Die Wolke ist eine der innovativsten Entwicklungen, seit der Jahrtausendwende und ermöglicht uns eine flächendeckende Nutzung neuronaler Netze, die wir im Volksmund als Large Language Models (LLM) bezeichnen. Dieser Technologiesprung ist nur noch durch Quantencomputing zu übertreffen. Aber genug der Buzzwords für die SEO-Optimierung, stattdessen schauen wir einmal hinter die Kulissen. Beginnen wir erst einmal damit, was Cloud überhaupt ist, und legen dafür die ganzen Marketingbegriffe einmal beiseite.
Am besten kann man sich die Wolke als gigantischen Supercomputer vorstellen, der aus vielen kleinen Computern bausteinartig zusammengesetzt wurde. Dadurch hat man theoretisch beliebig viel CPU‑Leistung, Arbeitsspeicher und Festplattenspeicher zusammenschalten. Auf diesem Supercomputer, der in einem Rechenzentrum läuft, können nun wiederum virtuelle Maschinen bereitgestellt werden, die einen echten Computer mit einer freidefinierbaren Hardware simulieren. Auf diese Weise können die physischen Hardwareresourcen optimal auf die bereitgestellten virtuellen Maschinen aufgeteilt werden.
Bei Cloud unterscheiden wir grob drei unterschiedliche Betriebslevel: Infrastructure as a Service (IaaS), Platform as a Service (PaaS) und Software as a Service. Die nachfolgende Abbildung gibt eine Vorstellung davon, wie sich diese Ebenen aufteilen.
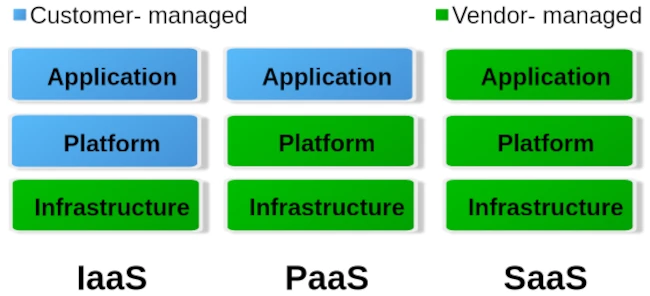
Vereinfacht kann man sagen, dass bei IaaS durch den Anbieter lediglich die Hardwarespezifikation bereitgestellt wird. Also CPU, RAM, Festplatte und Internetanschluss. Über die Administrationssoftware z. B. Kubernetes kann man nun eigene virtuelle Maschinen/Container erstellen und die entsprechenden Betriebssysteme und Services selbst installieren. Die gesamte Verantwortung der Sicherheit und des Netzwerkrouting liegt hier beim Kunden selbst. PaaS hingegen stellt bereits eine rudimentär eingerichtete virtuelle Maschine inklusive des ausgewählten Betriebssystems bereit. Was man schlussendlich auf diesem System oberhalb der Betriebssystemebene installiert, ist einem selbst überlassen. Aber auch hier ist das Thema Sicherheit zu großen Teilen in den Händen des Kunden. Bei den meisten Hostinganbietern sind typische PaaS-Produkte sogenannte virtuelle Server. Die geringste Freiheit haben Nutzer bei SaaS. Hier hat man meist nur die Berechtigung, durch ein Benutzerkonto eine Software zu nutzen. Sehr typische SaaS Produkte sind E-Mail Konten, aber auch sogenannte Managed Server. Managed Server findet man größtenteils zum Bereitstellen von eigenen Internetseiten. Hier wird die Version der Programmiersprache und der Datenbank durch den Betreiber des Servers vorgegeben.
Gerade die Managed Server haben eine lange Tradition. Sie kamen zur Jahrtausendwende auf um eine sofort benutzbare Umgebung für dynamische PHP Webseiten mit MySQL Datenbankanbindung bereitzustellen. Ähnlich verhält es sich mit den neu in Mode gekommenen Serverless Produkten. Je nach Erfahrungslevel kann man nun bei den Großen Anbietern AWS, Google und Microsoft Azure entsprechende Produkte kaufen.
Der Gedanke ist also, keine eigenen Server mehr für die Dienste zu betreiben und somit den kompletten Aufwand für Hardware, Betrieb und Sicherheit an die Cloudbetreiber auszulagern. Grundsätzlich ist das auch kein schlechter Gedanke, besonders wenn es sich um kleine Unternehmen oder Startups handelt, die einerseits nicht viele finanzielle Mittel zur Verfügung haben oder ihnen einfach das administrative Know-how für Netzwerk, Linux und Serversicherheit fehlt.
Natürlich kommt man mit vollständig extern verwalteten Serverless Angeboten auch schnell an Grenzen. Gerade wenn man die eigene entwickelte Individualsoftware Serverless mit möglichst wenig Aufwand in der Cloud bereitstellen möchte, kommt man an so manchem Stolperstein vorbei. Ein Problem ist oft die flexible Erweiterbarkeit bei wechselnden Anforderungen. Sicher kann man hier aus dem Portfolio der verschiedenen Anbieter Produkte zukaufen und diese wie ein Bausteinset beliebig kombinieren, aber die anfallenden Kosten können sich dabei schnell überschlagen.
Grundsätzlich ist an einem pay per use Modell (also bezahle, was du verwendest) nichts auszusetzen. Für Personen und Organisationen mit kleinem Geldbeutel ist das auf den ersten Blick keine schlechte Lösung. Aber auch hier sind es die kleinen Details, die schnell zu ernsthaften Problemen anwachsen können.
Wenn man sich für einen beliebigen Cloudanbieter entscheidet, ist man gut beraten, möglichst auf dessen proprietäre Management- und Automatisierungsprodukte zu verzichten und stattdessen nach Möglichkeit auf etablierte allgemeine Produkte auszuweichen. Bindet man sich mit allen Konsequenzen an einen Anbieter, so wird es nur unter sehr großem Aufwand möglich sein zu einem anderen Anbieter z wechseln. Änderungen der AGB oder kontinuierlich steigende Kosten sind mögliche Gründe für einen erzwungenen Wechsel. Daher prüfet, wer sich ewig bindet.
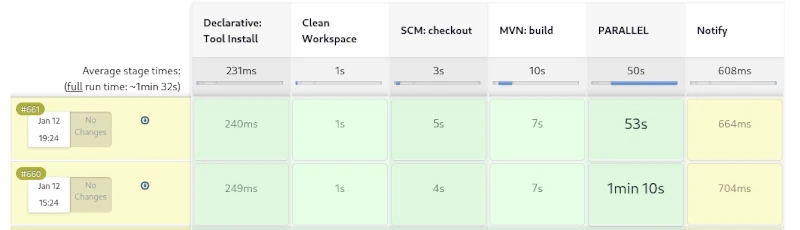
Aber auch unbedachte Ressourcennutzung in Cloudsystemen, z. B. durch falsche Konfigurationen oder ungünstige Deploy-Strategien, kann zu einer Kostenexplosion führen. Hier ist man gut beraten, wenn es die Möglichkeit gibt, Limits einzustellen, diese zu aktivieren. sodass man ab einem bestimmten Betrag darauf hingewiesen wird, dass nur noch ein ‚bestimmtes‘ Kontingent zur Verfügung steht. Gerade bei hochverfügbaren Diensten, die plötzlich sprunghaft enorm viele neue Anwender bekommen, können schnell durch solche Limits vom Netz abgestöpselt werden. Daher ist man immer gut beraten, möglichst zwei Lösungen im Bereich Cloud zu nutzen, eine für Entwicklung und eine separate für das Produktivsystem, um das Offlinerisiko zu minimieren.
Ähnlich wie beim Trading an der Börse, kann man auch bei Cloud Services wie AWS Schranken definieren. Die Stops an der Börse sollen verhindern, dass man eine Aktie nicht zu billig verkauft oder zu teuer einkauft. Durch das Pay per Use Modell ist es in der Cloud nicht viel anders. Hier muss man beim Anbieter geeignete Grenzen setzen, die verhindern, dass die Rechnung den Verfügungsrahmen des Kontos sprengt. Auch in der Cloud sind die Grenzen dynamisch. Das heißt, die Rahmenbedingungen verändern sich stetig, was bedeutet, dass die notwendigen Grenzen regelmäßig den Erfordernissen angepasst werden müssen. Um Engpässe rechtzeitig zu erkennen, sollte ein aussagekräftiges Monitoring etabliert sein. Die Mindestanforderung für ein AWS Node wird durch dessen Requests bestimmt. Die obere Schranke der verfügbaren Ressourcen wird durch das Limit bestimmt. Mit Werkzeugen wie Kubecost von IBM lässt sich die Kostenüberwachung in K8 Clustern weitgehend automatisieren.

Für Cloudentwicklungsumgebungen sollte man den eigenen Entwickler‑ und DevOps-Team auch ein wenig auf die Finger schauen. Wenn für eine einfache JavaScript Angular App ein NPM Docker Container von über 2 GB jedes Mal on the fly erstellt wird, sollte man diese Strategie durchaus hinterfragen. Auch wenn die Cloud scheinbar unendlich viele Ressourcen dynamisch allokieren kann, heißt das nicht, dass dies dann auch kostenfrei passiert.
Natürlich ist auch das Thema Sicherheit ein wichtiger Faktor. Natürlich kann man dem Cloudbetreiber so weit vertrauen, wenn er sagt, dass alles verschlüsselt ist und ein Zugriff auf Kundendaten und Geschäftsgeheimnisse nicht möglich ist. Sicher kann man davon ausgehen, dass die Informationen, die bei den meisten Unternehmungen abzugreifen sind, selten einen spannenden oder gar aufregenden Inhalt haben, der für große Cloudbetreiber von Interesse sein könnte. Wer dennoch auf Nummer sicher gehen möchte, sollte das Thema Serverless vollständig abschreiben und eher mit dem Gedanken spielen, seine eigene Cloud zu betreiben. Das geht dank moderner und freier Software mittlerweile leichter als gedacht.
Aus persönlicher Erfahrung habe ich gelernt, dass bei der Komplexität moderner Webanwendungen ein effizientes Monitoring mit Grafana und Prometheus oder anderen Lösungen wie dem ELK Stack oder Slunk unverzichtbar ist. Doch gerade mit der Datenerhebung und der richtigen Auswertung haben so manche DevOps Teams so ihre Schwierigkeiten. Hier sind vor allem die IT-Entscheider gefragt, sich einen technischen Überblick zu verschaffen, um nicht auf die wohlklingenden Marketingfallen bei Cloud und Serverless hereinzufallen.