For more than a decade, it has been widely accepted that computer systems should be kept up to date. Those who regularly install updates reduce the risk of having security gaps on their computer that could be misused. Always in the hope that manufacturers of software always fix in their updates also security flaws. Microsoft, for example, has imposed an update requirement on its users since the introduction of Windows 10. Basically, the idea was well-founded. Because unpatched operating systems allow hackers easy access. So the thought: ‘Latest is greatest’ prevailed a very long time ago.
Windows users had little leeway here. But even on mobile devices like smartphones and tablets, automatic updates are activated in the factory settings. If you host an open source project on GitHub, you will receive regular emails about new versions for the libraries used. So at first glance, this is a good thing. However, if you delve a bit deeper into the topic, you will quickly come to the conclusion that latest is not always the best.
The best-known example of this is Windows 10 and the update cycles enforced by Microsoft. It is undisputed that systems must be regularly checked for security problems and available updates must be installed. That the maintenance of computer systems also takes time is also understandable. However, it is problematic when updates installed by the manufacturer paralyze the entire system and a new installation becomes necessary because the update was not sufficiently tested. But also in the context of security updates unasked function changes to the user to bring in I consider unreasonable. Especially with Windows, there are a lot of additional programs installed, which can quickly become a security risk due to lack of further development. That means with all consequence forced Windows updates do not make a computer safe, since here the additionally installed software is not examined for weak points.
If we take a look at Android systems, the situation is much better. However, there are enough points of criticism here as well. The applications are updated regularly, so the security is actually improved significantly. But also with Android, every update usually means functional changes. A simple example is the very popular Google StreetMaps service. With every update, the map usage becomes more confusing for me, as a lot of unwanted additional information is displayed, which considerably reduces the already limited screen.
As a user, it has fortunately not yet happened to me that application updates on Android have paralyzed the entire phone. Which also proves that it is quite possible to test updates extensively before rolling them out to users. However, this does not mean that every update was unproblematic. Problems that can be observed here regularly are things like an excessively increased battery consumption.
Pure Android system updates, on the other hand, regularly cause the hardware to become so slow after almost two years that you often decide to buy a new smartphone. Although the old phone is still in good condition and could be used much longer. I have noticed that many experienced users turn off their Android updates after about a year, before the phone is sent into obsolescence by the manufacturer.
How do you get an update muffler to keep his systems up to date and secure? My approach as a developer and configuration manager is quite simple. I distinguish between feature update and security patch. If you follow the semantic versioning in the release process and use a branch by release model for SCM systems like Git, such a distinction can be easily implemented.
But I also dedicated myself to the question of a versionable configuration setting for software applications. For this, there is a reference implementation in the project TP-CORE on GitHub, which is described in detail in the two-part article Treasue Chest. After all, it must be clear to us that if we reset the entire configuration made by the user to factory settings during an update, as is quite often the case with Windows 10, quite unique security vulnerabilities can arise.
This also brings us to the point of programming and how GitHub motivates developers through emails to include new versions of the libraries used in their applications. Because if such an update is a major API change, the problem is the high migration effort for the developers. This is where an also fairly simple strategy has worked for me. Instead of being impressed by the notifications about updates from GitHub, I regularly check via OWASP whether my libraries contain known risks. Because if a problem is detected by OWASP, it doesn’t matter how costly an update can be. The update and the associated migration must be implemented promptly. This also applies to all releases that are still in production
However, one rule of thumb applies to avoid update hell from the start: Only install or use what you really need. The fewer programs are installed under Windows and the fewer apps there are on the smartphone, the fewer security risks there are. This also applies to program libraries. Less is more from a security perspective. Apart from that, we get a free performance measurement by dispensing with unnecessary programs.
Certainly, for many private users the question of system updates is hardly relevant. Only new unwanted functions in existing programs, performance degradations or now and then shot operating systems cause more or less strong displeasure. In the commercial surrounding field quite fast substantial costs can develop, which can affect also the straight implementing projects negatively. Companies and people who develop software can improve user satisfaction considerably if they differentiate between security patches and feature updates in their release publications. And a feature update should then also contain all known security updates.
Everyone does it, some even several times a day. But few are aware of the complex interlocking mechanisms that make up a complete software release. This is why it sometimes happens that a package gets in the way of the automated processing chain. With a bit of theory and a typical example from the Java universe, I show how you can take a little pressure out of the software development process in order to achieve lean, slightly automated processes.
To deal with standards in your own projects is not something bad. A well define release process based on common standards increase your productivity. Learn in this talk how you are able to simplify your daily work.
In the previous part of the article treasure chest, I described how the database connection for the TP-CORE library got established. Also I gave a insight to the internal structure of the ConfiguartionDO. Now in the second part I explain the ConfiguartionDAO and its corresponding service. With all this knowledge you able to include the application configuration feature of TP-CORE in your own project to build your own configuration registry.
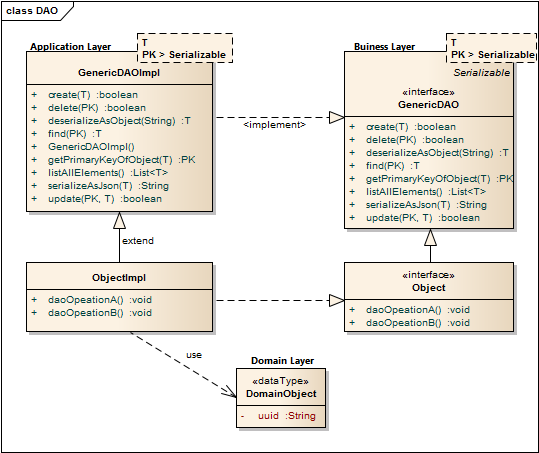
Lets resume in short the architectural design of the TP-CORE library and where the fragments of the features located. TP-CORE is organized as layer architecture as shown in the graphic below.
As you can see there are three relevant packages (layer) we have to pay attention. As first the business layer resides like all other layers in an equal named package. The whole API of TP-CORE is defined by interfaces and stored in the business layer. The implementation of the defined interfaces are placed in the application layer. Domain Objects are simple data classes and placed in the domain layer. Another important pattern is heavily used in the TP-CORE library is the Data Access Object (DAO).
Now the days micro services and RESTful application are state of the art. Especially in TP-CORE the defined services aren’t REST. This design decision is based on the mind that TP-CORE is a dependency and not a standalone service. Maybe in future, after I got more feedback how and where this library is used, I could rethink the current concept. For now we treat TP-CORE as what it is, a library. That implies for the usage in your project, you can replace, overwrite, extend or wrap the basic implementation of the ConfigurationDAO to your special necessities.
To keep the portability of changing the DBMS Hibernate (HBM) is used as JPA implementation and O/R mapper. The Spring configuration for Hibernate uses the EntityManager instead of the Session, to send requests to the DBMS. Since version 5 Hibernate use the JPA 2 standard to formulate queries.
As I already mentioned, the application configuration feature of TP-CORE is implemented as DAO. The domain object and the database connection was topic of the first part of this article. Now I discuss how to give access to the domain object with the ConfigurationDAO and its implementation ConfigurationHbmDAO. The domain object ConfigurationDO or a list of domain objects will be in general the return value of the DAO. Actions like create are void and throw just an exception in the case of a failure. For a better style the return type is defined as Boolean. This simplifies also writing unit tests.
Sometimes it could be necessary to overwrite a basic implementation. A common scenario is a protected delete. For example: a requirement exist that a special entry is protected against a unwanted deletion. The most easy solution is to overwrite the delete whit a statement, refuses every time a request to delete a domain object whit a specific UUID. Only adding a new method like protectedDelete() is not a god idea, because a developer could use by accident the default delete method and the protected objects are not protected anymore. To avoid this problem you should prefer the possibility of overwriting GenericDAO methods.
As default query to fetch an object, the identifier defined as primary key (PK) is used. A simple expression fetching an object is written in the find method of the GenericHbmDAO. In the specialization as ConfigurationHbmDAO are more complex queries formulated. To keep a good design it is important to avoid any native SQL. Listing 1 shows fetch operations.
The readability of these few lines of source is pretty easy. The query we formulated for getAllConfigurationSetEntries() returns a list of ConfigurationDO objects from the same module whit equal version of a configSet. A module is for example the library TP-CORE it self or an ACL and so on. The configSet is a namespace that describes configuration entries they belong together like a bundle and will used in a service like e-mail. The version is related to the service. If in future some changes needed the version number have increase. Lets get a bit closer to see how the e-mail example will work in particular.
We assume that a e-mail service in the module TP-CORE contains the configuration entries: mailer.host, mailer.port, user and password. As first we define the module=core, configSet=email and version=1. If we call now getAllConfigurationSetEntries(core, 1, email); the result is a list of four domain objects with the entries for mailer.host, mailer.port, user and password. If in a newer version of the email service more configuration entries will needed, a new version will defined. It is very important that in the database the already exiting entries for the mail service will be duplicated with the new version number. Of course as effect the registry table will grow continual, but with a stable and well planned development process those changes occur not that often. The TP-CORE library contains an simple SMTP Mailer which is using the ConfigurationDAO. If you wish to investigate the usage by the MailClient real world example you can have a look on the official documentation in the TP-CORE GitHub Wiki.
The benefit of duplicate all existing entries of a service, when the service configuration got changed is that a history is created. In the case of update a whole application it is now possible to compare the entries of a service by version to decide exist changes they take effect to the application. In practical usage this feature is very helpful, but it will not avoid that updates could change our actual configuration by accident. To solve this problem the domain object has two different entries for the configuration value: default and configuration.
The application configuration follows the convention over configuration paradigm. Each service need by definition for all existing configuration entries a fix defined default value. Those default values can’t changed itself but when the value in the ConfigurationDO is set then the defaultValue entry will ignored. If an application have to be updated its also necessary to support a procedure to capture all custom changes of the updated configuration set and restore them in the new service version. The basic functionality (API) for application configuration in TP-CORE release 3.0 is:
The following listing gives you an idea how a implementation in your own service could look like. This snipped is taken from the JavaMailClient and shows how the internal processing of the fetched ConfigurationDO objects are managed.
privatevoidprocessConfiguration(){ListconfigurationEntries=configurationDAO.getAllConfigurationSetEntries("core",1,"email");for(ConfigurationDOentry: configurationEntries){Stringvalue;if(StringUtils.isEmpty(entry.getValue())){ value =<strong>entry.getDefaultValue</strong>();}else{ value =<strong>entry.getValue</strong>();}if(entry.getKey().equals(cryptoTools.calculateHash("mailer.host",HashAlgorithm.SHA256))){configuration.replace("mailer.host", value);}elseif(entry.getKey().equals(cryptoTools.calculateHash("mailer.port",HashAlgorithm.SHA256))){configuration.replace("mailer.port", value);}elseif(entry.getKey().equals(cryptoTools.calculateHash("user",HashAlgorithm.SHA256))){configuration.replace("mailer.user", value);}elseif(entry.getKey().equals(cryptoTools.calculateHash("password",HashAlgorithm.SHA256))){configuration.replace("mailer.password", value);}}}
Java
Another functionality of the application configuration is located in the service layer. The ConfigurationService operates on the module perspective. The current methods resetModuleToDefault() and filterMandatoryFieldsOfConfigSet() already give a good impression what that means.
If you take a look on the MailClientService you detect the method updateDatabaseConfiguration(). May you wonder why this method is not part of the ConfigurationService? Of course this intention in general is not wrong, but in this specific implementation is the update functionality specialized to the MailClient configuration. The basic idea of the configuration layer is to combine several DAO objects to a composed functionality. The orchestration layer is the correct place to combine services together as a complex process.
Resume
The implementation of the application configuration inside the small library TP-CORE allows to define an application wide configuration registry. This works also in the case the application has a distribute architecture like micro services. The usage is quite simple and can easily extended to own needs. The proof that the idea is well working shows the real world usage in the MailClient and FeatureToggle implementation of TP-CORE.
I hope this article was helpful and may you also like to use TP-CORE in your own project. Feel free to do that, because of the Apache 2 license is also no restriction for commercial usage. If you have some suggestions feel free to leave a comment or give a thumbs up.
Through the years, different techniques to storage configuration settings for applications got established. We can choose between database, property files, XML or YAML, just to give a few impressions of the options we could choose from. But before we jumping into all technical details of a possible implementation, we need to get a bit familiar of some requirements.
Many times in my professional life I touched this topic. Problems occur periodically after an application was updated. My peak of frustration, I reached with Windows 10. After every major update many settings for security and privacy switched back to default, apps I already uninstalled messed up my system again and so on. This was reasons for me to chose an alternative to stop suffering. Now after I switched to Ubuntu Mate I’m fine, because those problems got disappear.
Several times I also had to maintain legacy projects and needed to migrate data to newer versions. A difficult and complex procedure. Because of those activities I questioned myself how this problem could handled in a proper way. My answer you can find in the open source project TP-CORE. The feature application configuration is my way how to avoid the effect of overwriting important configuration entries during the update procedure.
TP-CORE is a free available library with some useful functionality written in Java. The source code is available on GitHub and the binaries are published on Maven Central. To use TP-CORE in your project you can add it as dependency.
The feature of application configuration is implemented as ConfigurationDAO and use a database. My decision for a database approach was driven by the requirement of having a history. Off course the choice have also some limitations. Obviously has the configuration for the database connection needed to be stored somewhere else.
TP-CORE use Spring and Hibernate (JPA) to support several DBMS like PostgreSQL, Oracle or MariaDB. My personal preference is to use PostgreSQL, so we can as next step discuss how to setup our database environment. The easiest way running a PostgreSQL Server is to use the official Docker image. If you need a brief overview how to deal with Docker and PostgreSQL may you like to check my article: Learn to walk with Docker and PostgreSQL. Below is a short listing how the PostgreSQL container could get instantiated in Docker.
May you need to make some changes on the listing above to fit it for your system. After your DBMS is running well we have to create the schemata and the user with a proper password. In our case the schema is called together. the user is also called together and the password will be together too.
To establish the connection from your application to the PostgreSQL DBMS we use a XML configuration from the Spring Framework. The GitHub repository of TP-CORE contains already a working configuration file called spring-dao.xml. The Spring configuration includes some other useful features like transactions and a connection pool. All necessary dependencies are already included. You just need to replace the correct entries for the connection variables:
In the next step you need to tell your application how to instanciate the Spring context, using the configuration file spring-dao.xml. Depending on your application type you have two possibilities. For a standard Java app, you can add the following line to your main method:
The creation of the database table will managed by Hibernate during the application start. When you discover the GitHub repository of the TP-CORE project you will find in the directory /src/main/filters the file database.properties. This file contains more connection strings to other database systems. In the case you wish to compile TP-CORE by your own, you can modify database.properties to your preferred configuration. The full processed configuration file with all token replacements you will find in the target directory.
In the next paragraph we will have a closer look on the Domain Object ConfigurationDO
The most columns you see in the image above, is very clear, for what they got used. As first point we need to clarify, what makes an entry unique? Of course the UUID as primary key fits this requirement as well. In our case the UUID is the primary key and is auto generated by the application, when a new row will created. But using in an application all the time a non human readable id as key, to grab a value is heavily error prone and uncomfortable. For this use case I decided a combination of configuration key, module name and service version to define a unique key entry.
To understand the benefit of this construction I will give a simple example. Imagine you have functionality of sending E-Mails in your application. This functionality requires several configuration entries like host, user and password to connect with an SMTP server. to group all those entries together in one bundle we have the CONFIG_SET. If your application deals with an modular architecture like micro services, it could be also helpful to organize the configuration entries by module or service name. For this reason the MODULE_NAME was also included into this data structure. Both entries can be used like name spaces to fetch relevant information more efficient.
Now it could be possible that some changes of the functionality create new configuration entries or some entries got obsolete. To enable a history and allow a backward compatibility the data structure got extended by SERVICE_VERSION.
Every entry contains a mandatory default value and an optional configuration value. The application can overwrite the default value by filling the configuration value field. This allows updates without effect the custom configuration, as long the developer respect to not fill entries for configuration values and always use the default entry. This definition is the convention over configuration paradigm.
The flags deprecated and mandatory for a configuration key are very explicit and descriptive. Also the column comment don’t need as well any further explanation.
If there are changes of one or more configuration entries for a service, the whole configuration set has to be duplicated with the new service version. As example you can have a look on the MailClient functionality of TP-CORE how the application configuration is used.
A very important information is that the configuration key is in the DBMS stored as SHA-512 hash. This is a simple protection against a direct manipulation of the configuration in the DBMS, outside of the application. For sure this is not a huge security, but minimum it makes the things a bit uncomfortable. In the application code is a human readable key name used. The mapping is automatic, and we don’t need to worry about it.
Resume
In this first part I talked about why I had need my own implementation of a application registry to storage configuration settings. The solution I prefer is using a database and I showed how enable the database configuration in your own project. Shortly we also had a view on the data structure and how the Domain Object is working.
Many ideas are excellent on paper. However, people often lack the knowledge of how to implement brilliant concepts into their everyday work. This short workshop aims to bridge the gap between theory and practice and demonstrates the steps needed to achieve a stable API in the long term.
(c) 2021 Marco Schulz, Java PRO Ausgabe 1, S.31-34
When developing commercial software, many people involved often don’t realize that the application will be in use for a long time. Since our world is constantly changing, it’s easy to foresee that the application will require major and minor changes over the years. The project becomes a real challenge when the application to be extended is not isolated, but communicates with other system components. This means that in most cases, the users of the application also have to be adapted. A single stone quickly becomes an avalanche. With good avalanche protection, the situation can still be controlled. However, this is only possible if you consider that the measures described below are solely intended for prevention. But once the violence has been unleashed, there is little that can be done to stop it. So let’s first clarify what an API is.
A Matter of Negotiation
A software project consists of various components, each with its own specialized tasks. The most important are source code, configuration, and persistence. We’ll be focusing primarily on the source code area. I’m not revealing anything new when I say that implementations should always be against interfaces. This foundation is already taught in the introduction to object-oriented programming. In my daily work, however, I often see that many developers aren’t always fully aware of the importance of developing against interfaces, even though this is common practice when using the Java Standard API. The classic example of this is:
List<String>collection=newArrayList<>();
This short line uses the List interface, which is implemented as an ArrayList. Here we can also see that there is no suffix in the form of an “I” to identify the interface. The corresponding implementation also does not have “Impl” in its name. That’s a good thing! Especially with the implementation class, various solutions may be desired. In such cases, it is important to clearly label them and keep them easily distinguishable by name. ListImpl and ListImpl2 are understandably not as easy to distinguish as ArrayList and LinkedList. This also clears up the first point of a stringent and meaningful naming convention.
In the next step, we’ll focus on the program parts that we don’t want to expose to consumers of the application, as they are helper classes. Part of the solution lies in the structure of how the packages are organized. A very practical approach is:
my.package.path.business: Contains all interfaces
my.package.path.application: Contains the interface implementations
This simple architecture alone signals to other programmers that it’s not a good idea to use classes from the helper package. Starting with Java 9, there are even more far-reaching restrictions prohibiting the use of internal helper classes. Modularization, which was introduced in Java 9 with the Jingsaw project [1], allows packages to be hidden from view in the module-info.java module descriptor.
Separatists and their Escape from the Crowd
A closer look at most specifications reveals that many interfaces have been outsourced to their own libraries. From a technological perspective, based on the previous example, this would mean that the business package, which contains the interfaces, is outsourced to its own library. The separation of API and the associated implementation fundamentally makes it easier to interchange implementations. It also allows a client to exert greater influence over the implementation of their project with their contractual partner, as the developer receives the API pre-built by the client. As great as the idea is, a few rules must be observed to ensure it actually works as originally intended.
Example 1: JDBC. We know that Java Database Connectivity is a standard for connecting various database systems to an application. Aside from the problems associated with using native SQL, MySQL JDBC drivers cannot simply be replaced by PostgreSQL or Oracle. After all, every manufacturer deviates more or less from the standard in their implementation and also provides exclusive functionality of their own product via the driver. If you decide to make extensive use of these additional features in your own project, the easy interchangeability is over.
Example 2: XML. Here, you have the choice between several standards. It’s clear, of course, that the APIs of SAX, DOM, and StAX are incompatible. For example, if you want to switch from DOM to event-based SAX for better performance, this can potentially result in extensive code changes.
Example 3: PDF. Last but not least, I have a scenario for a standard that doesn’t have a standard. The Portable Document Format itself is a standard for how document files are structured, but when it comes to implementing usable program libraries for their own applications, each manufacturer has its own ideas.
These three small examples illustrate the common problems that must be overcome in daily project work. A small rule can have a big impact: only use third-party libraries when absolutely necessary. After all, every dependency used also poses a potential security risk. It’s also not necessary to include a library of just a few MB to save the three lines required to check a string for null and empty values.
Model Boys
If you’ve decided on an external library, it’s always beneficial to do the initial work and encapsulate the functionality in a separate class, which you can then use extensively. In my personal project TP-CORE on GitHub [2], I’ve done this in several places. The logger encapsulates the functionality of SLF4J and Logback. Compared to the PdfRenderer, the method signatures are independent of the logging libraries used and can therefore be more easily exchanged via a central location. To encapsulate external libraries in your own application as much as possible, the following design patterns are available: wrapper, facade, and proxy.
Wrapper: also called the adaptor pattern, belongs to the group of structural patterns. The wrapper couples one interface to another that are incompatible.
Facade: is also a structural pattern and bundles several interfaces into a simplified interface.
Proxy: also called a representative, also belongs to the category of structural patterns. Proxies are a generalization of a complex interface. They can be understood as complementary to the facade, which combines multiple interfaces into a single one.
It is certainly important in theory to separate these different scenarios in order to describe them correctly. In practice, however, it is not critical if hybrid forms of the design patterns presented here are used to encapsulate external functionality. For anyone interested in exploring design patterns in more depth, we recommend the book “Design Patterns from Head to Toe” [3].
Class Reunion
Another step toward a stable API is detailed documentation. Based on the interfaces discussed so far, there’s a small library that allows methods to be annotated based on the API version. In addition to status and version information, the primary implementations for classes can be listed using the consumers attribute. To add API Gaurdian to your project, you only need to add a few lines to the POM and replace the ${version} property with the current version.
Marking up methods and classes is just as easy. The @API annotation has the attributes: status, since, and consumers. The following values are possible for status:
DEPRECATED: Deprecated, should not be used any further.
EXPERIMENTAL: Indicates new features for which the developer would like feedback. Use with caution, as changes can always occur.
INTERNAL: For internal use only, may be discontinued without warning.
STABLE: Backward-compatible feature that remains unchanged for the existing major version.
MAINTAINED: Ensures backward stability for the future major release.
Now that all interfaces have been enriched with this useful meta information, the question arises where the added value can be found. I simply refer you to Figure 1, which demonstrates everyday work.
Figure 1: Suggestion in Netbeans with @API annotation in the JavaDoc
For service-based RESTful APIs, there is another tool called Swagger [4]. This also follows the approach of creating API documentation from annotations. However, Swagger itself scans Java web service annotations instead of introducing its own. It is also quite easy to use. All that is required is to integrate the swagger-maven-plugin and specify the packages in which the web services reside in the configuration. Subsequently, a description is created in the form of a JSON file for each build, from which Swagger UI then generates executable documentation. Swagger UI itself is available as a Docker image on DockerHub [5].
Figure 2: Swagger UI documentation of the TP-ACL RESTful API.
Versioning is an important aspect for APIs. Using semantic versioning, a lot can be gleaned from the version number. Regarding an API, the major segment is significant. This first digit indicates API changes that are incompatible with each other. Such incompatibility includes the removal of classes or methods. However, changing existing signatures or the return value of a method also requires adjustments from consumers as part of a migration. It’s always a good idea to bundle work that causes incompatibilities and publish it less frequently. This demonstrates project stability.
Versioning is also recommended for Web APIs. This is best done via the URL by including a version number. So far, I’ve had good experiences with only incrementing the version when incompatibilities occur.
Relationship Stress
The great advantage of a RESTful service, being able to get along well with “everyone,” is also its greatest curse. This means that a great deal of care must be taken, as many clients are being served. Since the interface is a collection of URIs, our focus is on the implementation details. For this, I’ll use an example from my TP-ACL project, which is also available on GitHub.
This is a short excerpt from the try block of the fetchRole method found in the RoleService class. The GET request returns a 404 error code if a role is not found. You probably already know what I’m getting at.
When implementing the individual actions GET, PUT, DELETE, etc. of a resource such as a role, it’s not enough to simply implement the so-called HappyPath. The possible stages of such an action should be considered during the design phase. For the implementation of a consumer (client), it makes a significant difference whether a request that cannot be completed with a 200 failed because the resource does not exist (404) or because access was denied (403). Here, I’d like to allude to the telling Windows message about the unexpected error.
Conclusion
When we talk about an API, we mean an interface that can be used by other programs. A major version change indicates to API consumers that there is an incompatibility with the previous version. This may require adjustments. It is completely irrelevant what type of API it is or whether the application uses it publicly or internally via the fetchRole method. The resulting consequences are identical. For this reason, you should carefully consider the externally visible areas of your application.
Work that leads to API incompatibility should be bundled by release management and, if possible, released no more than once per year. This also demonstrates the importance of regular code inspections for consistent quality.
After the gang of four (GOF) Erich Gamma, Richard Helm, Ralph Johnson, and John Vlissides published the book, Design Patterns: Elements of Reusable Object-Oriented Software, learning how to describe problems and solutions became popular in almost every field in software development. Likewise, learning to describe don’ts and anti-pattern became equally as popular.
In publications that discussed these concepts, we find helpful recommendations for software design, project management, configuration management, and much more. In this article, I will share my experience dealing with version numbers for software artifacts.
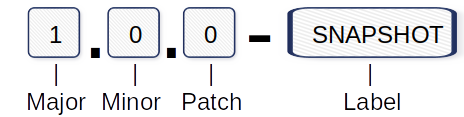
Most of us are already familiar with a method called semantic versioning, a powerful and easy-to-learn rule set for how version numbers have to be structured and how the segments should increase.
Version numbering example:
Major: Incompatible API changes.
Minor: Add new functionality.
Patch: Bugfixes and corrections.
Label: SNAPSHOT marking the “under development” status.
An incompatible API Change occurs when an externally accessible function or class was deleted or renamed. Another possibility is a change in the signature of a method. This means the return value or parameters has been changed from its original implementation. In these scenarios, it’s necessary to increase the Major segment of the version number. These changes present a high risk for API consumers because they need to adapt their own code.
When dealing with version numbers, it’s also important to know that 1.0.0 and 1.0 are equal. This has effect to the requirement that versions of a software release have to be unique. If not, it’s impossible to distinguish between artifacts. Several times in my professional experience, I was involved in projects where there was no well-defined processes for creating version numbers. The effect of these circumstances was that the team had to secure the quality of the artifact and got confused with which artifact version they were currently dealing with.
The biggest mistake I ever saw was the storage of the version of an artifact in a database together with other configuration entries. The correct procedure should be: place the version inside the artifact in a way that no one after a release can change from outside. The trap you could fall into is the process of how to update the version after a release or installation.
Maybe you have a checklist for all manual activities during a release. But what happens after a release is installed in a testing stage and for some reason another version of the application has to be installed. Are you still aware of changing the version number manually? How do you find out which version is installed or when the information of the database is incorrect?
Detect the correct version in this situation is a very difficult challenge. For that reason, we have the requirement to keep the version inside of the application. In the next step, we will discuss a secure and simple way on how to solve an automatic approach to this problem.
Our precondition is a simple Java library build with Maven. By default, the version number of the artifact is written down in the POM. After the build process, our artifact is created and named like: artifact-1.0.jar or similar. As long we don’t rename the artifact, we have a proper way to distinguish the versions. Even after a rename with a simple trick of packaging and checking, then, in the META-INF folder, we are able to find the correct value.
If you have the Version hardcoded in a property or class file, it would also work fine, as long you don’t forget to always update it. Maybe the branching and merging in SCM systems like Git could need your special attention to always have the correct version in your codebase.
Another solution is using Maven and the token placement mechanism. Before you run to try it out in your IDE, keep in mind that Maven uses to different folders: sources and resources. The token replacement in sources will not work properly. After a first run, your variable is replaced by a fixed number and gone. A second run will fail. To prepare your code for the token replacement, you need to configure Maven as a first in the build lifecycle:
After this step, you need to know the ${project.version} property form the POM. This allows you to create a file with the name version.property in the resources directory. The content of this file is just one line: version=${project.version}. After a build, you find in your artifact the version.property with the same version number you used in your POM. Now, you can write a function to read the file and use this property. You could store the result in a constant for use in your program. That’s all you have to do!
After Oracle introduces the new release cycle for Java I was not convinced of this new strategy. Even today I still have a different opinion. One of the point I criticize is the disregard of semantic versioning. Also the argument with this new cycle is more easy to deliver more faster new features, I’m not agree. In my opinion could occur some problems in the future. But wait, let’s start from the beginning, before I share my complete thoughts at once.
The six month release cycle Oracle announced in 2017 for Java ensure some insecurity to the community. The biggest fear was formulated by the popular question: Will be Java in future not anymore for free? Of course the answer is a clear no, but there are some impacts for companies they should be aware of it. If we think on huge Applications in production, are some points addressed to the risk management and the business continuing strategy. If the LTS support for security updates after the 3rd year of a published release have to be paid, force well defined strategies for updates into production. I see myself spending in future more time to migrate my projects to new java versions than implement new functionalities. One solution to avoid a permanent update orgy is move away from the Oracle JVM to OpenJDK.
In professional environment is quite popular that companies define a fixed setup to keep security. When I always are forced to update my components without a proof the new features are secure, it could create problems. Commercial projects running under other circumstances and need often special attention. Because you need a well defined environment where you know everything runs stable. Follow the law never touch a running system.
Absolutely I can understand the intention of Oracle to take this step. I guess it’s a way to get rid of old buggy and insecure installations. To secure the internet a bit more. Of course you can not support decades old deprecated versions. This have a heavy financial impact. but I wish they had chosen an less rough strategy. It’s sadly that the business often operate in this way. I wished it exist a more trustful communication.
By experience of preview releases of Java it always was taken a time until they get stable. In this context I remind myself to some heavy issues I was having with the change to 64 bit versions. The typical motto: latest is greatest, could be dangerous. Specially time based releases are good candidates for problems, even when the team is experienced. The pressure is extremely high to deliver in time.
Another fact which could discuss is the semantic versioning. It is a very powerful process, I always recommend. I ask myself If there really every six months new language features to have the reason increasing the Major number? Even for patches and enhancements? But what happens when in future is no new language enhancement? By the way adding by force often new features could decrease quality. In my opinion Java includes many educative features and not every new feature request increase the language capabilities. A simple example is the well known GOTO statement in other languages. When you learn programming often your mentor told you – it exist something if you see it you should run away. Never use GOTO. In Java inner classes I often compare with GOTO, because I think this should avoid. Until now I didn’t find any case where inner classes not a hint for design problems. The same is the heavy usage of functional statements. I can’t find any benefit to define a for loop as lambda function instead of the classical way.
In my opinion it looks like Oracle try to get some pieces from the cake to increase their business. Well this is not something bad,. But in the view of project management I don’t believe it is a well chosen strategy.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.