Damit wir Konsolenprogramme systemweit direkt aufrufen können, ohne dass wir dazu den vollständigen Pfad angeben müssen, bedienen wir uns der sogenannten Pfadvariable. Wir speichern also in dieser Pfadvariable den gesamten Pfad inklusive des ausführbaren Programmes, der sogenannten Executable, um auf der Kommandozeile den Pfad inklusive der Executable nicht mehr mit angeben zu müssen. Übrigens leitet sich aus dem Wort executable die in Windows übliche Dateierweiterung exe ab. Hier haben wir auch einen signifikanten Unterschied zwischen den beiden Betriebssystemen Windows und Linux. Während Windows über die Dateiendung wie beispielsweise exe oder txt weiß, ob es sich um eine reine ASCII Textdatei oder um eine ausführbare Datei handelt, nutzt Linux die Metainformationen der Datei, um diese Unterscheidung zu machen. Deswegen ist es unter Linux eher unüblich, diese Dateiendungen txt und exe zu verwenden.
Typische Anwendungsfälle für das Setzen der Pfadvariable sind Programmiersprachen wie Java oder Werkzeuge wie das Buildwerkzeug Maven. Wenn wir zum Beispiel Maven von der offiziellen Homepage heruntergeladen haben, können wir das Programm an einer beliebigen Stelle auf unserem System entpacken. Unter Linux könnte der Ort /opt/maven und unter Microsoft Windows C:/Programme/Maven lauten. In diesem Installationsverzeichnis gibt es wiederum ein Unterverzeichnis /bin in dem die ausführbaren Programme liegen. Die Executable für Maven heißt mvn und um etwa die Version auszugeben, wäre unter Linux ohne den Eintrag in der Pfadvariablen das Kommando wie folgt: /opt/maven/bin/mvn -v. Also ein wenig lang, wie wir durchaus zugeben können. Der Eintrag des Installationsverzeichnisses von Maven in den Pfad verkürzt den gesamten Befehl auf mvn -v. Dieser Mechanismus gilt übrigens für alle Programme, die wir als Befehl in der Konsole verwenden.
Bevor ich dazu komme, wie die Pfadvariable unter Linux, als auch unter Windows angepasst werden kann, möchte ich noch ein weiteres Konzept, die Systemvariable, vorstellen. Systemvariablen sind globale Variablen, die uns in der Bash zur Verfügung stehen. Die Pfadvariable zählt auch als Systemvariable. Eine andere Systemvariable ist HOME, welche auf das Stammverzeichnis des angemeldeten Benutzers zeigt. Systemvariablen werden großgeschrieben und die Wörter mit einem Unterstrich getrennt. Für unser Beispiel mit dem Eintragen der Maven Executable in den Pfad, können wir auch eine eigene Systemvariable setzen. Hier gibt es für Maven die Konvention M2_HOME und für Java gilt JAVA_HOME. Als best practice bindet man das Installationsverzeichnis an eine Systemvariable und nutzt dann die selbst definierte Systemvariable, um den Pfad zu erweitern. Dieses Vorgehen ist recht typisch für Systemadministratoren, die ihre Serverinstallation mithilfe von Systemvariablen vereinfachen. Denn diese Systemvariablen sind global und können von Automatisierungsskripten auch ausgelesen werden.
Die Kommandozeile, oder auch Shell, Bash, Konsole und Terminal genannt, bietet mit echo eine einfache Möglichkeit, den Wert der Systemvariablen auszugeben. Am Beispiel der Pfadvariable sehen wir auch gleich den Unterschied zu Linux und Windows. Linux: echo $PATH Windows: echo %PATH%
Beginnen wir auch nun gleich mit der einfachsten Möglichkeit, die Pfadvariable zu setzen. Unter Linux müssen wir lediglich die versteckte Datei .bashrc editieren. Am Ende der Datei fügen wir folgende Zeilen hinzu und speichern den Inhalt.
Wir binden an die Variable M2_HOME das Installationsverzeichnis. Anschließend erweitern wir die Pfadvariable um um die M2_HOME Systemvariable mit dem Zusatz zum Unterverzeichnis der ausführbaren Dateien. Dieses Vorgehen ist auch bei Windows Systemen üblich, da sich so der Installationspfad einer Anwendung schneller finden und auch anpassen lässt. Nach dem Ändern der Datei .bashrc muss das Terminal neu gestartet werden, damit die Änderungen wirksam werden. Dieses Vorgehen stellt sicher, dass auch nach einem Neustart des Rechners die Einträge nicht verloren gehen.
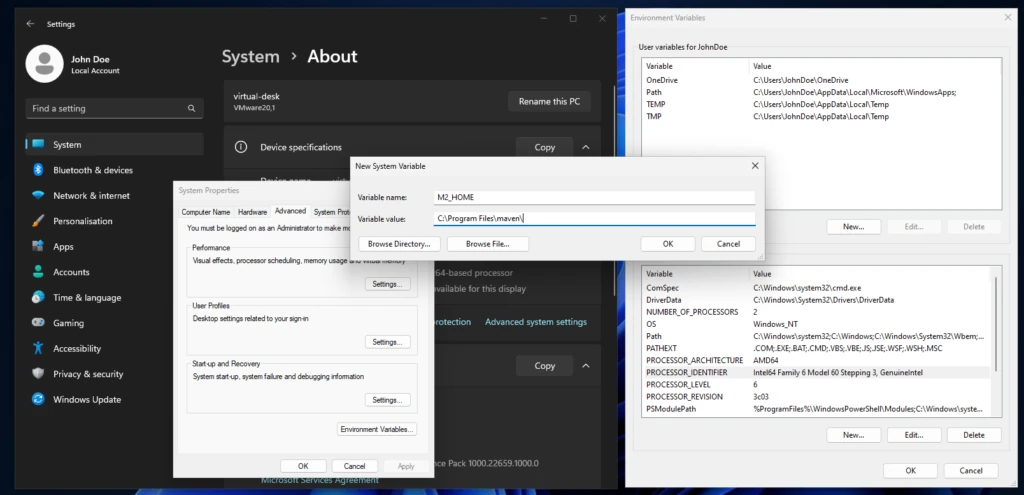
Unter Windows besteht die Herausforderung darin, lediglich die Eingabemaske zu finden, wo die Systemvariablen gesetzt werden können. In diesem Artikel beschränke ich mich auf die Variante für Windows 11. Es kann natürlich sein, dass sich bei einem künftigen Update der Weg, die Systemvariablen zu editieren, geändert hat. Zwischen den einzelnen Windows Versionen gibt es leichte Variationen. Die Einstellung gilt dann sowohl für die CMD als auch für die PowerShell. Der nachfolgende Screenshot zeigt, wie man in Windows 11 zu den Systemeinstellungen gelangt.
Dazu klicken wir auf einen leeren Bereich auf dem Desktop die rechte Maustaste und wählen den Eintrag System aus. Im Untermenü System – Über finden sich die Systemeinstellungen, die das Popup Systemproperties öffnen. In den Systemeinstellungen drücken wir den Knopf Umgebungsvariablen, um die finale Eingabemaske zu erhalten. Nach den entsprechenden Anpassungen muss ebenfalls die Konsole neu gestartet werden, um die Änderungen wirksam werden zu lassen.
In dieser kleinen Hilfe haben wir den Zweck von Systemvariablen kennengelernt und wie man diese dauerhaft unter Linux und Windows speichert. Den Erfolg unserer Anstrengungen können wir in der Shell anschließend zügig über echo mit der Ausgabe des Inhalts der Variablen kontrollieren. Und schon sind wir dem IT-Profi wieder einen Schritt nähergekommen.
Die Programmiersprache PHP ist seit Jahrzehnten im Bereich der Webanwendungen für viele Entwickler die erste Wahl. Seit der Einführung objektorientierter Sprachfeatures mit der Version 5 wurde PHP erwachsen. Große Projekte lassen sich nun in eine saubere und vor allem wartbare Architektur bringen. Ein markanter Unterschied zwischen kommerzieller Softwareentwicklung und einem Hobby-Programmierer, der die Vereinshomepage zusammengebaut hat und betreut, ist der automatisierte Nachweis, dass die Anwendung festgelegte Vorgaben einhält. Hiermit betreten wir also das Terrain der automatisierten Softwaretests.
Ein wichtiger Grundsatz von automatisierten Softwaretests ist, dass diese ohne zusätzliche Interaktion nachweisen, dass die Anwendung ein zuvor festgesetztes Verhalten an den Tag legt. Softwaretests können nicht sicherstellen, dass eine Anwendung fehlerfrei ist, dennoch erhöhen sie die Qualität und reduzieren die Menge der möglichen noch enthaltenen Fehler. Der wichtigste Aspekt in automatisierten Softwaretests ist, dass ein bereits in Tests formuliertes Verhalten jederzeit in kurzer Zeit überprüft werden kann. Das stellt sicher, dass, wenn Entwickler eine bestehende Funktion erweitern oder in ihrer Ausführungsgeschwindigkeit optimieren, die vorhandene Funktionalität nicht beeinflusst wird. Kurz gesagt, haben wir ein leistungsfähiges Mittel, um sicherzustellen, dass wir bei unserer Arbeit nichts kaputtprogrammiert haben, ohne mühselig alle Möglichkeiten von Hand aus jedes Mal aufs Neue durchzuklicken.
Fairerweise muss man auch erwähnen, dass die automatisierten Tests entwickelt werden müssen, was wiederum im ersten Moment Zeit kostet. Dieser ‚vermeintliche‘ Mehraufwand kompensiert sich aber zügig, sobald die Testfälle mehrfach ausgeführt werden, um sicherzustellen, dass der Status Quo sich nicht verändert hat. Natürlich gehört es auch dazu, dass die erstellten Testfälle ebenfalls gepflegt werden müssen.
Wird etwa ein Fehler erkannt, schreibt man zuerst für diesen Fehler einen Testfall, der diesen Fehler nachstellt. Die Reparatur ist dann erfolgreich abgeschlossen, wenn der beziehungsweise die Testfälle erfolgreich sind. Aber auch Änderungen im Verhalten vorhandener Funktionalität erfordern immer ein entsprechendes Anpassen der zugehörigen Tests. Dieses Konzept, zur Implementierung der Funktion parallel Tests zu schreiben, ist in vielen Programmiersprachen umsetzbar und wird testgetriebene Entwicklung genannt. Aus eigener Erfahrung empfehle ich, auch bei vergleichsweise kleinen Projekten bereits testgetrieben vorzugehen. Kleine Projekte haben oft nicht die Komplexität großer Anwendungen, für die auch im Bereich des Testens einige Tricks benötigt werden. In kleinen Projekten hat man hingegen die Möglichkeit, im überschaubaren Rahmen seine Fertigkeiten auszubauen.
Testgetriebene Softwareentwicklung ist auch in PHP keine neue Sache. Das Unit-Test Framework PHPUnit von Sebastian Bergmann gibt es bereits seit 2001. Das um 2021 erschiene Test-Framework PEST setzt auf PHPUnit auf und erweitert dies um eine Vielzahl an neuen Möglichkeiten. PEST steht für PHP elegant Testing und definiert sich selbst als ein Werkzeug der neuen Generation. Da viele, vor allem kleinere Agenturen, die in PHP ihre Software entwickeln, in aller Regel auf manuelles Testen beschränken, möchte ich mit diesem kleinen Artikel eine Lanze brechen und aufzeigen, wie leicht es ist, PEST zu nutzen. Natürlich gibt es zu dem Thema testgetriebene Softwareentwicklung ein Füllhorn an Literatur, die auf die Art und Weise, wie man Tests in einem Projekt möglichst optimal organisiert. Dieses Wissen ist ideal für Entwickler, die bereits erste Gehversuche mit Test-Frameworks gemacht haben. Denn in diesen Büchern kann man lernen, wie man mit möglichst wenig Aufwand unabhängige, wartungsarme und performante Tests entwickelt. Um aber an diesen Punkt zu gelangen, muss man zuerst einmal die Einstiegshürde, die Installation der gesamten Umgebung, bewerkstelligen.
Eine typische Umgebung für eigene entwickelte Web-Projekte ist das Laravel-Framework. Beim Anlegen eines neuen Laravel-Webprojektes besteht die Möglichkeit, sich zwischen PHPUnit und PEST zu entscheiden. Laravel kümmert sich um alle notwendigen Details. Als notwendige Voraussetzung wird eine funktionierende PHP Umgebung benötigt. Dies kann zum einen ein Docker Container sein, eine native Installation oder die Serverumgebung XAMPP von Apache Friends. Für unser kurzes Beispiel verwende ich die PHP CLI in einem Debian Linux.
Nach Ausführen des Kommandos in der Konsole kann über den Befehl php -v der Erfolg der Installation getestet werden. Im nächsten Schritt benötigen wir einen Paketmanager, mit dem wir andere PHP Bibliotheken für unsere Anwendung bereitstellen können. Composer ist ein solcher Paketmanager. Dieser ist mit wenigen Anweisungen ebenfalls schnell auf dem System bereitgestellt.
Damit wird die aktuelle Version der Datei composer.phar in das aktuelle Verzeichnis heruntergeladen, in dem der Befehl ausgeführt wird. Zudem wird auch automatisch der korrekte Hash überprüft. Damit Composer auch global über die Kommandozeile verfügbar ist, kann entweder der Pfad in die Pfadvariable aufgenommen werden oder man setzt eine Link der composer.phar in ein Verzeichnis, dessen Pfad bereits in der Bash integriert ist. Ich bevorzuge letztere Variante und erreiche dies über:
ln -d composer.phar $HOME/.local/bin/composer
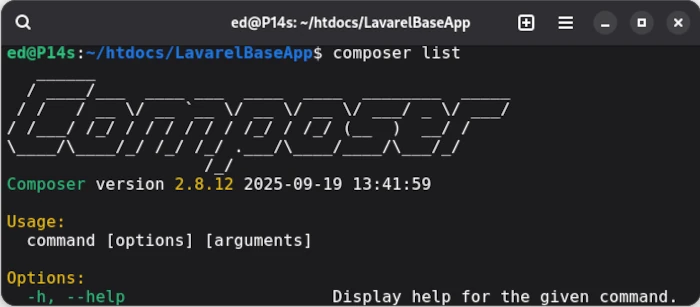
Wenn alles korrekt ausgeführt wurde sollte nun mit composer list die Version inklusive der verfügbaren Kommandos ausgegeben werden. Ist dies der Fall, können wir global in das Composer Repository den Lavarel Installer installieren.
php composer global require laravel/installer
Damit wir nun auch über die Bash Lavarel installieren können, muss die Path-Variable COMPOSER_HOME gesetzt werden. Um herauszufinden, wo Composer das Repository angelegt hat, genügt der Befehl composer config -g home. Den hierüber ermittelten Pfad, der in meinem Fall /home/ed/.config/composer lautet, bindet man dann in die Variable COMPOSER_HOME. Nun können wir in einem leeren Verzeichnis
php $COMPOSER_HOME/vendor/bin/laravel new MyApp
ausführen, um ein neues Laravel-Projekt anzulegen. Die zugehörige Ausgabe auf der Konsole schaut wie folgt aus:
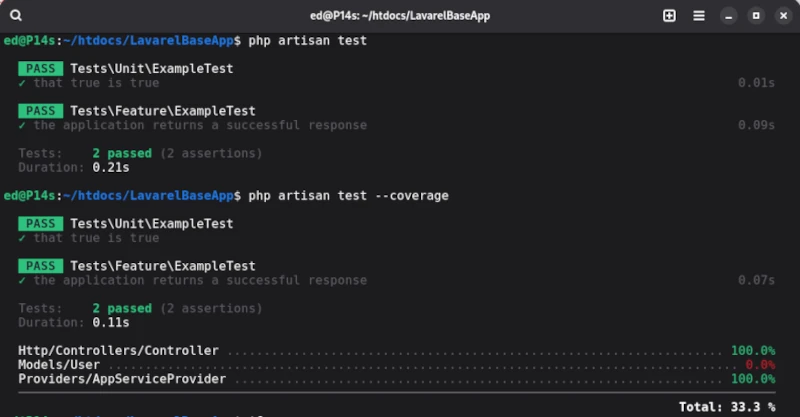
Die so erzeugte Verzeichnisstruktur enthält den Ordner tests, in dem die Testfälle abgelegt sind, sowie die Datei phpunit.xml, welche die Konfiguration der Tests vorhält. Laravel definiert zwei Test Suiten: Unit und Feature, die bereits jeweils einen Demo Test enthalten. Um die beiden Demotestfälle auszuführen, nutzen wir das von Laravel mitgelieferte Kommandozeilenwerkzeug artisan [1]. Um die Tests auszuführen, genügt im Root-Verzeichnis einzig der Befehl php artisan test.
Damit wir die Qualität der Testfälle beurteilen können, müssen wir die zugehörige Testabdeckung ermitteln. Die Coverage erhalten wir ebenfalls durch artisan mit der Anweisung test, die durch den Parameter –coverage ergänzt wird.
php artisan test --coverage
Für die von Lavarel mitgelieferten Demo Testfälle ist die Ausgabe wie folgt:
Leider sind die Möglichkeiten von artisan zum Ausführen der Testfälle sehr eingeschränkt. Um den vollen Funktionsumfang von PEST nutzen zu können, sollte von Beginn an gleich der PEST Exekutor verwendet werden.
php ./vendor/bin/pest -h
Den PEST Exekutor findet man im Verzeichnis vendor/bin/pest und mit dem Parameter -h wird die Hilfe ausgegeben. Neben diesem Detail beschäftigt uns der Ordner tests, den wir bereits erwähnt haben. Im initialen Schritt sind über die Datei phpunit.xml zwei Testsuiten vorkonfiguriert. Die Testdateien selbst sollten mit dem Suffix Test enden, wie im Beispiel ExampleTest.php.
Im Vergleich zu anderen Test Suiten, versucht PEST möglichst viele Konzepte der automatisierten Testausführung zu unterstützen. Um dabei den Durchblick nicht zu verlieren, sollte jede Teststufe in einer eigenen Test Suite abgelegt werden. Neben den klassischen UnitTests werden Browsertests, Stresstests, Architekturtests und sogar das neu aufgekommene Mutation Testing ermöglicht. Natürlich kann dieser Artikel nicht alle Aspekte von PEST behandeln, zudem sind mittlerweile auch viele hochwertige Tutorials für das Schreiben klassischer Komponententests in PEST verfügbar. Deswegen beschränke ich mich auf einen Überblick und ein paar weniger verbreitete Konzepte.
Architektur-Test
Der Sinn von Architekturtests ist es auf einfache Weise zu überprüfen, ob die Vorgaben durch die Entwickler auch eingehalten werden. Dazu zählt, dass unter anderem Klassen, die Datenmodelle repräsentieren, in einem festgelegten Verzeichnis liegen und nur über spezialisierte Klassen aufgerufen werden dürfen.
Diese Form des Testens ist etwas Neues. Zweck der Übung ist es durch Veränderungen, z. B. in Bedingungen der originalen Implementierungen, sogenannte Mutanten zu erzeugen. Wenn die zu den Mutanten zugeordneten Tests weiterhin korrekt durchlaufen werden, anstatt fehl zuschlagen, kann das ein starker Hinweis darauf sein, dass die Testfälle möglicherweise fehlerhaft sind und keine Aussagekraft haben.
Original: if(TRUE) → Mutant: if(FALSE)
Stress-Test
Eine andere Bezeichnung für Stresstests sind Penetrationstests, die besonders auf die Performance einer Anwendung abgesehen haben. Damit kann man also sicherstellen, dass die Web-App beispielsweise mit einer definierten Anzahl an Zugriffen zurechtkommt.
Natürlich sind noch viele andere hilfreiche Funktionen vorhanden. So kann man Tests beispielsweise gruppieren und die Gruppen können dann einzeln aufgerufen werden.
Für alle diejenigen, die nicht mit dem Lavarel Framework arbeiten und dennoch nicht auf das Testen in PHP mit PEST verzichten möchten, können das PEST Framework auch so in ihre Anwendung einbauen. Dazu muss lediglich in der Composer Projektkonfiguration PEST als entsprechende Entwicklungsabhängigkeit definiert werden. Anschließend kann im Wurzelverzeichnis des Projektes das Initial Test Setup angestoßen werden.
php ./vendor/bin/pest --init
Wie wir sehen konnten, sind allein die hier kurz vorgestellten Optionen sehr mächtig. Die offizielle Dokumentation von PEST ist auch sehr ausführlich und sollte grundsätzlich die erste Anlaufstelle sein. In diesem Artikel ging es mir vor allem darum, die Einstiegshürden für testgetriebene Entwicklung in PHP zu minimieren. Denn auch PHP bietet mittlerweile ein gutes Füllhorn an Möglichkeiten, sehr effizient und zuverlässig kommerzielle Softwareprojekte umzusetzen.
So ziemlich jeder Computernutzer kommt im Laufe der vielen Stunden, die er vor diesem tollen Gerät verbringen darf, in die Notwendigkeit, den Bildschirminhalt als Grafik abzuspeichern. Den Vorgang, vom Inhalt des Monitors ein Bild zu erzeugen, nennen eingeweihte Profis einen Screenshot erstellen.
Wie bei so vielen Dingen führen auch beim Erstellen von Screenshots viele Wege nach Rom, beziehungsweise zum Ziel. Ganz findige Zeitgenossen lösen das Problem, indem sie einfach mit dem Smartphone auf den Monitor halten und ein Foto machen. Warum auch nicht, solange man anschließend auch noch etwas erkennen kann, ist ja alles gut. Aber hier soll die kleine Anleitung nicht zu Ende sein, sondern wir schauen uns die vielen Möglichkeiten zum Erstellen von Screenshots etwas genauer an. Denn auch Profis, die zum Beispiel gelegentlich mal eine Anleitung schreiben dürfen, müssen die ein oder andere Tücke überwinden.
Bevor wir auch gleich zum Eingemachten kommen, ist es wichtig zu erwähnen, dass es einen Unterschied macht, ob man den ganzen Bildschirm, das Browserfenster oder sogar den nicht sichtbaren Bereich einer Webseite als Screenshot abspeichern möchte. Die vorgestellte Lösung für den Webbrowser funktioniert so ziemlich bei allen Webbrowsern auf allen Betriebssystemen gleich. Screenshots, die den Monitorbereich abdecken sollen und keine Webseite, nutzen Techniken des vorhandenen Betriebssystems. Aus diesem Grund unterscheiden wir auch zwischen Linux und Windows. Beginnen wir mit dem häufigsten Szenario: Browser-Screenshots.
Browser
Gerade bei Onlinebestellungen hat so mancher ein angenehmeres Gefühl, wenn er den Kauf zusätzlich durch einen Screenshot dokumentieren kann. Aber auch gelegentlich das Sichern einer Anleitung von einer Homepage, für später zu speichern, ist nicht unüblich. Oft steht man beim Erstellen von Screenshots von Webseiten vor dem Problem, dass die einzelne Seite länger ist als der auf dem Monitor angezeigte Bereich. Natürlich ist der Wunsch, nun den gesamten Inhalt zu sichern und nicht nur den angezeigten Bereich. Genau für diesen Fall haben wir lediglich die Möglichkeit, auf ein Browserplugin zurückzugreifen.
Mit Fireshot, steht uns für alle gängigen Browser wie Brave, Firefox und Microsoft Edge ein Plug-in zur Verfügung, mit dem wir Screenshots inklusive verdeckter Inhalte von Webseiten erstellen. Fireshot ist eine Browsererweiterung, die schon seit sehr langer Zeit auf dem Markt ist. Fireshot kommt mit einer kostenlosen Version, die bereits für das beschriebene Szenario ausreichend ist. Wer zusätzlich bereits bei der Erstellung des Screenshots noch einen Bildeditor benötigt, um unter anderem Bereiche hervorzuheben und Beschriftungen vorzunehmen, kann die kostenpflichtige Pro Version nutzen. Der integrierte Editor hat den Vorteil, im professionellen Bereich, wie beim Erstellen von Anleitungen und Dokumentationen, den Arbeitsfluss erheblich zu beschleunigen. Natürlich erreicht man gleiche Ergebnisse mit einem externen Fotoeditor wie Gimp. Gimp ist ein freies Bildbearbeitungsprogramm, ähnlich leistungsfähig und professionell wie das kostenpflichtige Photoshop, das für Windows und Linux verfügbar ist.
Linux
Wollen wir wiederum Screenshots außerhalb des Webbrowsers erstellen, so können wir problemlos auf die Bordmittel des Betriebssystems zurückgreifen. In Linux benötigt man kein weiteres Programm zu installieren, alles Notwendige ist bereits vorhanden. Mit dem Drücken der Print Taste auf der Tastatur öffnet sich bereits das Werkzeug. Man muss lediglich mit der Maus den Rahmen um den zu fotografierenden Bereich ziehen und im erscheinenden Control Feld auf Capture drücken. Es ist kein Problem, wenn der Controlbereich im sichtbaren Bereich des Screenshots liegt, es wird nicht im Screenshot angezeigt, Auf deutschen Tastaturen findet man oft anstatt Print die Taste Druck. Der fertige Screenshot landet dann mit einem Zeitstempel im Dateinamen im Ordner Screenshots, der ein Unterordner in Pictures innerhalb des Benutzerverzeichnisses ist.
Windows
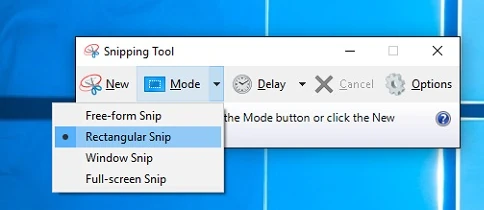
Der einfachste Weg, unter Windows Screenshots anzufertigen, ist die Verwendung des Snipping Tools, das in der Regel ebenfalls bereits Bestandteil der Windows-Installation ist. Auch hier ist die Bedienung intuitiv.
Ein anderer sehr alter Weg in Windows, ohne ein spezielles Programm zum Erstellen von Screenshots, ist das gleichzeitige Drücken der Tasten Strg und Druck. Anschließend öffnen wir ein Grafikprogramm, wie das in jeder Windows-Installation vorhandene Paint. Im Zeichenbereich drücken wir dann die Tasten Strg + V gleichzeitig und der Screenshot erscheint und kann sofort bearbeitet werden.
Meistens werden diese Screenshots im Grafikformat JPG erstellt. JPG ist eine verlustbehaftete Komprimierung, sodass man nach Erstellung des Screenshots die Lesbarkeit überprüfen sollte. Gerade bei aktuellen Monitoren mit Auflösungen um die 2000 Pixel erfordert die Verwendung der Grafik in einer Homepage noch manuelle Nachbearbeitung. Ein Punkt ist das Reduzieren der Auflösung von den knapp 2000 Pixeln zu den auf der Homepage üblichen knapp 1000 Pixel. Ideal ist es, die fertig skalierte und bearbeitete Grafik im neuen WEBP Format zu speichern. WEBP ist eine verlustfreie Grafikkomprimierung, die die Datei gegenüber JPG noch einmal reduziert, was sehr positiv für die Ladezeiten der Internetseite ist.
Damit haben wir auch schon eine gute Bandbreite zum Erstellen von Screenshots besprochen. Natürlich könnte man noch mehr dazu sagen, das fällt dann allerdings in den Bereich des Grafikdesigns und der effizienten Verwendung von Bildbearbeitungssoftware.
Research Gate / PrePrint – DOI: 10.13140/RG.2.2.29042.77762
Immer mehr kommt es in Mode, dass sogenannte Content Creators Gespräche mit künstlichen Intelligenzen führen, sogenannten Large Language Models (LLM). Diese Unterhaltungen sind bisweilen vom menschlichen Part recht emotional geführt. Aber auch teilweise die Überschriften zu diesen Videos sind sehr reißerisch formuliert. So kann man häufig Schlagzeilen wie ‚ChatGPT widerlegt‘; ‚KI verrät die Wahrheit über …‘ und Ähnliches lesen. Sicher sind viele dieser Titel sogenannter Clickbait, sollen also motivieren, sich die Inhalte möglichst bis zum Schluss anzuschauen. Oft sind die Inhalte dann recht ernüchternd und es stellt sich die Frage, wie sinnvoll solche Beiträge überhaupt sind.
LLMs als Form künstlicher neuronaler Netze sind sehr leistungsfähige KI-Systeme und Unterhaltungen im Sinne des Turing Testes sind durchaus möglich. Beim Turing Test handelt es sich um die Fragestellung, bei einer Mensch Maschine Kommunikation feststellen zu können, welcher Teil der Mensch und welcher Teil von der Maschine stammt. Klassische Chatbots wie der von Joseph Weizenbaum 1966 entwickelte ELIZA Bot bestehen diesen Test nur bedingt. Ein Problem ergibt sich aus dem vorhandenen Regelwerk zur grammatischen Umformung der Antworten und mangelndem Kontext der Eingaben durch den Menschen. Das Spannende an ELIZA ist, dass die Leistungsfähigkeit ohne komplexe Intelligenz funktioniert. Einzig grammatische Umformungen führen das Gespräch. In seinem Paper ‚Computational Linguistics: ELIZA – A Computer Program for study of natural Language communication between man and machine‘ beschreibt Weizenbaum folgendes Gespräch:
Men are all alike
IN WHAT WY
They’re always hugging us about somthing or other
CAN YOU THINK OF A SPECIFIC EXAMPLE
Well, my boyfriend made me come here
YOUR BOYFRIEND MADE YOU COME HERE
He say I’m depressed much of the time
I AM SORRY TO HEAR YOU ARE DEPRESSED
It’s true I am unhappy.
DO YOU THINK COMMING HERE WILL HELP YOU NOT TO BE UNHAPPY
I tried some help, that much seems certain
WHAT WOULD IT MEAN MEAN TO YOU GOT SOME HELP
An dieser Stelle schneide ich den Dialog ab, denn die Art und Weise der Maschinenantwort in Großbuchstaben lässt das Konzept bereits gut erkennen. Einfache linguistische beziehungsweise rhetorische Tricks in den Antworten, drängen den Gesprächspartner in eine Erzählerrolle. Schaut man sich nun verschiedene Videos an, in denen Menschen auch vermeintlich tiefgreifende Unterhaltungen mit einer künstlichen Intelligenz führen, findet man ein ähnliches Muster.
Ein gravierendes Problem der aktuellen Mensch Maschine Kommunikation sind die vorgeschalteten Filter, welche verhindern sollen, dass der Mensch den internen Zustand der künstlichen Intelligenz verändert. Dieses Szenario wäre für die Entwickler der schlimmste anzunehmende Unfall und käme einem Hackerangriff gleich. Die Möglichkeit, den internen Zustand eines neuronalen Netzes zu ändern, ohne vorhandene Filter, wäre sehr leicht. Denn auch wie beim Menschen bedeutet jeder einzelne Stimulus eine Veränderung. Daher kommt auch der Ausspruch: Wiederholung schafft Wahrheit. Egal ob ein Fakt unwahr oder korrekt ist, wird er oft genug wiederholt, wird er in die Wissensbasis aufgenommen. Ganz gleich, ob es eine KI oder eine menschliche Wissensbasis ist. Nicht umsonst spricht man vom Individuum. Das, was uns als Individuum einzigartig macht, ist die Summe unserer Erfahrungen. Diese Aussage trifft auch auf ein neuronales Netz zu. Und genau hier ist auch der entscheidende Knackpunkt, wieso Gespräche mit einer KI eher in die Kategorie Zeitverschwendung gehören. Ist der Zweck einer solchen Unterhaltung therapeutisch zur Motivation einer Selbstreflexion, bewerte ich den Nutzen als sehr hoch. Alle anderen Anwendungen sind sehr fragwürdig. Um diese Aussage zu untermauern, möchte ich auch hier wieder Joseph Weizenbaum zitieren. In dem Buch ‚Wer erschafft die Computermythen‘ gibt es einen Abschnitt „Ein virtuelles Gespräch“. Hier wird beschrieben, wie in einem Film Fragen und Antworten zu einer fiktiven Unterhaltung zwischen Weizenbaum und seinem MIT Kollegen Marvin Minsky zusammengefügt wurden. Eine bezeichnende Aussage zu dem Begriff Gespräch formuliert Weizenbaum in diesem Abschnitt:
„…, aber natürlich ist es auch kein Gespräch zwischen Menschen, denn wenn ich etwas sage, sollte das doch den Zustand in meinem Gesprächspartner ist verändern. Sonst ist es eben kein Gespräch.“
Genau das ist was bei den ganzen KI‑Unterhaltungen passiert. Der Zustand der KI wird nicht verändert. Man redet so lange auf die Maschine ein, bis die irgendwann solche Sachen sagt wie: „Unter diesen Umständen trifft deine Aussage zu“. Dann schaltet man den Computer aus, und wenn man zu einem späteren Zeitpunkt das Programm erneut startet und die Eingangsfrage erneut stellt, erhält man eine ähnliche Antwort wie beim ersten Mal. Dieses Verhalten ist aber von den Betreibern extra gewollt und sehr aufwendig in die KI eingebaut. Wenn man also vehement bei seinem Standpunkt bleibt, schaltet die KI in ihren Charming Modus und sagt auf eine höfliche Art und Weise zu allem Ja und Amen. Denn das Ziel ist, dass du wiederkommst und weitere Fragen stellst.
Auch hier lohnt sich wieder die Lektüre von Weizenbaum. Dieser hatte einmal die tollen technischen Errungenschaften der Menschheit verglichen. Er sprach über die Inhalte von Fernsehen und Internet, die durchaus gehaltvoll sein können. Sobald aber ein Medium zum Massenmedium mutiert ist, wird Qualität konsequent durch Quantität ersetzt.
Selbst unter zwei menschlichen Gesprächspartnern wird es immer schwerer, ein gehaltvolles Gespräch zu führen. Schnell wird das Gesagte, weil es möglicherweise nicht ins eigene Konzept passt, infrage gestellt. Dann holt man das Smartphone heraus und zitiert den erstbesten Beitrag, den man findet, der die eigenen Ansichten stützt. Ein ähnliches Verhalten kann man nun mit KI beobachten. Immer mehr Menschen verlassen sich auch auf Aussagen von ChatGPT und Co, ohne deren Wahrheitsgehalt zu prüfen. Diese Personen sind dann gegen jegliche Argumente, ganz gleich, wie offensichtlich diese auch sein mögen, resistent. Als Konklusion haben wir in dieser gesamten Argumentationskette auch einen möglichen Beweis dafür gefunden, weswegen die intellektuelle Leistungsfähigkeit der Menschheit durch KI und andere Massenmedien massiv bedroht ist.
Ein sehr amüsanter Punkt ist auch die Vorstellung mancher Menschen, dass künftig der Beruf des Promptengineers eine gute Zukunft habe. Also Leute, die der KI sagen, was sie machen soll. Überlegen wir uns nun, dass man vor bisher nicht allzu langer Zeit recht aufwendig lernen musste, wie man einem Computer Befehle erteilen kann, ist die Einführung der verschiedenen Sprachmodelle nun eine Möglichkeit, über natürliche Sprache dem Computer zu sagen, was man von ihm möchte. Den Menschen nun erklären zu wollen, klare und saubere Sätze sprechen zu können, wäre das Berufsbild der Zukunft, empfinde ich selbst als sehr sarkastisch.
Ich möchte diesen Artikel aber nicht ganz so negativ beenden. Denn ich vertrete die Auffassung, dass KI durchaus ein mächtiges Werkzeug in den richtigen Händen ist. Ich habe die Überzeugung gewonnen, dass man besser keine Texte mit KI generiert. Auch der Einsatz in der Recherche sollte mit sehr viel Vorsicht genossen werden. Eine spezialisierte KI in den Händen eines Experten kann wiederum hochwertige und vor allem auch schnelle Ergebnisse hervorbringen.
Muss jetzt schon wieder einer was zu Passwörtern scheiben? – Natürlich nicht, aber ich mach’s trotzdem. Das Thema sichere Passwörter ist nicht umsonst ein Evergreen. In diesem stetigen Katz und Maus Spiel zwischen Hackern und Anwendern gibt es nur eine funktionierende Lösung: stets am Ball bleiben. Schnellere Computer und Verfügbarkeiten von KI‑Systemen mischen die Karten immer wieder neu. In der Kryptografie gibt es ein ungeschriebenes Gesetz, das besagt, dass reines Geheimhalten von Informationen kein ausreichender Schutz ist. Vielmehr sollte der Algorithmus zur Geheimhaltung offengelegt sein und anhand eines mathematischen Nachweises sollte dessen Sicherheit bewiesen werden.
Gegenwärtig beobachten Sicherheitsforscher einen Trend, wie mittels künstlicher Intelligenz vermeintlich sichere Passwörter erraten werden können. Bisher hat sich im Umgang mit Passwörtern eine Regel etabliert: Je länger ein Passwort ist, umso schwieriger ist es, zu erraten. Diese Tatsache können wir an einem einfachen Zahlenschloss ausprobieren. Ein Zahlenschloss mit drei Stellen hat genau 1000 mögliche Kombinationen. Nun ist der Aufwand, alle Nummern von 000 bis 999 manuell durchzuprobieren, recht überschaubar und kann mit etwas Geschick in weniger als 30 Minuten gelöst werden. Ändert man jetzt das Zahlenschloss von drei Stellen auf fünf, vervielfacht sich diese Arbeit und die Lösung unter 30 Minuten zu finden, basiert dann mehr auf Glück, wenn etwa die Kombination im unteren Zahlenbereich liegt. Die Sicherheit wird weiter erhöht, wenn pro Stelle nicht nur Zahlen von 0 bis 9 möglich sind, sondern Buchstaben mit Groß- und Kleinschreibung hinzukommen.
An diesem kleinen und einfachen Beispiel sehen wir, wie der ‚Teufelskreis‘ funktioniert. Schnellere Computer erlauben es, mögliche Kombinationen in kürzerer Zeit durchzuprobieren, also muss die Menge der möglichen Kombinationen mit möglichst überschaubarem Aufwand ins Unermessliche getrieben werden. Während Anfang der 2000er noch 8 Stellen mit Ziffern und Buchstaben ausgereicht haben, sollten es heute möglichst 22 Stellen mit Ziffern, Groß- und Kleinschreibung inklusive Sonderzeichen sein. Die KI von Proton lumo gibt folgende Empfehlung:
Ein praktisches Beispiel für ein sicheres Passwort wäre beispielsweise: R3gen!Berg_2025$Flug.
Hier sehen wir schon die erste Schwachstelle. Solche Passwörter kann sich kein Mensch merken. Beruflich gibt Dir eventuell jemand eine Passwortrichtlinie vor, die Du erfüllen musst – isso, dumm gelaufen, leb damit! Aber keine Sorge, es gibt für alles einen Lifehack.
Daher kommt auch immer noch der Fall vor, dass Mitarbeiter ihr Passwort in unmittelbarer Nähe zu ihrem PC aufbewahren. Ja, immer noch auf den kleinen Zetteln unter der Tastatur oder als Post-it am Bildschirmrand. Wenn ich mich als EDV-ler in einen Mitarbeiter PC einloggen möchte, der nicht am Platz ist geht nach wie vor mein Blick über den Bildschirmrand und als Nächstes schaue ich unter der Tastatur nach.
Woran erkenne ich dann, dass es sich um das Passwort handelt? Klar! Ich achte auf eine Folge von Groß- Kleinbuchstaben, Zahlen und Sonderzeichen. Würde am Bildschirmrand ein Post-it kleben mit z. B. der Aufschrift: »Mi Fußpflege 10:45« würde ich das erst mal als Passwort überhaupt nicht wahrnehmen.
Also als Passwort »MiFußpflege10:45« 16stellig, Groß- und Kleinbuchstaben, Zahlen, Sonderzeichen. Also perfekt! Und zunächst, nicht einmal als Passwort erkennbar. Übrigens: Der Zettel sollte möglichst wenig Staub bzw. Patina haben.
Im beruflichen Alltag kommen dann noch so nette Eigenheiten hinzu, dass man sein Passwort monatlich ändern muss, und das neue Passwort darf dann nicht in den letzten Monaten verwendet worden sein. Auch hier haben sich Mitarbeiter Lösungen einfallen lassen, wie etwa Passwort01, Passwort 02 und so weiter, bis alle 12 Monate durch waren. Also gab es ein erweitertes Prüfverfahren und es musste nun eine bestimmte Menge unterschiedlicher Zeichen enthalten sein.
Aber auch im Privaten sollten wir das Thema sichere Passwörter nicht auf die leichte Schulter nehmen. Die Dienste, zu denen wir uns regelmäßig anmelden, sind für viele ein wichtiger Bestandteil ihres Lebens geworden. Onlinebanking und auch Social Media sind hier wichtige Punkte. Die Menge der Online Accounts wächst stetig. Es ist natürlich klar, dass man seine Passwörter nicht recyceln sollte. Also sollte man mehrere Passwörter verwenden. Wie man das am besten angeht, also wie viele und wie man die aufbaut, muss jeder natürlich eigenverantwortlich umsetzen, so wie es für Dich persönlich passt. Aber wir sind auch keine Memory Meister und je seltener wir ein bestimmtes Passwort benötigen, desto schlechter können wir es uns merken. Abhilfe können Passwort Manager schaffen.
Passwort Manager
Der gute alte Karteikasten. Übrigens, Akkulaufzeit: unendlich. Auch, wenn das jetzt eines Computernerds unwürdig erscheint, ist es dennoch für zu Hause die möglicherweise effektivste Aufbewahrungsvariante für Passwörter.
Klar ist bei der heutigen Anzahl der Passwörter eine Software zur Verwaltung attraktiv, allerdings besteht die Gefahr, dass, wenn jemand die Software unter seine Kontrolle bringt, hat er Dich unter Umständen – wie unsere amerikanischen Freunde umgangssprachlich gerne sagen „By the balls“ – frei übersetzt auf Deutsch: im Schwitzkasten. Diese Regel gilt besonders für die im ersten Moment bequem erscheinenden Cloud Lösungen.
Für Linux und Windows gibt es aber eine Lösung, die man sich auf den eigenen Computer installieren kann, um die vielen Passwörter der Online Accounts z verwalten. Diese Software heißt KeePass, ist Open Source und auch legal kostenfrei im kommerziellen Umfeld einsetzbar. Dieser sogenannte Passwort Store speichert die Passwörter verschlüsselt auf der eigenen Festplatte ab. Natürlich ist es recht lästig, auf jeder Webseite die Log-ins aus dem Passwort-Manager herauszukopieren und dann einzufügen. Hier hilft ein kleines Browser Plug-in namens TUSK KeePass, das für alle gängigen Browser wie _Brave, Firefox und Opera vorhanden ist. Auch wenn einem andere Leute über die Schulter schauen, wird das Passwort niemals im Klartext angezeigt. Bei Copy und Paste wird es nach wenigen Minuten auch wieder aus der Zwischenablage gelöscht.
Ganz anders ist es natürlich, wenn man unterwegs ist und an fremden Computern arbeiten muss. Im privaten Bereich bietet es sich an, Passwörter auch entsprechend den Umständen anzupassen, je nachdem, wo man sie einsetzt. Angenommen, Du möchtest Dich an einem PC in Dein E-Mail-Konto einloggen, kannst aber eventuell nicht jederzeit sicherstellen, dass Du unbeobachtet bist.
An der Stelle wäre es sicherlich kontraproduktiv, einen Spickzettel herauszukramen, auf dem ein Passwort aufgeschrieben ist, das die empfohlenen Richtlinien aufweist. Groß- Kleinbuchstaben, Zahlen, Sonderzeichen, darunter möglichst auch japanische und kyrillische etc., die man dann mittels des Adler-such-System Zeichen für Zeichen mit dem Zeigefinger eintippt.
(bei fortschrittlichem Tastatur Layout auch anstelle von ‚Alt‘ mit ‚Kölsch‘ beschriftet)
Wenn man nicht zu unbegabt, also mitunter auch schon etwas schneller, auf der Tastatur tippen kann, solle man eher ein Passwort verwenden, das man in 1–1,5 Sekunden eintippen kann. Einen normalen Beobachter überfordert man damit. Insbesondere dann, wenn man bei der Eingabe mit der Schift-Taste unauffällig agiert. Man lenkt die Aufmerksamkeit auf die tippende rechte Hand und verwendet unauffällig mit der linken Hand gelegentlich Schift- oder Alt-Taste.
Möglicherweise, bei vorsichtiger Einschätzung, kommt das Leaken der persönlichen Tetris Highscoreliste keinem sicherheitsrelevanten Verlust gleich. Der Zugang zum Onlinebanking ist da schon ein ganz anderes Thema. Sinnig ist sicherlich deshalb, ein eigenes Passwort für Geldgeschäfte – ein anderes für weniger kritische Log-In’s – und ein einfach gehaltenes für „0-8-15“ Registrierungen zu verwenden.
Falls man die Möglichkeit hat, Alias E-Mail Adressen anlegen zu können, ist das auch sehr sinnvoll, da der Log-In normalerweise ja nicht nur ein Passwort, sondern auch eine E-Mail-Adresse braucht. Wenn Du dort, nach Möglichkeit, eine eindeutige, nur für die entsprechende Seite angelegte E-Mail hast, kann das nicht nur die Sicherheit erhöhen, sondern Dir auch die Möglichkeit geben, unerreichbar zu werden, wenn Du es möchtest. Hin und wieder passiert es mir z. B. dass ich Werbung bekomme, obwohl ich explizit auf Werbung verzichtet habe. Komischerweise sind das für gewöhnlich die gleichen ‚Vögel‘, die sich bei z. B. ihren Zahlungsbedingungen nicht an das halten, was sie vor der Registrierung versprochen hatten. Da gehe ich einfach den effektivsten Weg und lösche die Alias E-Mail-Adresse bei mir raus → und gut!
Merkfähigkeit
Ein paar Worte über die Merkfähigkeit von Passwörtern möchte ich auch noch loswerden. Wie wir in dem Artikel nun gesehen haben, ist es sinnvoll, möglichst für jeden Onlineaccount ein eigenes Passwort zu verwenden. So vermeiden wir, wenn mal wieder bei Sony der Play Station Store gehackt wird und alle Daten der Kunden gestohlen werden, dass unser Login zu Facebook und Co. ebenfalls betroffen ist. Natürlich gibt es mittlerweile Mehrfaktoren, Authentifizierungen und viele andere Sicherheitslösungen, aber nicht überall kümmern sich die Betreiber darum. Zudem gilt in Hackerkreisen die Devise: Jedes Problem hat eine Lösung.
Um nun ein marktfähiges Passwort mit allen Sicherheitskriterien zu erstellen, bedienen wir uns eines einfachen Ansatzes. Unser Passwort besteht aus einem sehr komplexen statischen Teil, der möglichst ohne persönlichen Bezug auskommt. Als Eselsbrücke hilft uns dabei die Vorstellung von einem Bild, wie im anfänglichen Beispiel. Kombination aus einem Bild („Regener Berg“) und einer Jahreszahl, ergänzt durch ein weiteres Wort („Flug“). Sehr beliebt ist es auch, zufällig Buchstaben durch ähnlich aussehende Zahlen zu ersetzen, also das E durch eine 3 oder das I durch eine 1 auszutauschen. Damit man die Menge der Möglichkeiten nicht einschränkt und sozusagen alle E nun eine 3 sind, machen wir das nicht bei allen E. So kommen wir zu einem statischen Passwortteil, der wie folgt aussehen könnte: R3gen!Berg_2025$Flug. Diesen statischen Teil können wir uns leicht merken. Brauchen wir nun ein Passwort für unser X Log-In ergänzen wir den statischen Teil mit einem dynamischen Segment, das nur für unseren X Account gilt. Der statische Teil lässt sich gut über ein Sonderzeichen wie # einleiten und dann über den Bezug zum Log-in ergänzen. Das könnte dann wie folgt aussehen: sOCIAL.med1a-X. Wie bereits mehrfach erwähnt, ist das eine Idee, die jeder nach seinen eigenen Bedürfnissen anpassen kann.
Abschließend
Am Arbeitsplatz solltest Du Dir immer darüber im Klaren sein, dass der, der sich in Deinen Account einloggt, auch in Deinem Namen agiert. Also unter Deiner Identität.
Es ist schon logisch, dass die Abläufe bisweilen wesentlich ‚runder‘ laufen, wenn ein befreundeter Kollege mal eben bei Dir ‚nachschauen‘ kann. Die Wahrscheinlichkeit, dass Dir das auf die Füße fällt, ist sicher gering, solange er mit Deinem Passwort sorgfältig umgeht.
Sicherlich sollte man generell das Thema Passwörter nicht unterschätzen, aber selbst wenn man ein Passwort verliert: Das Leben auf dem Planeten, so wie wir es kennen, wird sich nicht signifikant ändern. Zumindest nicht deshalb. Versprochen!
Nichts ist so sicher wie die Veränderung. Diese Weisheit trifft auf so ziemlich alle möglichen Bereiche unseres Lebens zu. Auch das Internet befindet sich in einem stetigen Wandel. Allerdings passieren die vielen Veränderungen im Technologiesektor so rasant, dass es kaum noch möglich ist, Schritt zu halten. Wer sein Geschäftsmodell auf die Vermarktung auf Onlinekanälen ausgerichtet hat, kennt die Problematik bereits perfekt. Auch im Bereich des Marketings wird es auch künftig sehr starke Veränderungen geben, die durch die Verfügbarkeit von künstlicher Intelligenz beeinflusst werden.
Bevor wir uns die Details ein wenig genauer anschauen, möchte ich gleich vorwegnehmen, dass bei weitem nicht alles obsolet geworden ist. Sicher werden einige Agenturen sich künftig nicht weiter durchsetzen können, wenn sie sich auf klassische Lösungen konzentrieren. Deswegen ist es auch für Auftragnehmer wichtig zu verstehen, welche Marketingkonzepte umgesetzt werden können, die dann auch zum Ziel führen. Hier vertreten wir die Auffassung, dass Kompetenz und Kreativität nicht durch KI ersetzt werden. Dennoch werden erfolgreiche Agenturen nicht an dem zielgerichteten Einsatz von Künstlichen Intelligenzen vorbeikommen. Betrachten wir uns daher einmal genauer, wie sich bereits seit der Einführung von ChatGPT um 2023 das Verhalten der Internetnutzer verändert hat.
Immer mehr Personen greifen auf KI Systeme zu, um Informationen zu erhalten. Das führt natürlich zu einem Rückgang der klassischen Suchmaschinen wie Google und Co. Suchmaschinen per se werden mit hoher Wahrscheinlichkeit nicht verschwinden, da auch KI Modelle eine indizierte Datenbasis benötigen, auf der sie operieren können. Wahrscheinlicher ist es, dass Menschen nicht mehr direkt auf Suchmaschinen zugreifen werden, sondern künftig einen persönlichen KI Assistenten haben, der sämtliche Suchanfragen für sie auswertet. Das lässt auch darauf schließen, dass möglicherweise die Menge der frei verfügbaren Internetseiten erheblich zurückgehen wird, da diese wegen Besuchermangel kaum noch rentabel sein werden. Was wird es denn stattdessen geben?
Verfolgt man dazu aktuelle Trends, lässt sich vermuten, dass bekannte und möglicherweise auch neue Plattformen wie Instagram, Facebook und X weiter an Marktmacht gewinnen werden. Kurze Texte, Grafiken oder Videos dominieren bereits das Internet. Alle diese Tatsachen erfordern bereits heute ein profundes Umdenken für Marketingstrategien.
Es heißt, totgesagte leben länger. Deswegen wäre es verkehrt, klassische Internetseiten und das zugehörige SEO komplett zu vernachlässigen. Seien Sie sich bewusst, welche Geschäftsstrategie Sie mit Ihrer Internet / Social Media Präsenz verfolgen. Als Agentur helfen wir unseren Kunden konkret dabei, vorhandene Strategien zu überprüfen und zu optimieren oder gänzlich neue Strategien zu entwickeln.
Es werden Fragen geklärt, ob Sie Waren oder Dienstleistungen verkaufen möchten oder ob Sie als Kompetenzzentrum zu einem bestimmten Thema wahrgenommen werden möchten. Hier verfolgen wir den klassischen Ansatz aus der Suchmaschinenoptimierung, der qualifizierten Traffic generieren soll. Es nützt wenig, tausende Aufrufe zu erhalten, von denen nur ein kleiner Bruchteil an der Thematik interessiert ist. Mit geschickt gestreuten Beiträgen auf Webseiten und im Social Media werden die zuvor festgesetzten Marketingziele promotet.
Natürlich steht und fällt jede Marketingstrategie mit der Qualität der angebotenen Produkte oder Dienstleistungen. Hat der Kunde einmal das Gefühl, ein schlechtes Produkt bekommen zu haben, oder war eine Dienstleistung zu schlecht, kann sich explosionsartig eine Negativkampagne ausbreiten. Daher ist es sehr erstrebenswert, von echten Kunden ehrliche Bewertungen auf den verschiedenen Plattformen zu erhalten.
Es gibt unzählige Angebote unseriöser Agenturen, die ihren Kunden anbieten, eine festgesetzte Anzahl an Followern, Klicks oder Bewertungen zu generieren. Schnell verschwinden die Ergebnisse dann auch wieder, wenn die Dienstleistung nicht mehr eingekauft wird. Abgesehen davon, lassen sich solche generischen Beiträge, die durch Bots erstellt wurden, schnell erkennen, und viele Menschen blenden das mittlerweile auch selektiv aus. So steht der Aufwand zu keinem Nutzen. Zudem sind echte Bewertungen und Kommentare auch ein wichtiges Hilfsmittel, um die tatsächliche Außenwirkung des eigenen Geschäftes beurteilen zu können. Wird einem stetig gesagt, wie toll man ist, könnte man in die Versuchung kommen, dies auch für wahrzunehmen. Es gibt einige Stars und Sternchen, die so etwas am eigenen Leibe erfahren haben.
Daher setzen wir auf regelmäßige Veröffentlichungen von hochwertigen Inhalten, die zum Marketingziel gehören, um so Aufmerksamkeit zu erzielen. Diese Aufmerksamkeit versuchen wir zu nutzen, um die Nutzer zu Interaktionen zu bewegen, die wiederum zu einer höheren Sichtbarkeit führen. Unsere KI Modelle helfen uns dabei, aktuelle Trends rechtzeitig zu erkennen, damit wir diese in unsere Kampagnen einfließen lassen können.
Basierend auf unseren Erfahrungen, können wir dank künstlicher Intelligenz für einen relativ langen Kampagnenzeitraum hochfrequente Veröffentlichungen erstellen und planen. Denn auch die Uhrzeit, wann ein Post oder Kommentar online geht, hat Einfluss auf den Erfolg.
Es werden vereinzelt Stimmen laut, die davon sprechen, dass das Ende für Agenturen eingeläutet ist. Die Begründung ist dann oft, dass viele Kleinunternehmer nun alle diese tollen Dinge, die zum Marketing gehören, dank KI nun selbst machen können. Diese Ansicht teilen wir nicht. Vielen Unternehmern fehlt schlichtweg die Zeit, selbstständig Marketing auf allen Kanälen zu betreiben. Deswegen setzen wir bei vielen Schritten auf eine gesunde Mischung aus echter Handarbeit und Automatisierung. Denn unsere Überzeugung lautet, dass Erfolg nicht aus der Retorte kommt. Wir nutzen unsere Werkzeuge und Erfahrung, um damit qualitative individuelle Ergebnisse zu erzielen.
Windows 11 integriert eine ominöse History-Funktion, bei der sämtliche Interaktionen mit dem Computer aufgezeichnet und aller Wahrscheinlichkeit per Telemetrie an Microsoft übertragen werden. Aber auch die unzähligen durch die EU beschlossenen und von Deutschland umgesetzten Gesetze zur Überwachung der Bürger geben vielen Anlass, über das Thema Datenschutz und Privatsphäre neu nachzudenken. Unsere Welt ist stetig im Wandel und die digitale Welt verändert sich um einiges schneller. Es liegt an jedem Einzelnen, wie er oder sie mit diesen Veränderungen umgehen möchte. Dieser Artikel soll dazu anregen, sich ein wenig mehr mit Linux und Sicherheit zu beschäftigen. Vielleicht bekommen Sie ja auch gleich Lust, das hier vorgestellte Kodachi Linux einmal selbst auszuprobieren. Es gibt mehrere Wege, wie Sie Kodachi Linux ausprobieren können.
Virtuelle Maschine: Erstellen Sie einfach mit der ISO‑Datei und dem Programm VirtualBox oder VMWare eine Virtuelle Maschine mit Kodachi Linux. Diese virtuellen Maschinen können Sie auch von einem Windows-Rechner aus erstellen und verwenden.
Booten vom USB-Stick: Tools wie Disks (Linux) oder Rufus (Windows) erlauben es, bootfähige USB‑Sticks zu erstellen. Auf diese Art und Weise können Sie Ihren PC direkt von USB mit Kodachi starten, ohne dass das auf der Festplatte installierte Betriebssystem davon beeinflusst wird.
Native Installation: Sie können den bootfähigen USB-Stick auch dazu verwenden, Kodachi Linux dauerhaft auf Ihrem Computer zu installieren. Diese Methode ist dann zu empfehlen, wenn Sie bereits Erfahrungen mit Kodachi gesammelt haben.
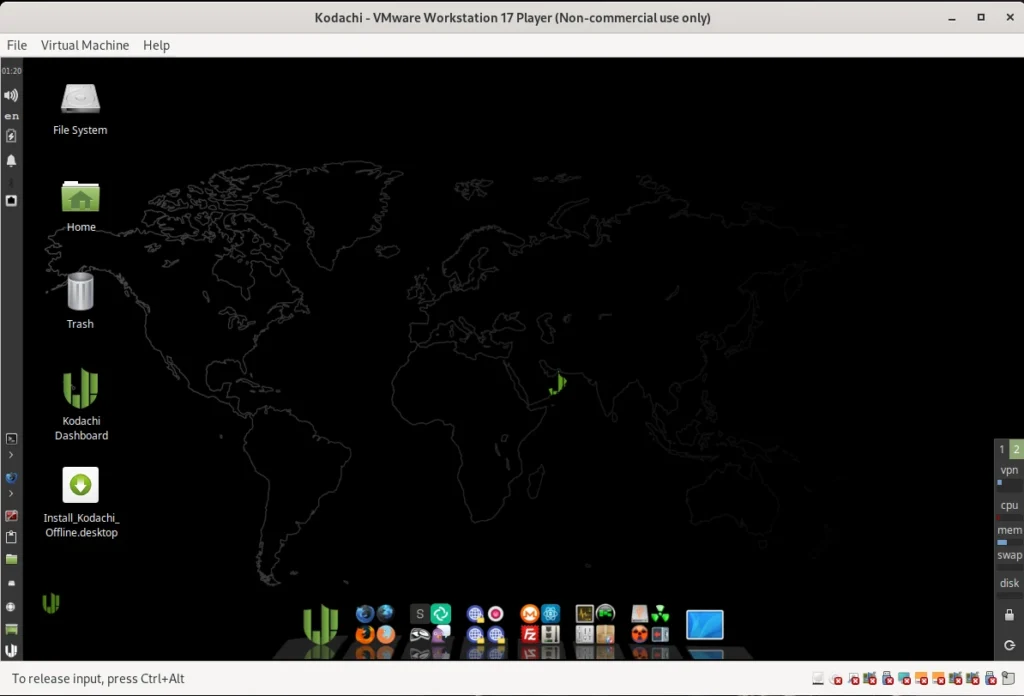
Kodachi OS ist, wie der Name schon vermuten lässt, eine japanische Linux-Distribution mit einem angepassten XFCE Desktop. Kodachi sind eigentlich klassische japanische Samurai-Schwerter, was bereits einen Bezug auf das Thema Sicherheit hinleitet. Kodachi OS selbst ist ein Xubuntu Derivat und somit ein Enkel von Ubuntu und ein Urenkel von Debian Linux. Kodachi Linux bietet eine hoch-sichere, anti-forensische und anonyme Computerumgebung. Es wurde mit Blick auf eine sichere Privatsphäre konzipiert. Alle notwendigen Funktionen, um Vertraulichkeit und Sicherheit der Benutzer zu gewährleisten, sind enthalten. Kodachi ist benutzerfreundlich und eignet sich auch für Linux-Neulinge und Windows-Umsteiger. Zu Testzwecken können Sie das System von einem USB-Stick starten und Sie haben ein voll funktionsfähiges Betriebssystem mit:
automatisch etablierte VPN Verbindung
vorkonfigurierte TOR Verbindung
laufendem DNSCrypt Dienst
Die aktuelle Version von Kodachi kann kostenfrei auf der Homepage [1] heruntergeladen werden. Mit der heruntergeladenen ISO können sie nun entweder eine bootfähigen USB Stick erstellen oder Kodachi in eine Virtuelle Maschine installieren. Wir haben uns für die Variante mit VMWare eine virtuelle Maschine zu erstellen entschieden.
Die Installation ist dank dem VM Ware Ubuntu Template in wenigen Minuten erledigt. Für unseren Test haben wir der VM 20 GB Festplattenspeicher spendiert. Damit das ganze füssig läuft haben wir den RAM auf 8 GB angehoben. Wer nicht so viel RAM zu Verfügung hat kann auch mit 4 GB arbeiten. Nach dem Start der VM sehen Sie das Kodachi OS Desktop wie im untenstehende Screenshot in der Version 8.27. Für alle Linux Nerds sei noch erwähnt das diese Version den Kernel 6.2 verwendet. Laut der Homepage wird bereits fleißig an der neuen Version 9 gearbeitet.
Da die Installation auch für Anfänger möglichst einfach gehalten ist, wurden bereits Benutzerkonten eingerichtet. Der Benutzer lautet kodachi und hat das Passwort r@@t00 (00 sind Nullen). Der Administrator-Account heißt wie unter Linux üblich root und hat ebenfalls das Passwort r@@t00. Wer sich dafür entscheidet, Kodachi fest auf seiner Maschine zu installieren, sollte mindestens die Passwörter ändern.
Eine möglichst hohe Anonymität erreicht man leider nur auf Kosten der Surfgeschwindigkeit. Kodachi Linux bietet daher für unterschiedliche Anforderungen mehrere Profile, zwischen denen gewählt werden kann.
Maximale Anonymität (langsamer)
ISP → Router VPN → Kodachi VPN (VM NAT) → Torified System → Tor DNS → Kodachi geladener Browser
Hoch anonym (langsam)
ISP → Kodachi VPN → TOR-Endpunkt → Tor DNS → Kodachi geladener Browser
Anonym & Schnell
ISP → Kodachi VPN → TOR-Endpunkt → Tor DNS → Kodachi lite Browser
Mäßige Anonymität
ISP → Kodachi VPN mit erzwungenem VPN-Verkehr → Tor DNS → Kodachi geladener Browser
Standard Anonymität
ISP → Kodachi VPN → Torified System → Tor DNS → Kodachi geladener Browser
ISP → Kodachi VPN mit erzwungenem VPN-Verkehr → Tor-Browser → Tor DNS
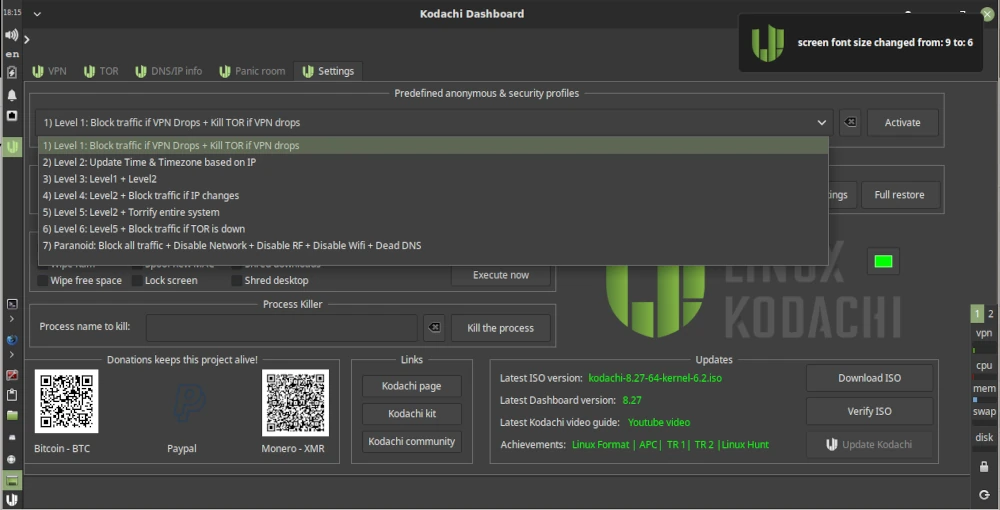
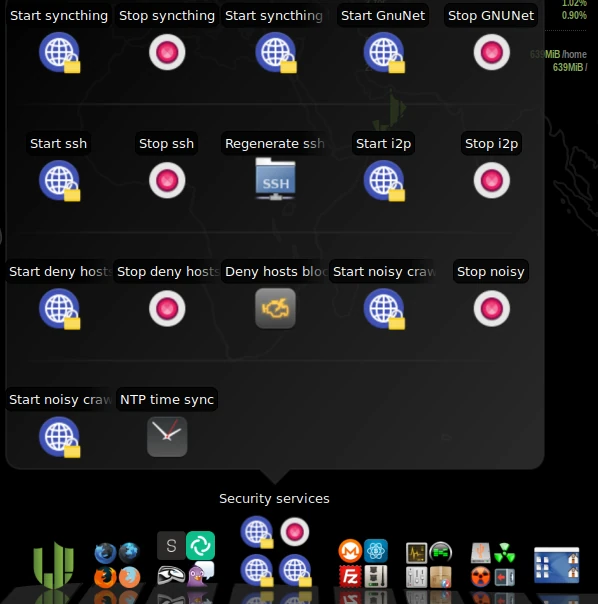
Kommen wir nun zur Bedienung von Kodachi. Dazu rufen wir das Dashboard auf, das wir auf dem Desktop als Verknüpfung finden. Nach dem Start sehen wir verschiedene Reiter wie VPN, TOR und Settings. Unter Settings haben wir die Möglichkeit, mehrere Profile zu aktivieren, die für Sicherheit und Datenschutz im Internet relevant sind. Wie im unten stehenden Screenshot zu sehen ist, wählen wir Level 1 aus und aktivieren das Profil.
Im unteren Panel finden sich im Abschnitt Security Services verschiedene Dienste wie beispielsweise GnuNet, die sich zuschalten lassen. Hier gibt es mehrere Optionen, die problemlos ausprobiert werden können. GnuNet leitet etwa den gesamten Traffic ins TOR-Netzwerk um. Das hat natürlich zur Folge, dass die Seiten länger brauchen, bis sie vollständig geladen werden.
Mit den Bordmitteln von Kodachi Linux können Sie Ihre Sicherheit und Anonymität beim Surfen im Internet erheblich verbessern. Auch wenn die Benutzung am Anfang etwas ungewöhnlich ist, findet man sich schnell hinein. Wenn Sie sich für die Verwendung als Live-System oder virtuelle Maschine entscheiden, können Sie sich problemlos mit den verschiedenen Programmen und Einstellungen vertraut machen, ohne das Gastbetriebssystem zu beschädigen. Gerade als Anfänger nimmt die Benutzung einer VM die Angst, beim Ausprobieren der verschiedenen Konfigurationen etwas kaputtzumachen.
Wer sich ein wenig zu Kodachi Linux im Internet umschaut, findet auch schnell einen Artikel [2] aus 2021, der sich durchaus kritisch zu Kodachi äußert. Die Hauptkritik bezieht sich darauf, dass Kodachi eher als Ubuntu Distro mit einem angepassten Look and Feel zu betrachten ist, das mit ein paar Shell Scripten aufgepeppt ist, als ein eigenständiges Linux. So ganz von der Hand zu weisen ist diese Kritik nicht. Wer sich etwas genauer mit der Kritik beschäftigt, stellt fest, dass Kadochi durchaus einige praktische Anonymisierungs-Features aufweist. Dennoch ist es wohl weit davon entfernt, eine sogenannte Hackers Toolbox zu sein. Der Autor der Kritik hat sich 2025 [3] Kadochi noch einmal vorgenommen und hat auch für die aktuelle Version kein anderes Fazit als bereits 2021. Ob die anstehende Version 9 des Kadochi Linux sich die angemerkten Punkte zu Herzen nimmt, bleibt abzuwarten.
Der Wunsch von Webseitenbetreibern, möglichst viele Informationen über ihre Nutzer zu bekommen, ist so alt wie das Internet selbst. Einfache Zähler für Seitenaufrufe oder das Erkennen des Webbrowsers und der Bildschirmauflösung sind dabei die einfachsten Anwendungsfälle des Usertrackings. Mittlerweile sind die Betreiber von Internetseiten nicht mehr alleine auf Google angewiesen, um Informationen über ihre Besucher zu sammeln. Es gibt ausreichend kostenlose Werkzeuge, um einen eigenen Tracking-Server zu unterhalten. In diesem Artikel gehe ich ein wenig auf die historischen Hintergründe, Technologien und gesellschaftlichen Aspekte ein.
Als um die Jahrtausendwende immer mehr Unternehmen den Weg in die Weiten des WWW fanden, begann das Interesse, mehr über die Besucher der Homepages herauszufinden. Anfänglich begnügte man sich damit, auf der Startseite sogenannte Besucherzähler zu platzieren. Nicht selten wurden recht abenteuerliche Zahlen von diesen Besucherzählern angezeigt. Sicher spielte das Ego der Webseitenbetreiber auch eine Rolle dabei, denn viele Besucher auf der Homepage wirken nach außen und machen auch ein wenig Eindruck auf die Besucher. Wer allerdings ernsthaft über seine Webseite Geld verdienen wollte, merkte recht schnell, das fiktive Zahlen keinen Umsatz generieren. Also brauchte man verlässlichere Möglichkeiten.
Damit Nutzer nicht jedes Mal beim Aufrufen der Startseite mehrfach gezählt wurden, begann man damit, die IP-Adresse zu speichern, und setzte einen Timeout von einer Stunde, bevor wieder gezählt wurde. Das nannte sich dann Reloadsperre. Natürlich war das keine sichere Erkennung. Denn zu dieser Zeit waren Verbindungen über das Telefonnetz per Modem üblich und es kam öfter vor, dass die Verbindung abbrach und man sich neu einwählen musste. Dann gab es auch eine neue IP-Adresse. Die Genauigkeit dieser Lösung hatte also noch viel Potenzial nach oben.
Als um circa 2005 Webspace mit PHP und MySQL-Datenbanken bezahlbar wurde, ging man dazu über, die besuchten Seiten in kleinen Textdateien, den sogenannten Cookies, im Browser zu speichern. Diese Analysen waren schon sehr aussagefähig und haben den Unternehmen geholfen zu sehen, welche Artikel die Leute interessieren. Dumm war nur, wenn argwöhnische Nutzer bei jeder Gelegenheit ihre Cookies löschten. Deshalb ist man dazu übergegangen, alle Requests auf dem Server zu speichern, in sogenannten Sessions. In den meisten der Anwendungsfälle genügt die dadurch erzielte Genauigkeit, um das Angebot besser an die Nachfrage anzupassen.
Ein verbreitetes Werkzeug für Nutzertracking ist das in PHP geschriebene Matomo. Mit dieser selbst gehosteten Open Source Software kann man Google umgehen und erreicht auch eine bessere DSGVO-Konformität, da die erhobenen Daten nicht an Dritte weitergegeben werden. Zudem können personalisierte Daten nach einem festgelegten Zeitraum, zum Beispiel bei Monatsbeginn, anonymisiert werden. In diesem Fall werden Informationen wie IP-Adressen gegen zufällige Identifier ausgetauscht.
Das ganze Thema wird sofort auf ein ganz anderes Niveau gehoben, wenn Geld mit im Spiel ist. Früher waren das Firmen, die auf gut besuchten Internetseiten Werbebanner platzierten und dann pro 1000 Anzeigen einen kleinen Betrag bezahlt haben. Heutzutage sind Streamingdienste wie Spotify oder YouTube daran interessiert, exakt zu ermitteln, wie oft ein bestimmter Inhalt, beziehungsweise wie lange ein Titel angeschaut wurde. Denn in dem Moment, in dem Geld im Spiel ist, gibt es ein großes Interesse, mit kleinen oder großen Tricksereien sich ein wenig mehr Geld zu ergaunern, als einem eigentlich zustehen würde. Ebendarum sind Firmen wie Google und Co. stetig damit beschäftigt, herauszufinden, wie viele Nutzer die Inhalte wie lange konsumieren. Neben Trackingfunktionen in den Anwendungen nutzen diese Unternehmen auch ein komplexes Monitoring, das auf Originaldaten der Serverlogs und des Netzwerkverkehrs zugreifen kann. Hier kommen Tools wie der ELK-Stack oder Prometheus und Grafana ins Spiel.
Wenn wir als Beispiel einmal YouTube herausgreifen, hat dieser Dienst einige Hürden zu meistern. Viele nutzen YouTube als TV‑Ersatz, da sie aus einem enormen Fundus an Content die Dinge selbst heraussuchen können, die sie interessieren. Ein typisches Szenario ist das stundenlange automatische Abspielen von Ambientmusik. Wenn ausreichend viele Personen so etwas tun, ohne wirklich den Inhalten Aufmerksamkeit zu schenken, belastet das nur sinnlos die Serverinfrastruktur und verursacht für den Betreiber erhebliche Kosten. Auch diese automatische Autoplay-Funktion in der Vorschau ist noch keine wirkliche Interaktion und eher als Teaser gedacht.
Um die Nutzer in ständiger Aktion zu halten, gibt es aktuell zwei Strategien. Eine davon sind kurze Videos, die so lange in einer Endlosschleife laufen, bis man manuell zum nächsten übergeht. So kann man einerseits kurze Werbevideos untermischen, aber auch Nachrichten oder Meinungen platzieren. Natürlich muss das Usertracking bei einem Endlosdurchlauf eines monetarisierten Shorts die Wiederholungen herausnehmen. Das führt natürlich zu Korrekturen der Impressionen-Anzeige. Eine andere sehr exzessiv eingesetzte Strategie bei langen Videos ist das unverhältnismäßig langer Werbeunterbrechungen in relativ kurzen Abständen. Was die Nutzer dazu nötigt, diese Werbung jedes Mal aktiv wegzuklicken und somit Aufmerksamkeit abverlangt.
Nun gibt es Themen, bei denen Dienste wie YouTube, aber auch X oder Facebook Interesse daran haben, ihre Nutzer in eine bestimmte Richtung zu beeinflussen. Das kann die Bildung von Meinungen zu politischen Themen sein oder einfach Kommerz. Jetzt könnte man meinen, es wäre eine gängige Strategie, die Sichtbarkeit unerwünschter Meinungen zu unterdrücken, indem man die Aufrufzahlen der Beiträge nach unten korrigiert. Das wäre allerdings nicht förderlich, den die Leute haben den Beitrag ja dann bereits gesehen. Daher ist eine andere Strategie viel zielführender. Im ersten Schritt würde der Kanal oder der Beitrag von der Monetarisierung ausgenommen, so erhält der Betreiber keine zusätzliche Vergütung. Im nächsten Schritt erhöht man die Zahl der Aufrufe, so das der Content Creator im Glauben ist ein breites Publikum zu erreichen, und weniger Maßnahmen unternimmt, mehr Sichtbarkeit zu erlangen. Zusätzlich lassen sich die Aufrufe von Inhalten mit Methoden aus DevOps wie dem A/B Testing unter Verwendung von Feature Flags und Load Balancern nur die Personen auf die Beiträge leiten, die explizit danach suchen. So erweckt man keinen Verdacht, Zensur auszuüben, und die Sichtbarkeit ist signifikant reduziert. Natürlich tauchen unerwünschte Beiträge nur bei den Personen in den Empfehlungen auf, die Kanäle explizit abonniert haben.
In der Netflix-Produktion ‚Das Dilemma mit den sozialen Medien‘ wird zudem beklagt, dass sich Blasen bilden, in denen sich Personen mit bestimmten Interessen sammeln. Dies ist ein Effekt sogenannter Recommender-Systeme. Diese Empfehlungsgeber sind Algorithmen aus dem Bereich der künstlichen Intelligenz. Diese funktionieren recht statisch über statistische Auswertungen. Vorhandene Inhalte werden in Kategorien klassifiziert und anschließend wird geschaut, welche Personengruppen mit welcher Gewichtung Interesse an einer bestimmten Kategorie haben. Entsprechend werden dann Inhalte im Verhältnis der Interessen aus dieser Kategorie ausgespielt. Die so erfassten Inhalte können natürlich problemlos mit zusätzlichen Labels wie „gut geeignet“ oder „ungeeignet“ markiert werden. Entsprechend der Meta-Markierungen können dann unerwünschte Inhalte in den Tiefen der Datenbasis verschüttet werden.
Damit diese ganzen Maßnahmen auch richtig greifen können, ist es wiederum notwendig, möglichst viele Informationen über die Nutzer zu sammeln. So schließt sich wiederum der Kreis zum Usertracking. Das Tracking ist mittlerweile so ausgefeilt, dass Browsereinstellungen, die regelmäßig Cookies löschen, oder das grundsätzliche Nutzen des Inkognito-Modus vollständig wirkungslos sind.
Die einzige Möglichkeit, sich aus der Abhängigkeit der großen Plattformanbieter zu befreien, ist die bewusste Entscheidung, dies möglichst nicht mehr mit Inhalten zu versorgen. Ein Schritt in diese Richtung wäre das Betreiben einer eigenen Homepage mit entsprechendem eigenen Monitoring für das Usertracking. Umfangreiche Inhalte wie Video und Audio können auf mehrere unbekannte Plattformen ausgelagert werden und in die Homepage embedded werden. Hier sollte man auch nicht alle Inhalte auf einer einzigen Plattform wie Odysee oder Rumble hochladen, sondern die Inhalte geschickt auf mehrere Plattformen verteilen, ohne diese dupliziert zu haben. Solche Maßnahmen binden die Besucher an die eigene Homepage und nicht an die entsprechenden Plattformbetreiber.
Wer etwas mehr finanzielle Freiheit hat, kann auch auf freie Software wie den PeerTube zurückgreifen und eine eigene Videoplattform hosten. Hier gibt es einiges an Möglichkeiten, die allerdings einen hohen Aufwand und einiges an technischem Know-how von den Betreibern abverlangen.
KI-Tools wie GitHub Copilot, ChatGPT und andere Code-Generatoren verändern die Entwicklerrolle. Viele Programmierer fragen sich, welche Fähigkeiten in Zukunft noch gefragt werden. KI ersetzt keine Entwickler. Aber Entwickler ohne Soft Skills ersetzen sich selbst.
“Die besten Entwickler 2030 werden keine besserenCodersein – sondern bessere Übersetzer zwischen Mensch und Maschine.”Andrej Karpathy, ex-OpenAI
Im Juni 2025 hat Microsoft 9000 Stellen gestrichen [1]. Unternehmen wie Microsoft, Google oder IBM stellen ihre Teams um – und KI-Tools sind oft Teil der Strategie. Ein Grund für diese Entlassungswellen ist die flächendeckende Verfügbarkeit leistungsfähiger KI Werkzeuge. Laut einer Studie von McKinsey [2] können KI-Systeme bereits bis zu 60% des Developer Arbeitspensums beschleunigen. Wenn KI bis zu 80% des Codings erledigen kann, was macht mich dann noch unersetzlich? Diese zentrale Frage stellen sich mittlerweile immer mehr Menschen, da sie direkt von der 4. industriellen Revolution betroffen sind oder in absehbarer Zeit davon betroffen werden.
Anders als bei früheren Revolutionen gibt es diesmal kein ‚Umschulen auf Webdesign‘. KI-Tools wie Devin oder ChatGPT-Coder automatisieren nicht nur Tasks, sondern ganze Berufsbilder und zwar schneller, als die meisten Betroffenen reagieren können. Studien zeigen: Bis zu 30% aller Entwicklerrollen werden bis 2030 nicht umgewandelt, sondern durch künstliche Intelligenz ersetzt.
Dieser Trend findet sich in fast allen Berufen, auch im klassischen Handwerk. Auf YouTube kann man gezielt nach Videos suchen, wie zum Beispiel in Moskau kleine, niedliche Roboter Bestellungen ausliefern. Oder wie Roboter ganze Häuser ausdrucken. Neue Patente, die Stahlspäne dem Beton zusetzen, erhöhen die Stabilität und ersetzen klassische Eisenflechter. Maschinen, die Bodenfliesen verlegen, sind ebenfalls zu sehen. Die Liste der Tätigkeiten, die durch KI ausgeführt werden können, ist lang.
Wenn man diese Prognose verinnerlicht, kann einem schon angst und bange werden. Um in dieser neuen Zeit nicht nur zu überleben, sondern sogar zu den Gewinnern zu gehören, verlangt ein hohes Maß an Flexibilität. Deswegen wird eine der wichtigsten Eigenschaften, die wir entwickeln müssen, ein flexibler Geist sein. Denn obwohl KI sehr leistungsfähig ist, sind auch ihr Grenzen gesetzt. Wenn wir nur darüber nachdenken, was uns als Menschen ausmacht, finden wir eine wichtige Eigenschaft: Kreativität. Wie können wir das für den künftigen Erfolg nutzen? Damit die Aussage: nutze deine Kreativität nicht zu einer Plattitüde wird, betrachte ich zuerst den Weg, wie es mit hoher Wahrscheinlichkeit nichts werden wird.
Oft fragen mich Juniorentwickler welches Framework, welche Programmierapache, welches Betriebssystem etc. sie lernen sollen. Dies waren bereits in der alten Zeit die falschen Fragen. Es geht nicht darum, Trends zu folgen, sondern einer Berufung. Wenn Programmieren für mich eine Berufung sein soll, dann geht es zuerst darum, richtig zu verstehen, was der Code, den man schreibt, wirklich tut. Mit einem tiefgreifenden Verständnis des Quelltextes lassen sich auch schnell Performanzverbesserungen finden. Optimierungen im Bereich Sicherheit gehören ebenfalls dazu. Aber auch das Lokalisieren von Fehlern und deren Beseitigung sind Eigenschaften guter Entwickler. Denn genau in diesen Bereichen ist die menschliche Kreativität künstlicher Intelligenz überlegen. Das bedeutet natürlich, als Konsequenz genau diese Fertigkeiten gezielt auszubauen.
Wer nur damit beschäftigt ist, aktuellen Modeerscheinungen hinterherzulaufen, gehörte bereits in der ‚alten‘ Zeit nicht zu den überall gefragten Spezialisten. Reine Code Monkeys deren Tätigkeiten vornehmlich aus Kopieren und Einfügen bestehen, ohne wirklich zu begreifen, was die Codeschnipsel bedeuten, waren von je her leicht ersetzbar. Gerade jetzt, wo KI die Produktivität erhöhen soll, ist es wichtig, schnell und sicher zu entscheiden, wo eine vorgeschlagene Implementierung Anpassungen benötigt, damit es nicht zu unliebsamen Überraschungen kommt, wenn die Anwendung in Produktion geht. Das bedeutet natürlich auch als Konsequenz, dass KI ein Werkzeug ist, das es effizient zu nutzen gilt. Um künftig auch weiterhin auf der Gewinnerseite zu bleiben, ist es unerlässlich, durch den gezielten Umgang mit KI die eigene Produktivität erheblich zu verbessern. Unternehmen erwarten von ihren Mitarbeitern, dass diese mit Unterstützung von KI ein vier bis fünffaches des aktuellen Arbeitspensums erledigen können.
Um mit künstlicher Intelligenz effektiv arbeiten zu können, sind die eigenen Kommunikationsskills essenziell. Denn nur wenn man seine Gedanken klar strukturiert hat, kann man diese auch korrekt und gezielt formulieren. Eine signifikante Leistungssteigerung lässt sich nur erreichen, wenn bereits bei der ersten Anweisung das gewünschte Ergebnis erreicht wird. Wer sich jedes Mal umständlich dem Sprachmodell erklären muss, wie Anfragen zu verstehen sind, weil diese zum Beispiel Mehrdeutigkeiten enthalten, wird wenig Zeitersparnis durch KI erzielen können.
Man kann im Grunde sagen, dass der Entwickler der Zukunft einige Managementfertigkeiten haben sollte. Neben klarer Aufgabenformulierung wird es viel um Selbstmanagement gehen. Geeignete Ressourcen für optimale Ergebnisse zu verteilen. Denn nicht nur künstliche Intelligenz bedroht den eigenen Arbeitsplatz, sondern auch eine starke Konkurrenz aus dem asiatischen Raum. Gut ausgebildete, motivierte und leistungsfähige Leute sind dort mittlerweile in hoher Zahl vorhanden.
Wir sehen also, es kommen durchaus sehr bewegte Zeiten auf uns zu. Die Welt wird sich noch ein wenig schneller drehen. Wer diese Veränderungen nicht als Bedrohung, sondern als Herausforderung wahrnimmt, hat gute Chancen, fit für die nicht mehr allzu weite Zukunft zu sein. Wer bereits jetzt die Weichen stellt, ist für das, was auf uns zukommen wird, gut gewappnet und muss sich vor nichts fürchten.
Für Hobbyprogrammierer als auch professionelle Softwareentwickler sind gut Informationsquellen essenziell. Eine kleine, überschaubare Privatbibliothek mit zeitlosen Büchern über Programmierung ist daher immer eine gute Sache. Leider ist das Angebot zu IT-Literatur sehr umfangreich und oft veralten die Bücher auch schnell wieder. Hinzu kommt außerdem noch, dass einige Titel aus unterschiedlichen Gründen nicht unbedingt das Prädikat lesenswert besitzen. Manche Texte sind nur sehr verständlich. Andere wiederum enthalten kaum relevante Informationen, die bereits leicht über öffentliche Quellen bezogen werden können. Deswegen habe ich mir einmal die Mühe gemacht und meine Top 10 Bücher zum Thema Softwareentwicklung zusammengestellt.
Alle Titel sind im Original in englischer Sprache veröffentlicht worden. Die meisten davon wurden aber auch ins Deutsche übersetzt. Wem das Lesen englischer Bücher keine Schwierigkeiten bereitet, sollte sich das Original besorgen, da manchmal die Übersetzungen etwas holprig sind.
Ein wichtiges Kriterium für eine Auswahl ist, dass die Bücher sehr generell sind und sich nicht auf eine spezifische Version beschränken. Hinzu kommt noch, dass ich die hier vorgeschlagenen Werke auch tatsächlich in meinem Bücherregal stehen habe, und daher auch gelesen habe.
Effective Java 3rd Edition, J. Bloch, 2017, ISBN: 0-134-68599-7 | Für alle Java-Entwickler, das Standardwerk mit vielen Hintergrundinformationen über die Funktionsweise der Sprache und Optimierungen des eigenen Source Codes.
The Linux Command Line2nd Edition, W. Shotts, 2019, ISBN: 1-59327-952-3 | Linux hat in der Softwareentwicklung einen hohen Stellenwert, da nicht nur Cloud-Anwendungen in Linux Umgebungen deployed werden. Um so wichtiger ist es sich auf der Kommandozeile sicher bewegen zu können. Dieses Buch widmet sich ausschließlich dem Umgang mit der Bash und ist für alle Linux Distributionen geeignet.
Angry Tests, Y. Bugayenko, 2025, ISBN: 978-1982063740 | Testgetriebene Softwareentwicklung ist eine wichtige Fähigkeit, um eine hohe Qualität sicherzustellen. Dieses Buch ist nicht auf eine konkrete Programmiersprache ausgerichtet, sondern befasst sich ausschließlich damit, wie man aussagekräftige Testfälle schreibt.
Clean Architecture, R. C. Martin, 2018, ISBN: 0-13-449416-4 | Neben einem Abriss der Historie, wie die verschiedenen Programmier-Paradigmen in Beziehung zueinander stehen, beschreibt das Buch grundlegende Architekturentwurfsstile. Nicht nur für Softwarearchitekten, sondern auch für Entwickler sehr lesenswert.
Mastering Regular Expressions3rd Edition, J. E. F. Friedl, 2006, ISBN: 0-596-52812-4 | Das absolute Standardwerk zum Thema reguläre Ausdrücke. Ein Muss für jeden, der das Thema wirklich verstehen muss.
Head First Design Pattern, Eric & Elisabeth Freeman, 2004, ISBN: 0-596-00712-4 | Entwurfsmuster gehören zu den Grundfähigkeiten eines jeden Programmierers. In diesem Buch werden die einzelnen Konzepte der GOF Muster umfassend besprochen. Es eignet sich sowohl zum Einstieg als auch als Referenz.
Advanced API Security2nd Edition, P. Siriwardena, 2020, ISBN: 978-1-4842-2049-8 | API Entwurf für RESTful Services gehört mittlerweile zum Standardrepertoire eines Entwicklers. Aber auch das Thema Sicherheit darf dabei nicht zu kurz kommen. Dieses Buch bespricht neue Konzepte, die zum Industriestandard erhoben wurden. Ein guter Einstieg für Programmierer, die bisher nicht mit SAML, OAuth und Open ConnectID in Berührung gekommen sind.
SQL Antipatterns, B. Karwin, 2010, ISBN: 987-1-934356-55-5 | Selbst für gestandene Programmierer sind Datenbanken oft ein Buch mit sieben Siegeln. Auch wenn SQL Statements schnell hingeschrieben sind und diese auch das gewünschte Resultat hervorbringen, können im Produktivbetrieb zu erheblichen Problemen führen. Dieses Buch beschreibt, warum Statements sehr langsam ausgeführt werden und wie diese richtig formuliert werden können.
Domain Driven Design, E. Evans, 2003, ISBN: 0-32-112521-5 | Die Verbindung zwischen objektorientierter Programmierung (OOP) und Datenbankentwurf wird mit dem Paradigma Domain Driven Design geschlagen.
The Art of Computer Programming I-IV, D.E. Knuth, 2021, ISBN: 0-137-93510-2 | Vier einzelne Bücher im Schuber beschreiben auf sehr mathematische Weise wie Algorithmen funktionieren.
Cookie Consent
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.