For many, Bitcoin (BTC) is a pure speculation object with which they only want to make money. However, the cryptocurrency Bitcoin is also ideal for payment. You do not need any in-depth technical knowledge to pay with Bitcoin. Bitcoin can also be bought with relatively small amounts, for example 10 euros. Everything you need to get started is explained in this article in an easy-to-understand manner.
To buy your first Bitcoin, you need a regular bank account, €20 and about 10 minutes of time. Depending on the bank, the transfer of euros until they are credited as Bitcoin can take up to a day. Incidentally, all of elmar-dott.com’s services can also be paid for using Bitcoin.
Before we start the first transaction, we need to create a wallet. Wallet is the English term for purse. This means that a Bitcoin wallet is nothing more than a digital purse. The program with which you can create and manage a wallet is very similar to the typical banking app. Wallets can be easily set up on computers, smartphones and tablets (Android & iPhone/iPad). There are also hardware wallets that work similarly to a USB stick and store the Bitcoins there.

The most important difference between a bank account and a wallet is that the bitcoins stored in your wallet actually belong to you. There is no bank or other institution that has access to this wallet. You can compare bitcoins stored in your wallet with the cash you have in your wallet. So let’s first look at how to create your own wallet. For this we use the free open source software Electrum. The Electrum Bitcoin Wallet was developed in Python 3 and is available for: Linux, Windows, MacOS and Android.
1st step: Create a wallet
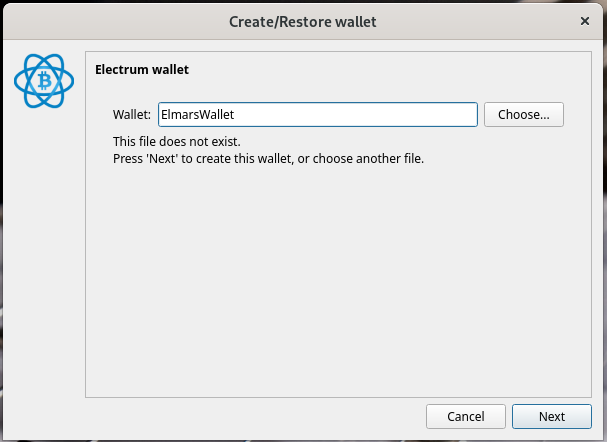
After the app has been downloaded and started, we can get started and create our first Bitcoin wallet. First, we give our wallet a name and press Next. We are then asked which wallet type we would like to create. Here we leave it at the default. We then have to create a seed. The seed is 12 randomly created words that we can expand with our own terms/character strings using the Options button. The specified terms (seed) are extremely important and must be kept safe. It is best to write them on a piece of paper.
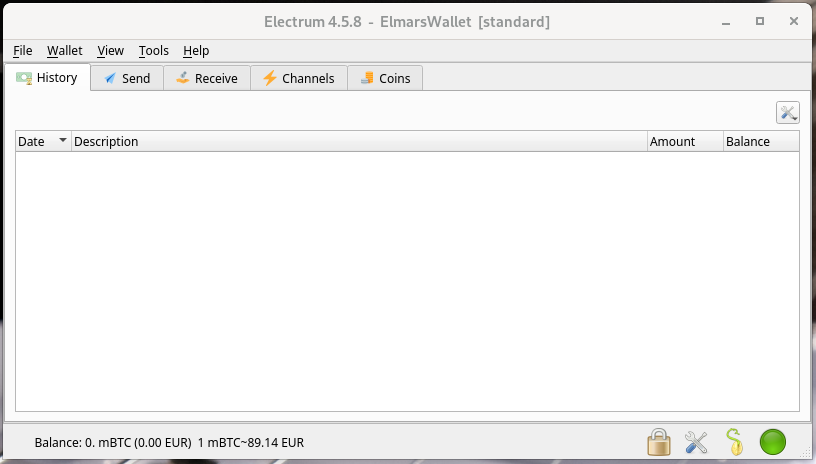
After the app has been downloaded and started, we can get started and create our Bitcoin wallet. First, we give our wallet a name and press Next. We are then asked which wallet type we would like to create. Here we leave it at the default. We then have to create a seed. The seed is 12 randomly created words that we can expand with our own terms/character strings using the Options button. The specified terms (seed) are extremely important and must be kept safe. It is best to write them on a piece of paper. The seed allows full access to your personal wallet. With the seed you can easily transfer your wallet to any device. A secure password is then assigned and the wallet file is encrypted. We have now created our own Bitcoin wallet, with which we can send and receive Bitcoin.
Screenshots




In this way, you can create as many wallets as you like. Many people use 2 or more wallets at the same time. This process is called proxy pay. This measure conceals the actual recipient and is intended to prevent transfer services from refusing transactions to undesirable recipients.
In order to convert your own euros into bitcoin, a so-called broker is required. You transfer euros or other currencies to this broker and receive bitcoin in return. The bitcoin is first transferred to a wallet managed by the broker. From this wallet you can already send bitcoin to any other wallet. As long as the bitcoin is still in the broker’s wallet, however, the broker can block the wallet or steal the bitcoin on it. Only when we transfer the purchased bitcoin to a self-managed wallet, as we created in step 1, are the coins in our possession and no outsider has access to them.
The problem that can arise is that these broker services, also called crypto exchanges, can keep a list of bitcoin wallets to which they do not send transactions. To avoid this, you transfer your Bitcoins from the wallet of the Bitcoin exchange where you bought your coins to your own wallet. You can also use multiple wallets to receive payments. This strategy makes it difficult to track payment flows. The money that has been received in various wallets can now be easily transferred to a central wallet where you can save your coins. It is important to know that fees are also charged when sending Bitcoin. Just like with a checking account.
Understanding Bitcoin Transaction Fees
Every time a transaction is made, it is stored in a block. These blocks have a limited size of 1MB, which limits the number of transactions per block. Since the number of transactions that can fit in a block is limited, users compete to have their transactions included in the next block. This is where Bitcoin transaction fees come in. Users offer fees to make their transactions more attractive to miners. The higher the fee, the more likely the transaction will be confirmed faster. The amount of fees depends on several factors:
- Network load: When load is high, fees increase because more users want to prioritize their transactions.
- Transaction size: Larger transactions require more space in the block and therefore incur higher fees.
- Market conditions: General demand for Bitcoin and market volatility can affect fees.
Most wallets calculate fees automatically based on these factors. However, some wallets offer the ability to manually adjust fees to either save costs or achieve faster confirmation.
Bitcoin transaction fees are not fixed and can vary widely. Bitcoin transactions can be confirmed within minutes to hours, depending on the amount of the fees. Bitcoin fees are not calculated based on the value of the transaction (i.e. how much Bitcoin you send), but rather based on the size of the transaction in bytes. The fee you pay is given in Satoshis per byte (sat/byte). A Satoshi is the smallest unit of Bitcoin (1 BTC = 100 million Satoshis).
You can find out how many Satoshi you get for €1 on coincodex.com and the current transaction fee can be found on bitinfocharts.com
Notes on the anonymity of Bitcoin
When you pay with Bitcoin, you send coins from your wallet to a recipient wallet. This transaction is publicly visible. Basically, when you create a wallet using software such as Electrum, the owner of the wallet is not stored. Nevertheless, conclusions about the owner of a wallet can be drawn from the transactions. Using multiple wallets can make it more difficult to assign them to a real person and conceal money flows. But 100% anonymity cannot be guaranteed. Only cash offers absolute anonymity.
Nevertheless, Bitcoin has some advantages over cash. If you travel a lot and don’t want to keep your money in your bank account, you can easily carry very large amounts with you without them being found and confiscated when crossing borders. You are also fairly well protected against theft. If you save your wallet in an encrypted file on various data storage devices, you can easily restore it using the seed.
2nd Step: Buy Bitcoin
Before we can start using Bitcoin, we first need to get our hands on Bitcoin. We can do this quite easily by buying Bitcoin. Since Bitcoin can be worth several thousand euros depending on the exchange rate, it makes sense to buy parts of a Bitcoin. As already mentioned, the smallest unit of a Bitcoin is Satoshi and corresponds to one μBTC (1 BTC = 100 million Satoshis). The easiest way to buy BTC is via an official Bitcoin exchange. A very easy-to-use exchange is Wallet of Satoshi for Android & iPhone.

With this app you can buy, receive and send Bitcoin. After you have installed the Wallet of Satoshi on your smartphone and the wallet is set up, you can also buy Satoshis immediately via bank transfer with just 20 euros via the menu.
A very practical detail is that you can also use the Wallet of Satoshi to buy Bitcoin using other currencies such as US dollars. This is excellent for international business relationships, where you no longer have to deal with all sorts of exchange rates. Since I consider Bitcoin to be an alternative means of payment, it makes sense for me to always leave an amount of 200 to 500 euros in the Wallet of Satoshi. Anything above that is transferred to the Electrum Wallet. This is purely a precautionary measure, because Wallet of Satoshi is based on the Lightning Network and is a private provider. True to the motto, it is better to be safe than sorry. This strategy also saves transaction fees, which can add up to a considerable amount, especially for micro payments of a few euros.
3rd Step: Pay with Bitcoin

In order to pay with Bitcoin, you need a valid wallet address. This address is usually a long, cryptic character string. Since things can quickly go wrong when entering it manually, this address is often given as a QR code.
To make a payment, for example, via the Wallet of Satoshi to any Bitcoin wallet, either the character string or, better yet, the QR code is required. To do this, open the application, press the send button and then use the camera to scan the QR code of the wallet where the Bitcoin should go.
For example, if you send Bitcoin to the Wallet of Satoshi, all transactions are completely transparent. That’s why you can also send Bitcoin to an anonymous wallet. In step 1, I showed in detail how the Electrum wallet is created. Now let’s look at how we get to the wallet’s address. To do this, we go to the Wallet entry in the Electrum menu and select the Information item. We then get a display like the one in the following screenshot.
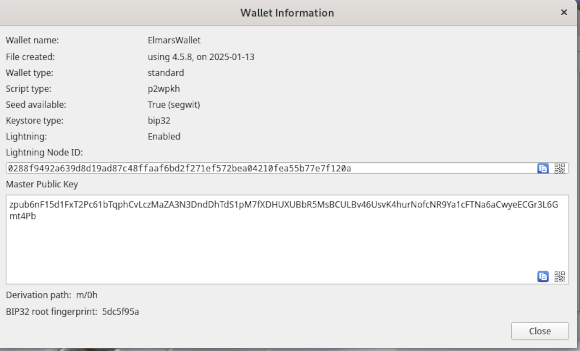
The master public key is the character string for our wallet to which Bitcoins can be sent. If you press the QR symbol in the bottom right of the field, you will receive the corresponding QR code, which can be saved as an image file. If you now make transfers from a Bitcoin exchange such as the Wallet of Satoshi, the exchange does not know who the owner is. In order to find this out, complex analyses are necessary.

Feel free to leave a comment about how you use Bitcoin and which software you work with.
If you think that the information in this article is very helpful then you can support my work by recommending this article or donating with Bitcoin or Satoshi to my Electrtum wallet. The address is:
zpub6nh5hzmJPGLHxV25hREtCUFLdS5RPjnxnxUhVq5MyDP9eUqYZe9JDoZRBj3eXBQ5nKK7133u7hpwHukxcPnJv4eP9xch4AiWHwThJuwrieA
 Unlock with Patreon
Unlock with Patreon