Apache Maven (kurz Maven) erschien erstmalig am 30. März 2002 als Apache Top Level Projekt unter der freien Apache 2.0 Lizenz. Diese Lizenz ermöglicht auch eine freie Nutzung für Unternehmen im kommerziellen Umfeld ohne das Lizenzgebühren fällig werden.
Das Wort Maven kommt aus dem Jiddischen und bedeutet so viel wie „Sammler des Wissens“.
Maven ist ein reines Kommandozeilenprogramm und wurde in der Programmiersprache Java entwickelt. Es gehört in die Kategorie der Build-Werkzeuge und findet vornehmlich in Java Softwareentwicklungsprojekten Verwendung. In der offiziellen Dokumentation bezeichnet sich Maven als Projektmanagement-Werkzeug, da die Funktionen weit über das Erstellen (Kompilieren) der binär ausführbaren Artefakte aus dem Quellcode hinausgehen. Mit Maven können Qualitätsanalysen von Programmcode und API-Dokumentationen erzeugt werden, um nur einige der vielfältigen Einsatzgebiete zu nennen.
Dieser Onlinekurs eignet sich sowohl für Anfänger ohne Vorkenntnisse, als auch für erfahrene Experten. Jede Lektion ist in sich geschlossen und kann individuell ausgewählt werden. Umfangreiches Zusatzmaterial erklärt Zusammenhänge und ist mit zahlreichen Referenzen unterlegt. Das ermöglicht Ihnen den Kurs Apache Maven Master Class auch als Nachschlagewerk zu nutzen. Kontinuierlich werden dem Kurs neue Inhalte hinzugefügt. Wenn Sie sich für eine Mitgliedschaft der Apache Maven Master Class entscheiden sollten, haben Sie außerdem vollen Zugriff auf exklusive Inhalte.
Entwickler
Maven Grundlagen
Maven auf der Kommandozeile
IDE Integration
Archetypes: Projektstrukturen anlegen
Testintegration (TDD & BDD) mit Maven
Testcontainers mit Maven
Multi Module Projekte für Microservices
Buildmanager / DevOps
Release Management mit Maven
Deploy nach Maven Central
Sonatype Nexus Repository Manager
Maven Docker Container
Docker Images mit Maven erstellen
verschlüsselte Passwörter
Prozess & Build Optimierung
Qualitätsmanager
Maven Site – Die Reporting Engine
Testabdeckung ermitteln & bewerten
statische Codeanalyse
Codingstyle Vorgaben überprüfen
In Person Live Seminar – Build Management mit Apache Maven
Wir haben bereits mit GPT4all eine Anleitung, wie man ein eigenes lokales LLM betreiben kann. Leider gibt es bei der vorangegangenen Lösung eine kleine Einschränkung. Es können keine Dokumente wie PDF verarbeitet werden. In diesem neuen Workshop installieren wir AnythingLLM mit Ollama um Dokumente analysieren zu können.
Auch für diesen Workshop gilt als Mindestvoraussetzung ein Computer mit 16 GB RAM auf dem optimalerweise ein Linux (Mint, Ubuntu oder Debian) installiert ist. Mit einigen Anpassungen kann diese Anleitung auf Windows und Apple Computer ebenfalls durchgeführt werden. Je geringer die Hardwareressourcen sind, um so länger dauern die Antwortzeiten.
Beginnen wir auch gleich mit dem ersten Schritt und installieren Ollama. Dazu öffnen wir die Bash und benötigen folgendes Kommando: sudo curl -fsSL https://ollama.com/install.sh | sh. Der Befehl bewirkt, das Ollama heruntergeladen wird und das Installationsscript ausgeführt wird. Damit die Installation auch beginnt, muss noch das Administratorkennwort eingegeben werden. Ollama ist ein Kommandozeilenprogramm, das über die Konsole gesteuert wird. Nach erfolgreicher Installation muss noch ein Sprachmodell geladen werden. Auf der Internetseite https://ollama.com/search sind entsprechende Modelle zu finden.
Bewährte Sprachmodelle sind:
lama 3.1 8B: Leistungsstark für anspruchsvollere Anwendungen.
Phi-3-5 3B: Gut geeignet für logisches Denken und Mehrsprachigkeit.
Llama 3.3 2B: Effizient für Anwendungen mit begrenzten Ressourcen.
Phi 4 14B: State-of-the-art Modell mit erhöhter Hardware-Anforderung aber Leistung vergleichbar mit deutlich größeren Modellen.
Nachdem man sich für ein Sprachmodell entschieden hat, kann man den entsprechenden Befehl aus der Übersicht kopieren und in das Terminal eingeben. Für unser Beispiel soll das zu Demonstrationszwecken DeepSeek R1 sein.
Wie im Screenshot zu sehen ist lautet der entsprechende Befehl, den wir benötigen, um das Modell lokal in Ollama zu installieren: ollama run deepseek-r1. Die Installation des Sprachmodells kann ein wenig Zeit in Anspruch nehmen, Das hängt von der Internetverbindung und der Geschwindigkeit des Rechners ab. Nachdem das Modell lokal in Ollama installiert wurde, können wir das Terminal wieder schließen und zum nächsten Schritt übergehen, der Installation von AnythingLLM
Die Installation von AnythingLLm erfolgt ganz analog zu der Installation von Ollama. Dazu öffen wir das Terminal und geben folgenden Befehl ein: curl -fsSL https://cdn.anythingllm.com/latest/installer.sh | sh. Wenn die Installation abgeschlossen ist, können wir in das Installationsverzeichnis wechseln, welches in der Regel /home/<user>/AnythingLLMDesktop ist. Dort navigieren wir zum Link start und machen diese ausführbar (rechtsklick und Eigenschaften auswählen) und erstellen noch zusätzlich eine Verknüpfung auf dem Desktop. Nun können wir AnythingLLM bequem vom Desktop aus starten, was wir auch gleich tun.
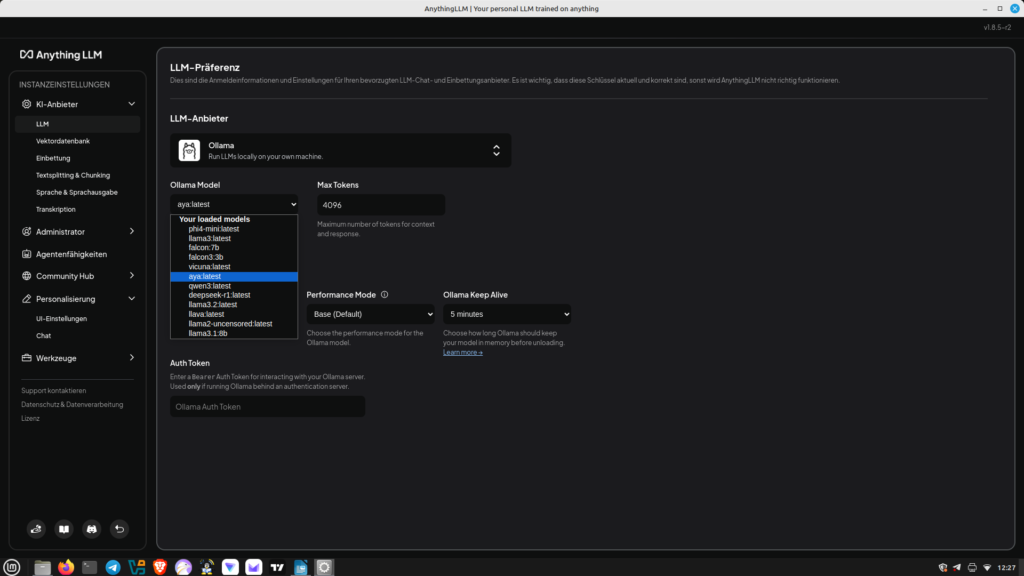
Nachdem wir den Workspace festgelegt haben, können wir Anything nun mit Ollama verknüpfen. Dazu gehen wir auf das kleine Schraubenschlüssel Icon (Einstellungen) im linken unteren Bereich. Dort wählen wir den Eintrag LLM und wählen Ollama aus. Nun können wir das für Ollama hinterlegte Sprachmodell auswählen. Jetzt speichern wir unsere Einstellung ab. Nun kann man in den Chatmodus wechseln. Es besteht natürlich jederzeit die Möglichkeit, das Sprachmodell zu wechseln. Im Gegensatz zu vorhergehenden Workshop können wir jetzt PDF Dokumente hochladen und zum Inhalt Fragen stellen. Viel Spaß damit.
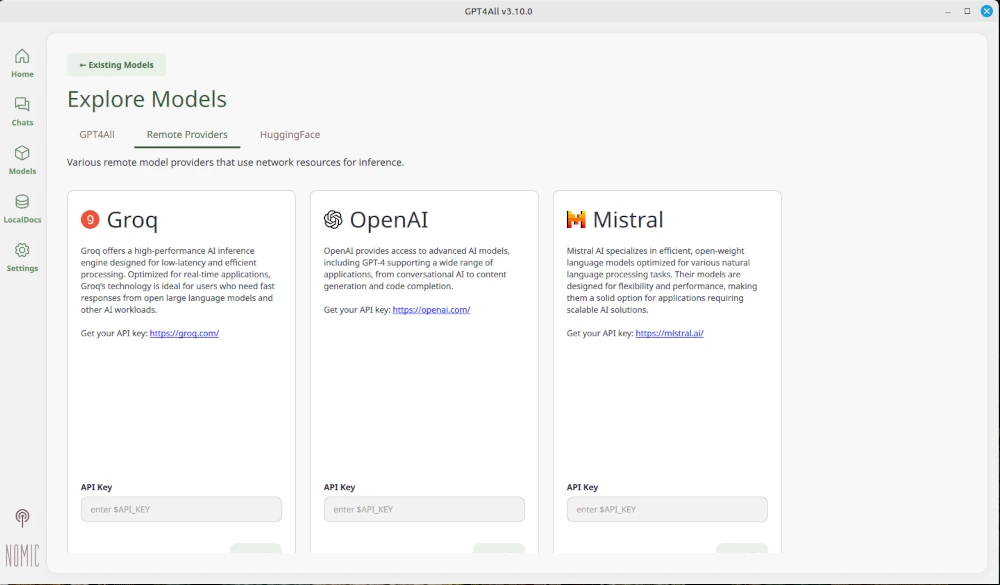
Künstliche Intelligenz ist ein sehr breites Feld, in dem man schnell den Überblick verlieren kann. Large Language Models (LLM), wie ChatGPD verarbeiten natürliche Sprache und können je nach Datenbasis verschiedene Probleme lösen. Neben netten Unterhaltungen, die durchaus therapeutischen Charakter haben können, kann man mit LLM durchaus komplexe Aufgaben bewältigen. Ein solches Szenario wäre das Verfassen von behördlichen Schreiben. In diesem Artikel gehen wir nicht darauf ein, wie Sie die KI nutzen können, sondern erklären Ihnen, wie Sie Ihre eigene KI auf Ihrem Computer lokal installieren können.
Bevor wir ans Eingemachte gehen, beantworten wir die Frage, wozu das Ganze überhaupt nütze ist. Man kann ja problemlos auf die zum Teil kostenlos online verfügbaren KI Systeme zurückgreifen.
Was vielen Menschen nicht bewusst ist, ist die Tatsache, dass alle Anfragen, die man an ChatGPT, DeepSeek und Co. sendet, protokolliert und dauerhaft gespeichert werden. Wie diese Protokollierung im Detail aussieht, können wir nicht beantworten, aber IP Adresse und Nutzeraccount mit der Prompt Anfrage dürften sicherlich zu den minimal erhobenen Daten gehören. Hat man indessen seine eigene KI auf dem lokalen Computer installiert, werden diese Informationen nicht ins Internet übertragen. Zudem kann man so oft man möchte mit der KI interagieren, ohne dass Gebühren erhoben werden.
Für unser Projekt, eine eigene künstliche Intelligenz auf dem eigenen Linux Rechner zu installieren, benötigen wir keine ausgefallene Hardware. Ein handelsüblicher Rechner reicht durchaus. Wie zuvor erwähnt: Als Betriebssystem verwenden wir Linux, da dies viel ressourcenschonender als Windows 10 oder Windows 11 ist. Für den Workshop kann jedes beliebige von Debian abgeleitetes Linux verwendet werden. Debian Derivate sind zum Beispiel Ubuntu und Linux Mint.
Als Arbeitsspeicher sollten mindestens 16 GB (RAM) vorhanden sein. Wer mehr RAM hat, umso besser. Dann läuft die KI viel flüssiger. Als Prozessor (CPU) sollte mindestens ein aktueller i5 / i7 oder AMD Ryzen 5+ verbaut sein. Wenn dann noch eine SSD mit 1 TB Speicher vorhanden ist haben wir das notwendige Setup komplett. Computer / Laptops mit dieser Spezifikation bekommt man schon für kleines Geld gebraucht. Ohne zu viel Werbung machen zu wollen, kann man sich ein wenig bei den gebrauchten Lenovo ThinkPad Laptops umschauen. Aber auch andere Hersteller mit den Mindestanforderungen zur Hardware leisten gute Dienste.
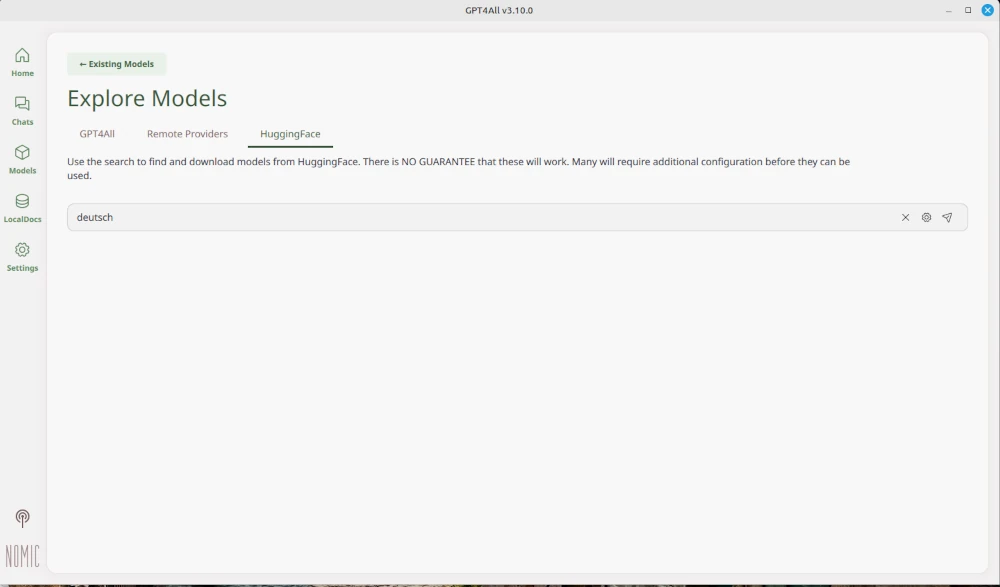
Nachdem die notwendigen Voraussetzungen geklärt sind, machen wir uns zuerst daran, GPT4all auf unserem Rechner zu installieren. Keine Sorge, das ist auch für Anfänger recht leicht zu bewerkstelligen. Es ist kein besonderes Vorwissen notwendig. Beginnen wir damit, die Datei gpd4all.run von der Homepage (https://gpt4all.io/index.html?ref=top-ai-list) herunterzuladen. Ist dies erledigt, machen wir uns daran, die Datei ausführbar (exikutierbar) zu machen.
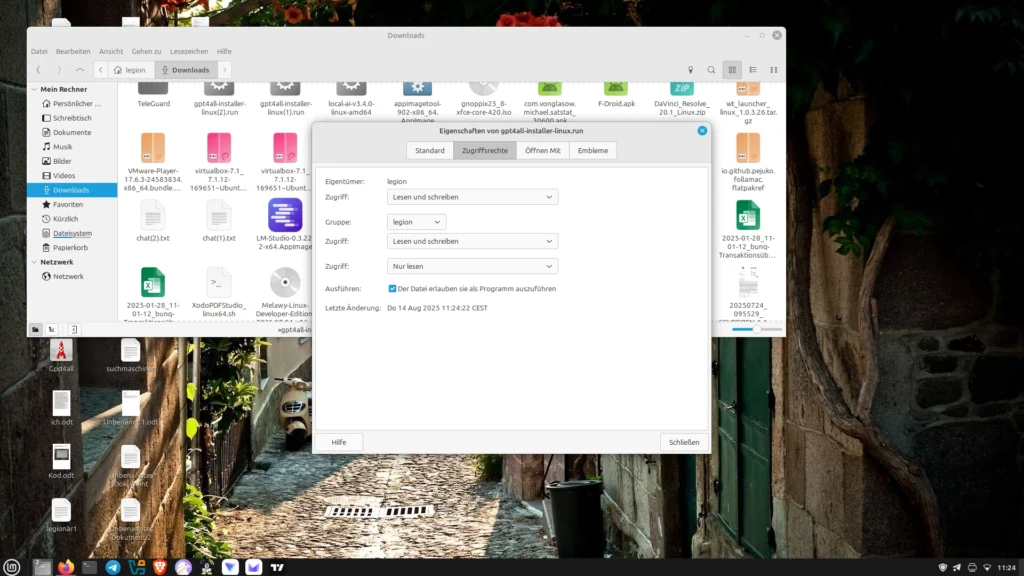
Wie im Screenshot zu sehen ist, selektieren wir die heruntergeladene Datei mit einem rechts Klick und wählen in dem Menü den Eintrag Eigenschaften aus. Unter dem Reiter Zugriffsrechte setzen wir dann das Häkchen bei Ausführen. Nun kann man die Datei mit dem gewohnten Doppelklick starten, was wir auch sofort tun.
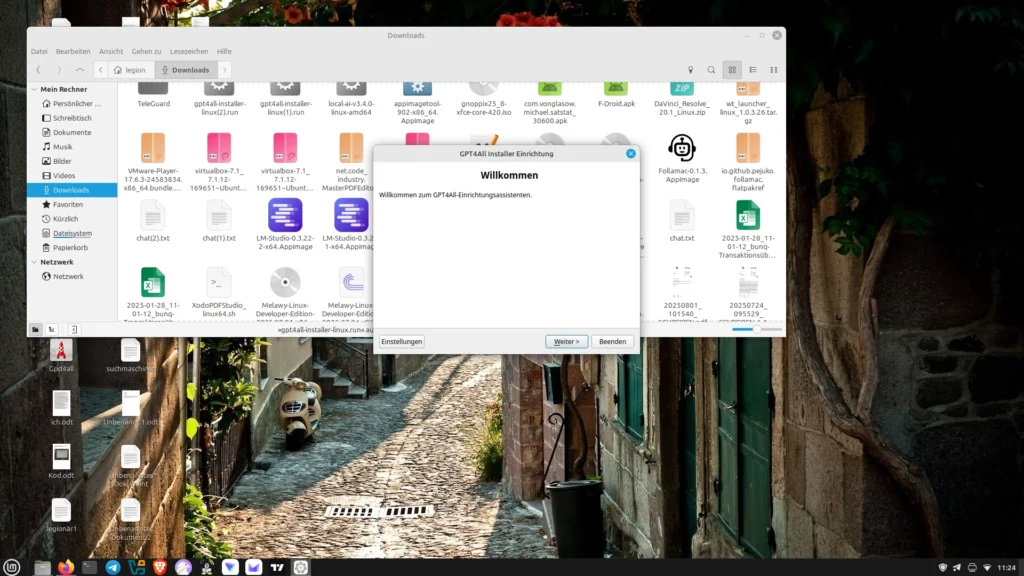
Nun beginnt der Installationsprozess, wo wir unter anderem auswählen können, an welchem Ort GPT4all installiert wird. Bei Linux kommen selbst installierte Programme in der Regel in das Verzeichnis /opt.
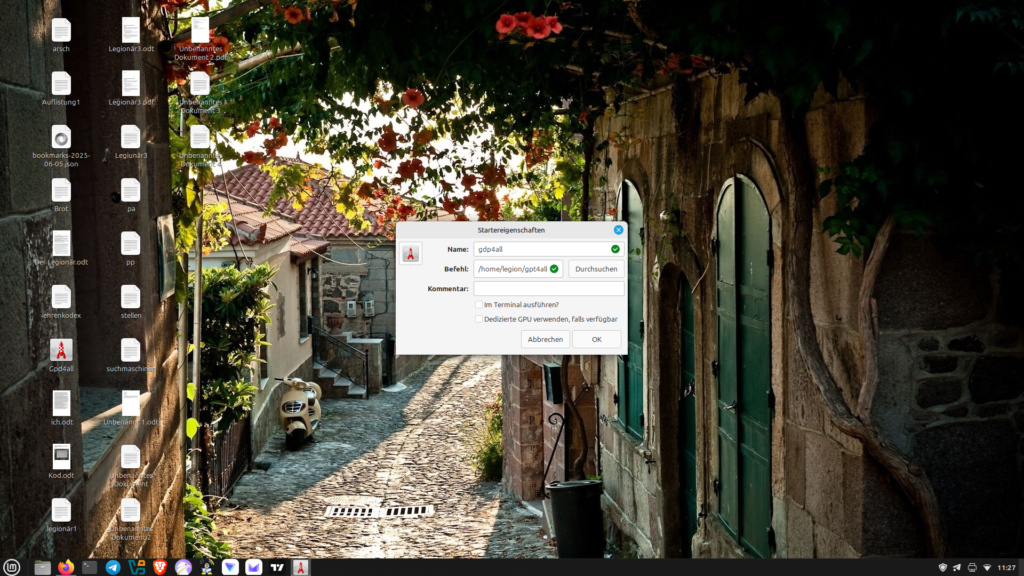
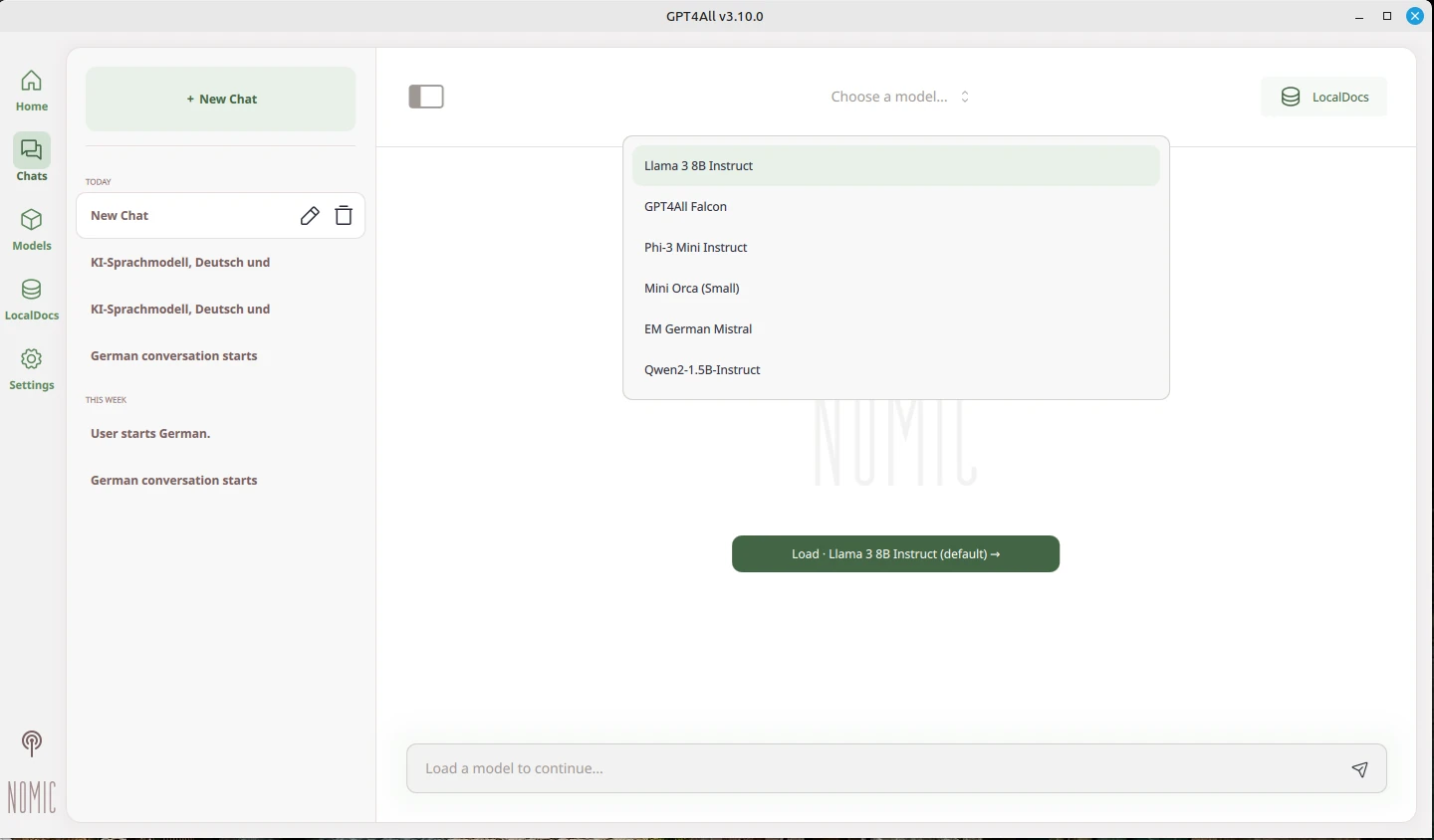
Im nächsten Schritt können wir noch eine Desktop-Verknüpfung anlegen. Dazu klicken wir mit der rechten Maustaste in den leeren Desktop und wählen Verknüpfung erstellen. In der aufpoppenden Maske tragen wir nun einen Namen für die Verknüpfung ein z. B. GPT 4 all und setzen den Pfad zur ausführbaren Datei bin/chat und bestätigen mit OK. Nun können wir GPT4all bequem von unserem Desktop aus starten.
Damit GPT4all auch funktioniert, muss ein Modell geladen werden. Wie in den Screenshots zu sehen ist, stehen verschiedene Modelle zur Verfügung. Das Modell muss bei jedem Start des Programms erneut ausgewählt werden. Nun kann die KI lokal auf dem eigenen Rechner genutzt werden.
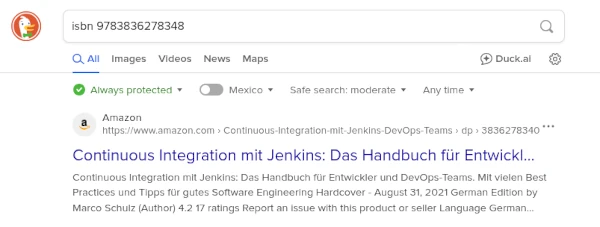
Regelmäßig stehen Entwickler vor der Aufgabe, Nutzereingaben auf Korrektheit zu prüfen. Mittlerweile existiert eine erhebliche Anzahl an standardisierten Datenformaten, mit denen solche Validierungsaufgaben leicht zu meistern sind. Die International Standard Book Number oder kurz ISBN ist ein solches Datenformat. ISBN gibt es in zwei Ausführungen: in einer zehnstelligen und in einer 13-stelligen Variante. Von 1970 bis 2006 wurde die zehnstellige Version der ISBN verwendet (ISBN-10), die im Januar 2007 von der 13-stelligen Fassung abgelöst wurde (ISBN-13). Heutzutage ist es in vielen Verlagen verbreitete Praxis, für Titel beide Versionen der ISBN bereitzustellen. Dass sich anhand dieser Nummer Bücher eindeutig identifizieren lassen, ist allgemein bekannt. Das bedeutet natürlich auch, dass diese Nummern eindeutig sind. Es gibt also keine zwei unterschiedlichen Bücher mit gleicher ISBN (Bild 1).
Der theoretische Hintergrund, um festzustellen, ob eine Zahlenfolge korrekt ist stammt aus der Codierungstheorie. Wer sich also etwas ausführlicher mit dem mathematischen Hintergrund Fehler-erkennender und Fehler-korrigierender Codes beschäftigen möchte, dem Sei das Buch „Codierungstheorie“ von Ralph Hardo Schulz empfohlen [1]. Darin lernt man beispielsweise, wie die Fehlerkorrektur bei Comact Disks (CD) funktioniert. Aber keine Sorge, wir reduzieren in diesem kleinen Workshop die notwendige Mathematik auf ein Minimum.
Bei der ISBN handelt es sich um einen Fehler erkennenden Code. Wir können also den erkannten Fehler nicht automatisch wieder beheben. Wir wissen nur, dass etwas falsch ist, kennen aber nicht den konkreten Fehler. Gehen wir der Sache daher ein wenig auf den Grund.
Warum man sich bei ISBN-13 genau auf 13 Stellen geeinigt hat, bleibt Spekulation. Zumindest haben sich die Entwickler nicht von irgendwelchem Aberglauben beeindrucken lassen. Das große Geheimnis hinter der Validierung ist die Bestimmung der Restklassen [2]. Die Algorithmen für ISBN-10 und ISBN-13 sind recht ähnlich. Beginnen wir also mit dem älteren Standard, ISBN-10, der sich wie folgt errechnet:
Keine Sorge, um die oben stehende Formel zu verstehen, müssen Sie kein Raketeningenieur bei SpaceX sein. Wir heben den Schleier der Verwirrung anschaulich mit einem kleinen Beispiel für die ISBN 3836278340. Daraus ergibt sich folgende Rechnung:
Die letzte Ziffer der ISBN ist die sogenannte Prüfziffer. In dem aufgeführten Beispiel lautet diese 0. Um diese Prüfziffer zu erhalten, multiplizieren wir jede Stelle mit ihrem Wert. Das heißt, an vierter Position steht eine 6, also rechnen wir 4 * 6. Das wiederholen wir mit allen Positionen und die einzelnen Ergebnisse addieren wir zusammen. So erhalten wir den Betrag 220. Die 220 wird mit der sogenannten Restwertoperation Modulo durch 11 geteilt. Da die 11 genau 20 mal in die 220 hineinpasst, bleibt ein Rest null. Das Ergebnis von 220 modulo 11 ist 0 und stimmt mit der Prüfziffer überein, was uns sagt das eine gültige ISBN-10 vorliegt.
Eine Besonderheit gibt es aber noch zu beachten. Bisweilen kommt es vor, dass die letzte Ziffer der ISBN mit X endet. In diesem Fall ist das X gegen 10 auszutauschen.
Wir sehen, der Algorithmus ist sehr einfach gehalten und kann leicht über eine einfache for-Schleife umgesetzt werden.
boolean success = false;
int[] isbn;
int sum = 0;
for(i=0; i<10; i++) {
sum += i*isbn[i];
}
if(sum%11 == 0) {
success = true;
}
Um den Algorithmus so einfach wie möglich zu halten, wird jede Stelle der ISBN-10-Nummer in einem Integer-Array gespeichert. Ausgehend von dieser Vorbereitung ist es nur noch nötig, das Array zu durchlaufen. Wenn dann die Überprüfung der Summe durch das Modulo 11 das Ergebnis 0 liefert, ist alles bestens.
Um die Funktion richtig zu testen, werden zwei Testfälle benötigt. Einerseits gilt es zu überprüfen ob eine ISBN korrekt erkannt wird. Der zweite Test überprüft die sogenannten false positives. Es wird also ein erwarteter Fehler mit einer falschen ISBN provoziert. Das lässt sich zügig bewerkstelligen, indem man von einer gültigen ISBN eine beliebige Stelle ändert.
Unser ISBN-10 Validator hat noch einen kleinen Schönheitsfehler. Ziffernfolgen, die kürzer oder länger als 10 sind, also dem erwarteten Format nicht entsprechen, könnten bereits vorher abgewiesen werden. Der Grund hierfür lässt sich in dem Beispiel erkennen: Die letzte Stelle der ISBN-10 ist eine 0 – somit ist das Zeichenergebnis auch 0. Wird die letzte Stelle also vergessen und eine Prüfung auf das korrekte Format fehlt, wird der Fehler nicht erkannt. Etwas das keine Auswirkung auf den Algorithmus hat, aber sehr hilfreich als Feedback bei Nutzereingaben ist, ist das Eingabefeld so lange auszugrauen und den Absenden-Button zu deaktivieren, bis das korrekte Format der ISBN eingegeben wurde.
Der Algorithmus für ISBN-13 ist ähnlich einfach aufgebaut.
Analog wie bei ISBN-10 steht xn für den Zahlenwert an der entsprechenden Position in er ISBN-13. Auch hier werden die Teilergebnisse aufsummiert und durch ein Modulo geteilt. Der große Unterschied ist, dass hier nur die geraden Positionen, also die Stellen 2, 4, 6, 8, 10 und 12, mit 3 multipliziert werden und das Ergebnis dann mit Modulo 10 dividiert wird. Als Beispiel berechnen wir die ISBN-13: 9783836278348.
Auch für die ISBN-13 lässt sich der Algorithmus in einer einfachen for-Schleife umsetzen.
boolean success = false;
int[] isbn;
int sum = 0;
for(i=0; i<13; i++) {
if(i%2 == 0) {
sum += 3*isbn[i];
} else {
sum += isbn[i];
}
}
if(sum%10 == 0) {
success = true;
}
Die beiden Codebeispiele zu ISBN-10 und ISBN-13 unterscheiden sich vor allem in der if-Bedingung. Der Ausdruck i % 2 berechnet den Modulo-Wert 2 zur jeweiligen Iteration. Wenn an dieser Stelle der Wert 0 herauskommt, bedeutet das, dass es sich um eine gerade Zahl handelt. Der dazugehörige Wert muss dann mit 3 multipliziert werden.
Hier zeigt sich wie praktisch die Modulo-Operation % für das Programmieren sein kann. Um die Implementierung möglichst kompakt zu halten, kann anstatt der if-else-Bedingung auch der sogenannte Dreifach-Operator verwendet werden. Der Ausdruck sum += (i%2) ? isbn[i] : 3 * isbn[3] ist wesentlich kompakter, dafür aber auch schwerer zu verstehen.
Nachfolgend finden Sie eine vollständig implementierte Klasse zur Prüfung der ISBN in den Programmiersprachen: Java, PHP und C#.
Die in den Beispielen vorgestellten Lösungen haben zwar alle denselben Kernansatz, unterscheiden sich aber nicht nur in syntaktischen Details. So bietet die Java-Version eine allumfassende Variante, die etwas generischer zwischen ISBN-10 und ISBN-13 unterscheidet. Das demonstriert zum einen, dass viele Wege nach Rom führen. Soll aber auch gerade weniger erfahrenen Entwicklern verschiedene Lösungsansätze zeigen und sie motivieren, eigene Anpassungen vorzunehmen. Um das Verständnis zu vereinfachen, wurde der Quelltext mit Kommentaren angereichert. Bei PHP, als untypisierte Sprache, entfällt insbesondere das Konvertieren des Strings in Nummern. Dafür wird eine RegEx genutzt, um sicherzustellen, dass die eingegebenen Zeichen typsicher sind.
Lessons Learned
Wie Sie sehen, handelt es sich bei der Überprüfung, ob eine ISBN korrekt ist, um keine Hexerei. Das Thema der Validierung von Benutzereingaben ist natürlich viel umfangreicher. Andere Beispiele sind Kreditkartennummern. Aber auch reguläre Ausdrücke leisten in diesem Zusammenhang wertvolle Dienste.
Ressourcen
[1] Ralph-Hardo Schulz, Codierungstheorie: Eine Einführung, 2003, ISBN 978-3-528-16419-5
[2] Begriff der Restklasse bei Wikipedia, https://de.wikipedia.org/wiki/Restklasse
Wer sein Git-Repository zur gemeinsamen Bearbeitung für Quelltexte benutzen möchte, benötigt einen Git-Server. Der Git Server ermöglicht die Kollaboration mehrere Entwickler auf der gleichen Codebasis. Die Installation des Git-Clients auf einem Linux Server ist zwar ein erster Schritt zur eigenen Serverlösung, aber bei Weitem nicht ausreichend. Um den Zugriff mehrere Personen auf ein Code Repository zu ermöglichen, benötigen wir eine Zugriffsberechtigung. Schließlich soll das Repository öffentlich über das Internet erreichbar sein. Wir möchten über die Benutzerverwaltung verhindern, dass unberechtigte Personen den Inhalt der Repositories lesen und verändern können.
Für den Betrieb eines Git-Servers gibt es viele hervorragende und komfortable Lösungen, die man einer nativen Serverlösung vorziehen sollte. Die Administration eines nativen Git Servers erfordert Linux Kenntnisse und wird ausschließlich über die Kommandozeile bewerkstelligt. Lösungen wie beispielsweise der SCM-Manager haben eine grafische Benutzeroberfläche und bringen viele nützliche Werkzeuge zur Administration des Servers mit. Diese Werkzeuge stehen bei einer nativen Installation nicht zur Verfügung.
Wieso sollte man nun Git als nativen Server installieren? Diese Frage lässt sich recht leicht beantworten. Der Grund ist wenn der Server, auf dem das Code Repository bereitgestellt werden soll, nur wenige Hardware-Ressourcen besitzt. Besonders der Arbeitsspeicher ist in diesem Zusammenhang immer ein wenig problematisch. Gerade bei angemieteten Virtuellen Private Servern (VPS) oder einem kleinen RaspberryPI ist das oft der Fall. Wir sehen also, es kann durchaus Sinn ergeben, einen nativen Git Server betreiben zu wollen.
Als Voraussetzung benötigen wir einen Linux-Server, auf dem wir den Git-Server installieren können. Das kann ein Debian oder Ubuntu Server sein. Wer CentOS oder andere Linux Distributionen verwendet, muss anstatt APT zur Softwareinstallation den Paketmanager seiner Distribution nutzen.
Wir beginnen im ersten Schritt mit der Aktualisierung der Pakete und der Installation des Git-Clients.
Als zweiten Schritt erstellen wir einen neuen Benutzer mit dem Namen git und legen für diesen ein eigenes home Verzeichnis an und aktivieren dort den SSH-Zugriff.
Nun können wir im dritten Schritt in dem neu angelegten home Verzeichnis des git Users unsere Git-Repositories erstellen. Diese unterscheiden sich gegenüber dem lokalen Arbeitsbereich darin, dass diese den Source Code nicht ausgecheckt haben.
Leider sind wir noch nicht ganz fertig mit unserem Vorhaben. Im vierten Schritt müssen wir die Benutzerberechtigung für das erstellte Repository setzen. Dies geschieht durch das Ablegen des öffentlichen Schlüssels auf dem Git Server für den SSH-Zugriff. Dazu kopieren wir den Inhalt aus der Datei unseres privaten Schlüssels in die Datei /home/git/.ssh/authorized_keys in eine eigene Zeile. Möchte man nun vorhandenen Nutzern den Zugriff verwehren, kommentiert man lediglich mit einem # die zeie des privaten Schlüssels wieder aus.
Wenn alles korrekt durchgeführt wurde, erhält man den Zugriff auf das Repository über folgenden Kommandozeilenbefehl: git clone ssh://git@<IP>/~/<repo>
Dabei ist <IP> durch die tatsächliche Server-IP zu ersetzen. Für unser Beispiel lautet der korrekte Pfad für <repo> project.git es ist also das von uns erstellte Verzeichnis für das Git-Repository.
Auf dem nativen Git Server können mehrere Repositories angelegt werden. Dabei gilt zu beachten, dass alle berechtigenden Nutzer auf alle so angelegenen Reposiories lesenden und schreibenden Zugriff haben. Das lässt sich nur dadurch einschränken, dass auf dem Linux-Server der unsere Git-Repositories bereitstellt, mehrere Benutzer auf dem Betriebssystem angelegt werden, denen dann die Repositories zugewiesen werden.
Wir sehen, dass eine native Git Server Installation zwar schnell umgesetzt werden kann, diese aber für die kommerzielle Softwareentwicklung nicht ausreichend ist. Wer gerne experimentiert, kann sich eine virtuelle Maschine erstellen und diesen Workshop darin ausprobieren.
Ruby ist seit vielen Jahren eine sehr etablierte Programmiersprache, die durchaus auch Anfängern empfohlen werden kann. Ruby folgt dem objektorientierten Paradigma und enthält sehr viele Konzepte, um OOP gut zu unterstützen. Außerdem lassen sich dank des Frameworks Ruby on Rails unkompliziert komplexe Webanwendungen entwickeln.
Die schwierigste Hürde beim Einstieg in Ruby, die es zu meistern gilt, ist die Installation der gesamten Entwicklungsumgebung. Angesichts dessen habe ich dieses kurze Tutorial zum Einstieg mit Ruby verfasst. Beginnen wir daher auch gleich mit der Installation.
Mein Betriebssystem ist ein Debian 12 Linux und Ruby lässt sich sehr einfach mit der Anweisung sudo apt-get install ruby-full installieren. Dieses Vorgehen kann auf alle Debian basierte Linux Distributionen wie z. B. Ubuntu übertragen werden. Anschließend kann mit ruby -v der Erfolg in der Bash überprüft werden.
Wenn wir nun dem Tutorial auf der Ruby on Rails Homepage folgen und das Rails Framework über gem rails installieren wollen, stoßen wir bereits auf das erste Problem. Wegen fehlender Berechtigungen lassen sich keine Bibliotheken für Ruby installieren. Nun konnten wir auf die Idee kommen, die Bibliotheken, als Superuser mit sudo zu installieren. Dies Losung ist leider nur temporär und verhindert, dass später in der Entwicklungsumgebung die Bibliotheken korrekt gefunden werden. Besser ist es, einen Ordner für die GEMs im home Verzeichnis des Nutzers anzulegen und dies über eine Systemvariable bereitzustellen.
Die oben stehende Zeile ist an das Ende der Datei .bashrc einzutragen, damit die Änderungen auch persistent bleiben. Wichtig ist, dass <user> gegen den richtigen Nutzernamen ausgetauscht wird. Den Erfolg dieser Aktion lasst sich über gem environment überprüfen und sollte eine ähnliche Ausgabe wie nachstehend ergeben.
Mit dieser Einstellung lassen sich nun ohne Schwierigkeiten Ruby GEMs installieren. Das probieren wir auch gleich aus und installieren, das Ruby on Rails Framework, was uns bei der Entwickelung von Webapplikationen unterstützt: gem install rails. Dies sollte indessen ohne Fehlermeldungen durchlaufen und mit dem Kommando rails -v sehen wir, ob wir erfolgreich waren.
Im nächsten Schritt können wir nun ein neues Rails Projekt anlegen. Hier bediene ich mich dem Beispiel aus der Ruby on Rails Dokumentation und schreibe in die Bash: rails new blog. Dies erzeugt ein entsprechendes Verzeichnis namens blog mit den Projektdateien. Nachdem wir in das Verzeichnis gewechselt sind müssen wir noch alle Abhängigkeiten installieren. Das geschieht über: bundle install.
Hier stoßen wir nun auf ein weiteres Problem. Die Installation kann nicht beendet werden, weil es anscheinend ein Problem mit der Bibliothek psych gibt. Das tatsächliche Problem ist allerdings, dass auf der Betriebssystemebene die Unterstützung für YAML-Dateien fehlt. Das lässt sich rasch beheben, indem das YAML-Paket nachinstalliert wird.
sudo apt-get install libyaml-dev
Das Problem mit psych bei Ruby on Rails besteht schon eine Weile und ist mit der YAML Installation behoben, so, dass nun auch die Anweisung bundle install erfolgreich durchläuft. Jetzt sind wir auch in der Lage, den Server für die Rails Anwendung zu starten: bin/rails server.
ed@:~/blog$bin/railsserver=> BootingPuma=> Rails7.1.3.3applicationstartingindevelopment=> Run`bin/rails server --help`for more startup optionsPumastartinginsinglemode...* Puma version: 6.4.2 (ruby3.1.2-p20)("The Eagle of Durango")* Min threads: 5* Max threads: 5* Environment: development* PID: 12316* Listening on http://127.0.0.1:3000* Listening on http://[::1]:3000UseCtrl-Ctostop
Rufen wir nun im Webbrowser die URL http://127.0.0.1:3000 auf, sehen wir unsere Rails Webanwendung.
Mit diesen Schritten haben wir nun eine funktionierende Ruby Umgebung auf unserem System erstellt. Nun ist es an der Zeit, sich für eine geeignete Entwicklungsumgebung zu entscheiden. Wer nur gelegentlich ein paar Scripte anpasst, dem genügen VIM und Sublime Text als Editoren. Für komplexe Softwareprojekte sollte wiederum auf eine vollständige IDE zurückgegriffen werden, da dies die Arbeit erheblich vereinfacht. Die beste Empfehlung ist die kostenpflichtige IDE RubyMine von JetBrains. Wer Ruby Open Source Projekte als Entwickler unterstützt, kann eine kostenfreie Lizenz beantragen.
Eine frei verfügbare Ruby IDE ist VSCode von Microsoft. Hier müssen aber zunächst ein paar Plug-ins eingebunden werden, und für meinen Geschmack ist VSCode auch nicht sehr intuitiv. Ruby Integration für die klassischen Java IDEs Eclipse und NetBeans sind recht veraltet und nur mit sehr viel Mühe zum Laufen zu bekommen.
Damit haben wir auch schon alle wichtigen Punkte, die notwendig sind, eine funktionierende Ruby-Umgebung auf dem eigenen System einzurichten, besprochen. Ich hoffe, mit diesem kleinen Workshop die Einstiegshürde zum Erlernen von Ruby erheblich gesenkt zu haben. Wenn Ihr diesen Artikel mögt, freue ich mich über ein Like und die Weiterempfehlung an eure Freunde.
README Dateien haben in Softwareprojekten eine lange Tradition. Diese ursprünglich reinen Textdateien enthielten Lizenzinformationen und Anweisungen wie aus dem Quellcode das entsprechende Artefakt kompiliert werden konnte oder aber wichtige Hinweise zu Installation des Programms. Es gibt keinen wirklichen Standard, wie man eine solche README Datei aufbauen sollte.
Seit dem GitHub (2018 von Microsoft übernommen) als kostenfreie Code Hosting Plattform für Open Source Projekte seinen Siegeszug angetreten ist, gab es schon recht früh die Funktion, dass die README Datei als Startseite des Repositories anzuzeigen. Dazu muss lediglich eine einfache Textdatei mit der Bezeichnung README.md im Hauptverzeichnis des Repository erstellt werden.
Um die README Dateien übersichtlicher strukturieren zu können, wurde eine Möglichkeit für eine einfache Formatierung gesucht. Schnell hatte man sich für die markdown Notation entschieden, da diese einfach zu nutzen ist und auch recht performant gerendert werden kann. Somit sind die Übersichtsseiten besser für Menschen zu lesen und können als Projektdokumentation genutzt werden.
Es ist möglich, mehrere solcher markdown Dateien als Projektdokumentation miteinander zu verknüpfen. Somit erhält man eine Art Mini WIKI das im Projekt enthalten ist und außerdem auch über Git versioniert wird.
Das Ganze wurde so erfolgreich, das Selfhosting-Lösungen wie GitLab oder das kommerzielle BitBucket diese Funktion ebenfalls übernommen haben.
Nun stellt sich aber die Frage welche Inhalte man am besten in solch eine README Datei schreibt, damit diese für Außenstehende auch einen wirklichen Mehrwert darstellen. Dabei haben sich im Laufe der Zeit folgende Punkte etabliert:
Kurzbeschreibung des Projekts
Bedingungen, unter denen der Quellcode verwendet werden darf (Lizenz)
Wie ist das Projekt zu verwenden (z.B. Anweisungen zum Compilieren oder wie wird die Bibliothek in eigene Projekte eingebunden)
Wer sind die Autoren des Projekts und wie kann man sie erreichen
Was ist zu tun wenn man das Projekt unterstützen möchte
Mittlerweile sind sogenannte Badges (Sticker) sehr populär. Diese referenzieren oft auf externe Dienste, wie beispielsweise der freie Continuous Integration Server TravisCI. Diese helfen Ausstehenden, die Qualität des Projekts zu beurteilen.
Auf GitHub gibt es auch diverse Vorlagen für README Dateien. Man muss allerdings auch ein wenig auf die tatsächlichen Gegebenheiten des eigenen Projekts schauen und beurteilen, welche Informationen für Nutzer bzw. Anwender wirklich relevant sind. Solche Vorlagen helfen aber sehr dabei, herauszufinden, ob man möglicherweise einen Punkt übersehen hat.
Da mittlerweile ziemlich jeder Hersteller von Source Control Management Serverlösungen die Funktion die README.md Datei als Projektstartseite für das Code Repository anzuzeigen integriert hat, bedeutet das eine README.me auch für kommerzielle Projekte eine sinnvolle Sache sind.
Auch wenn die Syntax für markdown leicht zu erlernen ist, kann es bei umfangreichen Editierungen solcher Dateien durchaus komfortabler sein, direkt einen MARKDOWN Editor zu nutzen. Dabei sollte man darauf achten, dass die Vorschau auch korrekt dargestellt wird und nicht nur ein einfaches Syntaxhighligting angeboten wird.
Auf alle Fälle lohnt sich ein Blick auf die GitHub Seite https://www.readme-templates.com zu werfen. Weitere Ressourcen zum Thema finden sich hier:
Als IT-Dienstleister müssen wir unsere Kunden oft dabei unterstützen, alte Windows-Systeme neu zu installieren. Die häufigste Herausforderung, der wir uns bei dieser Aktivität stellen müssen, besteht darin, alte Dateien zu sichern und sie auf dem neuen System wiederherzustellen. Nicht nur Privatpersonen, auch Unternehmen nutzen den E-Mail-Client Thunderbird. Deshalb haben wir uns entschlossen, diese kurze Anleitung zu veröffentlichen, wie Ihr Thunderbird-Profil gesichert und wiederhergestellt werden kann. Um einem Datenverlust vorzubeugen, sollten Sie regelmäßig Backups erstellen, falls Ihre Hardware oder Ihr Betriebssystem vollständig abgestürzt ist.
Sichern
Einen USB-Stick oder -Festplatte (USB-Medium) an den Rechner anschließen.
Erstellen Sie auf dem USB-Medium ein Verzeichnis Ihrer Wahl, zur Sicherung Ihres Profils. (z. B. 2022-01-19_Thunderbird-profil)
Halten Sie das „Explorer Fenster“ offen und achten Sie darauf, dass das Verzeichnis „aktiv“ ist.
Starten Sie nun Ihren Thunderbird E-Mail Client auf dem Rechner (Quelle) den Sie sichern möchten.
Zum Auffinden Ihres alten Profils klicken Sie auf die „drei Balken“ oben rechts.
In dem Fenster days such deann öffnent klicken Sie auf “Hilfe” (wie in dem Screenshot zu seen) 1️⃣ und dann 2️⃣ gehen Sie auf „weitere Hilfe zur Fehlerbehebung“.
Im nächsten, sich öffnenden Fenster, wählen Sie das Feld „Ordner öffnen“ aus.
Ein neues „Explorer Fenster“ öffnet sich und zeigt Ihnen alle Dateien Ihres Profils an.
Markieren Sie alle Dateien, indem Sie die 1. Datei anklicken, dann die <Shift> Taste auf Ihrer Tastatur gedrückt halten und gleichzeitig die Taste <Pfeil nach unten> solange gedrückt halten bis der graue „Scroll-Balken“ im Fenster ganz unten angekommen ist. Sind alle Dateien ausgewählt (blau markiert), klicken Sie mit der „rechten Maustaste„ auf eine beliebige Datei und wählen den Menüpunkt „Kopieren“ aus
Gehen Sie zurück zu dem „Explorer Fenster“ in dem Sie das USB Medium geöffnet haben und klicken die „rechte Maustaste“ und dann auf „Einfügen“.
Ist der Kopiervorgang abgeschlossen, können Sie den Thunderbird E-Mail Client schließen.
Wiederherstellen
Schließen Sie Ihr USB-Medium an den Ziel-Rechner an.
Öffnen Sie den „Explorer“ und legen Sie folgende Verzeichnisse an: „Daten“ ➡️ „ Thunderbird“ ➡️ „Postamt xxx“ (C:\Data\Thunderbird\Postamt-Office xxx\ xxx müssen Sie mit dem Namen Ihres Thunderbird Profiles ersetzen)
Kopieren Sie nun Ihre Profildaten von Ihrem USB-Medium in das neu erstellte Verzeichnis „C:\Data\Thunderbird\Postamt-Office xxx“.
Nach Abschluss des Kopiervorgangs müssen Sie Ihr neues Profil Verzeichnis noch in der Thunderbird Installtion einrichten.
Drücken Sie auf der Tastatur die Tasten <Windows Key>+<R>. Der Dialog „Ausführen” öffnet sich. Dort geben Sie im Screenshot „rot“ eingerahmten Befehl “thunderbird -p” ein und drücken die auf „OK“.
Im neu geöffneten Fenster „Thunderbird – Benutzerprofil wählen“ klicken Sie auf den Eintrag „Profil erstellen“.
Im 1. Fenster des „Profil-Assistent – Willkommen“ klicken Sie auf „Weiter“.
Im 2. Fenster des „Profil-Assistent – Fertigstellen” tragen Sie unter “1“ den „Profilnamen“ (Postamt xxx) ein. Unter „2“ wählen Sie den Profilpfad durch klicken auf „Ordner wählen“ aus. (C:\Daten\Thunderbird\Postamt xxx).
Zum Abschließen der Einrichtung Ihres Thunderbird Profils, müssen Sie nur noch auf „Fertigstellen“ drücken Sie können ab jetzt Thunderbird normal über die Startleiste starten – alle Ihre e-Mails & Einstellungen sind nun wiederhergestellt.
Wenn Sie Fragen oder Anregungen haben können Sie uns gerne eine E-Mail schreiben oder einen Kommentar hier hinterlassen. Wenn Sie diese kleine Anleitung hilfreich
Nach einigen Jahren hat das Virtualisierungstool Docker seine Bedeutung für die Softwarebranche unter Beweis gestellt. Wenn man von Virtualisierung hört, könnte man meinen, dass dies nur etwas für Administratoren ist und mich als Entwickler nicht so stark betrifft. Aber Moment mal. Da könntest du falsch liegen. Denn Grundkenntnisse über Docker können Entwicklern im Alltag helfen.
Schritt 1: Erstellen Sie den Container und initialisieren Sie die Datenbank
Wenn Sie möchten, dass PostgreSQL nach einem Neustart immer aktiv ist, ändern Sie die Neustartrichtlinie von „nein“ auf „immer“. Nachdem Sie die Instanz „pg-dbms“ Ihres PostgreSQL 11 Docker-Images erstellt haben, überprüfen Sie, ob der Neustart erfolgreich war. Dies gelingt über den Befehl:
dockerps-a
Schritt 2: Kopieren Sie das initialisierte Datenbankverzeichnis in ein lokales Verzeichnis auf Ihrem Hostsystem
Das größte Problem mit dem aktuellen Container ist, dass beim Löschen alle Daten verloren gehen. Wir müssen also eine Möglichkeit finden, diese Daten dauerhaft zu speichern. Am einfachsten kopieren Sie das Datenverzeichnis Ihres Containers in ein Verzeichnis auf Ihrem Hostsystem. Der Kopierbefehl benötigt die Parameter „Quelle“ und „Ziel“. Geben Sie als Quelle den Container an, aus dem die Dateien stammen sollen. In unserem Fall heißt der Container „pg-dbms“. Das Ziel ist ein PostgreSQL-Ordner im Home-Verzeichnis des Benutzers „ed“. Unter Windows funktioniert es genauso. Passen Sie einfach den Verzeichnispfad an und vermeiden Sie Leerzeichen. Sobald die Dateien im angegebenen Verzeichnis liegen, ist dieser Schritt abgeschlossen.
Schritt 3: Stoppen Sie den aktuellen Container
dockerstoppg-dbms
Wenn Sie einen Container starten möchten, ersetzen Sie einfach „Stop“ durch „Start“. Der Container, den wir zum Abrufen der ursprünglichen Dateien für das PostgreSQL-DBMS erstellt haben, wird nicht mehr benötigt. Wir können ihn löschen. Dazu muss jedoch zunächst der laufende Container gestoppt werden.
Schritt 4: Starten Sie den aktuellen Container
dockerstartpg-dbms
Nachdem der Container gestoppt wurde, können wir ihn löschen.
Schritt 5: Container mit einem externen Volume neu erstellen
Jetzt können wir das Verzeichnis mit der exportierten ursprünglichen Datenbank mit einem neu erstellten PostgreSQL-Container verknüpfen. Das ist alles. Der große Vorteil dieser Vorgehensweise ist, dass sich nun jede in PostgreSQL erstellte Datenbank und deren Daten außerhalb des Docker-Containers auf unserem lokalen Rechner befinden. Dies ermöglicht eine wesentlich einfachere Sicherung und verhindert Informationsverluste bei Containeraktualisierungen.
Wenn Sie anstelle von PostgreSQL andere Images haben, aus denen Sie Dateien zur Wiederverwendung extrahieren müssen, können Sie dieses Tutorial ebenfalls verwenden. Passen Sie es einfach an das Image und die benötigten Pfade an. Die Vorgehensweise ist nahezu identisch. Wenn Sie mehr über Docker erfahren möchten, können Sie sich auch mein Video „Docker-Grundlagen in weniger als 10 Minuten“ ansehen. Wenn Ihnen dieses kurze Tutorial gefällt, teilen Sie es mit Ihren Freunden und Kollegen. Abonnieren Sie meinen Newsletter, um auf dem Laufenden zu bleiben.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.