For hobby programmers and professional software developers, information sources are essential. A small, manageable private library with timeless books about programming is therefore always a good thing. Unfortunately, the offer for IT literature is very extensive and the books often outdo it again quickly. In addition, for various reasons, some titles do not necessarily have the predicate worth reading. Some texts are very understandable. Others contain hardly any relevant information that can already be easily obtained from public sources. That’s why I took the trouble and put together my top 10 books on the topic of software development.
All titles have been published in English. Most of them were also translated into German. If you don’t have any difficulties reading English books, you should get the original, since the translations are sometimes a bit bumpy.
An important criterion for a selection is that the books are very general and are not limited to a specific version. In addition, I actually have the works proposed here on my bookshelf and therefore also read.
Effective Java 3rd Edition, J. Bloch, 2017, ISBN: 0-134-68599-7 | For all Java developers, the standard work with many background information about the functioning of the language and optimizations of your own source code.
The Linux Command Line 2nd Edition, W. Shotts, 2019, ISBN: 1-59327-952-3 | Linux is very important in software development, since not only cloud applications in Linux are deployed. It is all the more important to be able to move safely on the command line. This book is only devoted to dealing with the Bash and is suitable for all Linux distributions.
Angry Tests, Y. Bugayenko, 2025, ISBN: 978-1982063740 | Test driven software development is an important ability to ensure high quality. This book is not geared towards a specific programming language, but only deals with how to write meaningful test cases.
Clean Architecture, R. C. Martin, 2018, ISBN: 0-13-449416-4 | In addition to a demolition of the history of how the various programming paradigms are related to each other, the book describes fundamental architectural design styles. Not only for software architects, but also very worth reading for developers.
Mastering Regular Expressions 3rd Edition, J. E. F. Friedl, 2006, ISBN: 0-596-52812-4 | The absolute standard work on regular expressions. A must for anyone who really has to understand the topic.
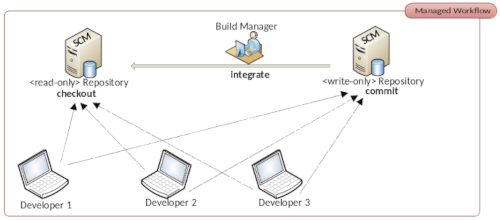
Abstract: Source Control Management (SCM) tools have a long tradition in the software development process and they inhabit an important part of the daily work in any development team. The first documented type of these systems SCCS appeared in 1975 and was described by Rochkind [1]. Til today a large number of other SCM systems have appeared in centralized or distributed forms. An example of centralized variants is Subversion (SVN) or for distributed solutions Git is a representative. Each new system brings many performance improvements and also a lot of new concepts. In “The History of Version Control” [2], Ruparelia gives an overview of the evolution of various free and commercial SCM systems. However, there is one basic use that all these systems have in common. Branching and merging. As simple as the concept seems: to fork a code baseline into a new branch and merge the changes back together later, for SCM systems is difficult to deal with. Giant pitfalls during branching and merging can cause a huge amount of merge conflicts that cannot be handled manually. This article discusses why and where semantic merge conflicts occur and what techniques can be used to avoid them.
Download the PDF:
1. Introduction
When we think about Source Control Management systems and their use, two core functionalities emerge. The most important and therefore the first function to be mentioned is the recording and management of changes to an existing code base. A single code change managed by SCM is called a revision. A revision can consist of any number of changes to only one file or to any number of files. This means a revision is equivalent to a version of the code base. Revisions usually have a ancestor and a descendant and this is forming a directed graph.
The second essential functionality is that SCM systems allow multiple developers to work on the same code base. This means that each developer creates a separate revision for the changes they make. This makes it very easy to track who made a change to a particular file at what time.
Especially the collaborative aspect can become a so-called merging hell if used clumsily. These problems can occur even with a simple linear approach, without further branching. It could happened that locally made changes can’t be integrated due to many semantic conflicts into a new revision. Therefore we discuss in detail in the following section why merge conflicts occur at all.
The term DevOps has been established in the software industry since around 2010. This describes the interaction between development (Dev) and operation (Ops). DevOps is a collection of concepts, methodologies around the software development process to ensure the productivity of the development team. The classical Configuration Management as it among other things in the “SWEBook – Guide to software engineering Body of knowledge” [5] was described is merged like also other special disciplines under the new term DevOps. Software Configuration Management concerns itself from technical view very intensively with the efficient use of SCM systems. This leads us to the Branch Models and from there directly to the next section which will discusses the different Merge strategies.
Another topic is where I examine selected SCM workflows and concepts of repository organization. This point is also an important part of the domain of Configuration Management. Many proven best practices can be described by the theory of expected conflict sets I introduce in last section before the conclusion. This leads to the thesis that the semantic merge conflicts arising in SCM systems are caused by a lack of Continuous Integration (CI) and may could be resolved recursively via partial merges.
2. How merge conflicts arise
If we think about how semantic merge conflicts arise in SCM systems, the pattern that occurs is always the same. The illustration does not require long-term or complex constructions with ramifications.
Even a simple test that can be performed in a few moments shows up the problem. Only one branch is needed, which is called main in a freshly created Git repository. A simple text file with the name test.txt is added to this branch. The file test.txt contains exactly one single line with the following content: “version=1.0-SNAPSHOT”. The text file filled in this way is first committed to the local repository and then pushed to the remote repository. This state describes revision 1 of the test.txt file and is the starting point for the following steps.
A second person now checks out the repository with the main branch to their own system using the clone command. The contents of test.txt are then changed as follows: “version=1.0.0” and transferred to the remote repository again. This gives the test.txt file revision 2.
Meanwhile, person 1 changes the content for test.txt in their own workspace to: “version=1.0.1” and commits the changes to their local repository.
If person 1 tries to push their changes to the shared remote repository, they will first be prompted to pull the changes they made in the meantime from the remote repository to the local repository. When this operation is performed, a conflict arises that cannot be resolved automatically.
Figure 2.01: Screenshot of how the conflict is displayed in TortoiseGit.
Certainly, the remark would be justified at this point that Git is a decentralized SCM. The question arises whether the described attempt in this arrangement can be taken over also for centralized SCM systems? Would the centralized Subversion (SVN) terminate in the same result like the decentralized Git? The answer to this is a clear YES. The major difference between centralized and decentralized SCM systems is that decentralized SCM tools create a copy of the remote repository locally, which is not the case with centralized representatives. Therefore, decentralized solutions need two steps to create a revision in the remote repository, while centralized tools do not need the intermediate step via the local repository.
Figure 2.02: Decision problem that leads to a conflict.
Before we now turn to the question of why the conflict occurred, let’s take a brief look at Figure 2.02, which once again graphically depicts the scenario in its sequences.
Using the following listing 2.01, the experiment can be recreate independently at any time. It is only important that the sequence of the individual steps is not changed.
Listing 2.01: A test setup for creating a conflict on the command line.
The result of the described experiment is not surprising, because SCM systems are usually line-based. If we now have changes in a file in the same line, automatic algorithms like the 3-way-merge based on the O(ND) Difference Algorithm discussed by Myers [3] cannot make a decision. This is expected, because the change has a semantic meaning that only the author knows. This then leads to the user having to manually intervene to resolve the conflict.
Figure 2.03: Displays the conflict by the Git log command.
To find a suitable solution for resolving the conflict, there are powerful tools that compare the changes of the two versions. The underlying theoretical work of 2-way-merge can be found, among others, in the paper syntactic software merging [4] by Buffenbarger.
Figure 2.04: Conflict resolution using Tortoise Git Merge.
To explore the problem further, we look at the ways in which different versions a file change can arise. Since SCM systems are line-based, we focus on the state that a single line can take:
unchanged
modified
delete / removed
add
move
It can already be guessed that moving larger text blocks within a file can also lead to conflicts. Now objections could be raised that such a procedure is rather theoretical nature and has little practical reference. However, I must vehemently contradict this. Since I was confronted with exactly this problem very early in my professional career.
Imagine a graphical editor in which you can create BPMN processes, for example. Such an editor saves the process description in an XML file. So that it can then be processed programmatically. XML as pure ASCII text file can be placed problem-free with a SCM system under Configuration Management. If the graphical editor uses the event driven SAX implementation in Java for XML to edit the XML structure, the changed blocks are usually moved to the end of the context block within the file.
If different blocks within the file are processed simultaneously, conflicts will occur. As a rule, these conflicts cannot be resolved manually with reasonable effort. The solution at that time was a strict coordination between the developers to clarify when the file is released for editing.
In larger teams, which may also work in far distance together, this can lead to massive delays. A simple solution would be to lock the corresponding file so that no editing by another user is possible. However, this way is rather questionable in the long run. Let’s think of a locked file that cannot be processed further because the person in question fell ill at short notice.
It is much more elegant to introduce an automated step that formats such files according to a specified coding guide before a commit. However, care must be taken to strictly preserve the semantics within the file.
Now that we know the mechanisms of how conflicts arise and we can start thinking about a suitable strategy to avoid conflicts if possible. As we have already seen, automated procedures have some difficulties in deciding which change to use. Therefore, concepts should be found to avoid conflicts from the beginning. The goal is to keep the amount of conflicts manageable, so that manual processing can be done quickly, easily and secure.
Since conflicts in day-to-day business mainly occur when merging branches, we turn to the different branch strategies in the following section.
Branch models
In older literature, the term branch is often used as a synonym for terms such as stream or tree. In simple terms, a branch is the duplication of an object which can then be further modified in the different versions independently of each other.
Branching the main line into parallel dedicated development branches is one of the most important features of SCM systems that developers are regularly confronted with.
Although the creation of a new branch from any revision is effortless, an ill-considered branch can quickly lead to serious difficulties when merging the different branches later. To get a better grasp of the problem, we will examine the various reasons why it may be necessary to create branches from the main development branch.
A quite broad overview to different branch strategies gives the Git Flow. Before I continue with a detailed explanation, however, I would like to note that Git Flow is not optimally suited for all software development projects because of its complexity. This hint can be found with an explanation for some time on the blog of Vincent Driessen [6], who has described the Git Flow in the article “A successful Git branching model”.
This model was conceived in 2010, now more than 10 years ago, and not very long after Git itself came into being. In those 10 years, git-flow (the branching model laid out in this article) has become hugely popular in many a software team to the point where people have started treating it like a standard of sorts — but unfortunately also as a dogma or panacea. […] This is not the class of software that I had in mind when I wrote the blog post 10 years ago. If your team is doing continuous delivery of software, I would suggest to adopt a much simpler workflow (like GitHub flow) instead of trying to shoehorn git-flow into your team. […]
V. Driessen, 5 March 2020
Main development branch: current development status of the project. In Subversion this branch is called trunk.
Developer Branch: isolates the workspace of a developer from the main development branch in order to be able to store as many revisions of their own work as possible without influencing the rest of the team.
Release Branch: an optional branch that is created when more than one release version is developed at the same time.
Hotfix Branch: an optional branch that is only created when a correction (Bugfix) has to be made for an existing release. No further development takes place in this branch.
Feature Branch: parallel development branch to the Main with a life cycle of at least one release cycle in order to encapsulate extensive functionalities.
If you look at the original illustration of Git Flow, you will see branches of branches. It is absolutely necessary to refrain from such a practice. The complexity that arises in this way can only be mastered through strong discipline.
A small detail in the conception of the Git Flow we see also with the idea beside a release Branch additionally a Hotfix Branch to create. Because in most cases the release branch is already responsible for the fixes. Whenever a release that is in production needs to be followed up with a fix, a branch is created from the revision of the corresponding release.
However, the situation changes when multiple release versions are under development. In this case it is highly recommended to keep the release changes always on the major development line and to branch off older releases as post-provisioning. This scenario should be reserved for major releases only, as they will contain API changes using the Semantic Versioning [7] and thus create per se incompatibilities. This strategy help to reduce the complexity of the branch model.
Now, however, for the release branches in which new functionality continues to be implemented, it is necessary to be able to supply the releases that are being created there with corrections. In order to have a distinction here the designation Hotfix Branch is very helpful. This is also reflected in the naming of the branches and is helpful for orientation in the repository.
If the name this branch is something like Hotfix branch, it will block the possibility of making further functional developments in this branch for the release in the future. In principle, branches of level 1 should be named Release_x.x. Branches of level 2 in turn should be called HotFix_x.x or BugFix_x.x etc. This pattern of naming fits in nicely with Semantic Versioning. Branches of a level higher than two should be strictly avoided. On the one hand, this increases the complexity of the repository structure, and on the other hand, it creates considerable effort in the administration and maintenance of subsequent components of an automated build and deploy pipeline.
The following figure puts what has just been described into a visual context. A technical description of Release Management from the perspective of Configuration Management via the creation of branches can be found in the paper “Expressions for Source Control Management Systems” [8], which proposes a vocabulary that helps to improve orientation in source repositories via the commit messages.
Figure 3.01: Branch naming pattern based on Semantic Versioning.
Certainly, an experienced configuration manager can correct unfavorably named Branches more or less easily with a little effort, depending on the SCM used. But it is important to remember that systems connected to the SCM, such as automation servers (also known as Build or CI servers), quality assurance tools such as SonarQube, etc., are also affected by such renaming. All this infrastructure and can not longer find the link to the original sources if the name of the branch got changed afterwards. Since this would be a disaster for Release Management, companies often refrain from refactoring the code repositories, which leads to very confusing graphs.
To ensure orientation in the repository, important revisions such as releases should be identified by a tag. This practice ensures that the complexity is not increased unnecessarily. All relevant revisions, so-called points of interests (POI), can be easily found again via a tag.
In contrast to branches, tags can be created arbitrarily in almost any SCM system and removed without leaving any residue. While Git supports the deletion of branches excellently, this is not easily possible with Subversion due to its internal structure.
It is also highly recommended to set an additional tag for releases that are in PRODUCTION. As soon as a release is no longer in production use, the tag that identifies a production release should be deleted. Current labels for releases in production allow you to decide very quickly from which release a resupply is needed.
Particularly in the case of very long-term projects, it is rarely possible to make a correction in the revision in which the error occurs for the first time because of the existing timeline, and it is not exactly sensible. For reasons of cost efficiency, this question is focused exclusively on the releases that are in production. We see that the use of release branches can lead to a very complex structure in the long run. Therefore it is a highly recommended strategy to close release branches that are no longer needed.
For this purpose an additional tag >EOL< can be introduced. EOL indicates that a branch has reached its end of lifetime. These measures visualize the current state of the branches in a repository and help to get a quick overview. In addition, it is also recommended to lock the closed release branches against unintentional changes. Many server solutions such as the SCM Manager or GitLab offer suitable tools for locking branches, directories and individual files. It is also strongly advised against deleting branches that are no longer needed and from which a release was created.
In this section, the different types of branches were introduced in their context. In addition, possibilities were shown how the orientation in the revisions of a repository can be ensured without having to read the source files. The following chapter discusses the various ways in which these branches can be merged.
The motivation of branches from the main development is already discussed in detail. Now it is time to inspect the various options for merging two branches.
Merging strategies
After we have discussed in detail the motivation for branches of the main development branch, it is now important to examine the different possibilities of merging two branches.
As I already demonstrated in the previous Chapter, conflicts can easily arise in the different versions of a file when merging, even in a linear progression. In this case it is a temporary branch that is immediately merged into a new revision as automatically as possible. If the automated merging fails, it is a semantic conflict that must be resolved manually. With clumsily chosen branch models, the number of such conflicts can be increased so massively that manual merging is no longer possible.
Figure 4.01: Git History; merge after resolving a conflict.
In Figure 4.01 we see the graph of the history of TortoisGit from the example of Listing 2. Although there is no additional branch at this point, we can see branches in the column of the graph. It is a representation of the different versions, which can continue to grow as more developers are involved.
A directed graph is therefore created for each object over time. If this object is frequently affected by edits due to its importance in the project, which are also made by different people, the complexity of the associated graph automatically increases. This effect is amplified if several branches have been created for this object.
Figure 4.02:Git merge strategies.
The current version of the SCM tool Git supports three different merge strategies that the user can choose from. These are the classic merge, the rebase and the cherry picking.
Figure 4.02 shows a schematic representation of the three different merge strategies for the Git SCM. Let’s have a look in detail at what these different strategies are and how they can be used.
– Merge is the best known and most common variant. Here, the last revision of branch B and the last revision of branch A are merged into a new revision C.
– Rebase, is a feature included in SCM Git [9]. Rebase can be understood as a partial commit. This means that for each individual revision in branch B, the corresponding predecessor revision in master branch A is determined and these are merged individually into a new revision in the master. As a consequence, the history of Git is overwritten.
– Cherry picking allows selected revisions from branch A to be transferred to a second branch B.
During my work as a configuration manager, I have experienced in some projects that developers were encouraged to perform every merge as a rebase. Such a procedure is quite critical as Git overwrites the existing history. One effect is that it may could happen that important revisions that represent a release are changed. This means that the reproducibility of Releases is no longer given. This in turn has the consequence that corrections, as discussed in the section branch models, contain additional code, which in turn has to be tested. This of course destroys the possibility of a simple re-test for correction releases and therefore increases the effort involved.
A tried and tested strategy is to perform every merge as a classic merge. If the number of semantic conflicts that have occurred cannot be resolved manually, an attempt should be made to rebase. To ensure that the history is affected as little as possible, the branches should be as short-lived as possible and should not have been created before an existing release.
Listing 4.01: Demonstration of history change by using rebase.
If this experiment is reproduced, the conflicts resulting from the rebase must be resolved sequentially. Only when all individual sequences have been run through is the rebase completed locally. The experiment thus demonstrates what the term partial commit means, in which each conflict must be resolved for each individual commit. Compared to a simple merge, the rebase allows us to break down an enormous number of merge conflicts into smaller and less complex segments. This can enable us to manually resolve an initially unmanageable number of semantic merge conflicts.
However, this help does not come without additional risks. As Figure 4.03 shows us with the output of the log, the history is overwritten. In the experiment described, a develop branch was created by the same user in which the two files 3 and 4 were changed. The two revisions in the Branch in which files 3 and 4 were edited appeared after the rebase in the history for the main Branch.
If rebase is used excessively and without reflection, this can lead to serious problems. If a rebase overwrites a revision from which a release was created, this release cannot be reproduced again as the original sources have been overwritten. If a correction release is now required for this release for which the sources have been overwritten, this cannot be created without further ado. A simple retest is no longer possible and at least the entire test procedure must be run to ensure that no new errors have been introduced.
Figure 4.03:Shows the history of the git rebase example.
We can therefore already formulate an initial assumption at this point. Semantic conflicts that result from merging two objects into a new version very often have their origin in a branch strategy that is too complex. We will examine this hypothesis further in the following chapter, which is dedicated to a detailed exploration of the organization of repositories.
Code repository organization and quality gates
The example of Listing 2, which shows how a semantic merge conflict arises, demonstrates the problem at the lowest level of complexity. The same applies to the rebase experiment in Listing 4. If increased the complexity of these examples by involving more users who in turn work in different branches, a statistical correlation can be identified: The higher the number of files in a repository and the more users have write access to this repository, the more likely it is that different users will work on the same file at the same time. This circumstance increases the probability of semantic merge conflicts arising.
This correlation suggests that both the software architecture and the organization of the project in the code repository can also have a decisive influence on the possible occurrence of merge conflicts. Robert C. Martin suggests some problems in his book Clean Architecture [10].
This thesis is underlined by my own many years of project experience, which have shown that software modules that are kept as compact as possible and can be compiled independently of other modules are best managed in their own repository. This also results in smaller teams and therefore fewer people creating several versions of a file at the same time.
This contrasts with the paper “The issue of Monorepo and Polyrepo in large enterprises” [11] by Brousse. It cites various large companies that have opted for one solution or the other. The main motivation for using a Monorepo is the corporate culture. The main aim is to improve internal communication between teams and avoid information silos. In addition, Monorepos bring their own class of challenges, as the example cited from Microsoft shows.
[…] Microsoft scaled Git to handle the largest Git Monorepo in the world […]
Even though Brousse speaks positively about the use of Monorepos in his work, there are only a few companies that really use such a concept successfully. Which in turn raises the question of why other companies have deliberately chosen not to use Monorepos.
If we examine long-term projects that implement an application architecture as a monolith, we find identical problems to those that occur in a Monorepo. In addition to the statistical circumstances described above, which can lead to semantic merge conflicts, there are other aspects such as security and erosion of the architecture.
These problems are countered with a modular architecture of independent components with the loosest possible binding. Microservices are an example of such an architecture. A quote from Simon Brown suggests that many problems in software development can be traced back to Conway’s Law [12].
If you can’t build a monolith, what makes your think microservices are the answer?
This is because components of a monolith can also be seen as independent modules that can be outsourced to their own repository. The following rule has proven to be very practical for organizing the source code in a repository: Never use more than one technology, module, component or standalone context per repository. This results in different sections through a project. We can roughly distinguish between back-end (business logic) and front-end (GUI or presentation logic). However, a distinction by technology or programming language is also very useful. For example, several graphical clients in different technologies can exist for a back-end. This can be an Angular or Vue.js JavaScript web client for the browser or a JavaFX desktop application or an Android Mobile UI.
The elegant implementation of using multiple repositories often fails due to a lack of knowledge about the correct use of repository managers, which manage and provide releases of binary artifacts for projects. Instead of reusing artifacts that have already been created and tested and integrating them into an application in your own project via the dependency mechanism of the build tool, I have observed very unconventional and particularly error-prone integration attempts in my professional career.
The most error-prone integration of different modules into an application that I have experienced was done using so-called externals with SCM Subversion. A repository was created into which the various components were linked. Git uses a similar mechanism called submodules [13]. This decision limited the branch strategy in the project exclusively to the use of the main development branch. The release process was also very limited and required great care. Subsequent supplies for important error corrections proved to be particularly problematic. The use of submodules or externals should therefore be avoided at all costs.
Another point that is influenced by branching and merging are the various workflows for organizing collaboration in SCM systems. A very old and now newly discovered workflow is the so-called Dictatorship Workflow. This has its origins in the open source community and prevents faulty implementations from destroying the code base. The Dictator plays a central role as a gatekeeper. He checks every single commit in the repository and only the commits that meet the quality requirements are included in the main development branch. For very large projects with many contributions, a single person can no longer manage this task. Which is why the so-called Lieutenant was included as an additional instance.
With the open source code hosting platform GitHub, the Dictatorship workflow has experienced a new renaissance and is now called Pull Request. GitLab has tried to establish its own name with the term Merge Request.
This approach is not new in the commercial environment either. The entire architecture of IBM’s Rational Synergy, released in 1990, is based on the principle of the Dictatorship workflow. What has proven to be useful for open source projects has turned out to be more of a bottleneck in the commercial environment. Due to the pressure to provide many features in a project, it can happen that the Pull Requests pile up. This leads to many small branches, which in turn generate an above-average number of merge conflicts due to the accumulation, as the changes made are only made available to the team with a delay. For this reason, workflows such as Pull Requests should also be avoided in a commercial environment. To ensure quality, there are more effective paradigms such as continuous integration, code inspections and refactoring.
Christian Bird from Microsoft Research formulated very clearly in the paper The Effect of Branching Strategies on Software Quality [15] that the branch strategy does have an influence on software quality. The paper also makes many references to the repository organization and the team and organization structure. This section narrows down the context to semantic merge conflicts and reveals how negative effects increase with increasing complexity.
Conflict Sets
The paper “A State-ot-the-Art Survey on Software Merging” [16] written by Tom Mens in 2002 distinguishes between syntactic and semantic merge conflicts. While Mens mainly focuses on syntactic merge conflicts, this paper mainly deals with semantic merge conflicts.
In the practice-oriented specialist literature on topics that deal with Source Control Management as a sub-area of the disciplines of Configuration Management or DevOps, the following principle applies uni sono: keep branches as short-lived as possible or synchronize them as often as possible. This insight has already been taken up in many scientific papers and can also be found in “To Branch or Not to Branch” by Premraj et al [17], among others.
In order to clarify the influence of the branch strategy, I differentiate the branches presented in the section branch models into two categories. Backward-oriented branches, which are referred to below as reverse branches (RB), and forward-oriented branches, which are referred to as forward branches (FB).
Reverse branches are created after an initial release for subsequent supply. Whereas a release branch, developer branch, pull requests or a feature branch are directed towards the future. Since such forward branches are often long-lived and are processed for at least a few days until they are included in the main development branch, the period in which the main development branch is not synchronized into the forward branch is considered a growth factor for conflicts. As can be expressed as a function over time.
The number of conflicts arising for a forward branch increases significantly if there is a lot of activity in the main development branch and increases with each day in which these changes are not synchronized in the forward branch. The largest possible conflict set between the two branches therefore accumulates over time.
The number of all changes in a reverse branch is limited to the resolution of one error, which considerably limits the number of conflicts that arise. This results in a minimal conflict set for this category. This can be formulated in the following two axioms:
This also explains the practices for pessimistic version control and optimistic version control described by Mens in [16]. I already demonstrated that conflicts can arise even without branches. If the best practices described in this thesis are adopted, there is little reason to introduce practices such as code freeze, feature freeze or branch blocking. This is because all the strategies established from pessimistic version control to deal with semantic merge conflicts only lead to a new type of problem and prevent modern automation concepts in the software development process.
Conclusion
With a view to high automation in DevOps processes, it is important to simplify complex processes as much as possible. Such simplification is achieved through the application of established standards. An important standard is for example semantic versioning, which simplifies the view of releases in the software development process. In the agile context it is also better to talk about production candidates instead of release candidates.
The implementation phase is completed by a release and the resulting artifact is immutable. After a release, a test phase is initiated. The results of this test phase are assigned to the tested release and documented. Only after a defined number of releases, when sufficient functionality has been achieved, is a release initiated that is intended for productive use.
The procedure described in this way significantly simplifies the branch model in the project and allows the best practices suggested in this paper to be easily applied. As a result, the development team has to deal less with semantic merge conflicts. The few conflicts that arise can be easily resolved in a short time.
An important instrument to avoid long-lasting feature branches is to use the design pattern feature flag, also known as feature toggles. In the 2010 article Feature Flags [18], Martin Fowler describes how functionality in a software artifact can be enabled or disabled by a configuration in production use.
The fact that version control is still very important in software development is shown in various chapters in Quio Liang’s book [19] “Continuous Delivery 2.0 – Business leading DevOps Essentials”, published in 2022. In the standard literature for DevOps practitioners, rules for avoiding semantic merge conflicts are usually described very well. This paper shows in detail how conflicts arise and gives an appropriate explanation of why these conflicts occur. With this background knowledge, we can decide whether a merge or a rebase should be performed.
Future Work
Given the many different source control management systems currently available, it would be very helpful to establish a common query language for code repositories. This query language should act as an abstraction layer between the SCM and the client or server. Designed as a Domain Specific Language (DSL). It should not be a copy of well-known query languages such as SQL. In addition to the usual interactions, it would be desirable to find a way to formulate entire processes and define the associated roles.
References
[1] Marc J. Rochkind. 1975. The Source Code Control System (SCCS). IEEE Transactions on Software Engineering. Vol. 1, No. 4, 1975, pp. 364–370. doi: 10.1109/tse.1975.6312866
[2] Nayan B. Ruparelia. 2010. The History of Version Control. ACM SIGSOFT Software Engineering Notes. Vol. 35, 2010, pp. 5-9.
[3] Eugene W. Myers. 1983. An O(ND) Difference Algorithm and Its Variations. Algorithmica 1. 1986. pp. 251–266. https://doi.org/10.1007/BF01840446
[4] Buffenbarger, J. 1995. Syntactic software merging. Lecture Notes in Computer Science. Vol 1005, 1995. doi: 10.1007/3-540-60578-9_14
[5] P. Bourque, R. E. Fairley, 2014, SWEBook v 3.0 – Guide to the Software Engineering Body of Knowledge, IEEE, ISBN: 0-7695-5166-1
[6] V. Driessen, 2023, A successful Git branching model, https://nvie.com/posts/a-successful-git-branching-model/
[7] Tom Preston-Werner, 2023, Semantic Versioning 2.0.0, https://semver.org
[8] Marco Schulz. 2022. Expressions for Source Control Management Systems. American Journal of Software Engineering and Applications. Vol. 11, No. 2, 2022, pp. 22-30. doi: 10.11648/j.ajsea.20221102.11
[9] Git Rebase Documentation, 2023, https://git-scm.com/book/en/v2/Git-Branching-Rebasing
[11] Robert C. Martin, 2018, Clean Architecture, Pearson, ISBN: 0-13-449416-4
[12] Brousse N., 2019, The Issue of Monorepo and Polyrepo in large enterprises. Companion Proceedings of the 3rd International Conference on the Art, Science, and Engineering of Programming. No. 2, 2019, pp. 1-4. doi: 10.1145/3328433.3328435
[13] Melvin E. Conway, 1968, How do committees invent? Datamation. Vol. 14, No. 4, 1968, pp. 28–31.
[15] Shihab, Emad & Bird, Christian & Zimmermann, Thomas, 2012, The Effect of Branching Strategies on Software Quality. Proceedings of the ACM-IEEE International Symposium on Empirical Software Engineering and Measurement. pp. 301–310. doi: 10.1145/2372251.2372305
[16] Tom Mens. 2002. A State-ot-the-Art Survey on Software Merging. IEEE Transactions on Software Engineering. Vol. 28, 2002, pp. 449-462. doi: 10.1109/TSE.2002.1000449
[17] Premraj et al. 2011. To Branch or Not to Branch. pp. 81-90. doi: 10.1145/1987875.1987890
[18] Martin Fowler, 2023, Article Feature Flags https://martinfowler.com/bliki/FeatureFlag.html
The topic of artificial intelligence will bring about significant changes for our society. The year 2022 heralded these changes with the launch of ChatGPT for private users. Powerful A.I. based tools are now seeing the light of day almost daily. They promise higher productivity and open up new and even unimagined possibilities. Even if what these tools do seems a bit scary at first, it’s also fascinating, because most of these applications we’ve been longing for for many years.
So before I get into the details, I’d like to say a few words of caution. Because as exciting as the whole topic is, it also has its downsides, which we should not overlook despite all the euphoria. Companies in particular must be aware that all requests to A.I. are logged and used for training purposes. This can be a security risk in the case of sensitive business secrets.
Technically, the A.I. tools discussed here are so-called artificial neural networks. Tools are so-called artificial neural networks and imitate the human brain. The description of how ChatGPT works includes the term Large Vision-Language Model (LVLM). This means that they understand the context of human speech and act or react accordingly. All the A.I. systems discussed in this article are, in contrast to living beings, not self-motivated. They need, so to speak, an initial spark to become active. No matter which living being on the other hand has permanently the necessity to find food for its own energy demand. If the creature does not succeed in finding food over a longer period of time, it dies and its being is lost forever. An artificial neural network, on the other hand, can process queries as long as the computer on which it is installed. If the computer breaks down, the neural network can be installed on a new computer and it can continue to work as before. But now enough of the technical details. If you want to know more, you can listen to my podcast or have a look at the other A.I. articles in this blog.
Now, before I introduce K. I. systems for home use, I would like to discuss a few highly specialized industrial applications. I must admit that I am very impressed by the performance of these systems. This also demonstrates the enormous versatility.
PTC CREO
PTC CREO is a computer-aided design (CAD) system that can be used to create engineering design drawings. CREO can also optimize existing designs based on material and manufacturing requirements.
YOU.COM
YOU.COM is an A.I. based search engine with an integrated chatbot. In contrast to Google and Co, YOU.COM does not present long lists of results from which you have to search for what you are looking for. Rather, you get a summary of the information found in response to your query.
absci
absci uses artificial neural networks to design drugs from scratch. This extremely accelerated process will enable the development of personalized drugs tailored to the patient in the future.
PassGAN
On the free source code hosting platform GitHub you can find the tool PassGAN, a Python written A.I. based password cracker. Even though its use is complicated and PassGAN is mainly used by security researchers, it is a matter of time before capable specialists use this tool for illegal activities.
If you now have a taste for it, you should definitely take a look at hugging face. On this website, the A.I. community hangs out and all kinds of LVLM can be tried out with different data sets. Of course there is also an extensive section with current scientific publications on the subject.
After I have demonstrated the potential of neural networks in a commercial environment with a few examples, it is now time to turn to tools for home use. In this way, the tools presented below can also be used for everyday tasks.
One of the oldest domains for artificial intelligence is the field of translation. All those who have already diligently used the Google Translator on holiday may not even know that it also uses A.I. technologies. For this, the translator also needs a connection to the internet, because even modern smartphones are not powerful enough for complex translations by neural networks. However, the Google Translator had considerable weaknesses for me in the past. Especially with complex sentences, the tool quickly reached its limits. I achieve much better results with DeepL, which I use primarily for the languages German / Spanish and English. With the browser plug-in of the same name, entire websites can also be translated. In the free version of DeepL, texts can be translated on the website with up to 1500 per request. However, if you often want to translate large documents in a short time, you can also switch to the commercial version. In this case, various formats such as PDF, DOCX etx can be uploaded to the website and in a few moments you will receive the corresponding translation. There is also an option to spice up the source text stylistically. This is particularly suitable for those who find it difficult to formulate their own texts (letters, etc.).
In turn, anyone who needed individual graphics for their homepage had to either hire a professional graphic designer or spend a long time searching for freely usable graphics on free platforms such as Pixabay. Especially in the area of A.I. supported image generation there is a considerable choice of solutions. Because currently in 2023 there are still no regulators for the copyright of the images generated by the A. I.. However, this could change in the next few years. Here we must wait and keep an eye on the current legal situation. In the private environment, of course, this is not an issue. Who should control all the decorative graphics in photo books or on invitation cards for weddings or birthdays. In the following you will find a list of different providers, which are quite identical in their basic functions, so that you can make your choice according to your personal taste and sensitivities.
Stable Diffusion has the focus to generate photorealistic images.
Another area of application predestined for A.I. is the generation of text. If you have difficulties with this, you can generate e.g. blog posts for your homepage with A.I. support. But also on legal formulations specialized application for the production of whole contract drafts, imprint texts etc. are very interesting for simple tasks also for private users. Simple sublease agreements, sales contracts, etc. are classic areas in which one does not immediately hire a lawyer. In the following I have compiled a small list of different A.I. based text generators:
Chat-GPT is a chatbot that can support research on new topics.
Wordtune allows to improve own formulations stylistically and to change them according to specifications like formal expression.
Rytr focuses on content creators and allows to specify SEO keywords. There is also a WordPress plugin.
BARD from Google supports the formulation of complex search queries to optimize the hit list.
If you think that we have already reached the end of possible applications with the systems already presented, you are mistaken. Another large area of application is audio / video editing. Here you don’t have to think of high quality film productions like they come from the Hollywood studios. There are many small tasks that are also relevant for home use. Extracting the text from audio or video files as an excerpt, then translating this template to create a new audio file in another language, for example. The conversion from text to audio and back again is not a novelty because it is an improvement of the quality of life especially for blind and deaf people.
Elevenlabs offered an A.I. based text-to-speech engine whose output already sounds very realistic.
Dadabots generates a music livestream and can imitate genres and well-known bands. Which allows the use of GEMA free music at events.
Elai.io allows to create personalized videos with digital avatars. Areas of application include education and marketing.
MuseNet supports musicians in composing new pieces based on given MIDI samples.
The last major application area for A. I. supported software in this list is the creation of source code. Even though code generators are not a novelty for programmers and have been speeding up the workflow for quite some time, the A. I. based approach offers much more flexibility. But also here applies as for all applications described before a watchful view of the user is inevitable. It is certainly possible to optimize existing program fragments according to specifications or to create so-called templates as templates, which can then be further elaborated manually. Most of the tools presented in the following are chargeable for commercial software development. However, there is a free version for students, teachers and open source developers on request.
CodeStarter an integration for Ubuntu Linux is specialized for web applications
CodeWP for WordPress and allows to create own plugins or templates.
Tabnineis an IDE extension available for Visual Studio Code, Android Studio, Eclipse und IDEA
As we can see, there are countless applications that are already usable and this list is far from complete. For this reason, I would like to conclude by introducing the Futurepedia website. There, new A.I. tools are regularly listed and briefly introduced. So if you haven’t found the right tool for you in this article, take a look at Futurepedia.
For many, Bitcoin (BTC) is a pure speculation object with which they only want to make money. However, the cryptocurrency Bitcoin is also ideal for payment. You do not need any in-depth technical knowledge to pay with Bitcoin. Bitcoin can also be bought with relatively small amounts, for example 10 euros. Everything you need to get started is explained in this article in an easy-to-understand manner.
To buy your first Bitcoin, you need a regular bank account, €20 and about 10 minutes of time. Depending on the bank, the transfer of euros until they are credited as Bitcoin can take up to a day. Incidentally, all of elmar-dott.com’s services can also be paid for using Bitcoin.
Before we start the first transaction, we need to create a wallet. Wallet is the English term for purse. This means that a Bitcoin wallet is nothing more than a digital purse. The program with which you can create and manage a wallet is very similar to the typical banking app. Wallets can be easily set up on computers, smartphones and tablets (Android & iPhone/iPad). There are also hardware wallets that work similarly to a USB stick and store the Bitcoins there.
The most important difference between a bank account and a wallet is that the bitcoins stored in your wallet actually belong to you. There is no bank or other institution that has access to this wallet. You can compare bitcoins stored in your wallet with the cash you have in your wallet. So let’s first look at how to create your own wallet. For this we use the free open source software Electrum. The Electrum Bitcoin Wallet was developed in Python 3 and is available for: Linux, Windows, MacOS and Android.
1st step: Create a wallet
After the app has been downloaded and started, we can get started and create our first Bitcoin wallet. First, we give our wallet a name and press Next. We are then asked which wallet type we would like to create. Here we leave it at the default. We then have to create a seed. The seed is 12 randomly created words that we can expand with our own terms/character strings using the Options button. The specified terms (seed) are extremely important and must be kept safe. It is best to write them on a piece of paper.
After the app has been downloaded and started, we can get started and create our Bitcoin wallet. First, we give our wallet a name and press Next. We are then asked which wallet type we would like to create. Here we leave it at the default. We then have to create a seed. The seed is 12 randomly created words that we can expand with our own terms/character strings using the Options button. The specified terms (seed) are extremely important and must be kept safe. It is best to write them on a piece of paper. The seed allows full access to your personal wallet. With the seed you can easily transfer your wallet to any device. A secure password is then assigned and the wallet file is encrypted. We have now created our own Bitcoin wallet, with which we can send and receive Bitcoin.
In this way, you can create as many wallets as you like. Many people use 2 or more wallets at the same time. This process is called proxy pay. This measure conceals the actual recipient and is intended to prevent transfer services from refusing transactions to undesirable recipients.
In order to convert your own euros into bitcoin, a so-called broker is required. You transfer euros or other currencies to this broker and receive bitcoin in return. The bitcoin is first transferred to a wallet managed by the broker. From this wallet you can already send bitcoin to any other wallet. As long as the bitcoin is still in the broker’s wallet, however, the broker can block the wallet or steal the bitcoin on it. Only when we transfer the purchased bitcoin to a self-managed wallet, as we created in step 1, are the coins in our possession and no outsider has access to them.
The problem that can arise is that these broker services, also called crypto exchanges, can keep a list of bitcoin wallets to which they do not send transactions. To avoid this, you transfer your Bitcoins from the wallet of the Bitcoin exchange where you bought your coins to your own wallet. You can also use multiple wallets to receive payments. This strategy makes it difficult to track payment flows. The money that has been received in various wallets can now be easily transferred to a central wallet where you can save your coins. It is important to know that fees are also charged when sending Bitcoin. Just like with a checking account.
Understanding Bitcoin Transaction Fees
Every time a transaction is made, it is stored in a block. These blocks have a limited size of 1MB, which limits the number of transactions per block. Since the number of transactions that can fit in a block is limited, users compete to have their transactions included in the next block. This is where Bitcoin transaction fees come in. Users offer fees to make their transactions more attractive to miners. The higher the fee, the more likely the transaction will be confirmed faster. The amount of fees depends on several factors:
Network load: When load is high, fees increase because more users want to prioritize their transactions.
Transaction size: Larger transactions require more space in the block and therefore incur higher fees.
Market conditions: General demand for Bitcoin and market volatility can affect fees.
Most wallets calculate fees automatically based on these factors. However, some wallets offer the ability to manually adjust fees to either save costs or achieve faster confirmation.
Bitcoin transaction fees are not fixed and can vary widely. Bitcoin transactions can be confirmed within minutes to hours, depending on the amount of the fees. Bitcoin fees are not calculated based on the value of the transaction (i.e. how much Bitcoin you send), but rather based on the size of the transaction in bytes. The fee you pay is given in Satoshis per byte (sat/byte). A Satoshi is the smallest unit of Bitcoin (1 BTC = 100 million Satoshis).
You can find out how many Satoshi you get for €1 on coincodex.com and the current transaction fee can be found on bitinfocharts.com
Notes on the anonymity of Bitcoin
When you pay with Bitcoin, you send coins from your wallet to a recipient wallet. This transaction is publicly visible. Basically, when you create a wallet using software such as Electrum, the owner of the wallet is not stored. Nevertheless, conclusions about the owner of a wallet can be drawn from the transactions. Using multiple wallets can make it more difficult to assign them to a real person and conceal money flows. But 100% anonymity cannot be guaranteed. Only cash offers absolute anonymity.
Nevertheless, Bitcoin has some advantages over cash. If you travel a lot and don’t want to keep your money in your bank account, you can easily carry very large amounts with you without them being found and confiscated when crossing borders. You are also fairly well protected against theft. If you save your wallet in an encrypted file on various data storage devices, you can easily restore it using the seed.
2nd Step: Buy Bitcoin
Before we can start using Bitcoin, we first need to get our hands on Bitcoin. We can do this quite easily by buying Bitcoin. Since Bitcoin can be worth several thousand euros depending on the exchange rate, it makes sense to buy parts of a Bitcoin. As already mentioned, the smallest unit of a Bitcoin is Satoshi and corresponds to one μBTC (1 BTC = 100 million Satoshis). The easiest way to buy BTC is via an official Bitcoin exchange. A very easy-to-use exchange is Wallet of Satoshi for Android & iPhone.
With this app you can buy, receive and send Bitcoin. After you have installed the Wallet of Satoshi on your smartphone and the wallet is set up, you can also buy Satoshis immediately via bank transfer with just 20 euros via the menu. A very practical detail is that you can also use the Wallet of Satoshi to buy Bitcoin using other currencies such as US dollars. This is excellent for international business relationships, where you no longer have to deal with all sorts of exchange rates. Since I consider Bitcoin to be an alternative means of payment, it makes sense for me to always leave an amount of 200 to 500 euros in the Wallet of Satoshi. Anything above that is transferred to the Electrum Wallet. This is purely a precautionary measure, because Wallet of Satoshi is based on the Lightning Network and is a private provider. True to the motto, it is better to be safe than sorry. This strategy also saves transaction fees, which can add up to a considerable amount, especially for micro payments of a few euros.
3rd Step: Pay with Bitcoin
In order to pay with Bitcoin, you need a valid wallet address. This address is usually a long, cryptic character string. Since things can quickly go wrong when entering it manually, this address is often given as a QR code.
To make a payment, for example, via the Wallet of Satoshi to any Bitcoin wallet, either the character string or, better yet, the QR code is required. To do this, open the application, press the send button and then use the camera to scan the QR code of the wallet where the Bitcoin should go.
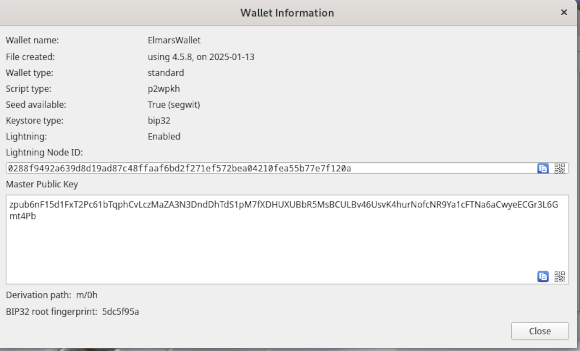
For example, if you send Bitcoin to the Wallet of Satoshi, all transactions are completely transparent. That’s why you can also send Bitcoin to an anonymous wallet. In step 1, I showed in detail how the Electrum wallet is created. Now let’s look at how we get to the wallet’s address. To do this, we go to the Wallet entry in the Electrum menu and select the Information item. We then get a display like the one in the following screenshot.
The master public key is the character string for our wallet to which Bitcoins can be sent. If you press the QR symbol in the bottom right of the field, you will receive the corresponding QR code, which can be saved as an image file. If you now make transfers from a Bitcoin exchange such as the Wallet of Satoshi, the exchange does not know who the owner is. In order to find this out, complex analyses are necessary.
Feel free to leave a comment about how you use Bitcoin and which software you work with.
If you think that the information in this article is very helpful then you can support my work by recommending this article or donating with Bitcoin or Satoshi to my Electrtum wallet. The address is:
The phrase: it’s better to have than to have had is something we have all experienced first-hand, whether in our professional or private lives. If only we hadn’t clicked on the malicious link in the email or something similar goes through our heads. But once the damage has been done, it’s already too late to take precautions.
What is usually just annoying in our private lives can very quickly become a threat to our existence in the business world. For this reason, it is important to set up a safety net in good time for the event of a potential loss. Unfortunately, many companies do not pay adequate attention to the issue of disaster recovery and business continuity, which then leads to high financial losses in an emergency.
The number of possible threat scenarios is long. Some scenarios are more likely to occur than others. It is therefore important to carry out a realistic risk assessment that weighs up the individual options. This helps to prevent the resulting costs from escalating.
The Corona pandemic was a life-changing experience for many people. The state-imposed hygiene rules in particular presented many companies with enormous challenges. The keyword here is home office. In order to get the situation under control, employees were sent home to work from there. Since there is no established culture and even less of an existing infrastructure for home working in German-speaking countries in particular, this had to be created quickly under great pressure. Of course, this was not without friction.
But it does not always have to be a drastic event. Even a mundane power failure or a power surge can cause considerable damage. It does not have to be a building fire or a flood that leads to an immediate standstill. A hacker attack also falls into the category of serious threat situations. That should be enough. I think the problem has been explained in detail with these examples. So let’s start by addressing the question of what good precautions can already be taken.
The easiest and most effective measure to implement is comprehensive data backup. To ensure that no data is lost, it helps to list and categorize the various data. Such a table should contain information about the storage paths to be backed up, approximate storage usage, prioritization according to confidentiality and category of data. Categories include project data, expulsions, email correspondence, financial accounting, supplier lists, payroll statements and so on. It is of course clear that in the context of data protection, not everyone in the company is authorized to read the information. This is why digestible data must be protected by encryption. Depending on the protection class, this can be a simple password for compressed data or a cryptographically encrypted directory or an encrypted hard drive. The question of how often a data backup should be carried out depends on how often the original data is changed. The more often the data is changed, the shorter the data backup intervals should be. Another point is the target storage of the data backup. A completely encrypted archive that is located locally in the company can certainly be uploaded to a cloud storage after a successful backup. However, this solution can be very expensive for large amounts of data and is therefore not necessarily suitable for small and medium-sized enterprises (SMEs). Of course, it is ideal if there are several replicas of a data backup that are stored in different places.
Of course, it is of little use to create extensive backups only to find out in an emergency that they are faulty. That is why verification of the backup is extremely important. Professional data backup tools contain a mechanism that compares the written data with the original. The Linux command rsync also uses this mechanism. A simple copy & paste does not meet the requirement. But a look at the file size of the backup is also important. This quickly shows whether information is missing. Of course, there is much more that can be said about backups, but that would go too far at this point. It is important to develop the right understanding of the topic.
If we take a look at the IT infrastructure of companies, we quickly realize that the provision of software installations is predominantly a manual process. If we consider that, for example, a computer system can no longer perform its service due to a hardware error, it is also important to have a suitable emergency aid strategy in hand. The time-consuming work when hardware errors occur is installing the programs after a device has been replaced. For many companies, it makes little sense to have a redundant infrastructure for cost reasons. A proven solution comes from the DevOps area and is called Infrastructure as a Code (IaaC). This is mainly about providing services such as email or databases etc. via script. For the business continuity & disaster recovery approach, it is sufficient if the automated installation or update is initiated manually. You should not rely on proprietary solutions from possible cloud providers, but use freely available tools. A possible scenario is also a price increase by the cloud provider or changes to the terms and conditions that are unacceptable for companies, which can make a quick change necessary. If the automation solution is based on a special technology that other providers cannot provide, a quick change is extremely difficult.
Employee flexibility should also be taken into account. Purchasing notebooks instead of desktop computers allows for a high level of mobility. This of course also includes permission to take the laptop home and log into the company network from there. Teams that were already familiar with home office at the beginning of 2020 were able to continue their work from home almost seamlessly. This has given the companies in question a huge competitive advantage. It can also be assumed that large, representative company headquarters will become less and less important as part of the digital transformation. The teams will then organize themselves flexibly remotely using modern communication tools. Current studies show that such a setup increases productivity in most cases. A colleague with a cold who still feels able to do his work can come to work without worrying without his colleagues running the risk of being infected.
We can already see how far this topic can be thought of. The challenge, however, is to carry out a gradual transformation. The result is a decentralized structure that works with redundancies. It is precisely these redundancies that provide sufficient room for maneuver in the event of a disruption compared to a centralized structure. Redundancies naturally cause an additional cost factor. Equipping employees with a laptop instead of a stationary desktop PC is somewhat more expensive to purchase. The price difference between the two solutions is no longer as dramatic as it was at the turn of the millennium, and the advantages outweigh the disadvantages. The transformation to maintaining business capability in the event of disruptions does not mean that you immediately rush out and buy all employees new equipment. Once you have determined what is necessary and useful for the company, new purchases can be prioritized. Colleagues whose equipment has been written off and is due for replacement now receive equipment in accordance with the new company guidelines. This model is now being followed in all other areas. This step-by-step optimization allows for a good learning process and ensures that every step that has already been completed has actually been implemented correctly.
Freelancers who acquire new orders have been experiencing significant changes for some time. Fewer and fewer companies have direct contact with their contractors when placing orders. Recruitment agencies are increasingly pushing themselves between companies and independent contractors.
When specialist knowledge is required for a project, companies are happy to turn to external specialists. This approach gives companies the greatest possible flexibility in controlling costs. But freelancers also have their advantages with this practice. They can only deal with topics in which they have a strong interest. This avoids being used for boring, routine standard tasks. Due to their experience in different organizational structures and the variety of projects, independent contractors have a broad portfolio of unconventional solution strategies. This knowledge base is very attractive for clients, even if a freelance external employee is initially more expensive than his permanent colleague. Due to their diverse experience, freelancers can bring positive impulses to the project that overcome a standstill.
Unfortunately, companies have not been trying to recruit the skilled workers they need on their own for some time. The task of recruiting staff has now been outsourced to external recruitment agencies almost everywhere. These so-called recruitment firms now advertise that they will find the most suitable candidates for open positions and propose them for filling them. After all, these recruiters have access to a large pool of applicant profiles. Companies that want to fill a vacancy often do not know how to find specialists and how to contact them directly. For this reason, the services offered by recruitment firms are also attractive for medium-sized companies. After sufficient personal experience, I have gained a completely different picture over the years. From what I have experienced, what recruitment firms promise is far from what they actually deliver.
I actually find the idea of having my own agent who takes over my order acquisition very appealing. It’s like in the film and music industry. You have an agent who has your back and gives you regular feedback. This gives you an idea of the technologies that are in demand and in which you can, for example, train yourself further. This improves your own market relevance and ensures regular orders. That would actually be an ideal win-win situation for everyone involved. Unfortunately, what actually happens in reality is something completely different.
Instead of recruitment agents building a good relationship with their specialists and promoting their development, these recruiters act like harmful parasites. They harm both the freelancers and the companies that want to fill vacancies. Because in business, it’s not about really finding the most suitable candidate for a company. It’s all about offering candidates who fit the profile you’re looking for at the lowest possible hourly rate. Whether these candidates can actually do the things they claim to be able to do is often questionable.
The approach of the recruitment agencies is very similar. They try to generate a large pool of current applicant profiles. These profiles are then searched for keywords using automatic AI text recognition systems. Then, from the suggested candidates, those with the lowest hourly rate are contacted for a preliminary interview. Anyone who does not show any major abnormalities in this preliminary interview is then suggested to the company for an interview. The profit for the recruitment agency is enormous. This is because they pocket the difference between the hourly rate paid by the client and the hourly rate received by the self-employed person. In some cases, this can be up to 40%.
But that’s not all that these parasitic intermediaries have to offer. They often delay the payment date for the invoice. They also try to shift the entire business risk onto the freelancer. This is done by demanding pointless liability insurance that is not relevant to the advertised position. As a result, companies then receive apparently skilled workers for vacant positions who are more likely to be declared as unskilled workers.
Now you might ask yourself why the companies continue to work with the intermediaries. One reason is the current political situation. For example, since around 2010 there have been laws in Germany that are intended to prevent bogus self-employment. Companies that work directly with freelancers are often pressured by pension insurance companies. This creates a lot of uncertainty and does not serve to protect freelancers. It only secures the business model of the intermediary companies.
I have now gotten into the habit of hanging up without comment and immediately when I notice various basic patterns. Such phone calls are a waste of time and lead to nothing except getting annoyed at the audacity of the recruiters. The most important sign of dubious recruiters is that a completely different person is suddenly on the phone than the one you contacted first. If this person then has a very strong Indian accent, you can be 100% sure that you are connected to a call center. Even if the number shows England as the area code, the people are actually located somewhere in India or Pakistan. Nothing that would underline their seriousness.
Over the course of many years of my career, I have registered on various job portals. My conclusion is that you can save yourself the time. 95% of all contacts that came about through these are recruiters as described above. These people then use the trick of saving them as a contact. But it is naive to believe that these so-called network requests are really about direct contact. The purpose of this action is to get onto the contact list. Many portals such as XING and LinkedIn have the setting that contacts can see the contacts from their own list or are offered them via the network function. These contact lists can be worth real money. You can find department heads or other professionals there who are definitely worth contacting. For this reason, I have also deactivated access to the friends list for friends in all social networks. I also reject all connection requests from people with the title Recruitment without exception. My presence on social networks now only serves to protect profiles against identity theft. I no longer respond to most requests to send a CV. But I also do not enter my personal information about jobs, studies and employers in these network profiles. Anyone who wants to contact me can do so via my homepage.
Another habit I have developed over the years is never to talk about my salary expectations first. If the person I am talking to cannot give a specific figure that they are willing to pay for my services, they just want to collect data. So another reason to end the conversation abruptly. None of these people care what hourly rate I have had in previous projects. They only use this information to drive down the price. If you are a bit sensitive and don’t want to give a rude answer, just name a very high hourly rate or daily rate.
As we can see, it is not that difficult to recognize the real black sheep very quickly by their behavior. My advice is, as soon as one of the patterns described above occurs, to save time and, above all, nerves and simply end the conversation. From experience, I can say that if the agents behave as described, no placement will be made. It is then better to concentrate your energy on realistic contacts. Because there are also really good placement companies. They are interested in a long-term collaboration and behave completely differently. They provide support and advice on how to improve your CV and advise companies on how to formulate realistic job offers.
Unfortunately, I fear that the situation will continue to worsen from year to year. The influence of economic development and the widespread availability of new technologies will also increase the pressure on the job market. Neither companies nor contractors will have any opportunities in the future if they do not adapt to the new times and take other paths.
If you want to use your Git repository for collaborative editing of source code, you need a Git server. The Git server enables multiple developers to collaborate on the same code base. Installing the Git client on a Linux server is a first step towards your own server solution, but it is far from sufficient. In order to allow multiple people to access a code repository, we need access authorization. After all, the repository should be publicly accessible via the Internet. We want to use user management to prevent unauthorized people from reading and changing the contents of the repositories.
There are many excellent and convenient solutions for operating a Git server that should be preferred to a native server solution. The administration of a native Git server requires Linux knowledge and is carried out exclusively via the command line. Solutions such as the SCM-Manager have a graphical user interface and come with many useful tools for administering the server. These tools are not available with a native installation.
Why should you install Git as a native server? This question is quite easy to answer. The reason is when the server on which the code repository is to be made available has only a few hardware resources. RAM in particular is always a bit of a problem in this context. This is often the case with rented virtual private servers (VPS) or a small RaspberryPI. So we can see that it can make sense to want to run a native Git server.
As a prerequisite, we need a Linux server on which we can install the Git server. This can be a Debian or Ubuntu server. If you use CentOs or other Linux distributions, you must use your distribution’s package manager instead of APT to install the software.
In the first step, we start by updating the packages and installing the Git client.
Now, in the third step, we can create our Git repositories in the newly created home directory of the git user. These differ from the local workspace in that they do not have the source code checked out.
Unfortunately, we are not quite finished with our project yet. In the fourth step, we have to set the user authorization for the created repository. This is done by storing the public key on the Git server for SSH access. To do this, we copy the contents of our private key file into the /home/git/.ssh/authorized_keys file in a separate line. If you now want to deny existing users access, simply comment out the private key number with a #.
If everything has been done correctly, you can access the repository using the following command line command: git clone ssh://git@<IP>/~/<repo>
Replace with the actual server IP. For our example, the correct path for is project.git, so it is the directory we created for the Git repository.
Multiple repositories can be created on the native Git server. It is important to note that all authorized users have read and write access to all repositories created in this way. This can only be restricted by creating multiple users on the operating system of the Linux server that provides our Git repositories, to whom the repositories are then assigned.
We see that a native Git server installation can be implemented quickly, but it is not sufficient for commercial software development. If you like to experiment, you can create a virtual machine and try out this workshop in it.
The secure use of source control management (SCM) systems such as Git is essential for programmers (development) and system administrators (operations). This group of tools has a long tradition in software development and enables development teams to work together on a code base. Four questions are answered: When was the change made? Who made the change? What was changed? Why was something changed? It is therefore a pure collaboration tool.
With the advent of the open source code hosting platform GitHub, so-called Pull Requests were introduced. Pull requests are a workflow in GitHub that allows developers to provide code changes for repositories to which they only have read access. Only after the owner of the original repository has reviewed the proposed changes and approved them are these changes integrated by him. This is also how the name comes about. A developer copies the original repository into his GitHub workspace, makes changes and requests the owner of the original repository to adopt the change. The latter can then accept the changes and if necessary adapt them himself or reject them with a reason.
Anyone who thinks that GitHub was particularly innovative is mistaken. This process is very old hat in the open source community. Originally, this procedure was called the Dictatorship Workflow. IBM’s commercial SCM Rational Synergy first published in 1990 is based precisely on the Dictatorship Workflow. With the class of distributed version management tools which Git also belongs to the Dictatorship Workflow is quite easy to implement. So it was obvious that GitHub would make this process available to its users. GitHub has chosen a much more appealing name. Anyone who works with the free DevOps solution GitLab, for example will know pull requests as merge requests. The most common Git servers now contain the pull request process. Without going into too much detail about the technical details of implementing pull requests we will focus our attention on the usual problems that open source projects face.
Developers who want to participate in an open source project are called maintainers. Almost every project has a short guide on how to support the project and which rules apply. For people who are learning to program, open source projects are ideal for quickly and significantly improving their own skills. For the open source project this means that you have maintainers with a wide range of skills and experience. If you don’t establish a control mechanism the code base will erode in a very short time.
If the project is quite large and there are a lot of maintainers working on the code base it is hardly possible for the owner of the repository to process all pull requests in a timely manner. To counteract this bottleneck the Dictatorship Workflow was expanded to the Dictatorship – Lieutenant Workflow. An intermediate instance was introduced that distributes the review of pull requests across several shoulders. This intermediate layer the so-called Lieutenants are particularly active maintainers with an already established reputation. The Dictator therefore only needs to review the Lieutenants’ pull requests. An immense reduction in workload that ensures that there is no backlog of features due to unprocessed pull requests. After all the improvements or extensions should be included in the code base as quickly as possible so that they can be made available to users in the next release.
This approach is still the standard in open source projects to ensure quality. You can never say who is involved in the project. There may even be one or two saboteurs. This idea is not so far-fetched. Companies that have strong competition for their commercial product from the free open source sector could come up with unfair ideas here if there were no regulations. In addition maintainers cannot be disciplined as is the case with team members in companies, for example. It is difficult to threaten a maintainer who is resistant to advice and does not adhere to the project’s conventions despite repeated requests with a pay cut. The only option is to exclude this person from the project.
Even if the problem of disciplining employees in commercial teams described above is not a problem. There are also difficulties in these environments that need to be overcome. These problems date back to the early days of version control tools. The first representatives of this species were not distributed solutions just centralized. CVS and Subversion (SVN) only ever keep the latest revision of the code base on the local development computer. Without a connection to the server you can actually not work. This is different with Git. Here you have a copy of the repository on your own computer, so you can do your work locally in a separate branch and when you are finished you bring these changes into the main development branch and then transfer them to the server. The ability to create offline branches and merge them locally has a decisive influence on the stability of your own work if the repository gets into an inconsistent state. Because in contrast to centralized SCM systems you can now continue working without having to wait for the main development branch to be repaired.
These inconsistencies arise very easily. All it takes is forgetting a file when committing and team members can no longer compile the project locally and are hampered in their work. The concept of Continuous Integration (CI) was established to overcome this problem. It is not as is often wrongly assumed about integrating different components into an application. The aim of CI is to keep the commit stage – the code repository – in a consistent state. For this purpose build servers were established which regularly check the repository for changes and then build the artifact from the source code. A very popular build server that has been established for many years is Jenkins. Jenkins originally emerged as a fork of the Hudson project. Build Servers now takes on many other tasks. That is why it makes a lot of sense to call this class of tools automation servers.
With this brief overview of the history of software development, we now understand the problems of open source projects and commercial software development. We have also discussed the history of the pull request. In commercial projects, it often happens that teams are forced by project management to work with pull requests. For a project manager without technical background knowledge, it makes a lot of sense to establish pull requests in his project as well. After all, he has the idea that this will improve code quality. Unfortunately, this is not the case. The only thing that happens is that a feature backlog is provoked and the team is forced to work harder without improving productivity. The pull request must be evaluated by a competent person. This causes unpleasant delays in large projects.
Now I often see the argument that pull requests can be automated. This means that the build server takes the branch with the pull request and tries to build it, and if the compilation and automated tests are successful, the server tries to incorporate the changes into the main development branch. Maybe I’m seeing something wrong, but where is the quality control? It’s a simple continuous integration process that maintains the consistency of the repository. Since pull requests are primarily found in the Git environment, a temporarily inconsistent repository does not mean a complete stop to development for the entire team, as is the case with Subversion.
Another interesting question is how to deal with semantic merge conflicts in an automatic merge. These are not a serious problem per se. This will certainly lead to the rejection of the pull request with a corresponding message to the developer so that the problem can be solved with a new pull request. However, unfavorable branch strategies can lead to disproportionate additional work.
I see no added value for the use of pull requests in commercial software projects, which is why I advise against using pull requests in this context. Apart from a complication of the CI / CD pipeline and increased resource consumption of the automation server which now does the work twice, nothing else has happened. The quality of a software project can be improved by introducing automated unit tests and a test-driven approach to implementing features. Here it is necessary to continuously monitor and improve the test coverage of the project. Static code analysis and activating compiler warnings bring better results with significantly less effort.
Personally, I believe that companies that rely on pull requests either use them for complicated CI or completely distrust their developers and deny that they do a good job. Of course, I am open to a discussion on the topic, perhaps an even better solution can be found. I would therefore be happy to receive lots of comments with your views and experiences about dealing with pull requests.


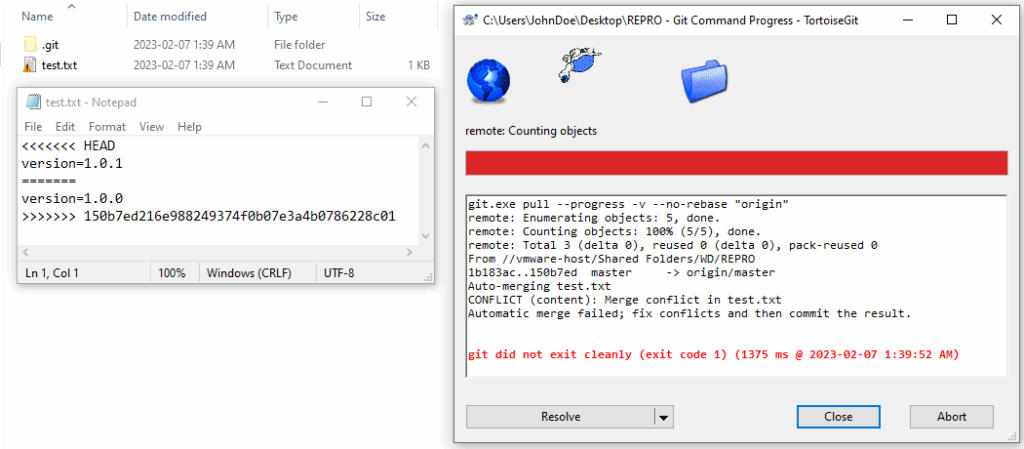
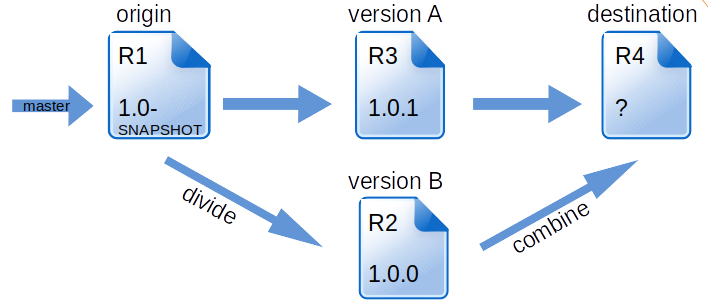
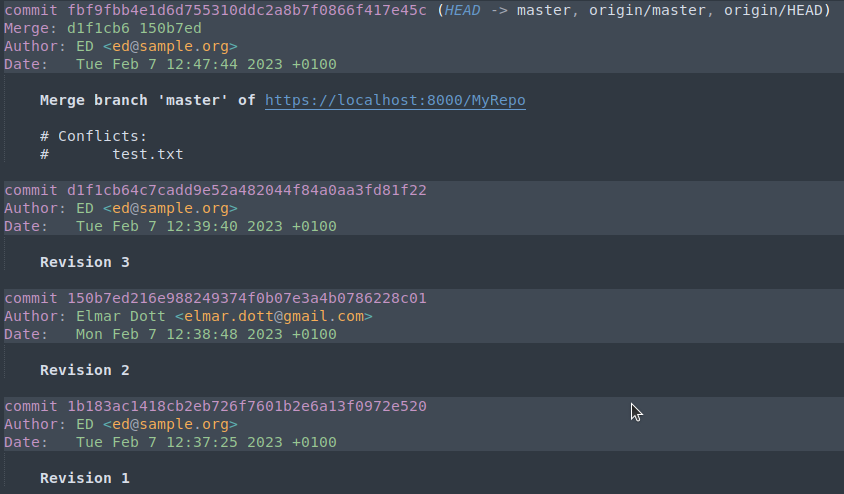
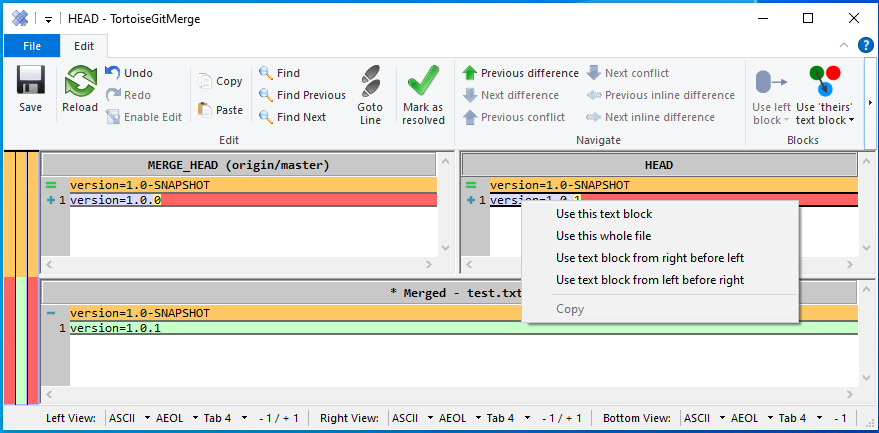
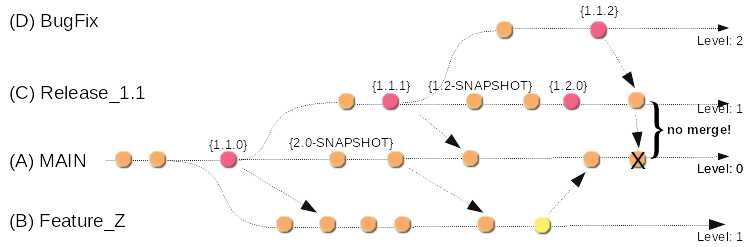
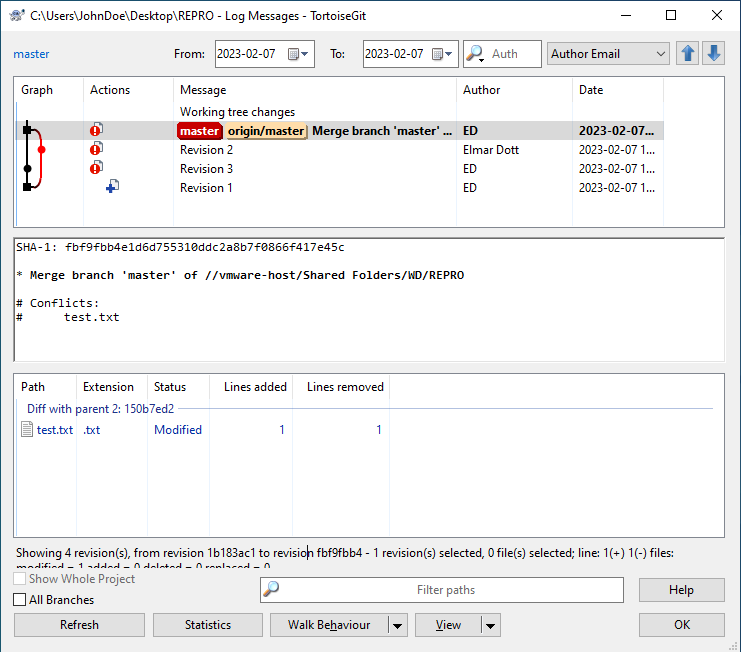
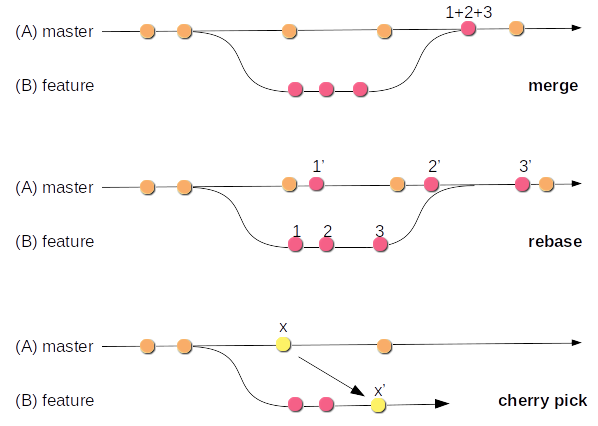
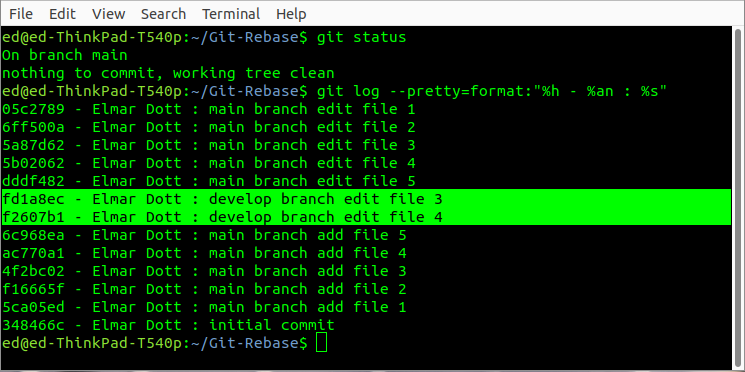
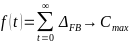

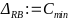





 Unlock with Patreon
Unlock with Patreon