
Schlagwort-Archiv: Source Control Management
Nativen Git Server unter Linux aufsetzen
Antworten
Wer sein Git-Repository zur gemeinsamen Bearbeitung für Quelltexte benutzen möchte, benötigt einen Git-Server. Der Git Server ermöglicht die Kollaboration mehrere Entwickler auf der gleichen Codebasis. Die Installation des Git-Clients auf einem Linux Server ist zwar ein erster Schritt zur eigenen Serverlösung, aber bei Weitem nicht ausreichend. Um den Zugriff mehrere Personen auf ein Code Repository zu ermöglichen, benötigen wir eine Zugriffsberechtigung. Schließlich soll das Repository öffentlich über das Internet erreichbar sein. Wir möchten über die Benutzerverwaltung verhindern, dass unberechtigte Personen den Inhalt der Repositories lesen und verändern können.
Für den Betrieb eines Git-Servers gibt es viele hervorragende und komfortable Lösungen, die man einer nativen Serverlösung vorziehen sollte. Die Administration eines nativen Git Servers erfordert Linux Kenntnisse und wird ausschließlich über die Kommandozeile bewerkstelligt. Lösungen wie beispielsweise der SCM-Manager haben eine grafische Benutzeroberfläche und bringen viele nützliche Werkzeuge zur Administration des Servers mit. Diese Werkzeuge stehen bei einer nativen Installation nicht zur Verfügung.
Wieso sollte man nun Git als nativen Server installieren? Diese Frage lässt sich recht leicht beantworten. Der Grund ist wenn der Server, auf dem das Code Repository bereitgestellt werden soll, nur wenige Hardware-Ressourcen besitzt. Besonders der Arbeitsspeicher ist in diesem Zusammenhang immer ein wenig problematisch. Gerade bei angemieteten Virtuellen Private Servern (VPS) oder einem kleinen RaspberryPI ist das oft der Fall. Wir sehen also, es kann durchaus Sinn ergeben, einen nativen Git Server betreiben zu wollen.
Als Voraussetzung benötigen wir einen Linux-Server, auf dem wir den Git-Server installieren können. Das kann ein Debian oder Ubuntu Server sein. Wer CentOS oder andere Linux Distributionen verwendet, muss anstatt APT zur Softwareinstallation den Paketmanager seiner Distribution nutzen.
Wir beginnen im ersten Schritt mit der Aktualisierung der Pakete und der Installation des Git-Clients.
sudo apt-get update
sudo apt-get upgrade
sudo apt-get install git
Als zweiten Schritt erstellen wir einen neuen Benutzer mit dem Namen git und legen für diesen ein eigenes home Verzeichnis an und aktivieren dort den SSH-Zugriff.
sudo useradd --create-home --shell /bin/bash git
sudo su - git
cd /home/git/
mkdir .ssh/ && chmod 700 .ssh/
touch .ssh/authorized_keys
chmod 600 .ssh/authorized_keys
Nun können wir im dritten Schritt in dem neu angelegten home Verzeichnis des git Users unsere Git-Repositories erstellen. Diese unterscheiden sich gegenüber dem lokalen Arbeitsbereich darin, dass diese den Source Code nicht ausgecheckt haben.
mkdir /home/git/repos/project.git
cd /home/git/repos/project.git
git init --bare
Leider sind wir noch nicht ganz fertig mit unserem Vorhaben. Im vierten Schritt müssen wir die Benutzerberechtigung für das erstellte Repository setzen. Dies geschieht durch das Ablegen des öffentlichen Schlüssels auf dem Git Server für den SSH-Zugriff. Dazu kopieren wir den Inhalt aus der Datei unseres privaten Schlüssels in die Datei /home/git/.ssh/authorized_keys in eine eigene Zeile. Möchte man nun vorhandenen Nutzern den Zugriff verwehren, kommentiert man lediglich mit einem # die zeie des privaten Schlüssels wieder aus.
Wenn alles korrekt durchgeführt wurde, erhält man den Zugriff auf das Repository über folgenden Kommandozeilenbefehl: git clone ssh://git@<IP>/~/<repo>
Dabei ist <IP> durch die tatsächliche Server-IP zu ersetzen. Für unser Beispiel lautet der korrekte Pfad für <repo> project.git es ist also das von uns erstellte Verzeichnis für das Git-Repository.
Auf dem nativen Git Server können mehrere Repositories angelegt werden. Dabei gilt zu beachten, dass alle berechtigenden Nutzer auf alle so angelegenen Reposiories lesenden und schreibenden Zugriff haben. Das lässt sich nur dadurch einschränken, dass auf dem Linux-Server der unsere Git-Repositories bereitstellt, mehrere Benutzer auf dem Betriebssystem angelegt werden, denen dann die Repositories zugewiesen werden.
Wir sehen, dass eine native Git Server Installation zwar schnell umgesetzt werden kann, diese aber für die kommerzielle Softwareentwicklung nicht ausreichend ist. Wer gerne experimentiert, kann sich eine virtuelle Maschine erstellen und diesen Workshop darin ausprobieren.




![Inhalt | Apache Maven [de]](https://elmar-dott.com/wp-content/uploads/kick-off-queue-billard-870x570.webp)

Flaschenhals Pull Requests
Der sichere Umgang mit Source Control Management (SCM) Systemen wie Git ist für Programmierer (Development) und auch Systemadministratoren (Operations) essenziell. Diese Gruppe von Werkzeugen hat eine lange Tradition in der Softwareentwicklung und versetzt Entwicklungsteams in die Lage, gemeinsam an einer Codebasis zu arbeiten. Dabei werden vier Fragen beantwortet: Wann wurde die Änderung gemacht? Wer hat die Änderung vorgenommen? Was wurde geändert? Warum wurde etwas geändert? Es ist also ein reines Kollaborationswerkzeug.
Mit dem Aufkommen der Open Source Code Hosting Plattform GitHub wurden sogenannte Pull Requests eingeführt. Pull Requests ist in GitHub ein Workflow, der es Entwicklern erlaubt, Codeänderungen für Repositories bereitzustellen, auf die sie nur lesenden Zugriff haben. Erst nachdem der Besitzer des originalen Repositories die vorgeschlagenen Änderungen überprüft und für gut befunden hat, werden diese Änderungen von ihm übernommen. So setzt sich auch die Bezeichnung zusammen. Ein Entwickler kopiert sozusagen das originale Repository in seinen GitHub Arbeitsbereich, nimmt Änderungen vor und stellt an den Inhaber des originalen Repositories eine Anfrage, die Änderung zu übernehmen. Dieser kann dann die Änderungen übernehmen und gegebenenfalls noch selbst anpassen oder mit einer Begründung zurückweisen.
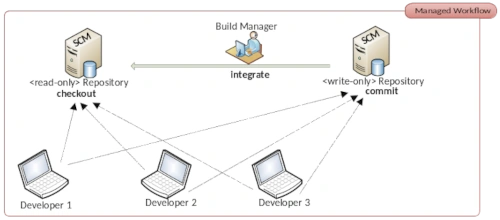
Wer nun glaubt, dass GitHub besonders innovativ war, der irrt. Denn dieser Prozess ist in der Open Source Community ein ‚sehr‘ alter Hut. Ursprünglich nennt man dieses Vorgehen Dictatorship Workflow. Das 1990 zum ersten Mal veröffentlichte kommerzielle SCM Rational Synergy von IBM basiert genau auf dem Dictarorship Workflow. Mit der Klasse der verteilten Versionsverwaltungswerkzeuge, zu denen auch Git gehört, lässt sich der Dictatorship Worflow recht einfach umsetzen. Also lag es auf der Hand das GitHub diesen Prozess seinen Nutzern auch zur Verfügung stellt. Lediglich die Namensgebung ist von GitHub weitaus ansprechender gewählt. Wer beispielsweise mit der freien DevOps Lösung GitLab arbeitet, kennt Pull Requests unter der Bezeichnung Merge Requests. Mittlerweile enthalten die gängigsten Git-Server den Prozess der Pull Requests. Ohne zu sehr auf die technischen Details zur Umsetzung der Pull Request einzugehen, richten wir unsere Aufmerksamkeit auf die üblichen Probleme mit denen Open Source Projekte konfrontiert sind.
Entwickler, die sich an einem Open Source Projekt beteiligen möchten, werden Maintainer genannt. Nahezu jedes Projekt hat eine kleine Anleitung, wie man das entsprechende Projekt unterstützen kann und welche Regeln gelten. Für Personen, die das Programmieren erlernen, eignen sich Open Source Projekte hervorragend, um die eigenen Fähigkeiten schnell signifikant zu verbessern. Das bedeutet für das Open Source Projekt, dass man Maintainer mit den unterschiedlichsten Fähigkeiten und Erfahrungsschatz hat. Wenn man also keinen Kontrollmechanismus etabliert, erodiert die Codebasis in sehr kurzer Zeit. Wenn das Projekt nun recht groß ist und sehr viele Mainatainer auf der Codebasis agieren, ist es für den Inhaber des Repositories kaum noch möglich, alle Pull Requests zeitnahe zu bearbeiten. Um diesem Bottelneck entgegenzuwirken, wurde der Dictatorship Workflow zum Dictatorship – Lieutenant Workflow erweitert. Es wurde also eine Zwischeninstanz eingeführt, mit der die Überprüfung der Pull Requests auf mehrere Schultern verteilt wird. Diese Zwischenschicht, die sogenannten Lieutenants sind besonders aktive Maintainer mit einer bereits etablierten Reputation. Somit braucht der Dictator nur noch die Pull Requests der Lieutenants zu reviewen. Eine ungemeine Arbeitsentlastung, die sicherstellt, dass es zu keinem Feature Stau durch nicht abgearbeitete Pull Requests kommt. Schließlich sollen die Verbesserungen beziehungsweise die Erweiterungen so schnell wie möglich in die Codebasis aufgenommen werden, um dann im nächsten Release den Nutzern zur Verfügung zu stehen.
Dieses Vorgehen ist bis heute der Standard in Open Source Projekten, um Qualität gewährleisten zu können. Man kann ja nie sagen, wer sich alles am Projekt beteiligt. Möglicherweise mag es ja auch den ein oder anderen Saboteur geben. Diese Überlegung ist nicht so abwegig. Unternehmen, die für ihr kommerzielles Produkt eine starke Konkurrenz aus dem feien Open Source Bereich haben, könnten hier auf unfaire Gedanken kommen, wenn es keine Reglementierungen geben würde. Außerdem lassen sich Maintainer nicht disziplinieren, wie es beispielsweise für Teammitglieder in Unternehmen gilt. Einem beratungsresistenten Maintainer, der sich trotz mehrfachen Bitten nicht an die Vorgaben des Projektes hält, kann man schwer mit Gehaltskürzungen drohen. Einzige Handhabe ist diese Person vom Projekt auszuschließen.
Auch wenn das gerade beschriebene Problem der Disziplinierung von Mitarbeitern in kommerziellen Teams kein Problem darstellt, gibt es in diesen Umgebungen ebenfalls Schwierigkeiten, die es zu meistern gilt. Diese Probleme rühren noch aus den Anfängen von Visualisierungswerkzeugen. Denn die ersten Vertreter dieser Spezies waren keine verteilten Lösungen, sondern zentralisiert. CVS und Subversion (SVN) halten auf dem lokalen Entwicklungsrechner immer nur die letzte Revision der Codebasis. Ohne Verbindung zum Server kann man faktisch nicht arbeiten. Bei Git ist dies anders. Hier hat man eine Kopie des Repositories auf dem eigenen Rechner, sodass man seine Arbeiten lokal in einem separaten Branch durchführt und wenn man fertig ist, bringt man diese Änderungen in den Hauptentwicklungszweig und überträgt diese dann auf den Server. Die Möglichkeit, offline Branches zu erstellen und diese lokal zu mergen hat einen entscheidenden Einfluss auf die Stabilität der eigenen Arbeit, wenn das Reopsitory in einen inkonsistenten Zustand gerät. Denn im Gegensatz zu zentralisierten SCM Systemen kann man nun weiter arbeiten, ohne darauf warten zu müssen, dass der Hauptentwicklungszweig repariert wurde.
Diese Inkonsistenten entstehen sehr leicht. Es genügt nur eine Datei beim Commit zu vergessen und schon können die Teamkollegen das Projekt nicht mehr lokal kompilieren und sind in der Arbeit behindert. Um diesem Problem Herr zu werden, wurde das Konzept Continuous Integration (CI) etabliert. Es handelt sich dabei nicht, wie oft fälschlicherweise angenommen, um die Integration verschiedener Komponenten zu einer Anwendung. Die Zielstellung bei CI ist die Commit Satge – das Code Repository – in einem konsistenten Zustand zu halten. Dazu wurden Build Server etabliert, die in regelmäßigen Abständen das Repository auf Änderungen überprüfen, um dann den aus dem Quelltext das Artefakt bauen. Ein sehr beliebter und seit vielen Jahren etablierter Build-Server ist Jenkins. Jenkins ging ursprünglich aus dem Projekt Hudson als Abspaltung hervor und übernahm mittlerweile viele weitere Aufgaben. Deswegen ist es sehr sinnvoll, diese Klasse von Tools als Automatisierungsserver zu bezeichnen.
Mit diesem kleinen Abriss in die Geschichte der Softwareentwicklung verstehen wir nun die Probleme von Open Source Projekten und kommerzieller Softwareentwicklung. Dazu haben wir die Entstehungsgeschichte der Pull Request besprochen. Indessen kommt es in kommerziellen Projekten sehr oft vor, dass Teams durch das Projektmanagement gezwungen werden mit Pull Requests zu arbeiten. Für einen Projektleiter ohne technisches Hintergrundwissen klingt es nun sehr sinnvoll, in seinem Projekt ebenfalls Pull Requests zu etablieren. Schließlich hat er die Idee, dass er somit die Codequalität verbessert. Leider ist das aber nicht der Fall. Das Einzige was passiert ist ein Feature Stau zu provozieren und eine erhöhte Auslastung des Teams zu erzwingen, ohne die Produktivität zu verbessern. Denn der Pull Request muss ja von einer kompetenten Person inhaltlich bewertet werden. Das verursacht bei großen Projekten unangenehme Verzögerungen.
Nun erlebe ich es oft, dass argumentiert wird, man könne die Pull Requests ja automatisieren. Das heißt, der Build Server nimmt den Branch, mit dem Pull Request versucht diesen zu bauen und im Fall dass das Kompilieren und die automatisierten Tests erfolgreich sind, versucht der Server die Änderungen in den Hauptentwicklungszweig zu übernehmen. Möglicherweise sehe ich da etwas falsch, aber wo ist die Qualitätskontrolle? Es handelt sich um einen einfachen Continuous Integration Prozess, der die Konsistenz des Repositories aufrechterhält. Da Pull Requests vornehmlich im Git Umfeld zu finden sind, bedeutet ein kurzzeitig inkonsistentes Repository kein kompletten Entwicklungstop für das gesamte Team, wie es bei Subversion der Fall ist.

Interessant ist auch die Frage wie man bei einem automatischen Merge mit semantischen Mergekonflikten umgeht. Die per se kein gravierendes Problem sind. Sicher führt das zur Ablehnung des Pull Requests mit entsprechender Nachricht an den Entwickler, um das Problem mit einem neuen Pull Request zu lösen. Ungünstige Branchstrategien können hier allerdings zu unverhältnismäßigen Mehraufwand führen.
Für die Verwendung von Pull Requests in kommerziellen Softwareprojekten sehe ich keinen Mehrwert, weswegen ich davon abrate, in diesem Kontext Pull Request zu verwenden. Außer einer Verkomplizierung der CI / CD Pipeline und einem erhöhten Ressourcenverbrauch des Automatisierungsservers, der nun die Arbeit doppelt macht, ist nichts passiert. Die Qualität eines Softwareprojektes verbessert man durch das Einführen von automatisierten Unit-Tests und einem testgetriebenen Vorgehen bei der Umsetzung von Features. Hier ist es notwendig, die Testabdeckung des Projekts kontinuierlich im Auge zu behalten und zu verbessern. Statische Codeanalyse und das Aktivieren von Compilerwarnings bringen mit erheblich weniger Aufwand bessere Ergebnisse.
Ich persönlich vertrete die Auffassung, dass Unternehmen, die auf Pull Requests setzen, diese entweder für ein verkompliziertes CI nutzen oder ihren Entwicklern komplett misstrauen und ihnen in Abrede stellen, gute Arbeit abzuliefern. Natürlich bin ich offen für eine Diskussion zum Thema, möglicherweise lässt sich dann eine noch bessere Lösung finden. Von daher freue ich mich über reichliche Kommentare mit euren Ansichten und Erfahrungen im Umgang mit Pull Requests.


Versionsverwaltung mit Expressions
m Umgang mit Source-Control-Management-Systemen (SCM) wie Git oder Subversion haben sich im Lauf der Zeit vielerlei Praktiken bewährt. Neben unzähligen Beiträgen über Workflows zum Branchen und Mergen ist auch das Formulieren verständlicher Beschreibungen in den Commit-Messages ein wichtiges Thema.

(c) 2018 Marco Schulz, Java PRO Ausgabe 3, S.50-51
Ab und zu kommt es vor, dass in kollaborativen Teams vereinzelte Code-Änderungen zurückgenommen werden müssen. So vielfältig die Gründe für ein Rollback auch sein mögen, das Identifizieren betroffener Code-Fragmente kann eine beachtliche Herausforderung sein. Die Möglichkeit jeder Änderung des Code-Repository eine Beschreibung anzufügen, erleichtert die Navigation zwischen den Änderungen. Sind die hinterlegten Kommentare der Entwickler dann so aussagekräftig wie „Layout-Anpassungen“ oder „Tests hinzugefügt“, hilft dies wenig weiter. Diese Ansicht vertreten auch diverse Blog-Beiträge [siehe Weitere Links] und sehen das Formulieren klarer Commit-Messages als wichtiges Instrument, um die interne Kommunikation zwischen einzelnen Team-Mitgliedern deutlich zu verbessern.
Das man als Entwickler nach vollbrachter Arbeit nicht immer den optimalen Ausdruck findet, seine Aktivitäten deutlich zu formulieren, kann einem hohen Termindruck geschuldet sein. Ein hilfreiches Instrument, ein aussagekräftiges Resümee der eigenen Arbeit zu ziehen, ist die nachfolgend vorgeschlagene Struktur und ein darauf operierendes aussagekräftiges Vokabular inklusive einer festgelegten Notation. Die vorgestellte Lösung lässt sich sehr leicht in die eigenen Prozesse einfügen und kann ohne großen Aufwand erweitert bzw. angepasst werden.
Mit den standardisierten Expressions besteht auch die Möglichkeit die vorhandenen Commit-Messages automatisiert zu Parsen, um die Projektevolution gegebenenfalls grafisch darzustellen. Sämtliche Einzelheiten der hier vorgestellten Methode sind in einem Cheat-Sheet auf einer Seite übersichtlich zusammengefasst und können so leicht im Team verbreitet werden. Das diesem Text zugrundeliegende Paper ist auf Research-Gate [1] in englischer Sprache frei verfügbar.
Eine Commit-Message besteht aus einer verpflichtenden (mandatory) ersten Zeile, die sich aus der Funktions-ID, einem Label und der Spezifikation zusammensetzt. Die zweite und dritte Zeile ist optional. Die Task-ID, die Issue-Management-Systeme wie Jira vergeben, wird in der zweiten Zeile notiert. Grund dafür ist, dass nicht jedes Projekt an ein Issue-Management-System gekoppelt ist. Viel wichtiger ist auch die Tatsache, dass Funktionen meist auf mehrere Tasks verteilt werden. Eine Suche nach der Funktions-ID fördert alle Teile einer Funktionalität zu tage, auch wenn dies unterschiedlichen Task-IDs zugeordnet ist. Die ausführliche Beschreibung in Zeile drei ist ebenfalls optional und rückt auf Zeile zwei vor, falls keine Task-ID notiert wird. Das gesamte Vokabular zu dem nachfolgenden Beispiel ist im Cheat-Sheet notiert und soll an dieser Stelle nicht wiederholt werden.

[CM-05] #CHANGE ’function:pom’
<QS-0815>
{Change version number of the dependency JUnit from 4 to 5.0.2}
Projektübergreifende Aufgaben wie das Anpassen der Build-Logik, Erzeugen eines Releases oder das Initiieren eines Repositories können in allgemeingültigen Funktions-IDs zusammengefasst werden. Entsprechende Beispiele sind im Cheat-Sheet angeführt.
Configuration Management [CM-00] #INIT, #REVIEW, #BRANCH, #MERGE, #RELEASE #BUILD-MNGT
Möchte man nun den Projektfortschritt ermitteln, ist es sinnvoll aussagekräftige Meilensteine miteinander zu vergleichen. Solche Punkte (POI) stellen üblicherweise Releases dar. So können bei Berücksichtigung des Standard-Release-Prozesses und des Semantic-Versionings Metriken über die Anzahl der Bug-Fixes pro Release erstellt werden. Aber auch klassische Erhebungen wie Lines-of-Code zwischen zwei Minor-Releases können interessante Erkenntnisse fördern.

Resourcen
Kontrollzentrum

Seit einiger Zeit steht die neue Version 1.5 des Versionsverwaltungs-Tools Subversion (SVN) zum kostenlosen Download bereit. Das Programm ist für verschiedene Plattformen erhältlich, dazu zählen Windows und Linux als die wichtigsten Vertreter. Der Artikel bezieht sich zwar auf das Windows-Betriebssystem, aber mit geringem Aufwand lassen sich die wenigen spezifischen Unterschiede leicht adaptieren. Man kann Subversion auf unterschiedliche Art und Weise betreiben. Für eine lokale Verwendung, bei sehr kleinen Projekten mit lediglich einem einzigen Entwickler, genügt oft die Installation eines Clients. Für Windows Systeme sollte die Wahl des Clients auf TortoiseSVN fallen. Die Anwendung arbeitet als Explorer-Erweiterung und beherrscht alle notwendigen Funktionen zur Arbeit mit SVN. Dazu zählt unter anderem das Anlegen der Projektverzeichnisse, die Repository genannt werden. Der Zugriff auf ein lokales Repository erfolgt über das file:///-Protokoll. Sobald das Repository für mehrere Entwickler bereitstehen soll, wird ein Server benötigt. Man hat die Wahl zwischen einem Standalone-Server oder einer Integration in den Apache Web Server. Die aktuelle Version des SVN-Servers bringt für Windows-Nutzer eine Verbesserung der Konfiguration als Windows-Dienst. Für den Standalone-Server stehen die Protokolle svn:// und svn+ssh:// zur Verfügung. Für diesen Artikel wird vor allem auf die Installation des Apache-Moduls eingegangen. Der Vorteil des Apache liegt darin, mit den Protokollen http:// und https:// auf die Projektverzeichnisse zugreifen zu können. Mit Subclipse liefert Tigris.org SVN als Plug-in für Eclipse, das dem Tortoise-Client kaum in etwas nachsteht. Dank der PHP-Tools ist die Eclipse-IDE nicht mehr nur von Java-Programmierern geschätzt. Abbildung 1 zeigt die Subversion View mit einem geöffneten Projekt in Eclipse.

Subversion im Apache
Eine sehr bequeme Möglichkeit Subversion zu nutzen, ist die Integration in den Apache Web Server; damit kann das Repository über das HTTP-Protokoll angesprochen werden. Die Installation ist nicht weiter schwierig, erfordert allerdings eine funktionsfähige Apache-Installation. Wer die aufwändige Installation einer vollständigen Serverumgebung scheut, kann getrost auf XAMPP [4] zurückgreifen. Als Erstes müssen dann die Binaries des SVN für den Apache 2.2.X von der Webseite [5] geladen werden. Die Dateien mod_dav_svn.so, mod_authz_svn.so und der Ordner iconv sind in das Verzeichnis %APACHE_HOME%\modules zu kopieren. Um die Module dem Webserver bekannt zu machen, muss schließlich die Datei httpd.conf im Verzeichnis conf des Apache gemäß Listing 1 editiert werden.
# Anpassungen der httpd.conf
LoadModule dav_svn_module modules/mod_dav_svn.so
LoadModule authz_svn_module modules/mod_authz_svn.so
Include conf/svn.confDie ersten beiden Zeilen aktivieren die SVN-Module für den Apache. Um die Konfigurationsdatei übersichtlich zu halten, wird die eigentliche Konfiguration von Subversion über die Anweisung aus Zeile drei in die Datei svn.conf ausgelagert (Listing 2). Die Datei muss im gleichen Verzeichnis wie die httpd.conf angelegt werden.
<IfModule dav_svn_module>
<Location /svn>
DAV svn
SVNListParentPath on
SVNParentPath D:\Subversion
</Location>
</IfModule>Über den Eintrag wird die darin eingeschlossene Konfiguration nur dann ausgeführt, wenn das Modul dav_svn_module wie in Listing 1 aktiviert wurde. bestimmt den Pfad, wie das Repository angesprochen werden soll. In diesem Fall ist http://127.0.0.1/svn der korrekte URL, um auf die Repositories zuzugreifen. Der absolute Pfad, in dem die Projektverzeichnisse abgelegt werden, wird mit dem Eintrag SVNParentPath gesetzt. Die Option SVN-ListPArentPath on listet alle Repositories in D:/Subversion über den URL http://localhost/svn auf. Kommentare werden mit # in Apache-Konfigurationsdateien eingeleitet und gelten nur bis zum Zeilenende. Sobald die Konfiguration abgeschlossen ist, muss der Server neu gestartet werden, um die Änderungen wirksam zu machen.
Das Repository
Wie schon erwähnt, heißt das Projektverzeichnis, das von SVN verwaltet wird, Repository. Für jedes Projekt wird üblicherweise ein eigenes Repository verwendet, es ist aber auch möglich, mehrere Projekte in einem gemeinsamen Verzeichnis abzulegen. Neue Projekte werden im Hauptverzeichnis Subversion angelegt, das für den Apache konfiguriert wurde. Für unser Beispiel aus Listing 2 ist dieses Hauptverzeichnis D:/Subversion. Darin wird ein neuer Ordner erzeugt, der den Namen des Projekts erhält. Im nächsten Schritt wird in dem neuen Ordner das eigentliche Repository generiert. Dazu wird mit einem Rechtsklick auf den Ordner, der das Projektverzeichnis beherbergen soll, der Eintrag TortoiseSVN/Projektverzeichnis hier erstellen ausgewählt. Die notwendigen Schritte werden von Tortoise anschließend automatisch ausgeführt und das Projektverzeichnis kann nun benutzt werden. Die von SVN angelegte Ordnerstruktur sollte nun nicht weiter verändert werden, alle Zugriffe auf das Verzeichnis erfolgen über den SVN-Client Tortoise.
In den einzelnen Repositories hat es sich bewährt, die Unterverzeichnisse trunk, branches und tags anzulegen. Der trunk (Stamm) beinhaltet das aktuelle Arbeitsverzeichnis, dort werden alle Projektdateien nach den persönlichen Vorlieben organisiert. Damit stellt der trunk den aktuellen Projektstand dar. In tags (Markierungen) werden spezielle Markierungen während des Projektfortschritts erzeugt. Eine solche Markierung ist beispielsweise eine neue Version der Anwendung. Branches (Verzweigungen) stellen parallele Entwicklungsstränge dar. Das ist meist dann der Fall, wenn eine Version abgeschlossen ist und nach einer Auslieferung weitergepflegt wird. Eine Weiterentwicklung von abgeschlossenen Versionen ist in der Regel dann notwendig, wenn nachträglich Fehler bekannt werden, die direkt behoben werden müssen, noch bevor eine neue Version ausgeliefert werden kann. Damit die Änderungen anschließend auch in der neuen Version verfügbar sind, können beide branches mit einem Merge zusammengeführt werden. Der besondere Vorteil von SVN gegenüber CVS ist die effiziente Art, wie die Verzweigungen und Markierungen gespeichert sind. Subversion erzeugt dafür keine physische Kopie, sondern nutzt Verlinkungen zum Hauptentwicklungsstrang.
Nachträgliche Manipulationen am Repository
Nach einem erfolgreichen Commit lassen sich mit der Standardeinstellung keine Änderungen mehr vornehmen. Wenn Logmeldungen nach dem Commit bearbeitet werden sollen, ist es notwendig, einige Veränderungen vorzunehmen. Dazu wechselt man in den Ordner hooks des betreffenden Repositories. Dort wird die Datei pre-revprop-change.bat mit dem folgenden Inhalt angelegt:
if “%4“ == “svn:log“ exit 0
echo Eigenschaft ‘%4‘ kann nicht geändert werden >&2
exit 1
Das Listing ermöglicht es, die Logmeldungen im Nachhinein noch zu ändern. In hooks können verschiedene Skripte abhängig zu den Aktionen gesteuert werden.
Erste Schritte mit SVN
Um die Projektstruktur in das Repository übertragen zu können, müssen die Ordner und Dateien zuerst im Dateisystem angelegt werden. Sobald das geschehen ist, kann der erste Commit ins Subversion erfolgen. Das Senden der Daten ist als Transaktion angelegt, das bedeutet, im Fehlerfall wird die gesamte Übertragung verworfen. Nur wenn alle Dateien erfolgreich übermittelt worden sind, ist die Änderung erfolgreich. Um einen Import auszuführen, muss auf das Root-Verzeichnis mit den zu übertragenden Dateien navigiert werden. Nun kann mit einem Rechtsklick auf den Hauptordner die Option TortoiseSVN/Import ausgewählt werden. Im Importdialog muss nun der URL zum Projektarchiv angegeben werden. Wenn der Apache Web Server nach Listing 2 konfiguriert wurde, lautet die richtige Adresse http://127.0.0.1/svn/[meinProjekt]. Dazu kann noch eine Logmeldung eingetragen werden.
Der Erfolg des Importierens kann wie üblich über eine Rechtsklick mit dem Eintrag TortoiseSVN/Projektarchiv kontrolliert werden. War der Import erfolgreich, kann die erzeugte Projektstruktur getrost gelöscht werden und es steht der erste Checkout aus dem Projektarchiv an. Dazu wird an die gewünschte Position im Dateisystem gewechselt und dort mit Rechtsklick der Eintrag SVN Auschecken genutzt. Damit nun nicht das gesamte Repository heruntergeladen wird, sondern nur der aktuelle Projektfortschritt, muss der Download-URL um das Verzeichnis trunk erweitert werden. Die übertragenen Dateien werden als lokale Arbeitskopie bezeichnet und sind
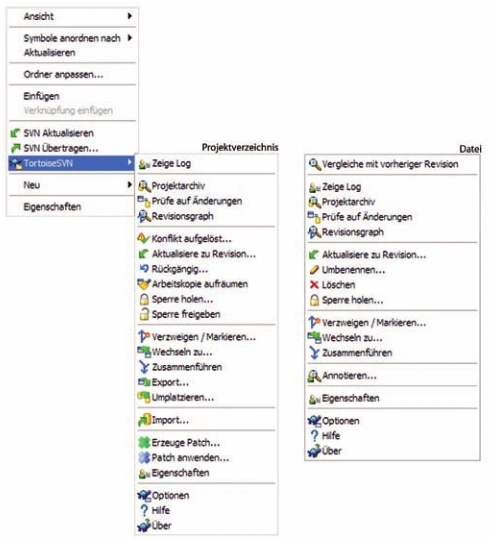
Der Screenshot in Abbildung 2 zeigt die typischen Funktionen von TortoiseSVN, die stets mit einem Rechtsklick erreicht werden. Das Kontextmenü unterscheidet bei einer Selektion zwischen Dateien und Verzeichnissen. Bei nichtversionierten Verzeichnissen stehen die Optionen Hinzufügen, Importieren und Ignorieren zur Auswahl. Wenn die Optionen gleich nach der Aufnahme neuer Dateien in die lokale Arbeitskopie gesetzt werden, sind spätere Falschübertragungen bei einem Commit wesentlich geringer. Durch die Verwendung solcher Markierungen werden stets die richtigen Dateien für die Übertragung vorselektiert, und einem falsch gesetzten Haken unter Zeitstress ist so einfach vorzubeugen.
Jeder Commit in das SVN lässt eine interne Revisionsnummer um eins erhöhen. Die letzte übermittelte Revision wird als HEAD bezeichnet und stellt immer den aktuellen Stand dar. Um auf frühere Versionen des Projekts zugreifen zu können, wird diese Revisionsnummer benötigt. Über die Logmeldungen lässt sich nachvollziehen, welche Änderung in einer Revision gemacht wurde. Es ist somit möglich, jederzeit eine bestimmte Revision aus dem Projektarchiv auszuchecken. Bei sehr vielen Revisionen kann die interne Suchfunktion des Clients verwendet werden, um bestimmte Schlüsselwörter in den Logs zu finden. Dies ist auch ein Grund, von vornherein mit Weitblick sinnvolle Beschreibungen zu finden. Eine Logmeldung sollte die Art der Änderung, die betroffenen Funktionen und eine kurze Beschreibung beinhalten. Ein Beispiel für eine solche Meldung ist: >>FEATURE: Kalender – Berechnung Ostersonntag hinzugefügt.<<
Revision oder Version?
Wichtig im Umgang mit einer Versionsverwaltung ist die Unterscheidung der Begriffe Build und Version. Ein Build ist ein einzelner Iterationsschritt, welcher der erstellten Anwendung nur eine einzige neue Funktion, beziehungsweise ein Feature hinzufügt. Ein Build ist mit der Revisionsnummer im SVN gleichzusetzen. Die Version einer Software ist eine Zusammenstellung verschiedener Funktionen und Features. Erst wenn die geforderte Funktionalität einer Version implementiert ist, erfolgt das Erhöhen der Versionsnummer. Die Version besteht also aus mehreren Builds.
In manchen Fällen ist es wichtig, im Repository Dateien gegen Veränderungen zu sichern. Dafür kann der Mechanismus Sperre holen und Sperre freigeben benutzt werden. Solange Dateien gesperrt sind, können sie nicht durch einen Commit verändert werden. Das beugt Konflikten vor, die entstehen, wenn eine Datei gleichzeitig editiert wird. Um Unterschiede in den Revisionen einer Datei zu erkennen, steht ein so genannter Diff zur Verfügung. Die Abbildung 3 zeigt einen solchen Diff. Es wird immer der Unterschied der aktuellen Arbeitskopie zur vorhergehenden Revision angezeigt. Tortoise lässt sich auch mit dem freien Tool WinMerge kombinieren, um weitere Funktionen zum Dateivergleich zur Verfügung zu haben. Das ist besonders dann interessant, wenn mehrere Revisionen einer Datei verglichen werden müssen. Dazu muss nicht immer das ganze Projekt ausgecheckt werden, es genügt durchaus, nur die betreffenden Files herunterzuladen.

Markieren und Verzweigen

Eine Markierung stellt einen semantischen Zusammenhang des Projektfortschritts zu einer Revisionsnummer im Repository dar. Um das Repository übersichtlich zu halten, werden nur vorher festgelegte Revisionen getaggt. Eine solche Revision kann beispielsweise der Sprung auf eine neue Version der eigenen Applikation sein oder ein Upgrade eines verwendeten Frameworks auf eine aktuelle Version. Wenn einmal eine Markierung nicht sofort angelegt wurde, ist dies auch nicht problematisch. Tags können jederzeit auch aus jeder beliebigen Revisionsnummer erzeugt werden. Daher ist es unproblematisch, nach mehreren Commits die gewünschte Revision im Nachhinein zu taggen. Um eine Markierung zu erzeugen, wird der Eintrag Verzweigen/Markieren im Kontexmenü benutzt. Dazu ist es wichtig, auch im Root-Ordner des gesamten Projekts zu sein, da sonst nur Teile getaggt werden. In Abbildung 4 ist der betreffende Dialog dargestellt. An der ersten Position ist das Quellverzeichnis angegeben. Im Eingabefeld Zu URL wird der Pfad von trunk nach tags korrigiert. In tags ist es notwendig, den Pfad mit einem neuen Ordner zu erweitern, der z. B. die Versionsnummer als Namen besitzt. Wenn der Pfad des trunks nicht erweitert wird, kommt es zu einer Fehlermeldung und der tag wird nicht angelegt. Als Nächstes wird die Auswahl getroffen, welche Revision verwendet werden soll. Zu guter Letzt darf natürlich auch eine Logmeldung nicht fehlen. Wenn nun das Projektarchiv geöffnet wird, ist im Verzeichnis tags ein neuer Ordner angelegt, der sämtliche Projektdateien zu einem bestimmten Revisionsstand enthält. In tags werden keine Änderungen übertragen.
Für Verzweigungen wird analog vorgegangen, nur dass das Verzeichnis tags durch branches ersetzt werden muss. Bei der späteren Arbeit mit Entwicklungszweigen, die vom trunk abweichen, muss der Commit auch stets in das entsprechende Unterverzeichnis von branches übertragen werden. Das Zusammenführen eines branchs mit der HEAD-Revision des trunks erfolgt über das Kontexmenü. Die vorhandenen Konflikte müssen von Hand über den Diff-Betrachter aufgelöst werden.
Fazit
Wie zu erkennen ist, handelt es sich bei Subversion um ein sehr leistungsfähiges Werkzeug, dessen Leistungsspektrum von diesem Artikel nur angerissen werden konnte. Eine ausführliche Abhandlung zur Theorie und weiterführende Konzepte mit Subversion sind im SVN Book zu finden.