
Schlagwort-Archiv: Administration
Frühjahrsputz für Docker
Antworten
Wer sich für diesen, eigentlich etwas spezialisierten Artikel interessiert, dem muss man nicht mehr erklären, was Docker ist und wofür das Virtualisierungswerkzeug eingesetzt wird. Daher richtet sich dieser Artikel vornehmlich an Systemadministratoren, DevOps und Cloud-Entwickler. Für alle, die bisher nicht ganz so fit mit der Technologie sind, empfehle ich unseren Docker Kurs: From Zero to Hero.

In einem Szenario, in dem wir regelmäßig neue Docker Images erstellen und verschiedene Container instanzieren, wird unsere Festplatte ordentlich gefordert. Images können je nach Komplexität durchaus problemlos einige hundert Megabyte bis Gigabyte erreichen. Damit das Erstellen neuer Images auch nicht gefühlt, wie ein Download einer drei Minuten langen MP3 mit einem 56k Modem dauert, nutzt Docker einen Build-Cache. Ist im Dockerfile wiederum ein Fehler, kann dieser Build-Cache recht lästig werden. Daher ist es eine gute Idee, den Build-Cache durchaus regelmäßig zu entleeren. Aber auch alte Containerinstanzen, die nicht mehr in Verwendung sind können zu komischen Fehlern führen. Wie hält man seine Dockerumgebung also stubenrein?
Sicher kommt man mit mit docker rm <container-nane> und docker rmi <image-id> schon recht weit. In Buildumgebungen wie Jenkins oder Serverclustern kann diese Strategie allerdings zu einer zeitintensiven und mühsamen Beschäftigung werden. Doch verschaffen wir uns zuerst einmal einen Überblick über die Gesamtsituation. Hier hilft uns der Befehl docker system df weiter.
root:/home# docker system df
TYPE TOTAL ACTIVE SIZE RECLAIMABLE
Images 15 9 5.07GB 2.626GB (51%)
Containers 9 7 11.05MB 5.683MB (51%)
Local Volumes 226 7 6.258GB 6.129GB (97%)
Build Cache 0 0 0B 0BBevor ich gleich in die Details eintauche, noch ein wichtiger Hinweis. Die vorgestellten Befehle sind sehr effizient und löschen unwiderruflich die entsprechenden Bereiche. Daher wendet diese Befehle erst auf einer Übungsumgebung an, bevor ihr damit Produktivsysteme außer Gefecht setzt. Zudem hat es sich für mich bewährt, auch die Befehle zur Instanzierung von Containern in deiner Textdatei unter Versionsverwaltung zu stellen.
Der naheliegendste Schritt bei einem Docker System Cleanup ist das Löschen der nichtbenutzten Container. Im Konkreten bedeute das, dass durch den Löschbefehl alle Instanzen der Docker Container, die nicht laufen (also nicht aktiv sind), unwiederbringlich gelöscht werden. Will man auf einem Jenkins Buildnode vor einem Deployment Tabula Rasa durchführen, kann man zuvor alle auf der Maschine laufenden Container mit einem Befehl beenden.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Der Parameter -f unterdrückt die Nachfrage, ob man diese Aktion wirklich durchführen möchte. Also die ideale Option für automatisierte Skripte. Durch das Löschen der Container erhalten wir vergleichsweise wenig Festplattenplatz zurück. Die Hauptlast findet sich bei den heruntergeladenen Images. Diese lassen sich ebenfalls mit nur einem Befehl entfernen. Damit Images allerdings gelöscht werden können, muss vorher sichergestellt sein, dass diese nicht durch Container (auch inaktive) in Verwendung sind. Das Entfernen ungenutzter Container hat noch einen ganz anderen praktischen Vorteil. Denn beispielsweise durch Container blockierte Ports werden so wieder freigegeben. Schließlich lässt sich ein Port einer Hostumgebung nur exakt einmal an einen Container binden. Das kann stellenweise schnell zu Fehlermeldungen führen. Also erweitern wir unser Skript um den Eintrag, alle nicht durch Container benutzten Docker Images ebenfalls zu löschen.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Eine weitere Konsequenz unserer Bemühungen umfasst die Docker Layers. Hier sollte man aus Performancegründen, besonders in CI Umgebungen Abstand nehmen. Docker Volumes hingegen sind hier weniger problematisch. Beim Entfernen der Volumes, werden nur die Referenzen in Docker entfernt. Die in die Container verlinkten Ordner und Dateien bleiben von der Löschung unberührt. Der Parameter -a löscht alle Docker Volumes.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Ein weiterer Bereich, der von unseren Aufräumarbeiten betroffen ist, ist der Build-Cache. Besonders wenn man gerade ein wenig mit dem Erstellen neuer Dockerfiles experimentiert, kann es durchaus sehr nützlich sein, den Cache hin und wieder manuell zu löschen. Diese Maßnahme verhindert, dass sich falsch erstellte Layer in den Builds erhalten und es später im instanziierten Container zu ungewöhnlichen Fehlern kommt. Der entsprechende Befehl lautet:
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Ganz radikal ist die Möglichkeit, alle nicht genutzten Ressourcen wieder freizugeben. Hierfür gibt es ebenfalls ein explizites Kommando für die Shell.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Wir können die gerade vorgestellten Befehle natürlich auch für CI Buildumgebungen wie Jenkins oder GitLab CI nutzen. Allerdings kann es sein, dass dies nicht unbedingt zum gewünschten Ziel führt. Ein bewährter Ansatz für Continuous Integration / Continuous Deployment ist das Aufsetzen einer eigenen Docker-Registry, wohin man selbst erstellte Images deployen kann. Diese Vorgehensweise, ist ein gutes Backup & Chaching System für die genutzten Docker Images. Einmal korrekt erstellte Images lassen sich so bequem über das lokale Netzwerk auf die verschiedenen Serverinstanzen deployen, ohne dass diese ständig lokal neu erstellt werden müssen. Daraus ergibt sich als bewährter Ansatz ein eigens für Docker Images / Container optimierter Buildnode, um die erstellten Images vor der Verwendung optimal zu testen. Auch auf Cloudinstanzen wie Azure und der AWS sollte man auf eine gute Performanz und ressourcenschonendes Arbeiten Wert legen. Schnell können die anfallenden Kosten explodieren und ein stabiles Projekt in massive Schieflage bringen.
In diesem Artikel konnten wir sehen, dass tiefe Kenntnisse der eingesetzten Werkzeuge einige Möglichkeiten zur Kostenersparnis erlauben. Gerade das Motto „Wir machen, weil wir es können“, ist im kommerzeillen Umfeld weniger hilfreich und kann schnell zur teuren Resourcenverschwendung ausarten.



Plattenspieler
Der Umgang mit Massenspeichern wie Festplatten (HDD), Solid State Drive (SSD), USB, Speicherkarten oder Network Attached Storages (NAS) ist unter Linux gar nicht so schwer, wie viele glauben. Man muss es lediglich schaffen, alte Gewohnheiten, die man sich unter Windows angeeignet hat, wieder loszulassen. In diesem Kompaktkurs erfahren Sie alles Notwendige, um auf Linux Desktops und -Servern mögliche aufkommende Probleme zu meistern.
Bevor wir auch gleich in aller Tiefe in das Thema eintauchen, noch ein paar wichtige Fakten über die Hardware selbst. Hier gilt vor allem der Grundsatz: Wer billig kauft, kauft doppelt. Wobei das Problem nicht einmal das Gerät selbst ist, was man austauschen muss, sondern die möglicherweise verlorenen Daten und der Aufwand, alles wieder neu einzurichten. Diese Erfahrung habe ich vor allem bei SSDs und Speicherkarten gemacht, wo es durchaus einmal vorkommen kann, dass man einem Fake Produkt aufgesessen ist und der versprochene Speicherplatz nicht vorhanden ist, obwohl das Betriebssystem die volle Kapazität anzeigt. Wie man mit solchen Situationen umgeht, besprechen wir allerdings ein wenig später.
Ein weiterer wichtiger Punkt ist die Verwendung im Dauerbetrieb. Die meisten Speichermedien sind nicht dafür geeignet, 24 Stunden jeden Tag, 7 Tage die Woche eingeschaltet zu sein und verwendet zu werden. Festplatten und SSDs, die für Laptops gemacht worden sind, gehen bei einer Dauerbelastung zügig kaputt. Deswegen sollte man sich bei Dauerbetrieb, wie es bei NAS‑Systemen der Fall ist, explizit nach solchen speziellen Geräten umschauen. Die Firma Western Digital hat zum Beispiel verschiedene Produktlinien. Die Linie Red ist für Dauerbetrieb ausgelegt, wie es bei Servern und NAS der Fall ist. Wichtig ist, dass in der Regel die Datentransfergeschwindigkeit bei Speichermedien etwas geringer ist, wenn dafür die Lebensdauer erhöht wird. Aber keine Sorge, wir verlieren uns jetzt nicht in den ganzen Details, die man noch zum Thema Hardware sagen könnte, und wollen es dabei belassen, um zum nächsten Punkt zu gelangen.
Ein signifikanter Unterschied zwischen Linux und Windows ist das Dateisystem. Also der Mechanismus, wie das Betriebssystem den Zugriff auf die Informationen organisiert. Windows Nutzt als Dateisystem NTFS und USB Sticks oder Speicherkarten sind oft auch unter FAT formatiert. Der Unterschied ist, dass mit NTFS Dateien, die über 4 GB groß sind, gespeichert werden können. FAT wird der Stabilität eher von Geräteherstellern in Navigationssystemen oder Autoradios bevorzugt. Unter Linux sind vornehmlich die Dateisysteme ext3 oder ext4 anzutreffen. Natürlich gibt es noch viele Spezialformate, die wir aber an dieser Stelle nicht weiter besprechen wollen. Der große Unterschied zwischen Linux- und Windows Dateisystemen ist das Sicherheitskonzept. Während NTFS keinen Mechanismus hat, um das Erstellen, Öffnen oder Ausführen von Dateien und Verzeichnissen zu kontrollieren, ist dies für ext3 und ext4 ein grundlegendes Konzept.
Speicher, die in NTFS oder FAT formatiert sind, können problemlos an Linux Rechner angeschlossen werden und die Inhalte können gelesen werden. Um beim Schreiben von Daten auf Netzwerkspeicher, die wegen der Kompatibilität oft auf NTFS formatiert sind, keine Verluste zu riskieren, nutzt man das SAMBA Protokoll. Samba ist meist bereits Bestandteil vieler Linux Distributionen und kann in wenigen Augenblicken auch installiert werden. Es ist keine spezielle Konfiguration des Dienstes notwendig.
Nachdem wir nun gelernt haben, was ein Dateisystem ist und wozu diese notwendig sind, stellt sich nun die Frage, wie man einen externen Speicher unter Linux formatieren kann. Die beiden grafischen Programme Disks und Gparted sind hierzu ein gutes Gespann. Disks ist ein wenig universeller nutzbar und es lassen sich mit diesem Programm bootfähige USB Sticks erstellen, mit denen man anschließend Computer installieren kann. Gparted ist eher geeignet, bei Festplatten oder SSDs bestehende Partitionen zu erweitern oder kaputte Partitionen zu reparieren.
Bevor sie nun weiterlesen und sich gegebenenfalls daran machen, den ein oder anderen Tipp nachzustellen, ist es wichtig, dass ich an dieser Stelle einen Warnhinweis gebe. Bevor Sie irgendetwas mit Ihren Speichermedien ausprobieren, fertigen Sie zuallererst eine Datensicherung an, auf die Sie bei Unglücken zurückgreifen können. Zudem weise ich ausdrücklich darauf hin, sich nur an den Szenarien zu versuchen, die Sie verstehen und bei denen Sie wissen, was Sie tun. Für mögliche Datenverluste übernehme ich keine Haftung.
Bootfähige USB & Speicherkarten mit DISKS
Ein Szenario, das wir gelegentlich benötigen, ist die Erstellung von bootfähigen Datenträgern. Ganz gleich, ob es ein USB‑Stick für die Installation eines Windows‑ oder Linux‑Betriebssystems oder das Installieren des Betriebssystems auf einer SD‑Karte für die Verwendung auf einem RaspberryPI ist: Das Vorgehen ist identisch. Bevor wir starten, benötigen wir ein Installationsmedium, das wir als ISO in der Regel von der Homepage des Betriebssystemherstellers herunterladen können, und einen zugehörigen USB‑Stick.
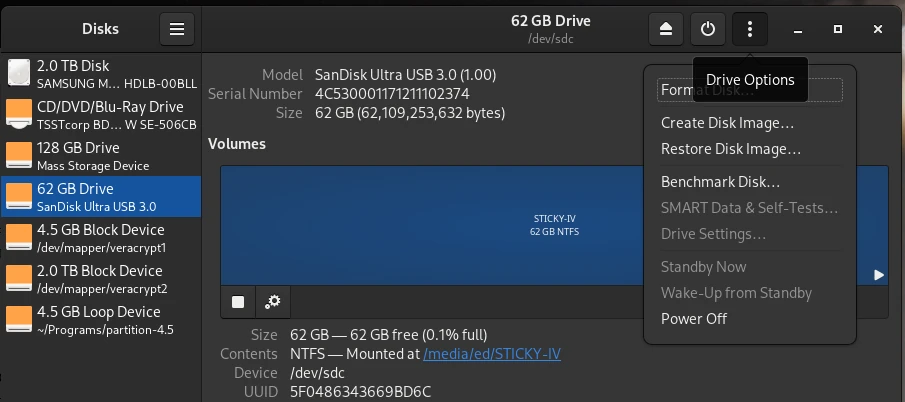
Als Nächstes öffnen wir das Programm Disks und wählen den USB Stick aus, auf den wir die ISO Datei installieren wollen. Danach klicken wir auf die drei Punkte im oberen Rahmen des Fensters und wählen aus dem erscheinenden Menü den Eintrag Restore Disk Image. In dem nun sich öffnenden Dialog wählen wir für das Eingabefeld Image to Restore unsere ISO Datei aus und klicken auf Start Restoring. Mehr ist nicht zu tun.
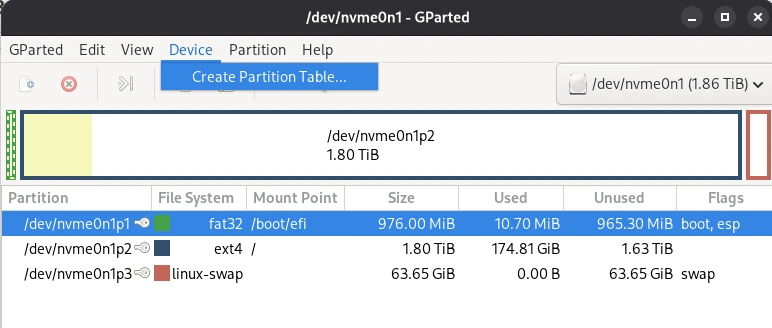
Partitionen und MTF mit Gparted reparieren
Ein anderes Szenario, mit dem man konfrontiert sein kann, ist das Daten auf einem Stick z. B. nicht lesbar sind. Wenn die Daten selbst nicht beschädigt sind, kann man Glück haben und mit GParted das Problem lösen. In einigen Fällen kann es sein, (A) dass die Partitionstabelle beschädigt ist und das Betriebssystem einfach nicht weiß, wo der Startpunkt ist. Eine andere Möglichkeit ist, (B) dass die sogenannte Master File Table (MFT) beschädigt ist. In der MTF ist der Vermerk, in welcher Speicherzelle eine Datei gefunden wird. Beide Probleme lassen sich mit GParted schnell wieder in Ordnung bringen.
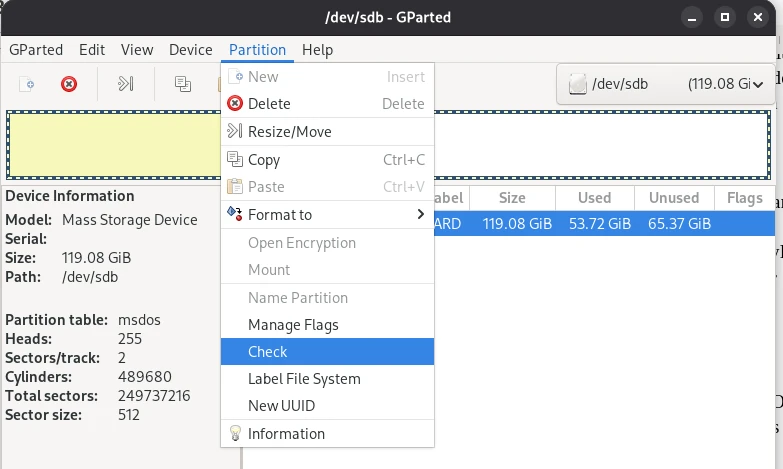
Natürlich ist es nicht möglich, in einem allgemeinen Artikel auf die vielen komplexen Aspekte der Datenrettung einzugehen.
Nachdem wir nun wissen, dass eine Festplatte aus Partitionen besteht und diese Partitionen ein Dateisystem enthalten. Können wir jetzt sagen, dass alle Informationen zu einer Partition mit dem darauf formatierten Dateisystem in der Partitionstabelle gespeichert sind. Um alle Dateien und Verzeichnisse innerhalb einer Partition zu finden, bedient sich das Betriebssystem eines Index, in dem es nachschauen kann, die sogenannten Master File Table (MFT). Dieser Zusammenhang führt uns bereits zum nächsten Punkt, dem sicheren Löschen von Speichermedien.
Datenschredder – sicheres Löschen
Wenn wir Daten auf einem Speichermedium löschen, wird lediglich der Eintrag, wo die Datei zu finden ist aus der MFT entfernt. Die Datei ist also weiterhin vorhanden und kann von speziellen Programmen immer noch gefunden und ausgelesen werden. Das sichere Löschen von Dateien gelingt nur, wenn wir den freien Speicherplatz mehrfach überschreiben. Da wir nie wissen können, wo eine Datei physisch auf einem Speichermedium geschrieben wurde, müssen wir nach dem löschen den gesamten freien Speicherplatz mehrfach überschreiben. Spezialisten raten zu drei Schreibvorgängen, bei denen jeweils unterschiedliche Muster geschrieben werden, um selbst Speziallaboren eine Wiederherstellung unmöglich zu machen. Ein Programm unter Linux, mit dem man zusätzlich noch ‚Datenmüll‘ zusammenkehrt und löscht, ist BleachBit.
Das sichere Überschreiben von gelöschten Dateien ist je nach Größe des Speichermediums eine etwas länger andauernde Aktion, weswegen man dies nur sporadisch macht. Ganz sicher sollte man alte Speichermedien aber rückstandsfrei löschen, wenn diese ‚aussortiert‘ werden und dann entweder entsorgt oder an andere weitergegeben werden.
Ganze Festplatten 1:1 spiegeln – CloneZilla
Ein weiteres Szenario, mit dem wir konfrontiert werden können, ist die Notwendigkeit, eine Kopie der Festplatte anzufertigen. Das ist dann relevant, wenn für den aktuellen Computer die bestehende Festplatte bzw. SSD gegen eine neue mit höherer Speicherkapazität ausgetauscht werden soll. Windowsnutzer nutzen hier oft die Gelegenheit, ihr System neu zu installieren, um in Übung zu bleiben. Wer bereits länger mit Linux arbeitet, weiß es zu schätzen, dass Linux-Systeme sehr stabil laufen und die Notwendigkeit einer Neuinstallation nur sporadisch besteht. Daher bietet es sich an die Daten der aktuellen Festplatte bitweise auf die neue Platte zu kopieren. Das gilt natürlich auch für SSDs beziehungsweise von HDD zu SSD und umgekehrt. Dieses Vorhaben gelingt uns mit dem freien Werkzeug CloneZilla. Dazu erstellen wir einen bootfähigen USB mit CloneZilla und starten den Rechner im Livesystem von CloneZilla. Danach schließen wir die neue Platte mit einem SATA / USB Adapter an den Rechner an und starten die Datenübertragung. Bevor wir nach Fertigstellung unseren Computer aufschrauben und die Platten tauschen, ändern wir im BIOS die boot Reihenfolge und schauen, ob unser Vorhaben überhaupt geglückt ist. Nur wenn sich der Rechner über die neue Platte problemlos starten lässt, machen wir uns an den physischen Austausch. Diese kleine Anleitung beschreibt das prinzipielle Vorgehen und ich habe bewusst auf eine detaillierte Beschreibung verzichtet, da sich die Oberfläche und Bedienung von neueren Clonezilla-Versionen unterscheiden kann.
SWAP – die Auslagerungsdatei unter Linux
An dieser Stelle verlassen wir auch nun die grafische Benutzeroberfläche und wenden uns der Kommandozeile zu. Wir kümmern uns um eine sehr spezielle Partition, die manchmal erweitert werden muss. Es geht um die SWAP File. Die SWAP File ist das, was bei Windows Auslagerungsdatei heißt. Das heißt, hier schreibt das Betriebssystem Daten hin, die nicht mehr in den RAM passen, und kann bei Bedarf diese Daten schneller wieder in den RAM einlesen. Indessen kann es vorkommen, dass diese Auslagerungsdatei zu klein ist und erweitert werden muss. Aber auch das ist kein Hexenwerk, wie wir gleich sehen werden.
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.
Wir haben an dieser Stelle bereits einiges über den Umgang mit Speichermedien unter Linux besprochen. Im zweiten Teil dieser Artikelserie vertiefen wir die Möglichkeiten von Kommandozeilenprogrammen und schauen zum Beispiel, wie NAS-Speicher permanent in das System gemountet werden können. Aber auch Strategien, um defekte Speicher zu identifizieren, werden Thema des nächsten Teils werden. Insofern hoffe ich, euer Interesse geweckt zu haben, und würde mich über ein reichliches Teilen der Artikel von diesem Block freuen.

PHP Elegant Testing in Laravel
Automatisierte Unit Tests mit PEST in PHP und dem Lavarel Framework für eigene Webanwendungen nutzen. Weiterlesen →



Kontrollzentrum

Seit einiger Zeit steht die neue Version 1.5 des Versionsverwaltungs-Tools Subversion (SVN) zum kostenlosen Download bereit. Das Programm ist für verschiedene Plattformen erhältlich, dazu zählen Windows und Linux als die wichtigsten Vertreter. Der Artikel bezieht sich zwar auf das Windows-Betriebssystem, aber mit geringem Aufwand lassen sich die wenigen spezifischen Unterschiede leicht adaptieren. Man kann Subversion auf unterschiedliche Art und Weise betreiben. Für eine lokale Verwendung, bei sehr kleinen Projekten mit lediglich einem einzigen Entwickler, genügt oft die Installation eines Clients. Für Windows Systeme sollte die Wahl des Clients auf TortoiseSVN fallen. Die Anwendung arbeitet als Explorer-Erweiterung und beherrscht alle notwendigen Funktionen zur Arbeit mit SVN. Dazu zählt unter anderem das Anlegen der Projektverzeichnisse, die Repository genannt werden. Der Zugriff auf ein lokales Repository erfolgt über das file:///-Protokoll. Sobald das Repository für mehrere Entwickler bereitstehen soll, wird ein Server benötigt. Man hat die Wahl zwischen einem Standalone-Server oder einer Integration in den Apache Web Server. Die aktuelle Version des SVN-Servers bringt für Windows-Nutzer eine Verbesserung der Konfiguration als Windows-Dienst. Für den Standalone-Server stehen die Protokolle svn:// und svn+ssh:// zur Verfügung. Für diesen Artikel wird vor allem auf die Installation des Apache-Moduls eingegangen. Der Vorteil des Apache liegt darin, mit den Protokollen http:// und https:// auf die Projektverzeichnisse zugreifen zu können. Mit Subclipse liefert Tigris.org SVN als Plug-in für Eclipse, das dem Tortoise-Client kaum in etwas nachsteht. Dank der PHP-Tools ist die Eclipse-IDE nicht mehr nur von Java-Programmierern geschätzt. Abbildung 1 zeigt die Subversion View mit einem geöffneten Projekt in Eclipse.

Subversion im Apache
Eine sehr bequeme Möglichkeit Subversion zu nutzen, ist die Integration in den Apache Web Server; damit kann das Repository über das HTTP-Protokoll angesprochen werden. Die Installation ist nicht weiter schwierig, erfordert allerdings eine funktionsfähige Apache-Installation. Wer die aufwändige Installation einer vollständigen Serverumgebung scheut, kann getrost auf XAMPP [4] zurückgreifen. Als Erstes müssen dann die Binaries des SVN für den Apache 2.2.X von der Webseite [5] geladen werden. Die Dateien mod_dav_svn.so, mod_authz_svn.so und der Ordner iconv sind in das Verzeichnis %APACHE_HOME%\modules zu kopieren. Um die Module dem Webserver bekannt zu machen, muss schließlich die Datei httpd.conf im Verzeichnis conf des Apache gemäß Listing 1 editiert werden.
# Anpassungen der httpd.conf
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
Include conf/svn.confDie ersten beiden Zeilen aktivieren die SVN-Module für den Apache. Um die Konfigurationsdatei übersichtlich zu halten, wird die eigentliche Konfiguration von Subversion über die Anweisung aus Zeile drei in die Datei svn.conf ausgelagert (Listing 2). Die Datei muss im gleichen Verzeichnis wie die httpd.conf angelegt werden.
<IfModule dav_svn_module>
<Location /svn>
DAV svn
SVNListParentPath on
SVNParentPath D:\Subversion
</Location>
</IfModule>Über den Eintrag wird die darin eingeschlossene Konfiguration nur dann ausgeführt, wenn das Modul dav_svn_module wie in Listing 1 aktiviert wurde. bestimmt den Pfad, wie das Repository angesprochen werden soll. In diesem Fall ist http://127.0.0.1/svn der korrekte URL, um auf die Repositories zuzugreifen. Der absolute Pfad, in dem die Projektverzeichnisse abgelegt werden, wird mit dem Eintrag SVNParentPath gesetzt. Die Option SVN-ListPArentPath on listet alle Repositories in D:/Subversion über den URL http://localhost/svn auf. Kommentare werden mit # in Apache-Konfigurationsdateien eingeleitet und gelten nur bis zum Zeilenende. Sobald die Konfiguration abgeschlossen ist, muss der Server neu gestartet werden, um die Änderungen wirksam zu machen.
Das Repository
Wie schon erwähnt, heißt das Projektverzeichnis, das von SVN verwaltet wird, Repository. Für jedes Projekt wird üblicherweise ein eigenes Repository verwendet, es ist aber auch möglich, mehrere Projekte in einem gemeinsamen Verzeichnis abzulegen. Neue Projekte werden im Hauptverzeichnis Subversion angelegt, das für den Apache konfiguriert wurde. Für unser Beispiel aus Listing 2 ist dieses Hauptverzeichnis D:/Subversion. Darin wird ein neuer Ordner erzeugt, der den Namen des Projekts erhält. Im nächsten Schritt wird in dem neuen Ordner das eigentliche Repository generiert. Dazu wird mit einem Rechtsklick auf den Ordner, der das Projektverzeichnis beherbergen soll, der Eintrag TortoiseSVN/Projektverzeichnis hier erstellen ausgewählt. Die notwendigen Schritte werden von Tortoise anschließend automatisch ausgeführt und das Projektverzeichnis kann nun benutzt werden. Die von SVN angelegte Ordnerstruktur sollte nun nicht weiter verändert werden, alle Zugriffe auf das Verzeichnis erfolgen über den SVN-Client Tortoise.
In den einzelnen Repositories hat es sich bewährt, die Unterverzeichnisse trunk, branches und tags anzulegen. Der trunk (Stamm) beinhaltet das aktuelle Arbeitsverzeichnis, dort werden alle Projektdateien nach den persönlichen Vorlieben organisiert. Damit stellt der trunk den aktuellen Projektstand dar. In tags (Markierungen) werden spezielle Markierungen während des Projektfortschritts erzeugt. Eine solche Markierung ist beispielsweise eine neue Version der Anwendung. Branches (Verzweigungen) stellen parallele Entwicklungsstränge dar. Das ist meist dann der Fall, wenn eine Version abgeschlossen ist und nach einer Auslieferung weitergepflegt wird. Eine Weiterentwicklung von abgeschlossenen Versionen ist in der Regel dann notwendig, wenn nachträglich Fehler bekannt werden, die direkt behoben werden müssen, noch bevor eine neue Version ausgeliefert werden kann. Damit die Änderungen anschließend auch in der neuen Version verfügbar sind, können beide branches mit einem Merge zusammengeführt werden. Der besondere Vorteil von SVN gegenüber CVS ist die effiziente Art, wie die Verzweigungen und Markierungen gespeichert sind. Subversion erzeugt dafür keine physische Kopie, sondern nutzt Verlinkungen zum Hauptentwicklungsstrang.
Nachträgliche Manipulationen am Repository
Nach einem erfolgreichen Commit lassen sich mit der Standardeinstellung keine Änderungen mehr vornehmen. Wenn Logmeldungen nach dem Commit bearbeitet werden sollen, ist es notwendig, einige Veränderungen vorzunehmen. Dazu wechselt man in den Ordner hooks des betreffenden Repositories. Dort wird die Datei pre-revprop-change.bat mit dem folgenden Inhalt angelegt:
if “%4“ == “svn:log“ exit 0
echo Eigenschaft ‘%4‘ kann nicht geändert werden >&2
exit 1
Das Listing ermöglicht es, die Logmeldungen im Nachhinein noch zu ändern. In hooks können verschiedene Skripte abhängig zu den Aktionen gesteuert werden.
Erste Schritte mit SVN
Um die Projektstruktur in das Repository übertragen zu können, müssen die Ordner und Dateien zuerst im Dateisystem angelegt werden. Sobald das geschehen ist, kann der erste Commit ins Subversion erfolgen. Das Senden der Daten ist als Transaktion angelegt, das bedeutet, im Fehlerfall wird die gesamte Übertragung verworfen. Nur wenn alle Dateien erfolgreich übermittelt worden sind, ist die Änderung erfolgreich. Um einen Import auszuführen, muss auf das Root-Verzeichnis mit den zu übertragenden Dateien navigiert werden. Nun kann mit einem Rechtsklick auf den Hauptordner die Option TortoiseSVN/Import ausgewählt werden. Im Importdialog muss nun der URL zum Projektarchiv angegeben werden. Wenn der Apache Web Server nach Listing 2 konfiguriert wurde, lautet die richtige Adresse http://127.0.0.1/svn/[meinProjekt]. Dazu kann noch eine Logmeldung eingetragen werden.
Der Erfolg des Importierens kann wie üblich über eine Rechtsklick mit dem Eintrag TortoiseSVN/Projektarchiv kontrolliert werden. War der Import erfolgreich, kann die erzeugte Projektstruktur getrost gelöscht werden und es steht der erste Checkout aus dem Projektarchiv an. Dazu wird an die gewünschte Position im Dateisystem gewechselt und dort mit Rechtsklick der Eintrag SVN Auschecken genutzt. Damit nun nicht das gesamte Repository heruntergeladen wird, sondern nur der aktuelle Projektfortschritt, muss der Download-URL um das Verzeichnis trunk erweitert werden. Die übertragenen Dateien werden als lokale Arbeitskopie bezeichnet und sind
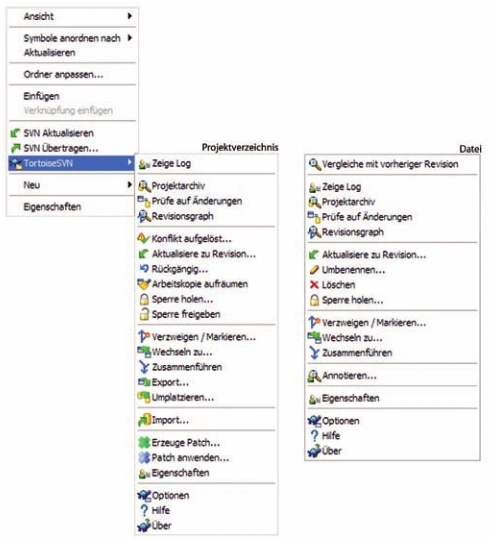
Der Screenshot in Abbildung 2 zeigt die typischen Funktionen von TortoiseSVN, die stets mit einem Rechtsklick erreicht werden. Das Kontextmenü unterscheidet bei einer Selektion zwischen Dateien und Verzeichnissen. Bei nichtversionierten Verzeichnissen stehen die Optionen Hinzufügen, Importieren und Ignorieren zur Auswahl. Wenn die Optionen gleich nach der Aufnahme neuer Dateien in die lokale Arbeitskopie gesetzt werden, sind spätere Falschübertragungen bei einem Commit wesentlich geringer. Durch die Verwendung solcher Markierungen werden stets die richtigen Dateien für die Übertragung vorselektiert, und einem falsch gesetzten Haken unter Zeitstress ist so einfach vorzubeugen.
Jeder Commit in das SVN lässt eine interne Revisionsnummer um eins erhöhen. Die letzte übermittelte Revision wird als HEAD bezeichnet und stellt immer den aktuellen Stand dar. Um auf frühere Versionen des Projekts zugreifen zu können, wird diese Revisionsnummer benötigt. Über die Logmeldungen lässt sich nachvollziehen, welche Änderung in einer Revision gemacht wurde. Es ist somit möglich, jederzeit eine bestimmte Revision aus dem Projektarchiv auszuchecken. Bei sehr vielen Revisionen kann die interne Suchfunktion des Clients verwendet werden, um bestimmte Schlüsselwörter in den Logs zu finden. Dies ist auch ein Grund, von vornherein mit Weitblick sinnvolle Beschreibungen zu finden. Eine Logmeldung sollte die Art der Änderung, die betroffenen Funktionen und eine kurze Beschreibung beinhalten. Ein Beispiel für eine solche Meldung ist: >>FEATURE: Kalender – Berechnung Ostersonntag hinzugefügt.<<
Revision oder Version?
Wichtig im Umgang mit einer Versionsverwaltung ist die Unterscheidung der Begriffe Build und Version. Ein Build ist ein einzelner Iterationsschritt, welcher der erstellten Anwendung nur eine einzige neue Funktion, beziehungsweise ein Feature hinzufügt. Ein Build ist mit der Revisionsnummer im SVN gleichzusetzen. Die Version einer Software ist eine Zusammenstellung verschiedener Funktionen und Features. Erst wenn die geforderte Funktionalität einer Version implementiert ist, erfolgt das Erhöhen der Versionsnummer. Die Version besteht also aus mehreren Builds.
In manchen Fällen ist es wichtig, im Repository Dateien gegen Veränderungen zu sichern. Dafür kann der Mechanismus Sperre holen und Sperre freigeben benutzt werden. Solange Dateien gesperrt sind, können sie nicht durch einen Commit verändert werden. Das beugt Konflikten vor, die entstehen, wenn eine Datei gleichzeitig editiert wird. Um Unterschiede in den Revisionen einer Datei zu erkennen, steht ein so genannter Diff zur Verfügung. Die Abbildung 3 zeigt einen solchen Diff. Es wird immer der Unterschied der aktuellen Arbeitskopie zur vorhergehenden Revision angezeigt. Tortoise lässt sich auch mit dem freien Tool WinMerge kombinieren, um weitere Funktionen zum Dateivergleich zur Verfügung zu haben. Das ist besonders dann interessant, wenn mehrere Revisionen einer Datei verglichen werden müssen. Dazu muss nicht immer das ganze Projekt ausgecheckt werden, es genügt durchaus, nur die betreffenden Files herunterzuladen.

Markieren und Verzweigen

Eine Markierung stellt einen semantischen Zusammenhang des Projektfortschritts zu einer Revisionsnummer im Repository dar. Um das Repository übersichtlich zu halten, werden nur vorher festgelegte Revisionen getaggt. Eine solche Revision kann beispielsweise der Sprung auf eine neue Version der eigenen Applikation sein oder ein Upgrade eines verwendeten Frameworks auf eine aktuelle Version. Wenn einmal eine Markierung nicht sofort angelegt wurde, ist dies auch nicht problematisch. Tags können jederzeit auch aus jeder beliebigen Revisionsnummer erzeugt werden. Daher ist es unproblematisch, nach mehreren Commits die gewünschte Revision im Nachhinein zu taggen. Um eine Markierung zu erzeugen, wird der Eintrag Verzweigen/Markieren im Kontexmenü benutzt. Dazu ist es wichtig, auch im Root-Ordner des gesamten Projekts zu sein, da sonst nur Teile getaggt werden. In Abbildung 4 ist der betreffende Dialog dargestellt. An der ersten Position ist das Quellverzeichnis angegeben. Im Eingabefeld Zu URL wird der Pfad von trunk nach tags korrigiert. In tags ist es notwendig, den Pfad mit einem neuen Ordner zu erweitern, der z. B. die Versionsnummer als Namen besitzt. Wenn der Pfad des trunks nicht erweitert wird, kommt es zu einer Fehlermeldung und der tag wird nicht angelegt. Als Nächstes wird die Auswahl getroffen, welche Revision verwendet werden soll. Zu guter Letzt darf natürlich auch eine Logmeldung nicht fehlen. Wenn nun das Projektarchiv geöffnet wird, ist im Verzeichnis tags ein neuer Ordner angelegt, der sämtliche Projektdateien zu einem bestimmten Revisionsstand enthält. In tags werden keine Änderungen übertragen.
Für Verzweigungen wird analog vorgegangen, nur dass das Verzeichnis tags durch branches ersetzt werden muss. Bei der späteren Arbeit mit Entwicklungszweigen, die vom trunk abweichen, muss der Commit auch stets in das entsprechende Unterverzeichnis von branches übertragen werden. Das Zusammenführen eines branchs mit der HEAD-Revision des trunks erfolgt über das Kontexmenü. Die vorhandenen Konflikte müssen von Hand über den Diff-Betrachter aufgelöst werden.
Fazit
Wie zu erkennen ist, handelt es sich bei Subversion um ein sehr leistungsfähiges Werkzeug, dessen Leistungsspektrum von diesem Artikel nur angerissen werden konnte. Eine ausführliche Abhandlung zur Theorie und weiterführende Konzepte mit Subversion sind im SVN Book zu finden.