Wenn Sie sich mit Java Enterprise beschäftigen möchten, mag es anfangs etwas überwältigend und verwirrend wirken. Aber keine Sorge, es ist nicht so schlimm, wie es scheint. Für den Anfang genügen grundlegende Kenntnisse über die Ideen und Konzepte.
Die Java Serie
zuletzt geändert::
Da Java EE weder ein Werkzeug noch ein Compiler ist, den man wie das Java Development Kit (JDK), auch bekannt als Software Development Kit (SDK), herunterlädt und verwendet, handelt es sich bei Java Enterprise um eine Reihe von Spezifikationen. Diese Spezifikationen werden durch eine API unterstützt, die wiederum eine Referenzimplementierung besitzt. Die Referenzimplementierung ist ein herunterladbares Paket namens Application Server.
Seit Java EE 8 wird Java Enterprise von der Eclipse Foundation gepflegt. Oracle und die Eclipse Foundation konnten sich nicht auf eine gemeinsame Vereinbarung zur Nutzung der Marke Java einigen, die Oracle gehört. Kurz gesagt: Die Eclipse Foundation benannte Java EE in Jakarta EE um. Dies hat auch Auswirkungen auf ältere Projekte, da sich in Jakarta EE 9 die Paketpfade von javax zu jakarta geändert haben. Jakarta EE 9.1 aktualisiert alle Komponenten von JDK 8 auf JDK 11.
Für die Entwicklung von Jakarta Enterprise [1]-Anwendungen sind einige Voraussetzungen erforderlich. Zunächst muss die richtige JDK-Version ausgewählt werden. Die Laufzeitumgebung Java Virtual Machine (JVM) ist bereits im JDK enthalten und muss nicht separat installiert werden. Eine gute Wahl ist stets die neueste LTS-Version. Java 17 JDK wurde 2021 veröffentlicht und wird bis 2024 unterstützt.
Um die Oracle-Lizenzbeschränkungen zu umgehen, können Sie auf eine freie Open-Source-Implementierung des JDK umsteigen. Eine der bekanntesten freien Varianten ist OpenJDK von adoptium [2]. Eine weitere interessante Implementierung ist GraalVM [3], das auf OpenJDK basiert. Die Enterprise Edition von GraalVM kann Ihre Anwendung um das 1,3-Fache beschleunigen. Für den Produktiveinsatz ist eine kommerzielle Lizenz der Enterprise Edition erforderlich. GraalVM enthält außerdem einen eigenen Compiler.
| Version | Year | JSR | Servlet | Tomcat | JavaSE |
| J2EE – 1.2 | 1999 | ||||
| J2EE – 1.3 | 2001 | JSR 58 | |||
| J2EE – 1.4 | 2003 | JSR 151 | |||
| Java EE 5 | 2006 | JSR 244 | |||
| Java EE 6 | 2009 | JSR 316 | |||
| Java EE 7 | 2013 | JSR 342 | |||
| Java EE 8 | 2017 | JSR 366 | |||
| Jakarta 8 | 2019 | 4.0 | 9.0 | 8 | |
| Jakarta 9 | 2020 | 5.0 | 10.0 | 8 & 11 | |
| Jakarta 9.1 | 2021 | 5.0 | 10.0 | 11 | |
| Jakarta 10 | 2022 | 6.0 | 10.1 | 11 | |
| Jakarta 11 | 2023 | 6.1 | 11.0 | 17 | |
| Jakarta 12 | under development | 6.2 | 21 |
Die obige Tabelle ist nicht vollständig, enthält aber die wichtigsten aktuellen Versionen. Sollten Ihnen weitere Informationen fehlen, schreiben Sie mir gerne eine Nachricht.
Bitte beachten Sie, dass die Jakarta EE-Spezifikation ein bestimmtes Java SDK benötigt und der Anwendungsserver möglicherweise ein anderes Java JDK als Laufzeitumgebung benötigt. Die beiden Java-Versionen müssen nicht identisch sein.
Dependencies (Maven):
<dependency>
<groupId>jakarta.platform</groupId>
<artifactId>jakarta.jakartaee-api</artifactId>
<version>${version}</version>
<scope>provided</scope>
</dependency> <dependency>
<groupId>org.eclipse.microprofile</groupId>
<artifactId>microprofile</artifactId>
<version>${version}</version>
<type>pom</type>
<scope>provided</scope>
</dependency>Im nächsten Schritt wählen Sie die Implementierung der Jakarta EE-Umgebung. Das bedeutet, Sie entscheiden sich für einen Anwendungsserver. Es ist sehr wichtig, dass der gewählte Anwendungsserver mit der auf Ihrem System installierten JVM-Version kompatibel ist. Der Grund dafür ist einfach: Der Anwendungsserver ist in Java implementiert. Wenn Sie ein Servlet-Projekt entwickeln möchten, benötigen Sie keinen vollständigen Anwendungsserver. Ein einfacher Servlet-Container wie Apache Tomcat (Catalina) oder Jetty enthält alles Notwendige.
Referenzimplementierungen für Jakarta Enterprise sind beispielsweise: Payara (ein Fork von Glassfish), WildFly (ehemals JBoss), Apache Geronimo, Apache TomEE, Apache Tomcat und Jetty.
Vielleicht haben Sie schon von Microprofile [4] gehört. Keine Sorge, es ist gar nicht so kompliziert, wie es zunächst scheint. Microprofiles sind im Allgemeinen eine Teilmenge von JakartaEE zum Ausführen von Microservices. Sie wurden um verschiedene Technologien erweitert, um den Status der Dienste zu verfolgen, zu beobachten und zu überwachen. Version 5 wurde im Dezember 2021 veröffentlicht und ist vollständig kompatibel mit JakartaEE 9.
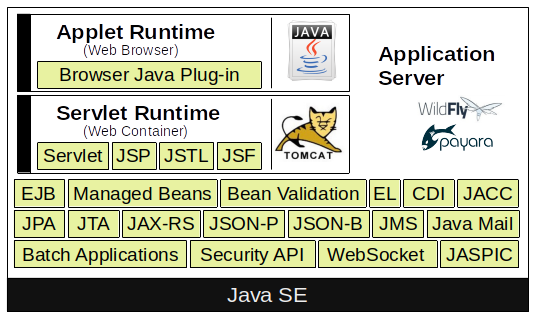
Core Technologies
Plain Old Java Beans
POJOs sind vereinfachte Java-Objekte ohne Geschäftslogik. Diese Art von Java-Beans enthält lediglich Attribute und die zugehörigen Getter und Setter. POJOs:
- Erweitern keine vordefinierten Klassen: z. B. ist
public class Test extends javax.servlet.http.HttpServletkeine POJO-Klasse. - Enthalten keine vordefinierten Annotationen: z. B. ist
@javax.persistence.Entity public class Testkeine POJO-Klasse. - Implementieren keine vordefinierten Schnittstellen: z. B. ist
public class Test implements javax.ejb.EntityBeankeine POJO-Klasse.
(Jakarta) Enterprise Java Beans
Eine EJB-Komponente, auch Enterprise Bean genannt, ist ein Codeblock mit Feldern und Methoden zur Implementierung von Modulen der Geschäftslogik. Man kann sich eine Enterprise Bean als Baustein vorstellen, der allein oder zusammen mit anderen Enterprise Beans verwendet werden kann, um Geschäftslogik auf dem Java-EE-Server auszuführen.
Enterprise Beans sind entweder zustandslose oder zustandsbehaftete Session Beans oder Message-Driven Beans. Zustandslos bedeutet, dass die Session Bean und ihre Daten gelöscht werden, sobald der Client die Ausführung beendet hat. Eine Message-Driven Bean kombiniert die Eigenschaften einer Session Bean mit denen eines Message Listeners und ermöglicht es einer Geschäftskomponente, asynchron (JMS-)Nachrichten zu empfangen.
(Jakarta) Servlet
Die Java-Servlet-Technologie ermöglicht die Definition HTTP-spezifischer Servlet-Klassen. Eine Servlet-Klasse erweitert die Funktionalität von Servern, die Anwendungen hosten, auf die über ein Anfrage-Antwort-Programmiermodell zugegriffen wird. Obwohl Servlets auf jede Art von Anfrage reagieren können, werden sie üblicherweise zur Erweiterung der von Webservern gehosteten Anwendungen eingesetzt.
(Jakarta) Server Pages
JSP ist eine UI-Technologie, mit der sich Servlet-Code-Schnipsel direkt in ein textbasiertes Dokument einfügen lassen. JSP-Dateien werden vom Compiler in ein Java-Servlet umgewandelt.
(Jakarta) Server Pages Standard Tag Library
Die JSTL kapselt Kernfunktionen, die vielen JSP-Anwendungen gemeinsam sind. Anstatt Tags verschiedener Anbieter in Ihren JSP-Anwendungen zu mischen, verwenden Sie einen einzigen, standardisierten Tag-Satz. Die JSTL enthält Iterator- und Bedingungs-Tags zur Ablaufsteuerung, Tags zur Bearbeitung von XML-Dokumenten, Internationalisierungs-Tags, Tags für den Datenbankzugriff mit SQL sowie Tags für häufig verwendete Funktionen.
(Jakarta) Server Faces
JSF ist ein Framework für Benutzeroberflächen zur Entwicklung von Webanwendungen. JSF wurde eingeführt, um das Problem von JSP zu lösen, bei dem Programmlogik und Layout stark voneinander getrennt waren.
(Jakarta) Managed Beans
Managed Beans sind leichtgewichtige, containerverwaltete Objekte (POJOs) mit minimalen Anforderungen. Sie unterstützen eine kleine Anzahl grundlegender Dienste wie Ressourceninjektion, Lebenszyklus-Callbacks und Interceptors. Managed Beans stellen eine Verallgemeinerung der von der Java Server Faces-Technologie spezifizierten Managed Beans dar und können überall in einer Java-EE-Anwendung eingesetzt werden, nicht nur in Webmodulen.
(Jakarta) Persistence API
Die Java Persistence API (JPA) ist eine auf Java-Standards basierende Lösung für die Datenpersistenz. Sie nutzt ein objektrelationales Mapping, um die Lücke zwischen einem objektorientierten Modell und einer relationalen Datenbank zu schließen. Die Java Persistence API kann auch in Java-SE-Anwendungen außerhalb der Java-EE-Umgebung verwendet werden. Hibernate und Eclipse Link sind Beispiele für JPA-Implementierungen.
(Jakarta) Transaction API
Die JTA bietet eine Standardschnittstelle zur Abgrenzung von Transaktionen. Die Java-EE-Architektur stellt standardmäßig einen automatischen Commit zur Verfügung, der Transaktions-Commits und -Rollbacks verarbeitet. Ein automatischer Commit bedeutet, dass alle anderen Anwendungen, die auf Daten zugreifen, nach jedem Lese- oder Schreibvorgang die aktualisierten Daten sehen. Führt Ihre Anwendung jedoch zwei voneinander abhängige Datenbankzugriffe durch, sollten Sie die JTA-API verwenden, um den Beginn, den Rollback und den Commit der gesamten Transaktion – einschließlich beider Operationen – festzulegen.
(Jakarta) API for RESTful Web Services
JAX-RS definiert APIs für die Entwicklung von Webdiensten gemäß dem REST-Architekturstil (Representational State Transfer). Eine JAX-RS-Anwendung ist eine Webanwendung, die aus Klassen besteht, die als Servlet in einer WAR-Datei zusammen mit den erforderlichen Bibliotheken verpackt sind.
(Jakarta) Dependency Injection for Java
Dependency Injection für Java definiert einen Standardsatz von Annotationen (und ein Interface) für die Verwendung injizierbarer Klassen wie Google Guice oder dem Sprig Framework. Auf der Java-EE-Plattform bietet CDI Unterstützung für Dependency Injection. Konkret können Injektionspunkte nur in einer CDI-fähigen Anwendung verwendet werden.
(Jakarta) Contexts & Dependency Injection for Java EE
CDI definiert eine Reihe von Kontextdiensten, die von Java-EE-Containern bereitgestellt werden und es Entwicklern erleichtern, Enterprise Beans zusammen mit Java Server Faces in Webanwendungen zu verwenden. CDI ist für die Verwendung mit zustandsbehafteten Objekten konzipiert, bietet aber auch viele weitere Einsatzmöglichkeiten und ermöglicht Entwicklern ein hohes Maß an Flexibilität bei der Integration verschiedener Komponententypen auf lose gekoppelte, aber typsichere Weise.
(Jakarta) Bean Validation
Die Bean-Validierungsspezifikation definiert ein Metadatenmodell und eine API zur Validierung von Daten in Java-Beans-Komponenten. Anstatt die Datenvalidierung auf mehrere Schichten, wie Browser und Server, zu verteilen, können die Validierungsbedingungen zentral definiert und schichtübergreifend genutzt werden.
(Jakarta) Message Service API
Die JMS-API ist ein Messaging-Standard, der es Java-EE-Anwendungskomponenten ermöglicht, Nachrichten zu erstellen, zu senden, zu empfangen und zu lesen. Sie ermöglicht eine lose gekoppelte, zuverlässige und asynchrone verteilte Kommunikation.
(Jakarta) EE Connector Architecture
Die Java-EE-Connector-Architektur wird von Softwareherstellern und Systemintegratoren verwendet, um Ressourcenadapter zu erstellen, die den Zugriff auf Enterprise-Informationssysteme (EIS) unterstützen und in jedes Java-EE-Produkt integriert werden können. Ein Ressourcenadapter ist eine Softwarekomponente, die es Java-EE-Anwendungskomponenten ermöglicht, auf den zugrunde liegenden Ressourcenmanager des EIS zuzugreifen und mit diesem zu interagieren. Da ein Ressourcenadapter spezifisch für seinen Ressourcenmanager ist, existiert typischerweise für jeden Datenbanktyp oder jedes Enterprise-Informationssystem ein eigener Ressourcenadapter.
Die Java EE Connector Architecture ermöglicht eine leistungsorientierte, sichere, skalierbare und nachrichtenbasierte Transaktionsintegration von Java EE-basierten Webdiensten mit bestehenden Enterprise-Integrated-Systemen (EIS), die sowohl synchron als auch asynchron arbeiten können. Bestehende Anwendungen und EIS, die über die Java EE Connector Architecture in die Java EE-Plattform integriert wurden, lassen sich mithilfe von JAX-WS und Java EE-Komponentenmodellen als XML-basierte Webdienste bereitstellen. JAX-WS und die Java EE Connector Architecture ergänzen sich somit ideal für die Enterprise Application Integration (EAI) und die durchgängige Geschäftsintegration.
(Jakarta) Mail API
Java-EE-Anwendungen nutzen die JavaMail-API zum Versenden von E-Mail-Benachrichtigungen. Die JavaMail-API besteht aus zwei Teilen:
- einer Anwendungsschnittstelle, die von den Anwendungskomponenten zum Versenden von E-Mails verwendet wird,
- und einer Dienstschnittstelle.
Die Java-EE-Plattform beinhaltet die JavaMail-API mit einem Dienstanbieter, der es Anwendungskomponenten ermöglicht, E-Mails über das Internet zu versenden.
(Jakarta) Authorization Contract for Containers
Die JACC-Spezifikation definiert einen Vertrag zwischen einem Java-EE-Anwendungsserver und einem Autorisierungsrichtlinienanbieter. Alle Java-EE-Container unterstützen diesen Vertrag. Die JACC-Spezifikation definiert java.security.Permission-Klassen, die dem Java-EE-Autorisierungsmodell entsprechen. Sie legt fest, wie Containerzugriffsentscheidungen an Operationen auf Instanzen dieser Berechtigungsklassen gebunden werden. Darüber hinaus definiert sie die Semantik von Richtlinienanbietern, die die neuen Berechtigungsklassen nutzen, um die Autorisierungsanforderungen der Java-EE-Plattform zu erfüllen, einschließlich der Definition und Verwendung von Rollen.
(Jakarta) Authentication Service Provider Interface for Containers
Die JASPIC-Spezifikation definiert eine Service-Provider-Schnittstelle (SPI), über die Authentifizierungsanbieter, die Mechanismen zur Nachrichtenauthentifizierung implementieren, in Client- oder Server-Container bzw. Laufzeitumgebungen zur Nachrichtenverarbeitung integriert werden können. Die über diese Schnittstelle integrierten Authentifizierungsanbieter verarbeiten Netzwerknachrichten, die ihnen von ihren aufrufenden Containern bereitgestellt werden. Sie transformieren ausgehende Nachrichten so, dass der Absender jeder Nachricht den Absender und der Empfänger den Absender authentifizieren kann. Eingehende Nachrichten werden von den Authentifizierungsanbietern authentifiziert, und die im Zuge der Nachrichtenauthentifizierung ermittelte Identität wird an die aufrufenden Container zurückgegeben.
(Jakarta) EE Security API
Ziel der Java EE Security API-Spezifikation ist die Modernisierung und Vereinfachung der Sicherheits-APIs. Dies geschieht durch die Etablierung einheitlicher Ansätze und Mechanismen sowie die Ausblendung komplexerer APIs aus der Entwicklersicht, wo immer möglich. Java EE Security führt die folgenden APIs ein:
- SecurityContext-Schnittstelle: Bietet einen einheitlichen Zugriffspunkt, über den Anwendungen Aspekte der Aufruferdaten prüfen und den Zugriff auf Ressourcen gewähren oder verweigern können.
- HttpAuthenticationMechanism-Schnittstelle: Authentifiziert Aufrufer einer Webanwendung und ist ausschließlich für die Verwendung im Servlet-Container vorgesehen.
- IdentityStore-Schnittstelle: Bietet eine Abstraktion eines Identitätsspeichers, der zur Authentifizierung von Benutzern und zum Abrufen von Aufrufergruppen verwendet werden kann.
(Jakarta) Java API for WebSocket
WebSocket ist ein Anwendungsprotokoll, das Vollduplex-Kommunikation zwischen zwei Teilnehmern über TCP ermöglicht. Die Java-API für WebSocket erlaubt es Java-EE-Anwendungen, Endpunkte mithilfe von Annotationen zu erstellen, die die Konfigurationsparameter des Endpunkts festlegen und seine Lebenszyklus-Callback-Methoden definieren.
(Jakarta) Java API for JSON Processing
JSON-P ermöglicht Java-EE-Anwendungen das Parsen, Transformieren und Abfragen von JSON-Daten mithilfe des Objektmodells oder des Streaming-Modells.
JavaScript Object Notation (JSON) ist ein textbasiertes Datenaustauschformat, das von JavaScript abgeleitet ist und in Webdiensten und anderen verbundenen Anwendungen verwendet wird.
(Jakarta) Java API for JSON Binding
JSON-B stellt eine Bindungsschicht für die Konvertierung von Java-Objekten in und aus JSON-Nachrichten bereit. JSON-B ermöglicht zudem die Anpassung des standardmäßigen Mapping-Prozesses dieser Bindungsschicht durch Java-Annotationen für ein bestimmtes Feld, eine JavaBean-Eigenschaft, einen Typ oder ein Paket oder durch die Implementierung einer Strategie zur Benennung von Eigenschaften. JSON-B wurde mit der Java EE 8-Plattform eingeführt.
(Jakarta) Concurrency Utilities für Java EE
Concurrency Utilities for Java EE ist eine Standard-API zur Bereitstellung asynchroner Funktionen für Java EE-Anwendungskomponenten durch die folgenden Objekttypen: Managed Executor Service, Managed Scheduled Executor Service, Managed Thread Factory und Context Service.
(Jakarta) Batch Applications for the Java Platform
Batch-Jobs sind Aufgaben, die ohne Benutzerinteraktion ausgeführt werden können. Die Spezifikation „Batch Applications for the Java Platform“ (BAJP) ist ein Batch-Framework, das die Erstellung und Ausführung von Batch-Jobs in Java-Anwendungen unterstützt. Das Framework besteht aus einer Batch-Laufzeitumgebung, einer auf XML basierenden Job-Spezifikationssprache, einer Java-API zur Interaktion mit der Batch-Laufzeitumgebung und einer Java-API zur Implementierung von Batch-Artefakten.
Resources
Abonnement / Subscription
[English] This content is only available to subscribers.
[Deutsch] Diese Inhalte sind nur für Abonnenten verfügbar.