auch eine weitverbreitete Option, Konfigurationen in einer Anwendung veränderlich zu speichern. Gegenüber INI und Property Dateien bietet XML mehr Flexibilität in der Definition der Daten. Ein sehr wichtiger Aspekt ist die Möglichkeit, fixe Strukturen durch eine Grammatik zu definieren. Dies erlaubt eine Validierung auch für sehr komplexe Daten. Dank der beiden Prüfmechanismen Wohlgeformtheit und Datenvalidierung gegen eine Grammatik lassen sich mögliche Konfigurationsfehler erheblich reduzieren.
Bekannte Einsatzszenarien für XML finden sich beispielsweise in Java Enterprise Projekten (J EE) mit der web.xml oder der Spring Framework und Hibernate Konfiguration. Die Mächtigkeit von XML gestattet sogar die Nutzung als Domain Specific Language (DSL), wie es bei dem Build-Werkzeug Apache Maven zum Einsatz kommt.
Dank vieler frei verfügbarer Bibliotheken existiert für nahezu jede Programmiersprache eine Implementierung, um XML-Dateien einzulesen und gezielt auf Daten zuzugreifen. Die bei Web-Entwicklern beliebte Sprache PHP hat zum Beispiel mit der Simple XML Erweiterung eine sehr einfache und intuitive Lösung, um mit XML umzugehen.
JavaScript Object Notation oder kurz JSON ist eine vergleichsweise neue Technik, obwohl diese mittlerweile auch schon einige Jahre existiert. Auch JSON hat für nahezu jede Programmiersprache eine entsprechende Implementierung. Das häufigste Einsatzszenario für JSON ist der Datentausch in Microservices. Der Grund liegt in der Kompaktheit von JSON. Gegenüber XML ist der zu übertragene Datenstrom in Webservices wie XML RPC oder SOAP mit JSON aufgrund der Notation wesentlich geringer.
Ein signifikanter Unterschied zwischen JSON und XML besteht aber auch im Bereich der Validierung. Grundsätzlich findet sich auf der offiziellen Homepage [1] zu JSON keine Möglichkeit, eine Grammatik wie in XML mit DTD oder Schema zu definieren. Auf GitHub existiert zwar ein Proposal zu einer JSON-Grammatik [2] hierzu fehlen aber entsprechende Implementierungen, um diese Technologie auch in Projekten einsetzen zu können.
Eine Weiterentwicklung zu JSON ist JSON5 [3], das bereits 2012 begonnen wurde und als Spezifikation in der Version 1.0.0 [4] seit dem Jahr 2018 offiziell veröffentlicht ist. Zweck dieser Entwicklung war es, die Lesbarkeit von JSON für Menschen erheblich zu verbessern. Hier wurden wichtige Funktionen, wie beispielsweise die Möglichkeit, Kommentare zu schreiben, hinzugefügt. JSON5 ist als Erweiterung vollständig zu JSON kompatibel. Um einen kurzen Eindruck zu JSON5 zu gewinnen, hier ein kleines Beispiel:
Viele moderne Anwendungen, wie zum Beispiel YAML, zur Konfiguration. Die sehr kompakte Notation erinnert stark an die Programmiersprache Python. Aktuell ist YAML in der Version 1.2 veröffentlicht.
Der Vorteil von YAML gegenüber anderen Spezifikationen ist die extreme Kompaktheit. Gleichzeitig besitzt die Version 1.2 eine Grammatik zu Validierung. Trotz der Kompaktheit liegt der Fokus von YAML 1.2 in einer guten Lesbarkeit für Maschinen als auch Menschen. Ob YAML dieses Ziel erreicht hat, überlasse ich jedem selbst zu entscheiden. Auf der offiziellen Homepage findet man alle Ressourcen, die für eine Verwendung im eigenen Projekt benötigt werden. Dazu zählt auch eine Übersicht zu den vorhandenen Implementierungen. Das Design der YAML Homepage gibt auch schon einen guten Vorgeschmack auf die Übersichtlichkeit von YAML Dateien. Anbei noch ein sehr kompaktes Beispiel einer Prometheus Konfiguration in YAML:
global:scrape_interval:15sevaluation_interval:15srule_files:# - "first.rules" # - "second.rules"#IP: 127.0.0.1scrape_configs:-job_name:prometheusstatic_configs:-targets:['127.0.0.1:8080']# SPRING BOOT WEB APP-job_name:spring-boot-samplescrape_interval:60sscrape_timeout:50sscheme:"http"metrics_path:'/actuator/prometheus'static_configs:-targets:['127.0.0.1:8888']tls_config:insecure_skip_verify:true
Resümee
Alle hier vorgestellten Techniken sind im praktischen Einsatz in vielen Projekten erprobt. Sicher mag es für spezielle Anwendungen wie REST Services einige Präferenzen geben. Für meinen persönlichen Geschmack bevorzuge ich für Konfigurationsdateien das XML Format. Dies ist leicht im Programm zu verarbeiten, extrem flexibel und bei geschickter Modellierung auch kompakt und hervorragend für Menschen lesbar.
Die meisten DevOps-Teams sind überzeugt, dass die Automatisierung selbst und die Automatisierung selbst eine große Herausforderung darstellt. Es scheint dringend notwendig zu sein, alles zu automatisieren – sogar die Automatisierung selbst. Dies ist für die meisten DevOps-Teams ein allgemeines Verständnis und somit Motivation. Werfen wir einen Blick auf typische, kontinuierliche Dummheiten bei der Transformation vom reinen Konfigurationsmanagement zum DevOps-Engineer.
Die meisten DevOps-Teams sind davon überzeugt, dass die Automatisierung selbst und die Automatisierung selbst eine große Herausforderung darstellt. Es scheint dringend notwendig zu sein, alles zu automatisieren – sogar die Automatisierung selbst. Dies ist für die meisten DevOps-Teams ein allgemeines Verständnis und somit Motivation. Werfen wir einen Blick auf typische, kontinuierliche Dummheiten bei der Transformation vom reinen Konfigurationsmanagement zum DevOps-Engineer.
Build-Logik kann eine fehlerhafte Architektur nicht reparieren. Zahlreiche SCM-Zusammenführungskonflikte entstehen durch die fehlende Kapselung der Geschäftslogik. Bei Funktionen, die über viele Module oder Dienste verteilt sind, ist die Wahrscheinlichkeit hoch, dass eine Datei von mehreren Entwicklern bearbeitet wird.
Die Notwendigkeit orchestrierter Builds deutet auf Architekturprobleme hin. Transitive Abhängigkeiten, fehlende Kapselung und eine umfangreiche Abhängigkeitskette sind typische Gründe für das Henne-Ei-Problem. Entwerfen Sie Ihre Artefakte so unabhängig wie möglich.
Build-Logik wird von Entwicklern und nicht von Administratoren entwickelt. Personen mit Fokus auf den Betrieb haben andere Konzepte zur Pflege von Artefakt-Builds als Softwareentwickler. Ein gutes Beispiel für eine Anti-Pattern-Build-Struktur sind webMethods der Software AG. webMethods bietet keinen Repository-Server wie Sonatype Nexus zum Teilen von Abhängigkeiten. Der Build verweist immer auf die Abhängigkeiten innerhalb einer webMethods-Installation. Diese Vorgehensweise verstößt gegen die Grundidee der Build-Automatisierung, die im Buch „Praktiken eines agilen Entwicklers“ von 2006 beschrieben wird.
Nicht alles auf einmal. Teilen Sie die Build-Jobs in konkrete Ziele auf, wie z. B. Artefakt erstellen, Abnahmetests durchführen, API-Dokumentation erstellen und Berichte generieren. Wenn einer der letzten Schritte fehlschlägt, müssen Sie nicht alles wiederholen. Die Ausführungszeit des Builds wird drastisch reduziert, und die Build-Infrastruktur lässt sich leichter warten.
Geben Sie Ihrer Build-Infrastruktur nicht zu viel Flexibilität. Dieser Punkt hängt eng mit dem ersten Thema zusammen, das ich erläutert habe. Ein undisziplinierter Build-Manager erstellt extrem komplexe Skripte, die niemand versteht. Der JavaScript-Task-Runner Grunt ist ein Beispiel dafür, wie eine Build-Logik unübersichtlich und unleserlich werden kann. Dies ist einer der Gründe, warum ich mich für Maven als Build-Tool für Java-Projekte entscheide, da es die Steuerung verständlicher Builds ermöglicht.
Es besteht keine Notwendigkeit, die Automatisierung zu automatisieren. Komplexe Automatisierungsstufen verursachen per Definition höhere Kosten als einfache Aufgaben. Überlegen Sie sich immer vorher, welchen Nutzen Ihre Automatisierungsaktivitäten bringen, um zu prüfen, ob es sich lohnt, Zeit und Geld dafür aufzuwenden.
Wir tun, was wir können, aber können wir auch, was wir tun? Oder mit den Worten von Gardy Bloch: „A fool with a tool is still a fool.“ Verstehen Sie die Anforderungen Ihres Projekts und entscheiden Sie auf dieser Grundlage, welches Tool Sie wählen. Wenn Ihnen die Ressourcen fehlen, kann Sie selbst die professionellste Lösung nicht unterstützen. Wenn Sie Ihr Problem verstanden haben, können Sie neue, professionelle und fortgeschrittene Prozesse erlernen.
Die Build-Logik wurde zunächst in der lokalen Entwicklungsumgebung ausgeführt. Wenn Ihr Build nicht auf Ihrem lokalen Entwicklungsrechner läuft, nennen Sie es nicht Build-Logik. Es ist nur ein Hack. Die Build-Logik muss plattform- und IDE-unabhängig sein.
Vermischen Sie Quellcode-Repositories nicht. mit anderen Dateien Die Organisation der Quellen in mehreren Ordnern innerhalb eines riesigen Verzeichnisses führt zu einem komplexen Build ohne jegliche Flexibilität. Quellen sollten nach Technologie oder separaten, unabhängigen Modulen strukturiert sein.
Viele der genannten Punkte lassen sich anhand der aktuellen Situation in fast jedem Projekt nachvollziehen. Die Lösung für eine erfolgreiche Problembehebung ist meist nicht allzu kompliziert. Sie erfordert lediglich ein wenig Aufmerksamkeit und gute Planung. Mein wichtigster Ratschlag ist das KISS-Prinzip (Keep it simple, stupid). Das bedeutet, den Standardprozess so weit wie möglich unverändert zu übernehmen. Man muss das Rad nicht neu erfinden. Es gibt Gründe, warum ein Standard zum Standard wird. Hier ist ein kurzer Plan, dem Sie folgen können:
Erstens: Verstehen Sie das Problem.
Zweitens: Suchen Sie nach einer Standardlösung für den Prozess.
Drittens: Entwickeln Sie einen Plan zur Integration der Lösung in die bestehende Prozesslandschaft. Dies bedeutet, Tools zu entfernen, die Standardprozesse nicht unterstützen.
Wenn Sie Ihren eigenen Weg Schritt für Schritt gehen, ohne zu weit zu springen, können Sie schnell positive Ergebnisse erzielen.
Übrigens: Wenn Sie Unterstützung für einen erfolgreichen DevOps-Prozess benötigen, kontaktieren Sie mich gerne. Ich biete praktische Beratung und Schulungen zum Aufbau eines leistungsstarken DevOps-Teams an.
Auch wenn es früher Konfigurationsmanagement hieß, bedeutet das nicht, dass die alten Probleme mit dem schönen neuen Namen DevOps beseitigt wurden. Durch die zunehmende Komplexität der Projekte und die Unkenntnis der Tools erreichen die heutigen Strategien und Arbeitsabläufe, die von den Entwicklungsteams erwartet werden, erst eine neue Qualität.
Viele DevOps-Teams verfolgen den Ansatz, alle möglichen Arbeitsschritte zu automatisieren. Das geht sogar so weit, dass sie versuchen, die Automatisierung selbst zu automatisieren. Daran wäre prinzipiell nichts auszusetzen, wenn die Lösung dann auch den Entwicklungsteams helfen würde, ihre täglichen Aufgaben effizient abzuarbeiten. Leider sind viele der Lösungen, die ich in den letzten Jahren in meinem Berufsleben kennen gelernt habe, weit davon entfernt. Vielmehr schaffen sie Entwicklungsumgebungen, die die tägliche Arbeit erschweren, anstatt sie zu vereinfachen. Schauen wir uns also gemeinsam an, welche gravierenden Auswirkungen unbedacht getroffene Entscheidungen auf den späteren Erfolg eines Projekts haben. Natürlich werden wir auch das eine oder andere Highlight aus der Entwicklung finden, das dem Unternehmen mehr als nur ein wenig Kopfzerbrechen bereitet.
Moderne Softwareentwicklung besteht aus viel mehr als nur aus Code und Kaffee. Ohne passende Deployment-Strategien und eine saubere Release-Verwaltung laufen selbst kleine Projekte schnell aus dem Ruder und werden unbeherrschbar.
Dieses Praxisbuch zeigt Ihnen, wie Sie mit Jenkins, Git und Nexus eine CI-Pipeline aufbauen. Erfahren Sie direkt aus der Praxis, was für erfolgreiche Software-Projekte essenziell ist: Source Control Management, flächendeckende Softwaretests mit einer sinnvollen Qualitätskontrolle und ein gut organisiertes Deployment. Marco Schulz gibt Ihnen seine Erfahrung aus zahlreichen internationalen IT-Projekten weiter und hält eine Menge Tipps und Überlegungen zu gutem Software Engineering für Sie parat.
Marco Schulz, 2021, 400 Seiten, Rheinwerk Computing, ISBN 978-3-8362-7834-8
The Big Picture DevOps, Continuous Deployment, Build Jobs, Pipelines … ist all das wirklich nötig, wenn es nur um ein paar Zeilen Java-Code geht? Marco Schulz zeigt Ihnen, welche Vorteile moderne Entwicklungsparadigmen bieten, wie Sie Open-Source-Werkzeuge zu einer effektiven Toolchain zusammenfügen und damit Ihre Software professionell und zeitgemäß verwalten.
Professionelle Code-Verwaltung Programmieren wäre viel einfacher, wenn Sie sich um den bestehenden Code keine Gedanken machen müssten. Da die Integration neuer Funktionen aber eine Standardaufgabe in der Software-Entwicklung ist, dreht sich hier alles um Merging-Konflikte, die Vergabe von sinnvollen Release-Nummern und das Schreiben von Unit- und Integrationstests. So behalten Sie den Überblick und arbeiten effektiv und agil im Team.
Toolchains für moderne Software-Projekte Jenkins ist das wichtigste Werkzeug, wenn es um komfortable CI-Pipelines und automatisierte Builds geht. In diesem Praxisbuch finden Sie aber noch viel mehr: Git, Maven, Nexus, SonarQube und viele andere Tools helfen Ihnen bei der Verwaltung Ihrer Codebasis.
Errata: Auch wenn die Erstellung des Buches mit viel Sorgfalt durchgeführt wurde, kommt es durchaus vor, das sich Fehler einschleichen. Dank hilfreicher Hinweise von aufmerksamen Lesern finden Sie an dieser Stelle Korrekturen.
Seite 32: Literaturliste
[2.1] Gene Kim, The Unicorn Project, 2019, IT Revolution Press, ISBN: 978-1942788768
[2.2] Gene Kim, The Phoenix Project, 2013, IT Revolution Press, ISBN: 978-0-9882625-7-7
Linux entwickelt sich mehr und mehr zu einem beliebten Betriebssystem für IT-Profis. Einer der Gründe für diese Entwicklung sind die Serverlösungen. Stabilität und geringer Ressourcenverbrauch sind einige der wichtigsten Eigenschaften für diese Wahl. Wer schon einmal mit einem Microsoft Server herumgespielt hat, wird den grafischen Desktop bei einem Linux Server vermissen. Nach dem Einloggen in einen Linux Server siht man nur die Kommandozeile, die auf Eingaben wartet.
In diesem kurzen Artikel stelle ich einige hilfreiche Linux-Programme zur Umgang mit Text Dateien auf der Kommandozeile vor. Auf diese Weise lassen sich leicht Informationen sammeln, zum Beispiel aus Protokolldateien (Logfiles). Bevor ich beginne, möchte ich noch einen einfachen und leistungsfähigen Editor namens joe empfehlen.
Strg + C – Abbrechen der aktuellen Bearbeitung einer Datei ohne Speichern der Änderungen Strg + KX – Beenden der aktuellen Bearbeitung und Speichern der Datei Strg + KF – Text in der aktuellen Datei suchen Strg + V – Einfügen der Zwischenablage in das Dokument (CMD + V für Mac) Strg + Y – Aktuelle Zeile an der Cursorposition löschen
Um joe auf einer Debian-basierten Linux-Distribution zu installieren, müssen Sie nur folgendes eingeben:
1. Wenn Sie Inhalte in einer großen Textdatei finden müssen, ist GREP Ihr bester Freund. Mit GREP können Sie nach Textmustern (Pattern) in Dateien suchen.
README Dateien haben in Softwareprojekten eine lange Tradition. Diese ursprünglich reinen Textdateien enthielten Lizenzinformationen und Anweisungen wie aus dem Quellcode das entsprechende Artefakt kompiliert werden konnte oder aber wichtige Hinweise zu Installation des Programms. Es gibt keinen wirklichen Standard, wie man eine solche README Datei aufbauen sollte.
Seit dem GitHub (2018 von Microsoft übernommen) als kostenfreie Code Hosting Plattform für Open Source Projekte seinen Siegeszug angetreten ist, gab es schon recht früh die Funktion, dass die README Datei als Startseite des Repositories anzuzeigen. Dazu muss lediglich eine einfache Textdatei mit der Bezeichnung README.md im Hauptverzeichnis des Repository erstellt werden.
Um die README Dateien übersichtlicher strukturieren zu können, wurde eine Möglichkeit für eine einfache Formatierung gesucht. Schnell hatte man sich für die markdown Notation entschieden, da diese einfach zu nutzen ist und auch recht performant gerendert werden kann. Somit sind die Übersichtsseiten besser für Menschen zu lesen und können als Projektdokumentation genutzt werden.
Es ist möglich, mehrere solcher markdown Dateien als Projektdokumentation miteinander zu verknüpfen. Somit erhält man eine Art Mini WIKI das im Projekt enthalten ist und außerdem auch über Git versioniert wird.
Das Ganze wurde so erfolgreich, das Selfhosting-Lösungen wie GitLab oder das kommerzielle BitBucket diese Funktion ebenfalls übernommen haben.
Nun stellt sich aber die Frage welche Inhalte man am besten in solch eine README Datei schreibt, damit diese für Außenstehende auch einen wirklichen Mehrwert darstellen. Dabei haben sich im Laufe der Zeit folgende Punkte etabliert:
Kurzbeschreibung des Projekts
Bedingungen, unter denen der Quellcode verwendet werden darf (Lizenz)
Wie ist das Projekt zu verwenden (z.B. Anweisungen zum Compilieren oder wie wird die Bibliothek in eigene Projekte eingebunden)
Wer sind die Autoren des Projekts und wie kann man sie erreichen
Was ist zu tun wenn man das Projekt unterstützen möchte
Mittlerweile sind sogenannte Badges (Sticker) sehr populär. Diese referenzieren oft auf externe Dienste, wie beispielsweise der freie Continuous Integration Server TravisCI. Diese helfen Ausstehenden, die Qualität des Projekts zu beurteilen.
Auf GitHub gibt es auch diverse Vorlagen für README Dateien. Man muss allerdings auch ein wenig auf die tatsächlichen Gegebenheiten des eigenen Projekts schauen und beurteilen, welche Informationen für Nutzer bzw. Anwender wirklich relevant sind. Solche Vorlagen helfen aber sehr dabei, herauszufinden, ob man möglicherweise einen Punkt übersehen hat.
Da mittlerweile ziemlich jeder Hersteller von Source Control Management Serverlösungen die Funktion die README.md Datei als Projektstartseite für das Code Repository anzuzeigen integriert hat, bedeutet das eine README.me auch für kommerzielle Projekte eine sinnvolle Sache sind.
Auch wenn die Syntax für markdown leicht zu erlernen ist, kann es bei umfangreichen Editierungen solcher Dateien durchaus komfortabler sein, direkt einen MARKDOWN Editor zu nutzen. Dabei sollte man darauf achten, dass die Vorschau auch korrekt dargestellt wird und nicht nur ein einfaches Syntaxhighligting angeboten wird.
Auf alle Fälle lohnt sich ein Blick auf die GitHub Seite https://www.readme-templates.com zu werfen. Weitere Ressourcen zum Thema finden sich hier:
Microsoft hat beispielsweise seit der Einführung von Windows 10 seinen Nutzern ein Update-Zwang auferlegt. Grundsätzlich war die Idee durchaus begründet. Denn ungepatchte Betriebssysteme ermöglichen Hackern leichten Zugriff. Also hat sich vor sehr langer Zeit der Gedanke: ‚Latest is greatest‘ durchgesetzt.
Windows-Nutzer habe hier wenig Freiräume. Aber auch auf mobilen Geräten wie Smartphones und Tabletts sind in der Werkseinstellung die automatischen Updates aktiviert. Wer auf GitHub ein Open Source Projekt hostet, bekommt regelmäßige E-Mails, um für verwendete Bibliotheken neue Versionen einzusetzen. Also auf den ersten Blick durchaus eine gute Sache. Wenn man sich mit der Thematik etwas tiefer auseinandersetzt, kommt man rasch zu dem Schluss, dass latest nicht wirklich immer das Beste ist.
Das bekannteste Beispiel hierfür ist Windows 10 und die durch Microsoft erzwungenen Update Zyklen. Dass Systeme regelmäßig auf Sicherheitsprobleme untersucht und verfügbare Aktualisierungen eingespielt werden müssen, ist unumstritten. Dass die Pflege von Rechnersysteme auch Zeit in Anspruch nimmt, ist ebenfalls einsichtig. Problematisch ist es, aber wenn durch den Hersteller eingespielte Aktualisierungen einerseits das gesamte System lahmlegen und so eine Neuinstallation notwendig wird, weil das Update nicht ausreichend getestet wurde. Aber auch im Rahmen von Sicherheitsaktualisierungen ungefragt Funktionsänderungen beim Nutzer einzubringen, halte ich für unzumutbar. Speziell bei Windows kommt noch hinzu, dass hier einiges an Zusatzprogrammen installiert ist, die durch mangelnde Weiterentwicklung schnell zu einem Sicherheitsrisiko werden können. Das bedeutet bei aller Konsequenz erzwungene Windowsupdates machen ein Computer nicht sicher, da hier die zusätzlich installierte Software nicht auf Schwachstellen untersucht wird.
Wenn wir einen Blick auf Android-Systeme werfen, gestaltet sich die Situation weitaus besser. Aber auch hier gibt es genügend Kritikpunkte. Zwar werden die Applikationen regelmäßig aktualisiert, so dass tatsächlich die Sicherheit markant verbessert wird. Aber auch bei Android bedeutet jedes Update in aller Regel auch funktionale Veränderungen. Ein einfaches Beispiel ist der sehr beliebte Dienst Google StreetMaps. Mit jedem Update wird die Kartennutzung für mich gefühlt unübersichtlicher, da eine Menge für mich unerwünschter Zusatzinformationen eingeblendet werden, die den bereits begrenzten Bildschirm erheblich verkleinern.
Als Nutzer ist es mir glücklicherweise bisher nicht passiert, dass Applikationsupdates unter Android das gesamte Telefon lahmgelegt haben. Was also auch beweist, dass es durchaus möglich ist, Aktualisierungen ausgiebig zu testen, bevor diese an die Nutzer ausgerollt werden. Was aber nicht heißt, dass jedes Update unproblematisch war. Probleme, die hier regelmäßig beobachtet werden können, sind Dinge wie ein übermäßig erhöhter Batterieverbrauch.
Reine Android Systemupdates wiederum sorgen regelmäßig dafür, dass die Hardware nach knapp zwei Jahren so langsam wird, dass man sich oft dazu entscheidet, ein neues Smartphone zu kaufen. Obwohl das alte Telefon noch in gutem Zustand ist und durchaus viel länger genutzt werden könnte. So ist mir bei vielen erfahrenen Nutzern aufgefallen, dass diese nach circa einem Jahr ihre Android-Updates ausschalten, bevor das Telefon durch den Hersteller in die Obsoleszenz geschickt wird.
Wie bekommt man ein Update-Muffel nun dazu, seine Systeme trotzdem aktuell und damit auch sicher zu halten? Mein Ansatz als Entwickler und Konfigurationsmanager ist hier recht einfach. Ich unterscheide zwischen Feature Update und Security Patch. Wenn man im Release Prozess dem Semantic Versioning folgt und für SCM Systeme wie Git ein Branch by Release Modell nutzt, lässt sich eine solche Unterscheidung durchaus leicht umsetzen.
Aber auch der Fragestellung einer versionierbaren Konfigurationseinstellung für Softwareanwendungen habe ich mich gewidmet. Hierzu gibt es im Projekt TP-CORE auf GitHub eine Referenzimplementierung, die in dem zweiteiligen Artikel ‘Treasue Chest’ ausführlich beschrieben wird. Denn es muss uns schon klar sein, dass wenn wir bei einem Update die gesamte vom Nutzer vorgenommene Konfiguration auf Werkseinstellung zurücksetzen, wie es recht oft bei Windows 10 der Fall ist, können ganz eigene Sicherheitslücken entstehen.
Das bringt uns auch zu dem Punkt Programmierung und wie GitHub Entwickler durch E-Mails dazu motiviert, neue Versionen der verwendeten Bibliotheken in ihre Applikationen einzubinden. Denn, wenn es sich bei einem solchen Update um eine umfangreiche API-Änderung handelt, ist das Problem der hohe Migrationsaufwand für die Entwickler. Hier hat sich für mich eine ebenfalls recht einfache Strategie bewährt. Anstatt mich von den Benachrichtigungen über Aktualisierungen von GitHub beeindrucken zu lassen, prüfe ich regelmäßig über OWASP, ob meine Bibliotheken bekannte Risiken enthalten. Denn wird durch OWASP ein Problem erkannt, spielt es keine Rolle, wie aufwendig eine Aktualisierung werden kann. Das Update und eine damit verbundene Migration muss zeitnahe umgesetzt werden. Dies gilt dann auch für alle noch in Produktion befindlichen Releases.
Um von Beginn an der Update Hölle zu entrinnen, gilt allerdings eine Faustegel: Installiere beziehungsweise nutze nur das, was du wirklich benötigst. Je weniger Programme unter Windows installiert sind und je weniger Apps auf dem Smartphone vorhanden sind, umso weniger Sicherheitsrisiken entstehen. Das gilt auch für Programmbibliotheken. Weniger ist aus Sicht der Security mehr. Abgesehen davon bekommen wir durch den Verzicht unnötiger Programme noch eine Performance Verbesserung frei Haus.
Sicher ist für viele private Anwender die Frage der Systemaktualisierung kaum relevant. Lediglich neue unerwünschte Funktionen in vorhandenen Programme, Leistungsverschlechterungen oder hin und wieder zerschossene Betriebssysteme verursache mehr oder weniger starken Unmut. Im kommerziellen Umfeld können recht schnell erhebliche Kosten entstehen, die sich auch auf die gerade umzusetzenden Projekte negativ auswirken können. Unternehmen und Personen, die Software entwickeln können die Nutzerzufriedenheit erheblich verbessern, wenn sie bei Ihren Release Veröffentlichungen zwischen Security Patches und Feature Updates unterscheiden. Und ein Feature Update sollte dann entsprechend auch allen bekannten Security Aktualisierungen enthalten.
DevOps4Agile – Prozesse verstehen und richtig anwenden
Jeder redet von Digitaler Transformation, Agilität und natürlich auch DevOps. Leider klappt die Integration moderner Paradigmen in2023-IT-Tage-FFM_DevOps4Agile Unternehmen nur sehr schwer. Ein Punkt der eine wichtige Rolle bei Transformationen spielt sind Prozesse. Oft fehlt ein richtiges Verständnis wie man von der abstrakten Beschreibung zu einer leichtgewichtigen Umsetzung im Unternehmen kommt. Nicht die Werkzeuge stehen in diesem Vortag im Vordergrund, sondern der Weg von der Planung zu einer konkreten Umsetzung, die offen für künftige Anpassungen ist.
Sämtlich in einem Unternehmen aufgestellten Regeln und durchgeführten Aktivitäten stellen Prozesse dar. Deswegen kann auch pauschal gesagt werden, das die Summe der Prozesse eine Organisation beschreibt. Leider sind manchmal die Prozesse so kompliziert gestaltet, das diese sich negativ auf das Unternehmen auswirken. Was kann also getan werden um die Situation zu verbessern?
(c) 2022 Marco Schulz, JAVA aktuell Ausgabe 6
Laut ISO 900 Definition ist ein Prozess, ein Satz von in Wechselbeziehung stehenden Tätigkeiten. der Eingaben in Ergebnisse umwandelt. Dabei spielt es keine Rolle, ob der Prozess atomar ist, also nicht weiter zerlegt werden kann oder aus mehreren Prozessen zusammengesetzt wurde. An dieser Stelle ist es wichtig auch kurz auf einige Begriffe einzugehen.
Choreographie: beschreibt einzelne Operationen, aber nicht die Nachrichtenreihenfolge (Ablauf). Es behandelt die etablierte Kommunikation zwischen zwei Teilnehmern.
Orchestration: beschreibt die Reihenfolge und Bedingungen der aufrufenden Teilprozesse.
Konversation: beschreibt die Abfolgen zwischen Prozessen. Es wird die gesamte zulässige Kommunikation (Vollständigkeit) zwischen zwei Teilnehmern beschrieben.
Die aufgeführten Begrifflichkeiten spielen für die Beschreibung von Prozessen eine wichtige Rolle. Wenn sie beispielsweise die Idee haben die für Ihr Unternehmen wichtigen Geschäftsprozesse in einem Prozessbrowser visualisiert darzustellen, müssen Sie sich bereits im Vorfeld über die Detailtiefe der bereitgestellten Informationen im Klaren sein. Sollten Sie die Absicht hegen möglichst alle Informationen in so einem Schaubild einzubringen, werden Sie schnell feststellen wie sehr die Übersichtlichkeit darunter leidet. Wählen Sie daher immer für die benötigte Anwendung die geeignete Darstellung aus.
Ansichtssachen
Hier kommen wir auch schon zur nächsten Fragestellung. Was sind geeignete Mittel um Prozesse verständlich darzustellen. Aus persönlicher Erfahrung hat sich in meinen Projekten ein Darstellung über den Informationsfluss gut bewährt. Dazu wiederum nutze ich die Business Process Model Notation, kurz BPMN die für solche Zwecke geschaffen wurde. Ein frei verfügbares Werkzeug um BPMN Prozesse aufzuzeichnen ist der BigAzi Modeler [1]. Die Möglichkeit aus BPMN Diagrammen wiederum softwaregestützte Programme mittels serviceorientierter Architekturen (SOA) zu erzeugen ist für ein Großteil der Unternehmen weniger nutzbringend und nicht so einfach umzusetzen wie es auf den ersten Blick scheint. Viel wichtiger bei einer Umsetzung zur grafischen Darstellung interner Unternehmensprozesse sind die so zu tage geförderten versteckten Erkenntnisse über mögliche Verbesserungen.
Besonders Unternehmen, die eine eigenständige Softwareentwicklung betreiben und die dort angewendeten Vorgehensweisen, möglichst in einem hohen Grade automatisieren wollen, können den Schritt zur Visualisierung interner Strukturen selten auslassen. Die hier viel zitierten Stichwörter Continuous Integration, Continuous Delivery und DevOps haben eine sehr hohe Automatisierungsstufe zum Ziel. Um in diesem Bereich erfolgreiche Ergebnisse erreichen zu können, ist es unumgänglich möglichst einfache und standardisierte Prozesse etabliert zu haben. Das beschreibt auch das Paradoxon der Automatisierung.
Prozessautomation reduziert das Risiko, dass Fehler gemacht werden. Aber hochkomplexe Prozesse sind naturgemäß nur sehr schwer zu automatisieren!
Wenn Sie den Entschluss gefasst haben die hauseigenen Geschäftsprozesse zu optimieren benötigen Sie selbstredend zuerst eine realistische Analyse des aktuellen IST – Zustands um daraus den gewünschten SOLL – Zustand zu beschreib
Abbildung 1: Die Transformation von der Ausgangssituation hin zu Zielstellung.
Es wäre an dieser Stelle nicht sehr hilfreich verschiedene Vorgehnsmodelle zu beschreiben, wie eine solche Transformation von statten gehen kann. Solche Vorhaben sind stets sehr individuell und den tatsächlichen Gegebenheiten im Unternehmen geschuldet. Hier sei Ihnen nur ein wichtiger Ratschlag mit auf den Weg gegeben. Gehen Sie kleine einfache Schritte und vermeiden Sie es möglichst alles auf einmal umsetzen zu wollen. Manchmal entdecken Sie während einer Umstellung wichtige Details die angepasst werden müssen. Das gelingt Ihnen gefahrlos wenn Sie genügend Reserven eingeplant haben. Sie sehen auch hier spiegeln sich agile Gedanken wieder, die Ihnen die Möglichkeit geben direkt auf Veränderungen einzugehen.
Richten Sie Ihr Augenmerk vor allem auf den zu erreichenden Sollzustand. Im Großen und Ganzen wird zwischen zwei Prozesstypen unterschieden. Autonome Prozesse laufen im Idealfall vollständig automatisiert ab und erfordern keinerlei manuelles Eingreifen. Dem gegenüber stehen die interaktiven Prozess, welche an ein oder mehreren Stellen auf eine manuelle Eingabe warten um weiter ausgeführt werden zu können. Ein sehr oft angestrebtes Ziel für den SOLL – Zustand der Prozesslandschaften sind möglichst kompakte und robuste autonome Prozesse um den Automatisierungsgrad zu verbessern. Folgende Punkte helfen Ihnen dabei das gesteckte Ziel zu erreichen:
Definieren Sie möglichst atomare Prozesse, die ausschließlich einen einzigen Vorgang oder einen Teilaspekt eines Vorgangs beschreiben.
Halten Sie die Prozessbeschreibung möglichst sehr einfach und orientieren Sie sich dabei an vorhanden Standards und suchen Sie nicht nach eigenen individuellen Lösungen.
Vermeiden Sie so gut es möglichst jegliche manuelle Interaktion.
Wägen Sie bei Ausnahmen sehr kritisch ab, wie oft diese tatsächlich auftreten und suchen Sie nach möglichen Lösungen diese Ausnahmen mit dem Standartvorgehen abarbeiten zu können.
Setzen Sie komplexe Prozessmodelle ausschließlich aus bereits vollständig beschriebenen atomaren Teilprozessen zusammen.
Sicher stellen Sie sich die Frage, was es mit meinem Hinweis auf die Verwendung von etablierten Standards auf sich hat. Viele der in einem Unternehmen auftretenden Probleme wurden meist bereist umfangreich und bewährt gelöst. Nicht nur aus Zeit und Kostengründen sollte bei der Verfügbarkeit bereits etablierter Vorgehensmodelle kein eigenes Süppchen gekocht werden. So erschweren Sie zum einem den Wissenstransfer zwischen Ihren Mitarbeitern und zum anderen erschweren Sie die Verwendung von standardisierter Branchensoftware. Hierzu möchte ich Ihnen ein kleines Beispiel aus meinem Alltag vorstellen, wo es darum geht in Unternehmen möglichst automatisierte DevOps Prozesse für die Softwareentwicklung und den Anwendungsbetrieb zu etablieren.
Die Kunst des Loslassen
Die größte Hürde die ein Unternehmen hier nehmen muss, ist eine Neuorientierung an dem Begriff Release und dem dahinterliegenden Prozess, der meist eigenwillig interpretiert wurde. Die Abweichung von bekannten Standards hat wiederum mehrere spürbare Folgen. Neben erhöhtem Personalaufwand für die administrativen Eingriffe im Releaseprozess besteht auch stets die Gefahr durch unglückliche äußere Umstände in zeitlichen Verzug zum aktuellen Plan zu geraten. Ohne auf die vielen ermüden technischen Details einzugehen liegt das gravierendste Missverständnis in dem Glauben es gäbe nach dem Erstellen eines Releases noch die Möglichkeit die in der Testphase erkannten Fehler im selben Release zu beheben. Das sieht dann folgendermaßen aus: nach einem Sprint wird beispielsweise das Release 2.3.0 erstellt, welches dann ausgiebig in der Testphase auf Herz und Nieren überprüft wird. Stellt man nun ein Fehler fest, ist es nicht möglich eine korrigiert Version 2.3.0 zu erzeugen. Die Korrektur hat ein neues Release zur Folge, welches dann die Versionsnummer 2.3.1 trägt. Ein wichtiger Standard der hier zum Tragen kommt ist die Verwendung des Semantic Versioning, welcher jedem einzelnen Segment der Versionsnummer eine Bedeutung zuordnet. In dem hier verwendeten Beispiel zeigt die letzte Stelle die für ein Release durchgeführten Korrekturen an. Falls Sie sich etwas intensiver mit dem Thema Semantic Versioning beschäftigen mögen, empfehle ich dazu die zugehörige Internetseite [2].
Was aber spricht nun dagegen ein bereits geplantes und auf den Weg gebrachtes Release bei der Detektion von Fehlern nicht zu stoppen, zu korrigieren und ‘repariert’ erneut unter der bereits vergebenen Versionsnummer auf den Weg zu schicken? Die Antwort ist recht einfach. Der erhebliche Arbeitsaufwand, welcher ausschließlich manuell durchgeführt werden muss, um den Fehler wieder auszubügeln. Abgesehen davon wird Ihre gesamte Entwicklungsarbeit für das Folgerelease erheblich ausgebremst. Ressourcen können nicht frei gegeben werden und der Fortschritt beginnt zu stagnieren.
Deswegen ist es wichtig sich so zu disziplinieren, das ein bereits auf den Weg gebrachtes Release sämtliche Prozeduren durchläuft und erst im letzten Schritt dann die manuell ausgeführte Entscheidung getroffen wird, ob das Release für den Produktive Einsatz auch geeignet ist. Deswegen rate ich grundsätzlich dazu den Begriff Release Kandidat aus dem Sprachgebrauch zu streichen und besser von einem Production Kandidat zu sprechen. Diese Bezeichnung spiegelt den Releaseprozess viel deutlicher wieder.
Sollten sich währen der Testphase Mängel aufzeigen, gilt zu erst zu entscheiden wie schwerwiegend diese sind und deren Behebung ist zu priorisieren. Das kann soweit gehen, das direkt ein Korrekturrelease auf den Weg gebracht werden muss, während parallel der nächste Sprint abgearbeitet wird. Weniger gravierende Fehler können dann auf die nächsten Folgesprits verteilt werden. Wie das alles in der täglichen Praxis umgesetzt werden kann – habe ich letztes Jahr in meinem Vortag “Rolling Stones: Vom Release überrollt” auf der JCON präsentiert. Den Videomitschnitt finden Sie frei zugänglich im Internet.
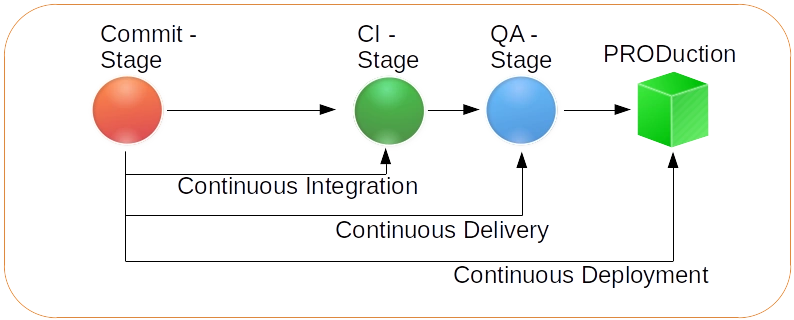
Unter dem Gesichtspunkt der Prozessoptimierung bedeute es für das aufgeführte Beispiel des Release Prozesses, das der Prozess beendet wurde, wenn aus dem Sourcecode erfolgreich eine binäres Artefakt mit einer noch nicht belegten Versionsnummer erstellt werden konnte. Das so entstandene Release wird umgehend an einer zentralen Stelle veröffentlicht (deliverd), wo es in den Testprozess übergeben werden kann. Erst wenn der Testprozess mit dem Ergebnis abgeschlossen wurde, dass das erzeugte Release auch in Produktion verwendet werden darf erfolgt die Übergabe in den Deployment Prozess. Sie sehen, das was vielerorts als ein gesamter Prozess angesehen wird ist genau betrachtet eine Orchestration aus mindestens 3 eiegnständigen Prozessen.
Abbildung 2: Continuous Delivery und Continuous Deployment.
Ein wichtiger Punkt den Sie In Abbildung 2 zum Thema DevOps ebenfalls herauslesen können ist, das der Schritt zwischen Continuous Delivery und Continuous Deployment besser nicht vollautomatisiert werden sollte, denn Deplyoment meint in diesem Kontext nicht das automatisierte bereitstellen der Anwendung auf allen verfügbaren Testinstanzen. Continuous Deployment meint in erste Linie ein automatisiertes Einsetzen der Anwendung in Produktion. Ob das immer eine gute Idee ist sollt sehr sorgfältig abgewogen werden.
Ein wertvoller Aspekt der Prozessbeschreibung in Organisationen ist die Ausarbeitung wichtiger Kriterien die erfüllt sein müssen, damit ein Prozess autonom ablaufen kann. Mit diesem Wissen können Sie bei der Evaluierung benötigter Werkzeuge sehr leicht einen Anforderungskatalog mit priorisierten Punkten erstellen, der einfach abgearbeitet wird. Kann das ins Auge gefasste Tool die aufgelisteten Punkte zufriedenstellend lösen und der aufgerufene Preis passt auch ins Budget, ist Ihre Suche erfolgreich beendet.
Fazit
Sehr oft wird mir entgegengebracht, das durch moderne DevOps Strategien der klassische Release Prozess obsolet geworden ist. Dem kann ich nicht zustimmen. Es mag wenige Ausnahmen geben, in den Unternehmen tatsächlich jede Codeänderung sofort in Produktion bringen. Aus Gründen der Gewährleistung und Haftung, kommt für viel Firmen ein so vollständig automatisiertes Vorgehen aber nicht in Frage. Auch der Datenschutz sorgt dafür, das die Bereich Entwicklung und Betrieb voneinander getrennt werden. Zudem benötigen umfangreiche Softwareprojekte auch eine strategische Planungsinstanz über die umzusetzenden Funktionalitäten. Diese Entscheidbarkeit wird auch künftig nicht beim Entwickler liegen, ganz gleich wie hervorgehoben der Punkt DevOps in der Stellenbeschreibung auch sein mag.
Wie Sie sehen ist das Thema der Prozessbeschreibung und Prozessoptimierung nicht ausschließlich ein Thema für produzierende Branchen. Auch der vielrorts detailreich beschriebene Softwareentwicklungsprozess hält einiges an Verbesserungspotenzial bereit. Ich hoffe ich konnte Sie mit meinen Zeilen ein wenig für das Thema sensibilisieren, ohne zu sehr ins technische verfallen zu sein.
Resourcen
https://www.bizagi.com/en/platform/modeler
https://semver.org
Cookie Consent
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.