Microsoft hat beispielsweise seit der Einführung von Windows 10 seinen Nutzern ein Update-Zwang auferlegt. Grundsätzlich war die Idee durchaus begründet. Denn ungepatchte Betriebssysteme ermöglichen Hackern leichten Zugriff. Also hat sich vor sehr langer Zeit der Gedanke: ‚Latest is greatest‘ durchgesetzt.
Windows-Nutzer habe hier wenig Freiräume. Aber auch auf mobilen Geräten wie Smartphones und Tabletts sind in der Werkseinstellung die automatischen Updates aktiviert. Wer auf GitHub ein Open Source Projekt hostet, bekommt regelmäßige E-Mails, um für verwendete Bibliotheken neue Versionen einzusetzen. Also auf den ersten Blick durchaus eine gute Sache. Wenn man sich mit der Thematik etwas tiefer auseinandersetzt, kommt man rasch zu dem Schluss, dass latest nicht wirklich immer das Beste ist.
Das bekannteste Beispiel hierfür ist Windows 10 und die durch Microsoft erzwungenen Update Zyklen. Dass Systeme regelmäßig auf Sicherheitsprobleme untersucht und verfügbare Aktualisierungen eingespielt werden müssen, ist unumstritten. Dass die Pflege von Rechnersysteme auch Zeit in Anspruch nimmt, ist ebenfalls einsichtig. Problematisch ist es, aber wenn durch den Hersteller eingespielte Aktualisierungen einerseits das gesamte System lahmlegen und so eine Neuinstallation notwendig wird, weil das Update nicht ausreichend getestet wurde. Aber auch im Rahmen von Sicherheitsaktualisierungen ungefragt Funktionsänderungen beim Nutzer einzubringen, halte ich für unzumutbar. Speziell bei Windows kommt noch hinzu, dass hier einiges an Zusatzprogrammen installiert ist, die durch mangelnde Weiterentwicklung schnell zu einem Sicherheitsrisiko werden können. Das bedeutet bei aller Konsequenz erzwungene Windowsupdates machen ein Computer nicht sicher, da hier die zusätzlich installierte Software nicht auf Schwachstellen untersucht wird.
Wenn wir einen Blick auf Android-Systeme werfen, gestaltet sich die Situation weitaus besser. Aber auch hier gibt es genügend Kritikpunkte. Zwar werden die Applikationen regelmäßig aktualisiert, so dass tatsächlich die Sicherheit markant verbessert wird. Aber auch bei Android bedeutet jedes Update in aller Regel auch funktionale Veränderungen. Ein einfaches Beispiel ist der sehr beliebte Dienst Google StreetMaps. Mit jedem Update wird die Kartennutzung für mich gefühlt unübersichtlicher, da eine Menge für mich unerwünschter Zusatzinformationen eingeblendet werden, die den bereits begrenzten Bildschirm erheblich verkleinern.
Als Nutzer ist es mir glücklicherweise bisher nicht passiert, dass Applikationsupdates unter Android das gesamte Telefon lahmgelegt haben. Was also auch beweist, dass es durchaus möglich ist, Aktualisierungen ausgiebig zu testen, bevor diese an die Nutzer ausgerollt werden. Was aber nicht heißt, dass jedes Update unproblematisch war. Probleme, die hier regelmäßig beobachtet werden können, sind Dinge wie ein übermäßig erhöhter Batterieverbrauch.
Reine Android Systemupdates wiederum sorgen regelmäßig dafür, dass die Hardware nach knapp zwei Jahren so langsam wird, dass man sich oft dazu entscheidet, ein neues Smartphone zu kaufen. Obwohl das alte Telefon noch in gutem Zustand ist und durchaus viel länger genutzt werden könnte. So ist mir bei vielen erfahrenen Nutzern aufgefallen, dass diese nach circa einem Jahr ihre Android-Updates ausschalten, bevor das Telefon durch den Hersteller in die Obsoleszenz geschickt wird.
Wie bekommt man ein Update-Muffel nun dazu, seine Systeme trotzdem aktuell und damit auch sicher zu halten? Mein Ansatz als Entwickler und Konfigurationsmanager ist hier recht einfach. Ich unterscheide zwischen Feature Update und Security Patch. Wenn man im Release Prozess dem Semantic Versioning folgt und für SCM Systeme wie Git ein Branch by Release Modell nutzt, lässt sich eine solche Unterscheidung durchaus leicht umsetzen.
Aber auch der Fragestellung einer versionierbaren Konfigurationseinstellung für Softwareanwendungen habe ich mich gewidmet. Hierzu gibt es im Projekt TP-CORE auf GitHub eine Referenzimplementierung, die in dem zweiteiligen Artikel ‘Treasue Chest’ ausführlich beschrieben wird. Denn es muss uns schon klar sein, dass wenn wir bei einem Update die gesamte vom Nutzer vorgenommene Konfiguration auf Werkseinstellung zurücksetzen, wie es recht oft bei Windows 10 der Fall ist, können ganz eigene Sicherheitslücken entstehen.
Das bringt uns auch zu dem Punkt Programmierung und wie GitHub Entwickler durch E-Mails dazu motiviert, neue Versionen der verwendeten Bibliotheken in ihre Applikationen einzubinden. Denn, wenn es sich bei einem solchen Update um eine umfangreiche API-Änderung handelt, ist das Problem der hohe Migrationsaufwand für die Entwickler. Hier hat sich für mich eine ebenfalls recht einfache Strategie bewährt. Anstatt mich von den Benachrichtigungen über Aktualisierungen von GitHub beeindrucken zu lassen, prüfe ich regelmäßig über OWASP, ob meine Bibliotheken bekannte Risiken enthalten. Denn wird durch OWASP ein Problem erkannt, spielt es keine Rolle, wie aufwendig eine Aktualisierung werden kann. Das Update und eine damit verbundene Migration muss zeitnahe umgesetzt werden. Dies gilt dann auch für alle noch in Produktion befindlichen Releases.
Um von Beginn an der Update Hölle zu entrinnen, gilt allerdings eine Faustegel: Installiere beziehungsweise nutze nur das, was du wirklich benötigst. Je weniger Programme unter Windows installiert sind und je weniger Apps auf dem Smartphone vorhanden sind, umso weniger Sicherheitsrisiken entstehen. Das gilt auch für Programmbibliotheken. Weniger ist aus Sicht der Security mehr. Abgesehen davon bekommen wir durch den Verzicht unnötiger Programme noch eine Performance Verbesserung frei Haus.
Sicher ist für viele private Anwender die Frage der Systemaktualisierung kaum relevant. Lediglich neue unerwünschte Funktionen in vorhandenen Programme, Leistungsverschlechterungen oder hin und wieder zerschossene Betriebssysteme verursache mehr oder weniger starken Unmut. Im kommerziellen Umfeld können recht schnell erhebliche Kosten entstehen, die sich auch auf die gerade umzusetzenden Projekte negativ auswirken können. Unternehmen und Personen, die Software entwickeln können die Nutzerzufriedenheit erheblich verbessern, wenn sie bei Ihren Release Veröffentlichungen zwischen Security Patches und Feature Updates unterscheiden. Und ein Feature Update sollte dann entsprechend auch allen bekannten Security Aktualisierungen enthalten.
DevOps4Agile – Prozesse verstehen und richtig anwenden
Jeder redet von Digitaler Transformation, Agilität und natürlich auch DevOps. Leider klappt die Integration moderner Paradigmen in2023-IT-Tage-FFM_DevOps4Agile Unternehmen nur sehr schwer. Ein Punkt der eine wichtige Rolle bei Transformationen spielt sind Prozesse. Oft fehlt ein richtiges Verständnis wie man von der abstrakten Beschreibung zu einer leichtgewichtigen Umsetzung im Unternehmen kommt. Nicht die Werkzeuge stehen in diesem Vortag im Vordergrund, sondern der Weg von der Planung zu einer konkreten Umsetzung, die offen für künftige Anpassungen ist.
Als mir im Studium die Vorzüge der objektorientierten Programmierung mit Java schmackhaft gemacht wurden, war ein sehr beliebtes Argument die Wiederverwendung. Dass der Grundsatz „write once use everywhere“ in der Praxis dann doch nicht so leicht umzusetzen ist, wie es die Theorie suggeriert, haben die meisten Entwickler bereits am eigenen Leib erfahren. Woran liegt es also, dass die Idee der Wiederverwendung in realen Projekten so schwer umzusetzen ist? Machen wir also einen gemeinsamen Streifzug durch die Welt der Informatik und betrachten verschiedene Vorhaben aus sicherer Distanz.
Wenn ich daran denke, wie viel Zeit ich während meines Studiums investiert habe, um eine Präsentationsvorlage für Referate zu erstellen. Voller Motivation habe ich alle erdenklichen Ansichten in weiser Voraussicht erstellt. Selbst rückblickend war das damalige Layout für einen Nichtgrafiker ganz gut gelungen. Trotzdem kam die tolle Vorlage nur wenige Male zum Einsatz und wenn ich im Nachhinein einmal Resümee ziehe, komme ich zu dem Schluss, dass die investierte Arbeitszeit in Bezug auf die tatsächliche Verwendung in keinem Verhältnis gestanden hat. Von den vielen verschiedenen Ansichten habe ich zum Schluss exakt zwei verwendet, das Deckblatt und eine allgemeine Inhaltsseite, mit der alle restlichen Darstellungen umgesetzt wurden. Die restlichen 15 waren halt da, falls man das künftig noch brauchen würde. Nach dieser Erfahrung plane ich keine eventuell zukünftig eintreffenden Anforderungen mehr im Voraus. Denn den wichtigsten Grundsatz in Sachen Wiederverwendung habe ich mit dieser Lektion für mich gelernt: Nichts ist so beständig wie die Änderung.
Diese kleine Anekdote trifft das Thema bereits im Kern. Denn viele Zeilen Code werden genau aus der gleichen Motivation heraus geschrieben. Der Kunde hat es noch nicht beauftragt, doch die Funktion wird er ganz sicher noch brauchen. Wenn wir in diesem Zusammenhang einmal den wirtschaftlichen Kontext ausblenden, gibt es immer noch ausreichend handfeste Gründe, durch die Fachabteilung noch nicht spezifizierte Funktionalität nicht eigenmächtig im Voraus zu implementieren. Für mich ist nicht verwendeter, auf Halde produzierter Code – sogenannter toter Code – in erster Linie ein Sicherheitsrisiko. Zusätzlich verursachen diese Fragmente auch Wartungskosten, da bei Änderungen auch diese Bereiche möglicherweise mit angepasst werden müssen. Schließlich muss die gesamte Codebasis kompilierfähig bleiben. Zu guter Letzt kommt noch hinzu, dass die Kollegen oft nicht wissen, dass bereits eine ähnliche Funktion entwickelt wurde, und diese somit ebenfalls nicht verwenden. Die Arbeit wird also auch noch doppelt ausgeführt. Nicht zu vergessen ist auch das von mir in großen und langjährig entwickelten Applikationen oft beobachtete Phänomen, dass ungenutzte Fragmente aus Angst, etwas Wichtiges zu löschen, über Jahre hinweg mitgeschleppt werden. Damit kommen wir auch schon zum zweiten Axiom der Wiederverwendung: Erstens kommt es anders und zweitens als man denkt.
Über die vielen Jahre, genauer gesagt Jahrzehnte, in denen ich nun verschiedenste IT- beziehungsweise Softwareprojekte begleitet habe, habe ich ein Füllhorn an Geschichten aus der Kategorie „Das hätte ich mir sparen können!“ angesammelt. Virtualisierung ist nicht erst seit Docker [1] auf der Bildfläche erschienen – es ist schon weitaus länger ein beliebtes Thema. Die Menge der von mir erstellten virtuellen Maschinen (VMs) kann ich kaum noch benennen – zumindest waren es sehr viele. Für alle erdenklichen Einsatzszenarien hatte ich etwas zusammengebaut. Auch bei diesen tollen Lösungen erging es mir letztlich nicht viel anders als bei meiner Office-Vorlage. Grundsätzlich gab es zwei Faktoren, die sich negativ ausgewirkt haben. Je mehr VMs erstellt wurden, desto mehr mussten dann auch gewertet werden. Ein Worst-Case-Szenario heutzutage wäre eine VM, die auf Windows 10 basiert, die dann jeweils als eine .NET- und eine Java-Entwicklungsumgebung oder Ähnliches spezialisiert wurde. Allein die Stunden, die man für Updates zubringt, wenn man die Systeme immer mal wieder hochfährt, summieren sich auf beachtliche Größen. Ein Grund für mich zudem, soweit es geht, einen großen Bogen um Windows 10 zu machen. Aus dieser Perspektive können selbsterstellte DockerContainer schnell vom Segen zum Fluch werden.
Dennoch darf man diese Dinge nicht gleich überbewerten, denn diese Aktivitäten können auch als Übung verbucht werden. Wichtig ist, dass solche „Spielereien“ nicht ausarten und man neben den technischen Erfahrungen auch den Blick für tatsächliche Bedürfnisse auf lange Sicht schärft.
Gerade bei Docker bin ich aus persönlicher Erfahrung dazu übergegangen, mir die für mich notwendigen Anpassungen zu notieren und zu archivieren. Komplizierte Skripte mit Docker-Compose spare ich mir in der Regel. Der Grund ist recht einfach: Die einzelnen Komponenten müssen zu oft aktualisiert werden und der Einsatz für jedes Skript findet in meinem Fall genau einmal statt. Bis man nun ein lauffähiges Skript zusammengestellt hat, benötigt man, je nach Erfahrung, mehrere oder weniger Anläufe. Also modifiziere ich das RUN-Kommando für einen Container, bis dieser das tut, was ich von ihm erwarte. Das vollständige Kommando hinterlege ich in einer Textdatei, um es bei Bedarf wiederverwenden zu können. Dieses Vorgehen nutze ich für jeden Dienst, den ich mit Docker virtualisiere. Dadurch habe ich die Möglichkeit, verschiedenste Konstellationen mit minimalen Änderungen nach dem „Klemmbaustein“-Prinzip zu rchestrieren. Wenn sich abzeichnet, dass ein Container sehr oft unter gleichen Bedienungen instanziiert wird, ist es sehr hilfreich, diese Konfiguration zu automatisieren. Nicht ohne Grund gilt für Docker-Container die Regel, möglichst nur einen Dienst pro Container zu virtualisieren.
Aus diesen beiden kleinen Geschichten lässt sich bereits einiges für Implementierungsarbeiten am Code ableiten. Ein klassischer Stolperstein, der mir bei der täglichen Projektarbeit regelmäßig unterkommt, ist, dass man mit der entwickelten Applikation eine eierlegende Wollmilchsau – oder, wie es in Österreich heißt: ein Wunderwutzi – kreieren möchte. Die Teams nehmen sich oft zu viel vor und das Projektmanagement versucht, den Product Owner auch nicht zu bekehren, lieber auf Qualität statt auf Quantität zu setzen. Was ich mit dieser Aussage deutlich machen möchte, lässt sich an einem kleinen Beispiel verständlich machen.
Gehen wir einmal davon aus, dass für eigene Projekte eine kleine Basisbibliothek benötigt wird, in der immer wiederkehrende Problemstellungen zusammengefasst werden – konkret: das Verarbeiten von JSON-Objekten [2]. Nun könnte man versuchen, alle erdenklichen Variationen im Umgang mit JSON abzudecken. Abgesehen davon, dass viel Code produziert wird, erzielt ein solches Vorgehen wenig Nutzen. Denn für so etwas gibt es bereits fertige Lösungen – etwa die freie Bibliothek Jackson [3]. Anstelle sämtlicher denkbarer JSON-Manipulationen ist in Projekten vornehmlich das Serialisieren und das Deserialisieren gefragt. Also eine Möglichkeit, wie man aus einem Java-Objekt einen JSON-String erzeugt, und umgekehrt. Diese beiden Methoden lassen sich leicht über eine Wrapper-Klasse zentralisieren. Erfüllt nun künftig die verwendete JSON-Bibliothek die benötigten Anforderungen nicht mehr, kann sie leichter durch eine besser geeignete Bibliothek ersetzt werden. Ganz nebenbei erhöhen wir mit diesem Vorgehen auch die Kompatibilität [4] unserer Bibliothek für künftige Erweiterungen. Wenn JSON im Projekt eine neu eingeführte Technologie ist, kann durch die Minimal-Implementierung stückweise Wissen aufgebaut werden. Je stärker der JSONWrapper nun in eigenen Projekten zum Einsatz kommt, desto wahrscheinlicher ist es, dass neue Anforderungen hinzukommen, die dann erst umgesetzt werden, wenn sie durch ein Projekt angefragt werden. Denn wer kann schon abschätzen, wie der tatsächliche Bedarf einer Funktionalität ist, wenn so gut wie keine Erfahrungen zu der eingesetzten Technologie vorhanden sind?
Das soeben beschriebene Szenario läuft auf einen einfachen Merksatz hinaus: Eine neue Implementierung möglichst so allgemein wie möglich halten, um sie nach Bedarf immer weiter zu spezialisieren.
Bei komplexen Fachanwendungen hilft uns das Domain-driven Design (DDD) Paradigma, Abgrenzungen zu Domänen ausfindig zu machen. Auch hierfür lässt sich ein leicht verständliches, allgemein gefasstes Beispiel finden. Betrachten wir dazu einmal die Domäne einer Access Control List (ACL). In der ACL wird ein Nutzerkonto benötigt, mit dem Berechtigungen zu verschiedenen Ressourcen verknüpft werden. Nun könnte man auf die Idee kommen, im Account in der ACL sämtliche Benutzerinformationen wie Homepage, Postadresse und Ähnliches abzulegen. Genau dieser Fall würde die Domäne der ACL verletzen, denn das Benutzerkonto benötigt lediglich Informationen, die zur Authentifizierung benötigt werden, um eine entsprechende Autorisierung zu ermöglichen.
Jede Anwendung hat für das Erfassen der benötigten Nutzerinformationen andere Anforderungen, weshalb diese Dinge nicht in eine ACL gehören sollten. Das würde die ACL zu sehr spezialisieren und stetige Änderungen verursachen. Daraus resultiert dann auch, dass die ACL nicht mehr universell einsatzfähig ist.
Man könnte nun auf die Idee kommen, eine sehr generische Lösung für den Speicher zusätzlicher Nutzerinformationen zu entwerfen und ihn in der ACL zu verwenden. Von diesem Ansatz möchte ich abraten. Ein wichtiger Grund ist, dass diese Lösung die Komplexität der ACL unnötig erhöht. Ich gehe obendrein so weit und möchte behaupten, dass unter ungünstigen Umständen sogar Code-Dubletten entstehen. Die Begründung dafür ist wie folgt: Ich sehe eine generische Lösung zum Speichern von Zusatzinformationen im klassischen Content Management (CMS) verortet. Die Verknüpfung zwischen ACL und CMS erfolgt über die Benutzer-ID aus der ACL. Somit haben wir gleichzeitig auch zwischen den einzelnen Domänen eine lose Kopplung etabliert, die uns bei der Umsetzung einer modularisierten Architektur sehr behilflich sein wird.
Zum Thema Modularisierung möchte ich auch kurz einwerfen, dass Monolithen [5] durchaus auch aus mehreren Modulen bestehen können und sogar sollten. Es ist nicht zwangsläufig eine Microservice-Architektur notwendig. Module können aus unterschiedlichen Blickwinkeln betrachtet werden. Einerseits erlauben sie es einem Team, in einem fest abgegrenzten Bereich ungestört zu arbeiten, zum anderen kann ein Modul mit einer klar abgegrenzten Domäne ohne viele Adaptionen tatsächlich in späteren Projekten wiederverwendet werden.
Nun ergibt sich klarerweise die Fragestellung, was mit dem Übergang von der Generalisierung zur Spezialisierung gemeint ist. Auch hier hilft uns das Beispiel der ACL weiter. Ein erster Entwurf könnte die Anforderung haben, dass, um unerwünschte Berechtigungen falsch konfigurierter Rollen zu vermeiden, die Vererbung von Rechten bestehender Rollen nicht erwünscht ist. Daraus ergibt sich dann der Umstand, dass jedem Nutzer genau eine Rolle zugewiesen werden kann. Nun könnte es sein, dass durch neue Anforderungen der Fachabteilung eine Mandantenfähigkeit eingeführt werden soll. Entsprechend muss nun in der ACL eine Möglichkeit geschaffen werden, um bestehende Rollen und auch Nutzeraccounts einem Mandanten zuzuordnen. Eine Domänen-Erweiterung dieser hinzugekommenen Anforderung ist nun basierend auf der bereits bestehenden Domäne durch das Hinzufügen neuer Tabellenspalten leicht umzusetzen.
Die bisher aufgeführten Beispiele beziehen sich ausschließlich auf die Implementierung der Fachlogik. Viel komplizierter verhält sich das Thema Wiederverwendung beim Punkt der grafischen Benutzerschnittelle (GUI). Das Problem, das sich hier ergibt, ist die Kurzlebigkeit vieler chnologien. Java Swing existiert zwar noch, aber vermutlich würde sich niemand, der heute eine neue Anwendung entwickelt, noch für Java Swing entscheiden. Der Grund liegt in veraltetem Look-and-Feel der Grafikkomponenten. Um eine Applikation auch verkaufen zu können, darf man den Aspekt der Optik nicht außen vor lassen. Denn auch das Auge isst bekanntlich mit. Gerade bei sogenannten Green-Field-Projekten ist der Wunsch, eine moderne, ansprechende Oberfläche anbieten zu können, implizit. Deswegen vertrete ich die Ansicht, dass das Thema Wiederverwendung für GUI – mit wenigen Ausnahmen – keine wirkliche Rolle spielt.
Lessons Learned
Sehr oft habe ich in der Vergangenheit erlebt, wie enthusiastisch bei Kick-off-Meetings die Möglichkeit der Wiederverwendung von Komponenten in Aussicht gestellt wurde. Dass dies bei den verantwortlichen Managern zu einem Glitzern in den Augen geführt hat, ist auch nicht verwunderlich. Als es dann allerdings zu ersten konkreten Anfragen gekommen ist, eine Komponente in einem anderen Projekt einzusetzen, mussten sich alle Beteiligten eingestehen, dass dieses Vorhaben gescheitert war. In den nachfolgenden Retrospektiven sind die Punkte, die ich in diesem Artikel vorgestellt habe, regelmäßig als Ursachen identifiziert worden. Im Übrigen genügt oft schon ein Blick in das Datenbankmodell oder auf die Architektur einer Anwendung, um eine Aussage treffen zu können, wie realistisch eine Wiederverwendung tatsächlich ist. Bei steigendem Komplexitätsgrad sinkt die Wahrscheinlichkeit, auch nur kleinste Segmente erfolgreich für eine Wiederverwendung herauslösen zu können.
Viele Ideen sind auf dem Papier hervorragend. Oft fehlt aber das Wissen wie man brillante Konzepte in den eigenen Alltag einbauen kann. Dieser kleine Workshop soll die Lücke zwischen Theorie und Praxis schließen und zeigt mit welchen Maßnahmen man langfristig zu einer stabile API gelangt.
(c) 2021 Marco Schulz, Java PRO Ausgabe 1, S.31-34
Bei der Entwicklung kommerzieller Software ist vielen Beteiligten oft nicht klar, das die Anwendung für lange Zeit in Benutzung sein wird. Da sich unsere Welt stetig im Wandel befindet, ist es leicht abzusehen, dass im Laufe der Jahre große und kleine Änderungen der Anwendung ausstehen werden. Zu einer richtigen Herausforderung wird das Vorhaben, wenn die zu erweiternde Anwendung nicht für sich isoliert ist, sondern mit anderen Systemkomponenten kommuniziert. Denn das bedeutet für die Konsumenten der eigenen Anwendung in den meisten Fällen, das sie ebenfalls angepasst werden müssen. Ein einzelner Stein wird so schnell zu einer Lawine. Mit einem guten Lawinenschutz lässt sich die Situation dennoch beherrschen. Das gelingt aber nur, wenn man berücksichtigt, das die im nachfolgenden beschriebenen Maßnahmen ausschließlich für eine Prävention gedacht sind. Hat sich die Gewalt aber erst einmal entfesselt, kann ihr kaum noch etwas entgegengesetzt werden. Klären wir deshalb zu erst was eine API ausmacht.
Verhandlungssache
Ein Softwareprojekt besteht aus verschieden Komponenten, denen spezialisierte Aufgaben zuteil werden. Die wichtigsten sind Quelltext, Konfiguration und Persistenz. Wir befassen uns hauptsächlich mit dem Bereich Quelltext. Ich verrate keine Neuigkeiten, wenn ich sage dass stets gegen Interfaces implementiert werden soll. Diese Grundlage bekommt man bereits in der Einführung der Objektorientierten Programmierung vermittelt. Bei meiner täglichen Arbeit sehe ich aber sehr oft, das so manchem Entwickler die Bedeutung der Forderung gegen Interfaces zu Entwickeln, nicht immer ganz klar ist, obwohl bei der Verwendung der Java Standard API, dies die übliche Praxis ist. Das klassische Beispiel hierfür lautet:
List<String> collection =newArrayList<>();
Diese kurze Zeile nutzt das Interface List, welches als eine ArrayList implementiert wurde. Hier sehen wir auch, das keine Anhängsel in Form eines I die Schnittstelle kennzeichnet. Auch die zugehörige Implementierung trägt kein Impl im Namen. Das ist auch gut so! Besonders bei der Implementierungsklasse könnten ja verschiedene Lösungen erwünscht sein. Dann ist es wichtig diese gut zu kennzeichnen und leicht durch den Namen unterscheidbar zu halten. ListImpl und ListImpl2 sind verständlicherweise nicht so toll wie ArrayList und LinkedList auseinander zu halten. Damit haben wir auch schon den ersten Punk einer stringenten und sprechenden Namenskonvention klären können.
Im nächsten Schritt beschäftigen uns die Programmteile, welche wir möglichst nicht für Konsumenten der Anwendung nach außen geben wollen, da es sich um Hilfsklassen handelt. Ein Teil der Lösung liegt in der Struktur, wie die Packages zu organisieren sind. Ein sehr praktikabler Weg ist:
Bereits über diese simple Architektur signalisiert man anderen Programmierern, das es keine gute Idee ist Klassen aus dem Package helper zu benutzen. Ab Java 9 gibt es noch weitreichendere Restriktion, das Verwenden interner Hilfsklassen zu unterbinden. Die Modularisierung, welche mit dem Projekt Jingsaw [1] in Java 9 Einzug genommen hat, erlaubt es im Moduldescriptor module-info.java Packages nach außen hin zu verstecken.
Separatisten und ihre Flucht vor der Masse
Schaut man sich die meisten Spezifikationen etwas genauer an, so stellt man fest, das viele Schnittstellen in eigene Bibliotheken ausgelagert wurden. Technologisch betrachtet würde das auf das vorherige Beispiel bezogen bedeuten, dass das Package business welches die Interfaces enthält in eine eigene Bibliothek ausgelagert wird. Die Trennung von API und der zugehörigen Implementierung erlaubt es grundsätzlich Implementierungen leichter gegeneinander auszutauschen. Es gestattet außerdem einem Auftraggeber eine stärkeren Einfluss auf die Umsetzung seines Projektes bei seinem Vertragspartner auszuüben, indem der Hersteller die API durch den Auftraggeber vorgefertigt bekommt. So toll wie die Idee auch ist, damit es dann auch tatsächlich so klappt, wie es ursprünglich gedacht wurde, sind aber ein paar Regeln zu beachten.
Beispiel 1: JDBC. Wir wissen, das die Java Database Connectivity ein Standard ist, um an eine Applikation verschiedenste Datenbanksysteme anbinden zu können. Sehen wir von den Probleme bei der Nutzung von nativem SQL einmal ab, können JDBC Treiber von MySQL nicht ohne weiteres durch postgreSQL oder Oracle ersetzt werden. Schließlich weicht jeder Hersteller bei seiner Implementierung vom Standard mehr oder weniger ab und stellt auch exklusive Funktionalität des eigene Produktes über den Treiber mit zu Verfügung. Entscheidet man sich im eigenen Projekt massiv diese Zusatzfeatures nutzen zu wollen, ist es mit der leichten Austauschbarkeit vorüber.
Beispiel 2: XML. Hier hat man gleich die Wahl zwischen mehreren Standards. Es ist natürlich klar das die APIs von SAX, DOM und StAX nicht zueinander kompatibel sind. Will man beispielsweise wegen einer besseren Performance von DOM zum ereignisbasierten SAX wechseln, kann das unter Umständen umfangreiche Codeänderungen nach sich ziehen.
Beispiel 3: PDF. Zu guter letzt habe ich noch ein Szenario von einem Standard parat, der keinen Standard hat. Das Portable Document Format selbst ist zwar ein Standard wie Dokumentdateien aufgebaut werden, aber bei der Implementierung nutzbarer Programmbibliotheken für die eigene Anwendung, köchelt jeder Hersteller sein eigenes Süppchen.
Die drei kleinen Beispiele zeigen die üblichen Probleme auf die im täglichen Projektgeschäft zu meistern sind. Eine kleine Regel bewirkt schon großes: Nur Fremdbibliotheken nutzen, wenn es wirklich notwendig ist. Schließlich birgt jede verwendete Abhängigkeit auch ein potenzielles Sicherheitsrisiko. Es ist auch nicht notwendig eine Bibliothek von wenigen MB einzubinden um die drei Zeile einzusparen, die benötigt werden um einen String auf leer und null zu prüfen.
Musterknaben
Wenn man sich für eine externe Bibliothek entschieden hat, so ist es immer vorteilhaft sich anfänglich die Arbeit zu machen und die Funktionalität über eine eigene Klasse zu kapseln, welche man dann exzessiv nutzen kann. In meinem persönlichen Projekt TP-CORE auf GitHub [2] habe ich dies an mehreren Stellen getan. Der Logger kapselt die Funktionalität von SLF4J und Logback. Im Vergleich zu den PdfRenderer ist die Signatur der Methoden von den verwendeten Logging Bibliotheken unabhängig und kann somit leichter über eine zentrale Stelle ausgetauscht werden. Um externe Bibliotheken in der eigenen Applikation möglichst zu kapseln, stehen die Entwurfsmuster: Wrapper, Fassade und Proxy zur Verfügung.
Wrapper: auch Adaptor Muster genannt, gehört in die Gruppe der Strukturmuster. Der Wrapper koppelt eine Schnittstelle zu einer anderen, die nicht kompatibel sind.
Fassade: ist ebenfalls ein Strukturmuster und bündelt mehrere Schnittstellen zu einer vereinfachten Schnittstelle.
Proxy: auch Stellvertreter genannt, gehört ebenfalls in die Kategorie der Strukturmuster. Proxies sind eine Verallgemeinerung einer komplexen Schnittstelle. Es kann als Komplementär der Fassade verstanden werden, die mehrere Schnittstellen zu einer einzigen zusammenführt.
Sicher ist es wichtig in der Theorie diese unterschiedlichen Szenarien zu trennen, um sie korrekt beschreiben zu können. In der Praxis ist es aber unkritisch, wenn zur Kapselung externer Funktionalität Mischformen der hier vorgestellten Entwurfsmuster entstehen. Für alle diejenigen die sich intensiver mit Design Pattern auseinander Setzen möchten, dem sei das Buch „Entwurfsmuster von Kopf bis Fuß“ [3] ans Herz gelegt.
Klassentreffen
Ein weiterer Schritt auf dem Weg zu einer stabilen API ist eine ausführliche Dokumentation. Basierend auf den bisher besprochenen Schnittstellen, gibt es eine kleine Bibliothek mit der Methoden basierend der API Version annotiert werden können. Neben Informationen zum Status und der Version, können für Klassen über das Attribute consumers die primäre Implementierungen aufgeführt werden. Um API Gaurdian dem eigenen Projekt zuzufügen sind nur wenige Zeilen der POM hinzuzufügen und die Property ${version} gegen die aktuelle Version zu ersetzen.
Die Auszeichnung der Methoden und Klassen ist ebenso leicht. Die Annotation @API hat die Attribute: status, since und consumers. Für Status sind die folgenden Werte möglich:
DEPRECATED: Veraltet, sollte nicht weiterverwendet werden.
EXPERIMENTAL: Kennzeichnet neue Funktionen, auf die der Hersteller gerne Feedback erhalten würde. Mit Vorsicht verwenden, da hier stets Änderungen erfolgen können.
INTERNAL: Nur zur internen Verwendung, kann ohne Vorwarnung entfallen.
STABLE: Rückwärts kompatibles Feature, das für die bestehende Major-Version unverändert bleibt.
MAINTAINED: Sichert die Rückwärtsstabilität auch für das künftige Major-Release zu.
Nachdem nun sämtliche Interfaces mit diesen nützlichen META Informationen angereichert wurden, stellt sich die Frage wo der Mehrwert zu finden ist. Dazu verweise ich schlicht auf Abbildung 1, welche den Arbeitsalltag demonstriert.
Abbildung 1: Suggestion in Netbeans mit @API Annotation in der JavaDoc
Für Service basierte RESTful APIs, gibt es ein anderes Werkzeug, welches auf den Namen Swagger [4] hört. Auch hier wird der Ansatz aus Annotationen eine API Dokumentation zu erstellen verfolgt. Swagger selbst scannt allerdings Java Webservice Annotationen, anstatt eigene einzuführen. Die Verwendung ist ebenfalls recht leicht umzusetzen. Es ist lediglich das swagger-maven-plugin einzubinden und in der Konfiguration die Packages anzugeben, in denen die Webservices residieren. Anschließend wird bei jedem Build eine Beschreibung in Form einer JSON Datei erstellt, aus der dann Swagger UI eine ausführbare Dokumentation generiert. Swagger UI selbst wiederum ist als Docker Image auf DockerHub [5] verfügbar.
Abbildung 2: Swagger UI Dokumentation der TP-ACL RESTful API.
Versionierung ist für APIs ein wichtiger Punkt. Unter Verwendung des Semantic Versioning lässt sich bereits einiges von der Versionsnummer ablesen. Im Bezug auf eine API ist das Major Segment von Bedeutung. Diese erste Ziffer kennzeichnet API Änderungen, die inkompatibel zueinander sind. Eine solche Inkompatibilität ist das Entfernen von Klassen oder Methoden. Aber auch das Ändern bestehender Singnaturen oder der Rückgabewert einer Methode erfordern bei Konsumenten im Rahmen einer Umstellung Anpassungen. Es ist immer eine gute Entscheidung Arbeiten, die Inkompatibilitäten verursachen zu bündeln und eher selten zu veröffentlichen. Dies zeugt von Stabilität im Projekt.
Auch für WebAPIs ist eine Versionierung angeraten. Die geschieht am besten über die URL, in dem eine Versionsnummer eingebaut wird. Bisher habe ich gute Erfahrungen gesammelt, wenn lediglich bei Inkompatibilitäten die Version hochgezählt wird.
Beziehungsstress
Der große Vorteil eines RESTful Service mit „jedem“ gut auszukommen, ist zugleich der größte Fluch. Denn das bedeutet das hier viel Sorgfalt walten muss, da viele Klienten versorgt werden. Da die Schnittstelle eine Ansammlung von URIs darstellt, liegt unser Augenmerk bei den Implementierungsdetails. Dazu nutze ich ein Beispiel aus meinen ebenfalls auf GitHub verfügbaren Projekt TP-ACL.
Der kurze Auszug aus dem try Block der fetchRole Methode die in der Klasse RoleService zu finden ist. Die GET Anfrage liefert für den Fall, das eine Rolle nicht gefunden wird den 404 Fehlercode zurück. Sie ahnen sicherlich schon worauf ich hinaus will.
Bei der Implementierung der einzelnen Aktionen GET, PUT, DELETE etc. einer Resource wie Rolle, genügt es nicht einfach nur den sogenannten HappyPath umzusetzen. Bereits während des Entwurfes sollte berücksichtigt werden, welche Stadien eine solche Aktion annehmen kann. Für die Implementierung eines Konsumenten (Client) ist es schon ein beachtlicher Unterschied ob eine Anfrage, die nicht mit 200 abgeschlossen werden kann gescheitert ist, weil die Ressource nicht existiert (404) oder weil der Zugriff verweigert wurde (403). Hier möchte ich an die vielsagende Windows Meldung mit dem unerwarteten Fehler anspielen.
Fazit
Wenn wir von eine API sprechen, dann bedeutet es, das es sich um eine Schnittstelle handelt, die von anderen Programmen genutzt werden kann. Der Wechsel eine Major Version indiziert Konsumenten der API, das Inkompatibilität zur vorherigen Version vorhanden ist. Weswegen möglicherweise Anpassungen erforderlich sind. Dabei ist es völlig irrelevant um welche Art API es sich handelt oder ob die Verwendung der Anwendung öffentlich beziehungsweise fetchRole Methode, die Unternehmensintern ist. Die daraus resultierenden Konsequenzen sind identisch. Aus diesem Grund sollte man sich mit den nach außen sichtbaren Bereichen seiner Anwendung gewissenhaft auseinandersetzen.
Arbeiten, welche zu einer API Inkompatibilität führen, sollten durch das Release Management gebündelt werden und möglichst nicht mehr als einmal pro Jahr veröffentlicht werden. Auch an dieser Stelle zeigt sich wie wichtig regelmäßige Codeinspektionen für eine stringente Qualität sind.
Jeder macht es, manche sogar mehrmals täglich. Aber nur wenige kennen die komplexen ineinander greifenden Mechanismen, die ein vollständiges Software Release ausmachen. Deshalb kommt es hin und wieder vor, das sich ein Paket in der automatisierten Verarbeitungskette querstellt.
Mit ein wenig Theorie und einem typischen Beispiele aus dem Java Universum zeige ich, wie man ein wenig Druck aus dem Softwareentwicklungsprozess nehmen kann, um zu schlanken leicht automatisierten Prozessen gelangt.
Nachdem die Gang Of Four (GOF) Erich Gamma, Richard Helm, Ralph Johnson und John Vlissides das Buch Design Patterns: Elements of Reusable Object-Oriented Software (Elemente wiederverwendbarer objektorientierter Software), wurde das Erlernen der Beschreibung von Problemmustern und deren Lösungen in fast allen Bereichen der Softwareentwicklung populär. Ebenso populär wurde das Erlernen der Beschreibung von Don’ts und Anti-Patterns.
In Publikationen, die sich mit den Konzepten der Entwurfsmuster und Anti-Pattern befassen, finden wir hilfreiche Empfehlungen für Softwaredesign, Projektmanagement, Konfigurationsmanagement und vieles mehr. In diesem Artikel möchte ich meine Erfahrungen im Umgang mit Versionsnummern für Software-Artefakte weitergeben.
Die meisten von uns sind bereits mit einer Methode namens semantische Versionierung vertraut, einem leistungsstarken und leicht zu erlernenden Regelwerk dafür, wie Versionsnummern strukturiert sein sollten und wie die einzelnen Segmente zu inkrementieren sind.
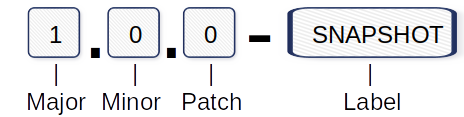
Beispiel für eine Versionsnummerierung:
Major: Inkompatible API-Änderungen.
Minor: Hinzufügen neuer Funktionen.
Patch: Fehlerbehebungen und Korrekturen.
Label: SNAPSHOT zur Kennzeichnung des Status “in Entwicklung”.
Eine inkompatible API-Änderung liegt dann vor, wenn eine von außen zugängliche Funktion oder Klasse gelöscht oder umbenannt wurde. Eine andere Möglichkeit ist eine Änderung der Signatur einer Methode. Das bedeutet, dass der Rückgabewert oder die Parameter gegenüber der ursprünglichen Implementierung geändert wurden. In diesen Fällen ist es notwendig, das Major-Segment der Versionsnummer zu erhöhen. Diese Änderungen stellen für API-Kunden ein hohes Risiko dar, da sie ihren eigenen Code anpassen müssen.
Beim Umgang mit Versionsnummern ist es auch wichtig zu wissen, dass 1.0.0 und 1.0 gleichwertig sind. Dies hat mit der Anforderung zu tun, dass die Versionen einer Softwareversion eindeutig sein müssen. Wenn dies nicht der Fall ist, ist es unmöglich, zwischen Artefakten zu unterscheiden. In meiner beruflichen Praxis war ich mehrfach an Projekten beteiligt, bei denen es keine klar definierten Prozesse für die Erstellung von Versionsnummern gab. Dies hatte zur Folge, dass das Team die Qualität des Artefakts sicherstellen musste und sich nicht mehr sicher war, mit welcher Version des Artefakts es sich gerade befasste.
Der größte Fehler, den ich je gesehen habe, war die Speicherung der Version eines Artefakts in einer Datenbank zusammen mit anderen Konfigurationseinträgen. Die korrekte Vorgehensweise sollte sein: die Version innerhalb des Artefakts so zu platzieren, dass niemand nach einem Release diese von außen ändern kann. Die Falle, in die man sonst tappt, ist der Prozess, wie man die Version nach einem Release oder Neuinstallation aktualisiert.
Vielleicht haben Sie eine Checkliste für alle manuellen Tätigkeiten während eines Release. Aber was passiert, nachdem eine Version in einer Testphase installiert wurde und aus irgendeinem Grund eine andere Version der Anwendung eneut installiert werden muss? Ist Ihnen noch bewusst, dass Sie die Versionsnummer manuell in der Datenbank ändern müssen? Wie finden Sie heraus, welche Version installiert ist, wenn die Informationen in der Datenbank nicht stimmen?
Die richtige Version in dieser Situation zu finden, ist eine sehr schwierige Aufgabe. Aus diesem Grund haben gibt es die Anforderung, die Version innerhalb der Anwendung zu halten. Im nächsten Schritt werden wir einen sicheren und einfachen Weg aufzeigen, wie man dieses Problem voll automatisiert lösen kann.
Die Voraussetzung ist eine einfache Java-Bibliothek die mit Maven gebaut wird. Standardmäßig wird die Versionsnummer des Artefakts in der POM notiert. Nach dem Build-Prozess wird unser Artefakt erstellt und wie folgt benannt: artifact-1.0.jar oder ähnlich. Solange wir das Artefakt nicht umbenennen, haben wir eine gute Möglichkeit, die Versionen zu unterscheiden. Selbst nach einer Umbenennung kann mit einem einfachen Trick nach einem Unzip des Archives im META-INF-Ordner der richtige Wert gefunden werden.
Wenn Sie die Version in einer Poroperty oder Klasse fest einkodiert haben, würde das auch funktionieren, solange Sie nicht vergessen diese immer aktuell zu halten. Vielleicht müssen Sie dem Branching und Merging in SCM Systemen wie Git besondere Aufmerksamkeit schenken, um immer die korrekte Version in Ihrer Codebasis zu haben.
Eine andere Lösung ist die Verwendung von Maven und dem Tokenreplacement. Bevor Sie dies in Ihrer IDE ausprobieren, sollten Sie bedenken, dass Maven zwei verschiedene Ordner verwendet: Sources und Ressourcen. Die Token-Ersetzung in den Quellen wird nicht richtig funktionieren. Nach einem ersten Durchlauf ist Ihre Variable durch eine feste Zahl ersetzt und verschwunden. Ein zweiter Durchlauf wird daher fehlschlagen. Um Ihren Code für die Token-Ersetzung vorzubereiten, müssen Sie Maven als erstes im Build-Lifecycle konfigurieren:
Nach diesem Schritt müssen Sie die Property ${project.version} aus dem POM kennen. Damit können Sie eine Datei mit dem Namen version.property im Verzeichnis resources erstellen. Der Inhalt dieser Datei besteht nur aus einer Zeile: version=${project.version}. Nach einem Build finden Sie in Ihrem Artefakt die version.property mit der gleichen Versionsnummer, die Sie in Ihrem POM verwendet haben. Nun können Sie eine Funktion schreiben, die die Datei liest und diese Property verwendet. Sie können das Ergebnis zum Beispiel in einer Konstante speichern, um es in Ihrem Programm zu verwenden. Das ist alles, was Sie tun müssen!
Nachdem Oracle den neuen Release-Zyklus für Java eingeführt hatte, war ich von dieser Strategie nicht überzeugt. Auch heute noch bin ich anderer Meinung. Ein Kritikpunkt ist die Vernachlässigung der semantischen Versionierung. Auch die Behauptung, der neue Zyklus ermögliche eine schnellere Bereitstellung neuer Funktionen, teile ich nicht. Meiner Ansicht nach könnten dadurch zukünftig Probleme auftreten. Doch Moment, fangen wir von vorne an, bevor ich meine Gedanken ausführlich darlege.
Der von Oracle 2017 angekündigte sechsmonatige Release-Zyklus für Java sorgte für Unsicherheit in der Community. Die größte Befürchtung wurde durch die weit verbreitete Frage formuliert: Wird Java in Zukunft nicht mehr kostenlos sein? Die Antwort ist natürlich ein klares Nein, aber Unternehmen sollten sich der Auswirkungen bewusst sein. Bei großen Produktionsanwendungen ergeben sich einige Punkte für das Risikomanagement und die Geschäftskontinuitätsstrategie. Wenn der LTS-Support für Sicherheitsupdates nach dem dritten Jahr einer veröffentlichten Version kostenpflichtig wird, sind klar definierte Update-Strategien für den Produktiveinsatz unerlässlich. Ich befürchte, zukünftig mehr Zeit mit der Migration meiner Projekte auf neue Java-Versionen verbringen zu müssen als mit der Implementierung neuer Funktionen. Eine Lösung, um ständige Update-Orgien zu vermeiden, wäre der Wechsel von der Oracle JVM zu OpenJDK.
Im professionellen Umfeld ist es üblich, dass Unternehmen aus Sicherheitsgründen ein festes Setup definieren. Wenn ich jedoch ständig gezwungen bin, meine Komponenten zu aktualisieren, ohne die Sicherheit der neuen Funktionen zu gewährleisten, kann das Probleme verursachen. Kommerzielle Projekte laufen unter anderen Bedingungen und benötigen oft besondere Aufmerksamkeit. Denn man braucht eine klar definierte Umgebung, in der alles stabil läuft. Es gilt: Niemals ein laufendes System anfassen.
Ich kann Oracles Intention hinter diesem Schritt durchaus nachvollziehen. Ich vermute, es ist ein Weg, alte, fehlerhafte und unsichere Installationen loszuwerden und das Internet sicherer zu machen. Natürlich kann man keine jahrzehntealten, veralteten Versionen mehr unterstützen. Das hätte erhebliche finanzielle Auswirkungen. Ich wünschte mir jedoch eine weniger rabiate Strategie. Leider ist es in der Geschäftswelt oft üblich, so zu agieren. Ich wünschte, es gäbe eine vertrauensvollere Kommunikation.
Erfahrungsgemäß dauert es bei Java-Vorabversionen immer eine Weile, bis sie stabil laufen. In diesem Zusammenhang erinnere ich mich an einige gravierende Probleme, die ich mit der Umstellung auf 64-Bit-Versionen hatte. Das gängige Motto „Das Neueste ist das Beste“ kann gefährlich sein. Insbesondere zeitbasierte Releases bergen ein hohes Risiko für Probleme, selbst bei erfahrenen Teams. Der Druck, pünktlich zu liefern, ist enorm.
Ein weiterer Diskussionspunkt ist die semantische Versionierung. Es ist ein sehr wirkungsvolles Verfahren, das ich stets empfehle. Ich frage mich jedoch, ob es wirklich alle sechs Monate neue Sprachfunktionen gibt, die eine Erhöhung der Major-Versionsnummer rechtfertigen? Selbst bei Patches und Erweiterungen? Was aber passiert, wenn zukünftig keine neuen Sprachfunktionen mehr benötigt werden? Das erzwungene Hinzufügen neuer Funktionen kann die Qualität beeinträchtigen. Meiner Meinung nach enthält Java viele lehrreiche Funktionen, und nicht jede neue Funktion erweitert den Funktionsumfang der Sprache. Ein einfaches Beispiel ist die bekannte GOTO-Anweisung in anderen Sprachen. Programmieranfänger haben oft gelernt: „Wenn du etwas siehst, lauf weg. Benutze niemals GOTO.“ In Java vergleiche ich innere Klassen oft mit GOTO, da ich denke, dass man dies vermeiden sollte. Bisher habe ich keinen Fall gefunden, in dem innere Klassen nicht auf Designprobleme hindeuten. Dasselbe gilt für die häufige Verwendung von Funktionsanweisungen. Ich sehe keinen Vorteil darin, eine for-Schleife als Lambda-Funktion anstatt auf die klassische Weise zu definieren.
Meiner Meinung nach versucht Oracle hier, sich ein Stück vom Kuchen zu sichern, um das eigene Geschäft auszubauen. Das ist an sich nicht schlecht. Aus Sicht des Projektmanagements halte ich diese Strategie jedoch für fragwürdig.
m Umgang mit Source-Control-Management-Systemen (SCM) wie Git oder Subversion haben sich im Lauf der Zeit vielerlei Praktiken bewährt. Neben unzähligen Beiträgen über Workflows zum Branchen und Mergen ist auch das Formulieren verständlicher Beschreibungen in den Commit-Messages ein wichtiges Thema.
(c) 2018 Marco Schulz, Java PRO Ausgabe 3, S.50-51
Ab und zu kommt es vor, dass in kollaborativen Teams vereinzelte Code-Änderungen zurückgenommen werden müssen. So vielfältig die Gründe für ein Rollback auch sein mögen, das Identifizieren betroffener Code-Fragmente kann eine beachtliche Herausforderung sein. Die Möglichkeit jeder Änderung des Code-Repository eine Beschreibung anzufügen, erleichtert die Navigation zwischen den Änderungen. Sind die hinterlegten Kommentare der Entwickler dann so aussagekräftig wie „Layout-Anpassungen“ oder „Tests hinzugefügt“, hilft dies wenig weiter. Diese Ansicht vertreten auch diverse Blog-Beiträge [siehe Weitere Links] und sehen das Formulieren klarer Commit-Messages als wichtiges Instrument, um die interne Kommunikation zwischen einzelnen Team-Mitgliedern deutlich zu verbessern.
Das man als Entwickler nach vollbrachter Arbeit nicht immer den optimalen Ausdruck findet, seine Aktivitäten deutlich zu formulieren, kann einem hohen Termindruck geschuldet sein. Ein hilfreiches Instrument, ein aussagekräftiges Resümee der eigenen Arbeit zu ziehen, ist die nachfolgend vorgeschlagene Struktur und ein darauf operierendes aussagekräftiges Vokabular inklusive einer festgelegten Notation. Die vorgestellte Lösung lässt sich sehr leicht in die eigenen Prozesse einfügen und kann ohne großen Aufwand erweitert bzw. angepasst werden.
Mit den standardisierten Expressions besteht auch die Möglichkeit die vorhandenen Commit-Messages automatisiert zu Parsen, um die Projektevolution gegebenenfalls grafisch darzustellen. Sämtliche Einzelheiten der hier vorgestellten Methode sind in einem Cheat-Sheet auf einer Seite übersichtlich zusammengefasst und können so leicht im Team verbreitet werden. Das diesem Text zugrundeliegende Paper ist auf Research-Gate [1] in englischer Sprache frei verfügbar.
Eine Commit-Message besteht aus einer verpflichtenden (mandatory) ersten Zeile, die sich aus der Funktions-ID, einem Label und der Spezifikation zusammensetzt. Die zweite und dritte Zeile ist optional. Die Task-ID, die Issue-Management-Systeme wie Jira vergeben, wird in der zweiten Zeile notiert. Grund dafür ist, dass nicht jedes Projekt an ein Issue-Management-System gekoppelt ist. Viel wichtiger ist auch die Tatsache, dass Funktionen meist auf mehrere Tasks verteilt werden. Eine Suche nach der Funktions-ID fördert alle Teile einer Funktionalität zu tage, auch wenn dies unterschiedlichen Task-IDs zugeordnet ist. Die ausführliche Beschreibung in Zeile drei ist ebenfalls optional und rückt auf Zeile zwei vor, falls keine Task-ID notiert wird. Das gesamte Vokabular zu dem nachfolgenden Beispiel ist im Cheat-Sheet notiert und soll an dieser Stelle nicht wiederholt werden.
[CM-05] #CHANGE ’function:pom’
<QS-0815>
{Change version number of the dependency JUnit from 4 to 5.0.2}
Projektübergreifende Aufgaben wie das Anpassen der Build-Logik, Erzeugen eines Releases oder das Initiieren eines Repositories können in allgemeingültigen Funktions-IDs zusammengefasst werden. Entsprechende Beispiele sind im Cheat-Sheet angeführt.
Möchte man nun den Projektfortschritt ermitteln, ist es sinnvoll aussagekräftige Meilensteine miteinander zu vergleichen. Solche Punkte (POI) stellen üblicherweise Releases dar. So können bei Berücksichtigung des Standard-Release-Prozesses und des Semantic-Versionings Metriken über die Anzahl der Bug-Fixes pro Release erstellt werden. Aber auch klassische Erhebungen wie Lines-of-Code zwischen zwei Minor-Releases können interessante Erkenntnisse fördern.
Schon in einem recht frühen Stadium müssen die fertigen Sourcen auf verschiedenste Zielsysteme eingespielt werden. Üblicherweise existieren mehrere zentrale Entwicklungsserver, zu denen noch für jeden Entwickler eine eigene lokale Installation hinzukommt. Bei dieser Vielzahl an Systemen, auf der das Projekt lauffähig sein muss, rechnet sich schnell der Aufwand, den eine zentrale und wiederverwendbare Build-Logik erfordert.
Wer schon das eine oder andere Deployment hinter sich gebracht hat, weiß, dass die Softwareverteilung einiges an Tücken zu bieten hat und in aller Regel nichts mal schnell eingespielt wird. Um die üblichen und immer wiederkehrenden Fallstricke vermeiden zu können, werden in der Software-Entwicklung seit Jahren verschiedenste Automatisierungswerkzeuge eingesetzt. In diesem Artikel lernen Sie das Werkzeug Ant kennen und erfahren, wie Sie es in Ihren PHP-Projekten verwenden können.
Das Akronym Ant steht für Another Neat Tool und bedeutet frei übersetzt: Ein weiteres hübsches Werkzeug. Zusätzlich bedeutet nt im Englischen Ameise. Genau diese Bezeichnung beschreibt Ant mit nur einem Wort sehr treffend, denn es ist wie eine Ameise: klein, fleißig, äußerst robust, zuverlässig und leistet im Vergleich zu seiner Größe Unglaubliches.
Ant ist ein Top-Level-Projekt der Apache Group und wird seit Jahren in unzähligen Projekten erfolgreich eingesetzt. Auf der Projekt-Homepage können die bereits kompilierten Binarys sowie die Sourcen kostenlos heruntergeladen werden. Die Grundintention von Ant ist die Verwendung als Build-Werkzeug im Java-Umfeld. Die enorme Vielfalt der Funktionen und die einfache Erweiterbarkeit machen das Tool auch außerhalb der Java-Welt interessant. Mit Ant können Sie unter anderem komplette Verzeichnisse kopieren, komprimieren und dabei einzelne Dateien ausschließen. In Textdateien können Variablen definiert werden, die dann durch konkrete Werte ersetzt werden, und es gibt FTP- und SVN-Anbindungen.
Besonders durch den Leistungsumfang, die Stabilität, die einfache Installation und die reichhaltige Dokumentation unterscheidet sich Ant von anderen Deployment-Tools für PHP, wie beispielsweise dem in Ruby implementierten PHP-Build-Tool Capistrano.
Deployment-Strategien
Unter Deployment versteht man in der IT sämtliche Maßnahmen, die zur Verteilung von Software auf die Zielumgebungen notwendig sind. Für PHP-Applikationen zählt dazu beispielsweise das Anpassen der Konfiguration des Webservers und der Datenbank sowie das Einspielen der Datenbankschemata und der PHP-Skripts.
Das folgende Szenario stellt den Rahmen für die Komposition unserer Build-Logik dar. Die Vorgehensweise lässt sich auch ohne Weiteres auf andere Projekte übertragen und den eigenen Anforderungen anpassen.
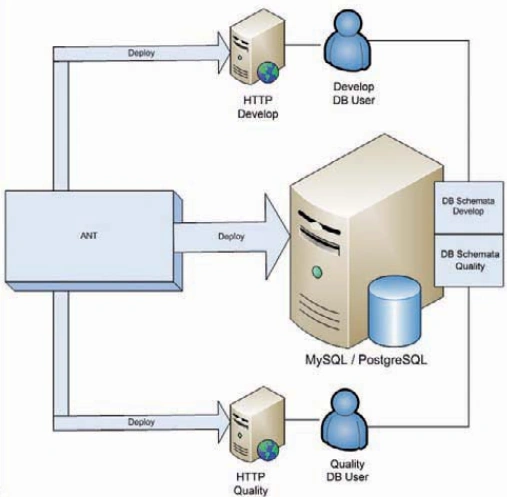
Auf dem Entwicklungsrechner befinden sich zwei unabhängige Webserver-Installationen sowie ein Datenbank-Server, den sich die beiden Webserver teilen. Ein Webserver wird Develop benannt und hat eine lockere Konfiguration der Sicherheitseinstellungen. Die Ausgabe von PHP- und SQL-Fehlern wird hier nicht unterdrückt. Beim zweiten Webserver verhält sich die Konfiguration schon bedeutend anders. Auf diesem als Quality benannten System herrschen starke Sicherheitsrestriktiven, zum Beispiel, dass keine Dateien per Remote im Skript verarbeitet werden dürfen. Der Quality-Server (QS) hat im Idealfall die gleiche Konfiguration wie später das Live-System des Kunden. Beide Systeme teilen sich einen Datenbank-Server, auf dem für jedes System ein eigener Benutzer mit eigenem Schema angelegt ist. Die Grafik in Bild 1 verdeutlicht den Zusammenhang.
Für unser Szenario ist der populäre Webshop Magento als Build-Projekt auserkoren, es kann aber auch jedes beliebige andere CMS- beziehungsweise PHP-Projekt zur Entwicklung Ihrer Deployment-Strategie genutzt werden.
Nach dem Download und dem Entpacken des aktuellen Magentos in ein frisches Projektverzeichnis auf dem Development-Server wird das Programm über den mitgelieferten Webinstaller auf dem Server Develop installiert. Dazu kommen noch alle notwendigen Translation-Files und zusätzliche Plug-ins. Nachdem der Shop so weit funktionsfähig ist, werden alle Dateien unter das Konfigurationsmanagement gestellt und dieser Stand mit inital installation markiert.
In dem hier beschriebenem Szenario soll das Konfigurationsmanagement der Wahl die Versionsverwaltung Subversion sein. Würden wir nun diesen Stand unverändert in das Live-System einspielen wollen, würden wir feststellen das der Shop nicht läuft, weil unter anderem die Datenbankparameter nicht korrekt sind. Außerdem ist es auch nicht wünschenswert, die .svn-Verzeichnisse samt Inhalt in das Live-System zu übertragen, da diese schnell zu einer nicht unerheblichen Datenmenge anwachsen.
Mit dem QS-System haben wir nun eine Zwischenstufe eingebaut, mit der das Deployment für das Zielsystem risikofrei getestet werden kann. In größeren Projekten werden zu diesem Zweck sogar mehrere QS-Instanzen parallel betrieben.
Die Installation
Bevor es losgeht, muss Ant auf dem Entwicklungsrechner verfügbar sein. Wer bereits Eclipse, Netbeans oder Intellij Idea als Entwicklungsumgebung verwendet, hat bereits alles an Bord, was notwendig ist. Sollte Ihre IDE keine native Ant-Integration besitzen, können Sie das Tool schnell nachinstallieren.
Ant selbst ist ein Programm, das klassisch über die Textkonsole im Root des aktuellen Projektverzeichnisses mit dem Kommando ant aufgerufen wird. Die einzelnen abzuarbeitenden Anweisungen innerhalb eines Targets werden Task genannt. Die build.xml beinhaltet die gesamte Build-Logik. Alle Anweisungen werden in XML notiert, und es ist keine zusätzliche Skriptsprache notwendig.
Damit die build.xml fehlerfrei von Ant verar-eitet werden kann, muss sie wohlgeformt und valide sein. Die Verwendung der bereits genannten Entwicklungsumgebungen unterstützt Sie tatkräftig beim Schreiben dieser Konfigurationsdatei und ermöglicht das komfortable Starten der einzelnen Tasks über eine grafische Oberfläche.
Die Konfigurationsdatei
Der Name der Konfigurationsdatei ist stets build.xml und sie befindet sich im Root-Verzeichnis des aktuellen Projekts. Listing 1 zeigt den grundlegenden Aufbau.
<projectname="Magento Project"default="start"basedir="."><description>Deploymentfile for PHP Projects</description><propertyfile="build.properties"/><propertyname=" deploy.directory” value=”_build”/> <target name="start" description="Full Deployment"> <echo>Ant PHP Deploy Script for PHP Projects</echo> <antcall target="clean_deploy_dir" /> </target> <target name="clean_deploy_dir"> <echo message="Delete the current Deploy Directory for clean up"/> <delete dir="${deploy.directory}" /> </target></project>
XML
Listing 1: Die build.xml
In wird angegeben, um welches Projekt es sich handelt und wo die Projektdateien relativ zur build.xml liegen. Es ist also durchaus möglich, die build.xml auch an eine andere Stelle als ins Root-Verzeichnis zu platzieren – was allerdings nicht zu empfehlen ist, da dies schnell zu ungewünschtem Verhalten führen kann. Mit erfolgt eine kurze Projektbeschreibung, die optional ist und zum besseren Verständnis beiträgt.
Über steigen wir schon voll in die Ant-Syntax ein. definiert Platzhalter, die dann über ${Platzhalter.Name} in der gesamten build.xml verwendet werden können. Diese Eigenschaft ist eine wichtige Grundlage, um saubere Build-Files zu schreiben, weshalb an dieser Stelle der Mechanismus etwas ausführlicher erläutert werden soll.
Platzhalter sind deswegen so wichtig, weil damit Werte befüllt werden, die sich oft ändern können. Beispielsweise wird der Pfad des Verzeichnisses, in das die fertigen Dateien kopiert werden sollen (deploy.directory) an vielen verschiedenen Stellen benötigt. Ändert sich nun dieser Wert, ist es lästig, die gesamte build.xml danach zu durchsuchen und das neue Verzeichnis per Hand an den jeweiligen Stellen zu ändern. Viel angenehmer ist es, diesen Wert zentral an einer festen Position pflegen zu können.
Mit dem Attribut file können die Propertys auch in eine Datei ausgelagert werden. Vor allem Werte, die sich in jedem Fall auf den einzelnen Systemen unterscheiden, sind hervorragende Kandidaten für ausgelagerte Propertys.
Auf diese Weise vermeidet man, dass der Entwickler aus Versehen in der build.xml Änderungen vornimmt und die Build-Logik damit zerstört. Die Syntax in solchen Property-Dateien folgt dem Schema key=value. Die anschließende Benutzung der Platzhalter in der build.xml erfolgt genauso wie für Propertys, die direkt in der Build-Datei definiert werden.
Im Listing sind außerdem zwei definiert. Das Target start wird automatisch beim Aufruf der build.xml ausgeführt. Das Attribut default in bestimmt für den Konsolenaufruf den Task, welcher initial ausgeführt werden soll. Im ersten Target wird ein auf ein weiteres Target mit der Bezeichnung clean_deploy_dir aufgerufen.
Das Auslagern kleiner Operationen in eigene Tasks erhöht die Lesbarkeit der gesamten Datei. Über den antcall können dann die Subtasks in einem zusammenführenden Task wieder orchestriert werden, wobei die Reihenfolge der einzelnen Calls von Bedeutung ist, da die Aufgaben nacheinander ausgeführt werden. Im zweiten Target wird ein delete aufgerufen, das die Verwendung des Platzhalters ${deploy.directory} für das zu löschende Verzeichnis demonstriert.
Eine der wichtigsten Operationen ist das Kopieren von Dateien. Im Kopiervorgang sollen die Inhalte der .svn-Ordner nicht mit berücksichtigt werden. Um wieder das Beispiel Magento aufzugreifen, sollen während des Copys auch noch die Datenbankparameter in der local.xml ersetzt werden. Um diese Aufgabe zu lösen, erweitern wir das vorige Listing um ein neues , das copy_all heißen soll (Listing 2).
Mit wird das Verzeichnis erzeugt, in dem anschließend die Dateien zu finden sind. Der -Befehl erwartet als Attribut todir für das Verzeichnis, in das die Dateien kopiert werden sollen. Hier macht sich die Verwendung der Propertys bezahlt. Mit overwrite=“true“ werden vorhandene Dateien überschrieben. Das eingebettet Element gilt für das Verzeichnis, in dem die build.xml liegt, was durch dir=“.“ bestimmt wird. Es können natürlich auch andere Verzeichnisse angegeben werden. Include und Exclude sind zwar selbsterklärend und es lässt sich schnell ahnen, welche Bewandtnis es damit hat. Die Verwendung ist aber nicht ganz so simpel. Als Werte sind für diese beiden Attribute unter anderem Wildcards möglich, /* bedeutet: »Nimm alles inklusive der Unterverzeichnisse.« Die Excludes sind der Übersicht halber wieder in eine eigene Property ausgelagert. Wie gut zu erkennen ist, dürfen die Verzeichnisse und Dateien kommasepariert als Wert übergeben werden. Auch hier sind verschiedene Kombinationen von Wildcards gestattet.
Als Nächstes lernen wir die Textersetzung kennen. Für die Datei local.xml sollen die Datenbank-Verbindungsparameter vom Zielsystem verwendet werden.
Die Ersetzung selbst ist recht einfach zu handhaben. Es wird der bereits bekannte -Task verwendet, der wiederum aufruft. Der Matcher sollte in der Form @ERSET-ZUNGSTEXT@ in den Template-Dateien verwendet werden.
Datenbanken
Eine weitere Grundfunktion von Ant ist der Zugriff auf Datenbanken. Um diese Funktion nutzen zu können, muss man wissen, dass Java-Programme die Java-Database-Connectivity-Treiber für den Zugriff auf Datenbanken benötigen. Diese Treiber sind einfache JAR-Dateien die von der Webseite des Datenbankherstellers heruntergeladen werden können. Das Listing 3 zeigt, wie mittels Ant auf eine MySQL-Datenbank zugegriffen wird.
In sind die spezifischen Datenbankparameter hinterlegt. In wird für Ant die Position zur JDBC-Treiberdatei hinterlegt. Neben der Angabe einer SQL-Datei in können innerhalb dieses Tags auch reine SQL-Statements eingetragen werden.
Es ist nun nicht weiter nötig, aufwendig ein Datenbank-Dump-File manuell zu erzeugen, um dieses dann auf die gleiche Art in das Zielsystem einzuspielen. Mit dem Task sql können Sie diese Aufgabe zukünftig an Ant delegieren.
Kompression und FTP
Nachdem alle notwendigen Dateien in das Deploy-Verzeichnis kopiert wurden, könnten die nächsten Aufgaben darin bestehen, die benötigten Skripts in einer ZIP-Datei zu komprimieren und per FTP auf den Webserver zu übertragen. Das Listing 4 bewirkt genau dieses.
Dank des bereits erworbenen Wissens ist das Listing selbsterklärend. Es stellt sich jedoch die Frage, was passiert, wenn die Datei auf dem Webserver übertragen wurde. Hier bietet sich die Verwendung eines einfachen PHP-Skripts zum Entpacken des Archivs an (Listing 5).
So einfach, wie das Skript gestaltet ist, hat auch diese Lösung ihre Eigenheiten. Wer eine komplette Magento-Installation komprimiert und auf diese Art auf dem Live-Server entpacken möchte, wird schnell die PHP-Grundeinstellung max_execution_time seines Servers kennenlernen. Komplexe Applikationen wie Magento sind sehr umfangreich und benötigen zum Entpacken eine längere Ausführungszeit des Skripts, als von der PHP-Konfiguration vorgesehen.
Eine Lösung wäre, die verschiedenen Verzeichnisse einzeln zu komprimieren und diese Dateien dann zu übertragen und nacheinander zu entpacken. Das bietet sich eher bei einer Gesamtinstallation an. Bei einem einfachem Update ist die Verwendung der Diff-Funktion der Versionsverwaltung wesentlich eleganter.
Ant Erweitern
Der modulare Aufbau von Ant erlaubt es auch, das Werkzeug um eigene Funktionen, die nicht im Core enthalten sind, zu erweitern. Neben der bereits erwähnten Erweiterung für Subversion existieren im Web noch zahlreiche weitere Plugins, zum Beispiel ein Javascript-Minimizer oder der PHP-Documentator.
Der Javascript-Minimizer optimiert die JavaScript-Dateien, in dem er unter anderem Kommentare und unnötige Leerzeichen entfernt (Listing 6). Nach der Komprimierung hat die Javascript-Datei einiges abgespeckt. Dadurch wird sie schneller vom Browser geladen. definiert einen neuen Task mit dem Namen jsmin und verweist mit classpath auf die Datei des Plug-ins. Der classname ist die ausführende Klasse und muss aus der Dokumentation des entsprechenden Plug-ins entnommen werden. Anschließend wird in das bereits bekannte Element verwendet, um die zu komprimierenden Javascript-Dateien anzugeben. Mit der Einstellung force=“true“ werden bereits vorhandene Dateien überschrieben.
<taskdefname="jsmin"classname="net.matthaynes.jsmin.JSMin_Task"classpath="jsmin-0.2.4.jar"/><targetname="jsCompressor"><echomessage="minimize all JS."/><jsminforce="true"><filesetdir="${deploy.dir}/js"includes="**/*.js"/></jsmin></target>
XML
Listing 6: JavaScript minimieren
Dokumentation erzeugen
Das an Java Doc angelehnte PHP Doc lässt sich auch mit Ant erzeugen. Mit ist Ant in der Lage, sogenannte Executables auszuführen. Da PHP Doc in PHP implementiert ist, muss die php.exe die Dokumentation generieren. Das Listing 7 demonstriert das Vorgehen.
Die Werte, welche durch übergeben werden, sind Kommandozeilen-Parameter, mit denen PHP gestartet wird. In der Property ${php.exe} wird der absolute Pfad zur php.exe hinterlegt. Der Dokumentator startet im aktuellen Projektverzeichnis, wozu er mit dir=“.“ bewegt wird. Die fertige Doku wird in das Verzeichnis geschrieben, das über die Property ${deploy.dir.phpdoc} angegeben wurde. Schließlich ist es noch notwendig, den Pfad zu PHP Doc anzugeben, was mit der Property ${phpdoc.extension .inc} getan wurde.
Cookie Consent
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.